Enables the hipSolver backend for ROCm builds
--------------------------------------------------------------------------
- Minimum ROCm version requirement - 5.3
- Introduces new macro USE_LINALG_SOLVER the controls enablement of both cuSOLVER and hipSOLVER
- Adds hipSOLVER API to hipification process
- combines hipSOLVER and hipSPARSE mappings into single SPECIAL map that takes priority among normal mappings
- Torch api to be moved to hipsolver backend (as opposed to magma) include: torch.svd(), torch.geqrf(), torch.orgqr(), torch.ormqr()
- Will enable 100+ linalg unit tests for ROCm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97370
Approved by: https://github.com/malfet
Notes:
- No segfaults observed in any CI tests: dynamo unittests, inductor unittests, dynamo-wrapped pytorch tests. So we remove the warning that using dynamo 3.11 may result in segfaults.
- Some dynamo-wrapped pytorch tests hang. They will be skipped in the dynamo-wrapped test suite and will be addressed in a future PR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99180
Approved by: https://github.com/malfet
Issue: #93684
# Problem
Reduce graph breaks when dynamo compiles python functions containing numpy functions and ndarray operations.
# Design (as I know it)
* Use torch_np.ndarray(a wrapper of tensor) to back a `VariableTracker`: `NumpyTensorVariable`.
* Translate all attributes and methods calls, on ndarray, to torch_np.ndarray equivalent.
This PR adds `NumpyTensorVariable` and supports:
1. tensor to ndarray, ndarray to tensor
2. numpy functions such as numpy.meshgrid()
3. ndarray attributes such as `itemsize`, `stride`
Next PR will handle returning `np.ndarray` and add support for ndarray methods
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95849
Approved by: https://github.com/ezyang
Add _int_mm primitive that binds cuBLAS int8@int8 -> int32 matmul and that translates to Triton based mm templates under max autotune. This is a very useful first step towards better supporting quantization on the GPU. This is a not a user facing API, but an internal primitive.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94339
Approved by: https://github.com/ngimel, https://github.com/jansel
Currently, if we multiply a transposed batch of matrices with shape
[b, m, n] and a matrix with shape [n, k], when computing the gradient
of the matrix, we instantiate a matrix of shape [b, n, k]. This may be
a very large matrix. Instead, we fold the batch of matrices into a
matrix, which avoids creating any large intermediary tensor.
Note that multiplying a batch of matrices and a matrix naturally occurs
within an attention module, so this case surely happens in the wild.
In particular, this issue was found while investigating the OOMs caused by the
improved folding algorithm in the next PR of this stack. See https://github.com/pytorch/pytorch/pull/76828#issuecomment-1432359980
This PR fixes those OOMs and decreases the memory footprint of the
backward of matmul.
I understand this is a tricky one, so I put it on its own PR to discuss it.
Differential Revision: [D43541495](https://our.internmc.facebook.com/intern/diff/D43541495)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95261
Approved by: https://github.com/ezyang
Follow-up of #89582 to drop flags like `CUDA11OrLater` in tests. Note that in some places it appears that `TEST_WITH_ROCM` is _implicitly_ guarded against via the `CUDA11OrLater` version check, based on my best-guess of how `torch.version.cuda` would behave in ROCM builds, so I've added `not TEST_WITH_ROCM` in cases where ROCM wasn't previously explicitly allowed.
CC @ptrblck @malfet @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92605
Approved by: https://github.com/ngimel
This achieves the same things as https://github.com/pytorch/pytorch/pull/85908 but using backends instead of kwargs (which breaks torchscript unfortunately). This also does mean we let go of numpy compatibility BUT the wins here are that users can control what opt einsum they wanna do!
The backend allows for..well you should just read the docs:
```
.. attribute:: torch.backends.opteinsum.enabled
A :class:`bool` that controls whether opt_einsum is enabled (on by default). If so,
torch.einsum will use opt_einsum (https://optimized-einsum.readthedocs.io/en/stable/path_finding.html)
to calculate an optimal path of contraction for faster performance.
.. attribute:: torch.backends.opteinsum.strategy
A :class:`str` that specifies which strategies to try when `torch.backends.opteinsum.enabled` is True.
By default, torch.einsum will try the "auto" strategy, but the "greedy" and "optimal" strategies are
also supported. Note that the "optimal" strategy is factorial on the number of inputs as it tries all
possible paths. See more details in opt_einsum's docs
(https://optimized-einsum.readthedocs.io/en/stable/path_finding.html).
```
In trying (and failing) to land 85908, I discovered that jit script does NOT actually pull from python's version of einsum (because it cannot support variadic args nor kwargs). Thus I learned that jitted einsum does not subscribe to the new opt_einsum path calculation. Overall, this is fine since jit script is getting deprecated, but where is the best place to document this?
## Test plan:
- added tests to CI
- locally tested that trying to set the strategy to something invalid will error properly
- locally tested that tests will pass even if you don't have opt-einsum
- locally tested that setting the strategy when opt-einsum is not there will also error properly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86219
Approved by: https://github.com/soulitzer, https://github.com/malfet
## This PR seeks to:
- [x] add c++ support for an optimize path
- [x] add python opt_einsum path passthrough
- [x] add opt_einsum to OSS requirements, but a soft one
- [x] show benchmark results here
Additional things I've explored + their conclusions:
- **Delaying the summing over dimensions** => added!
- The idea here is to not incur kernel calls to `sum` as we try to early sum out in einsum. Thus, we collect all the dimensions that need to be summed together in one contraction + sum at the end instead of summing as we go. While this optimization didn't feel like it made things faster for the random cases we've selected (they all summed 1 dim per contraction), it is a good principle and would help more common use cases that would reduce multiple dimensions at a time (like `bxy,xyi,xyj->bij`).
- **Caching contract_path based on equation and tensor sizes** => dropped :(
- The benchmarks were strictly worse for all the cases, and, from scanning the use cases, I observed people do not often call einsum on the same equation/tensor order enough for caching to be justified. I do think caching can be effective in the future, but it would require further investigation.
## Not a part of this PR (but are next steps):
- adding opt_einsum package to OSS CI
- adding it to internal CI
- potentially adding a kwarg path argument to the python API -- if the path is given, we wouldn't have to spend time calculating it, but there would be some time lost validating user input.
## Testing:
- Added more tests to CI
## Benchmarking:
**TL;DRs**
- **torch.einsum with opt_einsum is a definite win for the production case**.
- **torch.einsum with opt_einsum installed is consistently fast, but has an overhead** of needing to find the path. If the path is already found/optimal, it will be slightly slower.
- The einsum overhead decreases for bigger dimensions.
- **torch.einsum without opt_einsum installed is comparable to before this commit**, with occasional slowness potentially due to not reshaping/squeezing as we contract until the end.
- For many of the random generated cases, the dimensions were too similar and small where an optimal order wasn't that much more optimal than just going left to right. However, in production, dimensions are commonly quite distinct (batch size will be small, but the data will be huge).
- **torch.einsum opt is comparable (slightly faster overall) compared to numpy.einsum opt for the cpu case**. This is interesting given that torch.einsum currently spends time computing the path, but numpy.einsum takes it as input.
- **torch.einsum opt is significantly faster than numpy.einsum opt for the gpu case**. This is because numpy doesn't take advantage of GPUs.
The following benchmarks were done on an A100 GPU and Linux CPUs. The line in the first chart separates GPU (on top) from CPU, and the line in the second graph separates CPU (on top) and then GPU. Sorry it's flipped 😛 .
Production example (see [colab benchmark](https://colab.research.google.com/drive/1V2s4v1dOOKwRvp5T_DC-PNUosOV9FFJx?authuser=1#scrollTo=WZoQkC8Mdt6I) for more context):
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012636-9a68bfa7-2601-43b1-afeb-b4e0877db6a4.png">
Randomly generated examples (the same ones as in https://github.com/pytorch/pytorch/pull/60191)
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012804-1c639595-b3e6-48c9-a385-ad851c13e1c2.png">
Open below to see old + not super relevant benchmarking results:
<details>
Benchmark results BEFORE this PR (on Linux -- I will update devices so they are consistent later):
<img width="776" alt="image" src="https://user-images.githubusercontent.com/31798555/190807274-18f71fce-556e-47f4-b18c-e0f7d0c0d5aa.png">
Benchmark results with the code on this PR (on my x86 mac):
For the CPU internal use case --

For the general use case --
It looks like numpy opt still does better in several of these random cases, but torch einsum opt is consistently faster than torch.einsum.

<details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84890
Approved by: https://github.com/albanD, https://github.com/soulitzer
Summary: test_inverse_errors_large and test_linalg_solve_triangular fail for dtype=float64 when invoked on GPUs on Meta internal testing infra. Skip in Meta internal testing.
Test Plan: (observe tests skipped on Meta internal infra)
Reviewed By: mikekgfb
Differential Revision: D39785331
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85577
Approved by: https://github.com/malfet
Summary:
Re-submit for approved PR that was then reverted: https://github.com/pytorch/pytorch/pull/85084
Create unit test to detect cuBLAS breakage via large differences between CPU and GPU addmm invocations
Test Plan:
Sample unit test output --
[...]
test_cublas_addmm_size_10000_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_10000_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_10000_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
[...]
Reviewed By: mikekgfb
Differential Revision: D39433029
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85432
Approved by: https://github.com/zrphercule
Summary: Create unit test to detect cuBLAS breakage via large differences between CPU and GPU addmm invocations
Test Plan:
Sample unit test output --
[...]
test_cublas_addmm_size_10000_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_10000_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_10000_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
[...]
Reviewed By: mikekgfb
Differential Revision: D39433029
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85084
Approved by: https://github.com/zrphercule
`torch.norm` is very odd. Some notable issues are:
- The default value of `"fro"` in `torch.norm` has an odd behaviour when `dim=None`. This is handled in the new dispatch
- The treatment of the `dtype` argument in `torch.norm` was completely wrong. This should fix it
- Some `out=` variants in the previous implementation were also wrong. This should fix those.
- This new dispatch should make some paths much faster. For example, `torch.norm(x)` where `x` is complex.
I'll try to make the changes in these PRs as incremental as possible as this is a tricky one.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81761
Approved by: https://github.com/ngimel
As per title. I corrected a thing or two from my previous implementation
to make for better errors in some weird edge-cases and have a more clear
understanding of when does this function support low_precision types and
when it doesn't.
We also use the optimisation for bfloat16 within `vector_norm` within
this function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81113
Approved by: https://github.com/ngimel
This PR also adds complex support for logdet, and makes all these
functions support out= and be composite depending on one function. We
also extend the support of `logdet` to complex numbers and improve the
docs of all these functions.
We also use `linalg_lu_factor_ex` in these functions, so we remove the
synchronisation present before.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79742
Approved by: https://github.com/IvanYashchuk, https://github.com/albanD
This PR heavily simplifies the code of `linalg.solve`. At the same time,
this implementation saves quite a few copies of the input data in some
cases (e.g. A is contiguous)
We also implement it in such a way that the derivative goes from
computing two LU decompositions and two LU solves to no LU
decompositions and one LU solves. It also avoids a number of unnecessary
copies the derivative was unnecessarily performing (at least the copy of
two matrices).
On top of this, we add a `left` kw-only arg that allows the user to
solve `XA = B` rather concisely.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74046
Approved by: https://github.com/nikitaved, https://github.com/IvanYashchuk, https://github.com/mruberry
This PR simplifies the logic of `linalg.qr` using structured kernels. I
also took this chance and merged a few `copy_` operations with other
ops.
This PR removes a the previous magma implementation as is never faster
than that of cusolver and it's rather buggy. This has the side-effect
that now `qr` is not supported in Rocm. Ivan confirmed that this is
fine, given how incredibly slow was QR on Rocm anyway (we were marking
some tests as slow because of this...).
This PR also corrects the dispatch in geqrf. Before, if we called it
with a matrix for which `input.size(-2) <= 256 && batchCount(input) >= std::max<int64_t>(2, input.size(-2) / 16)` is false, and we have cublas but not cusolver, we would end up calling magma rather than cublas. This is not what the heuristic suggested.
Probaly we should benchmark these heuristics again, but that's beyond the scope of this PR.
Note. It looks like `torch.geqrf` maybe broken in MAGMA as per the
previous comment in `linalg_qr_helper_magma`. IvanYashchuk wdyt?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79054
Approved by: https://github.com/IvanYashchuk, https://github.com/ezyang
**BC-breaking note**:
This PR deprecates `torch.lu` in favor of `torch.linalg.lu_factor`.
A upgrade guide is added to the documentation for `torch.lu`.
Note this PR DOES NOT remove `torch.lu`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77636
Approved by: https://github.com/malfet
This PR adds `linalg.lu_solve`. While doing so, I found a bug in MAGMA
when calling the batched MAGMA backend with trans=True. We work around
that by solving the system solving two triangular systems.
We also update the heuristics for this function, as they were fairly
updated. We found that cuSolver is king, so luckily we do not need to
rely on the buggy backend from magma for this function.
We added tests testing this function left and right. We also added tests
for the different backends. We also activated the tests for AMD, as
those should work as well.
Fixes https://github.com/pytorch/pytorch/issues/61657
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77634
Approved by: https://github.com/malfet
This PR does a number of things:
- Move linalg.vector_norm to structured kernels and simplify the logic
- Fixes a number of prexisting issues with the dtype kwarg of these ops
- Heavily simplifies and corrects the logic of `linalg.matrix_norm` and `linalg.norm` to be consistent with the docs
- Before the `_out` versions of these functions were incorrect
- Their implementation is now as efficient as expected, as it avoids reimplementing these operations whenever possible.
- Deprecates `torch.frobenius_norm` and `torch.nuclear_norm`, as they were exposed in the API and they are apparently being used in mobile (??!!) even though they were not documented and their implementation was slow.
- I'd love to get rid of these functions already, but I guess we have to go through their deprecation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76547
Approved by: https://github.com/mruberry
This PR adds `linalg.lu_solve`. While doing so, I found a bug in MAGMA
when calling the batched MAGMA backend with trans=True. We work around
that by solving the system solving two triangular systems.
We also update the heuristics for this function, as they were fairly
updated. We found that cuSolver is king, so luckily we do not need to
rely on the buggy backend from magma for this function.
We added tests testing this function left and right. We also added tests
for the different backends. We also activated the tests for AMD, as
those should work as well.
Fixes https://github.com/pytorch/pytorch/issues/61657
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72935
Approved by: https://github.com/IvanYashchuk, https://github.com/mruberry
This PR modifies `lu_unpack` by:
- Using less memory when unpacking `L` and `U`
- Fuse the subtraction by `-1` with `unpack_pivots_stub`
- Define tensors of the correct types to avoid copies
- Port `lu_unpack` to be a strucutred kernel so that its `_out` version
does not incur on extra copies
Then we implement `linalg.lu` as a structured kernel, as we want to
compute its derivative manually. We do so because composing the
derivatives of `torch.lu_factor` and `torch.lu_unpack` would be less efficient.
This new function and `lu_unpack` comes with all the things it can come:
forward and backward ad, decent docs, correctness tests, OpInfo, complex support,
support for metatensors and support for vmap and vmap over the gradients.
I really hope we don't continue adding more features.
This PR also avoids saving some of the tensors that were previously
saved unnecessarily for the backward in `lu_factor_ex_backward` and
`lu_backward` and does some other general improvements here and there
to the forward and backward AD formulae of other related functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67833
Approved by: https://github.com/IvanYashchuk, https://github.com/nikitaved, https://github.com/mruberry
We derive and implement a more concise rule for the forward and backward
derivatives of the QR decomposition. While doing this we:
- Fix the composite compliance of `linalg.qr` and we make it support batches
- Improve the performance and simplify the implementation of both foward and backward
- Avoid saving the input matrix for the backward computation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76115
Approved by: https://github.com/nikitaved, https://github.com/albanD
Let's make sure we don't break anything in the next PRs of the stack.
Also some comprehensive testing of matmul on CPU and CUDA was long due.
Running this tests we see that the `out=` variant of matmul is broken
when used on 4D tensors. This hints what would be the amount of people
that use out= variants...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75193
Approved by: https://github.com/ngimel
This PR adds a function for computing the LDL decomposition and a function that can solve systems of linear equations using this decomposition. The result of `torch.linalg.ldl_factor_ex` is in a compact form and it's required to use it only through `torch.linalg.ldl_solve`. In the future, we could provide `ldl_unpack` function that transforms the compact representation into explicit matrices.
Fixes https://github.com/pytorch/pytorch/issues/54847.
cc @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69828
Approved by: https://github.com/Lezcano, https://github.com/mruberry, https://github.com/albanD
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73748
This adds CPU-only slow test jobs, which previously would never run.
Includes fixes/skips for slow tests which fail (they need to be skipped now because they used to never run)
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D34628803
Pulled By: davidberard98
fbshipit-source-id: c090ab7bf7bda9e24ec5cdefa6fd35c6310dbac0
(cherry picked from commit 06f7a94a57cc7023e9c5442be8298d20cd011144)
Summary:
Previous PR with the same content: https://github.com/pytorch/pytorch/pull/69752. Opening a new PR by request: https://github.com/pytorch/pytorch/pull/69752#issuecomment-1020829812.
------
Previously for single input matrix A and batched matrix B, matrix A was expanded and cloned before computing the LU decomposition and solving the linear system.
With this PR the LU decomposition is computed once for a single matrix and then expanded&cloned if required by a backend library call for the linear system solving.
Here's a basic comparison:
```python
# BEFORE THE PR
In [1]: import torch
In [2]: a = torch.randn(256, 256)
In [3]: b = torch.randn(1024, 256, 2)
In [4]: %%timeit
...: torch.linalg.solve(a, b)
...:
...:
329 ms ± 17.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# WITH THIS PR
In [1]: import torch
In [2]: a = torch.randn(256, 256)
In [3]: b = torch.randn(1024, 256, 2)
In [4]: %%timeit
...: torch.linalg.solve(a, b)
...:
...:
21.4 ms ± 23 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
```
Fixes https://github.com/pytorch/pytorch/issues/71406, fixes https://github.com/pytorch/pytorch/issues/71610
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71756
Reviewed By: ngimel
Differential Revision: D33771981
Pulled By: mruberry
fbshipit-source-id: 0917ee36a3eb622ff75d54787b1bffe26b41cb4a
(cherry picked from commit 9c30a05aaa972bc02dfc94c3d2463f0c5ee0c58c)
Summary:
This PR was opened as copy of https://github.com/pytorch/pytorch/pull/68812 by request https://github.com/pytorch/pytorch/pull/68812#issuecomment-1030215862.
-----
Fixes https://github.com/pytorch/pytorch/issues/67693.
Reference LAPACK (used in OpenBLAS) changed info error code for svd when inputs contain non-finite numbers. In PyTorch, we raise an internal assert error for negative `info` error codes because usually, it would indicate the wrong implementation. However, this is not the case with SVD now in newer versions of LAPACK. MKL (tried 2021.4.0) still gives a positive error code for this kind of input. This change aligns with the OpenBLAS and MKL behavior in our code.
MKL 2022 has uses the latest reference LAPACK behavior and returns the same `info` as OpenBLAS 0.3.15+
This PR also fixes https://github.com/pytorch/pytorch/issues/71645 that is due to the updated MKL version in CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72357
Reviewed By: albanD
Differential Revision: D34012245
Pulled By: ngimel
fbshipit-source-id: 2b66c173cc3458d8c766b542d0d569191cdce310
(cherry picked from commit fa29e65611)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/67693.
Reference LAPACK (used in OpenBLAS) changed info error code for svd when inputs contain non-finite numbers. In PyTorch, we raise an internal assert error for negative `info` error codes because usually, it would indicate wrong implementation. However, this is not the case with SVD now in newer versions of LAPACK. MKL (tried 2021.4.0) still gives a positive error code for this kind of input. This change aligns with the OpenBLAS and MKL behavior in our code.
**UPDATE:**
MKL 2022 has uses the latest reference LAPACK behavior and returns the same `info` as OpenBLAS 0.3.15+
This PR fixes https://github.com/pytorch/pytorch/issues/71645 that is due to the updated MKL version in CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68812
Reviewed By: mrshenli
Differential Revision: D33844257
Pulled By: ngimel
fbshipit-source-id: fd1c86e37e405b330633d039f49dce466391b66e
(cherry picked from commit c00a9bdeb0)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/67693.
Reference LAPACK (used in OpenBLAS) changed info error code for svd when inputs contain non-finite numbers. In PyTorch, we raise an internal assert error for negative `info` error codes because usually, it would indicate wrong implementation. However, this is not the case with SVD now in newer versions of LAPACK. MKL (tried 2021.4.0) still gives a positive error code for this kind of input. This change aligns with the OpenBLAS and MKL behavior in our code.
**UPDATE:**
MKL 2022 has uses the latest reference LAPACK behavior and returns the same `info` as OpenBLAS 0.3.15+
This PR fixes https://github.com/pytorch/pytorch/issues/71645 that is due to the updated MKL version in CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68812
Reviewed By: osalpekar
Differential Revision: D32626563
Pulled By: ngimel
fbshipit-source-id: 09042f07cdc9c24ce1fa5cd6f4483340c7b5b06c
(cherry picked from commit aadf507319)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70253
I included a derivation of the formula in the complex case, as it is
particularly tricky. As far as I know, this is the first time this formula
is derived in the literature.
I also implemented a more efficient and more accurate version of svd_backward.
More importantly, I also added a lax check in the complex case making sure the loss
function just depends on the subspaces spanned by the pairs of singular
vectors, and not their joint phase.
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: mikaylagawarecki
Differential Revision: D33751982
Pulled By: mruberry
fbshipit-source-id: c2a4a92a921a732357e99c01ccb563813b1af512
(cherry picked from commit 391319ed8f)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69827
In general, the current pattern allows for implementing optimisations
for all the backends in a common place (see for example the optimisation
for empty matrices).
After this PR, `torch.svd` is implemented in terms of `linalg.svd` and
`linalg.svdvals`, as expected. This makes it differentiable in the case
when `compute_uv=False`, although this is not particularly important, as
`torch.svd` will eventually be deprecated.
This PR also instantiates smaller `U` / `V` when calling cusolver_gesvdj
in the cases when `full_matrices=False` or `compute_uv=False`.
The memory for auxiliary `U` and `V` in the cases above, needed for some
cuSOLVER routines is allocated raw allocators rather than through fully
fledged tensors, as it's just a blob of memory the algorithm requests.
As the code is better structured now, it was easier to see that `U` and
`Vh` needn't be allocated when calling `svd_cusolver_gesvd`.
Now `linalg.svdvals` work as expected wrt the `out=` parameter.
Note that in the test `test_svd_memory_allocation` we were
passing a tensor of the wrong size and dtype and the test seemed to
pass...
This PR also changes the backward formula to avoid saving the input
matrix, as it's not necessary. In a follow up PR, I will clean the
backward formula and make it more numerically stable and efficient.
This PR also does a number of memory optimisations here and there, and fixes
the call to cusolver_gesvd, which were incorrect for m <= n. To test
this path, I compiled the code with a flag to unconditionally execute
the `if (!gesvdj_convergence_check.empty())` branch, and all the tests
passed.
I also took this chance to simplify the tests for these functions in
`test_linalg.py`, as we had lots of tests that were testing some
functionality that is already currently tested in the corresponding
OpInfos. I used xwang233's feature to test both MAGMA and CUDA
backends. This is particularly good for SVD, as cuSOLVER is always
chosen over MAGMA when available, so testing MAGMA otherwise would be
tricky.
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: mikaylagawarecki
Differential Revision: D33751983
Pulled By: mruberry
fbshipit-source-id: 11d48d977946345583d33d14fb11a170a7d14fd2
(cherry picked from commit a1860bd567)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68183
We do so in favour of
`make_fullrank_matrices_with_distinct_singular_values` as this latter
one not only has an even longer name, but also generates inputs
correctly for them to work with the PR that tests noncontig inputs
latter in this stack.
We also heavily simplified the generation of samples for the SVD, as it was
fairly convoluted and it was not generating the inputs correclty for
the noncontiguous test.
To do the transition, we also needed to fix the following issue, as it was popping
up in the tests:
Fixes https://github.com/pytorch/pytorch/issues/66856
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D32684853
Pulled By: mruberry
fbshipit-source-id: e88189c8b67dbf592eccdabaf2aa6d2e2f7b95a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D32834069
Pulled By: mruberry
fbshipit-source-id: 51ef12535fa91d292f419acf83b800b86ee9c7eb
Summary:
This PR fixes https://github.com/pytorch/pytorch/issues/64785 by introducing a `torch.LinAlgError` for reporting errors caused by bad values in linear algebra routines which should allow users to easily catch errors caused by numerical errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68571
Reviewed By: malfet
Differential Revision: D33254087
Pulled By: albanD
fbshipit-source-id: 94b59000fdb6a9765e397158e526d1f815f18f0f
Summary:
Per title.
This PR introduces a global flag that lets pytorch prefer one of the many backend implementations while calling linear algebra functions on GPU.
Usage:
```python
torch.backends.cuda.preferred_linalg_library('cusolver')
```
Available options (str): `'default'`, `'cusolver'`, `'magma'`.
Issue https://github.com/pytorch/pytorch/issues/63992 inspired me to write this PR. No heuristic is perfect on all devices, library versions, matrix shapes, workloads, etc. We can obtain better performance if we can conveniently switch linear algebra backends at runtime.
Performance of linear algebra operators after this PR should be no worse than before. The flag is set to **`'default'`** by default, which makes everything the same as before this PR.
The implementation of this PR is basically following that of https://github.com/pytorch/pytorch/pull/67790.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67980
Reviewed By: mruberry
Differential Revision: D32849457
Pulled By: ngimel
fbshipit-source-id: 679fee7744a03af057995aef06316306073010a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63570
There is a use of `at::triangular_solve_out` in the file
`torch/csrc/jit/tensorexpr/external_functions.cpp` that I have not dared
to move to `at::linalg_solve_triangular_out`.
**Deprecation note:**
This PR deprecates the `torch.triangular_solve` function in favor of
`torch.linalg.solve_triangular`. An upgrade guide is added to the
documentation for `torch.triangular_solve`.
Note that it DOES NOT remove `torch.triangular_solve`, but
`torch.triangular_solve` will be removed in a future PyTorch release.
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D32618035
Pulled By: anjali411
fbshipit-source-id: 0bfb48eeb6d96eff3e96e8a14818268cceb93c83
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D32521980
Pulled By: mruberry
fbshipit-source-id: 26a49ebd87f8a41472f8cd4e9de4ddfb7f5581fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63568
This PR adds the first solver with structure to `linalg`. This solver
has an API compatible with that of `linalg.solve` preparing these for a
possible future merge of the APIs. The new API:
- Just returns the solution, rather than the solution and a copy of `A`
- Removes the confusing `transpose` argument and replaces it by a
correct handling of conj and strides within the call
- Adds a `left=True` kwarg. This can be achieved via transposes of the
inputs and the result, but it's exposed for convenience.
This PR also implements a dataflow that minimises the number of copies
needed before calling LAPACK / MAGMA / cuBLAS and takes advantage of the
conjugate and neg bits.
This algorithm is implemented for `solve_triangular` (which, for this, is
the most complex of all the solvers due to the `upper` parameters).
Once more solvers are added, we will factor out this calling algorithm,
so that all of them can take advantage of it.
Given the complexity of this algorithm, we implement some thorough
testing. We also added tests for all the backends, which was not done
before.
We also add forward AD support for `linalg.solve_triangular` and improve the
docs of `linalg.solve_triangular`. We also fix a few issues with those of
`torch.triangular_solve`.
Resolves https://github.com/pytorch/pytorch/issues/54258
Resolves https://github.com/pytorch/pytorch/issues/56327
Resolves https://github.com/pytorch/pytorch/issues/45734
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32588230
Pulled By: mruberry
fbshipit-source-id: 69e484849deb9ad7bb992cc97905df29c8915910
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63568
This PR adds the first solver with structure to `linalg`. This solver
has an API compatible with that of `linalg.solve` preparing these for a
possible future merge of the APIs. The new API:
- Just returns the solution, rather than the solution and a copy of `A`
- Removes the confusing `transpose` argument and replaces it by a
correct handling of conj and strides within the call
- Adds a `left=True` kwarg. This can be achieved via transposes of the
inputs and the result, but it's exposed for convenience.
This PR also implements a dataflow that minimises the number of copies
needed before calling LAPACK / MAGMA / cuBLAS and takes advantage of the
conjugate and neg bits.
This algorithm is implemented for `solve_triangular` (which, for this, is
the most complex of all the solvers due to the `upper` parameters).
Once more solvers are added, we will factor out this calling algorithm,
so that all of them can take advantage of it.
Given the complexity of this algorithm, we implement some thorough
testing. We also added tests for all the backends, which was not done
before.
We also add forward AD support for `linalg.solve_triangular` and improve the
docs of `linalg.solve_triangular`. We also fix a few issues with those of
`torch.triangular_solve`.
Resolves https://github.com/pytorch/pytorch/issues/54258
Resolves https://github.com/pytorch/pytorch/issues/56327
Resolves https://github.com/pytorch/pytorch/issues/45734
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: zou3519, JacobSzwejbka
Differential Revision: D32283178
Pulled By: mruberry
fbshipit-source-id: deb672e6e52f58b76536ab4158073927a35e43a8
Summary:
### Create `linalg.cross`
Fixes https://github.com/pytorch/pytorch/issues/62810
As discussed in the corresponding issue, this PR adds `cross` to the `linalg` namespace (**Note**: There is no method variant) which is slightly different in behaviour compared to `torch.cross`.
**Note**: this is NOT an alias as suggested in mruberry's [https://github.com/pytorch/pytorch/issues/62810 comment](https://github.com/pytorch/pytorch/issues/62810#issuecomment-897504372) below
> linalg.cross being consistent with the Python Array API (over NumPy) makes sense because NumPy has no linalg.cross. I also think we can implement linalg.cross without immediately deprecating torch.cross, although we should definitely refer users to linalg.cross. Deprecating torch.cross will require additional review. While it's not used often it is used, and it's unclear if users are relying on its unique behavior or not.
The current default implementation of `torch.cross` is extremely weird and confusing. This has also been reported multiple times previously. (See https://github.com/pytorch/pytorch/issues/17229, https://github.com/pytorch/pytorch/issues/39310, https://github.com/pytorch/pytorch/issues/41850, https://github.com/pytorch/pytorch/issues/50273)
- [x] Add `torch.linalg.cross` with default `dim=-1`
- [x] Add OpInfo and other tests for `torch.linalg.cross`
- [x] Add broadcasting support to `torch.cross` and `torch.linalg.cross`
- [x] Remove out skip from `torch.cross` OpInfo
- [x] Add docs for `torch.linalg.cross`. Improve docs for `torch.cross` mentioning `linalg.cross` and the difference between the two. Also adds a warning to `torch.cross`, that it may change in the future (we might want to deprecate it later)
---
### Additional Fixes to `torch.cross`
- [x] Fix Doc for Tensor.cross
- [x] Fix torch.cross in `torch/overridres.py`
While working on `linalg.cross` I noticed these small issues with `torch.cross` itself.
[Tensor.cross docs](https://pytorch.org/docs/stable/generated/torch.Tensor.cross.html) still mentions `dim=-1` default which is actually wrong. It should be `dim=None` after the behaviour was updated in PR https://github.com/pytorch/pytorch/issues/17582 but the documentation for the `method` or `function` variant wasn’t updated. Later PR https://github.com/pytorch/pytorch/issues/41850 updated the documentation for the `function` variant i.e `torch.cross` and also added the following warning about the weird behaviour.
> If `dim` is not given, it defaults to the first dimension found with the size 3. Note that this might be unexpected.
But still, the `Tensor.cross` docs were missed and remained outdated. I’m finally fixing that here. Also fixing `torch/overrides.py` for `torch.cross` as well now, with `dim=None`.
To verify according to the docs the default behaviour of `dim=-1` should raise, you can try the following.
```python
a = torch.randn(3, 4)
b = torch.randn(3, 4)
b.cross(a) # this works because the implementation finds 3 in the first dimension and the default behaviour as shown in documentation is actually not true.
>>> tensor([[ 0.7171, -1.1059, 0.4162, 1.3026],
[ 0.4320, -2.1591, -1.1423, 1.2314],
[-0.6034, -1.6592, -0.8016, 1.6467]])
b.cross(a, dim=-1) # this raises as expected since the last dimension doesn't have a 3
>>> RuntimeError: dimension -1 does not have size 3
```
Please take a closer look (particularly the autograd part, this is the first time I'm dealing with `derivatives.yaml`). If there is something missing, wrong or needs more explanation, please let me know. Looking forward to the feedback.
cc mruberry Lezcano IvanYashchuk rgommers
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63285
Reviewed By: gchanan
Differential Revision: D32313346
Pulled By: mruberry
fbshipit-source-id: e68c2687c57367274e8ddb7ef28ee92dcd4c9f2c
Summary:
use product instead of zip to cover all cases
cc mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67635
Reviewed By: malfet
Differential Revision: D32310956
Pulled By: mruberry
fbshipit-source-id: 806c3313e2db26d77199d3145b2d5283b6ca3617
Summary:
stas00 uncovered an issue where certain half-precision GEMMs would produce outputs that looked like the result of strange rounding behavior (e.g., `10008.` in place of `10000.`). ptrblck suspected that this was due to the parameters being downcasted to the input types (which would reproduce the problematic output). Indeed, the GEMM and BGEMM cublas wrappers are currently converting the `alpha` and `beta` parameters to `scalar_t` (which potentially is reduced precision) before converting them back to `float`. This PR changes the "ARGTYPE" wrappers to use `acc_t` instead and adds a corresponding test.
CC ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67633
Reviewed By: mruberry
Differential Revision: D32076474
Pulled By: ngimel
fbshipit-source-id: 2540d9b9d0195c17d07d1161374fb6a5850779d5
Summary:
It appears that most NVIDIA architectures (well, at least there haven't been many reports of this issue) don't do reduced precision reductions (e.g., reducing in fp16 given fp16 inputs), but this change attempts to ensure that a reduced precision reduction is never done. The included test case currently fails on Volta but passes on Pascal and Ampere; setting this flag causes the test to pass on all three.
CC stas00 ngimel ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67578
Reviewed By: mruberry
Differential Revision: D32046030
Pulled By: ngimel
fbshipit-source-id: ac9aa8489ad6835f34bd0300c5d6f4ea76f333d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62734
Following https://github.com/pytorch/pytorch/pull/62715#discussion_r682610788
- squareCheckInputs takes a string with the name of the function
- We reuse more functions when checking the inputs
The state of the errors in torch.linalg is far from great though. We
leave a more comprehensive clean-up for the future.
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D31823230
Pulled By: mruberry
fbshipit-source-id: eccd531f10d590eb5f9d04a957b7cdcb31c72ea4
Summary:
Skip failing tests when LAPACK and MAGMA are not available for ` test_linalg.py` and ` test_ops.py`.
Note that there's no CI without LAPACK or MAGMA. I verified locally that now it works as expected, but in the future we have no guards against tests failing again for this situation.
<details>
<summary> test_ops.py failures that are fixed</summary>
```
FAILED test/test_ops.py::TestCommonCPU::test_out_linalg_tensorinv_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_reference_testing_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_reference_testing_linalg_tensorinv_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_linalg_tensorinv_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_triangular_solve_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_triangular_solve_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_linalg_tensorinv_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_triangular_solve_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_linalg_tensorinv_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_triangular_solve_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_linalg_tensorinv_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_triangular_solve_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestJitCPU::test_variant_consistency_jit_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestJitCPU::test_variant_consistency_jit_triangular_solve_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestJitCPU::test_variant_consistency_jit_triangular_solve_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_conj_view_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_conj_view_triangular_solve_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_neg_view_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_neg_view_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
```
</details>
<details>
<summary> test_linalg.py failures that are fixed</summary>
```
FAILED test/test_linalg.py::TestLinalgCPU::test_norm_dtype_cpu - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCPU::test_norm_matrix_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCPU::test_norm_matrix_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCPU::test_nuclear_norm_axes_small_brute_force_old_cpu - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_eigh_hermitian_grad_meta_complex128 - RuntimeError: Calling torch.linalg.eigh or eigvalsh on a CPU tensor requires compiling PyTorch with LAPACK. Please use PyTorch built with LAPACK support.
FAILED test/test_linalg.py::TestLinalgMETA::test_eigh_hermitian_grad_meta_float64 - RuntimeError: Calling torch.linalg.eigh or eigvalsh on a CPU tensor requires compiling PyTorch with LAPACK. Please use PyTorch built with LAPACK support.
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_col_maj_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_col_maj_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_col_maj_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_col_maj_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_col_maj_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_col_maj_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_lowrank_cuda_float64 - RuntimeError: Calling torch.lu on a CUDA tensor requires compiling PyTorch with MAGMA. lease rebuild with MAGMA.
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_col_maj_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_col_maj_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_col_maj_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_col_maj_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_col_maj_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_col_maj_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
```
</details>
Fixes https://github.com/pytorch/pytorch/issues/59662
cc mruberry jianyuh nikitaved pearu walterddr IvanYashchuk xwang233 Lezcano
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64930
Reviewed By: zou3519
Differential Revision: D31739416
Pulled By: mruberry
fbshipit-source-id: 153c40d8eeeb094b06816882a7cbb28c681509a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64181
This PR replaces all the calls to:
- `transpose(-2, -1)` or `transpose(-1, -2)` by `mT()` in C++ and `mT` in Python
- `conj().transpose(-2, -1)` or `transpose(-2, -1).conj()` or `conj().transpose(-1, -2)` or `transpose(-1, -2).conj()` by `mH()` in C++ and `mH` in Python.
It also simplifies two pieces of code, and fixes one bug where a pair
of parentheses were missing in the function `make_symmetric_matrices`.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D31692896
Pulled By: anjali411
fbshipit-source-id: e9112c42343663d442dc5bd53ff2b492094b434a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66645
Fixes:
```
test_cholesky_solve_batched_broadcasting_cpu_complex128 (__main__.TestLinalgCPU) ... test_linalg.py:3099: UserWarning: torch.cholesky is deprecated in favor of torch.linalg.cholesky and will be removed in a future PyTorch release.
```
Test Plan: Sandcastle
Reviewed By: mruberry
Differential Revision: D31635851
fbshipit-source-id: c377eb88d753fb573b3947f0c6ff5df055cb13d8
Summary:
Skip failing tests when LAPACK and MAGMA are not available for ` test_linalg.py` and ` test_ops.py`.
Note that there's no CI without LAPACK or MAGMA. I verified locally that now it works as expected, but in the future we have no guards against tests failing again for this situation.
<details>
<summary> test_ops.py failures that are fixed</summary>
```
FAILED test/test_ops.py::TestCommonCPU::test_out_linalg_tensorinv_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_reference_testing_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_reference_testing_linalg_tensorinv_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_linalg_tensorinv_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_triangular_solve_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_triangular_solve_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_linalg_tensorinv_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_triangular_solve_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_linalg_tensorinv_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_triangular_solve_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_linalg_tensorinv_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_triangular_solve_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestJitCPU::test_variant_consistency_jit_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestJitCPU::test_variant_consistency_jit_triangular_solve_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestJitCPU::test_variant_consistency_jit_triangular_solve_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_conj_view_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_conj_view_triangular_solve_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_neg_view_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_neg_view_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
```
</details>
<details>
<summary> test_linalg.py failures that are fixed</summary>
```
FAILED test/test_linalg.py::TestLinalgCPU::test_norm_dtype_cpu - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCPU::test_norm_matrix_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCPU::test_norm_matrix_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCPU::test_nuclear_norm_axes_small_brute_force_old_cpu - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_eigh_hermitian_grad_meta_complex128 - RuntimeError: Calling torch.linalg.eigh or eigvalsh on a CPU tensor requires compiling PyTorch with LAPACK. Please use PyTorch built with LAPACK support.
FAILED test/test_linalg.py::TestLinalgMETA::test_eigh_hermitian_grad_meta_float64 - RuntimeError: Calling torch.linalg.eigh or eigvalsh on a CPU tensor requires compiling PyTorch with LAPACK. Please use PyTorch built with LAPACK support.
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_col_maj_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_col_maj_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_col_maj_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_col_maj_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_col_maj_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_col_maj_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_lowrank_cuda_float64 - RuntimeError: Calling torch.lu on a CUDA tensor requires compiling PyTorch with MAGMA. lease rebuild with MAGMA.
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_col_maj_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_col_maj_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_col_maj_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_col_maj_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_col_maj_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_col_maj_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
```
</details>
Fixes https://github.com/pytorch/pytorch/issues/59662
cc mruberry jianyuh nikitaved pearu walterddr IvanYashchuk xwang233 Lezcano
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64930
Reviewed By: H-Huang
Differential Revision: D31137652
Pulled By: mruberry
fbshipit-source-id: c969f75d7cf185765211004a0878e7c8a5d3cbf7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63567
The current implementation called trtrs for CPU and trsm for CUDA.
See https://github.com/pytorch/pytorch/issues/56326#issuecomment-825496115 for a discussion on the differences between
these two functions and why we prefer trsm vs trtrs on CUDA.
This PR also exposes the `side` argument of this function which is used
in the second PR of this stack to optimise the number copies one needs to make
when preparing the arguments to be sent to the backends.
It also changes the use of `bool`s to a common enum type to represent
whether a matrix is transposed / conj transposed, etc. This makes the API
consistent, as before, the behaviour of these functions with `transpose=True`
and `conjugate_transpose=True` it was not well defined.
Functions to transform this type into the specific types / chars for the different
libraries are provided under the names `to_blas`, `to_lapack`, `to_magma`, etc.
This is the first of a stack of PRs that aim to improve the performance of
`linalg.solve_triangular`. `trsm` has an extra parameter (`side`), which allows to
ellide the copy of the triangular matrix in many cases.
Fixes https://github.com/pytorch/pytorch/issues/56326
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D30566479
Pulled By: mruberry
fbshipit-source-id: 3831af9b51e09fbfe272c17c88c21ecf45413212
Summary:
# Goal: Integrate mkldnn bf16 Gemm to pytorch
## BF16 Suport for mm, addmm, bmm, addbmm, baddbmm, mv, addmv, dot (with mkldnn matmul primitive):
https://oneapi-src.github.io/oneDNN/group__dnnl__api__matmul.html
For gemm related ops, we keep all inputs under plain format. So we will not introduce opaque tensor for these ops to save mem copy here.

The minimized integration is only dispatch to mkldnn in addmm, but for gemm with 3-D input (with additional dim for"batch") this will call mkldnn gemm for "batch" times. Since mkldnn matmul support input with multiple dims, we directly dispatch to mkldnn gemm in {bmm, addbmm, baddbmm} to reduce the time to create mkldnn memory desc, primitive, etc.
For the different definition for "bias" between mkldnn(which must be shape of (1, N)) and pytorch (which can be same shape with gemm result (M, N)), we use a fused sum to handle it.
## User Case:
User case is exactly same with before because no opaque tensor's is introduced. Since the pytorch has already support bf16 data type with CPU tensor before, we can leverage the existed bf16 gemm UT.
## Gemm performance gain on CPX 28Cores/Socket:
Note: data is collected using PyTorch operator benchmarks: https://github.com/pytorch/pytorch/tree/master/benchmarks/operator_benchmark (with adding bfloat16 dtype)
### use 1 thread on 1 core
### torch.addmm (M, N) * (N, K) + (M, K)
| impl |16x16x16|32x32x32| 64x64x64 | 128x128x128| 256x256x256| 512x512x512|1024x1024x1024|
|:---:|:---:| :---: | :---: | :---: | :---: | :---: | :---: |
| aten-fp32| 4.115us|4.583us|8.230us|26.972us|211.857us|1.458ms|11.258ms|
| aten-bf16 | 15.812us| 105.087us|801.787us|3.767ms|20.274ms|122.440ms|836.453ms|
| mkldnn-bf16 |20.561us |22.510us|24.551us|37.709us|143.571us|0.835ms|5.76ms|
We can see mkldnn-bf16 are better than aten bf16, but for smaller shapes, mkldnn bf16 are not better than aten fp32. This is because onednn overhead, this overhead more like a "constant" overhead and while problems get larger, we can ignore it. Also we are continue optimize the kernel efficiency and decrease the overhead as well.
More shapes
| impl |1x2048x2048|2048x1x2048| 2048x2048x1 |
|:---:|:---:| :---: | :---: |
| aten-fp32| 0.640ms|3.794ms|0.641ms|
| aten-bf16 | 2.924ms| 3.868ms|23.413ms|
| mkldnn-bf16 |0.335ms |4.490ms|0.368ms|
### use 1 socket (28 thread, 28 core)
| impl | 256x256x256| 512x512x512|1024x1024x1024| 2048x2048x2048|4096x4096x4096|
|:---:| :---: | :---: | :---: | :---: | :---: |
| aten-fp32| 35.943us |140.315us|643.510us|5.827ms|41.761ms|
| mkldnn-bf16 |53.432us|114.716us|421.858us|2.863ms|23.029ms|
More shapes
| impl |128x2048x2048|2048x128x2048| 2048x2048x128 |
|:---:|:---:| :---: | :---: |
| aten-fp32| 0.561ms|0.458ms|0.406ms|
| mkldnn-bf16 |0.369ms |0.331ms|0.239ms|
We dose not show aten-bf16 for this case since aten-bf16 always compute as single thread and the performance is extreme poor. The trend for this case is similar for 1 thread on 1 core.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61891
Reviewed By: iramazanli
Differential Revision: D29998114
Pulled By: VitalyFedyunin
fbshipit-source-id: 459dc5874c638d62f290c96684ca0a694ded4b5a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63554
Following https://github.com/pytorch/pytorch/pull/61840#issuecomment-884087809, this deprecates all the dtype getters publicly exposed in the `torch.testing` namespace. The reason for this twofold:
1. If someone is not familiar with the C++ dispatch macros PyTorch uses, the names are misleading. For example `torch.testing.floating_types()` will only give you `float32` and `float64` skipping `float16` and `bfloat16`.
2. The dtype getters provide very minimal functionality that can be easily emulated by downstream libraries.
We thought about [providing an replacement](https://gist.github.com/pmeier/3dfd2e105842ad0de4505068a1a0270a), but ultimately decided against it. The major problem is BC: by keeping it, either the namespace is getting messy again after a new dtype is added or we need to somehow version the return values of the getters.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D30662206
Pulled By: mruberry
fbshipit-source-id: a2bdb10ab02ae665df1b5b76e8afa9af043bbf56
Summary:
Before this PR for m x n input matrix, the return matrices were always allocated as m x m and n x n and then narrowed.
This unnecessarily requires a lot of memory that is then discarded.
With this PR when `compute_uv=True and full_matrices=False` correctly sized tensors are allocated. Moreover, if `compute_uv=False` U, V matrices are not allocated as they are not needed. However, cusolver's gesvdj routines fail when these matrices are not allocated, which is a bug, so this allocation is done separately in cusolver specific code path.
MAGMA doesn't work for this input because it tries to allocate a large matrix internally (ROCm doesn't work as it uses MAGMA). Example error:
```
CUBLAS error: memory mapping error (11) in magma_sgelqf at /opt/conda/conda-bld/magma-cuda110_1598416697386/work/src/sgelqf.cpp:161
CUBLAS error: out of memory (3) in magma_sgeqrf2_gpu at /opt/conda/conda-bld/magma-cuda110_1598416697386/work/src/sgeqrf2_gpu.cpp:145
CUBLAS error: not initialized (1) in magma_sgeqrf2_gpu at /opt/conda/conda-bld/magma-cuda110_1598416697386/work/src/sgeqrf2_gpu.cpp:145
MAGMA error: function-specific error, see documentation (1) in magma_sgeqrf2_gpu at /opt/conda/conda-bld/magma-cuda110_1598416697386/work/src/sgeqrf2_gpu.cpp:145
MAGMA error: function-specific error, see documentation (1) in magma_sgeqrf2_gpu at /opt/conda/conda-bld/magma-cuda110_1598416697386/work/src/sgeqrf2_gpu.cpp:145
python: /opt/conda/conda-bld/magma-cuda110_1598416697386/work/interface_cuda/interface.cpp:806: void magma_queue_create_internal(magma_device_t, magma_queue**, const char*, const char*, int): Assertion `queue->dAarray__ != __null' failed.
Aborted (core dumped)
```
Fixes https://github.com/pytorch/pytorch/issues/61949.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62022
Reviewed By: heitorschueroff
Differential Revision: D29994429
Pulled By: ngimel
fbshipit-source-id: c3f7744d7adc5fd6787f6cbb1ec41405f89a6d4c
Summary:
This PR adds the `cusolverDn<T>SyevjBatched` fuction to the backend of `torch.linalg.eigh` (eigenvalue solver for Hermitian matrix). Using the heuristics from https://github.com/pytorch/pytorch/pull/53040#issuecomment-788264724 and my local tests, the `syevj_batched` path is only used when `batch_size > 1` and `matrix_size <= 32`. This would give us huge performance boost in those cases.
Since there were known numerical issues on cusolver `syevj_batched` before cuda 11.3 update 1, this PR only enables the dispatch when cuda version is no less than that.
See also https://github.com/pytorch/pytorch/issues/42666#47953https://github.com/pytorch/pytorch/issues/53040
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62003
Reviewed By: heitorschueroff
Differential Revision: D30006316
Pulled By: ngimel
fbshipit-source-id: 3a65c5fc9adbbe776524f8957df5442c3d3aeb8e
Summary:
We are seeing some test failures on A100 machine, though TF32 matmul is not involved in these cases.
I tried `svd_lowrank` test. It passed while testing itself, but failed when I run the whole test suite. It's probably some random seed issue. Relax test tolerance would be much easier to do.
Some SVD tests failed when we compare CPU float32 vs GPU float32. Since linear algebra are sort of unstable at single precision, comparing two single precision results may give some false positives. So we calculate CPU results in float64 or complex128, which is much more accurate.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61101
Reviewed By: ngimel
Differential Revision: D29593483
Pulled By: mruberry
fbshipit-source-id: 3df651e3cca1b0effc1a4ae29d4f26b1cb4082ed
Summary:
In one of my previous PRs that rewrite `tensordot` implementation, I mistakenly take empty value of `dims_a` and `dims_b` as illegal values. This turns out to be not true. Empty `dims_a` and `dims_b` are supported, in fact common when `dims` is passed as an integer. This PR removes the unnecessary check.
Fixes https://github.com/pytorch/pytorch/issues/61096
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61331
Reviewed By: eellison
Differential Revision: D29578910
Pulled By: gmagogsfm
fbshipit-source-id: 96e58164491a077ddc7a1d6aa6ccef8c0c9efda2
Summary:
I added a test to `test_ops.py` that verifies that the op can run correctly from different cuda devices. This test revealed that `linalg_eigh`, `linalg_eigvalsh`, `linalg_matrix_rank`, `linalg_pinv` were failing. `matrix_rank` and `pinv` are calling `eigh` internally.
`linalg_eigh` and `lu_solve` internally use dispatch stubs, so they should be registered with `CPU, CUDA` dispatch keys. The generated code includes device guards in this case and the problem is not present.
Implemented a better out variant for `eigvalsh` and registered it with `CPU, CUDA` dispatch keys.
~I added a device guard to `linalg_eigh_kernel` as a fix for `eigvalsh` function. This function needs to be registered as CompositeImplicitAutograd, because it calls `at::linalg_eigh` if `at::GradMode::is_enabled()`.~
Fixes https://github.com/pytorch/pytorch/issues/60892.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60945
Reviewed By: mruberry
Differential Revision: D29589580
Pulled By: ngimel
fbshipit-source-id: 5851605958bdfc3a1a1768263934619449957168
Summary:
Improved torch.einsum testing and fixed a bug where lower case letters appeared before upper case letters in the sorted order which is inconsistent with NumPy.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59731
Reviewed By: SplitInfinity, ansley
Differential Revision: D29183078
Pulled By: heitorschueroff
fbshipit-source-id: a33980d273707da2d60a387a2af2fa41527ddb68
Summary:
This PR fixes `torch.linalg.inv_ex` with MAGMA backend.
`info` tensor was returned on CPU device even for CUDA inputs.
Now it's on the same device as input.
Fixes https://github.com/pytorch/pytorch/issues/58769
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59223
Reviewed By: ngimel
Differential Revision: D28814876
Pulled By: mruberry
fbshipit-source-id: f66c6f06fb8bc305cb2e22b08750a25c8888fb65
Summary:
Per title. Now `norm` with fp16/bfloat16 inputs and fp32 outputs on cuda won't do explicit cast
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59134
Reviewed By: mruberry
Differential Revision: D28775729
Pulled By: ngimel
fbshipit-source-id: 896daa4f02e8a817cb7cb99ae8a93c02fa8dd5e9
Summary:
This PR adds an alternative way of calling `torch.einsum`. Instead of specifying the subscripts as letters in the `equation` parameter, one can now specify the subscripts as a list of integers as in `torch.einsum(operand1, subscripts1, operand2, subscripts2, ..., [subscripts_out])`. This would be equivalent to `torch.einsum('<subscripts1>,<subscripts2>,...,->[<subscript_out>]', operand1, operand2, ...)`
TODO
- [x] Update documentation
- [x] Add more error checking
- [x] Update tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56625
Reviewed By: zou3519
Differential Revision: D28062616
Pulled By: heitorschueroff
fbshipit-source-id: ec50ad34f127210696e7c545e4c0675166f127dc
Summary:
This PR does several things to relax test tolerance
- Do not use TF32 in cuda matmul in test_c10d. See https://github.com/pytorch/pytorch/issues/52941.
- Do not use TF32 in cuda matmul in test_linalg. Increase atol for float and cfloat. See https://github.com/pytorch/pytorch/issues/50453
The tolerance is increased because most linear algebra operators are not that stable in single precision.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56114
Reviewed By: ailzhang
Differential Revision: D28554467
Pulled By: ngimel
fbshipit-source-id: 90416be8e4c048bedb16903b01315584d344ecdf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56613
Replace linalg_solve_helper with `lu_stub` + `lu_solve_stub`.
Once `lu_stub` and `lu_solve_stub` have cuSOLVER-based codepath,
`torch.linalg.solve` will have it as well.
Test Plan: Imported from OSS
Reviewed By: agolynski
Differential Revision: D28379394
Pulled By: mruberry
fbshipit-source-id: b47f66bc1ee12715da11dcffc92e31e67fa8c8f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58041
The shape of the returned result was different for NumPy and PyTorch for
`ord={-2, 2, None}`. Now it's fixed.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D28405147
Pulled By: mruberry
fbshipit-source-id: 30293a017a0c0a7e9e3aabd470386235fef7b6a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58040
This PR uses `torch.linalg.inv_ex` to determine the non-invertible
inputs and return the condition number of infinity for such inputs.
Added OpInfo entry for `torch.linalg.cond`.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D28405146
Pulled By: mruberry
fbshipit-source-id: 524b9a38309851fa6461cb787ef3fba5aa7d5328
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58039
The new function has the following signature
`inv_ex(Tensor inpit, *, bool check_errors=False) -> (Tensor inverse, Tensor info)`.
When `check_errors=True`, an error is thrown if the matrix is not invertible; `check_errors=False` - responsibility for checking the result is on the user.
`linalg_inv` is implemented using calls to `linalg_inv_ex` now.
Resolves https://github.com/pytorch/pytorch/issues/25095
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D28405148
Pulled By: mruberry
fbshipit-source-id: b8563a6c59048cb81e206932eb2f6cf489fd8531
Summary:
This one had a tricky usage of `torch.symeig` that had to be replaced. I tested the replacement locally though.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57732
Reviewed By: bdhirsh
Differential Revision: D28328189
Pulled By: mruberry
fbshipit-source-id: 7f000fcbf2b029beabc76e5a89ff158b47977474
Summary:
Backward methods for `torch.lu` and `torch.lu_solve` require the `torch.lu_unpack` method.
However, while `torch.lu` is a Python wrapper over a native function, so its gradient is implemented via `autograd.Function`,
`torch.lu_solve` is a native function, so it cannot access `torch.lu_unpack` as it is implemented in Python.
Hence this PR presents a native (ATen) `lu_unpack` version. It is also possible to update the gradients for `torch.lu` so that backward+JIT is supported (no JIT for `autograd.Function`) with this function.
~~The interface for this method is different from the original `torch.lu_unpack`, so it is decided to keep it hidden.~~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46913
Reviewed By: albanD
Differential Revision: D28355725
Pulled By: mruberry
fbshipit-source-id: 281260f3b6e93c15b08b2ba66d5a221314b00e78
Summary:
This PR adds a note to the documentation that torch.svd is deprecated together with an upgrade guide on how to use `torch.linalg.svd` and `torch.linalg.svdvals` (Lezcano's instructions from https://github.com/pytorch/pytorch/issues/57549).
In addition, all usage of the old svd function is replaced with a new one from torch.linalg module, except for the `at::linalg_pinv` function, that fails the XLA CI build (https://github.com/pytorch/xla/issues/2755, see failure in draft PR https://github.com/pytorch/pytorch/pull/57772).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57981
Reviewed By: ngimel
Differential Revision: D28345558
Pulled By: mruberry
fbshipit-source-id: 02dd9ae6efe975026e80ca128e9b91dfc65d7213
Summary:
Backward methods for `torch.lu` and `torch.lu_solve` require the `torch.lu_unpack` method.
However, while `torch.lu` is a Python wrapper over a native function, so its gradient is implemented via `autograd.Function`,
`torch.lu_solve` is a native function, so it cannot access `torch.lu_unpack` as it is implemented in Python.
Hence this PR presents a native (ATen) `lu_unpack` version. It is also possible to update the gradients for `torch.lu` so that backward+JIT is supported (no JIT for `autograd.Function`) with this function.
~~The interface for this method is different from the original `torch.lu_unpack`, so it is decided to keep it hidden.~~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46913
Reviewed By: astaff
Differential Revision: D28117714
Pulled By: mruberry
fbshipit-source-id: befd33db12ecc147afacac792418b6f4948fa4a4
Summary:
This PR is focused on the API for `linalg.matrix_norm` and delegates computations to `linalg.norm` for the moment.
The main difference between the norms is when `dim=None`. In this case
- `linalg.norm` will compute a vector norm on the flattened input if `ord=None`, otherwise it requires the input to be either 1D or 2D in order to disambiguate between vector and matrix norm
- `linalg.vector_norm` will flatten the input
- `linalg.matrix_norm` will compute the norm over the last two dimensions, treating the input as batch of matrices
In future PRs, the computations will be moved to `torch.linalg.matrix_norm` and `torch.norm` and `torch.linalg.norm` will delegate computations to either `linalg.vector_norm` or `linalg.matrix_norm` based on the arguments provided.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57127
Reviewed By: mrshenli
Differential Revision: D28186736
Pulled By: mruberry
fbshipit-source-id: 99ce2da9d1c4df3d9dd82c0a312c9570da5caf25
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57181
Documentation for torch.linalg.svd says:
> The returned decomposition is a named tuple `(U, S, Vh)`
The documentation is correct while the implementation was wrong.
Renamed `V` -> `Vh`. `h` stands for hermitian.
This is a BC-breaking change but our linalg module is beta, therefore we can do it without a deprecation notice or aliases.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D28142162
Pulled By: mruberry
fbshipit-source-id: 5e6e0ae5a63300f2db1575ca3259df381f8e1a7e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57180
We have now a separate function for computing only the singular values.
`compute_uv` argument is not needed and it was decided in the
offline discussion to remove it. This is a BC-breaking change but our
linalg module is beta, therefore we can do it without a deprecation
notice.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D28142163
Pulled By: mruberry
fbshipit-source-id: 3fac1fcae414307ad5748c9d5ff50e0aa4e1b853
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56613
Replace linalg_solve_helper with `lu_stub` + `lu_solve_stub`.
Once `lu_stub` and `lu_solve_stub` have cuSOLVER-based codepath,
`torch.linalg.solve` will have it as well.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D28248766
Pulled By: mruberry
fbshipit-source-id: 3003666056533d097d0ad659e0603f59fbfda9aa
Summary:
As per discussion here https://github.com/pytorch/pytorch/pull/57127#discussion_r624948215
Note that we cannot remove the optional type from the `dim` parameter because the default is to flatten the input tensor which cannot be easily captured by a value other than `None`
### BC Breaking Note
This PR changes the `ord` parameter of `torch.linalg.vector_norm` so that it no longer accepts `None` arguments. The default behavior of `2` is equivalent to the previous default of `None`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57662
Reviewed By: albanD, mruberry
Differential Revision: D28228870
Pulled By: heitorschueroff
fbshipit-source-id: 040fd8055bbe013f64d3c8409bbb4b2c87c99d13
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57316
CUDA support is implemented using cuSOLVER.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D28242071
Pulled By: mruberry
fbshipit-source-id: 6f0a1c50c21c376d2ee2907bddb618c6a600db1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57315
This PR ports `torch.ormqr` from TH to ATen.
CUDA path will be implemented in a follow-up PR.
With ATen port, support for complex and batched inputs is added.
The tests are rewritten and OpInfo entry is added.
We can implement the least squares solver with geqrf + ormqr +
triangular_solve. So it's useful to have this function renewed at least for the
internal code.
Resolves https://github.com/pytorch/pytorch/issues/24748
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D28242070
Pulled By: mruberry
fbshipit-source-id: f070bb6ac2f5a3269b163b22f7354e9089ed3061
Summary:
Testing 11.3 with current CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57223
Test Plan:
Relevant CI (11.3) pass!
Disclaimer: Skipped test_inverse_errors_large for CUDA 11.3 as it failed. Issue documented at https://github.com/pytorch/pytorch/issues/57482.
Reviewed By: malfet
Differential Revision: D28169393
Pulled By: janeyx99
fbshipit-source-id: 9f5cf7b6737ee6196de92bd80918a5bfbe5510ea
Summary:
The new function has the following signature `cholesky_ex(Tensor input, *, bool check_errors=False) -> (Tensor L, Tensor infos)`. When `check_errors=True`, an error is thrown if the decomposition fails; `check_errors=False` - responsibility for checking the decomposition is on the user.
When `check_errors=False`, we don't have host-device memory transfers for checking the values of the `info` tensor.
Rewrote the internal code for `torch.linalg.cholesky`. Added `cholesky_stub` dispatch. `linalg_cholesky` is implemented using calls to `linalg_cholesky_ex` now.
Resolves https://github.com/pytorch/pytorch/issues/57032.
Ref. https://github.com/pytorch/pytorch/issues/34272, https://github.com/pytorch/pytorch/issues/47608, https://github.com/pytorch/pytorch/issues/47953
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56724
Reviewed By: ngimel
Differential Revision: D27960176
Pulled By: mruberry
fbshipit-source-id: f05f3d5d9b4aa444e41c4eec48ad9a9b6fd5dfa5
Summary:
This test was disabled for ROCM 3.9. With latest updates, the test is passing in ROCM 4.1. Hence enabling this test in test/test_linalg.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57170
Reviewed By: astaff
Differential Revision: D28118217
Pulled By: mruberry
fbshipit-source-id: 1b830eed944a664c3b1b3e936b87096fef0c0ca2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56257
CPU and cuSOLVER path were fixed with refactoring of
`_linalg_qr_helper_default`.
Resolves https://github.com/pytorch/pytorch/issues/50576
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D27960157
Pulled By: mruberry
fbshipit-source-id: f923f3067a35e65218889e64c6a886364c3d1759
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54723
Renamed "cond" -> "rcond" to be NumPy compatible. The default value for
rcond was changed to match non-legacy NumPy behavior.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D27993741
Pulled By: mruberry
fbshipit-source-id: a4baf25aca6a8272f1af2f963600866bfda56fb3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54722
SciPy and NumPy operate only on non-batched input and return an empty array with shape (0,) if rank(a) != n.
The behavior for non-batched inputs is NumPy and SciPy compatible and the same result is computed.
For batched inputs, if any matrix in the batch has a rank less than `n`, then an empty tensor is returned.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D27993736
Pulled By: mruberry
fbshipit-source-id: 0d7cff967b322a5e816a23f282b6ce383c4468ef
Summary:
Currently `torch.linalg.matrix_rank` accepts only Python's float for `tol=` argument. The current behavior is not NumPy compatible and this PR adds the possibility to pass Tensor for matrix-wise tolerances.
Ref. https://github.com/pytorch/pytorch/issues/42666
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54157
Reviewed By: ezyang
Differential Revision: D27961548
Pulled By: mruberry
fbshipit-source-id: 47318eefa07a7876e6360dae089e5389b9939489
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56249
This PR ports `torch.geqrf` from TH to ATen. CUDA path will be
implemented in a follow-up PR.
With ATen port support for complex and batched inputs is added.
There were no correctness tests, they are
added in this PR and I added OpInfo for this operation.
We can implement the QR decomposition as a composition of geqrf and
orgqr (torch.linalg.householder_product).
Also we can implement the least squares solver with geqrf + ormqr +
trtrs. So it's useful to have this function renewed at least for the
internal code.
Resolves https://github.com/pytorch/pytorch/issues/24705
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D27907357
Pulled By: mruberry
fbshipit-source-id: 94e1806078977417e7903db76eab9d578305f585
Summary:
Fixes https://github.com/pytorch/pytorch/issues/56022.
Fixes https://github.com/pytorch/pytorch/issues/56316
For `torch.tensordot`,
1. `tensordot`'s out variant now resizes the output tensor provided as the `out` argument if necessary.
2. Added a check to verify if the output tensor provided as the argument for `out` is on the same device as the input tensors.
3. Added a check to verify if the dtype of the result is castable to the dtype of the output tensor provided as an argument for `out`.
4. Because of (2) & (3), `tensordot`'s out variant now [safely casts & copies output](https://github.com/pytorch/pytorch/wiki/Developer-FAQ#how-does-out-work-in-pytorch).
5. `test_tensordot` in `test_linalg.py` had a bug - the output tensor wasn't being defined to be on the same device as the input tensors. It was fixed by simply using a `device` argument in its definition.
6. Added an `OpInfo` for `tensordot` and modified the `OpInfo` for `inner`.
cc heitorschueroff mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56286
Reviewed By: ngimel
Differential Revision: D27845980
Pulled By: mruberry
fbshipit-source-id: 134ab163f05c31a6900dd65aefc745803019e037
Summary:
After MAGMA has been enabled, around 5k new tests are running now.
Out of these 5 tests (each having 4 datatypes) are failing on the latest ROCM
CI with Rocm 4.1. Disabling these tests for now so the ROCM CI does not fail.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55534
Reviewed By: ZolotukhinM
Differential Revision: D27630085
Pulled By: malfet
fbshipit-source-id: c48d124e6a2b4a4f3c6c4b6ac2bdf6c214f325c7
Summary:
This PR adds `torch.linalg.eig`, and `torch.linalg.eigvals` for NumPy compatibility.
MAGMA uses a hybrid CPU-GPU algorithm and doesn't have a GPU interface for the non-symmetric eigendecomposition. It means that it forces us to transfer inputs living in GPU memory to CPU first before calling MAGMA, and then transfer results from MAGMA to CPU. That is rather slow for smaller matrices and MAGMA is faster than CPU path only for matrices larger than 3000x3000.
Unfortunately, there is no cuSOLVER function for this operation.
Autograd support for `torch.linalg.eig` will be added in a follow-up PR.
Ref https://github.com/pytorch/pytorch/issues/42666
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52491
Reviewed By: anjali411
Differential Revision: D27563616
Pulled By: mruberry
fbshipit-source-id: b42bb98afcd2ed7625d30bdd71cfc74a7ea57bb5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52859
This reverts commit 92a4ee1cf6.
Added support for bfloat16 for CUDA 11 and removed fast-path for empty input tensors that was affecting autograd graph.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D27402390
Pulled By: heitorschueroff
fbshipit-source-id: 73c5ccf54f3da3d29eb63c9ed3601e2fe6951034
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53973
Two parts to this PR; I had to put them together because adding support for X causes more test code to be exercised, which in turn may require a fix for Y.
The first part is restoring the concept of storage to meta tensors. Previously, meta tensors had a nullptr storage (e.g., `meta_tensor.storage()` is an error.) As I was increasing the coverage of meta tensors, I started running into test cases (specifically memory overlap tests) that were failing because not having storage meant I couldn't check for memory overlap. After some discussion, we decided that it would make sense for meta tensors to model this as well (we already model strides, so getting accurate view information also seems useful). This PR does that by:
* Rewrite all of the factory functions in MetaTensor.cpp to use the generic versions (which are very carefully written to not actually poke at the data pointer, so everything works out). The key idea here is we give meta tensors a special allocator, MetaAllocator, which always returns a nullptr even if you ask for a nonzero number of bytes. resize_ is also made generic; the normal variant can be used directly rather than having to instruct it to avoid resizing storage
* Turn on memory overlap checking in TensorIterator even for meta tensors
* Although meta tensors now have storage, the concept of meta storage is NOT exposed to Python land (as it would imply I would have to codegen MetaFloatStorage, MetaDoubleStorage, etc. classes). So `x.storage()` still raises an error and I have a cludge in `__deepcopy__` to break storage sharing upon deep copy (this is wrong, but no tests exercise this at the moment).
The second part is adding more support for the most used functions in the test suite.
* Inplace operations have very simple meta functions. I added `fill_`, `zero_`, `random_`, `uniform_` and `normal_`. In the case of random, I take advantage of pbelevich's templates for defining random kernels, so that I can reuse the common scaffolding, and then just register a noop stub that actually does the RNG. (Look, another structured kernels tiny variant!)
* `copy_` is now implemented. Copying into a meta tensor is always OK, but copying out of a meta tensor raises an error (as we don't know what the "correct" data to copy out is in this case)
* `empty_strided` usage from structured kernels now is implemented (TBH, this could have been done as soon as `empty_strided` was added)
* Meta was missing in a few places in TensorOptions/DispatchKey utility functions, so I added them
* Autograd engine now correctly homes meta tensors with CPU tensors (they have -1 device index so CUDA queues wouldn't work anyway)
* `apply_`, `map_` and `map2_` are special cased to no-op on meta tensor self. These count as inplace operations too but they are implemented a little differently.
Getting more meta function support triggers a number of bugs in the test suite, which I then fix:
- Linear algebra functions sometimes don't report NotImplementedError because they get swallowed by catch all try blocks. This is tracked in https://github.com/pytorch/pytorch/issues/53739
- dlpack obviously doesn't work with meta tensors, I just disabled the test
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D27036572
Test Plan: Imported from OSS
Reviewed By: agolynski, bdhirsh
Pulled By: ezyang
fbshipit-source-id: 7005ecf4feb92a643c37389fdfbd852dbf00ac78
Summary:
The size of the workspace arrays should not be less than 1. This PR fixes lstsq calls to LAPACK and MAGMA. Also `max(1, ...)` guards were added to a few other functions (symeig, svd).
ROCm testing is enabled for lstsq, pinv, pinverse.
Fixes https://github.com/pytorch/pytorch/issues/53976
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54009
Reviewed By: ejguan
Differential Revision: D27155845
Pulled By: mruberry
fbshipit-source-id: 04439bfa82a5bdbe2297a6d62b6e68ba1c30e4a2
Summary:
This PR adds autograd support for `torch.orgqr`.
Since `torch.orgqr` is one of few functions that expose LAPACK's naming and all other linear algebra routines were renamed a long time ago, I also added a new function with a new name and `torch.orgqr` now is an alias for it.
The new proposed name is `householder_product`. For a matrix `input` and a vector `tau` LAPACK's orgqr operation takes columns of `input` (called Householder vectors or elementary reflectors) scalars of `tau` that together represent Householder matrices and then the product of these matrices is computed. See https://www.netlib.org/lapack/lug/node128.html.
Other linear algebra libraries that I'm aware of do not expose this LAPACK function, so there is some freedom in naming it. It is usually used internally only for QR decomposition, but can be useful for deep learning tasks now when it supports differentiation.
Resolves https://github.com/pytorch/pytorch/issues/50104
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52637
Reviewed By: agolynski
Differential Revision: D27114246
Pulled By: mruberry
fbshipit-source-id: 9ab51efe52aec7c137aa018c7bd486297e4111ce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53682
With this, under the meta device, 101 tests passed and 16953 skipped.
It ain't much, but it's a start.
Some various bits and bobs:
- NotImplementedError suppression at test level is implemented
in the same way as CUDA memory leak check, i.e., by wrapping
test methods and monkeypatching them back in.
- I had to reimplement assertRaises/assertRaisesRegex from scratch to
ignore NotImplementedError when _ignore_not_implemented_error is True.
The implementation relies on a small amount of private API that hasn't
changed since 2010
- expectedAlertNondeterministic doesn't really work so I skipped them
all; there's probably a way to do it better
I tested this using `pytest --disable-warnings --tb=native -k meta --sw
test/*.py` and a pile of extra patches to make collection actually work
(lol).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D26955539
Pulled By: ezyang
fbshipit-source-id: ac21c8734562497fdcca3b614a28010bc4c03d74
Summary:
Added OpInfo-based testing of the following linear algebra functions:
* cholesky, linalg.cholesky
* linalg.eigh
* inverse, linalg.inv
* qr, linalg.qr
* solve
The output of `torch.linalg.pinv` for empty inputs was not differentiable, now it's fixed.
In some cases, batched grad checks are disabled because it doesn't work well with 0x0 matrices (see https://github.com/pytorch/pytorch/issues/50743#issuecomment-767376085).
Ref. https://github.com/pytorch/pytorch/issues/50006
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51107
Reviewed By: albanD
Differential Revision: D27006115
Pulled By: mruberry
fbshipit-source-id: 3c1d00e3d506948da25d612fb114e6d4a478c5b1
Summary:
https://github.com/pytorch/pytorch/pull/51348 added CUDA support for orgqr but only a cuSOLVER path; the orgqr tests, however, were marked to run on builds with either MAGMA or cuSOLVER.
This PR addresses the issue by creating a skipCUDAIfNoCusolver decator and applying to the orgqr tests. It triggers ci-all because our CI build with MAGMA but no cuSOLVER is CUDA 9.2, which does run in the typical PR CI.
cc IvanYashchuk
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53975
Reviewed By: ngimel
Differential Revision: D27036683
Pulled By: mruberry
fbshipit-source-id: f6c0a3e526bde08c44b119ed2ae5d51fee27e283
Summary:
This PR adds the cuBLAS based path for `torch.triangular_solve`
The device dispatching helper function was removed from native_functions.yml, it is replaced with DECLARE/DEFINE_DISPATCH.
`magmaTriangularSolve` is removed and replaced with cuBLAS calls, this is not a BC-breaking change because internally MAGMA just calls the same cuBLAS function and doesn't do anything else.
Batched cuBLAS is faster than batched MAGMA for matrices of size up until 512x512, after that MAGMA is faster. For batches smaller than ~8 and matrix sizes larger than 64x64 a forloop of cuBLAS calls is faster than batched version.
Ref. https://github.com/pytorch/pytorch/issues/47953
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53147
Reviewed By: heitorschueroff
Differential Revision: D27007416
Pulled By: mruberry
fbshipit-source-id: ddfc190346e6a56b84145ed0a9af67ca9cde3506
Summary:
Fixes https://github.com/pytorch/pytorch/issues/44378 by providing a wider range of drivers similar to what SciPy is doing.
The supported CPU drivers are `gels, gelsy, gelsd, gelss`.
The CUDA interface has only `gels` implemented but only for overdetermined systems.
The current state of this PR:
- [x] CPU interface
- [x] CUDA interface
- [x] CPU tests
- [x] CUDA tests
- [x] Memory-efficient batch-wise iteration with broadcasting which fixes https://github.com/pytorch/pytorch/issues/49252
- [x] docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49093
Reviewed By: albanD
Differential Revision: D26991788
Pulled By: mruberry
fbshipit-source-id: 8af9ada979240b255402f55210c0af1cba6a0a3c
Summary:
As per title. Compared to the previous version, it is lighter on the usage of `at::solve` and `at::matmul` methods.
Fixes https://github.com/pytorch/pytorch/issues/51621
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52875
Reviewed By: mrshenli
Differential Revision: D26768653
Pulled By: anjali411
fbshipit-source-id: aab141968d02587440128003203fed4b94c4c655
Summary:
**Update:** MAGMA support was dropped from this PR. Only the cuSOLVER path is implemented and it's used exclusively.
**Original PR message:**
This PR adds support for CUDA inputs for `torch.orgqr`.
CUDA implementation is based on both [cuSOLVER](https://docs.nvidia.com/cuda/cusolver/index.html#cuSolverDN-lt-t-gt-orgqr) and MAGMA. cuSOLVER doesn't have a specialized routine for the batched case. While MAGMA doesn't have a specialized GPU native (without CPU sync) `orgqr`. But MAGMA has implemented (and not documented) the batched GPU native version of `larft` function (for small inputs of size <= 32), which together with `larfb` operation form `orgqr` (see the call graph [here at the end of the page](http://www.netlib.org/lapack/explore-html/da/dba/group__double_o_t_h_e_rcomputational_ga14b45f7374dc8654073aa06879c1c459.html)).
So now there are two main codepaths for CUDA inputs (if both MAGMA and cuSOLVER are available):
* if `batchsize > 1` and `tau.shape[-1] <= 32` then MAGMA based function is called
* else [cuSOLVER's `orgqr`](https://docs.nvidia.com/cuda/cusolver/index.html#cuSolverDN-lt-t-gt-orgqr) is used.
If MAGMA is not available then only cuSOLVER is used and vice versa.
Documentation updates and possibly a new name for this function will be in a follow-up PR.
Ref. https://github.com/pytorch/pytorch/issues/50104
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51348
Reviewed By: heitorschueroff
Differential Revision: D26882415
Pulled By: mruberry
fbshipit-source-id: 9f91ff962921932777ff108bedc133b55fe22842
Summary:
Fixes https://github.com/pytorch/pytorch/issues/51930
Running the reproducer under `cuda-gdb`, I see access violations in either [`zswap_kernel_batched`](4fd4634f35/magmablas/zgetf2_kernels.cu (lines-276)) (part of the LU factorization) and other times in [`zlaswp_columnserial_kernel`](4fd4634f35/magmablas/zlaswp_batched.cu (lines-335)) (part of the inverse).
The common factor between both of these is they use `ipiv` to index into the matrix. My best guess is the `ipiv` indices aren't written when the factorization fails, hence garbage data is used as matrix indices and we get an access violation. Initializing `ipiv` to a known-good value before the factorization fixes the issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53064
Reviewed By: zhangguanheng66
Differential Revision: D26829053
Pulled By: heitorschueroff
fbshipit-source-id: 842854a6ee182f20b2acad0d76d32d27cb51b061
Summary:
Enable test in test_linalg.py, test_optim.py, and test_vmap.py for ROCm because they are passing.
Signed-off-by: Kyle Chen <kylechen@amd.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52818
Reviewed By: H-Huang
Differential Revision: D26694091
Pulled By: mruberry
fbshipit-source-id: 285d17aa7f271f4d94b5fa9d9f6620de8a70847b
Summary:
Fixes https://github.com/pytorch/pytorch/issues/44378 by providing a wider range of drivers similar to what SciPy is doing.
The supported CPU drivers are `gels, gelsy, gelsd, gelss`.
The CUDA interface has only `gels` implemented but only for overdetermined systems.
The current state of this PR:
- [x] CPU interface
- [x] CUDA interface
- [x] CPU tests
- [x] CUDA tests
- [x] Memory-efficient batch-wise iteration with broadcasting which fixes https://github.com/pytorch/pytorch/issues/49252
- [x] docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49093
Reviewed By: H-Huang
Differential Revision: D26723384
Pulled By: mruberry
fbshipit-source-id: c9866a95f14091955cf42de22f4ac9e2da009713
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51807
Implemented torch.linalg.multi_dot similar to [numpy.linalg.multi_dot](https://numpy.org/doc/stable/reference/generated/numpy.linalg.multi_dot.html).
This function does not support broadcasting or batched inputs at the moment.
**NOTE**
numpy.linalg.multi_dot allows the first and last tensors to have more than 2 dimensions despite their docs stating these must be either 1D or 2D. This PR diverges from NumPy in that it enforces this restriction.
**TODO**
- [ ] Benchmark against NumPy
- [x] Add OpInfo testing
- [x] Remove unnecessary copy for out= argument
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D26375734
Pulled By: heitorschueroff
fbshipit-source-id: 839642692424c4b1783606c76dd5b34455368f0b
Summary:
Additional magma tests have been identified as failing after integrating hipMAGMA into the ROCm builds. Skipping is necessary until they can be fixed properly. This is blocking migration of ROCm CI to 4.0.1.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51915
Reviewed By: izdeby
Differential Revision: D26326404
Pulled By: malfet
fbshipit-source-id: 558cce66f216f404c0316ab036e2e5637fc99798
Summary:
Fixes https://github.com/pytorch/pytorch/issues/48831.
- CI image is updated to build hipMAGMA from source and set env MAGMA_HOME.
- CMake is updated to separate different requirements for CUDA versus ROCm MAGMA.
- Some unit tests that become enabled with MAGMA are currently skipped for ROCm due to failures. Fixing these failures will be follow-on work.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51238
Reviewed By: ngimel
Differential Revision: D26184918
Pulled By: malfet
fbshipit-source-id: ada632f1ae7b413e8cae6543fe931dcd46985821
{kind=link}
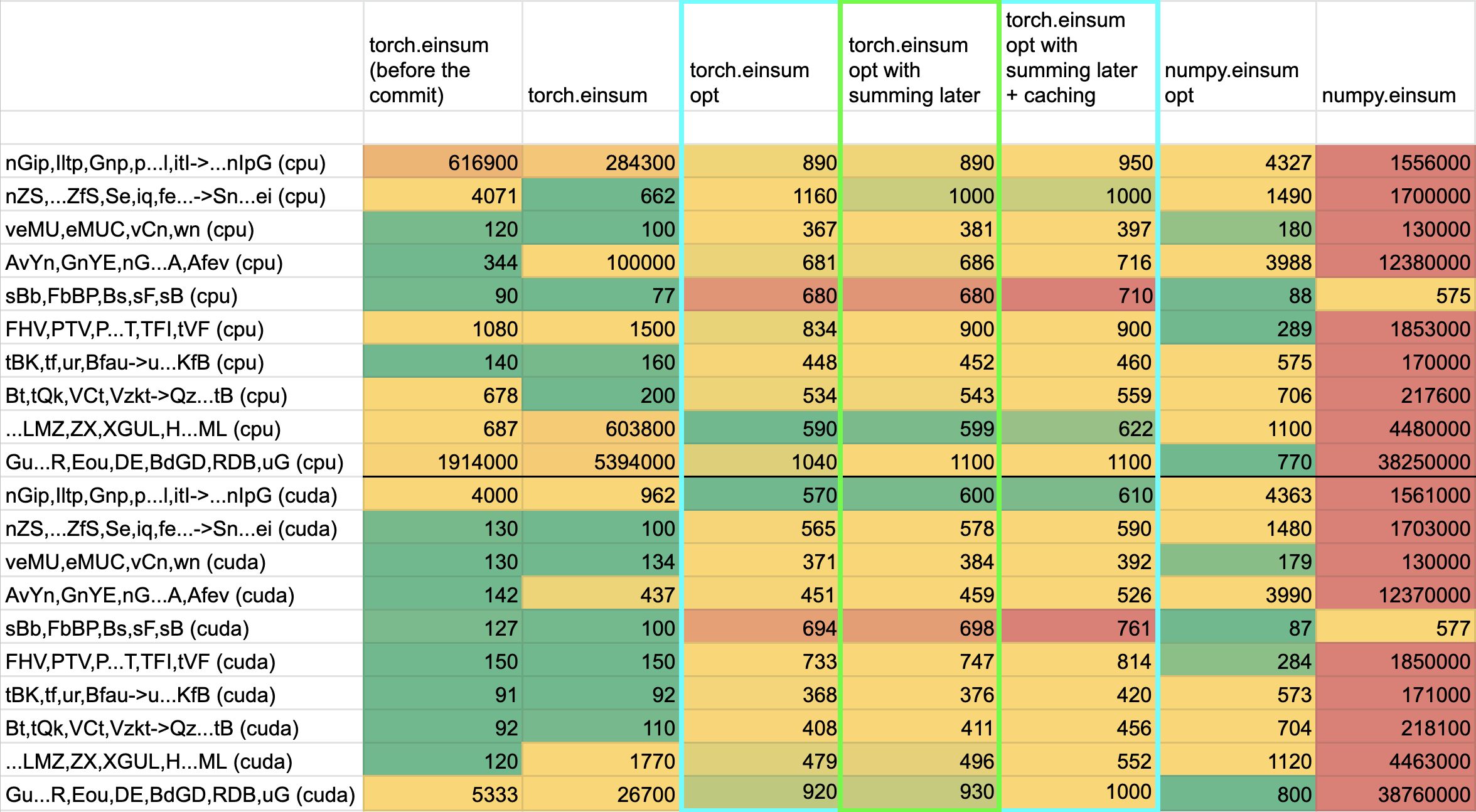{kind=link}
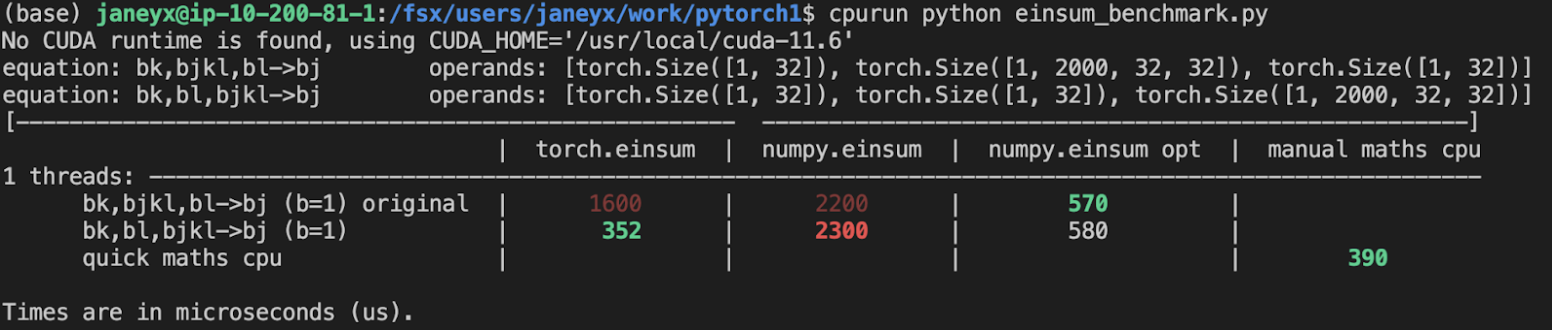{kind=link}
{kind=link}
{kind=link}
{kind=link}