- composable_kernel as a third_party submodule
- "ck" as a `torch.backends.cuda.preferred_linalg_library()`
- reference CK gemm implementations for float, bfloat16, and half types
Pull Request resolved: https://github.com/pytorch/pytorch/pull/131004
Approved by: https://github.com/xw285cornell, https://github.com/pruthvistony
Co-authored-by: Andres Lugo <Andy.LugoReyes@amd.com>
Co-authored-by: Pruthvi Madugundu <pruthvigithub@gmail.com>
The test is failing (flakily?) on periodic Windows CUDA jobs with the following error:
```
__________ TestLinalgCUDA.test_matmul_offline_tunableop_cuda_float16 __________
Traceback (most recent call last):
File "C:\actions-runner\_work\pytorch\pytorch\test\test_linalg.py", line 4618, in test_matmul_offline_tunableop
os.remove(filename)
PermissionError: [WinError 32] The process cannot access the file because it is being used by another process: 'tunableop_untuned0.csv'
```
For example, https://github.com/pytorch/pytorch/actions/runs/11292745299/job/31410578167#step:15:15097
The test tried to catch and ignore this, but this is Windows. So, the fix is to:
1. Ignore if these files couldn't be removed
2. Write them to a temp directory instead, otherwise, [assert_git_not_dirty](https://github.com/pytorch/pytorch/blob/main/.ci/pytorch/test.sh#L286) won't be happy
Pull Request resolved: https://github.com/pytorch/pytorch/pull/137835
Approved by: https://github.com/atalman
When enable tunableop, It is easy to have OOM since APP usually needs large video memory size, such as running a LLM for inference. So we need a offline mode to tune the GEMMs. This PR provide an offline mode for tunableOp:
- record untuned GEMMs to file.
- a python API named tune_gemm_in_file is added to read the untuned file and tune the GEMMs in file
Pull Request resolved: https://github.com/pytorch/pytorch/pull/128813
Approved by: https://github.com/jeffdaily, https://github.com/hongxiayang, https://github.com/naromero77amd
Co-authored-by: Nikita Shulga <2453524+malfet@users.noreply.github.com>
Related to #107302.
When built and tested with NumPy 2 the following unit tests failed.
```
=========================================================== short test summary info ============================================================
FAILED [0.0026s] test/test_linalg.py::TestLinalgCPU::test_householder_product_cpu_complex128 - TypeError: expected np.ndarray (got Tensor)
FAILED [0.0024s] test/test_linalg.py::TestLinalgCPU::test_householder_product_cpu_complex64 - TypeError: expected np.ndarray (got Tensor)
FAILED [0.0025s] test/test_linalg.py::TestLinalgCPU::test_householder_product_cpu_float32 - TypeError: expected np.ndarray (got Tensor)
FAILED [0.0024s] test/test_linalg.py::TestLinalgCPU::test_householder_product_cpu_float64 - TypeError: expected np.ndarray (got Tensor)
FAILED [0.0016s] test/test_linalg.py::TestLinalgCPU::test_nuclear_norm_axes_small_brute_force_old_cpu - ValueError: Unable to avoid copy while creating an array as requested.
FAILED [0.0054s] test/test_linalg.py::TestLinalgCPU::test_solve_cpu_complex128 - AssertionError: The values for attribute 'shape' do not match: torch.Size([0, 0]) != torch.Size([0, 0, 0]).
FAILED [0.0055s] test/test_linalg.py::TestLinalgCPU::test_solve_cpu_complex64 - AssertionError: The values for attribute 'shape' do not match: torch.Size([0, 0]) != torch.Size([0, 0, 0]).
FAILED [0.0048s] test/test_linalg.py::TestLinalgCPU::test_solve_cpu_float32 - AssertionError: The values for attribute 'shape' do not match: torch.Size([0, 0]) != torch.Size([0, 0, 0]).
FAILED [0.0054s] test/test_linalg.py::TestLinalgCPU::test_solve_cpu_float64 - AssertionError: The values for attribute 'shape' do not match: torch.Size([0, 0]) != torch.Size([0, 0, 0]).
=========================================== 9 failed, 1051 passed, 118 skipped in 152.51s (0:02:32) ============================================
```
This PR fixes them. The test is now compatible with both NumPy 1 & 2.
Some more details:
1. The `np.linalg.solve` has changed its behavior. So I added an adapt function in the unit test to keep its behavior the same no matter it is NumPy 1 or Numpy 2.
2. The cause of the failure is when passing a `torch.Tensor` to `np.linalg.qr`, the return type in NumPy 1 is `(np.ndarray, np.ndarray)`, while it is `(torch.Tensor, torch.Tensor)` in NumPy 2.
3. NumPy 2 does not allow `np.array(obj, copy=False)`, but recommended to use `np.asarray(obj)` instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/136800
Approved by: https://github.com/lezcano
Reland of #128143 but added `alpha` and `bias` initialization to `launchTunableGemmAndBias`
Thus far TunableOp was implemented for gemm, bgemm, and scaled_mm. gemm_and_bias was notably missing. This PR closes that gap.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/128919
Approved by: https://github.com/malfet
Summary:
When tunable ops load selected kernels from csv file, it will validate hipblaslt version defined in hipblaslt-version.h
This PR changes the validator to fetch hipblaslt version and revision from hipblaslt runtime instead of the header file, as in our environment we might rollout a new version of the run time prior to updating the header file fleet wide.
Test Plan:
Verified generated tunableops kernel selection has the correct hipblaslt version from runtime:
```
Validator,PT_VERSION,2.5.0
Validator,ROCBLAS_VERSION,4.0.0-72e57364-dirty
Validator,HIPBLASLT_VERSION,800-bf2c3184
Validator,ROCM_VERSION,6.0.0.0-12969-1544e39
Validator,GCN_ARCH_NAME,gfx942:sramecc+:xnack-
GemmTunableOp_BFloat16_TN,tn_8192_2_3584,Gemm_Hipblaslt_TN_572,0.0240676
GemmTunableOp_BFloat16_TN,tn_7168_2_8192,Gemm_Hipblaslt_TN_482,0.0359019
GemmTunableOp_BFloat16_TN,tn_8192_2_1024,Default,0.0173723
GemmTunableOp_BFloat16_TN,tn_1280_2_8192,Gemm_Hipblaslt_TN_491,0.0191047
```
Differential Revision: D59889043
Pull Request resolved: https://github.com/pytorch/pytorch/pull/131078
Approved by: https://github.com/jeffdaily, https://github.com/xw285cornell
Enables a few extra ruff rules, most of which do not have any violations as I already cleaned them with earlier PRs, these just turns them on to enforce them. Adds 1 noqa as we want the suboptimal lambda generation + call kept as a test. Also enables the test in flake8
Pull Request resolved: https://github.com/pytorch/pytorch/pull/130700
Approved by: https://github.com/justinchuby, https://github.com/ezyang
This PR is to update the input `weight` of `_convert_weight_to_int4pack` from `[n][k] int32` to `[n][k / 2] uint8`, both for CPU, CUDA and MPS, which can help decouple int4 model checkpoint with different ISAs and different platforms in `gpt-fast`. The advantage is int4 model checkpoint can be shared in different test machines, without re-generating in one certain platform. Meanwhile, the size of input `weight` can be reduced to `1 / 8`.
Before this PR, packed weight stored in CUDA specific layout: `[n/8][k/(InnerKTiles*16)][32][InnerKTiles/2]`, dtype int32, where InnerKTiles = 2, 4, 8. CPU packed weight viewed as the SAME shape but stored in different layout: `[n/64][k][32]`, dtype uint8. Weight is strongly coupled with platforms (CPU/CUDA) and ISAs (AVX512/AVX2/scalar). And users cannot use a generated weight in another different ISA or platform, because when loading weight into devices, the compute format is different.

Now, we use common serialized layout (`[n][k/2] uint8`) for different devices or ISAs as input `weight` of `_convert_weight_to_int4pack`, and each back chooses how to interpret as compute layout.

### Performance
Intel (R) Xeon (R) CPU Max 9480, single socket (56 cores)
There is no obvious regression of this PR.

Pull Request resolved: https://github.com/pytorch/pytorch/pull/129940
Approved by: https://github.com/jgong5, https://github.com/lezcano, https://github.com/mingfeima
This PR is to update the input `weight` of `_convert_weight_to_int4pack` from `[n][k] int32` to `[n][k / 2] uint8`, both for CPU, CUDA and MPS, which can help decouple int4 model checkpoint with different ISAs and different platforms in `gpt-fast`. The advantage is int4 model checkpoint can be shared in different test machines, without re-generating in one certain platform. Meanwhile, the size of input `weight` can be reduced to `1 / 8`.
Before this PR, packed weight stored in CUDA specific layout: `[n/8][k/(InnerKTiles*16)][32][InnerKTiles/2]`, dtype int32, where InnerKTiles = 2, 4, 8. CPU packed weight viewed as the SAME shape but stored in different layout: `[n/64][k][32]`, dtype uint8. Weight is strongly coupled with platforms (CPU/CUDA) and ISAs (AVX512/AVX2/scalar). And users cannot use a generated weight in another different ISA or platform, because when loading weight into devices, the compute format is different.

Now, we use common serialized layout (`[n][k/2] uint8`) for different devices or ISAs as input `weight` of `_convert_weight_to_int4pack`, and each back chooses how to interpret as compute layout.

### Performance
Intel (R) Xeon (R) CPU Max 9480, single socket (56 cores)
There is no obvious regression of this PR.

Pull Request resolved: https://github.com/pytorch/pytorch/pull/129940
Approved by: https://github.com/jgong5, https://github.com/lezcano, https://github.com/mingfeima
- Add AMD support for int4 kernel
- Only supports CDNA2 and CDNA3 gpus for now
- Uses `mfma_f32_16x16x16bf16` instruction for matrix multiply
- Uses `v_and_or_b32` instruction and `__hfma2` instrinsic for unpacking bf16 values
- Enable hipify for `__nv_bfloat16` and `__nv_bfloat162` data types
- Enable int4 unit tests for CDNA2 and CDNA3 AMD gpus
- Fix torchscript issues due to hipify for `__nv_bfloat16` type
- TorchScript has its own implementation for bfloat16 type
- Implemented in `__nv_bloat16` structure at [resource_strings.h](https://github.com/pytorch/pytorch/blob/main/torch/csrc/jit/codegen/fuser/cuda/resource_strings.h)
- So, we shouldn't hipify any reference of `__nv_bfloat16` in the torchscript implementation
- Hence moved the `__nv_bfloat16` direct references in `codegen.cpp` and `cuda_codegen.cpp` to `resource_strings.h` which is already exempted from hipify
Fixes#124699
Fixes pytorch-labs/gpt-fast/issues/154
Co-authored-by: Nikita Shulga <2453524+malfet@users.noreply.github.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/129710
Approved by: https://github.com/malfet
In nvidia internal testing, for slower devices such as Orin NX, on large dtypes like complex128, test_linalg_solve_triangular_large is taking multiple hours to complete and timing out CI. This PR adds a slowTest marker so it can be skipped due to speed issues. cc @nWEIdia
Pull Request resolved: https://github.com/pytorch/pytorch/pull/129903
Approved by: https://github.com/lezcano
We fix a number of bugs previously present in the complex
implementation.
We also heavily simplify the implementation, using, among
other things, that we now have conjugate views.
I saw there is a comment regarding how slow some checks on this
function are. As such, I removed quite a few of the combinations of inputs
to make the OpInfo lighter. I still left a couple relevant examples to not regress
coverage though.
Fixes https://github.com/pytorch/pytorch/issues/122188
Pull Request resolved: https://github.com/pytorch/pytorch/pull/125580
Approved by: https://github.com/pearu, https://github.com/peterbell10
Summary: This kernel is special-cased on ARM because it's important for LLMs, so let's have test coverage.
Test Plan: Ran locally and it passes. Intentionally broke fp16_gemv_trans and saw it fail, confirming it provides coverage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/126700
Approved by: https://github.com/malfet
- Implement a very straightforward Metal copy of CPU int4mm kernel
- Implement int8mm kernel by constructing a graph consisting of upcast, transpose and mm
- Add `isCapturing`, `isCaptureEnabled`, `startCapture` and `stopCapture` methods to `MPSProfile` which can be used to help one debug/profile Metal kernels by wrapping the calls with the following
```cpp
if (getMPSProfiler().profiler.isCaptureEnabled()) {
getMPSProfiler().startCapture(__func__, mpsStream);
}
...
if (getMPSProfiler().isCapturing()) {
getMPSProfiler().stopCapture(mpsStream);
}
```
that, if invoked with `MTL_CAPTURE_ENABLED` environment variable set to one, will produce .gputrace files, in the current working directory, which can later be loaded and used to debug or profiler the kernel
<img width="1093" alt="image" src="https://github.com/pytorch/pytorch/assets/2453524/a2bf27e8-df8a-442c-a525-1df67b8a376a">
- Added `test_int4mm` to TestLinalgMPS, which is mostly copy-n-paste of the test from `test_linalg`
TODOs:
- Add weight pack
- Perf-tune both kernels
Pull Request resolved: https://github.com/pytorch/pytorch/pull/125163
Approved by: https://github.com/mikekgfb
Following the example of PyTorch supporting a preferred Linalg library (cusolver or magma), this PR introduces a preferred blas library selector of either cublas or cublaslt for CUDA and hipblas or hipblaslt for ROCm via normal hipification of sources.
The default blas implementation remains cublas or hipblas. cublaslt or hipblaslt can be enabled using environment variable TORCH_BLAS_PREFER_CUBLASLT=1 (or TORCH_BLAS_PREFER_HIPBLASLT=1 as an alias) or by calling `torch.backends.cuda.preferred_blas_library(backend="cublaslt")` or as an alias `backend="hipblaslt"`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/122106
Approved by: https://github.com/lezcano
This replaces a bunch of unnecessary lambdas with the operator package. This is semantically equivalent, but the operator package is faster, and arguably more readable. When the FURB rules are taken out of preview, I will enable it as a ruff check.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/116027
Approved by: https://github.com/malfet
disable test int_mm for sm90 or later
```
python test/test_linalg.py -k test__int_mm_k_32_n_32_use_transpose_a_False_use_transpose_b_False_cuda
_ TestLinalgCUDA.test__int_mm_k_32_n_32_use_transpose_a_False_use_transpose_b_False_cuda _
Traceback (most recent call last):
File "/usr/lib/python3.10/unittest/case.py", line 59, in testPartExecutor
yield
File "/usr/lib/python3.10/unittest/case.py", line 591, in run
self._callTestMethod(testMethod)
File "/usr/lib/python3.10/unittest/case.py", line 549, in _callTestMethod
method()
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_utils.py", line 2410, in wrapper
method(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_utils.py", line 2410, in wrapper
method(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_device_type.py", line 428, in instantiated_test
raise rte
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_device_type.py", line 415, in instantiated_test
result = test(self, **param_kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_device_type.py", line 1084, in only_fn
return fn(slf, *args, **kwargs)
File "/opt/pytorch/pytorch/test/test_linalg.py", line 5719, in test__int_mm
_test(17, k, n, use_transpose_a, use_transpose_b)
File "/opt/pytorch/pytorch/test/test_linalg.py", line 5680, in _test
c_int32 = torch._int_mm(a_int8, b_int8)
RuntimeError: CUDA error: CUBLAS_STATUS_NOT_SUPPORTED when calling cublasLtMatmul with transpose_mat1 0 transpose_mat2 0 m 32 n 17 k 32 mat1_ld 32 mat2_ld 32 result_ld 32 abType 3 cType 10 computeType 72 scaleType 10
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/113327
Approved by: https://github.com/malfet
Currently, for `matrix_exp` function, if we have NaN values in the input matrices (small batches), it will keep outputting a "normal" result without any NaN value in it, and this will cause some problems that we may can't notice. This PR is for preventing such undefined behavior by "bring back" those NaN values.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/111539
Approved by: https://github.com/lezcano
Fixes#109604
Resubmit gh-109715 + several skips and small fixes to make tests pass.
The main fix here is by @ysiraichi : previously, dynamo did not resume tracing numpy ndarrays after a graph break.
While at it, fix several small issues Yukio's fix uncovers:
- graph break gracefully on numpy dtypes which do not map to torch.dtypes (uint16 etc)
- recognize array scalars in dynamo, treat them as 0D ndarrays
- make sure that iterating over torch.ndarray generates arrays not bare tensors
Pull Request resolved: https://github.com/pytorch/pytorch/pull/110512
Approved by: https://github.com/lezcano
Fixes#108754.
`hf_T5_generate` would encounter a regression when calling `extern_kernels.bmm`, if one input is `reinterpret_tensor(buf2, (8, 1, 64), (64, 0, 1))` rather than `reinterpret_tensor(buf2, (8, 1, 64), (64, 512, 1), 0)`. As @jgong5 mentioned in comment, in fact the two tensors are equivalent: The stride doesn't matter when the corresponding size is 1.
We revise the definition of contiguity in `bmm` to add the above situation as a contiguous case. Thus, when stride equals to 0, `extern_kernels.bmm` could still use `gemm` of MKL to gain the performance.
Speedup of `hf_T5_generate` is **1.343x** now and **1.138x** before, with script `bash inductor_single_test.sh multiple inference performance torchbench hf_T5_generate float32 first dynamic default 0`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/110811
Approved by: https://github.com/jgong5, https://github.com/lezcano, https://github.com/Chillee
Fixes#68972
Relands #107246
To avoid causing Meta-internal CI failures, this PR avoids always asserting that the default dtype is float in the `TestCase.setUp/tearDown` methods. Instead, the assert is only done if `TestCase._default_dtype_check_enabled == True`. `_default_dtype_check_enabled` is set to True in the `if __name__ == "__main__":` blocks of all the relevant test files that have required changes for this issue
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108088
Approved by: https://github.com/ezyang
This is a follow up to https://github.com/pytorch/pytorch/pull/105881 and replaces https://github.com/pytorch/pytorch/pull/103203
The batched linalg drivers from 103203 were brought in as part of the first PR. This change enables the ROCm unit tests that were enabled as a result of that change. Along with a fix to prioritize hipsolver over magma when the preferred linalg backend is set to `default`
The following 16 unit tests will be enabled for rocm in this change:
- test_inverse_many_batches_cuda*
- test_inverse_errors_large_cuda*
- test_linalg_solve_triangular_large_cuda*
- test_lu_solve_batched_many_batches_cuda*
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106620
Approved by: https://github.com/lezcano
Current test case causes an edge case tensor input that causes a single generated tensor to fail the tolerance assertion on ROCm only and only for float32. We have reviewed the logic with our libraries team and have discovered the discrepancy is due to a difference in order of operations on AMD GPUs. They came back with "working as intended" and found no perceivable bug. Interestingly, if we change the values in ks, ns, or bs, the test passes on ROCm. These particular sizes in this particular order generates a single problematic input that causes the assertion to fail the tolerance check by ~0.07. Again, this is not a bug, just differences in implementation. This PR loosens the tolerance for ROCm only.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104425
Approved by: https://github.com/jeffdaily, https://github.com/nikitaved, https://github.com/lezcano
Fixes#102678Fixes#102629Fixes#102558
HipSOLVER performance on ROCm5.4.2 and later no longer serves as massive bottleneck. Additionally, using magma on rocm in this case caused test_compare_cpu_lialg_pinv_singular_cuda_float32 to fail. Using hipSOLVER, the test now passes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103540
Approved by: https://github.com/lezcano
Current test case causes an edge case tensor input that causes a single generated tensor to fail the tolerance assertion on ROCm only and only for float32. We have reviewed the logic with our libraries team and have discovered the discrepancy is due to a difference in order of operations on AMD GPUs. They came back with "working as intended" and found no perceivable bug. Interestingly, if we change the values in ks, ns, or bs, the test passes on ROCm. These particular sizes in this particular order generates a single problematic input that causes the assertion to fail the tolerance check by ~0.07. Again, this is not a bug, just differences in implementation. This PR loosens the tolerance for ROCm only.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104425
Approved by: https://github.com/jeffdaily, https://github.com/nikitaved, https://github.com/lezcano
Enabling more tests on ASAN, meanwhile we disable float-divide-by-zero and float-cast-overflow, both are disabled because they are also disabled by default in latest clang.
The following cited doc explains the reasons.
```
-fsanitize=float-cast-overflow: Conversion to, from, or between floating-point types
which would overflow the destination. Because the range of representable values
for all floating-point types supported by Clang is [-inf, +inf], the only cases detected are
conversions from floating point to integer types.
-fsanitize=float-divide-by-zero: Floating point division by zero.
This is undefined per the C and C++ standards,
but is defined by Clang (and by ISO/IEC/IEEE 60559 / IEEE 754) as producing
either an infinity or NaN value,
so is not included in -fsanitize=undefined.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103647
Approved by: https://github.com/kit1980
Summary:
Currently, cuBLASLt-based fused GELU epilogue in the GPU back-end of the `_addmm_activation` operator uses tanh approximation, whereas other code paths on GPU don't.
With this PR, the GELU tanh approximation is switched on in all back-end code paths of `_addmm_activation` on GPU for better consistency.
Test Plan:
```
$ python test/test_linalg.py -k test_addmm_relu -v
test_addmm_relu_cpu_bfloat16 (__main__.TestLinalgCPU.test_addmm_relu_cpu_bfloat16) ... ok
test_addmm_relu_cpu_float32 (__main__.TestLinalgCPU.test_addmm_relu_cpu_float32) ... ok
test_addmm_relu_cpu_float64 (__main__.TestLinalgCPU.test_addmm_relu_cpu_float64) ... ok
test_addmm_relu_cuda_bfloat16 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_bfloat16) ... ok
test_addmm_relu_cuda_float32 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_float32) ... ok
test_addmm_relu_cuda_float64 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_float64) ... ok
----------------------------------------------------------------------
Ran 6 tests in 1.896s
OK
$ python test/test_linalg.py -k test_addmm_gelu -v
test_addmm_gelu_cpu_bfloat16 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_bfloat16) ... ok
test_addmm_gelu_cpu_float32 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_float32) ... ok
test_addmm_gelu_cpu_float64 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_float64) ... ok
test_addmm_gelu_cuda_bfloat16 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_bfloat16) ... ok
test_addmm_gelu_cuda_float32 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_float32) ... ok
test_addmm_gelu_cuda_float64 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_float64) ... ok
----------------------------------------------------------------------
Ran 6 tests in 2.050s
OK
```
Reviewers: @eellison
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104061
Approved by: https://github.com/eellison
Summary:
This PR fixes the wrong assertion in the `test_addmm_gelu` happening in the Windows CUDA CI job caused by #103811. The addmm + GELU fusion is likely not happening (or not using the tanh approximation) on Windows. See [this comment](https://github.com/pytorch/pytorch/pull/103811#issuecomment-1601936203) in the #103811 for the details of the error.
Test Plan:
```
$ python test/test_linalg.py -k test_addmm_relu -v
test_addmm_relu_cpu_bfloat16 (__main__.TestLinalgCPU.test_addmm_relu_cpu_bfloat16) ... ok
test_addmm_relu_cpu_float32 (__main__.TestLinalgCPU.test_addmm_relu_cpu_float32) ... ok
test_addmm_relu_cpu_float64 (__main__.TestLinalgCPU.test_addmm_relu_cpu_float64) ... ok
test_addmm_relu_cuda_bfloat16 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_bfloat16) ... ok
test_addmm_relu_cuda_float32 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_float32) ... ok
test_addmm_relu_cuda_float64 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_float64) ... ok
----------------------------------------------------------------------
Ran 6 tests in 2.131s
OK
$ python test/test_linalg.py -k test_addmm_gelu -v
test_addmm_gelu_cpu_bfloat16 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_bfloat16) ... ok
test_addmm_gelu_cpu_float32 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_float32) ... ok
test_addmm_gelu_cpu_float64 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_float64) ... ok
test_addmm_gelu_cuda_bfloat16 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_bfloat16) ... ok
test_addmm_gelu_cuda_float32 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_float32) ... ok
test_addmm_gelu_cuda_float64 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_float64) ... ok
----------------------------------------------------------------------
Ran 6 tests in 2.194s
OK
```
Reviewers: @eellison @huydhn
Subscribers:
Tasks:
Tags:
Differential Revision: [D46931688](https://our.internmc.facebook.com/intern/diff/D46931688)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104031
Approved by: https://github.com/huydhn, https://github.com/malfet
Summary:
Previously, addmm + GELU epilogue fusion was unconditionally disabled in `ATen/native/cuda/Blas.cpp` due to compilation and numerical issues in CUDA <= 11.4. This PR:
1. Enables addmm + GELU epilogue fusion for CUDA >= 11.8.
2. Restricts the usage of fused addmm epilogue to contiguous output (bugfix).
3. Extends unit tests with addmm epilogue fusion and GELU activation paths.
Test Plan:
$ python test/test_linalg.py -k test_addmm_relu -v
test_addmm_relu_cpu_bfloat16 (__main__.TestLinalgCPU.test_addmm_relu_cpu_bfloat16) ... ok
test_addmm_relu_cpu_float32 (__main__.TestLinalgCPU.test_addmm_relu_cpu_float32) ... ok
test_addmm_relu_cpu_float64 (__main__.TestLinalgCPU.test_addmm_relu_cpu_float64) ... ok
test_addmm_relu_cuda_bfloat16 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_bfloat16) ... ok
test_addmm_relu_cuda_float32 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_float32) ... ok
test_addmm_relu_cuda_float64 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_float64) ... ok
$ python test/test_linalg.py -k test_addmm_gelu -v
test_addmm_gelu_cpu_bfloat16 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_bfloat16) ... ok
test_addmm_gelu_cpu_float32 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_float32) ... ok
test_addmm_gelu_cpu_float64 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_float64) ... ok
test_addmm_gelu_cuda_bfloat16 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_bfloat16) ... ok
test_addmm_gelu_cuda_float32 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_float32) ... ok
test_addmm_gelu_cuda_float64 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_float64) ... ok
Reviewers: @eellison
Differential Revision: [D46829884](https://our.internmc.facebook.com/intern/diff/D46829884)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103811
Approved by: https://github.com/IvanYashchuk, https://github.com/eellison
Fixes#102678Fixes#102629Fixes#102558
HipSOLVER performance on ROCm5.4.2 and later no longer serves as massive bottleneck. Additionally, using magma on rocm in this case caused test_compare_cpu_lialg_pinv_singular_cuda_float32 to fail. Using hipSOLVER, the test now passes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103540
Approved by: https://github.com/lezcano
Enables the hipSolver backend for ROCm builds
--------------------------------------------------------------------------
- Minimum ROCm version requirement - 5.3
- Introduces new macro USE_LINALG_SOLVER the controls enablement of both cuSOLVER and hipSOLVER
- Adds hipSOLVER API to hipification process
- combines hipSOLVER and hipSPARSE mappings into single SPECIAL map that takes priority among normal mappings
- Torch api to be moved to hipsolver backend (as opposed to magma) include: torch.svd(), torch.geqrf(), torch.orgqr(), torch.ormqr()
- Will enable 100+ linalg unit tests for ROCm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97370
Approved by: https://github.com/malfet
Notes:
- No segfaults observed in any CI tests: dynamo unittests, inductor unittests, dynamo-wrapped pytorch tests. So we remove the warning that using dynamo 3.11 may result in segfaults.
- Some dynamo-wrapped pytorch tests hang. They will be skipped in the dynamo-wrapped test suite and will be addressed in a future PR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99180
Approved by: https://github.com/malfet
Issue: #93684
# Problem
Reduce graph breaks when dynamo compiles python functions containing numpy functions and ndarray operations.
# Design (as I know it)
* Use torch_np.ndarray(a wrapper of tensor) to back a `VariableTracker`: `NumpyTensorVariable`.
* Translate all attributes and methods calls, on ndarray, to torch_np.ndarray equivalent.
This PR adds `NumpyTensorVariable` and supports:
1. tensor to ndarray, ndarray to tensor
2. numpy functions such as numpy.meshgrid()
3. ndarray attributes such as `itemsize`, `stride`
Next PR will handle returning `np.ndarray` and add support for ndarray methods
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95849
Approved by: https://github.com/ezyang
Add _int_mm primitive that binds cuBLAS int8@int8 -> int32 matmul and that translates to Triton based mm templates under max autotune. This is a very useful first step towards better supporting quantization on the GPU. This is a not a user facing API, but an internal primitive.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94339
Approved by: https://github.com/ngimel, https://github.com/jansel
Currently, if we multiply a transposed batch of matrices with shape
[b, m, n] and a matrix with shape [n, k], when computing the gradient
of the matrix, we instantiate a matrix of shape [b, n, k]. This may be
a very large matrix. Instead, we fold the batch of matrices into a
matrix, which avoids creating any large intermediary tensor.
Note that multiplying a batch of matrices and a matrix naturally occurs
within an attention module, so this case surely happens in the wild.
In particular, this issue was found while investigating the OOMs caused by the
improved folding algorithm in the next PR of this stack. See https://github.com/pytorch/pytorch/pull/76828#issuecomment-1432359980
This PR fixes those OOMs and decreases the memory footprint of the
backward of matmul.
I understand this is a tricky one, so I put it on its own PR to discuss it.
Differential Revision: [D43541495](https://our.internmc.facebook.com/intern/diff/D43541495)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95261
Approved by: https://github.com/ezyang
Follow-up of #89582 to drop flags like `CUDA11OrLater` in tests. Note that in some places it appears that `TEST_WITH_ROCM` is _implicitly_ guarded against via the `CUDA11OrLater` version check, based on my best-guess of how `torch.version.cuda` would behave in ROCM builds, so I've added `not TEST_WITH_ROCM` in cases where ROCM wasn't previously explicitly allowed.
CC @ptrblck @malfet @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92605
Approved by: https://github.com/ngimel
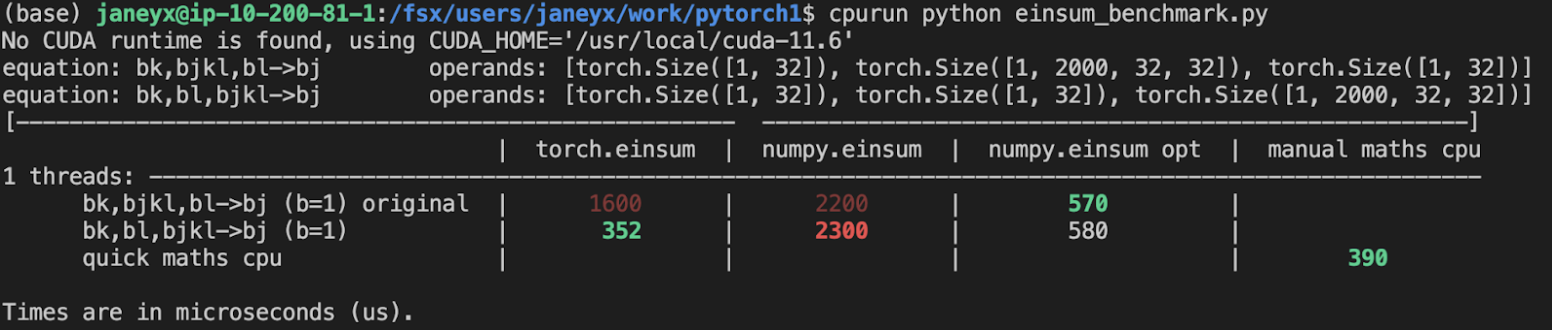
This achieves the same things as https://github.com/pytorch/pytorch/pull/85908 but using backends instead of kwargs (which breaks torchscript unfortunately). This also does mean we let go of numpy compatibility BUT the wins here are that users can control what opt einsum they wanna do!
The backend allows for..well you should just read the docs:
```
.. attribute:: torch.backends.opteinsum.enabled
A :class:`bool` that controls whether opt_einsum is enabled (on by default). If so,
torch.einsum will use opt_einsum (https://optimized-einsum.readthedocs.io/en/stable/path_finding.html)
to calculate an optimal path of contraction for faster performance.
.. attribute:: torch.backends.opteinsum.strategy
A :class:`str` that specifies which strategies to try when `torch.backends.opteinsum.enabled` is True.
By default, torch.einsum will try the "auto" strategy, but the "greedy" and "optimal" strategies are
also supported. Note that the "optimal" strategy is factorial on the number of inputs as it tries all
possible paths. See more details in opt_einsum's docs
(https://optimized-einsum.readthedocs.io/en/stable/path_finding.html).
```
In trying (and failing) to land 85908, I discovered that jit script does NOT actually pull from python's version of einsum (because it cannot support variadic args nor kwargs). Thus I learned that jitted einsum does not subscribe to the new opt_einsum path calculation. Overall, this is fine since jit script is getting deprecated, but where is the best place to document this?
## Test plan:
- added tests to CI
- locally tested that trying to set the strategy to something invalid will error properly
- locally tested that tests will pass even if you don't have opt-einsum
- locally tested that setting the strategy when opt-einsum is not there will also error properly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86219
Approved by: https://github.com/soulitzer, https://github.com/malfet
## This PR seeks to:
- [x] add c++ support for an optimize path
- [x] add python opt_einsum path passthrough
- [x] add opt_einsum to OSS requirements, but a soft one
- [x] show benchmark results here
Additional things I've explored + their conclusions:
- **Delaying the summing over dimensions** => added!
- The idea here is to not incur kernel calls to `sum` as we try to early sum out in einsum. Thus, we collect all the dimensions that need to be summed together in one contraction + sum at the end instead of summing as we go. While this optimization didn't feel like it made things faster for the random cases we've selected (they all summed 1 dim per contraction), it is a good principle and would help more common use cases that would reduce multiple dimensions at a time (like `bxy,xyi,xyj->bij`).
- **Caching contract_path based on equation and tensor sizes** => dropped :(
- The benchmarks were strictly worse for all the cases, and, from scanning the use cases, I observed people do not often call einsum on the same equation/tensor order enough for caching to be justified. I do think caching can be effective in the future, but it would require further investigation.
## Not a part of this PR (but are next steps):
- adding opt_einsum package to OSS CI
- adding it to internal CI
- potentially adding a kwarg path argument to the python API -- if the path is given, we wouldn't have to spend time calculating it, but there would be some time lost validating user input.
## Testing:
- Added more tests to CI
## Benchmarking:
**TL;DRs**
- **torch.einsum with opt_einsum is a definite win for the production case**.
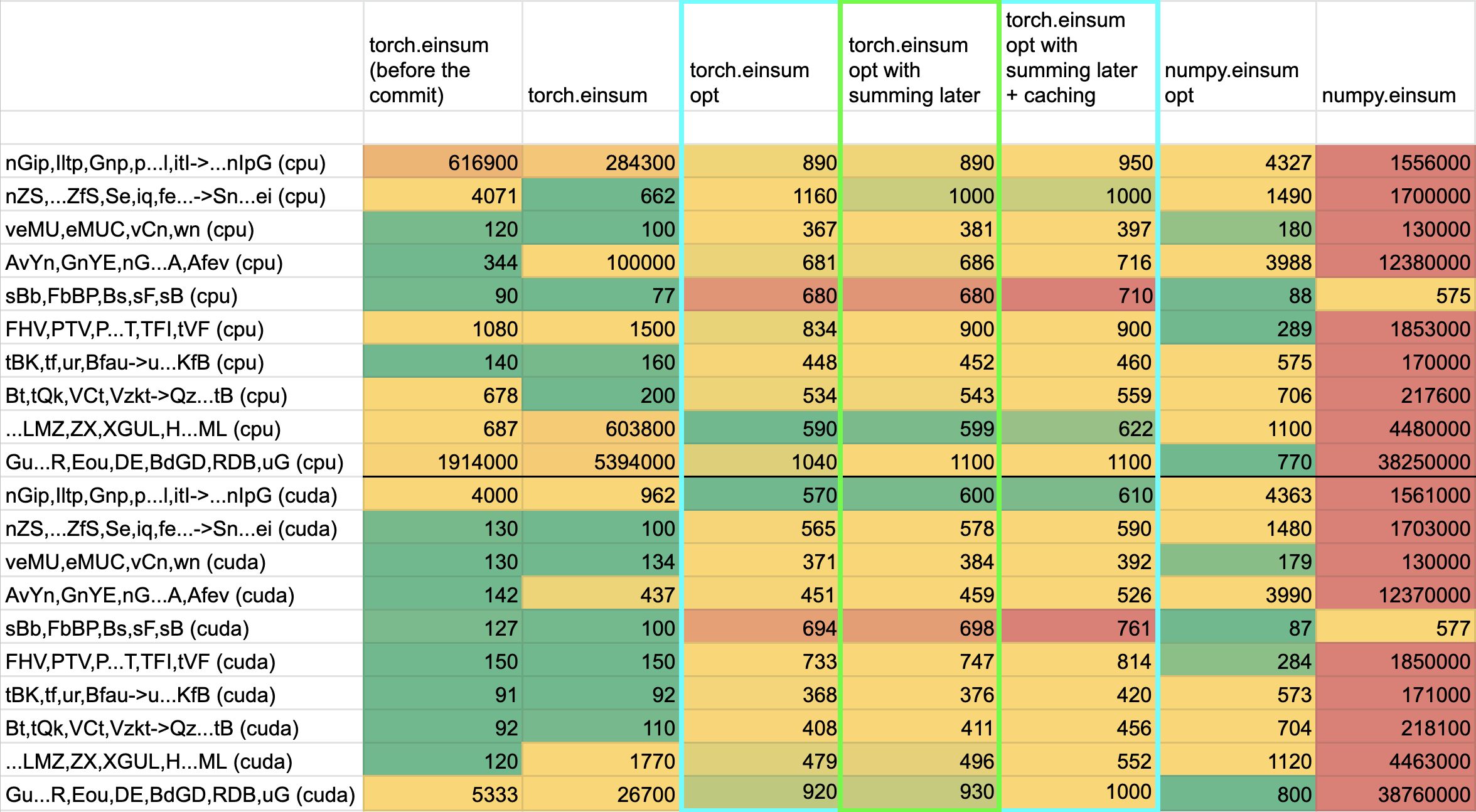
- **torch.einsum with opt_einsum installed is consistently fast, but has an overhead** of needing to find the path. If the path is already found/optimal, it will be slightly slower.
- The einsum overhead decreases for bigger dimensions.
- **torch.einsum without opt_einsum installed is comparable to before this commit**, with occasional slowness potentially due to not reshaping/squeezing as we contract until the end.
- For many of the random generated cases, the dimensions were too similar and small where an optimal order wasn't that much more optimal than just going left to right. However, in production, dimensions are commonly quite distinct (batch size will be small, but the data will be huge).
- **torch.einsum opt is comparable (slightly faster overall) compared to numpy.einsum opt for the cpu case**. This is interesting given that torch.einsum currently spends time computing the path, but numpy.einsum takes it as input.
- **torch.einsum opt is significantly faster than numpy.einsum opt for the gpu case**. This is because numpy doesn't take advantage of GPUs.
The following benchmarks were done on an A100 GPU and Linux CPUs. The line in the first chart separates GPU (on top) from CPU, and the line in the second graph separates CPU (on top) and then GPU. Sorry it's flipped 😛 .
Production example (see [colab benchmark](https://colab.research.google.com/drive/1V2s4v1dOOKwRvp5T_DC-PNUosOV9FFJx?authuser=1#scrollTo=WZoQkC8Mdt6I) for more context):
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012636-9a68bfa7-2601-43b1-afeb-b4e0877db6a4.png">
Randomly generated examples (the same ones as in https://github.com/pytorch/pytorch/pull/60191)
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012804-1c639595-b3e6-48c9-a385-ad851c13e1c2.png">
Open below to see old + not super relevant benchmarking results:
<details>
Benchmark results BEFORE this PR (on Linux -- I will update devices so they are consistent later):
<img width="776" alt="image" src="https://user-images.githubusercontent.com/31798555/190807274-18f71fce-556e-47f4-b18c-e0f7d0c0d5aa.png">
Benchmark results with the code on this PR (on my x86 mac):
For the CPU internal use case --

For the general use case --
It looks like numpy opt still does better in several of these random cases, but torch einsum opt is consistently faster than torch.einsum.

<details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84890
Approved by: https://github.com/albanD, https://github.com/soulitzer
Summary: test_inverse_errors_large and test_linalg_solve_triangular fail for dtype=float64 when invoked on GPUs on Meta internal testing infra. Skip in Meta internal testing.
Test Plan: (observe tests skipped on Meta internal infra)
Reviewed By: mikekgfb
Differential Revision: D39785331
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85577
Approved by: https://github.com/malfet
Summary:
Re-submit for approved PR that was then reverted: https://github.com/pytorch/pytorch/pull/85084
Create unit test to detect cuBLAS breakage via large differences between CPU and GPU addmm invocations
Test Plan:
Sample unit test output --
[...]
test_cublas_addmm_size_10000_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_10000_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_10000_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
[...]
Reviewed By: mikekgfb
Differential Revision: D39433029
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85432
Approved by: https://github.com/zrphercule
Summary: Create unit test to detect cuBLAS breakage via large differences between CPU and GPU addmm invocations
Test Plan:
Sample unit test output --
[...]
test_cublas_addmm_size_10000_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_10000_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_10000_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
[...]
Reviewed By: mikekgfb
Differential Revision: D39433029
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85084
Approved by: https://github.com/zrphercule
`torch.norm` is very odd. Some notable issues are:
- The default value of `"fro"` in `torch.norm` has an odd behaviour when `dim=None`. This is handled in the new dispatch
- The treatment of the `dtype` argument in `torch.norm` was completely wrong. This should fix it
- Some `out=` variants in the previous implementation were also wrong. This should fix those.
- This new dispatch should make some paths much faster. For example, `torch.norm(x)` where `x` is complex.
I'll try to make the changes in these PRs as incremental as possible as this is a tricky one.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81761
Approved by: https://github.com/ngimel
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}