This replaces a bunch of unnecessary lambdas with the operator package. This is semantically equivalent, but the operator package is faster, and arguably more readable. When the FURB rules are taken out of preview, I will enable it as a ruff check.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/116027
Approved by: https://github.com/malfet
disable test int_mm for sm90 or later
```
python test/test_linalg.py -k test__int_mm_k_32_n_32_use_transpose_a_False_use_transpose_b_False_cuda
_ TestLinalgCUDA.test__int_mm_k_32_n_32_use_transpose_a_False_use_transpose_b_False_cuda _
Traceback (most recent call last):
File "/usr/lib/python3.10/unittest/case.py", line 59, in testPartExecutor
yield
File "/usr/lib/python3.10/unittest/case.py", line 591, in run
self._callTestMethod(testMethod)
File "/usr/lib/python3.10/unittest/case.py", line 549, in _callTestMethod
method()
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_utils.py", line 2410, in wrapper
method(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_utils.py", line 2410, in wrapper
method(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_device_type.py", line 428, in instantiated_test
raise rte
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_device_type.py", line 415, in instantiated_test
result = test(self, **param_kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_device_type.py", line 1084, in only_fn
return fn(slf, *args, **kwargs)
File "/opt/pytorch/pytorch/test/test_linalg.py", line 5719, in test__int_mm
_test(17, k, n, use_transpose_a, use_transpose_b)
File "/opt/pytorch/pytorch/test/test_linalg.py", line 5680, in _test
c_int32 = torch._int_mm(a_int8, b_int8)
RuntimeError: CUDA error: CUBLAS_STATUS_NOT_SUPPORTED when calling cublasLtMatmul with transpose_mat1 0 transpose_mat2 0 m 32 n 17 k 32 mat1_ld 32 mat2_ld 32 result_ld 32 abType 3 cType 10 computeType 72 scaleType 10
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/113327
Approved by: https://github.com/malfet
Currently, for `matrix_exp` function, if we have NaN values in the input matrices (small batches), it will keep outputting a "normal" result without any NaN value in it, and this will cause some problems that we may can't notice. This PR is for preventing such undefined behavior by "bring back" those NaN values.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/111539
Approved by: https://github.com/lezcano
Fixes#109604
Resubmit gh-109715 + several skips and small fixes to make tests pass.
The main fix here is by @ysiraichi : previously, dynamo did not resume tracing numpy ndarrays after a graph break.
While at it, fix several small issues Yukio's fix uncovers:
- graph break gracefully on numpy dtypes which do not map to torch.dtypes (uint16 etc)
- recognize array scalars in dynamo, treat them as 0D ndarrays
- make sure that iterating over torch.ndarray generates arrays not bare tensors
Pull Request resolved: https://github.com/pytorch/pytorch/pull/110512
Approved by: https://github.com/lezcano
Fixes#108754.
`hf_T5_generate` would encounter a regression when calling `extern_kernels.bmm`, if one input is `reinterpret_tensor(buf2, (8, 1, 64), (64, 0, 1))` rather than `reinterpret_tensor(buf2, (8, 1, 64), (64, 512, 1), 0)`. As @jgong5 mentioned in comment, in fact the two tensors are equivalent: The stride doesn't matter when the corresponding size is 1.
We revise the definition of contiguity in `bmm` to add the above situation as a contiguous case. Thus, when stride equals to 0, `extern_kernels.bmm` could still use `gemm` of MKL to gain the performance.
Speedup of `hf_T5_generate` is **1.343x** now and **1.138x** before, with script `bash inductor_single_test.sh multiple inference performance torchbench hf_T5_generate float32 first dynamic default 0`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/110811
Approved by: https://github.com/jgong5, https://github.com/lezcano, https://github.com/Chillee
Fixes#68972
Relands #107246
To avoid causing Meta-internal CI failures, this PR avoids always asserting that the default dtype is float in the `TestCase.setUp/tearDown` methods. Instead, the assert is only done if `TestCase._default_dtype_check_enabled == True`. `_default_dtype_check_enabled` is set to True in the `if __name__ == "__main__":` blocks of all the relevant test files that have required changes for this issue
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108088
Approved by: https://github.com/ezyang
This is a follow up to https://github.com/pytorch/pytorch/pull/105881 and replaces https://github.com/pytorch/pytorch/pull/103203
The batched linalg drivers from 103203 were brought in as part of the first PR. This change enables the ROCm unit tests that were enabled as a result of that change. Along with a fix to prioritize hipsolver over magma when the preferred linalg backend is set to `default`
The following 16 unit tests will be enabled for rocm in this change:
- test_inverse_many_batches_cuda*
- test_inverse_errors_large_cuda*
- test_linalg_solve_triangular_large_cuda*
- test_lu_solve_batched_many_batches_cuda*
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106620
Approved by: https://github.com/lezcano
Current test case causes an edge case tensor input that causes a single generated tensor to fail the tolerance assertion on ROCm only and only for float32. We have reviewed the logic with our libraries team and have discovered the discrepancy is due to a difference in order of operations on AMD GPUs. They came back with "working as intended" and found no perceivable bug. Interestingly, if we change the values in ks, ns, or bs, the test passes on ROCm. These particular sizes in this particular order generates a single problematic input that causes the assertion to fail the tolerance check by ~0.07. Again, this is not a bug, just differences in implementation. This PR loosens the tolerance for ROCm only.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104425
Approved by: https://github.com/jeffdaily, https://github.com/nikitaved, https://github.com/lezcano
Fixes#102678Fixes#102629Fixes#102558
HipSOLVER performance on ROCm5.4.2 and later no longer serves as massive bottleneck. Additionally, using magma on rocm in this case caused test_compare_cpu_lialg_pinv_singular_cuda_float32 to fail. Using hipSOLVER, the test now passes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103540
Approved by: https://github.com/lezcano
Current test case causes an edge case tensor input that causes a single generated tensor to fail the tolerance assertion on ROCm only and only for float32. We have reviewed the logic with our libraries team and have discovered the discrepancy is due to a difference in order of operations on AMD GPUs. They came back with "working as intended" and found no perceivable bug. Interestingly, if we change the values in ks, ns, or bs, the test passes on ROCm. These particular sizes in this particular order generates a single problematic input that causes the assertion to fail the tolerance check by ~0.07. Again, this is not a bug, just differences in implementation. This PR loosens the tolerance for ROCm only.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104425
Approved by: https://github.com/jeffdaily, https://github.com/nikitaved, https://github.com/lezcano
Enabling more tests on ASAN, meanwhile we disable float-divide-by-zero and float-cast-overflow, both are disabled because they are also disabled by default in latest clang.
The following cited doc explains the reasons.
```
-fsanitize=float-cast-overflow: Conversion to, from, or between floating-point types
which would overflow the destination. Because the range of representable values
for all floating-point types supported by Clang is [-inf, +inf], the only cases detected are
conversions from floating point to integer types.
-fsanitize=float-divide-by-zero: Floating point division by zero.
This is undefined per the C and C++ standards,
but is defined by Clang (and by ISO/IEC/IEEE 60559 / IEEE 754) as producing
either an infinity or NaN value,
so is not included in -fsanitize=undefined.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103647
Approved by: https://github.com/kit1980
Summary:
Currently, cuBLASLt-based fused GELU epilogue in the GPU back-end of the `_addmm_activation` operator uses tanh approximation, whereas other code paths on GPU don't.
With this PR, the GELU tanh approximation is switched on in all back-end code paths of `_addmm_activation` on GPU for better consistency.
Test Plan:
```
$ python test/test_linalg.py -k test_addmm_relu -v
test_addmm_relu_cpu_bfloat16 (__main__.TestLinalgCPU.test_addmm_relu_cpu_bfloat16) ... ok
test_addmm_relu_cpu_float32 (__main__.TestLinalgCPU.test_addmm_relu_cpu_float32) ... ok
test_addmm_relu_cpu_float64 (__main__.TestLinalgCPU.test_addmm_relu_cpu_float64) ... ok
test_addmm_relu_cuda_bfloat16 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_bfloat16) ... ok
test_addmm_relu_cuda_float32 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_float32) ... ok
test_addmm_relu_cuda_float64 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_float64) ... ok
----------------------------------------------------------------------
Ran 6 tests in 1.896s
OK
$ python test/test_linalg.py -k test_addmm_gelu -v
test_addmm_gelu_cpu_bfloat16 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_bfloat16) ... ok
test_addmm_gelu_cpu_float32 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_float32) ... ok
test_addmm_gelu_cpu_float64 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_float64) ... ok
test_addmm_gelu_cuda_bfloat16 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_bfloat16) ... ok
test_addmm_gelu_cuda_float32 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_float32) ... ok
test_addmm_gelu_cuda_float64 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_float64) ... ok
----------------------------------------------------------------------
Ran 6 tests in 2.050s
OK
```
Reviewers: @eellison
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104061
Approved by: https://github.com/eellison
Summary:
This PR fixes the wrong assertion in the `test_addmm_gelu` happening in the Windows CUDA CI job caused by #103811. The addmm + GELU fusion is likely not happening (or not using the tanh approximation) on Windows. See [this comment](https://github.com/pytorch/pytorch/pull/103811#issuecomment-1601936203) in the #103811 for the details of the error.
Test Plan:
```
$ python test/test_linalg.py -k test_addmm_relu -v
test_addmm_relu_cpu_bfloat16 (__main__.TestLinalgCPU.test_addmm_relu_cpu_bfloat16) ... ok
test_addmm_relu_cpu_float32 (__main__.TestLinalgCPU.test_addmm_relu_cpu_float32) ... ok
test_addmm_relu_cpu_float64 (__main__.TestLinalgCPU.test_addmm_relu_cpu_float64) ... ok
test_addmm_relu_cuda_bfloat16 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_bfloat16) ... ok
test_addmm_relu_cuda_float32 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_float32) ... ok
test_addmm_relu_cuda_float64 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_float64) ... ok
----------------------------------------------------------------------
Ran 6 tests in 2.131s
OK
$ python test/test_linalg.py -k test_addmm_gelu -v
test_addmm_gelu_cpu_bfloat16 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_bfloat16) ... ok
test_addmm_gelu_cpu_float32 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_float32) ... ok
test_addmm_gelu_cpu_float64 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_float64) ... ok
test_addmm_gelu_cuda_bfloat16 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_bfloat16) ... ok
test_addmm_gelu_cuda_float32 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_float32) ... ok
test_addmm_gelu_cuda_float64 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_float64) ... ok
----------------------------------------------------------------------
Ran 6 tests in 2.194s
OK
```
Reviewers: @eellison @huydhn
Subscribers:
Tasks:
Tags:
Differential Revision: [D46931688](https://our.internmc.facebook.com/intern/diff/D46931688)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104031
Approved by: https://github.com/huydhn, https://github.com/malfet
Summary:
Previously, addmm + GELU epilogue fusion was unconditionally disabled in `ATen/native/cuda/Blas.cpp` due to compilation and numerical issues in CUDA <= 11.4. This PR:
1. Enables addmm + GELU epilogue fusion for CUDA >= 11.8.
2. Restricts the usage of fused addmm epilogue to contiguous output (bugfix).
3. Extends unit tests with addmm epilogue fusion and GELU activation paths.
Test Plan:
$ python test/test_linalg.py -k test_addmm_relu -v
test_addmm_relu_cpu_bfloat16 (__main__.TestLinalgCPU.test_addmm_relu_cpu_bfloat16) ... ok
test_addmm_relu_cpu_float32 (__main__.TestLinalgCPU.test_addmm_relu_cpu_float32) ... ok
test_addmm_relu_cpu_float64 (__main__.TestLinalgCPU.test_addmm_relu_cpu_float64) ... ok
test_addmm_relu_cuda_bfloat16 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_bfloat16) ... ok
test_addmm_relu_cuda_float32 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_float32) ... ok
test_addmm_relu_cuda_float64 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_float64) ... ok
$ python test/test_linalg.py -k test_addmm_gelu -v
test_addmm_gelu_cpu_bfloat16 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_bfloat16) ... ok
test_addmm_gelu_cpu_float32 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_float32) ... ok
test_addmm_gelu_cpu_float64 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_float64) ... ok
test_addmm_gelu_cuda_bfloat16 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_bfloat16) ... ok
test_addmm_gelu_cuda_float32 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_float32) ... ok
test_addmm_gelu_cuda_float64 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_float64) ... ok
Reviewers: @eellison
Differential Revision: [D46829884](https://our.internmc.facebook.com/intern/diff/D46829884)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103811
Approved by: https://github.com/IvanYashchuk, https://github.com/eellison
Fixes#102678Fixes#102629Fixes#102558
HipSOLVER performance on ROCm5.4.2 and later no longer serves as massive bottleneck. Additionally, using magma on rocm in this case caused test_compare_cpu_lialg_pinv_singular_cuda_float32 to fail. Using hipSOLVER, the test now passes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103540
Approved by: https://github.com/lezcano
Enables the hipSolver backend for ROCm builds
--------------------------------------------------------------------------
- Minimum ROCm version requirement - 5.3
- Introduces new macro USE_LINALG_SOLVER the controls enablement of both cuSOLVER and hipSOLVER
- Adds hipSOLVER API to hipification process
- combines hipSOLVER and hipSPARSE mappings into single SPECIAL map that takes priority among normal mappings
- Torch api to be moved to hipsolver backend (as opposed to magma) include: torch.svd(), torch.geqrf(), torch.orgqr(), torch.ormqr()
- Will enable 100+ linalg unit tests for ROCm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97370
Approved by: https://github.com/malfet
Notes:
- No segfaults observed in any CI tests: dynamo unittests, inductor unittests, dynamo-wrapped pytorch tests. So we remove the warning that using dynamo 3.11 may result in segfaults.
- Some dynamo-wrapped pytorch tests hang. They will be skipped in the dynamo-wrapped test suite and will be addressed in a future PR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99180
Approved by: https://github.com/malfet
Issue: #93684
# Problem
Reduce graph breaks when dynamo compiles python functions containing numpy functions and ndarray operations.
# Design (as I know it)
* Use torch_np.ndarray(a wrapper of tensor) to back a `VariableTracker`: `NumpyTensorVariable`.
* Translate all attributes and methods calls, on ndarray, to torch_np.ndarray equivalent.
This PR adds `NumpyTensorVariable` and supports:
1. tensor to ndarray, ndarray to tensor
2. numpy functions such as numpy.meshgrid()
3. ndarray attributes such as `itemsize`, `stride`
Next PR will handle returning `np.ndarray` and add support for ndarray methods
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95849
Approved by: https://github.com/ezyang
Add _int_mm primitive that binds cuBLAS int8@int8 -> int32 matmul and that translates to Triton based mm templates under max autotune. This is a very useful first step towards better supporting quantization on the GPU. This is a not a user facing API, but an internal primitive.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94339
Approved by: https://github.com/ngimel, https://github.com/jansel
Currently, if we multiply a transposed batch of matrices with shape
[b, m, n] and a matrix with shape [n, k], when computing the gradient
of the matrix, we instantiate a matrix of shape [b, n, k]. This may be
a very large matrix. Instead, we fold the batch of matrices into a
matrix, which avoids creating any large intermediary tensor.
Note that multiplying a batch of matrices and a matrix naturally occurs
within an attention module, so this case surely happens in the wild.
In particular, this issue was found while investigating the OOMs caused by the
improved folding algorithm in the next PR of this stack. See https://github.com/pytorch/pytorch/pull/76828#issuecomment-1432359980
This PR fixes those OOMs and decreases the memory footprint of the
backward of matmul.
I understand this is a tricky one, so I put it on its own PR to discuss it.
Differential Revision: [D43541495](https://our.internmc.facebook.com/intern/diff/D43541495)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95261
Approved by: https://github.com/ezyang
Follow-up of #89582 to drop flags like `CUDA11OrLater` in tests. Note that in some places it appears that `TEST_WITH_ROCM` is _implicitly_ guarded against via the `CUDA11OrLater` version check, based on my best-guess of how `torch.version.cuda` would behave in ROCM builds, so I've added `not TEST_WITH_ROCM` in cases where ROCM wasn't previously explicitly allowed.
CC @ptrblck @malfet @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92605
Approved by: https://github.com/ngimel
This achieves the same things as https://github.com/pytorch/pytorch/pull/85908 but using backends instead of kwargs (which breaks torchscript unfortunately). This also does mean we let go of numpy compatibility BUT the wins here are that users can control what opt einsum they wanna do!
The backend allows for..well you should just read the docs:
```
.. attribute:: torch.backends.opteinsum.enabled
A :class:`bool` that controls whether opt_einsum is enabled (on by default). If so,
torch.einsum will use opt_einsum (https://optimized-einsum.readthedocs.io/en/stable/path_finding.html)
to calculate an optimal path of contraction for faster performance.
.. attribute:: torch.backends.opteinsum.strategy
A :class:`str` that specifies which strategies to try when `torch.backends.opteinsum.enabled` is True.
By default, torch.einsum will try the "auto" strategy, but the "greedy" and "optimal" strategies are
also supported. Note that the "optimal" strategy is factorial on the number of inputs as it tries all
possible paths. See more details in opt_einsum's docs
(https://optimized-einsum.readthedocs.io/en/stable/path_finding.html).
```
In trying (and failing) to land 85908, I discovered that jit script does NOT actually pull from python's version of einsum (because it cannot support variadic args nor kwargs). Thus I learned that jitted einsum does not subscribe to the new opt_einsum path calculation. Overall, this is fine since jit script is getting deprecated, but where is the best place to document this?
## Test plan:
- added tests to CI
- locally tested that trying to set the strategy to something invalid will error properly
- locally tested that tests will pass even if you don't have opt-einsum
- locally tested that setting the strategy when opt-einsum is not there will also error properly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86219
Approved by: https://github.com/soulitzer, https://github.com/malfet
## This PR seeks to:
- [x] add c++ support for an optimize path
- [x] add python opt_einsum path passthrough
- [x] add opt_einsum to OSS requirements, but a soft one
- [x] show benchmark results here
Additional things I've explored + their conclusions:
- **Delaying the summing over dimensions** => added!
- The idea here is to not incur kernel calls to `sum` as we try to early sum out in einsum. Thus, we collect all the dimensions that need to be summed together in one contraction + sum at the end instead of summing as we go. While this optimization didn't feel like it made things faster for the random cases we've selected (they all summed 1 dim per contraction), it is a good principle and would help more common use cases that would reduce multiple dimensions at a time (like `bxy,xyi,xyj->bij`).
- **Caching contract_path based on equation and tensor sizes** => dropped :(
- The benchmarks were strictly worse for all the cases, and, from scanning the use cases, I observed people do not often call einsum on the same equation/tensor order enough for caching to be justified. I do think caching can be effective in the future, but it would require further investigation.
## Not a part of this PR (but are next steps):
- adding opt_einsum package to OSS CI
- adding it to internal CI
- potentially adding a kwarg path argument to the python API -- if the path is given, we wouldn't have to spend time calculating it, but there would be some time lost validating user input.
## Testing:
- Added more tests to CI
## Benchmarking:
**TL;DRs**
- **torch.einsum with opt_einsum is a definite win for the production case**.
- **torch.einsum with opt_einsum installed is consistently fast, but has an overhead** of needing to find the path. If the path is already found/optimal, it will be slightly slower.
- The einsum overhead decreases for bigger dimensions.
- **torch.einsum without opt_einsum installed is comparable to before this commit**, with occasional slowness potentially due to not reshaping/squeezing as we contract until the end.
- For many of the random generated cases, the dimensions were too similar and small where an optimal order wasn't that much more optimal than just going left to right. However, in production, dimensions are commonly quite distinct (batch size will be small, but the data will be huge).
- **torch.einsum opt is comparable (slightly faster overall) compared to numpy.einsum opt for the cpu case**. This is interesting given that torch.einsum currently spends time computing the path, but numpy.einsum takes it as input.
- **torch.einsum opt is significantly faster than numpy.einsum opt for the gpu case**. This is because numpy doesn't take advantage of GPUs.
The following benchmarks were done on an A100 GPU and Linux CPUs. The line in the first chart separates GPU (on top) from CPU, and the line in the second graph separates CPU (on top) and then GPU. Sorry it's flipped 😛 .
Production example (see [colab benchmark](https://colab.research.google.com/drive/1V2s4v1dOOKwRvp5T_DC-PNUosOV9FFJx?authuser=1#scrollTo=WZoQkC8Mdt6I) for more context):
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012636-9a68bfa7-2601-43b1-afeb-b4e0877db6a4.png">
Randomly generated examples (the same ones as in https://github.com/pytorch/pytorch/pull/60191)
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012804-1c639595-b3e6-48c9-a385-ad851c13e1c2.png">
Open below to see old + not super relevant benchmarking results:
<details>
Benchmark results BEFORE this PR (on Linux -- I will update devices so they are consistent later):
<img width="776" alt="image" src="https://user-images.githubusercontent.com/31798555/190807274-18f71fce-556e-47f4-b18c-e0f7d0c0d5aa.png">
Benchmark results with the code on this PR (on my x86 mac):
For the CPU internal use case --

For the general use case --
It looks like numpy opt still does better in several of these random cases, but torch einsum opt is consistently faster than torch.einsum.

<details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84890
Approved by: https://github.com/albanD, https://github.com/soulitzer
Summary: test_inverse_errors_large and test_linalg_solve_triangular fail for dtype=float64 when invoked on GPUs on Meta internal testing infra. Skip in Meta internal testing.
Test Plan: (observe tests skipped on Meta internal infra)
Reviewed By: mikekgfb
Differential Revision: D39785331
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85577
Approved by: https://github.com/malfet
Summary:
Re-submit for approved PR that was then reverted: https://github.com/pytorch/pytorch/pull/85084
Create unit test to detect cuBLAS breakage via large differences between CPU and GPU addmm invocations
Test Plan:
Sample unit test output --
[...]
test_cublas_addmm_size_10000_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_10000_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_10000_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
[...]
Reviewed By: mikekgfb
Differential Revision: D39433029
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85432
Approved by: https://github.com/zrphercule
Summary: Create unit test to detect cuBLAS breakage via large differences between CPU and GPU addmm invocations
Test Plan:
Sample unit test output --
[...]
test_cublas_addmm_size_10000_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_10000_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_10000_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
[...]
Reviewed By: mikekgfb
Differential Revision: D39433029
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85084
Approved by: https://github.com/zrphercule
`torch.norm` is very odd. Some notable issues are:
- The default value of `"fro"` in `torch.norm` has an odd behaviour when `dim=None`. This is handled in the new dispatch
- The treatment of the `dtype` argument in `torch.norm` was completely wrong. This should fix it
- Some `out=` variants in the previous implementation were also wrong. This should fix those.
- This new dispatch should make some paths much faster. For example, `torch.norm(x)` where `x` is complex.
I'll try to make the changes in these PRs as incremental as possible as this is a tricky one.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81761
Approved by: https://github.com/ngimel
As per title. I corrected a thing or two from my previous implementation
to make for better errors in some weird edge-cases and have a more clear
understanding of when does this function support low_precision types and
when it doesn't.
We also use the optimisation for bfloat16 within `vector_norm` within
this function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81113
Approved by: https://github.com/ngimel
This PR also adds complex support for logdet, and makes all these
functions support out= and be composite depending on one function. We
also extend the support of `logdet` to complex numbers and improve the
docs of all these functions.
We also use `linalg_lu_factor_ex` in these functions, so we remove the
synchronisation present before.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79742
Approved by: https://github.com/IvanYashchuk, https://github.com/albanD
This PR heavily simplifies the code of `linalg.solve`. At the same time,
this implementation saves quite a few copies of the input data in some
cases (e.g. A is contiguous)
We also implement it in such a way that the derivative goes from
computing two LU decompositions and two LU solves to no LU
decompositions and one LU solves. It also avoids a number of unnecessary
copies the derivative was unnecessarily performing (at least the copy of
two matrices).
On top of this, we add a `left` kw-only arg that allows the user to
solve `XA = B` rather concisely.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74046
Approved by: https://github.com/nikitaved, https://github.com/IvanYashchuk, https://github.com/mruberry
This PR simplifies the logic of `linalg.qr` using structured kernels. I
also took this chance and merged a few `copy_` operations with other
ops.
This PR removes a the previous magma implementation as is never faster
than that of cusolver and it's rather buggy. This has the side-effect
that now `qr` is not supported in Rocm. Ivan confirmed that this is
fine, given how incredibly slow was QR on Rocm anyway (we were marking
some tests as slow because of this...).
This PR also corrects the dispatch in geqrf. Before, if we called it
with a matrix for which `input.size(-2) <= 256 && batchCount(input) >= std::max<int64_t>(2, input.size(-2) / 16)` is false, and we have cublas but not cusolver, we would end up calling magma rather than cublas. This is not what the heuristic suggested.
Probaly we should benchmark these heuristics again, but that's beyond the scope of this PR.
Note. It looks like `torch.geqrf` maybe broken in MAGMA as per the
previous comment in `linalg_qr_helper_magma`. IvanYashchuk wdyt?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79054
Approved by: https://github.com/IvanYashchuk, https://github.com/ezyang
**BC-breaking note**:
This PR deprecates `torch.lu` in favor of `torch.linalg.lu_factor`.
A upgrade guide is added to the documentation for `torch.lu`.
Note this PR DOES NOT remove `torch.lu`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77636
Approved by: https://github.com/malfet
This PR adds `linalg.lu_solve`. While doing so, I found a bug in MAGMA
when calling the batched MAGMA backend with trans=True. We work around
that by solving the system solving two triangular systems.
We also update the heuristics for this function, as they were fairly
updated. We found that cuSolver is king, so luckily we do not need to
rely on the buggy backend from magma for this function.
We added tests testing this function left and right. We also added tests
for the different backends. We also activated the tests for AMD, as
those should work as well.
Fixes https://github.com/pytorch/pytorch/issues/61657
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77634
Approved by: https://github.com/malfet
This PR does a number of things:
- Move linalg.vector_norm to structured kernels and simplify the logic
- Fixes a number of prexisting issues with the dtype kwarg of these ops
- Heavily simplifies and corrects the logic of `linalg.matrix_norm` and `linalg.norm` to be consistent with the docs
- Before the `_out` versions of these functions were incorrect
- Their implementation is now as efficient as expected, as it avoids reimplementing these operations whenever possible.
- Deprecates `torch.frobenius_norm` and `torch.nuclear_norm`, as they were exposed in the API and they are apparently being used in mobile (??!!) even though they were not documented and their implementation was slow.
- I'd love to get rid of these functions already, but I guess we have to go through their deprecation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76547
Approved by: https://github.com/mruberry
This PR adds `linalg.lu_solve`. While doing so, I found a bug in MAGMA
when calling the batched MAGMA backend with trans=True. We work around
that by solving the system solving two triangular systems.
We also update the heuristics for this function, as they were fairly
updated. We found that cuSolver is king, so luckily we do not need to
rely on the buggy backend from magma for this function.
We added tests testing this function left and right. We also added tests
for the different backends. We also activated the tests for AMD, as
those should work as well.
Fixes https://github.com/pytorch/pytorch/issues/61657
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72935
Approved by: https://github.com/IvanYashchuk, https://github.com/mruberry
This PR modifies `lu_unpack` by:
- Using less memory when unpacking `L` and `U`
- Fuse the subtraction by `-1` with `unpack_pivots_stub`
- Define tensors of the correct types to avoid copies
- Port `lu_unpack` to be a strucutred kernel so that its `_out` version
does not incur on extra copies
Then we implement `linalg.lu` as a structured kernel, as we want to
compute its derivative manually. We do so because composing the
derivatives of `torch.lu_factor` and `torch.lu_unpack` would be less efficient.
This new function and `lu_unpack` comes with all the things it can come:
forward and backward ad, decent docs, correctness tests, OpInfo, complex support,
support for metatensors and support for vmap and vmap over the gradients.
I really hope we don't continue adding more features.
This PR also avoids saving some of the tensors that were previously
saved unnecessarily for the backward in `lu_factor_ex_backward` and
`lu_backward` and does some other general improvements here and there
to the forward and backward AD formulae of other related functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67833
Approved by: https://github.com/IvanYashchuk, https://github.com/nikitaved, https://github.com/mruberry
We derive and implement a more concise rule for the forward and backward
derivatives of the QR decomposition. While doing this we:
- Fix the composite compliance of `linalg.qr` and we make it support batches
- Improve the performance and simplify the implementation of both foward and backward
- Avoid saving the input matrix for the backward computation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76115
Approved by: https://github.com/nikitaved, https://github.com/albanD
Let's make sure we don't break anything in the next PRs of the stack.
Also some comprehensive testing of matmul on CPU and CUDA was long due.
Running this tests we see that the `out=` variant of matmul is broken
when used on 4D tensors. This hints what would be the amount of people
that use out= variants...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75193
Approved by: https://github.com/ngimel
This PR adds a function for computing the LDL decomposition and a function that can solve systems of linear equations using this decomposition. The result of `torch.linalg.ldl_factor_ex` is in a compact form and it's required to use it only through `torch.linalg.ldl_solve`. In the future, we could provide `ldl_unpack` function that transforms the compact representation into explicit matrices.
Fixes https://github.com/pytorch/pytorch/issues/54847.
cc @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69828
Approved by: https://github.com/Lezcano, https://github.com/mruberry, https://github.com/albanD
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73748
This adds CPU-only slow test jobs, which previously would never run.
Includes fixes/skips for slow tests which fail (they need to be skipped now because they used to never run)
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D34628803
Pulled By: davidberard98
fbshipit-source-id: c090ab7bf7bda9e24ec5cdefa6fd35c6310dbac0
(cherry picked from commit 06f7a94a57cc7023e9c5442be8298d20cd011144)
Summary:
Previous PR with the same content: https://github.com/pytorch/pytorch/pull/69752. Opening a new PR by request: https://github.com/pytorch/pytorch/pull/69752#issuecomment-1020829812.
------
Previously for single input matrix A and batched matrix B, matrix A was expanded and cloned before computing the LU decomposition and solving the linear system.
With this PR the LU decomposition is computed once for a single matrix and then expanded&cloned if required by a backend library call for the linear system solving.
Here's a basic comparison:
```python
# BEFORE THE PR
In [1]: import torch
In [2]: a = torch.randn(256, 256)
In [3]: b = torch.randn(1024, 256, 2)
In [4]: %%timeit
...: torch.linalg.solve(a, b)
...:
...:
329 ms ± 17.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# WITH THIS PR
In [1]: import torch
In [2]: a = torch.randn(256, 256)
In [3]: b = torch.randn(1024, 256, 2)
In [4]: %%timeit
...: torch.linalg.solve(a, b)
...:
...:
21.4 ms ± 23 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
```
Fixes https://github.com/pytorch/pytorch/issues/71406, fixes https://github.com/pytorch/pytorch/issues/71610
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71756
Reviewed By: ngimel
Differential Revision: D33771981
Pulled By: mruberry
fbshipit-source-id: 0917ee36a3eb622ff75d54787b1bffe26b41cb4a
(cherry picked from commit 9c30a05aaa972bc02dfc94c3d2463f0c5ee0c58c)
Summary:
This PR was opened as copy of https://github.com/pytorch/pytorch/pull/68812 by request https://github.com/pytorch/pytorch/pull/68812#issuecomment-1030215862.
-----
Fixes https://github.com/pytorch/pytorch/issues/67693.
Reference LAPACK (used in OpenBLAS) changed info error code for svd when inputs contain non-finite numbers. In PyTorch, we raise an internal assert error for negative `info` error codes because usually, it would indicate the wrong implementation. However, this is not the case with SVD now in newer versions of LAPACK. MKL (tried 2021.4.0) still gives a positive error code for this kind of input. This change aligns with the OpenBLAS and MKL behavior in our code.
MKL 2022 has uses the latest reference LAPACK behavior and returns the same `info` as OpenBLAS 0.3.15+
This PR also fixes https://github.com/pytorch/pytorch/issues/71645 that is due to the updated MKL version in CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72357
Reviewed By: albanD
Differential Revision: D34012245
Pulled By: ngimel
fbshipit-source-id: 2b66c173cc3458d8c766b542d0d569191cdce310
(cherry picked from commit fa29e65611)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/67693.
Reference LAPACK (used in OpenBLAS) changed info error code for svd when inputs contain non-finite numbers. In PyTorch, we raise an internal assert error for negative `info` error codes because usually, it would indicate wrong implementation. However, this is not the case with SVD now in newer versions of LAPACK. MKL (tried 2021.4.0) still gives a positive error code for this kind of input. This change aligns with the OpenBLAS and MKL behavior in our code.
**UPDATE:**
MKL 2022 has uses the latest reference LAPACK behavior and returns the same `info` as OpenBLAS 0.3.15+
This PR fixes https://github.com/pytorch/pytorch/issues/71645 that is due to the updated MKL version in CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68812
Reviewed By: mrshenli
Differential Revision: D33844257
Pulled By: ngimel
fbshipit-source-id: fd1c86e37e405b330633d039f49dce466391b66e
(cherry picked from commit c00a9bdeb0)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/67693.
Reference LAPACK (used in OpenBLAS) changed info error code for svd when inputs contain non-finite numbers. In PyTorch, we raise an internal assert error for negative `info` error codes because usually, it would indicate wrong implementation. However, this is not the case with SVD now in newer versions of LAPACK. MKL (tried 2021.4.0) still gives a positive error code for this kind of input. This change aligns with the OpenBLAS and MKL behavior in our code.
**UPDATE:**
MKL 2022 has uses the latest reference LAPACK behavior and returns the same `info` as OpenBLAS 0.3.15+
This PR fixes https://github.com/pytorch/pytorch/issues/71645 that is due to the updated MKL version in CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68812
Reviewed By: osalpekar
Differential Revision: D32626563
Pulled By: ngimel
fbshipit-source-id: 09042f07cdc9c24ce1fa5cd6f4483340c7b5b06c
(cherry picked from commit aadf507319)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70253
I included a derivation of the formula in the complex case, as it is
particularly tricky. As far as I know, this is the first time this formula
is derived in the literature.
I also implemented a more efficient and more accurate version of svd_backward.
More importantly, I also added a lax check in the complex case making sure the loss
function just depends on the subspaces spanned by the pairs of singular
vectors, and not their joint phase.
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: mikaylagawarecki
Differential Revision: D33751982
Pulled By: mruberry
fbshipit-source-id: c2a4a92a921a732357e99c01ccb563813b1af512
(cherry picked from commit 391319ed8f)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69827
In general, the current pattern allows for implementing optimisations
for all the backends in a common place (see for example the optimisation
for empty matrices).
After this PR, `torch.svd` is implemented in terms of `linalg.svd` and
`linalg.svdvals`, as expected. This makes it differentiable in the case
when `compute_uv=False`, although this is not particularly important, as
`torch.svd` will eventually be deprecated.
This PR also instantiates smaller `U` / `V` when calling cusolver_gesvdj
in the cases when `full_matrices=False` or `compute_uv=False`.
The memory for auxiliary `U` and `V` in the cases above, needed for some
cuSOLVER routines is allocated raw allocators rather than through fully
fledged tensors, as it's just a blob of memory the algorithm requests.
As the code is better structured now, it was easier to see that `U` and
`Vh` needn't be allocated when calling `svd_cusolver_gesvd`.
Now `linalg.svdvals` work as expected wrt the `out=` parameter.
Note that in the test `test_svd_memory_allocation` we were
passing a tensor of the wrong size and dtype and the test seemed to
pass...
This PR also changes the backward formula to avoid saving the input
matrix, as it's not necessary. In a follow up PR, I will clean the
backward formula and make it more numerically stable and efficient.
This PR also does a number of memory optimisations here and there, and fixes
the call to cusolver_gesvd, which were incorrect for m <= n. To test
this path, I compiled the code with a flag to unconditionally execute
the `if (!gesvdj_convergence_check.empty())` branch, and all the tests
passed.
I also took this chance to simplify the tests for these functions in
`test_linalg.py`, as we had lots of tests that were testing some
functionality that is already currently tested in the corresponding
OpInfos. I used xwang233's feature to test both MAGMA and CUDA
backends. This is particularly good for SVD, as cuSOLVER is always
chosen over MAGMA when available, so testing MAGMA otherwise would be
tricky.
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: mikaylagawarecki
Differential Revision: D33751983
Pulled By: mruberry
fbshipit-source-id: 11d48d977946345583d33d14fb11a170a7d14fd2
(cherry picked from commit a1860bd567)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68183
We do so in favour of
`make_fullrank_matrices_with_distinct_singular_values` as this latter
one not only has an even longer name, but also generates inputs
correctly for them to work with the PR that tests noncontig inputs
latter in this stack.
We also heavily simplified the generation of samples for the SVD, as it was
fairly convoluted and it was not generating the inputs correclty for
the noncontiguous test.
To do the transition, we also needed to fix the following issue, as it was popping
up in the tests:
Fixes https://github.com/pytorch/pytorch/issues/66856
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D32684853
Pulled By: mruberry
fbshipit-source-id: e88189c8b67dbf592eccdabaf2aa6d2e2f7b95a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D32834069
Pulled By: mruberry
fbshipit-source-id: 51ef12535fa91d292f419acf83b800b86ee9c7eb
Summary:
This PR fixes https://github.com/pytorch/pytorch/issues/64785 by introducing a `torch.LinAlgError` for reporting errors caused by bad values in linear algebra routines which should allow users to easily catch errors caused by numerical errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68571
Reviewed By: malfet
Differential Revision: D33254087
Pulled By: albanD
fbshipit-source-id: 94b59000fdb6a9765e397158e526d1f815f18f0f
Summary:
Per title.
This PR introduces a global flag that lets pytorch prefer one of the many backend implementations while calling linear algebra functions on GPU.
Usage:
```python
torch.backends.cuda.preferred_linalg_library('cusolver')
```
Available options (str): `'default'`, `'cusolver'`, `'magma'`.
Issue https://github.com/pytorch/pytorch/issues/63992 inspired me to write this PR. No heuristic is perfect on all devices, library versions, matrix shapes, workloads, etc. We can obtain better performance if we can conveniently switch linear algebra backends at runtime.
Performance of linear algebra operators after this PR should be no worse than before. The flag is set to **`'default'`** by default, which makes everything the same as before this PR.
The implementation of this PR is basically following that of https://github.com/pytorch/pytorch/pull/67790.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67980
Reviewed By: mruberry
Differential Revision: D32849457
Pulled By: ngimel
fbshipit-source-id: 679fee7744a03af057995aef06316306073010a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63570
There is a use of `at::triangular_solve_out` in the file
`torch/csrc/jit/tensorexpr/external_functions.cpp` that I have not dared
to move to `at::linalg_solve_triangular_out`.
**Deprecation note:**
This PR deprecates the `torch.triangular_solve` function in favor of
`torch.linalg.solve_triangular`. An upgrade guide is added to the
documentation for `torch.triangular_solve`.
Note that it DOES NOT remove `torch.triangular_solve`, but
`torch.triangular_solve` will be removed in a future PyTorch release.
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D32618035
Pulled By: anjali411
fbshipit-source-id: 0bfb48eeb6d96eff3e96e8a14818268cceb93c83
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D32521980
Pulled By: mruberry
fbshipit-source-id: 26a49ebd87f8a41472f8cd4e9de4ddfb7f5581fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63568
This PR adds the first solver with structure to `linalg`. This solver
has an API compatible with that of `linalg.solve` preparing these for a
possible future merge of the APIs. The new API:
- Just returns the solution, rather than the solution and a copy of `A`
- Removes the confusing `transpose` argument and replaces it by a
correct handling of conj and strides within the call
- Adds a `left=True` kwarg. This can be achieved via transposes of the
inputs and the result, but it's exposed for convenience.
This PR also implements a dataflow that minimises the number of copies
needed before calling LAPACK / MAGMA / cuBLAS and takes advantage of the
conjugate and neg bits.
This algorithm is implemented for `solve_triangular` (which, for this, is
the most complex of all the solvers due to the `upper` parameters).
Once more solvers are added, we will factor out this calling algorithm,
so that all of them can take advantage of it.
Given the complexity of this algorithm, we implement some thorough
testing. We also added tests for all the backends, which was not done
before.
We also add forward AD support for `linalg.solve_triangular` and improve the
docs of `linalg.solve_triangular`. We also fix a few issues with those of
`torch.triangular_solve`.
Resolves https://github.com/pytorch/pytorch/issues/54258
Resolves https://github.com/pytorch/pytorch/issues/56327
Resolves https://github.com/pytorch/pytorch/issues/45734
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32588230
Pulled By: mruberry
fbshipit-source-id: 69e484849deb9ad7bb992cc97905df29c8915910
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63568
This PR adds the first solver with structure to `linalg`. This solver
has an API compatible with that of `linalg.solve` preparing these for a
possible future merge of the APIs. The new API:
- Just returns the solution, rather than the solution and a copy of `A`
- Removes the confusing `transpose` argument and replaces it by a
correct handling of conj and strides within the call
- Adds a `left=True` kwarg. This can be achieved via transposes of the
inputs and the result, but it's exposed for convenience.
This PR also implements a dataflow that minimises the number of copies
needed before calling LAPACK / MAGMA / cuBLAS and takes advantage of the
conjugate and neg bits.
This algorithm is implemented for `solve_triangular` (which, for this, is
the most complex of all the solvers due to the `upper` parameters).
Once more solvers are added, we will factor out this calling algorithm,
so that all of them can take advantage of it.
Given the complexity of this algorithm, we implement some thorough
testing. We also added tests for all the backends, which was not done
before.
We also add forward AD support for `linalg.solve_triangular` and improve the
docs of `linalg.solve_triangular`. We also fix a few issues with those of
`torch.triangular_solve`.
Resolves https://github.com/pytorch/pytorch/issues/54258
Resolves https://github.com/pytorch/pytorch/issues/56327
Resolves https://github.com/pytorch/pytorch/issues/45734
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: zou3519, JacobSzwejbka
Differential Revision: D32283178
Pulled By: mruberry
fbshipit-source-id: deb672e6e52f58b76536ab4158073927a35e43a8
Summary:
### Create `linalg.cross`
Fixes https://github.com/pytorch/pytorch/issues/62810
As discussed in the corresponding issue, this PR adds `cross` to the `linalg` namespace (**Note**: There is no method variant) which is slightly different in behaviour compared to `torch.cross`.
**Note**: this is NOT an alias as suggested in mruberry's [https://github.com/pytorch/pytorch/issues/62810 comment](https://github.com/pytorch/pytorch/issues/62810#issuecomment-897504372) below
> linalg.cross being consistent with the Python Array API (over NumPy) makes sense because NumPy has no linalg.cross. I also think we can implement linalg.cross without immediately deprecating torch.cross, although we should definitely refer users to linalg.cross. Deprecating torch.cross will require additional review. While it's not used often it is used, and it's unclear if users are relying on its unique behavior or not.
The current default implementation of `torch.cross` is extremely weird and confusing. This has also been reported multiple times previously. (See https://github.com/pytorch/pytorch/issues/17229, https://github.com/pytorch/pytorch/issues/39310, https://github.com/pytorch/pytorch/issues/41850, https://github.com/pytorch/pytorch/issues/50273)
- [x] Add `torch.linalg.cross` with default `dim=-1`
- [x] Add OpInfo and other tests for `torch.linalg.cross`
- [x] Add broadcasting support to `torch.cross` and `torch.linalg.cross`
- [x] Remove out skip from `torch.cross` OpInfo
- [x] Add docs for `torch.linalg.cross`. Improve docs for `torch.cross` mentioning `linalg.cross` and the difference between the two. Also adds a warning to `torch.cross`, that it may change in the future (we might want to deprecate it later)
---
### Additional Fixes to `torch.cross`
- [x] Fix Doc for Tensor.cross
- [x] Fix torch.cross in `torch/overridres.py`
While working on `linalg.cross` I noticed these small issues with `torch.cross` itself.
[Tensor.cross docs](https://pytorch.org/docs/stable/generated/torch.Tensor.cross.html) still mentions `dim=-1` default which is actually wrong. It should be `dim=None` after the behaviour was updated in PR https://github.com/pytorch/pytorch/issues/17582 but the documentation for the `method` or `function` variant wasn’t updated. Later PR https://github.com/pytorch/pytorch/issues/41850 updated the documentation for the `function` variant i.e `torch.cross` and also added the following warning about the weird behaviour.
> If `dim` is not given, it defaults to the first dimension found with the size 3. Note that this might be unexpected.
But still, the `Tensor.cross` docs were missed and remained outdated. I’m finally fixing that here. Also fixing `torch/overrides.py` for `torch.cross` as well now, with `dim=None`.
To verify according to the docs the default behaviour of `dim=-1` should raise, you can try the following.
```python
a = torch.randn(3, 4)
b = torch.randn(3, 4)
b.cross(a) # this works because the implementation finds 3 in the first dimension and the default behaviour as shown in documentation is actually not true.
>>> tensor([[ 0.7171, -1.1059, 0.4162, 1.3026],
[ 0.4320, -2.1591, -1.1423, 1.2314],
[-0.6034, -1.6592, -0.8016, 1.6467]])
b.cross(a, dim=-1) # this raises as expected since the last dimension doesn't have a 3
>>> RuntimeError: dimension -1 does not have size 3
```
Please take a closer look (particularly the autograd part, this is the first time I'm dealing with `derivatives.yaml`). If there is something missing, wrong or needs more explanation, please let me know. Looking forward to the feedback.
cc mruberry Lezcano IvanYashchuk rgommers
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63285
Reviewed By: gchanan
Differential Revision: D32313346
Pulled By: mruberry
fbshipit-source-id: e68c2687c57367274e8ddb7ef28ee92dcd4c9f2c
Summary:
use product instead of zip to cover all cases
cc mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67635
Reviewed By: malfet
Differential Revision: D32310956
Pulled By: mruberry
fbshipit-source-id: 806c3313e2db26d77199d3145b2d5283b6ca3617
Summary:
stas00 uncovered an issue where certain half-precision GEMMs would produce outputs that looked like the result of strange rounding behavior (e.g., `10008.` in place of `10000.`). ptrblck suspected that this was due to the parameters being downcasted to the input types (which would reproduce the problematic output). Indeed, the GEMM and BGEMM cublas wrappers are currently converting the `alpha` and `beta` parameters to `scalar_t` (which potentially is reduced precision) before converting them back to `float`. This PR changes the "ARGTYPE" wrappers to use `acc_t` instead and adds a corresponding test.
CC ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67633
Reviewed By: mruberry
Differential Revision: D32076474
Pulled By: ngimel
fbshipit-source-id: 2540d9b9d0195c17d07d1161374fb6a5850779d5
Summary:
It appears that most NVIDIA architectures (well, at least there haven't been many reports of this issue) don't do reduced precision reductions (e.g., reducing in fp16 given fp16 inputs), but this change attempts to ensure that a reduced precision reduction is never done. The included test case currently fails on Volta but passes on Pascal and Ampere; setting this flag causes the test to pass on all three.
CC stas00 ngimel ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67578
Reviewed By: mruberry
Differential Revision: D32046030
Pulled By: ngimel
fbshipit-source-id: ac9aa8489ad6835f34bd0300c5d6f4ea76f333d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62734
Following https://github.com/pytorch/pytorch/pull/62715#discussion_r682610788
- squareCheckInputs takes a string with the name of the function
- We reuse more functions when checking the inputs
The state of the errors in torch.linalg is far from great though. We
leave a more comprehensive clean-up for the future.
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D31823230
Pulled By: mruberry
fbshipit-source-id: eccd531f10d590eb5f9d04a957b7cdcb31c72ea4
Summary:
Skip failing tests when LAPACK and MAGMA are not available for ` test_linalg.py` and ` test_ops.py`.
Note that there's no CI without LAPACK or MAGMA. I verified locally that now it works as expected, but in the future we have no guards against tests failing again for this situation.
<details>
<summary> test_ops.py failures that are fixed</summary>
```
FAILED test/test_ops.py::TestCommonCPU::test_out_linalg_tensorinv_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_reference_testing_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_reference_testing_linalg_tensorinv_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_linalg_tensorinv_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_triangular_solve_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_triangular_solve_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_linalg_tensorinv_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_triangular_solve_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_linalg_tensorinv_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_triangular_solve_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_linalg_tensorinv_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_triangular_solve_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestJitCPU::test_variant_consistency_jit_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestJitCPU::test_variant_consistency_jit_triangular_solve_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestJitCPU::test_variant_consistency_jit_triangular_solve_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_conj_view_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_conj_view_triangular_solve_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_neg_view_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_neg_view_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
```
</details>
<details>
<summary> test_linalg.py failures that are fixed</summary>
```
FAILED test/test_linalg.py::TestLinalgCPU::test_norm_dtype_cpu - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCPU::test_norm_matrix_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCPU::test_norm_matrix_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCPU::test_nuclear_norm_axes_small_brute_force_old_cpu - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_eigh_hermitian_grad_meta_complex128 - RuntimeError: Calling torch.linalg.eigh or eigvalsh on a CPU tensor requires compiling PyTorch with LAPACK. Please use PyTorch built with LAPACK support.
FAILED test/test_linalg.py::TestLinalgMETA::test_eigh_hermitian_grad_meta_float64 - RuntimeError: Calling torch.linalg.eigh or eigvalsh on a CPU tensor requires compiling PyTorch with LAPACK. Please use PyTorch built with LAPACK support.
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_col_maj_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_col_maj_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_col_maj_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_col_maj_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_col_maj_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_col_maj_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_lowrank_cuda_float64 - RuntimeError: Calling torch.lu on a CUDA tensor requires compiling PyTorch with MAGMA. lease rebuild with MAGMA.
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_col_maj_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_col_maj_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_col_maj_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_col_maj_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_col_maj_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_col_maj_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
```
</details>
Fixes https://github.com/pytorch/pytorch/issues/59662
cc mruberry jianyuh nikitaved pearu walterddr IvanYashchuk xwang233 Lezcano
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64930
Reviewed By: zou3519
Differential Revision: D31739416
Pulled By: mruberry
fbshipit-source-id: 153c40d8eeeb094b06816882a7cbb28c681509a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64181
This PR replaces all the calls to:
- `transpose(-2, -1)` or `transpose(-1, -2)` by `mT()` in C++ and `mT` in Python
- `conj().transpose(-2, -1)` or `transpose(-2, -1).conj()` or `conj().transpose(-1, -2)` or `transpose(-1, -2).conj()` by `mH()` in C++ and `mH` in Python.
It also simplifies two pieces of code, and fixes one bug where a pair
of parentheses were missing in the function `make_symmetric_matrices`.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D31692896
Pulled By: anjali411
fbshipit-source-id: e9112c42343663d442dc5bd53ff2b492094b434a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66645
Fixes:
```
test_cholesky_solve_batched_broadcasting_cpu_complex128 (__main__.TestLinalgCPU) ... test_linalg.py:3099: UserWarning: torch.cholesky is deprecated in favor of torch.linalg.cholesky and will be removed in a future PyTorch release.
```
Test Plan: Sandcastle
Reviewed By: mruberry
Differential Revision: D31635851
fbshipit-source-id: c377eb88d753fb573b3947f0c6ff5df055cb13d8
Summary:
Skip failing tests when LAPACK and MAGMA are not available for ` test_linalg.py` and ` test_ops.py`.
Note that there's no CI without LAPACK or MAGMA. I verified locally that now it works as expected, but in the future we have no guards against tests failing again for this situation.
<details>
<summary> test_ops.py failures that are fixed</summary>
```
FAILED test/test_ops.py::TestCommonCPU::test_out_linalg_tensorinv_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_reference_testing_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_reference_testing_linalg_tensorinv_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_linalg_tensorinv_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_triangular_solve_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_triangular_solve_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_linalg_tensorinv_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_triangular_solve_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_linalg_tensorinv_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_triangular_solve_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_linalg_tensorinv_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_triangular_solve_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestJitCPU::test_variant_consistency_jit_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestJitCPU::test_variant_consistency_jit_triangular_solve_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestJitCPU::test_variant_consistency_jit_triangular_solve_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_conj_view_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_conj_view_triangular_solve_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_neg_view_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_neg_view_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
```
</details>
<details>
<summary> test_linalg.py failures that are fixed</summary>
```
FAILED test/test_linalg.py::TestLinalgCPU::test_norm_dtype_cpu - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCPU::test_norm_matrix_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCPU::test_norm_matrix_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCPU::test_nuclear_norm_axes_small_brute_force_old_cpu - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_eigh_hermitian_grad_meta_complex128 - RuntimeError: Calling torch.linalg.eigh or eigvalsh on a CPU tensor requires compiling PyTorch with LAPACK. Please use PyTorch built with LAPACK support.
FAILED test/test_linalg.py::TestLinalgMETA::test_eigh_hermitian_grad_meta_float64 - RuntimeError: Calling torch.linalg.eigh or eigvalsh on a CPU tensor requires compiling PyTorch with LAPACK. Please use PyTorch built with LAPACK support.
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_col_maj_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_col_maj_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_col_maj_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_col_maj_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_col_maj_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_col_maj_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_lowrank_cuda_float64 - RuntimeError: Calling torch.lu on a CUDA tensor requires compiling PyTorch with MAGMA. lease rebuild with MAGMA.
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_col_maj_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_col_maj_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_col_maj_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_col_maj_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_col_maj_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_col_maj_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
```
</details>
Fixes https://github.com/pytorch/pytorch/issues/59662
cc mruberry jianyuh nikitaved pearu walterddr IvanYashchuk xwang233 Lezcano
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64930
Reviewed By: H-Huang
Differential Revision: D31137652
Pulled By: mruberry
fbshipit-source-id: c969f75d7cf185765211004a0878e7c8a5d3cbf7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63567
The current implementation called trtrs for CPU and trsm for CUDA.
See https://github.com/pytorch/pytorch/issues/56326#issuecomment-825496115 for a discussion on the differences between
these two functions and why we prefer trsm vs trtrs on CUDA.
This PR also exposes the `side` argument of this function which is used
in the second PR of this stack to optimise the number copies one needs to make
when preparing the arguments to be sent to the backends.
It also changes the use of `bool`s to a common enum type to represent
whether a matrix is transposed / conj transposed, etc. This makes the API
consistent, as before, the behaviour of these functions with `transpose=True`
and `conjugate_transpose=True` it was not well defined.
Functions to transform this type into the specific types / chars for the different
libraries are provided under the names `to_blas`, `to_lapack`, `to_magma`, etc.
This is the first of a stack of PRs that aim to improve the performance of
`linalg.solve_triangular`. `trsm` has an extra parameter (`side`), which allows to
ellide the copy of the triangular matrix in many cases.
Fixes https://github.com/pytorch/pytorch/issues/56326
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D30566479
Pulled By: mruberry
fbshipit-source-id: 3831af9b51e09fbfe272c17c88c21ecf45413212
Summary:
# Goal: Integrate mkldnn bf16 Gemm to pytorch
## BF16 Suport for mm, addmm, bmm, addbmm, baddbmm, mv, addmv, dot (with mkldnn matmul primitive):
https://oneapi-src.github.io/oneDNN/group__dnnl__api__matmul.html
For gemm related ops, we keep all inputs under plain format. So we will not introduce opaque tensor for these ops to save mem copy here.

The minimized integration is only dispatch to mkldnn in addmm, but for gemm with 3-D input (with additional dim for"batch") this will call mkldnn gemm for "batch" times. Since mkldnn matmul support input with multiple dims, we directly dispatch to mkldnn gemm in {bmm, addbmm, baddbmm} to reduce the time to create mkldnn memory desc, primitive, etc.
For the different definition for "bias" between mkldnn(which must be shape of (1, N)) and pytorch (which can be same shape with gemm result (M, N)), we use a fused sum to handle it.
## User Case:
User case is exactly same with before because no opaque tensor's is introduced. Since the pytorch has already support bf16 data type with CPU tensor before, we can leverage the existed bf16 gemm UT.
## Gemm performance gain on CPX 28Cores/Socket:
Note: data is collected using PyTorch operator benchmarks: https://github.com/pytorch/pytorch/tree/master/benchmarks/operator_benchmark (with adding bfloat16 dtype)
### use 1 thread on 1 core
### torch.addmm (M, N) * (N, K) + (M, K)
| impl |16x16x16|32x32x32| 64x64x64 | 128x128x128| 256x256x256| 512x512x512|1024x1024x1024|
|:---:|:---:| :---: | :---: | :---: | :---: | :---: | :---: |
| aten-fp32| 4.115us|4.583us|8.230us|26.972us|211.857us|1.458ms|11.258ms|
| aten-bf16 | 15.812us| 105.087us|801.787us|3.767ms|20.274ms|122.440ms|836.453ms|
| mkldnn-bf16 |20.561us |22.510us|24.551us|37.709us|143.571us|0.835ms|5.76ms|
We can see mkldnn-bf16 are better than aten bf16, but for smaller shapes, mkldnn bf16 are not better than aten fp32. This is because onednn overhead, this overhead more like a "constant" overhead and while problems get larger, we can ignore it. Also we are continue optimize the kernel efficiency and decrease the overhead as well.
More shapes
| impl |1x2048x2048|2048x1x2048| 2048x2048x1 |
|:---:|:---:| :---: | :---: |
| aten-fp32| 0.640ms|3.794ms|0.641ms|
| aten-bf16 | 2.924ms| 3.868ms|23.413ms|
| mkldnn-bf16 |0.335ms |4.490ms|0.368ms|
### use 1 socket (28 thread, 28 core)
| impl | 256x256x256| 512x512x512|1024x1024x1024| 2048x2048x2048|4096x4096x4096|
|:---:| :---: | :---: | :---: | :---: | :---: |
| aten-fp32| 35.943us |140.315us|643.510us|5.827ms|41.761ms|
| mkldnn-bf16 |53.432us|114.716us|421.858us|2.863ms|23.029ms|
More shapes
| impl |128x2048x2048|2048x128x2048| 2048x2048x128 |
|:---:|:---:| :---: | :---: |
| aten-fp32| 0.561ms|0.458ms|0.406ms|
| mkldnn-bf16 |0.369ms |0.331ms|0.239ms|
We dose not show aten-bf16 for this case since aten-bf16 always compute as single thread and the performance is extreme poor. The trend for this case is similar for 1 thread on 1 core.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61891
Reviewed By: iramazanli
Differential Revision: D29998114
Pulled By: VitalyFedyunin
fbshipit-source-id: 459dc5874c638d62f290c96684ca0a694ded4b5a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63554
Following https://github.com/pytorch/pytorch/pull/61840#issuecomment-884087809, this deprecates all the dtype getters publicly exposed in the `torch.testing` namespace. The reason for this twofold:
1. If someone is not familiar with the C++ dispatch macros PyTorch uses, the names are misleading. For example `torch.testing.floating_types()` will only give you `float32` and `float64` skipping `float16` and `bfloat16`.
2. The dtype getters provide very minimal functionality that can be easily emulated by downstream libraries.
We thought about [providing an replacement](https://gist.github.com/pmeier/3dfd2e105842ad0de4505068a1a0270a), but ultimately decided against it. The major problem is BC: by keeping it, either the namespace is getting messy again after a new dtype is added or we need to somehow version the return values of the getters.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D30662206
Pulled By: mruberry
fbshipit-source-id: a2bdb10ab02ae665df1b5b76e8afa9af043bbf56
{kind=link}
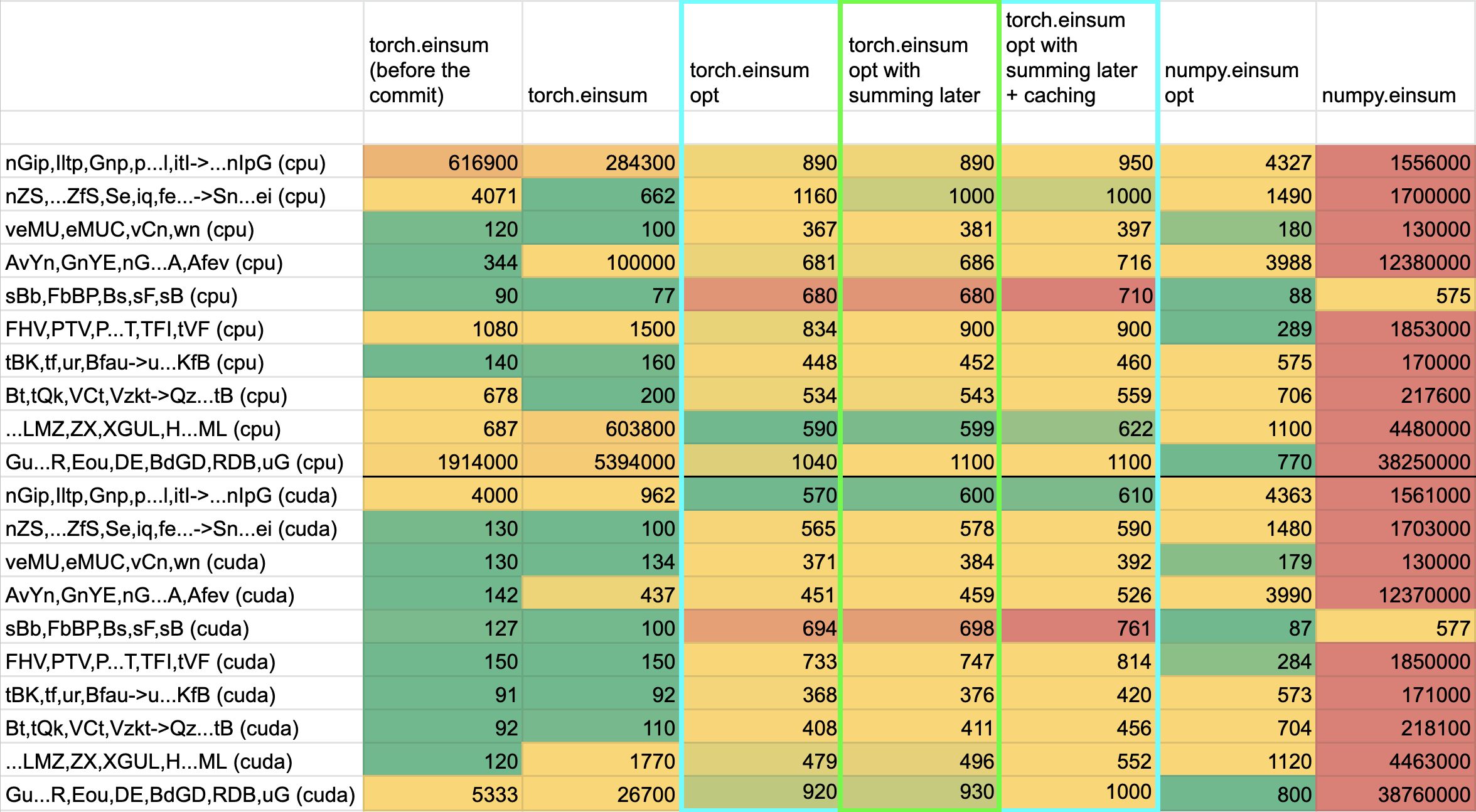{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}