Historically, we work out `size_hint` by working it out on the fly by doing a substitution on the sympy expression with the `var_to_val` mapping. With this change, we also maintain the hint directly on SymNode (in `expr._hint`) and use it in lieu of Sympy substitution when it is available (mostly guards on SymInt, etc; in particular, in idiomatic Inductor code, we typically manipulate Sympy expressions directly and so do not have a way to conveniently maintain hints.)
While it's possible this will give us modest performance improvements, this is not the point of this PR; the goal is to make it easier to carefully handle unbacked SymInts, where hints are expected not to be available. You can now easily test if a SymInt is backed or not by checking `symint.node.hint is None`.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94201
Approved by: https://github.com/voznesenskym
Previously, Dynamo faked support for item() when `capture_scalar_outputs` was True by representing it internally as a Tensor. With dynamic shapes, this is no longer necessary; we can represent it directly as a SymInt/SymFloat. Do so. Doing this requires you to use dynamic shapes; in principle we could support scalar outputs WITHOUT dynamic shapes but I won't do this unless someone hollers for it.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Differential Revision: [D42885775](https://our.internmc.facebook.com/intern/diff/D42885775)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93150
Approved by: https://github.com/voznesenskym
**Motivation**
When adding support for default args (#90575), a lot of VariableTrackers missing sources were encountered. Currently, in a lot of cases it seems OK to skip the source for VariableTrackers created (especially during inlining), but that assumption breaks down when inlining functions with default arguments.
**Summary** of changes
- propagate the self.source of the VariableBuilder to the new variables being built, which seems like it was an omission previously
- Add SuperSource to track usages of super(), so that SuperVariables can support function calls with default args
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91729
Approved by: https://github.com/ezyang
Whenever you guard on something, you're supposed to tell GuardBuilder about it, so GuardBuilder knows that it has to actually bind it in scope when it creates the guard function. But shape env guards bypass that mechanism completely. Well, now they don't.
For the most part, this didn't matter in practice, because we usually had a `TENSOR_MATCH` guard floating around that made sure that the guard stayed live. But if we ever eliminate those guards (e.g., because we build it into the shape guard directly; something we'll probably want to do when https://github.com/pytorch/pytorch/pull/89707 goes online) then this will indeed matter.
One complication: some of the shape env guards are on globals. You have to make sure to shunt the usage to the correct guard builder in that case. Maybe it would be better if we refactored things so there is only one GuardBuilder. Not sure.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91058
Approved by: https://github.com/voznesenskym
I'm going to need this in the follow up PR. Instead of storing only Source.name() in Symbol, I now store a full on Source. Lots of replumbing reoccurs. In particular:
- Move Source to torch._guards to break cycles
- I have to add TensorPropertySource and NegateSource to handle x.size()[0] and -x codegen that I was doing with string manipulation previously
- I tighten up invariants so that I never pass source=None; instead I pass ConstantSource (these are constant sources right) and test for that rather than source being missing. I think this is more parsimonious
- Some mypy wobbles from new imports
I didn't move LocalSource and friends to torch._guards, but I ended up needing to access them in a few places. The main annoyance with moving these is that then I also need to move the bytecode codegen stuff, and that's not so easy to move without bringing in the kitchen sink.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91057
Approved by: https://github.com/albanD, https://github.com/voznesenskym, https://github.com/zou3519
I'm going to need this in the follow up PR. Instead of storing only Source.name() in Symbol, I now store a full on Source. Lots of replumbing reoccurs. In particular:
- Move Source to torch._guards to break cycles
- I have to add TensorPropertySource and NegateSource to handle x.size()[0] and -x codegen that I was doing with string manipulation previously
- I tighten up invariants so that I never pass source=None; instead I pass ConstantSource (these are constant sources right) and test for that rather than source being missing. I think this is more parsimonious
- Some mypy wobbles from new imports
I didn't move LocalSource and friends to torch._guards, but I ended up needing to access them in a few places. The main annoyance with moving these is that then I also need to move the bytecode codegen stuff, and that's not so easy to move without bringing in the kitchen sink.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91057
Approved by: https://github.com/albanD, https://github.com/voznesenskym
This PR adds `@comptime`, a decorator that causes a given function to be executed at compile time when Dynamo is symbolically evaluating their program. To query the Dynamo state, we offer a public ComptimeContext API which provides a limited set of APIs for querying Dynamo's internal state. We intend for users to use this API and plan to keep it stable. Here are some things you can do with it:
* You want to breakpoint Dynamo compilation when it starts processing a particular line of user code: give comptime a function that calls breakpoint
* You want to manually induce a graph break for testing purposes; give comptime a function that calls unimplemented
* You want to perform a debug print, but you don't want to induce a graph break; give comptime a function that prints.
* You can print what the symbolic locals at a given point in time are.
* You can print out the partial graph the Dynamo had traced at this point.
* (My original motivating use case.) You want to add some facts to the shape env, so that a guard evaluation on an unbacked SymInt doesn't error with data-dependent. Even if you don't know what the final user API for this should be, with comptime you can hack out something quick and dirty. (This is not in this PR, as it depends on some other in flight PRs.)
Check out the tests to see examples of comptime in action.
In short, comptime is a very powerful debugging tool that lets you drop into Dynamo from user code, without having to manually jerry-rig pdb inside Dynamo to trigger after N calls.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90983
Approved by: https://github.com/jansel
GraphArgs worked fairly well, but it was still missing sources
sometimes. Now, we maintain an auxiliary data structure which we
MUST populate whenever we fakeify a tensor / allocate a bare SymInt.
This should guarantee once and for all that every symbol is available.
Should fix swin_base_patch4_window7_224.
While I was at it, I moved fakeification utility back to builder
as it was only used at once call site.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90911
Approved by: https://github.com/voznesenskym
Instead of inferring shape mappings from a bunch of data structures that were plumbed in InstructionTranslator, we instead work out mappings by just iterating over the GraphArgs and mapping symbols to arguments as they show up. If multiple argument sizes/strides/offset map to the same symbol, this means they are duck sized, so we also generate extra equality tests that they must be equal. Finally, we generate 0/1 specialization guards. The resulting code is much shorter, and I think also easier to understand.
TODO: Delete all the tensor ref tracking code, it's unnecessary
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90528
Approved by: https://github.com/voznesenskym
Wow, I had to sweat so much to get this PR out lol.
This PR enforces the invariant that whenever we allocate SymInts as part of fakeification, the SymInt is associated with a Source, and in fact we store the string source name on SymbolWithSourceName. We use 'sname' as the shorthand for source name, as 'name' is already used by sympy to name symbols.
In order to store source names, we have to plumb source names from Dynamo to PyTorch. This made doing this PR a bit bone crushing, because there are many points in the Dynamo codebase where we are improperly converting intermediate tensors into fake tensors, where there is no source (and there cannot be, because it's a frickin' intermediate tensor). I've fixed all of the really awful cases in earlier PRs in the stack. This PR is just plumbing in source names from places where we do have it.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90295
Approved by: https://github.com/voznesenskym
Happy to split this PR more if it helps.
This PR adds functorch.grad support for autograd.Function. There's a lot
going on; here is the high level picture and there are more details as
comments in the code.
Mechanism (PyOperator)
- Somehow, autograd.Function needs to dispatch with functorch. This is
necessary because every layer of functorch needs to see the
autograd.Function; grad layers need to preserve the backward pass.
- The mechanism for this is via PyOperator. If functorch transforms are
active, then we wrap the autograd.Function in a `custom_function_call`
PyOperator where we are able to define various rules for functorch
transforms.
- `custom_function_call` has a rule for the functorch grad transform.
autograd.Function changes
- I needed to make some changes to autograd.Function to make this work.
- First, this PR splits autograd.Function into a _SingleLevelFunction
(that works with a single level of functorch transform) and
autograd.Function (which works with multiple levels). This is necessary
because functorch's grad rule needs some way of specifying a backward
pass for that level only.
- This PR changes autograd.Function's apply to eitehr call
`custom_function_call` (if functorch is active) or super().apply (if
functorch isn't active).
Testing
- Most of this PR is just testing. It creates an autograd.Function
OpInfo database that then gets passed to the functorch grad-based tests
(grad, vjp, vjpvjp).
- Since functorch transform tests are autogenerated from OpInfo tests,
this is the easiest way to test various autograd.Function with
functorch.
Future
- jvp and vmap support coming next
- better error message (functorch only supports autograd.Function that
have the optional setup_context staticmethod)
- documentation to come when we remove the feature flag
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89860
Approved by: https://github.com/soulitzer
The old code didn't actually fakeify traceable tensor subclasses at the
time they are added as a GraphArg to the module; now we do, by ignoring
the subclass during fakeification and relying on Dynamo to simulate
the subclass on top. See comments for more details.
BTW, this codepath is super broken, see filed issues linked on the
inside.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90009
Approved by: https://github.com/wconstab, https://github.com/voznesenskym
Summary:
This diff is reverting D41682843
D41682843 has been identified to be causing the following test or build failures:
Tests affected:
- https://www.internalfb.com/intern/test/281475048939643/
Here's the Multisect link:
https://www.internalfb.com/intern/testinfra/multisect/1444954
Here are the tasks that are relevant to this breakage:
T93770103: 5 tests started failing for oncall assistant_multimodal in the last 2 weeks
We're generating a revert to back out the changes in this diff, please note the backout may land if someone accepts it.
Test Plan: NA
Reviewed By: zyan0, atuljangra, YazhiGao
Differential Revision: D41710749
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90132
Approved by: https://github.com/awgu
This was separated out from the previous PR to decouple. Since not all builds include `torch.distributed`, we should define the globals in the dynamo file and import to distributed instead of vice versa. Unlike the version from the previous PR, this PR prefixes the globals with `_` to future proof against `_dynamo/` eventually becoming public.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89913
Approved by: https://github.com/wconstab
- This is a strict requirement given the way dynamo+FSDP is implemented,
but isn't convenient to assert.
- By plumbing use_orig_param field on all wrapped modules, we can
do this assertion inside dynamo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89523
Approved by: https://github.com/awgu
### Summary
Making dynamo treat the nn.Modules inside FSDP wrappers as 'Unspecialized'
results in dynamo-produced graphs where nn.module parameters are inputs
to the graph rather than attributes of the outer graphmodule.
This helps in FSDP since it forces dynamo to pick the latest copy
of the parameters off the user's nn.Module (which FSDP mutates every pre_forward),
solving the ordering issue in backward.
### Details
Imagine this toy model
```
class MyModule(torch.nn.Module):
def __init__(self, a, b):
super(MyModule, self).__init__()
self.net = nn.Sequential(
nn.Linear(a, b),
nn.ReLU(),
)
def forward(self, x):
return self.net(x)
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net = nn.Sequential(
*[MyModule(10, 10000)]
+ [MyModule(10000, 1000)]
+ [MyModule(1000, 5)]
)
def forward(self, x):
return self.net(x)
```
Where FSDP is recursively wrapped around each `MyModule`, then dynamo-compiled, with dynamo already configured to skip/break in FSDP code. You'd expect to get 3 compiled AOT functions, corresponding to the contents of `MyModule`, and then see FSDP's communication ops happen inbetween them (eagerly). This almost happens (everything works out fine in forward), but in backward there is an ordering issue.
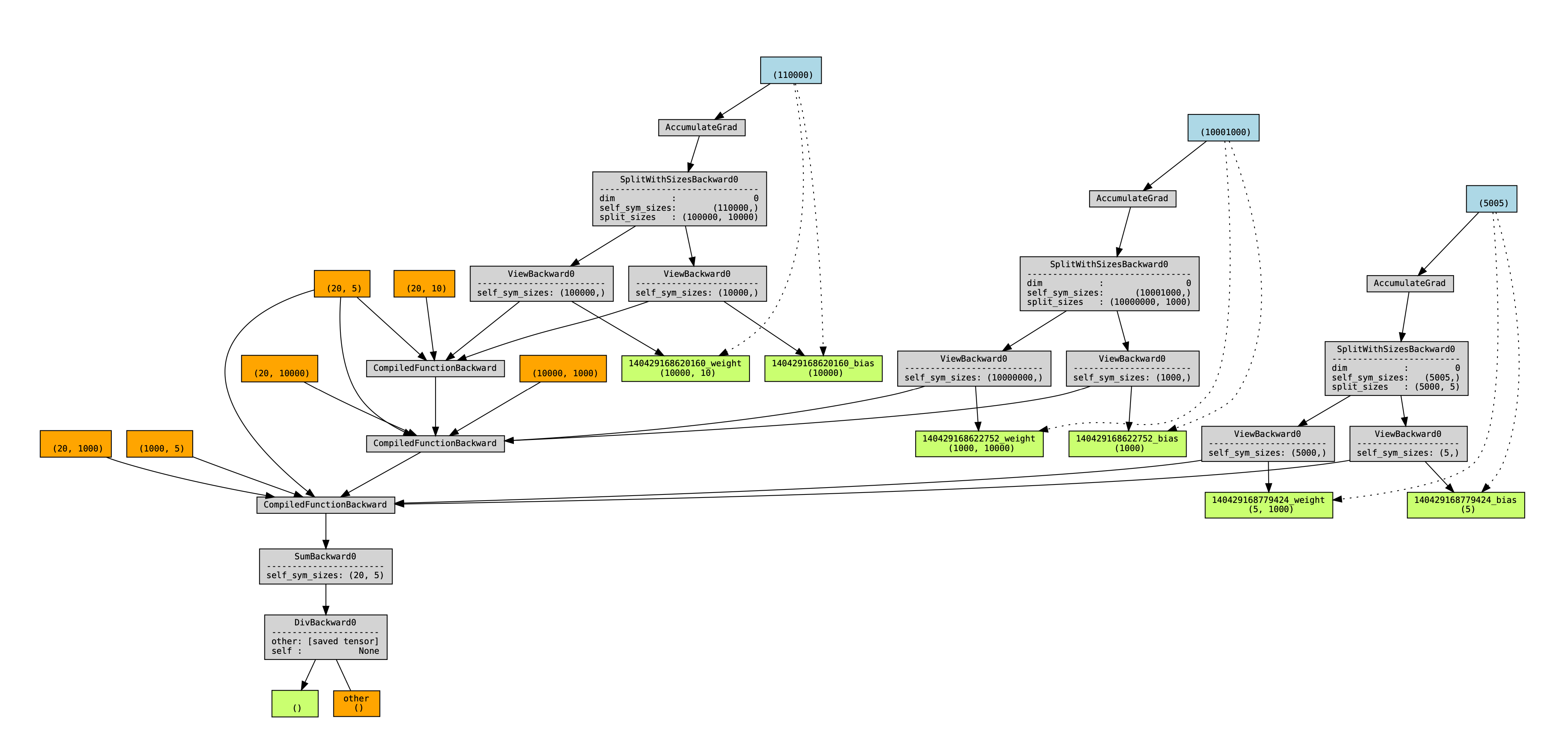
FSDP creates a flat buffer for all the parameters that are bucketed together, and then creates views into this buffer to replace the original parameters. On each iteration of forward, it creates a new view after 'filling' the flatbuffer with data from an all-gather operation, to 'unshard' the parameters from remote devices. Dynamo traces the first such view and stores it in a compiled graphmodule.
During tracing, we see (1) view created for first MyModule, (2) compile first MyModule, (3) ... for the rest of layers
Then during runtime, we see (A) view created for first MyModule (and orphaned), (B) execute first compiled MyModule, using old view, ...
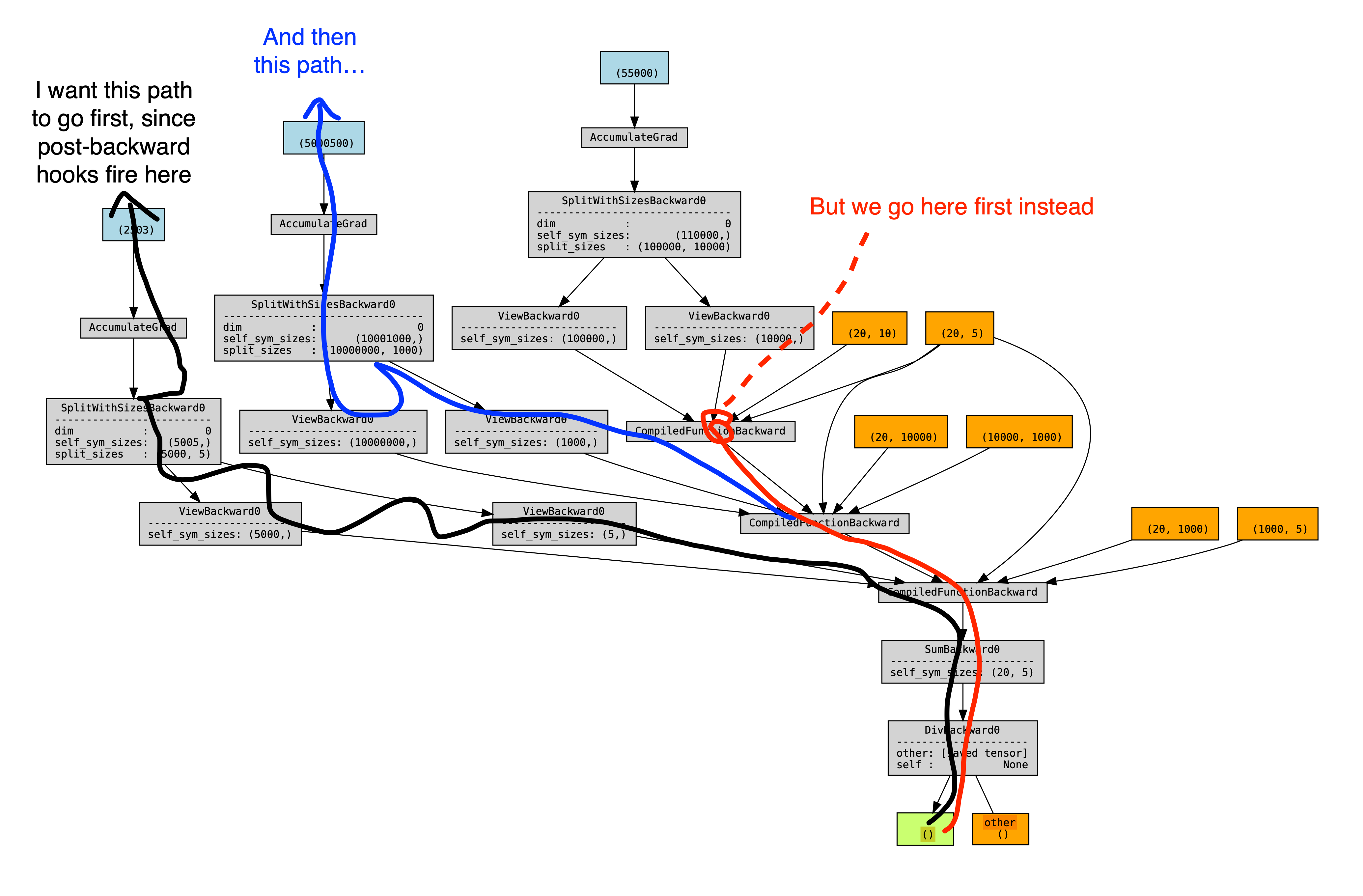
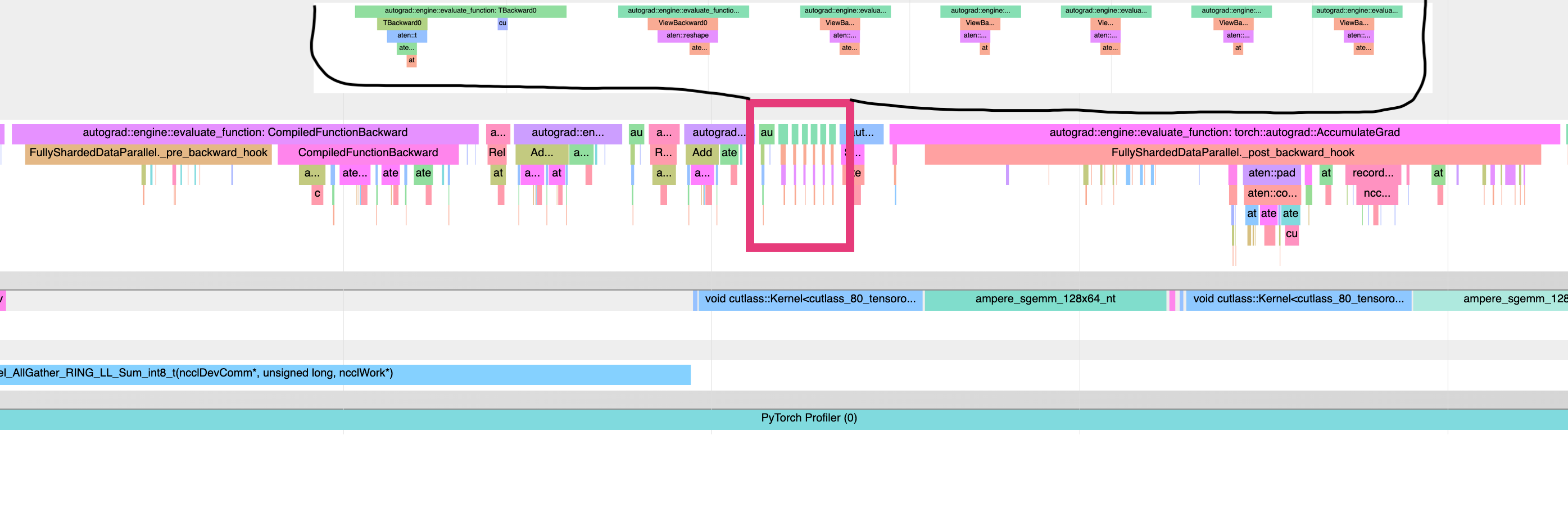
This is a problem, because we want backward hooks to run right after each compiled-backward, but autograd executes those hooks in an order mirroring their execution order during forward. Since we are forever using the views created during steps (1, 3, .. N), which all happen before the steps (A, B, ...), this means that all the hooks will happen after all the compiled backwards. An illustration of the problem - a torchviz graph showing the 2 possible orderings of autograd, and a profile showing the view-backwards ops happening after all the compiled backwards, and before all the backward hooks.
<img width="2069" alt="image" src="https://user-images.githubusercontent.com/4984825/202828002-32dbbd15-8fc3-4281-93e9-227ab5e32683.png">
<img width="2069" alt="image" src="https://user-images.githubusercontent.com/4984825/202828632-33e40729-9a7f-4e68-9ce1-571e3a8dd2dd.png">
A solution is to make dynamo not specialize on these nn modules. It is worth pointing out that this nn.module specialization is de-facto failing, as we are modifying .parameters and this bypasses dynamo's __setattr__ monkeypatch, which should have automatically kicked us out to Unspecialized and forced a recompile.
After unspecializing, the new views (created during steps A, C, ...) are actually _used_ at runtime by the module, making their creation order interleaved, making autograd execute their backwards interleaved.
The new torchviz graph (this time with names added for the view tensors):
<img width="2043" alt="image" src="https://user-images.githubusercontent.com/4984825/202828480-d30005ba-0d20-45d8-b647-30b7ff5e91d3.png">
And a new profile showing the interleaving of compiled backwards and hooks, allowing overlapping of reduce-scatter.
<img width="2293" alt="image" src="https://user-images.githubusercontent.com/4984825/202828533-bb20a041-19b8-499c-b3cf-02808933df47.png">
@jansel @davidberard98 @aazzolini @mrshenli @awgu @ezyang @soumith @voznesenskym @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89330
Approved by: https://github.com/davidberard98
This is a slight regression: RAdam and Adagrad don't appear to
trace at all under fake tensors. But I think this is a more accurate
reflection of the current state of affairs.
Along the way fix some problems on the fake tensor path.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89643
Approved by: https://github.com/anjali411
Previously, we hackily wrapped unspecialized integers into
tensors and treated them as tensor inputs. Sometimes, downstream
operations would not be able to deal with the tensor input. Now,
we wrap them into SymInt, so more correct overload selection occurs.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89639
Approved by: https://github.com/anjali411
{kind=link}
{kind=link}
{kind=link}
{kind=link}