mirror of
https://github.com/zebrajr/pytorch.git
synced 2025-12-07 00:21:07 +01:00
### Summary
Making dynamo treat the nn.Modules inside FSDP wrappers as 'Unspecialized'
results in dynamo-produced graphs where nn.module parameters are inputs
to the graph rather than attributes of the outer graphmodule.
This helps in FSDP since it forces dynamo to pick the latest copy
of the parameters off the user's nn.Module (which FSDP mutates every pre_forward),
solving the ordering issue in backward.
### Details
Imagine this toy model
```
class MyModule(torch.nn.Module):
def __init__(self, a, b):
super(MyModule, self).__init__()
self.net = nn.Sequential(
nn.Linear(a, b),
nn.ReLU(),
)
def forward(self, x):
return self.net(x)
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net = nn.Sequential(
*[MyModule(10, 10000)]
+ [MyModule(10000, 1000)]
+ [MyModule(1000, 5)]
)
def forward(self, x):
return self.net(x)
```
Where FSDP is recursively wrapped around each `MyModule`, then dynamo-compiled, with dynamo already configured to skip/break in FSDP code. You'd expect to get 3 compiled AOT functions, corresponding to the contents of `MyModule`, and then see FSDP's communication ops happen inbetween them (eagerly). This almost happens (everything works out fine in forward), but in backward there is an ordering issue.
FSDP creates a flat buffer for all the parameters that are bucketed together, and then creates views into this buffer to replace the original parameters. On each iteration of forward, it creates a new view after 'filling' the flatbuffer with data from an all-gather operation, to 'unshard' the parameters from remote devices. Dynamo traces the first such view and stores it in a compiled graphmodule.
During tracing, we see (1) view created for first MyModule, (2) compile first MyModule, (3) ... for the rest of layers
Then during runtime, we see (A) view created for first MyModule (and orphaned), (B) execute first compiled MyModule, using old view, ...
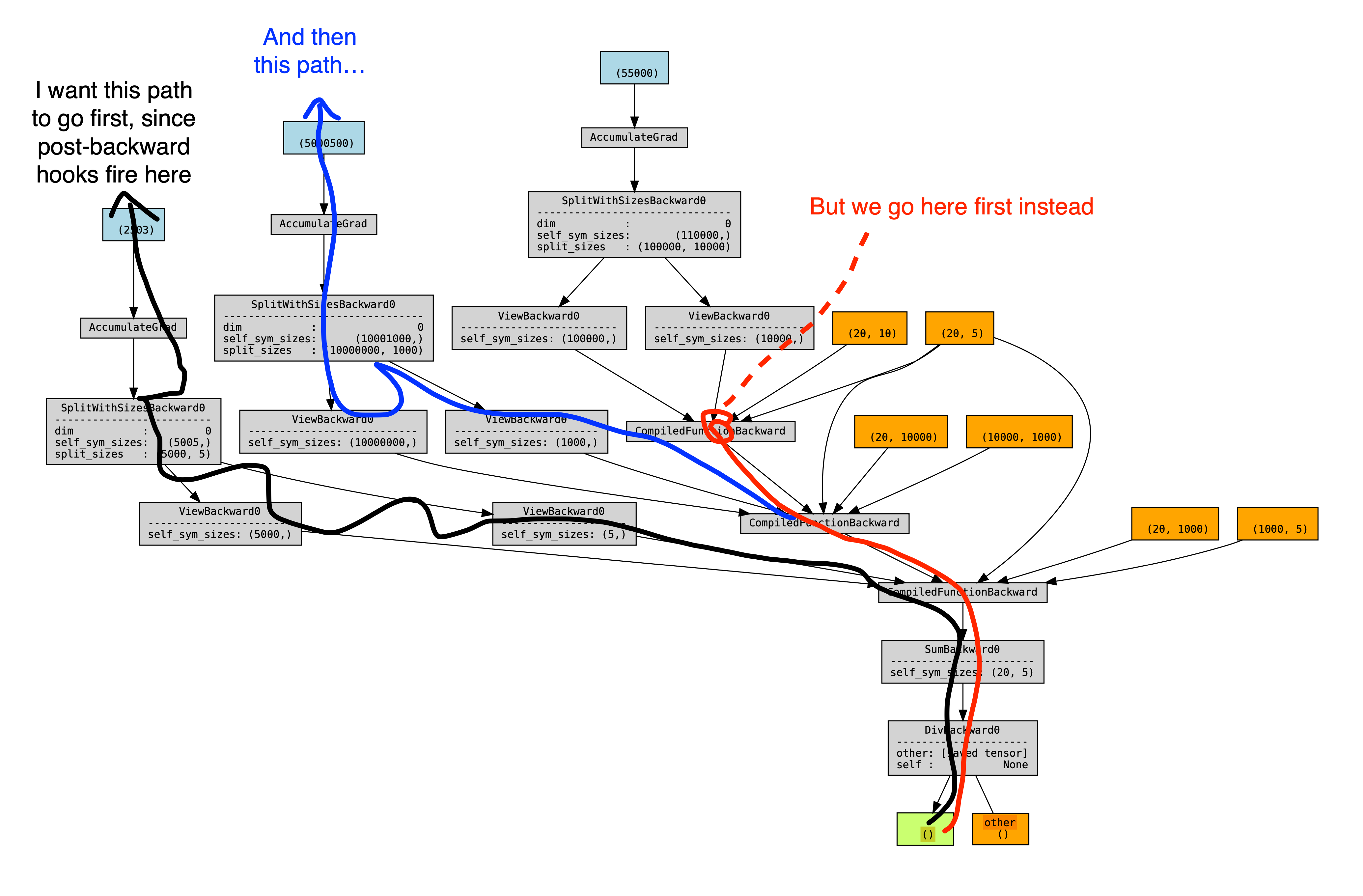
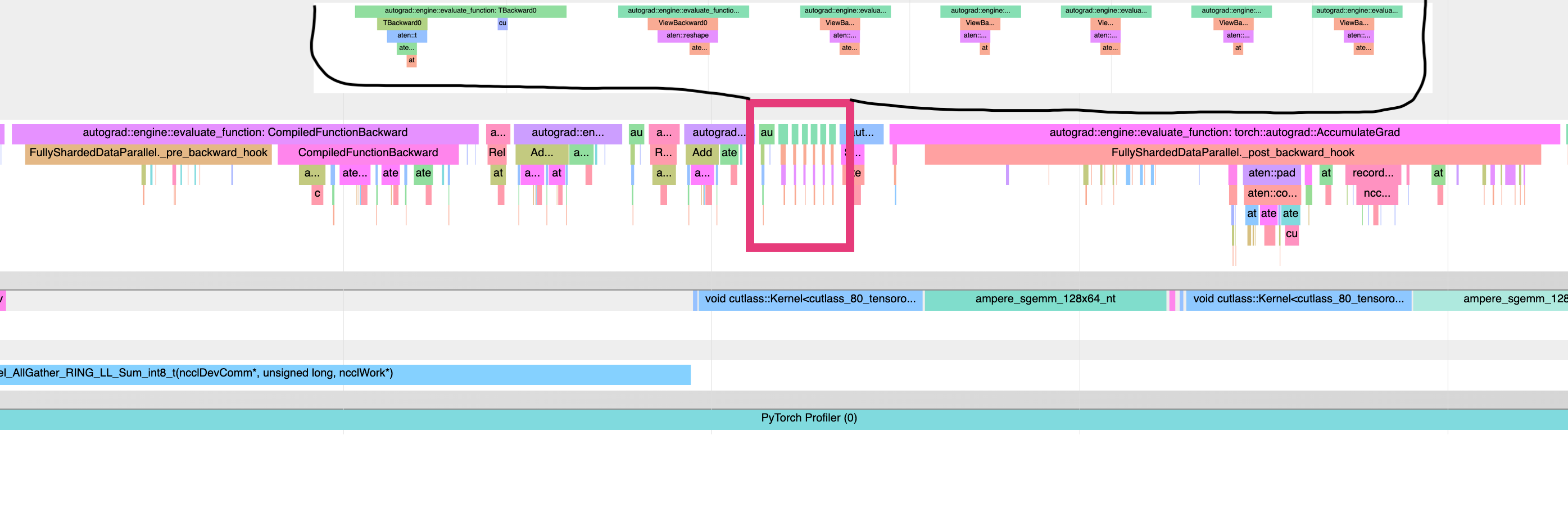
This is a problem, because we want backward hooks to run right after each compiled-backward, but autograd executes those hooks in an order mirroring their execution order during forward. Since we are forever using the views created during steps (1, 3, .. N), which all happen before the steps (A, B, ...), this means that all the hooks will happen after all the compiled backwards. An illustration of the problem - a torchviz graph showing the 2 possible orderings of autograd, and a profile showing the view-backwards ops happening after all the compiled backwards, and before all the backward hooks.
<img width="2069" alt="image" src="https://user-images.githubusercontent.com/4984825/202828002-32dbbd15-8fc3-4281-93e9-227ab5e32683.png">
<img width="2069" alt="image" src="https://user-images.githubusercontent.com/4984825/202828632-33e40729-9a7f-4e68-9ce1-571e3a8dd2dd.png">
A solution is to make dynamo not specialize on these nn modules. It is worth pointing out that this nn.module specialization is de-facto failing, as we are modifying .parameters and this bypasses dynamo's __setattr__ monkeypatch, which should have automatically kicked us out to Unspecialized and forced a recompile.
After unspecializing, the new views (created during steps A, C, ...) are actually _used_ at runtime by the module, making their creation order interleaved, making autograd execute their backwards interleaved.
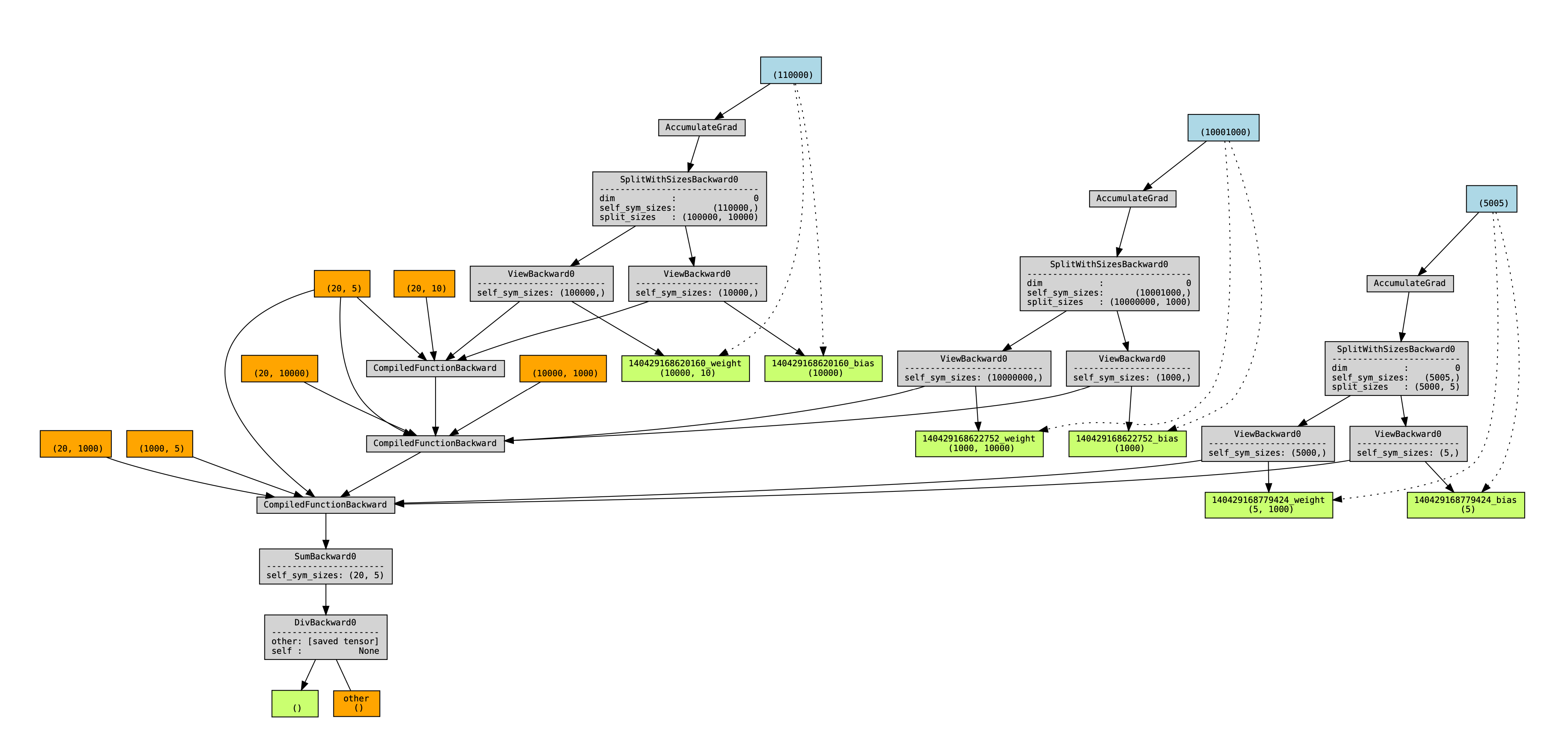
The new torchviz graph (this time with names added for the view tensors):
<img width="2043" alt="image" src="https://user-images.githubusercontent.com/4984825/202828480-d30005ba-0d20-45d8-b647-30b7ff5e91d3.png">
And a new profile showing the interleaving of compiled backwards and hooks, allowing overlapping of reduce-scatter.
<img width="2293" alt="image" src="https://user-images.githubusercontent.com/4984825/202828533-bb20a041-19b8-499c-b3cf-02808933df47.png">
@jansel @davidberard98 @aazzolini @mrshenli @awgu @ezyang @soumith @voznesenskym @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89330
Approved by: https://github.com/davidberard98
{kind=link}
{kind=link}
{kind=link}
{kind=link}
812 lines
30 KiB
Python
812 lines
30 KiB
Python
import collections
|
|
import dataclasses
|
|
import enum
|
|
import functools
|
|
import inspect
|
|
import math
|
|
import numbers
|
|
import operator
|
|
import re
|
|
import types
|
|
from abc import ABCMeta
|
|
from typing import Any, Union
|
|
|
|
import numpy as np
|
|
from functorch.experimental.ops import PyOperator
|
|
|
|
import torch
|
|
from torch.fx.immutable_collections import immutable_list
|
|
|
|
from .. import config, mutation_guard, replay_record, skipfiles
|
|
from ..allowed_functions import is_allowed, is_builtin_callable, is_numpy
|
|
from ..exc import unimplemented
|
|
from ..guards import GuardBuilder, GuardSource
|
|
from ..side_effects import SideEffects
|
|
from ..source import (
|
|
AttrSource,
|
|
ConstantSource,
|
|
GetItemSource,
|
|
GlobalSource,
|
|
GlobalWeakRefSource,
|
|
is_constant_source,
|
|
LocalSource,
|
|
RandomValueSource,
|
|
Source,
|
|
TupleIteratorGetItemSource,
|
|
)
|
|
from ..utils import (
|
|
clone_input,
|
|
get_fake_value,
|
|
getfile,
|
|
global_key_name,
|
|
is_namedtuple,
|
|
is_numpy_int_type,
|
|
is_typing,
|
|
istensor,
|
|
istype,
|
|
odict_values,
|
|
preserve_rng_state,
|
|
tuple_iterator,
|
|
tuple_iterator_getitem,
|
|
tuple_iterator_len,
|
|
wrap_to_fake_tensor_and_record,
|
|
)
|
|
|
|
from .base import MutableLocal, typestr
|
|
from .builtin import BuiltinVariable
|
|
from .constant import ConstantVariable, EnumVariable
|
|
from .dicts import (
|
|
ConstDictVariable,
|
|
DataClassVariable,
|
|
DefaultDictVariable,
|
|
HFPretrainedConfigVariable,
|
|
)
|
|
from .functions import UserFunctionVariable
|
|
from .lists import (
|
|
ListIteratorVariable,
|
|
ListVariable,
|
|
NamedTupleVariable,
|
|
RangeVariable,
|
|
SizeVariable,
|
|
SliceVariable,
|
|
TupleVariable,
|
|
)
|
|
from .misc import (
|
|
AutogradFunctionVariable,
|
|
GetAttrVariable,
|
|
InspectSignatureVariable,
|
|
LambdaVariable,
|
|
NumpyVariable,
|
|
PythonModuleVariable,
|
|
SkipFilesVariable,
|
|
TypingVariable,
|
|
)
|
|
from .nn_module import UnspecializedNNModuleVariable
|
|
from .tensor import (
|
|
DynamicShapeVariable,
|
|
FakeItemVariable,
|
|
TensorVariable,
|
|
TensorWithTFOverrideVariable,
|
|
UnspecializedNumpyVariable,
|
|
UnspecializedPythonVariable,
|
|
)
|
|
from .torch import (
|
|
tensor_dunder_fns,
|
|
torch_special_class_types,
|
|
TorchPyOperator,
|
|
TorchVariable,
|
|
)
|
|
from .user_defined import UserDefinedClassVariable, UserDefinedObjectVariable
|
|
|
|
|
|
class _missing:
|
|
pass
|
|
|
|
|
|
@dataclasses.dataclass
|
|
class GraphArg:
|
|
source: Source
|
|
example: Any
|
|
is_unspecialized: bool
|
|
|
|
def __post_init__(self):
|
|
if isinstance(self.example, torch._subclasses.fake_tensor.FakeTensor):
|
|
raise AssertionError("Fake Tensor observed in TorchDynamo Fx graph inputs")
|
|
|
|
def load(self, tx):
|
|
return self.source.reconstruct(tx)
|
|
|
|
def get_examples(self):
|
|
return [self.example]
|
|
|
|
def __len__(self):
|
|
return 1
|
|
|
|
def erase(self):
|
|
self.example = None
|
|
|
|
|
|
class VariableBuilder:
|
|
"""Wrap a python value in a VariableTracker() instance"""
|
|
|
|
def __init__(
|
|
self,
|
|
tx,
|
|
source: Source,
|
|
):
|
|
super(VariableBuilder, self).__init__()
|
|
self.tx = tx
|
|
self.source = source
|
|
self.name = source.name()
|
|
|
|
def __call__(self, value):
|
|
if value in self.tx.output.side_effects:
|
|
# TODO(jansel): add guard for alias relationship
|
|
return self.tx.output.side_effects[value]
|
|
return self._wrap(value).clone(**self.options())
|
|
|
|
@staticmethod
|
|
@functools.lru_cache(None)
|
|
def _common_constants():
|
|
return set(range(17)).union(
|
|
{
|
|
20,
|
|
30,
|
|
40,
|
|
32,
|
|
64,
|
|
96,
|
|
128,
|
|
144,
|
|
240,
|
|
256,
|
|
672,
|
|
1024,
|
|
2048,
|
|
4096,
|
|
0.1,
|
|
0.01,
|
|
0.001,
|
|
0.5,
|
|
0.05,
|
|
800,
|
|
1.873536229133606,
|
|
4.135166556742356, # Work around for vision_maskrcnn where torch.clamp can't be on different devices
|
|
}
|
|
)
|
|
|
|
@staticmethod
|
|
def list_type(value):
|
|
if is_namedtuple(value):
|
|
return functools.partial(NamedTupleVariable, tuple_cls=type(value))
|
|
return {
|
|
tuple: TupleVariable,
|
|
list: ListVariable,
|
|
odict_values: ListVariable,
|
|
torch.nn.ParameterList: ListVariable,
|
|
torch.nn.ModuleList: ListVariable,
|
|
}[type(value)]
|
|
|
|
def get_source(self):
|
|
return self.source
|
|
|
|
def options(self):
|
|
return {"source": self.get_source()}
|
|
|
|
def make_guards(self, *guards):
|
|
source = self.get_source()
|
|
if (
|
|
isinstance(source, ConstantSource)
|
|
or source.guard_source() == GuardSource.CONSTANT
|
|
):
|
|
return None
|
|
return {source.make_guard(guard) for guard in guards}
|
|
|
|
def _wrap(self, value):
|
|
make_guards = self.make_guards
|
|
if istype(value, (torch.SymInt, torch.SymFloat)):
|
|
return self.wrap_sym(value)
|
|
if istensor(value):
|
|
return self.wrap_tensor(value)
|
|
elif istype(value, (tuple, list, odict_values)) or is_namedtuple(value):
|
|
# One can index a tensor with a list/tuple. Therefore, we need to
|
|
# have a stricter match.
|
|
if istype(value, (tuple, list)) and all(
|
|
[isinstance(x, int) or is_numpy_int_type(x) or x is None for x in value]
|
|
):
|
|
guards = self.make_guards(GuardBuilder.EQUALS_MATCH)
|
|
else:
|
|
guards = self.make_guards(GuardBuilder.LIST_LENGTH)
|
|
output = [
|
|
VariableBuilder(self.tx, GetItemSource(self.get_source(), i))(
|
|
item
|
|
).add_guards(guards)
|
|
for i, item in enumerate(value)
|
|
]
|
|
result = self.list_type(value)(output, guards=guards)
|
|
if istype(value, list):
|
|
return self.tx.output.side_effects.track_list(
|
|
self.source, value, result
|
|
)
|
|
return result
|
|
elif istype(value, tuple_iterator):
|
|
guards = self.make_guards(GuardBuilder.TUPLE_ITERATOR_LEN)
|
|
output = [
|
|
VariableBuilder(
|
|
self.tx, TupleIteratorGetItemSource(self.get_source(), i)
|
|
)(tuple_iterator_getitem(value, i)).add_guards(guards)
|
|
for i in range(tuple_iterator_len(value))
|
|
]
|
|
return ListIteratorVariable(
|
|
output, mutable_local=MutableLocal(), guards=guards
|
|
)
|
|
elif istype(value, (slice, range)):
|
|
items = [
|
|
VariableBuilder(self.tx, AttrSource(self.get_source(), k))(
|
|
getattr(value, k)
|
|
)
|
|
for k in ("start", "stop", "step")
|
|
]
|
|
if isinstance(value, slice):
|
|
return SliceVariable(items, guards=make_guards(GuardBuilder.TYPE_MATCH))
|
|
else:
|
|
return RangeVariable(
|
|
items, guards=make_guards(GuardBuilder.EQUALS_MATCH)
|
|
)
|
|
elif istype(
|
|
value, (dict, collections.defaultdict, collections.OrderedDict)
|
|
) and all(
|
|
map(
|
|
lambda k: ConstantVariable.is_literal(k)
|
|
or self.tensor_can_be_dict_key(k),
|
|
value.keys(),
|
|
)
|
|
):
|
|
guards = self.make_guards(GuardBuilder.DICT_KEYS)
|
|
|
|
# store key variables in global location for reconstruction
|
|
for key in value.keys():
|
|
if self.tensor_can_be_dict_key(key):
|
|
self.tx.store_dict_key(global_key_name(key), key)
|
|
|
|
def index_source(key):
|
|
if self.tensor_can_be_dict_key(key):
|
|
return GlobalWeakRefSource(global_key_name(key))
|
|
else:
|
|
return key
|
|
|
|
result = dict(
|
|
[
|
|
(
|
|
k,
|
|
VariableBuilder(
|
|
self.tx, GetItemSource(self.get_source(), index_source(k))
|
|
)(value[k]).add_guards(guards),
|
|
)
|
|
for k in value.keys()
|
|
]
|
|
)
|
|
|
|
if istype(value, collections.defaultdict):
|
|
result = DefaultDictVariable(
|
|
result, type(value), value.default_factory, guards=guards
|
|
)
|
|
else:
|
|
result = ConstDictVariable(result, type(value), guards=guards)
|
|
|
|
return self.tx.output.side_effects.track_dict(self.source, value, result)
|
|
elif isinstance(value, torch.nn.Module):
|
|
if mutation_guard.is_dynamic_nn_module(value):
|
|
# created dynamically, don't specialize on it
|
|
result = UnspecializedNNModuleVariable(
|
|
value, guards=make_guards(GuardBuilder.TYPE_MATCH)
|
|
)
|
|
if not SideEffects.cls_supports_mutation_side_effects(type(value)):
|
|
# don't allow STORE_ATTR mutation with custom __setattr__
|
|
return result
|
|
return self.tx.output.side_effects.track_object_existing(
|
|
self.source, value, result
|
|
)
|
|
elif getattr(value, "_is_fsdp_managed_module", False) or issubclass(
|
|
value.__class__, torch.nn.parallel.distributed.DistributedDataParallel
|
|
):
|
|
# See note [Dynamo treats FSDP wrapped modules as UnspecializedNNModule]
|
|
# in fully_sharded_data_parallel.py for more information
|
|
return UnspecializedNNModuleVariable(
|
|
value, guards=make_guards(GuardBuilder.TYPE_MATCH)
|
|
)
|
|
else:
|
|
return self.tx.output.register_attr_or_module(
|
|
value,
|
|
self.name,
|
|
source=self.get_source(),
|
|
# Guards are added inside register_attr_or_module
|
|
)
|
|
elif ConstantVariable.is_literal(value) or istype(
|
|
value, (torch.Size, torch.device, torch.dtype)
|
|
):
|
|
if type(value) in (int, float) and not config.specialize_int_float:
|
|
# unspecializing int/float by default, but still
|
|
# specialize for the following conditions
|
|
if (
|
|
value in self._common_constants()
|
|
or isinstance(self.source, GlobalSource)
|
|
or isinstance(self.source, GetItemSource)
|
|
or (
|
|
isinstance(self.source, AttrSource)
|
|
and isinstance(self.source.base, GlobalSource)
|
|
)
|
|
):
|
|
return ConstantVariable(
|
|
value=value,
|
|
guards=make_guards(GuardBuilder.CONSTANT_MATCH),
|
|
)
|
|
else:
|
|
return self.wrap_unspecialized_primitive(value)
|
|
else:
|
|
return ConstantVariable(
|
|
value=value,
|
|
guards=make_guards(GuardBuilder.CONSTANT_MATCH),
|
|
)
|
|
elif isinstance(value, frozenset) and (
|
|
all(is_allowed(x) or ConstantVariable.is_literal(x) for x in value)
|
|
):
|
|
# For frozenset, we can guard by object ID instead of value
|
|
# equality, this allows us to handle non-literal values
|
|
return ConstantVariable(
|
|
value=value,
|
|
guards=make_guards(GuardBuilder.ID_MATCH),
|
|
)
|
|
elif isinstance(value, enum.Enum):
|
|
return EnumVariable(
|
|
value=value,
|
|
guards=make_guards(GuardBuilder.ID_MATCH),
|
|
)
|
|
elif is_builtin_callable(value):
|
|
return BuiltinVariable(
|
|
value,
|
|
guards=make_guards(GuardBuilder.BUILTIN_MATCH),
|
|
)
|
|
elif is_allowed(value):
|
|
return TorchVariable(
|
|
value,
|
|
guards=make_guards(GuardBuilder.FUNCTION_MATCH),
|
|
)
|
|
elif is_typing(value):
|
|
# typing.List, typing.Mapping, etc.
|
|
return TypingVariable(
|
|
value,
|
|
guards=make_guards(GuardBuilder.ID_MATCH),
|
|
)
|
|
elif value is inspect.signature:
|
|
return LambdaVariable(
|
|
InspectSignatureVariable.create,
|
|
guards=make_guards(GuardBuilder.FUNCTION_MATCH),
|
|
)
|
|
elif value is dataclasses.fields:
|
|
return LambdaVariable(
|
|
_dataclasses_fields_lambda,
|
|
guards=make_guards(GuardBuilder.FUNCTION_MATCH),
|
|
)
|
|
elif is_numpy(value):
|
|
return NumpyVariable(
|
|
value,
|
|
guards=make_guards(
|
|
GuardBuilder.FUNCTION_MATCH
|
|
if callable(value)
|
|
else GuardBuilder.TYPE_MATCH
|
|
),
|
|
)
|
|
elif value in tensor_dunder_fns:
|
|
return TorchVariable(
|
|
value,
|
|
guards=make_guards(GuardBuilder.FUNCTION_MATCH),
|
|
)
|
|
elif (
|
|
istype(value, (type, types.FunctionType))
|
|
and skipfiles.check(getfile(value), allow_torch=True)
|
|
and not inspect.getattr_static(value, "_torchdynamo_inline", False)
|
|
):
|
|
return SkipFilesVariable(
|
|
value, guards=make_guards(GuardBuilder.FUNCTION_MATCH)
|
|
)
|
|
elif istype(value, (type, ABCMeta)):
|
|
# TODO(whc) the following seems preferable but breaks some tests, debug
|
|
# elif inspect.isclass(value):
|
|
return UserDefinedClassVariable(
|
|
value, guards=make_guards(GuardBuilder.FUNCTION_MATCH)
|
|
)
|
|
elif value in tensor_dunder_fns:
|
|
return TorchVariable(
|
|
value,
|
|
guards=make_guards(GuardBuilder.FUNCTION_MATCH),
|
|
)
|
|
elif istype(value, types.FunctionType):
|
|
return UserFunctionVariable(
|
|
value,
|
|
guards=make_guards(GuardBuilder.FUNCTION_MATCH),
|
|
)
|
|
elif istype(value, (types.ModuleType, replay_record.DummyModule)):
|
|
return PythonModuleVariable(
|
|
value,
|
|
guards=make_guards(GuardBuilder.PYMODULE_MATCH),
|
|
)
|
|
elif type(value) is torch.autograd.function.FunctionMeta:
|
|
return AutogradFunctionVariable(
|
|
value, guards=make_guards(GuardBuilder.FUNCTION_MATCH)
|
|
)
|
|
elif (
|
|
isinstance(value, types.BuiltinFunctionType)
|
|
and type(getattr(value, "__self__", None))
|
|
is torch.autograd.function.FunctionMeta
|
|
and getattr(value, "__name__", "") == "apply"
|
|
and value == getattr(value.__self__, "apply", None)
|
|
):
|
|
# handle aliased autograd function `apply` calls
|
|
return GetAttrVariable(
|
|
AutogradFunctionVariable(
|
|
value.__self__, guards=make_guards(GuardBuilder.FUNCTION_MATCH)
|
|
),
|
|
"apply",
|
|
)
|
|
elif isinstance(value, (int, float, np.number)):
|
|
return self.wrap_unspecialized_primitive(value)
|
|
elif DataClassVariable.is_matching_object(value):
|
|
return DataClassVariable.wrap(self, value).add_guards(
|
|
make_guards(GuardBuilder.TYPE_MATCH)
|
|
)
|
|
elif HFPretrainedConfigVariable.is_matching_object(value):
|
|
return HFPretrainedConfigVariable(
|
|
value, guards=make_guards(GuardBuilder.TYPE_MATCH)
|
|
)
|
|
elif isinstance(value, PyOperator):
|
|
return TorchPyOperator(
|
|
value,
|
|
guards=self.make_guards(
|
|
GuardBuilder.TYPE_MATCH, GuardBuilder.NAME_MATCH
|
|
),
|
|
)
|
|
elif type(value).__name__ == "builtin_function_or_method" and isinstance(
|
|
value.__self__, torch_special_class_types
|
|
):
|
|
return TorchVariable(
|
|
value,
|
|
guards=make_guards(GuardBuilder.FUNCTION_MATCH),
|
|
)
|
|
else:
|
|
result = UserDefinedObjectVariable(
|
|
value,
|
|
guards=self.make_guards(GuardBuilder.TYPE_MATCH),
|
|
)
|
|
if not SideEffects.cls_supports_mutation_side_effects(type(value)):
|
|
# don't allow STORE_ATTR mutation with custom __setattr__
|
|
return result
|
|
return self.tx.output.side_effects.track_object_existing(
|
|
self.source, value, result
|
|
)
|
|
|
|
def tensor_can_be_dict_key(self, value):
|
|
# only allow Parameter and another specific Tensor can be used as dict key
|
|
return (
|
|
isinstance(value, torch.nn.Parameter)
|
|
or isinstance(self.source, AttrSource)
|
|
and self.source.member == "state"
|
|
and isinstance(self.source.base, LocalSource)
|
|
)
|
|
|
|
def tensor_should_specialize(self):
|
|
return (
|
|
self.source
|
|
and isinstance(self.source, GetItemSource)
|
|
and isinstance(self.source.base, GetItemSource)
|
|
and self.source.base.index == "params"
|
|
and isinstance(self.source.base.base, GetItemSource)
|
|
and isinstance(self.source.base.base.base, AttrSource)
|
|
and self.source.base.base.base.member == "param_groups"
|
|
and isinstance(self.source.base.base.base.base, LocalSource)
|
|
and (
|
|
isinstance(
|
|
self.tx.f_locals[self.source.base.base.base.base.local_name],
|
|
torch.optim.Optimizer,
|
|
)
|
|
if self.source.base.base.base.base.local_name in self.tx.f_locals.keys()
|
|
else True
|
|
)
|
|
)
|
|
|
|
def wrap_sym(self, value: Union[torch.SymInt, torch.SymFloat]):
|
|
if not is_constant_source(self.get_source()):
|
|
self.tx.output.graphargs.append(GraphArg(self.get_source(), value, False))
|
|
elif is_constant_source(self.get_source()):
|
|
return self.tx.output.register_attr_or_module(
|
|
value,
|
|
re.sub(r"[^a-zA-Z0-9]+", "_", self.name),
|
|
source=None,
|
|
dyn_shape=value
|
|
# shape Guards live their own rich life via shape_env
|
|
)
|
|
return DynamicShapeVariable.create(
|
|
tx=self.tx,
|
|
proxy=self.tx.output.create_graph_input(
|
|
re.sub(r"[^a-zA-Z0-9]+", "_", self.name), type(value)
|
|
),
|
|
dyn_shape=value
|
|
# shape Guards live their own rich life via shape_env
|
|
)
|
|
|
|
def wrap_tensor(self, value: torch.Tensor):
|
|
if self.get_source().guard_source().is_nn_module():
|
|
return self.tx.output.register_attr_or_module(
|
|
value,
|
|
self.name,
|
|
source=self.get_source(),
|
|
# Guards are done inside register_attr_or_module
|
|
# guards=self.make_guards(GuardBuilder.TENSOR_MATCH),
|
|
)
|
|
else:
|
|
if not is_constant_source(self.get_source()):
|
|
self.tx.output.graphargs.append(
|
|
GraphArg(self.get_source(), value, False)
|
|
)
|
|
# Disable __torch_function__ to prevent cloning of `value` to hit
|
|
# us
|
|
with torch._C.DisableTorchFunction():
|
|
if is_constant_source(self.get_source()):
|
|
return self.tx.output.register_attr_or_module(
|
|
value,
|
|
re.sub(r"[^a-zA-Z0-9]+", "_", self.name),
|
|
source=None,
|
|
# Guards are added inside register_attr_or_module
|
|
)
|
|
tensor_variable = wrap_fx_proxy(
|
|
tx=self.tx,
|
|
proxy=self.tx.output.create_graph_input(
|
|
re.sub(r"[^a-zA-Z0-9]+", "_", self.name), type(value)
|
|
),
|
|
example_value=value,
|
|
guards=self.make_guards(GuardBuilder.TENSOR_MATCH),
|
|
should_specialize=self.tensor_should_specialize(),
|
|
)
|
|
if torch.overrides.has_torch_function_unary(value):
|
|
subclass_torch_function__func = value.__torch_function__.__func__
|
|
subclass_type = type(value)
|
|
return TensorWithTFOverrideVariable(
|
|
tensor_variable,
|
|
self.get_source(),
|
|
subclass_torch_function__func,
|
|
subclass_type,
|
|
)
|
|
return tensor_variable
|
|
|
|
def wrap_unspecialized_primitive(self, value):
|
|
if self.name in self.tx.output.unspec_variable_map:
|
|
return self.tx.output.unspec_variable_map[self.name]
|
|
else:
|
|
if config.dynamic_shapes and isinstance(value, int):
|
|
shape_env = self.tx.output.shape_env
|
|
wrapped_value = shape_env.create_symintnode(
|
|
shape_env.create_symbol(value)
|
|
)
|
|
# TODO: Do float
|
|
else:
|
|
# TODO: Eliminate this case entirely
|
|
wrapped_value = torch.tensor(value)
|
|
if not is_constant_source(self.get_source()):
|
|
self.tx.output.graphargs.append(
|
|
GraphArg(self.get_source(), wrapped_value, True)
|
|
)
|
|
if not isinstance(self.get_source(), RandomValueSource):
|
|
guards = {self.get_source().make_guard(GuardBuilder.TYPE_MATCH, True)}
|
|
options = {"guards": guards}
|
|
else:
|
|
options = {}
|
|
options.update({"source": self.get_source()})
|
|
if isinstance(wrapped_value, torch.Tensor):
|
|
options.update({"raw_value": value})
|
|
|
|
proxy = self.tx.output.create_graph_input(
|
|
re.sub(r"[^a-zA-Z0-9]+", "_", self.name), type(wrapped_value)
|
|
)
|
|
|
|
if isinstance(value, np.number):
|
|
unspec_var = wrap_fx_proxy_cls(
|
|
UnspecializedNumpyVariable,
|
|
tx=self.tx,
|
|
proxy=proxy,
|
|
example_value=wrapped_value,
|
|
**options,
|
|
)
|
|
else:
|
|
unspec_var = wrap_fx_proxy_cls(
|
|
UnspecializedPythonVariable,
|
|
tx=self.tx,
|
|
proxy=proxy,
|
|
example_value=wrapped_value,
|
|
**options,
|
|
)
|
|
self.tx.output.unspec_variable_map[self.name] = unspec_var
|
|
return unspec_var
|
|
|
|
|
|
def _dataclasses_fields_lambda(obj):
|
|
if isinstance(obj, UserDefinedObjectVariable):
|
|
value = obj.value
|
|
elif isinstance(obj, DataClassVariable):
|
|
value = obj.user_cls
|
|
else:
|
|
unimplemented(f"Dataclass fields handling fails for type {obj}")
|
|
items = []
|
|
for field in dataclasses.fields(value):
|
|
source = None
|
|
if obj.source:
|
|
source = GetItemSource(
|
|
AttrSource(obj.source, "__dataclass_fields__"), field.name
|
|
)
|
|
items.append(UserDefinedObjectVariable(field, source=source).add_options(obj))
|
|
return TupleVariable(items).add_options(obj)
|
|
|
|
|
|
def wrap_fx_proxy(tx, proxy, example_value=None, **options):
|
|
return wrap_fx_proxy_cls(
|
|
target_cls=TensorVariable,
|
|
tx=tx,
|
|
proxy=proxy,
|
|
example_value=example_value,
|
|
**options,
|
|
)
|
|
|
|
|
|
# Note: Unfortunate split due to some gross classes existing that subclass TensorVariable
|
|
# Should be compositional instead
|
|
def wrap_fx_proxy_cls(target_cls, tx, proxy, example_value=None, **options):
|
|
if "guards" in options and options["guards"] is not None:
|
|
tx.output.guards.update(options["guards"])
|
|
|
|
assert "example_value" not in proxy.node.meta
|
|
if not config.dynamic_propagation:
|
|
if isinstance(example_value, torch.Tensor):
|
|
options.update(target_cls.specialize(example_value))
|
|
return target_cls(proxy, **options)
|
|
|
|
initial_example_value = example_value
|
|
|
|
def _clone_input(value):
|
|
if isinstance(value, torch.Tensor):
|
|
# tensor subclasses will not be converted to FakeTensors and need to be cloned
|
|
if not isinstance(value, torch._subclasses.fake_tensor.FakeTensor):
|
|
# NB: ensure strides are preserved
|
|
value = clone_input(value)
|
|
|
|
return value
|
|
|
|
with preserve_rng_state():
|
|
if example_value is None:
|
|
example_value = get_fake_value(proxy.node, tx)
|
|
|
|
else:
|
|
proxy.tracer.real_value_cache[proxy.node] = _clone_input(example_value)
|
|
fake_wrapper = functools.partial(wrap_to_fake_tensor_and_record, tx=tx)
|
|
example_value = fake_wrapper(example_value)
|
|
|
|
if isinstance(example_value, torch.Tensor):
|
|
is_parameter = isinstance(example_value, torch.nn.Parameter)
|
|
should_specialize = options.pop("should_specialize", False)
|
|
if is_parameter or should_specialize:
|
|
specialized_value = initial_example_value
|
|
else:
|
|
specialized_value = None
|
|
|
|
example_value = _clone_input(example_value)
|
|
proxy.node.meta["example_value"] = example_value
|
|
specialized_props = target_cls.specialize(example_value)
|
|
if isinstance(example_value, torch._subclasses.fake_tensor.FakeTensor):
|
|
specialized_props["class_type"] = (
|
|
torch.nn.Parameter if is_parameter else torch.Tensor
|
|
)
|
|
|
|
specialized_props["specialized_value"] = specialized_value
|
|
|
|
options.update(specialized_props)
|
|
return target_cls(proxy, **options)
|
|
elif (
|
|
hasattr(proxy.node.target, "__name__")
|
|
and proxy.node.target.__name__ == "set_state"
|
|
and isinstance(proxy.node.target.__self__, torch._C.Generator)
|
|
or proxy.node.target == torch.random.set_rng_state
|
|
):
|
|
from . import TorchVariable
|
|
|
|
return TorchVariable(proxy.node.target)
|
|
elif (
|
|
proxy.node.target == torch._C._DisableFuncTorch
|
|
or proxy.node.target == torch.cuda._is_in_bad_fork
|
|
):
|
|
from . import UserDefinedObjectVariable
|
|
|
|
return UserDefinedObjectVariable(example_value)
|
|
elif istype(example_value, (int, bool, float)) and config.dynamic_shapes:
|
|
proxy.node.meta["example_value"] = example_value
|
|
return DynamicShapeVariable.create(tx, proxy, example_value, **options)
|
|
elif istype(example_value, torch.Size) and config.dynamic_shapes:
|
|
proxy.node.meta["example_value"] = example_value
|
|
sizes = []
|
|
for i, v in enumerate(example_value):
|
|
proxy_i = proxy[i]
|
|
sizes.append(DynamicShapeVariable.create(tx, proxy_i, v, **options))
|
|
return SizeVariable(sizes, proxy, **options)
|
|
elif istype(example_value, int) and proxy.node.target in (
|
|
torch.seed,
|
|
operator.mod,
|
|
# some mac builds are missing torch.distributed.get_rank()
|
|
getattr(torch.distributed, "get_rank", _missing),
|
|
getattr(torch.distributed, "get_world_size", _missing),
|
|
):
|
|
if config.dynamic_shapes:
|
|
proxy.node.meta["example_value"] = example_value
|
|
return DynamicShapeVariable.create(tx, proxy, example_value, **options)
|
|
else:
|
|
return ConstantVariable(example_value, **options)
|
|
elif istype(example_value, torch.Size) and all(
|
|
[isinstance(x, int) for x in example_value]
|
|
):
|
|
sizes = [ConstantVariable(x) for x in example_value]
|
|
return SizeVariable(sizes, **options)
|
|
elif isinstance(example_value, (tuple, list)):
|
|
unpacked = []
|
|
for i, val in enumerate(example_value):
|
|
if val is None:
|
|
# nn.MultiheadAttention() can return None, see issue #175
|
|
unpacked.append(
|
|
ConstantVariable(None, **options),
|
|
)
|
|
else:
|
|
unpacked.append(
|
|
wrap_fx_proxy(
|
|
tx,
|
|
proxy.tracer.create_proxy(
|
|
"call_function", operator.getitem, (proxy, i), {}
|
|
),
|
|
example_value=val,
|
|
**options,
|
|
)
|
|
)
|
|
if istype(example_value, tuple):
|
|
return TupleVariable(unpacked, **options)
|
|
elif istype(example_value, (list, immutable_list)):
|
|
return ListVariable(unpacked, mutable_local=MutableLocal(), **options)
|
|
else:
|
|
assert (
|
|
example_value.__class__.__module__ == "torch.return_types"
|
|
or hasattr(example_value, "_fields")
|
|
), ("namedtuple?")
|
|
return NamedTupleVariable(unpacked, example_value.__class__, **options)
|
|
elif example_value is None or proxy.node.target is torch.manual_seed:
|
|
return ConstantVariable(None, **options)
|
|
elif (
|
|
isinstance(example_value, int)
|
|
and proxy.node.target is torch._utils._element_size
|
|
):
|
|
proxy.node.meta["example_value"] = example_value
|
|
return ConstantVariable(example_value, **options)
|
|
elif (
|
|
isinstance(example_value, numbers.Number)
|
|
and (proxy.node.target == "item" or proxy.node.target in {math.sqrt, math.pow})
|
|
and config.capture_scalar_outputs
|
|
):
|
|
# item raw value should not be accessed
|
|
return wrap_fx_proxy_cls(
|
|
FakeItemVariable,
|
|
tx=tx,
|
|
proxy=proxy,
|
|
example_value=torch.tensor(example_value),
|
|
**options,
|
|
)
|
|
elif isinstance(example_value, (torch.SymInt, torch.SymFloat)):
|
|
proxy.node.meta["example_value"] = example_value
|
|
return DynamicShapeVariable(proxy, example_value, **options)
|
|
else:
|
|
raise AssertionError(
|
|
"torch.* op returned non-Tensor "
|
|
+ f"{typestr(example_value)} {proxy.node.op} {proxy.node.target}"
|
|
)
|