Summary:
I think there was a typo in #20690 here https://github.com/pytorch/pytorch/pull/20690/files#diff-b47a50873394e38a005b4c1acd151957R130.
Original conditional was ` common_backend == Backend::CUDA && op.tensor.type().backend() == Backend::CPU)`, now it is `op.device.is_cuda() && op.tensor.device().is_cpu()`. It seems that `op.device` and `op.tensor.device()` should be the same, so this conditional is never true. This leads to spurious h2d copies for operations between cuda tensors and cpu scalars, because cpu scalars are now sent to gpu, instead of being passed to lambdas directly.
Unfortunately, I don't know how to test this change, because functionally everything was fine after #20690, it was just a performance regression.
cc colesbury
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21236
Differential Revision: D15592754
Pulled By: soumith
fbshipit-source-id: 105bfecc61c222cfdb7294a03c9ecae3cc7f5817
Summary:
`Tensor.is_cuda` and `is_leaf` is not a predicate function but a `bool` attribute. This patch fixes the type hints in `torch/__init__.pyi` for those attributes.
```diff
- def is_cuda(self) -> bool: ...
+ is_cuda: bool
- def is_leaf(self) -> bool: ...
+ is_leaf: bool
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21192
Differential Revision: D15592766
Pulled By: soumith
fbshipit-source-id: 8c4ecd6939df8b8a8a19e1c9db6d40193bca7e4a
Summary:
This makes file-line reporting also work for things loaded using `torch.jit.load()` as well as the string frontend (via `CompilationUnit`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21217
Differential Revision: D15590838
Pulled By: jamesr66a
fbshipit-source-id: 6b6a12574bf9eca0b83f24f0b50535fda5863243
Summary:
Studied why sparse tensor coalesce was slow: issue #10757.
Using nv-prof, and writing a simple benchmark, I determined bulk of the time was used ``kernelTransformReduceInnermostDimIndex``, which is called when sparse tensor is constructed with sparse_coo_tensor when it does sanity check on the minimum and maximum indices. However, we do not need this sanity check because after coalescing the tensor, these min/maxs won't change.
On my benchmark with 1 million non-zeros, the runtime of coalesce. was about 10x from 0.52s to 0.005 sec.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21214
Reviewed By: bddppq
Differential Revision: D15584338
Pulled By: akyrola
fbshipit-source-id: a08378baa018dbd0b45d7aba661fc9aefd3791e0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21163
These two backend transformation share some common traits. Therefore we want to reuse the data struct/code as much as possible.
Reviewed By: hlu1
Differential Revision: D15561177
fbshipit-source-id: 35f5d63b2b5b3657f4ba099634fd27c3af545f1b
Summary:
Some of the functions are only used in this file - mark them `static`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21140
Differential Revision: D15578076
Pulled By: Krovatkin
fbshipit-source-id: 71ae67baabebd40c38ecb9292b5b8202ad2b9fc1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21152
Migrate existing add benchmark to use the new op front-end
Reviewed By: zheng-xq
Differential Revision: D15325524
fbshipit-source-id: 34e969e1bd289913d881c476711bce9f8ac18a29
Summary:
i will do loops in a follow up after some other changes I am working on have landed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20911
Differential Revision: D15497205
Pulled By: eellison
fbshipit-source-id: 8cac197c6a6045b27b552cbb39e6fc86ca747b18
Summary:
Following on #19747, this implements most of the `torch.jit.script()` changes laid out in #20939.
Still to do:
* Accessing a method from Python does not add it as a `ScriptMethod` (so only `export`ed methods and `forward` are compiled)
* Calling a method other than `forward` on a submodule doesn't work
](https://our.intern.facebook.com/intern/diff/15560490/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20708
Pulled By: driazati
Differential Revision: D15560490
fbshipit-source-id: cc7ef3a1c2772eff9beba5f3e66546d2b7d7198a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21085
Now that torch::jit::RegisterOperators() always passes through to torch::RegisterOperators() (see diffs stacked below this), we can remove the old custom op implementation.
Reviewed By: dzhulgakov
Differential Revision: D15542261
fbshipit-source-id: ef437e6c71950e58fdd237d6abd035826753c2e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21084
- Now AliasAnalysisKind can be set using the torch::RegisterOperators() API
- This also allows us to remove the last place in torch::jit::RegisterOperators that didn't use c10 yet.
Reviewed By: dzhulgakov
Differential Revision: D15542097
fbshipit-source-id: ea127ecf051a5c1e567e035692deed44e04faa9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21181
Implement c10::OperatorOptions as a class to store metadata about operators.
This is meant to replace torch::jit::OperatorOptions.
Reviewed By: dzhulgakov
Differential Revision: D15569897
fbshipit-source-id: 95bf0bf917c1ef2bdf32702405844e1a116d9a64
Summary:
This reduces DenseNet load time by about 25% (down to 5.3s on my laptop) and gets AliasAnalysis out of the profile top hits entirely.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21203
Differential Revision: D15578155
fbshipit-source-id: ddbb1ad25c9540b5214702830084aa51cc6fd3cb
Summary:
Adds persistent cuda kernels that speed up SoftMax applied over the fast dimension, i.e. torch.nn.Softmax(dim=-1) and torch.nn.LogSoftmax(dim=-1). When the size is <= 1024, this code is 2-10x faster than the current code, speedup is higher for smaller sizes. This code works for half, float and double tensors with 1024 or fewer elements in the fast dimension. Numerical accuracy is on par with the current code, i.e. relative error is ~1e-8 for float tensors and ~1e-17 for double tensors. Relative error was computed against the CPU code.
The attached image shows kernel time in us for torch.nn.Softmax(dim=-1) applied to a half precision tensor of shape [16384,n], n is plotted along the horizontal axis. Similar uplifts can be seen for the backward pass and for LogSoftmax.
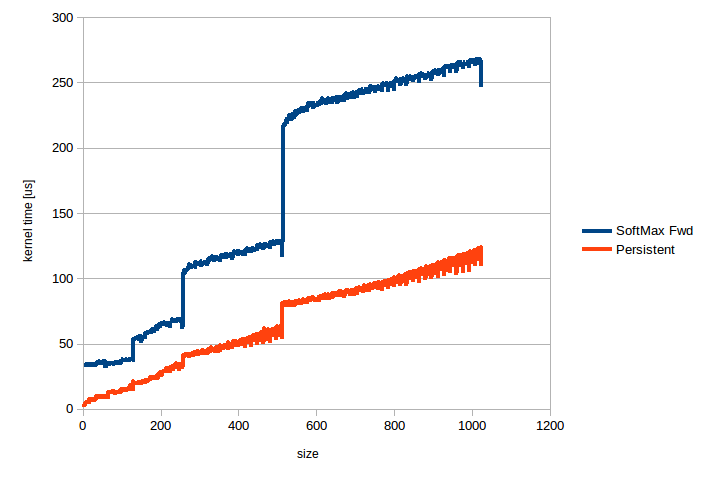
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20827
Differential Revision: D15582509
Pulled By: ezyang
fbshipit-source-id: 65805db37487cebbc4ceefb1a1bd486d24745f80
Summary:
This is a follow up on Jame's PR: https://github.com/pytorch/pytorch/pull/19041. The idea is to replace the legacy `sinh` / `cosh` ops that are being dispatched to TH with the operations defined in `Vec256` for better performance.
benchmark(from Jame's script):
```python
import torch, time
ops = ['sinh', 'cosh']
x = torch.rand(1024, 1024)
NITER = 10000
print('op', 'time per iter (ms)', 'gops/s', 'GB/s', sep='\t')
for op in ops:
s = time.time()
for i in range(NITER):
getattr(x, op)()
elapsed_sec = ((time.time() - s) / NITER)
print(op, elapsed_sec * 1000, (1024*1024/elapsed_sec)/1e9, (1024*1024*4*2) / elapsed_sec / 1e9, sep='\t')
```
code on master:
```
op time per iter (ms) gops/s GB/s
sinh 3.37614369392395 0.3105839369002935 2.484671495202348
cosh 3.480502033233643 0.3012714803748572 2.4101718429988574
```
after change (on Macbook pro 2018):
```
op time per iter (ms) gops/s GB/s
sinh 0.8956503868103027 1.1707425301677301 9.365940241341841
cosh 0.9392147302627564 1.1164390487217428 8.931512389773943
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21115
Reviewed By: ljk53
Differential Revision: D15574580
Pulled By: xta0
fbshipit-source-id: 392546a0df11ed4f0945f2bc84bf5dea2750b60e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21196
we'll add `quantize(quantizer)` as a tensor method later when we expose `quantizer` in Python frontend
Python
```
torch.quantize_linear(t, ...)
```
C++
```
at::quantize_linear(t, ...)
```
Differential Revision: D15577123
fbshipit-source-id: d0abeea488418fa9ab212f84b0b97ee237124240
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21169
We should minimize dependency from perfkernels (we were including eigen header files only in cc files not compiled with avx or avx2 options but better to be very strict because it's easy to introduce illegal instruction errors in perfkernels)
Reviewed By: salexspb
Differential Revision: D15563839
fbshipit-source-id: d4b1bca22d7f2e6f20f23664d4b99498e5984586
Summary:
Most important fix: Correct "tensor.rst" to "tensors.rst"
Secondary fix: some minor English spelling/grammar fixes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21029
Differential Revision: D15523230
Pulled By: umanwizard
fbshipit-source-id: 6052d8609c86efa41a4289cd3a099b2f1037c810
Summary:
Dynamically creating a type at runtime was messing up the MRO and has been causing many other problems. I think it's best to delete it, this causes a regression since
```python
self.linear = nn.Linear(10, 10)
isinstance(self.linear, nn.Linear)
```
will now be `False` again, but this will be fixed once recursive script mode is the default (#20939)
](https://our.intern.facebook.com/intern/diff/15560549/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21107
Pulled By: driazati
Differential Revision: D15560549
fbshipit-source-id: 7bd6b958acb4f353d427d66196bb4ee577ecb1a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21148
The diff modifies the interface for Caffe2 operators in the benchmark suite
Reviewed By: zheng-xq
Differential Revision: D15433888
fbshipit-source-id: c264a95906422d7a26c10b1f9836ba8b35e36b53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21147
This diff introduces a new interface to add PT/C2 operators to the benchmark suite.
The following steps are needed to add a new operator:
1. Specify the input shapes, args to an operator in configs
2. Create a PT/C2 benchmark class which includes ```init``` (create tensors), ```forward``` (specify the operator to be tested.), and ```backward```(gradient of an op.) methods
3. call generate_pt_test/generate_c2_test to create test cases based on configs
Reviewed By: zheng-xq
Differential Revision: D15250380
fbshipit-source-id: 1025a7cf60d2427baa0f3f716455946d3d3e6a27
Summary:
This should pass once https://github.com/pytorch/vision/pull/971 is merged.
To remove torchvision as baseline, we just compare to sum of all param.sum() in pretrained resnet18 model, which means we need to manually update the number only when that pretrained weights are changed, which is generally rare.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21132
Differential Revision: D15563078
Pulled By: ailzhang
fbshipit-source-id: f28c6874149a1e6bd9894402f6847fd18f38b2b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21164
Write a List type to be used in operator kernels. This abstracts away from the concrete list type used (e.g. std::vector vs SmallVector)
and allows us to change these implementation details without breaking the kernel API.
Also, this class allows for handling List<bool>, which would not work with ArrayRef because vector<bool> is a bitset and can't be converted to ArrayRef<bool>.
Reviewed By: ezyang
Differential Revision: D15476434
fbshipit-source-id: 5855ae36b45b70437f996c81580f34a4c91ed18c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21156
we'll add `quantize(quantizer)` as a tensor method later when we expose `quantizer` in Python frontend
Python
```
torch.quantize_linear(t, ...)
```
C++
```
at::quantize_linear(t, ...)
```
Differential Revision: D15558784
fbshipit-source-id: 0b194750c423f51ad1ad5e9387a12b4d58d969a9
Summary:
In the previous implementation of triu / tril, we passed the batch size in the 2nd dimension of a grid. This is limited to 65535, which means that performing triu / tril on a tensor with batch size > 65535 will throw an error. This PR removes the dependence on the 2nd dimension, and corresponding non-contiguity constraints.
Changelog:
- Compute offset, row and col in the kernel
- Use 1st dimension of grid alone
- Remove unnecessary contiguity checks on tensors as a result of this change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21067
Differential Revision: D15572501
Pulled By: ezyang
fbshipit-source-id: 93851cb661918ce794d43eeb12c8a38762e1358c
{kind=link}