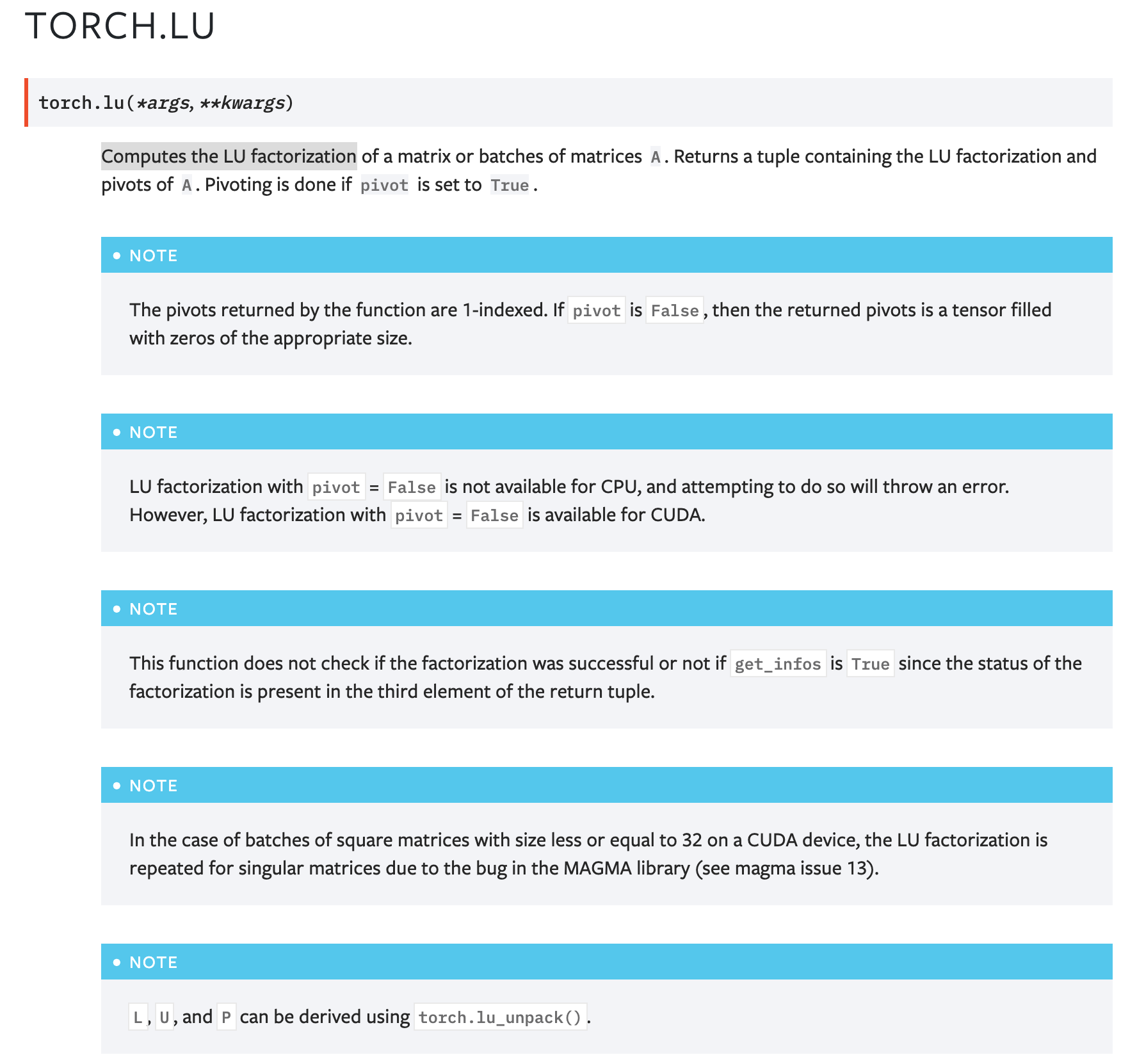
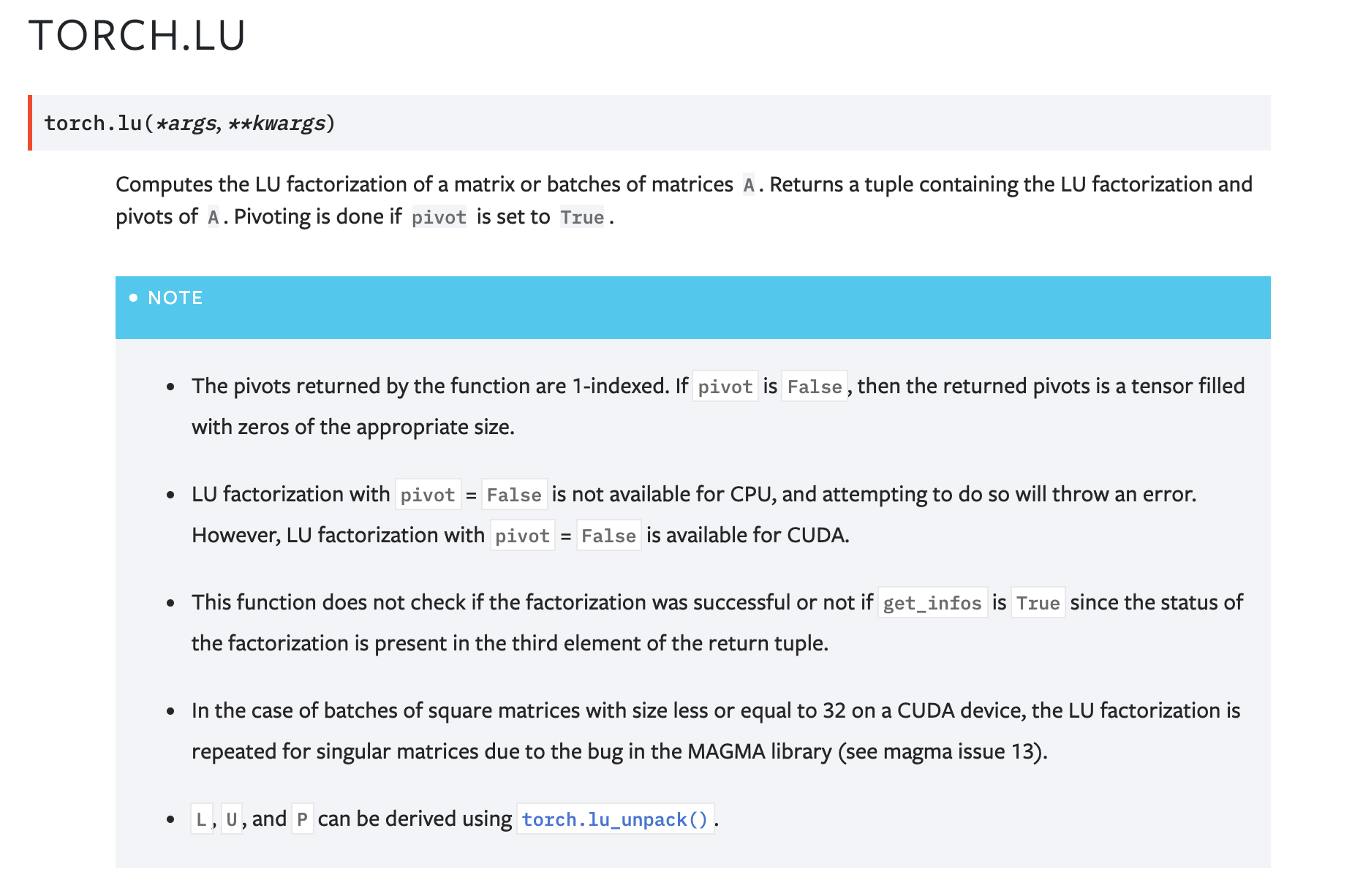
**BC-breaking note**:
This PR deprecates `torch.lu` in favor of `torch.linalg.lu_factor`.
A upgrade guide is added to the documentation for `torch.lu`.
Note this PR DOES NOT remove `torch.lu`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77636
Approved by: https://github.com/malfet
I figured these out by unconditionally turning on a no-op torch function
mode on the test suite and then fixing errors as they showed up. Here's
what I found:
- _parse_to failed internal assert when __torch_function__'ed because it
claims its name is "to" to the argument parser; added a name override
so we know how to find the correct name
- Infix operator magic methods on Tensor did not uniformly handle
__torch_function__ and TypeError to NotImplemented. Now, we always
do the __torch_function__ handling in
_wrap_type_error_to_not_implemented and your implementation of
__torch_function__ gets its TypeErrors converted to NotImplemented
(for better or for worse; see
https://github.com/pytorch/pytorch/issues/75462 )
- A few cases where code was incorrectly testing if a Tensor was
Tensor-like in the wrong way, now use is_tensor_like (in grad
and in distributions). Also update docs for has_torch_function to
push people to use is_tensor_like.
- is_grads_batched was dropped from grad in handle_torch_function, now
fixed
- Report that you have a torch function even if torch function is
disabled if a mode is enabled. This makes it possible for a mode
to return NotImplemented, pass to a subclass which does some
processing and then pass back to the mode even after the subclass
disables __torch_function__ (so the tensors are treated "as if"
they are regular Tensors). This brings the C++ handling behavior
in line with the Python behavior.
- Make the Python implementation of overloaded types computation match
the C++ version: when torch function is disabled, there are no
overloaded types (because they all report they are not overloaded).
Signed-off-by: Edward Z. Yang <ezyangfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75484
Approved by: https://github.com/zou3519
This creates a `histogramdd` operator with overloads matching the `Union`
behaviour used in the functional variant. Moving into C++ is preferred because
it can handle torch function automatically instead of needing to differentiate
between the overloads manually.
This also adds a new return type: `std::tuple<Tensor, std::vector<Tensor>>`. For
which I've updated `wrap` to be completely generic for tuples and removed the
old manual definitions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74200
Approved by: https://github.com/ezyang
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71993
I've kept the symbol `torch.functional.istft` because it looks like public API,
but it could just as easily be moved to `_torch_docs.py`.
Moving this into its own PR until TorchScript starts recognizing `input`
as a keyword argument.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D34461399
Pulled By: anjali411
fbshipit-source-id: 3275fb74bef2fa0e030e61f7ee188daf8b5b2acf
(cherry picked from commit 5b4b083de894eba9ab16cea53b77746bcfd0fe32)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72833Closes#72550
The latest version of librosa breaks backward compatibility in two
ways:
- Everything except the input tensor is now keyword-only
- `pad_mode` now defaults to `'constant'` for zero-padding
https://librosa.org/doc/latest/generated/librosa.stft.html
This changes the test to match the old behaior even when using the new
library and updates the documentation to explicitly say that
`torch.stft` doesn't exactly follow the librosa API. This was always
true (`torch.stft` it has new arguments, a different default window
and supports complex input), but it can't hurt to be explicit.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D34386897
Pulled By: mruberry
fbshipit-source-id: 6adc23f48fcb368dacf70602e9197726d6b7e0c1
(cherry picked from commit b5c5ed4196)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D32834069
Pulled By: mruberry
fbshipit-source-id: 51ef12535fa91d292f419acf83b800b86ee9c7eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D32521980
Pulled By: mruberry
fbshipit-source-id: 26a49ebd87f8a41472f8cd4e9de4ddfb7f5581fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68367
- bmm_test.py was using syntax not allowed in 3.6
- Some suppressions were not placed on the correct line.
With this file,
```
lintrunner --paths-cmd='git grep -Il .'
```
passes successfully.
Test Plan: Imported from OSS
Reviewed By: janeyx99, mrshenli
Differential Revision: D32436644
Pulled By: suo
fbshipit-source-id: ae9300c6593d8564fb326822de157d00f4aaa3c2
Summary:
This is step 3/7 of https://github.com/pytorch/pytorch/issues/50276. It only adds support for the argument but doesn't implement new indexing modes yet.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62722
Test Plan:
Verified this is not FC breaking by adding logging to both meshgrid
overloads and then called meshgrid twice:
`meshgrid(*tensors)`
and
`meshgrid(*tensors, indexing='ij')`
This confirmed that the former signature triggered the original native
function and the latter signature triggered the new native function.
Reviewed By: H-Huang
Differential Revision: D30394313
Pulled By: dagitses
fbshipit-source-id: e265cb114d8caae414ee2305dc463b34fdb57fa6
Summary:
Fixes https://github.com/pytorch/pytorch/issues/62793
This is mostly a quick fix. I think the more correct fix could be updating `unique_dim` to `_unique_dim` which could be BC-breaking for C++ users (� maybe). Maybe something else I am missing.
~~Not sure how to add a test for it.~~ Have tested it locally.
We can add a test like following. Tested this locally, it fails currently but passes with the fix.
```python
def test_wildcard_import(self):
exec('from torch import *')
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63080
Reviewed By: gchanan
Differential Revision: D30738711
Pulled By: zou3519
fbshipit-source-id: b86d0190e45ba0b49fd2cffdcfd2e3a75cc2a35e
Summary:
The PR fixes two issues:
- See https://github.com/pytorch/pytorch/issues/62747 and https://github.com/pytorch/audio/issues/1409. The length mismatch when the given ``length`` parameter is longer than expected. Add padding logic in consistent with librosa.
- See https://github.com/pytorch/pytorch/issues/62323. The current implementations checks if the min value of window_envelop.abs() is greater than zero. In librosa they normalize the signal on non-zero values by indexing. Like
```
approx_nonzero_indices = ifft_window_sum > util.tiny(ifft_window_sum)
y[approx_nonzero_indices] /= ifft_window_sum[approx_nonzero_indices]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63469
Reviewed By: fmassa
Differential Revision: D30695827
Pulled By: nateanl
fbshipit-source-id: d034e53f0d65b3fd1dbd150c9c5acf3faf25a164
Summary:
torch.norm has a couple documentation issues, like https://github.com/pytorch/pytorch/issues/44552 and https://github.com/pytorch/pytorch/issues/38595, but since it's deprecated this PR simply clarifies that the documentation (and implementation) of torch.norm maybe be incorrect. This should be additional encouragement for users to migrate to torch.linalg.vector_norm and torch.linalg.matrix_norm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63310
Reviewed By: ngimel
Differential Revision: D30337997
Pulled By: mruberry
fbshipit-source-id: 0fdcc438f36e4ab29e21e0a64709e4f35a2467ba
Summary:
In one of my previous PRs that rewrite `tensordot` implementation, I mistakenly take empty value of `dims_a` and `dims_b` as illegal values. This turns out to be not true. Empty `dims_a` and `dims_b` are supported, in fact common when `dims` is passed as an integer. This PR removes the unnecessary check.
Fixes https://github.com/pytorch/pytorch/issues/61096
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61331
Reviewed By: eellison
Differential Revision: D29578910
Pulled By: gmagogsfm
fbshipit-source-id: 96e58164491a077ddc7a1d6aa6ccef8c0c9efda2
Summary:
There is a very common error when writing docs: One forgets to write a matching `` ` ``, and something like ``:attr:`x`` is rendered in the docs. This PR fixes most (all?) of these errors (and a few others).
I found these running ``grep -r ">[^#<][^<]*\`"`` on the `docs/build/html/generated` folder. The regex finds an HTML tag that does not start with `#` (as python comments in example code may contain backticks) and that contains a backtick in the rendered HTML.
This regex has not given any false positive in the current codebase, so I am inclined to suggest that we should add this check to the CI. Would this be possible / reasonable / easy to do malfet ?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60474
Reviewed By: mrshenli
Differential Revision: D29309633
Pulled By: albanD
fbshipit-source-id: 9621e0e9f87590cea060dd084fa367442b6bd046
Summary:
Improved torch.einsum testing and fixed a bug where lower case letters appeared before upper case letters in the sorted order which is inconsistent with NumPy.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59731
Reviewed By: SplitInfinity, ansley
Differential Revision: D29183078
Pulled By: heitorschueroff
fbshipit-source-id: a33980d273707da2d60a387a2af2fa41527ddb68
Summary:
This PR adds an alternative way of calling `torch.einsum`. Instead of specifying the subscripts as letters in the `equation` parameter, one can now specify the subscripts as a list of integers as in `torch.einsum(operand1, subscripts1, operand2, subscripts2, ..., [subscripts_out])`. This would be equivalent to `torch.einsum('<subscripts1>,<subscripts2>,...,->[<subscript_out>]', operand1, operand2, ...)`
TODO
- [x] Update documentation
- [x] Add more error checking
- [x] Update tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56625
Reviewed By: zou3519
Differential Revision: D28062616
Pulled By: heitorschueroff
fbshipit-source-id: ec50ad34f127210696e7c545e4c0675166f127dc
Summary:
Backward methods for `torch.lu` and `torch.lu_solve` require the `torch.lu_unpack` method.
However, while `torch.lu` is a Python wrapper over a native function, so its gradient is implemented via `autograd.Function`,
`torch.lu_solve` is a native function, so it cannot access `torch.lu_unpack` as it is implemented in Python.
Hence this PR presents a native (ATen) `lu_unpack` version. It is also possible to update the gradients for `torch.lu` so that backward+JIT is supported (no JIT for `autograd.Function`) with this function.
~~The interface for this method is different from the original `torch.lu_unpack`, so it is decided to keep it hidden.~~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46913
Reviewed By: albanD
Differential Revision: D28355725
Pulled By: mruberry
fbshipit-source-id: 281260f3b6e93c15b08b2ba66d5a221314b00e78
Summary:
**BC-breaking note**
This PR updates the deprecation notice for torch.norm to point users to the new torch.linalg.vector_norm and torch.linalg.matrix_norm functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57986
Reviewed By: nikithamalgifb
Differential Revision: D28353625
Pulled By: heitorschueroff
fbshipit-source-id: 5de77d89f0e84945baa5fea91f73918dc7eeafd4
Summary:
This one's easy. I also included a bugfix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57735
Reviewed By: bdhirsh
Differential Revision: D28318277
Pulled By: mruberry
fbshipit-source-id: c3c4546a11ba5b555b99ee79b1ce6c0649fa7323
Summary:
Backward methods for `torch.lu` and `torch.lu_solve` require the `torch.lu_unpack` method.
However, while `torch.lu` is a Python wrapper over a native function, so its gradient is implemented via `autograd.Function`,
`torch.lu_solve` is a native function, so it cannot access `torch.lu_unpack` as it is implemented in Python.
Hence this PR presents a native (ATen) `lu_unpack` version. It is also possible to update the gradients for `torch.lu` so that backward+JIT is supported (no JIT for `autograd.Function`) with this function.
~~The interface for this method is different from the original `torch.lu_unpack`, so it is decided to keep it hidden.~~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46913
Reviewed By: astaff
Differential Revision: D28117714
Pulled By: mruberry
fbshipit-source-id: befd33db12ecc147afacac792418b6f4948fa4a4
Summary:
As this diff shows, currently there are a couple hundred instances of raw `noqa` in the codebase, which just ignore all errors on a given line. That isn't great, so this PR changes all existing instances of that antipattern to qualify the `noqa` with respect to a specific error code, and adds a lint to prevent more of this from happening in the future.
Interestingly, some of the examples the `noqa` lint catches are genuine attempts to qualify the `noqa` with a specific error code, such as these two:
```
test/jit/test_misc.py:27: print(f"{hello + ' ' + test}, I'm a {test}") # noqa E999
test/jit/test_misc.py:28: print(f"format blank") # noqa F541
```
However, those are still wrong because they are [missing a colon](https://flake8.pycqa.org/en/3.9.1/user/violations.html#in-line-ignoring-errors), which actually causes the error code to be completely ignored:
- If you change them to anything else, the warnings will still be suppressed.
- If you add the necessary colons then it is revealed that `E261` was also being suppressed, unintentionally:
```
test/jit/test_misc.py:27:57: E261 at least two spaces before inline comment
test/jit/test_misc.py:28:35: E261 at least two spaces before inline comment
```
I did try using [flake8-noqa](https://pypi.org/project/flake8-noqa/) instead of a custom `git grep` lint, but it didn't seem to work. This PR is definitely missing some of the functionality that flake8-noqa is supposed to provide, though, so if someone can figure out how to use it, we should do that instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56272
Test Plan:
CI should pass on the tip of this PR, and we know that the lint works because the following CI run (before this PR was finished) failed:
- https://github.com/pytorch/pytorch/runs/2365189927
Reviewed By: janeyx99
Differential Revision: D27830127
Pulled By: samestep
fbshipit-source-id: d6dcf4f945ebd18cd76c46a07f3b408296864fcb
Summary:
Fixes https://github.com/pytorch/pytorch/issues/54631
I removed the phrase "When `onesided` is the default value `True`". It's not always the default and it's also confusing because it doesn't seem to relate to the bullet points it's introducing. It makes more sense in the sentence before, i.e. these frequencies are included "when the output is onesided". So, I've rewritten it as that meaning and included the correct formula for frequencies.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54877
Reviewed By: ngimel
Differential Revision: D27562785
Pulled By: mruberry
fbshipit-source-id: d7f36382611e8e176e3370393d1b371d577d46bb
Summary:
As per title.
Numerical stability increased by replacing inverses with solutions to systems of linear triangular equations.
Unblocks computing `torch.det` for FULL-rank inputs of complex dtypes via the LU decomposition once https://github.com/pytorch/pytorch/pull/48125/files is merged:
```
LU, pivots = input.lu()
P, L, U = torch.lu_unpack(LU, pivots)
det_input = P.det() * torch.prod(U.diagonal(0, -1, -2), dim=-1) # P is not differentiable, so we are fine even if it is complex.
```
Unfortunately, since `lu_backward` is implemented as `autograd.Function`, we cannot support both autograd and scripting at the moment.
The solution would be to move all the lu-related methods to ATen, see https://github.com/pytorch/pytorch/issues/53364.
Resolves https://github.com/pytorch/pytorch/issues/52891
TODOs:
* extend lu_backward for tall/wide matrices of full rank.
* move lu-related functionality to ATen and make it differentiable.
* handle rank-deficient inputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53994
Reviewed By: pbelevich
Differential Revision: D27188529
Pulled By: anjali411
fbshipit-source-id: 8e053b240413dbf074904dce01cd564583d1f064
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53424
Fixes https://github.com/pytorch/pytorch/issues/24807 and supersedes the stale https://github.com/pytorch/pytorch/issues/25093 (Cc Microsheep). If you now run the reproduction
```python
import torch
if __name__ == "__main__":
t = torch.tensor([1, 2, 3], dtype=torch.float64)
```
with `pylint==2.6.0`, you get the following output
```
test_pylint.py:1:0: C0114: Missing module docstring (missing-module-docstring)
test_pylint.py:4:8: E1101: Module 'torch' has no 'tensor' member; maybe 'Tensor'? (no-
member)
test_pylint.py:4:38: E1101: Module 'torch' has no 'float64' member (no-member)
```
Now `pylint` doesn't recognize `torch.tensor` at all, but it is promoted in the stub. Given that it also doesn't recognize `torch.float64`, I think fixing this is out of scope of this PR.
---
## TL;DR
This BC-breaking only for users that rely on unintended behavior. Since `torch/__init__.py` loaded `torch/tensor.py` it was populated in `sys.modules`. `torch/__init__.py` then overwrote `torch.tensor` with the actual function. With this `import torch.tensor as tensor` does not fail, but returns the function rather than the module. Users that rely on this import need to change it to `from torch import tensor`.
Reviewed By: zou3519
Differential Revision: D26223815
Pulled By: bdhirsh
fbshipit-source-id: 125b9ff3d276e84a645cd7521e8d6160b1ca1c21
Summary:
This PR addresses [a two-year-old TODO in `test/test_type_hints.py`](12942ea52b/test/test_type_hints.py (L21-L22)) by replacing most of the body of our custom `get_examples_from_docstring` function with [a function from Python's built-in `doctest.DocTestParser` class](https://docs.python.org/3/library/doctest.html#doctest.DocTestParser.get_examples). This mostly made the parser more strict, catching a few errors in existing doctests:
- missing `...` in multiline statements
- missing space after `>>>`
- unmatched closing parenthesis
Also, as shown by [the resulting diff of the untracked `test/generated_type_hints_smoketest.py` file](https://pastebin.com/vC5Wz6M0) (also linked from the test plan below), this introduces a few incidental changes as well:
- standalone comments are no longer preserved
- indentation is now visually correct
- [`example_torch_promote_types`](4da9ceb743/torch/_torch_docs.py (L6753-L6772)) is now present
- an example called `example_torch_tensor___array_priority__` is added, although I can't tell where it comes from
- the last nine lines of code from [`example_torch_tensor_align_as`](5d45140d68/torch/_tensor_docs.py (L386-L431)) are now present
- the previously-misformatted third line from [`example_torch_tensor_stride`](5d45140d68/torch/_tensor_docs.py (L3508-L3532)) is now present
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50596
Test Plan:
Checkout the base commit, typecheck the doctests, and save the generated file:
```
$ python test/test_type_hints.py TestTypeHints.test_doc_examples
$ cp test/generated_type_hints_smoketest.py /tmp
```
Then checkout this PR, do the same thing, and compare:
```
$ python test/test_type_hints.py TestTypeHints.test_doc_examples
$ git diff --no-index {/tmp,test}/generated_type_hints_smoketest.py
```
The test should succeed, and the diff should match [this paste](https://pastebin.com/vC5Wz6M0).
Reviewed By: walterddr
Differential Revision: D25926245
Pulled By: samestep
fbshipit-source-id: 23bc379ff438420e556263c19582dba06d8e42ec
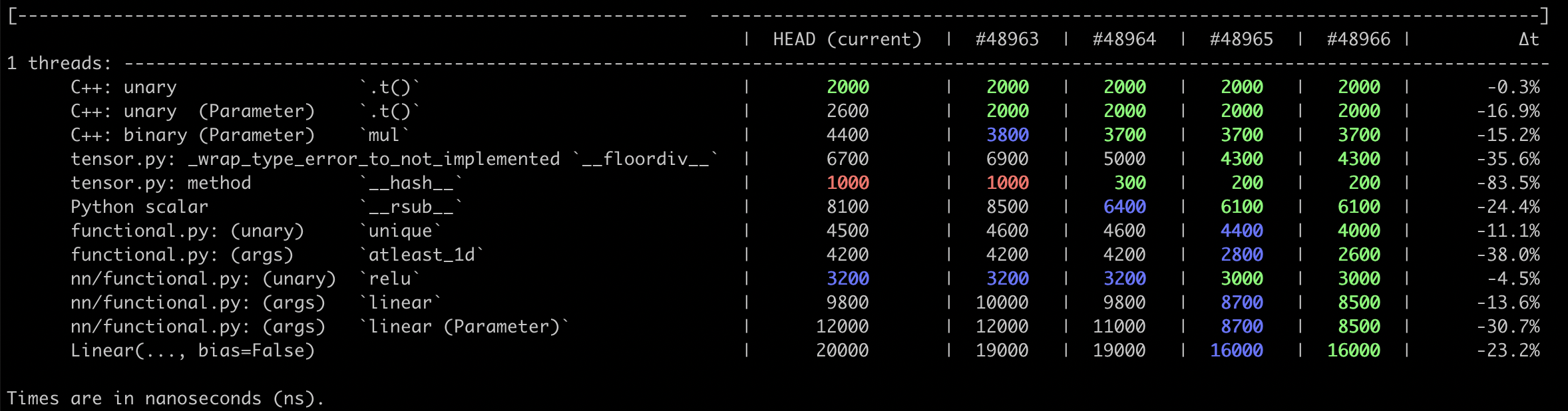
Summary:
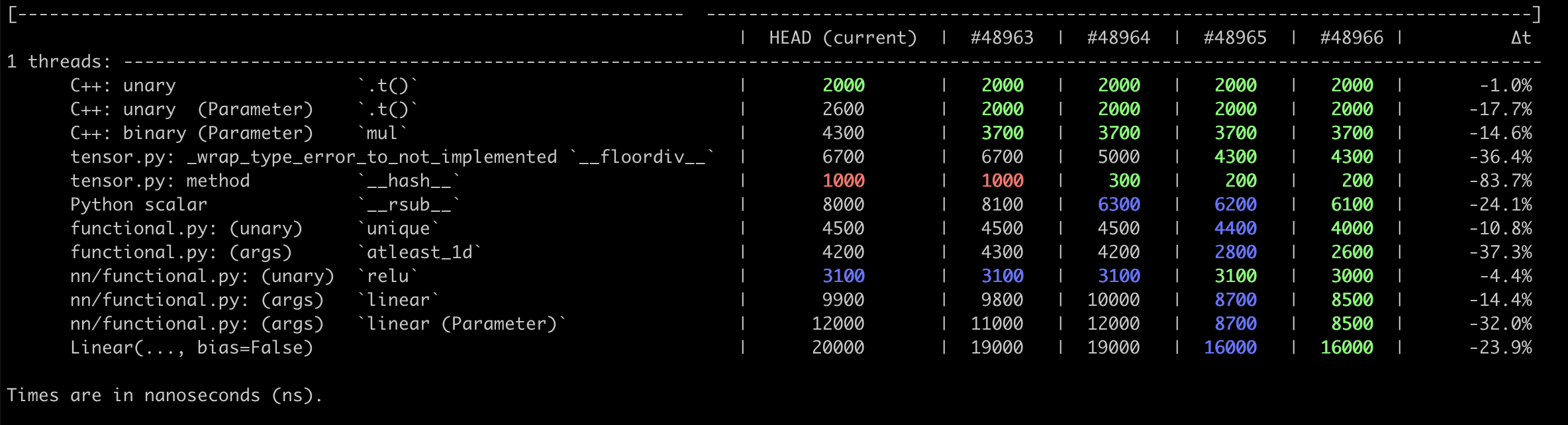
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48965
This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API.
Test Plan: Existing unit tests. Benchmarks are in #48966
Reviewed By: ezyang
Differential Revision: D25590732
Pulled By: robieta
fbshipit-source-id: 6bd74788f06cdd673f3a2db898143d18c577eb42
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49022
**BC-breaking note**:
Previously torch.stft took an optional `return_complex` parameter that indicated whether the output would be a floating point tensor or a complex tensor. By default `return_complex` was False to be consistent with the previous behavior of torch.stft. This PR changes this behavior so `return_complex` is a required argument.
**PR Summary**:
* **#49022 stft: Change require_complex warning to an error**
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D25658906
Pulled By: mruberry
fbshipit-source-id: 11932d1102e93f8c7bd3d2d0b2a607fd5036ec5e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49189
This reverts commit d307601365 and fixes the bug with diagonals and ellipsis combined.
Test Plan: Imported from OSS
Reviewed By: glaringlee
Differential Revision: D25540722
Pulled By: heitorschueroff
fbshipit-source-id: 86d0c9a7dcfda600b546457dad102af2ff33e353
Summary:
**BC-breaking note:**
Previously, when given a complex input, `torch.linalg.norm` and `torch.norm` would return a complex output. `torch.linalg.cond` would sometimes return a complex output and sometimes return a real output when given a complex input, depending on its `p` argument. This PR changes this behavior to match `numpy.linalg.norm` and `numpy.linalg.cond`, so that a complex input will result in the downgraded real number type, consistent with NumPy.
**PR Summary:**
The following cases were previously unsupported for complex inputs, and this commit adds support:
- Frobenius norm
- Norm order 2 (vector and matrix)
- CUDA vector norm
Part of https://github.com/pytorch/pytorch/issues/47833
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48284
Reviewed By: H-Huang
Differential Revision: D25420880
Pulled By: mruberry
fbshipit-source-id: 11f6a2f3cad57d66476d30921c3f6ab8f3cd4017
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47860
This PR makes torch.einsum compatible with numpy.einsum except for the sublist input option as requested here https://github.com/pytorch/pytorch/issues/21412. It also fixed 2 performance issues linked below and adds a check for reducing to torch.dot instead of torch.bmm which is faster in some cases.
fixes#45854, #37628, #30194, #15671fixes#41467 with benchmark below
```python
import torch
from torch.utils.benchmark import Timer
a = torch.randn(10000, 100, 101, device='cuda')
b = torch.randn(10000, 101, 3, device='cuda')
c = torch.randn(10000, 100, 1, device='cuda')
d = torch.randn(10000, 100, 1, 3, device='cuda')
print(Timer(
stmt='torch.einsum("bij,bjf->bif", a, b)',
globals={'a': a, 'b': b}
).blocked_autorange())
print()
print(Timer(
stmt='torch.einsum("bic,bicf->bif", c, d)',
globals={'c': c, 'd': d}
).blocked_autorange())
```
```
<torch.utils.benchmark.utils.common.Measurement object at 0x7fa37c413850>
torch.einsum("bij,bjf->bif", a, b)
Median: 4.53 ms
IQR: 0.00 ms (4.53 to 4.53)
45 measurements, 1 runs per measurement, 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7fa37c413700>
torch.einsum("bic,bicf->bif", c, d)
Median: 63.86 us
IQR: 1.52 us (63.22 to 64.73)
4 measurements, 1000 runs per measurement, 1 thread
```
fixes#32591 with benchmark below
```python
import torch
from torch.utils.benchmark import Timer
a = torch.rand(1, 1, 16, 2, 16, 2, 16, 2, 2, 2, 2, device="cuda")
b = torch.rand(729, 1, 1, 2, 1, 2, 1, 2, 2, 2, 2, device="cuda")
print(Timer(
stmt='(a * b).sum(dim = (-3, -2, -1))',
globals={'a': a, 'b': b}
).blocked_autorange())
print()
print(Timer(
stmt='torch.einsum("...ijk, ...ijk -> ...", a, b)',
globals={'a': a, 'b': b}
).blocked_autorange())
```
```
<torch.utils.benchmark.utils.common.Measurement object at 0x7efe0de28850>
(a * b).sum(dim = (-3, -2, -1))
Median: 17.86 ms
2 measurements, 10 runs per measurement, 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7efe0de286a0>
torch.einsum("...ijk, ...ijk -> ...", a, b)
Median: 296.11 us
IQR: 1.38 us (295.42 to 296.81)
662 measurements, 1 runs per measurement, 1 thread
```
TODO
- [x] add support for ellipsis broadcasting
- [x] fix corner case issues with sumproduct_pair
- [x] update docs and add more comments
- [x] add tests for error cases
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D24923679
Pulled By: heitorschueroff
fbshipit-source-id: 47e48822cd67bbcdadbdfc5ffa25ee8ba4c9620a
Summary:
Fixes https://github.com/pytorch/pytorch/issues/43837
This adds a `torch.broadcast_shapes()` function similar to Pyro's [broadcast_shape()](7c2c22c10d/pyro/distributions/util.py (L151)) and JAX's [lax.broadcast_shapes()](https://jax.readthedocs.io/en/test-docs/_modules/jax/lax/lax.html). This helper is useful e.g. in multivariate distributions that are parameterized by multiple tensors and we want to `torch.broadcast_tensors()` but the parameter tensors have different "event shape" (e.g. mean vectors and covariance matrices). This helper is already heavily used in Pyro's distribution codebase, and we would like to start using it in `torch.distributions`.
- [x] refactor `MultivariateNormal`'s expansion logic to use `torch.broadcast_shapes()`
- [x] add unit tests for `torch.broadcast_shapes()`
- [x] add docs
cc neerajprad
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43935
Reviewed By: bdhirsh
Differential Revision: D25275213
Pulled By: neerajprad
fbshipit-source-id: 1011fdd597d0a7a4ef744ebc359bbb3c3be2aadc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46398
This PR makes torch.einsum compatible with numpy.einsum except for the sublist input option as requested here https://github.com/pytorch/pytorch/issues/21412. It also fixed 2 performance issues linked below and adds a check for reducing to torch.dot instead of torch.bmm which is faster in some cases.
fixes#45854, #37628, #30194, #15671fixes#41467 with benchmark below
```python
import torch
from torch.utils.benchmark import Timer
a = torch.randn(10000, 100, 101, device='cuda')
b = torch.randn(10000, 101, 3, device='cuda')
c = torch.randn(10000, 100, 1, device='cuda')
d = torch.randn(10000, 100, 1, 3, device='cuda')
print(Timer(
stmt='torch.einsum("bij,bjf->bif", a, b)',
globals={'a': a, 'b': b}
).blocked_autorange())
print()
print(Timer(
stmt='torch.einsum("bic,bicf->bif", c, d)',
globals={'c': c, 'd': d}
).blocked_autorange())
```
```
<torch.utils.benchmark.utils.common.Measurement object at 0x7fa37c413850>
torch.einsum("bij,bjf->bif", a, b)
Median: 4.53 ms
IQR: 0.00 ms (4.53 to 4.53)
45 measurements, 1 runs per measurement, 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7fa37c413700>
torch.einsum("bic,bicf->bif", c, d)
Median: 63.86 us
IQR: 1.52 us (63.22 to 64.73)
4 measurements, 1000 runs per measurement, 1 thread
```
fixes#32591 with benchmark below
```python
import torch
from torch.utils.benchmark import Timer
a = torch.rand(1, 1, 16, 2, 16, 2, 16, 2, 2, 2, 2, device="cuda")
b = torch.rand(729, 1, 1, 2, 1, 2, 1, 2, 2, 2, 2, device="cuda")
print(Timer(
stmt='(a * b).sum(dim = (-3, -2, -1))',
globals={'a': a, 'b': b}
).blocked_autorange())
print()
print(Timer(
stmt='torch.einsum("...ijk, ...ijk -> ...", a, b)',
globals={'a': a, 'b': b}
).blocked_autorange())
```
```
<torch.utils.benchmark.utils.common.Measurement object at 0x7efe0de28850>
(a * b).sum(dim = (-3, -2, -1))
Median: 17.86 ms
2 measurements, 10 runs per measurement, 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7efe0de286a0>
torch.einsum("...ijk, ...ijk -> ...", a, b)
Median: 296.11 us
IQR: 1.38 us (295.42 to 296.81)
662 measurements, 1 runs per measurement, 1 thread
```
TODO
- [x] add support for ellipsis broadcasting
- [x] fix corner case issues with sumproduct_pair
- [x] update docs and add more comments
- [x] add tests for error cases
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D24860367
Pulled By: heitorschueroff
fbshipit-source-id: 31110ee598fd598a43acccf07929b67daee160f9
Summary:
Fixes https://github.com/pytorch/pytorch/issues/40869
Resubmit of https://github.com/pytorch/pytorch/pull/33818.
Adds support for `list()` by desugaring it to a list comprehension.
Last time I landed this it made one of the tests slow, and got unlanded. I think that's bc the previous PR changed the emission of `list()` on a list input or a str input to a list comprehension, which is the more general way of emitting `list()`, but also a little bit slower. I updated this version to emit to the builtin operators for these two case. Hopefully it can land without being reverted this time...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42382
Reviewed By: navahgar
Differential Revision: D24767674
Pulled By: eellison
fbshipit-source-id: a1aa3d104499226b28f47c3698386d365809c23c
Summary:
As per title. Limitations: only for batches of squared full-rank matrices.
CC albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46284
Reviewed By: zou3519
Differential Revision: D24448266
Pulled By: albanD
fbshipit-source-id: d98215166268553a648af6bdec5a32ad601b7814
Summary:
* Removes incorrect statement that "the vector norm will be applied to the last dimension".
* More clearly describe each different combination of `p`, `ord`, and input size.
* Moves norm tests from `test/test_torch.py` to `test/test_linalg.py`
* Adds test ensuring that `p='fro'` and `p=2` give same results for mutually valid inputs
Fixes https://github.com/pytorch/pytorch/issues/41388
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42696
Reviewed By: bwasti
Differential Revision: D23876862
Pulled By: mruberry
fbshipit-source-id: 36f33ccb6706d5fe13f6acf3de8ae14d7fbdff85
Summary:
This PR makes the deprecation warnings for existing fft functions more prominent and makes the torch.stft deprecation warning consistent with our current deprecation planning.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45409
Reviewed By: ngimel
Differential Revision: D23974975
Pulled By: mruberry
fbshipit-source-id: b90d8276095122ac3542ab625cb49b991379c1f8
Summary:
Changes the deprecation of norm to a docs deprecation, since PyTorch components still rely on norm and some behavior, like automatically flattening tensors, may need to be ported to torch.linalg.norm. The documentation is also updated to clarify that torch.norm and torch.linalg.norm are distinct.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45415
Reviewed By: ngimel
Differential Revision: D23958252
Pulled By: mruberry
fbshipit-source-id: fd54e807c59a2655453a6bcd9f4073cb2c12e8ac
Summary:
Ref https://github.com/pytorch/pytorch/issues/42175, fixes https://github.com/pytorch/pytorch/issues/34797
This adds complex support to `torch.stft` and `torch.istft`. Note that there are really two issues with complex here: complex signals, and returning complex tensors.
## Complex signals and windows
`stft` currently assumes all signals are real and uses `rfft` with `onesided=True` by default. Similarly, `istft` always takes a complex fourier series and uses `irfft` to return real signals.
For `stft`, I now allow complex inputs and windows by calling the full `fft` if either are complex. If the user gives `onesided=True` and the signal is complex, then this doesn't work and raises an error instead. For `istft`, there's no way to automatically know what to do when `onesided=False` because that could either be a redundant representation of a real signal or a complex signal. So there, the user needs to pass the argument `return_complex=True` in order to use `ifft` and get a complex result back.
## stft returning complex tensors
The other issue is that `stft` returns a complex result, represented as a `(... X 2)` real tensor. I think ideally we want this to return proper complex tensors but to preserver BC I've had to add a `return_complex` argument to manage this transition. `return_complex` defaults to false for real inputs to preserve BC but defaults to True for complex inputs where there is no BC to consider.
In order to `return_complex` by default everywhere without a sudden BC-breaking change, a simple transition plan could be:
1. introduce `return_complex`, defaulted to false when BC is an issue but giving a warning. (this PR)
2. raise an error in cases where `return_complex` defaults to false, making it a required argument.
3. change `return_complex` default to true in all cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43886
Reviewed By: glaringlee
Differential Revision: D23760174
Pulled By: mruberry
fbshipit-source-id: 2fec4404f5d980ddd6bdd941a63852a555eb9147
Summary:
- `torch._VF` is a hack to work around the lack of support for `torch.functional` in the JIT
- that hack hides `torch._VF` functions from Mypy
- could be worked around by re-introducing a stub file for `torch.functional`, but that's undesirable
- so instead try to make both happy at the same time: the type ignore comments are needed for Mypy, and don't seem to affect the JIT after excluding them from the `get_type_line()` logic
Encountered this issue while trying to make `mypy` run on `torch/functional.py` in gh-43446.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43454
Reviewed By: glaringlee
Differential Revision: D23305579
Pulled By: malfet
fbshipit-source-id: 50e490693c1e53054927b57fd9acc7dca57e88ca
Summary:
According to pytorch/rfcs#3
From the goals in the RFC:
1. Support subclassing `torch.Tensor` in Python (done here)
2. Preserve `torch.Tensor` subclasses when calling `torch` functions on them (done here)
3. Use the PyTorch API with `torch.Tensor`-like objects that are _not_ `torch.Tensor`
subclasses (done in https://github.com/pytorch/pytorch/issues/30730)
4. Preserve `torch.Tensor` subclasses when calling `torch.Tensor` methods. (done here)
5. Propagating subclass instances correctly also with operators, using
views/slices/indexing/etc. (done here)
6. Preserve subclass attributes when using methods or views/slices/indexing. (done here)
7. A way to insert code that operates on both functions and methods uniformly
(so we can write a single function that overrides all operators). (done here)
8. The ability to give external libraries a way to also define
functions/methods that follow the `__torch_function__` protocol. (will be addressed in a separate PR)
This PR makes the following changes:
1. Adds the `self` argument to the arg parser.
2. Dispatches on `self` as well if `self` is not `nullptr`.
3. Adds a `torch._C.DisableTorchFunction` context manager to disable `__torch_function__`.
4. Adds a `torch::torch_function_enabled()` and `torch._C._torch_function_enabled()` to check the state of `__torch_function__`.
5. Dispatches all `torch._C.TensorBase` and `torch.Tensor` methods via `__torch_function__`.
TODO:
- [x] Sequence Methods
- [x] Docs
- [x] Tests
Closes https://github.com/pytorch/pytorch/issues/28361
Benchmarks in https://github.com/pytorch/pytorch/pull/37091#issuecomment-633657778
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37091
Reviewed By: ngimel
Differential Revision: D22765678
Pulled By: ezyang
fbshipit-source-id: 53f8aa17ddb8b1108c0997f6a7aa13cb5be73de0
Summary:
**BC-Breaking Note:**
BC breaking changes in the case where keepdim=True. Before this change, when calling `torch.norm` with keepdim=True and p='fro' or p=number, leaving all other optional arguments as their default values, the keepdim argument would be ignored. Also, any time `torch.norm` was called with p='nuc', the result would have one fewer dimension than the input, and the dimensions could be out of order depending on which dimensions were being reduced. After the change, for each of these cases, the result has the same number and order of dimensions as the input.
**PR Summary:**
* Fix keepdim behavior
* Throw descriptive errors for unsupported sparse norm args
* Increase unit test coverage for these cases and for complex inputs
These changes were taken from part of PR https://github.com/pytorch/pytorch/issues/40924. That PR is not going to be merged because it overrides `torch.norm`'s interface, which we want to avoid. But these improvements are still useful.
Issue https://github.com/pytorch/pytorch/issues/24802
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41956
Reviewed By: albanD
Differential Revision: D22837455
Pulled By: mruberry
fbshipit-source-id: 509ecabfa63b93737996f48a58c7188b005b7217
Summary:
I added the following to the docs:
1. `torch.save`.
1. Added doc for `_use_new_zipfile_serialization` argument.
2. Added a note telling that extension does not matter while saving.
3. Added an example showing the use of above argument along with `pickle_protocol=5`.
2. `torch.split`
1. Added an example showing the use of the function.
3. `torch.squeeze`
1. Added a warning for batch_size=1 case.
4. `torch.set_printoptions`
1. Changed the docs of `sci_mode` argument from
```
sci_mode: Enable (True) or disable (False) scientific notation. If
None (default) is specified, the value is defined by `_Formatter`
```
to
```
sci_mode: Enable (True) or disable (False) scientific notation. If
None (default=False) is specified, the value is defined by
`torch._tensor_str._Formatter`.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39303
Differential Revision: D21904504
Pulled By: zou3519
fbshipit-source-id: 92a324257d09d6bcfa0b410d4578859782b94488
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}