Summary: This commit adds qconfigs with special observers for fixed
qparams ops in get_default_qconfig_mapping and
get_default_qat_qconfig_mapping. For correctness, we also require
users to use these special observers if we detect these fixed
qparams ops in prepare.
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Reviewers: jerryzh168, vkuzo
Subscribers: jerryzh168, vkuzo
Differential Revision: [D37396379](https://our.internmc.facebook.com/intern/diff/D37396379)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80184
Approved by: https://github.com/jerryzh168
https://github.com/pytorch/pytorch/pull/80543 doesn't work in preventing batch from interpreting the multiline env vars. We will remove the lines from these env vars instead, since PR_BODY and COMMIT_MESSAGES are both used to determine what disabled tests to not skip.
Test plan is using the following below and making sure tests still pass, which they do.
Summary: previous versions of sparsity utils either allowed for a leading '.' for fqns, or would only allow for that.
Per discussion with ao team about
fqns don't have a leading '.'
fqn of root module is ''
these utilities have been updated to align with these definitions.
module_to_fqn was changed to not generate a leading '.' and output ''
for root module
fqn_to_module was changed to output the root rather than None for
path=''
get_arg_info_from_tensor_fqn had explicit handling for a leading '.'
that was removed. The previous implementation overwrote the tensor_fqn
if it had a leading '.' which resulted in undesirable behavior of
rewriting arguments provided by the user.
Also refactored utils to be simpler and added comments, formatting and
test
Test Plan:
python test/test_ao_sparsity.py
python test/test_ao_sparsity.py TestSparsityUtilFunctions
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80548
Approved by: https://github.com/mehtanirav
Summary: This PR removes the is_reference flag from the existing
convert_fx API and replaces it with a new convert_to_reference
function. This separates (1) converting the prepared model to a
reference model from (2) lowering the reference model to a quantized
model, enabling users to call their custom lowering function for
custom backends. For the native fbgemm backend, for example, the
following are equivalent:
```
from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx
prepared = prepare_fx(model, ...)
quantized = convert_fx(prepared, ...)
```
```
from torch.ao.quantization.fx import lower_to_fbgemm
from torch.ao.quantization.quantize_fx import (
prepare_fx,
convert_to_reference
)
prepared = prepare_fx(model, ...)
reference = convert_to_reference(prepared, ...)
quantized = lower_to_fbgemm(reference, ...)
```
Note that currently `lower_to_fbgemm` takes in two other arguments
that are difficult for users to provide. A future commit will remove
these arguments to make the helper function more user friendly.
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Reviewers: jerryzh168, vkuzo
Subscribers: jerryzh168, vkuzo
Differential Revision: [D37359946](https://our.internmc.facebook.com/intern/diff/D37359946)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80091
Approved by: https://github.com/jerryzh168
Summary:
Add an `ignore_parameters_and_buffers` parameter which will tell the graph drawer
to leave off adding parameter and buffer nodes in the dot graph.
This is useful for large networks, where we want to view the graph to get an idea of
the topology and the shapes without needing to see every detail. Removing these buffers
de-clutters the graph significantly without detracting much information.
Reviewed By: jfix71
Differential Revision: D37317917
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79982
Approved by: https://github.com/jfix71
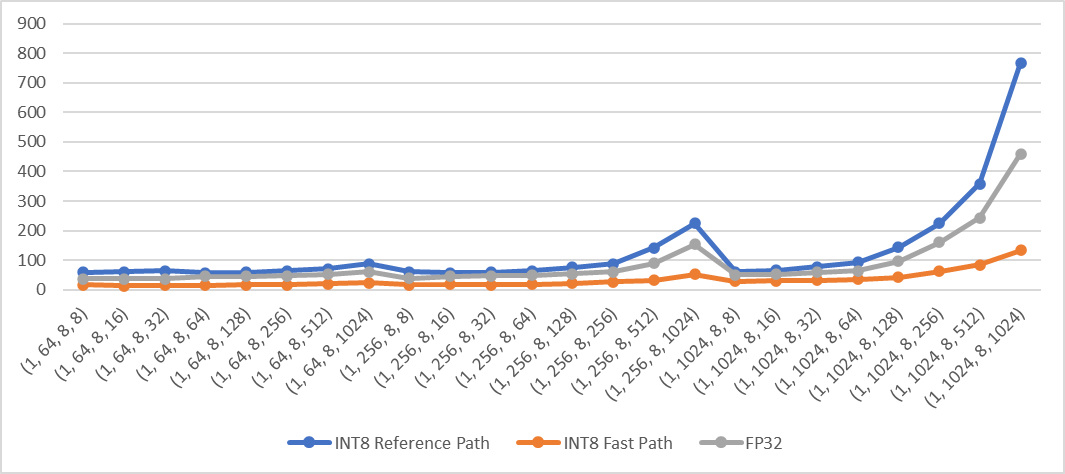
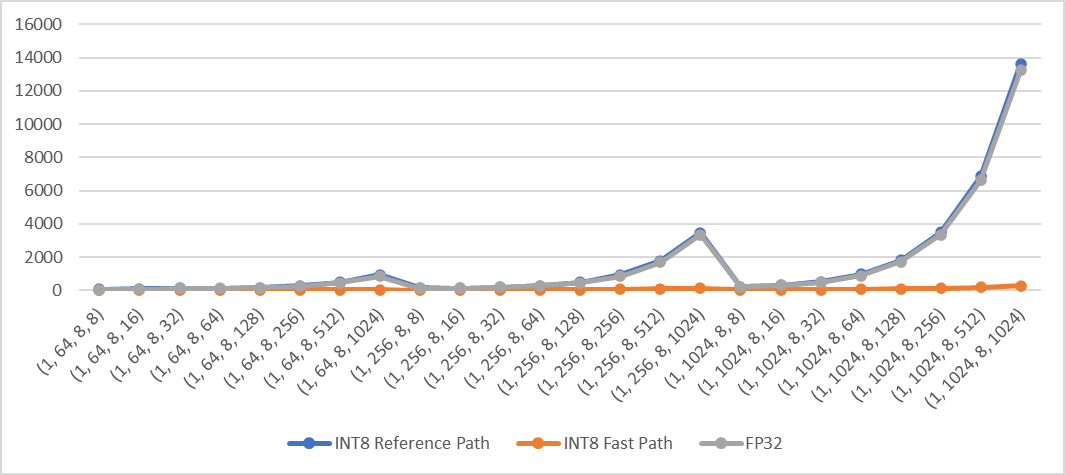
Add fast path of qmean and qstd when computation is done in innermost dimensions for quantized CPU. The fast path supports inputs in contiguous memory format.
For example:
```python
X = torch.randn((2,3,4,5), dtype=torch.float)
qX = torch.quantize_per_tensor(X, scale, zero_point, torch_type)
# dim can be: -1, (-1, -2), (-1, -2, -3), (-1, -2, -3, -4), 3, (3, 2), (3, 2, 1), (3, 2, 1, 0) or None
dim = -1
qY = torch.mean(qX, dim) # qY = torch.std(qX, dim)
```
**Performance test results**
Test Env:
- Intel® Xeon® CLX-8260
- 1 instance, 4 cores
- Using Jemalloc
Test method:
Create 4d contiguous tensors as inputs, set `dim` to the innermost two dimensions `(-1, -2)`, then do the following tests
- Quantize inputs and use the fast path
- Quantize inputs and use the reference path
- Use fp32 kernel (no quantization)
Mean: exec time (us) vs. shape
Std: exec time (us) vs. shape
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70172
Approved by: https://github.com/malfet
There is a problem that pybind11 silently converts Python's complex scalar to `bool` and uses `define_constant<bool>` overload. It was unnoticed because `0j` corresponds to `False` and tests passed, with `2j` scalar tests for `_refs.where` would fail without proper bindings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80522
Approved by: https://github.com/ngimel
Fixes `_unsafe_view` for functionalization - previously, autograd debug-asserts were failing in `test/test_functionalization.py`, but this should fix them (PS: looking forward to when we run a debug-build test in our CI infra)
In a previous PR, I tried to fix `_unsafe_view` by "fixing" its alias annotations in native_functions.yaml to reflect the fact that it's a view, and adding new operators for `_unsafe_view_copy` and `_unsafe_view_copy.out`
That broke some torchscript tests. It also feels too heavy-weight, since the whole point of `_unsafe_view` is that we shouldn't actually have to worry about treating it like a real view: we don't need to worry about having to propagate mutations between the input and the output, because the input is meant to be a temporary tensor that gets thrown away.
So instead, I just wrote a one-off kernel for `_unsafe_view` for functionalization - it does the same thing as the old (boxed fallback) kernel would do, but also correctly aliases the storages together, to appease autograd asserts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80526
Approved by: https://github.com/ezyang
As with `jitted_gpu_kernel_impl`, this
1. Hoists static variables out and into a parent funciton
2. Moves template arguments into the `jit::KernelDescriptor` struct,
as well as changing `vt0` to just be a runtime argument
3. Changes the types of pass-through arguments to `void*`
On my build I see a 0.5 MB decrease in binary size for `libtorch_cuda.so`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80138
Approved by: https://github.com/ngimel
Previously, a new `jitted_gpu_kernel_impl` was instantiated for every
combination of kernel and data types. This adds a new intermediate,
`jitted_gpu_kernel_generic`, which is only templated on the arity of
the input function. So, the compiler is free to re-use this code
between different kernels. `UnaryOperators.cu` as an example will
only need to compile one version.
This is achieved by:
1. Hoisting static variables out of the `launch_` functions and into
`JittedKernelVariantCache`, stored in `jitted_gpu_kernel_impl`,
which is templated on the kernel name and dtypes.
2. Moving arguments describing the kernel's static properties
(e.g. `name` and `f_inputs_type`) into runtime variables
which are packaged into a new `jit::KernelDescriptor` struct.
3. changing `extra_args` from a tuple to `c10::ArrayRef<void*>`
We can expect benefits in both binary size and compile times. On my
build, I see an 11 MB reduction in binary size for `libtorch_cuda.so`
and this saving scales linearly with the number of jiterated kernels.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80103
Approved by: https://github.com/ngimel
This test is currently flaky due to randomly generated inputs sometimes producing results very slightly outside the specified tolerance. For example:
```
Mismatched elements: 1 / 2744 (0.0%)
Greatest absolute difference: 0.0001068115234375 at index (0, 7, 2, 3, 4) (up to 0.0001 allowed)
Greatest relative difference: 3.0445612311553214e-05 at index (0, 7, 2, 3, 4) (up to 1.3e-06 allowed)
```
Fixes#79509
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80518
Approved by: https://github.com/jbschlosser
Step 1 to gradually change our generated workflow scripts to be more compatible with reusable workflows.
This PR extracts three pieces of functionality into composite actions:
- Checking out the branch
- Setting up EC2 linux
- Building the linux binary
It also regenerates the workflows to use these new composite actions
This is not a complete list of things we'd like to extract. Keeping this PR small to get early feedback
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80462
Approved by: https://github.com/seemethere
This TODO is no longer needed, as we use `_register_fused_optim` to register the overlapped optimizer in DDP. Also, remove comment about API being experimental, as this API is no longer going to be used by end user.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80453
Approved by: https://github.com/awgu
Summary:
https://github.com/pytorch/pytorch/pull/78757 recently added
a lot of functions to the type stub, but it missed a few of them.
This change will make sure every function is included, by making
sure this list is up-to-date with: `torch/csrc/jit/python/python_ir.cpp`.
This change only does this for Node and Value.
Differential Revision: D37189713
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79654
Approved by: https://github.com/ezyang
Summary: Introduce nlohmann/json as a submodule within pytorch/third_party. This library is already a transitive dependency and is included in our licenses file. Adding it directly to third_party will enable its use by the CoreML backend.
Test Plan: There are no code changes, so submodule sync and perform the steps outline in the building from source section of the pytorch readme.
Differential Revision: D37449817
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80322
Approved by: https://github.com/mcr229
Currently, pre- and post-division steps in `FullyShardedDataParallel._post_backward_hook` state the following:
> Average grad by world_size for consistency with PyTorch DDP.
This is not matching what is actually going on, i.e. pre-divide factor may be equal to `world_size` and may not.
For example, for `world_size = 3 `, `predivide_factor=2`
This PR clarifies pre- and post-division in the code
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80456
Approved by: https://github.com/rohan-varma
{kind=link}
{kind=link}