Tweak dynamo behavior in 2 places when calling nn.Modules,
to route the call to __call__ instead of .forward(), since
__call__ is the codepath that eager users hit and will dispatch
to hooks correctly.
(1) inside NNModuleVariable.call_function, which covers the common case
of calling a module from code dynamo is already tracing
(2) at the OptimizedModule layer, which is the entrypoint
into a top-level nn.Module dynamo is about to compile
This exposes a new bug: NNModuleVariable used to special-case calling
module.forward() (which is a method) as a UserFunctionVariable with an extra
'self' arg. After tracing into module.__call__, there is no longer a special
case for the eventual call into .forward, and it gets wrapped in a
UserDefinedObjectVariable following standard behavior of ._wrap(). UDOV can't be
called, so this broke some tests.
- Fix: add a new special case in _wrap() that treats methods as a UserDefinedMethod
instead of UserDefinedObjectVariable. Now, the forward method can be called.
Also, fix NNModuleVar.call_method routing forward back to __call__
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92125
Approved by: https://github.com/ezyang, https://github.com/jansel, https://github.com/voznesenskym
After some thoughts, I find it difficult to come up with a robust naming convention that satisfies the following constraints at the same time: 1. the new name should be a valid nn.Moule attribute (as required by minifier and it's a good thing to have in general) 2. it can cover various cases such as GetItemSource, GetAttrSource 3. it's easy to recover the original path 4. robust to users' naming scheme.
Thanks to @yanboliang for pointing out the original access path is preserved in Source, now we just need to add an additonal value source.name() to node.meta["nn_module_stack"] to get the access path in original module.
We also address some TODO in quantization, which relies on the original naming convention in nn_module_stack.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94945
Approved by: https://github.com/jansel, https://github.com/yanboliang
Currently, when unrolling an nn.Sequential, we use an integer to represent its submodule's name. This produces some difficulty in tracking the origin of the parameters in the export path:
```python
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
```
Currently, the submodules will have names such as model.0, model.1 instead of model.conv1, model.relu1. This discrepency causes it difficult to track the origin of paramers because they are represented as model.conv1.foo and model.relu1.foo in model.named_parameters().
We replace enumerate() with named_children() to keep submodule's name.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94913
Approved by: https://github.com/jansel
**Summary**: torch.nn.Module implementations previously did not support custom implementations of `__getattr__`; if a torch.nn.Module subclass implemented `__getattr__` and we tried to access an attribute that was expected to be present in `__getattr__`, dynamo would not check `__getattr__` and would error out with an AttributeError. This PR copies the functionality from UserDefinedObjectVariable into torch.nn.Module so that it also supports `__getattr__`
Example of a module which previously would fail:
```python
class MyMod(torch.nn.Module):
def __init__(self):
super().__init__()
self.custom_dict = {"queue": [torch.rand((2, 2)) for _ in range(3)]}
self.other_attr = torch.rand((2, 2))
def __getattr__(self, name):
custom_dict = self.custom_dict
if name in custom_dict:
return custom_dict[name]
return super().__getattr__(name)
def forward(self, x):
return x @ self.other_attr + self.queue[-1]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94658
Approved by: https://github.com/yanboliang, https://github.com/jansel
Summary:
This PR supports the following feature for QConfigMapping:
```
qconfig_mapping = QConfigMapping().set_object_type(torch.nn.Conv2d, qconfig)
backend_config = get_qnnpack_pt2e_backend_config()
m = prepare_pt2e(m, qconfig_mapping, example_inputs, backend_config)
```
which means users want to set the qconfig for all calls to `torch.nn.Conv2d` to use `qconfig`, note this is only verified for the case when the module is broken down to a single aten op right now, e.g. torch.nn.Conv2d will be torch.ops.aten.convolution op when traced through. will need to support more complicated modules that is broken down to multiple operators later, e.g. (MaxPool)
Test Plan:
python test/test_quantization.py TestQuantizePT2E.test_qconfig_module_type
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92355
Approved by: https://github.com/jcaip
**Motivation**
When adding support for default args (#90575), a lot of VariableTrackers missing sources were encountered. Currently, in a lot of cases it seems OK to skip the source for VariableTrackers created (especially during inlining), but that assumption breaks down when inlining functions with default arguments.
**Summary** of changes
- propagate the self.source of the VariableBuilder to the new variables being built, which seems like it was an omission previously
- Add SuperSource to track usages of super(), so that SuperVariables can support function calls with default args
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91729
Approved by: https://github.com/ezyang
### Summary
Making dynamo treat the nn.Modules inside FSDP wrappers as 'Unspecialized'
results in dynamo-produced graphs where nn.module parameters are inputs
to the graph rather than attributes of the outer graphmodule.
This helps in FSDP since it forces dynamo to pick the latest copy
of the parameters off the user's nn.Module (which FSDP mutates every pre_forward),
solving the ordering issue in backward.
### Details
Imagine this toy model
```
class MyModule(torch.nn.Module):
def __init__(self, a, b):
super(MyModule, self).__init__()
self.net = nn.Sequential(
nn.Linear(a, b),
nn.ReLU(),
)
def forward(self, x):
return self.net(x)
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net = nn.Sequential(
*[MyModule(10, 10000)]
+ [MyModule(10000, 1000)]
+ [MyModule(1000, 5)]
)
def forward(self, x):
return self.net(x)
```
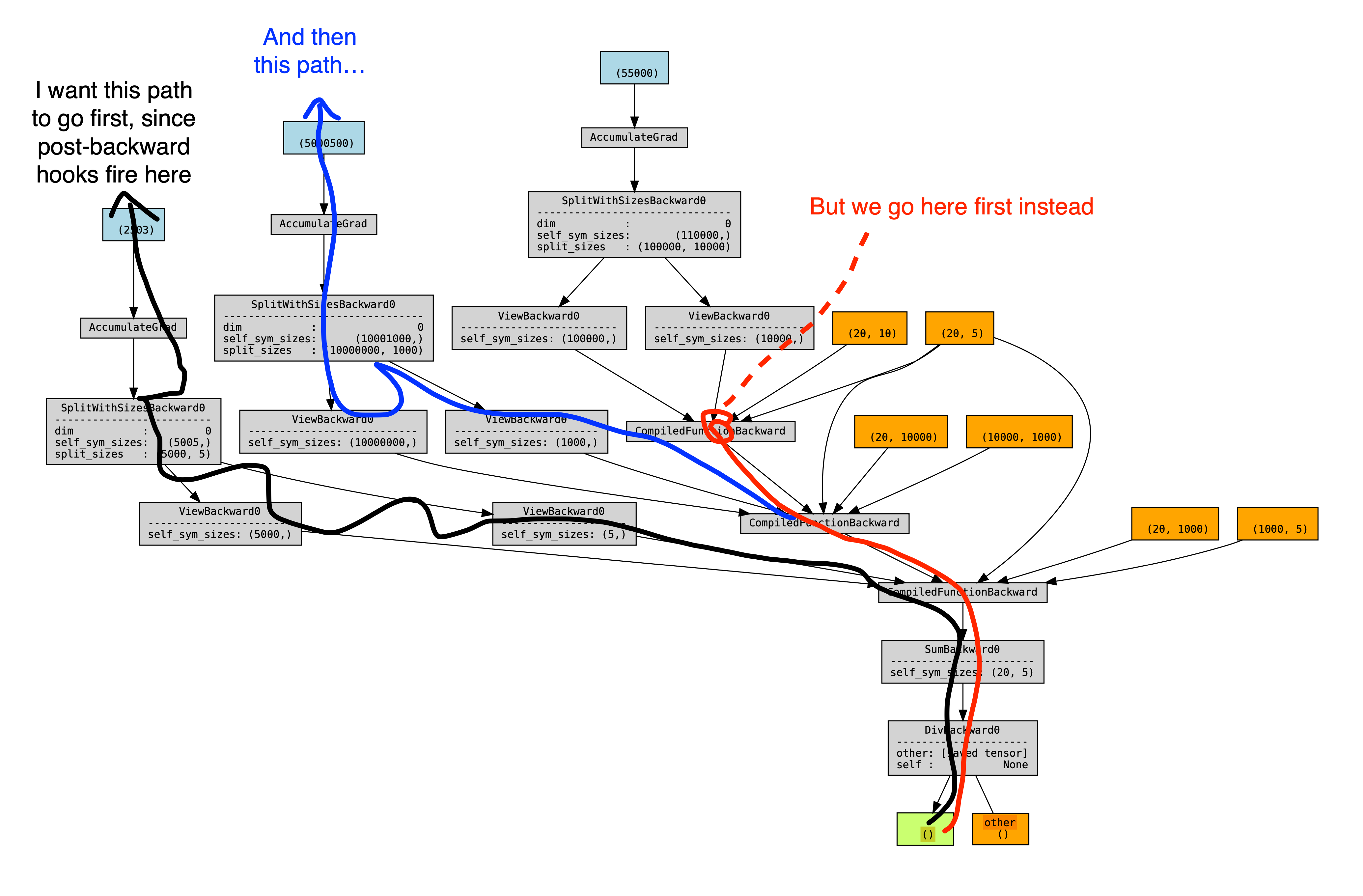
Where FSDP is recursively wrapped around each `MyModule`, then dynamo-compiled, with dynamo already configured to skip/break in FSDP code. You'd expect to get 3 compiled AOT functions, corresponding to the contents of `MyModule`, and then see FSDP's communication ops happen inbetween them (eagerly). This almost happens (everything works out fine in forward), but in backward there is an ordering issue.
FSDP creates a flat buffer for all the parameters that are bucketed together, and then creates views into this buffer to replace the original parameters. On each iteration of forward, it creates a new view after 'filling' the flatbuffer with data from an all-gather operation, to 'unshard' the parameters from remote devices. Dynamo traces the first such view and stores it in a compiled graphmodule.
During tracing, we see (1) view created for first MyModule, (2) compile first MyModule, (3) ... for the rest of layers
Then during runtime, we see (A) view created for first MyModule (and orphaned), (B) execute first compiled MyModule, using old view, ...
This is a problem, because we want backward hooks to run right after each compiled-backward, but autograd executes those hooks in an order mirroring their execution order during forward. Since we are forever using the views created during steps (1, 3, .. N), which all happen before the steps (A, B, ...), this means that all the hooks will happen after all the compiled backwards. An illustration of the problem - a torchviz graph showing the 2 possible orderings of autograd, and a profile showing the view-backwards ops happening after all the compiled backwards, and before all the backward hooks.
<img width="2069" alt="image" src="https://user-images.githubusercontent.com/4984825/202828002-32dbbd15-8fc3-4281-93e9-227ab5e32683.png">
<img width="2069" alt="image" src="https://user-images.githubusercontent.com/4984825/202828632-33e40729-9a7f-4e68-9ce1-571e3a8dd2dd.png">
A solution is to make dynamo not specialize on these nn modules. It is worth pointing out that this nn.module specialization is de-facto failing, as we are modifying .parameters and this bypasses dynamo's __setattr__ monkeypatch, which should have automatically kicked us out to Unspecialized and forced a recompile.
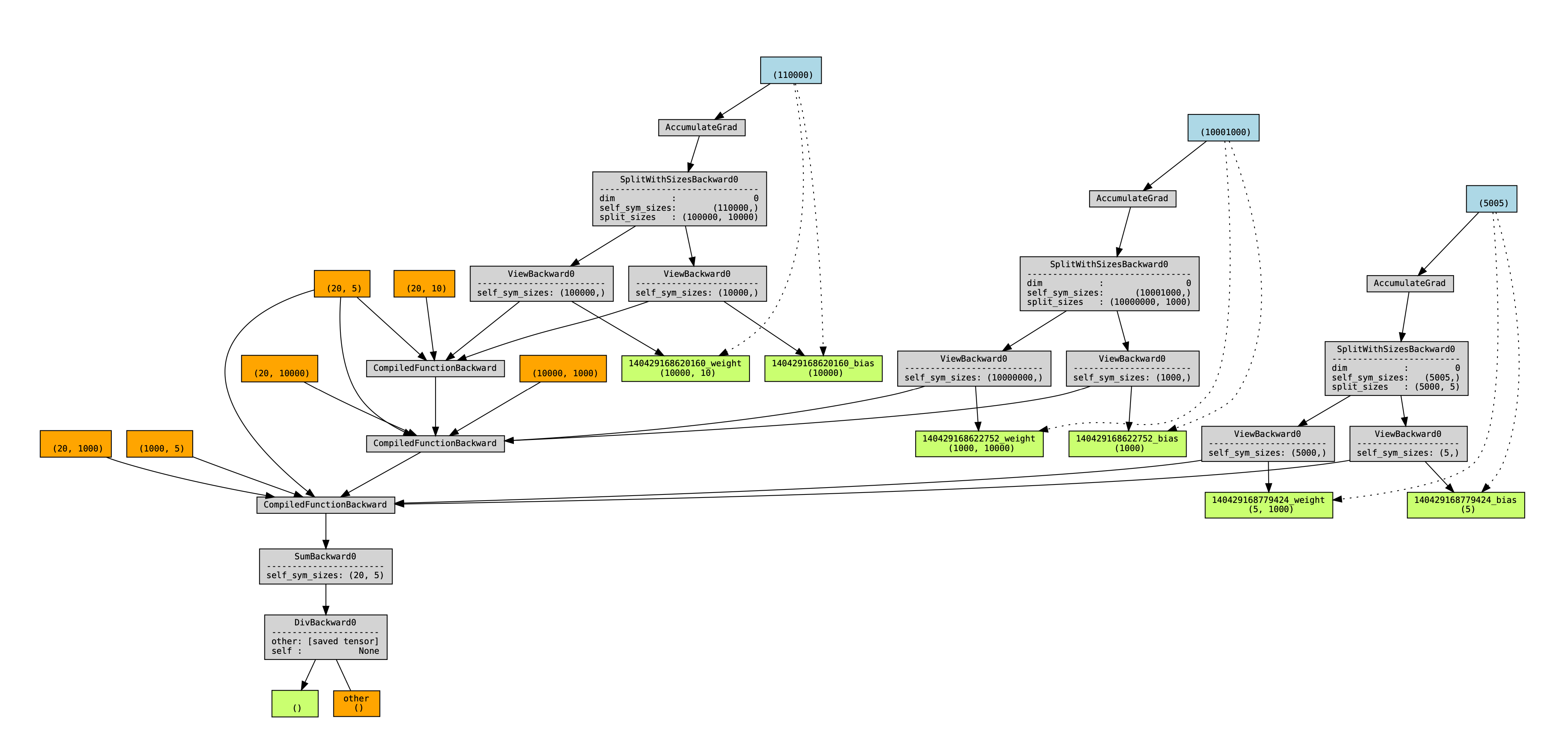
After unspecializing, the new views (created during steps A, C, ...) are actually _used_ at runtime by the module, making their creation order interleaved, making autograd execute their backwards interleaved.
The new torchviz graph (this time with names added for the view tensors):
<img width="2043" alt="image" src="https://user-images.githubusercontent.com/4984825/202828480-d30005ba-0d20-45d8-b647-30b7ff5e91d3.png">
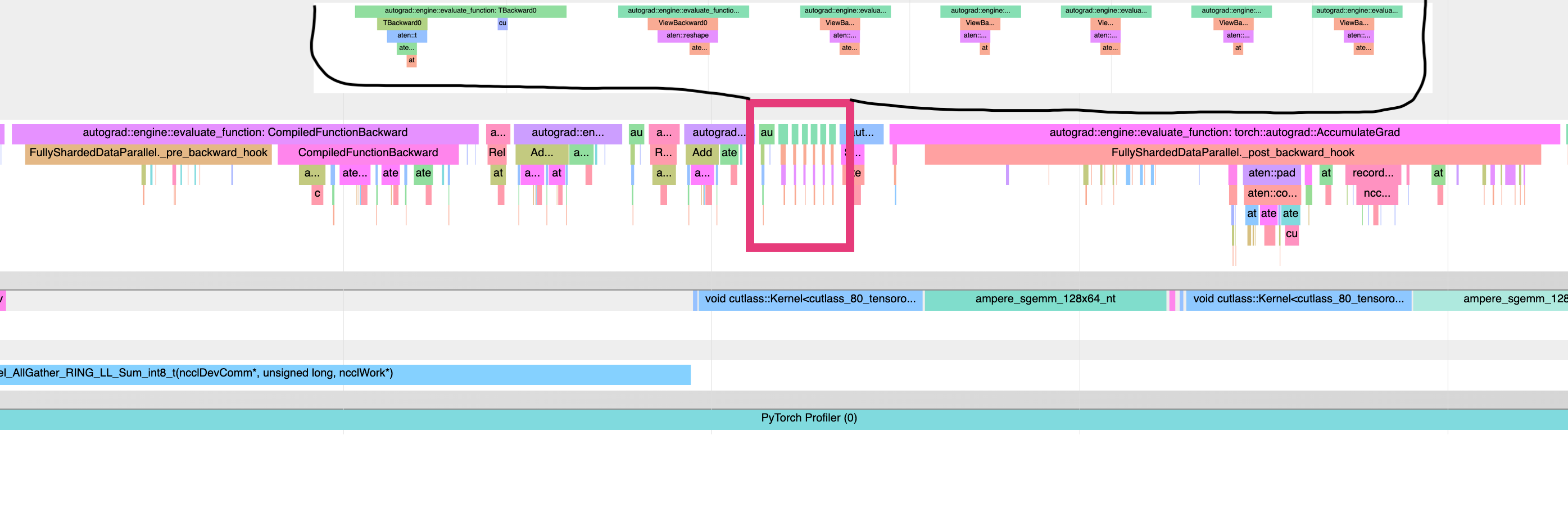
And a new profile showing the interleaving of compiled backwards and hooks, allowing overlapping of reduce-scatter.
<img width="2293" alt="image" src="https://user-images.githubusercontent.com/4984825/202828533-bb20a041-19b8-499c-b3cf-02808933df47.png">
@jansel @davidberard98 @aazzolini @mrshenli @awgu @ezyang @soumith @voznesenskym @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89330
Approved by: https://github.com/davidberard98
I'm not sure why this never caused problems before. The error
manifests as `TypeError: 'MyModule' object is not subscriptable`
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89625
Approved by: https://github.com/albanD
Right now, example_value is doing two jobs:
- We use it to propagate metadata (e.g. return type, shapes, etc.)
throughout the graph
- We use it to satisfy queries for the actual value (e.g. torch.cond,
`assume_constant_result`)
This is further complicated by the fact that we have two modes, one
where `example_value` is a fake tensor, and one where it is a real
tensor (this is the `fake_tensor_propagation` config flag).
This leads to scenarios where we don't support every combination of
job + mode,
e.g. if `fake_tensor_propagation=False`, `assume_constant_result` is
broken.
This is made worse by the fact that "fake tensor mode" is the default
and is required if you want dynamic shapes to work.
So, this PR introduces a `get_real_value` API that just runs the graph
up to `node` in order to get a concrete value. This API is orthogonal
to
`example_value`, so it doesn't care about `fake_tensor_propagation`.
When `fake_tensor_propagation=True`: `example_value` is a fake tensor,
you must use the `get_real_value` API to get a concrete value. This
will
be the only configuration in the future.
When `fake_tensor_propagation=False`: `example_value` and
`get_real_value` will produce the same value. This is redundant but we
will be removing this config soon.
To support this, I introduce a cache for computed real values, to
memoize the work involved if we're asking for real values a lot.
I attached this state to `OutputGraph` because it seems to be what
historically managed `example_value` lifetimes, but idk.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87091
Approved by: https://github.com/wconstab
{kind=link}
{kind=link}
{kind=link}
{kind=link}