beartype has served us well in identifying type errors and ensuring we call internal functions with the correct arguments (thanks!). However, the value of having beartype is diminished because of the following:
1. When beartype improves support for better Dict[] type checking, it discovered typing mistakes in some functions that were previously uncaught. This caused the exporter to fail with newer versions beartype when it used to succeed. Since we cannot fix PyTorch and release a new version just because of this, it creates confusion for users that have beartype in their environment from using torch.onnx
2. beartype adds an additional call line in the traceback, which makes the already thick dynamo stack even larger, affecting readability when users diagnose errors with the traceback.
3. Since the typing annotations need to be evaluated, we cannot use new syntaxes like `|` because we need to maintain compatibility with Python 3.8. We don't want to wait for PyTorch take py310 as the lowest supported Python before using the new typing syntaxes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/130484
Approved by: https://github.com/titaiwangms
beartype has served us well in identifying type errors and ensuring we call internal functions with the correct arguments (thanks!). However, the value of having beartype is diminished because of the following:
1. When beartype improves support for better Dict[] type checking, it discovered typing mistakes in some functions that were previously uncaught. This caused the exporter to fail with newer versions beartype when it used to succeed. Since we cannot fix PyTorch and release a new version just because of this, it creates confusion for users that have beartype in their environment from using torch.onnx
2. beartype adds an additional call line in the traceback, which makes the already thick dynamo stack even larger, affecting readability when users diagnose errors with the traceback.
3. Since the typing annotations need to be evaluated, we cannot use new syntaxes like `|` because we need to maintain compatibility with Python 3.8. We don't want to wait for PyTorch take py310 as the lowest supported Python before using the new typing syntaxes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/130484
Approved by: https://github.com/titaiwangms
beartype has served us well in identifying type errors and ensuring we call internal functions with the correct arguments (thanks!). However, the value of having beartype is diminished because of the following:
1. When beartype improves support for better Dict[] type checking, it discovered typing mistakes in some functions that were previously uncaught. This caused the exporter to fail with newer versions beartype when it used to succeed. Since we cannot fix PyTorch and release a new version just because of this, it creates confusion for users that have beartype in their environment from using torch.onnx
2. beartype adds an additional call line in the traceback, which makes the already thick dynamo stack even larger, affecting readability when users diagnose errors with the traceback.
3. Since the typing annotations need to be evaluated, we cannot use new syntaxes like `|` because we need to maintain compatibility with Python 3.8. We don't want to wait for PyTorch take py310 as the lowest supported Python before using the new typing syntaxes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/130484
Approved by: https://github.com/titaiwangms
Fixes https://github.com/pytorch/pytorch/issues/84365 and more
This PR addresses not only the issue above, but the entire family of issues related to `torch._C.Value.type()` parsing when `scalarType()` or `dtype()` is not available.
This issue exists before `JitScalarType` was introduced, but the new implementation refactored the bug in because the new api `from_name` and `from_dtype` requires parsing `torch._C.Value.type()` to get proper inputs, which is exactly the root cause for this family of bugs.
Therefore `from_name` and `from_dtype` must be called when the implementor knows the `name` and `dtype` without parsing a `torch._C.Value`. To handle the corner cases hidden within `torch._C.Value`, a new `from_value` API was introduced and it should be used in favor of the former ones for most cases. The new API is safer and doesn't require type parsing from user, triggering JIT asserts in the core of pytorch.
Although CI is passing for all tests, please review carefully all symbolics/helpers refactoring to make sure the meaning/intetion of the old call are not changed in the new call
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87245
Approved by: https://github.com/justinchuby, https://github.com/BowenBao
This PR create the `GraphContext` class and relays all graph methods to _C.Graph as well as implements the `g.op` method. The GraphContext object is passed into the symbolic functions in place of _C.Graph for compatibility with existing symbolic functions.
This way (1) we can type annotate all `g` args because the method is defined and (2) we can use additional context information in symbolic functions. (3) no more monkey patching on `_C.Graph`
Also
- Fix return type of `_jit_pass_fixup_onnx_controlflow_node`
- Create `torchscript.py` to house torch.Graph related functions
- Change `GraphContext.op` to create nodes in the Block instead of the Graph
- Create `add_op_with_blocks` to handle scenarios where we need to directly manipulate sub-blocks. Update loop and if symbolic functions to use this function.
## Discussion
Should we put all the context inside `SymbolicContext` and make it an attribute in the `GraphContext` class? This way we only define two attributes `GraphContext.graph` and `GraphContext.context`. Currently all context attributes are directly defined in the class.
### Decision
Keep GraphContext flatand note that it will change in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84728
Approved by: https://github.com/AllenTiTaiWang, https://github.com/BowenBao
## This PR seeks to:
- [x] add c++ support for an optimize path
- [x] add python opt_einsum path passthrough
- [x] add opt_einsum to OSS requirements, but a soft one
- [x] show benchmark results here
Additional things I've explored + their conclusions:
- **Delaying the summing over dimensions** => added!
- The idea here is to not incur kernel calls to `sum` as we try to early sum out in einsum. Thus, we collect all the dimensions that need to be summed together in one contraction + sum at the end instead of summing as we go. While this optimization didn't feel like it made things faster for the random cases we've selected (they all summed 1 dim per contraction), it is a good principle and would help more common use cases that would reduce multiple dimensions at a time (like `bxy,xyi,xyj->bij`).
- **Caching contract_path based on equation and tensor sizes** => dropped :(
- The benchmarks were strictly worse for all the cases, and, from scanning the use cases, I observed people do not often call einsum on the same equation/tensor order enough for caching to be justified. I do think caching can be effective in the future, but it would require further investigation.
## Not a part of this PR (but are next steps):
- adding opt_einsum package to OSS CI
- adding it to internal CI
- potentially adding a kwarg path argument to the python API -- if the path is given, we wouldn't have to spend time calculating it, but there would be some time lost validating user input.
## Testing:
- Added more tests to CI
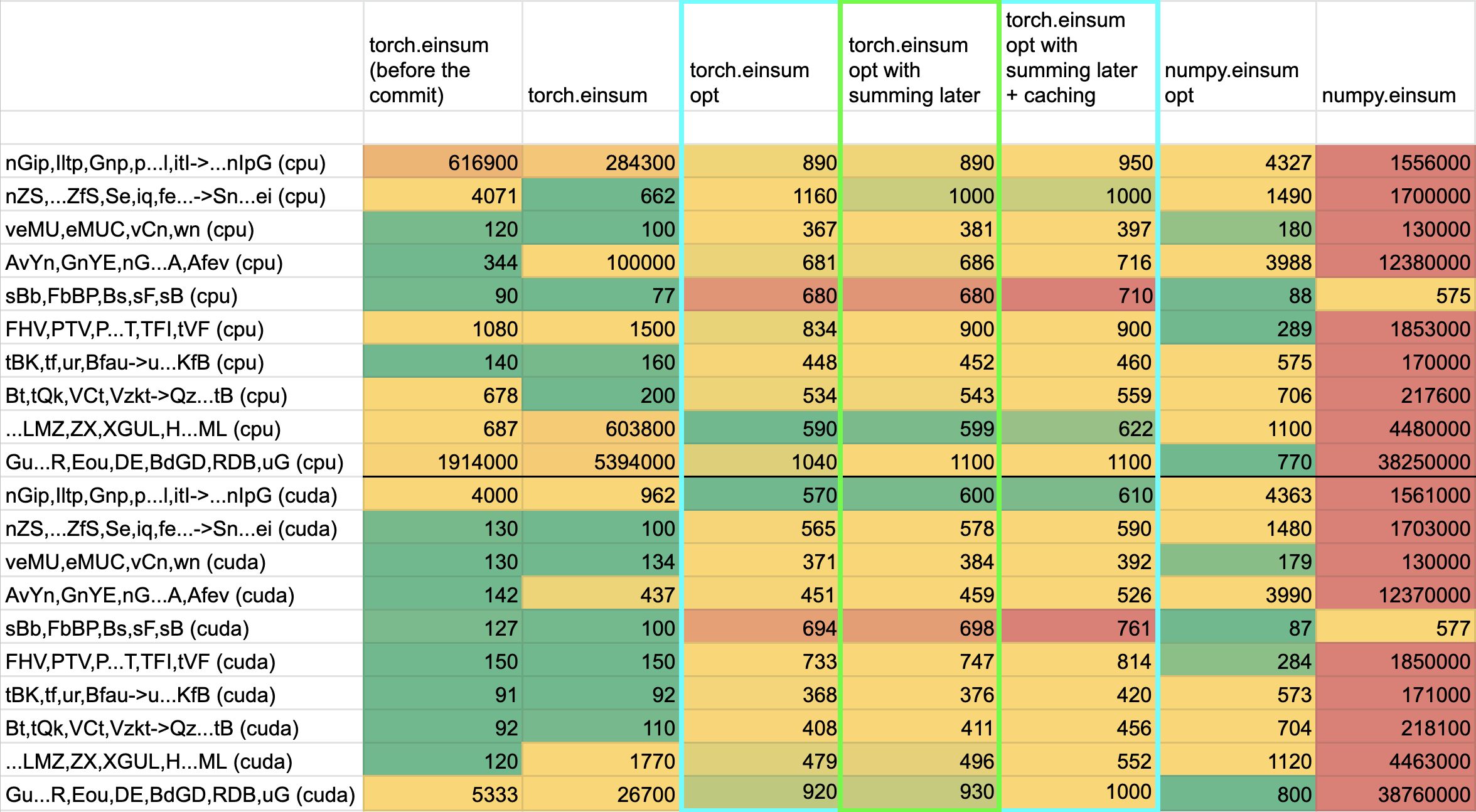
## Benchmarking:
**TL;DRs**
- **torch.einsum with opt_einsum is a definite win for the production case**.
- **torch.einsum with opt_einsum installed is consistently fast, but has an overhead** of needing to find the path. If the path is already found/optimal, it will be slightly slower.
- The einsum overhead decreases for bigger dimensions.
- **torch.einsum without opt_einsum installed is comparable to before this commit**, with occasional slowness potentially due to not reshaping/squeezing as we contract until the end.
- For many of the random generated cases, the dimensions were too similar and small where an optimal order wasn't that much more optimal than just going left to right. However, in production, dimensions are commonly quite distinct (batch size will be small, but the data will be huge).
- **torch.einsum opt is comparable (slightly faster overall) compared to numpy.einsum opt for the cpu case**. This is interesting given that torch.einsum currently spends time computing the path, but numpy.einsum takes it as input.
- **torch.einsum opt is significantly faster than numpy.einsum opt for the gpu case**. This is because numpy doesn't take advantage of GPUs.
The following benchmarks were done on an A100 GPU and Linux CPUs. The line in the first chart separates GPU (on top) from CPU, and the line in the second graph separates CPU (on top) and then GPU. Sorry it's flipped 😛 .
Production example (see [colab benchmark](https://colab.research.google.com/drive/1V2s4v1dOOKwRvp5T_DC-PNUosOV9FFJx?authuser=1#scrollTo=WZoQkC8Mdt6I) for more context):
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012636-9a68bfa7-2601-43b1-afeb-b4e0877db6a4.png">
Randomly generated examples (the same ones as in https://github.com/pytorch/pytorch/pull/60191)
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012804-1c639595-b3e6-48c9-a385-ad851c13e1c2.png">
Open below to see old + not super relevant benchmarking results:
<details>
Benchmark results BEFORE this PR (on Linux -- I will update devices so they are consistent later):
<img width="776" alt="image" src="https://user-images.githubusercontent.com/31798555/190807274-18f71fce-556e-47f4-b18c-e0f7d0c0d5aa.png">
Benchmark results with the code on this PR (on my x86 mac):
For the CPU internal use case --

For the general use case --
It looks like numpy opt still does better in several of these random cases, but torch einsum opt is consistently faster than torch.einsum.

<details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84890
Approved by: https://github.com/albanD, https://github.com/soulitzer
This is the 4th PR in the series of #83787. It enables the use of `@onnx_symbolic` across `torch.onnx`.
- **Backward breaking**: Removed some symbolic functions from `__all__` because of the use of `@onnx_symbolic` for registering the same function on multiple aten names.
- Decorate all symbolic functions with `@onnx_symbolic`
- Move Quantized and Prim ops out from classes to functions defined in the modules. Eliminate the need for `isfunction` checking, speeding up the registration process by 60%.
- Remove the outdated unit test `test_symbolic_opset9.py`
- Symbolic function registration moved from the first call to `_run_symbolic_function` to init time.
- Registration is fast:

Pull Request resolved: https://github.com/pytorch/pytorch/pull/84448
Approved by: https://github.com/AllenTiTaiWang, https://github.com/BowenBao
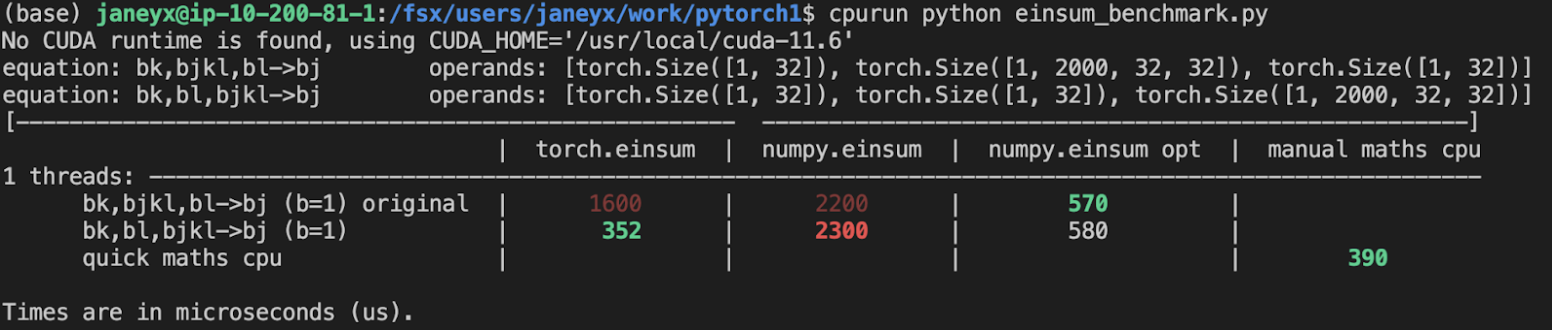
Enable runtime type checking for all torch.onnx public apis, symbolic functions and most helpers (minus two that does not have a checkable type: `_.JitType` does not exist) by adding the beartype decorator. Fix type annotations to makes unit tests green.
Profile:
export `torchvision.models.alexnet(pretrained=True)`
```
with runtime type checking: 21.314 / 10 passes
without runtime type checking: 20.797 / 10 passes
+ 2.48%
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84091
Approved by: https://github.com/BowenBao, https://github.com/thiagocrepaldi
Enable runtime type checking for all torch.onnx public apis, symbolic functions and most helpers (minus two that does not have a checkable type: `_.JitType` does not exist) by adding the beartype decorator. Fix type annotations to makes unit tests green.
Profile:
export `torchvision.models.alexnet(pretrained=True)`
```
with runtime type checking: 21.314 / 10 passes
without runtime type checking: 20.797 / 10 passes
+ 2.48%
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84091
Approved by: https://github.com/BowenBao
Replace runtime errors in torch.onnx with `errors.SymbolicValueError` for more context around jit values.
- Extend `_unimplemented`, `_onnx_unsupported`, `_onnx_opset_unsupported`, `_onnx_opset_unsupported_detailed` errors to include JIT value information
- Replace plain RuntimeError with `errors.SymbolicValueError`
- Clean up: Use `_is_bool` to replace string comparison on jit types
- Clean up: Remove the todo `Remove type ignore after #81112`
#77316
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83332
Approved by: https://github.com/AllenTiTaiWang, https://github.com/thiagocrepaldi, https://github.com/BowenBao
### Description
- Clearer error messages with more context
- Created `SymbolicValueError` which adds context of the value to the error message
- Type annotation
example error message:
```
torch.onnx.errors.SymbolicValueError: ONNX symbolic does not understand the Constant node '%1 : Long(2, strides=[1], device=cpu) = onnx::Constant[value= 3 3 [ CPULongType{2} ]]()
' specified with descriptor 'is'. [Caused by the value '1 defined in (%1 : Long(2, strides=[1], device=cpu) = onnx::Constant[value= 3 3 [ CPULongType{2} ]]()
)' (type 'Tensor') in the TorchScript graph. The containing node has kind 'onnx::Constant'.]
Inputs:
Empty
Outputs:
#0: 1 defined in (%1 : Long(2, strides=[1], device=cpu) = onnx::Constant[value= 3 3 [ CPULongType{2} ]]()
) (type 'Tensor')
```
### Issue
- #77316 (Runtime error during symbolic conversion)
### Testing
Unit tested
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83007
Approved by: https://github.com/BowenBao
Re-land #81953
Add `_type_utils` for handling data type conversion among JIT, torch and ONNX.
- Replace dictionary / list indexing with methods in ScalarType
- Breaking: **Remove ScalarType from `symbolic_helper`** and move it to `_type_utils`
- Deprecated: "cast_pytorch_to_onnx", "pytorch_name_to_type", "scalar_name_to_pytorch", "scalar_type_to_onnx", "scalar_type_to_pytorch_type" in `symbolic_helper`
- Deprecate the type mappings and lists. Remove all internal references
- Move _cast_func_template to opset 9 and remove its reference elsewhere (clean up). Added documentation for easy discovery
Why: List / dictionary indexing and lookup are error-prone and convoluted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82995
Approved by: https://github.com/kit1980
Add `_type_utils` for handling data type conversion among JIT, torch and ONNX.
- Replace dictionary / list indexing with methods in ScalarType
- Breaking: **Remove ScalarType from `symbolic_helper`** and move it to `_type_utils`
- Breaking: **Remove "cast_pytorch_to_onnx", "pytorch_name_to_type", "scalar_name_to_pytorch", "scalar_type_to_onnx", "scalar_type_to_pytorch_type"** from `symbolic_helper`
- Deprecate the type mappings and lists. Remove all internal references
- Move _cast_func_template to opset 9 and remove its reference elsewhere (clean up). Added documentation for easy discovery
Why: List / dictionary indexing and lookup are error-prone and convoluted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81953
Approved by: https://github.com/AllenTiTaiWang, https://github.com/BowenBao
The default for `torch.onnx.export` is `TrainingMode.EVAL`:
0d76299ff7/torch/onnx/__init__.py (L63)
That means that this warning is only printed when the caller overrides
that and explicitly specifies that they want training ops like Dropout.
We should assume the user knows what they're doing and not warn.
Also set `do_constant_folding=False` in the dropout related training tests. Without this, warnings are printed like:
```
UserWarning: It is recommended that constant folding be turned off ('do_constant_folding=False') when exporting the model in training-amenable mode
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78309
Approved by: https://github.com/justinchuby, https://github.com/BowenBao
Cleaning up onnx module imports to prepare for updating `__init__`.
- Simplify importing the `_C` and `_C._onnx` name spaces
- Remove alias of the symbolic_helper module in imports
- Remove any module level function imports. Import modules instead
- Alias `symbilic_opsetx` as `opsetx`
- Fix some docstrings
Requires:
- https://github.com/pytorch/pytorch/pull/77448
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77423
Approved by: https://github.com/BowenBao
Reduce circular dependencies
- Lift constants and flags from `symbolic_helper` to `_constants` and `_globals`
- Standardized constant naming to make it consistant
- Make `utils` strictly dependent on `symbolic_helper`, removing inline imports from symbolic_helper
- Move side effects from `utils` to `_patch_torch`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77142
Approved by: https://github.com/garymm, https://github.com/BowenBao
Currently ONNX exporter symbolics can emit ATen operators when `operator_export_type==ONNX_ATEN_FALLBACK`. However, this is a behavior specific to Caffe2 builds, as the intend use of `ONNX_ATEN_FALLBACK` is to emit ATen operators only when there is no ONNX equivalent.
The reason Caffe2 choses to emit ATen operators when ONNX counterpart exists is for performance on their particular engine implementation, which might not be true for other implementations. e.g. ONNX Runtime can optimize the generated ONNX graph into something more efficient
This PR must be merged only after https://github.com/pytorch/pytorch/pull/73954
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74680
Approved by: https://github.com/garymm, https://github.com/malfet
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73280
This PR adds a new attribute overload_name to the Aten node so that third party applications can implement calls to libtorch without using PyTorch source code.
This is necessary because torch's torch::jit::findOperatorFor(fullname) requires a full name, including operator and overload names.
ATen op was originally created for Caffe2, which leveraged the availability of the pytorch yaml files to create calls to the aten oeprators directly, not relying on torch::jit::findOperatorFor
The first part of the PR refactors all symbolics that create Aten ops, so that there is a single helper for this operator. Next all symbolics are updated to pass in the relevant overload name, if empty string is not applicable
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D34625645
Pulled By: malfet
fbshipit-source-id: 37d58cfb5231833768172c122efc42edf7d8609a
(cherry picked from commit e92f09117d3645b38bc3235b30aba4b4c7c71dfa)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67805
Also fix Reduce ops on binary_cross_entropy_with_logits
The graph says the output is a scalar but with `keepdims=1`
(the default), the output should be a tensor of rank 1. We set keep
`keepdims=0` to make it clear that we want a scalar output.
This previously went unnoticed because ONNX Runtime does not strictly
enforce shape inference mismatches if the model is not using the latest
opset version.
Test Plan: Imported from OSS
Reviewed By: msaroufim
Differential Revision: D32181304
Pulled By: malfet
fbshipit-source-id: 1462d8a313daae782013097ebf6341a4d1632e2c
Co-authored-by: Bowen Bao <bowbao@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58695
As PEP8 says: "Pick a rule and stick to it." [1]
[1] https://www.python.org/dev/peps/pep-0008/#string-quotes
Test Plan: Imported from OSS
Reviewed By: driazati
Differential Revision: D28714811
Pulled By: SplitInfinity
fbshipit-source-id: c95103aceb1725c17c034dc6fc8216627f189548
Co-authored-by: Gary Miguel <garymiguel@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56166
Support tensordot in symbolic function of opset 12, and add tests accordingly.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D27866140
Pulled By: SplitInfinity
fbshipit-source-id: 68e218cfbd630900fb92871fc7c0de3e7e8c8c3d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54869
Add symbolic fuction to support torch.outer export to onnx.
Support for transfo-xl-wt103 model.
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D27408978
Pulled By: SplitInfinity
fbshipit-source-id: 70c89a9fc1a5e4a4ddcf674afb1e82e492a7d3b9
Summary:
* Lowering NLLLoss/CrossEntropyLoss to ATen dispatch
* This allows the MLC device to override these ops
* Reduce code duplication between the Python and C++ APIs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53789
Reviewed By: ailzhang
Differential Revision: D27345793
Pulled By: albanD
fbshipit-source-id: 99c0d617ed5e7ee8f27f7a495a25ab4158d9aad6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50906
In opset 13, squeeze/unsqueeze is updated to take axes as input, instead of attribute.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26050883
Pulled By: SplitInfinity
fbshipit-source-id: 7b5faf0e016d476bc75cbf2bfee6918d77e8aecd
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}