## Description
Fixes https://github.com/pytorch/pytorch/issues/114450. This PR builds upon the work from @imzhuhl done in https://github.com/pytorch/pytorch/pull/114451.
This PR requires https://github.com/pytorch/pytorch/pull/122472 to land firstly.
We leverage the serialization and deserialization API from oneDNN v3.4.1 to save the opaque MKLDNN tensor during the compilation and restore the opaque tensor when loading the compiled .so.
ideep version is updated so that we won't break any pipeline even if third_party/ideep is not updated at the same time.
### Test plan:
```sh
python -u test/inductor/test_aot_inductor.py -k AOTInductorTestNonABICompatibleCpu.test_freezing_non_abi_compatible_cpu
python -u test/inductor/test_aot_inductor.py -k AOTInductorTestNonABICompatibleCpu.test_conv_freezing_non_abi_compatible_cpu
python -u test/inductor/test_aot_inductor.py -k AOTInductorTestNonABICompatibleCpu.test_deconv_freezing_non_abi_compatible_cpu
python -u test/inductor/test_aot_inductor.py -k AOTInductorTestNonABICompatibleCpu.test_linear_freezing_non_abi_compatible_cpu
```
### TODOs in follow-up PRs
1. We found that using `AOTI_TORCH_CHECK` will cause performance drop on several models (`DistillGPT2`, `MBartForConditionalGeneration`, `T5ForConditionalGeneration`, `T5Small`) compared with JIT Inductor which uses `TORCH_CHECK`. This may need further discussion how to address (`AOTI_TORCH_CHECK` is introduced in
https://github.com/pytorch/pytorch/pull/119220).
2. Freezing in non-ABI compatible mode will work with the support in this PR. While for ABI compatible mode, we need to firstly address this issue: `AssertionError: None, i.e. optional output is not supported`.
6c4f43f826/torch/_inductor/codegen/cpp_wrapper_cpu.py (L2023-L2024)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/124350
Approved by: https://github.com/jgong5, https://github.com/desertfire
## Context
This stack prototypes automatic micro-pipelining of `all-gather -> matmul` and `matmul -> reduce-scatter` via Inductor. The idea originates from the paper [Overlap Communication with Dependent Computation via
Decomposition in Large Deep Learning Models](https://dl.acm.org/doi/pdf/10.1145/3567955.3567959). The implementation and some key optimizations are heavily influenced by @lw's implementation in xformers.
The stack contains several components:
- `ProcessGroupCudaP2P` - a thin wrapper around `ProcessGroupNCCL`. It in addition maintains a P2P workspace that enables SM-free, one-sided P2P communication which is needed for optimal micro-pipelining.
- `fused_all_gather_matmul` and `fused_matmul_reduce_scatter` dispatcher ops.
- Post-grad fx pass that detects `all-gather -> matmul` and `matmul -> reduce-scatter` and replaces them with the fused dispatcher ops.
To enable the prototype feature:
- Set the distributed backend to `cuda_p2p`.
- Set `torch._inductor.config._micro_pipeline_tp` to `True`.
*NOTE: the prototype sets nothing in stone w.r.t to each component's design. The purpose is to have a performant baseline with reasonable design on which each component can be further improved.*
## Benchmark
Setup:
- 8 x H100 (500W) + 3rd gen NVSwitch.
- Llama3 8B training w/ torchtitan.
- 8-way TP. Reduced the number of layers from 32 to 8 for benchmarking purpose.
Trace (baseline): https://interncache-all.fbcdn.net/manifold/perfetto-artifacts/tree/ui/index.html#!/?url=https://interncache-all.fbcdn.net/manifold/perfetto_internal_traces/tree/shared_trace/yifu_tmpjaz8zgx0
<img width="832" alt="image" src="https://github.com/pytorch/pytorch/assets/4156752/4addba77-5abc-4d2e-93ea-f68078587fe1">
Trace (w/ micro pipelining): https://interncache-all.fbcdn.net/manifold/perfetto-artifacts/tree/ui/index.html#!/?url=https://interncache-all.fbcdn.net/manifold/perfetto_internal_traces/tree/shared_trace/yifu_tmpn073b4wn
<img width="963" alt="image" src="https://github.com/pytorch/pytorch/assets/4156752/4f44e78d-8196-43ab-a1ea-27390f07e9d2">
## This PR
`ProcessGroupCudaP2P` is a thin wrapper around `ProcessGroupNCCL`. By default, it routes all collectives to the underlying `ProcessGroupNCCL`. In addition, `ProcessGroupCudaP2P` initializes a P2P workspace that allows direct GPU memory access among the members. The workspace can be used in Python to optimize intra-node communication patterns or to create custom intra-node collectives in CUDA.
`ProcessGroupCudaP2P` aims to bridge the gap where certain important patterns can be better optimized via fine-grained P2P memory access than with collectives in the latest version of NCCL. It is meant to complement NCCL rather than replacing it.
Usage:
```
# Using ProcessGroupCudaP2P
dist.init_process_group(backend="cuda_p2p", ...)
# Using ProcessGroupCudaP2P while specifying ProcessGroupCudaP2P.Options
pg_options = ProcessGroupCudaP2P.Options()
dist.init_process_group(backend="cuda_p2p", pg_options=pg_options, ...)
# Using ProcessGroupCudaP2P while specifying ProcessGroupNCCL.Options
pg_options = ProcessGroupNCCL.Options()
dist.init_process_group(backend="cuda_p2p", pg_options=pg_options, ...)
# Using ProcessGroupCudaP2P while specifying both
# ProcessGroupCudaP2P.Options and ProcessGroupNCCL.Options
pg_options = ProcessGroupCudaP2P.Options()
pg_options.nccl_options = ProcessGroupNCCL.Options()
dist.init_process_group(backend="cuda_p2p", pg_options=pg_options, ...)
# Down-casting the backend to access p2p buffers for cuda_p2p specific
# optimizations
if is_cuda_p2p_group(group):
backend = get_cuda_p2p_backend(group)
if required_p2p_buffer_size > backend.get_buffer_size():
# fallback
p2p_buffer = backend.get_p2p_buffer(...)
else:
# fallback
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/122163
Approved by: https://github.com/wanchaol
This PR is a follow-up of RFC https://github.com/pytorch/pytorch/issues/115545.
In this PR, we are trying to enable a cache mechanism to accelerate **eager-through-torch.compile**. When **eager-through-torch.compile** is enabled, we will store a persistent config to cache the kernel information for the aten operation.
The persistent config consists of two parts - meta_info and kernel_path.
- meta_info: The input tensors' shape, stride, device type, data type, and symbolic flag.
- kernel_path: The path of the kernel produced by Inductor.
When an aten operation is registered, the `kernel_holder` will load the persistent config and parse it to build the cache map; the meta_info is key, and the kernel library is the value.
Currently, this PR only supports static shape to guard the kernel.
Take a `mul` as an example.
```python
class MulKernel:
def __init__(self) -> None:
pass
def __call__(self, *args: Any, **kwargs: Any) -> Any:
with torch._C._SetExcludeDispatchKeyGuard(torch._C.DispatchKey.Python, False):
opt_fn = torch.compile(torch.ops.aten.mul, dynamic=False, options={
"aot_inductor.eager_mode": True,
"aot_inductor.eager_op_name": "mul_Tensor"
}
)
return opt_fn(*args, **kwargs)
torch_compile_op_lib_impl = torch.library.Library("aten", "IMPL")
_, overload_names = torch._C._jit_get_operation("aten::mul")
schema = torch._C._get_schema("aten::mul", overload_name)
reg_name = schema.name
if schema.overload_name:
reg_name = f"{reg_name}.{schema.overload_name}"
torch_compile_op_lib_impl.impl(
reg_name,
MulKernel(),
"CUDA",
compile_mode=True)
a = torch.randn(1024, 1024, device=device)
b = torch.randn(1024, 1024, device=device)
warm_up_iter = 1000
iter = 10000
fn = torch.mul
# Warm up
for _ in range(warm_up_iter):
fn(a, b)
# Collect performance
beg = time.time()
for _ in range(iter):
fn(a, b)
end = time.time()
print(f"E2E run: {end - beg}")
```
It will produce the config as follows.
```json
[
{
"meta_info": [
{
"is_symbolic": false,
"device_type": "cuda",
"dtype": "torch.float32",
"sizes": [1024, 1024],
"strides": [1024, 1]
},
{
"is_symbolic": false,
"device_type": "cuda",
"dtype": "torch.float32",
"sizes": [1024, 1024],
"strides": [1024, 1]
}
],
"kernel_path": "/tmp/torchinductor_eikan/e4/ce4jw46i5l2e7v3tvr2pyglpjmahnp7x3hxaqotrvxwoeh5t6qzc.so"
}
]
```
Performance-wise, we collected mul.Tensor through torch.compile w/ 10000 runs(e2e). The data is as follows. And we will collect data when we support dynamic shape.
- Eager: ~266.11ms
- W/O Cache: ~3455.54ms
- W/ Cache and Cache Miss: ~3555.3ms
- W/ Cache and Cache Hit: ~267.12ms
Hardware:
- CPU: Intel(R) Xeon(R) Platinum 8260 CPU @ 2.40GHz
- GPU: CUDA A10
Software:
- PyTorch Version: 39df084001
- GPU Driver Version: 525.147.05
- CUDA Version: 12.0
Differential Revision: [D57216427](https://our.internmc.facebook.com/intern/diff/D57216427)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/116368
Approved by: https://github.com/jansel, https://github.com/atalman
MTIA device has its own Module in PyTorch now.
torch.mtia has following APIs similar to other backends. The lazy_init is also supported.
```
__all__ = [
"init",
"is_available",
"synchronize",
"device_count",
"current_device",
"current_stream",
"default_stream",
"set_stream",
"stream",
"device",
]
```
------------
For device management. We expand AccleratorHooksInterface to support generic device management and it can be used in both C++ and PyThon.
```
def _accelerator_hooks_device_count() -> _int: ...
def _accelerator_hooks_set_current_device(device_index: _int) -> None: ...
def _accelerator_hooks_get_current_device() -> _int : ...
def _accelerator_hooks_exchange_device(device_index: _int) -> _int : ...
def _accelerator_hooks_maybe_exchange_device(device_index: _int) -> _int : ...
```
---------
Adding get_device_module API to retrieve device modules for different device types.
```
def get_device_module(device: Optional[Union[torch.device, str]] = None)
```
---------
Pull Request resolved: https://github.com/pytorch/pytorch/pull/123612
Approved by: https://github.com/albanD
ghstack dependencies: #123611
MTIA device has its own Module in PyTorch now.
torch.mtia has following APIs similar to other backends. The lazy_init is also supported.
```
__all__ = [
"init",
"is_available",
"synchronize",
"device_count",
"current_device",
"current_stream",
"default_stream",
"set_stream",
"stream",
"device",
]
```
------------
For device management. We expand AccleratorHooksInterface to support generic device management and it can be used in both C++ and PyThon.
```
def _accelerator_hooks_device_count() -> _int: ...
def _accelerator_hooks_set_current_device(device_index: _int) -> None: ...
def _accelerator_hooks_get_current_device() -> _int : ...
def _accelerator_hooks_exchange_device(device_index: _int) -> _int : ...
def _accelerator_hooks_maybe_exchange_device(device_index: _int) -> _int : ...
```
---------
Adding get_device_module API to retrieve device modules for different device types.
```
def get_device_module(device: Optional[Union[torch.device, str]] = None)
```
---------
Differential Revision: [D56443356](https://our.internmc.facebook.com/intern/diff/D56443356)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/123612
Approved by: https://github.com/albanD
ghstack dependencies: #123611
This diff intends to build device generic torch.Stream and torch.Event for newly added accelerators in PyTorch.
------------
**torch.Stream APIs**
```
# Defined in torch/csrc/Stream.cpp
class Stream(_StreamBase):
stream_id: _int # Stream id
device_index: _int
device_type: _int
device: _device # The device of the stream
@overload
def __new__(self, device: Optional[DeviceLikeType] = None, priority: _int = 0) -> Stream: ...
@overload
def __new__(self, stream_id: _int, device_index: _int, device_type: _int, priority: _int = 0) -> Stream: ...
def wait_event(self, event: Event) -> None: ...
def wait_stream(self, other: Stream) -> None: ...
def record_event(self, event: Optional[Event] = None) -> Event: ...
def query(self) -> None: ...
def synchronize(self) -> None: ...
def __hash__(self) -> _int: ...
def __repr__(self) -> str: ...
def __eq__(self, other: object) -> _bool: ...
```
------------------
**torch.Event APIs**:
- IPC related APIs are not implemented, since many device backends don't support it, but we leave interfaces there for future adaption of torch.cuda.Stream.
- currently only the enable_timing is supported, since it is the most common one used in other device backends. We have to refactor the event flag system in PyTorch to support more fancy flag.
- elapsedTime API is added to c10::Event
```
# Defined in torch/csrc/Event.cpp
class Event(_EventBase):
device: _device # The device of the Event
event_id: _int # The raw event created by device backend
def __new__(self,
device: Optional[DeviceLikeType] = None,
enable_timing: _bool = False,
blocking: _bool = False,
interprocess: _bool = False) -> Event: ...
@classmethod
def from_ipc_handle(self, device: DeviceLikeType, ipc_handle: bytes) -> Event: ...
def record(self, stream: Optional[Stream] = None) -> None: ...
def wait(self, stream: Optional[Stream] = None) -> None: ...
def query(self) -> _bool: ...
def elapsed_time(self, other: Event) -> _float: ...
def synchronize(self) -> None: ...
def ipc_handle(self) -> bytes: ...
def __repr__(self) -> str: ...
```
-----------
c10::Event provides new APIs
- calculate **elapsedTime**.
- Get raw event id
- Synchronize event.
```
double elapsedTime(const Event& event) const {
return impl_.elapsedTime(event.impl_);
}
void* eventId() const {
return impl_.eventId();
}
void synchronize() const {
return impl_.synchronize();
}
```
----------
TODO: need to find a good way to test them in PyTorch with API mocks.
Differential Revision: [D56443357](https://our.internmc.facebook.com/intern/diff/D56443357)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/123611
Approved by: https://github.com/albanD, https://github.com/jeffdaily
Support fused_sgd_kernel support for CPU.
## Bench result:
32 core/sockets ICX
Test Scripts:
https://gist.github.com/zhuhaozhe/688763e17e93e4c5e12f25f676ec90d9https://gist.github.com/zhuhaozhe/ad9938694bc7fae8b66d376f4dffc6c9
```
Tensor Size: 262144, Num Tensor 4, Num Threads: 1
_single_tensor_sgd time: 0.2301 seconds
_fused_sgd time: 0.0925 seconds
Tensor Size: 4194304, Num Tensor 32, Num Threads: 32
_single_tensor_sgd time: 2.6195 seconds
_fused_sgd time: 1.7543 seconds
```
## Test Plan:
```
python test_optim.py -k test_fused_matches_forloop
python test_optim.py -k test_fused_large_tensor
python test_optim.py -k test_can_load_older_state_dict
python test_optim.py -k test_grad_scaling_autocast_fused_optimizers
python test_torch.py -k test_grad_scaling_autocast_fused
python test_torch.py -k test_params_invalidated_with_grads_invalidated_between_unscale_and_step
```
Looks like we already have some PRs under this issue https://github.com/pytorch/pytorch/issues/123451 to unified the UTs, I did not modified UT in this PR.
Co-authored-by: Jane Xu <janeyx@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/123629
Approved by: https://github.com/jgong5, https://github.com/janeyx99
On par with `CUDA` implementation.
For `autocast` logic, same with `CUDA` + `Fused Adam`:
- check inf in `gradscalar.step`
- In fused kernel, if there is `inf`, do nothing. If not, unscale the grad ( also write back) and update the param.
**TestPlan**:
```
# extend CUDA only test for CPU fused adagrad
python test_optim.py -k test_fused_matches_forloop
python test_optim.py -k test_fused_large_tensor
python test_torch.py -k test_grad_scaling_autocast_fused
# extend fused test
python test_torch.py -k test_params_invalidated_with_grads_invalidated_between_unscale_and_step
python test_optim.py -k test_can_load_older_state_dict
# newly added test (follow 6b1f13ea2f/test/test_cuda.py (L1108))
python test_optim.py -k test_grad_scaling_autocast_fused_optimizers
```
**Benchmark**:
**5.1x** on 56 core SPR
**Parameter-size=1M**
**Nparams=10**
[test script](https://gist.github.com/zhuhaozhe/ef9a290ad3f8f4067b3373a3bdaa33e7)
```
numactl -C 0-55 -m 0 python bench_adam.py
non-fused 6.0174267292022705 s
fused 1.1787631511688232 s
```
**Note: Fused kernel accuracy**
The accuracy failure in CI shows a little higher than default tolerance
```
2024-04-02T06:09:16.2213887Z Mismatched elements: 21 / 64 (32.8%)
2024-04-02T06:09:16.2214339Z Greatest absolute difference: 1.5735626220703125e-05 at index (6, 6) (up to 1e-05 allowed)
2024-04-02T06:09:16.2214813Z Greatest relative difference: 1.0073336852656212e-05 at index (4, 1) (up to 1.3e-06 allowed)
```
I have debug it step by step and unfortunately we may not able to make the `fused kernel` exactly same with `non fused` one due to compiler optimizations.
For example, in non-fused impl
```
exp_avg_sq.mul_(beta2).addcmul_(grad, grad.conj(), value=1 - beta2)
```
and in fused impl
```
exp_avg_sq_ptr[d] = scalar_t(beta2) * exp_avg_sq_ptr[d];
// std::cout << "exp_avg_sq " << exp_avg_sq_ptr[d] << std::endl;
exp_avg_sq_ptr[d] = exp_avg_sq_ptr[d] +
scalar_t(exp_avg_sq_grad_coefficient) * grad_val * grad_val;
```
If I keep `std::cout`, I can get exactly same results in UT
```
===============param
0.6796758770942688
0.6796758770942688
```
But when I comment out it, there will be a difference
```
===============param
0.6796758770942688
0.6796759366989136
```
So I will make the tolerance a little higher than default one.
Co-authored-by: Jane Xu <janeyx@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/123074
Approved by: https://github.com/jgong5, https://github.com/janeyx99
MTIA device has its own Module in PyTorch now.
torch.mtia has following APIs similar to other backends. The lazy_init is also supported.
```
__all__ = [
"init",
"is_available",
"synchronize",
"device_count",
"current_device",
"current_stream",
"default_stream",
"set_stream",
"stream",
"device",
]
```
------------
For device management. We expand AccleratorHooksInterface to support generic device management and it can be used in both C++ and PyThon.
```
def _accelerator_hooks_device_count() -> _int: ...
def _accelerator_hooks_set_current_device(device_index: _int) -> None: ...
def _accelerator_hooks_get_current_device() -> _int : ...
def _accelerator_hooks_exchange_device(device_index: _int) -> _int : ...
def _accelerator_hooks_maybe_exchange_device(device_index: _int) -> _int : ...
```
---------
Adding get_device_module API to retrieve device modules for different device types.
```
def get_device_module(device: Optional[Union[torch.device, str]] = None)
```
---------
@exported-using-ghexport
Differential Revision: [D52923602](https://our.internmc.facebook.com/intern/diff/D52923602/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/123612
Approved by: https://github.com/albanD
ghstack dependencies: #123611
This diff intends to build device generic torch.Stream and torch.Event for newly added accelerators in PyTorch.
------------
**torch.Stream APIs**
```
# Defined in torch/csrc/Stream.cpp
class Stream(_StreamBase):
stream_id: _int # Stream id
device_index: _int
device_type: _int
device: _device # The device of the stream
@overload
def __new__(self, device: Optional[DeviceLikeType] = None, priority: _int = 0) -> Stream: ...
@overload
def __new__(self, stream_id: _int, device_index: _int, device_type: _int, priority: _int = 0) -> Stream: ...
def query(self) -> _bool: ...
def synchronize(self) -> None: ...
def wait_event(self, event: Event) -> None: ...
def wait_stream(self, other: Stream) -> None: ...
def record_event(self, event: Optional[Event] = None) -> Event: ...
def query(self) -> None: ...
def synchronize(self) -> None: ...
def __hash__(self) -> _int: ...
def __repr__(self) -> str: ...
def __eq__(self, other: object) -> _bool: ...
```
------------------
**torch.Event APIs**:
- IPC related APIs are not implemented, since many device backends don't support it, but we leave interfaces there for future adaption of torch.cuda.Stream.
- currently only the enable_timing is supported, since it is the most common one used in other device backends. We have to refactor the event flag system in PyTorch to support more fancy flag.
- elapsedTime API is added to c10::Event
```
# Defined in torch/csrc/Event.cpp
class Event(_EventBase):
device: _device # The device of the Event
event_id: _int # The raw event created by device backend
def __new__(self,
device: Optional[DeviceLikeType] = None,
enable_timing: _bool = False,
blocking: _bool = False,
interprocess: _bool = False) -> Event: ...
@classmethod
def from_ipc_handle(self, device: DeviceLikeType, ipc_handle: bytes) -> Event: ...
def record(self, stream: Optional[Stream] = None) -> None: ...
def wait(self, stream: Optional[Stream] = None) -> None: ...
def query(self) -> _bool: ...
def elapsed_time(self, other: Event) -> _float: ...
def synchronize(self) -> None: ...
def ipc_handle(self) -> bytes: ...
def __repr__(self) -> str: ...
```
-----------
c10::Event provides new APIs
- calculate **elapsedTime**.
- Get raw event id
- Synchronize event.
```
double elapsedTime(const Event& event) const {
return impl_.elapsedTime(event.impl_);
}
void* eventId() const {
return impl_.eventId();
}
void synchronize() const {
return impl_.synchronize();
}
```
----------
TODO: need to find a good way to test them in PyTorch with API mocks.
Differential Revision: [D55351839](https://our.internmc.facebook.com/intern/diff/D55351839/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/123611
Approved by: https://github.com/albanD
VariableInfo is used by both `custom_function.h` (in a templated class) and `compiled_autograd.h` (in a class with some templated methods). Another way could have been to make a `compiled_autograd.cpp` and forward declare VariableInfo, but this VariableInfo was also being used in other nodes like PyNode so it felt cleaner to do it this way.
Differential Revision: [D54287007](https://our.internmc.facebook.com/intern/diff/D54287007)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/120732
Approved by: https://github.com/jansel
# Motivation
As mentioned in [[RFC] Intel GPU Runtime Upstreaming](https://github.com/pytorch/pytorch/issues/114842), the next runtime component we would like to upstream is `Event` which handles the status of an operation that is being executed. Typically, in some circumstances, we can fine-grain control of the operation execution via `Event`.
# Design
`XPUEvent` is a movable but not a copyable wrapper around sycl event. It should be created lazily on an XPU device when recording an `XPUStream`. Meanwhile, `XPUEvent` can wait for another `XPUEvent` or all the submitted kernels on an `XPUStream` to complete. Align to the other backend, the C++ files related to `Event` will be placed in `aten/src/ATen/xpu` folder. For frontend code, `XPUEvent` runtime API will be bound to Python `torch.xpu.Event`. The corresponding C++ code will be placed in `torch/csrc/xpu/Event.cpp` and Python code will be placed in `torch/xpu/streams.py` respectively.
# Additional Context
It is worth mentioning that the `elapsed_time` method is temporarily not supported by `XPUEvent`. We will be adding support for it soon. Meanwhile `XPUEvent` doesn't support IPC from different processes. For the other parts, we have almost a 1:1 mapping with CUDA.
lack of the below APIs:
- `torch.cuda.Event.ipc_handle`
- `CUDAEvent`'s constructor with `IpcEventHandle`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/117734
Approved by: https://github.com/EikanWang, https://github.com/gujinghui, https://github.com/jgong5, https://github.com/malfet
ghstack dependencies: #117611, #117619
Replaces `view_func()` closures with a reified `ViewFunc` data structure. Codegen generates a `ViewFunc` subclass for each view op (e.g. `NarrowViewFunc`) containing state needed to reconstruct the view. The `ViewFunc` API allows for querying and hot-swapping any `SymInt`s or `Tensors` in the state through `get_symints()` / `get_tensors()` / `clone_and_set()`, which will be essential for fake-ification later on.
```cpp
/// Base class for view functions, providing reapplication of a view on a new base.
/// Each view op should get a codegenerated subclass of this class containing
/// any state needed to reconstruct the view. The class also provides convenience
/// accessors for saved SymInts / tensor state. This is useful for e.g. fake-ification,
/// where we want to use symbolic values or fake tensors instead.
struct TORCH_API ViewFunc {
virtual ~ViewFunc() {}
/// Returns any SymInts in the saved state.
virtual std::vector<c10::SymInt> get_symints() const { return {}; }
/// Returns the number of SymInts in the saved state.
virtual size_t num_symints() const { return 0; }
/// Returns any tensors in the saved state.
virtual std::vector<at::Tensor> get_tensors() const { return {}; }
/// Returns the number of tensors in the saved state.
virtual size_t num_tensors() const { return 0; }
/// Reapplies the view on the given base using the saved state.
virtual at::Tensor operator()(const at::Tensor&) const = 0;
/// Returns a clone of this ViewFunc, optionally with the specified saved state.
virtual std::unique_ptr<ViewFunc> clone_and_set(
std::optional<std::vector<c10::SymInt>> = c10::nullopt,
std::optional<std::vector<at::Tensor>> = c10::nullopt) const = 0;
protected:
/// Sets the values of any SymInts in the saved state. The input vector size must
/// match the number of SymInts in the saved state (i.e. the size of the list
/// returned by get_symints()).
virtual void set_symints(std::vector<c10::SymInt>) {}
/// Sets the values of any Tensors in the saved state. The input vector size must
/// match the number of Tensors in the saved state (i.e. the size of the list
/// returned by get_tensors()).
virtual void set_tensors(std::vector<at::Tensor>) {}
};
```
New codegen files:
* `torch/csrc/autograd/generated/ViewFunc.h`
* `torch/csrc/autograd/generated/ViewFuncs.cpp`
The templates for these also contains impls for `ChainedViewFunc` and `ErroringViewFunc` which are used in a few places within autograd.
Example codegen for `slice.Tensor`:
```cpp
// torch/csrc/autograd/generated/ViewFuncs.h
#define SLICE_TENSOR_VIEW_FUNC_AVAILABLE
struct SliceTensorViewFunc : public torch::autograd::ViewFunc {
SliceTensorViewFunc(int64_t dim, c10::optional<c10::SymInt> start, c10::optional<c10::SymInt> end, c10::SymInt step) : dim(dim), start(start), end(end), step(step)
{};
virtual ~SliceTensorViewFunc() override {};
virtual std::vector<c10::SymInt> get_symints() const override;
virtual size_t num_symints() const override;
virtual std::vector<at::Tensor> get_tensors() const override;
virtual size_t num_tensors() const override;
virtual at::Tensor operator()(const at::Tensor&) const override;
virtual std::unique_ptr<ViewFunc> clone_and_set(
std::optional<std::vector<c10::SymInt>> = c10::nullopt,
std::optional<std::vector<at::Tensor>> = c10::nullopt) const override;
protected:
virtual void set_symints(std::vector<c10::SymInt>) override;
virtual void set_tensors(std::vector<at::Tensor>) override;
private:
int64_t dim;
c10::optional<c10::SymInt> start;
c10::optional<c10::SymInt> end;
c10::SymInt step;
};
...
// torch/csrc/autograd/generated/ViewFuncs.cpp
std::vector<c10::SymInt> SliceTensorViewFunc::get_symints() const {
::std::vector<c10::SymInt> symints;
symints.reserve((start.has_value() ? 1 : 0) + (end.has_value() ? 1 : 0) + 1);
if(start.has_value()) symints.insert(symints.end(), *(start));
if(end.has_value()) symints.insert(symints.end(), *(end));
symints.push_back(step);
return symints;
}
size_t SliceTensorViewFunc::num_symints() const {
return static_cast<size_t>((start.has_value() ? 1 : 0) + (end.has_value() ? 1 : 0) + 1);
}
void SliceTensorViewFunc::set_symints(std::vector<c10::SymInt> symints) {
TORCH_INTERNAL_ASSERT(symints.size() == num_symints());
auto i = 0;
if(start.has_value()) start = symints[i];
i += (start.has_value() ? 1 : 0);
if(end.has_value()) end = symints[i];
i += (end.has_value() ? 1 : 0);
step = symints[i];
}
std::vector<at::Tensor> SliceTensorViewFunc::get_tensors() const {
::std::vector<at::Tensor> tensors;
return tensors;
}
size_t SliceTensorViewFunc::num_tensors() const {
return static_cast<size_t>(0);
}
void SliceTensorViewFunc::set_tensors(std::vector<at::Tensor> tensors) {
TORCH_INTERNAL_ASSERT(tensors.size() == num_tensors());
}
at::Tensor SliceTensorViewFunc::operator()(const at::Tensor& input_base) const {
return at::_ops::slice_Tensor::call(input_base, dim, start, end, step);
}
std::unique_ptr<ViewFunc> SliceTensorViewFunc::clone_and_set(
std::optional<std::vector<c10::SymInt>> symints,
std::optional<std::vector<at::Tensor>> tensors) const {
auto output = std::make_unique<SliceTensorViewFunc>(dim, start, end, step);
if (symints.has_value()) {
output->set_symints(std::move(*(symints)));
}
if (tensors.has_value()) {
output->set_tensors(std::move(*(tensors)));
}
return output;
}
```
The `_view_func()` / `_view_func_unsafe()` methods now accept two additional (optional) args for `symint_visitor_fn` / `tensor_visitor_fn`. If these are defined, they are expected to be python callables that operate on a single SymInt / tensor and return a new one. This allows for the hot-swapping needed during fake-ification.
For testing, there are extensive pre-existing tests, and I added a test to ensure that hot-swapping functions correctly.
```sh
python test/test_autograd.py -k test_view_func_replay
python test/test_ops.py -k test_view_replay
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/118404
Approved by: https://github.com/ezyang
Some operations, such as GEMMs, could be implemented using more than one library or more than one technique. For example, a GEMM could be implemented for CUDA or ROCm using either the blas or blasLt libraries. Further, ROCm's rocblas and hipblaslt libraries allow the user to query for all possible algorithms and then choose one. How does one know which implementation is the fastest and should be chosen? That's what TunableOp provides.
See the README.md for additional details.
TunableOp was ported from onnxruntime starting from commit 08dce54266. The content was significantly modified and reorganized for use within PyTorch. The files copied and their approximate new names or source content location within aten/src/ATen/cuda/tunable include the following:
- onnxruntime/core/framework/tunable.h -> Tunable.h
- onnxruntime/core/framework/tuning_context.h -> Tunable.h
- onnxruntime/core/framework/tuning_context_impl.h -> Tunable.cpp
- onnxruntime/core/providers/rocm/tunable/gemm_common.h -> GemmCommon.h
- onnxruntime/core/providers/rocm/tunable/gemm_hipblaslt.h -> GemmHipblaslt.h
- onnxruntime/core/providers/rocm/tunable/gemm_rocblas.h -> GemmRocblas.h
- onnxruntime/core/providers/rocm/tunable/gemm_tunable.cuh -> TunableGemm.h
- onnxruntime/core/providers/rocm/tunable/rocm_tuning_context.cc -> Tunable.cpp
- onnxruntime/core/providers/rocm/tunable/util.h -> StreamTimer.h
- onnxruntime/core/providers/rocm/tunable/util.cc -> StreamTimer.cpp
Pull Request resolved: https://github.com/pytorch/pytorch/pull/114894
Approved by: https://github.com/xw285cornell, https://github.com/jianyuh
# Motivation
According to [[1/2] Intel GPU Runtime Upstreaming for Stream](https://github.com/pytorch/pytorch/pull/117611), as mentioned in [[RFC] Intel GPU Runtime Upstreaming](https://github.com/pytorch/pytorch/issues/114842), the second PR covers the changes under `python frontend`.
# Design
Currently, it primarily offers stream-related APIs, including
- `torch.xpu.StreamContext`
- `torch.xpu.current_stream`
- `torch.xpu.set_stream`
- `torch.xpu.synchronize`
- `torch._C._xpu_getCurrentRawStream`
# Additional Context
We will implement functions like `torch.xpu.Stream.wait_event`, `torch.xpu.Stream.wait_stream`, and `torch.xpu.Stream.record_event` in the next PR related with `Event`.
The differences with CUDA:
no default and external stream in XPU and lack of below APIs:
- `torch.cuda.ExternalStream`
- `torch.cuda.default_stream`
- `toch.cuda.is_current_stream_capturing`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/117619
Approved by: https://github.com/EikanWang, https://github.com/jgong5, https://github.com/gujinghui, https://github.com/albanD
ghstack dependencies: #117611
Replaces `view_func()` closures with a reified `ViewFunc` data structure. Codegen generates a `ViewFunc` subclass for each view op (e.g. `NarrowViewFunc`) containing state needed to reconstruct the view. The `ViewFunc` API allows for querying and hot-swapping any `SymInt`s or `Tensors` in the state through `get_symints()` / `get_tensors()` / `clone_and_set()`, which will be essential for fake-ification later on.
```cpp
/// Base class for view functions, providing reapplication of a view on a new base.
/// Each view op should get a codegenerated subclass of this class containing
/// any state needed to reconstruct the view. The class also provides convenience
/// accessors for saved SymInts / tensor state. This is useful for e.g. fake-ification,
/// where we want to use symbolic values or fake tensors instead.
struct TORCH_API ViewFunc {
virtual ~ViewFunc() {}
/// Returns any SymInts in the saved state.
virtual std::vector<c10::SymInt> get_symints() const { return {}; }
/// Returns the number of SymInts in the saved state.
virtual size_t num_symints() const { return 0; }
/// Returns any tensors in the saved state.
virtual std::vector<at::Tensor> get_tensors() const { return {}; }
/// Returns the number of tensors in the saved state.
virtual size_t num_tensors() const { return 0; }
/// Reapplies the view on the given base using the saved state.
virtual at::Tensor operator()(const at::Tensor&) const = 0;
/// Returns a clone of this ViewFunc, optionally with the specified saved state.
virtual std::unique_ptr<ViewFunc> clone_and_set(
std::optional<std::vector<c10::SymInt>> = c10::nullopt,
std::optional<std::vector<at::Tensor>> = c10::nullopt) const = 0;
protected:
/// Sets the values of any SymInts in the saved state. The input vector size must
/// match the number of SymInts in the saved state (i.e. the size of the list
/// returned by get_symints()).
virtual void set_symints(std::vector<c10::SymInt>) {}
/// Sets the values of any Tensors in the saved state. The input vector size must
/// match the number of Tensors in the saved state (i.e. the size of the list
/// returned by get_tensors()).
virtual void set_tensors(std::vector<at::Tensor>) {}
};
```
New codegen files:
* `torch/csrc/autograd/generated/ViewFunc.h`
* `torch/csrc/autograd/generated/ViewFuncs.cpp`
The templates for these also contains impls for `ChainedViewFunc` and `ErroringViewFunc` which are used in a few places within autograd.
Example codegen for `slice.Tensor`:
```cpp
// torch/csrc/autograd/generated/ViewFuncs.h
#define SLICE_TENSOR_VIEW_FUNC_AVAILABLE
struct SliceTensorViewFunc : public torch::autograd::ViewFunc {
SliceTensorViewFunc(int64_t dim, c10::optional<c10::SymInt> start, c10::optional<c10::SymInt> end, c10::SymInt step) : dim(dim), start(start), end(end), step(step)
{};
virtual ~SliceTensorViewFunc() override {};
virtual std::vector<c10::SymInt> get_symints() const override;
virtual size_t num_symints() const override;
virtual std::vector<at::Tensor> get_tensors() const override;
virtual size_t num_tensors() const override;
virtual at::Tensor operator()(const at::Tensor&) const override;
virtual std::unique_ptr<ViewFunc> clone_and_set(
std::optional<std::vector<c10::SymInt>> = c10::nullopt,
std::optional<std::vector<at::Tensor>> = c10::nullopt) const override;
protected:
virtual void set_symints(std::vector<c10::SymInt>) override;
virtual void set_tensors(std::vector<at::Tensor>) override;
private:
int64_t dim;
c10::optional<c10::SymInt> start;
c10::optional<c10::SymInt> end;
c10::SymInt step;
};
...
// torch/csrc/autograd/generated/ViewFuncs.cpp
std::vector<c10::SymInt> SliceTensorViewFunc::get_symints() const {
::std::vector<c10::SymInt> symints;
symints.reserve((start.has_value() ? 1 : 0) + (end.has_value() ? 1 : 0) + 1);
if(start.has_value()) symints.insert(symints.end(), *(start));
if(end.has_value()) symints.insert(symints.end(), *(end));
symints.push_back(step);
return symints;
}
size_t SliceTensorViewFunc::num_symints() const {
return static_cast<size_t>((start.has_value() ? 1 : 0) + (end.has_value() ? 1 : 0) + 1);
}
void SliceTensorViewFunc::set_symints(std::vector<c10::SymInt> symints) {
TORCH_INTERNAL_ASSERT(symints.size() == num_symints());
auto i = 0;
if(start.has_value()) start = symints[i];
i += (start.has_value() ? 1 : 0);
if(end.has_value()) end = symints[i];
i += (end.has_value() ? 1 : 0);
step = symints[i];
}
std::vector<at::Tensor> SliceTensorViewFunc::get_tensors() const {
::std::vector<at::Tensor> tensors;
return tensors;
}
size_t SliceTensorViewFunc::num_tensors() const {
return static_cast<size_t>(0);
}
void SliceTensorViewFunc::set_tensors(std::vector<at::Tensor> tensors) {
TORCH_INTERNAL_ASSERT(tensors.size() == num_tensors());
}
at::Tensor SliceTensorViewFunc::operator()(const at::Tensor& input_base) const {
return at::_ops::slice_Tensor::call(input_base, dim, start, end, step);
}
std::unique_ptr<ViewFunc> SliceTensorViewFunc::clone_and_set(
std::optional<std::vector<c10::SymInt>> symints,
std::optional<std::vector<at::Tensor>> tensors) const {
auto output = std::make_unique<SliceTensorViewFunc>(dim, start, end, step);
if (symints.has_value()) {
output->set_symints(std::move(*(symints)));
}
if (tensors.has_value()) {
output->set_tensors(std::move(*(tensors)));
}
return output;
}
```
The `_view_func()` / `_view_func_unsafe()` methods now accept two additional (optional) args for `symint_visitor_fn` / `tensor_visitor_fn`. If these are defined, they are expected to be python callables that operate on a single SymInt / tensor and return a new one. This allows for the hot-swapping needed during fake-ification.
For testing, there are extensive pre-existing tests, and I added a test to ensure that hot-swapping functions correctly.
```sh
python test/test_autograd.py -k test_view_func_replay
python test/test_ops.py -k test_view_replay
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/118404
Approved by: https://github.com/ezyang
# Motivation
This PR intends to extend `cuda_lazy_init` to `device_lazy_init` which is a device-agnostic API that can support any backend. And change `maybe_initialize_cuda` to `maybe_initialize_device` to support lazy initialization for CUDA while maintaining scalability.
# Design
We maintain a flag for each backend to manage the lazy initialization state separately.
# Additional Context
No need more UTs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/118846
Approved by: https://github.com/malfet
# Motivation
According to [[1/4] Intel GPU Runtime Upstreaming for Device](https://github.com/pytorch/pytorch/pull/116019), As mentioned in [[RFC] Intel GPU Runtime Upstreaming](https://github.com/pytorch/pytorch/issues/114842), this third PR covers the changes under `libtorch_python`.
# Design
This PR primarily offers device-related APIs in python frontend, including
- `torch.xpu.is_available`
- `torch.xpu.device_count`
- `torch.xpu.current_device`
- `torch.xpu.set_device`
- `torch.xpu.device`
- `torch.xpu.device_of`
- `torch.xpu.get_device_name`
- `torch.xpu.get_device_capability`
- `torch.xpu.get_device_properties`
- ====================
- `torch.xpu._DeviceGuard`
- `torch.xpu._is_compiled`
- `torch.xpu._get_device`
# Additional Context
We will implement the support of lazy initialization in the next PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/116850
Approved by: https://github.com/EikanWang, https://github.com/jgong5, https://github.com/gujinghui, https://github.com/malfet
Summary: Now we can allocate an AOTIModelContainerRunner object instead of relying on torch.utils.cpp_extension.load_inline. Also renamed AOTInductorModelRunner to AOTIRunnerUtil in this PR.
Test Plan: CI
Reviewed By: khabinov
Differential Revision: D52339116
Pull Request resolved: https://github.com/pytorch/pytorch/pull/116269
Approved by: https://github.com/khabinov
## Summary
This PR added 3 intra-node GPU allreduce algorithms to PyTorch:
- One-shot allreduce (inspired by FasterTransformer): all ranks simultaneously read and accumulate data from other ranks.
- Two-shot allreduce (inspired by FasterTransformer): all ranks simultanesouly read and accumulate `1 / world_size` data from other ranks. Then all ranks read accumulated data from other ranks. (effectively one-shot reduce-scatter + one-shot all-gather).
- Hybrid cube mesh allreduce (original): a one-shot allreduce variant that avoids transmission over PCIe on HCM topology.
## Micro Benchmarks



## Details
The intra-node algos are organized behind `c10d::IntraNodeComm`, which is responsible for:
- Managing handshaking and cuda IPC handle exchange among ranks.
- Querying NVLink connection and detecting topology.
- Performing algo selection based on available info.
- Launching the selected allreduce kernel.
`c10d::IntraNodeComm` is integrated into `c10d::ProcessGroupNCCL` as follows:
- When the `ENABLE_INTRA_NODE_COMM` environment variable is set, `c10d::ProcessGroupNCCL` initialize a `c10d::IntraNodeComm` for its ranks.
- If the setup is not suitable for intra-node comm (e.g. not all ranks are from the same node), the rendezvous logic guarantees all participants fall back consistently.
- `c10d::ProcessGroupNCCL::allreduce` consults `c10d::IntraNodeComm` whether to use intra-node allreduce and carries out the communication accordingly.
We currently detect two types of topoloies from the nNVLink connection mesh:
- Fully connected: all GPU pairs has direct NVLink connection (e.g. NVSwitch or fully connected sub-set of hybrid cube mesh)
- `msg <= 256KB`: one-shot allreduce.
- `256KB < msg <= 10MB`: two-shot allreduce.
- `msg > 10MB`: instructs the caller to fallback to NCCL.
- Hybrid cube mesh
- `msg <= 256KB`: one-shot allreduce.
- `msg > 256KB`: instructs the caller to fallback to NCCL.
## Next Steps
- Fine tune algo selection based on GPU model, topology, link speed.
- Potentially optimize the two-shot allreduce impl. Accroding to FasterTransformer, two-shot allreduce is preferred until 50MB. There might be room for improvement, but PyTorch does impose more constraints:
- FasterTransformer uses a single process to drive multiple devices. It can use `cudaDeviceEnablePeerAccess` enable device-level peer access.
- PyTorch uses multiple process to drive multiple devices. With cuda IPC, a device can only share a specific region to other devices. This means extra copies may be unavoidable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/114001
Approved by: https://github.com/yf225
## Summary
This PR added 3 intra-node GPU allreduce algorithms to PyTorch:
- One-shot allreduce (inspired by FasterTransformer): all ranks simultaneously read and accumulate data from other ranks.
- Two-shot allreduce (inspired by FasterTransformer): all ranks simultanesouly read and accumulate `1 / world_size` data from other ranks. Then all ranks read accumulated data from other ranks. (effectively one-shot reduce-scatter + one-shot all-gather).
- Hybrid cube mesh allreduce (original): a one-shot allreduce variant that avoids transmission over PCIe on HCM topology.
## Micro Benchmarks



## Details
The intra-node algos are organized behind `c10d::IntraNodeComm`, which is responsible for:
- Managing handshaking and cuda IPC handle exchange among ranks.
- Querying NVLink connection and detecting topology.
- Performing algo selection based on available info.
- Launching the selected allreduce kernel.
`c10d::IntraNodeComm` is integrated into `c10d::ProcessGroupNCCL` as follows:
- When the `ENABLE_INTRA_NODE_COMM` environment variable is set, `c10d::ProcessGroupNCCL` initialize a `c10d::IntraNodeComm` for its ranks.
- If the setup is not suitable for intra-node comm (e.g. not all ranks are from the same node), the rendezvous logic guarantees all participants fall back consistently.
- `c10d::ProcessGroupNCCL::allreduce` consults `c10d::IntraNodeComm` whether to use intra-node allreduce and carries out the communication accordingly.
We currently detect two types of topoloies from the nNVLink connection mesh:
- Fully connected: all GPU pairs has direct NVLink connection (e.g. NVSwitch or fully connected sub-set of hybrid cube mesh)
- `msg <= 256KB`: one-shot allreduce.
- `256KB < msg <= 10MB`: two-shot allreduce.
- `msg > 10MB`: instructs the caller to fallback to NCCL.
- Hybrid cube mesh
- `msg <= 256KB`: one-shot allreduce.
- `msg > 256KB`: instructs the caller to fallback to NCCL.
## Next Steps
- Fine tune algo selection based on GPU model, topology, link speed.
- Potentially optimize the two-shot allreduce impl. Accroding to FasterTransformer, two-shot allreduce is preferred until 50MB. There might be room for improvement, but PyTorch does impose more constraints:
- FasterTransformer uses a single process to drive multiple devices. It can use `cudaDeviceEnablePeerAccess` enable device-level peer access.
- PyTorch uses multiple process to drive multiple devices. With cuda IPC, a device can only share a specific region to other devices. This means extra copies may be unavoidable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/114001
Approved by: https://github.com/yf225
This PR introduces a native version of c10d_functional ops. The main goal is to add collective support in AOTInductor and allow collective ops to work in multi-threaded native runtimes.
The native version also incorporated API improvements we wished to implement in Python c10d_functional:
- Removed `ranks` and `group_size` from collective op signatures which were proven to be redundant.
- Use tensor storage as opposed to `void*` to resolve in-flight work.
The native process group registration/resolution mechansim is only used for native c10d_functional in the PR. It will become the single source of truth in upcoming PRs.
The upcoming PRs will implement Inductor/AOTInductor support for c10d_functional, after which native c10d_functional will replace Python c10d_functional.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/110570
Approved by: https://github.com/wanchaol
Removes the existing integration code & build of nvfuser in TorchScript.
Note that I intentionally left the part where we wipe out `third_party/nvfuser` repo. I'll do that in a separate PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/111093
Approved by: https://github.com/albanD
This reverts commit 314a502eb0.
Changes since original PR:
Reland 1
* rename torch.distributed.hooks to torch.distributed._hooks
Reland 2
* make _hooks importable even if !distributed.is_available()
* handle cuda driver exit intermittent failure caused by new cuda api usage in callback caller (see prev PR in stack)
(original PR https://github.com/pytorch/pytorch/pull/108815 desc copied below)
Expose a set of observability hooks into C10D such that our users can
detect collectives failure both faster and more easily.
The design is similar to NCCL desync debug that it minimized the
overhead by doing most of the work out of the main thread.
This PR introduces a new module torch.distributed.hooks that exposes the following set of methods:
register_collective_start_hook
register_collective_end_hook
register_process_group_hook
The process group hook exposes PG creation on the member ranks and call them inline from the
the PG creation code. This is fine since this happens during initialization and a limited number of times.
The collective start/end hooks are fired from a single background thread. It reads
events from a C++ queue and dispatches over.
Queue notification is oddly done using a pipe, this is needed so python can abort the thread on shutdown
and have it as background thread. This is not possible with more reasonable choices like a condvar.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/111072
Approved by: https://github.com/malfet
ghstack dependencies: #111061
`libshm.so` depends on the torch library exclusively for `at::RefcountedMapAllocator`,
so it makes sense to move it to c10 along with the other memory allocators.
This means `libshm.so` only depends on `c10` and we don't need to relink
`libshm.so` for every ATen change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/109881
Approved by: https://github.com/albanD
Summary: Introduce a utility class AOTIModelRunner to take care of running an AOTInductor compiled model. It does things like dlopen a model, initialize the model container, setup inputs and outputs, and destroy the model container.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/110891
Approved by: https://github.com/chenyang78
ghstack dependencies: #110652
This reverts commit ff0358b038.
(original PR https://github.com/pytorch/pytorch/pull/108815 desc copied below)
Expose a set of observability hooks into C10D such that our users can
detect collectives failure both faster and more easily.
The design is similar to NCCL desync debug that it minimized the
overhead by doing most of the work out of the main thread.
This PR introduces a new module torch.distributed.hooks that exposes the following set of methods:
register_collective_start_hook
register_collective_end_hook
register_process_group_hook
The process group hook exposes PG creation on the member ranks and call them inline from the
the PG creation code. This is fine since this happens during initialization and a limited number of times.
The collective start/end hooks are fired from a single background thread. It reads
events from a C++ queue and dispatches over.
Queue notification is oddly done using a pipe, this is needed so python can abort the thread on shutdown
and have it as background thread. This is not possible with more reasonable choices like a condvar.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/110907
Approved by: https://github.com/fduwjj
`libshm.so` depends on the torch library exclusively for `at::RefcountedMapAllocator`,
so it makes sense to move it to c10 along with the other memory allocators.
This means `libshm.so` only depends on `c10` and we don't need to relink
`libshm.so` for every ATen change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/109881
Approved by: https://github.com/albanD
Expose a set of observability hooks into C10D such that our users can
detect collectives failure both faster and more easily.
The design is similar to NCCL desync debug that it minimized the
overhead by doing most of the work out of the main thread.
This PR introduces a new module torch.distributed.hooks that exposes the following set of methods:
register_collective_start_hook
register_collective_end_hook
register_process_group_hook
The process group hook exposes PG creation on the member ranks and call them inline from the
the PG creation code. This is fine since this happens during initialization and a limited number of times.
The collective start/end hooks are fired from a single background thread. It reads
events from a C++ queue and dispatches over.
Queue notification is oddly done using a pipe, this is needed so python can abort the thread on shutdown
and have it as background thread. This is not possible with more reasonable choices like a condvar.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108815
Approved by: https://github.com/wconstab, https://github.com/fduwjj
We want users to be able to define custom ops in C++ but put the
abstract impl in Python (since it is easier to write them in Python and
the abstract impl better models device semantics and data-dependent
operators).
`m.impl_abstract_pystub(opname, python_module, context)` declares the
abstract_impl of the operator to exist in the given python module.
When the abstract_impl needs to be accessed (either via FakeTensor or
Meta), and it does not exist, the PyTorch Dispatcher will yell
with a descriptive error message.
Some details:
- We construct a new global AbstractImplPyStub mapping in
Dispatcher.cpp. Read/write to this map is protected by the Dispatcher
lock.
- We add a new Meta Tensor fallback kernel. The fallback errors out if there is
no meta kernel, but also offers a nicer error message if we see that there is
a pystub.
- We create a `torch._utils_internal.throw_abstract_impl_not_imported_error`
helper function to throw errors. This way, we can throw different error
messages in OSS PyTorch vs internal PyTorch. To invoke this from C++, we
added a PyInterpreter::throw_abstract_impl_not_imported_error.
Differential Revision: [D49464753](https://our.internmc.facebook.com/intern/diff/D49464753/)
Differential Revision: [D49464753](https://our.internmc.facebook.com/intern/diff/D49464753)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/109529
Approved by: https://github.com/ezyang, https://github.com/bdhirsh
Summary:
This PR adds a limited C shim layer for libtorch. The ultimate goal is to ban any direct reference to aten/c10 data structures or functions, to avoid ABI breakage by providing stable C interfaces.
To make the review and landing easier, we broke the changes into several steps. In this PR (a combination of https://github.com/pytorch/pytorch/pull/109022 and https://github.com/pytorch/pytorch/pull/109351), we add C interfaces for certain libtorch functions and modify the wrapper codegen to generate calls to those interfaces. There are a few other items to be addressed in future PRs:
* The AOTInductor runtime interface still takes lists of aten tensors as input and output
* The interaction with ProxyExecutor (general fallback support) needs to move away from aten tensor
* Remove all references to aten/c10 headers in the AOTInductor-generated code
Differential Revision: D49302669
Pull Request resolved: https://github.com/pytorch/pytorch/pull/109391
Approved by: https://github.com/chenyang78
# Summary
## PR Dependencies
I don't use ghstack :( this is a PR where it would have been helpful. That beings said I am going to peel off some PRs to make reviewing this easier:
- [x] Separate build flags for Flash and MemEff: #107985
### Description
This pull request updates the version of _scaled_dot_product_flash_attention from version 1 to version 2. The changes are based on the flash attention code originally authored by @tridao
### Changes Made
The majority of the changes in this pull request involve:
- Copying over the flash_attention sources.
- Updating header files.
- Removing padding and slicing code from within the flash_attention kernel and relocating it to the composite implicit region of the SDPA. This was need to make the kernel functional and appease autograd.
- Introducing a simple kernel generator to generate different instantiations of the forward and backward flash templates.
- Adding conditional compilation (ifdef) to prevent building when nvcc is invoked with gencode < sm80.
- Introducing a separate dependent option for mem_eff_attention, as flash_attention v2 lacks support for Windows and cannot be built for sm50 generation codes.
- Modifying build.sh to reduce parallelization on sm86 runners and to lower the maximum parallelization on the manywheel builds. This adjustment was made to address out-of-memory issues during the compilation of FlashAttentionV2 sources.
- Adding/Updating tests.
### Notes for Reviewers
This is not a fun review, and I apologize in advance.
Most of the files-changed are in the flash_attn/ folder. The only files of interest here IMO:
- aten/src/ATen/native/transformers/cuda/flash_attn/flash_api.cpp
- aten/src/ATen/native/transformers/cuda/flash_attn/kernels/generate_kernels.py ( this has been incorporated upstream to flash-attention github)
There are a number of files all related to avoiding OOMs in CI/CD. These are typically shell scripts.
### Follow up items
- Include the updates from e07aa036db and 9e5e8bc91e | https://github.com/pytorch/pytorch/issues/108108
### Work Items
- [x] I don't think Windows will be supported for 3.1.0 - Need to update cmakee
- [x] Let multi_query/attention pass through and test | UPDATE: I have the fast path implemented here: https://github.com/pytorch/pytorch/pull/106730 but since this will require changes to semantics of math to call repeat_interleave, I think this should be done as a followup.
- [x] Had to drop cutlass back to 3.0.0 to get it to compile. Need to figure out how to upgrade to 3.1.0 and later. Spoke with Tri and he is going to be taking a look. Note: compiling with clang currently errors for the cute headers.
- [x] Update test exercise above codepath
- [x] Still need to disable on seq_len % 128 != 0 for backward( Tri beat me to it a4f148b6ab)
- [x] Add determinism warning to BWD, Tri got to this one as well: 1c41d2b
- [x] Update dispatcher to universally prefer FlashV2
- [x] Update tests to exercise new head_dims
- [x] Move the head_dim padding from kernel to top level composite implicit function in order to make it purely functional
- [x] Create template generator script
- [x] Initial cmake support for building kernels/ folder
- [x] Replay CudaGraph changes
### Results
#### Forward only
The TFlops are reported here are on a100 that is underclocked.

#### Forward+Backward
Ran a sweep and for large compute bound sizes we do see a ~2x performance increase for forw+back.
<img width="1684" alt="Screenshot 2023-07-20 at 3 47 47 PM" src="https://github.com/pytorch/pytorch/assets/32754868/fdd26e07-0077-4878-a417-f3a418b6fb3b">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105602
Approved by: https://github.com/huydhn, https://github.com/cpuhrsch
**Background**: "TorchDynamo Cache Lookup" events appear in traces to indicate a dynamo cache lookup; it's useful to check when cache lookups are taking a long time. To add a profiler event, one can use the `torch.profiler.record_function` context manager, or the C++ equivalent. Previously, the python version was used; first, when the profiler was enabled, callbacks for record_function_enter and record_function_exit were registered; then those would be called before and after every cache lookup.
**This PR**: Instead of calling the python bindings for `torch.profiler.record_function`, directly call the C++ implementation. This simplifies a lot of the code for binding C/C++. It also improves performance; previously there was a lot of overhead in the "TorchDynamo Cache Lookup" event, making the event artificially take a long time. After this change the events now appear shorter, because there's less overhead in starting/stopping the event: in other words, the profiler no longer distorts the results as much.
**Performance results**:
I ran using the script below on a cpu-only 1.6GHz machine. I report the median time (from 100 measurements) of a "TorchDynamo Cache Lookup" event before and after this PR. I think it is reasonable to consider the difference to be due to a reduction in overhead.
<details>
<summary>Benchmarking script</summary>
```python
def fn(x, y):
return (x * y).relu()
a, b = [torch.rand((4, 4), requires_grad=True) for _ in range(2)]
opt_fn = torch.compile(fn)
opt_fn(a, b)
opt_fn(a, b)
with torch.profiler.profile() as prof:
opt_fn(a, b)
```
</details>
Median before PR: 198-228 us (median of 100, measured 5 times)
Median after PR: 27us
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108436
Approved by: https://github.com/anijain2305, https://github.com/jansel
# Summary
## PR Dependencies
I don't use ghstack :( this is a PR where it would have been helpful. That beings said I am going to peel off some PRs to make reviewing this easier:
- [x] Separate build flags for Flash and MemEff: #107985
### Description
This pull request updates the version of _scaled_dot_product_flash_attention from version 1 to version 2. The changes are based on the flash attention code originally authored by @tridao
### Changes Made
The majority of the changes in this pull request involve:
- Copying over the flash_attention sources.
- Updating header files.
- Removing padding and slicing code from within the flash_attention kernel and relocating it to the composite implicit region of the SDPA. This was need to make the kernel functional and appease autograd.
- Introducing a simple kernel generator to generate different instantiations of the forward and backward flash templates.
- Adding conditional compilation (ifdef) to prevent building when nvcc is invoked with gencode < sm80.
- Introducing a separate dependent option for mem_eff_attention, as flash_attention v2 lacks support for Windows and cannot be built for sm50 generation codes.
- Modifying build.sh to reduce parallelization on sm86 runners and to lower the maximum parallelization on the manywheel builds. This adjustment was made to address out-of-memory issues during the compilation of FlashAttentionV2 sources.
- Adding/Updating tests.
### Notes for Reviewers
This is not a fun review, and I apologize in advance.
Most of the files-changed are in the flash_attn/ folder. The only files of interest here IMO:
- aten/src/ATen/native/transformers/cuda/flash_attn/flash_api.cpp
- aten/src/ATen/native/transformers/cuda/flash_attn/kernels/generate_kernels.py ( this has been incorporated upstream to flash-attention github)
There are a number of files all related to avoiding OOMs in CI/CD. These are typically shell scripts.
### Follow up items
- Include the updates from e07aa036db and 9e5e8bc91e | https://github.com/pytorch/pytorch/issues/108108
### Work Items
- [x] I don't think Windows will be supported for 3.1.0 - Need to update cmakee
- [x] Let multi_query/attention pass through and test | UPDATE: I have the fast path implemented here: https://github.com/pytorch/pytorch/pull/106730 but since this will require changes to semantics of math to call repeat_interleave, I think this should be done as a followup.
- [x] Had to drop cutlass back to 3.0.0 to get it to compile. Need to figure out how to upgrade to 3.1.0 and later. Spoke with Tri and he is going to be taking a look. Note: compiling with clang currently errors for the cute headers.
- [x] Update test exercise above codepath
- [x] Still need to disable on seq_len % 128 != 0 for backward( Tri beat me to it a4f148b6ab)
- [x] Add determinism warning to BWD, Tri got to this one as well: 1c41d2b
- [x] Update dispatcher to universally prefer FlashV2
- [x] Update tests to exercise new head_dims
- [x] Move the head_dim padding from kernel to top level composite implicit function in order to make it purely functional
- [x] Create template generator script
- [x] Initial cmake support for building kernels/ folder
- [x] Replay CudaGraph changes
### Results
#### Forward only
The TFlops are reported here are on a100 that is underclocked.

#### Forward+Backward
Ran a sweep and for large compute bound sizes we do see a ~2x performance increase for forw+back.
<img width="1684" alt="Screenshot 2023-07-20 at 3 47 47 PM" src="https://github.com/pytorch/pytorch/assets/32754868/fdd26e07-0077-4878-a417-f3a418b6fb3b">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105602
Approved by: https://github.com/huydhn, https://github.com/cpuhrsch
# Summary
## PR Dependencies
I don't use ghstack :( this is a PR where it would have been helpful. That beings said I am going to peel off some PRs to make reviewing this easier:
- [x] Separate build flags for Flash and MemEff: #107985
### Description
This pull request updates the version of _scaled_dot_product_flash_attention from version 1 to version 2. The changes are based on the flash attention code originally authored by @tridao
### Changes Made
The majority of the changes in this pull request involve:
- Copying over the flash_attention sources.
- Updating header files.
- Removing padding and slicing code from within the flash_attention kernel and relocating it to the composite implicit region of the SDPA. This was need to make the kernel functional and appease autograd.
- Introducing a simple kernel generator to generate different instantiations of the forward and backward flash templates.
- Adding conditional compilation (ifdef) to prevent building when nvcc is invoked with gencode < sm80.
- Introducing a separate dependent option for mem_eff_attention, as flash_attention v2 lacks support for Windows and cannot be built for sm50 generation codes.
- Modifying build.sh to reduce parallelization on sm86 runners and to lower the maximum parallelization on the manywheel builds. This adjustment was made to address out-of-memory issues during the compilation of FlashAttentionV2 sources.
- Adding/Updating tests.
### Notes for Reviewers
This is not a fun review, and I apologize in advance.
Most of the files-changed are in the flash_attn/ folder. The only files of interest here IMO:
- aten/src/ATen/native/transformers/cuda/flash_attn/flash_api.cpp
- aten/src/ATen/native/transformers/cuda/flash_attn/kernels/generate_kernels.py ( this has been incorporated upstream to flash-attention github)
There are a number of files all related to avoiding OOMs in CI/CD. These are typically shell scripts.
### Follow up items
- Include the updates from e07aa036db and 9e5e8bc91e | https://github.com/pytorch/pytorch/issues/108108
### Work Items
- [x] I don't think Windows will be supported for 3.1.0 - Need to update cmakee
- [x] Let multi_query/attention pass through and test | UPDATE: I have the fast path implemented here: https://github.com/pytorch/pytorch/pull/106730 but since this will require changes to semantics of math to call repeat_interleave, I think this should be done as a followup.
- [x] Had to drop cutlass back to 3.0.0 to get it to compile. Need to figure out how to upgrade to 3.1.0 and later. Spoke with Tri and he is going to be taking a look. Note: compiling with clang currently errors for the cute headers.
- [x] Update test exercise above codepath
- [x] Still need to disable on seq_len % 128 != 0 for backward( Tri beat me to it a4f148b6ab)
- [x] Add determinism warning to BWD, Tri got to this one as well: 1c41d2b
- [x] Update dispatcher to universally prefer FlashV2
- [x] Update tests to exercise new head_dims
- [x] Move the head_dim padding from kernel to top level composite implicit function in order to make it purely functional
- [x] Create template generator script
- [x] Initial cmake support for building kernels/ folder
- [x] Replay CudaGraph changes
### Results
#### Forward only
The TFlops are reported here are on a100 that is underclocked.

#### Forward+Backward
Ran a sweep and for large compute bound sizes we do see a ~2x performance increase for forw+back.
<img width="1684" alt="Screenshot 2023-07-20 at 3 47 47 PM" src="https://github.com/pytorch/pytorch/assets/32754868/fdd26e07-0077-4878-a417-f3a418b6fb3b">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105602
Approved by: https://github.com/huydhn, https://github.com/cpuhrsch
We have a plethora of error types for various errors raised from c10d. These include `RuntimeError`, `TimeoutError`, `SocketError`, `DistBackendError` etc.
This results in messy code during error handling somewhat like this:
```
if "NCCL" in exception_str:
...
if "Timed out initializing process group in store based barrier on rank" in exception_str:
...
if "The client socket has timed out after" in exception_str:
...
if "Broken pipe" in exception_str:
...
if "Connection reset by peer" in exception_str:
...
```
To address this issue, in this PR I've ensured added these error types:
1. **DistError** - the base type of all distributed errors
2. **DistBackendError** - this already existed and referred to PG backend errors
3. **DistStoreError** - for errors originating from the store
4. **DistNetworkError** - for general network errors coming from the socket library
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108191
Approved by: https://github.com/H-Huang
We have a plethora of error types for various errors raised from c10d. These include `RuntimeError`, `TimeoutError`, `SocketError`, `DistBackendError` etc.
This results in messy code during error handling somewhat like this:
```
if "NCCL" in exception_str:
...
if "Timed out initializing process group in store based barrier on rank" in exception_str:
...
if "The client socket has timed out after" in exception_str:
...
if "Broken pipe" in exception_str:
...
if "Connection reset by peer" in exception_str:
...
```
To address this issue, in this PR I've ensured added these error types:
1. **DistError** - the base type of all distributed errors
2. **DistBackendError** - this already existed and referred to PG backend errors
3. **DistStoreError** - for errors originating from the store
4. **DistNetworkError** - for general network errors coming from the socket library
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107651
Approved by: https://github.com/H-Huang
Feature RFC: https://github.com/pytorch/rfcs/pull/56.
The flash attention CPU kernel is added, for forward path FP32. Blocking is applied on dimensions of query length and kv length and the fusion of gemm + softmax update + gemm is done at once for each block. Parallelization is on the dimensions of batch size, head number and query length. In addition, the causal attention mask is supported. As the attention is masked for the unseen tokens, early termination is applied and we only calculate the blocks in the lower triangular part.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103826
Approved by: https://github.com/drisspg, https://github.com/jgong5
ghstack dependencies: #104583, #104584
Fixes #ISSUE_NUMBER
as the title, add context support for custom device and testcase.
And in the future, we may want to refactor these hooks for different device to unify the APIs, would you agree my
idea? @albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105056
Approved by: https://github.com/albanD
This branch:
1) converts the autograd tape into an FX graph
2) caches that conversion using a "shadow" graph
3) compiles and runs the generated FX graph instead of the normal autograd
What works currently:
1) Caching, capture, and initial integration
2) Backwards hooks
3) Inlining AotAutograd generated subgraphs
4) torch.compiling the generated FX graph
5) Auto-detecting dynamic shapes based on changes
Future work
1) Larger scale testing
1) Boxed calling convention, so memory can be freed incrementally
1) Support hooks on SavedTensor
1) Additional testing by running eager autograd tests under compiled_autograd.enable()
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103822
Approved by: https://github.com/ezyang, https://github.com/albanD
**Summary**
- Update the quantization document that default qconfig with oneDNN backend is recommended to be used on CPUs with Vector Neural Network Instruction support.
- Add the warning message when user uses default qconfig with oneDNN backend on CPU without Vector Neural Network Instruction support.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103653
Approved by: https://github.com/jgong5, https://github.com/malfet
At high current implementation of constrains functions (constrain_as_**) will raise exception for the following code snippets:
```
def f(x):
a = x.item()
constrain_as_size(a, 4, 7)
return torch.empty((a, 4))
inp = torch.tensor([5])
ep = torch._export.export(f, (inp,))
```
The reason is because current constrain logic is:
1) Purely python so it won't survive AOT export (the full node is gone after AOT export since AOT export only maintains aten level op).
2) Utilize side effect to add range constraints for traced symbol's shape env ([code](9591e52880/torch/fx/experimental/symbolic_shapes.py (L370-L372))).
3) If runtime assertion is turned on (by default). [`_AddRuntimeAssertionsForConstraintsPass`](9591e52880/torch/_export/passes/add_runtime_assertions_for_constraints_pass.py (L98-L100)) will try to append assertion node based on range constrains extracted from shape env of symbol during another interpretation round.
4). However, since 1), in the round of AOT export, range constraints logic won't run for symbols generated during this round. And later there is no range constrains information available for assertion round and caused issue.
5) As a result of above, it will failure at `torch.empty((a, 4))` (there is no constrains for `a` that it must be positive).
The fix here is just to implement range constrain logic as a native aten op (CPU implementation as no-op) to make it be able to survive AOT export.
**NOTE:**
[Logic](2d745b95d7/torch/fx/experimental/symbolic_shapes.py (L350-L365C15)) within [`constrain_range`](2d745b95d7/torch/fx/experimental/symbolic_shapes.py (LL313C74-L313C74)) is split out as `constrain_range_int` to capture case when non `SymInt` is passed in and reused in the new `_constrain_range`. The reason is when non `SymInt` is provided:
* If it directly calls `sym_constrain_range`, the C++ version will be called which will be no-op.
* So in this case it calls `constrain_range_int` instead to be able to capture issue like user provides a input whose tensor's shape could be out of range during exporting, like the following for above code example:
```
...
inp = torch.tensor([10])
ep = torch._export.export(f, (inp,)) # immediately raise error
```
Differential Revision: [D46734204](https://our.internmc.facebook.com/intern/diff/D46734204)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103346
Approved by: https://github.com/tugsbayasgalan
Now, when you do an inplace mutation and the view is naughty, you get this message:
```
RuntimeError: A view was created in no_grad mode and is being modified inplace with grad mode enabled. Given that this use case is ambiguous and error-prone, it is forbidden. You can clarify your code by moving both the view and the inplace either both inside the no_grad block (if you don't want the inplace to be tracked) or both outside (if you want the inplace to be tracked). To find out where this view was allocated, run your entire forward region under anomaly mode (torch.autograd.detect_anomaly(check_nan=False)).
```
When you run under anomaly mode, you get:
```
RuntimeError: A view was created in no_grad mode and is being modified inplace with grad mode enabled. Given that this use case is ambiguous and error-prone, it is forbidden. You can clarify your code by moving both the view and the inplace either both inside the no_grad block (if you don't want the inplace to be tracked) or both outside (if you want the inplace to be tracked). This view was allocated at:
File "/data/users/ezyang/c/pytorch/test/test_autograd.py", line 4299, in arglebargle
File "/data/users/ezyang/c/pytorch/test/test_autograd.py", line 4306, in test_anomaly_gives_view_stack
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/case.py", line 549, in _callTestMethod
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/case.py", line 591, in run
File "/data/users/ezyang/c/pytorch/torch/testing/_internal/common_utils.py", line 2266, in _run_with_retry
File "/data/users/ezyang/c/pytorch/torch/testing/_internal/common_utils.py", line 2337, in run
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/case.py", line 650, in __call__
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/suite.py", line 122, in run
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/suite.py", line 84, in __call__
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/suite.py", line 122, in run
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/suite.py", line 84, in __call__
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/runner.py", line 184, in run
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/main.py", line 271, in runTests
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/main.py", line 101, in __init__
File "/data/users/ezyang/c/pytorch/torch/testing/_internal/common_utils.py", line 894, in run_tests
File "/data/users/ezyang/c/pytorch/test/test_autograd.py", line 11209, in <module>
```
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103185
Approved by: https://github.com/zdevito
In this stack of PRs we adding caching to output tensors for cudagraph trees after we've done initial recording. On initial recording we do not cache tensor outputs because this prevents memory from being reclaimed. On subsequent exeuctions we do cache them to avoid overhead. However, because there is an extra reference around, this caused divergent recording & execution behavior in both autocast caching and autograd gradient stealing. Divergent recording & execution would keep on re-recording and eventually stabilize, but it's not what you want to see happen.
This pr makes the autocast cache and buffer stealing aware of the cudagraph static output tensors.
I will add this to the other cudagraph impl in another pr.
Not sure if this should be in autograd or in autocast since it affects both.. Or somewhere else
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99368
Approved by: https://github.com/albanD, https://github.com/ezyang
Summary:
Original commit changeset: ba36f8751adc
Original Phabricator Diff: D44788697
Test Plan: model loading is fine after reverting the diff
Reviewed By: zyan0, sayitmemory
Differential Revision: D44921259
---
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99168
Approved by: https://github.com/izaitsevfb
This refactors the stack trace facility specific to memory profiling
in python+cuda to make a generic facility to generate combined stack
traces.
The generic facility (combined_traceback.h) does not require
python to be around to work, but will return python stacks if it is
present.
This facility is then used to add support for stack trace gathering in memory profiling that
happens directly from C++.
It is also used to expose a python API for gathering and symbolizing
combineds stacks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95541
Approved by: https://github.com/ezyang
Fixes internal linking problem after `DECLARE_DISPATCH` was introduced in SparseTensorUtils.cpp, but implemented inside the native library.
Also, fix `sign-unsigned` compare in `_flatten_indices_impl`
Followups:
Move code declared/implemented in `SparseTensorUtils.*` to `at::native` namespace
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96696
Approved by: https://github.com/albanD
Adds the ability to quickly generate stack traces for C++,
and combine Python, TorchScript, and C++ frames into a single trace.
This makes it possible for the memory tracer to record allocations inside
C++ code (e.g. convolution temporaries, backward operators).
The unwinder code is ~10x faster than execinfo.h's backward because it
cache fast unwinder routines for instruction pointers that have already been seen.
It is also only 1.2--2x slower than copying the entire stack (the approach perf takes),
while using 2 orders of magnitude less space per stack.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95357
Approved by: https://github.com/bertmaher
This patch is aimed to add support to XPU profiler which will co-work with Kineto. After this PR, kineto will follow these API to fit itself. Also, the development of interface in python is near done.
Signed-off-by: Huang, Xunsong <xunsong.huang@intel.com>
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94502
Approved by: https://github.com/ezyang
**Summary**: This PR adds C++ stacktraces to jit::ErrorReports. After this PR, if you run with `TORCH_SHOW_CPP_STACKTRACES=1` environment variable and a jit::ErrorReport is thrown, then the C++ stacktrace should be displayed.
**More background**: This behavior already occurs for c10::Error; but not for jit::ErrorReport. jit::ErrorReport _does_ usually have a python stacktrace for the python source, but it is sometimes still helpful to know where in the C++ codebase the error came from.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94842
Approved by: https://github.com/qihqi
- This PR is a prerequisite for the upcoming Memory Leak Detection PR.
- Enable global manual seeding via `torch.manual_seed()` + test case
- Add `torch.mps.synchronize()` to wait for MPS stream to finish + test case
- Enable the following python interfaces for MPS:
`torch.mps.[get_rng_state(), set_rng_state(), synchronize(), manual_seed(), seed()]`
- Added some test cases in test_mps.py
- Added `mps.rst` to document the `torch.mps` module.
- Fixed the failure with `test_public_bindings.py`
Description of new files added:
- `torch/csrc/mps/Module.cpp`: implements `torch._C` module functions for `torch.mps` and `torch.backends.mps`.
- `torch/mps/__init__.py`: implements Python bindings for `torch.mps` module.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94417
Approved by: https://github.com/albanD
- This PR is a prerequisite for the upcoming Memory Leak Detection PR.
- Enable global manual seeding via `torch.manual_seed()` + test case
- Add `torch.mps.synchronize()` to wait for MPS stream to finish + test case
- Enable the following python interfaces for MPS:
`torch.mps.[get_rng_state(), set_rng_state(), synchronize(), manual_seed(), seed()]`
- Added some test cases in test_mps.py
- Added `mps.rst` to document the `torch.mps` module.
- Fixed the failure with `test_public_bindings.py`
Description of new files added:
- `torch/csrc/mps/Module.cpp`: implements `torch._C` module functions for `torch.mps` and `torch.backends.mps`.
- `torch/mps/__init__.py`: implements Python bindings for `torch.mps` module.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94417
Approved by: https://github.com/albanD
### Motivation of this PR
This patch is to migrate `spmm_reduce` from `torch-sparse` (a 3rd party dependency for PyG) to `torch`, which is a response to the initial proposal for fusion of **Gather, Apply Scatter** in Message Passing of GNN inference/training. https://github.com/pytorch/pytorch/issues/71300
**GAS** is the major step for Message Passing, the behavior of **GAS** can be classified into 2 kinds depending on the storage type of `EdgeIndex` which records the connections of nodes:
* COO: the hotspot is `scatter_reduce`
* CSR: the hotspot is `spmm_reduce`
The reduce type can be choose from: "max", "mean", "max", "min".
extend `torch.sparse.mm` with an `reduce` argument, maps to `torch.sparse_mm.reduce` internally.
`sparse_mm_reduce` is registered under the TensorTypeId of `SparseCsrCPU`, and this operator requires an internal interface `_sparse_mm_reduce_impl` which has dual outputs:
* `out` - the actual output
* `arg_out` - records output indices in the non zero elements if the reduce type is "max" or "min", this is only useful for training. So for inference, it will not be calculated.
### Performance
Benchmark on GCN for obgn-products on Xeon single socket, the workload is improved by `4.3x` with this patch.
Performance benefit for training will be bigger, the original backward impl for `sum|mean` is sequential; the original backward impl for `max|min` is not fused.
#### before:
```
----------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
----------------------------- ------------ ------------ ------------ ------------ ------------ ------------
torch_sparse::spmm_sum 97.09% 56.086s 97.09% 56.088s 6.232s 9
aten::linear 0.00% 85.000us 1.38% 795.485ms 88.387ms 9
aten::matmul 0.00% 57.000us 1.38% 795.260ms 88.362ms 9
aten::mm 1.38% 795.201ms 1.38% 795.203ms 88.356ms 9
aten::relu 0.00% 50.000us 0.76% 440.434ms 73.406ms 6
aten::clamp_min 0.76% 440.384ms 0.76% 440.384ms 73.397ms 6
aten::add_ 0.57% 327.801ms 0.57% 327.801ms 36.422ms 9
aten::log_softmax 0.00% 23.000us 0.10% 55.503ms 18.501ms 3
```
#### after
```
----------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
----------------------------- ------------ ------------ ------------ ------------ ------------ ------------
aten::spmm_sum 87.35% 11.826s 87.36% 11.827s 1.314s 9
aten::linear 0.00% 92.000us 5.87% 794.451ms 88.272ms 9
aten::matmul 0.00% 62.000us 5.87% 794.208ms 88.245ms 9
aten::mm 5.87% 794.143ms 5.87% 794.146ms 88.238ms 9
aten::relu 0.00% 53.000us 3.35% 452.977ms 75.496ms 6
aten::clamp_min 3.35% 452.924ms 3.35% 452.924ms 75.487ms 6
aten::add_ 2.58% 348.663ms 2.58% 348.663ms 38.740ms 9
aten::argmax 0.42% 57.473ms 0.42% 57.475ms 14.369ms 4
aten::log_softmax 0.00% 22.000us 0.39% 52.605ms 17.535ms 3
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83727
Approved by: https://github.com/jgong5, https://github.com/cpuhrsch, https://github.com/rusty1s, https://github.com/pearu
This PR is the first step towards refactors the build for nvfuser in order to have the coegen being a standalone library.
Contents inside this PR:
1. nvfuser code base has been moved to `./nvfuser`, from `./torch/csrc/jit/codegen/cuda/`, except for registration code for integration (interface.h/interface.cpp)
2. splits the build system so nvfuser is generating its own `.so` files. Currently there are:
- `libnvfuser_codegen.so`, which contains the integration, codegen and runtime system of nvfuser
- `nvfuser.so`, which is nvfuser's python API via pybind. Python frontend is now exposed via `nvfuser._C.XXX` instead of `torch._C._nvfuser`
3. nvfuser cpp tests is currently being compiled into `nvfuser_tests`
4. cmake is refactored so that:
- nvfuser now has its own `CMakeLists.txt`, which is under `torch/csrc/jit/codegen/cuda/`.
- nvfuser backend code is not compiled inside `libtorch_cuda_xxx` any more
- nvfuser is added as a subdirectory under `./CMakeLists.txt` at the very end after torch is built.
- since nvfuser has dependency on torch, the registration of nvfuser at runtime is done via dlopen (`at::DynamicLibrary`). This avoids circular dependency in cmake, which will be a nightmare to handle. For details, look at `torch/csrc/jit/codegen/cuda/interface.cpp::LoadingNvfuserLibrary`
Future work that's scoped in following PR:
- Currently since nvfuser codegen has dependency on torch, we need to refactor that out so we can move nvfuser into a submodule and not rely on dlopen to load the library. @malfet
- Since we moved nvfuser into a cmake build, we effectively disabled bazel build for nvfuser. This could impact internal workload at Meta, so we need to put support back. cc'ing @vors
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89621
Approved by: https://github.com/davidberard98
For the cudagraphs implementation, we would like to reuse objects that are defined in python across the forward and backward. The backward is run in a different thread, so to handle this we add an api for copying over arbitrary python objects in pytorch's thread local state, in the same way that C++ objects are copied over currently.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89169
Approved by: https://github.com/albanD
This reverts commit e525f433e1.
Original PR: #85849
Fixes #ISSUE_NUMBER
In addition to reverting the revert, this PR:
- defines the virtual destructor of FunctionPreHook in the header. Why? Presumably the internal build imports the header from somewhere, but does not have function_hooks.cpp (where the virtual destructor was previously defined) in the same compilation unit.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92559
Approved by: https://github.com/albanD
### Target and Background
This PR is improving the performance of `sampled_addmm` on CPU device. This is part of effort for improving PyG performance on CPU for GNN training/inference.
The current implementation is a reference design which converts `SparseCSR` tensor back to dense tensor and then do the addmm and convert back to `SparseCSR` again: this is going to be very slow and won't be able to run most of the datasets under https://github.com/snap-stanford/ogb (convert to dense would trigger `OOM`).
### Benchmarks
Right now we don't have any hands-on benchmark or workload to test this since this operator is not used in PyG yet. I fetched the dataset from `ogb-products` where:
* number of nodes: 2.4 * 10^6
* number of edges: 1.26 * 10^8
* number of features: 128
So if we store the **adjacency matrix** is dense, it is going to be 2.4 * 2.4 * 4 * 10^12 bytes, this will be OOB on current code. I abstract the first 1k rows to compare, **1100x** speedup:
CPU: Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz, dual socket, 20 cores per socket.
```
### before: run 1000 rows from the whole dataset
sampled_addmm: running dataset ogb-products first 1000 rows: each iter takes 1212.000 ms!
### after: run 1000 rows from the whole dataset
sampled_addmm: running dataset ogb-products first 1000 rows: each iter takes 1.102 ms!
### after: run the whole dataset
sampled_addmm: running dataset ogb-products (the whole dataset) 2449029 rows: each iter takes 873.306 ms!
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90978
Approved by: https://github.com/pearu, https://github.com/cpuhrsch
We have an older torch.vmap implementation. It is no longer supported.
It still needs to exist somewhere for the sake of BC with
torch.autograd.functional.
This PR makes it clear what files are meant for implementing the old
vmap implementation. I've seen a couple of PRs recently adding support
for the old vmap implementation, so this will lessen the confusion.
Test Plan:
- CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90324
Approved by: https://github.com/samdow
Fixes#43144
This uses the Backend system added by [82682](https://github.com/pytorch/pytorch/pull/82682) to change allocators dynamically during the code execution. This will allow us to use RMM, use CUDA managed memory for some portions of the code that do not fit in GPU memory. Write static memory allocators to reduce fragmentation while training models and improve interoperability with external DL compilers/libraries.
For example, we could have the following allocator in c++
```c++
#include <sys/types.h>
#include <cuda_runtime_api.h>
#include <iostream>
extern "C" {
void* my_malloc(ssize_t size, int device, cudaStream_t stream) {
void *ptr;
std::cout<<"alloc "<< size<<std::endl;
cudaMalloc(&ptr, size);
return ptr;
}
void my_free(void* ptr) {
std::cout<<"free "<<std::endl;
cudaFree(ptr);
}
}
```
Compile it as a shared library
```
nvcc allocator.cc -o alloc.so -shared --compiler-options '-fPIC'
```
And use it from PyTorch as follows
```python
import torch
# Init caching
# b = torch.zeros(10, device='cuda')
new_alloc = torch.cuda.memory.CUDAPluggableAllocator('alloc.so', 'my_malloc', 'my_free')
old = torch.cuda.memory.get_current_allocator()
torch.cuda.memory.change_current_allocator(new_alloc)
b = torch.zeros(10, device='cuda')
# This will error since the current allocator was already instantiated
torch.cuda.memory.change_current_allocator(old)
```
Things to discuss
- How to test this, needs compiling external code ...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86786
Approved by: https://github.com/albanD
Summary: This diff merges both previous implementations of constructors for nested tensors, the one from lists of tensors and the one with arbitrary python lists, adn implements it in pytorch core so no extensions are needed to construct NT.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88213
Approved by: https://github.com/cpuhrsch
Syncing nvfuser devel branch to upstream master. https://github.com/csarofeen/pytorch/
Codegen changes include:
* codegen improvement:
i. allow non-root trivial reductions, allow empty/no-op fusion
ii. fixes vectorization checks and size calculation
iii. bank conflict handle improvement
iv. enables transpose scheduler
* misc:
i. CI tests failure fixes
ii. cpp tests file clean up
iii. trivial forwarding supports added in codegen runtime
iv. added factory methods support in codegen
Commits that's in this PR from the devel branch:
```
7117a7e37ebec372d9e802fdfb8abb7786960f4a patching nvfuser conv cudnn test numerics mismatch (#2048)
65af1a4e7013f070df1ba33701f2d524de79d096 Inserting sync for redundant parallel types is already done at the (#2023)
6ac74d181689c8f135f60bfc1ec139d88941c98c Fix sync map (#2047)
f5bca333355e2c0033523f3402de5b8aac602c00 Bank conflict checker improvements (#2032)
d2ca7e3fd203537946be3f7b435303c60fa7f51e Minor update on cp.async code generation. (#1901)
d36cf61f5570c9c992a748126287c4e7432228e0 Test file cleanup (#2040)
0b8e83f49c2ea9f04a4aad5061c1e7f4268474c6 Allow non-root trivial reductions (#2037)
a2dfe40b27cd3f5c04207596f0a1818fbd5e5439 Fix vectorize size calculation (#2035)
e040676a317fe34ea5875276270c7be88f6eaa56 Use withPredicate to replace setPredicate to maintain Exprs immutable (#2025)
197221b847ad5eb347d7ec1cf2706733aacbf97c removing ci workflow (#2034)
40e2703d00795526e7855860aa00b9ab7160755f Reduction rand like patch (#2031)
bc772661cbdb3b711d8e9854ae9b8b7052e3e4a3 Add utility for checking bank conflict of shared memory (#2029)
ddd1cf7695f3fb172a0e4bcb8e4004573617a037 Add back FusionReductionWithTrivialReduction_CUDA (#2030)
fbd97e5ef15fa0f7573800e6fbb5743463fd9e57 Revert "Cleanup trivial reduction workarounds (#2006)" (#2024)
bca20c1dfb8aa8d881fc7973e7579ce82bc6a894 Cleanup trivial reduction workarounds (#2006)
e4b65850eee1d70084105bb6e1f290651adde23e Trivial forwarding (#1995)
1a0e355b5027ed0df501989194ee8f2be3fdd37a Fix contiguity analysis of predicates to match updated contiguity. (#1991)
a4effa6a5f7066647519dc56e854f4c8a2efd2a7 Enable output allocation cache (#2010)
35440b7953ed8da164a5fb28f87d7fd760ac5e00 Patching bn inference (#2016)
0f9f0b4060dc8ca18dc65779cfd7e0776b6b38e8 Add matmul benchmark (#2007)
45045cd05ea268f510587321dbcc8d7c2977cdab Enable tests previously disabled due to an aliasing bug (#2005)
967aa77d2c8e360c7c01587522eec1c1d377c87e Contiguous indexing for View operations (#1990)
a43cb20f48943595894e345865bc1eabf58a5b48 Make inlining even more modular (#2004)
dc458358c0ac91dfaf4e6655a9b3fc206fc0c897 Test util cleanup (#2003)
3ca21ebe4d213f0070ffdfa4ae5d7f6cb0b8e870 More strict validation (#2000)
a7a7d573310c4707a9f381831d3114210461af01 Fix build problem (#1999)
fc235b064e27921fa9d6dbb9dc7055e5bae1c222 Just fixes comments (#1998)
482386c0509fee6edb2964c5ae72074791f3e43a cleanup (#1997)
4cbe0db6558a82c3097d281eec9c85ad2ea0893a Improve divisible split detection (#1970)
42ccc52bdc18bab0330f4b93ed1399164e2980c9 Minor build fix. (#1996)
fcf8c091f72d46f3055975a35afd06263324ede6 Cleanup of lower_utils.cpp: Isolate out GpuLower usage (#1989)
15f2f6dba8cbf408ec93c344767c1862c30f7ecc Move ConcretizedBroadcastDomains to shared_ptr in GpuLower. (#1988)
8f1c7f52679a3ad6acfd419d28a2f4be4a7d89e2 Minor cleanup lower_unroll.cpp (#1994)
1d9858c80319ca7f0037db7de5f04e47f540d76c Minor cleanup (#1992)
f262d9cab59f41c669f53799c6d4a6b9fc4267eb Add support for uniform RNG (#1986)
eb1dad10c73f855eb1ecb20a8b1f7b6edb0c9ea3 Remove non-const functions, remove GpuLower instance on build, pass in ca_map. (#1987)
634820c5e3586c0fe44132c51179b3155be18072 Add support for some empty fusion (#1981)
eabe8d844ad765ee4973faa4821d451ef71b83c3 Segment self mapping fusions (#1954)
e96aacfd9cf9b3c6d08f120282762489bdf540c8 Enable Transpose operation (#1882)
425dce2777420248e9f08893765b5402644f4161 Add a null scheduler that helps segmenting away no-op schedules (#1835)
306d4a68f127dd1b854b749855e48ba23444ba60 Fix canScheduleCompileTime check of transpose scheduler (#1969)
b1bd32cc1b2ae7bbd44701477bddbcfa6642a9be Minor fix (#1967)
bd93578143c1763c1e00ba613a017f8130a6b989 Enable transpose scheduler (#1927)
b7a206e93b4ac823c791c87f12859cf7af264a4c Move scheduler vectorize utilities into their own file (#1959)
d9420e4ca090489bf210e68e9912bb059b895baf View scheduling (#1928)
c668e13aea0cf21d40f95b48e0163b812712cdf2 Upstream push ci fixes (#1965)
c40202bb40ce955955bb97b12762ef3b6b612997 Fix dump effective bandwidth (#1962)
93505bcbb90a7849bd67090fe5708d867e8909e4 WAR on index mapping when exact and permissive maps differ (#1960)
45e95fd1d3c773ee9b2a21d79624c279d269da9f Allow splitting inner-most ID to create virtual innermost ID in transpose scheduler (#1930)
a3ecb339442131f87842eb56955e4f17c544e99f Improve the comments at the beginning of index_compute.h (#1946)
f7bc3417cc2923a635042cc6cc361b2f344248d6 Remove unused variables (#1955)
df3393adbb5cb0309d091f358cfa98706bd4d313 Some cleanup (#1957)
7d1d7c8724ab5a226fad0f5a80feeac04975a496 TVDomainGuard factory (#1953)
357ba224c0fb41ed3e4e8594d95599c973f4a0ca Fill allocation with nan on tests (#1956)
8eafc54685d406f5ac527bcbacc475fda4492d7a Fix detection of unmappable root domains (#1952)
90a51f282601ba8ebd4c84b9334efd7762a234bc Some indexing cleanups, Add eye support (#1940)
ddc01e4e16428aec92f9c84d698f959b6436a971 Exclude unsupported data types (#1951)
992e17c0688fe690c51b50e81a75803621b7e6aa test the groups the same order as they are merged (#1949)
208262b75d1fed0597a0329d61d57bc8bcd7ff14 Move detection of self mapping IDs to IterDomainGraph from (#1941)
ac4de38c6ee53b366e85fdfe408c3642d32b57df Merge pull request #1945 from csarofeen/master_merge_0828
631094891a96f715d8c9925fb73d41013ca7f2e3 Add full, full_like, zeros, zeros_like, ones, ones_like (#1943)
aab10bce4541204c46b91ff0f0ed9878aec1bfc4 Merge remote-tracking branch 'upstream/viable/strict' into HEAD
4c254c063bb55887b45677e3812357556a7aa80d Fix arange when step is negative (#1942)
89330aa23aa804340b2406ab58899d816e3dc3d2 Tensor factories must set the output shape as its input (#1939)
```
RUN_TORCHBENCH: nvfuser
Differential Revision: [D40869846](https://our.internmc.facebook.com/intern/diff/D40869846)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87779
Approved by: https://github.com/davidberard98
* Add support to use Linux kernel perf subsystem via the profiler.
* For now the perf configurability is quite limited to just event names. Threading etc. to come later.
* Given we want to support variety of different cpu types, number of events list (in addition to the standard set of events) is also limited.
* Rather than failing with unsupported feature for non-Linux platforms, it returns zeros for all the event counts.
* For now, max event counts is capped at 4, time multiplexing is not allowed.
* Threadpool recreate hack is restricted to mobile only - need to add better support for threading in general
Differential Revision: [D40238033](https://our.internmc.facebook.com/intern/diff/D40238033/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D40238033/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87866
Approved by: https://github.com/SS-JIA
This refactor was prompted by challenges handling mixed int/float
operations in C++. A previous version of this patch
added overloads for each permutation of int/float and was unwieldy
https://github.com/pytorch/pytorch/pull/87722/ This PR takes a different
approach.
The general outline of the patch is to combine the C++ types SymIntNode
and SymFloatNode into a single type, SymNode. This is type erased; we
no longer know statically at C++ if we have an int/float and have to test
it with the is_int()/is_float() virtual methods. This has a number of
knock on effects.
- We no longer have C++ classes to bind to Python. Instead, we take an
entirely new approach to our Python API, where we have a SymInt/SymFloat
class defined entirely in Python, which hold a SymNode (which corresponds
to the C++ SymNode). However, SymNode is not pybind11-bound; instead,
it lives as-is in Python, and is wrapped into C++ SymNode using PythonSymNode
when it goes into C++. This implies a userland rename.
In principle, it is also possible for the canonical implementation of SymNode
to be written in C++, and then bound to Python with pybind11 (we have
this code, although it is commented out.) However, I did not implement
this as we currently have no C++ implementations of SymNode.
Because we do return SymInt/SymFloat from C++ bindings, the C++ binding
code needs to know how to find these classes. Currently, this is done
just by manually importing torch and getting the attributes.
- Because SymInt/SymFloat are easy Python wrappers, __sym_dispatch__ now
takes SymInt/SymFloat, rather than SymNode, bringing it in line with how
__torch_dispatch__ works.
Some miscellaneous improvements:
- SymInt now has a constructor that takes SymNode. Note that this
constructor is ambiguous if you pass in a subclass of SymNode,
so an explicit downcast is necessary. This means toSymFloat/toSymInt
are no more. This is a mild optimization as it means rvalue reference
works automatically.
- We uniformly use the caster for c10::SymInt/SymFloat, rather than
going the long way via the SymIntNode/SymFloatNode.
- Removed some unnecessary toSymInt/toSymFloat calls in normalize_*
functions, pretty sure this doesn't do anything.
- guard_int is now a free function, since to guard on an int you cannot
assume the method exists. A function can handle both int and SymInt
inputs.
- We clean up the magic method definition code for SymInt/SymFloat/SymNode.
ONLY the user classes (SymInt/SymFloat) get magic methods; SymNode gets
plain methods; this is to help avoid confusion between the two types.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
cc @jansel @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87817
Approved by: https://github.com/albanD, https://github.com/anjali411
Summary: This commit adds support for moving NestedTensors from CPU to GPU and back. The implementation includes requires implementing empty_like(), which is based on PR#83140.
Test Plan: Added a new unit test based on the unit test for the main .to() implementation. All unit tests must pass, as well as every sandcastle job.
Differential Revision: D40437585
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87146
Approved by: https://github.com/drisspg
The legacy profiler is an eyesore in the autograd folder. At this point the implementation is almost completely decoupled from the rest of profiler, and it is in maintaince mode pending deprecation.
As a result, I'm moving it to `torch/csrc/profiler/standalone`. Unfortuantely BC requires that the symbols remain in `torch::autograd::profiler`, so I've put some basic forwarding logic in `torch/csrc/autograd/profiler.h`.
One strange bit is that `profiler_legacy.h` forward declares `torch::autograd::Node`, but doesn't seem to do anything with it. I think we can delete it, but I want to test to make sure.
(Note: this should not land until https://github.com/pytorch/torchrec/pull/595 is landed.)
Differential Revision: [D39108648](https://our.internmc.facebook.com/intern/diff/D39108648/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85512
Approved by: https://github.com/aaronenyeshi
There are a number of instrumentation utils which have been added to the profiler toolkit. They are generally small and self contained, often wrapping vendor APIs. (NVTX, ITT)
They don't really interact with the much more expansive machinery of the PyTorch profiler beyond registration / unregistration, minor util sharing, and reusing the profiler base class. Just as in the case of stubs, it makes sense to group them in a dedicated subfolder.
Differential Revision: [D39108649](https://our.internmc.facebook.com/intern/diff/D39108649/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D39108649/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85511
Approved by: https://github.com/albanD
There is a concept in profiler of a stub that wraps a profiling API. It was introduced for CUDA profiling before Kineto, and ITT has adopted it to call into VTune APIs. However for the most part we don't really interact with them when developing the PyTorch profiler.
Thus it makes sense to unify the fallback registration mechanism and create a subfolder to free up real estate in the top level `torch/csrc/profiler` directory.
Differential Revision: [D39108647](https://our.internmc.facebook.com/intern/diff/D39108647/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85510
Approved by: https://github.com/aaronenyeshi
Sometimes the driving process want to save memory snapshots but isn't Python.
Add a simple API to turn it on without python stack traces. It still
saves to the same format for the vizualization and summary scripts, using
the C++ Pickler.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86190
Approved by: https://github.com/ezyang
### About this PR
* Update the broadcast op to dispatch to cpu and cuda implementations. Right now they both perform the same logic so this is essentially a no-op.
* Add test to validate that a separate device implementation is not supported.
### About this stack
In the future we will repurpose ProcessGroup to instead contain a list of Backends (ProcessGroupNCCL/Gloo/UCC) and perform dispatching to them based on tensor type. The CPU and CUDA implementations will be updated to have process group select its CPU and CUDA backends respectively.
Differential Revision: [D38876771](https://our.internmc.facebook.com/intern/diff/D38876771)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83735
Approved by: https://github.com/kwen2501
Syncing nvfuser devel branch to upstream master. https://github.com/csarofeen/pytorch/
Codegen changes include:
- codegen improvement:
i. improved view support on pointwise and transpose scheduler
ii. grouped grid welford added for better outer-norm grid persistence in normalization
- misc:
i. new composite ops added: variance_mean , arange,
ii. fixes misaligned address for transpose scheduler
iii. refactor on separation of compilation API from execution API to prepare us for async compilation
iv. double type support on expression evaluator
v. PYTORCH_NVFUSER_DUMP refactor to save PTX and CUBIN
Commits that's in this PR from the devel branch:
```
89330aa23aa804340b2406ab58899d816e3dc3d2 Tensor factories must set the output shape as its input (#1939)
b2fd01ea9346712c6d6f623ca6addbc4888d008e arange support (#1933)
56c00fd3922dad7dfc57351ad7d780f0f2f8e4ed Double support on all expression evaluators (#1937)
371f28223e57fe3f6b5e50a0a45177e6a5c0785c Improve trivial reduction merge support (#1931)
1d0c26790e5647920b40d419d26815bbe310b3a6 Test `rand` in a fusion with zero tensor input (#1932)
0dab160fb2177d178eef3148c6a529e0855009e9 Fix softmax bwd sizes. (#1890)
ef98f360f6d3e3e1cc662ecb65202d88150f128d Fix a bug (#1936)
63132a0c56508c550084b07fb76a3df865102d00 Propagate permissive mapping information into indexing pass (#1929)
b4ac2c88d78078ee4d8b21c4fc51645b5710a282 Map IterationDomains through view operations. (#1919)
c0a187a7619d7cf9dc920294e15461791e8d6d4d do not use deprecated functions (#1935)
88de85e758c5e4afb7b6e746573c0d9a53b4cea7 Upstream cherry pick fixes 0811 (#1934)
b247dcf7c57dc6ac3f7a799b0a6beb7770536a74 Separate kernel compilation API from kernel execution API (#1914)
b34e3b93ee1a8030730c14af3995dd95665af07d Fix `ir_utils::hasBlockSync` + misc fixes in transpose scheduler (#1924)
14a53e6707f43bf760494c238a46386d69830822 Nullary RNGOp (#1892)
3c3c89e638f5172cafb0761f22bacd1fd695eec3 Misc fixes/tuning for transpose scheduler (#1912)
20cf109c8b44d48f61977e35bae94368985144ac Grouped grid welford (#1921)
6cf7eb024c9e53c358cbe56597e117bad56efefd Transpose scheduler small dim sizes better support (#1910)
9341ea9a5bf42f9b14ccad0c94edbc79fc5bb552 Disabled ViewPersistentShmoo sizes that results in NAN (#1922)
057237f66deeea816bb943d802a97c1b7e4414ab Fix CUDA driver error: misaligned address for transpose scheduler (#1918)
3fb3d80339e4f794767a53eb8fdd61e64cf404a2 Add variance_mean function using Welford (#1907)
98febf6aa3b8c6fe4fdfb2864cda9e5d30089262 Remove DisableOption::UnrollWithRng (#1913)
ee8ef33a5591b534cf587d347af11e48ba7a15d4 Minor fix for the debug interface of using PTX directly (#1917)
6e8f953351f9dabfd1f991d8431cecb6c2ce684d Add PYTORCH_NVFUSER_DUMP options to save PTX and CUBIN (#1916)
5eefa9a72385f6a4b145680a9dcc52d7e8293763 dopt is only available since nvrtc 11.7 (#1915)
2ec8fc711eafc72451eebf0f5e2a98a38bf3f6ef Kill computeAtBetween (#1911)
d0d106a1d9af118d71673173674e875be35d259d Improve view support on pointwise and transpose scheduler (#1906)
e71e1ecefe67219846070590bbed54bbc7416b79 Fix name clash of RNG with shared memory (#1904)
3381793a253689abf224febc73fd3fe2a0dbc921 Fix mutator and sameAs for expanded IterDomain (#1902)
```
RUN_TORCHBENCH: nvfuser
Differential Revision: [D39324552](https://our.internmc.facebook.com/intern/diff/D39324552)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84626
Approved by: https://github.com/malfet
This moves functorch's python bindings to torch/csrc/functorch/init.cpp.
Coming next is the torchdim move. I didn't do torchdim yet because
moving functorch's python bindings unblocks some other things that I
want to do first.
Test Plan:
- tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85426
Approved by: https://github.com/ezyang
{kind=link}
{kind=link}
{kind=link}
{kind=link}
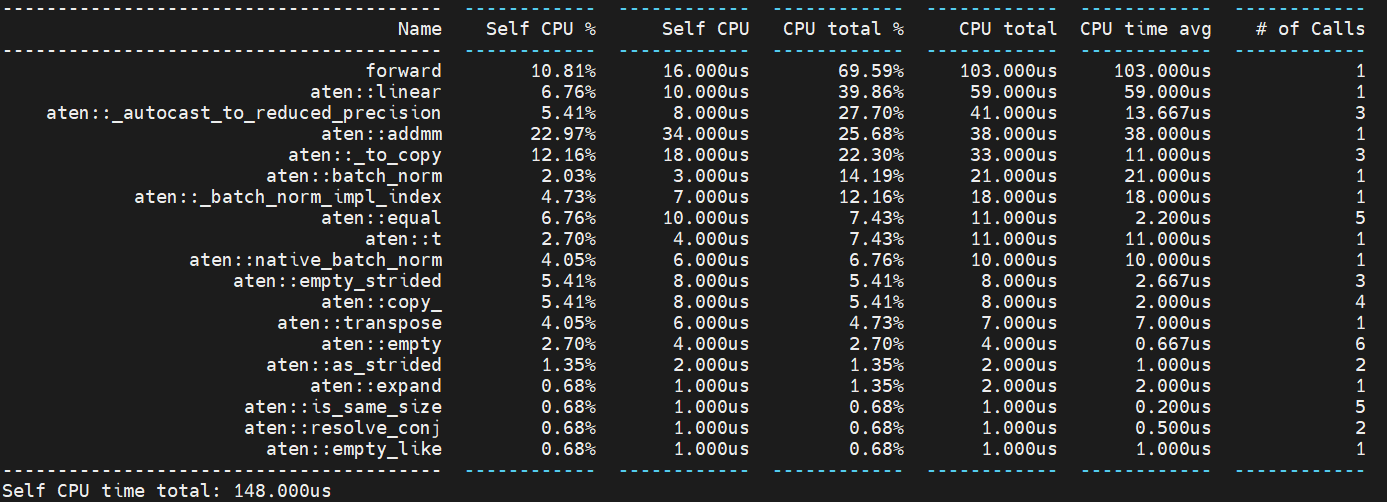{kind=link}
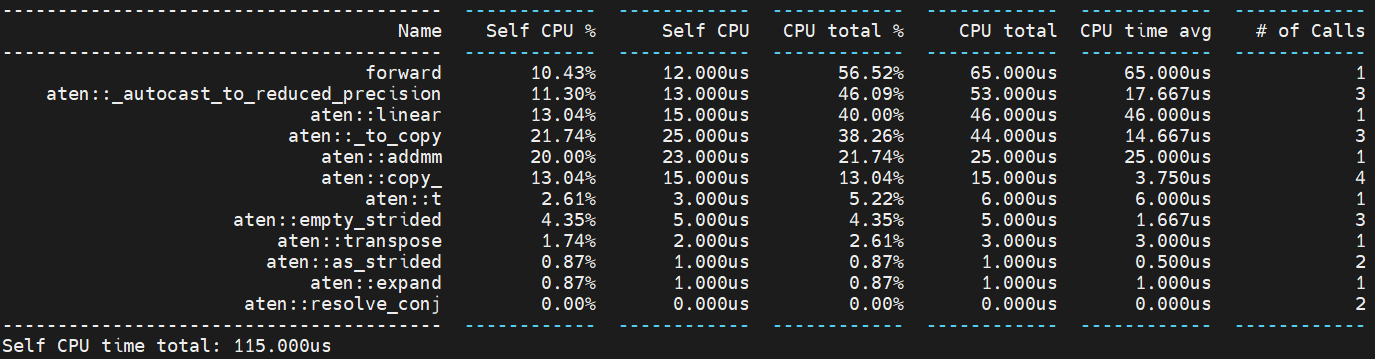{kind=link}
{kind=link}