mirror of
https://github.com/zebrajr/pytorch.git
synced 2025-12-06 12:20:52 +01:00
[JIT] Frozen Graph Linear-BatchNormNd Folding (#86706)
This PR adds linear-batchnormNd folding for JIT frozen graphs. **Performance benchmark** A preliminary benchmark with a simple model of linear+bn1d tested on first socket, physical cores of skylake machine. **FP32, JIT** without linear-bn folding 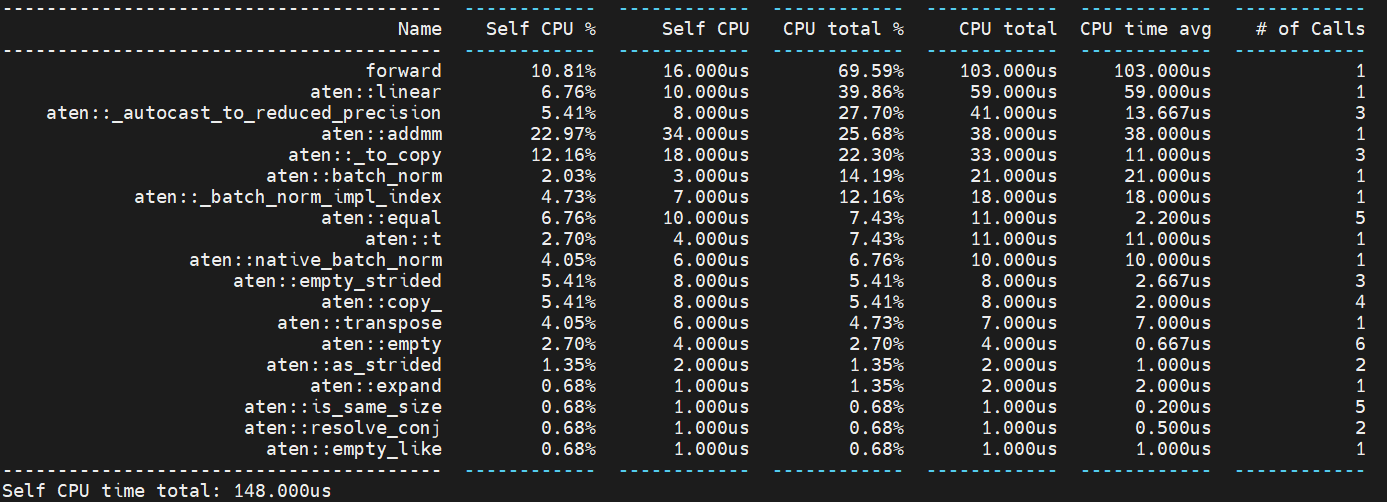 with linear-bn folding 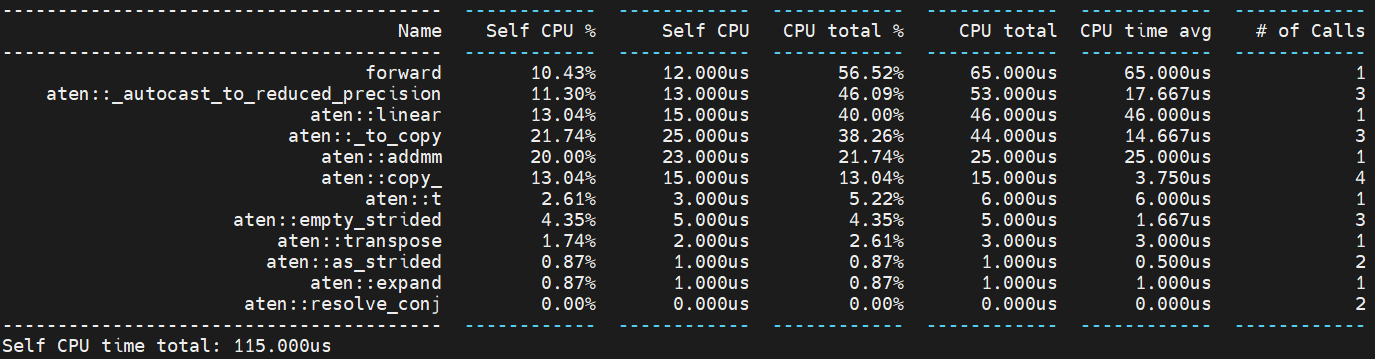 Pull Request resolved: https://github.com/pytorch/pytorch/pull/86706 Approved by: https://github.com/davidberard98
{kind=link}
{kind=link}
This commit is contained in:
parent
1ca9d43d4e
commit
e585156c59
|
|
@ -296,10 +296,12 @@ core_sources_full_mobile_no_backend_interface_xplat = [
|
|||
"torch/csrc/jit/passes/remove_mutation.cpp",
|
||||
"torch/csrc/jit/passes/prepack_folding.cpp",
|
||||
"torch/csrc/jit/passes/fold_conv_bn.cpp",
|
||||
"torch/csrc/jit/passes/fold_linear_bn.cpp",
|
||||
"torch/csrc/jit/passes/dbr_quantization/remove_redundant_aliases.cpp",
|
||||
"torch/csrc/jit/passes/frozen_concat_linear.cpp",
|
||||
"torch/csrc/jit/passes/frozen_conv_add_relu_fusion.cpp",
|
||||
"torch/csrc/jit/passes/frozen_conv_folding.cpp",
|
||||
"torch/csrc/jit/passes/frozen_linear_folding.cpp",
|
||||
"torch/csrc/jit/passes/frozen_linear_transpose.cpp",
|
||||
"torch/csrc/jit/passes/frozen_ops_to_mkldnn.cpp",
|
||||
"torch/csrc/jit/passes/frozen_graph_optimizations.cpp",
|
||||
|
|
|
|||
|
|
@ -2223,6 +2223,107 @@ class TestFrozenOptimizations(JitTestCase):
|
|||
FileCheck().check("conv").check_not("aten::batch_norm").run(traced_model.graph)
|
||||
FileCheck().check("conv").check_not("aten::add").run(traced_model.graph)
|
||||
|
||||
def test_linear_bn_folding(self):
|
||||
module_pairs = [(nn.Linear, nn.BatchNorm1d), (nn.Linear, nn.BatchNorm2d), (nn.Linear, nn.BatchNorm3d)]
|
||||
use_tracing = [True, False]
|
||||
bn_running_stats = [True, False]
|
||||
|
||||
for modules, tracing, track_stats in product(module_pairs, use_tracing, bn_running_stats):
|
||||
class LinearBN(torch.nn.Module):
|
||||
def __init__(self, in_features, out_features):
|
||||
super(LinearBN, self).__init__()
|
||||
self.linear = modules[0](in_features, out_features)
|
||||
self.bn = modules[1](out_features, eps=0.001, track_running_stats=track_stats)
|
||||
|
||||
def forward(self, x):
|
||||
x = self.linear(x)
|
||||
return self.bn(x)
|
||||
|
||||
mod_eager = LinearBN(32, 32).eval()
|
||||
|
||||
inps = [3, 32]
|
||||
if modules[1] == nn.BatchNorm2d:
|
||||
inps.append(inps[-1])
|
||||
inps.append(inps[-1])
|
||||
if modules[1] == nn.BatchNorm3d:
|
||||
inps.append(inps[-1])
|
||||
inps.append(inps[-1])
|
||||
inps.append(inps[-1])
|
||||
|
||||
inp = torch.rand(inps)
|
||||
|
||||
if tracing:
|
||||
scripted_mod = torch.jit.trace(mod_eager, (inp))
|
||||
else:
|
||||
scripted_mod = torch.jit.script(mod_eager)
|
||||
|
||||
self.run_pass("inline", scripted_mod.graph)
|
||||
self.run_pass("peephole", scripted_mod.graph)
|
||||
self.run_pass("constant_propagation", scripted_mod.graph)
|
||||
|
||||
FileCheck().check("linear").check("batch").run(scripted_mod.graph)
|
||||
# successfully no-ops with non-const inputs
|
||||
self.run_pass("fold_frozen_linear_bn", scripted_mod.graph)
|
||||
FileCheck().check("linear").check("aten::batch_norm").run(scripted_mod.graph)
|
||||
|
||||
scripted_mod = torch.jit.freeze(scripted_mod)
|
||||
self.run_pass("fold_frozen_linear_bn", scripted_mod.graph)
|
||||
if track_stats:
|
||||
FileCheck().check("linear").check_not("aten::batch_norm").run(scripted_mod.graph)
|
||||
else:
|
||||
FileCheck().check("linear").check("aten::batch_norm").run(scripted_mod.graph)
|
||||
|
||||
self.assertEqual(mod_eager(inp), scripted_mod(inp))
|
||||
self.assertEqual(mod_eager(inp), scripted_mod(inp))
|
||||
|
||||
@skipCUDAMemoryLeakCheckIf(True)
|
||||
@unittest.skipIf(not TEST_CUDA, "Optimization currently only run for GPU")
|
||||
def test_linear_bn_folding_autocast_scenario_cuda(self):
|
||||
module_pairs = [(nn.Linear, nn.BatchNorm1d), (nn.Linear, nn.BatchNorm2d), (nn.Linear, nn.BatchNorm3d)]
|
||||
use_tracing = [True, False]
|
||||
bn_running_stats = [True, False]
|
||||
|
||||
for modules, tracing, track_stats in product(module_pairs, use_tracing, bn_running_stats):
|
||||
class LinearBN(torch.nn.Module):
|
||||
def __init__(self, in_features, out_features):
|
||||
super(LinearBN, self).__init__()
|
||||
self.linear = modules[0](in_features, out_features, bias=False, dtype=torch.half)
|
||||
self.bn = modules[1](out_features, eps=0.001, dtype=torch.float)
|
||||
|
||||
def forward(self, x):
|
||||
x = self.linear(x)
|
||||
return self.bn(x)
|
||||
|
||||
mod_eager = LinearBN(32, 32).cuda().eval()
|
||||
|
||||
inps = [3, 32]
|
||||
if modules[1] == nn.BatchNorm2d:
|
||||
inps.append(inps[-1])
|
||||
inps.append(inps[-1])
|
||||
if modules[1] == nn.BatchNorm3d:
|
||||
inps.append(inps[-1])
|
||||
inps.append(inps[-1])
|
||||
inps.append(inps[-1])
|
||||
|
||||
x = torch.rand(inps, dtype=torch.half).cuda()
|
||||
|
||||
if tracing:
|
||||
scripted_mod = torch.jit.trace(mod_eager, (x))
|
||||
else:
|
||||
scripted_mod = torch.jit.script(mod_eager)
|
||||
scripted_mod = torch.jit.freeze(scripted_mod)
|
||||
FileCheck().check("linear").check_not("aten::batch_norm").run(scripted_mod.graph)
|
||||
lin_node = scripted_mod.graph.findNode("aten::linear", True)
|
||||
self.assertTrue(lin_node is not None)
|
||||
weight_input = lin_node.namedInput("weight")
|
||||
bias_input = lin_node.namedInput("bias")
|
||||
self.assertTrue(bias_input is not None)
|
||||
self.assertTrue(weight_input.type().dtype() == torch.half)
|
||||
self.assertTrue(bias_input.type().dtype() == torch.half)
|
||||
|
||||
self.assertEqual(mod_eager(x), scripted_mod(x), atol=1e-2, rtol=1e-2)
|
||||
self.assertEqual(mod_eager(x), scripted_mod(x), atol=1e-2, rtol=1e-2)
|
||||
|
||||
@unittest.skipIf(not TEST_CUDA, "Optimization currently only run for GPU")
|
||||
def test_linear_concat(self):
|
||||
out_dimms = [[5, 10], [1, 5]]
|
||||
|
|
|
|||
28
torch/csrc/jit/passes/fold_linear_bn.cpp
Normal file
28
torch/csrc/jit/passes/fold_linear_bn.cpp
Normal file
|
|
@ -0,0 +1,28 @@
|
|||
#include <torch/csrc/jit/passes/fold_linear_bn.h>
|
||||
|
||||
#include <ATen/TensorOperators.h>
|
||||
|
||||
#ifndef AT_PER_OPERATOR_HEADERS
|
||||
#include <ATen/Functions.h>
|
||||
#else
|
||||
#include <ATen/ops/rsqrt.h>
|
||||
#endif
|
||||
|
||||
namespace torch {
|
||||
namespace jit {
|
||||
|
||||
std::tuple<at::Tensor, at::Tensor> computeUpdatedLinearWeightAndBias(
|
||||
const LinearBNParameters& p) {
|
||||
at::Tensor bn_scale = p.bn_w * at::rsqrt(p.bn_rv + p.bn_eps);
|
||||
at::Tensor fused_w = p.linear_w * bn_scale.unsqueeze(-1);
|
||||
at::Tensor fused_b = (p.linear_b - p.bn_rm) * bn_scale + p.bn_b;
|
||||
|
||||
auto linear_w_dtype = p.linear_w.dtype();
|
||||
auto linear_b_dtype = p.linear_b.dtype();
|
||||
|
||||
return std::make_tuple(
|
||||
fused_w.to(linear_w_dtype), fused_b.to(linear_b_dtype));
|
||||
}
|
||||
|
||||
} // namespace jit
|
||||
} // namespace torch
|
||||
29
torch/csrc/jit/passes/fold_linear_bn.h
Normal file
29
torch/csrc/jit/passes/fold_linear_bn.h
Normal file
|
|
@ -0,0 +1,29 @@
|
|||
#pragma once
|
||||
|
||||
#include <torch/csrc/jit/api/module.h>
|
||||
|
||||
namespace torch {
|
||||
namespace jit {
|
||||
|
||||
struct TORCH_API LinearBNParameters {
|
||||
at::Tensor linear_w;
|
||||
at::Tensor linear_b;
|
||||
at::Tensor bn_rm;
|
||||
at::Tensor bn_rv;
|
||||
double bn_eps = 0.0;
|
||||
at::Tensor bn_w;
|
||||
at::Tensor bn_b;
|
||||
};
|
||||
|
||||
/**
|
||||
* Given the current weight and bias tensors of a Linear module and parameters
|
||||
* of the BatchNorm module we're folding with, compute the updated values
|
||||
* for the weight and bias.
|
||||
*
|
||||
* The function is basically copied from torch/nn/utils/fusion.py
|
||||
*/
|
||||
TORCH_API std::tuple<at::Tensor, at::Tensor> computeUpdatedLinearWeightAndBias(
|
||||
const LinearBNParameters& p);
|
||||
|
||||
} // namespace jit
|
||||
} // namespace torch
|
||||
|
|
@ -4,6 +4,7 @@
|
|||
#include <torch/csrc/jit/passes/frozen_concat_linear.h>
|
||||
#include <torch/csrc/jit/passes/frozen_conv_folding.h>
|
||||
#include <torch/csrc/jit/passes/frozen_graph_optimizations.h>
|
||||
#include <torch/csrc/jit/passes/frozen_linear_folding.h>
|
||||
#include <torch/csrc/jit/passes/remove_dropout.h>
|
||||
#include <torch/csrc/jit/runtime/graph_executor.h>
|
||||
#include <torch/csrc/utils/memory.h>
|
||||
|
|
@ -24,6 +25,7 @@ void OptimizeFrozenGraph(
|
|||
changed |= FoldFrozenConvBatchnorm(graph);
|
||||
changed |= FoldFrozenConvAddOrSub(graph);
|
||||
changed |= FoldFrozenConvMulOrDiv(graph);
|
||||
changed |= FoldFrozenLinearBatchnorm(graph);
|
||||
} while (changed);
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -8,6 +8,7 @@
|
|||
* - FoldFrozenConvBatchnorm
|
||||
* - FoldFrozenConvAddOrSub
|
||||
* - FoldFrozenConvMulOrDiv
|
||||
* - FoldFrozenLinearBatchnorm
|
||||
*/
|
||||
|
||||
namespace torch {
|
||||
|
|
|
|||
127
torch/csrc/jit/passes/frozen_linear_folding.cpp
Normal file
127
torch/csrc/jit/passes/frozen_linear_folding.cpp
Normal file
|
|
@ -0,0 +1,127 @@
|
|||
#include <torch/csrc/jit/ir/constants.h>
|
||||
#include <torch/csrc/jit/ir/ir.h>
|
||||
#include <torch/csrc/jit/passes/dead_code_elimination.h>
|
||||
#include <torch/csrc/jit/passes/fold_linear_bn.h>
|
||||
#include <torch/csrc/jit/passes/frozen_linear_folding.h>
|
||||
#include <torch/csrc/jit/passes/utils/optimization_utils.h>
|
||||
|
||||
#ifndef AT_PER_OPERATOR_HEADERS
|
||||
#include <ATen/Functions.h>
|
||||
#else
|
||||
#include <ATen/ops/ones_like.h>
|
||||
#include <ATen/ops/zeros_like.h>
|
||||
#endif
|
||||
|
||||
namespace torch {
|
||||
namespace jit {
|
||||
|
||||
namespace {
|
||||
|
||||
using Tensor = at::Tensor;
|
||||
|
||||
bool supportedLinearNode(Node* n) {
|
||||
if (n->kind() == aten::linear) {
|
||||
return true;
|
||||
} else {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
bool FoldFrozenLinearBatchnorm(Block* b) {
|
||||
bool graph_modified = false;
|
||||
for (Node* n : b->nodes()) {
|
||||
for (Block* block : n->blocks()) {
|
||||
graph_modified |= FoldFrozenLinearBatchnorm(block);
|
||||
}
|
||||
|
||||
if (n->kind() == aten::batch_norm &&
|
||||
supportedLinearNode(n->inputs().at(0)->node())) {
|
||||
auto linear = n->inputs().at(0)->node();
|
||||
auto bn = n;
|
||||
|
||||
if (nonConstantParameters(linear) || nonConstantParameters(bn)) {
|
||||
continue;
|
||||
}
|
||||
|
||||
auto bn_rm_ivalue = bn->namedInput("running_mean");
|
||||
auto bn_rv_ivalue = bn->namedInput("running_var");
|
||||
|
||||
// check running_mean and running_var has value, if they are
|
||||
// None(track_running_stats=False), skiping the folding path.
|
||||
if (bn_rm_ivalue->type() == NoneType::get() &&
|
||||
bn_rv_ivalue->type() == NoneType::get()) {
|
||||
continue;
|
||||
}
|
||||
|
||||
auto bn_rm = constant_as<Tensor>(bn->namedInput("running_mean")).value();
|
||||
auto bn_rv = constant_as<Tensor>(bn->namedInput("running_var")).value();
|
||||
auto bn_eps = constant_as<double>(bn->namedInput("eps")).value();
|
||||
auto linear_w = constant_as<Tensor>(linear->namedInput("weight")).value();
|
||||
|
||||
// implementation taken from torch/nn/utils/fusion.py
|
||||
Tensor linear_b;
|
||||
if (linear->namedInput("bias")->type() == NoneType::get()) {
|
||||
at::ScalarType bias_dtype = bn_rm.scalar_type();
|
||||
at::ScalarType weight_dtype = linear_w.scalar_type();
|
||||
at::DeviceType weight_device = linear_w.device().type();
|
||||
if (weight_device == at::kCUDA &&
|
||||
(weight_dtype == at::kHalf || weight_dtype == at::kBFloat16) &&
|
||||
bias_dtype == at::kFloat) {
|
||||
bias_dtype = weight_dtype;
|
||||
}
|
||||
linear_b = at::zeros_like(bn_rm, at::TensorOptions().dtype(bias_dtype));
|
||||
} else {
|
||||
linear_b = constant_as<Tensor>(linear->namedInput("bias")).value();
|
||||
}
|
||||
Tensor bn_w;
|
||||
if (bn->namedInput("weight")->type() == NoneType::get()) {
|
||||
bn_w = at::ones_like(bn_rm);
|
||||
} else {
|
||||
bn_w = constant_as<Tensor>(bn->namedInput("weight")).value();
|
||||
}
|
||||
Tensor bn_b;
|
||||
if (n->namedInput("bias")->type() == NoneType::get()) {
|
||||
bn_b = at::zeros_like(bn_rm);
|
||||
} else {
|
||||
bn_b = constant_as<Tensor>(bn->namedInput("bias")).value();
|
||||
}
|
||||
|
||||
LinearBNParameters params;
|
||||
params.linear_w = linear_w;
|
||||
params.linear_b = linear_b;
|
||||
params.bn_rm = bn_rm;
|
||||
params.bn_rv = bn_rv;
|
||||
params.bn_eps = bn_eps;
|
||||
params.bn_w = bn_w;
|
||||
params.bn_b = bn_b;
|
||||
std::tuple<Tensor, Tensor> out =
|
||||
computeUpdatedLinearWeightAndBias(params);
|
||||
WithInsertPoint guard(linear);
|
||||
auto fused_linear_w = b->owningGraph()->insertConstant(std::get<0>(out));
|
||||
auto fused_linear_b = b->owningGraph()->insertConstant(std::get<1>(out));
|
||||
auto linear_w_value = linear->namedInput("weight");
|
||||
auto linear_b_value = linear->namedInput("bias");
|
||||
|
||||
fused_linear_w->setDebugName(linear_w_value->debugName() + "_fused_bn");
|
||||
fused_linear_b->setDebugName(linear_b_value->debugName() + "_fused_bn");
|
||||
|
||||
linear->replaceInputWith(linear_w_value, fused_linear_w);
|
||||
linear->replaceInputWith(linear_b_value, fused_linear_b);
|
||||
|
||||
bn->output()->replaceAllUsesWith(linear->output());
|
||||
graph_modified = true;
|
||||
}
|
||||
}
|
||||
return graph_modified;
|
||||
}
|
||||
|
||||
} // namespace
|
||||
|
||||
bool FoldFrozenLinearBatchnorm(std::shared_ptr<Graph>& graph) {
|
||||
bool graph_modified = FoldFrozenLinearBatchnorm(graph->block());
|
||||
EliminateDeadCode(graph);
|
||||
return graph_modified;
|
||||
}
|
||||
|
||||
} // namespace jit
|
||||
} // namespace torch
|
||||
14
torch/csrc/jit/passes/frozen_linear_folding.h
Normal file
14
torch/csrc/jit/passes/frozen_linear_folding.h
Normal file
|
|
@ -0,0 +1,14 @@
|
|||
#pragma once
|
||||
|
||||
#include <torch/csrc/jit/ir/ir.h>
|
||||
|
||||
namespace torch {
|
||||
namespace jit {
|
||||
|
||||
// Fuses Linear -> BatchNormNd into a single Linear by
|
||||
// folding batchnorm weights into linear weights.
|
||||
// This pass only works on Frozen Graphs; otherwise it is a No-Op.
|
||||
TORCH_API bool FoldFrozenLinearBatchnorm(std::shared_ptr<Graph>& graph);
|
||||
|
||||
} // namespace jit
|
||||
} // namespace torch
|
||||
|
|
@ -40,6 +40,7 @@
|
|||
#include <torch/csrc/jit/passes/frozen_conv_add_relu_fusion.h>
|
||||
#include <torch/csrc/jit/passes/frozen_conv_folding.h>
|
||||
#include <torch/csrc/jit/passes/frozen_graph_optimizations.h>
|
||||
#include <torch/csrc/jit/passes/frozen_linear_folding.h>
|
||||
#include <torch/csrc/jit/passes/frozen_linear_transpose.h>
|
||||
#include <torch/csrc/jit/passes/frozen_ops_to_mkldnn.h>
|
||||
#include <torch/csrc/jit/passes/fuse_linear.h>
|
||||
|
|
@ -399,6 +400,7 @@ void initJITBindings(PyObject* module) {
|
|||
.def("_jit_pass_fold_frozen_conv_bn", &FoldFrozenConvBatchnorm)
|
||||
.def("_jit_pass_fold_frozen_conv_add_or_sub", &FoldFrozenConvAddOrSub)
|
||||
.def("_jit_pass_fold_frozen_conv_mul_or_div", &FoldFrozenConvMulOrDiv)
|
||||
.def("_jit_pass_fold_frozen_linear_bn", &FoldFrozenLinearBatchnorm)
|
||||
.def("_jit_pass_convert_frozen_ops_to_mkldnn", &ConvertFrozenOpsToMKLDNN)
|
||||
.def("_jit_pass_fuse_frozen_conv_add_relu", &FuseFrozenConvAddRelu)
|
||||
.def("_jit_pass_transpose_frozen_linear", &FrozenLinearTranspose)
|
||||
|
|
|
|||
Loading…
Reference in New Issue
Block a user