Summary:
This stack of PR's integrates cuSPARSELt into PyTorch.
This PR adds support for cuSPARSELt into the build process.
It adds in a new flag, USE_CUSPARSELT that defaults to false.
When USE_CUSPASRELT=1 is specified, the user can also specify
CUSPASRELT_ROOT, which defines the path to the library.
Compiling pytorch with cusparselt support can be done as follows:
``
USE_CUSPARSELT=1
CUSPARSELT_ROOT=/path/to/cusparselt
python setup.py develop
```
Test Plan:
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103700
Approved by: https://github.com/albanD
This change adds the TensorPipe header files to `torch_package_data` if `USE_DISTRIBUTED` is set to `ON` in the CMake cache. The TensorPipe library and CMake config is already available in the Torch wheel, but the headers are not. This resolves issue where out-of-tree backends could not implement TensorPipe converters, because the definition of the `tensorpipe::Message` struct is defined in the TensorPipe headers.
Fixes#105224.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105521
Approved by: https://github.com/albanD
Summary:
Original PR at https://github.com/pytorch/pytorch/pull/104977. Landing from fbcode instead.
Add an aot_inductor backend (Export+AOTInductor) in the benchmarking harness. Note it is not a dynamo backend.
Moved files from torch/_inductor/aot_inductor_include to torch/csrc/inductor as a more standard way for exposing headers
Created a caching function in benchmarks/dynamo/common.py for compiling, loading and caching the .so file, as a proxy for a pure C++ deployment, but easier for benchmarking.
Differential Revision: D47452591
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105221
Approved by: https://github.com/jansel
This PR combines the C++ code for the AOTInductor's model and interface with Bin Bao's changes to AOTInductor codegen.
It adds a number of AOTInductor C interfaces that can be used by an inference runtime. Under the hood of the interfaces, the model code generated by the AOTInductor's codegen is wrapped into a class, AOTInductorModel, which manages tensors and run the model inference.
On top of AOTInductorModel, we provide one more abstract layer, AOTInductorModelContainer, which allows the user to have multiple inference runs concurrently for the same model.
This PR also adjusts the compilation options for AOT codegen, particularly some fbcode-related changes such as libs to be linked and header-file search paths.
Note that this is the very first version of the AOTInductor model and interface, so many features (e.g. dynamic shape) are incomplete. We will support those missing features in in future PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104202
Approved by: https://github.com/desertfire
Now, when you do an inplace mutation and the view is naughty, you get this message:
```
RuntimeError: A view was created in no_grad mode and is being modified inplace with grad mode enabled. Given that this use case is ambiguous and error-prone, it is forbidden. You can clarify your code by moving both the view and the inplace either both inside the no_grad block (if you don't want the inplace to be tracked) or both outside (if you want the inplace to be tracked). To find out where this view was allocated, run your entire forward region under anomaly mode (torch.autograd.detect_anomaly(check_nan=False)).
```
When you run under anomaly mode, you get:
```
RuntimeError: A view was created in no_grad mode and is being modified inplace with grad mode enabled. Given that this use case is ambiguous and error-prone, it is forbidden. You can clarify your code by moving both the view and the inplace either both inside the no_grad block (if you don't want the inplace to be tracked) or both outside (if you want the inplace to be tracked). This view was allocated at:
File "/data/users/ezyang/c/pytorch/test/test_autograd.py", line 4299, in arglebargle
File "/data/users/ezyang/c/pytorch/test/test_autograd.py", line 4306, in test_anomaly_gives_view_stack
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/case.py", line 549, in _callTestMethod
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/case.py", line 591, in run
File "/data/users/ezyang/c/pytorch/torch/testing/_internal/common_utils.py", line 2266, in _run_with_retry
File "/data/users/ezyang/c/pytorch/torch/testing/_internal/common_utils.py", line 2337, in run
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/case.py", line 650, in __call__
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/suite.py", line 122, in run
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/suite.py", line 84, in __call__
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/suite.py", line 122, in run
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/suite.py", line 84, in __call__
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/runner.py", line 184, in run
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/main.py", line 271, in runTests
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/main.py", line 101, in __init__
File "/data/users/ezyang/c/pytorch/torch/testing/_internal/common_utils.py", line 894, in run_tests
File "/data/users/ezyang/c/pytorch/test/test_autograd.py", line 11209, in <module>
```
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103185
Approved by: https://github.com/zdevito
Updating the pin to the same hash as https://github.com/pytorch/pytorch/pull/100922
On the XLA side, build have switch from CMake to bazel, which requires number of changes on PyTorch side:
- Copy installed headers back to the `torch/` folder before starting the build
- Install `torch/csrc/lazy/python/python_utils.h`
- Define `LD_LIBRARY_PATH`
TODO:
- Enable bazel caching
- Pass CXX11_ABI flag to `//test/cpp:all` to reuse build artifacts from `//:_XLAC.so`
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at cd4768b</samp>
> _To fix the XLA tests that were failing_
> _We updated the submodule and scaling_
> _We added `python_util.h`_
> _And copied `torch` as well_
> _And set `LD_LIBRARY_PATH` for linking_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102446
Approved by: https://github.com/huydhn
Failing mechanism on #95424 :
In dynamo mode, when passing numpy.int_ to 'shape' like param (Sequence[Union[int, symint]]) is wrapped as list with FakeTensor. However, in python_arg_parser, parser expect int in symint_list but got FakeTensor.
Following #85759, this PR allow tensor element in symint_list when in dynamo mode
This PR also fix below test with similar failing mechanism
pytest ./generated/test_huggingface_diffusers.py -k test_016
pytest ./generated/test_ustcml_RecStudio.py -k test_036
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97508
Approved by: https://github.com/yanboliang
implementation of DataPtr context for copy-on-write tensors
Summary:
Copy-on-write storage
=====================
This library adds support for copy-on-write storage, i.e. lazy copies,
to tensors. The design maintains the PyTorch invariant that tensors
alias if and only if they share a storage. Thus, tensors that are lazy
copies of one another will have distinct storages that share a data
allocation.
Thread-safety
-------------
The correctness of this design hinges on the pre-existing PyTorch user
requirement (and general default programming assumption) that users
are responsible for guaranteeing that writes do not take places
concurrently with reads and other writes.
Lazily copied tensors add a complication to this programming model
because users are not required to know if lazy copies exist and are
not required to serialize writes across lazy copies. For example: two
tensors with distinct storages that share a copy-on-write data context
may be given to different threads that may do whatever they wish to
them, and the runtime is required to guarantee its safety.
It turns out that this is not that difficult to protect because, due
to the copy-on-write requirement, we just need to materialize a tensor
upon writing. This could be done entirely without synchronization if
we materialized each copy, however, we have a common-sense
optimization to elide the copy for the last remaining reference. This
requires waiting for any pending copies.
### Thread-safety detailed design
There are two operations that affect the copy-on-write details of a
tensor:
1) lazy-clone (e.g. an explicit call or a hidden implementation detail
added through an operator like reshape)
2) materialization (i.e. any write to the tensor)
The key insight that we exploit is that lazy-clone is logically a read
operation and materialization is logically a write operation. This
means that, for a given set of tensors that share a storage, if
materialization is taking place, no other read operation, including
lazy-clone, can be concurrent with it.
However, this insight only applies within a set of tensors that share
a storage. We also have to be concerned with tensors with different
storages that share a copy-on-write context. In this world,
materialization can race with lazy-clone or even other
materializations. _However_, in order for this to be the case, there
must be _at least_ two references to the context. This means that the
context _can not_ vanish out from under you if you are performing a
lazy-clone, and hence, it only requires an atomic refcount bump.
The most complicated case is that all lazy-copies are concurrently
materializing. In this case, because a write is occurring, there are
no in-flight lazy-copies taking place. We must simply ensure that all
lazy-copies are able to materialize (read the data) concurrently. If
we didn't have the aforementioned optimization where the last copy
steals the data, we could get away with no locking whatsoever: each
makes a copy and decrements the refcount. However, because of the
optimization, we require the loser of the materializing race wait for
the pending copies to finish, and then steal the data without copying
it.
We implement this by taking a shared lock when copying the data and
taking an exclusive lock when stealing the data. The exclusive lock
acquisition ensures that all pending shared locks are finished before
we steal the data.
Test Plan: 100% code coverage.
---
Stack created with [Sapling](https://sapling-scm.com). Best reviewed with [ReviewStack](https://reviewstack.dev/pytorch/pytorch/pull/100818).
* #100821
* #100820
* #100819
* __->__ #100818
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100818
Approved by: https://github.com/ezyang
Follow up for https://github.com/pytorch/pytorch/pull/96532. Including this in setup.py so the package will be available for CI.
Fsspec package size:
```
du -h /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg
264K /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg/fsspec/__pycache__
58K /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg/fsspec/implementations/__pycache__
377K /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg/fsspec/implementations
1017K /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg/fsspec
96K /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg/EGG-INFO
1.2M /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99768
Approved by: https://github.com/kit1980
Add a PrivateUse1 folder to contain all the feature adaptations for PrivateUse1 under Aten,For example GetGeneratorPrivate which is used for the three-party backend to register his own Generator implementation.This makes it easier for us to centrally manage these features, and it will increase the convenience of adaptation for different back-end manufacturers. For more info: https://github.com/pytorch/pytorch/issues/98073
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98127
Approved by: https://github.com/bdhirsh
1. Packaging nvfuser header for support c++ build against nvfuser;
2. Moving `#include <torch/csrc/jit/codegen/fuser/interface.h>` from `torch/csrc/jit/runtime/register_ops_utils.h` to `torch/csrc/jit/runtime/register_prim_ops_fulljit.cpp` to avoid missing header, since pytorch doesn't package `interface.h`;
3. Patching DynamicLibrary load of nvfuser to leak the handle, this avoids double de-allocation of `libnvfuser_codegen.so`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97404
Approved by: https://github.com/davidberard98
Summary:
Extra C binding module for flatbuffer was introduced because
not all dependencies of Pytorch want (or can) bundle in flatbuffer.
However, flatbuffer is in by default now so this separate binding is not longer needed.
Test Plan: existing unit tests
Differential Revision: D44352583
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97476
Approved by: https://github.com/dbort
This PR do two things:
1. It moves some Windows warning suppression from various CMake files into the main CMakeList.txt, following the conventions of gcc and clang.
2. It fixes some Windows warnings in the source code. Most importantly, it fixes lots of dll warnings by adjusting C10_API to TORCH_API or TORCH_PYTHON_API. There are still some dll warnings because some TORCH_API functions are actually built as part of libtorch_python
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94927
Approved by: https://github.com/malfet
Add triton support for ROCm builds of PyTorch.
* Enables inductor and dynamo when rocm is detected
* Adds support for pytorch-triton-mlir backend
* Adds check_rocm support for verify_dynamo.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94660
Approved by: https://github.com/malfet
Changes:
1. `typing_extensions -> typing-extentions` in dependency. Use dash rather than underline to fit the [PEP 503: Normalized Names](https://peps.python.org/pep-0503/#normalized-names) convention.
```python
import re
def normalize(name):
return re.sub(r"[-_.]+", "-", name).lower()
```
2. Import `Literal`, `Protocal`, and `Final` from standard library as of Python 3.8+
3. Replace `Union[Literal[XXX], Literal[YYY]]` to `Literal[XXX, YYY]`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94490
Approved by: https://github.com/ezyang, https://github.com/albanD
This PR is the first step towards refactors the build for nvfuser in order to have the coegen being a standalone library.
Contents inside this PR:
1. nvfuser code base has been moved to `./nvfuser`, from `./torch/csrc/jit/codegen/cuda/`, except for registration code for integration (interface.h/interface.cpp)
2. splits the build system so nvfuser is generating its own `.so` files. Currently there are:
- `libnvfuser_codegen.so`, which contains the integration, codegen and runtime system of nvfuser
- `nvfuser.so`, which is nvfuser's python API via pybind. Python frontend is now exposed via `nvfuser._C.XXX` instead of `torch._C._nvfuser`
3. nvfuser cpp tests is currently being compiled into `nvfuser_tests`
4. cmake is refactored so that:
- nvfuser now has its own `CMakeLists.txt`, which is under `torch/csrc/jit/codegen/cuda/`.
- nvfuser backend code is not compiled inside `libtorch_cuda_xxx` any more
- nvfuser is added as a subdirectory under `./CMakeLists.txt` at the very end after torch is built.
- since nvfuser has dependency on torch, the registration of nvfuser at runtime is done via dlopen (`at::DynamicLibrary`). This avoids circular dependency in cmake, which will be a nightmare to handle. For details, look at `torch/csrc/jit/codegen/cuda/interface.cpp::LoadingNvfuserLibrary`
Future work that's scoped in following PR:
- Currently since nvfuser codegen has dependency on torch, we need to refactor that out so we can move nvfuser into a submodule and not rely on dlopen to load the library. @malfet
- Since we moved nvfuser into a cmake build, we effectively disabled bazel build for nvfuser. This could impact internal workload at Meta, so we need to put support back. cc'ing @vors
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89621
Approved by: https://github.com/davidberard98
setup.py clean now won't remove paths matching .gitignore patterns across the entire OS. Instead, now only files from the repository will be removed.
`/build_*` had to be removed from .gitignore because with the wildcard fixed, build_variables.bzl file was deleted on cleanup.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91503
Approved by: https://github.com/soumith
Summary:
This diff is reverting D42257039
D42257039 has been identified to be causing the following test or build failures:
Tests affected:
- [assistant/neural_dm/rl/modules/tests:action_mask_classifier_test - main](https://www.internalfb.com/intern/test/281475048940766/)
Here's the Multisect link:
https://www.internalfb.com/intern/testinfra/multisect/1493969
Here are the tasks that are relevant to this breakage:
T93770103: 1 test started failing for oncall assistant_multimodal in the last 2 weeks
We're generating a revert to back out the changes in this diff, please note the backout may land if someone accepts it.
Test Plan: NA
Reviewed By: weiwangmeta
Differential Revision: D42272391
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91548
Approved by: https://github.com/kit1980
## Job
Test running on most CI jobs.
## Test binary
* `test_main.cpp`: entry for gtest
* `test_operator_registration.cpp`: test cases for gtest
## Helper sources
* `operator_registry.h/cpp`: simple operator registry for testing purpose.
* `Evalue.h`: a boxed data type that wraps ATen types, for testing purpose.
* `selected_operators.yaml`: operators Executorch care about so far, we should cover all of them.
## Templates
* `NativeFunctions.h`: for generating headers for native functions. (not compiled in the test, since we will be using `libtorch`)
* `RegisterCodegenUnboxedKernels.cpp`: for registering boxed operators.
* `Functions.h`: for declaring operator C++ APIs. Generated `Functions.h` merely wraps `ATen/Functions.h`.
## Build files
* `CMakeLists.txt`: generate code to register ops.
* `build.sh`: driver file, to be called by CI job.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89596
Approved by: https://github.com/ezyang
E.g. `test_cpp_extensions_aot_ninja` fails as it includes `vec.h` which requires the vec/vsx/* headers and `sleef.h`. The latter is also required for AVX512 builds on non MSVC compilers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85547
Approved by: https://github.com/kit1980
In this PR, we replace OMP SIMD with `aten::vec` to optimize TorchInductor vectorization performance. Take `res=torch.exp(torch.add(x, y))` as the example. The generated code is as follows if `config.cpp.simdlen` is 8.
```C++
extern "C" void kernel(const float* __restrict__ in_ptr0,
const float* __restrict__ in_ptr1,
float* __restrict__ out_ptr0,
const long ks0,
const long ks1)
{
#pragma omp parallel num_threads(48)
{
#pragma omp for
for(long i0=0; i0<((ks0*ks1) / 8); ++i0)
{
auto tmp0 = at::vec::Vectorized<float>::loadu(in_ptr0 + 8*i0);
auto tmp1 = at::vec::Vectorized<float>::loadu(in_ptr1 + 8*i0);
auto tmp2 = tmp0 + tmp1;
auto tmp3 = tmp2.exp();
tmp3.store(out_ptr0 + 8*i0);
}
#pragma omp for simd simdlen(4)
for(long i0=8*(((ks0*ks1) / 8)); i0<ks0*ks1; ++i0)
{
auto tmp0 = in_ptr0[i0];
auto tmp1 = in_ptr1[i0];
auto tmp2 = tmp0 + tmp1;
auto tmp3 = std::exp(tmp2);
out_ptr0[i0] = tmp3;
}
}
}
```
The major pipeline is as follows.
- Check whether the loop body could be vectorized by `aten::vec`. The checker consists of two parts. [One ](bf66991fc4/torch/_inductor/codegen/cpp.py (L702))is to check whether all the `ops` have been supported. The [other one](355326faa3/torch/_inductor/codegen/cpp.py (L672)) is to check whether the data access could be vectorized.
- [`CppSimdVecKernelChecker`](355326faa3/torch/_inductor/codegen/cpp.py (L655))
- Create the `aten::vec` kernel and original omp simd kernel. Regarding the original omp simd kernel, it serves for the tail loop when the loop is vectorized.
- [`CppSimdVecKernel`](355326faa3/torch/_inductor/codegen/cpp.py (L601))
- [`CppSimdVecOverrides`](355326faa3/torch/_inductor/codegen/cpp.py (L159)): The ops that we have supported on the top of `aten::vec`
- Create kernel
- [`aten::vec` kernel](355326faa3/torch/_inductor/codegen/cpp.py (L924))
- [`Original CPP kernel - OMP SIMD`](355326faa3/torch/_inductor/codegen/cpp.py (L929))
- Generate code
- [`CppKernelProxy`](355326faa3/torch/_inductor/codegen/cpp.py (L753)) is used to combine the `aten::vec` kernel and original cpp kernel
- [Vectorize the most inner loop](355326faa3/torch/_inductor/codegen/cpp.py (L753))
- [Generate code](355326faa3/torch/_inductor/codegen/cpp.py (L821))
Next steps:
- [x] Support reduction
- [x] Vectorize the tail loop with `aten::vec`
- [ ] Support BF16
- [ ] Optimize the loop condition and loop index calculation by replacing `div` with `add`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87068
Approved by: https://github.com/jgong5, https://github.com/jansel
Adds `/FS` option to `CMAKE_CXX_FLAGS` and `CMAKE_CUDA_FLAGS`.
So far I've encountered this kind of errors:
```
C:\Users\MyUser\AppData\Local\Temp\tmpxft_00004728_00000000-7_cuda.cudafe1.cpp: fatal error C1041: cannot open program database 'C:\Projects\pytorch\build\third_party\gloo\gloo\CMakeFiles\gloo_cuda.dir\vc140.pdb'; if multiple CL.EXE write to the same .PDB file, please use /FS
```
when building with VS 2022.
cc @peterjc123 @mszhanyi @skyline75489 @nbcsm
Related issues:
- https://github.com/pytorch/pytorch/issues/87691
- https://github.com/pytorch/pytorch/issues/39989
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88084
Approved by: https://github.com/ezyang
Also, add `torchtriton` and `jinja2` as extra `dynamo` dependency to PyTorch wheels,
Version packages as first 10 characters of pinned repo hash and make `torch[dynamo]` wheel depend on the exact version it was build against.
TODO: Automate uploading to nightly wheels storage
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87234
Approved by: https://github.com/msaroufim
The legacy profiler is an eyesore in the autograd folder. At this point the implementation is almost completely decoupled from the rest of profiler, and it is in maintaince mode pending deprecation.
As a result, I'm moving it to `torch/csrc/profiler/standalone`. Unfortuantely BC requires that the symbols remain in `torch::autograd::profiler`, so I've put some basic forwarding logic in `torch/csrc/autograd/profiler.h`.
One strange bit is that `profiler_legacy.h` forward declares `torch::autograd::Node`, but doesn't seem to do anything with it. I think we can delete it, but I want to test to make sure.
(Note: this should not land until https://github.com/pytorch/torchrec/pull/595 is landed.)
Differential Revision: [D39108648](https://our.internmc.facebook.com/intern/diff/D39108648/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85512
Approved by: https://github.com/aaronenyeshi
There is a concept in profiler of a stub that wraps a profiling API. It was introduced for CUDA profiling before Kineto, and ITT has adopted it to call into VTune APIs. However for the most part we don't really interact with them when developing the PyTorch profiler.
Thus it makes sense to unify the fallback registration mechanism and create a subfolder to free up real estate in the top level `torch/csrc/profiler` directory.
Differential Revision: [D39108647](https://our.internmc.facebook.com/intern/diff/D39108647/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85510
Approved by: https://github.com/aaronenyeshi
https://github.com/pytorch/pytorch/pull/85780 updated all c10d headers in pytorch to use absolute path following the other distributed components. However, the headers were still copied to `${TORCH_INSTALL_INCLUDE_DIR}/torch`, thus external extentions still have to reference the c10d headers as `<c10d/*.h>`, making the usage inconsistent (the only exception was c10d/exception.h, which was copied to `${TORCH_INSTALL_INCLUDE_DIR}/torch/csrc/distributed/c10d`).
This patch fixes the installation step to copy all c10d headers to `${TORCH_INSTALL_INCLUDE_DIR}/torch/csrc/distributed/c10d`, thus external extensions can consistently reference c10d headers with the absolute path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86257
Approved by: https://github.com/kumpera
Depends on https://github.com/pytorch/pytorch/pull/84890.
This PR adds opt_einsum to CI, enabling path optimization for the multi-input case. It also updates the installation sites to install torch with einsum, but those are mostly to make sure it would work on the user's end (as opt-einsum would have already been installed in the docker or in prior set up steps).
This PR also updates the windows build_pytorch.bat script to use the same bdist_wheel and install commands as on Linux, replacing the `setup.py install` that'll become deprecated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85574
Approved by: https://github.com/huydhn, https://github.com/soulitzer
## This PR seeks to:
- [x] add c++ support for an optimize path
- [x] add python opt_einsum path passthrough
- [x] add opt_einsum to OSS requirements, but a soft one
- [x] show benchmark results here
Additional things I've explored + their conclusions:
- **Delaying the summing over dimensions** => added!
- The idea here is to not incur kernel calls to `sum` as we try to early sum out in einsum. Thus, we collect all the dimensions that need to be summed together in one contraction + sum at the end instead of summing as we go. While this optimization didn't feel like it made things faster for the random cases we've selected (they all summed 1 dim per contraction), it is a good principle and would help more common use cases that would reduce multiple dimensions at a time (like `bxy,xyi,xyj->bij`).
- **Caching contract_path based on equation and tensor sizes** => dropped :(
- The benchmarks were strictly worse for all the cases, and, from scanning the use cases, I observed people do not often call einsum on the same equation/tensor order enough for caching to be justified. I do think caching can be effective in the future, but it would require further investigation.
## Not a part of this PR (but are next steps):
- adding opt_einsum package to OSS CI
- adding it to internal CI
- potentially adding a kwarg path argument to the python API -- if the path is given, we wouldn't have to spend time calculating it, but there would be some time lost validating user input.
## Testing:
- Added more tests to CI
## Benchmarking:
**TL;DRs**
- **torch.einsum with opt_einsum is a definite win for the production case**.
- **torch.einsum with opt_einsum installed is consistently fast, but has an overhead** of needing to find the path. If the path is already found/optimal, it will be slightly slower.
- The einsum overhead decreases for bigger dimensions.
- **torch.einsum without opt_einsum installed is comparable to before this commit**, with occasional slowness potentially due to not reshaping/squeezing as we contract until the end.
- For many of the random generated cases, the dimensions were too similar and small where an optimal order wasn't that much more optimal than just going left to right. However, in production, dimensions are commonly quite distinct (batch size will be small, but the data will be huge).
- **torch.einsum opt is comparable (slightly faster overall) compared to numpy.einsum opt for the cpu case**. This is interesting given that torch.einsum currently spends time computing the path, but numpy.einsum takes it as input.
- **torch.einsum opt is significantly faster than numpy.einsum opt for the gpu case**. This is because numpy doesn't take advantage of GPUs.
The following benchmarks were done on an A100 GPU and Linux CPUs. The line in the first chart separates GPU (on top) from CPU, and the line in the second graph separates CPU (on top) and then GPU. Sorry it's flipped 😛 .
Production example (see [colab benchmark](https://colab.research.google.com/drive/1V2s4v1dOOKwRvp5T_DC-PNUosOV9FFJx?authuser=1#scrollTo=WZoQkC8Mdt6I) for more context):
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012636-9a68bfa7-2601-43b1-afeb-b4e0877db6a4.png">
Randomly generated examples (the same ones as in https://github.com/pytorch/pytorch/pull/60191)
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012804-1c639595-b3e6-48c9-a385-ad851c13e1c2.png">
Open below to see old + not super relevant benchmarking results:
<details>
Benchmark results BEFORE this PR (on Linux -- I will update devices so they are consistent later):
<img width="776" alt="image" src="https://user-images.githubusercontent.com/31798555/190807274-18f71fce-556e-47f4-b18c-e0f7d0c0d5aa.png">
Benchmark results with the code on this PR (on my x86 mac):
For the CPU internal use case --

For the general use case --
It looks like numpy opt still does better in several of these random cases, but torch einsum opt is consistently faster than torch.einsum.

<details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84890
Approved by: https://github.com/albanD, https://github.com/soulitzer
Move functorch/functorch into `functorch` folder
- Add functorch/CMakeLists.txt that adds `functorch` native python exension
- Modify `setup.py` to package pytorch and functorch together into a single wheel
- Modify `functorch.__version__` is not equal to that of `torch.__version__`
- Add dummy `functorch/setup.py` file for the projects that still want to build it
Differential Revision: [D39058811](https://our.internmc.facebook.com/intern/diff/D39058811)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83464
Approved by: https://github.com/zou3519
# Summary:
- I added a new submodule Cutlass pointing to 2.10 release. The inclusion of flash_attention code should be gated by the flag: USE_FLASH_ATTENTION. This is defaulted to off resulting in flash to not be build anywhere. This is done on purpose since we don't have A100 machines to compile and test on.
- Only looked at CMake did not attempt bazel or buck yet.
- I included the mha_fwd from flash_attention that has ben refactored to use cutlass 2.10. There is currently no backwards kernel on this branch. That would be a good follow up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81434
Approved by: https://github.com/cpuhrsch
Fixes#81181 by creating a temporary LICENCE file that has all the third-party licenses concatenated together when creating a wheel. Also update the `third_party/LICENSES_BUNDLED.txt` file.
The `third_party/LICENSES_BUNDLED.txt` file is supposed to be tested via `tests/test_license.py`, but the test is not running?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81500
Approved by: https://github.com/rgommers, https://github.com/seemethere
Description:
While using Pytorch header
"torch/csrc/jit/serialization/export.h" got compilation error.
File export_bytecode.h accesses
"#include <torch/csrc/jit/mobile/function.h>"
This mobile folder isn't present in torch installation dir.
This PR adds mobile folder to torch installation setup.
Fixes#79190
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79864
Approved by: https://github.com/ngimel
Syncing nvfuser devel branch to upstream master. https://github.com/csarofeen/pytorch/
Bug fixes and minor refactor
Squashed commits to WAR github API
Commits that's actually in this PR from the devel branch:
```
4c60e7dff22a494632370e5df55c011007340d06 Add examples infrastructure for using nvFuser in a standalone program (#1725)
02a05d98334ffa580d73ccb28fdb8c577ad296fe Fix issue #1751 (#1753)
8a69aa320bd7629e1709fe5ceb7104d2c88ec84c Refactor NvFuser transpose API to match eager mode behavior (#1746)
ffdf6b7709048170d768217fcd7083fc8387f932 Remove BroadcastWithoutStride. (#1738)
02bab16035e70734450c02124f5cdaa95cf5749d Fix flipping of a boolean flag (#1745)
465d66890c8242e811224359cbdb1c2915490741 cleanup (#1744)
26d354e68720bc7dd2d3b1338ac01b707a230b6a fixing noncontig broadcast (#1742)
856b6b2f9073662dd98ca22ba6c3540e20eb1cdd Add IterDomainBuilder (#1736)
1fd974f912cd4c1e21cbd16e2abb23598d66a02f fixing warning for gcc7 (#1732)
de2740a43a869f8272c2648e091d7b8235097db9 disabling complex in python tests for #1730 (#1733)
fbbbe0a2e7c7a63e0e2719b8bfccb759b714221a fixing MSVC build (#1728)
b5feee5e2b28be688dbddc766f3c0220389c8175 Fix the fused reduction runtime kernel (#1729)
5247682dff5980bb66edf8d3aac25dea2ef2ced5 Re-entrant GroupedGridReduction (#1727)
```
RUN_TORCHBENCH: nvfuser
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79147
Approved by: https://github.com/davidberard98
Package config/template files with torchgen
This PR packages native_functions.yaml, tags.yaml and ATen/templates
with torchgen.
This PR:
- adds a step to setup.py to copy the relevant files over into torchgen
- adds a docstring for torchgen (so `import torchgen; help(torchgen)`
says something)
- adds a helper function in torchgen so you can get the torchgen root
directory (and figure out where the packaged files are)
- changes some scripts to explicitly pass the location of torchgen,
which will be helpful for the first item in the Future section.
Future
======
- torchgen, when invoked from the command line, should use sources
in torchgen/packaged instead of aten/src. I'm unable to do this because
people (aka PyTorch CI) invokes `python -m torchgen.gen` without
installing torchgen.
- the source of truth for all of these files should be in torchgen.
This is a bit annoying to execute on due to potential merge conflicts
and dealing with merge systems
- CI and testing. The way things are set up right now is really fragile,
we should have a CI job for torchgen.
Test Plan
=========
I ran the following locally:
```
python -m torchgen.gen -s torchgen/packaged
```
and verified that it outputted files.
Furthermore, I did a setup.py install and checked that the files are
actually being packaged with torchgen.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78942
Approved by: https://github.com/ezyang
Fixes#78490
Following command:
```
conda install pytorch torchvision torchaudio -c pytorch-nightly
```
Installs libiomp . Hence we don't want to package libiomp with conda installs. However, we still keep it for libtorch and wheels.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78632
Approved by: https://github.com/malfet
Next stage of breaking up https://github.com/pytorch/pytorch/pull/74710
IR builder class introduced to decouple the explicit usage of `TsNode` in core lazy tensors.
Requires https://github.com/pytorch/pytorch/pull/75324 to be merged in first.
**Background**
- there are ~ 5 special ops used in lazy core but defined as :public {Backend}Node. (DeviceData, Expand, Scalar...)
- we currently require all nodes derive from {Backend}Node, so that backends can make this assumption safely
- it is hard to have shared 'IR classes' in core/ because they depend on 'Node'
**Motivation**
1. avoid copy-paste of "special" node classes for each backend
2. in general decouple and remove all dependencies that LTC has on the TS backend
**Summary of changes**
- new 'IRBuilder' interface that knows how to make 5 special ops
- move 'special' node classes to `ts_backend/`
- implement TSIRBuilder that makes the special TS Nodes
- new backend interface API to get the IRBuilder
- update core code to call the builder
CC: @wconstab @JackCaoG @henrytwo
Partially Fixes#74628
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75433
Approved by: https://github.com/wconstab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74387
Make temporary python bindings for flatbuffer to test ScriptModule save / load.
(Note: this ignores all push blocking failures!)
Test Plan: unittest
Reviewed By: iseeyuan
Differential Revision: D34968080
fbshipit-source-id: d23b16abda6e4b7ecf6b1198ed6e00908a3db903
(cherry picked from commit 5cbbc390c5f54146a1c469106ab4a6286c754325)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74643
Previously `torch/csrc/deploy/interpreter/Optional.hpp` wasn't getting included in the wheel distribution created by `USE_DEPLOY=1 python setup.py bdist_wheel`, this pr fixes that
Test Plan: Imported from OSS
Reviewed By: d4l3k
Differential Revision: D35094459
Pulled By: PaliC
fbshipit-source-id: 50aea946cc5bb72720b993075bd57ccf8377db30
(cherry picked from commit 6ad5d96594f40af3d49d2137c2b3799a2d493b36)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73991
Automatically generate `datapipe.pyi` via CMake and removing the generated .pyi file from Git. Users should have the .pyi file locally after building for the first time.
I will also be adding an internal equivalent diff for buck.
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D34868001
Pulled By: NivekT
fbshipit-source-id: 448c92da659d6b4c5f686407d3723933c266c74f
(cherry picked from commit 306dbc5f469e63bc141dac57ef310e6f0e16d9cd)
Summary:
RFC: https://github.com/pytorch/rfcs/pull/40
This PR (re)introduces python codegen for unboxing wrappers. Given an entry of `native_functions.yaml` the codegen should be able to generate the corresponding C++ code to convert ivalues from the stack to their proper types. To trigger the codegen, run
```
tools/jit/gen_unboxing.py -d cg/torch/share/ATen
```
Merged changes on CI test. In https://github.com/pytorch/pytorch/issues/71782 I added an e2e test for static dispatch + codegen unboxing. The test exports a mobile model of mobilenetv2, load and run it on a new binary for lite interpreter: `test/mobile/custom_build/lite_predictor.cpp`.
## Lite predictor build specifics
1. Codegen: `gen.py` generates `RegisterCPU.cpp` and `RegisterSchema.cpp`. Now with this PR, once `static_dispatch` mode is enabled, `gen.py` will not generate `TORCH_LIBRARY` API calls in those cpp files, hence avoids interaction with the dispatcher. Once `USE_LIGHTWEIGHT_DISPATCH` is turned on, `cmake/Codegen.cmake` calls `gen_unboxing.py` which generates `UnboxingFunctions.h`, `UnboxingFunctions_[0-4].cpp` and `RegisterCodegenUnboxedKernels_[0-4].cpp`.
2. Build: `USE_LIGHTWEIGHT_DISPATCH` adds generated sources into `all_cpu_cpp` in `aten/src/ATen/CMakeLists.txt`. All other files remain unchanged. In reality all the `Operators_[0-4].cpp` are not necessary but we can rely on linker to strip them off.
## Current CI job test coverage update
Created a new CI job `linux-xenial-py3-clang5-mobile-lightweight-dispatch-build` that enables the following build options:
* `USE_LIGHTWEIGHT_DISPATCH=1`
* `BUILD_LITE_INTERPRETER=1`
* `STATIC_DISPATCH_BACKEND=CPU`
This job triggers `test/mobile/lightweight_dispatch/build.sh` and builds `libtorch`. Then the script runs C++ tests written in `test_lightweight_dispatch.cpp` and `test_codegen_unboxing.cpp`. Recent commits added tests to cover as many C++ argument type as possible: in `build.sh` we installed PyTorch Python API so that we can export test models in `tests_setup.py`. Then we run C++ test binary to run these models on lightweight dispatch enabled runtime.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69881
Reviewed By: iseeyuan
Differential Revision: D33692299
Pulled By: larryliu0820
fbshipit-source-id: 211e59f2364100703359b4a3d2ab48ca5155a023
(cherry picked from commit 58e1c9a25e3d1b5b656282cf3ac2f548d98d530b)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69255
One thing that I've found as I optimize profier is that there's a lot of intermingled code, where the kineto profiler relies on the legacy (autograd) profiler for generic operations. This made optimization hard because I had to manage too many complex dependencies. (Exaserbated by the USE_KINETO #ifdef's sprinkled around.) This PR is the first of several to restructure the profiler(s) so the later optimizations go in easier.
Test Plan: Unit tests
Reviewed By: aaronenyeshi
Differential Revision: D32671972
fbshipit-source-id: efa83b40dde4216f368f2a5fa707360031a85707
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68247
This splits `Functions.h`, `Operators.h`, `NativeFunctions.h` and
`NativeMetaFunctions.h` into seperate headers per operator base name.
With `at::sum` as an example, we can include:
```cpp
<ATen/core/sum.h> // Like Functions.h
<ATen/core/sum_ops.h> // Like Operators.h
<ATen/core/sum_native.h> // Like NativeFunctions.h
<ATen/core/sum_meta.h> // Like NativeMetaFunctions.h
```
The umbrella headers are still being generated, but all they do is
include from the `ATen/ops' folder.
Further, `TensorBody.h` now only includes the operators that have
method variants. Which means files that only include `Tensor.h` don't
need to be rebuilt when you modify function-only operators. Currently
there are about 680 operators that don't have method variants, so this
is potentially a significant win for incremental builds.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D32596272
Pulled By: albanD
fbshipit-source-id: 447671b2b6adc1364f66ed9717c896dae25fa272
Summary:
Remove all hardcoded AMD gfx targets
PyTorch build and Magma build will use rocm_agent_enumerator as
backup if PYTORCH_ROCM_ARCH env var is not defined
PyTorch extensions will use same gfx targets as the PyTorch build,
unless PYTORCH_ROCM_ARCH env var is defined
torch.cuda.get_arch_list() now works for ROCm builds
PyTorch CI dockers will continue to be built for gfx900 and gfx906 for now.
PYTORCH_ROCM_ARCH env var can be a space or semicolon separated list of gfx archs eg. "gfx900 gfx906" or "gfx900;gfx906"
cc jeffdaily sunway513 jithunnair-amd ROCmSupport KyleCZH
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61706
Reviewed By: seemethere
Differential Revision: D32735862
Pulled By: malfet
fbshipit-source-id: 3170e445e738e3ce373203e1e4ae99c84e645d7d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69251
This adds some actual documentation for deploy, which is probably useful
since we told everyone it was experimentally available so they will
probably be looking at what the heck it is.
It also wires up various compoenents of the OSS build to actually work
when used from an external project.
Differential Revision:
D32783312
D32783312
Test Plan: Imported from OSS
Reviewed By: wconstab
Pulled By: suo
fbshipit-source-id: c5c0a1e3f80fa273b5a70c13ba81733cb8d2c8f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68817
Looks like these files are getting used by downstream xla so we need to
include them in our package_data
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D32622241
Pulled By: seemethere
fbshipit-source-id: 7b64e5d4261999ee58bc61185bada6c60c2bb5cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68226
**Note that this PR is unusually big due to the urgency of the changes. Please reach out to me in case you wish to have a "pair" review.**
This PR introduces a major refactoring of the socket implementation of the C10d library. A big portion of the logic is now contained in the `Socket` class and a follow-up PR will further consolidate the remaining parts. As of today the changes in this PR offer:
- significantly better error handling and much more verbose logging (see the example output below)
- explicit support for IPv6 and dual-stack sockets
- correct handling of signal interrupts
- better Windows support
A follow-up PR will consolidate `send`/`recv` logic into `Socket` and fully migrate to non-blocking sockets.
## Example Output
```
[I logging.h:21] The client socket will attempt to connect to an IPv6 address on (127.0.0.1, 29501).
[I logging.h:21] The client socket is attempting to connect to [localhost]:29501.
[W logging.h:28] The server socket on [localhost]:29501 is not yet listening (Error: 111 - Connection refused), retrying...
[I logging.h:21] The server socket will attempt to listen on an IPv6 address.
[I logging.h:21] The server socket is attempting to listen on [::]:29501.
[I logging.h:21] The server socket has started to listen on [::]:29501.
[I logging.h:21] The client socket will attempt to connect to an IPv6 address on (127.0.0.1, 29501).
[I logging.h:21] The client socket is attempting to connect to [localhost]:29501.
[I logging.h:21] The client socket has connected to [localhost]:29501 on [localhost]:42650.
[I logging.h:21] The server socket on [::]:29501 has accepted a connection from [localhost]:42650.
[I logging.h:21] The client socket has connected to [localhost]:29501 on [localhost]:42722.
[I logging.h:21] The server socket on [::]:29501 has accepted a connection from [localhost]:42722.
[I logging.h:21] The client socket will attempt to connect to an IPv6 address on (127.0.0.1, 29501).
[I logging.h:21] The client socket is attempting to connect to [localhost]:29501.
[I logging.h:21] The client socket has connected to [localhost]:29501 on [localhost]:42724.
[I logging.h:21] The server socket on [::]:29501 has accepted a connection from [localhost]:42724.
[I logging.h:21] The client socket will attempt to connect to an IPv6 address on (127.0.0.1, 29501).
[I logging.h:21] The client socket is attempting to connect to [localhost]:29501.
[I logging.h:21] The client socket has connected to [localhost]:29501 on [localhost]:42726.
[I logging.h:21] The server socket on [::]:29501 has accepted a connection from [localhost]:42726.
```
ghstack-source-id: 143501987
Test Plan: Run existing unit and integration tests on devserver, Fedora, Ubuntu, macOS Big Sur, Windows 10.
Reviewed By: Babar, wilson100hong, mrshenli
Differential Revision: D32372333
fbshipit-source-id: 2204ffa28ed0d3683a9cb3ebe1ea8d92a831325a
Summary:
CAFFE2 has been deprecated for a while, but still included in every PyTorch build.
We should stop building it by default, although CI should still validate that caffe2 code is buildable.
Build even fewer dependencies when compiling mobile builds without Caffe2
Introduce `TEST_CAFFE2` in torch.common.utils
Skip `TestQuantizedEmbeddingOps` and `TestJit.test_old_models_bc` is code is compiled without Caffe2
Should be landed after https://github.com/pytorch/builder/pull/864
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66658
Reviewed By: driazati, seemethere, janeyx99
Differential Revision: D31669156
Pulled By: malfet
fbshipit-source-id: 1cc45e2d402daf913a4685eb9f841cc3863e458d
Summary:
This PR introduces a new `torchrun` entrypoint that simply "points" to `python -m torch.distributed.run`. It is shorter and less error-prone to type and gives a nicer syntax than a rather cryptic `python -m ...` command line. Along with the new entrypoint the documentation is also updated and places where `torch.distributed.run` are mentioned are replaced with `torchrun`.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse agolynski SciPioneer H-Huang mrzzd cbalioglu gcramer23
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64049
Reviewed By: cbalioglu
Differential Revision: D30584041
Pulled By: kiukchung
fbshipit-source-id: d99db3b5d12e7bf9676bab70e680d4b88031ae2d
Summary:
Using https://github.com/mreineck/pocketfft
Also delete explicit installation of pocketfft during the build as it will be available via submodule
Limit PocketFFT support to cmake-3.10 or newer, as `set_source_files_properties` does not seem to work as expected with cmake-3.5
Partially addresses https://github.com/pytorch/pytorch/issues/62821
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62841
Reviewed By: seemethere
Differential Revision: D30140441
Pulled By: malfet
fbshipit-source-id: d1a1cf1b43375321f5ec5b3d0b538f58082f7825
Summary:
This PR: (1) enables the use of a system-provided Intel TBB for building PyTorch, (2) removes `tbb:task_scheduler_init` references since it has been removed from TBB a while ago (3) marks the implementation of `_internal_set_num_threads` with a TODO as it requires a revision that fixes its thread allocation logic.
Tested with `test/run_test`; no new tests are introduced since there are no behavioral changes (removal of `tbb::task_scheduler_init` has no impact on the runtime behavior).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61934
Reviewed By: malfet
Differential Revision: D29805416
Pulled By: cbalioglu
fbshipit-source-id: 22042b428b57b8fede9dfcc83878d679a19561dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61903
### Remaining Tasks
- [ ] Collate results of benchmarks on two Intel Xeon machines (with & without CUDA, to check if CPU throttling causes issues with GPUs) - make graphs, including Roofline model plots (Intel Advisor can't make them with libgomp, though, but with Intel OpenMP).
### Summary
1. This draft PR produces binaries with with 3 types of ATen kernels - default, AVX2, AVX512 . Using the environment variable `ATEN_AVX512_256=TRUE` also results in 3 types of kernels, but the compiler can use 32 ymm registers for AVX2, instead of the default 16. ATen kernels for `CPU_CAPABILITY_AVX` have been removed.
2. `nansum` is not using AVX512 kernel right now, as it has poorer accuracy for Float16, than does AVX2 or DEFAULT, whose respective accuracies aren't very good either (#59415).
It was more convenient to disable AVX512 dispatch for all dtypes of `nansum` for now.
3. On Windows , ATen Quantized AVX512 kernels are not being used, as quantization tests are flaky. If `--continue-through-failure` is used, then `test_compare_model_outputs_functional_static` fails. But if this test is skipped, `test_compare_model_outputs_conv_static` fails. If both these tests are skipped, then a third one fails. These are hard to debug right now due to not having access to a Windows machine with AVX512 support, so it was more convenient to disable AVX512 dispatch of all ATen Quantized kernels on Windows for now.
4. One test is currently being skipped -
[test_lstm` in `quantization.bc](https://github.com/pytorch/pytorch/issues/59098) - It fails only on Cascade Lake machines, irrespective of the `ATEN_CPU_CAPABILITY` used, because FBGEMM uses `AVX512_VNNI` on machines that support it. The value of `reduce_range` should be used as `False` on such machines.
The list of the changes is at https://gist.github.com/imaginary-person/4b4fda660534f0493bf9573d511a878d.
Credits to ezyang for proposing `AVX512_256` - these use AVX2 intrinsics but benefit from 32 registers, instead of the 16 ymm registers that AVX2 uses.
Credits to limo1996 for the initial proposal, and for optimizing `hsub_pd` & `hadd_pd`, which didn't have direct AVX512 equivalents, and are being used in some kernels. He also refactored `vec/functional.h` to remove duplicated code.
Credits to quickwritereader for helping fix 4 failing complex multiplication & division tests.
### Testing
1. `vec_test_all_types` was modified to test basic AVX512 support, as tests already existed for AVX2.
Only one test had to be modified, as it was hardcoded for AVX2.
2. `pytorch_linux_bionic_py3_8_gcc9_coverage_test1` & `pytorch_linux_bionic_py3_8_gcc9_coverage_test2` are now using `linux.2xlarge` instances, as they support AVX512. They were used for testing AVX512 kernels, as AVX512 kernels are being used by default in both of the CI checks. Windows CI checks had already been using machines with AVX512 support.
### Would the downclocking caused by AVX512 pose an issue?
I think it's important to note that AVX2 causes downclocking as well, and the additional downclocking caused by AVX512 may not hamper performance on some Skylake machines & beyond, because of the double vector-size. I think that [this post with verifiable references is a must-read](https://community.intel.com/t5/Software-Tuning-Performance/Unexpected-power-vs-cores-profile-for-MKL-kernels-on-modern-Xeon/m-p/1133869/highlight/true#M6450). Also, AVX512 would _probably not_ hurt performance on a high-end machine, [but measurements are recommended](https://lemire.me/blog/2018/09/07/avx-512-when-and-how-to-use-these-new-instructions/). In case it does, `ATEN_AVX512_256=TRUE` can be used for building PyTorch, as AVX2 can then use 32 ymm registers instead of the default 16. [FBGEMM uses `AVX512_256` only on Xeon D processors](https://github.com/pytorch/FBGEMM/pull/209), which are said to have poor AVX512 performance.
This [official data](https://www.intel.com/content/dam/www/public/us/en/documents/specification-updates/xeon-scalable-spec-update.pdf) is for the Intel Skylake family, and the first link helps understand its significance. Cascade Lake & Ice Lake SP Xeon processors are said to be even better when it comes to AVX512 performance.
Here is the corresponding data for [Cascade Lake](https://cdrdv2.intel.com/v1/dl/getContent/338848) -


The corresponding data isn't publicly available for Intel Xeon SP 3rd gen (Ice Lake SP), but [Intel mentioned that the 3rd gen has frequency improvements pertaining to AVX512](https://newsroom.intel.com/wp-content/uploads/sites/11/2021/04/3rd-Gen-Intel-Xeon-Scalable-Platform-Press-Presentation-281884.pdf). Ice Lake SP machines also have 48 KB L1D caches, so that's another reason for AVX512 performance to be better on them.
### Is PyTorch always faster with AVX512?
No, but then PyTorch is not always faster with AVX2 either. Please refer to #60202. The benefit from vectorization is apparent with with small tensors that fit in caches or in kernels that are more compute heavy. For instance, AVX512 or AVX2 would yield no benefit for adding two 64 MB tensors, but adding two 1 MB tensors would do well with AVX2, and even more so with AVX512.
It seems that memory-bound computations, such as adding two 64 MB tensors can be slow with vectorization (depending upon the number of threads used), as the effects of downclocking can then be observed.
Original pull request: https://github.com/pytorch/pytorch/pull/56992
Reviewed By: soulitzer
Differential Revision: D29266289
Pulled By: ezyang
fbshipit-source-id: 2d5e8d1c2307252f22423bbc14f136c67c3e6184
Summary:
Since v1.7, oneDNN (MKL-DNN) has supported the use of Compute Library
for the Arm architeture to provide optimised convolution primitives
on AArch64.
This change enables the use of Compute Library in the PyTorch build.
Following the approach used to enable the use of CBLAS in MKLDNN,
It is enabled by setting the env vars USE_MKLDNN and USE_MKLDNN_ACL.
The location of the Compute Library build must be set useing `ACL_ROOT_DIR`.
This is an extension of the work in https://github.com/pytorch/pytorch/pull/50400
which added support for the oneDNN/MKL-DNN backend on AArch64.
_Note: this assumes that Compute Library has been built and installed at
ACL_ROOT_DIR. Compute library can be downloaded here:
`https://github.com/ARM-software/ComputeLibrary`_
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55913
Reviewed By: ailzhang
Differential Revision: D28559516
Pulled By: malfet
fbshipit-source-id: 29d24996097d0a54efc9ab754fb3f0bded290005
Summary:
In order to make it more convenient for maintainers to review the ATen AVX512 implementation, the namespace `vec256` is being renamed to `vec` in this PR, as modifying 77 files & creating 2 new files only took a few minutes, as these changes aren't significant, so fewer files would've to be reviewed while reviewing https://github.com/pytorch/pytorch/issues/56992.
The struct `Vec256` is not being renamed to `Vec`, but `Vectorized` instead, because there are some `using Vec=` statements in the codebase, so renaming it to `Vectorized` was more convenient. However, I can still rename it to `Vec`, if required.
### Changes made in this PR -
Created `aten/src/ATen/cpu/vec` with subdirectory `vec256` (vec512 would be added via https://github.com/pytorch/pytorch/issues/56992).
The changes were made in this manner -
1. First, a script was run to rename `vec256` to `vec` & `Vec` to `Vectorized` -
```
# Ref: https://stackoverflow.com/a/20721292
cd aten/src
grep -rli 'vec256\/vec256\.h' * | xargs -i@ sed -i 's/vec256\/vec256\.h/vec\/vec\.h/g' @
grep -rli 'vec256\/functional\.h' * | xargs -i@ sed -i 's/vec256\/functional\.h/vec\/functional\.h/g' @
grep -rli 'vec256\/intrinsics\.h' * | xargs -i@ sed -i 's/vec256\/intrinsics\.h/vec\/vec256\/intrinsics\.h/g' @
grep -rli 'namespace vec256' * | xargs -i@ sed -i 's/namespace vec256/namespace vec/g' @
grep -rli 'Vec256' * | xargs -i@ sed -i 's/Vec256/Vectorized/g' @
grep -rli 'vec256\:\:' * | xargs -i@ sed -i 's/vec256\:\:/vec\:\:/g' @
grep -rli 'at\:\:vec256' * | xargs -i@ sed -i 's/at\:\:vec256/at\:\:vec/g' @
cd ATen/cpu
mkdir vec
mv vec256 vec
cd vec/vec256
grep -rli 'cpu\/vec256\/' * | xargs -i@ sed -i 's/cpu\/vec256\//cpu\/vec\/vec256\//g' @
grep -rli 'vec\/vec\.h' * | xargs -i@ sed -i 's/vec\/vec\.h/vec\/vec256\.h/g' @
```
2. `vec256` & `VEC256` were replaced with `vec` & `VEC` respectively in 4 CMake files.
3. In `pytorch_vec/aten/src/ATen/test/`, `vec256_test_all_types.h` & `vec256_test_all_types.cpp` were renamed.
4. `pytorch_vec/aten/src/ATen/cpu/vec/vec.h` & `pytorch_vec/aten/src/ATen/cpu/vec/functional.h` were created.
Both currently have one line each & would have 5 when AVX512 support would be added for ATen.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58438
Reviewed By: malfet
Differential Revision: D28509615
Pulled By: ezyang
fbshipit-source-id: 63840df5f23b3b59e203d25816e2977c6a901780
Summary:
This PR is step 0 of adding PyTorch convolution bindings using the cuDNN frontend. The cuDNN frontend is the recommended way of using cuDNN v8 API. It is supposed to have faster release cycles, so that, for example, if people find a specific kernel has a bug, they can report it, and that kernel will be blocked in the cuDNN frontend and frameworks could just update that submodule without the need for waiting for a whole cuDNN release.
The work is not complete, and this PR is only step 0.
**What this PR does:**
- Add cudnn-frontend as a submodule.
- Modify cmake to build that submodule.
- Add bindings for convolution forward in `Conv_v8.cpp`, which is disabled by a macro by default.
- Tested manually by enabling the macro and run `test_nn.py`. All tests pass except those mentioned below.
**What this PR doesn't:**
- Only convolution forward, no backward. The backward will use v7 API.
- No 64bit-indexing support for some configuration. This is a known issue of cuDNN, and will be fixed in a later cuDNN version. PyTorch will not implement any workaround for issue, but instead, v8 API should be disabled on problematic cuDNN versions.
- No test beyond PyTorch's unit tests.
- Not tested for correctness on real models.
- Not benchmarked for performance.
- Benchmark cache is not thread-safe. (This is marked as `FIXME` in the code, and will be fixed in a follow-up PR)
- cuDNN benchmark is not supported.
- There are failing tests, which will be resolved later:
```
FAILED test/test_nn.py::TestNNDeviceTypeCUDA::test_conv_cudnn_nhwc_cuda_float16 - AssertionError: False is not true : Tensors failed to compare as equal!With rtol=0.001 and atol=1e-05, found 32 element(s) (out of 32) whose difference(s) exceeded the margin of error (in...
FAILED test/test_nn.py::TestNNDeviceTypeCUDA::test_conv_cudnn_nhwc_cuda_float32 - AssertionError: False is not true : Tensors failed to compare as equal!With rtol=1.3e-06 and atol=1e-05, found 32 element(s) (out of 32) whose difference(s) exceeded the margin of error (...
FAILED test/test_nn.py::TestNNDeviceTypeCUDA::test_conv_large_cuda - RuntimeError: CUDNN_BACKEND_OPERATION: cudnnFinalize Failed cudnn_status: 9
FAILED test/test_nn.py::TestNN::test_Conv2d_depthwise_naive_groups_cuda - AssertionError: False is not true : Tensors failed to compare as equal!With rtol=0 and atol=1e-05, found 64 element(s) (out of 64) whose difference(s) exceeded the margin of error (including 0 an...
FAILED test/test_nn.py::TestNN::test_Conv2d_deterministic_cudnn - RuntimeError: not supported yet
FAILED test/test_nn.py::TestNN::test_ConvTranspose2d_groups_cuda_fp32 - RuntimeError: cuDNN error: CUDNN_STATUS_BAD_PARAM
FAILED test/test_nn.py::TestNN::test_ConvTranspose2d_groups_cuda_tf32 - RuntimeError: cuDNN error: CUDNN_STATUS_BAD_PARAM
```
Although this is not a complete implementation of cuDNN v8 API binding, I still want to merge this first. This would allow me to do small and incremental work, for the ease of development and review.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51390
Reviewed By: malfet
Differential Revision: D28513167
Pulled By: ngimel
fbshipit-source-id: 9cc20c9dec5bbbcb1f94ac9e0f59b10c34f62740
Summary:
This adds some more compiler warnings ignores for everything that happens on a standard CPU build (CUDA builds still have a bunch of warnings so we can't turn on `-Werror` everywhere yet).
](https://our.intern.facebook.com/intern/diff/28005063/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56630
Pulled By: driazati
Reviewed By: malfet
Differential Revision: D28005063
fbshipit-source-id: 541ed415eb0470ddf7e08c22c5eb6da9db26e9a0
Summary:
[distutils](https://docs.python.org/3/library/distutils.html) is on its way out and will be deprecated-on-import for Python 3.10+ and removed in Python 3.12 (see [PEP 632](https://www.python.org/dev/peps/pep-0632/)). There's no reason for us to keep it around since all the functionality we want from it can be found in `setuptools` / `sysconfig`. `setuptools` includes a copy of most of `distutils` (which is fine to use according to the PEP), that it uses under the hood, so this PR also uses that in some places.
Fixes#56527
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57040
Pulled By: driazati
Reviewed By: nikithamalgifb
Differential Revision: D28051356
fbshipit-source-id: 1ca312219032540e755593e50da0c9e23c62d720
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56868
See __init__.py for a summary of the tool.
The following sections are present in this initial version
- Model Size. Show the total model size, as well as a breakdown by
stored files, compressed files, and zip overhead. (I expect this
breakdown to be a bit more useful once data.pkl is compressed.)
- Model Structure. This is basically the output of
`show_pickle(data.pkl)`, but as a hierarchical structure.
Some structures cause this view to crash right now, but it can be
improved incrementally.
- Zip Contents. This is basically the output of `zipinfo -l`.
- Code. This is the TorchScript code. It's integrated with a blame
window at the bottom, so you can click "Blame Code", then click a bit
of code to see where it came from (based on the debug_pkl). This
currently doesn't render properly if debug_pkl is missing or
incomplete.
- Extra files (JSON). JSON dumps of each json file under /extra/, up to
a size limit.
- Extra Pickles. For each .pkl file in the model, we safely unpickle it
with `show_pickle`, then render it with `pprint` and include it here
if the size is not too large. We aren't able to install the pprint
hack that thw show_pickle CLI uses, so we get one-line rendering for
custom objects, which is not very useful. Built-in types look fine,
though. In particular, bytecode.pkl seems to look fine (and we
hard-code that file to ignore the size limit).
I'm checking in the JS dependencies to avoid a network dependency at
runtime. They were retrieved from the following URLS, then passed
through a JS minifier:
https://unpkg.com/htm@3.0.4/dist/htm.module.js?modulehttps://unpkg.com/preact@10.5.13/dist/preact.module.js?module
Test Plan:
Manually ran on a few models I had lying around.
Mostly tested in Chrome, but I also poked around in Firefox.
Reviewed By: dhruvbird
Differential Revision: D28020849
Pulled By: dreiss
fbshipit-source-id: 421c30ed7ca55244e9fda1a03b8aab830466536d
Summary:
Fixes https://github.com/pytorch/pytorch/issues/50577
Learning rate schedulers had not yet been implemented for the C++ API.
This pull request introduces the learning rate scheduler base class and the StepLR subclass. Furthermore, it modifies the existing OptimizerOptions such that the learning rate scheduler can modify the learning rate.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52268
Reviewed By: mrshenli
Differential Revision: D26818387
Pulled By: glaringlee
fbshipit-source-id: 2b28024a8ea7081947c77374d6d643fdaa7174c1
Summary:
In setup.py add logic to:
- Get list of submodules from .gitmodules file
- Auto-fetch submodules if none of them has been fetched
In CI:
- Test this on non-docker capable OSes (Windows and Mac)
- Use shallow submodule checkouts whenever possible
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53461
Reviewed By: ezyang
Differential Revision: D26871119
Pulled By: malfet
fbshipit-source-id: 8b23d6a4fcf04446eac11446e0113819476ef6ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53489
It appears that D26675801 (1fe6a6507e) broke Glow builds (and probably other instals) with the inclusion of the python_arg_parser include. That dep lives in a directory of its own and was not included in the setup.py.
Test Plan: OSS tests should catch this.
Reviewed By: ngimel
Differential Revision: D26878180
fbshipit-source-id: 70981340226a9681bb9d5420db56abba75e7f0a5
Summary:
Currently there's only one indicator for build_ext regarding distributed backend `USE_DISTRIBUTED`.
However one can build with selective backends. adding the 3 distributed backend option in setup.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53214
Test Plan: Set the 3 options in environment and locally ran `python setup.py build_ext`
Reviewed By: janeyx99
Differential Revision: D26818259
Pulled By: walterddr
fbshipit-source-id: 688e8f83383d10ce23ee1f019be33557ce5cce07
Summary:
Do not build PyTorch if `setup.py` is called with 'sdist' option
Regenerate bundled license while sdist package is being built
Refactor `check_submodules` out of `build_deps` and check that submodules project are present during source package build stage.
Test that sdist package is configurable during `asan-build` step
Fixes https://github.com/pytorch/pytorch/issues/52843
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52908
Reviewed By: walterddr
Differential Revision: D26685176
Pulled By: malfet
fbshipit-source-id: 972a40ae36e194c0b4e0fc31c5e1af1e7a815185
Summary:
Move NumPy initialization from `initModule()` to singleton inside
`torch::utils::is_numpy_available()` function.
This singleton will print a warning, that NumPy integration is not
available, rather than fails to import torch altogether.
The warning be printed only once, and will look something like the
following:
```
UserWarning: Failed to initialize NumPy: No module named 'numpy.core' (Triggered internally at ../torch/csrc/utils/tensor_numpy.cpp:66.)
```
This is helpful if PyTorch was compiled with wrong NumPy version, of
NumPy is not commonly available on the platform (which is often the case
on AARCH64 or Apple M1)
Test that PyTorch is usable after numpy is uninstalled at the end of
`_test1` CI config.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52794
Reviewed By: seemethere
Differential Revision: D26650509
Pulled By: malfet
fbshipit-source-id: a2d98769ef873862c3704be4afda075d76d3ad06
Summary:
Previously header files from jit/tensorexpr were not copied, this PR should enable copying.
This will allow other OSS projects like Glow to used TE.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49933
Reviewed By: Krovatkin, mruberry
Differential Revision: D25725927
Pulled By: protonu
fbshipit-source-id: 9d5a0586e9b73111230cacf044cd7e8f5c600ce9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49201
This unblocks kineto profiler for 1.8 release.
This PR supercedes https://github.com/pytorch/pytorch/pull/48391
Note: this will somewhat increase the size of linux server binaries, bc
we add libkineto.a and libcupti_static.a:
-rw-r--r-- 1 jenkins jenkins 1107502 Dec 10 21:16 build/lib/libkineto.a
-rw-r--r-- 1 root root 13699658 Nov 13 2019 /usr/local/cuda/lib64/libcupti_static.a
Test Plan:
CI
https://github.com/pytorch/pytorch/pull/48391
Imported from OSS
Reviewed By: ngimel
Differential Revision: D25480770
fbshipit-source-id: 037cd774f5547d9918d6055ef5cc952a54e48e4c
Summary:
This would be the case when package is build for local development rather than for installation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47390
Reviewed By: janeyx99
Differential Revision: D24738416
Pulled By: malfet
fbshipit-source-id: 22bd676bc46e5d50a09539c969ce56d37cfe5952
Summary:
As typing.NoReturn is used in the codebase
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47314
Reviewed By: seemethere
Differential Revision: D24712847
Pulled By: malfet
fbshipit-source-id: f0692d408316d630bc11f1ee881b695437fb47d4
Summary:
libiomp runtime is the only external dependency OS X package has if compiled with MKL
Copy it to the stage directory from one of the available rpathes
And remove all absolute rpathes, since project shoudl have none
Fixes https://github.com/pytorch/pytorch/issues/38607
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47262
Reviewed By: walterddr
Differential Revision: D24705094
Pulled By: malfet
fbshipit-source-id: 9f588a3ec3c6c836c8986d858fb53df815a506c8
Summary:
Also, be a bit future-proof in support version list
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46921
Reviewed By: seemethere
Differential Revision: D24568733
Pulled By: malfet
fbshipit-source-id: ae34f8da1ed39b80dc34db0b06e4ef142104a3ff
Summary:
import print_function to make setup.py invoked by Python2 print human readable error:
```
% python2 setup.py
Python 2 has reached end-of-life and is no longer supported by PyTorch.
```
Also, remove `future` from the list of the PyTorch package install dependencies
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46317
Reviewed By: walterddr, bugra
Differential Revision: D24305004
Pulled By: malfet
fbshipit-source-id: 9181186170562384dd2c0e6a8ff0b1e93508f221
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45844
Someone pointed out that dataclasses were actually added to the python
stdlib in 3.7 and not 3.8, so bumping down the dependency on dataclasses
from 3.8 -> 3.7 makes sense here
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: walterddr, malfet
Differential Revision: D24113367
Pulled By: seemethere
fbshipit-source-id: 03d2d93f7d966d48a30a8e2545fd07dfe63b4fb3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45610
Also add to the usual documentation places that this option exists.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D24058199
Pulled By: suo
fbshipit-source-id: 81574fbd042f47587e2c7820c726fac0f68af2a7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45611
dataclasses was made a standard library item in 3.8
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: walterddr
Differential Revision: D24031740
Pulled By: seemethere
fbshipit-source-id: 15bdf1fe0d8de9b8ba7912e4a651f06b18d516ee
Summary:
There is a module called `2to3` which you can target for future specifically to remove these, the directory of `caffe2` has the most redundant imports:
```2to3 -f future -w caffe2```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45033
Reviewed By: seemethere
Differential Revision: D23808648
Pulled By: bugra
fbshipit-source-id: 38971900f0fe43ab44a9168e57f2307580d36a38
Summary:
The ATen/native/cuda headers were copied to torch/include, but then not included in the final package. Further, add ATen/native/hip headers to the installation, as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45097
Reviewed By: mruberry
Differential Revision: D23831006
Pulled By: malfet
fbshipit-source-id: ab527928185faaa912fd8cab208733a9b11a097b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44577
I would like to to move this to cmake so that I can depend on it
happening from other parts of the build.
This PR pulls out the logic for determining the version string and
writing the version file into its own module. `setup.py` still receives
the version string and uses it as before, but now the code for writing
out `torch/version.py` lives in a custom command in torch/CMakeLists.txt
I noticed a small inconsistency in how version info is populated.
`TORCH_BUILD_VERSION` is populated from `setup.py` at configuration
time, while `torch/version.py` is written at build time. So if, e.g. you
configured cmake on a certain git rev, then built it in on another, the
two versions would be inconsistent.
This does not appear to matter, so I opted to preserve the existing
behavior.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D23734781
Pulled By: suo
fbshipit-source-id: 4002c9ec8058503dc0550f8eece2256bc98c03a4
Summary:
This can be taken from the system in which case it is not used from the submodule. Hence the check here limits the usage unnecessarily
ccing malfet
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44278
Reviewed By: malfet
Differential Revision: D23568552
Pulled By: ezyang
fbshipit-source-id: 7fd2613251567f649b12eca0b1fe7663db9cb58d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42629
How to approach reviewing this diff:
- The new codegen itself lives in `tools/codegen`. Start with `gen.py`, then read `model.py` and them the `api/` folder. The comments at the top of the files describe what is going on. The CLI interface of the new codegen is similar to the old one, but (1) it is no longer necessary to explicitly specify cwrap inputs (and now we will error if you do so) and (2) the default settings for source and install dir are much better; to the extent that if you run the codegen from the root source directory as just `python -m tools.codegen.gen`, something reasonable will happen.
- The old codegen is (nearly) entirely deleted; every Python file in `aten/src/ATen` was deleted except for `common_with_cwrap.py`, which now permanently finds its home in `tools/shared/cwrap_common.py` (previously cmake copied the file there), and `code_template.py`, which now lives in `tools/codegen/code_template.py`. We remove the copying logic for `common_with_cwrap.py`.
- All of the inputs to the old codegen are deleted.
- Build rules now have to be adjusted to not refer to files that no longer exist, and to abide by the (slightly modified) CLI.
- LegacyTHFunctions files have been generated and checked in. We expect these to be deleted as these final functions get ported to ATen. The deletion process is straightforward; just delete the functions of the ones you are porting. There are 39 more functions left to port.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D23183978
Pulled By: ezyang
fbshipit-source-id: 6073ba432ad182c7284a97147b05f0574a02f763
Summary:
This prevents confusing errors when the interpreter encounters some
syntax errors in the middle.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42870
Reviewed By: albanD
Differential Revision: D23269265
Pulled By: ezyang
fbshipit-source-id: 61f62cbe294078ad4a909fa87aa93abd08c26344
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42522
Main changes:
- Consolidated CMake files to have a single entry point, rather than having a specialized one for PyTorch.
- Changed the way the preprocessor flags are provided, and changed their name.
There were a few instances in PyTorch's CMake files where we were directly adding TensorPipe's source directory as an include path, which however doesn't contain the auto-generated header we now added. We fix that by adding the `tensorpipe` CMake target as a dependency, so that the include paths defined by TensorPipe are used, which contain that auto-generated header. So instead we link those targets to the tensorpipe target in order for them to pick up the correct include directories.
I'm turning off SHM and CMA for now because they have never been covered by the CI. I'll enable them in a separate PR so that if they turn out to be flaky we can revert that change without reverting this one.
Test Plan: CI
Reviewed By: malfet
Differential Revision: D22959472
fbshipit-source-id: 1959a41c4a66ef78bf0f3bd5e3964969a2a1bf67
Summary:
Import __future__ to make `print(*args)` a syntactically correct statement under Python-2
Otherwise, if once accidentally invokes setup.py using Python-2 interpreter they will be greeted by:
```
File "setup.py", line 229
print(*args)
^
SyntaxError: invalid syntax
```
instead of:
```
Python 2 has reached end-of-life and is no longer supported by PyTorch.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41960
Reviewed By: orionr, seemethere
Differential Revision: D22710174
Pulled By: malfet
fbshipit-source-id: ffde3ddd585707ba1d39e57e0c6bc9c4c53f8004
Summary:
Switch off `/Z7` so that we don't generate debug info in Release and MinSizeRel builds, so that we will probably get smaller static libraries and object files and faster build time
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39703
Differential Revision: D21960684
Pulled By: ezyang
fbshipit-source-id: 909a237a138183591d667885b13fc311470eed65
Summary:
It just depends on a single `torch_python` library.
C library does not depend on standard C++ library and as result it closes https://github.com/pytorch/pytorch/issues/36941
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39375
Reviewed By: orionr
Differential Revision: D21840645
Pulled By: malfet
fbshipit-source-id: 777c189feee9d6fc686816d92cb9f109b8aac7ca
Summary:
**Summary**
This commit adds the headers required to define and use JIT backends to
`package_data` in `setup.py` so that they are exported and copied to the
same place as the rest of the headers when PyTorch is installed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38525
Differential Revision: D21601806
Pulled By: SplitInfinity
fbshipit-source-id: 1615dd4047777926e013d7dd14fe427d5ffb8b70
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35617
Python 2 has reached end-of-life and is no longer supported by PyTorch.
Now we can clean up some cruft that we put in place to support it.
Test Plan: CI
Differential Revision: D20842883
Pulled By: dreiss
fbshipit-source-id: 18dc5219ba99658c0ca7e2f26863df008c420e6a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38157
This removes the error prone process of assembling `torch/__init__.pyi`
(and frequently forgetting to expose things), since now we can simply
rely on the true source file to get things done. Most of the old
codegen in gen_pyi.py is now rerouted to various files:
- `torch/_C/__init__.pyi` (the dumping pile of all misc bindings)
- `torch/_C/_nn.pyi` (NN function bindings)
- `torch/_C/_VariableFunctions.pyi` (torch function bindings)
`torch.types` grew a bunch more definitions that previously where
defined in `torch/__init__.pyi`
Some miscellaneous changes
- Fixed a bug where we treat single TensorList argument as implying
varargs are accepted. This is actually only supported on IntList.
This means we can correctly generate a stub for dequantize.
- Add missing manual stub for nonzero
- Switched torch/onnx/operators.py to directly refer to _C module,
since apparently mypy doesn't think that methods prefixed with
underscores get reexported. This may be a recurring theme; maybe
we need to find a better way to solve it.
Because I was really lazy, I dumped namedtuple definitions in both
`torch._C` and `torch._C._VariableFunctions`. This is definitely wrong.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21497400
Pulled By: ezyang
fbshipit-source-id: 07b126141c82efaca37be27c07255cb2b9b3f064
Summary:
We should not rely on the async exceptions. Catching C++ only exception is more sensible and may get a boost in both space (1163 MB -> 1073 MB, 0.92x) and performance(51m -> 49m, 0.96x).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37235
Differential Revision: D21256918
Pulled By: ezyang
fbshipit-source-id: 572ee96f2e4c48ad13f83409e4e113483b3a457a
Summary:
These options are disabled by default, and are supposed to be used by
linux distro developers. With the existing shortcut option
USE_SYSTEM_LIBS toggled, these new options will be enabled as well.
Additionally, when USE_SYSTEM_LIBS is toggled, setup.py should
no longer check the existence of git submodules.
ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37277
Differential Revision: D21256999
Pulled By: ezyang
fbshipit-source-id: 84f97d008db5a5e41a289cb7bce94906de3c52cf
Summary:
Line 33+ contains instructions on how to disable use, 108+ on how to enable it.
The default in CMakeLists.txt is enabled, so drop the latter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36993
Differential Revision: D21161793
Pulled By: ngimel
fbshipit-source-id: 08c5eecaf8768491f90d4a52c338ecea32a0c35e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35613
Python 2 has reached end-of-life and is no longer supported by PyTorch.
To spare users from a long, doomed setup when trying to use PyTorch with
Python 2, detect this case early and fail with a clear message. This
commit covers setup.py.
Test Plan: Attempted to build PyTorch with Python 2 and saw a clear error *quickly*.
Differential Revision: D20842881
Pulled By: dreiss
fbshipit-source-id: caaaa0dbff83145ff668bd25df6d7d4b3ce12e47
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35411
The file and class names in ATen/core/boxing were quite confusing.
Let's rename them for readability.
Also move function schema inference out of the boxing logic into op_registration.h where it belongs.
ghstack-source-id: 101539206
Test Plan: waitforsandcastle
Differential Revision: D20653621
fbshipit-source-id: 6a79c73d5758bee1e072d543c030913b18a69c7c
Summary:
The original behavior of pytorch c10d only supports built-in c10d backends, such as
nccl/gloo/mpi. This patch is used to extend the c10d capability to support dynamically
loading 3rd party communication libraries which are derived from ProcessGroup base class.
related RFC is in: https://github.com/pytorch/pytorch/issues/27955
Through this way, user just need specify a 3rd party c10d backend name when invoking
torch.distributed.init_process_group(). The proposed logic will try to load corresponding
c10d backend cpp extension automatically. as for how to develop a new 3rd party c10d backend
through cpp extension, pls refer to test/cpp_extensions/cpp_c10d_extension.cpp
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28068
Differential Revision: D19174838
Pulled By: agolynski
fbshipit-source-id: 3409a504a43ce7260e6f9d1207c00e87471fac62
Summary:
As a followup to https://github.com/pytorch/pytorch/pull/35042 this removes python2 from setup.py and adds Python 3.8 to the list of supported versions. We're already testing this in CircleCI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35539
Differential Revision: D20709060
Pulled By: orionr
fbshipit-source-id: 5d40bc14cb885374fec370fc7c5d3cde8769039a
Summary:
## Motivation
This PR upgrades MKL-DNN from v0.20 to DNNL v1.2 and resolves https://github.com/pytorch/pytorch/issues/30300.
DNNL (Deep Neural Network Library) is the new brand of MKL-DNN, which improves performance, quality, and usability over the old version.
This PR focuses on the migration of all existing functionalities, including minor fixes, performance improvement and code clean up. It serves as the cornerstone of our future efforts to accommodate new features like OpenCL support, BF16 training, INT8 inference, etc. and to let the Pytorch community derive more benefits from the Intel Architecture.
<br>
## What's included?
Even DNNL has many breaking changes to the API, we managed to absorb most of them in ideep. This PR contains minimalist changes to the integration code in pytorch. Below is a summary of the changes:
<br>
**General:**
1. Replace op-level allocator with global-registered allocator
```
// before
ideep::sum::compute<AllocForMKLDNN>(scales, {x, y}, z);
// after
ideep::sum::compute(scales, {x, y}, z);
```
The allocator is now being registeted at `aten/src/ATen/native/mkldnn/IDeepRegistration.cpp`. Thereafter all tensors derived from the `cpu_engine` (by default) will use the c10 allocator.
```
RegisterEngineAllocator cpu_alloc(
ideep::engine::cpu_engine(),
[](size_t size) {
return c10::GetAllocator(c10::DeviceType::CPU)->raw_allocate(size);
},
[](void* p) {
c10::GetAllocator(c10::DeviceType::CPU)->raw_deallocate(p);
}
);
```
------
2. Simplify group convolution
We had such a scenario in convolution where ideep tensor shape mismatched aten tensor: when `groups > 1`, DNNL expects weights tensors to be 5-d with an extra group dimension, e.g. `goihw` instead of `oihw` in 2d conv case.
As shown below, a lot of extra checks came with this difference in shape before. Now we've completely hidden this difference in ideep and all tensors are going to align with pytorch's definition. So we could safely remove these checks from both aten and c2 integration code.
```
// aten/src/ATen/native/mkldnn/Conv.cpp
if (w.ndims() == x.ndims() + 1) {
AT_ASSERTM(
groups > 1,
"Only group _mkldnn_conv2d weights could have been reordered to 5d");
kernel_size[0] = w.get_dim(0) * w.get_dim(1);
std::copy_n(
w.get_dims().cbegin() + 2, x.ndims() - 1, kernel_size.begin() + 1);
} else {
std::copy_n(w.get_dims().cbegin(), x.ndims(), kernel_size.begin());
}
```
------
3. Enable DNNL built-in cache
Previously, we stored DNNL jitted kernels along with intermediate buffers inside ideep using an LRU cache. Now we are switching to the newly added DNNL built-in cache, and **no longer** caching buffers in order to reduce memory footprint.
This change will be mainly reflected in lower memory usage from memory profiling results. On the code side, we removed couple of lines of `op_key_` that depended on the ideep cache before.
------
4. Use 64-bit integer to denote dimensions
We changed the type of `ideep::dims` from `vector<int32_t>` to `vector<int64_t>`. This renders ideep dims no longer compatible with 32-bit dims used by caffe2. So we use something like `{stride_.begin(), stride_.end()}` to cast parameter `stride_` into a int64 vector.
<br>
**Misc changes in each commit:**
**Commit:** change build options
Some build options were slightly changed, mainly to avoid name collisions with other projects that include DNNL as a subproject. In addition, DNNL built-in cache is enabled by option `DNNL_ENABLE_PRIMITIVE_CACHE`.
Old | New
-- | --
WITH_EXAMPLE | MKLDNN_BUILD_EXAMPLES
WITH_TEST | MKLDNN_BUILD_TESTS
MKLDNN_THREADING | MKLDNN_CPU_RUNTIME
MKLDNN_USE_MKL | N/A (not use MKL anymore)
------
**Commit:** aten reintegration
- aten/src/ATen/native/mkldnn/BinaryOps.cpp
Implement binary ops using new operation `binary` provided by DNNL
- aten/src/ATen/native/mkldnn/Conv.cpp
Clean up group convolution checks
Simplify conv backward integration
- aten/src/ATen/native/mkldnn/MKLDNNConversions.cpp
Simplify prepacking convolution weights
- test/test_mkldnn.py
Fixed an issue in conv2d unit test: it didn't check conv results between mkldnn and aten implementation before. Instead, it compared the mkldnn with mkldnn as the default cpu path will also go into mkldnn. Now we use `torch.backends.mkldnn.flags` to fix this issue
- torch/utils/mkldnn.py
Prepack weight tensor on module `__init__` to achieve better performance significantly
------
**Commit:** caffe2 reintegration
- caffe2/ideep/ideep_utils.h
Clean up unused type definitions
- caffe2/ideep/operators/adam_op.cc & caffe2/ideep/operators/momentum_sgd_op.cc
Unify tensor initialization with `ideep::tensor::init`. Obsolete `ideep::tensor::reinit`
- caffe2/ideep/operators/conv_op.cc & caffe2/ideep/operators/quantization/int8_conv_op.cc
Clean up group convolution checks
Revamp convolution API
- caffe2/ideep/operators/conv_transpose_op.cc
Clean up group convolution checks
Clean up deconv workaround code
------
**Commit:** custom allocator
- Register c10 allocator as mentioned above
<br><br>
## Performance
We tested inference on some common models based on user scenarios, and most performance numbers are either better than or on par with DNNL 0.20.
ratio: new / old | Latency (batch=1 4T) | Throughput (batch=64 56T)
-- | -- | --
pytorch resnet18 | 121.4% | 99.7%
pytorch resnet50 | 123.1% | 106.9%
pytorch resnext101_32x8d | 116.3% | 100.1%
pytorch resnext50_32x4d | 141.9% | 104.4%
pytorch mobilenet_v2 | 163.0% | 105.8%
caffe2 alexnet | 303.0% | 99.2%
caffe2 googlenet-v3 | 101.1% | 99.2%
caffe2 inception-v1 | 102.2% | 101.7%
caffe2 mobilenet-v1 | 356.1% | 253.7%
caffe2 resnet101 | 100.4% | 99.8%
caffe2 resnet152 | 99.8% | 99.8%
caffe2 shufflenet | 141.1% | 69.0% †
caffe2 squeezenet | 98.5% | 99.2%
caffe2 vgg16 | 136.8% | 100.6%
caffe2 googlenet-v3 int8 | 100.0% | 100.7%
caffe2 mobilenet-v1 int8 | 779.2% | 943.0%
caffe2 resnet50 int8 | 99.5% | 95.5%
_Configuration:
Platform: Skylake 8180
Latency Test: 4 threads, warmup 30, iteration 500, batch size 1
Throughput Test: 56 threads, warmup 30, iteration 200, batch size 64_
† Shufflenet is one of the few models that require temp buffers during inference. The performance degradation is an expected issue since we no longer cache any buffer in the ideep. As for the solution, we suggest users opt for caching allocator like **jemalloc** as a drop-in replacement for system allocator in such heavy workloads.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32422
Test Plan:
Perf results: https://our.intern.facebook.com/intern/fblearner/details/177790608?tab=Experiment%20Results
10% improvement for ResNext with avx512, neutral on avx2
More results: https://fb.quip.com/ob10AL0bCDXW#NNNACAUoHJP
Reviewed By: yinghai
Differential Revision: D20381325
Pulled By: dzhulgakov
fbshipit-source-id: 803b906fd89ed8b723c5fcab55039efe3e4bcb77
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34774
This PR provides pybind11's `type_caster<at::Generator>` that allows mapping `at::Generator` instance returned from user-defined method to python `torch::Generator`, defined as `THPGenerator ` c++ class.
This allows 1) defining custom RNG in c++ extension 2) using custom RNG in python code.
`TestRNGExtension.test_rng` shows how to use custom RNG defined in `rng_extension.cpp`
Test Plan: Imported from OSS
Differential Revision: D20549451
Pulled By: pbelevich
fbshipit-source-id: 312a6deccf8228f7f60695bbf95834620d52f5eb
Summary:
Because `past` is used in `caffe2.python.core`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35057
Test Plan: CI
Differential Revision: D20547042
Pulled By: malfet
fbshipit-source-id: cad2123c7b88271fea37f21e616df551075383a8
Summary:
Was originally not a requirement but we should add it back here since
it's required on import and we require it anyways for our conda
packages.
Tested with:
```
❯ pkginfo -f requires_dist *.whl
requires_dist: ['numpy']
```
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34510
Differential Revision: D20352125
Pulled By: seemethere
fbshipit-source-id: 383e396fe500ed7043d83c3df57d1772d0fff1e6
Summary:
Per https://github.com/pytorch/pytorch/issues/19161 PyTorch is incompatible with 3.6.0 due to the missing `PySlice_Unpack`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34724
Test Plan: CI + try to load pytorch binary using python-3.6.0
Differential Revision: D20449052
Pulled By: malfet
fbshipit-source-id: 2c787fc64f5d1377c7f935ad2f3c77f46723d7dd
Summary:
Attempt to build pytorch with ASAN on system with gcc-8 fails due to the mismatch system compilation flags.
Address the issue by using original compiler to build `torch._C` extension
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34549
Test Plan: Run `.jenkins/pytorch/build-asan.sh` on FC-30
Differential Revision: D20373781
Pulled By: malfet
fbshipit-source-id: 041c8d25f96b4436385a5e0eb6fc46e9b5fdf3f1
Summary:
This PR move glu to Aten(CPU).
Test script:
```
import torch
import torch.nn.functional as F
import time
torch.manual_seed(0)
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
device = "cpu"
#warm up
for n in [10, 100, 1000, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n // 2, device=device)
for i in range(1000):
output = F.glu(input)
output.backward(grad_output)
for n in [10, 100, 1000, 10000]:
fwd_t = 0
bwd_t = 0
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n // 2, device=device)
for i in range(10000):
t1 = _time()
output = F.glu(input)
t2 = _time()
output.backward(grad_output)
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
Test device: **skx-8180.**
Before:
```
input size(128, 10) forward time is 0.04 (ms); backwad avg time is 0.08 (ms).
input size(128, 100) forward time is 0.06 (ms); backwad avg time is 0.14 (ms).
input size(128, 1000) forward time is 0.11 (ms); backwad avg time is 0.31 (ms).
input size(128, 10000) forward time is 1.52 (ms); backwad avg time is 2.04 (ms).
```
After:
```
input size(128, 10) forward time is 0.02 (ms); backwad avg time is 0.05 (ms).
input size(128, 100) forward time is 0.04 (ms); backwad avg time is 0.09 (ms).
input size(128, 1000) forward time is 0.07 (ms); backwad avg time is 0.17 (ms).
input size(128, 10000) forward time is 0.13 (ms); backwad avg time is 1.03 (ms).
```
Fix https://github.com/pytorch/pytorch/issues/24707, https://github.com/pytorch/pytorch/issues/24708.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33179
Differential Revision: D19839835
Pulled By: VitalyFedyunin
fbshipit-source-id: e4d3438556a1068da2c4a7e573d6bbf8d2a6e2b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32325
The purpose of this PR is to enable PyTorch dispatching on `at::Generator*` parameters and demonstrate how it can be used in cpp extensions to implement custom RNG.
1. `CustomRNGKeyId` value added to DispatchKey enum and `DispatchKeySet key_set_` added to `at::Generator`
2. The overloaded `operator()(at::Generator* gen)` added to MultiDispatchKeySet.
3. The existing CPUGenerator and CUDAGenerator class are supplied with CPUTensorId and CUDATensorId dispatch keys
4. The implementation of CPU's `cauchy_kernel`(as an example, because it's already moved to ATen) was templatized and moved to `ATen/native/cpu/DistributionTemplates.h` to make it available for cpp extensions
5. Minor CMake changes to make native/cpu tensors available for cpp extensions
6. RegisterCustomRNG test that demonstrates how CustomCPUGenerator class can be implemented and how custom_rng_cauchy_ native function can be registered to handle Tensor::cauchy_ calls.
Test Plan: Imported from OSS
Differential Revision: D19604558
Pulled By: pbelevich
fbshipit-source-id: 2619f14076cee5742094a0be832d8530bba72728
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30445
Create distributed and rpc directories under caffe/test for better management
of unit tests.
Differential Revision: D18702786
fbshipit-source-id: e9daeed0cfb846ef68806f6decfcb57c0e0e3606
Summary:
This PR adds a more complete list of pytorch header files to be installed at build time. It also fixes one instance of including a header from local src directory instead of installed directory.
A more complete set of headers enable other modules to correctly work with pyTorch built for ROCm.
cc: ezyang bddppq iotamudelta
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32076
Differential Revision: D19372933
Pulled By: ezyang
fbshipit-source-id: 3b5f3241c001fa05ea448c359a706ce9a8214aa0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31155
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19262584
Pulled By: ezyang
fbshipit-source-id: 147ac5a9c36e813ea9a2f68b498880942d661be5
Summary:
We dont have ATen/native/*.h in torch target before, and we would like it to be exposed for external use.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30835
Differential Revision: D18836160
Pulled By: zrphercule
fbshipit-source-id: 7330a9c9d8b65f173cc332b1cfeeb18c7dca20a8
Summary:
This adds the HIP_VERSION cmake variable as hip_version.
This should help detecting ROCm, e.g. in https://github.com/pytorch/pytorch/issues/22091.
To parallel CUDA, hip_version is a string.
An alternative variant might be to split by '.' and only take the first two parts.
The method suffers a bit from ROCm not being as monolithic as CUDA.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29815
Differential Revision: D18532267
Pulled By: bddppq
fbshipit-source-id: 1bde4ad0cfacc47bfd1c0945e130921d8575a5bf
Summary:
Also move the logic that installs the pybind11 headers from setup.py to cmake (to align with other headers).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29659
Differential Revision: D18458208
Pulled By: bddppq
fbshipit-source-id: cfd1e74b892d4a65591626ab321780c8c87b810d
Summary:
We dont have ATen/native/quantized/cpu/*.h in torch target before, and we would like it to be exposed for external use.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29418
Differential Revision: D18383534
Pulled By: zrphercule
fbshipit-source-id: 72c06ae2c10e8cc49e7256c9e9b89288263bbfde
Summary:
This problem is from issue [https://github.com/pytorch/pytorch/issues/28753](https://github.com/pytorch/pytorch/issues/28753)
The header files on directories`math` and `threadpool` should be included on the built package because they are included on the other header files, such as on file `torch/include/caffe2/utils/math.h`
```
#include "caffe2/core/common.h"
#include "caffe2/core/types.h"
#include "caffe2/utils/math/broadcast.h"
#include "caffe2/utils/math/elementwise.h"
#include "caffe2/utils/math/reduce.h"
#include "caffe2/utils/math/transpose.h"
#include "caffe2/utils/math/utils.h"
```
But the `setup.py` doesn't include the header files on `master` branch. The header files on `utils` directory of a built `torch` package are the following:
```
> ls include/caffe2/utils
bench_utils.h conversions.h eigen_utils.h map_utils.h murmur_hash3.h proto_wrap.h smart_tensor_printer.h
cast.h cpuid.h filler.h math-detail.h proto_convert.h signal_handler.h string_utils.h
cblas.h cpu_neon.h fixed_divisor.h math.h proto_utils.h simple_queue.h zmq_helper.h
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28869
Differential Revision: D18226319
Pulled By: soumith
fbshipit-source-id: 51575ddc559181c069b3324aa9b2d1669310ba25
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26140
Per https://github.com/pytorch/pytorch/issues/25883, we want to work
towards C++/Python API parity. This diff adds clip_grad_norm_ to the c++ API to
improve parity.
ghstack-source-id: 91334333
ghstack-source-id: 91334333
Test Plan: Added a unit test
Differential Revision: D17312367
fbshipit-source-id: 753ba3a4d084d01f3cc8919da3108e67c809ad65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27149
Extract version to version.txt and add reading version logic to setup.py and fb/torch_version.py
ghstack-source-id: 91271883
Test Plan: N/A
Reviewed By: gchanan, ezyang
Differential Revision: D17689307
fbshipit-source-id: 21899502027cec71b63d9dc151e09ff5ff3f279d
Summary:
FindCUDNN.cmake and cuda.cmake have done the detection. This commit deletes `tools/setup_helpers/cudnn.py` as it is no longer needed.
Previously in https://github.com/pytorch/pytorch/issues/25482, one test failed because TensorRT detects cuDNN differently, and there may be situations we can find cuDNN but TensorRT cannot. This is fixed by passing our detection result down to TensorRT.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25876
Differential Revision: D17346270
Pulled By: ezyang
fbshipit-source-id: c1e7ad4a1cb20f964fe07a72906f2f002425d894
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26337
- Factor out boxing and unboxing functionality from the c10 dispatcher into a c10::KernelFunction class
- Move that class and everything else it depends on into ATen/core/boxing
- This also allows us to get rid of c10::KernelCache. Instead, we now store a pointer to the unboxed functor in c10::KernelFunction.
- We're also getting rid of the DispatchTableEntry struct and instead store KernelFunction directly.
- To make this work, we need to change the dispatcher calling API from Dispatcher::lookup().callBoxed/callUnboxed and OperatorEntry::lookup().callBoxed/callUnboxed to Dispatcher::callBoxed/callUnboxed and OperatorEntry::callBoxed/callUnboxed.
ghstack-source-id: 90459911
Test Plan: unit tests
Differential Revision: D17416607
fbshipit-source-id: fd221f1d70eb3f1b4d33092eaa7e37d25684c934
Summary:
This PR aims to re-organize C++ API `torch::nn` folder structure in the following way:
- Every module in `torch/csrc/api/include/torch/nn/modules/` (except `any.h`, `named_any.h`, `modulelist.h`, `sequential.h`, `embedding.h`) has a strictly equivalent Python file in `torch/nn/modules/`. For example:
`torch/csrc/api/include/torch/nn/modules/pooling.h` -> `torch/nn/modules/pooling.py`
`torch/csrc/api/include/torch/nn/modules/conv.h` -> `torch/nn/modules/conv.py`
`torch/csrc/api/include/torch/nn/modules/batchnorm.h` -> `torch/nn/modules/batchnorm.py`
`torch/csrc/api/include/torch/nn/modules/sparse.h` -> `torch/nn/modules/sparse.py`
- Containers such as `any.h`, `named_any.h`, `modulelist.h`, `sequential.h` are moved into `torch/csrc/api/include/torch/nn/modules/container/`, because their implementations are too long to be combined into one file (like `torch/nn/modules/container.py` in Python API)
- `embedding.h` is not renamed to `sparse.h` yet, because we have another work stream that works on API parity for Embedding and EmbeddingBag, and renaming the file would cause conflict. After the embedding API parity work is done, we will rename `embedding.h` to `sparse.h` to match the Python file name, and move the embedding options out to options/ folder.
- `torch/csrc/api/include/torch/nn/functional/` is added, and the folder structure mirrors that of `torch/csrc/api/include/torch/nn/modules/`. For example, `torch/csrc/api/include/torch/nn/functional/pooling.h` contains the functions for pooling, which are then used by the pooling modules in `torch/csrc/api/include/torch/nn/modules/pooling.h`.
- `torch/csrc/api/include/torch/nn/options/` is added, and the folder structure mirrors that of `torch/csrc/api/include/torch/nn/modules/`. For example, `torch/csrc/api/include/torch/nn/options/pooling.h` contains MaxPoolOptions, which is used by both MaxPool modules in `torch/csrc/api/include/torch/nn/modules/pooling.h`, and max_pool functions in `torch/csrc/api/include/torch/nn/functional/pooling.h`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26262
Differential Revision: D17422426
Pulled By: yf225
fbshipit-source-id: c413d2a374ba716dac81db31516619bbd879db7f
Summary:
local build is slow... test in CI...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26083
Differential Revision: D17346949
Pulled By: ailzhang
fbshipit-source-id: f552d1a4be55ad4e2bd915af7c5a2c1b6667c446
Summary:
What dist_check.py does is largely merely determining whether we should
use set "USE_IBVERBS" to ON or OFF when the user sets "USE_GLOO_IBVERBS"
to ON. But this is unnecessary, because this complicated determination
will always be overrided by gloo:
2101e02cea/cmake/Dependencies.cmake (L19-L28)
Since dist_check.py becomes irrelevant, this commit also simplifies the
setting of `USE_DISTRIBUTED` (by removing its explicit setting in Python scripts), and deprecate `USE_GLOO_IBVERBS` in favor
of `USE_IBVERBS`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25879
Differential Revision: D17282395
Pulled By: pietern
fbshipit-source-id: a10735f50728d89c3d81fd57bcd26764e7f84dd1
Summary:
FindCUDNN.cmake and cuda.cmake have done the detection. This commit deletes `tools/setup_helpers/cudnn.py` as it is no longer needed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25482
Differential Revision: D17226408
Pulled By: ezyang
fbshipit-source-id: abd9cd0244cabea1f5d9f93f828d632d77c8dd5e
Summary:
In facebookincubator/gloo#212, a libuv based Gloo transport was introduced,
which allows us to use Gloo on macOS (and later perhaps also Windows). This
commit updates CMake code to enable building with USE_DISTRIBUTED=1 on macOS.
A few notes:
* The Caffe2 ops are not compiled, for they depend on `gloo::transport::tcp`.
* The process group implementation uses `gloo::transport::tcp` on Linux (because of `epoll(2)` on Linux and `gloo::transport::uv` on macOS).
* The TCP store works but sometimes crashes on process termination.
* The distributed tests are not yet run.
* The nightly builds don't use `USE_DISTRIBUTED=1`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25260
Reviewed By: mrshenli
Differential Revision: D17202381
Pulled By: pietern
fbshipit-source-id: ca80a82e78a05b4154271d2fb0ed31c8d9f26a7c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25083
I missed this in the last PR
Test Plan: Imported from OSS
Differential Revision: D17005372
Pulled By: jamesr66a
fbshipit-source-id: 1200a6cd88fb9051aed8baf3162a9f8ffbf65189
Summary:
`python_requires` helps the installer choose the correct version of this package for the user's running Python.
This is especially necessary when dropping Python 2 (https://github.com/pytorch/pytorch/issues/23795) but is useful now too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23863
Differential Revision: D16692908
Pulled By: soumith
fbshipit-source-id: 3c9ba2eb1d1cf12763d6284daa4f18f605abb373
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23895
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16688489
Pulled By: ezyang
fbshipit-source-id: a56d0180a0bc57775badd9e31ea3d441d5fd4f88
Summary:
add setup metadata to help PyPI flesh out content on pypi package page.
Apparently this might help flesh out the "Used By" feature according to driazati
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22085
Differential Revision: D16604703
Pulled By: soumith
fbshipit-source-id: ddb4f7ba7c24fdf718260aed28cc7bc9afb46de9
Summary:
Currently the build type is decided by the environment variable DEBUG
and REL_WITH_DEB_INFO. This commit also lets CMAKE_BUILD_TYPE be
effective. This makes the interface more consistent with CMake. This
also prepares https://github.com/pytorch/pytorch/issues/22776.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22875
Differential Revision: D16281663
Pulled By: ezyang
fbshipit-source-id: 952f92aad85ff59f1c7abe8256eca8a4a0936026
Summary:
---
How does the current code subsume all detections in the deleted `nccl.py`?
- The dependency of `USE_NCCL` on the OS and `USE_CUDA` is handled as dependency options in `CMakeLists.txt`.
- The main NCCL detection happens in [FindNCCL.cmake](8377d4b32c/cmake/Modules/FindNCCL.cmake), which is called by [nccl.cmake](8377d4b32c/cmake/External/nccl.cmake). When `USE_SYSTEM_NCCL` is false, the previous Python code defer the detection to `find_package(NCCL)`. The change in `nccl.cmake` retains this.
- `USE_STATIC_NCCL` in the previous Python code simply changes the name of the detected library. This is done in `IF (USE_STATIC_NCCL)`.
- Now we only need to look at how the lines below line 20 in `nccl.cmake` are subsumed. These lines list paths to header and library directories that NCCL headers and libraries may reside in and try to search these directories for the key header and library files in turn. These are done by `find_path` for headers and `find_library` for the library files in `FindNCCL.cmake`.
* The call of [find_path](https://cmake.org/cmake/help/v3.8/command/find_path.html) (Search for `NO_DEFAULT_PATH` in the link) by default searches for headers in `<prefix>/include` for each `<prefix>` in `CMAKE_PREFIX_PATH` and `CMAKE_SYSTEM_PREFIX_PATH`. Like the Python code, this commit sets `CMAKE_PREFIX_PATH` to search for `<prefix>` in `NCCL_ROOT_DIR` and home to CUDA. `CMAKE_SYSTEM_PREFIX_PATH` includes the standard directories such as `/usr/local` and `/usr`. `NCCL_INCLUDE_DIR` is also specifically handled.
* Similarly, the call of [find_library](https://cmake.org/cmake/help/v3.8/command/find_library.html) (Search for `NO_DEFAULT_PATH` in the link) by default searches for libraries in directories including `<prefix>/lib` for each `<prefix>` in `CMAKE_PREFIX_PATH` and `CMAKE_SYSTEM_PREFIX_PATH`. But it also handles the edge cases intended to be solved in the Python code more properly:
- It only searches for `<prefix>/lib64` (and `<prefix>/lib32`) if it is appropriate on the system.
- It only searches for `<prefix>/lib/<arch>` for the right `<arch>`, unlike the Python code searches for `lib/<arch>` in a generic way (e.g., the Python code searches for `/usr/lib/x86_64-linux-gnu` but in reality systems have `/usr/lib/x86_64-some-customized-name-linux-gnu`, see https://unix.stackexchange.com/a/226180/38242 ).
---
Regarding for relevant issues:
- https://github.com/pytorch/pytorch/issues/12063 and https://github.com/pytorch/pytorch/issues/2877: These are properly handled, as explained in the updated comment.
- https://github.com/pytorch/pytorch/issues/2941 does not changes NCCL detection specifically for Windows (it changed CUDA detection).
- b7e258f81e A versioned library detection is added, but the order is reversed: The unversioned library becomes preferred. This is because normally unversioned libraries are linked to versioned libraries and preferred by users, and local installation by users are often unversioned. Like the document of [find_library](https://cmake.org/cmake/help/v3.8/command/find_library.html) suggests:
> When using this to specify names with and without a version suffix, we recommend specifying the unversioned name first so that locally-built packages can be found before those provided by distributions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22930
Differential Revision: D16440275
Pulled By: ezyang
fbshipit-source-id: 11fe80743d4fe89b1ed6f96d5d996496e8ec01aa
Summary:
MKL-DNN is the main library for computation when we use ideep device. It can use kernels implemented by different algorithms (including JIT, CBLAS, etc.) for computation. We add the "USE_MKLDNN_CBLAS" (default OFF) build option so that users can decide whether to use CBLAS computation methods or not.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19014
Differential Revision: D16094090
Pulled By: ezyang
fbshipit-source-id: 3f0b1d1a59a327ea0d1456e2752f2edd78d96ccc
Summary:
Following up b811b6d5c0
* Use property instead of __setattr__ in CMake.
* Add a comment clarifying when built_ext.run is called.
---
cc ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21792
Differential Revision: D15860606
Pulled By: umanwizard
fbshipit-source-id: ba1fa07f58d4eac81ac27fa9dc7115d1cdd3dec0
Summary:
Currently when building extensions, variables such as USE_CUDA, USE_CUDNN are used to determine what libraries should be linked. But we should use what CMake has detected, because:
1. If CMake found them unavailable but the variables say some libraries should be linked, the build would fail.
2. If the first build is made using a set of non-default build options, rebuild must have these option passed to setup.py again, otherwise the extension build process is inconsistent with CMake. For example,
```bash
# First build
USE_CUDA=0 python setup.py install
# Subsequent builds like this would fail, unless "build/" is deleted
python setup.py install
```
This commit addresses the above issues by using variables from CMakeCache.txt when building the extensions.
---
The changes in `setup.py` may look lengthy, but the biggest changed block is mostly moving them into a function `configure_extension_build` (along with some variable names changed to `cmake_cache_vars['variable name']` and other minor changes), because it must be called after CMake has been called (and thus the options used and system environment detected by CMake become available).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21653
Differential Revision: D15824506
Pulled By: ezyang
fbshipit-source-id: 1e1eb7eec7debba30738f65472ccad966ee74028
Summary:
This renames the CMake `caffe2` target to `torch`, as well as renaming `caffe2_gpu` to `torch_gpu` (and likewise for other gpu target variants). Many intermediate variables that don't manifest as artifacts of the build remain for now with the "caffe2" name; a complete purge of `caffe2` from CMake variable names is beyond the scope of this PR.
The shell `libtorch` library that had been introduced as a stopgap in https://github.com/pytorch/pytorch/issues/17783 is again flattened in this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20774
Differential Revision: D15769965
Pulled By: kostmo
fbshipit-source-id: b86e8c410099f90be0468e30176207d3ad40c821
Summary:
Add an option to setup.py to stop the build process once cmake terminates. This leaves users a chance to fine adjust build options. Also update README accordingly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21034
Differential Revision: D15530096
Pulled By: soumith
fbshipit-source-id: 71ac6ff8483c3ee77c38d88f0d059db53a7d3901
Summary:
Sometimes users forget using the "--recursive" option when they update submodules. This added check should help expose this issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20937
Differential Revision: D15502846
Pulled By: mrshenli
fbshipit-source-id: 34c28a2c71ee6442d16b8b741ea44a18733b1536
{kind=link}
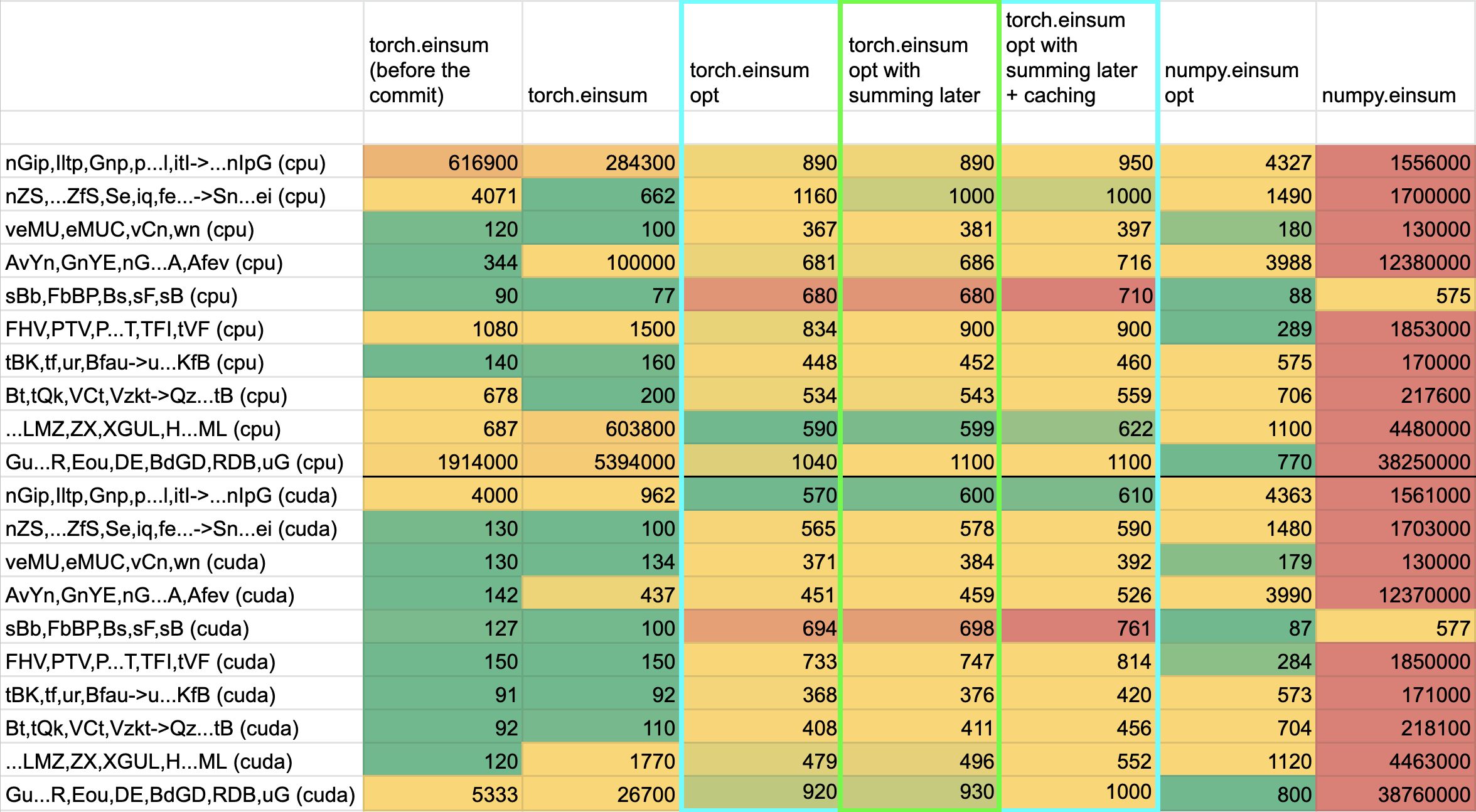{kind=link}
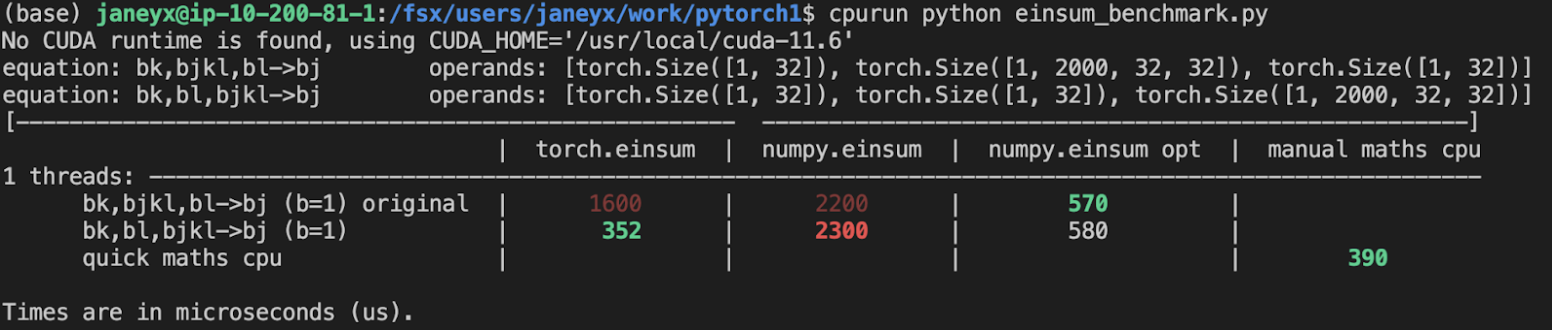{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}