mirror of
https://github.com/zebrajr/pytorch.git
synced 2025-12-06 12:20:52 +01:00
4e666ba011
28 Commits
| Author | SHA1 | Message | Date | |
|---|---|---|---|---|
|
|
4e666ba011 |
Update torch.autograd.graph logging to not print out grad_output (#116523)
Instead of printing the tensor's data print the dtype and shape metadata of the tensor. ``` Executing: <VarMeanBackward0 object at 0x1352d0e20> with grad_outputs: [None,f32[]] ``` This is important in order to avoid doing a cuda sync and also useful to reduce verbosity. Pull Request resolved: https://github.com/pytorch/pytorch/pull/116523 Approved by: https://github.com/albanD |
||
|
|
77d979f748 |
Autograd attaches logging hooks only in debug level (#116522)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/116522 Approved by: https://github.com/albanD |
||
|
|
cfb3cd11c1 |
Add basic autograd TORCH_LOGS support (#115438)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/115438 Approved by: https://github.com/albanD |
||
|
|
91c90f232a |
Fix docstring errors in reductions.py, spawn.py, pool.py, parameter.py, cpp.py, grad.py, __init__.py, profiler.py, queue.py, graph.py (#113052)
Fixes #112595 - `torch/autograd/profiler.py` </br> **Before: 37** ``` torch/autograd/profiler.py:1 at module level: D100: Missing docstring in public module torch/autograd/profiler.py:91 in public class `profile`: D205: 1 blank line required between summary line and description (found 0) torch/autograd/profiler.py:175 in public method `__init__`: D107: Missing docstring in __init__ torch/autograd/profiler.py:261 in public method `config`: D102: Missing docstring in public method torch/autograd/profiler.py:272 in public method `__enter__`: D105: Missing docstring in magic method torch/autograd/profiler.py:290 in public method `__exit__`: D105: Missing docstring in magic method torch/autograd/profiler.py:308 in public method `__repr__`: D105: Missing docstring in magic method torch/autograd/profiler.py:313 in public method `__str__`: D105: Missing docstring in magic method torch/autograd/profiler.py:322 in public method `table`: D102: Missing docstring in public method torch/autograd/profiler.py:346 in public method `export_chrome_trace`: D102: Missing docstring in public method torch/autograd/profiler.py:355 in public method `export_stacks`: D102: Missing docstring in public method torch/autograd/profiler.py:361 in public method `key_averages`: D102: Missing docstring in public method torch/autograd/profiler.py:368 in public method `total_average`: D102: Missing docstring in public method torch/autograd/profiler.py:377 in public method `self_cpu_time_total`: D205: 1 blank line required between summary line and description (found 0) torch/autograd/profiler.py:377 in public method `self_cpu_time_total`: D400: First line should end with a period (not 'f') torch/autograd/profiler.py:555 in public class `record_function`: D205: 1 blank line required between summary line and description (found 0) torch/autograd/profiler.py:555 in public class `record_function`: D400: First line should end with a period (not 'f') torch/autograd/profiler.py:591 in public method `__init__`: D107: Missing docstring in __init__ torch/autograd/profiler.py:602 in public method `__enter__`: D105: Missing docstring in magic method torch/autograd/profiler.py:608 in public method `__exit__`: D105: Missing docstring in magic method torch/autograd/profiler.py:625 in private method `_call_end_callbacks_on_future`: D205: 1 blank line required between summary line and description (found 0) torch/autograd/profiler.py:625 in private method `_call_end_callbacks_on_future`: D400: First line should end with a period (not 'c') torch/autograd/profiler.py:707 in public method `__init__`: D107: Missing docstring in __init__ torch/autograd/profiler.py:712 in public method `__enter__`: D105: Missing docstring in magic method torch/autograd/profiler.py:733 in public method `__exit__`: D105: Missing docstring in magic method torch/autograd/profiler.py:826 in public method `__init__`: D107: Missing docstring in __init__ torch/autograd/profiler.py:831 in public method `__enter__`: D105: Missing docstring in magic method torch/autograd/profiler.py:853 in public method `__exit__`: D105: Missing docstring in magic method torch/autograd/profiler.py:863 in public function `load_nvprof`: D401: First line should be in imperative mood (perhaps 'Open', not 'Opens') torch/autograd/profiler.py:874 in public method `__init__`: D107: Missing docstring in __init__ torch/autograd/profiler.py:877 in public method `see`: D102: Missing docstring in public method torch/autograd/profiler.py:883 in public function `parse_nvprof_trace`: D103: Missing docstring in public function torch/autograd/profiler.py:951 in public class `KinetoStepTracker`: D205: 1 blank line required between summary line and description (found 0) torch/autograd/profiler.py:991 in public method `init_step_count`: D102: Missing docstring in public method torch/autograd/profiler.py:995 in public method `erase_step_count`: D102: Missing docstring in public method torch/autograd/profiler.py:1000 in public method `increment_step`: D205: 1 blank line required between summary line and description (found 0) torch/autograd/profiler.py:1023 in public method `current_step`: D102: Missing docstring in public method 37 ``` **After: 27** ``` torch/autograd/profiler.py:1 at module level: D100: Missing docstring in public module torch/autograd/profiler.py:176 in public method `__init__`: D107: Missing docstring in __init__ torch/autograd/profiler.py:262 in public method `config`: D102: Missing docstring in public method torch/autograd/profiler.py:273 in public method `__enter__`: D105: Missing docstring in magic method torch/autograd/profiler.py:291 in public method `__exit__`: D105: Missing docstring in magic method torch/autograd/profiler.py:309 in public method `__repr__`: D105: Missing docstring in magic method torch/autograd/profiler.py:314 in public method `__str__`: D105: Missing docstring in magic method torch/autograd/profiler.py:323 in public method `table`: D102: Missing docstring in public method torch/autograd/profiler.py:347 in public method `export_chrome_trace`: D102: Missing docstring in public method torch/autograd/profiler.py:356 in public method `export_stacks`: D102: Missing docstring in public method torch/autograd/profiler.py:362 in public method `key_averages`: D102: Missing docstring in public method torch/autograd/profiler.py:369 in public method `total_average`: D102: Missing docstring in public method torch/autograd/profiler.py:593 in public method `__init__`: D107: Missing docstring in __init__ torch/autograd/profiler.py:604 in public method `__enter__`: D105: Missing docstring in magic method torch/autograd/profiler.py:610 in public method `__exit__`: D105: Missing docstring in magic method torch/autograd/profiler.py:708 in public method `__init__`: D107: Missing docstring in __init__ torch/autograd/profiler.py:713 in public method `__enter__`: D105: Missing docstring in magic method torch/autograd/profiler.py:734 in public method `__exit__`: D105: Missing docstring in magic method torch/autograd/profiler.py:827 in public method `__init__`: D107: Missing docstring in __init__ torch/autograd/profiler.py:832 in public method `__enter__`: D105: Missing docstring in magic method torch/autograd/profiler.py:854 in public method `__exit__`: D105: Missing docstring in magic method torch/autograd/profiler.py:875 in public method `__init__`: D107: Missing docstring in __init__ torch/autograd/profiler.py:878 in public method `see`: D102: Missing docstring in public method torch/autograd/profiler.py:884 in public function `parse_nvprof_trace`: D103: Missing docstring in public function torch/autograd/profiler.py:993 in public method `init_step_count`: D102: Missing docstring in public method torch/autograd/profiler.py:997 in public method `erase_step_count`: D102: Missing docstring in public method torch/autograd/profiler.py:1025 in public method `current_step`: D102: Missing docstring in public method 27 ``` - `torch/autograd/graph.py` </br> **Before: 22** ``` torch/autograd/graph.py:1 at module level: D100: Missing docstring in public module torch/autograd/graph.py:24 in public class `Node`: D101: Missing docstring in public class torch/autograd/graph.py:27 in public method `name`: D401: First line should be in imperative mood (perhaps 'Return', not 'Returns') torch/autograd/graph.py:42 in public method `next_functions`: D102: Missing docstring in public method torch/autograd/graph.py:47 in public method `metadata`: D401: First line should be in imperative mood (perhaps 'Return', not 'Returns') torch/autograd/graph.py:56 in public method `register_hook`: D401: First line should be in imperative mood (perhaps 'Register', not 'Registers') torch/autograd/graph.py:94 in public method `register_prehook`: D401: First line should be in imperative mood (perhaps 'Register', not 'Registers') torch/autograd/graph.py:129 in public method `__subclasshook__`: D105: Missing docstring in magic method torch/autograd/graph.py:147 in public function `get_gradient_edge`: D205: 1 blank line required between summary line and description (found 0) torch/autograd/graph.py:147 in public function `get_gradient_edge`: D400: First line should end with a period (not 'f') torch/autograd/graph.py:147 in public function `get_gradient_edge`: D401: First line should be in imperative mood; try rephrasing (found 'This') torch/autograd/graph.py:166 in public function `increment_version`: D205: 1 blank line required between summary line and description (found 0) torch/autograd/graph.py:166 in public function `increment_version`: D400: First line should end with a period (not 'd') torch/autograd/graph.py:166 in public function `increment_version`: D401: First line should be in imperative mood; try rephrasing (found 'This') torch/autograd/graph.py:243 in public method `__init__`: D107: Missing docstring in __init__ torch/autograd/graph.py:251 in public method `__enter__`: D105: Missing docstring in magic method torch/autograd/graph.py:256 in public method `__exit__`: D105: Missing docstring in magic method torch/autograd/graph.py:261 in public class `save_on_cpu`: D205: 1 blank line required between summary line and description (found 0) torch/autograd/graph.py:261 in public class `save_on_cpu`: D400: First line should end with a period (not 'e') torch/autograd/graph.py:303 in public method `__init__`: D107: Missing docstring in __init__ torch/autograd/graph.py:365 in public function `register_multi_grad_hook`: D401: First line should be in imperative mood (perhaps 'Register', not 'Registers') torch/autograd/graph.py:588 in public function `allow_mutation_on_saved_tensors`: D400: First line should end with a period (not 'd') 22 ``` **After: 8** ``` torch/autograd/graph.py:1 at module level: D100: Missing docstring in public module torch/autograd/graph.py:24 in public class `Node`: D101: Missing docstring in public class torch/autograd/graph.py:42 in public method `next_functions`: D102: Missing docstring in public method torch/autograd/graph.py:129 in public method `__subclasshook__`: D105: Missing docstring in magic method torch/autograd/graph.py:244 in public method `__init__`: D107: Missing docstring in __init__ torch/autograd/graph.py:252 in public method `__enter__`: D105: Missing docstring in magic method torch/autograd/graph.py:257 in public method `__exit__`: D105: Missing docstring in magic method torch/autograd/graph.py:303 in public method `__init__`: D107: Missing docstring in __init__ 8 ``` - `torch/multiprocessing/pool.py` </br> **Before: 6** ``` torch/multiprocessing/pool.py:1 at module level: D100: Missing docstring in public module torch/multiprocessing/pool.py:7 in public function `clean_worker`: D103: Missing docstring in public function torch/multiprocessing/pool.py:18 in public class `Pool`: D205: 1 blank line required between summary line and description (found 0) torch/multiprocessing/pool.py:18 in public class `Pool`: D209: Multi-line docstring closing quotes should be on a separate line torch/multiprocessing/pool.py:29 in private method `_repopulate_pool`: D205: 1 blank line required between summary line and description (found 0) torch/multiprocessing/pool.py:29 in private method `_repopulate_pool`: D400: First line should end with a period (not ',') 6 ``` **After: 2** ``` torch/multiprocessing/pool.py:1 at module level: D100: Missing docstring in public module torch/multiprocessing/pool.py:7 in public function `clean_worker`: D103: Missing docstring in public function 2 ``` - `torch/multiprocessing/queue.py` </br> **Before: 11** ``` torch/multiprocessing/queue.py:1 at module level: D100: Missing docstring in public module torch/multiprocessing/queue.py:8 in public class `ConnectionWrapper`: D205: 1 blank line required between summary line and description (found 0) torch/multiprocessing/queue.py:8 in public class `ConnectionWrapper`: D209: Multi-line docstring closing quotes should be on a separate line torch/multiprocessing/queue.py:8 in public class `ConnectionWrapper`: D400: First line should end with a period (not 'o') torch/multiprocessing/queue.py:11 in public method `__init__`: D107: Missing docstring in __init__ torch/multiprocessing/queue.py:14 in public method `send`: D102: Missing docstring in public method torch/multiprocessing/queue.py:19 in public method `recv`: D102: Missing docstring in public method torch/multiprocessing/queue.py:23 in public method `__getattr__`: D105: Missing docstring in magic method torch/multiprocessing/queue.py:29 in public class `Queue`: D101: Missing docstring in public class torch/multiprocessing/queue.py:30 in public method `__init__`: D107: Missing docstring in __init__ torch/multiprocessing/queue.py:38 in public class `SimpleQueue`: D101: Missing docstring in public class 11 ``` **After: 8** ``` torch/multiprocessing/queue.py:1 at module level: D100: Missing docstring in public module torch/multiprocessing/queue.py:10 in public method `__init__`: D107: Missing docstring in __init__ torch/multiprocessing/queue.py:13 in public method `send`: D102: Missing docstring in public method torch/multiprocessing/queue.py:18 in public method `recv`: D102: Missing docstring in public method torch/multiprocessing/queue.py:22 in public method `__getattr__`: D105: Missing docstring in magic method torch/multiprocessing/queue.py:28 in public class `Queue`: D101: Missing docstring in public class torch/multiprocessing/queue.py:29 in public method `__init__`: D107: Missing docstring in __init__ torch/multiprocessing/queue.py:37 in public class `SimpleQueue`: D101: Missing docstring in public class 8 ``` - `torch/multiprocessing/reductions.py` </br> **Before: 31** ``` torch/multiprocessing/reductions.py:1 at module level: D100: Missing docstring in public module torch/multiprocessing/reductions.py:24 in public class `StorageWeakRef`: D209: Multi-line docstring closing quotes should be on a separate line torch/multiprocessing/reductions.py:31 in public method `__init__`: D107: Missing docstring in __init__ torch/multiprocessing/reductions.py:38 in public method `from_weakref`: D102: Missing docstring in public method torch/multiprocessing/reductions.py:44 in public method `expired`: D102: Missing docstring in public method torch/multiprocessing/reductions.py:47 in public method `__del__`: D105: Missing docstring in magic method torch/multiprocessing/reductions.py:50 in public method `__hash__`: D105: Missing docstring in magic method torch/multiprocessing/reductions.py:53 in public method `__eq__`: D105: Missing docstring in magic method torch/multiprocessing/reductions.py:60 in public class `SharedCache`: D400: First line should end with a period (not 'f') torch/multiprocessing/reductions.py:62 in public method `__init__`: D107: Missing docstring in __init__ torch/multiprocessing/reductions.py:75 in public method `get`: D102: Missing docstring in public method torch/multiprocessing/reductions.py:79 in public method `__setitem__`: D105: Missing docstring in magic method torch/multiprocessing/reductions.py:85 in public method `free_dead_references`: D102: Missing docstring in public method torch/multiprocessing/reductions.py:99 in public function `rebuild_event`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:103 in public function `reduce_event`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:108 in public function `rebuild_tensor`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:121 in public function `rebuild_cuda_tensor`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:189 in public function `reduce_tensor`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:347 in public function `rebuild_nested_tensor`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:364 in public function `reduce_nested_tensor`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:389 in public function `fd_id`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:397 in public function `storage_from_cache`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:404 in public function `rebuild_storage_fd`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:417 in public function `rebuild_storage_filename`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:437 in public function `rebuild_storage_empty`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:441 in public function `rebuild_typed_storage`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:446 in public function `reduce_typed_storage`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:450 in public function `rebuild_typed_storage_child`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:455 in public function `reduce_typed_storage_child`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:459 in public function `reduce_storage`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:488 in public function `init_reductions`: D103: Missing docstring in public function 31 ``` **After: 29** ``` torch/multiprocessing/reductions.py:1 at module level: D100: Missing docstring in public module torch/multiprocessing/reductions.py:32 in public method `__init__`: D107: Missing docstring in __init__ torch/multiprocessing/reductions.py:39 in public method `from_weakref`: D102: Missing docstring in public method torch/multiprocessing/reductions.py:45 in public method `expired`: D102: Missing docstring in public method torch/multiprocessing/reductions.py:48 in public method `__del__`: D105: Missing docstring in magic method torch/multiprocessing/reductions.py:51 in public method `__hash__`: D105: Missing docstring in magic method torch/multiprocessing/reductions.py:54 in public method `__eq__`: D105: Missing docstring in magic method torch/multiprocessing/reductions.py:63 in public method `__init__`: D107: Missing docstring in __init__ torch/multiprocessing/reductions.py:76 in public method `get`: D102: Missing docstring in public method torch/multiprocessing/reductions.py:80 in public method `__setitem__`: D105: Missing docstring in magic method torch/multiprocessing/reductions.py:86 in public method `free_dead_references`: D102: Missing docstring in public method torch/multiprocessing/reductions.py:100 in public function `rebuild_event`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:104 in public function `reduce_event`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:109 in public function `rebuild_tensor`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:122 in public function `rebuild_cuda_tensor`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:190 in public function `reduce_tensor`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:348 in public function `rebuild_nested_tensor`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:365 in public function `reduce_nested_tensor`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:390 in public function `fd_id`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:398 in public function `storage_from_cache`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:405 in public function `rebuild_storage_fd`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:418 in public function `rebuild_storage_filename`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:438 in public function `rebuild_storage_empty`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:442 in public function `rebuild_typed_storage`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:447 in public function `reduce_typed_storage`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:451 in public function `rebuild_typed_storage_child`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:456 in public function `reduce_typed_storage_child`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:460 in public function `reduce_storage`: D103: Missing docstring in public function torch/multiprocessing/reductions.py:489 in public function `init_reductions`: D103: Missing docstring in public function 29 ``` - `torch/multiprocessing/spawn.py` </br> **Before: 19** ``` torch/multiprocessing/spawn.py:1 at module level: D100: Missing docstring in public module torch/multiprocessing/spawn.py:11 in public class `ProcessException`: D101: Missing docstring in public class torch/multiprocessing/spawn.py:14 in public method `__init__`: D107: Missing docstring in __init__ torch/multiprocessing/spawn.py:20 in public method `__reduce__`: D105: Missing docstring in magic method torch/multiprocessing/spawn.py:25 in public class `ProcessRaisedException`: D205: 1 blank line required between summary line and description (found 0) torch/multiprocessing/spawn.py:25 in public class `ProcessRaisedException`: D400: First line should end with a period (not 'n') torch/multiprocessing/spawn.py:30 in public method `__init__`: D107: Missing docstring in __init__ torch/multiprocessing/spawn.py:40 in public class `ProcessExitedException`: D205: 1 blank line required between summary line and description (found 0) torch/multiprocessing/spawn.py:40 in public class `ProcessExitedException`: D400: First line should end with a period (not 'l') torch/multiprocessing/spawn.py:47 in public method `__init__`: D107: Missing docstring in __init__ torch/multiprocessing/spawn.py:59 in public method `__reduce__`: D105: Missing docstring in magic method torch/multiprocessing/spawn.py:85 in public class `ProcessContext`: D101: Missing docstring in public class torch/multiprocessing/spawn.py:86 in public method `__init__`: D107: Missing docstring in __init__ torch/multiprocessing/spawn.py:93 in public method `pids`: D102: Missing docstring in public method torch/multiprocessing/spawn.py:97 in public method `join`: D205: 1 blank line required between summary line and description (found 0) torch/multiprocessing/spawn.py:97 in public method `join`: D401: First line should be in imperative mood (perhaps 'Try', not 'Tries') torch/multiprocessing/spawn.py:166 in public class `SpawnContext`: D101: Missing docstring in public class torch/multiprocessing/spawn.py:167 in public method `__init__`: D107: Missing docstring in __init__ torch/multiprocessing/spawn.py:180 in public function `start_processes`: D103: Missing docstring in public function 19 ``` **After: 13** ``` torch/multiprocessing/spawn.py:1 at module level: D100: Missing docstring in public module torch/multiprocessing/spawn.py:11 in public class `ProcessException`: D101: Missing docstring in public class torch/multiprocessing/spawn.py:14 in public method `__init__`: D107: Missing docstring in __init__ torch/multiprocessing/spawn.py:20 in public method `__reduce__`: D105: Missing docstring in magic method torch/multiprocessing/spawn.py:27 in public method `__init__`: D107: Missing docstring in __init__ torch/multiprocessing/spawn.py:41 in public method `__init__`: D107: Missing docstring in __init__ torch/multiprocessing/spawn.py:53 in public method `__reduce__`: D105: Missing docstring in magic method torch/multiprocessing/spawn.py:79 in public class `ProcessContext`: D101: Missing docstring in public class torch/multiprocessing/spawn.py:80 in public method `__init__`: D107: Missing docstring in __init__ torch/multiprocessing/spawn.py:87 in public method `pids`: D102: Missing docstring in public method torch/multiprocessing/spawn.py:161 in public class `SpawnContext`: D101: Missing docstring in public class torch/multiprocessing/spawn.py:162 in public method `__init__`: D107: Missing docstring in __init__ torch/multiprocessing/spawn.py:175 in public function `start_processes`: D103: Missing docstring in public function 13 ``` - `torch/multiprocessing/__init__.py` </br> **Before: 0** ``` torch/multiprocessing/__init__.py:1 at module level: D205: 1 blank line required between summary line and description (found 0) torch/multiprocessing/__init__.py:1 at module level: D400: First line should end with a period (not '`') torch/multiprocessing/__init__.py:57 in public function `set_sharing_strategy`: D401: First line should be in imperative mood (perhaps 'Set', not 'Sets') torch/multiprocessing/__init__.py:69 in public function `get_sharing_strategy`: D401: First line should be in imperative mood (perhaps 'Return', not 'Returns') torch/multiprocessing/__init__.py:74 in public function `get_all_sharing_strategies`: D401: First line should be in imperative mood (perhaps 'Return', not 'Returns') 5 ``` **After: 0** - `torch/nn/__init__.py` </br> **Before: 3** ``` torch/nn/__init__.py:1 at module level: D104: Missing docstring in public package torch/nn/__init__.py:14 in public function `factory_kwargs`: D205: 1 blank line required between summary line and description (found 0) torch/nn/__init__.py:14 in public function `factory_kwargs`: D400: First line should end with a period (not 'd') 3 ``` **After: 1** ``` torch/nn/__init__.py:1 at module level: D104: Missing docstring in public package 1 ``` - `torch/nn/cpp.py` </br> **Before: 16** ``` torch/nn/cpp.py:7 in public class `OrderedDictWrapper`: D205: 1 blank line required between summary line and description (found 0) torch/nn/cpp.py:7 in public class `OrderedDictWrapper`: D400: First line should end with a period (not 'e') torch/nn/cpp.py:16 in public method `__init__`: D107: Missing docstring in __init__ torch/nn/cpp.py:21 in public method `cpp_dict`: D102: Missing docstring in public method torch/nn/cpp.py:27 in public method `items`: D102: Missing docstring in public method torch/nn/cpp.py:30 in public method `keys`: D102: Missing docstring in public method torch/nn/cpp.py:33 in public method `values`: D102: Missing docstring in public method torch/nn/cpp.py:36 in public method `__iter__`: D105: Missing docstring in magic method torch/nn/cpp.py:39 in public method `__len__`: D105: Missing docstring in magic method torch/nn/cpp.py:42 in public method `__contains__`: D105: Missing docstring in magic method torch/nn/cpp.py:45 in public method `__getitem__`: D105: Missing docstring in magic method torch/nn/cpp.py:50 in public class `ModuleWrapper`: D205: 1 blank line required between summary line and description (found 0) torch/nn/cpp.py:50 in public class `ModuleWrapper`: D400: First line should end with a period (not 'd') torch/nn/cpp.py:55 in public method `__init__`: D107: Missing docstring in __init__ torch/nn/cpp.py:83 in public method `training`: D102: Missing docstring in public method torch/nn/cpp.py:90 in public method `__repr__`: D105: Missing docstring in magic method 16 ``` **After: 12** ``` torch/nn/cpp.py:16 in public method `__init__`: D107: Missing docstring in __init__ torch/nn/cpp.py:21 in public method `cpp_dict`: D102: Missing docstring in public method torch/nn/cpp.py:27 in public method `items`: D102: Missing docstring in public method torch/nn/cpp.py:30 in public method `keys`: D102: Missing docstring in public method torch/nn/cpp.py:33 in public method `values`: D102: Missing docstring in public method torch/nn/cpp.py:36 in public method `__iter__`: D105: Missing docstring in magic method torch/nn/cpp.py:39 in public method `__len__`: D105: Missing docstring in magic method torch/nn/cpp.py:42 in public method `__contains__`: D105: Missing docstring in magic method torch/nn/cpp.py:45 in public method `__getitem__`: D105: Missing docstring in magic method torch/nn/cpp.py:52 in public method `__init__`: D107: Missing docstring in __init__ torch/nn/cpp.py:80 in public method `training`: D102: Missing docstring in public method torch/nn/cpp.py:87 in public method `__repr__`: D105: Missing docstring in magic method 12 ``` - `torch/nn/grad.py` </br> **Before: 10** ``` torch/nn/grad.py:1 at module level: D400: First line should end with a period (not 'e') torch/nn/grad.py:8 in public function `conv1d_input`: D205: 1 blank line required between summary line and description (found 0) torch/nn/grad.py:8 in public function `conv1d_input`: D401: First line should be in imperative mood (perhaps 'Compute', not 'Computes') torch/nn/grad.py:40 in public function `conv1d_weight`: D401: First line should be in imperative mood (perhaps 'Compute', not 'Computes') torch/nn/grad.py:71 in public function `conv2d_input`: D205: 1 blank line required between summary line and description (found 0) torch/nn/grad.py:71 in public function `conv2d_input`: D401: First line should be in imperative mood (perhaps 'Compute', not 'Computes') torch/nn/grad.py:103 in public function `conv2d_weight`: D401: First line should be in imperative mood (perhaps 'Compute', not 'Computes') torch/nn/grad.py:134 in public function `conv3d_input`: D205: 1 blank line required between summary line and description (found 0) torch/nn/grad.py:134 in public function `conv3d_input`: D401: First line should be in imperative mood (perhaps 'Compute', not 'Computes') torch/nn/grad.py:166 in public function `conv3d_weight`: D401: First line should be in imperative mood (perhaps 'Compute', not 'Computes') 10 ``` **After: 0** - `torch/nn/parameter.py` </br> **Before: 17** ``` torch/nn/parameter.py:1 at module level: D100: Missing docstring in public module torch/nn/parameter.py:14 in public class `Parameter`: D204: 1 blank line required after class docstring (found 0) torch/nn/parameter.py:33 in public method `__new__`: D102: Missing docstring in public method torch/nn/parameter.py:54 in public method `__deepcopy__`: D105: Missing docstring in magic method torch/nn/parameter.py:62 in public method `__repr__`: D105: Missing docstring in magic method torch/nn/parameter.py:65 in public method `__reduce_ex__`: D105: Missing docstring in magic method torch/nn/parameter.py:84 in public class `UninitializedTensorMixin`: D101: Missing docstring in public class torch/nn/parameter.py:105 in public method `materialize`: D205: 1 blank line required between summary line and description (found 0) torch/nn/parameter.py:125 in public method `shape`: D102: Missing docstring in public method torch/nn/parameter.py:132 in public method `share_memory_`: D102: Missing docstring in public method torch/nn/parameter.py:138 in public method `__repr__`: D105: Missing docstring in magic method torch/nn/parameter.py:141 in public method `__reduce_ex__`: D105: Missing docstring in magic method torch/nn/parameter.py:149 in public method `__torch_function__`: D105: Missing docstring in magic method torch/nn/parameter.py:164 in public function `is_lazy`: D103: Missing docstring in public function torch/nn/parameter.py:186 in public method `__new__`: D102: Missing docstring in public method torch/nn/parameter.py:191 in public method `__deepcopy__`: D105: Missing docstring in magic method torch/nn/parameter.py:217 in public method `__new__`: D102: Missing docstring in public method 17 ``` **After: 15** ``` torch/nn/parameter.py:1 at module level: D100: Missing docstring in public module torch/nn/parameter.py:34 in public method `__new__`: D102: Missing docstring in public method torch/nn/parameter.py:55 in public method `__deepcopy__`: D105: Missing docstring in magic method torch/nn/parameter.py:63 in public method `__repr__`: D105: Missing docstring in magic method torch/nn/parameter.py:66 in public method `__reduce_ex__`: D105: Missing docstring in magic method torch/nn/parameter.py:85 in public class `UninitializedTensorMixin`: D101: Missing docstring in public class torch/nn/parameter.py:127 in public method `shape`: D102: Missing docstring in public method torch/nn/parameter.py:134 in public method `share_memory_`: D102: Missing docstring in public method torch/nn/parameter.py:140 in public method `__repr__`: D105: Missing docstring in magic method torch/nn/parameter.py:143 in public method `__reduce_ex__`: D105: Missing docstring in magic method torch/nn/parameter.py:151 in public method `__torch_function__`: D105: Missing docstring in magic method torch/nn/parameter.py:166 in public function `is_lazy`: D103: Missing docstring in public function torch/nn/parameter.py:188 in public method `__new__`: D102: Missing docstring in public method torch/nn/parameter.py:193 in public method `__deepcopy__`: D105: Missing docstring in magic method torch/nn/parameter.py:219 in public method `__new__`: D102: Missing docstring in public method 15 ``` Pull Request resolved: https://github.com/pytorch/pytorch/pull/113052 Approved by: https://github.com/mikaylagawarecki, https://github.com/soulitzer |
||
|
|
5e8be63e99 |
Allow specifiying inputs as GradientEdge in autograd APIs (#110867)
This can be useful for advanced users (like AOTAutograd) who don't want to keep the corresponding Tensor alive (for memory reasons for example) or when inplace op will change the Tensor's grad_fn (but gradients wrt to the original value is needed). I went minimal API change but open to suggestions. Pull Request resolved: https://github.com/pytorch/pytorch/pull/110867 Approved by: https://github.com/soulitzer |
||
|
|
b1e8e01e50 |
[BE]: Apply PYI autofixes to various types (#107521)
Applies some autofixes from the ruff PYI rules to improve the typing of PyTorch. I haven't enabled most of these ruff rules yet as they do not have autofixes. Pull Request resolved: https://github.com/pytorch/pytorch/pull/107521 Approved by: https://github.com/ezyang |
||
|
|
3bf922a6ce |
Apply UFMT to low traffic torch modules (#106249)
Signed-off-by: Edward Z. Yang <ezyang@meta.com> Pull Request resolved: https://github.com/pytorch/pytorch/pull/106249 Approved by: https://github.com/Skylion007 |
||
|
|
79c5e33349 |
[BE] Enable ruff's UP rules and autoformat nn/ mps/ and torch/ (#105436)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105436 Approved by: https://github.com/malfet, https://github.com/albanD |
||
|
|
2961ea80f5 |
Deprecate "Type" and support more devices for save_on_cpu (#103245)
Fixes #ISSUE_NUMBER 1、the class named "Type" has not been used anymore in anywhere, so I add warning message to remove it in the future. 2、add a arg(default is "cuda") for save_on_cpu so that it can support more device type (like privateuse1) Pull Request resolved: https://github.com/pytorch/pytorch/pull/103245 Approved by: https://github.com/soulitzer |
||
|
|
9866408167 |
Multihooks should not keep tensor alive in closure (#102859)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102859 Approved by: https://github.com/albanD |
||
|
|
35991df5d6 |
fix(docs): torch.autograd.graph.Node.register_hook can override grad_inputs, not grad_outputs (#100272)
Fixes #99165 Pull Request resolved: https://github.com/pytorch/pytorch/pull/100272 Approved by: https://github.com/soulitzer |
||
|
|
985fc66b30 |
Bind increment_version to python (#96852)
Should be convenient when writing python-only kernels (with triton) that don't have access to the C++ APIs. Pull Request resolved: https://github.com/pytorch/pytorch/pull/96852 Approved by: https://github.com/soulitzer |
||
|
|
457396fcdc |
[Autograd] expand_as instead of clone to get AccumulateGrad (#96356)
This PR makes a minor change to the multi-grad hook implementation. This should decrease peak memory since we avoid one `clone()` per tensor passed into the multi-grad hook. Let me know if there are technical reasons why we need to clone. If so, is there a way for some use cases to not clone? Before with `clone()`: 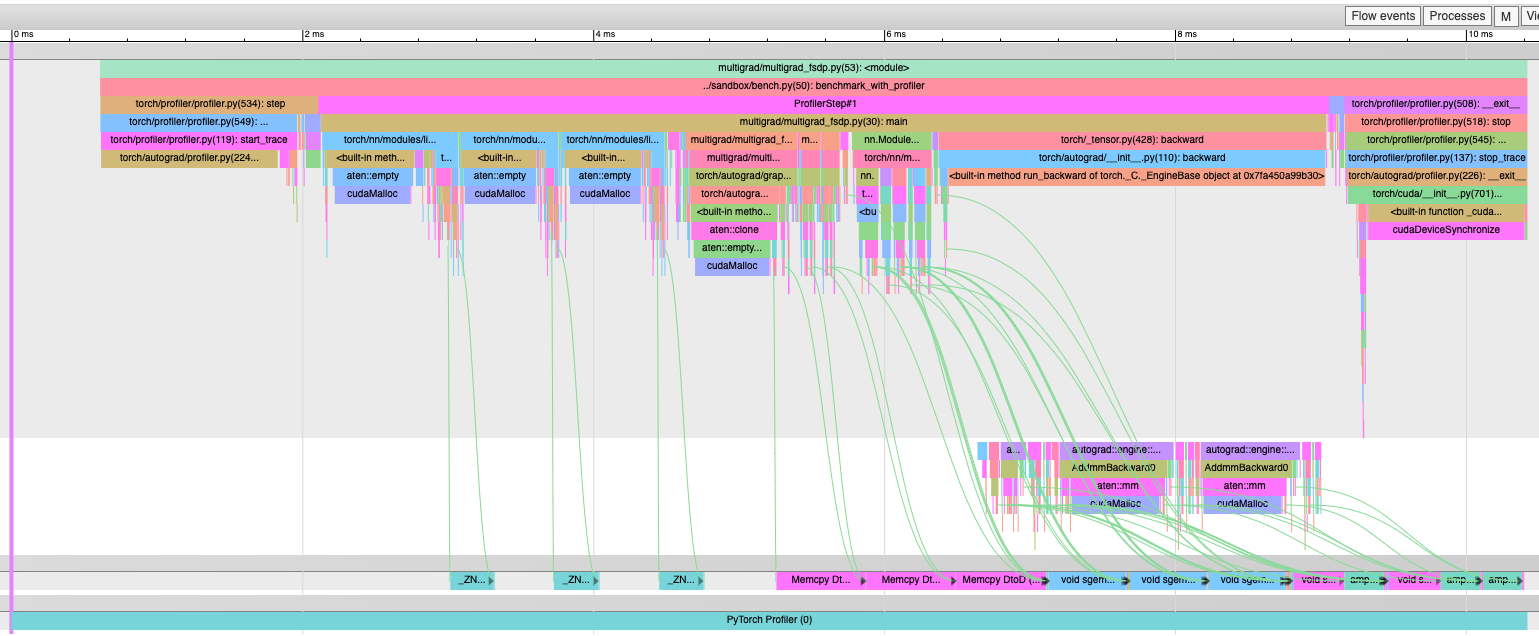 After with `expand_as()` -- no more "Memcpy DtoD" kernels: 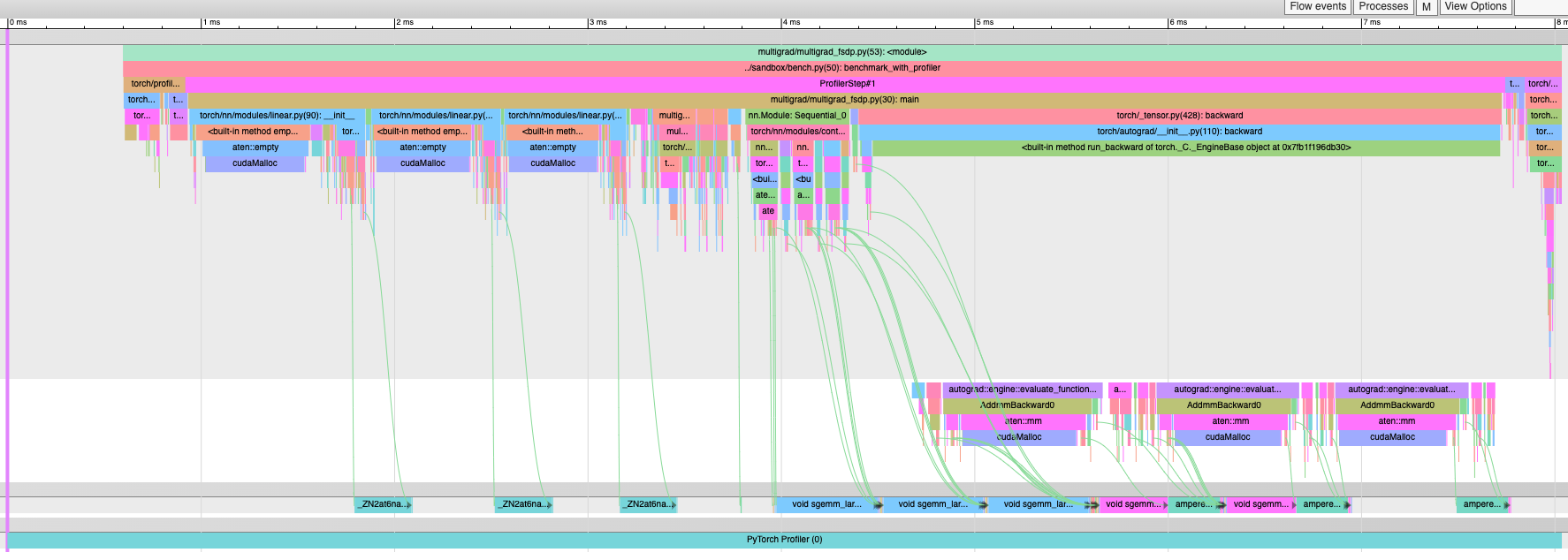 Pull Request resolved: https://github.com/pytorch/pytorch/pull/96356 Approved by: https://github.com/soulitzer |
||
|
|
88366a9075 |
Document hooks ordering behavior in the autograd note (#91667)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91667 Approved by: https://github.com/albanD |
||
|
|
388b245d54 |
Expose autograd.graph.Node as an abstract base class (#91475)
This PR: - registers all of the codegened Nodes to the torch._C._functions module, this is where special nodes like AccumulateGrad are already registered. - creates a autograd.graph.Node abstract base class that all of the newly registered nodes subclass from. We make the subclassing happen by implementing the ``__subclasshook__`` method - enables static type checking to work and also enables Sphinx to generate documentation for the Node and its methods - handles both the custom Function and codegened cases Pull Request resolved: https://github.com/pytorch/pytorch/pull/91475 Approved by: https://github.com/albanD |
||
|
|
ad782ff7df |
Enable xdoctest runner in CI for real this time (#83816)
Builds on #83317 and enables running the doctests. Just need to figure out what is causing the failures. Pull Request resolved: https://github.com/pytorch/pytorch/pull/83816 Approved by: https://github.com/ezyang, https://github.com/malfet |
||
|
|
b92acee8f8 |
Add context manager to allow mutation on saved tensors (#79056)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79056 Approved by: https://github.com/albanD |
||
|
|
a6c0442cce |
Add __all__ to torch.{autograd, fx, cuda} submodules (#85343)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85343 Approved by: https://github.com/albanD |
||
|
|
ba3fde6aa0 |
Add multi-grad hooks (#86260)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86260 Approved by: https://github.com/albanD |
||
|
|
a262ccea58 |
Change torch.autograd.graph.disable_saved_tensors_hooks to be public API (#85994)
Also addresses some comments from the review in https://github.com/pytorch/pytorch/pull/85971 Pull Request resolved: https://github.com/pytorch/pytorch/pull/85994 Approved by: https://github.com/albanD, https://github.com/soulitzer |
||
|
|
7c72bc48d8 |
Add mechanism to disable the "saved tensors hooks" feature (#85971)
The rationale for this is that functorch doesn't work with saved variable hooks at the moment or checkpointing and we need some way to disable it. Concretely: - there's a context manager that does the disabling - this feature is disabled on a thread-local basis - one can set an error message or use the default error message that says the feature has been disabled Since it is thread local I needed to update ATen/ThreadLocalState. To make things nicer, this PR refactors all the "saved tensors hooks" related TLS things into a single struct. Test Plan: - new test Differential Revision: [D39970936](https://our.internmc.facebook.com/intern/diff/D39970936) Pull Request resolved: https://github.com/pytorch/pytorch/pull/85971 Approved by: https://github.com/albanD, https://github.com/soulitzer |
||
|
|
801818f9e6 |
Revert "Add mechanism to disable the "saved tensors hooks" feature (#85553)"
This reverts commit
|
||
|
|
5aa183d2bc |
Add mechanism to disable the "saved tensors hooks" feature (#85553)
The rationale for this is that functorch doesn't work with saved variable hooks at the moment or checkpointing and we need some way to disable it. Concretely: - there's a context manager that does the disabling - this feature is disabled on a thread-local basis - one can set an error message or use the default error message that says the feature has been disabled Since it is thread local I needed to update ATen/ThreadLocalState. To make things nicer, this PR refactors all the "saved tensors hooks" related TLS things into a single struct. Test Plan: - new test Pull Request resolved: https://github.com/pytorch/pytorch/pull/85553 Approved by: https://github.com/soulitzer |
||
|
|
b136f3f310 |
More doctest refinements. (#83317)
Follow up to #82797 Now that the doctests themselves are in a better state, we should be able to enable xdoctest on the CI so they stay that way. @ezyang @vadimkantorov Pull Request resolved: https://github.com/pytorch/pytorch/pull/83317 Approved by: https://github.com/ezyang |
||
|
|
4618371da5 |
Integrate xdoctest - Rebased (#82797)
This is a new version of #15648 based on the latest master branch. Unlike the previous PR where I fixed a lot of the doctests in addition to integrating xdoctest, I'm going to reduce the scope here. I'm simply going to integrate xdoctest, and then I'm going to mark all of the failing tests as "SKIP". This will let xdoctest run on the dashboards, provide some value, and still let the dashboards pass. I'll leave fixing the doctests themselves to another PR. In my initial commit, I do the bare minimum to get something running with failing dashboards. The few tests that I marked as skip are causing segfaults. Running xdoctest results in 293 failed, 201 passed tests. The next commits will be to disable those tests. (unfortunately I don't have a tool that will insert the `#xdoctest: +SKIP` directive over every failing test, so I'm going to do this mostly manually.) Fixes https://github.com/pytorch/pytorch/issues/71105 @ezyang Pull Request resolved: https://github.com/pytorch/pytorch/pull/82797 Approved by: https://github.com/ezyang |
||
|
|
a3b7dd7b78 |
Enable nested default hooks (#70932)
Summary: When default hooks are set, they are pushed onto a stack. When nesting context-manager, only the inner-most hooks will be applied. There is special care needed to update the TLS code. See also https://github.com/pytorch/pytorch/issues/70940 (i.e. do we need to be storing the enabled flag as well?) Fixes https://github.com/pytorch/pytorch/issues/70134 Pull Request resolved: https://github.com/pytorch/pytorch/pull/70932 Reviewed By: mruberry Differential Revision: D33530370 Pulled By: albanD fbshipit-source-id: 3197d585d77563f36c175d3949115a0776b309f4 |
||
|
|
ed7ece389d |
Forbid inplace modification of a saved tensor's pack_hook input (#62717)
Summary: When using saved tensors hooks (especially default hooks), if the user defines a `pack_hook` that modifies its input, it can cause some surprising behavior. The goal of this PR is to prevent future user headache by catching inplace modifications of the input of `pack_hook` and raising an error if applicable. Pull Request resolved: https://github.com/pytorch/pytorch/pull/62717 Reviewed By: albanD Differential Revision: D30255243 Pulled By: Varal7 fbshipit-source-id: 8d73f1e1b50b697a59a2849b5e21cf0aa7493b76 |
||
|
|
557047eb4c |
Add docstring for saved tensors default hooks (#62361)
Summary: Add documentation for the saved tensors default hooks introduced in https://github.com/pytorch/pytorch/issues/61834 / https://github.com/pytorch/pytorch/issues/62563 Sister PR: https://github.com/pytorch/pytorch/issues/62362 (will add a link from autograd.rst to notes/autograd in whatever PR does not land first) Pull Request resolved: https://github.com/pytorch/pytorch/pull/62361 Reviewed By: zou3519 Differential Revision: D30081997 Pulled By: Varal7 fbshipit-source-id: cb923e943e1d96db9669c1d863d693af30910c62 |
{kind=link}
{kind=link}