Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45766
As per subj, making KeyError message more verbose.
Test Plan:
Verified that breakage can be successfully investigated with verbose error message
unit tests
Reviewed By: esqu1
Differential Revision: D24080362
fbshipit-source-id: f4e22a78809e5cff65a69780d5cbbc1e8b11b2e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45642
Prior to https://github.com/pytorch/pytorch/pull/45181, initializing a
NCCL process group would work even if no GPUs were present. Although, now since
init_process_group calls `barrier()` this would fail.
In general the problem was that we could initialize ProcessGroupNCCL without
GPUs and then if we called a method like `barrier()` the process would crash
since we do % numGPUs resulting in division by zero.
ghstack-source-id: 113490343
Test Plan: waitforbuildbot
Reviewed By: osalpekar
Differential Revision: D24038839
fbshipit-source-id: a1f1db52cabcfb83e06c1a11ae9744afbf03f8dc
Summary:
Rename jobs for testing GraphExecutor configurations to something a little bit more sensical.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45715
Reviewed By: ezyang, anjali411
Differential Revision: D24114344
Pulled By: Krovatkin
fbshipit-source-id: 89e5f54aaebd88f8c5878e060e983c6f1f41b9bb
Summary:
The torchbind tests didn't work be cause somehow we missed the rename of caffe2_gpu to torch_... (hip for us) in https://github.com/pytorch/pytorch/issues/20774 (merged 2019-06-13, oops) and still tried to link against it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45426
Reviewed By: VitalyFedyunin
Differential Revision: D24112439
Pulled By: walterddr
fbshipit-source-id: a66a574e63714728183399c543d2dafbd6c028f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45776
Splitting out backend and custom class registration into their own library is
not currently implemented in fbcode, so detect that we are running tests in
fbcode and disable those tests.
Test Plan: buck test mode/no-gpu mode/dev caffe2/test:jit
Reviewed By: smessmer
Differential Revision: D24085871
fbshipit-source-id: 1fcc0547880bc4be59428e2810b6a7f6e50ef798
Summary:
* Add a pass at end of runCleanupPasses to annotate `aten::warn` so that each has its unique id
* Enhanced interpreter so that it tracks which `aten::warn` has been executed before and skip them
* Improved insertInstruction so that it correctly checks for overflow
Fixes https://github.com/pytorch/pytorch/issues/45108
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45382
Reviewed By: mrshenli
Differential Revision: D24060677
Pulled By: gmagogsfm
fbshipit-source-id: 9221bc55b9ce36b374bdf614da3fe47496b481c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45726
FB has an old internal platform that uses some random llvm version
that looks sort of like llvm 7. I've guarded that with the appropriate
LLVM_VERSION_PATCH.
I've also swapped out some of our uses of ThreadSafeModule/ThreadSafeContext
for the variants without ThreadSafe in the name. As far as I can tell we
weren't using the bundled locks anyways, but I'm like 85% sure this is OK since
we compile under the Torch JIT lock anyways.
Test Plan: unit tests
Reviewed By: ZolotukhinM, asuhan
Differential Revision: D24072697
fbshipit-source-id: 7f56b9f3cbe5e6d54416acdf73876338df69ddb2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44220
Closes https://github.com/pytorch/pytorch/issues/44009
Currently if a dataloader returns objects created with a
collections.namedtuple, this will incorrectly be cast to a tuple. As a result, if we have data of these types, there can be runtime errors during the forward pass if the module is expecting a named tuple.
Fix this in
`scatter_gather.py` to resolve the issue reported in
https://github.com/pytorch/pytorch/issues/44009
ghstack-source-id: 113423287
Test Plan: CI
Reviewed By: colesbury
Differential Revision: D23536752
fbshipit-source-id: 3838e60162f29ebe424e83e474c4350ae838180b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45543
This PR adds documentation for the c10d Store to the public docs. Previously these docs were missing although we exposed a lightly-used (but potentially useful) Python API for our distributed key-value store.
ghstack-source-id: 113409195
Test Plan: Will verify screenshots by building the docs.
Reviewed By: pritamdamania87
Differential Revision: D24005598
fbshipit-source-id: 45c3600e7c3f220710e99a0483a9ce921d75d044
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45464
Usage of Symbols to find arguments requires one to generate a nonsense symbol for inputs which don't already have one. The intention of symbols appears to be something of an internalized string, but the namespace component doesn't apply to an argument. In order to access the arguments by name without adding new symbols, versions of those functions with std::string input was added. These can be proved valid based on the existing codepath. Additionally, a hasNamedInput convenience function was added to remove the necessity of a try/catch block in user code.
The primary motivation is to be able to easily handle the variable number of arguments in glow, so that the arange op may be implemented.
Reviewed By: eellison
Differential Revision: D23972315
fbshipit-source-id: 3e0b41910cf07e916186f1506281fb221725a91b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44678
This is a prototype PR that introduces 4 bit qtensors. The new dtype added for this is c10::quint4x2
The underlying storage for this is still uint8_t, so we pack 2 4-bit values in a byte while quantizing it.
This change uses most of the existing scaffolding for qtensor storage. We allocate storage
based on the dtype before creating a new qtensor.
It also adds a dispatch mechanism for this dtype so we can use this to get the bitwidth, qmin and qmax info
while quantizing and packing the qtensor (when we add 2-bit qtensor)
Kernels that use this dtype should be aware of the packing format.
Test Plan:
Locally tested
```
x = torch.ones((100, 100), dtype=torch.float)
qx_8bit = torch.quantize_per_tensor(x, scale=1.0, zero_point=2, dtype=torch.quint8)
qx = torch.quantize_per_tensor(x, scale=1.0, zero_point=2, dtype=torch.quint4x2)
torch.save(x, "temp.p")
print('Size float (B):', os.path.getsize("temp.p"))
os.remove('temp.p')
torch.save(qx_8bit, "temp.p")
print('Size quantized 8bit(B):', os.path.getsize("temp.p"))
os.remove('temp.p')
torch.save(qx, "temp.p")
print('Size quantized 4bit(B):', os.path.getsize("temp.p"))
os.remove('temp.p')
```
Size float (B): 40760
Size quantized 8bit(B): 10808
Size quantized 4bit(B): 5816
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D23993134
fbshipit-source-id: 073bf262f9680416150ba78ed2d932032275946d
Summary:
This modifies the default bailout depth to 20 which gives us a reasonable performance in benchmarks we considered (fastrnns, maskrcnn, hub/benchmark, etc)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45710
Reviewed By: robieta
Differential Revision: D24071861
Pulled By: Krovatkin
fbshipit-source-id: 472aacc136f37297b21f577750c1d60683a6c81e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45693
**Summary**
This commit updates the docstring for
`torch.distributions.NegativeBinomial` to better match actual behaviour.
In particular, the parameter currently documented as probability of
success is actually probability of failure.
**Test Plan**
1) Ran the code from the issue to make sure this is still an issue (it
is)
2) `make html` and viewed the docs in a browser.
*Before*
<img width="879" alt="Captura de Pantalla 2020-10-01 a la(s) 1 35 28 p m" src="https://user-images.githubusercontent.com/4392003/94864456-db3a5680-03f0-11eb-977e-3bab0fb9c206.png">
*After*
<img width="877" alt="Captura de Pantalla 2020-10-01 a la(s) 2 12 24 p m" src="https://user-images.githubusercontent.com/4392003/94864478-e42b2800-03f0-11eb-965a-51493ca27c80.png">
**Fixes**
This commit closes#42449.
Test Plan: Imported from OSS
Reviewed By: robieta
Differential Revision: D24071048
Pulled By: SplitInfinity
fbshipit-source-id: d345b4de721475dbe26233e368af62eb57a47970
Summary:
We are trying to build libtorch statically (BUILD_SHARED_LIBS=OFF) then link it into a DLL. Our setup hits the infinite loop mentioned [here](54c05fa34e/torch/csrc/autograd/engine.cpp (L228)) because we build with `BUILD_SHARED_LIBS=OFF` but still link it all into a DLL at the end of the day.
This PR fixes the issue by changing the condition to guard on which windows runtime the build links against using the `CAFFE2_USE_MSVC_STATIC_RUNTIME` flag. `CAFFE2_USE_MSVC_STATIC_RUNTIME` defaults to ON when `BUILD_SHARED_LIBS=OFF`, so backwards compatibility is maintained.
I'm not entirely confident I understand the subtleties of the windows runtime versus linking setup, but this setup works for us and should not affect the existing builds.
Fixes https://github.com/pytorch/pytorch/issues/44470
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43532
Reviewed By: mrshenli
Differential Revision: D24053767
Pulled By: albanD
fbshipit-source-id: 1127fefe5104d302a4fc083106d4e9f48e50add8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45672
This PR merges all quantization mode and will only expose the following top level functions:
```
prepare_fx
prepare_qat_fx
convert_fx
```
Test Plan:
Imported from OSS
Imported from OSS
Reviewed By: z-a-f
Differential Revision: D24053439
fbshipit-source-id: 03d545e26a36bc22a73349061b751eeb35171e64
Summary:
WIP: This PR is working in progress for the partition of fx graph module. _class partitioner_ generates partitions for the graph module. _class partition_ is a partition node in the partitions.
_Partitioner()_ : create a partitioner
_partition_graph(self, fx_module: GraphModule, devices: List[str]) -> None_:
use fx graph module and devices as the input and create partition_ids for each node inside the graph module
_dump_partition_DAG(self) -> None_:
print out the information about each partition, including its id, its backend type (what type of device this partition uses), all the nodes included in this partition, its parent partitions, children partitions, input nodes, and output nodes.
So far, only a single partition is considered, which means there is only one device with unlimited memory.
A test unit call _test_find_single_partition()_ is added to test if all nodes in the graph are marked for the only partition.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45429
Reviewed By: izdeby
Differential Revision: D24026268
Pulled By: scottxu0730
fbshipit-source-id: 119d506f33049a59b54ad993670f4ba5d8e15b0b
Summary:
Fixes https://github.com/pytorch/pytorch/issues/42855. Previously, back quotes weren't rendering correctly in
equations. This is because we were quoting things like `'mean'`. In
order to backquote properly in latex in text-mode, the back-quote needs
to be written as a back-tick.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45662
Test Plan:
- built docs locally and viewed the changes.
For NLLLoss (which is not the original module mentioned in the issue, but it has the same problem), we can see how the back quotes now render properly:

Reviewed By: glaringlee
Differential Revision: D24049880
Pulled By: zou3519
fbshipit-source-id: 61a1257994144549eb8f29f19d639aea962dfec0
Summary:
This PR adds support for complex-valued input for `torch.symeig`.
TODO:
- [ ] complex cuda tests raise `RuntimeError: _th_bmm_out not supported on CUDAType for ComplexFloat`
Update: Added xfailing tests for complex dtypes on CUDA. Once support for complex `bmm` is added these tests will work.
Fixes https://github.com/pytorch/pytorch/issues/45061.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45121
Reviewed By: mrshenli
Differential Revision: D24049649
Pulled By: anjali411
fbshipit-source-id: 2cd11f0e47d37c6ad96ec786762f2da57f25dac5
Summary:
Amp gradient unscaling is a great use case for multi tensor apply (in fact it's the first case I wrote it for). This PR adds an MTA unscale+infcheck functor. Really excited to have it for `torch.cuda.amp`. izdeby your interface was clean and straightforward to use, great work!
Labeled as bc-breaking because the native_functions.yaml exposure of unscale+infcheck changes from [`_amp_non_finite_check_and_unscale_` to `_amp_foreach_non_finite_check_and_unscale_`]( https://github.com/pytorch/pytorch/pull/44778/files#diff-f1e4b2c15de770d978d0eb77b53a4077L6289-L6293).
The PR also modifies Unary/Binary/Pointwise Functors to
- do ops' internal math in FP32 for FP16 or bfloat16 inputs, which improves precision ([and throughput, on some architectures!](https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#arithmetic-instructions)) and has no downside for the ops we care about.
- accept an instantiated op functor rather than an op functor template (`template<class> class Op`). This allows calling code to pass lambdas.
Open question: As written now, the PR has MTA Functors take care of pre- and post-casting FP16/bfloat16 inputs to FP32 before running the ops. However, alternatively, the pre- and post-math casting could be deferred/written into the ops themselves, which gives them a bit more control. I can easily rewrite it that way if you prefer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44778
Reviewed By: gchanan
Differential Revision: D23944102
Pulled By: izdeby
fbshipit-source-id: 22b25ccad5f69b413c77afe8733fa9cacc8e766d
Summary:
* Support propagating `dim_param` in ONNX by encoding as `ShapeSymbol` in `SymbolicShape` of outputs. If export is called with `dynamic_axes` provided, shape inference will start with these axes set as dynamic.
* Add new test file `test_pytorch_onnx_shape_inference.py`, reusing all test cases from `test_pytorch_onnx_onnxruntime.py`, but focus on validating shape for all nodes in graph. Currently this is not enabled in the CI, since there are still quite some existing issues and corner cases to fix. The test is default to run only at opset 12.
* Bug fixes, such as div, _len, and peephole.cpp passes for PackPadded, and LogSoftmaxCrossEntropy.
* This PR depends on existing PR such as 44332.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44920
Reviewed By: eellison
Differential Revision: D23958398
Pulled By: bzinodev
fbshipit-source-id: 00479d9bd19c867d526769a15ba97ec16d56e51d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45292
This PR merges all quantization mode and will only expose the following top level functions:
```
prepare_fx
prepare_qat_fx
convert_fx
```
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23913105
fbshipit-source-id: 4e335286d6de225839daf51d1df54322d52d68e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45343
Current default dynamic quant observer is not correct since we don't accumulate
min/max and we don't need to calculate qparams.
Test Plan: Imported from OSS
Reviewed By: supriyar
Differential Revision: D23933995
fbshipit-source-id: 3ff497c9f5f74c687e8e343ab9948d05ccbba09b
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/45586
Test Plan: The unit test has been softened to be less platform sensitive.
Reviewed By: mruberry
Differential Revision: D24025415
Pulled By: robieta
fbshipit-source-id: ee986933b984e736cf1525e1297de6b21ac1f0cf
Summary:
This is an attempt at refactoring `torch.distributed` implementation. Goal is to push Python layer's global states (like _default_pg) to C++ layer such that `torch.distributed` becomes more TorchScript friendly.
This PR adds the skeleton of C++ implementation, at the moment it is not included in any build (and won't be until method implementations are filled in). If you see any test failures related, feel free to revert.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45547
Reviewed By: izdeby
Differential Revision: D24024213
Pulled By: gmagogsfm
fbshipit-source-id: 2762767f63ebef43bf58e17f9447d53cf119f05f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45585
I discovered this bug when I was trying to print the graph to a file. Turns out I had to close the file, but flushing should be a good safeguard in case other users forget.
Test Plan:
Tested with and without flushing.
with P144064292
without P144064767
Reviewed By: mortzur
Differential Revision: D24023819
fbshipit-source-id: 39574b3615feb28e5b5939664c04ddfb1257706a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45474
When batchnorm affine is set to false, weight and bias is set to None, which is not supported in this case. Added a fix to set weights to 1 and bias to 0 if they are not set.
Test Plan: Add unit test for testing fusing conv, batchnorm where batchnorm is in affine=False mode.
Reviewed By: z-a-f
Differential Revision: D23977080
fbshipit-source-id: 2782be626dc67553f3d27d8f8b1ddc7dea022c2a
Summary:
Export of embedding bag with dynamic list of offsets.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44693
Reviewed By: malfet
Differential Revision: D23831980
Pulled By: bzinodev
fbshipit-source-id: 3eaff1a0f20d1bcfb8039e518d78c491be381e1a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45377
This PR adds a C++ implementation of the TripletMarginWithDistanceLoss, for which the Python implementation was introduced in PR #43680. It's based on PR #44072, but I'm resubmitting this to unlink it from Phabricator.
Test Plan: Imported from OSS
Reviewed By: izdeby
Differential Revision: D24003973
fbshipit-source-id: 2d9ada7260a6f27425ff2fdbbf623dad0fb79405
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44826
As described in https://github.com/pytorch/pytorch/issues/43690, there
is a need for DDP to be able to ignore certain parameters in the module (not
install allreduce hooks) for certain use cases. `find_unused_parameters` is
sufficient from a correctness perspective, but we can get better performance
with this upfront list if users know which params are unused, since we won't
have to traverse the autograd graph every iteration.
To enable this, we add a field `parameters_to_ignore` to DDP init and don't
pass in that parameter to reducer if that parameter is in the given list.
ghstack-source-id: 113210109
Test Plan: Added unittest
Reviewed By: xw285cornell, mrshenli
Differential Revision: D23740639
fbshipit-source-id: a0411712a8b0b809b9c9e6da04bef2b955ba5314
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45461
This PR disables autograd for all C -> C, R -> C functions which are not included in the whitelist `GRADIENT_IMPLEMENTED_FOR_COMPLEX`. In practice, there will be a RuntimeError during forward computation when the outputs are differentiable:
```
>>> x=torch.randn(4, 4, requires_grad=True, dtype=torch.cdouble)
>>> x.pow(3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: pow does not support automatic differentiation for outputs with complex dtype.
```
The implicit assumption here is that all the C -> R functions have correct backward definitions. So before merging this PR, the following functions must be tested and verified to have correct backward definitions:
`torch.abs` (updated in #39955 ), `torch.angle`, `torch.norm`, `torch.irfft`, `torch.istft`.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D23998156
Pulled By: anjali411
fbshipit-source-id: 370eb07fe56ac84dd8e2233ef7bf3a3eb8aeb179
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45532
- updated documentation
- explicitly not supporting negative values for beta (previously the
result was incorrect)
- Removing default value for beta in the backwards function, since it's
only used internally by autograd (as per convention)
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D24002415
Pulled By: bdhirsh
fbshipit-source-id: 980c141019ec2d437b771ee11fc1cec4b1fcfb48
Summary:
This PR allows Timer to collect deterministic instruction counts for (some) snippets. Because of the intrusive nature of Valgrind (effectively replacing the CPU with an emulated one) we have to perform our measurements in a separate process. This PR writes a `.py` file containing the Timer's `setup` and `stmt`, and executes it within a `valgrind` subprocess along with a plethora of checks and error handling. There is still a bit of jitter around the edges due to the Python glue that I'm using, but the PyTorch signal is quite good and thus this provides a low friction way of getting signal. I considered using JIT as an alternative, but:
A) Python specific overheads (e.g. parsing) are important
B) JIT might do rewrites which would complicate measurement.
Consider the following bit of code, related to https://github.com/pytorch/pytorch/issues/44484:
```
from torch.utils._benchmark import Timer
counts = Timer(
"x.backward()",
setup="x = torch.ones((1,)) + torch.ones((1,), requires_grad=True)"
).collect_callgrind()
for c, fn in counts[:20]:
print(f"{c:>12} {fn}")
```
```
812800 ???:_dl_update_slotinfo
355600 ???:update_get_addr
308300 work/Python/ceval.c:_PyEval_EvalFrameDefault'2
304800 ???:__tls_get_addr
196059 ???:_int_free
152400 ???:__tls_get_addr_slow
138400 build/../c10/core/ScalarType.h:c10::typeMetaToScalarType(caffe2::TypeMeta)
126526 work/Objects/dictobject.c:_PyDict_LoadGlobal
114268 ???:malloc
101400 work/Objects/unicodeobject.c:PyUnicode_FromFormatV
85900 work/Python/ceval.c:_PyEval_EvalFrameDefault
79946 work/Objects/typeobject.c:_PyType_Lookup
72000 build/../c10/core/Device.h:c10::Device::validate()
70000 /usr/include/c++/8/bits/stl_vector.h:std::vector<at::Tensor, std::allocator<at::Tensor> >::~vector()
66400 work/Objects/object.c:_PyObject_GenericGetAttrWithDict
63000 ???:pthread_mutex_lock
61200 work/Objects/dictobject.c:PyDict_GetItem
59800 ???:free
58400 work/Objects/tupleobject.c:tupledealloc
56707 work/Objects/dictobject.c:lookdict_unicode_nodummy
```
Moreover, if we backport this PR to 1.6 (just copy the `_benchmarks` folder) and load those counts as `counts_1_6`, then we can easily diff them:
```
print(f"Head instructions: {sum(c for c, _ in counts)}")
print(f"1.6 instructions: {sum(c for c, _ in counts_1_6)}")
count_dict = {fn: c for c, fn in counts}
for c, fn in counts_1_6:
_ = count_dict.setdefault(fn, 0)
count_dict[fn] -= c
count_diffs = sorted([(c, fn) for fn, c in count_dict.items()], reverse=True)
for c, fn in count_diffs[:15] + [["", "..."]] + count_diffs[-15:]:
print(f"{c:>8} {fn}")
```
```
Head instructions: 7609547
1.6 instructions: 6059648
169600 ???:_dl_update_slotinfo
101400 work/Objects/unicodeobject.c:PyUnicode_FromFormatV
74200 ???:update_get_addr
63600 ???:__tls_get_addr
46800 work/Python/ceval.c:_PyEval_EvalFrameDefault
33512 work/Objects/dictobject.c:_PyDict_LoadGlobal
31800 ???:__tls_get_addr_slow
31700 build/../aten/src/ATen/record_function.cpp:at::RecordFunction::RecordFunction(at::RecordScope)
28300 build/../torch/csrc/utils/python_arg_parser.cpp:torch::FunctionSignature::parse(_object*, _object*, _object*, _object**, bool)
27800 work/Objects/object.c:_PyObject_GenericGetAttrWithDict
27401 work/Objects/dictobject.c:lookdict_unicode_nodummy
24115 work/Objects/typeobject.c:_PyType_Lookup
24080 ???:_int_free
21700 work/Objects/dictobject.c:PyDict_GetItemWithError
20700 work/Objects/dictobject.c:PyDict_GetItem
...
-3200 build/../c10/util/SmallVector.h:at::TensorIterator::binary_op(at::Tensor&, at::Tensor const&, at::Tensor const&, bool)
-3400 build/../aten/src/ATen/native/TensorIterator.cpp:at::TensorIterator::resize_outputs(at::TensorIteratorConfig const&)
-3500 /usr/include/c++/8/x86_64-redhat-linux/bits/gthr-default.h:std::unique_lock<std::mutex>::unlock()
-3700 build/../torch/csrc/utils/python_arg_parser.cpp:torch::PythonArgParser::raw_parse(_object*, _object*, _object**)
-4207 work/Objects/obmalloc.c:PyMem_Calloc
-4500 /usr/include/c++/8/bits/stl_vector.h:std::vector<at::Tensor, std::allocator<at::Tensor> >::~vector()
-4800 build/../torch/csrc/autograd/generated/VariableType_2.cpp:torch::autograd::VariableType::add__Tensor(at::Tensor&, at::Tensor const&, c10::Scalar)
-5000 build/../c10/core/impl/LocalDispatchKeySet.cpp:c10::impl::ExcludeDispatchKeyGuard::ExcludeDispatchKeyGuard(c10::DispatchKey)
-5300 work/Objects/listobject.c:PyList_New
-5400 build/../torch/csrc/utils/python_arg_parser.cpp:torch::FunctionParameter::check(_object*, std::vector<pybind11::handle, std::allocator<pybind11::handle> >&)
-5600 /usr/include/c++/8/bits/std_mutex.h:std::unique_lock<std::mutex>::unlock()
-6231 work/Objects/obmalloc.c:PyMem_Free
-6300 work/Objects/listobject.c:list_repeat
-11200 work/Objects/listobject.c:list_dealloc
-28900 build/../torch/csrc/utils/python_arg_parser.cpp:torch::FunctionSignature::parse(_object*, _object*, _object**, bool)
```
Remaining TODOs:
* Include a timer in the generated script for cuda sync.
* Add valgrind to CircleCI machines and add a unit test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44717
Reviewed By: soumith
Differential Revision: D24010742
Pulled By: robieta
fbshipit-source-id: df6bc765f8efce7193893edba186cd62b4b23623
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45482
Working on some models that need these ops on lite interpreter.
Test Plan: locally build and load/run the TS model without problem.
Reviewed By: iseeyuan
Differential Revision: D23906581
fbshipit-source-id: 01b9de2af2046296165892b837bc14a7e5d59b4e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45520
With this change `Load`s and `Store`s no longer accept `Placeholder`s in
their constructor and `::make` functions and can only be built with
`Buf`.
`Placeholder` gets its own `store`, `load`, `storeWithMask`, and
`loadWithMask` method for more convenient construction.
Test Plan: Imported from OSS
Reviewed By: glaringlee
Differential Revision: D23998789
Pulled By: ZolotukhinM
fbshipit-source-id: 3fe018e00c1529a563553b2b215f403b34aea912
Summary:
This might be an alternative to reverting https://github.com/pytorch/pytorch/issues/45396 .
The obvious rough edge is that I'm not really seeing the work group limits that TensorExpr produces.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45506
Reviewed By: zhangguanheng66
Differential Revision: D23991410
Pulled By: Krovatkin
fbshipit-source-id: 11d3fc4600e4bffb1d1192c6b8dd2fe22c1e064e
Summary:
This PR adds a new GraphManipulation library for operating on the GraphModule nodes.
It also adds an implementation of replace_target_nodes_with, which replaces all nodes in the GraphModule or a specific op/target with a new specified op/target. An example use of this function would be replacing a generic operator with an optimized operator for specific sizes and shapes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44775
Reviewed By: jamesr66a
Differential Revision: D23874561
Pulled By: gcatron
fbshipit-source-id: e1497cd11e0bbbf1fabdf137d65c746248998e0b
Summary:
Per feedback in the recent design review. Also tweaks the documentation to clarify what "deterministic" means and adds a test for the behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45410
Reviewed By: ngimel
Differential Revision: D23974988
Pulled By: mruberry
fbshipit-source-id: e48307da9c90418fc6834fbd67b963ba2fe0ba9d
Summary:
Updated `cholesky_backward` to work correctly for complex input.
Note that the current implementation gives the conjugate of what JAX would return. anjali411 is that correct thing to do?
Ref. https://github.com/pytorch/pytorch/issues/44895
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45267
Reviewed By: bwasti
Differential Revision: D23975269
Pulled By: anjali411
fbshipit-source-id: 9908b0bb53c411e5ad24027ff570c4f0abd451e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45488
model_name logging was broken, issue is from the recent change of assigning the method name into the module name, this diff is fixing it.
ghstack-source-id: 113103942
Test Plan:
made sure that now the model_name is logged from module_->name().
verified with one model which does not contain the model metadata, and the model_name field is logged as below:
09-28 21:59:30.065 11530 12034 W module.cpp: TESTINGTESTING run() module = __torch__.Model
09-28 21:59:30.065 11530 12034 W module.cpp: TESTINGTESTING metadata does not have model_name assigning to __torch__.Model
09-28 21:59:30.066 11530 12034 W MobileModuleQPLObserver.cpp: TESTINGTESTING onEnterRunMethod log model_name = __torch__.Model
09-28 21:59:30.066 11530 12034 W MobileModuleQPLObserver.cpp: TESTINGTESTING onEnterRunMethod log method_name = labels
09-28 21:59:30.068 11530 12034 W MobileModuleQPLObserver.cpp: TESTINGTESTING onExitRunMethod()
Reviewed By: linbinyu
Differential Revision: D23984165
fbshipit-source-id: 5b00f50ea82106b695c2cee14029cb3b2e02e2c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45261
**Summary**
This commit enables `unused` syntax for ignoring
properties. Inoring properties is more intuitive with this feature enabled.
`ignore` is not supported because class type properties cannot be
executed in Python (because they exist only as TorchScript types) like
an `ignored` function and module properties that cannot be scripted
are not added to the `ScriptModule` wrapper so that they
may execute in Python.
**Test Plan**
This commit updates the existing unit tests for class type and module
properties to test properties ignored using `unused`.
Test Plan: Imported from OSS
Reviewed By: navahgar, Krovatkin, mannatsingh
Differential Revision: D23971881
Pulled By: SplitInfinity
fbshipit-source-id: 8d3cc1bbede7753d6b6f416619e4660c56311d33
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45479
Add a top level boolean attribute to the model called mobile_optimized that is set to true if it is optimized.
Test Plan: buck test //caffe2/test:mobile passes
Reviewed By: kimishpatel
Differential Revision: D23956728
fbshipit-source-id: 79c5931702208b871454319ca2ab8633596b1eb8
Summary:
Fix `torch._C._autocast_*_nesting` declarations in __init__.pyi
Fix iterable constructor logic: not every iterable can be constructed using `type(val)(val)` trick, for example it would not work for `val=range(10)` although `isinstance(val, Iterable)` is True
Change optional resolution logic to meet mypy expectations
Fixes https://github.com/pytorch/pytorch/issues/45436
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45480
Reviewed By: walterddr
Differential Revision: D23982822
Pulled By: malfet
fbshipit-source-id: 6418a28d04ece1b2427dcde4b71effb67856a872
Summary:
This PR makes the deprecation warnings for existing fft functions more prominent and makes the torch.stft deprecation warning consistent with our current deprecation planning.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45409
Reviewed By: ngimel
Differential Revision: D23974975
Pulled By: mruberry
fbshipit-source-id: b90d8276095122ac3542ab625cb49b991379c1f8
Summary:
PR opened just to run the CI tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44465
Reviewed By: ngimel
Differential Revision: D23907565
Pulled By: mruberry
fbshipit-source-id: 620661667877f1e9a2bab17d19988e2dc986fc0f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44846
The save function traverses the model state dict to pick out the observer stats
load function traverse the module hierarchy to load the state dict into module attributes depending on observer type
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_save_observer_state_dict
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D23746821
fbshipit-source-id: 05c571b62949a2833602d736a81924d77e7ade55
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45390
Tensor objects should always refer to their Function's bufs. Currently
we never create a Tensor with a buffer different than of its function,
but having it in two places seems incorrect and dangerous.
Differential Revision: D23952865
Test Plan: Imported from OSS
Reviewed By: nickgg
Pulled By: ZolotukhinM
fbshipit-source-id: e63fc26d7078427514649d9ce973b74ea635a94a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45388
Classes defined in these files are closely related, so it is reasonable
to have them all in one file. The change is purely a code move.
Differential Revision: D23952867
Test Plan: Imported from OSS
Reviewed By: nickgg
Pulled By: ZolotukhinM
fbshipit-source-id: 12cfaa968bdfc4dff00509e34310a497c7b59155
Summary:
In profiler, cuda did not report self time, so for composite functions there was no way to determine which function is really taking time. In addition, "total cuda time" reported was frequently more than total wallclock time. This PR adds "self CUDA time" in profiler, and computes total cuda time based on self cuda time, similar to how it's done for CPU. Also, slight formatting changes to make table more compact. Before:
```
-------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg CUDA total % CUDA total CUDA time avg Number of Calls
-------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------
aten::matmul 0.17% 890.805us 99.05% 523.401ms 5.234ms 49.91% 791.184ms 7.912ms 100
aten::mm 98.09% 518.336ms 98.88% 522.511ms 5.225ms 49.89% 790.885ms 7.909ms 100
aten::t 0.29% 1.530ms 0.49% 2.588ms 25.882us 0.07% 1.058ms 10.576us 100
aten::view 0.46% 2.448ms 0.46% 2.448ms 12.238us 0.06% 918.936us 4.595us 200
aten::transpose 0.13% 707.204us 0.20% 1.058ms 10.581us 0.03% 457.802us 4.578us 100
aten::empty 0.14% 716.056us 0.14% 716.056us 7.161us 0.01% 185.694us 1.857us 100
aten::as_strided 0.07% 350.935us 0.07% 350.935us 3.509us 0.01% 156.380us 1.564us 100
aten::stride 0.65% 3.458ms 0.65% 3.458ms 11.527us 0.03% 441.258us 1.471us 300
-------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------
Self CPU time total: 528.437ms
CUDA time total: 1.585s
Recorded timeit time: 789.0814 ms
```
Note recorded timeit time (with proper cuda syncs) is 2 times smaller than "CUDA time total" reported by profiler
After
```
-------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg # of Calls
-------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
aten::matmul 0.15% 802.716us 99.06% 523.548ms 5.235ms 302.451us 0.04% 791.151ms 7.912ms 100
aten::mm 98.20% 519.007ms 98.91% 522.745ms 5.227ms 790.225ms 99.63% 790.848ms 7.908ms 100
aten::t 0.27% 1.406ms 0.49% 2.578ms 25.783us 604.964us 0.08% 1.066ms 10.662us 100
aten::view 0.45% 2.371ms 0.45% 2.371ms 11.856us 926.281us 0.12% 926.281us 4.631us 200
aten::transpose 0.15% 783.462us 0.22% 1.173ms 11.727us 310.016us 0.04% 461.282us 4.613us 100
aten::empty 0.11% 591.603us 0.11% 591.603us 5.916us 176.566us 0.02% 176.566us 1.766us 100
aten::as_strided 0.07% 389.270us 0.07% 389.270us 3.893us 151.266us 0.02% 151.266us 1.513us 100
aten::stride 0.60% 3.147ms 0.60% 3.147ms 10.489us 446.451us 0.06% 446.451us 1.488us 300
-------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 528.498ms
CUDA time total: 793.143ms
Recorded timeit time: 788.9832 ms
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45209
Reviewed By: zou3519
Differential Revision: D23925491
Pulled By: ngimel
fbshipit-source-id: 7f9c49238d116bfd2db9db3e8943355c953a77d0
Summary:
Inline pytorch into wrapper, which is especially helpful in combination
with dead code elimination to reduce IR size and compilation times when
a lot of parameters are unused.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45445
Test Plan: CI
Reviewed By: ZolotukhinM
Differential Revision: D23969009
Pulled By: asuhan
fbshipit-source-id: a21509d07e4c130b6aa6eae5236bb64db2748a3d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43612
**Summary**
This commit modifies the `torch._C._jit_to_backend` function so that it
accepts `ScriptModules` as inputs. It already returns `ScriptModules`
(as opposed to C++ modules), so this makes sense and makes the API more
intuitive.
**Test Plan**
Continuous integration, which includes unit tests and out-of-tree tests
for custom backends.
**Fixes**
This commit fixes#41432.
Test Plan: Imported from OSS
Reviewed By: suo, jamesr66a
Differential Revision: D23339854
Pulled By: SplitInfinity
fbshipit-source-id: 08ecef729c4e1e6bddf3f483276947fc3559ea88
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45280
Performance is the same on CPU and on CUDA is only 1-1.05x slower. This change is necessary for the future nan ops including nan(min|max|median)
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D23908796
Pulled By: heitorschueroff
fbshipit-source-id: c2b57acbe924cfa59fbd85216811f29f4af05088
Summary:
Stumbled upon a little gem in the audio conversion for `SummaryWriter.add_audio()`: two Python `for` loops to convert a float array to little-endian int16 samples. On my machine, this took 35 seconds for a 30-second 22.05 kHz excerpt. The same can be done directly in numpy in 1.65 milliseconds. (No offense, I'm glad that the functionality was there!)
Would also be ready to extend this to support stereo waveforms, or should this become a separate PR?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44201
Reviewed By: J0Nreynolds
Differential Revision: D23831002
Pulled By: edward-io
fbshipit-source-id: 5c8f1ac7823d1ed41b53c4f97ab9a7bac33ea94b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45214
When in verbose mode the package exporter will produce an html visualization
of dependencies of a module to make it easier to trim out unneeded code,
or debug inclusion of things that cannot be exported.
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D23873525
Pulled By: zdevito
fbshipit-source-id: 6801991573d8dd5ab8c284e09572b36a35e1e5a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45401
Added a DeleteKey API for the TCP Store
ghstack-source-id: 112997162
Test Plan:
Modified the existing get/set test to use delete. verified that the
correct keys were deleted and that the numKeys API returned the right values
Reviewed By: mrshenli
Differential Revision: D23955730
fbshipit-source-id: 5c9f82be34ff4521c59f56f8d9c1abf775c67f9f
Summary:
Recent changes to the seq_num correlation behavior in profiler (PR https://github.com/pytorch/pytorch/issues/42565) has changed the behavior for emit_nvtx(record_shapes=True) which doesn't print the name of the operator properly.
Created PR to dump out the name in roctx traces, irrespective of the sequence number assigned only for ROCm.
cc: jeffdaily sunway513
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45229
Reviewed By: zou3519
Differential Revision: D23932902
Pulled By: albanD
fbshipit-source-id: c782667ff002b70b51f1cc921afd1b1ac533b39d
Summary:
This PR cleans up some of the rough edges around `Timer` and `Compare`
* Moves `Measurement` to be dataclass based
* Adds a bunch of type annotations. MyPy is now happy.
* Allows missing entries in `Compare`. This is one of the biggest usability issues with `Compare` right now, both from an API perspective and because the current failure mode is really unpleasant.
* Greatly expands the testing of `Compare`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45361
Test Plan: Changes to Timer are covered under existing tests, changes to `Compare` are covered by the expanded `test_compare` method.
Reviewed By: bwasti
Differential Revision: D23966816
Pulled By: robieta
fbshipit-source-id: 826969f73b42f72fa35f4de3c64d0988b61474cd
Summary:
Export of view op with dynamic input shape is broken when using tensors with a 0-dim.
This fix removes symbolic use of static input size to fix this issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43558
Reviewed By: ailzhang
Differential Revision: D23965090
Pulled By: bzinodev
fbshipit-source-id: 628e9d7ee5d53375f25052340ca6feabf7ba7c53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45291
It's not necessary, you can just check if the dtype is integral.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23911963
Pulled By: gchanan
fbshipit-source-id: 230139e1651eb76226f4095e31068dded30e03e8
Summary:
As per title. Fixes [#{38948}](https://github.com/pytorch/pytorch/issues/38948). Therein you can find some blueprints for the algorithm being used in this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43002
Reviewed By: zou3519
Differential Revision: D23931326
Pulled By: albanD
fbshipit-source-id: e6994af70d94145f974ef87aa5cea166d6deff1e
Summary:
Changes the deprecation of norm to a docs deprecation, since PyTorch components still rely on norm and some behavior, like automatically flattening tensors, may need to be ported to torch.linalg.norm. The documentation is also updated to clarify that torch.norm and torch.linalg.norm are distinct.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45415
Reviewed By: ngimel
Differential Revision: D23958252
Pulled By: mruberry
fbshipit-source-id: fd54e807c59a2655453a6bcd9f4073cb2c12e8ac
Summary:
Fix a couple of issues with scripting inplace indexing in prepare_inplace_ops_for_onnx pass.
1- Tracing index copy (such as cases lik x[1:3] = data) already applies broadcasting on rhs if needed. The broadcasting node (aten::expand) is missing in scripting cases.
2- Inplace indexing with ellipsis (aten::copy_) is replaced with aten::index_put and then handled with slice+select in this pass.
Support for negative indices for this op added.
Shape inference is also enabled for scripting tests using new JIT API.
A few more tests are enabled for scripting.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44351
Reviewed By: ezyang
Differential Revision: D23880267
Pulled By: bzinodev
fbshipit-source-id: 78b33444633eb7ae0fbabc7415e3b16001f5207f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45143
This PR prevents freezing cleaning up a submodule when user requests to
preserve a submodule.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D23844969
Pulled By: bzinodev
fbshipit-source-id: 80e6db3fc12460d62e634ea0336ae2a3551c2151
Summary:
in ONNX NegativeLogLikelihoodLoss specification, ignore_index is optional without default value.
therefore, when convert nll op to ONNX, we need to set ignore_index attribute even if it is not specified (e.g. ignore_index=-100).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44816
Reviewed By: ezyang
Differential Revision: D23880354
Pulled By: bzinodev
fbshipit-source-id: d0bdd58d0a4507ed9ce37133e68533fe6d1bdf2b
Summary:
Optimize export_onnx api to reduce string and model proto exchange in export.cpp
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44332
Reviewed By: bwasti, eellison
Differential Revision: D23880129
Pulled By: bzinodev
fbshipit-source-id: 1d216d8f710f356cbba2334fb21ea15a89dd16fa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44419
Closes https://github.com/pytorch/pytorch/issues/39969
This PR adds support for propagation of input shapes over the wire when the profiler is invoked with `record_shapes=True` over RPC. Previously, we did not respect this argument.
This is done by saving the shapes as an ivalue list and recovering it as the type expected (`std::vector<std::vector<int>>` on the client). Test is added to ensure that remote ops have the same `input_shapes` as if the op were run locally.
ghstack-source-id: 112977899
Reviewed By: pritamdamania87
Differential Revision: D23591274
fbshipit-source-id: 7cf3b2e8df26935ead9d70e534fc2c872ccd6958
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44967
When enabling profiler on server, if it is a different machine it may
not have CUDA while caller does. In this case, we would crash but now we
fallback to CPU and log a warning.
ghstack-source-id: 112977906
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D23790729
fbshipit-source-id: dc6eba172b7e666842d54553f52a6b9d5f0a5362
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43963
Added a DeleteKey API for the TCP Store
ghstack-source-id: 112939762
Test Plan:
Modified the existing get/set test to use delete. verified that the
correct keys were deleted and that the numKeys API returned the right values
Reviewed By: jiayisuse
Differential Revision: D23009117
fbshipit-source-id: 1a0d95b43d79e665a69b2befbaa059b2b50a1f66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43962
TCPStore needs a getNumKeys API for our logging needs.
ghstack-source-id: 112939761
Test Plan: Adding tests to C++ Store Tests
Reviewed By: pritamdamania87
Differential Revision: D22985085
fbshipit-source-id: 8a0d286fbd6fd314dcc997bae3aad0e62b51af83
Summary:
This PR adds get_all_users_of function. The function returns all the users of a specific node. A test unit is also added.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45216
Reviewed By: ezyang
Differential Revision: D23883572
Pulled By: scottxu0730
fbshipit-source-id: 3eb68a411c3c6db39ed2506c9cb7bb7337520ee4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45221
This PR introduces a distributed functional optimizer, so that
distributed optimizer can reuse the functional optimizer APIs and
maintain their own states. This could enable the torchscript compatible
functional optimizer when using distributed optimizer, helps getting rid
of GIL and improve overall performance of training, especially distributed
model parallel training
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D23935256
Pulled By: wanchaol
fbshipit-source-id: 59b6d77ff4693ab24a6e1cbb6740bcf614cc624a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44715
We have provided a nice and intuitive API in Python. But in the context of large scale distributed training (e.g. Distributed Model Parallel), users often want to use multithreaded training instead of multiprocess training as it provides better resource utilization and efficiency.
This PR introduces functional optimizer concept (that is similar to the concept of `nn.functional`), we split optimizer into two parts: 1. optimizer state management 2. optimizer computation. We expose the computation part as a separate functional API that is available to be used by internal and OSS developers, the caller of the functional API will maintain their own states in order to directly calls the functional API. While maintaining the end user API be the same, the functional API is TorchScript friendly, and could be used by the distributed optimizer to speed up the training without GIL.
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D23935258
Pulled By: wanchaol
fbshipit-source-id: d2a5228439edb3bc64f7771af2bb9e891847136a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45353
Temporarily removing this feature, will add this back after branch cut.
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D23939865
Pulled By: mrshenli
fbshipit-source-id: 7dceaffea6b9a16512b5ba6036da73e7f8f83a8e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44433
Not entirely sure why, but changing the type of beta from `float` to `double in autocast_mode.cpp and FunctionsManual.h fixes my compiler errors, failing instead at link time
fixing some type errors, updated fn signature in a few more files
removing my usage of Scalar, making beta a double everywhere instead
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D23636720
Pulled By: bdhirsh
fbshipit-source-id: caea2a1f8dd72b3b5fd1d72dd886b2fcd690af6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45181
`init_process_group` and `new_group` update a bunch of global
variables after initializing the actual process group. As a result, there is a
race that after initializing the process group on say rank 0, if we immediately
check the default process group on rank 1 (say via RPC), we might actually get
an error since rank 1 hasn't yet updated its _default_pg variable.
To resolve this issue, I've added barrier() at the end of both of these calls.
This ensures that once these calls return we are guaranteed about correct
initialization on all ranks.
Since these calls are usually done mostly during initialization, it should be
fine to add the overhead of a barrier() here.
#Closes: https://github.com/pytorch/pytorch/issues/40434, https://github.com/pytorch/pytorch/issues/40378
ghstack-source-id: 112923112
Test Plan:
Reproduced the failures in
https://github.com/pytorch/pytorch/issues/40434 and
https://github.com/pytorch/pytorch/issues/40378 and verified that this PR fixes
the issue.
Reviewed By: mrshenli
Differential Revision: D23858025
fbshipit-source-id: c4d5e46c2157981caf3ba1525dec5310dcbc1830
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45188
This is a symbolically traceable alternative to Python's `assert`.
It should be useful to allow people who want to use FX to also
be able to assert things.
A bunch of TODO(before) land are inline - would love thoughts
on where is the best place for this code to live, and what this
function should be called (since `assert` is reserved).
Test Plan:
```
python test/test_fx.py TestFX.test_symbolic_trace_assert
```
Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D23861567
fbshipit-source-id: d9d6b9556140faccc0290eba1fabea401d7850de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44923
This ensures that RPC profiling works in single-threaded server
scenarios and that we won't make the assumption that we'll have multiple
threads when working on this code. For example, this assumption resulted in a
bug in the previous diff (which was fixed)
ghstack-source-id: 112868469
Test Plan: CI
Reviewed By: lw
Differential Revision: D23691304
fbshipit-source-id: b17d34ade823794cbe949b70a5ab35723d974203
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44664
Closes https://github.com/pytorch/pytorch/issues/39971. This PR adds support for functions decorated with `rpc.functions.async_execution` to be profiled over RPC as builtins, jit functions, and blocking python UDFs currently can be. The reasoning for this is to provide complete feature support in terms of RPC profiling and the various types of functions users can run.
To enable this, the PR below this enables calling `disableProfiler()` safely from another thread. We use that functionality to defer disabling the profiler on the server until the future corresponding to the RPC request completes (rather than only the blocking `processRPC` call as was done previously). Since when the future completes we've kicked off the async function and the future corresponding to it has completed, we are able to capture any RPCs the function would have called and the actual work done on the other node.
For example, if the following async function is ran on a server over RPC:
```
def slow_add(x, y):
time.sleep(1)
return torch.add(x, y)
rpc.functions.async_execution
def slow_async_add(to, x, y):
return rpc.rpc_async(to, slow_add, args=(x, y))
```
we expect to see the original RPC profiled, the nested RPC profiled, and the actual torch.add() work. All of these events should be recorded with the correct node id. Here is an example profiling output:
```
------------------------------------------------------------------------------------------------------------------------- --------------- --------------- --------------- --------
------- --------------- --------------- ---------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg Number of Calls Node ID
------------------------------------------------------------------------------------------------------------------------- --------------- --------------- --------------- --------
------- --------------- --------------- --------------- rpc_async#slow_async_add(worker1 -> worker2) 0.00% 0.000us 0 1.012s
1.012s 1 1
aten::empty 7.02% 11.519us 7.02% 11.519us 11.519us 1 1
rpc_async#slow_async_add(worker1 -> worker2)#remote_op: rpc_async#slow_add(worker2 -> worker3) 0.00% 0.000us 0 1.006s
1.006s 1 2 rpc_async#slow_async_add(worker1 -> worker2)#remote_op: aten::empty 7.21% 11.843us 7.21% 11.843us
11.843us 1 2
rpc_async#slow_async_add(worker1 -> worker2)#remote_op: rpc_async#slow_add(worker2 -> worker3)#remote_op: aten::add 71.94% 118.107us 85.77% 140.802us 140.802us 1 3
rpc_async#slow_async_add(worker1 -> worker2)#remote_op: rpc_async#slow_add(worker2 -> worker3)#remote_op: aten::empty 13.82% 22.695us 13.82% 22.695us
22.695us 1 3 ------------------------------------------------------------------------------------------------------------------------- --------------- --------------- --------------- --------
------- --------------- --------------- ---------------
Self CPU time total: 164.164us
```
This PR also moves a bunch of the profiling logic to `rpc/utils.cpp` to declutter `request_callback` code.
ghstack-source-id: 112868470
Test Plan:
```
rvarm1@devbig978:fbcode (52dd34f6)$ buck test mode/no-gpu mode/dev-nosan //caffe2/test/distributed/rpc:process_group_agent -- test_rpc_profiling_async_function --print-passing-details --stress-runs 1
```
Reviewed By: mrshenli
Differential Revision: D23638387
fbshipit-source-id: eedb6d48173a4ecd41d70a9c64048920bd4807c4
Summary:
The Cuda HalfChecker casts up all loads and stores of Half to Float, so we do math in Float on the device. It didn't cast up HalfImmediate (ie. constants) so they could insert mixed-size ops. Fix is to do that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45213
Reviewed By: ezyang
Differential Revision: D23885287
Pulled By: nickgg
fbshipit-source-id: 912991d85cc06ebb282625cfa5080d7525c8eba9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45257
Currently we inline fork-wait calls when we insert observers for quantization
In the case where fork and wait are in different subgraphs, inlining the fork-wait calls
only gets rid of the fork. This leaves the aten::wait call in the graph with a torch.Tensor as input,
which is currently not supported.
To avoid this we check to make sure input to all wait calls in the graph is of type Future[tensor]
in the cleanup phase
Test Plan:
python test/test_quantization.py TestQuantizeJitPasses.test_quantize_fork_wait
Imported from OSS
Reviewed By: qizzzh
Differential Revision: D23895412
fbshipit-source-id: 3c58c6be7d7e7904eb6684085832ac21f827a399
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44071
Previously, tracing re-gathered ScalarType, Layout, Device, bool into a TensorOptions object and called `tracer::addInput()` on the gathered TensorOptions argument. `tracer::addInput()` then scattered them again and added the individual scattered arguments to the traced graph. This PR avoids the extraneous gathering and re-scattering step and calls `tracer::addInput()` on the individual arguments directly. This avoid the perf hit for an unnecessary gathering step.
This applies to both c10-full and non-c10-full ops. In the case of c10-full ops, the tracing kernels takes scattered arguments and we can directly pass them to `tracer::addInput()`. In the case of non-c10-full ops, the kernel takes a `TensorOptions` argument but we still call `tracer::addInput()` on the scattered arguments.
ghstack-source-id: 112825793
Test Plan:
waitforsandcastle
vs master: https://www.internalfb.com/intern/fblearner/details/216129483/
vs previous diff: https://www.internalfb.com/intern/fblearner/details/216170069/
Reviewed By: ezyang
Differential Revision: D23486638
fbshipit-source-id: e0b53e6673cef8d7f94158e718301eee261e5d22
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44062
Previously, BackendSelect kernels were still written in the legacy way, i.e. they took one TensorOptions argument instead of scattered dtype, layout, device, pin_memory, and they used hacky_wrapper to be callable. This caused a re-wrapping step. Calling into a BackencSelect kernel required taking the individual scattered arguments, packing them into a TensorOptions, and the kernel itself then gathered them again for redispatch.
Now with this PR, BackendSelect kernels are written in the new way and no hacky_wrapper or rewrapping is needed for them.
ghstack-source-id: 112825789
Test Plan:
vs master: https://www.internalfb.com/intern/fblearner/details/216117032/
vs previous diff: https://www.internalfb.com/intern/fblearner/details/216170194/
Reviewed By: ezyang
Differential Revision: D23484192
fbshipit-source-id: e8fb49c4692404b6b775d18548b990c4cdddbada
Summary:
A lot of changes are in this update, some highlights:
- Added Doxygen config file
- Split the fusion IR (higher level TE like IR) from kernel IR (lower level CUDA like IR)
- Improved latency with dynamic shape handling for the fusion logic
- Prevent recompilation for pointwise + reduction fusions when not needed
- Improvements to inner dimension reduction performance
- Added input -> kernel + kernel launch parameters cache, added eviction policy
- Added reduction fusions with multiple outputs (still single reduction stage)
- Fixed code generation bugs for symbolic tiled GEMM example
- Added thread predicates to prevent shared memory form being loaded multiple times
- Improved sync threads placements with shared memory and removed read before write race
- Fixes to FP16 reduction fusions where output would come back as FP32
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45218
Reviewed By: ezyang
Differential Revision: D23905183
Pulled By: soumith
fbshipit-source-id: 12f5ad4cbe03e9a25043bccb89e372f8579e2a79
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45317
Eager mode quantization depends on the presence of the `config`
model attribute. Currently converting a model to use `SyncBatchNorm`
removes the qconfig - fixing this. This is important if a BN is not
fused to anything during quantization convert.
Test Plan:
```
python test/test_quantization.py TestDistributed.test_syncbn_preserves_qconfig
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23922072
fbshipit-source-id: cc1bc25c8e5243abb924c6889f78cf65a81be158
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44430
log metadata even when model loading is failed
Test Plan: {F331550976}
Reviewed By: husthyc
Differential Revision: D23577711
fbshipit-source-id: 0504e75625f377269f1e5df0f1ebe34b8e564c4b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45162
This test was flaky because it was not able to validate that the
overall record_function's CPU times are greater than the sum of its children.
It turns out that this is a general bug in the profiler that can be reproduced
without RPC, see https://github.com/pytorch/pytorch/issues/45160. Hence,
removing this from the test and replacing it by just validating the expected
children.
Ran the test 1000 times and they all passed.
ghstack-source-id: 112632327
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D23851854
fbshipit-source-id: 5d9023acd17800a6668ba4849659d8cc902b8d6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44972
Previously, our fusion strategy would be:
- start at the end of the block, find a fusable node
- iteratively try to merge inputs into the fusion group, sorted topologically
This strategy works pretty well, but has the possibility of missing fusion groups. See my attached test case for an example where we wouldn't find all possible fusion groups. bertmaher found an example of a missed fusion groups in one of our rnn examples (jit_premul) that caused a regression from the legacy fuser.
Here, I'm updating our fusion strategy to be the same as our other fusion passes - create_autodiff_subgraphs, and graph_fuser.cpp.
The basic strategy is:
- iterate until you find a fusible node
- try to merge the nodes inputs, whenever a succesful merge occurs restart at the beginning of the nodes inputs
- after you've exhausted a node, continue searching the block for fusion opportunities from the node
- continue doing this on the block until we go through an iteration without an succesful merges
Since we create the fusion groups once, and only re-specialize within the fusion groups, we should be running this very infrequently (only re-triggers when we fail undefinedness specializations). Also bc it's the same algorithm as the existing fuser it is unlikely to cause a regression.
Test Plan: Imported from OSS
Reviewed By: Krovatkin, robieta
Differential Revision: D23821581
Pulled By: eellison
fbshipit-source-id: e513d1ef719120dadb0bfafc7a14f4254cd806ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44238
Refactor create_autodiff_subgraphs to use the same updating of output aliasing properties logic as tensorexpr fuser, and factor that out to a common function in subgraph utils.
Test Plan: Imported from OSS
Reviewed By: Krovatkin, robieta
Differential Revision: D23871565
Pulled By: eellison
fbshipit-source-id: 72df253b16baf8e4aabf3d68b103b29e6a54d44c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44643
This method is not used anywhere else.
Also formatted the file.
Test Plan: buck test caffe2/test/distributed/algorithms/ddp_comm_hooks:test_ddp_hooks
Reviewed By: pritamdamania87
Differential Revision: D23675945
fbshipit-source-id: 2d04f94589a20913e46b8d71e6a39b70940c1461
Summary:
- The thresholds of some tests are bumped up. Depending on the random generator, sometimes these tests fail with things like 0.0059 is not smaller than 0.005. I ran `test_nn.py` and `test_torch.py` for 10+ times to check these are no longer flaky.
- Add `tf32_on_and_off` to new `matrix_exp` tests.
- Disable TF32 on test suites other than `test_nn.py` and `test_torch.py`
cc: ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44240
Reviewed By: mruberry
Differential Revision: D23882498
Pulled By: ngimel
fbshipit-source-id: 44a9ec08802c93a2efaf4e01d7487222478b6df8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45238
Adds a warning when there is much higher than expected amount of
discrepancy of inputs across different processes when running with uneven
inputs. This is because a skew in the thousands can reduce performance a
nontrivial amount as shown in benchmarks, and it was proposed to add this
warning as a result. Tested by running the tests so the threshold is hit and
observing the output.
ghstack-source-id: 112773552
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D23719270
fbshipit-source-id: 306264f62c1de65e733696a912bdb6e9376d5622
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45144
Moves prim ops from C10 back to JIT.
These were originally moved to C10 from JIT in D19237648 (f362cd510d)
ghstack-source-id: 112775781
Test Plan:
buck test //caffe2/test/cpp/jit:jit
https://pxl.cl/1l22N
buck test adsatlas/gavel/lib/ata_processor/tests:ata_processor_test
https://pxl.cl/1lBxD
Reviewed By: iseeyuan
Differential Revision: D23697598
fbshipit-source-id: 36d1eb8c346e9b161ba6af537a218440a9bafd27
Summary:
I noticed that the recently introduced adaptive_autorange tests occasionally timeout CI, and I've been meaning to improve the Timer tests for a while. This PR allows unit tests to swap the measurement portion of `Timer` with a deterministic mock so we can thoroughly test behavior without having to worry about flaky CI measurements. It also means that the tests can be much more detailed and still finish very quickly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45173
Test Plan: You're lookin' at it.
Reviewed By: ezyang
Differential Revision: D23873548
Pulled By: robieta
fbshipit-source-id: 26113e5cea0cbf46909b9bf5e90c878c29e87e88
Summary:
In this PR:
1) Added binary operations with ScalarLists.
2) Fixed _foreach_div(...) bug in native_functions
3) Covered all possible cases with scalars and scalar lists in tests
4) [minor] fixed bug in native_functions by adding "use_c10_dispatcher: full" to all _foreach functions
tested via unit tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44743
Reviewed By: bwasti, malfet
Differential Revision: D23753711
Pulled By: izdeby
fbshipit-source-id: bf3e8c54bc07867e8f6e82b5d3d35ff8e99b5a0a
Summary:
For integral types, isnan is meaningless. Provide specializations for
maximum and minimum which don't call it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44984
Test Plan: python test/test_jit_fuser_te.py -k TestTEFuser.test_minmax_int_ops
Reviewed By: ezyang
Differential Revision: D23885259
Pulled By: asuhan
fbshipit-source-id: 2e6da2c43c0ed18f0b648a2383d510894c574437
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44550
Part of the `torch.fft` work (gh-42175).
This adds n-dimensional transforms: `fftn`, `ifftn`, `rfftn` and `irfftn`.
This is aiming for correctness first, with the implementation on top of the existing `_fft_with_size` restrictions. I plan to follow up later with a more efficient rewrite that makes `_fft_with_size` work with arbitrary numbers of dimensions.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D23846032
Pulled By: mruberry
fbshipit-source-id: e6950aa8be438ec5cb95fb10bd7b8bc9ffb7d824
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45149
The choose_qparams_optimized calculates the the optimized qparams.
It uses a greedy approach to nudge the min and max and calculate the l2 norm
and tries to minimize the quant error by doing `torch.norm(x-fake_quant(x,s,z))`
Test Plan: Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D23848060
fbshipit-source-id: c6c57c9bb07664c3f1c87dd7664543e09f634aee
Summary:
We need to check if dtypes differ in scalar type or lanes to decide between
Cast and Broadcast.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45179
Test Plan: test_tensorexpr --gtest_filter=TensorExprTest.SimplifyBroadcastTermExpander
Reviewed By: bwasti
Differential Revision: D23873316
Pulled By: asuhan
fbshipit-source-id: ca141be67e10c2b6c5f2ff9c11e42dcfc62ac620
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44835
This is for feature parity with fx graph mode quantization
Test Plan: Imported from OSS
Reviewed By: z-a-f
Differential Revision: D23745086
fbshipit-source-id: ae2fc86129f9896d5a9039b73006a4da15821307
Summary:
Arithmetic operations on Bool aren't fully supported in the evaluator. Moreover,
such semantics can be implemented by the client code through insertion of
explicit casts to widen and narrow to the desired types.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44677
Test Plan:
test_tensorexpr --gtest_filter=TensorExprTest.ExprDisallowBoolArithmetic
python test/test_jit_fuser_te.py
Reviewed By: agolynski
Differential Revision: D23801412
Pulled By: asuhan
fbshipit-source-id: fff5284e3a216655dbf5a9a64d1cb1efda271a36
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43872
This PR allows the recursive scripting to have a separate
submodule_stubs_fn to create its submodule with specific user provided
rules.
Fixes https://github.com/pytorch/pytorch/issues/43729
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D23430176
Pulled By: wanchaol
fbshipit-source-id: 20530d7891ac3345b36f1ed813dc9c650b28d27a
Summary:
When doing a splitWithMask we only mask if the loop extent is not cleanly divide by the split factor. However, the logic does not simplify so any nontrivial loop extents will always cause a mask to be added, e.g. if the loop had been previously split. Unlike splitWithTail, the masks added by splitWithMask are always overhead and we don't have the analysis to optimize them out if they are unnecessary, so it's good to avoid inserting them if we can.
The fix is just to simplify the loop extents before doing the extent calculation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45141
Reviewed By: ezyang
Differential Revision: D23869170
Pulled By: nickgg
fbshipit-source-id: 44686fd7b802965ca4f5097b0172a41cf837a1f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44856
Support following format of qconfig_dict
```python
qconfig_dict = {
# optional, global config
"": qconfig?,
# optional, used for module and function types
# could also be split into module_types and function_types if we prefer
"object_type": [
(nn.Conv2d, qconfig?),
(F.add, qconfig?),
...,
],
# optional, used for module names
"module_name": [
("foo.bar", qconfig?)
...,
],
# optional, matched in order, first match takes precedence
"module_name_regex": [
("foo.*bar.*conv[0-9]+", qconfig?)
...,
]
# priority (in increasing order): global, object_type, module_name_regex, module_name
# qconfig == None means fusion and quantization should be skipped for anything
# matching the rule
}
```
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23751304
fbshipit-source-id: 5b98f4f823502b12ae2150c93019c7b229c49c50
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44684
The ad-hoc quantization benchmarking script in D23689062 recently highlighted that quantized ops were surprisingly slow after the introduction of support for custom ops in torch.fx in D23203204 (f15e27265f).
Using strobelight, it's immediately clear that up to 66% of samples were seen in `c10::get_backtrace`, which is descends from `torch::is_tensor_and_apppend_overloaded -> torch::check_has_torch_function -> torch::PyTorch_LookupSpecial -> PyObject_HasAttrString -> PyObject_GetAttrString`.
I'm no expert by any means so please correct any/all misinterpretation, but it appears that:
- `check_has_torch_function` only needs to return a bool
- `PyTorch_LookupSpecial` should return `NULL` if a matching method is not found on the object
- in the impl of `PyTorch_LookupSpecial` the return value from `PyObject_HasAttrString` only serves as a bool to return early, but ultimately ends up invoking `PyObject_GetAttrString`, which raises, spawning the generation of a backtrace
- `PyObject_FastGetAttrString` returns `NULL` (stolen ref to an empty py::object if the if/else if isn't hit) if the method is not found, anyway, so it could be used singularly instead of invoking both `GetAttrString` and `FastGetAttrString`
- D23203204 (f15e27265f) compounded (but maybe not directly caused) the problem by increasing the number of invocations
so, removing it in this diff and seeing how many things break :)
before:
strobelight: see internal section
output from D23689062 script:
```
$ ./buck-out/gen/scripts/v/test_pt_quant_perf.par
Sequential(
(0): Quantize(scale=tensor([0.0241]), zero_point=tensor([60]), dtype=torch.quint8)
(1): QuantizedLinear(in_features=4, out_features=4, scale=0.017489388585090637, zero_point=68, qscheme=torch.per_tensor_affine)
(2): DeQuantize()
)
fp 0.010896682739257812
q 0.11908197402954102
```
after:
strobelight: see internal section
output from D23689062 script:
```
$ ./buck-out/gen/scripts/v/test_pt_quant_perf.par
Sequential(
(0): Quantize(scale=tensor([0.0247]), zero_point=tensor([46]), dtype=torch.quint8)
(1): QuantizedLinear(in_features=4, out_features=4, scale=0.012683945707976818, zero_point=41, qscheme=torch.per_tensor_affine)
(2): DeQuantize()
)
fp 0.011141300201416016
q 0.022639036178588867
```
which roughly restores original performance seen in P142370729
UPDATE: 9/22 mode/opt benchmarks
```
buck run //scripts/x:test_pt_quant_perf mode/opt
Sequential(
(0): Quantize(scale=tensor([0.0263]), zero_point=tensor([82]), dtype=torch.quint8)
(1): QuantizedLinear(in_features=4, out_features=4, scale=0.021224206313490868, zero_point=50, qscheme=torch.per_tensor_affine)
(2): DeQuantize()
)
fp 0.002968311309814453
q 0.5138928890228271
```
with patch:
```
buck run //scripts/x:test_pt_quant_perf mode/opt
Sequential(
(0): Quantize(scale=tensor([0.0323]), zero_point=tensor([70]), dtype=torch.quint8)
(1): QuantizedLinear(in_features=4, out_features=4, scale=0.017184294760227203, zero_point=61, qscheme=torch.per_tensor_affine)
(2): DeQuantize()
)
fp 0.0026655197143554688
q 0.0064449310302734375
```
Reviewed By: ezyang
Differential Revision: D23697334
fbshipit-source-id: f756d744688615e01c94bf5c48c425747458fb33
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43790
Interface calls were not handled properly when they are used in fork
subgraph. This PR fixes this issue.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D23402039
Pulled By: bzinodev
fbshipit-source-id: 41adc5ee7d942250e732e243ab30e356d78d9bf7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45159
By default, pybind11 binds void* to be capsules. After a lot of
Googling, I have concluded that this is not actually useful:
you can't actually create a capsule from Python land, and our
data_ptr() function returns an int, which means that the
function is effectively unusable. It didn't help that we had no
tests exercising it.
I've replaced the void* with uintptr_t, so that we now accept int
(and you can pass data_ptr() in directly). I'm not sure if we
should make these functions accept ctypes types; unfortunately,
pybind11 doesn't seem to have any easy way to do this.
Fixes#43006
Also added cudaHostUnregister which was requested.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: lw
Differential Revision: D23849731
Pulled By: ezyang
fbshipit-source-id: 8a79986f3aa9546abbd2a6a5828329ae90fd298f
Summary:
This is a small developer quality of life improvement. I commonly try to run some snippet of python as I'm working on a PR and forget that I've cd-d into the local clone to run some git commands, resulting in annoying failures like:
`ImportError: cannot import name 'default_generator' from 'torch._C' (unknown location)`
This actually took a non-trivial amount of time to figure out the first time I hit it, and even now it's annoying because it happens just infrequently enough to not sit high in the mental cache.
This PR adds a check to `torch/__init__.py` and warns if `import torch` is likely resolving to the wrong thing:
```
WARNING:root:You appear to be importing PyTorch from a clone of the git repo:
/data/users/taylorrobie/repos/pytorch
This will prevent `import torch` from resolving to the PyTorch install
(instead it will try to load /data/users/taylorrobie/repos/pytorch/torch/__init__.py)
and will generally lead to other failures such as a failure to load C extensions.
```
so that the soon to follow internal import failure makes some sense. I elected to make this a warning rather than an exception because I'm not 100% sure that it's **always** wrong. (e.g. weird `PYTHONPATH` or `importlib` corner cases.)
EDIT: There are now separate cases for `cwd` vs. `PYTHONPATH`, and failure is an `ImportError`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39995
Reviewed By: malfet
Differential Revision: D23817209
Pulled By: robieta
fbshipit-source-id: d9ac567acb22d9c8c567a8565a7af65ac624dbf7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44983
`_all_gather` was converted from `_wait_all_workers` and inherited its
5 seconds fixed timeout. As `_all_gather` meant to support a broader
set of use cases, the timeout configuration should be more flexible.
This PR makes `rpc._all_gather` use the global default RPC timeout.
Test Plan: Imported from OSS
Reviewed By: pritamdamania87
Differential Revision: D23794383
Pulled By: mrshenli
fbshipit-source-id: 382f52c375f0f25c032c5abfc910f72baf4c5ad9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44960
Since we have templated selective build, it should be safe to move the operators to prim so that they can be selectively built in mobile
Test Plan: CI
Reviewed By: linbinyu
Differential Revision: D23772025
fbshipit-source-id: 52cebae76e4df5a6b2b51f2cd82f06f75e2e45d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45065
To preserve backwards compatibility with applications that were passing in some ProcessGroupRpcBackendOptions but were not explicitly setting backend=BackendType.PROCESS_GROUP, we're here now inferring the backend type from the options if only the latter ones are passed. If neither are passed, we'll default to TensorPipe, as before this change.
ghstack-source-id: 112586258
Test Plan: Added new unit tests.
Reviewed By: pritamdamania87
Differential Revision: D23814289
fbshipit-source-id: f4be7919e0817a4f539a50ab12216dc3178cb752
Summary:
combineMultilane used the wrong order when ramp was on the left hand side,
which matters for subtract.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45157
Test Plan: test_tensorexpr --gtest_filter=TensorExprTest.SimplifyRampSubBroadcast
Reviewed By: ailzhang
Differential Revision: D23851751
Pulled By: asuhan
fbshipit-source-id: 864d1611e88769fb43327ef226bb3310017bf858
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45015
torch.package allows you to write packages of code, pickled python data, and
arbitrary binary and text resources into a self-contained package.
torch.package.PackageExporter writes the packages and
torch.package.PackageImporter reads them.
The importers can load this code in a hermetic way, such that code is loaded
from the package rather than the normal python import system. This allows
for the packaging of PyTorch model code and data so that it can be run
on a server or used in the future for transfer learning.
The code contained in packages is copied file-by-file from the original
source when it is created, and the file format is a specially organized
zip file. Future users of the package can unzip the package, and edit the code
in order to perform custom modifications to it.
The importer for packages ensures that code in the module can only be loaded from
within the package, except for modules explicitly listed as external using :method:`extern_module`.
The file `extern_modules` in the zip archive lists all the modules that a package externally depends on.
This prevents "implicit" dependencies where the package runs locally because it is importing
a locally-installed package, but then fails when the package is copied to another machine.
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D23824337
Pulled By: zdevito
fbshipit-source-id: 1247c34ba9b656f9db68a83e31f2a0fbe3bea6bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44655
Since `toHere()` does not execute operations over RPC and simply
transfers the value to the local node, we don't need to enable the profiler
remotely for this message. This causes unnecessary overhead and is not needed.
Since `toHere` is a blocking call, we already profile the call on the local node using `RECORD_USER_SCOPE`, so this does not change the expected profiler results (validated by ensuring all remote profiling tests pass).
ghstack-source-id: 112605610
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D23641466
fbshipit-source-id: 109d9eb10bd7fe76122b2026aaf1c7893ad10588
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44653
This changes the profiler per a discussion with ilia-cher offline that enables `disableProfiler()` event consolidation logic to be called from different threads (i.e. threads where the profiler was not explicitly enabled). This is needed to support the functionality enabled by D23638387 where we defer profiling event collection until executing an async callback that can execute on a different thread, to support RPC async function profiling.
This is done by introducing 2 flags `cleanupTLSState` and `consolidate` which controls whether we should clean up thread local settings (we don't do this when calling `disableProfiler()` on non-main threads) and whether we should consolidate all profiled events. Backwards compatiblity is ensured since both options are true by default.
Added a test in `test_misc.cpp` to test this.
ghstack-source-id: 112605620
Reviewed By: mrshenli
Differential Revision: D23638499
fbshipit-source-id: f5bbb0d41ef883c5e5870bc27e086b8b8908f46b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44646
Per a discussion with ilia-cher, this is not needed anymore and
removing it would make some future changes to support async RPC profiling
easier. Tested by ensuring profiling tests in `test_autograd.py` still pass.
ghstack-source-id: 112605618
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D23683998
fbshipit-source-id: 4e49a439509884fe04d922553890ae353e3331ab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45098
**Summary**
This commit adds support for default arguments in methods of class
types. Similar to how default arguments are supported for regular
script functions and methods on scripted modules, default values are
retrieved from the definition of a TorchScript class in Python as Python
objects, converted to IValues, and then attached to the schemas of
already compiled class methods.
**Test Plan**
This commit adds a set of new tests to TestClassType to test default
arguments.
**Fixes**
This commit fixes#42562.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D23844769
Pulled By: SplitInfinity
fbshipit-source-id: ceedff7703bf9ede8bd07b3abcb44a0f654936bd
Summary:
This flag simply allows users to get fusion groups that will *eventually* have shapes (such that `getOperation` is a valid).
This is useful for doing early analysis and compiling just in time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44401
Reviewed By: ZolotukhinM
Differential Revision: D23656140
Pulled By: bwasti
fbshipit-source-id: 9a26c202752399d1932ad7d69f21c88081ffc1e5
Summary:
NVIDIA GPUs are binary compatible within major compute capability revision
This would prevent: "GeForce RTX 3080 with CUDA capability sm_86 is not compatible with the current PyTorch installation." messages from appearing, since CUDA-11 do not support code generation for sm_85.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45130
Reviewed By: ngimel
Differential Revision: D23841556
Pulled By: malfet
fbshipit-source-id: bcfc9e8da63dfe62cdec06909b6c049aaed6a18a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44766
There might be modules that are not symbolically traceable, e.g. LSTM (since it has
input dependent control flows), to support quantization in these cases, user will provide
the corresponding observed and quantized version of the custom module, the observed
custom module with observers already inserted in the module and the quantized version will
have the corresponding ops quantized. And use
```
from torch.quantization import register_observed_custom_module_mapping
from torch.quantization import register_quantized_custom_module_mapping
register_observed_custom_module_mapping(CustomModule, ObservedCustomModule)
register_quantized_custom_module_mapping(CustomModule, QuantizedCustomModule)
```
to register the custom module mappings, we'll also need to define a custom delegate class
for symbolic trace in order to prevent the custom module from being traced:
```python
class CustomDelegate(DefaultDelegate):
def is_leaf_module(self, m):
return (m.__module__.startswith('torch.nn') and
not isinstance(m, torch.nn.Sequential)) or \
isinstance(m, CustomModule)
m = symbolic_trace(original_m, delegate_class=CustomDelegate)
```
Test Plan: Imported from OSS
Reviewed By: z-a-f
Differential Revision: D23723455
fbshipit-source-id: 50d666e29b94cbcbea5fb6bcc73b00cff87eb77a
Summary:
This is a sub-task for addressing: https://github.com/pytorch/pytorch/issues/42969. We re-enable type check for `autocast_test_lists `.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45107
Test Plan:
`python test/test_type_hints.py` passed:
```
(pytorch) bash-5.0$ with-proxy python test/test_type_hints.py
....
----------------------------------------------------------------------
Ran 4 tests in 103.871s
OK
```
Reviewed By: walterddr
Differential Revision: D23842884
Pulled By: Hangjun
fbshipit-source-id: a39f3810e3abebc6b4c1cb996b06312f6d42ffd6
Summary:
Fixes a subtask of https://github.com/pytorch/pytorch/issues/42969
Tested the following and no warnings were seen.
python test/test_type_hints.py
....
----------------------------------------------------------------------
Ran 4 tests in 180.759s
OK
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44971
Reviewed By: walterddr
Differential Revision: D23822274
Pulled By: visweshfb
fbshipit-source-id: e3485021e348ee0a8508a9d128f04bad721795ef
Summary:
Previously, `prim::EnumValue` is serialized to `ops.prim.EnumValue`, which doesn't have the right implementation to refine return type. This diff correctly serializes it to enum.value, thus fixing the issue.
Fixes https://github.com/pytorch/pytorch/issues/44892
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44891
Reviewed By: malfet
Differential Revision: D23818962
Pulled By: gmagogsfm
fbshipit-source-id: 6edfdf9c4b932176b08abc69284a916cab10081b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43680
As discussed [here](https://github.com/pytorch/pytorch/issues/43342),
adding in a Python-only implementation of the triplet-margin loss that takes a
custom distance function. Still discussing whether this is necessary to add to
PyTorch Core.
Test Plan:
python test/run_tests.py
Imported from OSS
Reviewed By: albanD
Differential Revision: D23363898
fbshipit-source-id: 1cafc05abecdbe7812b41deaa1e50ea11239d0cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39111
In our present alias analysis, we consider any Value that enter another container as entering the heap, and thus aliasing all other heap values of the same type. There are a number of advantages to this approach:
- it is not to hard to maintain the aliasDb implementation
- it is much easier from an op schema perspective - there are many composite list ops registered internally and externally that would be tricky to register and get right if we did something more complicated
- It limits the size of the AliasDb, because a container of size 10 only contains a single memory dag element instead of 10 elements.
The downside is that we have are unable to handle the simple and extremely common case of a list of tensors being used in an ATen op.
In an example like:
```
def foo(input):
x = torch.tensor([1, 2, 3, 4])
y = [x, x]
input.add_(1)
return torch.cat(y)
```
we will consider x to be written to. any write to any wildcard element (an element that enters a tuple, an element that is taken from a list) will mark x as written to. This can be limiting for our ability to create a functional subset and fuse graphs - as a result, 4 of TorchVision classification models could not be functionalized.
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D23828003
Pulled By: eellison
fbshipit-source-id: 9109fcb6f2ca20ca897cae71683530285da9d537
Summary:
Change from self to self._class_() in _DecoratorManager to ensure a new object is every time a function is called recursively
Fixes https://github.com/pytorch/pytorch/issues/44531
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44633
Reviewed By: agolynski
Differential Revision: D23783601
Pulled By: albanD
fbshipit-source-id: a818664dee7bdb061a40ede27ef99e9546fc80bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39955
resolves https://github.com/pytorch/pytorch/issues/36323 by adding `torch.sgn` for complex tensors.
`torch.sgn` returns `x/abs(x)` for `x != 0` and returns `0 + 0j` for `x==0`
This PR doesn't test the correctness of the gradients. It will be done as a part of auditing all the ops in future once we decide the autograd behavior (JAX vs TF) and add gradchek.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D23460526
Pulled By: anjali411
fbshipit-source-id: 70fc4e14e4d66196e27cf188e0422a335fc42f92
Summary:
We currently are fetching an allreduced tensor from Python in C++ in, where we are storing the resulting tensor in a struct's parameter. This PR removes extra tensor paratemeter in the function parameter and fetch from a single place.
Fixes https://github.com/pytorch/pytorch/issues/43960
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44914
Reviewed By: rohan-varma
Differential Revision: D23798888
Pulled By: bugra
fbshipit-source-id: ad1b8c31c15e3758a57b17218bbb9dc1f61f1577
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45088Fixes#45082
Found a few problems while working on #44983
1. We deliberately swallow RPC timeouts during shutdown, as we haven't
found a good way to handle those. When we convert `_wait_all_workers`
into `_all_gather`, the same logic was inherited. However, as
`_all_gather` meant to be used in more general scenarios, we should
no longer keep silent about errors. This commit let the error throw
in `_all_gather` and also let `shutdown()` to catch them and log.
2. After fixing (1), I found that `UnpickledPythonCall` needs to
acquire GIL on destruction, and this can lead to deadlock when used
in conjuction with `ProcessGroup`. Because `ProcessGroup` ctor is a
synchronization point which holds GIL. In `init_rpc`, followers
(`rank != 0`) can exit before the leader (`rank == 0`). If the two
happens together, we could get a) on a follower, it exits `init_rpc`
after running `_broadcast_to_followers` and before the reaching dtor
of `UnpickledPythonCall`. Then it runs the ctor of `ProcessGroup`,
which holds the GIL and wait for the leader to join. However, the
leader is waiting for the response from `_broadcast_to_followers`,
which is blocked by the dtor of `UnpickledPythonCall`. And hence
the deadlock. This commit drops the GIL in `ProcessGroup` ctor.
3. After fixing (2), I found that `TensorPipe` backend
nondeterministically fails with `test_local_shutdown`, due to a
similar reason as (2), but this time it is that `shutdown()` on a
follower runs before the leader finishes `init_rpc`. This commit
adds a join for `TensorPipe` backend `init_rpc` after `_all_gather`.
The 3rd one should be able to solve the 2nd one as well. But since
I didn't see a reason to hold GIL during `ProcessGroup` ctor, I
made that change too.
Test Plan: Imported from OSS
Reviewed By: pritamdamania87
Differential Revision: D23825592
Pulled By: mrshenli
fbshipit-source-id: 94920f2ad357746a6b8e4ffaa380dd56a7310976
Summary:
This would force jit.script to raise an error if someone tries to mutate tuple
```
Tuple[int, int] does not support subscripted assignment:
File "/home/nshulga/test/tupleassignment.py", line 9
torch.jit.script
def foo(x: Tuple[int, int]) -> int:
x[-1] = x[0] + 1
~~~~~ <--- HERE
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44929
Reviewed By: suo
Differential Revision: D23777668
Pulled By: malfet
fbshipit-source-id: 8efaa4167354ffb4930ccb3e702736a3209151b6
Summary:
Fixes https://github.com/pytorch/pytorch/issues/43622
- Moves the model loading part of `torch.hub.load()` into a new `torch.hub.load_local()` function that takes in a path to a local directory that contains a `hubconf.py` instead of a repo name.
- Refactors `torch.hub.load()` so that it now calls `torch.hub.load_local()` after downloading and extracting the repo.
- Updates `torch.hub` docs to include the new function + minor fixes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44204
Reviewed By: malfet
Differential Revision: D23817429
Pulled By: ailzhang
fbshipit-source-id: 788fd83c87a94f487b558715b2809d346ead02b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45014
Pull Request resolved: https://github.com/pytorch/tensorpipe/pull/219
Pull Request resolved: https://github.com/pytorch/tensorpipe/pull/212
+ Introduce buffer.h defining the buffer struct(s). The `CpuBuffer`
struct is always defined, while the `CudaBuffer` struct is defined
only when `TENSORPIPE_SUPPORTS_CUDA` is true.
+ Update all channels to take a `CpuBuffer` or `CudaBuffer` for
`send`/`recv` rather than a raw pointer and a length.
+ Make the base `Channel`/`Context` classes templated on `TBuffer`,
effectively creating two channel hierarchies (one for CPU channels,
one for CUDA channels).
+ Update the Pipe and the generic channel tests to use the new API. So
far, generic channel tests are CPU only, and tests for the CUDA IPC
channel are (temporarily) disabled. A subsequent PR will take care of
refactoring tests so that generic tests work for CUDA channels. An
other PR will add support for CUDA tensors in the Pipe.
Differential Revision: D23598033
Test Plan: Imported from OSS
Reviewed By: lw
Pulled By: beauby
fbshipit-source-id: 1d6c3f91e288420858835cd5e7962e8da051b44b
Summary:
A previous fix for masking Cuda dimensions (https://github.com/pytorch/pytorch/issues/44733) changed the behaviour of inserting thread synchronization barriers in the Cuda CodeGen, causing the CudaSharedMemReduce_1 to be flaky and ultimately disabled.
The issue is working out where these barriers must be inserted - solving this optimally is very hard, and I think not possible without dependency analysis we don't have, so I've changed our logic to be quite pessimistic. We'll insert barriers before and after any blocks that have thread dimensions masked (even between blocks that have no data dependencies). This should be correct, but it's an area we could improve performance. To address this somewhat I've added a simplifier pass that removes obviously unnecessary syncThreads.
To avoid this test being flaky again, I've added a check against the generated code to ensure there is a syncThread in the right place.
Also fixed a couple of non-functional but clarity issues in the generated code: fixed the missing newline after Stores in the CudaPrinter, and prevented the PrioritizeLoad mutator from pulling out loads contained within simple Let statements (such as those produced by the Registerizer).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44909
Reviewed By: agolynski
Differential Revision: D23800565
Pulled By: nickgg
fbshipit-source-id: bddef1f40d8d461da965685f01d00b468d8a2c2f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44894
Looks like we added double backwards support but only turned on the ModuleTests.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23762544
Pulled By: gchanan
fbshipit-source-id: b5cef579608dd71f3de245c4ba92e49216ce8a5e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43208
This PR adds gradcheck for complex. The logic used for complex gradcheck is described in Section 3.5.3 here: https://arxiv.org/pdf/1701.00392.pdf
More concretely, this PR introduces the following changes:
1. Updates get_numerical_jacobian to take as input a scalar value for vector (v). Adds gradcheck logic for C -> C, C-> R, R -> C. For R -> C functions, only the real value of gradient is propagated.
2. Adds backward definition for `torch.complex` and also adds a test to verify the definition added.
3. Updates backward for `mul`, `sin`, `cos`, `sinh`, `cosh`.
4. Adds tests for all `torch.real`, `torch.imag`, `torch.view_as_real`, `torch.view_as_complex`, `torch.conj`.
Follow up tasks:
1. Add more thorough tests for R -> C cases. Specifically, add R->C test variants for functions. for e.g., `torch.mul(complex_tensor, real_tensor)`
2. Add back commented test in `common_methods_invocation.py`.
3. Add more special case checking for complex gradcheck to make debugging easier.
4. Update complex autograd note.
5. disable complex autograd for operators not tested for complex.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D23655088
Pulled By: anjali411
fbshipit-source-id: caa75e09864b5f6ead0f988f6368dce64cf15deb
Summary:
These alias are consistent with NumPy. Note that C++'s naming would be different (std::multiplies and std::divides), and that PyTorch's existing names (mul and div) are consistent with Python's dunders.
This also improves the instructions for adding an alias to clarify that dispatch keys should be removed when copying native_function.yaml entries to create the alias entries.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44463
Reviewed By: ngimel
Differential Revision: D23670782
Pulled By: mruberry
fbshipit-source-id: 9f1bdf8ff447abc624ff9e9be7ac600f98340ac4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44956
Makes buffer shapes for HistogramObserver have the
same shapes in uninitialized versus initialized states.
This is useful because the detectron2 checkpointer assumes
that these states will stay the same, so it removes the
need for manual hacks around the shapes changing.
Test Plan:
```
python test/test_quantization.py TestObserver.test_histogram_observer_consistent_buffer_shape
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D23785382
fbshipit-source-id: 1a83fd4f39b244b00747c368d5d305a07d877c92
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44795
Today, we build our cpp tests twice, once as a standalone gtest binary,
and once linked in `libtorch_python` so we can call them from
`test_jit.py`.
This is convenient (it means that `test_jit.py` is a single entry point
for all our tests), but has a few drawbacks:
1. We can't actually use the gtest APIs, since we don't link gtest into
`libtorch_python`. We're stuck with the subset that we want to write
polyfills for, and an awkward registration scheme where you have to
write a test then include it in `tests.h`).
2. More seriously, we register custom operators and classes in these
tests. In a world where we may be linking many `libtorch_python`s, this
has a tendency to cause errors with `libtorch`.
So now, only tests that explicitly require cooperation with Python are
built into `libtorch_python`. The rest are built into
`build/bin/test_jit`.
There are tests which require that we define custom classes and
operators. In these cases, I've built thm into separate `.so`s that we
call `torch.ops.load_library()` on.
Test Plan: Imported from OSS
Reviewed By: SplitInfinity, ZolotukhinM
Differential Revision: D23735520
Pulled By: suo
fbshipit-source-id: d146bf4e7eb908afa6f96b394e4d395d63ad72ff
Summary:
Adds a pass to the IR Simplifier which fuses together the bodies of Cond statements which have identical conditions. e.g.
```
if (i < 10) {
do_thing_1;
} else {
do_thing_2;
}
if (i < 10) {
do_thing_3;
}
```
is transformed into:
```
if (i < 10) {
do_thing_1;
do_thing_3;
} else {
do_thing_2;
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44886
Reviewed By: glaringlee
Differential Revision: D23768565
Pulled By: nickgg
fbshipit-source-id: 3fe40d91e82bdfff8dcb8c56a02a4fd579c070df
Summary:
Moved description of tool and changes in function name
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44124
Reviewed By: albanD
Differential Revision: D23674618
Pulled By: bzinodev
fbshipit-source-id: 5db0bb14fc106fc96358b1e0590f08e975388c6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44254
Add a device parameter to RemoteModule, so it can be placed on any device
and not just CPU.
Original PR issue: RemoteModule enhancements #40550
Test Plan: buck test test/distributed/rpc:process_group_agent -- RemoteModule
Reviewed By: pritamdamania87
Differential Revision: D23483803
fbshipit-source-id: 4918583c15c6a38a255ccbf12c9168660ab7f6db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44786
This predates gradcheck and gradcheck does the same and more.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23731902
Pulled By: gchanan
fbshipit-source-id: 425fd30e943194f63a663708bada8960265b8f05
Summary:
Ref https://github.com/pytorch/pytorch/issues/42175, fixes https://github.com/pytorch/pytorch/issues/34797
This adds complex support to `torch.stft` and `torch.istft`. Note that there are really two issues with complex here: complex signals, and returning complex tensors.
## Complex signals and windows
`stft` currently assumes all signals are real and uses `rfft` with `onesided=True` by default. Similarly, `istft` always takes a complex fourier series and uses `irfft` to return real signals.
For `stft`, I now allow complex inputs and windows by calling the full `fft` if either are complex. If the user gives `onesided=True` and the signal is complex, then this doesn't work and raises an error instead. For `istft`, there's no way to automatically know what to do when `onesided=False` because that could either be a redundant representation of a real signal or a complex signal. So there, the user needs to pass the argument `return_complex=True` in order to use `ifft` and get a complex result back.
## stft returning complex tensors
The other issue is that `stft` returns a complex result, represented as a `(... X 2)` real tensor. I think ideally we want this to return proper complex tensors but to preserver BC I've had to add a `return_complex` argument to manage this transition. `return_complex` defaults to false for real inputs to preserve BC but defaults to True for complex inputs where there is no BC to consider.
In order to `return_complex` by default everywhere without a sudden BC-breaking change, a simple transition plan could be:
1. introduce `return_complex`, defaulted to false when BC is an issue but giving a warning. (this PR)
2. raise an error in cases where `return_complex` defaults to false, making it a required argument.
3. change `return_complex` default to true in all cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43886
Reviewed By: glaringlee
Differential Revision: D23760174
Pulled By: mruberry
fbshipit-source-id: 2fec4404f5d980ddd6bdd941a63852a555eb9147
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44345
As part of enhancing profiler support for RPC, when executing TorchScript functions over RPC, we would like to be able to support user-defined profiling scopes created by `with record_function(...)`.
Since after https://github.com/pytorch/pytorch/pull/34705, we support `with` statements in TorchScript, this PR adds support for `with torch.autograd.profiler.record_function` to be used within TorchScript.
This can be accomplished via the following without this PR:
```
torch.opts.profiler._record_function_enter(...)
# Script code, such as forward pass
torch.opts.profiler._record_function_exit(....)
```
This is a bit hacky and it would be much cleaner to use the context manager now that we support `with` statements. Also, `_record_function_` type operators are internal operators that are subject to change, this change will help avoid BC issues in the future.
Tested with `python test/test_jit.py TestWith.test_with_record_function -v`
ghstack-source-id: 112320645
Test Plan:
Repro instructions:
1) Change `def script_add_ones_return_any(x) -> Any` to `def script_add_ones_return_any(x) -> Tensor` in `jit/rpc_test.py`
2) `buck test mode/dev-nosan //caffe2/test/distributed/rpc:process_group_agent -- test_record_function_on_caller_rpc_async --print-passing-details`
3) The function which ideally should accept `Future[Any]` is `def _call_end_callbacks_on_future` in `autograd/profiler.py`.
python test/test_jit.py TestWith.test_with_foo -v
Reviewed By: pritamdamania87
Differential Revision: D23332074
fbshipit-source-id: 61b0078578e8b23bfad5eeec3b0b146b6b35a870
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44798
[test all]
Update for relanding: in ddp.join(), moved _rebuild_buckets from end of backward to beginning of forward as well.
Part of relanding PR #41954, this refactoring is to move rebuild_buckets call from end of first iteration to beginning of second iteration
ghstack-source-id: 112279261
ghstack-source-id: 112279261
Test Plan: unit tests
Reviewed By: rohan-varma
Differential Revision: D23735185
fbshipit-source-id: c26e0efeecb3511640120faa1122a2c856cd694e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44000
This wasn't documented, so add a doc saying all ranks are used when
ranks=None
ghstack-source-id: 111206308
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D23465034
fbshipit-source-id: 4c51f37ffcba3d58ffa5a0adcd5457e0c5676a5d
Summary:
* Implement tuple sort by traversing contained IValue types and generate a lambda function as comparator for sort.
* Tuple, class objects can now arbitrarily nest within each other and still be sortable
Fixes https://github.com/pytorch/pytorch/issues/43219
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43448
Reviewed By: eellison
Differential Revision: D23352273
Pulled By: gmagogsfm
fbshipit-source-id: b6efa8d00e112178de8256da3deebdba7d06c0e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44773
The model is created and prepared using fx APIs and then scripted for training.
In order to test QAT on scriptmodel we need to be able to disable/enable fake_quant
and observer modules on it.
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_qat_and_script
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23741354
fbshipit-source-id: 3fee7aa9b049d9901313b977710f4dc1c4501532
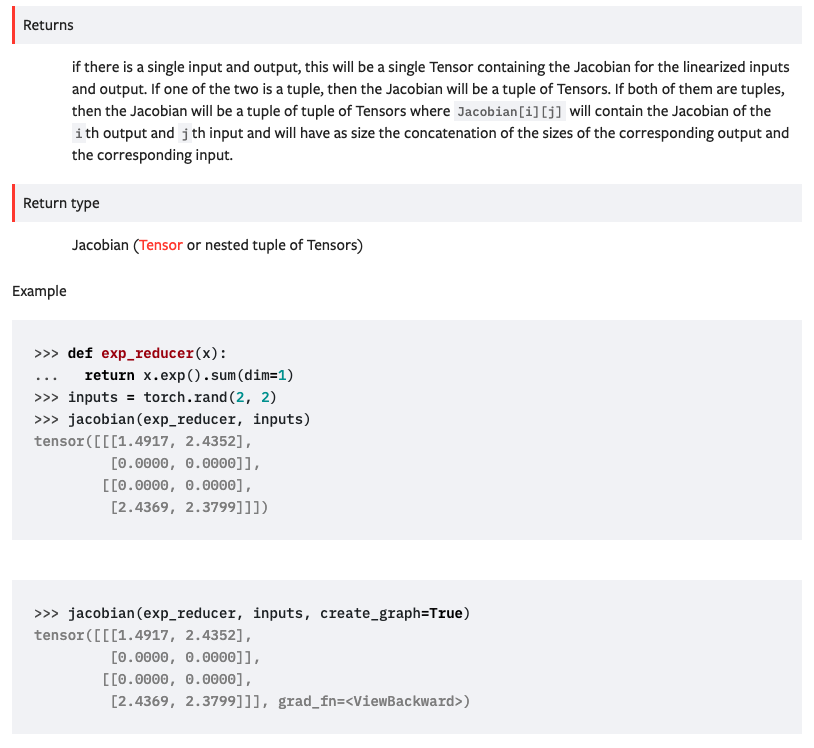{kind=link}
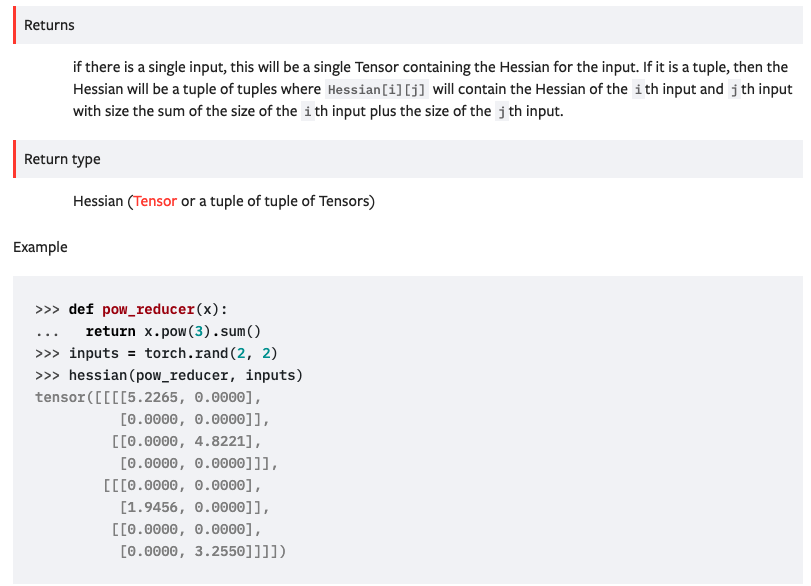{kind=link}
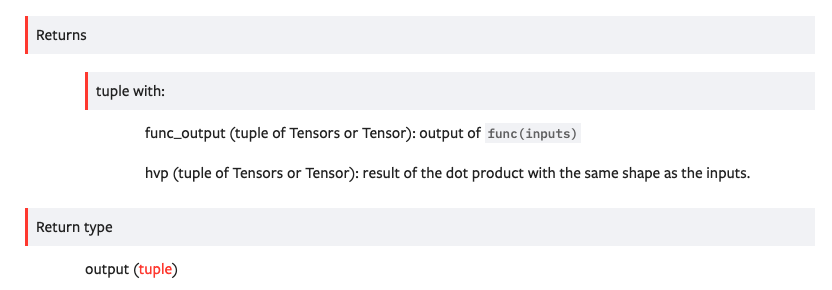{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}