Summary:
This PR makes Caffe2 compatible with TensorRT 6. To make sure it works well, new unit test is added. This test checks PyTorch->ONNX->TRT6 inference flow for all classification models from TorhchVision Zoo.
Note on CMake changes: it has to be done in order to import onnx-tensorrt project. See https://github.com/pytorch/pytorch/issues/18524 for details.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26426
Reviewed By: hl475
Differential Revision: D17495965
Pulled By: houseroad
fbshipit-source-id: 3e8dbe8943f5a28a51368fd5686c8d6e86e7f693
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27562
Adds memory_format keyword argument (positional for cpp).
'Preserve' behavior now follows next rules:
1) If tensor is non-overlapping and dense - output tensor will have the same strides as input tensor.
2) If not (1) and tensor is stored in the channels last format, output tensor going to have channels last format.
3) Output tensor is going to be contiguous in all other cases.
---
Dense tensor is the tensor that store values in a contiguous block of memory.
Non-overlapping tensor is the tensor in which elements occupy individual non-repetitive memory.
Test Plan: Imported from OSS
Differential Revision: D17980313
Pulled By: VitalyFedyunin
fbshipit-source-id: 9ca8453dc1a554ceea93c6949e01263cc576384b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27270
Adds memory_format keyword argument (positional for cpp).
'Preserve' behavior now follows next rules:
1) If tensor is non-overlapping and dense - output tensor will have the same strides as input tensor.
2) If not (1) and tensor is stored in the channels last format, output tensor going to have channels last format.
3) Output tensor is going to be contiguous in all other cases.
---
Dense tensor is the tensor that store values in a contiguous block of memory.
Non-overlapping tensor is the tensor in which elements occupy individual non-repetitive memory.
Test Plan: Imported from OSS
Differential Revision: D17980312
Pulled By: VitalyFedyunin
fbshipit-source-id: 5da9530f6b239306dbb66d1dfeefe88237f13bbd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27262
Adds memory_format keyword argument (positional for cpp).
'Preserve' behavior now follows next rules:
1) If tensor is non-overlapping and dense - output tensor will have the same strides as input tensor.
2) If not (1) and tensor is stored in the channels last format, output tensor going to have channels last format.
3) Output tensor is going to be contiguous in all other cases.
---
Dense tensor is the tensor that store values in a contiguous block of memory.
Non-overlapping tensor is the tensor in which elements occupy individual non-repetitive memory.
Test Plan: Imported from OSS
Differential Revision: D17980309
Pulled By: VitalyFedyunin
fbshipit-source-id: 1761a9939aa7c5ab23e927b897e25e225089a8e7
Summary:
Fix Slice/Select trace arguments. This PR stashes arguments to functions in order to avoid tracing them as constants.
This PR depends on a fix for select op in PR:
https://github.com/pytorch/pytorch/pull/25273
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26549
Reviewed By: hl475
Differential Revision: D17623851
Pulled By: houseroad
fbshipit-source-id: ae314004266688d2c25c5bada2dcedbfc4f39c5b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28242
There is no reason to have it in a general API of Module/Method - it's
just another graph pass. It was there because some time ago modules were
not first class and all graphs were lowered. After that changed, this
API was added for easier transition, but now we don't need it anymore.
Test Plan: Imported from OSS
Differential Revision: D17986724
Pulled By: ZolotukhinM
fbshipit-source-id: 279a1ec450cd8fac8164ee581515b09f1d755630
Summary:
We currently support exporting traced interpolate ops to ONNX.
Scripting interpolate op invokes aten::__interpolate in the Torch IR (instead of aten::upsample_[mode][dim]d), which we do not support yet.
This PR implements the ONNX symbolic for __interpolate() to support exporting interpolate in scripting scenarios.
Related open issue: https://github.com/pytorch/pytorch/issues/25807
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27566
Reviewed By: hl475
Differential Revision: D17817731
Pulled By: houseroad
fbshipit-source-id: e091793df503e2497f24821cf2954ff157492c75
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27107
Adds memory_format keyword argument (positional for cpp).
'Preserve' behavior now follows next rules:
1) If tensor is non-overlapping and dense - output tensor will have the same strides as input tensor.
2) If not (1) and tensor is stored in the channels last format, output tensor going to have channels last format.
3) Output tensor is going to be contiguous in all other cases.
---
Dense tensor is the tensor that store values in a contiguous block of memory.
Non-overlapping tensor is the tensor in which elements occupy individual non-repetitive memory.
Test Plan: Imported from OSS
Differential Revision: D17931062
Pulled By: VitalyFedyunin
fbshipit-source-id: 2c5dd3dd05bf58a9a29f25562cd45190b009c3f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27850
Many of these are real problems in the documentation (i.e., link or
bullet point doesn't display correctly).
Test Plan: - built and viewed the documentation for each change locally.
Differential Revision: D17908123
Pulled By: zou3519
fbshipit-source-id: 65c92a352c89b90fb6b508c388b0874233a3817a
Summary:
Exporting a scripted module to ONNX, with ops like torch.zeros(), fails when the dtype is not specified.
This PR adds support to exporting scripted torch.zeros() ops (and similar ops) without specifying the dtype (dtype will default to float).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27577
Reviewed By: hl475
Differential Revision: D17822318
Pulled By: houseroad
fbshipit-source-id: b2d4300b869e782a9b72534fea1263eb83744953
Summary:
Exporting torch.select when index = negative one (x[:,-1]) was broken. This PR has the fix in symbolic function for select.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25273
Reviewed By: hl475
Differential Revision: D17159707
Pulled By: houseroad
fbshipit-source-id: 2c3b275421082758f1b63c1c9b6e578f03ca9f76
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27106
Adds memory_format option to the `clone` operator.
Introduce new `clone` behavior if used with `input_t.clone(memory_format=torch.preserve_format)`:
1) If tensor is non-overlapping and dense - output tensor will have the same strides as input tensor.
2) If not (1) and tensor is stored in the channels last format, output tensor going to have channels last format.
3) Output tensor is going to be contiguous in all other cases.
---
Dense tensor is the tensor that store values in a contiguous block of memory.
Non-overlapping tensor is the tensor in which elements occupy individual non-repetitive memory.
Test Plan: Imported from OSS
Differential Revision: D17699357
Pulled By: VitalyFedyunin
fbshipit-source-id: 5ae1537c2aca1abf0bf1eec4416846129c156f66
Summary:
Bumping up the `producer_version` in exported ONNX models in view of the next release. Updating tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26976
Reviewed By: hl475
Differential Revision: D17631902
Pulled By: houseroad
fbshipit-source-id: 6d58964657402ac23963c49c07fcc813386aabf0
Summary:
ONNX does not support dictionaries for inputs and output. The reason is that the arg flattening and unflattening does not handle Dictionary types.
This PR adds flattening/unflattening support for dictionaries and strings.
However this feature should be handled with caution for input dictionaries; and users need to verify their dict inputs carefully, and keep in mind that dynamic lookups are not available.
This PR will allow exporting cases where models have dictionnary outputs (detection and segmentation models in torchvision), and where dictionary inputs are used for model configurations (MultiScaleRoiAlign in torchvision).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25889
Reviewed By: hl475
Differential Revision: D17613605
Pulled By: houseroad
fbshipit-source-id: c62da4f35e5dc2aa23a85dfd5e2e11f63e9174db
Summary:
Currently, we export invalid ONNX models when size() is used with a negative dim.
This PR fixes the issue and allows exporting these models to ONNX (ex: input.size(-1)).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26436
Reviewed By: hl475
Differential Revision: D17565905
Pulled By: houseroad
fbshipit-source-id: 036bc384b25de77506ef9fbe24ceec0f7e3cff8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26778
- Add support for linear and cubic interpolate in opset 11.
- Add support for 1d and 3d interpolate in nearest mode for opset 7 and 8.
- Add tests for all cases of interpolate in ORT tests (nearest/linear/cubic, 1d/2d/3d, upsample/downsample).
Original PR resolved: https://github.com/pytorch/pytorch/pull/24805
Reviewed By: hl475
Differential Revision: D17564911
Pulled By: houseroad
fbshipit-source-id: 591e1f5b361854ace322eca1590f8f84d29c1a5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26738
someone may use torch._export directly. Here we change the onnx_export_type's default value to None,
and if it's pytorch onnx caffe2 bundle, we set it to ONNX_ATEN_FALLBACK, otherwise, it's ONNX.
Test Plan: ci
Reviewed By: hl475
Differential Revision: D17546452
fbshipit-source-id: 38e53926e2b101484bbbce7b58ebcd6af8c42438
Summary:
- Add support for linear and cubic interpolate in opset 11.
- Add support for 1d and 3d interpolate in nearest mode for opset 7 and 8.
- Add tests for all cases of interpolate in ORT tests (nearest/linear/cubic, 1d/2d/3d, upsample/downsample).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24805
Reviewed By: hl475
Differential Revision: D17330801
Pulled By: houseroad
fbshipit-source-id: 1bdefff9e72f5e70c51f4721e1d7347478b7505b
Summary:
This is a follow-up PR for https://github.com/pytorch/pytorch/pull/23284. In that PR we had removed changing the default behavior for `keep_initializers_as_input` argument to the export API. With this PR we are enabling that change in that if `keep_initializers_as_input` is not specified then value/behavior for this argument is chosen automatically depending on whether the export type is ONNX or not.
This was part of the earlier PR was removed for further review. The test points have also been updated.
This change may fail some internal tests which may require explicitly setting `keep_initializers_as_input=True` to preserve old behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26146
Reviewed By: hl475
Differential Revision: D17369677
Pulled By: houseroad
fbshipit-source-id: 2aec2cff50d215714ee8769505ef24d2b7865a11
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26487
The way it is implemented currently is bad because while we're inlining
to a graph G, we are also mutating all the graphs that are being
inlined. The problem is that the graphs we're inlining are usually the
original graphs of functions, so we're silently changing them behind the
scenes, and we don't have a way to recover 'unoptimized' graphs
afterwards.
Test Plan: Imported from OSS
Differential Revision: D17485748
Pulled By: ZolotukhinM
fbshipit-source-id: 6094ef56077240e9379d4c53680867df1b6e79ef
Summary:
Added support for gelu in symbolic opset9 + op and ORT tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24475
Reviewed By: hl475
Differential Revision: D17088708
Pulled By: houseroad
fbshipit-source-id: 9d2f9d7d91481c57829708793d88f786d6c3956f
Summary:
This pass tries to resolve scalar type mismatch issues between input tensors introduced by the implicit type conversions on scalars.
e.g. https://github.com/pytorch/pytorch/issues/23724
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24378
Reviewed By: hl475
Differential Revision: D17088682
Pulled By: houseroad
fbshipit-source-id: 3de710f70c3b70b9f76fd36a7c4c76e168dbc756
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25052
Previously we would not inline nested functions, now we do.
Test Plan: Imported from OSS
Differential Revision: D16973848
Pulled By: suo
fbshipit-source-id: 94aa0b6f84a2577a663f4e219f930d2c6396d585
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24284
This PR finishes the unification of all Tensor types into a single object.
ProfiledTensorType is renamed to TensorType and the old TensorType is
deleted.
Notes:
* Fixes bug in merge for VaryingShape by changing its representation to an
optional list of optional ints.
* Removes ProfiledTensorType::create(type) invocations that can now
simply be expect calls on tensor type.
Test Plan: Imported from OSS
Differential Revision: D16794034
Pulled By: zdevito
fbshipit-source-id: 10362398d0bb166d0d385d74801e95d9b87d9dfc
Summary:
~~In case of tensor indexing with a scalar index, index_select returns a tensor with the same rank as the input. To match this behavior in ONNX, we make index a 1D tensor so that with a gather
it also produces a tensor with the same rank as the input.~~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23507
Differential Revision: D16586805
Pulled By: bddppq
fbshipit-source-id: 8f5d964d368873ec372773a29803b25f29a81def
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23799
Before, we inlined as part of the initial IR generation process, which
has a few disadvantages:
1. It loses information about what nodes came from which function/method
calls. Other parties who want to implement transformations on the
function/module level don't have a reliable way of doing so.
2. It duplicates a ton of code if we are inlining the same
function/method a tons of times.
After this PR: inline is deferred to the optimization stage, so
optimizations that rely on inlining will still work. But things get
serialized with the function/method calls in.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23799
Differential Revision: D16652819
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Pulled By: suo
fbshipit-source-id: a11af82aec796487586f81f5a9102fefb6c246db
Summary:
Added support for cumsum in symbolic opset 11 + op and ORT tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24476
Differential Revision: D16896780
Pulled By: bddppq
fbshipit-source-id: b52355796ee9f37004c9258f710688ad4b1ae8a2
Summary:
Empty and empty_like return uninitialized tensors with specific sizes.
The values in the tensor cannot be predicted, that's why tests in test_pytorch_onnx_onnxruntime.py and test_pytorch_onnx_caffe2.py are not added.
The tests in test_operators.py verify the onnx graph and output shape.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24166
Differential Revision: D16831571
Pulled By: bddppq
fbshipit-source-id: b2500f36ced4735da9a8418d87a39e145b74f63a
Summary:
Existing code adds two enumerators to the set instead of forming their union.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23974
Differential Revision: D16732762
Pulled By: ezyang
fbshipit-source-id: 787737b7cf4b97ca4e2597e2da4a6ade863ce85c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24077
This replaces all uses of DimensionedTensorType with ProfiledTensorType.
For places where we propagate shape information, we still follow the
dimension-only propagation rules, meaning that even if full size information
is known on inputs the outputs will only have dimension information.
This fixes several bugs in existing implentations that this change uncovered:
* requires_grad was not propgated correctly across loops
* requires_grad on ProfiledTensorType returned false when requires_grad information
is unknown but the conservative result is true
* some equality code on ProfiledTensorType contained bugs.
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D16729581
Pulled By: zdevito
fbshipit-source-id: bd9f823c1c6b1d06a236a1b5b2b2fcdf0245edce
Summary:
Starting ONNX IR version 4, the initializers in the ONNX graph do not have to be inputs of the graphs. This constraint, which existed in IR version 3 and earlier, was relaxed in IR version 4. This PR provides an API level argument to allow ONNX export with the relaxed constraint of IR version 4, i.e. provides the option to not include initializers as inputs. This allows backends/runtimes to do certain optimizations, such as constant folding, better.
*Edit*: After discussion with houseroad we have the following behavior. For any OperatorExportType, except OperatorExportTypes.ONNX, the current status of export is maintained in this PR by default. However, the user can override it by setting the `keep_initializers_as_inputs` argument to the export API. But when exporting to ONNX, i.e. OperatorExportType is OperatorExportTypes.ONNX, the current status is changed in that by default the initializers are NOT part of the input. Again, the default can be overridden by setting the `keep_initializers_as_inputs` argument.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23284
Differential Revision: D16459961
Pulled By: bddppq
fbshipit-source-id: b8f0270dfaba47cdb8e04bd4cc2d6294f1cb39cf
Summary:
Added a number of opset10 tests from Caffe2 to ORT
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22993
Differential Revision: D16467954
Pulled By: bddppq
fbshipit-source-id: 0b92694c7c0213bdf8e77e6f8e07e6bc8a85170a
Summary:
Don't automatically unwrap top layer DataParalllel for users. Instead, we provide useful error information and tell users what action to take.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23365
Reviewed By: zrphercule
Differential Revision: D16514273
Pulled By: houseroad
fbshipit-source-id: f552de5c53fb44807e9d9ad62126c98873ed106e
Summary:
Support exporting
* Standard tensor indexing like
```
x = torch.ones(4, 5)
ind = torch.tensor([0, 1])
return x[ind]
```
* [Advanced indexing](https://docs.scipy.org/doc/numpy/reference/arrays.indexing.html#advanced-indexing) like
```
x = torch.ones(4,5,6,7,8)
ind1 = torch.tensor([0, 1])
ind2 = torch.tensor([[3], [2]])
ind3 = torch.tensor([[2, 2], [4, 5]])
return x[2:4, ind1, None, ind2, ind3, :]
```
It would be ideal if ONNX can natively support indexing in future opsets, but for opset <= 10 it will always need this kind of workarounds.
There are still various limitations, such as not supporting advanced indexing with negative indices, not supporting mask indices of rank > 1, etc. My feeling is that these are less common cases that requires great effort to support using current opset, and it's better to not make the index export more cumbersome than it already is.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21716
Reviewed By: zrphercule
Differential Revision: D15902199
Pulled By: houseroad
fbshipit-source-id: 5f1cc687fc9f97da18732f6a2c9dfe8f6fdb34a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23180
This pass needs to be run later because it breaks jit graph invariants and the lower_all_tuples pass still needs a valid jit graph.
Reviewed By: houseroad
Differential Revision: D16427680
fbshipit-source-id: 427c7e74c59a3d7d62f2855ed626cf6258107509
Summary:
Some overlap with https://github.com/pytorch/pytorch/pull/21716 regarding caffe2 nonzero. Will rebase the other one accordingly whichever gets merged first.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22601
Reviewed By: zrphercule
Differential Revision: D16224660
Pulled By: houseroad
fbshipit-source-id: dbfd1b8776cb626601e0bf83b3fcca291806e653
Summary:
Bumping up the producer_version in exported ONNX models in view of the next release. Updating tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23120
Reviewed By: zrphercule
Differential Revision: D16420917
Pulled By: houseroad
fbshipit-source-id: 6686b10523c102e924ecaf96fd3231240b4219a9
Summary:
This is an extension to the original PR https://github.com/pytorch/pytorch/pull/21765
1. Increase the coverage of different opsets support, comments, and blacklisting.
2. Adding backend tests for both caffe2 and onnxruntime on opset 7 and opset 8.
3. Reusing onnx model tests in caffe2 for onnxruntime.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22421
Reviewed By: zrphercule
Differential Revision: D16225518
Pulled By: houseroad
fbshipit-source-id: 01ae3eed85111a83a0124e9e95512b80109d6aee
Summary:
Currently ONNX constant folding (`do_constant_folding=True` arg in `torch.onnx.export` API) supports only opset 9 of ONNX. For opset 10, it is a no-op. This change enables ONNX constant folding for opset 10. Specifically there are three main changes:
1) Turn on constant folding ONNX pass for opset 10.
2) Update support for opset 10 version of `onnx::Slice` op for backend computation during constant folding.
3) Enable constant folding tests in `test/onnx/test_utility_funs.py` for multiple opsets (9 and 10).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22515
Reviewed By: zrphercule
Differential Revision: D16189336
Pulled By: houseroad
fbshipit-source-id: 3e2e748a06e4228b69a18c5458ca71491bd13875
Summary:
re-apply changes reverted in:
https://github.com/pytorch/pytorch/pull/22412
Also change log_softmax to take positional arguments. Long-term we do want the kwarg-only interface, but seems to currently be incompatible with jit serialization.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22456
Differential Revision: D16097159
Pulled By: nairbv
fbshipit-source-id: 8cb73e9ca18fc66b35b873cf4a574b167a578b3d
Summary:
- Fix typo in ```torch/onnx/utils.py``` when looking up registered custom ops.
- Add a simple test case
1. Register custom op with ```TorchScript``` using ```cpp_extension.load_inline```.
2. Register custom op with ```torch.onnx.symbolic``` using ```register_custom_op_symbolic```.
3. Export model with custom op, and verify with Caffe2 backend.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21321
Differential Revision: D16101097
Pulled By: houseroad
fbshipit-source-id: 084f8b55e230e1cb6e9bd7bd52d7946cefda8e33
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22499
Another place where onnx export is running dead code elimination after making the jit graph invalid. Fixing it.
Reviewed By: houseroad
Differential Revision: D16111969
fbshipit-source-id: 5ba80340c06d091988858077f142ea4e3da0638c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22476
Dead code elimination assumes a valid jit graph because it checks if operators have side effects.
The onnx export path destroys the jit graph right before calling dead code elimination, but it actually doesn't care about side effects.
We can just call dead code elimination and disable side effect lookup and things should work.
Reviewed By: houseroad
Differential Revision: D16100172
fbshipit-source-id: 8c790055e0d76c4227394cafa93b07d1310f2cea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22413
_jit_pass_erase_number_types invalidates the jit graph but parts of _jit_pass_onnx rely on having a valid jit graph.
This splits _jit_pass_onnx into _jit_pass_onnx_remove_print and _jit_pass_onnx_preprocess_caffe2 (which rely on the valid jit graph), runs these before _jit_pass_erase_number_types,
and then runs the rest of _jit_pass_onnx after _jit_pass_erase_number_types
Reviewed By: houseroad
Differential Revision: D16079890
fbshipit-source-id: ae68b87dced077f76cbf1335ef3bf89984413224
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22319
The onnx pass replacing ints with Tensors produces an invalid JIT graph. It should only be called right before the onnx pass.
Also, it should only be called if we actually export to onnx.
Reviewed By: houseroad
Differential Revision: D16040374
fbshipit-source-id: e78849ee07850acd897fd9eba60b6401fdc4965b
Summary:
This change is backwards incompatible in *C++ only* on mean(), sum(), and prod() interfaces that accepted either of:
```
Tensor sum(IntArrayRef dim, bool keepdim=false) const;
Tensor sum(IntArrayRef dim, ScalarType dtype) const;
```
but now to specify both the dim and dtype will require the keepdim parameter:
```
Tensor sum(IntArrayRef dim, bool keepdim=false, c10::optional<ScalarType> dtype=c10::nullopt) const;
```
[xla ci]
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21088
Reviewed By: ailzhang
Differential Revision: D15944971
Pulled By: nairbv
fbshipit-source-id: 53473c370813d9470b190aa82764d0aea767ed74
Summary:
cosine_similarity has two non-tensor parameters, needs some special handling. Add the support for its export in this diff.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21884
Reviewed By: zrphercule
Differential Revision: D15866807
Pulled By: houseroad
fbshipit-source-id: a165fbc00c65c44b276df89ae705ca8960349d48
Summary:
When converting pixel_shuffle to reshape + transpose + reshape, the first reshape should
be:
[N, C * r^2, H, W] => [N, C, r, r, H, W]
in order to match pytorch's implementation (see ATen PixelShuffle.cpp).
This previously wasn't caught by the test case, since it uses C = r = 4. Updated test case to
have C = 2, r = 4.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21486
Reviewed By: houseroad
Differential Revision: D15700945
Pulled By: houseroad
fbshipit-source-id: 47019691fdc20e152e867c7f6fd57da104a12948
Summary:
- [x] Add tests after https://github.com/pytorch/pytorch/pull/20256 is merged
- Support exporting ScriptModule with inputs/outputs of arbitrarily constructed tuples.
- Moved the assigning of output shapes to after graph conversion to ONNX is completed. By then all tuples in the IR has already been lowered by the pass ```_jit_pass_lower_all_tuples```. If assigning output shapes is required to happen before that, we'll need to hand parse the tuple structures in the graph, and repeat the same logic in ```_jit_pass_lower_all_tuples```. Handling inputs is easier because all tuple information is encoded within the input tensor type.
- Swap the order of ```_jit_pass_lower_all_tuples``` and ```_jit_pass_erase_number_types```. Ops like ```prim::TupleIndex``` relies on index being a scalar. ```_jit_pass_erase_number_types``` will convert these kind of scalars to tensors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20784
Reviewed By: zrphercule
Differential Revision: D15484171
Pulled By: houseroad
fbshipit-source-id: 4767a84038244c929f5662758047af6cb92228d3
Summary:
This could serve as a alternative solution to export ```torch.gather``` before something similar goes into ONNX spec. The exported model is verified to be correct against onnxruntime backend. We weren't able to test against Caffe2 backend because it doesn't seem to support OneHot opset9.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21235
Differential Revision: D15613039
Pulled By: houseroad
fbshipit-source-id: 7fc097f85235c071474730233ede7d83074c347f
Summary:
This PR adds support for torch.rand export in the PyTorch ONNX exporter. There are other generator ops that need to be supported for export and they will added in subsequent PRs. This op is needed with priority for a model on our end.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20559
Differential Revision: D15379653
Pulled By: houseroad
fbshipit-source-id: d590db04a4cbb256c966f4010a9361ab8eb3ade3
Summary:
Remove Dropout from the opset 10 blacklist.
ONNX Dropout was modified in opset 10, but only the output "mask" was modified, which is not exported in pytorch opset 9. So we can still fallback on the opset 9 op.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20710
Differential Revision: D15571248
Pulled By: houseroad
fbshipit-source-id: 15267eb63308a29a435261034b2f07324db1dea6
Summary:
In onnx spec, the supported input/output type for `And` and `Or` is `Bool` only.
Thus in exporting, cast to/from `Bool` is inserted for input/output.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17894
Reviewed By: zrphercule
Differential Revision: D15103148
Pulled By: houseroad
fbshipit-source-id: 3e1068ea236c743260d42882fb11f0e3a21707e6
Summary:
#19975 was separated by 2 PRs.
This one:
Introduce MemoryFormat argument to the `x.is_contiguous(memory_format=torch.channels_last)` and to the `y = x.contiguous(memory_format=torch.channels_last)` functions.
At this moment both functions just operate with strides and doesn't store any tensor state.
(Original RFC #19092)
-----
Expands functionality of two tensor functions `.is_contiguous` and `.contiguous` (both python and c++ api).
Note: We had several complaints about `.to(memory_format)` function, and decided not to support it.
1. `.contiguous` now support optional keyword-only argument - `memory_format`, which can be either `torch.contiguous_format` or `torch.channels_last`.
- Using `torch.contiguous_format` will preserve existing `.contiguous()` behavior.
- Calling `x.contiguous(memory_format=torch.channels_last)` returns new tensor which maintain same semantical layout (NCHW), but have different memory allocation pattern.
`x.contiguous(memory_format=torch.channels_last)` expects input tensor to be 3d, 4d or 5d; and fails otherwise.
2. `.is_contiguous` now support optional keyword-only argument - `memory_format`, which can be either `torch.contiguous_format` or `torch.channels_last`.
- `x.is_contiguous(memory_format=torch.contiguous_format)` preserves same functionality as `x.is_contiguous()` and remains unchanged.
- `x.is_contiguous(memory_format=torch.channels_last)` returns true if A) input tensor is contiguous in memory AND B) allocated in the memory in NWHC (or similar for 3d,5d) format.
Note: By the end of the phase one `x.is_contiguous(memory_format=torch.channels_last)` will calculate state of the Tensor on every call. This functionality going to be updated later.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20455
Differential Revision: D15341577
Pulled By: VitalyFedyunin
fbshipit-source-id: bbb6b4159a8a49149110ad321109a3742383185d
Summary: This can be used for problems where the action vector must sum to 1
Reviewed By: kittipatv
Differential Revision: D15206348
fbshipit-source-id: 665fbed893d8c52d451a12d3bb2e73b2638b7963
Summary:
As a work around for dynamic shape case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20093
Reviewed By: zrphercule
Differential Revision: D15220661
Pulled By: houseroad
fbshipit-source-id: de271fce542be380bd49a3c74032c61f9aed3b67
Summary:
Input argument `f` in `_model_to_graph()` method in `torch/onnx/utils.py` is unused. This PR removes it. If there's a reason to keep it around, please let me know.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19647
Reviewed By: dzhulgakov
Differential Revision: D15071720
Pulled By: houseroad
fbshipit-source-id: 59e0dd7a4d5ebd64d0e30f274b3892a4d218c496
Summary:
in functional interfaces we do boolean dispatch, but all to max_pool\*d_with_indices. This change it to emit max_pool\*d op instead when it's not necessary to expose with_indices ops to different backends (for jit).
It also bind max_pool\*d to the torch namespace, which is the same behavior with avg_pool\*d
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19449
Differential Revision: D15016839
Pulled By: wanchaol
fbshipit-source-id: f77cd5f0bcd6d8534c1296d89b061023a8288a2c
Summary:
Strip the doc_string by default from the exported ONNX models (this string has the stack trace and information about the local repos and folders, which can be confidential).
The users can still generate the doc_string by specifying add_doc_string=True in torch.onnx.export().
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18882
Differential Revision: D14889684
Pulled By: houseroad
fbshipit-source-id: 26d2c23c8dc3f484544aa854b507ada429adb9b8
Summary:
Make it possible to construct a pinned memory tensor without creating a storage first and without calling pin_memory() function. It is also faster, as copy operation is unnecessary.
Supported functions:
```python
torch.rand_like(t, pin_memory=True)
torch.randn_like(t, pin_memory=True)
torch.empty_like(t, pin_memory=True)
torch.full_like(t, 4, pin_memory=True)
torch.zeros_like(t, pin_memory=True)
torch.ones_like(t, pin_memory=True)
torch.tensor([10,11], pin_memory=True)
torch.randn(3, 5, pin_memory=True)
torch.rand(3, pin_memory=True)
torch.zeros(3, pin_memory=True)
torch.randperm(3, pin_memory=True)
torch.empty(6, pin_memory=True)
torch.ones(6, pin_memory=True)
torch.eye(6, pin_memory=True)
torch.arange(3, 5, pin_memory=True)
```
Part of the bigger: `Remove Storage` plan.
Now compatible with both torch scripts:
` _1 = torch.zeros([10], dtype=6, layout=0, device=torch.device("cpu"), pin_memory=False)`
and
` _1 = torch.zeros([10], dtype=6, layout=0, device=torch.device("cpu"))`
Same checked for all similar functions `rand_like`, `empty_like` and others
It is fixed version of #18455
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18952
Differential Revision: D14801792
Pulled By: VitalyFedyunin
fbshipit-source-id: 8dbc61078ff7a637d0ecdb95d4e98f704d5450ba
Summary:
If JIT constant propagation doesn't work, we have to handle the ListConstructor in symbolic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19102
Reviewed By: zrphercule
Differential Revision: D14875588
Pulled By: houseroad
fbshipit-source-id: d25c847d224d2d32db50aae1751100080e115022
Summary:
Almost there, feel free to review.
these c10 operators are exported to _caffe2 domain.
TODO:
- [x] let the onnx checker pass
- [x] test tensor list as argument
- [x] test caffe2 backend and converter
- [x] check the c10 schema can be exported to onnx
- [x] refactor the test case to share some code
- [x] fix the problem in ONNX_ATEN_FALLBACK
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18210
Reviewed By: zrphercule
Differential Revision: D14600916
Pulled By: houseroad
fbshipit-source-id: 2592a75f21098fb6ceb38c5d00ee40e9e01cd144
Summary:
Introduce this check to see whether it will break any existing workflow
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18145
Reviewed By: dzhulgakov
Differential Revision: D14511711
Pulled By: houseroad
fbshipit-source-id: a7bb6ac84c9133fe94d3fe2f1a8566faed14a136
Summary:
Make it possible to construct a pinned memory tensor without creating a storage first and without calling pin_memory() function. It is also faster, as copy operation is unnecessary.
Supported functions:
```python
torch.rand_like(t, pin_memory=True)
torch.randn_like(t, pin_memory=True)
torch.empty_like(t, pin_memory=True)
torch.full_like(t, 4, pin_memory=True)
torch.zeros_like(t, pin_memory=True)
torch.ones_like(t, pin_memory=True)
torch.tensor([10,11], pin_memory=True)
torch.randn(3, 5, pin_memory=True)
torch.rand(3, pin_memory=True)
torch.zeros(3, pin_memory=True)
torch.randperm(3, pin_memory=True)
torch.empty(6, pin_memory=True)
torch.ones(6, pin_memory=True)
torch.eye(6, pin_memory=True)
torch.arange(3, 5, pin_memory=True)
```
Part of the bigger: `Remove Storage` plan.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18455
Reviewed By: ezyang
Differential Revision: D14672084
Pulled By: VitalyFedyunin
fbshipit-source-id: 9d0997ec00f59500ee018f8b851934d334012124
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18598
ghimport-source-id: c74597e5e7437e94a43c163cee0639b20d0d0c6a
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18598 Turn on F401: Unused import warning.**
This was requested by someone at Facebook; this lint is turned
on for Facebook by default. "Sure, why not."
I had to noqa a number of imports in __init__. Hypothetically
we're supposed to use __all__ in this case, but I was too lazy
to fix it. Left for future work.
Be careful! flake8-2 and flake8-3 behave differently with
respect to import resolution for # type: comments. flake8-3 will
report an import unused; flake8-2 will not. For now, I just
noqa'd all these sites.
All the changes were done by hand.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14687478
fbshipit-source-id: 30d532381e914091aadfa0d2a5a89404819663e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18512
Ceil and Floor have been supported since version 6 of ONNX: export them using the native onnx ops instead of an Aten op.
Similarly, support for the Where op has been added in version 9, so we don't need to wrap these op in an Aten op.
Reviewed By: houseroad
Differential Revision: D14635130
fbshipit-source-id: d54a2b6e295074a6214b5939b21051a6735c9958
Summary:
Is Tensor has been brought up as misleading a couple times, rename it isCompleteTensor for clarity.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18437
Differential Revision: D14605223
Pulled By: eellison
fbshipit-source-id: 189f67f12cbecd76516a04e67d8145c260c79036
Summary:
Set value as tensor of 1 element instead of scalar, according to ONNX spec.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18199
Reviewed By: dzhulgakov
Differential Revision: D14542588
Pulled By: houseroad
fbshipit-source-id: 70dc978d870ebe6ef37c519ba4a20061c3f07372
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/12598
This PR was originally authorized by ptrblck at https://github.com/pytorch/pytorch/pull/15495, but since there was no update for months after the request change, I clone that branch and resolve the code reviews here. Hope everything is good now. Especially, the implementation of count is changed from ptrblck's original algorithm to the one ngimel suggest, i.e. using `unique_by_key` and `adjacent_difference`.
The currently implementation of `_unique_dim` is VERY slow for computing inverse index and counts, see https://github.com/pytorch/pytorch/issues/18405. I will refactor `_unique_dim` in a later PR. For this PR, please allow me to keep the implementation as is.
cc: ptrblck ezyang ngimel colesbury
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18391
Reviewed By: soumith
Differential Revision: D14605905
Pulled By: VitalyFedyunin
fbshipit-source-id: 555f5a12a8e28c38b10dfccf1b6bb16c030bfdce
Summary:
So, we will keep the names of ONNX initializers the same as the names in PyTorch state dict.
Later, we will make this as the default behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17551
Reviewed By: dzhulgakov
Differential Revision: D14491920
Pulled By: houseroad
fbshipit-source-id: f355c02e1b90d7ebbebf4be7c0fb6ae208ec795f
Summary:
The output format of NonZero in ONNX(numpy https://docs.scipy.org/doc/numpy/reference/generated/numpy.nonzero.html) differs from that in PyTorch:
In ONNX: `[rank_of_input, num_of_nonzeros]`, whereas in PyTorch: `[num_of_nonzeros, rank_of_input]`.
To resolve the difference a Transpose op after the nonzero output is added in the exporter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18047
Differential Revision: D14475081
Pulled By: ezyang
fbshipit-source-id: 7a3e4899f3419766b6145d3e9261e92859e81dc4
Summary:
1) The changes in the new opset won't affect internal pipeline.
2) The CI won't be affected by the ONNX changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17736
Reviewed By: zrphercule
Differential Revision: D14358710
Pulled By: houseroad
fbshipit-source-id: 4ef15d2246b50f6875ee215ce37ecf92d555ca6a
Summary:
Similar to `nn.Parameter`s, this PR lets you store any `IValue` on a module as an attribute on a `ScriptModule` (only from the Python front-end currently). To mark something as an attribute, it should wrapped in `jit.Attribute(value, type)` (ex. `self.table = torch.jit.Attribute(table, Dict[str, torch.Tensor])`)
Followup Work:
* (de)serializing for use in C++
* change `self.training` to be a `bool` attribute instead of a buffer
* mutable attributes
* string frontend support
* documentation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17309
Differential Revision: D14354316
Pulled By: driazati
fbshipit-source-id: 67e08ab5229366b67fbc837e67b58831a4fb3318
Summary:
Currently, serialization of model parameters in ONNX export depends on the order in which they are stored in a container (`list` on Python side and `std::vector` on C++ side). This has worked fine till now, but if we need to do any pass on that graph that mutates the parameter list, then strictly order-based serialization may not work.
This PR is the first in a set to bring in more passes (such as constant folding) related to ONNX export. This PR lays the groundwork by moving the serialization in ONNX export from order-based to name based approach, which is more amenable to some of the passes.
houseroad - As discussed this change uses a map for export, and removes the code from `export.cpp` that relies on the order to compute initializer names.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17420
Differential Revision: D14361993
Pulled By: houseroad
fbshipit-source-id: da93e945d55755c126de06641f35df87d1648cc4
Summary:
resize_ and resize_as resize the input tensor. because our shape analysis
is flow invariant, we don't do shape analysis on any op that relies on a Tensor that can alias a resized Tensor.
E.g. in the following graph the x += 10 x may have been resized.
```
torch.jit.script
def test(x, y):
for i in range(10):
x += 10
x.resize_as_([1 for i in int(range(torch.rand())))
return x
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17518
Differential Revision: D14249835
Pulled By: eellison
fbshipit-source-id: f281b468ccb8c29eeb0f68ca5458cc7246a166d9
Summary:
Still wip, need more tests and correct handling for opset 8 in symbolics.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16068
Reviewed By: zrphercule
Differential Revision: D14185855
Pulled By: houseroad
fbshipit-source-id: 55200be810c88317c6e80a46bdbeb22e0b6e5f9e
Summary:
Trying to land again, make prim::None into a case of prim::Constant. Reverted the previous landing because it broke an important onnx export test.
https://github.com/pytorch/pytorch/pull/16160
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17186
Differential Revision: D14115304
Pulled By: eellison
fbshipit-source-id: 161435fc30460b4e116cdd62c7b2e5b94581dcb7
Summary:
This change simplifies analysis done on constants since prim::None does not need to be handled separately now. To check if a constant node is None, use node->isNone().
Next step will be to remove prim::Undefined.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16160
Differential Revision: D14109636
Pulled By: eellison
fbshipit-source-id: d26fd383976163a2ddd4c24984bd672a541cc876
Summary:
This PR is a follow up of #15460, it did the following things:
* remove the undefined tensor semantic in jit script/tracing mode
* change ATen/JIT schema for at::index and other index related ops with `Tensor?[]` to align with what at::index is really doing and to adopt `optional[tensor]` in JIT
* change python_print to correctly print the exported script
* register both TensorList and ListOfOptionalTensor in JIT ATen ops to support both
* Backward compatibility for `torch.jit.annotate(Tensor, None)`
List of follow ups:
* remove the undefined tensor semantic in jit autograd, autodiff and grad_of
* remove prim::Undefined fully
For easy reviews, please turn on `hide white space changes` in diff settings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16379
Differential Revision: D13855677
Pulled By: wanchaol
fbshipit-source-id: 0e21c14d7de250c62731227c81bfbfb7b7da20ab
Summary:
This PR does three things:
~~Allow `int64_t?` in function schema, which provide an elegant way of implementing null-able int arguments, as discussed in https://github.com/pytorch/pytorch/pull/15208#pullrequestreview-185230081~~
~~Originally implemented in https://github.com/pytorch/pytorch/pull/15235~~
~~Example:~~
```yaml
- func: myop(Tensor self, int64_t? dim=None) -> Tensor
variants: function
```
~~cc: zou3519~~
Edit: implemented in https://github.com/pytorch/pytorch/pull/15234
Previously tried in https://github.com/pytorch/pytorch/pull/12064. There was a problem that C++ does not have kwarg support, which makes it confusing to know whether `unique(t, 1)` actually means `unique(t, dim=1)` or `unique(t, sorted=1)`.
Now I think I have a better idea on how to implement this: there are two ATen operators: `unique` and `unique_dim`. `unique` has the same signature as in python, and exported to both python and C++. `unique_dim` has signature `unique_dim(tensor, dim, sorted=False, return_inverse=False)`, and only exported to C++, which could be used more naturally for a C++ user.
Differential Revision: D13540278
Pulled By: wanchaol
fbshipit-source-id: 3768c76a90b0881f565a1f890459ebccbdfe6ecd
Summary:
Submitting this PR as an update to existing PR (https://github.com/pytorch/pytorch/pull/15938) on houseroad 's request.
This PR replaces the use of ONNX op `ConstantLike` with `ConstantOfShape` in the ONNX exporter. In addition to removing the call sites in `symbolic.py`, it also replace the call site in `peephole.cpp`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16095
Differential Revision: D13745723
Pulled By: houseroad
fbshipit-source-id: e2a5f534f01adf199df9e27544f7afcfa540e1f0
Summary:
While integrating fork/join into production translation, we found that trying to export `transpose()` where the input is of `TensorType` (rather than `CompleteTensorType`) failed. This is not ideal, since `TensorType` still contains the number of dimensions of the tensor, and that's all the `transpose` symbolic needs.
This PR introduces a pybind binding for `dim()` on `TensorType` (and `CompleteTensorType` by inheritance). We now use this in places where it logically makes sense in the symbolics: those symbolics which only require knowledge of the number of dimensions rather than concrete sizes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15933
Differential Revision: D13639657
Pulled By: jamesr66a
fbshipit-source-id: 6e50e407e93060085fd00a686a928764d0ec888d
Summary:
* With the update of split output to dynamic list it breaks the export to onnx.
Now split ir becomes two ops: 1. Dynamic[] <= Split(), and 2. out1, out2, out3
<= Prim::ListUnpack. In this fix these two consecutive ops get fused when being
exported to onnx.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15092
Reviewed By: dzhulgakov
Differential Revision: D13583832
Pulled By: houseroad
fbshipit-source-id: 3eb18c871e750921ad6d5cc179254bee9bcf4c99
Summary:
Before this pr, rsub did not convert two elements into the same dtype, therefore "1 - x" may export to an onnx model that two elements of rsub having different dtype.
By adding this symbolic patch this bug should be fixed.
Related test cases also created.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15707
Differential Revision: D13583042
Pulled By: zrphercule
fbshipit-source-id: 3a2de47a1a8d1ded1a0adfb911adbe6ac729cdef
Summary:
This is the an updated version of the earlier PR https://github.com/pytorch/pytorch/pull/15185, since that one was closed.
Currently PyTorch ONNX exporter exports the logical ops (lt, gt, le, ge, eq, ne) with output type in corresponding ONNX ops as type tensor(uint8). But ONNX spec allows for only tensor(bool), which is why models that have these ops fail to load properly.
This issue is captured in #11339. Part of this issue, relating to the allowed input types, has been fixed in ONNX spec by houseroad. This PR fixes the other part pertaining to output type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15677
Reviewed By: dzhulgakov
Differential Revision: D13568450
Pulled By: houseroad
fbshipit-source-id: a6afbea1afdb4edad8f8b1bc492f50b14e5f2fce
Summary:
Short term solution, export group norm as an ATen op to unblock users.
Long term will add GroupNorm to onnx.
Add an end to end test for this one.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15569
Differential Revision: D13554293
Pulled By: houseroad
fbshipit-source-id: b4974c9ea2a1b81338ca1e5c6747efe2715d7932
Summary:
Currently PyTorch ONNX exporter exports the logical ops (`lt`, `gt`, `le`, `ge`, `eq`) with output type in corresponding ONNX ops as type `tensor(uint8)`. But ONNX spec allows for only `tensor(bool)`, which is why models that have these ops fail to load properly.
This issue is captured in https://github.com/pytorch/pytorch/issues/11339. Part of this issue, relating to the allowed input types, has been fixed in ONNX spec by houseroad. This PR fixes the other part pertaining to output type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15185
Differential Revision: D13494873
Pulled By: houseroad
fbshipit-source-id: 069d2f956a5ae9bf0ac2540a32594a31b01adef8
Summary:
max and reducemax are smashed together, we need to support one input case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15241
Reviewed By: yinghai
Differential Revision: D13473312
Pulled By: houseroad
fbshipit-source-id: 9b8c847286a2631b006ca900271bc0d26574101a
Summary:
`torch.expand` and `torch.ne` are used often in models and this PR adds ONNX export support for them. ArmenAg has created issue https://github.com/pytorch/pytorch/issues/10882 for this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15050
Differential Revision: D13453036
Pulled By: houseroad
fbshipit-source-id: 4724b4ffcebda6cd6b2acac51d6733cb27318daf
Summary:
This PR does the following:
1) Updates the ONNX export for `torch.zeros_like` and `torch.full_like` ops to use ONNX op `ConstantLike`. This reduces the export of experimental op `ConstantFill`, which may possibly be removed in future, see https://github.com/onnx/onnx/pull/1434).
2) It also adds export support for `torch.ones_like`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14903
Differential Revision: D13383700
Pulled By: houseroad
fbshipit-source-id: 566d00a943e9497172fcd5a034b638a650ab13a2
Summary:
[ note: stacked on expect files changes, will unstack once they land ]
This adds DeviceObjType (cannot use DeviceType it is already an enum)
to the type hierarchy and an isDevice/toDevice pair to IValue.
Previous hacks which used an int[] to represent Device are removed
and at::Device is used instead.
Note: the behavior or .to is only a subset of python, we need to
fix the aten op so that it accepts Option[Device] and Optional[ScalarType].
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14666
Reviewed By: suo
Differential Revision: D13290405
Pulled By: zdevito
fbshipit-source-id: 68b4381b292f5418a6a46aaa077f1c902750b134
Summary:
Stacked on https://github.com/pytorch/pytorch/pull/14378, only look at the last commit.
This changes the way methods are defined in TorchScript archives to use
PythonPrint rather than ONNX protobufs.
It also updates torch.proto to directly document the tensor data
structure actually being serialized.
Notes:
* because PythonPrint prints all the methods at once per module, this
removes MethodDef in favor of a single torchscript_area and a separate
caffe2_graphs entry. Note that NetDef's already have method names,
so there is no need or a separate method name entry.
* This switches cpp/pickle area to RecordRef (references to a file in
the container format) since it is possible the data in these arenas
may be large and not suited to json ouput.
* Removes 'annotations' -- annotations should be re-added on the first
commit that actually has a practical use for them. In the current state
it is unlikely they are representing the right information.
* Some expect files have changed because PythonPrint is preserving more
debug name information for parameter names.
* MethodEncoder (the ONNX output format) has been deleted. There is still
some cleanup possible combining EncoderBase and GraphEncode now that there
is only a single pathway using EncoderBase.
* This incorporates the changes from #14397
to define TensorDef
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14400
Reviewed By: suo
Differential Revision: D13231800
Pulled By: zdevito
fbshipit-source-id: af5c1152d0bd6bca8b06c4703f59b161bb19f571
Summary:
This speeds-up "advanced" indexing (indexing a tensor by a tensor)
on CPU and GPU. There's still a bunch of work to do, including
speeding up indexing by a byte (boolean) mask and speeding up the derivative
calculation for advanced indexing.
Here's some speed comparisons to indexing on master using a little [benchmark script](https://gist.github.com/colesbury/c369db72aad594e5e032c8fda557d909) with 16 OpenMP threads and on a P100. The test cases are listed as (input shape -> output shape).
| Test case | CPU (old vs. new) | CUDA (old vs. new) |
|-----------------------|---------------------|------------------------|
| 1024x1024 -> 512x1024 | 225 us vs. **57 us** | 297 us vs. **47 us** |
| 1024x1024 -> 1024x512 | 208 us vs. **153 us** | 335 us vs. **54 us** |
| 50x50 -> 20000x50 | 617 us vs. **77 us** | 239 us vs. **54 us** |
| 50x50 -> 50x20000 | 575 us vs. **236 us** | 262 us vs. **58 us** |
| 2x5x10 -> 10 | 65 us vs. **18 us** | 612 us vs. **93 us** |
See #11647
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13420
Reviewed By: soumith
Differential Revision: D13088936
Pulled By: colesbury
fbshipit-source-id: 0a5c2ee9aa54e15f96d06692d1694c3b24b924e2
Summary:
This PR adds a `try_outplace` option to the tracer. When `try_outplace` is true, the tracer will attempt to out-of-place ops (similar to how things are done today). When it's false, the correct in-place op is emitted.
I made `try_outplace` false by default, but flipped it to true for ONNX export utils. zdevito jamesr66a, anywhere else I should preserve the existing behavior?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14254
Reviewed By: eellison
Differential Revision: D13166691
Pulled By: suo
fbshipit-source-id: ce39fdf73ac39811c55100e567466d53108e856b
Summary:
This is probably slow but it should make the traces more understandable and make debugging easier. Any suggestions for how to make it faster (i.e. make it so we don't have to traverse all of locals() and globals()) would be appreciated
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13441
Differential Revision: D12879763
Pulled By: jamesr66a
fbshipit-source-id: b84133dc2ef9ca6cfbfaf2e3f9106784cc42951e
Summary:
We updated the description of upsample_op in onnx: https://github.com/onnx/onnx/pull/1467
Therefore, we need to support the new upsample_op in caffe2-onnx backend as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13272
Reviewed By: houseroad
Differential Revision: D12833656
Pulled By: zrphercule
fbshipit-source-id: 21af5282abaae12d2d044e4018a2b152aff79917
Summary:
There should really be a single place to erase or do special treatment to the prim::ListConstruct during ONNX export, this will make it consistent across different calls. e.g it will give a correct output graph in the following case:
```python
class Test(torch.nn.Module):
def forward(self, input):
return torch.cat([input, torch.zeros(input.size(0), 1).type_as(input)], dim=1)
```
Before this PR, we have the onnx graph as:
```
graph(%0 : Byte(2, 3)) {
%1 : Long() = onnx::Constant[value={0}](), scope: Test
%2 : Dynamic = onnx::Shape(%0), scope: Test
%3 : Long() = onnx::Gather[axis=0](%2, %1), scope: Test
%4 : Long() = onnx::Constant[value={1}](), scope: Test
%5 : Dynamic = onnx::Unsqueeze[axes=[0]](%3)
%6 : Dynamic = onnx::Unsqueeze[axes=[0]](%4)
%7 : int[] = onnx::Concat[axis=0](%5, %6)
%8 : Float(2, 1) = onnx::ConstantFill[dtype=1, input_as_shape=1, value=0](%7), scope: Test
%9 : Byte(2, 1) = onnx::Cast[to=2](%8), scope: Test
%10 : Byte(2, 4) = onnx::Concat[axis=1](%0, %9), scope: Test
return (%10);
}
```
Which is wrong since onnx does not have a concept of `int[]`, here is the onnx graph after this PR:
```
graph(%0 : Byte(2, 3)) {
%1 : Long() = onnx::Constant[value={0}](), scope: Test
%2 : Dynamic = onnx::Shape(%0), scope: Test
%3 : Long() = onnx::Gather[axis=0](%2, %1), scope: Test
%4 : Long() = onnx::Constant[value={1}](), scope: Test
%5 : Dynamic = onnx::Unsqueeze[axes=[0]](%3)
%6 : Dynamic = onnx::Unsqueeze[axes=[0]](%4)
%7 : Dynamic = onnx::Concat[axis=0](%5, %6)
%8 : Float(2, 1) = onnx::ConstantFill[dtype=1, input_as_shape=1, value=0](%7), scope: Test
%9 : Byte(2, 1) = onnx::Cast[to=2](%8), scope: Test
%10 : Byte(2, 4) = onnx::Concat[axis=1](%0, %9), scope: Test
return (%10);
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13195
Differential Revision: D12812541
Pulled By: wanchaol
fbshipit-source-id: db6be8bf0cdc85c426d5cbe09a28c5e5d860eb3e
Summary:
This PR changes the compiler to correctly emit in-place operators for augmented assignments (`+=` and friends).
- To better match the Python AST structure, add an `AugAssign` tree view and make `Assign` apply only to `=` assignments.
- Emit those `AugAssign` exprs in the compiler, dispatching to in-place aten ops for tensors and lowering to simple assignments for scalar types.
- In order to preserve (suspect) ONNX export semantics, add a pass to lower the in-place operators to out-of-place operators.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13364
Differential Revision: D12899734
Pulled By: suo
fbshipit-source-id: bec83be0062cb0235eb129aed78d6110a9e2c146
Summary:
Currently, `a = 1 - torch.tensor([1]).to('cuda:1')` puts `a` in `cuda:1` but reports `a.device` as `cuda:0` which is incorrect, and it causes illegal memory access error when trying to access `a`'s memory (e.g. when printing). This PR fixes the error.
Fixes https://github.com/pytorch/pytorch/issues/10850.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12956
Differential Revision: D12835992
Pulled By: yf225
fbshipit-source-id: 5737703d2012b14fd00a71dafeedebd8230a0b04
Summary:
This will enable the updated attribute and input format of operator upsample.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13152
Reviewed By: houseroad
Differential Revision: D12812491
Pulled By: zrphercule
fbshipit-source-id: d5db200365f1ab2bd1f052667795841d7ee6beb3
Summary:
Addresses #9499. Completed work on the forward function, tests should be passing for that. Working on backward function now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10885
Differential Revision: D9643786
Pulled By: SsnL
fbshipit-source-id: 2930d6f3d2975c45b2ba7042c55773cbdc8fa3ac
Summary:
This PR adds optional type to ATen native, autograd, JIT schema and Python Arg parser, closes#9513. It allows us to use optional default values (including None) for function signature and implementations like clamp, etc., and also let us remove the python_default_init hack.
Follow up:
remove python_default_init completely.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12582
Differential Revision: D10417423
Pulled By: wanchaol
fbshipit-source-id: 1c80f0727bb528188b47c595629e2996be269b89
Summary:
These were indiscriminately dumping `onnx::` instructions into traces, and making it so you couldn't run the traces in the JIT interpreter
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12803
Differential Revision: D10443526
Pulled By: jamesr66a
fbshipit-source-id: 07172004bf31be9f61e498b5772759fe9262e9b3
Summary:
Using Transpose + Reshape, not using DepthToSpace, since they are not available in C2 yet.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12192
Reviewed By: BIT-silence
Differential Revision: D10129913
Pulled By: houseroad
fbshipit-source-id: b60ee6d53b8ee95fd22f12e628709b951a83fab6
Summary:
Add AdaptiveAvgPool2d and AdaptiveMaxPool2d to ONNX.symbolic
Due to limitations in ONNX only output_size=1 is supported.
AdaptiveAvgPool2d -> GlobalAveragePool
AdaptiveMaxPool2d -> GlobalMaxPool
Fixes#5310
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9711
Differential Revision: D10363462
Pulled By: ezyang
fbshipit-source-id: ccc9f8ef036e1e54579753e50813b09a6f1890da
Summary:
Implement contiguous as `aten::contiguous` so it can be recorded during tracing. This was causing issues with both the trace checker as well as when a `contiguous()`-ed tensor was used downstream in a view that expected certain strides
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12541
Differential Revision: D10304028
Pulled By: jamesr66a
fbshipit-source-id: dc4c878771d052f5a0e9674f610fdec3c6782c41
Summary:
There's some action at a distance issues and not having this is disabling quantization in C2 for prod use cases
ref T34831022
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12538
Differential Revision: D10302931
Pulled By: jamesr66a
fbshipit-source-id: 700dc8c5c4297e942171992266ffb67b815be754
Summary:
ATenOp was handling `torch.where` incorrectly. Whereas the `torch.where` overload (and `aten::` function) had arguments in the order `Tensor condition, Tensor self, Tensor other`, ATenOp was emitting code that assumed that `self` was the 0th argument, and thus was trying to interpret the wrong value as the condition.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12353
Differential Revision: D10218435
Pulled By: jamesr66a
fbshipit-source-id: afe31c5d4f941e5fa500e6b0ef941346659c8d95
Summary:
reduce sum negative indices turn to positive as caffe2 not supporting it. GE/LE symbolic operand order is wrong..
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12123
Reviewed By: houseroad
Differential Revision: D10095467
Pulled By: wanchaol
fbshipit-source-id: eb20248de5531c25040ee68b89bd18743498138d
Summary:
- Disable addmm fusion. The reason for this is explained in the comment.
- Tiny change in `stack.h` that lets us avoid constructing an unnecessary temporary `IValue` on the (C++) stack (it will only get created on the interpreter stack directly).
- Fixed a correctness issue in requires grad propagation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11654
Reviewed By: colesbury
Differential Revision: D9813739
Pulled By: apaszke
fbshipit-source-id: 23e83bc8605802f39bfecf447efad9239b9421c3
Summary:
The PR fixes#10873
The context is aten::add and aten::sub ST overloads don't have alpha, so onnx symbolic does not match.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10972
Reviewed By: jamesr66a
Differential Revision: D9724224
Pulled By: wanchaol
fbshipit-source-id: eb5d1b09fa8f1604b288f4a62b8d1f0bc66611af
Summary:
Requires https://github.com/onnx/onnx/pull/1377
This PR makes it so that slices with dynamic boundary values can be exported from pytorch and run in caffe2 via ONNX.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11255
Differential Revision: D9790216
Pulled By: jamesr66a
fbshipit-source-id: 6adfcddc5788df4d34d7ca98341077140402a3e2
Summary:
This also removes the usage of torch.onnx.symbolic_override in instance_norm. Fixes#8439.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10792
Differential Revision: D9800643
Pulled By: li-roy
fbshipit-source-id: fa13a57de5a31fbfa2d4d02639d214c867b9e1f1
Summary:
This PR contains a C++ implementation of weight norm. The user-side exposure of weight norm through torch.nn.utils.weight_norm is unchanged.
If running on the GPU, and the norm is requested over the first or last dimension of the weight tensor, the forward pass is carried out using the fused kernels I wrote for our Fairseq GTC hero run, which offer superior performance to primitive ops and superior numerical stability when running in FP16. In the common case that the backward pass is not itself constructing a graph (ie not attempting to set up double backward) the backward pass will be carried out using another fused kernel. If the backward pass is constructing a graph, an alternate code path is taken, which does the math using differentiable primitive ops. In this way, the implementation allows double backward, even if the fused kernel was used in forward (although in this case, you don't benefit from the performance and stability of the fused backward kernel).
If running on the CPU, or if norming over an interior dim, the forward pass is carried out using double-differentiable primitive ops.
Figuring out how to generate all the right plumbing for this was tricky, but it was a fun experience learning how the autogenerator works and how the graph is constructed. Thanks to colesbury for useful guidance on this front.
I do have a few lingering questions:
- Should I unify my return statements (ie by default-constructing Tensors outside if blocks and using operator= within)?
- What is the significance of `non_blocking` when calling e.g. `auto norms = saved_norms.to(saved_g.type().scalarType(), non_blocking=True/False);`? I am currently omitting `non_blocking`, so it defaults to False, but I didn't see any associated synchronizes on the timeline, so I'm wondering what it means.
- Is there an "official" mapping from at::ScalarTypes to corresponding accumulate types, as there are for the PODs + Half in [AccumulateType.h](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/AccumulateType.h)? I looked for an equivalent mapping for ScalarTypes, didn't find one, and ended up rigging it myself (` at::ScalarType AccType = g.type().scalarType() == at::ScalarType::Half ? at::ScalarType::Float : g.type().scalarType();`).
- Are sparse tensors a concern? Should I include another check for sparse tensors in the `_weight_norm` entry point, and send those along the fallback CPU path as well?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10842
Differential Revision: D9735531
Pulled By: ezyang
fbshipit-source-id: 24431d46532cf5503876b3bd450d5ca775b3eaee
Summary:
Many constructors like `torch.zeros` or `torch.randn` didn't support
size tracing correctly which is fixed by this pass. Same issue has been
fixed in legacy tensor constructors.
Additionally, new tensor constructors, which do not participate in
tracing (most notably `torch.tensor`, `torch.as_tensor` and
`torch.from_numpy`) raise a warning when they are used.
Finally, entering a traceable operation disables the tracing in its body.
This is needed because
zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11288
Reviewed By: ezyang
Differential Revision: D9751183
Pulled By: apaszke
fbshipit-source-id: 51444a39d76a3e164adc396c432fd5ee3c8d5f7f
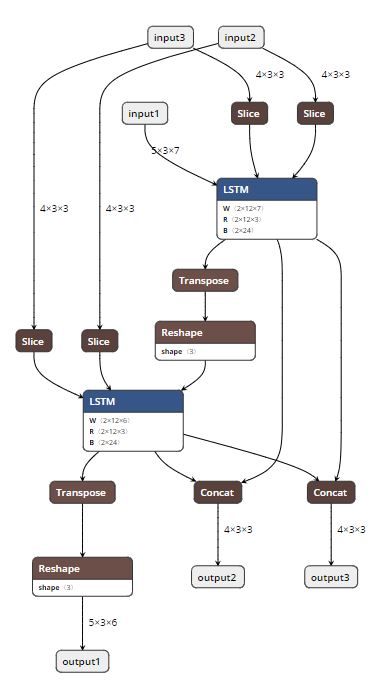
Summary:
Fixes the issue discussed in #10838. `hidden_size` should be the last dimension regardless if we're in ONNX or PyTorch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11368
Differential Revision: D9734814
Pulled By: soumith
fbshipit-source-id: 7f69947a029964e092c7b88d1d79b188a417bf5f
Summary:
- In Python 2, use of `/` (regardless of int/float/Tensor) causes a compiler error if
`from __future__ import division` is not imported in the file.
- The / operator is universally set to do "true" division for integers
- Added a `prim::FloorDiv` operator because it is used in loop unrolling.
The error if users use '/' in python 2 without importing from __future__
occurs when building the JIT AST.
cc apaszke zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11016
Differential Revision: D9613527
Pulled By: zou3519
fbshipit-source-id: 0cebf44d5b8c92e203167733692ad33c4ec9dac6
{kind=link}
{kind=link}