mirror of
https://github.com/zebrajr/pytorch.git
synced 2025-12-07 12:21:27 +01:00
Summary: Rewritten version of https://github.com/pytorch/pytorch/pull/17771 using graph C++ APIs. This PR adds the ability to do constant folding on ONNX graphs during PT->ONNX export. This is done mainly to optimize the graph and make it leaner. The two attached snapshots show a multiple-node LSTM model before and after constant folding. A couple of notes: 1. Constant folding is by default turned off for now. The goal is to turn it on by default once we have validated it through all the tests. 2. Support for folding in nested blocks is not in place, but will be added in the future, if needed. **Original Model:**  **Constant-folded model:** 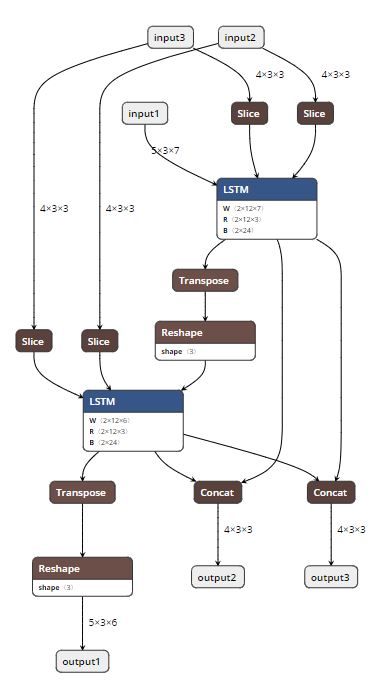 Pull Request resolved: https://github.com/pytorch/pytorch/pull/18698 Differential Revision: D14889768 Pulled By: houseroad fbshipit-source-id: b6616b1011de9668f7c4317c880cb8ad4c7b631a
{kind=link}
{kind=link}
1616 lines
63 KiB
Python
1616 lines
63 KiB
Python
from __future__ import absolute_import
|
|
from __future__ import division
|
|
from __future__ import print_function
|
|
from __future__ import unicode_literals
|
|
|
|
import numpy as np
|
|
import sys
|
|
import unittest
|
|
import itertools
|
|
|
|
import torch.onnx
|
|
import torch.onnx.operators
|
|
from torch.onnx import ExportTypes
|
|
from torch import nn
|
|
from torch.autograd import Variable, function
|
|
import torch.utils.model_zoo as model_zoo
|
|
from torch.nn.utils import rnn as rnn_utils
|
|
from debug_embed_params import run_embed_params
|
|
import io
|
|
|
|
# Import various models for testing
|
|
from torchvision.models.alexnet import alexnet
|
|
from torchvision.models.inception import inception_v3
|
|
from torchvision.models.densenet import densenet121
|
|
from torchvision.models.resnet import resnet50
|
|
from torchvision.models.vgg import vgg16, vgg16_bn, vgg19, vgg19_bn
|
|
|
|
from model_defs.squeezenet import SqueezeNet
|
|
from model_defs.super_resolution import SuperResolutionNet
|
|
from model_defs.srresnet import SRResNet
|
|
import model_defs.dcgan as dcgan
|
|
import model_defs.word_language_model as word_language_model
|
|
from model_defs.mnist import MNIST
|
|
from model_defs.lstm_flattening_result import LstmFlatteningResult
|
|
from model_defs.rnn_model_with_packed_sequence import RnnModelWithPackedSequence
|
|
from caffe2.python.operator_test.torch_integration_test import (generate_rois_rotated,
|
|
create_bbox_transform_inputs)
|
|
|
|
import onnx
|
|
import caffe2.python.onnx.backend as c2
|
|
|
|
from test_pytorch_common import skipIfTravis, skipIfNoLapack, skipIfNoCuda
|
|
import verify
|
|
|
|
skip = unittest.skip
|
|
|
|
|
|
def skipIfEmbed(func):
|
|
def wrapper(self):
|
|
if self.embed_params:
|
|
raise unittest.SkipTest("Skip embed_params verify test")
|
|
return func(self)
|
|
return wrapper
|
|
|
|
|
|
# def import_model(proto, input, workspace=None, use_gpu=True):
|
|
# model_def = onnx.ModelProto.FromString(proto)
|
|
# onnx.checker.check_model(model_def)
|
|
#
|
|
# if workspace is None:
|
|
# workspace = {}
|
|
# if isinstance(input, tuple):
|
|
# for i in range(len(input)):
|
|
# workspace[model_def.graph.input[i]] = input[i]
|
|
# else:
|
|
# workspace[model_def.graph.input[0]] = input
|
|
#
|
|
# caffe2_out_workspace = c2.run_model(
|
|
# init_graph=None,
|
|
# predict_graph=graph_def,
|
|
# inputs=workspace,
|
|
# use_gpu=use_gpu)
|
|
# caffe2_out = caffe2_out_workspace[0]
|
|
# return caffe2_out
|
|
|
|
|
|
def do_export(model, inputs, *args, **kwargs):
|
|
f = io.BytesIO()
|
|
out = torch.onnx._export(model, inputs, f, *args, **kwargs)
|
|
return f.getvalue(), out
|
|
|
|
|
|
torch.set_default_tensor_type('torch.FloatTensor')
|
|
try:
|
|
import torch
|
|
except ImportError:
|
|
print('Cannot import torch, hence caffe2-torch test will not run.')
|
|
sys.exit(0)
|
|
|
|
|
|
BATCH_SIZE = 2
|
|
|
|
RNN_BATCH_SIZE = 7
|
|
RNN_SEQUENCE_LENGTH = 11
|
|
RNN_INPUT_SIZE = 5
|
|
RNN_HIDDEN_SIZE = 3
|
|
|
|
model_urls = {
|
|
'alexnet': 'https://download.pytorch.org/models/alexnet-owt-4df8aa71.pth',
|
|
'dcgan_b': 'https://s3.amazonaws.com/pytorch/test_data/export/netG_bedroom_epoch_1-0649e76b.pth',
|
|
'dcgan_f': 'https://s3.amazonaws.com/pytorch/test_data/export/netG_faces_epoch_49-d86035a6.pth',
|
|
'densenet121': 'https://download.pytorch.org/models/densenet121-d66d3027.pth',
|
|
'inception_v3_google': 'https://download.pytorch.org/models/inception_v3_google-1a9a5a14.pth',
|
|
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
|
|
'srresNet': 'https://s3.amazonaws.com/pytorch/demos/srresnet-e10b2039.pth',
|
|
'super_resolution': 'https://s3.amazonaws.com/pytorch/test_data/export/superres_epoch100-44c6958e.pth',
|
|
'squeezenet1_0': 'https://download.pytorch.org/models/squeezenet1_0-a815701f.pth',
|
|
'squeezenet1_1': 'https://download.pytorch.org/models/squeezenet1_1-f364aa15.pth',
|
|
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
|
|
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth',
|
|
}
|
|
|
|
|
|
class TestCaffe2Backend(unittest.TestCase):
|
|
embed_params = False
|
|
|
|
def setUp(self):
|
|
torch.manual_seed(0)
|
|
if torch.cuda.is_available():
|
|
torch.cuda.manual_seed_all(0)
|
|
np.random.seed(seed=0)
|
|
|
|
def convert_cuda(self, model, input):
|
|
cuda_model = model.cuda()
|
|
# input might be nested - we want to move everything to GPU
|
|
cuda_input = function._nested_map(
|
|
lambda o: isinstance(o, Variable) or torch.is_tensor(o),
|
|
lambda o: o.cuda())(input)
|
|
return cuda_model, cuda_input
|
|
|
|
def run_debug_test(self, model, train, batch_size, state_dict=None,
|
|
input=None, use_gpu=True, example_outputs=None,
|
|
do_constant_folding=False):
|
|
"""
|
|
# TODO: remove this from the final release version
|
|
This test is for our debugging only for the case where
|
|
embed_params=False
|
|
"""
|
|
if not isinstance(model, torch.jit.ScriptModule):
|
|
model.train(train)
|
|
if state_dict is not None:
|
|
model.load_state_dict(state_dict)
|
|
|
|
# Either user specified input or random (deterministic) input
|
|
if input is None:
|
|
input = torch.randn(batch_size, 3, 224, 224, requires_grad=True)
|
|
if use_gpu:
|
|
model, input = self.convert_cuda(model, input)
|
|
|
|
onnxir, torch_out = do_export(model, input, export_params=self.embed_params, verbose=False,
|
|
example_outputs=example_outputs,
|
|
do_constant_folding=do_constant_folding)
|
|
if isinstance(torch_out, torch.autograd.Variable):
|
|
torch_out = (torch_out,)
|
|
|
|
caffe2_out = run_embed_params(onnxir, model, input, state_dict, use_gpu)
|
|
for _, (x, y) in enumerate(zip(torch_out, caffe2_out)):
|
|
np.testing.assert_almost_equal(x.data.cpu().numpy(), y, decimal=3)
|
|
|
|
def run_actual_test(self, model, train, batch_size, state_dict=None,
|
|
input=None, use_gpu=True, rtol=0.001, atol=1e-7,
|
|
example_outputs=None, do_constant_folding=False):
|
|
"""
|
|
This is what the user facing version will look like
|
|
"""
|
|
# set the training/test mode for the model
|
|
if not isinstance(model, torch.jit.ScriptModule):
|
|
model.train(train)
|
|
# use the pre-trained model params if available
|
|
if state_dict is not None:
|
|
model.load_state_dict(state_dict)
|
|
|
|
# Either user specified input or random (deterministic) input
|
|
if input is None:
|
|
input = torch.randn(batch_size, 3, 224, 224, requires_grad=True)
|
|
# GPU-ize the model, if requested
|
|
if use_gpu:
|
|
model, input = self.convert_cuda(model, input)
|
|
|
|
# Verify the model runs the same in Caffe2
|
|
verify.verify(model, input, c2, rtol=rtol, atol=atol,
|
|
do_constant_folding=do_constant_folding)
|
|
|
|
def run_model_test(self, model, train, batch_size, state_dict=None,
|
|
input=None, use_gpu=True, rtol=0.001, atol=1e-7,
|
|
example_outputs=None, do_constant_folding=False):
|
|
use_gpu_ = torch.cuda.is_available() and use_gpu
|
|
if self.embed_params:
|
|
self.run_actual_test(model, train, batch_size, state_dict, input,
|
|
use_gpu=use_gpu_, rtol=rtol, atol=atol,
|
|
example_outputs=example_outputs,
|
|
do_constant_folding=do_constant_folding)
|
|
else:
|
|
self.run_debug_test(model, train, batch_size, state_dict, input,
|
|
use_gpu=use_gpu_, example_outputs=example_outputs,
|
|
do_constant_folding=do_constant_folding)
|
|
|
|
def test_linear(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
self.many_fc = nn.Sequential(
|
|
nn.Linear(4, 5, bias=True),
|
|
nn.ReLU(inplace=True),
|
|
nn.Linear(5, 6, bias=True),
|
|
nn.ReLU(inplace=True),
|
|
nn.Linear(6, 7, bias=True),
|
|
)
|
|
|
|
def forward(self, input):
|
|
return self.many_fc(input)
|
|
|
|
model = MyModel()
|
|
input = torch.randn(3, 4, requires_grad=True)
|
|
self.run_model_test(model, train=False, batch_size=0, input=input)
|
|
|
|
def test_onnx_export_with_parameter_renaming(self):
|
|
class SimpleFcNet(nn.Module):
|
|
def __init__(self):
|
|
super(SimpleFcNet, self).__init__()
|
|
self.fc1 = nn.Linear(5, 10)
|
|
|
|
def forward(self, input):
|
|
return self.fc1(input)
|
|
|
|
model = SimpleFcNet()
|
|
input = torch.randn(7, 5)
|
|
output = model(input)
|
|
|
|
f = io.BytesIO()
|
|
# Note that the export call explicitly sets the names of not just the input,
|
|
# but also the parameters. This test checks that the model can be loaded and
|
|
# executed in Caffe2 backend correctly.
|
|
torch.onnx._export(model, input, f, verbose=True, export_type=ExportTypes.ZIP_ARCHIVE,
|
|
input_names=['input1', 'parameter1', 'parameter2'])
|
|
|
|
f.seek(0)
|
|
model_c2 = c2.prepare_zip_archive(f)
|
|
result = model_c2.run(input.numpy())
|
|
np.testing.assert_almost_equal(output.data.cpu().numpy(), result[0], decimal=3)
|
|
|
|
def test_onnx_export_param_name_duplication(self):
|
|
class SimpleFcNet(nn.Module):
|
|
def __init__(self):
|
|
super(SimpleFcNet, self).__init__()
|
|
self.fc1 = nn.Linear(5, 10)
|
|
|
|
def forward(self, input):
|
|
return self.fc1(input)
|
|
|
|
model = SimpleFcNet()
|
|
input = torch.randn(7, 5)
|
|
output = model(input)
|
|
|
|
f = io.BytesIO()
|
|
# The export call explicitly sets the names of the input, and the first parameter.
|
|
# But note that the target first parameter name is the same as the second parameter name.
|
|
# This test checks that given this edge condition, the model can be loaded and executed
|
|
# in Caffe2 backend correctly.
|
|
torch.onnx._export(model, input, f, verbose=True, export_type=ExportTypes.ZIP_ARCHIVE,
|
|
input_names=['input1', 'fc1.bias'], _retain_param_name=False)
|
|
|
|
f.seek(0)
|
|
model_c2 = c2.prepare_zip_archive(f)
|
|
result = model_c2.run(input.numpy())
|
|
np.testing.assert_almost_equal(output.data.cpu().numpy(), result[0], decimal=3)
|
|
|
|
def test_lstm_cell(self):
|
|
model = nn.LSTMCell(RNN_INPUT_SIZE, RNN_HIDDEN_SIZE)
|
|
input = torch.randn(BATCH_SIZE, RNN_INPUT_SIZE)
|
|
h0 = torch.randn(BATCH_SIZE, RNN_HIDDEN_SIZE)
|
|
c0 = torch.randn(BATCH_SIZE, RNN_HIDDEN_SIZE)
|
|
self.run_model_test(model, train=False, batch_size=BATCH_SIZE, input=(input, (h0, c0)), use_gpu=False)
|
|
|
|
def test_gru_cell(self):
|
|
model = nn.GRUCell(RNN_INPUT_SIZE, RNN_HIDDEN_SIZE)
|
|
input = torch.randn(BATCH_SIZE, RNN_INPUT_SIZE)
|
|
h0 = torch.randn(BATCH_SIZE, RNN_HIDDEN_SIZE)
|
|
self.run_model_test(model, train=False, batch_size=BATCH_SIZE, input=(input, h0), use_gpu=False)
|
|
|
|
def _dispatch_rnn_test(self, name, *args, **kwargs):
|
|
if name == 'elman':
|
|
self._elman_rnn_test(*args, **kwargs)
|
|
if name == 'lstm':
|
|
self._lstm_test(*args, **kwargs)
|
|
if name == 'gru':
|
|
self._gru_test(*args, **kwargs)
|
|
|
|
def _elman_rnn_test(self, layers, nonlinearity, bidirectional,
|
|
initial_state, packed_sequence, dropout):
|
|
model = nn.RNN(RNN_INPUT_SIZE, RNN_HIDDEN_SIZE,
|
|
layers,
|
|
nonlinearity=nonlinearity,
|
|
bidirectional=bidirectional,
|
|
dropout=dropout)
|
|
|
|
if packed_sequence == 1:
|
|
model = RnnModelWithPackedSequence(model, False)
|
|
if packed_sequence == 2:
|
|
model = RnnModelWithPackedSequence(model, True)
|
|
|
|
def make_input(batch_size):
|
|
seq_lengths = np.random.randint(1, RNN_SEQUENCE_LENGTH + 1, size=batch_size)
|
|
seq_lengths = list(reversed(sorted(map(int, seq_lengths))))
|
|
inputs = [torch.randn(l, RNN_INPUT_SIZE) for l in seq_lengths]
|
|
inputs = rnn_utils.pad_sequence(inputs)
|
|
if packed_sequence == 2:
|
|
inputs = inputs.transpose(0, 1)
|
|
inputs = [inputs]
|
|
|
|
directions = 2 if bidirectional else 1
|
|
|
|
if initial_state:
|
|
h0 = torch.randn(directions * layers, batch_size, RNN_HIDDEN_SIZE)
|
|
inputs.append(h0)
|
|
if packed_sequence != 0:
|
|
inputs.append(torch.IntTensor(seq_lengths))
|
|
if len(inputs) == 1:
|
|
input = inputs[0]
|
|
else:
|
|
input = tuple(inputs)
|
|
return input
|
|
|
|
input = make_input(RNN_BATCH_SIZE)
|
|
self.run_model_test(model, train=False, batch_size=RNN_BATCH_SIZE, input=input, use_gpu=False, atol=1e-7)
|
|
|
|
# test that the model still runs with a different batch size
|
|
onnxir, _ = do_export(model, input)
|
|
other_input = make_input(RNN_BATCH_SIZE + 1)
|
|
_ = run_embed_params(onnxir, model, other_input, use_gpu=False)
|
|
|
|
def _lstm_test(self, layers, bidirectional, initial_state,
|
|
packed_sequence, dropout):
|
|
model = LstmFlatteningResult(
|
|
RNN_INPUT_SIZE, RNN_HIDDEN_SIZE, layers,
|
|
bidirectional=bidirectional, dropout=dropout)
|
|
if packed_sequence == 1:
|
|
model = RnnModelWithPackedSequence(model, False)
|
|
if packed_sequence == 2:
|
|
model = RnnModelWithPackedSequence(model, True)
|
|
|
|
def make_input(batch_size):
|
|
seq_lengths = np.random.randint(1, RNN_SEQUENCE_LENGTH + 1, size=batch_size)
|
|
seq_lengths = list(reversed(sorted(map(int, seq_lengths))))
|
|
inputs = [torch.randn(l, RNN_INPUT_SIZE) for l in seq_lengths]
|
|
inputs = rnn_utils.pad_sequence(inputs)
|
|
if packed_sequence == 2:
|
|
inputs = inputs.transpose(0, 1)
|
|
inputs = [inputs]
|
|
|
|
directions = 2 if bidirectional else 1
|
|
|
|
if initial_state:
|
|
h0 = torch.randn(directions * layers, batch_size, RNN_HIDDEN_SIZE)
|
|
c0 = torch.randn(directions * layers, batch_size, RNN_HIDDEN_SIZE)
|
|
inputs.append((h0, c0))
|
|
if packed_sequence != 0:
|
|
inputs.append(torch.IntTensor(seq_lengths))
|
|
if len(inputs) == 1:
|
|
input = inputs[0]
|
|
else:
|
|
input = tuple(inputs)
|
|
return input
|
|
|
|
input = make_input(RNN_BATCH_SIZE)
|
|
self.run_model_test(model, train=False, batch_size=RNN_BATCH_SIZE, input=input, use_gpu=False)
|
|
|
|
# test that the model still runs with a different batch size
|
|
onnxir, _ = do_export(model, input)
|
|
other_input = make_input(RNN_BATCH_SIZE + 1)
|
|
_ = run_embed_params(onnxir, model, other_input, use_gpu=False)
|
|
|
|
def _gru_test(self, layers, bidirectional, initial_state,
|
|
packed_sequence, dropout):
|
|
model = nn.GRU(RNN_INPUT_SIZE, RNN_HIDDEN_SIZE, layers,
|
|
bidirectional=bidirectional, dropout=dropout)
|
|
if packed_sequence == 1:
|
|
model = RnnModelWithPackedSequence(model, False)
|
|
if packed_sequence == 2:
|
|
model = RnnModelWithPackedSequence(model, True)
|
|
|
|
def make_input(batch_size):
|
|
seq_lengths = np.random.randint(1, RNN_SEQUENCE_LENGTH + 1, size=batch_size)
|
|
seq_lengths = list(reversed(sorted(map(int, seq_lengths))))
|
|
inputs = [torch.randn(l, RNN_INPUT_SIZE) for l in seq_lengths]
|
|
inputs = rnn_utils.pad_sequence(inputs)
|
|
if packed_sequence == 2:
|
|
inputs = inputs.transpose(0, 1)
|
|
inputs = [inputs]
|
|
|
|
directions = 2 if bidirectional else 1
|
|
|
|
if initial_state:
|
|
h0 = torch.randn(directions * layers, batch_size, RNN_HIDDEN_SIZE)
|
|
inputs.append(h0)
|
|
if packed_sequence != 0:
|
|
inputs.append(torch.IntTensor(seq_lengths))
|
|
if len(inputs) == 1:
|
|
input = inputs[0]
|
|
else:
|
|
input = tuple(inputs)
|
|
return input
|
|
|
|
input = make_input(RNN_BATCH_SIZE)
|
|
self.run_model_test(model, train=False, batch_size=RNN_BATCH_SIZE, input=input, use_gpu=False)
|
|
|
|
# test that the model still runs with a different batch size
|
|
onnxir, _ = do_export(model, input)
|
|
other_input = make_input(RNN_BATCH_SIZE + 1)
|
|
_ = run_embed_params(onnxir, model, other_input, use_gpu=False)
|
|
|
|
def test_rnn_init_predict_split(self):
|
|
model = nn.LSTM(RNN_INPUT_SIZE, RNN_HIDDEN_SIZE, 3, bidirectional=True)
|
|
seq_lengths = np.random.randint(1, RNN_SEQUENCE_LENGTH + 1, size=7)
|
|
seq_lengths = list(reversed(sorted(map(int, seq_lengths))))
|
|
input = [torch.randn(l, RNN_INPUT_SIZE) for l in seq_lengths]
|
|
input = rnn_utils.pad_sequence(input)
|
|
|
|
# Test that we are correctly splitting between init and
|
|
# predict net. When we embed parameters, there should be more
|
|
# ops in the init net.
|
|
mp = onnx.ModelProto.FromString(do_export(model, input, export_params=self.embed_params)[0])
|
|
prepared = c2.prepare(mp, device='CPU')
|
|
if self.embed_params:
|
|
assert len(prepared.init_net.op) == 875
|
|
assert len(prepared.predict_net.op) == 130
|
|
else:
|
|
assert len(prepared.init_net.op) == 8
|
|
assert len(prepared.predict_net.op) == 997
|
|
|
|
def test_alexnet(self):
|
|
state_dict = model_zoo.load_url(model_urls['alexnet'], progress=False)
|
|
self.run_model_test(alexnet(), train=False, batch_size=BATCH_SIZE,
|
|
state_dict=state_dict, atol=1e-3)
|
|
|
|
@skipIfNoCuda
|
|
def test_dcgan(self):
|
|
# dcgan is flaky on some seeds, see:
|
|
# https://github.com/ProjectToffee/onnx/pull/70
|
|
torch.manual_seed(1)
|
|
if torch.cuda.is_available():
|
|
torch.cuda.manual_seed_all(1)
|
|
|
|
netD = dcgan._netD(1)
|
|
netD.apply(dcgan.weights_init)
|
|
input = torch.randn(BATCH_SIZE, 3, dcgan.imgsz, dcgan.imgsz)
|
|
self.run_model_test(netD, train=False, batch_size=BATCH_SIZE,
|
|
input=input)
|
|
|
|
netG = dcgan._netG(1)
|
|
netG.apply(dcgan.weights_init)
|
|
state_dict = model_zoo.load_url(model_urls['dcgan_b'], progress=False)
|
|
# state_dict = model_zoo.load_url(model_urls['dcgan_f'], progress=False)
|
|
noise = torch.randn(BATCH_SIZE, dcgan.nz, 1, 1).normal_(0, 1)
|
|
self.run_model_test(netG, train=False, batch_size=BATCH_SIZE,
|
|
input=noise, state_dict=state_dict, rtol=1e-2, atol=1e-6)
|
|
|
|
@unittest.skipIf(not torch.cuda.is_available(),
|
|
"model on net has cuda in it, awaiting fix")
|
|
def test_densenet(self):
|
|
state_dict = model_zoo.load_url(model_urls['densenet121'], progress=False)
|
|
self.run_model_test(densenet121(), train=False, batch_size=BATCH_SIZE,
|
|
state_dict=state_dict, atol=1e-7)
|
|
|
|
@skip("doesn't match exactly...")
|
|
# TODO: figure out the numerical instabilities
|
|
def test_inception(self):
|
|
x = torch.randn(BATCH_SIZE, 3, 299, 299, requires_grad=True)
|
|
# state_dict = model_zoo.load_url(model_urls['inception_v3_google'], progress=False)
|
|
state_dict = None
|
|
self.run_model_test(inception_v3(), train=False, batch_size=BATCH_SIZE,
|
|
state_dict=state_dict, input=x)
|
|
|
|
def test_resnet(self):
|
|
state_dict = model_zoo.load_url(model_urls['resnet50'], progress=False)
|
|
self.run_model_test(resnet50(), train=False, batch_size=BATCH_SIZE,
|
|
state_dict=state_dict, atol=1e-6)
|
|
|
|
def test_squeezenet(self):
|
|
sqnet_v1_1 = SqueezeNet(version=1.1)
|
|
state_dict = model_zoo.load_url(model_urls['squeezenet1_1'], progress=False)
|
|
# state_dict = model_zoo.load_url(model_urls['squeezenet1_0'], progress=False)
|
|
self.run_model_test(sqnet_v1_1, train=False, batch_size=BATCH_SIZE,
|
|
state_dict=state_dict)
|
|
|
|
# @skip('takes long to run, LAPACK needed for gpu')
|
|
@skipIfNoLapack
|
|
@unittest.skip("This model takes too much memory")
|
|
def test_srresnet(self):
|
|
super_resolution_net = SRResNet(
|
|
rescale_factor=4, n_filters=64, n_blocks=8)
|
|
state_dict = model_zoo.load_url(model_urls['srresNet'], progress=False)
|
|
x = torch.randn(1, 3, 224, 224, requires_grad=True)
|
|
self.run_model_test(super_resolution_net, train=False,
|
|
batch_size=1, state_dict=state_dict,
|
|
input=x, use_gpu=False)
|
|
|
|
@skipIfTravis
|
|
@skipIfNoLapack
|
|
@skipIfNoCuda
|
|
def test_super_resolution(self):
|
|
super_resolution_net = SuperResolutionNet(upscale_factor=3)
|
|
state_dict = model_zoo.load_url(model_urls['super_resolution'], progress=False)
|
|
x = torch.randn(1, 1, 224, 224, requires_grad=True)
|
|
self.run_model_test(super_resolution_net, train=False,
|
|
batch_size=BATCH_SIZE, state_dict=state_dict,
|
|
input=x, use_gpu=False, atol=1e-6)
|
|
|
|
@unittest.skip("This model takes too much memory")
|
|
def test_vgg16(self):
|
|
state_dict = model_zoo.load_url(model_urls['vgg16'], progress=False)
|
|
self.run_model_test(vgg16(), train=False, batch_size=BATCH_SIZE,
|
|
state_dict=state_dict)
|
|
|
|
@skip("disable to run tests faster...")
|
|
def test_vgg16_bn(self):
|
|
self.run_model_test(vgg16_bn(), train=False,
|
|
batch_size=BATCH_SIZE)
|
|
|
|
@skip("disable to run tests faster...")
|
|
def test_vgg19(self):
|
|
state_dict = model_zoo.load_url(model_urls['vgg19'], progress=False)
|
|
self.run_model_test(vgg19(), train=False, batch_size=BATCH_SIZE,
|
|
state_dict=state_dict)
|
|
|
|
@skip("disable to run tests faster...")
|
|
def test_vgg19_bn(self):
|
|
self.run_model_test(vgg19_bn(), train=False,
|
|
batch_size=BATCH_SIZE)
|
|
|
|
def run_word_language_model(self, model_name):
|
|
ntokens = 50
|
|
emsize = 5
|
|
nhid = 5
|
|
nlayers = 5
|
|
dropout = 0.2
|
|
tied = False
|
|
batchsize = 5
|
|
model = word_language_model.RNNModel(model_name, ntokens, emsize,
|
|
nhid, nlayers, dropout, tied,
|
|
batchsize)
|
|
x = torch.arange(0, ntokens).long().view(-1, batchsize)
|
|
# Only support CPU version, since tracer is not working in GPU RNN.
|
|
self.run_model_test(model, train=False, input=(x, model.hidden),
|
|
batch_size=batchsize, use_gpu=False)
|
|
|
|
def test_word_language_model_RNN_TANH(self):
|
|
self.run_word_language_model("RNN_TANH")
|
|
|
|
def test_word_language_model_RNN_RELU(self):
|
|
self.run_word_language_model("RNN_RELU")
|
|
|
|
def test_word_language_model_LSTM(self):
|
|
self.run_word_language_model("LSTM")
|
|
|
|
def test_word_language_model_GRU(self):
|
|
self.run_word_language_model("GRU")
|
|
|
|
def test_batchnorm1d_special(self):
|
|
c = torch.randn(BATCH_SIZE, 224)
|
|
model = nn.BatchNorm1d(224)
|
|
self.run_model_test(model, train=True, input=c, batch_size=BATCH_SIZE)
|
|
|
|
def test_batchnorm2d_noaffine(self):
|
|
c = torch.randn(128, 128, 1, 1)
|
|
model = nn.BatchNorm2d(128, affine=False)
|
|
self.run_model_test(model, train=False, input=c, batch_size=BATCH_SIZE)
|
|
|
|
def test_constant(self):
|
|
c = torch.randn(BATCH_SIZE, 3, 224, 224)
|
|
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, input):
|
|
return input + c.type_as(input)
|
|
|
|
self.run_model_test(MyModel(), train=False, batch_size=BATCH_SIZE)
|
|
|
|
def test_consumed_bn(self):
|
|
underlying = nn.BatchNorm2d(3)
|
|
self.run_model_test(underlying, train=True, batch_size=BATCH_SIZE)
|
|
|
|
def _test_index_generic(self, fn):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, input):
|
|
return fn(input)
|
|
|
|
m1 = torch.randn(3, 4)
|
|
self.run_model_test(MyModel(), input=m1, train=False, batch_size=BATCH_SIZE)
|
|
|
|
def test_index_1d(self):
|
|
self._test_index_generic(lambda input: input[0])
|
|
|
|
def test_index_2d_1dimslice(self):
|
|
self._test_index_generic(lambda input: input[0:1, :])
|
|
|
|
def test_index_2d_sliceint(self):
|
|
self._test_index_generic(lambda input: input[1, :])
|
|
|
|
def test_index_2d_neg_slice(self):
|
|
self._test_index_generic(lambda input: input[0:-1, :])
|
|
|
|
# TODO: Slicing along two dimensions is currently unsupported by the caffe2
|
|
# backend. Revisit if this becomes supported in the future.
|
|
"""
|
|
def test_index_2d_2dimslice(self):
|
|
self._test_index_generic(lambda input: input[0:1, 0:1])
|
|
"""
|
|
"""
|
|
def test_index_2d_neg_slice2dim(self):
|
|
self._test_index_generic(lambda input: input[0:-1, 0:-1])
|
|
"""
|
|
|
|
def test_chunk(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, input):
|
|
# TODO: Why index? This returns a tuple and test runner doesn't
|
|
# support tuple comparison.
|
|
return input.chunk(8, dim=2)[-1]
|
|
self.run_model_test(MyModel(), train=False, batch_size=BATCH_SIZE)
|
|
|
|
def test_sqrt(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, input):
|
|
return input.sqrt()
|
|
input = torch.empty(BATCH_SIZE, 10, 10).uniform_(4, 9)
|
|
self.run_model_test(MyModel(), train=False, input=input, batch_size=BATCH_SIZE)
|
|
|
|
def test_log(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, input):
|
|
return input.log()
|
|
input = torch.empty(BATCH_SIZE, 10, 10).uniform_(4, 9)
|
|
self.run_model_test(MyModel(), train=False, input=input, batch_size=BATCH_SIZE)
|
|
|
|
def test_erf(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, input):
|
|
return input.erf()
|
|
input = torch.empty(BATCH_SIZE, 10, 10).uniform_(4, 9)
|
|
self.run_model_test(MyModel(), train=False, input=input, batch_size=BATCH_SIZE)
|
|
|
|
def test_trigonometry(self):
|
|
def test_func(name):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, input):
|
|
return getattr(input, name)()
|
|
input = torch.empty(BATCH_SIZE, 10, 10).uniform_()
|
|
self.run_model_test(MyModel(), train=False, input=input, batch_size=BATCH_SIZE)
|
|
|
|
test_func('cos')
|
|
test_func('sin')
|
|
test_func('tan')
|
|
test_func('acos')
|
|
test_func('asin')
|
|
test_func('atan')
|
|
|
|
def test_addconstant(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, input):
|
|
# TODO: Why index? This returns a tuple and test runner doesn't
|
|
# support tuple comparison.
|
|
return input + 1
|
|
self.run_model_test(MyModel(), train=False, batch_size=BATCH_SIZE)
|
|
|
|
def test_subconstant(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, input):
|
|
# TODO: Why index? This returns a tuple and test runner doesn't
|
|
# support tuple comparison.
|
|
return input - 1
|
|
self.run_model_test(MyModel(), train=False, batch_size=BATCH_SIZE)
|
|
|
|
def test_embedding(self):
|
|
model = nn.Embedding(10, 3, padding_idx=-1)
|
|
input = torch.LongTensor(list(range(10))[::-1])
|
|
self.run_model_test(model, train=False, input=input, batch_size=BATCH_SIZE)
|
|
|
|
def test_constantpad2d(self):
|
|
model = nn.ConstantPad2d((1, 2, 3, 4), 3.5)
|
|
self.run_model_test(model, train=False, batch_size=BATCH_SIZE)
|
|
|
|
def test_reflectionpad2d(self):
|
|
model = nn.ReflectionPad2d((1, 2, 3, 4))
|
|
self.run_model_test(model, train=False, batch_size=BATCH_SIZE)
|
|
|
|
def test_replicationpad2d(self):
|
|
model = nn.ReplicationPad2d((1, 2, 3, 4))
|
|
self.run_model_test(model, train=False, batch_size=BATCH_SIZE)
|
|
|
|
def test_maxpool2d(self):
|
|
model = nn.MaxPool2d(5, padding=(1, 2))
|
|
self.run_model_test(model, train=False, batch_size=BATCH_SIZE)
|
|
|
|
def test_maxpool2d_single_padding(self):
|
|
model = nn.MaxPool2d(5, padding=2)
|
|
self.run_model_test(model, train=False, batch_size=BATCH_SIZE)
|
|
|
|
def test_maxpool1d_ceil(self):
|
|
model = nn.MaxPool1d(3, 2, ceil_mode=True)
|
|
x = torch.randn(20, 16, 50, requires_grad=True)
|
|
self.run_model_test(model, train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_maxpool2d_ceil(self):
|
|
model = nn.MaxPool2d(3, 2, ceil_mode=True)
|
|
x = torch.randn(20, 16, 50, 32, requires_grad=True)
|
|
self.run_model_test(model, train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_maxpool3d_ceil(self):
|
|
model = nn.MaxPool3d(3, 2, ceil_mode=True)
|
|
x = torch.randn(20, 16, 50, 44, 31, requires_grad=True)
|
|
self.run_model_test(model, train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
@unittest.skip("C2 and PyTorch have small difference in padding implementation")
|
|
def test_avgpool2d(self):
|
|
model = nn.AvgPool2d(5, padding=(2))
|
|
self.run_model_test(model, train=False, batch_size=BATCH_SIZE)
|
|
|
|
def test_avgpool2d_with_count_include_pad_set_false(self):
|
|
model = nn.AvgPool2d(7, padding=(2), count_include_pad=False)
|
|
self.run_model_test(model, train=False, batch_size=BATCH_SIZE)
|
|
|
|
def test_avgpool2d_with_count_include_pad_set_true(self):
|
|
model = nn.AvgPool2d(7, padding=(2), count_include_pad=True)
|
|
self.run_model_test(model, train=False, batch_size=BATCH_SIZE)
|
|
|
|
def test_avgpool2d_no_padding(self):
|
|
model = nn.AvgPool2d(5)
|
|
self.run_model_test(model, train=False, batch_size=BATCH_SIZE)
|
|
|
|
def test_avg_pool1D_ceil(self):
|
|
model = torch.nn.AvgPool1d(3, 2, ceil_mode=True)
|
|
x = torch.randn(1, 1, 7, requires_grad=True)
|
|
self.run_model_test(model, train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_avg_pool2D_ceil(self):
|
|
model = torch.nn.AvgPool2d(3, 2, ceil_mode=True)
|
|
x = torch.randn(20, 16, 50, 32, requires_grad=True)
|
|
self.run_model_test(model, train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_avg_pool3D_ceil(self):
|
|
model = torch.nn.AvgPool3d(3, 2, ceil_mode=True)
|
|
x = torch.randn(20, 16, 50, 44, 31, requires_grad=True)
|
|
self.run_model_test(model, train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_adaptive_avg_pool1D(self):
|
|
model = torch.nn.AdaptiveAvgPool1d((5))
|
|
x = torch.randn(20, 16, 50, requires_grad=True)
|
|
self.run_model_test(model, train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_adaptive_avg_pool2D(self):
|
|
model = torch.nn.AdaptiveAvgPool2d((5, 4))
|
|
x = torch.randn(20, 16, 50, 32, requires_grad=True)
|
|
self.run_model_test(model, train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_adaptive_avg_pool3D(self):
|
|
model = torch.nn.AdaptiveAvgPool3d((5, 4, 3))
|
|
x = torch.randn(20, 16, 50, 44, 30, requires_grad=True)
|
|
self.run_model_test(model, train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_adaptive_max_pool1D(self):
|
|
model = torch.nn.AdaptiveMaxPool1d((5))
|
|
x = torch.randn(20, 16, 50, requires_grad=True)
|
|
self.run_model_test(model, train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_adaptive_max_pool2D(self):
|
|
model = torch.nn.AdaptiveMaxPool2d((5, 4))
|
|
x = torch.randn(20, 16, 50, 32, requires_grad=True)
|
|
self.run_model_test(model, train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_adaptive_max_pool3D(self):
|
|
model = torch.nn.AdaptiveMaxPool3d((5, 4, 3))
|
|
x = torch.randn(20, 16, 50, 44, 30, requires_grad=True)
|
|
self.run_model_test(model, train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_weight_norm(self):
|
|
model = nn.utils.weight_norm(nn.Conv1d(1, 1, 3))
|
|
input = torch.randn(1, 1, 5, requires_grad=True)
|
|
self.run_model_test(
|
|
model, train=True, batch_size=0, input=input, use_gpu=False
|
|
)
|
|
|
|
def test_mnist(self):
|
|
model = MNIST()
|
|
input = torch.randn(BATCH_SIZE, 1, 28, 28)
|
|
state_dict = None
|
|
# TODO: test with state_dict
|
|
self.run_model_test(model, train=False, input=input, batch_size=BATCH_SIZE,
|
|
state_dict=state_dict)
|
|
|
|
def test_mm(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, m1, m2):
|
|
return torch.mm(m1, m2)
|
|
m1 = torch.randn(3, 4)
|
|
m2 = torch.randn(4, 5)
|
|
self.run_model_test(MyModel(), train=False, input=(m1, m2), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_addmm(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, ma, m1, m2):
|
|
return torch.addmm(ma, m1, m2)
|
|
ma = torch.randn(5)
|
|
m1 = torch.randn(3, 4)
|
|
m2 = torch.randn(4, 5)
|
|
self.run_model_test(MyModel(), train=False, input=(ma, m1, m2), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
# test for a pytorch optimization pass, see https://github.com/pytorch/pytorch/pull/7872
|
|
def test_consecutive_transposes(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, x):
|
|
return x.transpose(1, 2).transpose(2, 3)
|
|
x = torch.randn(5, 6, 7, 8)
|
|
self.run_model_test(MyModel(), train=False, input=x, batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_sum(self):
|
|
shape = (3, 4, 5)
|
|
for params in [{}] + [{'dim': i} for i in range(len(shape))]:
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, x):
|
|
return torch.sum(x, **params)
|
|
x = torch.randn(*shape)
|
|
self.run_model_test(MyModel(), train=False, input=(x), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_cumsum(self):
|
|
shape = (3, 4, 5)
|
|
for params in [{'dim': i} for i in range(len(shape))]:
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, x):
|
|
return torch.cumsum(x, **params)
|
|
x = torch.randn(*shape)
|
|
self.run_model_test(MyModel(), train=False, input=(x), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_layer_norm(self):
|
|
shape = (20, 5, 10, 10)
|
|
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
self.ln = torch.nn.LayerNorm([5, 10, 10])
|
|
|
|
def forward(self, x):
|
|
return self.ln(x)
|
|
|
|
x = torch.randn(*shape)
|
|
self.run_model_test(MyModel(), train=False, input=(x,), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_lstm_constant_folding(self):
|
|
class LstmNet(nn.Module):
|
|
def __init__(self, input_size, hidden_size, num_layers, bidirectional):
|
|
super(LstmNet, self).__init__()
|
|
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, bidirectional=bidirectional)
|
|
|
|
def forward(self, input, initial_state):
|
|
return self.lstm(input, initial_state)
|
|
|
|
def get_LstmNet_model_and_inputs(input_size, hidden_size, num_layers, batch_size,
|
|
seq_len, bidirectional):
|
|
num_directions = 2 if bidirectional else 1
|
|
model = LstmNet(input_size, hidden_size, num_layers, bidirectional)
|
|
input = torch.randn(seq_len, batch_size, input_size)
|
|
h0 = torch.randn(num_layers * num_directions, batch_size, hidden_size)
|
|
c0 = torch.randn(num_layers * num_directions, batch_size, hidden_size)
|
|
return model, (input, (h0, c0))
|
|
|
|
batch_size1 = 3
|
|
model1, input1 = get_LstmNet_model_and_inputs(7, 3, 2, batch_size1, 5, True)
|
|
self.run_actual_test(model1, train=False, batch_size=batch_size1, input=input1, use_gpu=False, do_constant_folding=True)
|
|
|
|
batch_size2 = 4
|
|
model2, input2 = get_LstmNet_model_and_inputs(5, 4, 3, batch_size2, 7, False)
|
|
self.run_actual_test(model2, train=False, batch_size=batch_size2, input=input2, use_gpu=False, do_constant_folding=True)
|
|
|
|
def test_gru_constant_folding(self):
|
|
class GruNet(nn.Module):
|
|
def __init__(self, input_size, hidden_size, num_layers, bidirectional):
|
|
super(GruNet, self).__init__()
|
|
self.mygru = nn.GRU(input_size, hidden_size, num_layers, bidirectional=bidirectional)
|
|
|
|
def forward(self, input, initial_state):
|
|
out = self.mygru(input, initial_state)
|
|
return out
|
|
|
|
def get_GruNet_model_and_inputs(input_size, hidden_size, num_layers, batch_size,
|
|
seq_len, bidirectional):
|
|
num_directions = 2 if bidirectional else 1
|
|
model = GruNet(input_size, hidden_size, num_layers, bidirectional)
|
|
input = torch.randn(seq_len, batch_size, input_size)
|
|
h0 = torch.randn(num_layers * num_directions, batch_size, hidden_size)
|
|
return model, (input, h0)
|
|
|
|
batch_size1 = 3
|
|
model1, input1 = get_GruNet_model_and_inputs(7, 3, 2, batch_size1, 5, True)
|
|
self.run_actual_test(model1, train=False, batch_size=batch_size1, input=input1, use_gpu=False, do_constant_folding=True)
|
|
|
|
batch_size2 = 4
|
|
model2, input2 = get_GruNet_model_and_inputs(5, 4, 3, batch_size2, 7, False)
|
|
self.run_actual_test(model2, train=False, batch_size=batch_size2, input=input2, use_gpu=False, do_constant_folding=True)
|
|
|
|
def test_repeat(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, x):
|
|
return x.repeat(1, 2, 3, 4)
|
|
|
|
x = torch.randn(4, 3, 2, 1, requires_grad=True)
|
|
self.run_model_test(MyModel(), train=False, input=(x), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_upsample(self):
|
|
x = torch.randn(1, 2, 3, 4, requires_grad=True)
|
|
model = nn.Upsample(size=[v * 2 for v in x.size()[2:]], mode='nearest')
|
|
self.run_model_test(model, train=False, input=(x),
|
|
batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_interpolate_upsample(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, x):
|
|
size = [v * 2 for v in x.size()[2:]]
|
|
# work around for now: turn the dynamic sizes into constant
|
|
size = [int(i) for i in size]
|
|
return nn.functional.interpolate(x,
|
|
size=size,
|
|
mode='nearest')
|
|
|
|
x = torch.randn(1, 2, 3, 4, requires_grad=True)
|
|
model = MyModel()
|
|
self.run_model_test(model, train=False, input=(x),
|
|
batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_repeat_dim_overflow(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, x):
|
|
return x.repeat(1, 2, 3, 4)
|
|
|
|
x = torch.randn(1, 2, requires_grad=True)
|
|
self.run_model_test(MyModel(), train=False, input=(x), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_repeat_dynamic(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, x, y):
|
|
return x.repeat(y.size()[0] / 2, y.size()[1] * 2)
|
|
|
|
x = torch.randn(1, 2, requires_grad=True)
|
|
y = torch.randn(2, 4, requires_grad=True)
|
|
self.run_model_test(MyModel(), train=False, input=(x, y), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_mean(self):
|
|
shape = (3, 4, 5)
|
|
for params in [{}] + [{'dim': i} for i in range(len(shape))]:
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, x):
|
|
return torch.mean(x, **params)
|
|
x = torch.randn(*shape)
|
|
self.run_model_test(MyModel(), train=False, input=(x), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
# TODO: Add test cases for prod once Caffe2 has support for ReduceProd
|
|
def test_softmax(self):
|
|
for i in range(2, 8):
|
|
for d in range(0, i - 1):
|
|
model = nn.Softmax(dim=d)
|
|
dims = [2] * (i - 2) + [3, 4]
|
|
input = torch.ones(*dims, requires_grad=True)
|
|
self.run_model_test(model, train=False, batch_size=BATCH_SIZE, input=input)
|
|
|
|
def test_softmax_dtype(self):
|
|
class SoftmaxModel(torch.nn.Module):
|
|
def forward(self, input):
|
|
return nn.functional.softmax(input, dim=0, dtype=torch.float64)
|
|
|
|
x = torch.randn(1, 2, 3, requires_grad=True, dtype=torch.float32)
|
|
self.run_model_test(SoftmaxModel(), train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_logsoftmax(self):
|
|
for i in range(7)[2:]:
|
|
model = nn.LogSoftmax(dim=i - 1)
|
|
dims = [2] * (i - 2) + [3, 4]
|
|
input = torch.ones(*dims, requires_grad=True)
|
|
self.run_model_test(model, train=False, batch_size=BATCH_SIZE, input=input)
|
|
|
|
def test_randn(self):
|
|
x = torch.randn(1, 2, 3, 4)
|
|
|
|
class MyModule(torch.nn.Module):
|
|
def forward(self, x):
|
|
return (torch.randn(1, 2, 3, 4) + x).shape
|
|
self.run_model_test(MyModule(), train=False, input=(x),
|
|
batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_convtranspose(self):
|
|
model = nn.ConvTranspose2d(3, 3, 3, stride=3, bias=False, padding=1, output_padding=2)
|
|
self.run_model_test(model, train=False, batch_size=BATCH_SIZE, atol=1e-7)
|
|
|
|
def test_unsqueeze(self):
|
|
shape = (3, 4, 5)
|
|
for dim in range(len(shape) + 1):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, x):
|
|
return x.unsqueeze(dim)
|
|
x = torch.randn(*shape)
|
|
self.run_model_test(MyModel(), train=False, input=(x), batch_size=BATCH_SIZE, atol=1e-7)
|
|
|
|
# NB: InstanceNorm model includes unused weights, so skip this in TestCaffe2BackendEmbed
|
|
# TODO: We should have another pass to eliminate the unused initializers in ONNX models.
|
|
@skipIfEmbed
|
|
def test_instance_norm(self):
|
|
underlying = nn.InstanceNorm2d(3)
|
|
self.run_model_test(underlying, train=False, batch_size=BATCH_SIZE)
|
|
|
|
def test_pixel_shuffle(self):
|
|
underlying = nn.PixelShuffle(4)
|
|
shape = (1, 64, 5, 5)
|
|
input = Variable(torch.randn(*shape),
|
|
requires_grad=True)
|
|
self.run_model_test(underlying, train=False, input=(input),
|
|
batch_size=BATCH_SIZE)
|
|
|
|
def test_dynamic_sizes(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, x):
|
|
shape = torch.onnx.operators.shape_as_tensor(x)
|
|
new_shape = torch.cat((torch.LongTensor([-1]), shape[0].view(1)))
|
|
return torch.onnx.operators.reshape_from_tensor_shape(x, new_shape)
|
|
x = torch.randn(3, 5, 7)
|
|
self.run_model_test(MyModel(), train=False, input=x, batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_advanced_broadcast(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, x, y):
|
|
return torch.mul(x, y)
|
|
x = torch.randn(1, 5, 10)
|
|
y = torch.randn(1, 5, 1)
|
|
self.run_model_test(MyModel(), train=False, input=(x, y), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_int8_export(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
self.param = torch.ByteTensor(3, 4).random_()
|
|
|
|
def forward(self, x):
|
|
return x * self.param.float()
|
|
|
|
import io
|
|
f = io.BytesIO()
|
|
from torch.onnx import ExportTypes
|
|
torch.onnx._export(MyModel(), (torch.rand(3, 4),), f, verbose=True, export_type=ExportTypes.ZIP_ARCHIVE)
|
|
|
|
X = np.random.rand(3, 4).astype(np.float32)
|
|
|
|
f.seek(0)
|
|
import caffe2.python.onnx.backend as c2
|
|
model = c2.prepare_zip_archive(f)
|
|
model.run(X)
|
|
|
|
def test_neg_slice(self):
|
|
class NegSlice(torch.nn.Module):
|
|
def forward(self, x):
|
|
return x[-1, :, :]
|
|
|
|
x = torch.randn(3, 4, 5)
|
|
self.run_model_test(NegSlice(), train=False, input=(x,), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_neg_slice_large(self):
|
|
class NegSlice(torch.nn.Module):
|
|
def forward(self, x):
|
|
return x[:, :, :, :, -3]
|
|
|
|
x = torch.randn(3, 4, 5, 6, 7)
|
|
self.run_model_test(NegSlice(), train=False, input=(x,), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
@unittest.skip('https://github.com/pytorch/pytorch/issues/10984')
|
|
def test_neg_slice_large_negone(self):
|
|
class NegSlice(torch.nn.Module):
|
|
def forward(self, x):
|
|
return x[:, :, :, :, -1]
|
|
|
|
x = torch.randn(3, 4, 5, 6, 7)
|
|
self.run_model_test(NegSlice(), train=False, input=(x,), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_dynamic_slice(self):
|
|
class DynamicSliceExportMod(torch.nn.Module):
|
|
def forward(self, x):
|
|
results = []
|
|
for i in range(4):
|
|
results.append(x[:x.size(0) - i, i:x.size(2), i:3])
|
|
return tuple(results)
|
|
|
|
x = torch.rand(5, 5, 5)
|
|
self.run_model_test(DynamicSliceExportMod(), train=False, input=(x,), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_dynamic_slice_to_the_end(self):
|
|
class DynamicSliceExportMod(torch.nn.Module):
|
|
def forward(self, x):
|
|
results = []
|
|
for i in range(4):
|
|
results.append(x[:, i:, x.size(2) - 5])
|
|
return tuple(results)
|
|
|
|
x = torch.rand(5, 5, 5)
|
|
self.run_model_test(DynamicSliceExportMod(), train=False, input=(x,), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_tensor_factories(self):
|
|
class TensorFactory(torch.nn.Module):
|
|
def forward(self, x):
|
|
return torch.zeros(x.size()) + torch.ones(x.size())
|
|
|
|
x = torch.randn(2, 3, 4)
|
|
self.run_model_test(TensorFactory(), train=False, input=(x,), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_where_functional(self):
|
|
class WhereFunctional(torch.nn.Module):
|
|
def forward(self, x):
|
|
return torch.where(x > 2.0, x, torch.neg(x))
|
|
|
|
x = torch.randn(3, 4)
|
|
self.run_model_test(WhereFunctional(), train=False, input=(x,), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_where_method(self):
|
|
class WhereMethod(torch.nn.Module):
|
|
def forward(self, x):
|
|
return x.where(x > 2.0, torch.neg(x))
|
|
|
|
x = torch.randn(3, 4)
|
|
self.run_model_test(WhereMethod(), train=False, input=(x,), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_data_dependent_zeros_factory(self):
|
|
class ZerosFactory(torch.nn.Module):
|
|
def forward(self, input):
|
|
return torch.cat([input, torch.zeros(input.size(0), 1).type_as(input)], dim=1)
|
|
|
|
x = torch.zeros(3, 4)
|
|
self.run_model_test(ZerosFactory(), train=False, input=(x,), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_implicit_expand(self):
|
|
class ImplicitExpandExportMod(torch.nn.Module):
|
|
def forward(self, x):
|
|
return x + 1
|
|
|
|
x = torch.randn(3, 4)
|
|
self.run_model_test(ImplicitExpandExportMod(), train=False, input=(x,), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_reduce_sum(self):
|
|
class ReduceSumNegativeIndices(torch.nn.Module):
|
|
def forward(self, x):
|
|
return x.sum(-1)
|
|
|
|
x = torch.randn(2, 3, 4)
|
|
self.run_model_test(ReduceSumNegativeIndices(), train=False, input=(x,), batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_group_norm(self):
|
|
c = torch.randn(BATCH_SIZE, 6, 224)
|
|
model = nn.GroupNorm(3, 6)
|
|
self.run_model_test(model, train=True, input=c, batch_size=BATCH_SIZE)
|
|
|
|
def test_rsub(self):
|
|
class RsubModel(torch.nn.Module):
|
|
def forward(self, x):
|
|
return 1 - x
|
|
|
|
x = torch.randn(1, 2)
|
|
self.run_model_test(RsubModel(), train=False, input=(x,),
|
|
batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_isnan(self):
|
|
class IsNaNModel(torch.nn.Module):
|
|
def forward(self, input):
|
|
return torch.isnan(input)
|
|
|
|
x = torch.tensor([1.0, float('nan'), 2.0])
|
|
self.run_model_test(IsNaNModel(), train=False, input=x, batch_size=BATCH_SIZE, use_gpu=False)
|
|
|
|
def test_flatten(self):
|
|
class FlattenModel(torch.nn.Module):
|
|
def forward(self, input):
|
|
return torch.flatten(input)
|
|
|
|
x = torch.randn(1, 2, 3, 4, requires_grad=True)
|
|
self.run_model_test(FlattenModel(), train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_flatten2D(self):
|
|
class FlattenModel(torch.nn.Module):
|
|
def forward(self, input):
|
|
return torch.flatten(input, 1)
|
|
|
|
x = torch.randn(1, 2, 3, 4, requires_grad=True)
|
|
self.run_model_test(FlattenModel(), train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_argmax(self):
|
|
class ArgmaxModel(torch.nn.Module):
|
|
def forward(self, input):
|
|
return torch.argmax(input, dim=1)
|
|
|
|
x = torch.randn(4, 4, requires_grad=True)
|
|
self.run_model_test(ArgmaxModel(), train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_argmax_none_dim(self):
|
|
class ArgmaxModel(torch.nn.Module):
|
|
def forward(self, input):
|
|
return torch.argmax(input)
|
|
|
|
x = torch.randn(4, 4, requires_grad=True)
|
|
self.run_model_test(ArgmaxModel(), train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_argmin(self):
|
|
class ArgminModel(torch.nn.Module):
|
|
def forward(self, input):
|
|
return torch.argmin(input, dim=1)
|
|
|
|
x = torch.randn(4, 4, requires_grad=True)
|
|
self.run_model_test(ArgminModel(), train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_argmin_none_dim(self):
|
|
class ArgminModel(torch.nn.Module):
|
|
def forward(self, input):
|
|
return torch.argmin(input)
|
|
|
|
x = torch.randn(4, 4, requires_grad=True)
|
|
self.run_model_test(ArgminModel(), train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_reshape(self):
|
|
class ReshapeModel(torch.nn.Module):
|
|
def forward(self, input):
|
|
return input.reshape(1, 1)
|
|
|
|
x = torch.randn(1, requires_grad=True)
|
|
self.run_model_test(ReshapeModel(), train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_reshape_as(self):
|
|
class ReshapeAsModel(torch.nn.Module):
|
|
def forward(self, input):
|
|
y = torch.randn(3, 1, 2, 1, requires_grad=False)
|
|
return input.reshape_as(y)
|
|
|
|
x = torch.randn(2, 3, requires_grad=True)
|
|
self.run_model_test(ReshapeAsModel(), train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_narrow(self):
|
|
class NarrowModel(torch.nn.Module):
|
|
def forward(self, input):
|
|
return torch.narrow(input, 0, 0, 2)
|
|
|
|
x = torch.randn(3, 3, requires_grad=True)
|
|
self.run_model_test(NarrowModel(), train=False, input=x, batch_size=BATCH_SIZE)
|
|
|
|
def test_traced_ints(self):
|
|
A = 4
|
|
H = 10
|
|
W = 8
|
|
img_count = 3
|
|
|
|
# in this model, the constant propagation in JIT doesn't work
|
|
# so we have ListConstruct in the symbolic
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
self.conv = torch.nn.Conv2d(A, 4 * A, 1, stride=1)
|
|
|
|
def forward(self, feature, im_info, anchors):
|
|
bbox_deltas = self.conv(feature)
|
|
a, b = torch.ops._caffe2.GenerateProposals(
|
|
feature, bbox_deltas, im_info, anchors,
|
|
2.0, 6000, 300, 0.7, 16, True, -90, 90, 1.0,
|
|
)
|
|
output = torch.ops._caffe2.RoIAlign(
|
|
feature, a,
|
|
order="NCHW",
|
|
spatial_scale=1.0,
|
|
pooled_h=3,
|
|
pooled_w=3,
|
|
sampling_ratio=0,
|
|
)
|
|
return output
|
|
|
|
feature = torch.Tensor(img_count, A, H, W)
|
|
im_info = torch.ones(img_count, 3, dtype=torch.float32)
|
|
anchors = torch.ones(A, 4, dtype=torch.float32)
|
|
inputs = (feature, im_info, anchors)
|
|
|
|
model = MyModel()
|
|
with torch.no_grad():
|
|
self.run_model_test(MyModel(), train=False, input=inputs, batch_size=BATCH_SIZE)
|
|
|
|
def test_c2_roi_align(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, feature, rois):
|
|
roi_feature = torch.ops._caffe2.RoIAlign(
|
|
feature, rois, order="NCHW", spatial_scale=1.0,
|
|
pooled_h=3, pooled_w=3, sampling_ratio=3,
|
|
)
|
|
return roi_feature
|
|
|
|
def rand_roi(N, C, H, W):
|
|
return [
|
|
float(int(N * np.random.rand())),
|
|
0.5 * np.random.rand() * W,
|
|
0.5 * np.random.rand() * H,
|
|
(0.5 + 0.5 * np.random.rand()) * W,
|
|
(0.5 + 0.5 * np.random.rand()) * H,
|
|
]
|
|
|
|
N, C, H, W = 1, 4, 10, 8
|
|
feature = torch.randn(N, C, H, W)
|
|
rois = torch.tensor([rand_roi(N, C, H, W) for _ in range(10)])
|
|
inputs = (feature, rois)
|
|
self.run_model_test(MyModel(), train=False, input=inputs, batch_size=3)
|
|
|
|
def test_c2_generate_proposals(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, scores, bbox_deltas, im_info, anchors):
|
|
a, b = torch.ops._caffe2.GenerateProposals(
|
|
scores, bbox_deltas, im_info, anchors,
|
|
2.0, 6000, 300, 0.7, 16, True, -90, 90, 1.0,
|
|
)
|
|
return a, b
|
|
|
|
A = 4
|
|
H = 10
|
|
W = 8
|
|
img_count = 3
|
|
scores = torch.ones(img_count, A, H, W, dtype=torch.float32)
|
|
bbox_deltas = torch.linspace(0, 10, steps=img_count * 4 * A * H * W,
|
|
dtype=torch.float32)
|
|
bbox_deltas = bbox_deltas.view(img_count, 4 * A, H, W)
|
|
im_info = torch.ones(img_count, 3, dtype=torch.float32)
|
|
anchors = torch.ones(A, 4, dtype=torch.float32)
|
|
inputs = (scores, bbox_deltas, im_info, anchors)
|
|
self.run_model_test(MyModel(), train=False, input=inputs, batch_size=3)
|
|
|
|
def test_c2_bbox_transform(self):
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, rois, deltas, im_info):
|
|
a, b = torch.ops._caffe2.BBoxTransform(
|
|
rois,
|
|
deltas,
|
|
im_info,
|
|
weights=[1., 1., 1., 1.],
|
|
apply_scale=False,
|
|
rotated=True,
|
|
angle_bound_on=True,
|
|
angle_bound_lo=-90,
|
|
angle_bound_hi=90,
|
|
clip_angle_thresh=0.5,
|
|
)
|
|
return a, b
|
|
|
|
roi_counts = [0, 2, 3, 4, 5]
|
|
batch_size = len(roi_counts)
|
|
total_rois = sum(roi_counts)
|
|
im_dims = np.random.randint(100, 600, batch_size)
|
|
rois = generate_rois_rotated(roi_counts, im_dims)
|
|
box_dim = 5
|
|
num_classes = 7
|
|
deltas = np.random.randn(total_rois, box_dim * num_classes).astype(np.float32)
|
|
im_info = np.zeros((batch_size, 3)).astype(np.float32)
|
|
im_info[:, 0] = im_dims
|
|
im_info[:, 1] = im_dims
|
|
im_info[:, 2] = 1.0
|
|
im_info = torch.zeros((batch_size, 3))
|
|
inputs = (torch.tensor(rois), torch.tensor(deltas), torch.tensor(im_info))
|
|
self.run_model_test(MyModel(), train=False, input=inputs, batch_size=3)
|
|
|
|
# BoxWithNMSLimits has requirements for the inputs, so randomly generated inputs
|
|
# in Caffe2BackendTestEmbed doesn't work with this op.
|
|
@skipIfEmbed
|
|
def test_c2_box_with_nms_limits(self):
|
|
roi_counts = [0, 2, 3, 4, 5]
|
|
num_classes = 7
|
|
rotated = False
|
|
angle_bound_on = True
|
|
clip_angle_thresh = 0.5
|
|
rois, deltas, im_info = create_bbox_transform_inputs(
|
|
roi_counts, num_classes, rotated
|
|
)
|
|
pred_bbox, batch_splits = [
|
|
t.detach().numpy()
|
|
for t in torch.ops._caffe2.BBoxTransform(
|
|
torch.tensor(rois),
|
|
torch.tensor(deltas),
|
|
torch.tensor(im_info),
|
|
[1.0, 1.0, 1.0, 1.0],
|
|
False,
|
|
rotated,
|
|
angle_bound_on,
|
|
-90,
|
|
90,
|
|
clip_angle_thresh,
|
|
)
|
|
]
|
|
class_prob = np.random.randn(sum(roi_counts), num_classes).astype(np.float32)
|
|
score_thresh = 0.5
|
|
nms_thresh = 0.5
|
|
topk_per_image = int(sum(roi_counts) / 2)
|
|
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, class_prob, pred_bbox, batch_splits):
|
|
a, b, c, d = torch.ops._caffe2.BoxWithNMSLimit(
|
|
class_prob,
|
|
pred_bbox,
|
|
batch_splits,
|
|
score_thresh=score_thresh,
|
|
nms=nms_thresh,
|
|
detections_per_im=topk_per_image,
|
|
soft_nms_enabled=False,
|
|
soft_nms_method="linear",
|
|
soft_nms_sigma=0.5,
|
|
soft_nms_min_score_thres=0.001,
|
|
rotated=rotated,
|
|
)
|
|
return a, b, c, d
|
|
|
|
inputs = (torch.tensor(class_prob), torch.tensor(pred_bbox), torch.tensor(batch_splits))
|
|
self.run_model_test(MyModel(), train=False, input=inputs, batch_size=3)
|
|
|
|
def test_c2_inference_lstm(self):
|
|
num_layers = 4
|
|
seq_lens = 6
|
|
emb_lens = 10
|
|
has_bias = True
|
|
batch_first = True
|
|
is_bidirectional = True
|
|
|
|
class MyModel(torch.nn.Module):
|
|
def __init__(self):
|
|
super(MyModel, self).__init__()
|
|
|
|
def forward(self, lstm_in):
|
|
a, b, c = torch.ops._caffe2.InferenceLSTM(
|
|
lstm_in, num_layers, has_bias, batch_first, is_bidirectional
|
|
)
|
|
return a, b, c
|
|
|
|
num_directions = 2
|
|
bsz = 5
|
|
hidden_size = 7
|
|
hx = np.zeros((num_layers * num_directions, bsz, hidden_size), dtype=np.float32)
|
|
inputs = np.random.randn(bsz, seq_lens, emb_lens).astype(np.float32)
|
|
torch_lstm = torch.nn.LSTM(
|
|
emb_lens,
|
|
hidden_size,
|
|
batch_first=batch_first,
|
|
bidirectional=is_bidirectional,
|
|
bias=has_bias,
|
|
num_layers=num_layers,
|
|
)
|
|
lstm_in = [
|
|
torch.from_numpy(inputs),
|
|
torch.from_numpy(hx),
|
|
torch.from_numpy(hx),
|
|
] + [param.detach() for param in torch_lstm._flat_weights]
|
|
|
|
self.run_model_test(MyModel(), train=False, input=lstm_in, batch_size=3)
|
|
|
|
|
|
# a bit of metaprogramming to set up all the rnn tests
|
|
|
|
|
|
def make_test(name, base, layer, bidirectional, initial_state,
|
|
variable_length, dropout,
|
|
**extra_kwargs):
|
|
test_name = str('_'.join([
|
|
'test', name, layer[1],
|
|
bidirectional[1], initial_state[1],
|
|
variable_length[1], dropout[1]
|
|
]))
|
|
|
|
def f(self):
|
|
self._dispatch_rnn_test(
|
|
base,
|
|
layers=layer[0],
|
|
bidirectional=bidirectional[0],
|
|
initial_state=initial_state[0],
|
|
packed_sequence=variable_length[0],
|
|
dropout=dropout[0],
|
|
**extra_kwargs)
|
|
|
|
f.__name__ = test_name
|
|
setattr(TestCaffe2Backend, f.__name__, f)
|
|
|
|
|
|
def setup_rnn_tests():
|
|
layers_opts = [
|
|
(1, 'unilayer'),
|
|
(3, 'trilayer')
|
|
]
|
|
bidirectional_opts = [
|
|
(False, 'forward'),
|
|
(True, 'bidirectional')
|
|
]
|
|
initial_state_opts = [
|
|
(True, 'with_initial_state'),
|
|
(False, 'no_initial_state')
|
|
]
|
|
variable_length_opts = [
|
|
(0, 'without_sequence_lengths'),
|
|
(1, 'with_variable_length_sequences'),
|
|
(2, 'with_batch_first_sequence_lengths')
|
|
]
|
|
dropout_opts = [
|
|
(0.2, 'with_dropout'),
|
|
(0.0, 'without_dropout')
|
|
]
|
|
test_count = 0
|
|
for (layer, bidirectional, initial_state, variable_length, dropout) in \
|
|
itertools.product(
|
|
layers_opts,
|
|
bidirectional_opts,
|
|
initial_state_opts,
|
|
variable_length_opts,
|
|
dropout_opts,
|
|
):
|
|
|
|
for base, name, extra_kwargs in (
|
|
('elman', 'elman_relu', {'nonlinearity': u'relu'}),
|
|
('elman', 'elman_tanh', {'nonlinearity': u'tanh'}),
|
|
('lstm', 'lstm', {}),
|
|
('gru', 'gru', {})
|
|
):
|
|
make_test(name, base, layer, bidirectional, initial_state,
|
|
variable_length, dropout,
|
|
**extra_kwargs)
|
|
test_count += 1
|
|
|
|
# sanity check that a representative example does exist
|
|
TestCaffe2Backend.test_gru_trilayer_forward_with_initial_state_without_sequence_lengths_with_dropout
|
|
|
|
# make sure no one accidentally disables all the tests without
|
|
# noticing
|
|
assert test_count == 192, test_count
|
|
setup_rnn_tests()
|
|
|
|
# add the same test suite as above, but switch embed_params=False
|
|
# to embed_params=True
|
|
TestCaffe2BackendEmbed = type(str("TestCaffe2BackendEmbed"),
|
|
(unittest.TestCase,),
|
|
dict(TestCaffe2Backend.__dict__, embed_params=True))
|
|
|
|
|
|
if __name__ == '__main__':
|
|
unittest.main()
|