mirror of
https://github.com/zebrajr/pytorch.git
synced 2025-12-07 12:21:27 +01:00
> Note: This is a reopen of https://github.com/pytorch/pytorch/pull/70172 which was merged then reverted. Add fast path of qmean and qstd when computation is done in innermost dimensions for quantized CPU. The fast path supports inputs in contiguous memory format. For example: ```python X = torch.randn((2,3,4,5), dtype=torch.float) qX = torch.quantize_per_tensor(X, scale, zero_point, torch_type) # dim can be: -1, (-1, -2), (-1, -2, -3), (-1, -2, -3, -4), 3, (3, 2), (3, 2, 1), (3, 2, 1, 0) or None dim = -1 qY = torch.mean(qX, dim) # qY = torch.std(qX, dim) ``` **Performance test results** Test Env: - Intel® Xeon® CLX-8260 - 1 instance, 4 cores - Using Jemalloc Test method: Create 4d contiguous tensors as inputs, set `dim` to the innermost two dimensions `(-1, -2)`, then do the following tests - Quantize inputs and use the fast path - Quantize inputs and use the reference path - Use fp32 kernel (no quantization) Mean: exec time (us) vs. shape 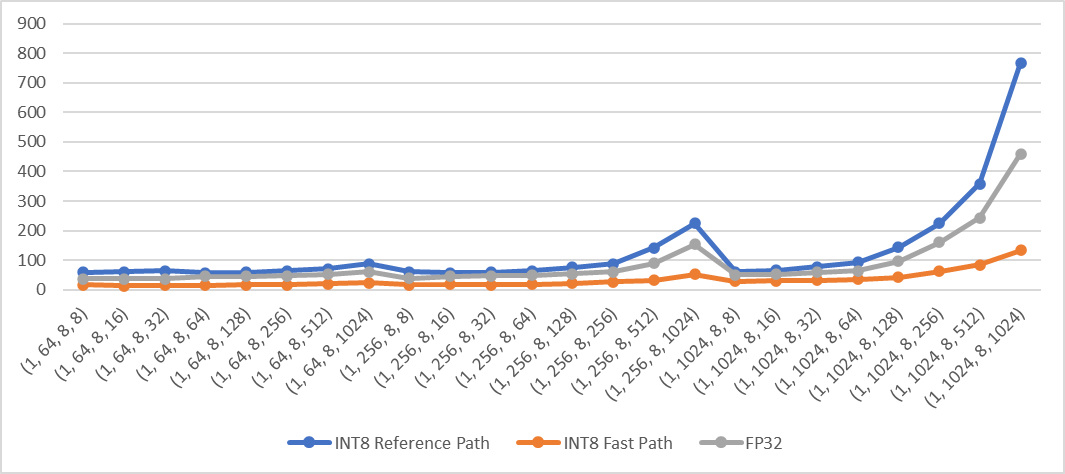 Std: exec time (us) vs. shape 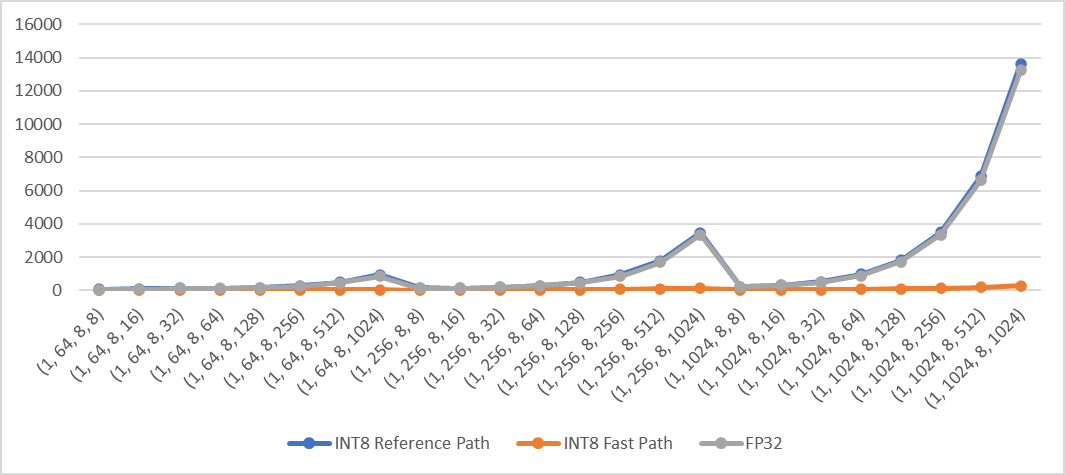 Pull Request resolved: https://github.com/pytorch/pytorch/pull/80579 Approved by: https://github.com/malfet |
||
|---|---|---|
| .. | ||
| experimental | ||
| __init__.py | ||
| test_docs.py | ||
| test_quantized_functional.py | ||
| test_quantized_module.py | ||
| test_quantized_op.py | ||
| test_quantized_tensor.py | ||
| test_utils.py | ||
| test_workflow_module.py | ||
| test_workflow_ops.py | ||
{kind=link}
{kind=link}