mirror of
https://github.com/zebrajr/pytorch.git
synced 2025-12-07 12:21:27 +01:00
## This PR seeks to:
- [x] add c++ support for an optimize path
- [x] add python opt_einsum path passthrough
- [x] add opt_einsum to OSS requirements, but a soft one
- [x] show benchmark results here
Additional things I've explored + their conclusions:
- **Delaying the summing over dimensions** => added!
- The idea here is to not incur kernel calls to `sum` as we try to early sum out in einsum. Thus, we collect all the dimensions that need to be summed together in one contraction + sum at the end instead of summing as we go. While this optimization didn't feel like it made things faster for the random cases we've selected (they all summed 1 dim per contraction), it is a good principle and would help more common use cases that would reduce multiple dimensions at a time (like `bxy,xyi,xyj->bij`).
- **Caching contract_path based on equation and tensor sizes** => dropped :(
- The benchmarks were strictly worse for all the cases, and, from scanning the use cases, I observed people do not often call einsum on the same equation/tensor order enough for caching to be justified. I do think caching can be effective in the future, but it would require further investigation.
## Not a part of this PR (but are next steps):
- adding opt_einsum package to OSS CI
- adding it to internal CI
- potentially adding a kwarg path argument to the python API -- if the path is given, we wouldn't have to spend time calculating it, but there would be some time lost validating user input.
## Testing:
- Added more tests to CI
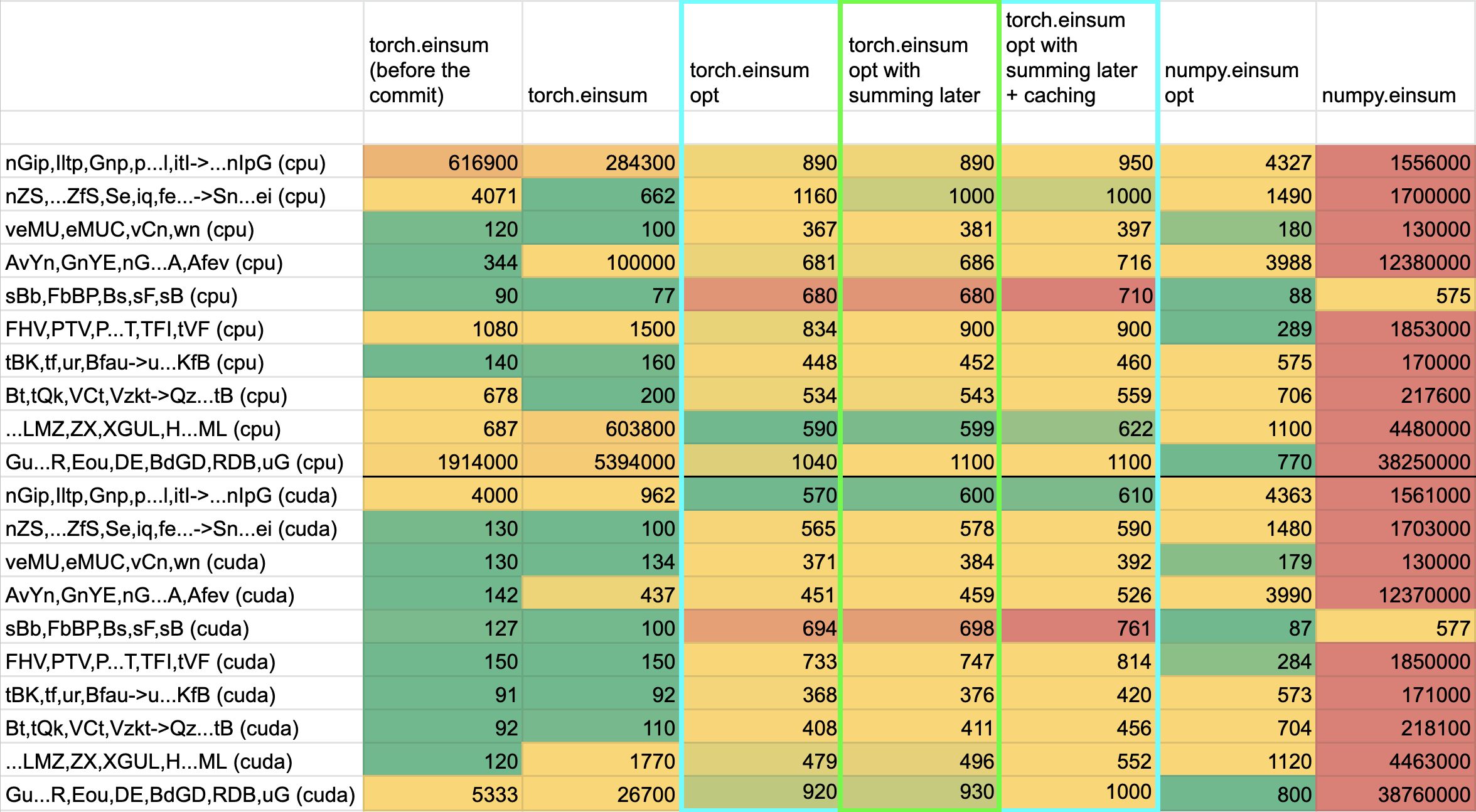
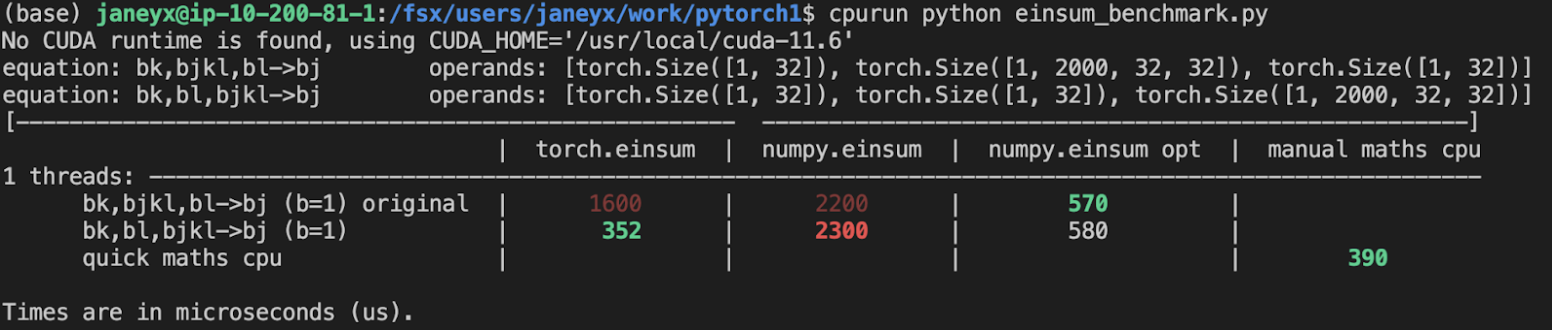
## Benchmarking:
**TL;DRs**
- **torch.einsum with opt_einsum is a definite win for the production case**.
- **torch.einsum with opt_einsum installed is consistently fast, but has an overhead** of needing to find the path. If the path is already found/optimal, it will be slightly slower.
- The einsum overhead decreases for bigger dimensions.
- **torch.einsum without opt_einsum installed is comparable to before this commit**, with occasional slowness potentially due to not reshaping/squeezing as we contract until the end.
- For many of the random generated cases, the dimensions were too similar and small where an optimal order wasn't that much more optimal than just going left to right. However, in production, dimensions are commonly quite distinct (batch size will be small, but the data will be huge).
- **torch.einsum opt is comparable (slightly faster overall) compared to numpy.einsum opt for the cpu case**. This is interesting given that torch.einsum currently spends time computing the path, but numpy.einsum takes it as input.
- **torch.einsum opt is significantly faster than numpy.einsum opt for the gpu case**. This is because numpy doesn't take advantage of GPUs.
The following benchmarks were done on an A100 GPU and Linux CPUs. The line in the first chart separates GPU (on top) from CPU, and the line in the second graph separates CPU (on top) and then GPU. Sorry it's flipped 😛 .
Production example (see [colab benchmark](https://colab.research.google.com/drive/1V2s4v1dOOKwRvp5T_DC-PNUosOV9FFJx?authuser=1#scrollTo=WZoQkC8Mdt6I) for more context):
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012636-9a68bfa7-2601-43b1-afeb-b4e0877db6a4.png">
Randomly generated examples (the same ones as in https://github.com/pytorch/pytorch/pull/60191)
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012804-1c639595-b3e6-48c9-a385-ad851c13e1c2.png">
Open below to see old + not super relevant benchmarking results:
<details>
Benchmark results BEFORE this PR (on Linux -- I will update devices so they are consistent later):
<img width="776" alt="image" src="https://user-images.githubusercontent.com/31798555/190807274-18f71fce-556e-47f4-b18c-e0f7d0c0d5aa.png">
Benchmark results with the code on this PR (on my x86 mac):
For the CPU internal use case --

For the general use case --
It looks like numpy opt still does better in several of these random cases, but torch einsum opt is consistently faster than torch.einsum.

<details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84890
Approved by: https://github.com/albanD, https://github.com/soulitzer
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1739 lines
72 KiB
Python
1739 lines
72 KiB
Python
from typing import (
|
|
List, Tuple, Optional, Union, Any, Sequence, TYPE_CHECKING
|
|
)
|
|
|
|
import torch
|
|
from torch._C import _add_docstr
|
|
import torch.nn.functional as F
|
|
from ._lowrank import svd_lowrank, pca_lowrank
|
|
from .overrides import (
|
|
has_torch_function, has_torch_function_unary, has_torch_function_variadic,
|
|
handle_torch_function)
|
|
from ._jit_internal import boolean_dispatch
|
|
from ._jit_internal import _overload as overload
|
|
|
|
Tensor = torch.Tensor
|
|
from torch import _VF
|
|
|
|
# Set a global declaring that we have opt_einsum
|
|
from importlib.util import find_spec as _find_spec
|
|
if _find_spec('opt_einsum') is not None:
|
|
import opt_einsum as _opt_einsum # type: ignore[import]
|
|
else:
|
|
_opt_einsum = None
|
|
|
|
|
|
__all__ = [
|
|
'atleast_1d',
|
|
'atleast_2d',
|
|
'atleast_3d',
|
|
'align_tensors',
|
|
'broadcast_shapes',
|
|
'broadcast_tensors',
|
|
'cartesian_prod',
|
|
'block_diag',
|
|
'cdist',
|
|
'chain_matmul',
|
|
'einsum',
|
|
'istft',
|
|
'lu',
|
|
'norm',
|
|
'meshgrid',
|
|
'pca_lowrank',
|
|
'split',
|
|
'stft',
|
|
'svd_lowrank',
|
|
'tensordot',
|
|
'unique',
|
|
'unique_consecutive',
|
|
]
|
|
|
|
|
|
def broadcast_tensors(*tensors):
|
|
r"""broadcast_tensors(*tensors) -> List of Tensors
|
|
|
|
Broadcasts the given tensors according to :ref:`broadcasting-semantics`.
|
|
|
|
Args:
|
|
*tensors: any number of tensors of the same type
|
|
|
|
.. warning::
|
|
|
|
More than one element of a broadcasted tensor may refer to a single
|
|
memory location. As a result, in-place operations (especially ones that
|
|
are vectorized) may result in incorrect behavior. If you need to write
|
|
to the tensors, please clone them first.
|
|
|
|
Example::
|
|
|
|
>>> x = torch.arange(3).view(1, 3)
|
|
>>> y = torch.arange(2).view(2, 1)
|
|
>>> a, b = torch.broadcast_tensors(x, y)
|
|
>>> a.size()
|
|
torch.Size([2, 3])
|
|
>>> a
|
|
tensor([[0, 1, 2],
|
|
[0, 1, 2]])
|
|
"""
|
|
# This wrapper exists to support variadic args.
|
|
if has_torch_function(tensors):
|
|
return handle_torch_function(broadcast_tensors, tensors, *tensors)
|
|
return _VF.broadcast_tensors(tensors) # type: ignore[attr-defined]
|
|
|
|
|
|
def broadcast_shapes(*shapes):
|
|
r"""broadcast_shapes(*shapes) -> Size
|
|
|
|
Similar to :func:`broadcast_tensors` but for shapes.
|
|
|
|
This is equivalent to
|
|
``torch.broadcast_tensors(*map(torch.empty, shapes))[0].shape``
|
|
but avoids the need create to intermediate tensors. This is useful for
|
|
broadcasting tensors of common batch shape but different rightmost shape,
|
|
e.g. to broadcast mean vectors with covariance matrices.
|
|
|
|
Example::
|
|
|
|
>>> torch.broadcast_shapes((2,), (3, 1), (1, 1, 1))
|
|
torch.Size([1, 3, 2])
|
|
|
|
Args:
|
|
\*shapes (torch.Size): Shapes of tensors.
|
|
|
|
Returns:
|
|
shape (torch.Size): A shape compatible with all input shapes.
|
|
|
|
Raises:
|
|
RuntimeError: If shapes are incompatible.
|
|
"""
|
|
# This wrapper exists to support variadic args.
|
|
# TODO Move this to C++ once the jit has better support for torch.Size.
|
|
if not torch.jit.is_tracing():
|
|
max_len = 0
|
|
for shape in shapes:
|
|
if isinstance(shape, int):
|
|
if max_len < 1:
|
|
max_len = 1
|
|
elif isinstance(shape, tuple) or isinstance(shape, list):
|
|
s = len(shape)
|
|
if max_len < s:
|
|
max_len = s
|
|
result = [1] * max_len
|
|
for shape in shapes:
|
|
if isinstance(shape, int):
|
|
shape = (shape,)
|
|
if isinstance(shape, tuple) or isinstance(shape, list):
|
|
for i in range(-1, -1 - len(shape), -1):
|
|
if shape[i] < 0:
|
|
raise RuntimeError("Trying to create tensor with negative dimension ({}): ({})"
|
|
.format(shape[i], shape[i]))
|
|
if shape[i] == 1 or shape[i] == result[i]:
|
|
continue
|
|
if result[i] != 1:
|
|
raise RuntimeError("Shape mismatch: objects cannot be broadcast to a single shape")
|
|
result[i] = shape[i]
|
|
else:
|
|
raise RuntimeError("Input shapes should be of type ints, a tuple of ints, or a list of ints, got ", shape)
|
|
return torch.Size(result)
|
|
else:
|
|
# with implementation above, torch.jit.trace hardcodes the sizes which makes subsequent replays fail
|
|
with torch.no_grad():
|
|
scalar = torch.zeros((), device="cpu")
|
|
tensors = [scalar.expand(shape) for shape in shapes]
|
|
tensors = broadcast_tensors(*tensors)
|
|
return tensors[0].shape
|
|
|
|
|
|
def split(
|
|
tensor: Tensor, split_size_or_sections: Union[int, List[int]], dim: int = 0
|
|
) -> List[Tensor]:
|
|
r"""Splits the tensor into chunks. Each chunk is a view of the original tensor.
|
|
|
|
If :attr:`split_size_or_sections` is an integer type, then :attr:`tensor` will
|
|
be split into equally sized chunks (if possible). Last chunk will be smaller if
|
|
the tensor size along the given dimension :attr:`dim` is not divisible by
|
|
:attr:`split_size`.
|
|
|
|
If :attr:`split_size_or_sections` is a list, then :attr:`tensor` will be split
|
|
into ``len(split_size_or_sections)`` chunks with sizes in :attr:`dim` according
|
|
to :attr:`split_size_or_sections`.
|
|
|
|
Args:
|
|
tensor (Tensor): tensor to split.
|
|
split_size_or_sections (int) or (list(int)): size of a single chunk or
|
|
list of sizes for each chunk
|
|
dim (int): dimension along which to split the tensor.
|
|
|
|
Example::
|
|
|
|
>>> a = torch.arange(10).reshape(5,2)
|
|
>>> a
|
|
tensor([[0, 1],
|
|
[2, 3],
|
|
[4, 5],
|
|
[6, 7],
|
|
[8, 9]])
|
|
>>> torch.split(a, 2)
|
|
(tensor([[0, 1],
|
|
[2, 3]]),
|
|
tensor([[4, 5],
|
|
[6, 7]]),
|
|
tensor([[8, 9]]))
|
|
>>> torch.split(a, [1,4])
|
|
(tensor([[0, 1]]),
|
|
tensor([[2, 3],
|
|
[4, 5],
|
|
[6, 7],
|
|
[8, 9]]))
|
|
"""
|
|
if has_torch_function_unary(tensor):
|
|
return handle_torch_function(
|
|
split, (tensor,), tensor, split_size_or_sections, dim=dim)
|
|
# Overwriting reason:
|
|
# This dispatches to two ATen functions depending on the type of
|
|
# split_size_or_sections. The branching code is in _tensor.py, which we
|
|
# call here.
|
|
return tensor.split(split_size_or_sections, dim)
|
|
|
|
|
|
def einsum(*args: Any) -> Tensor:
|
|
r"""einsum(equation, *operands) -> Tensor
|
|
|
|
Sums the product of the elements of the input :attr:`operands` along dimensions specified using a notation
|
|
based on the Einstein summation convention.
|
|
|
|
Einsum allows computing many common multi-dimensional linear algebraic array operations by representing them
|
|
in a short-hand format based on the Einstein summation convention, given by :attr:`equation`. The details of
|
|
this format are described below, but the general idea is to label every dimension of the input :attr:`operands`
|
|
with some subscript and define which subscripts are part of the output. The output is then computed by summing
|
|
the product of the elements of the :attr:`operands` along the dimensions whose subscripts are not part of the
|
|
output. For example, matrix multiplication can be computed using einsum as `torch.einsum("ij,jk->ik", A, B)`.
|
|
Here, j is the summation subscript and i and k the output subscripts (see section below for more details on why).
|
|
|
|
Equation:
|
|
|
|
The :attr:`equation` string specifies the subscripts (letters in `[a-zA-Z]`) for each dimension of
|
|
the input :attr:`operands` in the same order as the dimensions, separating subcripts for each operand by a
|
|
comma (','), e.g. `'ij,jk'` specify subscripts for two 2D operands. The dimensions labeled with the same subscript
|
|
must be broadcastable, that is, their size must either match or be `1`. The exception is if a subscript is
|
|
repeated for the same input operand, in which case the dimensions labeled with this subscript for this operand
|
|
must match in size and the operand will be replaced by its diagonal along these dimensions. The subscripts that
|
|
appear exactly once in the :attr:`equation` will be part of the output, sorted in increasing alphabetical order.
|
|
The output is computed by multiplying the input :attr:`operands` element-wise, with their dimensions aligned based
|
|
on the subscripts, and then summing out the dimensions whose subscripts are not part of the output.
|
|
|
|
Optionally, the output subscripts can be explicitly defined by adding an arrow ('->') at the end of the equation
|
|
followed by the subscripts for the output. For instance, the following equation computes the transpose of a
|
|
matrix multiplication: 'ij,jk->ki'. The output subscripts must appear at least once for some input operand and
|
|
at most once for the output.
|
|
|
|
Ellipsis ('...') can be used in place of subscripts to broadcast the dimensions covered by the ellipsis.
|
|
Each input operand may contain at most one ellipsis which will cover the dimensions not covered by subscripts,
|
|
e.g. for an input operand with 5 dimensions, the ellipsis in the equation `'ab...c'` cover the third and fourth
|
|
dimensions. The ellipsis does not need to cover the same number of dimensions across the :attr:`operands` but the
|
|
'shape' of the ellipsis (the size of the dimensions covered by them) must broadcast together. If the output is not
|
|
explicitly defined with the arrow ('->') notation, the ellipsis will come first in the output (left-most dimensions),
|
|
before the subscript labels that appear exactly once for the input operands. e.g. the following equation implements
|
|
batch matrix multiplication `'...ij,...jk'`.
|
|
|
|
A few final notes: the equation may contain whitespaces between the different elements (subscripts, ellipsis,
|
|
arrow and comma) but something like `'. . .'` is not valid. An empty string `''` is valid for scalar operands.
|
|
|
|
.. note::
|
|
|
|
``torch.einsum`` handles ellipsis ('...') differently from NumPy in that it allows dimensions
|
|
covered by the ellipsis to be summed over, that is, ellipsis are not required to be part of the output.
|
|
|
|
.. note::
|
|
|
|
This function uses opt_einsum (https://optimized-einsum.readthedocs.io/en/stable/) to speed up computation or to
|
|
consume less memory by optimizing contraction order. Note that finding _the_ optimal path is an NP-hard problem,
|
|
thus, opt_einsum relies on different heuristics to achieve near-optimal results. If opt_einsum is not available,
|
|
the default order is to contract from left to right.
|
|
|
|
.. note::
|
|
|
|
As of PyTorch 1.10 :func:`torch.einsum` also supports the sublist format (see examples below). In this format,
|
|
subscripts for each operand are specified by sublists, list of integers in the range [0, 52). These sublists
|
|
follow their operands, and an extra sublist can appear at the end of the input to specify the output's
|
|
subscripts., e.g. `torch.einsum(op1, sublist1, op2, sublist2, ..., [subslist_out])`. Python's `Ellipsis` object
|
|
may be provided in a sublist to enable broadcasting as described in the Equation section above.
|
|
|
|
Args:
|
|
equation (str): The subscripts for the Einstein summation.
|
|
operands (List[Tensor]): The tensors to compute the Einstein summation of.
|
|
|
|
Examples::
|
|
|
|
>>> # trace
|
|
>>> # xdoctest: +IGNORE_WANT("non-deterministic")
|
|
>>> torch.einsum('ii', torch.randn(4, 4))
|
|
tensor(-1.2104)
|
|
|
|
>>> # diagonal
|
|
>>> # xdoctest: +IGNORE_WANT("non-deterministic")
|
|
>>> torch.einsum('ii->i', torch.randn(4, 4))
|
|
tensor([-0.1034, 0.7952, -0.2433, 0.4545])
|
|
|
|
>>> # outer product
|
|
>>> # xdoctest: +IGNORE_WANT("non-deterministic")
|
|
>>> x = torch.randn(5)
|
|
>>> y = torch.randn(4)
|
|
>>> torch.einsum('i,j->ij', x, y)
|
|
tensor([[ 0.1156, -0.2897, -0.3918, 0.4963],
|
|
[-0.3744, 0.9381, 1.2685, -1.6070],
|
|
[ 0.7208, -1.8058, -2.4419, 3.0936],
|
|
[ 0.1713, -0.4291, -0.5802, 0.7350],
|
|
[ 0.5704, -1.4290, -1.9323, 2.4480]])
|
|
|
|
>>> # batch matrix multiplication
|
|
>>> # xdoctest: +IGNORE_WANT("non-deterministic")
|
|
>>> As = torch.randn(3,2,5)
|
|
>>> Bs = torch.randn(3,5,4)
|
|
>>> torch.einsum('bij,bjk->bik', As, Bs)
|
|
tensor([[[-1.0564, -1.5904, 3.2023, 3.1271],
|
|
[-1.6706, -0.8097, -0.8025, -2.1183]],
|
|
|
|
[[ 4.2239, 0.3107, -0.5756, -0.2354],
|
|
[-1.4558, -0.3460, 1.5087, -0.8530]],
|
|
|
|
[[ 2.8153, 1.8787, -4.3839, -1.2112],
|
|
[ 0.3728, -2.1131, 0.0921, 0.8305]]])
|
|
|
|
>>> # with sublist format and ellipsis
|
|
>>> # xdoctest: +IGNORE_WANT("non-deterministic")
|
|
>>> torch.einsum(As, [..., 0, 1], Bs, [..., 1, 2], [..., 0, 2])
|
|
tensor([[[-1.0564, -1.5904, 3.2023, 3.1271],
|
|
[-1.6706, -0.8097, -0.8025, -2.1183]],
|
|
|
|
[[ 4.2239, 0.3107, -0.5756, -0.2354],
|
|
[-1.4558, -0.3460, 1.5087, -0.8530]],
|
|
|
|
[[ 2.8153, 1.8787, -4.3839, -1.2112],
|
|
[ 0.3728, -2.1131, 0.0921, 0.8305]]])
|
|
|
|
>>> # batch permute
|
|
>>> A = torch.randn(2, 3, 4, 5)
|
|
>>> torch.einsum('...ij->...ji', A).shape
|
|
torch.Size([2, 3, 5, 4])
|
|
|
|
>>> # equivalent to torch.nn.functional.bilinear
|
|
>>> A = torch.randn(3,5,4)
|
|
>>> l = torch.randn(2,5)
|
|
>>> r = torch.randn(2,4)
|
|
>>> torch.einsum('bn,anm,bm->ba', l, A, r)
|
|
tensor([[-0.3430, -5.2405, 0.4494],
|
|
[ 0.3311, 5.5201, -3.0356]])
|
|
"""
|
|
# This wrapper exists to support variadic args.
|
|
if len(args) < 2:
|
|
raise ValueError('einsum(): must specify the equation string and at least one operand, '
|
|
'or at least one operand and its subscripts list')
|
|
|
|
equation = None
|
|
operands = None
|
|
|
|
if isinstance(args[0], torch.Tensor):
|
|
# Convert the subscript list format which is an interleaving of operand and its subscripts
|
|
# list with an optional output subscripts list at the end (see documentation for more details on this)
|
|
# to the equation string format by creating the equation string from the subscripts list and grouping the
|
|
# input operands into a tensorlist (List[Tensor]).
|
|
def parse_subscript(n: int) -> str:
|
|
if n == Ellipsis:
|
|
return '...'
|
|
if n >= 0 and n < 26:
|
|
return chr(ord('A') + n)
|
|
if n >= 26 and n < 52:
|
|
return chr(ord('a') + n - 26)
|
|
raise ValueError('einsum(): subscript in subscript list is not within the valid range [0, 52)')
|
|
|
|
# Parse subscripts for input operands
|
|
equation = ','.join(''.join(parse_subscript(s) for s in l) for l in args[1::2])
|
|
|
|
# Parse optional output subscripts (provided when the number of arguments is odd)
|
|
if len(args) % 2 == 1:
|
|
equation += '->' + ''.join(parse_subscript(s) for s in args[-1])
|
|
operands = args[:-1:2]
|
|
else:
|
|
operands = args[::2]
|
|
else:
|
|
equation = args[0]
|
|
operands = args[1:]
|
|
|
|
if has_torch_function(operands):
|
|
return handle_torch_function(einsum, operands, equation, *operands)
|
|
|
|
if len(operands) == 1 and isinstance(operands[0], (list, tuple)):
|
|
# the old interface of passing the operands as one list argument
|
|
_operands = operands[0]
|
|
# recurse incase operands contains value that has torch function
|
|
# in the original implementation this line is omitted
|
|
return einsum(equation, *_operands)
|
|
|
|
if len(operands) <= 2:
|
|
# the path for contracting 0 or 1 time(s) is already optimized
|
|
return _VF.einsum(equation, operands) # type: ignore[attr-defined]
|
|
|
|
path = None
|
|
if _opt_einsum is not None:
|
|
tupled_path = _opt_einsum.contract_path(equation, *operands)[0]
|
|
# flatten path for dispatching to C++
|
|
path = [item for pair in tupled_path for item in pair]
|
|
return _VF.einsum(equation, operands, path=path) # type: ignore[attr-defined]
|
|
|
|
|
|
# This wrapper exists to support variadic args.
|
|
if TYPE_CHECKING:
|
|
# The JIT doesn't understand Union, so only add type annotation for mypy
|
|
def meshgrid(*tensors: Union[Tensor, List[Tensor]],
|
|
indexing: Optional[str] = None) -> Tuple[Tensor, ...]:
|
|
return _meshgrid(*tensors, indexing=indexing)
|
|
else:
|
|
def meshgrid(*tensors, indexing: Optional[str] = None) -> Tuple[Tensor, ...]:
|
|
r"""Creates grids of coordinates specified by the 1D inputs in `attr`:tensors.
|
|
|
|
This is helpful when you want to visualize data over some
|
|
range of inputs. See below for a plotting example.
|
|
|
|
Given :math:`N` 1D tensors :math:`T_0 \ldots T_{N-1}` as
|
|
inputs with corresponding sizes :math:`S_0 \ldots S_{N-1}`,
|
|
this creates :math:`N` N-dimensional tensors :math:`G_0 \ldots
|
|
G_{N-1}`, each with shape :math:`(S_0, ..., S_{N-1})` where
|
|
the output :math:`G_i` is constructed by expanding :math:`T_i`
|
|
to the result shape.
|
|
|
|
.. note::
|
|
0D inputs are treated equivalently to 1D inputs of a
|
|
single element.
|
|
|
|
.. warning::
|
|
`torch.meshgrid(*tensors)` currently has the same behavior
|
|
as calling `numpy.meshgrid(*arrays, indexing='ij')`.
|
|
|
|
In the future `torch.meshgrid` will transition to
|
|
`indexing='xy'` as the default.
|
|
|
|
https://github.com/pytorch/pytorch/issues/50276 tracks
|
|
this issue with the goal of migrating to NumPy's behavior.
|
|
|
|
.. seealso::
|
|
|
|
:func:`torch.cartesian_prod` has the same effect but it
|
|
collects the data in a tensor of vectors.
|
|
|
|
Args:
|
|
tensors (list of Tensor): list of scalars or 1 dimensional tensors. Scalars will be
|
|
treated as tensors of size :math:`(1,)` automatically
|
|
|
|
indexing: (str, optional): the indexing mode, either "xy"
|
|
or "ij", defaults to "ij". See warning for future changes.
|
|
|
|
If "xy" is selected, the first dimension corresponds
|
|
to the cardinality of the second input and the second
|
|
dimension corresponds to the cardinality of the first
|
|
input.
|
|
|
|
If "ij" is selected, the dimensions are in the same
|
|
order as the cardinality of the inputs.
|
|
|
|
Returns:
|
|
seq (sequence of Tensors): If the input has :math:`N`
|
|
tensors of size :math:`S_0 \ldots S_{N-1}``, then the
|
|
output will also have :math:`N` tensors, where each tensor
|
|
is of shape :math:`(S_0, ..., S_{N-1})`.
|
|
|
|
Example::
|
|
|
|
>>> x = torch.tensor([1, 2, 3])
|
|
>>> y = torch.tensor([4, 5, 6])
|
|
|
|
Observe the element-wise pairings across the grid, (1, 4),
|
|
(1, 5), ..., (3, 6). This is the same thing as the
|
|
cartesian product.
|
|
>>> grid_x, grid_y = torch.meshgrid(x, y, indexing='ij')
|
|
>>> grid_x
|
|
tensor([[1, 1, 1],
|
|
[2, 2, 2],
|
|
[3, 3, 3]])
|
|
>>> grid_y
|
|
tensor([[4, 5, 6],
|
|
[4, 5, 6],
|
|
[4, 5, 6]])
|
|
|
|
This correspondence can be seen when these grids are
|
|
stacked properly.
|
|
>>> torch.equal(torch.cat(tuple(torch.dstack([grid_x, grid_y]))),
|
|
... torch.cartesian_prod(x, y))
|
|
True
|
|
|
|
`torch.meshgrid` is commonly used to produce a grid for
|
|
plotting.
|
|
>>> # xdoctest: +REQUIRES(module:matplotlib)
|
|
>>> import matplotlib.pyplot as plt
|
|
>>> xs = torch.linspace(-5, 5, steps=100)
|
|
>>> ys = torch.linspace(-5, 5, steps=100)
|
|
>>> x, y = torch.meshgrid(xs, ys, indexing='xy')
|
|
>>> z = torch.sin(torch.sqrt(x * x + y * y))
|
|
>>> ax = plt.axes(projection='3d')
|
|
>>> ax.plot_surface(x.numpy(), y.numpy(), z.numpy())
|
|
>>> plt.show()
|
|
|
|
.. image:: ../_static/img/meshgrid.png
|
|
:width: 512
|
|
|
|
"""
|
|
return _meshgrid(*tensors, indexing=indexing)
|
|
|
|
|
|
def _meshgrid(*tensors, indexing: Optional[str]):
|
|
if has_torch_function(tensors):
|
|
return handle_torch_function(meshgrid, tensors, *tensors, indexing=indexing)
|
|
if len(tensors) == 1 and isinstance(tensors[0], (list, tuple)):
|
|
# the old interface of passing the operands as one list argument
|
|
tensors = tensors[0] # type: ignore[assignment]
|
|
|
|
# Continue allowing call of old method that takes no indexing
|
|
# kwarg for forward compatibility reasons.
|
|
#
|
|
# Remove this two weeks after landing.
|
|
kwargs = {} if indexing is None else {'indexing': indexing}
|
|
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
|
|
|
|
|
|
def stft(input: Tensor, n_fft: int, hop_length: Optional[int] = None,
|
|
win_length: Optional[int] = None, window: Optional[Tensor] = None,
|
|
center: bool = True, pad_mode: str = 'reflect', normalized: bool = False,
|
|
onesided: Optional[bool] = None,
|
|
return_complex: Optional[bool] = None) -> Tensor:
|
|
r"""Short-time Fourier transform (STFT).
|
|
|
|
.. warning::
|
|
From version 1.8.0, :attr:`return_complex` must always be given
|
|
explicitly for real inputs and `return_complex=False` has been
|
|
deprecated. Strongly prefer `return_complex=True` as in a future
|
|
pytorch release, this function will only return complex tensors.
|
|
|
|
Note that :func:`torch.view_as_real` can be used to recover a real
|
|
tensor with an extra last dimension for real and imaginary components.
|
|
|
|
The STFT computes the Fourier transform of short overlapping windows of the
|
|
input. This giving frequency components of the signal as they change over
|
|
time. The interface of this function is modeled after (but *not* a drop-in
|
|
replacement for) librosa_ stft function.
|
|
|
|
.. _librosa: https://librosa.org/doc/latest/generated/librosa.stft.html
|
|
|
|
Ignoring the optional batch dimension, this method computes the following
|
|
expression:
|
|
|
|
.. math::
|
|
X[\omega, m] = \sum_{k = 0}^{\text{win\_length-1}}%
|
|
\text{window}[k]\ \text{input}[m \times \text{hop\_length} + k]\ %
|
|
\exp\left(- j \frac{2 \pi \cdot \omega k}{\text{win\_length}}\right),
|
|
|
|
where :math:`m` is the index of the sliding window, and :math:`\omega` is
|
|
the frequency :math:`0 \leq \omega < \text{n\_fft}` for ``onesided=False``,
|
|
or :math:`0 \leq \omega < \lfloor \text{n\_fft} / 2 \rfloor + 1` for ``onesided=True``.
|
|
|
|
* :attr:`input` must be either a 1-D time sequence or a 2-D batch of time
|
|
sequences.
|
|
|
|
* If :attr:`hop_length` is ``None`` (default), it is treated as equal to
|
|
``floor(n_fft / 4)``.
|
|
|
|
* If :attr:`win_length` is ``None`` (default), it is treated as equal to
|
|
:attr:`n_fft`.
|
|
|
|
* :attr:`window` can be a 1-D tensor of size :attr:`win_length`, e.g., from
|
|
:meth:`torch.hann_window`. If :attr:`window` is ``None`` (default), it is
|
|
treated as if having :math:`1` everywhere in the window. If
|
|
:math:`\text{win\_length} < \text{n\_fft}`, :attr:`window` will be padded on
|
|
both sides to length :attr:`n_fft` before being applied.
|
|
|
|
* If :attr:`center` is ``True`` (default), :attr:`input` will be padded on
|
|
both sides so that the :math:`t`-th frame is centered at time
|
|
:math:`t \times \text{hop\_length}`. Otherwise, the :math:`t`-th frame
|
|
begins at time :math:`t \times \text{hop\_length}`.
|
|
|
|
* :attr:`pad_mode` determines the padding method used on :attr:`input` when
|
|
:attr:`center` is ``True``. See :meth:`torch.nn.functional.pad` for
|
|
all available options. Default is ``"reflect"``.
|
|
|
|
* If :attr:`onesided` is ``True`` (default for real input), only values for
|
|
:math:`\omega` in :math:`\left[0, 1, 2, \dots, \left\lfloor
|
|
\frac{\text{n\_fft}}{2} \right\rfloor + 1\right]` are returned because
|
|
the real-to-complex Fourier transform satisfies the conjugate symmetry,
|
|
i.e., :math:`X[m, \omega] = X[m, \text{n\_fft} - \omega]^*`.
|
|
Note if the input or window tensors are complex, then :attr:`onesided`
|
|
output is not possible.
|
|
|
|
* If :attr:`normalized` is ``True`` (default is ``False``), the function
|
|
returns the normalized STFT results, i.e., multiplied by :math:`(\text{frame\_length})^{-0.5}`.
|
|
|
|
* If :attr:`return_complex` is ``True`` (default if input is complex), the
|
|
return is a ``input.dim() + 1`` dimensional complex tensor. If ``False``,
|
|
the output is a ``input.dim() + 2`` dimensional real tensor where the last
|
|
dimension represents the real and imaginary components.
|
|
|
|
Returns either a complex tensor of size :math:`(* \times N \times T)` if
|
|
:attr:`return_complex` is true, or a real tensor of size :math:`(* \times N
|
|
\times T \times 2)`. Where :math:`*` is the optional batch size of
|
|
:attr:`input`, :math:`N` is the number of frequencies where STFT is applied
|
|
and :math:`T` is the total number of frames used.
|
|
|
|
.. warning::
|
|
This function changed signature at version 0.4.1. Calling with the
|
|
previous signature may cause error or return incorrect result.
|
|
|
|
Args:
|
|
input (Tensor): the input tensor
|
|
n_fft (int): size of Fourier transform
|
|
hop_length (int, optional): the distance between neighboring sliding window
|
|
frames. Default: ``None`` (treated as equal to ``floor(n_fft / 4)``)
|
|
win_length (int, optional): the size of window frame and STFT filter.
|
|
Default: ``None`` (treated as equal to :attr:`n_fft`)
|
|
window (Tensor, optional): the optional window function.
|
|
Default: ``None`` (treated as window of all :math:`1` s)
|
|
center (bool, optional): whether to pad :attr:`input` on both sides so
|
|
that the :math:`t`-th frame is centered at time :math:`t \times \text{hop\_length}`.
|
|
Default: ``True``
|
|
pad_mode (str, optional): controls the padding method used when
|
|
:attr:`center` is ``True``. Default: ``"reflect"``
|
|
normalized (bool, optional): controls whether to return the normalized STFT results
|
|
Default: ``False``
|
|
onesided (bool, optional): controls whether to return half of results to
|
|
avoid redundancy for real inputs.
|
|
Default: ``True`` for real :attr:`input` and :attr:`window`, ``False`` otherwise.
|
|
return_complex (bool, optional): whether to return a complex tensor, or
|
|
a real tensor with an extra last dimension for the real and
|
|
imaginary components.
|
|
|
|
Returns:
|
|
Tensor: A tensor containing the STFT result with shape described above
|
|
|
|
"""
|
|
if has_torch_function_unary(input):
|
|
return handle_torch_function(
|
|
stft, (input,), input, n_fft, hop_length=hop_length, win_length=win_length,
|
|
window=window, center=center, pad_mode=pad_mode, normalized=normalized,
|
|
onesided=onesided, return_complex=return_complex)
|
|
# NOTE: Do not edit. This code will be removed once the forward-compatibility
|
|
# period is over for PR #73432
|
|
if center:
|
|
signal_dim = input.dim()
|
|
extended_shape = [1] * (3 - signal_dim) + list(input.size())
|
|
pad = int(n_fft // 2)
|
|
input = F.pad(input.view(extended_shape), [pad, pad], pad_mode)
|
|
input = input.view(input.shape[-signal_dim:])
|
|
return _VF.stft(input, n_fft, hop_length, win_length, window, # type: ignore[attr-defined]
|
|
normalized, onesided, return_complex)
|
|
|
|
|
|
istft = _add_docstr(
|
|
torch.istft,
|
|
"istft(input, n_fft, hop_length=None, win_length=None, window=None, center=True, "
|
|
"normalized=False, onesided=None, length=None, return_complex=False) -> Tensor:\n"
|
|
r"""
|
|
Inverse short time Fourier Transform. This is expected to be the inverse of :func:`~torch.stft`.
|
|
|
|
It has the same parameters (+ additional optional parameter of :attr:`length`) and it should return the
|
|
least squares estimation of the original signal. The algorithm will check using the NOLA condition (
|
|
nonzero overlap).
|
|
|
|
Important consideration in the parameters :attr:`window` and :attr:`center` so that the envelop
|
|
created by the summation of all the windows is never zero at certain point in time. Specifically,
|
|
:math:`\sum_{t=-\infty}^{\infty} |w|^2[n-t\times hop\_length] \cancel{=} 0`.
|
|
|
|
Since :func:`~torch.stft` discards elements at the end of the signal if they do not fit in a frame,
|
|
``istft`` may return a shorter signal than the original signal (can occur if :attr:`center` is False
|
|
since the signal isn't padded). If `length` is given in the arguments and is longer than expected,
|
|
``istft`` will pad zeros to the end of the returned signal.
|
|
|
|
If :attr:`center` is ``True``, then there will be padding e.g. ``'constant'``, ``'reflect'``, etc.
|
|
Left padding can be trimmed off exactly because they can be calculated but right padding cannot be
|
|
calculated without additional information.
|
|
|
|
Example: Suppose the last window is:
|
|
``[17, 18, 0, 0, 0]`` vs ``[18, 0, 0, 0, 0]``
|
|
|
|
The :attr:`n_fft`, :attr:`hop_length`, :attr:`win_length` are all the same which prevents the calculation
|
|
of right padding. These additional values could be zeros or a reflection of the signal so providing
|
|
:attr:`length` could be useful. If :attr:`length` is ``None`` then padding will be aggressively removed
|
|
(some loss of signal).
|
|
|
|
[1] D. W. Griffin and J. S. Lim, "Signal estimation from modified short-time Fourier transform,"
|
|
IEEE Trans. ASSP, vol.32, no.2, pp.236-243, Apr. 1984.
|
|
|
|
Args:
|
|
input (Tensor): The input tensor. Expected to be output of :func:`~torch.stft`,
|
|
can either be complex (``channel``, ``fft_size``, ``n_frame``), or real
|
|
(``channel``, ``fft_size``, ``n_frame``, 2) where the ``channel``
|
|
dimension is optional.
|
|
|
|
.. deprecated:: 1.8.0
|
|
Real input is deprecated, use complex inputs as returned by
|
|
``stft(..., return_complex=True)`` instead.
|
|
n_fft (int): Size of Fourier transform
|
|
hop_length (Optional[int]): The distance between neighboring sliding window frames.
|
|
(Default: ``n_fft // 4``)
|
|
win_length (Optional[int]): The size of window frame and STFT filter. (Default: ``n_fft``)
|
|
window (Optional[torch.Tensor]): The optional window function.
|
|
(Default: ``torch.ones(win_length)``)
|
|
center (bool): Whether :attr:`input` was padded on both sides so that the :math:`t`-th frame is
|
|
centered at time :math:`t \times \text{hop\_length}`.
|
|
(Default: ``True``)
|
|
normalized (bool): Whether the STFT was normalized. (Default: ``False``)
|
|
onesided (Optional[bool]): Whether the STFT was onesided.
|
|
(Default: ``True`` if ``n_fft != fft_size`` in the input size)
|
|
length (Optional[int]): The amount to trim the signal by (i.e. the
|
|
original signal length). (Default: whole signal)
|
|
return_complex (Optional[bool]):
|
|
Whether the output should be complex, or if the input should be
|
|
assumed to derive from a real signal and window.
|
|
Note that this is incompatible with ``onesided=True``.
|
|
(Default: ``False``)
|
|
|
|
Returns:
|
|
Tensor: Least squares estimation of the original signal of size (..., signal_length)
|
|
""")
|
|
|
|
|
|
if TYPE_CHECKING:
|
|
# These _impl functions return a variable number of tensors as output with
|
|
# __torch_function__; tuple unpacking is done already rather than being
|
|
# done by the caller of the _impl function
|
|
_unique_impl_out = Any
|
|
else:
|
|
_unique_impl_out = Tuple[Tensor, Tensor, Tensor]
|
|
|
|
|
|
def _unique_impl(input: Tensor, sorted: bool = True,
|
|
return_inverse: bool = False, return_counts: bool = False,
|
|
dim: Optional[int] = None) -> _unique_impl_out:
|
|
r"""unique(input, sorted=True, return_inverse=False, return_counts=False, dim=None) -> Tuple[Tensor, Tensor, Tensor]
|
|
|
|
Returns the unique elements of the input tensor.
|
|
|
|
.. note:: This function is different from :func:`torch.unique_consecutive` in the sense that
|
|
this function also eliminates non-consecutive duplicate values.
|
|
|
|
.. note:: Currently in the CUDA implementation and the CPU implementation when dim is specified,
|
|
`torch.unique` always sort the tensor at the beginning regardless of the `sort` argument.
|
|
Sorting could be slow, so if your input tensor is already sorted, it is recommended to use
|
|
:func:`torch.unique_consecutive` which avoids the sorting.
|
|
|
|
Args:
|
|
input (Tensor): the input tensor
|
|
sorted (bool): Whether to sort the unique elements in ascending order
|
|
before returning as output.
|
|
return_inverse (bool): Whether to also return the indices for where
|
|
elements in the original input ended up in the returned unique list.
|
|
return_counts (bool): Whether to also return the counts for each unique
|
|
element.
|
|
dim (int): the dimension to apply unique. If ``None``, the unique of the
|
|
flattened input is returned. default: ``None``
|
|
|
|
Returns:
|
|
(Tensor, Tensor (optional), Tensor (optional)): A tensor or a tuple of tensors containing
|
|
|
|
- **output** (*Tensor*): the output list of unique scalar elements.
|
|
- **inverse_indices** (*Tensor*): (optional) if
|
|
:attr:`return_inverse` is True, there will be an additional
|
|
returned tensor (same shape as input) representing the indices
|
|
for where elements in the original input map to in the output;
|
|
otherwise, this function will only return a single tensor.
|
|
- **counts** (*Tensor*): (optional) if
|
|
:attr:`return_counts` is True, there will be an additional
|
|
returned tensor (same shape as output or output.size(dim),
|
|
if dim was specified) representing the number of occurrences
|
|
for each unique value or tensor.
|
|
|
|
Example::
|
|
|
|
>>> output = torch.unique(torch.tensor([1, 3, 2, 3], dtype=torch.long))
|
|
>>> output
|
|
tensor([1, 2, 3])
|
|
|
|
>>> output, inverse_indices = torch.unique(
|
|
... torch.tensor([1, 3, 2, 3], dtype=torch.long), sorted=True, return_inverse=True)
|
|
>>> output
|
|
tensor([1, 2, 3])
|
|
>>> inverse_indices
|
|
tensor([0, 2, 1, 2])
|
|
|
|
>>> output, inverse_indices = torch.unique(
|
|
... torch.tensor([[1, 3], [2, 3]], dtype=torch.long), sorted=True, return_inverse=True)
|
|
>>> output
|
|
tensor([1, 2, 3])
|
|
>>> inverse_indices
|
|
tensor([[0, 2],
|
|
[1, 2]])
|
|
|
|
"""
|
|
if has_torch_function_unary(input):
|
|
return handle_torch_function(
|
|
unique, (input,), input, sorted=sorted, return_inverse=return_inverse,
|
|
return_counts=return_counts, dim=dim)
|
|
|
|
if dim is not None:
|
|
output, inverse_indices, counts = _VF.unique_dim(
|
|
input,
|
|
dim,
|
|
sorted=sorted,
|
|
return_inverse=return_inverse,
|
|
return_counts=return_counts,
|
|
)
|
|
else:
|
|
output, inverse_indices, counts = torch._unique2(
|
|
input,
|
|
sorted=sorted,
|
|
return_inverse=return_inverse,
|
|
return_counts=return_counts,
|
|
)
|
|
return output, inverse_indices, counts
|
|
|
|
|
|
def _unique_consecutive_impl(input: Tensor, return_inverse: bool = False,
|
|
return_counts: bool = False,
|
|
dim: Optional[int] = None) -> _unique_impl_out:
|
|
r"""Eliminates all but the first element from every consecutive group of equivalent elements.
|
|
|
|
.. note:: This function is different from :func:`torch.unique` in the sense that this function
|
|
only eliminates consecutive duplicate values. This semantics is similar to `std::unique`
|
|
in C++.
|
|
|
|
Args:
|
|
input (Tensor): the input tensor
|
|
return_inverse (bool): Whether to also return the indices for where
|
|
elements in the original input ended up in the returned unique list.
|
|
return_counts (bool): Whether to also return the counts for each unique
|
|
element.
|
|
dim (int): the dimension to apply unique. If ``None``, the unique of the
|
|
flattened input is returned. default: ``None``
|
|
|
|
Returns:
|
|
(Tensor, Tensor (optional), Tensor (optional)): A tensor or a tuple of tensors containing
|
|
|
|
- **output** (*Tensor*): the output list of unique scalar elements.
|
|
- **inverse_indices** (*Tensor*): (optional) if
|
|
:attr:`return_inverse` is True, there will be an additional
|
|
returned tensor (same shape as input) representing the indices
|
|
for where elements in the original input map to in the output;
|
|
otherwise, this function will only return a single tensor.
|
|
- **counts** (*Tensor*): (optional) if
|
|
:attr:`return_counts` is True, there will be an additional
|
|
returned tensor (same shape as output or output.size(dim),
|
|
if dim was specified) representing the number of occurrences
|
|
for each unique value or tensor.
|
|
|
|
Example::
|
|
|
|
>>> x = torch.tensor([1, 1, 2, 2, 3, 1, 1, 2])
|
|
>>> output = torch.unique_consecutive(x)
|
|
>>> output
|
|
tensor([1, 2, 3, 1, 2])
|
|
|
|
>>> output, inverse_indices = torch.unique_consecutive(x, return_inverse=True)
|
|
>>> output
|
|
tensor([1, 2, 3, 1, 2])
|
|
>>> inverse_indices
|
|
tensor([0, 0, 1, 1, 2, 3, 3, 4])
|
|
|
|
>>> output, counts = torch.unique_consecutive(x, return_counts=True)
|
|
>>> output
|
|
tensor([1, 2, 3, 1, 2])
|
|
>>> counts
|
|
tensor([2, 2, 1, 2, 1])
|
|
"""
|
|
if has_torch_function_unary(input):
|
|
return handle_torch_function(
|
|
unique_consecutive, (input,), input, return_inverse=return_inverse,
|
|
return_counts=return_counts, dim=dim)
|
|
output, inverse_indices, counts = _VF.unique_consecutive( # type: ignore[attr-defined]
|
|
input, return_inverse=return_inverse, return_counts=return_counts, dim=dim)
|
|
return output, inverse_indices, counts
|
|
|
|
|
|
def _return_counts(input, sorted=True, return_inverse=False, return_counts=False, dim=None):
|
|
# type: (Tensor, bool, bool, bool, Optional[int]) -> Tuple[Tensor, Tensor]
|
|
|
|
if has_torch_function_unary(input):
|
|
return _unique_impl(input, sorted, return_inverse, return_counts, dim)
|
|
|
|
output, _, counts = _unique_impl(input, sorted, return_inverse, return_counts, dim)
|
|
return output, counts
|
|
|
|
|
|
def _return_output(input, sorted=True, return_inverse=False, return_counts=False, dim=None):
|
|
# type: (Tensor, bool, bool, bool, Optional[int]) -> Tensor
|
|
|
|
if has_torch_function_unary(input):
|
|
return _unique_impl(input, sorted, return_inverse, return_counts, dim)
|
|
|
|
output, _, _ = _unique_impl(input, sorted, return_inverse, return_counts, dim)
|
|
return output
|
|
|
|
|
|
def _return_inverse(input, sorted=True, return_inverse=False, return_counts=False, dim=None):
|
|
# type: (Tensor, bool, bool, bool, Optional[int]) -> Tuple[Tensor, Tensor]
|
|
|
|
if has_torch_function_unary(input):
|
|
return _unique_impl(input, sorted, return_inverse, return_counts, dim)
|
|
|
|
output, inverse_indices, _ = _unique_impl(input, sorted, return_inverse, return_counts, dim)
|
|
return output, inverse_indices
|
|
|
|
|
|
_return_inverse_false = boolean_dispatch(
|
|
arg_name='return_counts',
|
|
arg_index=3,
|
|
default=False,
|
|
if_true=_return_counts,
|
|
if_false=_return_output,
|
|
module_name=__name__,
|
|
func_name='unique')
|
|
|
|
_return_inverse_true = boolean_dispatch(
|
|
arg_name='return_counts',
|
|
arg_index=3,
|
|
default=False,
|
|
if_true=_unique_impl,
|
|
if_false=_return_inverse,
|
|
module_name=__name__,
|
|
func_name='unique')
|
|
|
|
# The return type of unique depends on `return_inverse`, and `return_counts` so in order to
|
|
# resolve the output type in TorchScript we need to statically know the value of both parameters
|
|
|
|
unique = boolean_dispatch(
|
|
arg_name='return_inverse',
|
|
arg_index=2,
|
|
default=False,
|
|
if_true=_return_inverse_true,
|
|
if_false=_return_inverse_false,
|
|
module_name=__name__,
|
|
func_name='unique')
|
|
unique.__doc__ = _unique_impl.__doc__
|
|
|
|
|
|
def _consecutive_return_counts(input, return_inverse=False, return_counts=False, dim=None):
|
|
# type: (Tensor, bool, bool, Optional[int]) -> Tuple[Tensor, Tensor]
|
|
|
|
if has_torch_function_unary(input):
|
|
return _unique_consecutive_impl(input, return_inverse, return_counts, dim)
|
|
|
|
output, _, counts = _unique_consecutive_impl(input, return_inverse, return_counts, dim)
|
|
return output, counts
|
|
|
|
|
|
def _consecutive_return_output(input, return_inverse=False, return_counts=False, dim=None):
|
|
# type: (Tensor, bool, bool, Optional[int]) -> Tensor
|
|
|
|
if has_torch_function_unary(input):
|
|
return _unique_consecutive_impl(input, return_inverse, return_counts, dim)
|
|
|
|
output, _, _ = _unique_consecutive_impl(input, return_inverse, return_counts, dim)
|
|
return output
|
|
|
|
|
|
def _consecutive_return_inverse(input, return_inverse=False, return_counts=False, dim=None):
|
|
# type: (Tensor, bool, bool, Optional[int]) -> Tuple[Tensor, Tensor]
|
|
|
|
if has_torch_function_unary(input):
|
|
return _unique_consecutive_impl(input, return_inverse, return_counts, dim)
|
|
|
|
output, inverse_indices, _ = _unique_consecutive_impl(input, return_inverse, return_counts, dim)
|
|
return output, inverse_indices
|
|
|
|
|
|
_consecutive_return_inverse_false = boolean_dispatch(
|
|
arg_name='return_counts',
|
|
arg_index=1,
|
|
default=False,
|
|
if_true=_consecutive_return_counts,
|
|
if_false=_consecutive_return_output,
|
|
module_name=__name__,
|
|
func_name='unique_consecutive')
|
|
|
|
_consecutive_return_inverse_true = boolean_dispatch(
|
|
arg_name='return_counts',
|
|
arg_index=1,
|
|
default=False,
|
|
if_true=_unique_consecutive_impl,
|
|
if_false=_consecutive_return_inverse,
|
|
module_name=__name__,
|
|
func_name='unique_consecutive')
|
|
|
|
# The return type of unique depends on `return_inverse`, and `return_counts` so in order to
|
|
# resolve the output type in TorchScript we need to statically know the value of both parameters
|
|
|
|
unique_consecutive = boolean_dispatch(
|
|
arg_name='return_inverse',
|
|
arg_index=2,
|
|
default=False,
|
|
if_true=_consecutive_return_inverse_true,
|
|
if_false=_consecutive_return_inverse_false,
|
|
module_name=__name__,
|
|
func_name='unique_consecutive')
|
|
unique_consecutive.__doc__ = _unique_consecutive_impl.__doc__
|
|
|
|
if TYPE_CHECKING:
|
|
pass
|
|
# There's no good way to use this type annotation without breaking JIT
|
|
# overloads. So leave untyped for mypy for now.
|
|
else:
|
|
@overload
|
|
def tensordot(a, b, dims: int = 2, out: Optional[torch.Tensor] = None):
|
|
pass
|
|
|
|
@overload # noqa: F811
|
|
def tensordot(a, b, dims: Tuple[List[int], List[int]], out: Optional[torch.Tensor] = None): # noqa: F811
|
|
pass
|
|
|
|
@overload # noqa: F811
|
|
def tensordot(a, b, dims: List[List[int]], out: Optional[torch.Tensor] = None): # noqa: F811
|
|
pass
|
|
|
|
@overload # noqa: F811
|
|
def tensordot(a, b, dims: torch.Tensor, out: Optional[torch.Tensor] = None): # noqa: F811
|
|
pass
|
|
|
|
|
|
def tensordot(a, b, dims=2, out: Optional[torch.Tensor] = None): # noqa: F811
|
|
r"""Returns a contraction of a and b over multiple dimensions.
|
|
|
|
:attr:`tensordot` implements a generalized matrix product.
|
|
|
|
Args:
|
|
a (Tensor): Left tensor to contract
|
|
b (Tensor): Right tensor to contract
|
|
dims (int or Tuple[List[int], List[int]] or List[List[int]] containing two lists or Tensor): number of dimensions to
|
|
contract or explicit lists of dimensions for :attr:`a` and
|
|
:attr:`b` respectively
|
|
|
|
When called with a non-negative integer argument :attr:`dims` = :math:`d`, and
|
|
the number of dimensions of :attr:`a` and :attr:`b` is :math:`m` and :math:`n`,
|
|
respectively, :func:`~torch.tensordot` computes
|
|
|
|
.. math::
|
|
r_{i_0,...,i_{m-d}, i_d,...,i_n}
|
|
= \sum_{k_0,...,k_{d-1}} a_{i_0,...,i_{m-d},k_0,...,k_{d-1}} \times b_{k_0,...,k_{d-1}, i_d,...,i_n}.
|
|
|
|
When called with :attr:`dims` of the list form, the given dimensions will be contracted
|
|
in place of the last :math:`d` of :attr:`a` and the first :math:`d` of :math:`b`. The sizes
|
|
in these dimensions must match, but :func:`~torch.tensordot` will deal with broadcasted
|
|
dimensions.
|
|
|
|
Examples::
|
|
|
|
>>> a = torch.arange(60.).reshape(3, 4, 5)
|
|
>>> b = torch.arange(24.).reshape(4, 3, 2)
|
|
>>> torch.tensordot(a, b, dims=([1, 0], [0, 1]))
|
|
tensor([[4400., 4730.],
|
|
[4532., 4874.],
|
|
[4664., 5018.],
|
|
[4796., 5162.],
|
|
[4928., 5306.]])
|
|
|
|
>>> # xdoctest: +REQUIRES(env:TORCH_DOCTEST_CUDA)
|
|
>>> a = torch.randn(3, 4, 5, device='cuda')
|
|
>>> b = torch.randn(4, 5, 6, device='cuda')
|
|
>>> c = torch.tensordot(a, b, dims=2).cpu()
|
|
tensor([[ 8.3504, -2.5436, 6.2922, 2.7556, -1.0732, 3.2741],
|
|
[ 3.3161, 0.0704, 5.0187, -0.4079, -4.3126, 4.8744],
|
|
[ 0.8223, 3.9445, 3.2168, -0.2400, 3.4117, 1.7780]])
|
|
|
|
>>> a = torch.randn(3, 5, 4, 6)
|
|
>>> b = torch.randn(6, 4, 5, 3)
|
|
>>> torch.tensordot(a, b, dims=([2, 1, 3], [1, 2, 0]))
|
|
tensor([[ 7.7193, -2.4867, -10.3204],
|
|
[ 1.5513, -14.4737, -6.5113],
|
|
[ -0.2850, 4.2573, -3.5997]])
|
|
"""
|
|
if has_torch_function_variadic(a, b):
|
|
return handle_torch_function(tensordot, (a, b), a, b, dims=dims, out=out)
|
|
|
|
if not isinstance(dims, (tuple, list, torch.Tensor, int)):
|
|
raise RuntimeError("tensordot expects dims to be int or "
|
|
+ "Tuple[List[int], List[int]] or "
|
|
+ "List[List[int]] containing two lists, but got "
|
|
+ f"dims={dims}")
|
|
|
|
dims_a: List[int] = []
|
|
dims_b: List[int] = []
|
|
|
|
if isinstance(dims, (tuple, list)):
|
|
dims_a, dims_b = dims
|
|
|
|
if isinstance(dims, torch.Tensor):
|
|
num_elements = dims.numel()
|
|
if num_elements > 1:
|
|
assert dims.size()[0] == 2
|
|
dims_a = torch.jit.annotate(List[int], dims[0].tolist())
|
|
dims_b = torch.jit.annotate(List[int], dims[1].tolist())
|
|
else:
|
|
dims_val = int(dims.item())
|
|
if dims_val < 0:
|
|
raise RuntimeError(f"tensordot expects dims >= 0, but got dims={dims}")
|
|
dims_a = list(range(-dims_val, 0))
|
|
dims_b = list(range(dims_val))
|
|
|
|
if isinstance(dims, int):
|
|
if dims < 0:
|
|
raise RuntimeError(f"tensordot expects dims >= 0, but got dims={dims}")
|
|
dims_a = list(range(-dims, 0))
|
|
dims_b = list(range(dims))
|
|
|
|
if out is None:
|
|
return _VF.tensordot(a, b, dims_a, dims_b) # type: ignore[attr-defined]
|
|
else:
|
|
return _VF.tensordot(a, b, dims_a, dims_b, out=out) # type: ignore[attr-defined]
|
|
|
|
|
|
def cartesian_prod(*tensors: Tensor) -> Tensor:
|
|
"""Do cartesian product of the given sequence of tensors. The behavior is similar to
|
|
python's `itertools.product`.
|
|
|
|
Args:
|
|
*tensors: any number of 1 dimensional tensors.
|
|
|
|
Returns:
|
|
Tensor: A tensor equivalent to converting all the input tensors into lists,
|
|
do `itertools.product` on these lists, and finally convert the resulting list
|
|
into tensor.
|
|
|
|
Example::
|
|
|
|
>>> import itertools
|
|
>>> a = [1, 2, 3]
|
|
>>> b = [4, 5]
|
|
>>> list(itertools.product(a, b))
|
|
[(1, 4), (1, 5), (2, 4), (2, 5), (3, 4), (3, 5)]
|
|
>>> tensor_a = torch.tensor(a)
|
|
>>> tensor_b = torch.tensor(b)
|
|
>>> torch.cartesian_prod(tensor_a, tensor_b)
|
|
tensor([[1, 4],
|
|
[1, 5],
|
|
[2, 4],
|
|
[2, 5],
|
|
[3, 4],
|
|
[3, 5]])
|
|
"""
|
|
# This wrapper exists to support variadic args.
|
|
if has_torch_function(tensors):
|
|
return handle_torch_function(cartesian_prod, tensors, *tensors)
|
|
return _VF.cartesian_prod(tensors) # type: ignore[attr-defined]
|
|
|
|
|
|
def block_diag(*tensors):
|
|
"""Create a block diagonal matrix from provided tensors.
|
|
|
|
Args:
|
|
*tensors: One or more tensors with 0, 1, or 2 dimensions.
|
|
|
|
Returns:
|
|
Tensor: A 2 dimensional tensor with all the input tensors arranged in
|
|
order such that their upper left and lower right corners are
|
|
diagonally adjacent. All other elements are set to 0.
|
|
|
|
Example::
|
|
|
|
>>> import torch
|
|
>>> A = torch.tensor([[0, 1], [1, 0]])
|
|
>>> B = torch.tensor([[3, 4, 5], [6, 7, 8]])
|
|
>>> C = torch.tensor(7)
|
|
>>> D = torch.tensor([1, 2, 3])
|
|
>>> E = torch.tensor([[4], [5], [6]])
|
|
>>> torch.block_diag(A, B, C, D, E)
|
|
tensor([[0, 1, 0, 0, 0, 0, 0, 0, 0, 0],
|
|
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
|
|
[0, 0, 3, 4, 5, 0, 0, 0, 0, 0],
|
|
[0, 0, 6, 7, 8, 0, 0, 0, 0, 0],
|
|
[0, 0, 0, 0, 0, 7, 0, 0, 0, 0],
|
|
[0, 0, 0, 0, 0, 0, 1, 2, 3, 0],
|
|
[0, 0, 0, 0, 0, 0, 0, 0, 0, 4],
|
|
[0, 0, 0, 0, 0, 0, 0, 0, 0, 5],
|
|
[0, 0, 0, 0, 0, 0, 0, 0, 0, 6]])
|
|
"""
|
|
# This wrapper exists to support variadic args.
|
|
if has_torch_function(tensors):
|
|
return handle_torch_function(block_diag, tensors, *tensors)
|
|
return torch._C._VariableFunctions.block_diag(tensors) # type: ignore[attr-defined]
|
|
|
|
|
|
def cdist(x1, x2, p=2., compute_mode='use_mm_for_euclid_dist_if_necessary'):
|
|
# type: (Tensor, Tensor, float, str) -> (Tensor)
|
|
r"""Computes batched the p-norm distance between each pair of the two collections of row vectors.
|
|
|
|
Args:
|
|
x1 (Tensor): input tensor of shape :math:`B \times P \times M`.
|
|
x2 (Tensor): input tensor of shape :math:`B \times R \times M`.
|
|
p: p value for the p-norm distance to calculate between each vector pair
|
|
:math:`\in [0, \infty]`.
|
|
compute_mode:
|
|
'use_mm_for_euclid_dist_if_necessary' - will use matrix multiplication approach to calculate
|
|
euclidean distance (p = 2) if P > 25 or R > 25
|
|
'use_mm_for_euclid_dist' - will always use matrix multiplication approach to calculate
|
|
euclidean distance (p = 2)
|
|
'donot_use_mm_for_euclid_dist' - will never use matrix multiplication approach to calculate
|
|
euclidean distance (p = 2)
|
|
Default: use_mm_for_euclid_dist_if_necessary.
|
|
|
|
If x1 has shape :math:`B \times P \times M` and x2 has shape :math:`B \times R \times M` then the
|
|
output will have shape :math:`B \times P \times R`.
|
|
|
|
This function is equivalent to `scipy.spatial.distance.cdist(input,'minkowski', p=p)`
|
|
if :math:`p \in (0, \infty)`. When :math:`p = 0` it is equivalent to
|
|
`scipy.spatial.distance.cdist(input, 'hamming') * M`. When :math:`p = \infty`, the closest
|
|
scipy function is `scipy.spatial.distance.cdist(xn, lambda x, y: np.abs(x - y).max())`.
|
|
|
|
Example:
|
|
|
|
>>> a = torch.tensor([[0.9041, 0.0196], [-0.3108, -2.4423], [-0.4821, 1.059]])
|
|
>>> a
|
|
tensor([[ 0.9041, 0.0196],
|
|
[-0.3108, -2.4423],
|
|
[-0.4821, 1.0590]])
|
|
>>> b = torch.tensor([[-2.1763, -0.4713], [-0.6986, 1.3702]])
|
|
>>> b
|
|
tensor([[-2.1763, -0.4713],
|
|
[-0.6986, 1.3702]])
|
|
>>> torch.cdist(a, b, p=2)
|
|
tensor([[3.1193, 2.0959],
|
|
[2.7138, 3.8322],
|
|
[2.2830, 0.3791]])
|
|
"""
|
|
if has_torch_function_variadic(x1, x2):
|
|
return handle_torch_function(
|
|
cdist, (x1, x2), x1, x2, p=p, compute_mode=compute_mode)
|
|
if compute_mode == 'use_mm_for_euclid_dist_if_necessary':
|
|
return _VF.cdist(x1, x2, p, None) # type: ignore[attr-defined]
|
|
elif compute_mode == 'use_mm_for_euclid_dist':
|
|
return _VF.cdist(x1, x2, p, 1) # type: ignore[attr-defined]
|
|
elif compute_mode == 'donot_use_mm_for_euclid_dist':
|
|
return _VF.cdist(x1, x2, p, 2) # type: ignore[attr-defined]
|
|
else:
|
|
raise ValueError(f"{compute_mode} is not a valid value for compute_mode")
|
|
|
|
|
|
def atleast_1d(*tensors):
|
|
r"""
|
|
Returns a 1-dimensional view of each input tensor with zero dimensions.
|
|
Input tensors with one or more dimensions are returned as-is.
|
|
|
|
Args:
|
|
input (Tensor or list of Tensors)
|
|
|
|
Returns:
|
|
output (Tensor or tuple of Tensors)
|
|
|
|
Example::
|
|
|
|
>>> x = torch.arange(2)
|
|
>>> x
|
|
tensor([0, 1])
|
|
>>> torch.atleast_1d(x)
|
|
tensor([0, 1])
|
|
>>> x = torch.tensor(1.)
|
|
>>> x
|
|
tensor(1.)
|
|
>>> torch.atleast_1d(x)
|
|
tensor([1.])
|
|
>>> x = torch.tensor(0.5)
|
|
>>> y = torch.tensor(1.)
|
|
>>> torch.atleast_1d((x,y))
|
|
(tensor([0.5000]), tensor([1.]))
|
|
"""
|
|
# This wrapper exists to support variadic args.
|
|
if has_torch_function(tensors):
|
|
return handle_torch_function(atleast_1d, tensors, *tensors)
|
|
if len(tensors) == 1:
|
|
tensors = tensors[0]
|
|
return _VF.atleast_1d(tensors) # type: ignore[attr-defined]
|
|
|
|
|
|
def atleast_2d(*tensors):
|
|
r"""
|
|
Returns a 2-dimensional view of each input tensor with zero dimensions.
|
|
Input tensors with two or more dimensions are returned as-is.
|
|
|
|
Args:
|
|
input (Tensor or list of Tensors)
|
|
|
|
Returns:
|
|
output (Tensor or tuple of Tensors)
|
|
|
|
Example::
|
|
|
|
>>> x = torch.tensor(1.)
|
|
>>> x
|
|
tensor(1.)
|
|
>>> torch.atleast_2d(x)
|
|
tensor([[1.]])
|
|
>>> x = torch.arange(4).view(2,2)
|
|
>>> x
|
|
tensor([[0, 1],
|
|
[2, 3]])
|
|
>>> torch.atleast_2d(x)
|
|
tensor([[0, 1],
|
|
[2, 3]])
|
|
>>> x = torch.tensor(0.5)
|
|
>>> y = torch.tensor(1.)
|
|
>>> torch.atleast_2d((x,y))
|
|
(tensor([[0.5000]]), tensor([[1.]]))
|
|
"""
|
|
# This wrapper exists to support variadic args.
|
|
if has_torch_function(tensors):
|
|
return handle_torch_function(atleast_2d, tensors, *tensors)
|
|
if len(tensors) == 1:
|
|
tensors = tensors[0]
|
|
return _VF.atleast_2d(tensors) # type: ignore[attr-defined]
|
|
|
|
|
|
def atleast_3d(*tensors):
|
|
r"""
|
|
Returns a 3-dimensional view of each input tensor with zero dimensions.
|
|
Input tensors with three or more dimensions are returned as-is.
|
|
|
|
Args:
|
|
input (Tensor or list of Tensors)
|
|
|
|
Returns:
|
|
output (Tensor or tuple of Tensors)
|
|
|
|
Example:
|
|
|
|
>>> x = torch.tensor(0.5)
|
|
>>> x
|
|
tensor(0.5000)
|
|
>>> torch.atleast_3d(x)
|
|
tensor([[[0.5000]]])
|
|
>>> y = torch.arange(4).view(2,2)
|
|
>>> y
|
|
tensor([[0, 1],
|
|
[2, 3]])
|
|
>>> torch.atleast_3d(y)
|
|
tensor([[[0],
|
|
[1]],
|
|
<BLANKLINE>
|
|
[[2],
|
|
[3]]])
|
|
>>> x = torch.tensor(1).view(1, 1, 1)
|
|
>>> x
|
|
tensor([[[1]]])
|
|
>>> torch.atleast_3d(x)
|
|
tensor([[[1]]])
|
|
>>> x = torch.tensor(0.5)
|
|
>>> y = torch.tensor(1.)
|
|
>>> torch.atleast_3d((x,y))
|
|
(tensor([[[0.5000]]]), tensor([[[1.]]]))
|
|
"""
|
|
# This wrapper exists to support variadic args.
|
|
if has_torch_function(tensors):
|
|
return handle_torch_function(atleast_3d, tensors, *tensors)
|
|
if len(tensors) == 1:
|
|
tensors = tensors[0]
|
|
return _VF.atleast_3d(tensors) # type: ignore[attr-defined]
|
|
|
|
|
|
if TYPE_CHECKING:
|
|
pass
|
|
# There's no good way to use this type annotation; cannot rename norm() to
|
|
# _norm_impl() in a way that doesn't break JIT overloads. So leave untyped
|
|
# for mypy for now.
|
|
# def norm(input: Tensor,
|
|
# p: Optional[Union[str, Number]] = "fro",
|
|
# dim: Optional[Union[int, List[int]]] = None,
|
|
# keepdim: bool = False,
|
|
# out: Optional[Tensor] = None,
|
|
# dtype: _dtype = None) -> Tensor:
|
|
# return _norm_impl(input, p, dim, keepdim, out, dtype)
|
|
else:
|
|
# TODO: type dim as BroadcastingList when
|
|
# https://github.com/pytorch/pytorch/issues/33782 is fixed
|
|
@overload
|
|
def norm(input, p="fro", dim=None, keepdim=False, out=None, dtype=None):
|
|
# type: (Tensor, str, Optional[List[int]], bool, Optional[Tensor], Optional[int]) -> Tensor
|
|
pass
|
|
|
|
@overload # noqa: F811
|
|
def norm(input, p="fro", dim=None, keepdim=False, out=None, dtype=None): # noqa: F811
|
|
# type: (Tensor, Optional[number], Optional[List[int]], bool, Optional[Tensor], Optional[int]) -> Tensor
|
|
pass
|
|
|
|
@overload # noqa: F811
|
|
def norm(input, p="fro", dim=None, keepdim=False, out=None, dtype=None): # noqa: F811
|
|
# type: (Tensor, Optional[number], Optional[int], bool, Optional[Tensor], Optional[int]) -> Tensor
|
|
pass
|
|
|
|
@overload # noqa: F811
|
|
def norm(input, p="fro", dim=None, keepdim=False, out=None, dtype=None): # noqa: F811
|
|
# type: (Tensor, str, Optional[int], bool, Optional[Tensor], Optional[int]) -> Tensor
|
|
pass
|
|
|
|
|
|
def norm(input, p="fro", dim=None, keepdim=False, out=None, dtype=None): # noqa: F811
|
|
r"""Returns the matrix norm or vector norm of a given tensor.
|
|
|
|
.. warning::
|
|
|
|
torch.norm is deprecated and may be removed in a future PyTorch release.
|
|
Its documentation and behavior may be incorrect, and it is no longer
|
|
actively maintained.
|
|
|
|
Use :func:`torch.linalg.norm`, instead, or :func:`torch.linalg.vector_norm`
|
|
when computing vector norms and :func:`torch.linalg.matrix_norm` when
|
|
computing matrix norms. Note, however, the signature for these functions
|
|
is slightly different than the signature for torch.norm.
|
|
|
|
Args:
|
|
input (Tensor): The input tensor. Its data type must be either a floating
|
|
point or complex type. For complex inputs, the norm is calculated using the
|
|
absolute value of each element. If the input is complex and neither
|
|
:attr:`dtype` nor :attr:`out` is specified, the result's data type will
|
|
be the corresponding floating point type (e.g. float if :attr:`input` is
|
|
complexfloat).
|
|
|
|
p (int, float, inf, -inf, 'fro', 'nuc', optional): the order of norm. Default: ``'fro'``
|
|
The following norms can be calculated:
|
|
|
|
====== ============== ==========================
|
|
ord matrix norm vector norm
|
|
====== ============== ==========================
|
|
'fro' Frobenius norm --
|
|
'nuc' nuclear norm --
|
|
Number -- sum(abs(x)**ord)**(1./ord)
|
|
====== ============== ==========================
|
|
|
|
The vector norm can be calculated across any number of dimensions.
|
|
The corresponding dimensions of :attr:`input` are flattened into
|
|
one dimension, and the norm is calculated on the flattened
|
|
dimension.
|
|
|
|
Frobenius norm produces the same result as ``p=2`` in all cases
|
|
except when :attr:`dim` is a list of three or more dims, in which
|
|
case Frobenius norm throws an error.
|
|
|
|
Nuclear norm can only be calculated across exactly two dimensions.
|
|
|
|
dim (int, tuple of ints, list of ints, optional):
|
|
Specifies which dimension or dimensions of :attr:`input` to
|
|
calculate the norm across. If :attr:`dim` is ``None``, the norm will
|
|
be calculated across all dimensions of :attr:`input`. If the norm
|
|
type indicated by :attr:`p` does not support the specified number of
|
|
dimensions, an error will occur.
|
|
keepdim (bool, optional): whether the output tensors have :attr:`dim`
|
|
retained or not. Ignored if :attr:`dim` = ``None`` and
|
|
:attr:`out` = ``None``. Default: ``False``
|
|
out (Tensor, optional): the output tensor. Ignored if
|
|
:attr:`dim` = ``None`` and :attr:`out` = ``None``.
|
|
dtype (:class:`torch.dtype`, optional): the desired data type of
|
|
returned tensor. If specified, the input tensor is casted to
|
|
:attr:`dtype` while performing the operation. Default: None.
|
|
|
|
.. note::
|
|
Even though ``p='fro'`` supports any number of dimensions, the true
|
|
mathematical definition of Frobenius norm only applies to tensors with
|
|
exactly two dimensions. :func:`torch.linalg.norm` with ``ord='fro'`` aligns
|
|
with the mathematical definition, since it can only be applied across
|
|
exactly two dimensions.
|
|
|
|
Example::
|
|
|
|
>>> import torch
|
|
>>> a = torch.arange(9, dtype= torch.float) - 4
|
|
>>> b = a.reshape((3, 3))
|
|
>>> torch.norm(a)
|
|
tensor(7.7460)
|
|
>>> torch.norm(b)
|
|
tensor(7.7460)
|
|
>>> torch.norm(a, float('inf'))
|
|
tensor(4.)
|
|
>>> torch.norm(b, float('inf'))
|
|
tensor(4.)
|
|
>>> c = torch.tensor([[ 1, 2, 3],[-1, 1, 4]] , dtype= torch.float)
|
|
>>> torch.norm(c, dim=0)
|
|
tensor([1.4142, 2.2361, 5.0000])
|
|
>>> torch.norm(c, dim=1)
|
|
tensor([3.7417, 4.2426])
|
|
>>> torch.norm(c, p=1, dim=1)
|
|
tensor([6., 6.])
|
|
>>> d = torch.arange(8, dtype= torch.float).reshape(2,2,2)
|
|
>>> torch.norm(d, dim=(1,2))
|
|
tensor([ 3.7417, 11.2250])
|
|
>>> torch.norm(d[0, :, :]), torch.norm(d[1, :, :])
|
|
(tensor(3.7417), tensor(11.2250))
|
|
"""
|
|
|
|
if has_torch_function_unary(input):
|
|
return handle_torch_function(
|
|
norm, (input,), input, p=p, dim=dim, keepdim=keepdim, out=out, dtype=dtype)
|
|
|
|
ndim = input.dim()
|
|
|
|
# catch default case
|
|
if dim is None and out is None and dtype is None and p is not None:
|
|
if isinstance(p, str):
|
|
if p == "fro":
|
|
return _VF.frobenius_norm(input, dim=(), keepdim=keepdim)
|
|
if not isinstance(p, str):
|
|
_dim = [i for i in range(ndim)] # noqa: C416 TODO: rewrite as list(range(m))
|
|
return _VF.norm(input, p, dim=_dim, keepdim=keepdim) # type: ignore[attr-defined]
|
|
|
|
# TODO: when https://github.com/pytorch/pytorch/issues/33782 is fixed
|
|
# remove the overloads where dim is an int and replace with BraodcastingList1
|
|
# and remove next four lines, replace _dim with dim
|
|
if dim is not None:
|
|
if isinstance(dim, int):
|
|
_dim = [dim]
|
|
else:
|
|
_dim = dim
|
|
else:
|
|
_dim = None # type: ignore[assignment]
|
|
|
|
if isinstance(p, str):
|
|
if p == "fro":
|
|
if dtype is not None:
|
|
raise ValueError("dtype argument is not supported in frobenius norm")
|
|
|
|
if _dim is None:
|
|
_dim = list(range(ndim))
|
|
if out is None:
|
|
return _VF.frobenius_norm(input, _dim, keepdim=keepdim)
|
|
else:
|
|
return _VF.frobenius_norm(input, _dim, keepdim=keepdim, out=out)
|
|
elif p == "nuc":
|
|
if dtype is not None:
|
|
raise ValueError("dtype argument is not supported in nuclear norm")
|
|
if _dim is None:
|
|
if out is None:
|
|
return _VF.nuclear_norm(input, keepdim=keepdim)
|
|
else:
|
|
return _VF.nuclear_norm(input, keepdim=keepdim, out=out)
|
|
else:
|
|
if out is None:
|
|
return _VF.nuclear_norm(input, _dim, keepdim=keepdim)
|
|
else:
|
|
return _VF.nuclear_norm(input, _dim, keepdim=keepdim, out=out)
|
|
raise RuntimeError(f"only valid string values are 'fro' and 'nuc', found {p}")
|
|
else:
|
|
if _dim is None:
|
|
_dim = list(range(ndim))
|
|
|
|
if out is None:
|
|
if dtype is None:
|
|
return _VF.norm(input, p, _dim, keepdim=keepdim) # type: ignore[attr-defined]
|
|
else:
|
|
return _VF.norm(input, p, _dim, keepdim=keepdim, dtype=dtype) # type: ignore[attr-defined]
|
|
else:
|
|
if dtype is None:
|
|
return _VF.norm(input, p, _dim, keepdim=keepdim, out=out) # type: ignore[attr-defined]
|
|
else:
|
|
return _VF.norm(input, p, _dim, keepdim=keepdim, dtype=dtype, out=out) # type: ignore[attr-defined]
|
|
|
|
|
|
def chain_matmul(*matrices, out=None):
|
|
r"""Returns the matrix product of the :math:`N` 2-D tensors. This product is efficiently computed
|
|
using the matrix chain order algorithm which selects the order in which incurs the lowest cost in terms
|
|
of arithmetic operations (`[CLRS]`_). Note that since this is a function to compute the product, :math:`N`
|
|
needs to be greater than or equal to 2; if equal to 2 then a trivial matrix-matrix product is returned.
|
|
If :math:`N` is 1, then this is a no-op - the original matrix is returned as is.
|
|
|
|
.. warning::
|
|
|
|
:func:`torch.chain_matmul` is deprecated and will be removed in a future PyTorch release.
|
|
Use :func:`torch.linalg.multi_dot` instead, which accepts a list of two or more tensors
|
|
rather than multiple arguments.
|
|
|
|
Args:
|
|
matrices (Tensors...): a sequence of 2 or more 2-D tensors whose product is to be determined.
|
|
out (Tensor, optional): the output tensor. Ignored if :attr:`out` = ``None``.
|
|
|
|
Returns:
|
|
Tensor: if the :math:`i^{th}` tensor was of dimensions :math:`p_{i} \times p_{i + 1}`, then the product
|
|
would be of dimensions :math:`p_{1} \times p_{N + 1}`.
|
|
|
|
Example::
|
|
|
|
>>> # xdoctest: +IGNORE_WANT("non-deterministic")
|
|
>>> a = torch.randn(3, 4)
|
|
>>> b = torch.randn(4, 5)
|
|
>>> c = torch.randn(5, 6)
|
|
>>> d = torch.randn(6, 7)
|
|
>>> # will raise a deprecation warning
|
|
>>> torch.chain_matmul(a, b, c, d)
|
|
tensor([[ -2.3375, -3.9790, -4.1119, -6.6577, 9.5609, -11.5095, -3.2614],
|
|
[ 21.4038, 3.3378, -8.4982, -5.2457, -10.2561, -2.4684, 2.7163],
|
|
[ -0.9647, -5.8917, -2.3213, -5.2284, 12.8615, -12.2816, -2.5095]])
|
|
|
|
.. _`[CLRS]`: https://mitpress.mit.edu/books/introduction-algorithms-third-edition
|
|
"""
|
|
# This wrapper exists to support variadic args.
|
|
if has_torch_function(matrices):
|
|
return handle_torch_function(chain_matmul, matrices, *matrices)
|
|
|
|
if out is None:
|
|
return _VF.chain_matmul(matrices) # type: ignore[attr-defined]
|
|
else:
|
|
return _VF.chain_matmul(matrices, out=out) # type: ignore[attr-defined]
|
|
|
|
|
|
def _lu_impl(A, pivot=True, get_infos=False, out=None):
|
|
# type: (Tensor, bool, bool, Any) -> Tuple[Tensor, Tensor, Tensor]
|
|
r"""Computes the LU factorization of a matrix or batches of matrices
|
|
:attr:`A`. Returns a tuple containing the LU factorization and
|
|
pivots of :attr:`A`. Pivoting is done if :attr:`pivot` is set to
|
|
``True``.
|
|
|
|
.. warning::
|
|
|
|
:func:`torch.lu` is deprecated in favor of :func:`torch.linalg.lu_factor`
|
|
and :func:`torch.linalg.lu_factor_ex`. :func:`torch.lu` will be removed in a
|
|
future PyTorch release.
|
|
``LU, pivots, info = torch.lu(A, compute_pivots)`` should be replaced with
|
|
|
|
.. code:: python
|
|
|
|
LU, pivots = torch.linalg.lu_factor(A, compute_pivots)
|
|
|
|
``LU, pivots, info = torch.lu(A, compute_pivots, get_infos=True)`` should be replaced with
|
|
|
|
.. code:: python
|
|
|
|
LU, pivots, info = torch.linalg.lu_factor_ex(A, compute_pivots)
|
|
|
|
.. note::
|
|
* The returned permutation matrix for every matrix in the batch is
|
|
represented by a 1-indexed vector of size ``min(A.shape[-2], A.shape[-1])``.
|
|
``pivots[i] == j`` represents that in the ``i``-th step of the algorithm,
|
|
the ``i``-th row was permuted with the ``j-1``-th row.
|
|
* LU factorization with :attr:`pivot` = ``False`` is not available
|
|
for CPU, and attempting to do so will throw an error. However,
|
|
LU factorization with :attr:`pivot` = ``False`` is available for
|
|
CUDA.
|
|
* This function does not check if the factorization was successful
|
|
or not if :attr:`get_infos` is ``True`` since the status of the
|
|
factorization is present in the third element of the return tuple.
|
|
* In the case of batches of square matrices with size less or equal
|
|
to 32 on a CUDA device, the LU factorization is repeated for
|
|
singular matrices due to the bug in the MAGMA library
|
|
(see magma issue 13).
|
|
* ``L``, ``U``, and ``P`` can be derived using :func:`torch.lu_unpack`.
|
|
|
|
.. warning::
|
|
The gradients of this function will only be finite when :attr:`A` is full rank.
|
|
This is because the LU decomposition is just differentiable at full rank matrices.
|
|
Furthermore, if :attr:`A` is close to not being full rank,
|
|
the gradient will be numerically unstable as it depends on the computation of :math:`L^{-1}` and :math:`U^{-1}`.
|
|
|
|
Args:
|
|
A (Tensor): the tensor to factor of size :math:`(*, m, n)`
|
|
pivot (bool, optional): controls whether pivoting is done. Default: ``True``
|
|
get_infos (bool, optional): if set to ``True``, returns an info IntTensor.
|
|
Default: ``False``
|
|
out (tuple, optional): optional output tuple. If :attr:`get_infos` is ``True``,
|
|
then the elements in the tuple are Tensor, IntTensor,
|
|
and IntTensor. If :attr:`get_infos` is ``False``, then the
|
|
elements in the tuple are Tensor, IntTensor. Default: ``None``
|
|
|
|
Returns:
|
|
(Tensor, IntTensor, IntTensor (optional)): A tuple of tensors containing
|
|
|
|
- **factorization** (*Tensor*): the factorization of size :math:`(*, m, n)`
|
|
|
|
- **pivots** (*IntTensor*): the pivots of size :math:`(*, \text{min}(m, n))`.
|
|
``pivots`` stores all the intermediate transpositions of rows.
|
|
The final permutation ``perm`` could be reconstructed by
|
|
applying ``swap(perm[i], perm[pivots[i] - 1])`` for ``i = 0, ..., pivots.size(-1) - 1``,
|
|
where ``perm`` is initially the identity permutation of :math:`m` elements
|
|
(essentially this is what :func:`torch.lu_unpack` is doing).
|
|
|
|
- **infos** (*IntTensor*, *optional*): if :attr:`get_infos` is ``True``, this is a tensor of
|
|
size :math:`(*)` where non-zero values indicate whether factorization for the matrix or
|
|
each minibatch has succeeded or failed
|
|
|
|
Example::
|
|
|
|
>>> # xdoctest: +REQUIRES(env:TORCH_DOCTEST_LAPACK)
|
|
>>> # xdoctest: +IGNORE_WANT("non-determenistic")
|
|
>>> A = torch.randn(2, 3, 3)
|
|
>>> A_LU, pivots = torch.lu(A)
|
|
>>> A_LU
|
|
tensor([[[ 1.3506, 2.5558, -0.0816],
|
|
[ 0.1684, 1.1551, 0.1940],
|
|
[ 0.1193, 0.6189, -0.5497]],
|
|
|
|
[[ 0.4526, 1.2526, -0.3285],
|
|
[-0.7988, 0.7175, -0.9701],
|
|
[ 0.2634, -0.9255, -0.3459]]])
|
|
>>> pivots
|
|
tensor([[ 3, 3, 3],
|
|
[ 3, 3, 3]], dtype=torch.int32)
|
|
>>> A_LU, pivots, info = torch.lu(A, get_infos=True)
|
|
>>> if info.nonzero().size(0) == 0:
|
|
... print('LU factorization succeeded for all samples!')
|
|
LU factorization succeeded for all samples!
|
|
"""
|
|
# If get_infos is True, then we don't need to check for errors and vice versa
|
|
return torch._lu_with_info(A, pivot=pivot, check_errors=(not get_infos))
|
|
|
|
if TYPE_CHECKING:
|
|
_ListOrSeq = Sequence[Tensor]
|
|
else:
|
|
_ListOrSeq = List[Tensor]
|
|
|
|
|
|
def _check_list_size(out_len: int, get_infos: bool, out: _ListOrSeq) -> None:
|
|
get_infos_int = 1 if get_infos else 0
|
|
if out_len - get_infos_int != 2:
|
|
raise TypeError(f"expected tuple of {2 + int(get_infos)} elements but got {out_len}")
|
|
if not isinstance(out, (tuple, list)):
|
|
raise TypeError(f"argument 'out' must be tuple of Tensors, not {type(out).__name__}")
|
|
|
|
|
|
def _lu_with_infos(A, pivot=True, get_infos=False, out=None):
|
|
# type: (Tensor, bool, bool, Optional[Tuple[Tensor, Tensor, Tensor]]) -> Tuple[Tensor, Tensor, Tensor]
|
|
if has_torch_function_unary(A):
|
|
return handle_torch_function(
|
|
lu, (A,), A, pivot=pivot, get_infos=get_infos, out=out)
|
|
result = _lu_impl(A, pivot, get_infos, out)
|
|
if out is not None:
|
|
_check_list_size(len(out), get_infos, out)
|
|
for i in range(len(out)):
|
|
out[i].resize_as_(result[i]).copy_(result[i])
|
|
return out
|
|
else:
|
|
return result # A_LU, pivots, infos
|
|
|
|
|
|
def _lu_no_infos(A, pivot=True, get_infos=False, out=None):
|
|
# type: (Tensor, bool, bool, Optional[Tuple[Tensor, Tensor]]) -> Tuple[Tensor, Tensor]
|
|
# need to check for torch_function here so that we exit if
|
|
if has_torch_function_unary(A):
|
|
return handle_torch_function(
|
|
lu, (A,), A, pivot=pivot, get_infos=get_infos, out=out)
|
|
result = _lu_impl(A, pivot, get_infos, out)
|
|
if out is not None:
|
|
_check_list_size(len(out), get_infos, out)
|
|
for i in range(len(out)):
|
|
out[i].resize_as_(result[i]).copy_(result[i])
|
|
return out
|
|
else:
|
|
return result[0], result[1] # A_LU, pivots
|
|
|
|
# The return type of lu depends on `get_infos`, so in order to resolve the output type
|
|
# of lu in TorchScript we need to statically know the value of `get_infos`
|
|
lu = boolean_dispatch(
|
|
arg_name='get_infos',
|
|
arg_index=2,
|
|
default=False,
|
|
if_true=_lu_with_infos,
|
|
if_false=_lu_no_infos,
|
|
module_name=__name__,
|
|
func_name='lu')
|
|
lu.__doc__ = _lu_impl.__doc__
|
|
|
|
|
|
def align_tensors(*tensors):
|
|
raise RuntimeError('`align_tensors` not yet implemented.')
|