mirror of
https://github.com/zebrajr/pytorch.git
synced 2025-12-07 00:21:07 +01:00
Summary: I have noticed a small discrepancy between theory and the implementation of AdamW and in general Adam. The epsilon in the denominator of the following Adam update should not be scaled by the bias correction [(Algorithm 2, L9-12)](https://arxiv.org/pdf/1711.05101.pdf). Only the running average of the gradient (_m_) and squared gradients (_v_) should be scaled by their corresponding bias corrections. 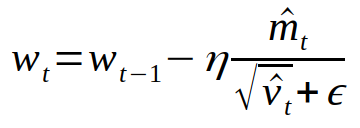 In the current implementation, the epsilon is scaled by the square root of `bias_correction2`. I have plotted this ratio as a function of step given `beta2 = 0.999` and `eps = 1e-8`. In the early steps of optimization, this ratio slightly deviates from theory (denoted by the horizontal red line). 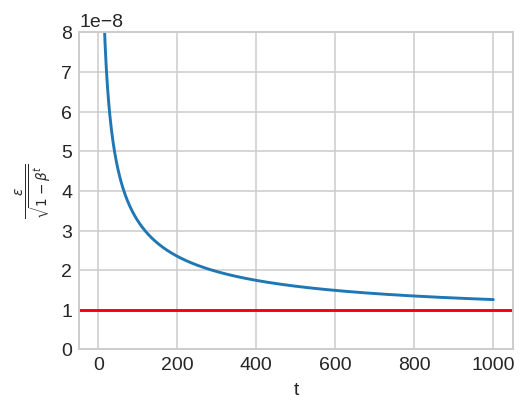 Pull Request resolved: https://github.com/pytorch/pytorch/pull/22628 Differential Revision: D16589914 Pulled By: vincentqb fbshipit-source-id: 8791eb338236faea9457c0845ccfdba700e5f1e7
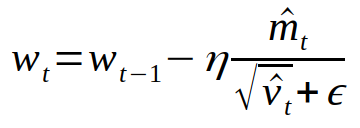{kind=link}
{kind=link}
110 lines
4.5 KiB
Python
110 lines
4.5 KiB
Python
import math
|
|
import torch
|
|
from .optimizer import Optimizer
|
|
|
|
|
|
class Adam(Optimizer):
|
|
r"""Implements Adam algorithm.
|
|
|
|
It has been proposed in `Adam: A Method for Stochastic Optimization`_.
|
|
|
|
Arguments:
|
|
params (iterable): iterable of parameters to optimize or dicts defining
|
|
parameter groups
|
|
lr (float, optional): learning rate (default: 1e-3)
|
|
betas (Tuple[float, float], optional): coefficients used for computing
|
|
running averages of gradient and its square (default: (0.9, 0.999))
|
|
eps (float, optional): term added to the denominator to improve
|
|
numerical stability (default: 1e-8)
|
|
weight_decay (float, optional): weight decay (L2 penalty) (default: 0)
|
|
amsgrad (boolean, optional): whether to use the AMSGrad variant of this
|
|
algorithm from the paper `On the Convergence of Adam and Beyond`_
|
|
(default: False)
|
|
|
|
.. _Adam\: A Method for Stochastic Optimization:
|
|
https://arxiv.org/abs/1412.6980
|
|
.. _On the Convergence of Adam and Beyond:
|
|
https://openreview.net/forum?id=ryQu7f-RZ
|
|
"""
|
|
|
|
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8,
|
|
weight_decay=0, amsgrad=False):
|
|
if not 0.0 <= lr:
|
|
raise ValueError("Invalid learning rate: {}".format(lr))
|
|
if not 0.0 <= eps:
|
|
raise ValueError("Invalid epsilon value: {}".format(eps))
|
|
if not 0.0 <= betas[0] < 1.0:
|
|
raise ValueError("Invalid beta parameter at index 0: {}".format(betas[0]))
|
|
if not 0.0 <= betas[1] < 1.0:
|
|
raise ValueError("Invalid beta parameter at index 1: {}".format(betas[1]))
|
|
defaults = dict(lr=lr, betas=betas, eps=eps,
|
|
weight_decay=weight_decay, amsgrad=amsgrad)
|
|
super(Adam, self).__init__(params, defaults)
|
|
|
|
def __setstate__(self, state):
|
|
super(Adam, self).__setstate__(state)
|
|
for group in self.param_groups:
|
|
group.setdefault('amsgrad', False)
|
|
|
|
def step(self, closure=None):
|
|
"""Performs a single optimization step.
|
|
|
|
Arguments:
|
|
closure (callable, optional): A closure that reevaluates the model
|
|
and returns the loss.
|
|
"""
|
|
loss = None
|
|
if closure is not None:
|
|
loss = closure()
|
|
|
|
for group in self.param_groups:
|
|
for p in group['params']:
|
|
if p.grad is None:
|
|
continue
|
|
grad = p.grad.data
|
|
if grad.is_sparse:
|
|
raise RuntimeError('Adam does not support sparse gradients, please consider SparseAdam instead')
|
|
amsgrad = group['amsgrad']
|
|
|
|
state = self.state[p]
|
|
|
|
# State initialization
|
|
if len(state) == 0:
|
|
state['step'] = 0
|
|
# Exponential moving average of gradient values
|
|
state['exp_avg'] = torch.zeros_like(p.data)
|
|
# Exponential moving average of squared gradient values
|
|
state['exp_avg_sq'] = torch.zeros_like(p.data)
|
|
if amsgrad:
|
|
# Maintains max of all exp. moving avg. of sq. grad. values
|
|
state['max_exp_avg_sq'] = torch.zeros_like(p.data)
|
|
|
|
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
|
|
if amsgrad:
|
|
max_exp_avg_sq = state['max_exp_avg_sq']
|
|
beta1, beta2 = group['betas']
|
|
|
|
state['step'] += 1
|
|
bias_correction1 = 1 - beta1 ** state['step']
|
|
bias_correction2 = 1 - beta2 ** state['step']
|
|
|
|
if group['weight_decay'] != 0:
|
|
grad.add_(group['weight_decay'], p.data)
|
|
|
|
# Decay the first and second moment running average coefficient
|
|
exp_avg.mul_(beta1).add_(1 - beta1, grad)
|
|
exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
|
|
if amsgrad:
|
|
# Maintains the maximum of all 2nd moment running avg. till now
|
|
torch.max(max_exp_avg_sq, exp_avg_sq, out=max_exp_avg_sq)
|
|
# Use the max. for normalizing running avg. of gradient
|
|
denom = (max_exp_avg_sq.sqrt() / math.sqrt(bias_correction2)).add_(group['eps'])
|
|
else:
|
|
denom = (exp_avg_sq.sqrt() / math.sqrt(bias_correction2)).add_(group['eps'])
|
|
|
|
step_size = group['lr'] / bias_correction1
|
|
|
|
p.data.addcdiv_(-step_size, exp_avg, denom)
|
|
|
|
return loss
|