I'm going to need this in the follow up PR. Instead of storing only Source.name() in Symbol, I now store a full on Source. Lots of replumbing reoccurs. In particular:
- Move Source to torch._guards to break cycles
- I have to add TensorPropertySource and NegateSource to handle x.size()[0] and -x codegen that I was doing with string manipulation previously
- I tighten up invariants so that I never pass source=None; instead I pass ConstantSource (these are constant sources right) and test for that rather than source being missing. I think this is more parsimonious
- Some mypy wobbles from new imports
I didn't move LocalSource and friends to torch._guards, but I ended up needing to access them in a few places. The main annoyance with moving these is that then I also need to move the bytecode codegen stuff, and that's not so easy to move without bringing in the kitchen sink.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91057
Approved by: https://github.com/albanD, https://github.com/voznesenskym
Previously, we planned to lift the parameters and weights while exporting and implement our own transformer to "unlift" the lifted weights and params back to the graph as attributes. But this is bit challenging because:
- We need to maintain correct ordering for weights and parameters that are passed as inputs so that we know how to map them back.
- Some weights are unused in the graph, so our transformer needs to be aware of which weights and parameters are not used in the graph. And we need to distinguish which are real user input and which are parameters.
- There can be more edge cases we haven't seen in other models yet.
I am aware that @Chillee and @bdhirsh mentioned that functionalization won't work with fake-tensor attributes but this is fine for the short term as we don't expect users to be modifying weights and params in inference mode. In fact, we explicitly disable attribute mutation in torchdynamo export mode right now.
Given above condition, it might be ok to just fakify params when we need. I use a flag to guard against this change.
Differential Revision: [D41891201](https://our.internmc.facebook.com/intern/diff/D41891201)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90417
Approved by: https://github.com/eellison
The big idea is to add `create_unbacked_symfloat` and `create_unbacked_symint` to ShapeEnv, allowing you to allocate symbolic floats/ints corresponding to data you don't know about at compile time. Then, instead of immediately erroring out when you try to call local_scalar_dense on a FakeTensor, we instead create a fresh symint/symfloat and return that.
There a bunch of odds and ends that need to be handled:
* A number of `numel` calls converted to `sym_numel`
* When we finally return from item(), we need to ensure we actually produce a SymInt/SymFloat when appropriate. The previous binding code assumed that you would have to get a normal Python item. I add a pybind11 binding for Scalar (to PyObject only) and refactor the code to use that. There is some trickiness where you are NOT allowed to go through c10::SymInt if there isn't actually any SymInt involved. See comment.
* One of our unit tests tripped an implicit data dependent access which occurs when you pass a Tensor as an argument to a sizes parameter. This is also converted to support symbolic shapes
* We now support tracking bare SymInt/SymFloat returns in proxy tensor mode (this was already in symbolic-shapes branch)
* Whenever we allocate an unbacked symint, we record the stack trace it was allocated at. These get printed when you attempt data dependent access on the symint (e.g., you try to guard on it)
* Subtlety: unbacked symints are not necessarily > 1. I added a test for this.
These unbacked symints are not very useful right now as you will almost always immediately raise an error later when you try to guard on them. The next logical step is adding an assertion refinement system that lets ShapeEnv learn facts about unbacked symints so it can do a better job eliding guards that are unnecessary.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90624
Approved by: https://github.com/Skylion007, https://github.com/voznesenskym
Instead of inferring shape mappings from a bunch of data structures that were plumbed in InstructionTranslator, we instead work out mappings by just iterating over the GraphArgs and mapping symbols to arguments as they show up. If multiple argument sizes/strides/offset map to the same symbol, this means they are duck sized, so we also generate extra equality tests that they must be equal. Finally, we generate 0/1 specialization guards. The resulting code is much shorter, and I think also easier to understand.
TODO: Delete all the tensor ref tracking code, it's unnecessary
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90528
Approved by: https://github.com/voznesenskym
So, uh, I have a new strategy for generating dupe guards, one where I don't actually need to allocate symints for every tensor that is fakeified. So I'm reverting the changes I made from earlier PRs in this one.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90381
Approved by: https://github.com/voznesenskym
We may need to express guards on the size/stride/storage offset of
a tensor, but we cannot do this if it's already been duck sized.
This PR guarantees that we allocate a symbol (or negation of the
symbol) whenever we ask to create a SymInt, and propagates this
symbol to SymNode so that Dynamo can look at it (not in this PR).
This PR doesn't actually add guards, nor does Dynamo do anything
with these symbols.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89879
Approved by: https://github.com/albanD
The idea is to add a custom handler to Functionalize key in Python
dispatcher that runs the functionalized version along side a non
functionalized version, and checks that their outputs agree in the
end. (Technically, for metadata mutation we should also check the
inputs, but for now we're relying on those functions returning self.)
I turned this on for test_functionalize.py (new TestCrossRefFunctionalize)
and found a bunch of failures that look legit.
This probably doesn't interact that nicely if you're also tracing at
the same time, probably need more special logic for that (directly,
just disabling tracing for when we create the nested fake tensor mode,
but IDK if there's a more principled way to organize this.)
There are some misc fixups which I can split if people really want.
- xfail_inherited_tests moved to test common_utils
- Bindings for _dispatch_tls_set_dispatch_key_included,
_dispatch_tls_is_dispatch_key_included and _functionalization_reapply_views_tls
- Type stubs for _enable_functionalization, _disable_functionalization
- all_known_overloads utility to let you iterate over all OpOverloads
in all namespaces. Iterator support on all torch._ops objects to let
you iterate over their members.
- suspend_functionalization lets you temporarily disable functionalization mode
in a context
- check_metadata_matches for easily comparing outputs of functions and see
if they match (TODO: there are a few copies of this logic, consolidate!)
- _fmt for easily printing the metadata of a tensor without its data
- _uncache_dispatch for removing a particular dispatch key from the cache,
so that we force it to regenerate
- check_significant_strides new kwarg only_cuda to let you also do stride
test even when inputs are not CUDA
- Functionalize in torch._C.DispatchKey
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89498
Approved by: https://github.com/malfet
We add most in-place references in a generic way. We also implement a
wrapper to implement the annoying interface that `nn.functional`
nonlinearities have.
We fix along the way a couple decompositions for some non-linearities by
extending the arguments that the references have.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88117
Approved by: https://github.com/mruberry
Fake tensor behaves pretty differently depending on if you have
symbolic shapes or not. This leads to bugs; for example, we
weren't getting correct convolution_backward strides because we
bypassed the correct stride logic in fake tensor on symbolic
shapes.
This PR attempts to unify the two codepaths. I don't manage to
unify everything, but I get most of it. The algorithm is delicate
and I'm still hosing down test failures.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89038
Approved by: https://github.com/anjali411
This refactor was prompted by challenges handling mixed int/float
operations in C++. A previous version of this patch
added overloads for each permutation of int/float and was unwieldy
https://github.com/pytorch/pytorch/pull/87722/ This PR takes a different
approach.
The general outline of the patch is to combine the C++ types SymIntNode
and SymFloatNode into a single type, SymNode. This is type erased; we
no longer know statically at C++ if we have an int/float and have to test
it with the is_int()/is_float() virtual methods. This has a number of
knock on effects.
- We no longer have C++ classes to bind to Python. Instead, we take an
entirely new approach to our Python API, where we have a SymInt/SymFloat
class defined entirely in Python, which hold a SymNode (which corresponds
to the C++ SymNode). However, SymNode is not pybind11-bound; instead,
it lives as-is in Python, and is wrapped into C++ SymNode using PythonSymNode
when it goes into C++. This implies a userland rename.
In principle, it is also possible for the canonical implementation of SymNode
to be written in C++, and then bound to Python with pybind11 (we have
this code, although it is commented out.) However, I did not implement
this as we currently have no C++ implementations of SymNode.
Because we do return SymInt/SymFloat from C++ bindings, the C++ binding
code needs to know how to find these classes. Currently, this is done
just by manually importing torch and getting the attributes.
- Because SymInt/SymFloat are easy Python wrappers, __sym_dispatch__ now
takes SymInt/SymFloat, rather than SymNode, bringing it in line with how
__torch_dispatch__ works.
Some miscellaneous improvements:
- SymInt now has a constructor that takes SymNode. Note that this
constructor is ambiguous if you pass in a subclass of SymNode,
so an explicit downcast is necessary. This means toSymFloat/toSymInt
are no more. This is a mild optimization as it means rvalue reference
works automatically.
- We uniformly use the caster for c10::SymInt/SymFloat, rather than
going the long way via the SymIntNode/SymFloatNode.
- Removed some unnecessary toSymInt/toSymFloat calls in normalize_*
functions, pretty sure this doesn't do anything.
- guard_int is now a free function, since to guard on an int you cannot
assume the method exists. A function can handle both int and SymInt
inputs.
- We clean up the magic method definition code for SymInt/SymFloat/SymNode.
ONLY the user classes (SymInt/SymFloat) get magic methods; SymNode gets
plain methods; this is to help avoid confusion between the two types.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
cc @jansel @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87817
Approved by: https://github.com/albanD, https://github.com/anjali411
**Introduces symbolic shape guards into dynamo.**
In this PR, we take the existing fake tensor infra and plumbing in dynamo and we start passing a shape_env around. This shape_env does not get plumbed down to middle layers / backend yet - it only collects expressions from frontend invocations at the moment. We then translate these expressions into guards at the point where we take other guards installed throughout dynamo - and add them to check_fn.
Part 1 of https://docs.google.com/document/d/1QJ-M4zfMkD-fjHIqW089RptjLl9EgozZGCceUbvmgfY/edit#
cc @jansel @lezcano @fdrocha @mlazos @soumith @yanboliang @penguinwu @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87570
Approved by: https://github.com/ezyang
Big-bang PR to symintify **all** .sizes() calls in derivatives.yaml, which will be needed for symbolic tracing.
* with the exception of `split()`, which is tougher to land because it requires internal changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86610
Approved by: https://github.com/albanD
This reverts commit 978b46d7c9.
Reverted https://github.com/pytorch/pytorch/pull/86488 on behalf of https://github.com/osalpekar due to Broke executorch builds internally with the following message: RuntimeError: Missing out variant for functional op: aten::split.Tensor(Tensor(a -> *) self, SymInt split_size, int dim=0) -> Tensor(a)[] . Make sure you have loaded your custom_ops_generated_lib
symintify split_with_sizes, dropout, fused_fake_obs_quant. meta for padding_2d ops
add meta_bernoulli_
meta kernel for at::gather
get pytorch_struct to pass: meta for scatter_add, fix backward
symintify split ops
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86488
Approved by: https://github.com/ezyang
symintify split_with_sizes, dropout, fused_fake_obs_quant. meta for padding_2d ops
add meta_bernoulli_
meta kernel for at::gather
get pytorch_struct to pass: meta for scatter_add, fix backward
symintify split ops
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86334
Approved by: https://github.com/ezyang
It's not clear to me what's the difference between `unfold` and `unfold_copy`, as this latter one is codegen'd
I also took this chance to clean the implementation of unfold and its reference
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85629
Approved by: https://github.com/mruberry
- TensorGeometry supports symint
- check_size supports symint
- functorch batch rule improved symint
- Some operator support for symint in LTC
- More supported operations on SymInt and SymFloat
- More symint support in backwards formulas
This merge includes code contributions from bdhirsh and anjali411.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86160
Approved by: https://github.com/Chillee
Duck shaping says that when two input tensors have the same
size, we assume they are symbolically related. This follows
the same optimization done by inductor.
This optimization is not done completely because we don't
currently install guards corresponding to the duck shape
relationships we created, but overall the guard propagation
for dynamic shape tracing is incomplete at the moment.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85808
Approved by: https://github.com/albanD
This is based on wconstab tests from #84680
Technically, slice is covered by the __getitem__ opinfo, but it is
easier to debug/test on a more narrow internal function that only
uses this functionality and not other advanced indexing stuff.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85554
Approved by: https://github.com/mruberry, https://github.com/wconstab
This results in some test wobbling, which looks legit. I also
added some debug helpers for stuff that I found useful while
working on this.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85260
Approved by: https://github.com/albanD
- Support storing SymFloat in IValue
- Add SymFloat to JIT type system (erases to float)
- Printing support for SymFloat
- add/sub/mul/truediv operator support for SymFloat
- Support truediv on integers, it returns a SymFloat
- Support parsing SymFloat from Python object
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85411
Approved by: https://github.com/albanD
- previous impl compared the summed bool values of the tensor to its nelem, which in a symbolic world is a symint and can't be coerced back into a bool for the purpose of shoving into a result tensor
- new impl adds one extra negation op but avoids the need to compare to the symbolic nelem
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85352
Approved by: https://github.com/ezyang, https://github.com/mruberry
- Lazily allocate FX nodes for size/stride accessors on proxy tensor
- Properly track derived computations on strides/numel/etc
- Remove unnecessary tree_map at end of proxy tensor trace checking
invariants; we will just have to be smart (it's too expensive)
- Avoid tree_map in sym proxy tracing
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85049
Approved by: https://github.com/wconstab
Signed-off-by: Edward Z. Yang <ezyangfb.com>
From @ezyang's original PR:
There are a number of situations where we have non-backend kernels (e.g., CompositeImplicitAutograd, batching rules) which we would like to port to Python, but we have no way to integrate these ports with the overall system while using preexisting C++ registrations otherwise. This PR changes that by introducing a Python dispatcher (which can have its own kernels directly in Python), which can be interpose over ordinary C++ dispatch. The ingredients:
We introduce a new PythonDispatcher dispatch key, that has the same tenor as FuncTorchDynamicLayerFrontMode: it works by getting triggered before every other dispatch key in the dispatch key, and shunting to a Python implementation
The Python dispatcher is a per-interpreter global object that is enabled/disabled via the guard EnablePythonDispatcher/DisablePythonDispatcher. We don't make it compositional as I have no idea what a compositional version of this feature would look like. Because it is global, we don't need to memory manage it and so I use a simpler SafePyHandle (newly added) to control access to this pointer from non-Python C++. Like __torch_dispatch__, we use PyInterpreter to get to the Python interpreter to handle the dispatch.
I need to reimplement dispatch table computation logic in Python. To do this, I expose a lot more helper functions for doing computations on alias dispatch keys and similar. I also improve the pybind11 handling for DispatchKey so that you can either accept the pybind11 bound enum or a string; this simplifies our binding code. See https://github.com/pybind/pybind11/issues/483#issuecomment-1237418106 for how this works; the technique is generally useful.
I need to be able to call backend fallbacks. I do this by permitting you to call at a dispatch key which doesn't have a kernel for the operator; if the kernel doesn't exist, we check the backend fallback table instead.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84826
Approved by: https://github.com/ezyang
A longstanding confusion in the implementation of fake tensor and proxy tensor is what to do about torch.ops.aten.sym_sizes and related calls. In particular, when you have a tensor that (1) has symbolic shapes and (2) has a `__torch_dispatch__` call, previously, you would always get `__torch_dispatch__` calls for sizes/strides query, *even if you didn't request it* via the dispatch kwargs in `make_wrapper_subclass`.
The reason for this is because we were previously mixing several concepts: "I want to dispatch to Python", "I want to call a virtual method" and "I have dynamic shapes". A single boolean variable controlled all of these things, and so it was not possible to understand inside TensorImpl what the user had actually originally requested.
In this PR, we track each of these concepts individually so that we can preserve user intent. Then, we combine these into a single "policy" variable that controls whether or not we can use the fastpath or not. For the policy to trigger, we only need one of the exceptional cases to be true.
Billing of changes:
* Rename `set_sizes_strides_policy` to `set_custom_sizes_strides`; in general, you cannot DIRECTLY set policy; you have to indirectly set it by the public functions.
* Some helpers for sizes and strides, since it's more complicated (as it is an enum, rather than just bools as is the case for device and layout). `matches_python_custom` is used to test the Python dispatch user ask. `matches_policy` does the policy test (only used in the user facing functions.)
* I reorged the accessor methods so that they are more logical. This makes the diff bad, so I recommend reading the final code directly.
* The default custom implementations now more reliably call their default() implementations
* As bonus refactor, I devirtualized some functions that don't need to be virtual
* `set_sym_sizes_and_strides` is renamed to `set_sizes_and_strides` to make it easier to use in template contexts; it optionally takes a storage offset now so you can set all three values at the same time. If you use the SymInt overload but there are no symbolic integers, we give you a normal resize.
* This adds `sym_storage_offset` since we had that in the symbolic shapes branch and there's no reason not to put it in (and it reduces merge conflicts)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84641
Approved by: https://github.com/wconstab
linalg.eigvals fails in some cases with functorch and the root of the
problem is that it is not composite compliant.
In particular, checks that branch on whether or not a Tensor requires
grad do not work with functorch. In order to support functorch with
them, we have to include an additional "if the tensor is a Tensor
Subclass, then assume that it MAY require grad, so we must always go
through the differentiable path".
This PR also changes the batching rule for linalg.eigvals to be a
decomposition instead of what it was previously. What it was previously
was masking the error in functorch's test suite.
Unfortunately we don't comprehensive tests for this on the functorch
side which is why this was not caught before. I'll look into why
that is in the future; it's a bit complicated.
Test Plan:
- wait for tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84137
Approved by: https://github.com/Lezcano, https://github.com/IvanYashchuk, https://github.com/samdow
Also Back out "Revert D39075159: [acc_tensor] Use SymIntArrayRef for overloaded empty.memory_format's signature"
Original commit changeset: dab4a9dba4fa
Original commit changeset: dcaf16c037a9
Original Phabricator Diff: D38984222
Original Phabricator Diff: D39075159
Also update Metal registrations for C++ registration changes.
Also update NNPI registration to account for tightened schema checking
Differential Revision: [D39084762](https://our.internmc.facebook.com/intern/diff/D39084762/)
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D39084762/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84173
Approved by: https://github.com/Krovatkin
Previously, we introduced new SymInt overloads for every function we wanted. This led to a lot of boilerplate, and also a lot of confusion about how the overloads needed to be implemented.
This PR takes a simpler but more risky approach: just take the original function and changes its ints to SymInts.
This is BC-breaking in the following ways:
* The C++ API for registering implementations for aten operators will change from int64_t to SymInt whenever you make this change. Code generated registrations in PyTorch do not change as codegen handles the translation automatically, but manual registrations will need to follow the change. Typically, if you now accept a SymInt where you previously only took int64_t, you have to convert it back manually. This will definitely break XLA, see companion PR https://github.com/pytorch/xla/pull/3914 Note that not all dispatch keys get the automatic translation; all the composite keys and Meta keys are modified to take SymInt directly (because they should handle them directly), and so there are adjustments for this.
This is not BC-breaking in the following ways:
* The user facing C++ API remains compatible. Even if a function changes from int to SymInt, the default C++ binding still takes only ints. (e.g., at::empty(IntArrayRef, ...). To call with SymInts, you must call at::empty_symint instead. This involved adding two more signatures to CppSignatureGroup; in many cases I refactored code to iterate over all signatures in the group instead of hard-coding the two that previously existed.
* This is TorchScript compatible; internally we treat SymInts as ints so there is no change to what happens at runtime in TorchScript. In particular, it's OK to reference an empty schema by its old type (using int types), as long as you're not doing string equality (which you shouldn't be), these parse to the same underyling type.
Structure of the PR:
* The general strategy of this PR is that, even when you write `SymInt` inside `native_functions.yaml`, sometimes, we will treat it *as if* it were an `int`. This idea pervades the codegen changes, where we have a translation from SymInt to c10::SymInt or int64_t, and this is controlled by a symint kwarg which I added and then audited all call sites to decide which I wanted. Here are some of the major places where we pick one or the other:
* The C++ FunctionSchema representation represents `SymInt` as `int`. There are a few places we do need to know that we actually have a SymInt and we consult `real_type()` to get the real type in this case. In particular:
* When we do schema validation of C++ operator registration, we must compare against true schema (as the C++ API will provide `c10::SymInt`, and this will only be accepted if the schema is `SymInt`. This is handled with cloneWithRealTypes before we check for schema differences.
* In `toIValue` argument parsing, we parse against the true schema value. For backwards compatibility reasons, I do still accept ints in many places where Layout/SymInt/etc were expected. (Well, accepting int where SymInt is expected is not BC, it's just the right logic!)
* In particular, because SymInt never shows up as type() in FunctionSchema, this means that we no longer need a dedicated Tag::SymInt. This is good, because SymInts never show up in mobile anyway.
* Changes to functorch/aten are mostly about tracking changes to the C++ API registration convention. Additionally, since SymInt overloads no longer exist, registrations for SymInt implementations are deleted. In many cases, the old implementations did not properly support SymInts; I did not add any new functionality with this PR, but I did try to annotate with TODOs where this is work to do. Finally, because the signature of `native::` API changed from int to SymInt, I need to find alternative APIs for people who were directly calling these functions to call. Typically, I insert a new dispatch call when perf doesn't matter, or use `at::compositeexplicitautograd` namespace to handle other caes.
* The change to `make_boxed_from_unboxed_functor.h` is so that we accept a plain IntList IValue anywhere a SymIntList is expected; these are read-only arguments so covariant typing is OK.
* I change how unboxing logic works slightly. Previously, we interpret the C++ type for Layout/etc directly as IntType JIT type, which works well because the incoming IValue is tagged as an integer. Now, we interpret the C++ type for Layout as its true type, e.g., LayoutType (change to `jit_type.h`), but then we accept an int IValue for it anyway. This makes it symmetric with SymInt, where we interpret the C++ type as SymIntType, and then accept SymInt and int IValues for it.
* I renamed the `empty.names` overload to `empty_names` to make it less confusing (I kept mixing it up with the real empty overload)
* I deleted the `empty.SymInt` overload, which ended up killing a pile of functions. (This was originally a separate PR but the profiler expect test was giving me grief so I folded it in.)
* I deleted the LazyDynamicOpsTest tests. These were failing after these changes, and I couldn't figure out why they used to be passing: they make use of `narrow_copy` which didn't actually support SymInts; they were immediately converted to ints.
* I bashed LTC into working. The patches made here are not the end of the story. The big problem is that SymInt translates into Value, but what if you have a list of SymInt? This cannot be conveniently represented in the IR today, since variadic Values are not supported. To work around this, I translate SymInt[] into plain int[] (this is fine for tests because LTC dynamic shapes never actually worked); but this will need to be fixed for proper LTC SymInt support. The LTC codegen also looked somewhat questionable; I added comments based on my code reading.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83628
Approved by: https://github.com/albanD, https://github.com/bdhirsh
Previously, we introduced new SymInt overloads for every function we wanted. This led to a lot of boilerplate, and also a lot of confusion about how the overloads needed to be implemented.
This PR takes a simpler but more risky approach: just take the original function and changes its ints to SymInts.
This is BC-breaking in the following ways:
* The C++ API for registering implementations for aten operators will change from int64_t to SymInt whenever you make this change. Code generated registrations in PyTorch do not change as codegen handles the translation automatically, but manual registrations will need to follow the change. Typically, if you now accept a SymInt where you previously only took int64_t, you have to convert it back manually. This will definitely break XLA, see companion PR https://github.com/pytorch/xla/pull/3914 Note that not all dispatch keys get the automatic translation; all the composite keys and Meta keys are modified to take SymInt directly (because they should handle them directly), and so there are adjustments for this.
This is not BC-breaking in the following ways:
* The user facing C++ API remains compatible. Even if a function changes from int to SymInt, the default C++ binding still takes only ints. (e.g., at::empty(IntArrayRef, ...). To call with SymInts, you must call at::empty_symint instead. This involved adding two more signatures to CppSignatureGroup; in many cases I refactored code to iterate over all signatures in the group instead of hard-coding the two that previously existed.
* This is TorchScript compatible; internally we treat SymInts as ints so there is no change to what happens at runtime in TorchScript. In particular, it's OK to reference an empty schema by its old type (using int types), as long as you're not doing string equality (which you shouldn't be), these parse to the same underyling type.
Structure of the PR:
* The general strategy of this PR is that, even when you write `SymInt` inside `native_functions.yaml`, sometimes, we will treat it *as if* it were an `int`. This idea pervades the codegen changes, where we have a translation from SymInt to c10::SymInt or int64_t, and this is controlled by a symint kwarg which I added and then audited all call sites to decide which I wanted. Here are some of the major places where we pick one or the other:
* The C++ FunctionSchema representation represents `SymInt` as `int`. There are a few places we do need to know that we actually have a SymInt and we consult `real_type()` to get the real type in this case. In particular:
* When we do schema validation of C++ operator registration, we must compare against true schema (as the C++ API will provide `c10::SymInt`, and this will only be accepted if the schema is `SymInt`. This is handled with cloneWithRealTypes before we check for schema differences.
* In `toIValue` argument parsing, we parse against the true schema value. For backwards compatibility reasons, I do still accept ints in many places where Layout/SymInt/etc were expected. (Well, accepting int where SymInt is expected is not BC, it's just the right logic!)
* In particular, because SymInt never shows up as type() in FunctionSchema, this means that we no longer need a dedicated Tag::SymInt. This is good, because SymInts never show up in mobile anyway.
* Changes to functorch/aten are mostly about tracking changes to the C++ API registration convention. Additionally, since SymInt overloads no longer exist, registrations for SymInt implementations are deleted. In many cases, the old implementations did not properly support SymInts; I did not add any new functionality with this PR, but I did try to annotate with TODOs where this is work to do. Finally, because the signature of `native::` API changed from int to SymInt, I need to find alternative APIs for people who were directly calling these functions to call. Typically, I insert a new dispatch call when perf doesn't matter, or use `at::compositeexplicitautograd` namespace to handle other caes.
* The change to `make_boxed_from_unboxed_functor.h` is so that we accept a plain IntList IValue anywhere a SymIntList is expected; these are read-only arguments so covariant typing is OK.
* I change how unboxing logic works slightly. Previously, we interpret the C++ type for Layout/etc directly as IntType JIT type, which works well because the incoming IValue is tagged as an integer. Now, we interpret the C++ type for Layout as its true type, e.g., LayoutType (change to `jit_type.h`), but then we accept an int IValue for it anyway. This makes it symmetric with SymInt, where we interpret the C++ type as SymIntType, and then accept SymInt and int IValues for it.
* I renamed the `empty.names` overload to `empty_names` to make it less confusing (I kept mixing it up with the real empty overload)
* I deleted the `empty.SymInt` overload, which ended up killing a pile of functions. (This was originally a separate PR but the profiler expect test was giving me grief so I folded it in.)
* I deleted the LazyDynamicOpsTest tests. These were failing after these changes, and I couldn't figure out why they used to be passing: they make use of `narrow_copy` which didn't actually support SymInts; they were immediately converted to ints.
* I bashed LTC into working. The patches made here are not the end of the story. The big problem is that SymInt translates into Value, but what if you have a list of SymInt? This cannot be conveniently represented in the IR today, since variadic Values are not supported. To work around this, I translate SymInt[] into plain int[] (this is fine for tests because LTC dynamic shapes never actually worked); but this will need to be fixed for proper LTC SymInt support. The LTC codegen also looked somewhat questionable; I added comments based on my code reading.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83628
Approved by: https://github.com/albanD, https://github.com/bdhirsh
- nondeterministic_seeded was not applied to enough functions. I added
some heuristics to codegen for identifying functions that are likely
to be random and added a bunch of these tags to functions. Not sure
I got all of them.
- Don't constant propagate through nondeterministic functions in FX
tracing.
It would be better to do some testing for the tag but this would be quite an effort.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83650
Approved by: https://github.com/bdhirsh, https://github.com/eellison
I was working on https://github.com/pytorch/torchdynamo/issues/80 and my
working hypothesis for what was causing the error was that proxy tensor
was not advertising correct dispatch keys, causing AMP to operate
differently when you traced. I could have fixed this directly by
replicating fake tensor's fix for setting dispatch keys to also apply to
proxy tensor, but I was like, "Why must I repeat myself."
This PR is the result. It completely deletes the ProxyTensor wrapper
subclass, so that when we are tracing, the tensors flowing through the
program are the *original* real or fake tensors, depending on what the
user requested in the top-level API. There is no more wrapping. To
store the Proxy objects necessary for actually doing tracing, I store
the property directly on the tensors. (Note: I never
clean up old entries from the map at the moment, this is easily fixed
by using a weak map)
Benefits of doing this:
* No more tip-toeing around no_dispatch() creation of new ProxyTensors;
we never create new tensors (except when we call the underlying func),
so you don't have to worry about accidentally tracing them.
* No more syncing up metadata from in place operators. In particular
https://github.com/pytorch/pytorch/issues/81526 is mooted
* This fixes https://github.com/pytorch/torchdynamo/issues/519 as we no longer need to teach proxy tensor to support sparse tensor.
* No more schlepping symbolic integers from the inner fake tensor to the
outer proxy tensor. If you can make a fake tensor with symbolic ints,
you're done, nothing else to do.
To avoid having to rewrite all of the guts, when I get to the actual
proxy tensor handler, I first "fetch" the stored ProxyTensor data from
the weakmap via a tree_map, and then operate on the consequent data as
before. A more optimized implementation is possible.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83330
Approved by: https://github.com/Chillee
We're on our way to deleting ProxyTensor entirely (see https://github.com/pytorch/pytorch/pull/83330 ), but before we can do that, we have to delete ProxySymInt first. Here's the plan.
Changes in torch.fx.experimental.symbolic_shapes
* The general idea is to do mode based tracing. This means we need a mode that can interpose on all SymInt operations. There are a few ways to do this, but I've done it the easy way: (1) I have a separate mode for SymInt operations specifically called SymDispatchMode, and (2) this mode operates on PySymInt (and not the basic SymInt which is user visible). I elided Int from the name because if we add SymFloats I want to use the same mode to handle those as well, and I used Dispatch rather than Function because this is the "inner" dispatch operating PySymInt and not SymInt (this is not a perfect analogy, but SymFunctionMode definitely seemed wrong as you still must go through the C++ binding.) The mode is entirely implemented in Python for ease of implementation. We could have implemented this more symmetrically to TorchFunctionMode in C++, but I leave that as later work; this API is unlikely to get used by others (unlike TorchFunctionMode). One downside to not doing the mode in C++ is that we still have to do the hop via a preexisting PySymInt to wrap; this is currently not a big deal as conversion to SymInts only really happens when there is already another SymInt floating around. SymDispatchMode is pared down from TorchDispatchMode; there is no ancestor tracking since I don't expect people to be mixing up SymDispatchModes.
* I made some improvements for tracing. When I invoke the SymDispatchMode handler, I would like constants to show up as constants, so they can be directly inlined into the FX graph (rather than going through a wrapping process first, and then the wrapped SymInt being used in the operation). To do this, I directly track if a PySymInt is a constant at construction time. Only wrapped PySymInts are constants.
* For convenience, PySymInts now support all magic methods that regular SymInts do. This is so that redispatch inside the SymDispatchMode can be written the idiomatic way `func(*args, **kwargs)` where func is an operator. The original names are retained for direct C++ calls.
Changes in torch.fx.experimental.proxy_tensor
* OK, so we got a new SymDispatchMode, so we define a ProxySymDispatchMode and activate it when we start tracing. This mode is currently unconditionally activated although technically we only need to activate it when doing symbolic tracing (it doesn't matter either way as there are no SymInts if you are not doing symbolic tracing).
* We delete ProxySymInt. To do this, we must now record the proxy for the SymInt some other way. Based on discussion with Chillee, it is more intuitive to him if the proxies are still recorded on the SymInt in some way. So we store them in the `__dict__` of the PySymInt, indexed by Tracer. An improvement is to make this a weak map, so that we remove all of these entries when the tracer dies. In an original version of this PR, I keyed on the mode itself, but tracer is better as it is accessible from both modes (and as you will see, we will need to fetch the map from both the ProxySymDispatchMode as well as the ProxyTorchDispatchMode.) The implementation of SymDispatchMode now simply retrieves the proxies, performs the underlying operation as well as the FX graph recording, and then records the output proxy to the PySymInt. Note that FX tracing does not work with proxies and SymInts, so we manually call `call_function` to ensure that the correct operations get recorded to the graph. This means conventional FX retracing with proxies only will not work with these graphs, but there wasn't really any reason to do this (as opposed to `make_fx` retracing) anyway. Constants are detected and converted directly into Python integers.
* SymInts can show up as arguments to tensor operations, so they must be accounted for in ProxyTorchDispatchMode as well. This is done by searching for SymInt arguments and converting them into proxies before the proxy call. This can be done more efficiently in a single `tree_map` but I'm lazy. The helper `unwrap_symint_proxy` conveniently implements the unwrapping in one place given a tracer; unfortunately it cannot be shared with SymDispatchMode as SymDispatchMode gets PySymInts, but ProxyTensorMode gets SymInts. Similarly, tensors that are returned from tensor operations can have SymInts in their shapes, which need fresh proxies allocated. To avoid leaking internal details of SymInt shape computation to the tensor operation graph, these SymInts are always given proxies derived from `x.size(dim)` call on their return tensor. We also need to do this for strides and numel but have not done so yet. Furthermore, we must avoid tracing internal SymInt calls while we run meta operations on the true operation; this is achieved by also disabling SymInt tracing on the inside of tensor tracing. This is analogous to how tensor tracing is disabled inside the implementation of tracing mode, but unfortunately we are unable to use the same mechanism (this would have been easier if the two modes could be combined somehow, and I am amenable to suggestions to try harder to achieve this.)
* Because there are no more ProxySymInts, we no longer need to do anything to unwrap SymInt. Furthermore, we do not need to reallocate ProxySymInts on class creation.
* If a bare SymInt without a Proxy is encountered, it is assumed that this must be a constant. `create_arg` handles this case. Non-constant free SymInts result in an assert error.
* The initial input handling in `dispatch_trace` involves traversing all of the input tensors, traversing over their shapes, and assigning proxies for the SymInts in shapes in the same way we handle proxies for the output tensors.
The preexisting testing is inadequate but will be better after I rebase past https://github.com/pytorch/pytorch/pull/82209
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83380
Approved by: https://github.com/samdow
This should fix a few of the errors I was seeing when I turned on functionalization in torchbench. It also fixes this AOTAutograd repro with resnet18:
```
import torch
from torchvision.models import resnet18
from functorch._src.compilers import nop
from functorch._src.aot_autograd import aot_module
from functorch.compile import config
config.use_functionalize = True
model = resnet18().cuda().half().to(memory_format=torch.channels_last)
input = torch.randn(256, 3, 224, 224, device='cuda', dtype=torch.float16) \
.to(memory_format=torch.channels_last).detach().requires_grad_(True)
input_expected = input.clone().detach().requires_grad_(True)
fn = aot_module(model, nop)
out = fn(input)
out_expected = model(input_expected)
print(torch.allclose(out, out_expected))
out.sum().backward()
out_expected.sum().backward()
print(torch.allclose(input.grad, input_expected.grad))
```
The problem was that functorch adds a decomp to the decomp table for `new_zeros`:
```
@register_decomposition(aten.new_zeros, aot_autograd_decompositions)
def new_zeros(inp, size, dtype=None, layout=None, device=None, pin_memory=None):
return torch.zeros(size, dtype=inp.dtype, device=inp.device)
```
When calling that decomp from inside of `ProxyTensorDispatchMode`, the ProxyTensorMode is already disabled, and `torch.zeros` doesn't take in any tensor-like arguments, so we never end up dispatching back into python again.
The way that manifests is that the output of `new_zeros()` gets baked as a constant into the AOTAutograd FX graph.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83207
Approved by: https://github.com/ezyang
This allows you to directly call into the CompositeImplicitAutograd
implementation of an operator, *without* changing any aspects of the
dispatcher state. In particular, you can use this to recursively call
into a decomposition, dispatching back to your tensor subclass/mode
as desired.
Hypothetically, we should also make these available in the
decompositions dictionary, but I'm leaving this as future work as
enumerating these decompositions is annoying (as operators are lazily
registered.)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83075
Approved by: https://github.com/albanD
Reference: #69991
This adds a new CompositeExplicit Operator `at::assert_all_true` (also exposed in Python) to check the truthiness of a tensor and throw an error based on that.
This helps us mitigate `TORCH_CHECK(t.all().item<bool>(), "err_msg")` pattern which is not composite compliant.
Using the mentioned operator, we fix `quantile` and `nanquantile` to be Composite Compliant.
Question: Should it be documented?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81767
Approved by: https://github.com/zou3519
This gives us tests for fake (all passing) and symbolic (not all passing).
I needed to add a gadget for xfail'ing tests in symbolic. It might be
generally useful, let me know what you think.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82746
Approved by: https://github.com/eellison
I intend to run all of the proxy tensor tests on each of our tracing
modes, but to do this I have to make the tests parametrized on
tracing mode first. This does that refactor, without adding any
new tests.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82739
Approved by: https://github.com/eellison
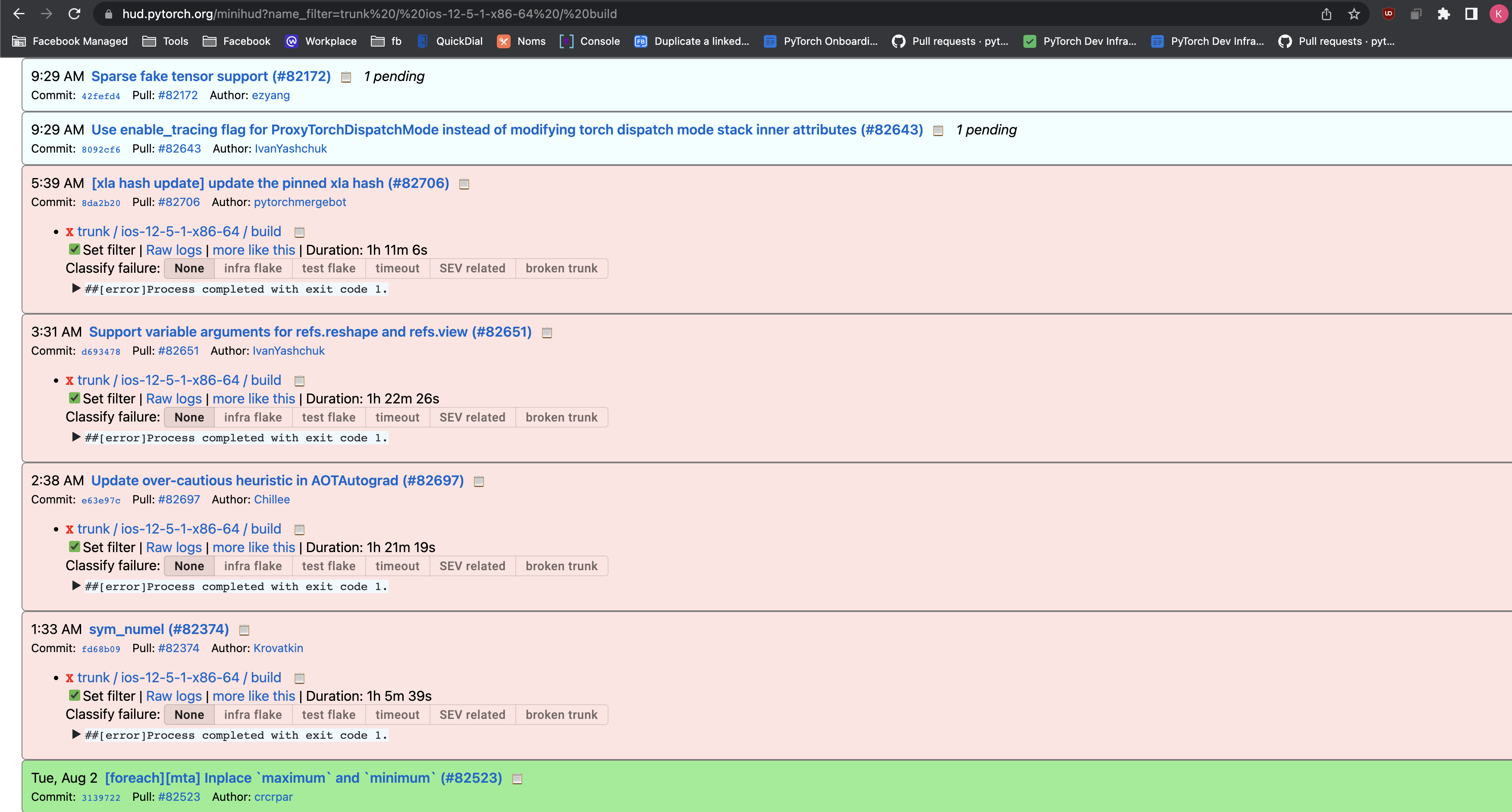
This PR relands sym_numel #82374 and fixes the ios build break in this commit : 8cbd0031c5
which was a type mismatch in an equality.
### Description
<!-- What did you change and why was it needed? -->
### Issue
<!-- Link to Issue ticket or RFP -->
### Testing
<!-- How did you test your change? -->
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82731
Approved by: https://github.com/malfet
Add support for sparse fake tensors.
- The testing strategy is to run a fake tensor cross ref test on `test_sparse.py`. This is necessary because OpInfo sparse coverage is completely nonexistent. We could have tried to turn on cross ref testing globally for all files, but that would be very time consuming and the tests I'm interested in are mostly in this file. There are some exclusions in testing for things that don't work.
- I make fake tensor converter raise a UnsupportedFakeTensorException if the meta converter fails to do a conversion (which can happen in a relatively large number of situations).
- I relax fake tensor invariants so that you can make a fake tensor from a meta tensor. This is useful because in the cross ref test sometimes we operate on meta tensors.
- Fake tensor wrapping is improved to handle the case when a function doesn't return any tensors
- Meta converter is taught how to convert sparse tensors to meta
There's still a little more cleanup that needs to be done, but this is good for review.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82172
Approved by: https://github.com/eellison
Adds a new context manager `TorchRefsNvfuserCapabilityMode` for conditional rewrite of `torch.*` calls to `torch._refs.*` based on whether the decomposition consisting of prims supports nvFuser execution or not.
A new optional argument for `TorchRefsMode` is added - `should_fallback_fn`, a callable that returns whether the original `torch.foo` or the replacement `torch._refs.foo` should be used.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81764
Approved by: https://github.com/ezyang
This makes symbolic tracing tests for logsigmoid and xlogy start working again.
While I'm at it, add pin_memory and layout kwargs to empty; but they
don't actually do anything and raise an error if they are non standard.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82332
Approved by: https://github.com/eellison
{kind=link}