add skips to tests that involve record_context_cpp on ARM as it is only supported on linux x86_64 arch. Error is reported as below:
```
Traceback (most recent call last):
File "/usr/lib/python3.10/unittest/case.py", line 59, in testPartExecutor
yield
File "/usr/lib/python3.10/unittest/case.py", line 591, in run
self._callTestMethod(testMethod)
File "/usr/lib/python3.10/unittest/case.py", line 549, in _callTestMethod
method()
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_utils.py", line 2674, in wrapper
method(*args, **kwargs)
File "/opt/pytorch/pytorch/test/test_cuda.py", line 3481, in test_direct_traceback
c = gather_traceback(True, True, True)
RuntimeError: record_context_cpp is not support on non-linux non-x86_64 platforms
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/117344
Approved by: https://github.com/malfet, https://github.com/drisspg
…reference) (#109065)
Summary:
Modify the way we update gc_count in CUDACachingAlloctor to make it faster.
Originally D48481557, but reverted due to nullptr dereference in some cases (D49003756). This diff changed to use correct constructor for search key (so avoid nullptr dereference). Also, added nullptr check (and returns 0 if it is) in gc_count functions.
Differential Revision: D49068760
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/117064
Approved by: https://github.com/zdevito
Updates flake8 to v6.1.0 and fixes a few lints using sed and some ruff tooling.
- Replace `assert(0)` with `raise AssertionError()`
- Remove extraneous parenthesis i.e.
- `assert(a == b)` -> `assert a == b`
- `if(x > y or y < z):`->`if x > y or y < z:`
- And `return('...')` -> `return '...'`
Co-authored-by: Nikita Shulga <2453524+malfet@users.noreply.github.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/116591
Approved by: https://github.com/albanD, https://github.com/malfet
The following two cases fail due to a small oversight `CUDAGraph::reset()` that causes failures in graph destructor
```Python
import torch
x = torch.zeros(4, device="cuda")
g = torch.cuda.CUDAGraph()
with torch.cuda.graph(g):
x = x + 1
g.reset()
del g
```
that fails with:
```
terminate called after throwing an instance of 'c10::Error'
what(): uc >= 0 INTERNAL ASSERT FAILED at ".../pytorch/c10/cuda/CUDACachingAllocator.cpp":2157, please report a bug to PyTorch.
```
and reset and subsequent re-capture
```Python
import torch
x = torch.zeros(4, device="cuda")
g = torch.cuda.CUDAGraph()
with torch.cuda.graph(g):
x = x + 1
g.reset()
with torch.cuda.graph(g):
x = x + 1
g.replay()
```
which fails with:
```
Traceback (most recent call last):
File "test_graph.py", line 11, in <module>
with torch.cuda.graph(g):
File ".../pytorch/torch/cuda/graphs.py", line 192, in __enter__
self.cuda_graph.capture_begin(
File ".../pytorch/torch/cuda/graphs.py", line 77, in capture_begin
super().capture_begin(pool=pool, capture_error_mode=capture_error_mode)
RuntimeError: This CUDAGraph instance already owns a captured graph. To capture a new graph, create a new instance.
```
This PR fixes `CUDAGraph::reset()` function for above to use cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108896
Approved by: https://github.com/ezyang
> capture_error_mode (str, optional): specifies the cudaStreamCaptureMode for the graph capture stream.
Can be "global", "thread_local" or "relaxed". During cuda graph capture, some actions, such as cudaMalloc,
may be unsafe. "global" will error on actions in other threads, "thread_local" will only error for
actions in the current thread, and "relaxed" will not error on these actions.
Inductor codegen is single-threaded, so it should be safe to enable "thread_local" for inductor's cuda graph capturing. We have seen errors when inductor cudagraphs has been used concurrently with data preprocessing in other threads.
Differential Revision: [D48656014](https://our.internmc.facebook.com/intern/diff/D48656014)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107407
Approved by: https://github.com/albanD, https://github.com/eqy
This updates ruff to 0.285 which is faster, better, and have fixes a bunch of false negatives with regards to fstrings.
I also enabled RUF017 which looks for accidental quadratic list summation. Luckily, seems like there are no instances of it in our codebase, so enabling it so that it stays like that. :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107519
Approved by: https://github.com/ezyang
This updates ruff to 0.285 which is faster, better, and have fixes a bunch of false negatives with regards to fstrings.
I also enabled RUF017 which looks for accidental quadratic list summation. Luckily, seems like there are no instances of it in our codebase, so enabling it so that it stays like that. :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107519
Approved by: https://github.com/ezyang
Previously when we recorded a free action in a memory trace, we would provide
the stack for when the block was allocated. This is faster because we do not
have to record stacks for free, which would otherwise double the number of stacks
collected. However, sometimes knowing the location of a free is useful for
figuring out why a tensor was live. So this PR adds this behavior. If
performance ends up being a concern the old behavior is possible by passing
"alloc" to the context argument rather than "all".
Also refactors some of glue logic to be consistent across C++ and Python and
routes the Python API through the C++ version.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106758
Approved by: https://github.com/albanD
This PR:
- adds a capturable API for NAdam similar to Adam(W)
- adds tests accordingly
- discovered and fixed bugs in the differentiable implementation (now tested through the capturable codepath).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106615
Approved by: https://github.com/albanD
We want to display the stack for the original cudaMalloc that created a segment.
Previously we could only report the last time the segment memory was used,
or the record of the segment_alloc could appear in the list of allocator actions.
This PR ensure regardless of whether we still have the segment_alloc action,
the context for a segment is still available. The visualizer is updated to
be able to incorporate this information.
This PR adds a new field to Block. However the previous stacked cleanup PR
removed a field of the same size, making the change to Block size-neutral.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106113
Approved by: https://github.com/aaronenyeshi
For free blocks of memory in the allocator, we previously kept a linked list
of the stack frames of previous allocations that lived there. This was only
ever used in one flamegraph visualization and never proved useful at
understanding what was going on. When memory history tracing was added, it
became redundant, since we can see the history of the free space from recording
the previous actions anyway.
This patch removes this functionality and simplifies the snapshot format:
allocated blocks directly have a 'frames' attribute rather than burying stack frames in the history.
Previously the memory history tracked the real size of allocations before rounding.
Since history was added, 'requested_size' has been added directly to the block which records the same information,
so this patch also removes that redundancy.
None of this functionality has been part of a PyTorch release with BC guarentees, so it should be safe to alter
this part of the format.
This patch also updates our visualization tools to work with the simplified format. Visualization tools keep
support for the old format in `_legacy` functions so that during the transition old snapshot files can still be read.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106079
Approved by: https://github.com/eellison
Mostly refactor, that moves all the tests from `test_cuda` that benefit from multiGPU environment into its own file.
- Add `TestCudaMallocAsync` class for Async tests ( to separate them from `TestCudaComm`)
- Move individual tests from `TestCuda` to `TestCudaMultiGPU`
- Move `_create_scaling_models_optimizers` and `_create_scaling_case` to `torch.testing._internal.common_cuda`
- Add newly created `test_cuda_multigpu` to the multigpu periodic test
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at f4d46fa</samp>
This pull request fixes a flaky test and improves the testing of gradient scaling on multiple GPUs. It adds verbose output for two CUDA tests, and refactors some common code into helper functions in `torch/testing/_internal/common_cuda.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104059
Approved by: https://github.com/huydhn
Reference cycles are freed by the cycle collector rather than being cleaned up
when the objects in the cycle first become unreachable. If a cycle points to a tensor,
the CUDA memory for that tensor will not be freed until garbage collection runs.
Accumulation of CUDA allocations can lead to out of memory errors (OOMs), as well as
non-deterministic allocation behavior which is harder to debug.
This visualizer installs a garbage collection hook to look for cycles containing
CUDA tensors and saves a visualization of the garbage:
```
from torch.cuda._cycleviz import warn_tensor_cycles
warn_tensor_cycles()
# do some work that results in a cycle getting garbage collected
# ...
> WARNING:root:Reference cycle includes a CUDA Tensor see visualization of cycle /tmp/tmpeideu9gl.html
```
Reland to make windows skip the test.
This reverts commit 7b3b6dd426.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104051
Approved by: https://github.com/aaronenyeshi, https://github.com/malfet
Reference cycles are freed by the cycle collector rather than being cleaned up
when the objects in the cycle first become unreachable. If a cycle points to a tensor,
the CUDA memory for that tensor will not be freed until garbage collection runs.
Accumulatin of CUDA allocations can lead to out of memory errors (OOMs), as well as
non-deterministic allocation behavior which is harder to debug.
This visualizer installs a garbage collection hook to look for cycles containing
CUDA tensors and saves a visualization of the garbage:
```
from torch.cuda._cycleviz import warn_tensor_cycles
warn_tensor_cycles()
# do some work that results in a cycle getting garbage collected
# ...
> WARNING:root:Reference cycle includes a CUDA Tensor see visualization of cycle /tmp/tmpeideu9gl.html
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102656
Approved by: https://github.com/aaronenyeshi
This replaces the invidual visualization routines in _memory_viz.py with
a single javascript application.
The javascript application can load pickled snapshot dumps directly using
drag/drop, requesting them via fetch, or by embedding them in a webpage.
The _memory_viz.py commands use the embedding approach.
We can also host MemoryViz.js on a webpage to use the drag/drop approach, e.g.
https://zdevito.github.io/assets/viz/
(eventually this should be hosted with the pytorch docs).
All views/multiple cuda devices are supported on one page.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103565
Approved by: https://github.com/eellison, https://github.com/albanD
Skip all cuda graph-related unit tests by setting env var `PYTORCH_TEST_SKIP_CUDAGRAPH=1`
This PR refactors the `TEST_CUDA` python variable in test_cuda.py into common_utils.py. This PR also creates a new python variable `TEST_CUDA_GRAPH` in common_utils.py, which has an env var switch to turn off all cuda graph-related tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103032
Approved by: https://github.com/malfet
Do not try to parse raised exception for no good reason
Add short description
Reduce script to a single line
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at ea4164e</samp>
> _`test_no_triton_on_import`_
> _Cleans up the code, adds docs_
> _No hidden errors_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102674
Approved by: https://github.com/cpuhrsch, https://github.com/albanD
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 08f7a6a</samp>
This pull request adds support for triton kernels in `torch` and `torch/cuda`, and refactors and tests the existing triton kernel for BSR matrix multiplication. It also adds a test case to ensure that importing `torch` does not implicitly import `triton`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98403
Approved by: https://github.com/malfet, https://github.com/cpuhrsch
On Arm, I got
```
Traceback (most recent call last):
File "/opt/pytorch/pytorch/test/test_cuda.py", line 5260, in test_cpp_memory_snapshot_pickle
mem = run()
File "/opt/pytorch/pytorch/test/test_cuda.py", line 5257, in run
t = the_script_fn()
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_utils.py", line 496, in prof_func_call
return prof_callable(func_call, *args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_utils.py", line 493, in prof_callable
return callable(*args, **kwargs)
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
File "/opt/pytorch/pytorch/test/test_cuda.py", line 5254, in the_script_fn
@torch.jit.script
def the_script_fn():
return torch.rand(311, 411, device='cuda')
~~~~~~~~~~ <--- HERE
RuntimeError: record_context_cpp is not support on non-linux non-x86_64 platforms
```
dfe484a3b3/torch/csrc/profiler/unwind/unwind.cpp (L4-L24) seems related
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101366
Approved by: https://github.com/zdevito
When we run cudagraph trees we are not allowed to have permanent workspace allocations like in cublas because we might need to reclaim that memory for a previous cudagraph recording, and it is memory that is not accounted for in output weakrefs so it does not work with checkpointing. Previously, I would check that we didn't have any additional allocations through snapshotting. This was extremely slow so I had to turn it off.
This PR first does the quick checking to see if we are in an error state, then if we are does the slow logic of creating snapshot. Also turns on history recording so we get a stacktrace of where the bad allocation came from.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99985
Approved by: https://github.com/zdevito
Why?
* To reduce the latency of hot path in https://github.com/pytorch/pytorch/pull/97377
Concern - I had to add `set_offset` in all instances of `GeneratorImpl`. I don't know if there is a better way.
~~~~
import torch
torch.cuda.manual_seed(123)
print(torch.cuda.get_rng_state())
torch.cuda.set_rng_state_offset(40)
print(torch.cuda.get_rng_state())
tensor([123, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0], dtype=torch.uint8)
tensor([123, 0, 0, 0, 0, 0, 0, 0, 40, 0, 0, 0, 0, 0,
0, 0], dtype=torch.uint8)
~~~~
Reland of https://github.com/pytorch/pytorch/pull/98965
(cherry picked from commit 8214fe07e8)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99565
Approved by: https://github.com/anijain2305
Common advice we give for handling memory fragmentation issues is to
allocate a big block upfront to reserve memory which will get split up later.
For programs with changing tensor sizes this can be especially helpful to
avoid OOMs that happen the first time we see a new largest input and would
otherwise have to allocate new segments.
However the issue with allocating a block upfront is that is nearly impossible
to correctly estimate the size of that block. If too small, space in the block
will run out and the allocator will allocate separate blocks anyway. Too large,
and other non-PyTorch libraries might stop working because they cannot allocate
any memory.
This patch provides the same benefits as using a pre-allocating block but
without having to choose its size upfront. Using the cuMemMap-style APIs,
it adds the ability to expand the last block in a segment when more memory is
needed.
Compared to universally using cudaMallocAsync to avoid fragmentation,
this patch can fix this common fragmentation issue while preserving most
of the existing allocator behavior. This behavior can be enabled and disabled dynamically.
This should allow users to, for instance, allocate long-lived parameters and state in individual buffers,
and put temporary state into the large expandable blocks, further reducing
fragmentation.
See inline comments for information about the implementation and its limitations.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96995
Approved by: https://github.com/eellison
CUDA Graph Trees
Design doc: https://docs.google.com/document/d/1ZrxLGWz7T45MSX6gPsL6Ln4t0eZCSfWewtJ_qLd_D0E/edit
Not currently implemented :
- Right now, we are using weak tensor refs from outputs to check if a tensor has dies. This doesn't work because a) aliasing, and b) aot_autograd detaches tensors (see note [Detaching saved tensors in AOTAutograd]). Would need either https://github.com/pytorch/pytorch/issues/91395 to land to use storage weak refs or manually add a deleter fn that does what I want. This is doable but theres some interactions with the caching allocator checkpointing so saving for a stacked pr.
- Reclaiming memory from the inputs during model recording. This isn't terribly difficult but deferring to another PR. You would need to write over the input memory during warmup, and therefore copy the inputs to cpu. Saving for a stacked pr.
- Warning on overwriting previous generation outputs. and handling nested torch.compile() calls in generation tracking
Differential Revision: [D43999887](https://our.internmc.facebook.com/intern/diff/D43999887)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89146
Approved by: https://github.com/ezyang
This refactors the stack trace facility specific to memory profiling
in python+cuda to make a generic facility to generate combined stack
traces.
The generic facility (combined_traceback.h) does not require
python to be around to work, but will return python stacks if it is
present.
This facility is then used to add support for stack trace gathering in memory profiling that
happens directly from C++.
It is also used to expose a python API for gathering and symbolizing
combineds stacks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95541
Approved by: https://github.com/ezyang
When we checkpoint the state of the private pool allocator, we will need to make sure that its current live allocated blocks will get properly cleaned up when the tensors they correspond to die. Return DataPtrs for these new allocated blocks that the callee can swap onto live Tensors.
The exact api for setting the checkpoint can be manipulated after this as the cudagraph implementation is built out, but this at least shows its sufficiently general.
This should be the last PR touching cuda caching allocator necessary for new cudagraphs integration.
Differential Revision: [D43999888](https://our.internmc.facebook.com/intern/diff/D43999888)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95020
Approved by: https://github.com/zdevito
Copying note from cuda caching allocator:
```
* Note [Checkpointing PrivatePoolState]
*
* Refer above to Note [Interaction with CUDA graph capture]. Allocations made
* during graph capture are made from a separate private pool. During graph
* capture allocations behave as usual. During graph replay the allocator
* state does not change even as new tensors are created. The private pool
* will not free its blocks to the main caching allocator until cuda graph use
* is finished to prevent an allocation from eager clobbering the memory from
* a live but unaccounted for tensor that was created during replay.
*
* `make_graphed_callables`, a series of separate callables chained in
* successive cuda graphs, can share a memory pool because after a cuda graph
* recording the allocations in the shared private pool exactly reflect the
* tensors that are allocated.
*
* We would like to extend callable chaining to support a graphed callable
* tree. In this scenario, we have a tree of callable chains which will be
* captured with cuda graphs. In the diagram below, we have a tree with four
* callables, A, B, C, and D. Suppose we have captured, and subsequently
* replayed, A, B, and C. Then on a new invocation, we replay A and B, but
* would now like to record D. At this point the private pool will not reflect
* any of the live tensors created during graph replay. Allocations made
* during a new recording with the pool could overwrite those live tensors.
*
* In order to record a new graph capture after replaying prior callables in
* the tree, we need the allocator to reflect the state of the live tensors.
* We checkpoint the state of the private after each recording, and then
* reapply it when we are starting a new recording chain. Additionally, we
* must free the allocations for any tensors that died between the end of our
* previous graph replaying and our new recording (TODO). All of the allocated
* segments that existed in the checkpointed state must still exist in the
* pool. There may also exist new segments, which we will free (TODO : link
* note [live tensors between iterations] when it exists).
*
*
* ---------------> A ---------------> B ---------------> C
* |
* |
* |
* |
* ---------------> D
```
A few TODOs:
- need to add logic for freeing tensors that have died between a last replay and current new recording
- Add logic for free that might be called on a pointer multiple times (because we are manually freeing live tensors)
The two scenarios above have not been exercised in the tests yet.
Differential Revision: [D43999889](https://our.internmc.facebook.com/intern/diff/D43999889)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94653
Approved by: https://github.com/zdevito
Adds the ability to quickly generate stack traces for C++,
and combine Python, TorchScript, and C++ frames into a single trace.
This makes it possible for the memory tracer to record allocations inside
C++ code (e.g. convolution temporaries, backward operators).
The unwinder code is ~10x faster than execinfo.h's backward because it
cache fast unwinder routines for instruction pointers that have already been seen.
It is also only 1.2--2x slower than copying the entire stack (the approach perf takes),
while using 2 orders of magnitude less space per stack.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95357
Approved by: https://github.com/bertmaher
Fixes https://github.com/pytorch/serve/issues/1937
A fairly common query I see folks running while using pytorch is
`nvidia-smi --format=csv,noheader,nounits --query-gpu=utilization.gpu,utilization.memory,memory.total,memory.used,temperature.gpu,power.draw,clocks.current.sm,clocks.current.memory -l 10`
Existing metrics we have
* For kernel utilization`torch.cuda.utilization()`
* For memory utilization we have them under `torch.cuda.memory` the memory allocated with `torch.cuda.memory.memory_allocated()`
* For total available memory we have `torch.cuda.get_device_properties(0).total_memory`
Which means the only metrics we're missing are
* Temperature: now in `torch.cuda.temperature()`
* Power draw: now in `torch.cuda.power()`
* Clock speed: now in `torch.cuda.clock_speed()`
With some important details on each
* Clock speed settings: I picked the SM clock domain which is documented here https://docs.nvidia.com/deploy/nvml-api/group__nvmlDeviceEnumvs.html#group__nvmlDeviceEnumvs_1g805c0647be9996589fc5e3f6ff680c64
* Temperature: I use `pynvml.nvmlDeviceGetTemperature(handle, 0)` where 0 refers to the GPU die temperature
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91717
Approved by: https://github.com/ngimel
With the release of ROCm 5.3 hip now supports a hipGraph implementation.
All necessary backend work and hipification is done to support the same functionality as cudaGraph.
Unit tests are modified to support a new TEST_GRAPH feature which allows us to create a single check for graph support instead of attempted to gather the CUDA level in annotations for every graph test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88202
Approved by: https://github.com/jithunnair-amd, https://github.com/pruthvistony, https://github.com/malfet
Summary:
The caching allocator can be configured to round memory allocations in order to reduce fragmentation. Sometimes however, the overhead from rounding can be higher than the fragmentation it helps reduce.
We have added a new stat to CUDA caching allocator stats to help track if rounding is adding too much overhead and help tune the roundup_power2_divisions flag:
- "requested_bytes.{current,peak,allocated,freed}": memory requested by client code, compare this with allocated_bytes to check if allocation rounding adds too much overhead
Test Plan: Added test case in caffe2/test/test_cuda.py
Differential Revision: D40810674
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88575
Approved by: https://github.com/zdevito
Follow-up of #86167 ; The number of pools was mistakenly ignored and the default workspace size appears to be too small to match selected cuBLAS kernels before the explicit allocation change.
CC @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89027
Approved by: https://github.com/ngimel
Essentially the same change as #67946, except that the default is to disallow reduced precision reductions in `BFloat16` GEMMs (for now). If performance is severely regressed, we can change the default, but this option appears to be necessary to pass some `addmm` `BFloat16` tests on H100.
CC @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89172
Approved by: https://github.com/ngimel
Summary:
1. use pytree to allow any input format for make_graphed_callables
2. add allow_unused_input argument for make_graphed_callables
Test Plan: buck2 test mode/dev-nosan //caffe2/test:cuda -- --print-passing-details
Differential Revision: D42077976
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90941
Approved by: https://github.com/ngimel
Preparation for the next PR in this stack: #89559.
I replaced
- `self.assertTrue(torch.equal(...))` with `self.assertEqual(..., rtol=0, atol=0, exact_device=True)`,
- the same for `self.assertFalse(...)` with `self.assertNotEqual(...)`, and
- `assert torch.equal(...)` with `torch.testing.assert_close(..., rtol=0, atol=0)` (note that we don't need to set `check_device=True` here since that is the default).
There were a few instances where the result of `torch.equal` is used directly. In that cases I've replaced with `(... == ...).all().item()` while sometimes also dropping the `.item()` depending on the context.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89527
Approved by: https://github.com/mruberry
Fixes#87894
This PR adds a warning if captured graph is empty (consists of zero nodes).
The example snippet where would it be useful:
```python
import torch
x = torch.randn(10)
z = torch.zeros(10)
g = torch.cuda.CUDAGraph()
with torch.cuda.graph(g):
z = x * x
# Warn user
```
and in #87894
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88754
Approved by: https://github.com/ezyang
Summary:
Improved roundup_power2_divisions knob so it allows better control of rouding in the PyTorch CUDA Caching Allocator.
This new version allows setting the number of divisions per power of two interval starting from 1MB and ending at 64GB and above. An example use case is when rouding is desirable for small allocations but there are also very large allocations which are persistent, thus would not benefit from rounding and take up extra space.
Test Plan: Tested locally
Differential Revision: D40103909
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87290
Approved by: https://github.com/zdevito
As per #87979, `custom_bwd` seems to forcefully use `torch.float16` for `torch.autograd.Function.backward` regardless of the `dtype` used in the forward.
Changes:
- store the `dtype` in `args[0]`
- update tests to confirm the dtype of intermediate result tensors that are outputs of autocast compatible `torch` functions
cc @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88029
Approved by: https://github.com/ngimel
We currently can take snapshots of the state of the allocated cuda memory, but we do not have a way to correlate these snapshots with the actions the allocator that were taken between snapshots. This PR adds a simple fixed-sized buffer that records the major actions that the allocator takes (ALLOC, FREE, SEGMENT_ALLOC, SEGMENT_FREE, OOM, SNAPSHOT) and includes these with the snapshot information. Capturing period snapshots with a big enough trace buffer makes it possible to see how the allocator state changes over time.
We plan to use this functionality to guide how settings in the allocator can be adjusted and eventually have a more robust overall algorithm.
As a component of this functionality, we also add the ability to get a callback when the allocator will throw an OOM, primarily so that snapshots can be taken immediately to see why the program ran out of memory (most programs have some C++ state that would free tensors before the OutOfMemory exception can be caught).
This PR also updates the _memory_viz.py script to pretty-print the trace information and provide a better textual summary of snapshots distinguishing between internal and external fragmentation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86241
Approved by: https://github.com/ngimel
Sometimes the driving process want to save memory snapshots but isn't Python.
Add a simple API to turn it on without python stack traces. It still
saves to the same format for the vizualization and summary scripts, using
the C++ Pickler.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86190
Approved by: https://github.com/ezyang
Summary:
- expose a python call to set the allocator settings, it uses the same format as the value for PYTORCH_CUDA_ALLOCATOR
- keep the implementation contained within the cpp file to avoid increasing build times, only expose a function to call the setting
- make some of the Allocator Config methods public, now it looks more like a singleton
Test Plan: added the unit test
Differential Revision: D39487522
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84970
Approved by: https://github.com/zdevito
Fixes#84614
Prior to this PR CUDAGraph did not store the RNG seed, that is why `torch.cuda.manual_seed(new_seed)` would only reset the offset but not update the seed at all keeping whatever value was used during graph capture.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84967
Approved by: https://github.com/ngimel
Added ROCm support for the test_lazy_init unit test by including a condition on TEST_WITH_ROCM to switch CUDA_VISIBLE_DEVICES with HIP_VISIBLE_DEVICES.
This is needed because HIP_VISIBLE_DEVICES is set when running the single-GPU tests in CI: a47bc96fb7/.jenkins/pytorch/test.sh (L38), but this test sets CUDA_VISIBLE_DEVICES, which takes lower precedence than HIP_VISIBLE_DEVICES on ROCm.
**Testing Logs (to show behavior difference)**
12:40:41 Aug 30 11:40:41 CUDA_VISIBLE_DEVICES='0': 0
12:40:41 Aug 30 11:40:41 1
12:40:41 Aug 30 11:40:41 CUDA_VISIBLE_DEVICES='32': 32
12:40:41 Aug 30 11:40:41 1
12:40:41 Aug 30 11:40:41 HIP_VISIBLE_DEVICES='0': 0
12:40:41 Aug 30 11:40:41 1
12:40:41 Aug 30 11:40:41 HIP_VISIBLE_DEVICES='32': 32
12:40:41 Aug 30 11:40:41 0
**Passing UT**
Aug 30 17:03:15 test_lazy_init (main.TestCuda)
Aug 30 17:03:17 Validate that no CUDA calls are made during import torch call ... ok (2.471s)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84333
Approved by: https://github.com/jithunnair-amd, https://github.com/malfet
There there are conflicts between `torch.clear_autocast_cache()` and `cudaMallocAsync` from #82682.
Moreover, the use of autocast caching is not reasonable during training which is the main target of `make_graphed_callables`.
cc @eqy @ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84289
Approved by: https://github.com/ngimel
This problem updates the the PR [#73040](https://github.com/pytorch/pytorch/pull/73040)
The compilation error in pyTorch with ROCm is successful with these changes when `NDEBUG` is enabled.
Solution:
For HIP we keep `__device__ __assert_fail()`
and for host side compilation we want to use the `__assert_fail()` from the glibc library.
Tested the code by compiling with below steps
```
python3 tools/amd_build/build_amd.py
python3 setup.py develop --cmake-only
cmake -DHIP_HIPCC_FLAGS_RELEASE="-DNDEBUG" build
cmake --build build
```
The UT test_fixed_cuda_assert_async is still skipped due performance overhead.
cc @jithunnair-amd
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81790
Approved by: https://github.com/shintaro-iwasaki, https://github.com/jeffdaily, https://github.com/malfet
Record stack trace information for each allocated segment in the allocator.
It takes around 1.5us to record 50 stack frames of context.
Since invoking a Pytorch operator is around 8us, this adds minimal overhead but we still leave it disabled by default so that we can test it more on real workloads first.
Stack information is kept both for allocated blocks and the last allocation used inactive blocks. We could potential keep around the _first_ allocation that caused the block to get allocated from cuda as well.
Potential Followups:
* stack frame entries are small (16 bytes), but the list of Frames is not compressed eventhough most frames will share some entries. So far this doesn't produce huge dumps (7MB for one real workload that uses all memory on the GPU), but it can be much smaller through compression.
* Code to format the information is slow (a few seconds) because it uses python and FlameGraph.pl
* Things allocated during the backward pass have no stack frames because they are run on another C++ thread.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82146
Approved by: https://github.com/albanD
### Description
Since the major changes for `_TypedStorage` and `_UntypedStorage` are now complete, they can be renamed to be public.
`TypedStorage._untyped()` is renamed to `TypedStorage.untyped()`.
Documentation for storages is improved as well.
### Issue
Fixes#82436
### Testing
N/A
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82438
Approved by: https://github.com/ezyang
cuDNN via the V8 API supports `bfloat16` on Ampere (`>= (8, 0)` but not older devices) which might be unexpected given current test settings. This PR fixes some dispatching to check the device capability before dispatching `bfloat16` convs and adjusts the expected failure conditions for the autocast test.
CC @xwang233 @ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81139
Approved by: https://github.com/ngimel
Near term fix for https://github.com/pytorch/pytorch/issues/76368.
Q. Why does the user need to request `capturable=True` in the optimizer constructor? Why can't capture safety be completely automatic?
A. We need to set up capture-safe (device-side) state variables before capture. If we don't, and step() internally detects capture is underway, it's too late: the best we could do is create a device state variable and copy the current CPU value into it, which is not something we want baked into the graph.
Q. Ok, why not just do the capture-safe approach with device-side state variables all the time?
A. It incurs several more kernel launches per parameter, which could really add up and regress cpu overhead for ungraphed step()s. If the optimizer won't be captured, we should allow step() to stick with its current cpu-side state handling.
Q. But cuda RNG is a stateful thing that maintains its state on the cpu outside of capture and replay, and we capture it automatically. Why can't we do the same thing here?
A. The graph object can handle RNG generator increments because its capture_begin, capture_end, and replay() methods can see and access generator object. But the graph object has no explicit knowledge of or access to optimizer steps in its capture scope. We could let the user tell the graph object what optimizers will be stepped in its scope, ie something like
```python
graph.will_use_optimizer(opt)
graph.capture_begin()
...
```
but that seems clunkier than an optimizer constructor arg.
I'm open to other ideas, but right now I think constructor arg is necessary and the least bad approach.
Long term, https://github.com/pytorch/pytorch/issues/71274 is a better fix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77862
Approved by: https://github.com/ezyang
Resubmit of https://github.com/pytorch/pytorch/pull/77673, which was reverted due to Windows test failures: https://github.com/pytorch/pytorch/pull/77673#issuecomment-1130425845.
I suspect these failures happened because I don't explicitly set a side stream for graph capture in the new test.
Not setting a side stream explicitly is alright on Linux because cuda tests implicitly use a side stream.
I think Windows cuda tests implicitly use the default stream, breaking capture and leaving the backend in a bad state.
Other graphs tests explicitly set side streams and don't error in Windows builds, so i'm 95% sure doing the same for the new test will work.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77789
Approved by: https://github.com/ezyang
In preparation of adopting future rocblas library options, it is necessary to track when the backward pass of training is executing. The scope-based helper class `BackwardPassGuard` is provided to toggle state.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71881
Approved by: https://github.com/albanD
release_cached_blocks calls this:
```
void synchronize_and_free_events() {
TORCH_INTERNAL_ASSERT(captures_underway == 0);
```
Which means we can't call that function when we are capturing a cuda graph:
```
import torch
with torch.cuda.graph(torch.cuda.CUDAGraph()):
torch.zeros(2 ** 40, device="cuda")
```
results in:
```
RuntimeError: captures_underway == 0INTERNAL ASSERT FAILED at "/tmp/torch/c10/cuda/CUDACachingAllocator.cpp":1224, please report a bug to PyTorch.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76247
Approved by: https://github.com/ngimel
Summary:
Recent change (https://github.com/pytorch/pytorch/pull/69751) introduced the requirement of using `.coalesce()` explicitly in the tests. Unfortunately, not all tests are run in the current CI configuration and one test failure slipped through.
Fixes https://github.com/pytorch/pytorch/issues/74015.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74027
Reviewed By: samdow
Differential Revision: D34858112
Pulled By: mruberry
fbshipit-source-id: 8904fac5e2b5335684a21f95a22646469478eb81
(cherry picked from commit 06d6e6d2a796af0e8444f4c57841a07ec4f67c9f)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73040
This patch fixes a compilation error in PyTorch with ROCm when `NDEBUG` is passed.
## Problem
Forward declaration of `__host__ __device__ __assert_fail()` is used in `c10/macros/Macros.h` for HIP compilation when `NDEBUG` is set However, HIP has `__device__ __assert_fail()` in `hip/amd_detail/amd_device_functions.h`, causing a function type error.
This issue does not appear in ROCm CI tests since it happens only when `NDEBUG` is passed.
## Solution
[EDIT] After the discussion on GitHub, we chose to entirely disable `CUDA_KERNEL_ASSERT()` for ROCm.
---
To solve this compilation error, this patch disables `CUDA_KERNEL_ASSERT()`, which uses `__assert_fail()` when
1. `c10/macros/Macros.h` is included for `*.hip` (precisely speaking, `__HIP__` or `__HIP_ARCH__` is defined), and
2. `NDEBUG` is passed.
Note that there's no impact on default compilation because, without a special compilation flag, those HIP files are compiled without `-NDEBUG`. And that's why this issue has not been found.
### Justification
[1] We cannot declare one host-and-device function for two separate host and device functions.
```
__device__ int func() {return 0};
__host__ int func() {return 0};
// Compile error (hipcc)
// __device__ __host__ int func();
```
[2] Forward declaration of a correct `__device__` only `__assert_fail()` for `__HIP__` causes the following error:
```
pytorch/c10/util/TypeCast.h:135:7: error: reference to __device__ function '__assert_fail' in __host__ __device__ function
ERROR_UNSUPPORTED_CAST
^
pytorch/c10/util/TypeCast.h:118:32: note: expanded from macro 'ERROR_UNSUPPORTED_CAST'
#define ERROR_UNSUPPORTED_CAST CUDA_KERNEL_ASSERT(false);
^
pytorch/c10/macros/Macros.h:392:5: note: expanded from macro 'CUDA_KERNEL_ASSERT'
__assert_fail(
```
[3] Maybe there's a way to properly define `__assert_fail()` for HIP + NDEBUG, but this might be too much. Please let me just disable it.
### Technical details
Error
```
pytorch/c10/macros/Macros.h:368:5: error: __host__ __device__ function '__assert_fail' cannot overload __device__ function '__assert_fail'
__assert_fail(
^
/opt/rocm/hip/include/hip/amd_detail/amd_device_functions.h:1173:6: note: previous declaration is here
void __assert_fail(const char *assertion,
```
CUDA definition (9.x) of `__assert_fail()`
```
#elif defined(__GNUC__)
extern __host__ __device__ __cudart_builtin__ void __assert_fail(
const char *, const char *, unsigned int, const char *)
__THROW;
```
ROCm definition (the latest version)
```
// 2b59661f3e/include/hip/amd_detail/amd_device_functions.h (L1172-L1177)
extern "C" __device__ __attribute__((noinline)) __attribute__((weak))
void __assert_fail(const char *assertion,
const char *file,
unsigned int line,
const char *function);
```
Test Plan:
CI + reproducer
```
python3 tools/amd_build/build_amd.py
python3 setup.py develop --cmake-only
cmake -DHIP_HIPCC_FLAGS_RELEASE="-DNDEBUG" build
cmake --build build
```
Reviewed By: xw285cornell
Differential Revision: D34310555
fbshipit-source-id: 7542288912590533ced3f20afd2e704b6551991b
(cherry picked from commit 9e52196e36820abe36bf6427cabc7389d3ea6cb5)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69299https://github.com/pytorch/pytorch/pull/68906 + https://github.com/pytorch/pytorch/pull/68749 plugged one correctness hole (non-blocking copies of offset pinned memory tensors) while introducing another (non-blocking copies of pinned memory tensors with a non-standard DataPtr context).
In this revision, we use both the tensor data pointer and context to attempt to identify the originating block in the pinned memory allocator.
Test Plan: New unit tests added to cover the missing case previously.
Reviewed By: yinghai
Differential Revision: D32787087
fbshipit-source-id: 0cb0d29d7c39a13f433eb1cd423dc0d2a303c955
(cherry picked from commit 297157b1a1)
Summary:
Also fixes the documentation failing to appear and adds a test to validate that op works with multiple devices properly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69640
Reviewed By: ngimel
Differential Revision: D32965391
Pulled By: mruberry
fbshipit-source-id: 4fe502809b353464da8edf62d92ca9863804f08e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68749
The logic for asynchronous copies (either HtoD or DtoH) using cudaMemcpyAsync relies on recording an event with the caching host allocator to notify it that a given allocation has been used on a stream - and thus it should wait for that stream to proceed before reusing the host memory.
This tracking is based on the allocator maintaining a map from storage allocation pointers to some state.
If we try to record an event for a pointer we don't understand, we will silently drop the event and ignore it (9554ebe44e/aten/src/ATen/cuda/CachingHostAllocator.cpp (L171-L175)).
Thus, if we use the data_ptr of a Tensor instead of the storage allocation, then reasonable code can lead to incorrectness due to missed events.
One way this can occur is simply by slicing a tensor into sub-tensors - which have different values of `data_ptr()` but share the same storage, for example:
```
image_batch = torch.randn(M, B, C, H, W).pin_memory()
for m in range(M):
sub_batch = image_batch[m].cuda(non_blocking=True)
# sub_batch.data_ptr() != image_batch.data_ptr() except for m == 0.
# however, sub_batch.storage().data_ptr() == image_batch.storage().data_ptr() always.
```
Therefore, we instead use the storage context pointer when recording events, as this is the same state that is tracked by the caching allocator itself. This is a correctness fix, although it's hard to determine how widespread this issue is.
Using the storage context also allows us to use a more efficient structure internally to the caching allocator, which will be sent in future diffs.
Test Plan: Test added which demonstrates the issue, although it's hard to demonstrate the race explicitly.
Reviewed By: ngimel
Differential Revision: D32588785
fbshipit-source-id: d87cc5e49ff8cbf59052c3c97da5b48dd1fe75cc
Summary:
https://github.com/pytorch/pytorch/issues/67578 disabled reduced precision reductions for FP16 GEMMs. After benchmarking, we've found that this has substantial performance impacts for common GEMM shapes (e.g., those found in popular instantiations of multiheaded-attention) on architectures such as Volta. As these performance regressions may come as a surprise to current users, this PR adds a toggle to disable reduced precision reductions
`torch.backends.cuda.matmul.allow_fp16_reduced_precision_reduction = `
rather than making it the default behavior.
CC ngimel ptrblck
stas00 Note that the behavior after the previous PR can be replicated with
`torch.backends.cuda.matmul.allow_fp16_reduced_precision_reduction = False`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67946
Reviewed By: zou3519
Differential Revision: D32289896
Pulled By: ngimel
fbshipit-source-id: a1ea2918b77e27a7d9b391e030417802a0174abe
Summary:
Fixes https://github.com/pytorch/pytorch/issues/62533.
In very rare cases, the decorator for detecting memory leak is throwing assertion, even when the test is passing, and the memory is being freed with a tiny delay. The issue is not being reproduced in internal testing, but shows up sometimes in CI environment.
Reducing the severity of such detection to warning, so as not to fail the CI tests, as the actual test is not failing, rather only the check inside the decorator is failing.
Limiting the change to ROCM only for now.
cc jeffdaily sunway513 jithunnair-amd ROCmSupport
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65973
Reviewed By: anjali411
Differential Revision: D31776154
Pulled By: malfet
fbshipit-source-id: 432199fca17669648463c4177c62adb553cacefd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66798
get_cycles_per_ms is copied and used in a few places, move it to common_utils so that it can be used as a shared util function
ghstack-source-id: 140790599
Test Plan: unit tests
Reviewed By: pritamdamania87
Differential Revision: D31706870
fbshipit-source-id: e8dccecb13862646a19aaadd7bad7c8f414fd4ab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62030
Remove dtype tracking from Python Storage interface, remove all the different `<type>Storage` classes except for `ByteStorage`, and update serialization accordingly, while maintaining as much FC/BC as possible
Fixes https://github.com/pytorch/pytorch/issues/47442
* **THE SERIALIZATION FORMAT IS FULLY FC/BC.** We worked very hard to make sure this is the case. We will probably want to break FC at some point to make the serialization structure of tensors make more sense, but not today.
* There is now only a single torch.ByteStorage class. Methods like `Tensor.set_` no longer check that the dtype of storage is appropriate.
* As we no longer know what dtype of a storage is, we've **removed** the size method from Storage, replacing it with nbytes. This is to help catch otherwise silent errors where you confuse number of elements with number of bytes.
* `Storage._new_shared` takes a `nbytes` kwarg and will reject previous positional only calls. `Storage._new_with_file` and `_set_from_file` require explicit element size arguments.
* It's no longer possible to convert storages to different types using the float/double/etc methods. Instead, do the conversion using a tensor.
* It's no longer possible to allocate a typed storage directly using FloatStorage/DoubleStorage/etc constructors. Instead, construct a tensor and extract its storage. The classes still exist but they are used purely for unpickling.
* The preexisting serialization format stores dtype with storage, and in fact this dtype is used to determine the dtype of the tensor overall.
To accommodate this case, we introduce a new TypedStorage concept that exists only during unpickling time which is used to temporarily store the dtype so we can construct a tensor. **If you overrode the handling of pickling/unpickling, you MUST add handling for TypedStorage** or your serialization code will degrade to standard file-based serialization.
Original pull request: https://github.com/pytorch/pytorch/pull/59671
Reviewed By: soulitzer, ngimel
Differential Revision: D29466819
Pulled By: ezyang
fbshipit-source-id: 4a14e5d3c2b08e06e558683d97f7378a3180b00e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64261
Note that this does not preserve byte-for-byte compatibility with
existing names.
Test Plan:
* Rely on CI to catch gross errors.
* Merge after release cut to catch subtle issues.
Reviewed By: albanD
Differential Revision: D30700647
Pulled By: dagitses
fbshipit-source-id: 7b02f34b8fae3041240cc78fbc6bcae498c3acd4
Summary:
Graphed workloads that try to capture a full backward pass must do warmup on a non-default stream. If warmup happens on the default stream, AccumulateGrad functions might tag themselves to run on the default stream, and therefore won't be capturable.
ngimel and I suspect some test_cuda.py tests run with the default stream as the ambient stream, which breaks `test_graph_grad_scaling` because `test_graph_grad_scaling` does warmup on the ambient stream _assuming_ the ambient stream is a non-default stream.
This PR explicitly sets a side stream for the warmup in `test_graph_grad_scaling`, which is what I should have done all along because it's what the new documentation recommends.
I pushed the PR branch straight to the main pytorch repo because we need to run ci-all on it, and I'm not sure what the requirements are these days.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64339
Reviewed By: mruberry
Differential Revision: D30690711
Pulled By: ngimel
fbshipit-source-id: 91ad75f46a11f311e25bc468ea184e22acdcc25a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62664
Skipping a test for ROCm because of issue #62602
Test Plan: Imported from OSS
Reviewed By: soulitzer
Differential Revision: D30079534
Pulled By: NivekT
fbshipit-source-id: a9cf35e5d3a8d218edc9c5a704d1f9599d2f38a6
Summary:
Closes https://github.com/pytorch/pytorch/issues/59846.
https://github.com/pytorch/pytorch/issues/59846 is likely paranoia, and some of the test_streaming_backward_* in test_cuda.py already use gradient stealing (ie, they start with `.grad`s as None before backward). Regardless, this PR augments one of the tests to stress gradient stealing a bit more directly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60065
Reviewed By: mrshenli
Differential Revision: D29779518
Pulled By: ngimel
fbshipit-source-id: ccbf278543c3adebe5f4ba0365b1dace9a14da9b
Summary:
Before https://github.com/pytorch/pytorch/pull/57833, calls to backward() or grad() synced only the calling thread's default stream with autograd leaf streams at the end of backward. This made the following weird pattern safe:
```python
with torch.cuda.stream(s):
# imagine forward used many streams, so backward leaf nodes may run on many streams
loss.backward()
# no sync
use grads
```
but a more benign-looking pattern was unsafe:
```python
with torch.cuda.stream(s):
# imagine forward used a lot of streams, so backward leaf nodes may run on many streams
loss.backward()
# backward() syncs the default stream with all the leaf streams, but does not sync s with anything,
# so counterintuitively (even though we're in the same stream context as backward()!)
# it is NOT SAFE to use grads here, and there's no easy way to make it safe,
# unless you manually sync on all the streams you used in forward,
# or move "use grads" back to default stream outside the context.
use grads
```
mruberry ngimel and I decided backward() should have the [same user-facing stream semantics as any cuda op](https://pytorch.org/docs/master/notes/cuda.html#stream-semantics-of-backward-passes).** In other words, the weird pattern should be unsafe, and the benign-looking pattern should be safe. Implementationwise, this meant backward() should sync its calling thread's current stream, not default stream, with the leaf streams.
After https://github.com/pytorch/pytorch/pull/57833, backward syncs the calling thread's current stream AND default stream with all leaf streams at the end of backward. The default stream syncs were retained for temporary backward compatibility.
This PR finishes https://github.com/pytorch/pytorch/pull/57833's work by deleting syncs on the default stream.
With this PR, graph-capturing an entire backward() call should be possible (see the [test_graph_grad_scaling diffs](https://github.com/pytorch/pytorch/compare/master...mcarilli:streaming_backwards_remove_default_syncs?expand=1#diff-893b1eea27352f336f4cd832919e48d721e4e90186e63400b8596db6b82e7450R3641-R3642)).
** first paragraph has a formatting error which this PR should also fix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60421
Reviewed By: albanD
Differential Revision: D29370344
Pulled By: ngimel
fbshipit-source-id: 3248bc5fb92fc517db0c15c897e5d7250f67d7fe
Summary:
Before https://github.com/pytorch/pytorch/pull/57833, calls to backward() or grad() synced only the calling thread's default stream with autograd leaf streams at the end of backward. This made the following weird pattern safe:
```python
with torch.cuda.stream(s):
# imagine forward used many streams, so backward leaf nodes may run on many streams
loss.backward()
# no sync
use grads
```
but a more benign-looking pattern was unsafe:
```python
with torch.cuda.stream(s):
# imagine forward used a lot of streams, so backward leaf nodes may run on many streams
loss.backward()
# backward() syncs the default stream with all the leaf streams, but does not sync s with anything,
# so counterintuitively (even though we're in the same stream context as backward()!)
# it is NOT SAFE to use grads here, and there's no easy way to make it safe,
# unless you manually sync on all the streams you used in forward,
# or move "use grads" back to default stream outside the context.
use grads
```
mruberry ngimel and I decided backward() should have the [same user-facing stream semantics as any cuda op](https://pytorch.org/docs/master/notes/cuda.html#stream-semantics-of-backward-passes).** In other words, the weird pattern should be unsafe, and the benign-looking pattern should be safe. Implementationwise, this meant backward() should sync its calling thread's current stream, not default stream, with the leaf streams.
After https://github.com/pytorch/pytorch/pull/57833, backward syncs the calling thread's current stream AND default stream with all leaf streams at the end of backward. The default stream syncs were retained for temporary backward compatibility.
This PR finishes https://github.com/pytorch/pytorch/pull/57833's work by deleting syncs on the default stream.
With this PR, graph-capturing an entire backward() call should be possible (see the [test_graph_grad_scaling diffs](https://github.com/pytorch/pytorch/compare/master...mcarilli:streaming_backwards_remove_default_syncs?expand=1#diff-893b1eea27352f336f4cd832919e48d721e4e90186e63400b8596db6b82e7450R3641-R3642)).
** first paragraph has a formatting error which this PR should also fix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60421
Reviewed By: VitalyFedyunin, albanD
Differential Revision: D29342234
Pulled By: ngimel
fbshipit-source-id: 98e6be7fdd8550872f0a78f9a66cb8dfe75abf63
Summary:
Fixes https://github.com/pytorch/pytorch/issues/59844.
Streaming backwards collects "leaf streams" for AccumulateGrad functions that stash or accumulate .grad attributes for autograd leaf tensors, and syncs those streams with some ambient stream(s) so later ops can safely consume the grads on the ambient stream(s).
But, currently, streaming backwards does not collect leaf streams for grads produced out-of-place (ie, not stashed onto a .grad attribute) by `torch.autograd.grad`, because these out-of-place grads are "captured" and returned before they reach an AccumulateGrad function. Some out-of-place grads might not even have an AccumulateGrad function to go to, because `torch.autograd.grad` can be told to make grads for non-leaf temporaries.[1]
The upshot is, when streaming backwards makes ops that produce out-of-place gradients run on side streams, no ambient stream is told to sync on these side streams, so `torch.autograd.grad` doesn't offer the same post-call safe-use guarantees for grads as the leaf accumulation of `torch.autograd.backward`.
This PR ensures `torch.autograd.grad` gives the same safe-use guarantees as `torch.autograd.backward` by also stashing leaf streams for grads created out-of-place.
I augmented a streaming backwards test to include a torch.autograd.grad attempt. The test fails on current master[2] and passes with the engine.cpp diffs.
I have no idea if this bug or its fix matter to distributed autograd. pritamdamania mrshenli should take a look before it's merged.
[1] example:
```python
leaf = torch.tensor(..., requires_grad=True)
tmp = leaf * 2
loss = tmp.sum()
torch.autograd.grad(loss, inputs=(tmp, leaf))
```
Technically, because `torch.autograd.grad` can be told to produce grads for non-leaf temporaries, these streams might NOT be "leaf streams". Maybe I should rename `leaf_streams`?
[2] the way the test currently fails is fun: it reports
```
AssertionError: False is not true : Tensors failed to compare as equal!With rtol=1.3e-06 and atol=1e-05, found 0 element(s) (out of 25) whose difference(s) exceeded the margin of error (including 0 nan comparisons). The greatest difference was 0.0 (5.0 vs. 5.0), which occurred at index (0, 0).
```
I suspect this [kafka trap](https://en.wiktionary.org/wiki/Kafkatrap) happens because assertEqual does a comparison test on the device, syncs on some bool result, sees failure and prints the tensors post-sync at which point is IS safe to access the values.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60127
Reviewed By: mrshenli
Differential Revision: D29276581
Pulled By: albanD
fbshipit-source-id: a9f797e2fd76e2f884cce5a32ecf5d9b704c88ee
Summary:
Previous is https://github.com/pytorch/pytorch/issues/57781
We add now two CUDA bindings to avoid using ctypes to fix a windows issue.
However, we use ctypes to allocate the stream and create its pointer
(we can do this with a 0-dim tensor too if it feels better).
CC. ezyang rgommers ngimel mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59527
Reviewed By: albanD
Differential Revision: D29053062
Pulled By: ezyang
fbshipit-source-id: 661e7e58de98b1bdb7a0871808cd41d91fe8f13f
Summary:
This is required in https://github.com/pytorch/pytorch/pull/57110#issuecomment-828357947
We need to provide means to synchronize on externally allocated streams for dlpack support in python array data api.
cc mruberry rgommers leofang asi1024 kmaehashi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57781
Reviewed By: mrshenli
Differential Revision: D28326365
Pulled By: ezyang
fbshipit-source-id: b67858c8033949951b49a3d319f649884dfd0a91
Summary:
Graphs tests are sometimes flaky in CI ([example](https://app.circleci.com/pipelines/github/pytorch/pytorch/328930/workflows/0311199b-a0be-4802-a286-cf1e73f96c70/jobs/13793451)) because when the GPU runs near its max memory capacity (which is not unusual during a long test), sometimes, to satisfy new allocations that don't match any existing unused blocks, the caching allocator may call `synchronize_and_free_events` to wait on block end-of-life events and cudaFree unused blocks, then re-cudaMalloc a new block. For ungraphed ops this isn't a problem, but synchronizing or calling cudaFree while capturing is illegal, so `synchronize_and_free_events` raises an error if called during capture.
The graphs tests themselves don't use much memory, so calling torch.cuda.empty_cache() at some point before their captures should ensure memory is available and the captures never need `synchronize_and_free_events`.
I was already calling empty_cache() near the beginning of several graphs tests. This PR extends it to the ones I forgot.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59233
Reviewed By: mruberry
Differential Revision: D28816691
Pulled By: ngimel
fbshipit-source-id: 5cd83e48e43b1107daed5cfa2efff0fdb4f99dff
Summary:
This is based on https://github.com/pytorch/pytorch/issues/48224.
To make `foreach` more flexible, this PR pushes unsupported cases to slow path.
Also, this adds some tests to verify that
- `foreach` functions work with tensors of different dtypes and/or memory layouts in 7bd4b2c89f
- `foreach` functions work with tensors on different devices in a list, but are on the same device if the indices are the same: def4b9b5a1
Future plans:
1. Improve the coverage of unittests using `ops` decorator & updating `foreach_unary_op_db` and creating `foreach_(binary|pointwise|minmax)_db`.
2. Support broadcasting in slow path. Ref: https://github.com/pytorch/pytorch/pull/52448
3. Support type promotion in fast path. Ref https://github.com/pytorch/pytorch/pull/52449
CC: ngimel mcarilli ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56993
Reviewed By: zou3519
Differential Revision: D28630580
Pulled By: ngimel
fbshipit-source-id: e26ee74a39a591025e18c1ead48948cb7ec53c19
Summary:
Right now** there's a bug in libcuda.so that triggers sometimes when graphs with certain topologies are replayed back to back without a sync in between. Replays that hit this bug turn into spaghetti: kernels reordered ignoring dependencies, kernels elided, corrupted results. Currently, the only workaround I know that fixes all our repros is a manual sync between replays.
I'll remove the sync (or special case it based on cuda version) in a later PR, as soon as a fixed libcuda.so is available.
The only substantive change is the cudaDeviceSynchronize, other lines changed are de-indenting an unneeded scope.
** The bug is in current and semi-recent public versions of libcuda.so. We discovered the bug recently and we're not sure yet which public release was first affected. The version that ships with 11.3 is definitely affected, versions that shipped with 11.1 and earlier are likely not affected.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57556
Reviewed By: mruberry
Differential Revision: D28343043
Pulled By: ngimel
fbshipit-source-id: 3b907241aebdb8ad47ae96a6314a8b02de7bfa77
Summary:
https://github.com/pytorch/pytorch/pull/56433 was reverted because the test perceived internal dropout state creation as a memory leak. This PR resubmits with the leak check skipped.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57373
Reviewed By: anjali411
Differential Revision: D28152186
Pulled By: ezyang
fbshipit-source-id: 9a593fcdbbabbb09dc4e4221191663e94b697503
Summary:
I'd like the following pattern (a natural composition of Amp with full fwd+bwd capture) to work:
```python
# Create "static_input" with dummy data, run warmup iterations,
# call optimizer.zero_grad(set_to_none=True), then
g = torch.cuda._Graph()
s.wait_stream(torch.cuda.current_stream())
with torch.cuda.stream(s):
optimizer.zero_grad(set_to_none=True)
g.capture_begin()
with autocast():
out = model(static_input)
loss = loss_fn(out)
scaler.scale(loss).backward()
g.capture_end()
torch.cuda.current_stream().wait_stream(s)
# Training loop:
for b in data:
# optimizer.zero_grad() deliberately omitted, replay()'s baked-in backward will refill statically held .grads
static_input.copy_(b)
g.replay()
scaler.step(optimizer)
scaler.update()
```
Right now `GradScaler` can't work with this pattern because `update()` creates the scale tensor for the next iteration out of place. This PR changes `update()` to act in place on a long-lived scale tensor that stays static across iterations.
I'm not sure how this change affects XLA (see https://github.com/pytorch/pytorch/pull/48570), so we shouldn't merge without approval from ailzhang yaochengji.
Tagged bc-breaking because it's a change to the amp update utility function in native_functions.yaml. The function was never meant to be user-facing though.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55562
Reviewed By: zou3519
Differential Revision: D28046159
Pulled By: ngimel
fbshipit-source-id: 02018c221609974546c562f691e20ab6ac611910
Summary:
Cudnn rnn calls that use use cudnn dropout maintain a "state" buffer across calls. [DropoutState](fe3f6f2da2/aten/src/ATen/native/cudnn/RNN.cpp (L1388-L1402))'s lock() and unlock() ensure the current call's use of the state buffer syncs with the end of the previous call's use of the state buffer (in case the previous call was on a different stream).
Telling a capturing stream to wait on an event recorded in a non-capturing stream is an error (1). Telling a non-capturing stream to wait on an event recorded during capture is also an error (2). So DropoutState's flow can error in either of two simple use cases:
```python
rnn = nn.LSTM(512, 512, 2, dropout=0.5).cuda()
out1 = rnn(in1)
# calling cudnn rnn with dropout in capture after calling it uncaptured triggers 1
capture_stream.wait_stream(torch.cuda.current_stream())
with torch.cuda.stream(capture_stream):
graph.capture_begin()
out2 = rnn(in2)
graph.capture_end()
torch.cuda.current_stream().wait_stream(capture_stream)
# calling cudnn rnn with dropout uncaptured after calling it in capture triggers 2
out3 = rnn(in3)
```
This PR fixes both cases by telling `DropoutState::lock()`: "if the most recent end-of-usage event was in a different capture state (ie, we crossed a capturing<->noncapturing border) or in a different capture, don't sync on it." While considering the fix I had two assumptions in mind:
- only one capture using the RNN can be underway at a time in this process
- no noncapturing ops in this process are issuing RNN calls while the capture using the RNN is underway.
That second assumption seems brittle if, for example, someone wants to capture an internal region of the forward method of a model wrapped with DataParallel: multiple threads could be issuing RNN calls with some currently capturing and some not. We should talk about whether that use case seems realistic.
(Bigger-picture thoughts: I don't know if forcing calls to serialize on using the shared state buffer is the best design. And if we want to do it that way, we might as well run all cudnn rnns with dropout on a dedicated side stream synced with the surrounding stream (capturing or not), in which case I don't think this PR's event-handling diffs would be needed.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56433
Reviewed By: heitorschueroff
Differential Revision: D27966444
Pulled By: ezyang
fbshipit-source-id: fe0df843c521e0d48d7f2c81a17aff84c5497e20
Summary:
Safely deallocating and repurposing memory used across streams relies on recording end-of-life events in all an allocation's usage streams beyond its original allocation stream. The events are later queried to see if all GPU work in those extra streams that could have used the allocation is done (from the CPU's perspective) before repurposing the allocation for use in its original stream.
The trouble is, calling EventQuery on an ordinary event recorded in a capturing stream is illegal. Calling EventQuery while capture is underway is also illegal. So when we call `tensor.record_stream` (or `c10::cuda::cudaCachingAllocator::recordStream`) on any tensor that's used or deleted in or around a capture, we often end up with a confusing error thrown from the cudaEventQuery in DeviceCachingAllocator::process_events().
This PR enables hopefully-safe deletion of tensors used across streams in or around capture with a conservative but simple approach: don't record or process end of life events for such tensors until the allocator's sure no captures are underway. You could whiteboard cases where this causes cross-stream-used allocations to be unavailable for reuse longer than absolutely necessary, but cross-stream-used allocations are uncommon, so for practical purposes this approach's impact on the memory footprint of captured sequences should be small.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55860
Reviewed By: ejguan
Differential Revision: D27822557
Pulled By: ezyang
fbshipit-source-id: b2e18a19d83ed05bad67a8157a14a606ed14d04e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52859
This reverts commit 92a4ee1cf6.
Added support for bfloat16 for CUDA 11 and removed fast-path for empty input tensors that was affecting autograd graph.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D27402390
Pulled By: heitorschueroff
fbshipit-source-id: 73c5ccf54f3da3d29eb63c9ed3601e2fe6951034
Summary:
**BC-breaking note**: This change throws errors for cases that used to silently pass. The old behavior can be obtained by setting `error_if_nonfinite=False`
Fixes https://github.com/pytorch/pytorch/issues/46849
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53843
Reviewed By: malfet
Differential Revision: D27291838
Pulled By: jbschlosser
fbshipit-source-id: 216d191b26e1b5919a44a3af5cde6f35baf825c4
Summary:
This reduces the memory usage of matmul significantly for expanded batch size.
This reduces the peak memory usage of
```
a = torch.rand(1, 1024, 1024, device="cuda")
b = torch.rand(1024, 1024, 1, device="cuda")
out = torch.matmul(a, b)
```
From 4GB to 16MB which is not too bad.
It also fixes the same problem when `b` is not batched.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54616
Reviewed By: ailzhang
Differential Revision: D27327056
Pulled By: albanD
fbshipit-source-id: 4bb5f4015aeab4174148512f3c5b8d1ffa97bf54
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53511
torch.det does depend on torch.prod, which in turn depends on several other functions, and they also depend on torch.prod, so there is a circular relationship, hence this PR will enable complex backward support for several functions at once.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48125
Reviewed By: pbelevich
Differential Revision: D27188589
Pulled By: anjali411
fbshipit-source-id: bbb80f8ecb83a0c3bea2b917627d3cd3b84eb09a
Summary:
Resubmit of https://github.com/pytorch/pytorch/pull/51436.
Apparently some non-public windows builds run cuda tests on the default stream, so I changed a few capture tests to manually ensure all captures happen on non-default streams.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54038
Reviewed By: mruberry
Differential Revision: D27068649
Pulled By: ngimel
fbshipit-source-id: 4284475fa40ee38c0f8faff05a2faa310cf8a207
Summary:
Implements https://github.com/pytorch/pytorch/issues/51075#issuecomment-768884685 and additions discussed offline with ezyang ngimel . (Calling it "simple" is charitable but it's not too bad).
[High level strategy](https://github.com/pytorch/pytorch/pull/51436/files#diff-acc6337586bf9cdcf0a684380779300ec171897d05b8569bf439820dc8c93bd5R57-R82)
The current design aggregates stats from private pools with the ordinary pools, which may or may not be what we want.
Instead of adding PrivatePools as an internal feature of DeviceAllocator, I could inherit from DeviceAllocator (eg `DevicePrivateAllocator : public DeviceAllocator`) and create separate per-graph instances of the inherited class. I'm not sure if that would be better.
Graph bindings in Python are almost unchanged from https://github.com/pytorch/pytorch/pull/48875:
```python
# Same bindings as 48875, but now implicitly grabs a private mempool
graph1.capture_begin()
graph1.capture_end()
# pool=... is new. It hints that allocations during graph2's capture may share graph1's mempool
graph2.capture_begin(pool=graph1.pool())
graph2.capture_end()
# graph3 also implicitly creates its own mempool
graph3.capture_begin()
graph3.capture_end()
```
Test plan (other suggestions appreciated):
- [x] Stop maintaining manual references for all the tensors in my existing graphs+RNG tests. If private pools somehow give bad allocations, they should start failing intermittently. They run eager ops and eager allocations mixed with graph replays, so they may expose if eager ops and replays corrupt each other.
- [x] `test_graph_two_successive`: Capture successive graphs, with the second graph using the first graph's result. Try with and without sharing a pool. Check results, also check memory stats to confirm sharing a pool saves memory.
- [x] `test_graph_concurrent_replay`: Capture some graphs in separate private pools, replay them concurrently in different streams, check the results to make sure they don't corrupt each other's memory. Capture some graphs with a shared pool, replay them concurrently in different streams, check results, confirm they DO corrupt each other's memory.
- [x] `test_graph_three_successive`: A three-graph case, checking the safe and unsafe replay patterns in [Restrictions of the Strawman API](https://github.com/pytorch/pytorch/issues/51075)).
- [x] `test_graph_memory_stats_and_use_result_after_destroy_graph`: Comprehensively check torch.cuda.memory_stats() changes that result from graph capture and delete. Check that a tensor ref created during capture and held after graph delete stays valid until the tensor itself is deleted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51436
Reviewed By: mruberry
Differential Revision: D26993790
Pulled By: ngimel
fbshipit-source-id: a992eaee1b8c23628e7b388a5a3c26e0f80e54da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53276
- One of the tests had a syntax error (but the test
wasn't fine grained enough to catch this; any error
was a pass)
- Doesn't work on ROCm
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D26820048
Test Plan: Imported from OSS
Reviewed By: mruberry
Pulled By: ezyang
fbshipit-source-id: b02c4252d10191c3b1b78f141d008084dc860c45
Summary:
Enabling four test cases in test_cuda.py for ROCm because they are passing.
Signed-off-by: Kyle Chen <kylechen@amd.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52739
Reviewed By: H-Huang
Differential Revision: D26706321
Pulled By: ngimel
fbshipit-source-id: 6907c548c4ac4e387f0eb7c646e8a01f0d036c8a
Summary:
Fixes #{[50510](https://github.com/pytorch/pytorch/issues/50510)}
Allows ```torch.nn.parallel.scatter_gather.gather``` to accept a list of NamedTuples as input and returns a NamedTuple whose elements are tensors. I added the author's fix using the ```is_namedtuple``` function.
While testing this fix, I encountered a deprecation warning instructing me to use ```'cpu'``` instead of ```-1``` to move the outputs to the CPU. However, doing this causes an assertion error in the ```_get_device_index``` function. I solved this by handling the CPU case in the affected ```forward``` function.
rohan-varma
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51104
Reviewed By: albanD
Differential Revision: D26395578
Pulled By: rohan-varma
fbshipit-source-id: 6e98c9ce1d9f1725973c18d24a6554c1bceae465
Summary:
These tests are failing for ROCm 4.0/4.0.1 release. Disable the tests until they are fixed.
- TestCuda.test_cudnn_multiple_threads_same_device
- TestCudaFuser.test_reduction
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51510
Reviewed By: H-Huang
Differential Revision: D26205179
Pulled By: seemethere
fbshipit-source-id: 0c3d29989d711deab8b5046b458c772a1543d8ed
Summary:
Building on top of the work of anjali411 (https://github.com/pytorch/pytorch/issues/46640)
Things added in this PR:
1. Modify backward and double-backward formulas
2. Add complex support for `new module tests` and criterion tests (and add complex tests for L1)
3. Modify some existing tests to support complex
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49912
Reviewed By: zhangguanheng66
Differential Revision: D25853036
Pulled By: soulitzer
fbshipit-source-id: df619f1b71c450ab2818eb17804e0c55990aa8ad
Summary:
Add a new function, torch.cuda.set_per_process_memory_fraction(fraction, device), to torch.cuda. Related: https://github.com/pytorch/pytorch/issues/18626
The fraction (float type, from 0 to 1) is used to limit memory of cashing allocator on GPU device . One can set it on any visible GPU. The allowed memory equals total memory * fraction. It will raise an OOM error when try to apply GPU memory more than the allowed value. This function is similar to Tensorflow's per_process_gpu_memory_fraction
Note, this setting is just limit the cashing allocator in one process. If you are using multiprocess, you need to put this setting in to the subprocess to limit its GPU memory, because subprocess could have its own allocator.
## usage
In some cases, one needs to split a GPU device as two parts. Can set limitation before GPU memory using.
Eg. device: 0, each part takes half memory, the code as follows:
```
torch.cuda.set_per_process_memory_fraction(0.5, 0)
```
There is an example to show what it is.
```python
import torch
torch.cuda.set_per_process_memory_fraction(0.5, 0)
torch.cuda.empty_cache()
total_memory = torch.cuda.get_device_properties(0).total_memory
# less than 0.5 will be ok:
tmp_tensor = torch.empty(int(total_memory * 0.499), dtype=torch.int8, device='cuda')
del tmp_tensordel tmp_tensor
torch.cuda.empty_cache()
# this allocation will raise a OOM:
torch.empty(total_memory // 2, dtype=torch.int8, device='cuda')
"""
It raises an error as follows:
RuntimeError: CUDA out of memory. Tried to allocate 5.59 GiB (GPU 0; 11.17 GiB total capacity; 0 bytes already allocated; 10.91 GiB free; 5.59 GiB allowed; 0 bytes reserved in total by PyTorch)
"""
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48172
Reviewed By: bdhirsh
Differential Revision: D25275381
Pulled By: VitalyFedyunin
fbshipit-source-id: d8e7af31902c2eb795d416b57011cc8a22891b8f
Summary:
Fixes https://github.com/pytorch/pytorch/issues/48049
Root cause of the issue explained [here](https://github.com/pytorch/pytorch/issues/48049#issuecomment-736701769).
This PR implements albanD's suggestion to add the `!t.is_view()` check and disable autocast caching for views of tensors.
The added test checks for an increase in memory usage by comparing the initially allocated memory with the memory after 3 iterations using a single `nn.Linear` layer in a `no_grad` and `autocast` context.
After this PR the memory usage in the original issue doesn't grow anymore and yields:
```python
autocast: True
0: 0MB (peak 1165MB)
1: 0MB (peak 1264MB)
2: 0MB (peak 1265MB)
3: 0MB (peak 1265MB)
4: 0MB (peak 1265MB)
5: 0MB (peak 1265MB)
6: 0MB (peak 1265MB)
7: 0MB (peak 1265MB)
8: 0MB (peak 1265MB)
9: 0MB (peak 1265MB)
```
CC ngimel mcarilli
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48696
Reviewed By: bdhirsh
Differential Revision: D25276231
Pulled By: ngimel
fbshipit-source-id: e2571e9f166c0a6f6f569b0c28e8b9ca34132743
Summary:
Otherwise, this test will appear flaky for ROCm even though it is a generic PyTorch issue.
CC albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48405
Reviewed By: mrshenli
Differential Revision: D25183473
Pulled By: ngimel
fbshipit-source-id: 0fa19b5497a713cc6c5d251598e57cc7068604be
Summary:
It is incorrect to assume that a newly recorded event will immediately query as False.
This test is flaky on ROCm due to this incorrect assumption.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46857
Reviewed By: albanD
Differential Revision: D24565581
Pulled By: mrshenli
fbshipit-source-id: 0e9ba02cf52554957b29dbeaa5093696dc914b67
Summary:
This pull request enables the following tests on ROCm:
* TestCuda.test_tiny_half_norm_
* TestNNDeviceTypeCUDA.test_softmax_cuda_float16
* TestNNDeviceTypeCUDA.test_softmax_cuda_float32
* TestNNDeviceTypeCUDA.test_softmax_results_cuda_float16
* TestNNDeviceTypeCUDA.test_softmax_results_cuda_float32
The earlier failures, because of which the tests were skipped, were because of a precision issue for FP16 compute on MI25 hardware with ROCm 3.7 and older. The fix was delivered in the compiler in ROCm 3.8.
The pull request fixes https://github.com/pytorch/pytorch/issues/37493
cc: jeffdaily ezyang malfet mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46363
Reviewed By: heitorschueroff
Differential Revision: D24325639
Pulled By: ezyang
fbshipit-source-id: a7dbb238cf38c04b6592baad40b4d71725a358c9
Summary:
Currently, a GraphRoot instance doesn't have an associated stream. Streaming backward synchronization logic assumes the instance ran on the default stream, and tells consumer ops to sync with the default stream. If the gradient the GraphRoot instance passes to consumer backward ops was populated on a non-default stream, we have a race condition.
The race condition can exist even if the user doesn't give a manually populated gradient:
```python
with torch.cuda.stream(side_stream):
# loss.backward() implicitly synthesizes a one-element 1.0 tensor on side_stream
# GraphRoot passes it to consumers, but consumers first sync on default stream, not side_stream.
loss.backward()
# Internally to backward(), streaming-backward logic takes over, stuff executes on the same stream it ran on in forward,
# and the side_stream context is irrelevant. GraphRoot's interaction with its first consumer(s) is the spot where
# the side_stream context causes a problem.
```
This PR fixes the race condition by associating a GraphRoot instance, at construction time, with the current stream(s) on the device(s) of the grads it will pass to consumers. (i think this relies on GraphRoot executing in the main thread, before backward thread(s) fork, because the grads were populated on the main thread.)
The test demonstrates the race condition. It fails reliably without the PR's GraphRoot diffs and passes with the GraphRoot diffs.
With the GraphRoot diffs, manually populating an incoming-gradient arg for `backward` (or `torch.autograd.grad`) and the actual call to `autograd.backward` will have the same stream-semantics relationship as any other pair of ops:
```python
# implicit population is safe
with torch.cuda.stream(side_stream):
loss.backward()
# explicit population in side stream then backward in side stream is safe
with torch.cuda.stream(side_stream):
kickoff_grad = torch.ones_like(loss)
loss.backward(gradient=kickoff_grad)
# explicit population in one stream then backward kickoff in another stream
# is NOT safe, even with this PR's diffs, but that unsafety is consistent with
# stream-semantics relationship of any pair of ops
kickoff_grad = torch.ones_like(loss)
with torch.cuda.stream(side_stream):
loss.backward(gradient=kickoff_grad)
# Safe, as you'd expect for any pair of ops
kickoff_grad = torch.ones_like(loss)
side_stream.wait_stream(torch.cuda.current_stream())
with torch.cuda.stream(side_stream):
loss.backward(gradient=kickoff_grad)
```
This PR also adds the last three examples above to cuda docs and references them from autograd docstrings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45787
Reviewed By: nairbv
Differential Revision: D24138376
Pulled By: albanD
fbshipit-source-id: bc4cd9390f9f0358633db530b1b09f9c1080d2a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44220
Closes https://github.com/pytorch/pytorch/issues/44009
Currently if a dataloader returns objects created with a
collections.namedtuple, this will incorrectly be cast to a tuple. As a result, if we have data of these types, there can be runtime errors during the forward pass if the module is expecting a named tuple.
Fix this in
`scatter_gather.py` to resolve the issue reported in
https://github.com/pytorch/pytorch/issues/44009
ghstack-source-id: 113423287
Test Plan: CI
Reviewed By: colesbury
Differential Revision: D23536752
fbshipit-source-id: 3838e60162f29ebe424e83e474c4350ae838180b
Summary:
Amp gradient unscaling is a great use case for multi tensor apply (in fact it's the first case I wrote it for). This PR adds an MTA unscale+infcheck functor. Really excited to have it for `torch.cuda.amp`. izdeby your interface was clean and straightforward to use, great work!
Labeled as bc-breaking because the native_functions.yaml exposure of unscale+infcheck changes from [`_amp_non_finite_check_and_unscale_` to `_amp_foreach_non_finite_check_and_unscale_`]( https://github.com/pytorch/pytorch/pull/44778/files#diff-f1e4b2c15de770d978d0eb77b53a4077L6289-L6293).
The PR also modifies Unary/Binary/Pointwise Functors to
- do ops' internal math in FP32 for FP16 or bfloat16 inputs, which improves precision ([and throughput, on some architectures!](https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#arithmetic-instructions)) and has no downside for the ops we care about.
- accept an instantiated op functor rather than an op functor template (`template<class> class Op`). This allows calling code to pass lambdas.
Open question: As written now, the PR has MTA Functors take care of pre- and post-casting FP16/bfloat16 inputs to FP32 before running the ops. However, alternatively, the pre- and post-math casting could be deferred/written into the ops themselves, which gives them a bit more control. I can easily rewrite it that way if you prefer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44778
Reviewed By: gchanan
Differential Revision: D23944102
Pulled By: izdeby
fbshipit-source-id: 22b25ccad5f69b413c77afe8733fa9cacc8e766d
Summary:
Modify contbuild to disable sanitizers, add option to run "cuda" test using TPX RE
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: walterddr, cspanda
Differential Revision: D23854578
fbshipit-source-id: 327d7cc3655c17034a6a7bc78f69967403290623
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45159
By default, pybind11 binds void* to be capsules. After a lot of
Googling, I have concluded that this is not actually useful:
you can't actually create a capsule from Python land, and our
data_ptr() function returns an int, which means that the
function is effectively unusable. It didn't help that we had no
tests exercising it.
I've replaced the void* with uintptr_t, so that we now accept int
(and you can pass data_ptr() in directly). I'm not sure if we
should make these functions accept ctypes types; unfortunately,
pybind11 doesn't seem to have any easy way to do this.
Fixes#43006
Also added cudaHostUnregister which was requested.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: lw
Differential Revision: D23849731
Pulled By: ezyang
fbshipit-source-id: 8a79986f3aa9546abbd2a6a5828329ae90fd298f
Summary:
Fixes gh-42282
This adds a device-mismatch check to `addmm` on CPU and CUDA. Although it seems like the dispatcher is always selecting the CUDA version here if any of the inputs are on GPU. So in theory the CPU check is unnecessary, but probably better to err on the side of caution.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43505
Reviewed By: mruberry
Differential Revision: D23331651
Pulled By: ngimel
fbshipit-source-id: 8eb2f64f13d87e3ca816bacec9d91fe285d83ea0
Summary:
Should close https://github.com/pytorch/pytorch/issues/36428.
The cudnn RNN API expects weights to occupy a flat buffer in memory with a particular layout. This PR implements a "speed of light" fix: [`_cudnn_rnn_cast_reflatten`](https://github.com/pytorch/pytorch/pull/42385/files#diff-9ef93b6a4fb5a06a37c562b83737ac6aR327) (the autocast wrapper assigned to `_cudnn_rnn`) copies weights to the right slices of a flat FP16 buffer with a single read/write per weight (as opposed to casting them to FP16 individually then reflattening the individual FP16 weights, which would require 2 read/writes per weight).
It isn't pretty but IMO it doesn't make rnn bindings much more tortuous than they already are.
The [test](https://github.com/pytorch/pytorch/pull/42385/files#diff-e68a7bc6ba14f212e5e7eb3727394b40R2683) tries a forward under autocast and a backward for the full cross product of RNN options and input/weight/hidden dtypes. As for all FP16list autocast tests, forward output and backward grads are checked against a control where inputs (including RNN module weights in this case) are precasted to FP16 on the python side.
Not sure who to ask for review, tagging ezyang and ngimel because Ed wrote this file (almost 2 years ago) and Natalia did the most recent major [surgery](https://github.com/pytorch/pytorch/pull/12600).
Side quests discovered:
- Should we update [persistent RNN heuristics](dbdd28207c/aten/src/ATen/native/cudnn/RNN.cpp (L584)) to include compute capability 8.0? Could be another PR but seems easy enough to include.
- Many (maybe all?!) the raw cudnn API calls in [RNN.cpp](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cudnn/RNN.cpp) are deprecated in cudnn 8. I don't mind taking the AI to update them since my mental cache is full of rnn stuff, but that would be a substantial separate PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42385
Reviewed By: zhangguanheng66
Differential Revision: D23077782
Pulled By: ezyang
fbshipit-source-id: a2afb1bdab33ba0442879a703df13dc87f03ec2e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42139
A bunch of tests were failing with buck since we would output to
stdout and buck would fail parsing stdout in some cases.
Moving these print statements to stderr fixes this issue.
ghstack-source-id: 108606579
Test Plan: Run the offending unit tests.
Reviewed By: mrshenli
Differential Revision: D22779135
fbshipit-source-id: 789af3b16a03b68a6cb12377ed852e5b5091bbad
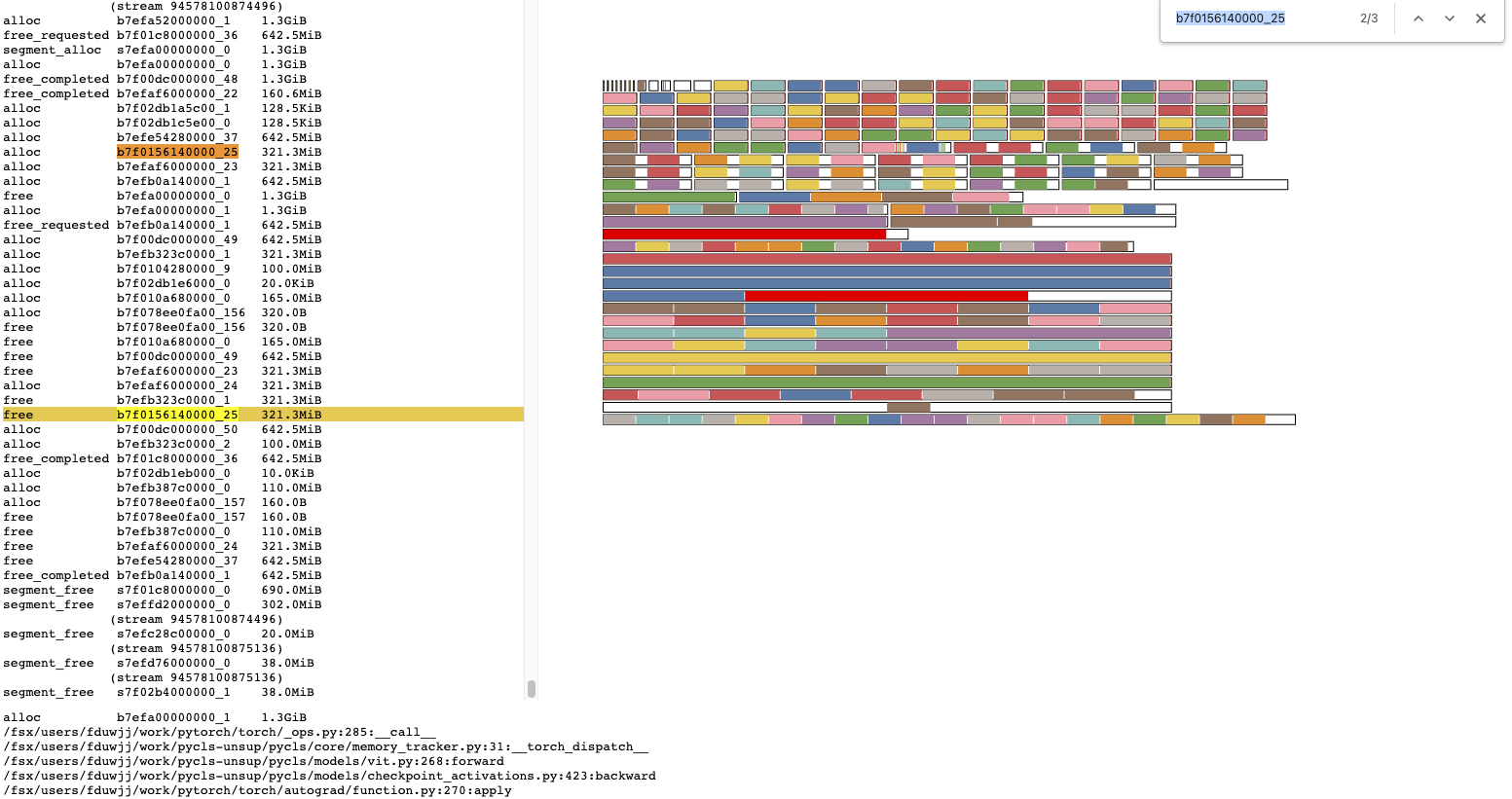{kind=link}