- Add graph index to the profile information of the Inductor kernel for better debugability.
The generated code for different graphs could produce kernels with the same name. The side effect is that it is hard to identify the portion of E2E performance for these kernels because the profiler will aggregate the performance with the same kernel name regardless of different graphs. Hence, this PR added the graph index to the profile information to address this limitation.
- Label arbitrary code ranges for `eager` and `opt` modes for better debugability
The profile information of dynamo benchmarks mixes the eager mode and opt mode. It is hard to separate the range for different modes. This PR added eager and opt marks to the profile information to address this limitation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90008
Approved by: https://github.com/jgong5, https://github.com/jansel
This PR is targeting to automatically enable vectorization optimization for TorchInductor. It refined the semantics of `config.cpp.simdlen`.
Originally, `None` means to disable vectorization while a specific value means the number of elements to be vectorized once time. But it depends on the data. Regarding 256bit SVE/SIMD ISA for ARM and X86, the `simdlen` should be 16 for Float while 32 for BFloat. Hence, this PR defined the `simdlen` as the bit width. The detailed semantics are as follows.
- **_simdlen = None_**: Automatically determine the SIMD bit width. Detect HW information and pick the proper vectorization ISA. Specific for X86, the priority of AVX512 is higher than AVX2.
- **_simdlen <=1_**: Explicitly disable SIMD
- **_simdlen > 1_**: Explicitly specify the SIMD bit width. It equals the disabled semantic if the bit width does not match the ISA width.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89263
Approved by: https://github.com/jgong5, https://github.com/jansel
By itself, libdevice version of erf has the same perf as our decomposition, but in real workloads it leads to better fusion groups (due to fewer ops in the fused kernel).
Bonus: a few fp64 test skips removed, because our decomposition wasn't accurate enough for fp64, but libdevice version is.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89388
Approved by: https://github.com/jansel
This PR is targeting to automatically enable vectorization optimization for TorchInductor. It refined the semantics of `config.cpp.simdlen`.
Originally, `None` means to disable vectorization while a specific value means the number of elements to be vectorized once time. But it depends on the data. Regarding 256bit SVE/SIMD ISA for ARM and X86, the `simdlen` should be 16 for Float while 32 for BFloat. Hence, this PR defined the `simdlen` as the bit width. The detailed semantics are as follows.
- **_simdlen = None_**: Automatically determine the SIMD bit width. Detect HW information and pick the proper vectorization ISA. Specific for X86, the priority of AVX512 is higher than AVX2.
- **_simdlen <=1_**: Explicitly disable SIMD
- **_simdlen > 1_**: Explicitly specify the SIMD bit width. It equals the disabled semantic if the bit width does not match the ISA width.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88482
Approved by: https://github.com/jgong5, https://github.com/jansel
- Propagates origin fx nodes through inlining during lowering
- Concatenates op names into kernel name
- Adds config to cap the number of ops in the kernel name so they don't get too long
Caveats:
- The ordering in the name may not match the order that the ops are executed in the kernel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88624
Approved by: https://github.com/anijain2305, https://github.com/jansel
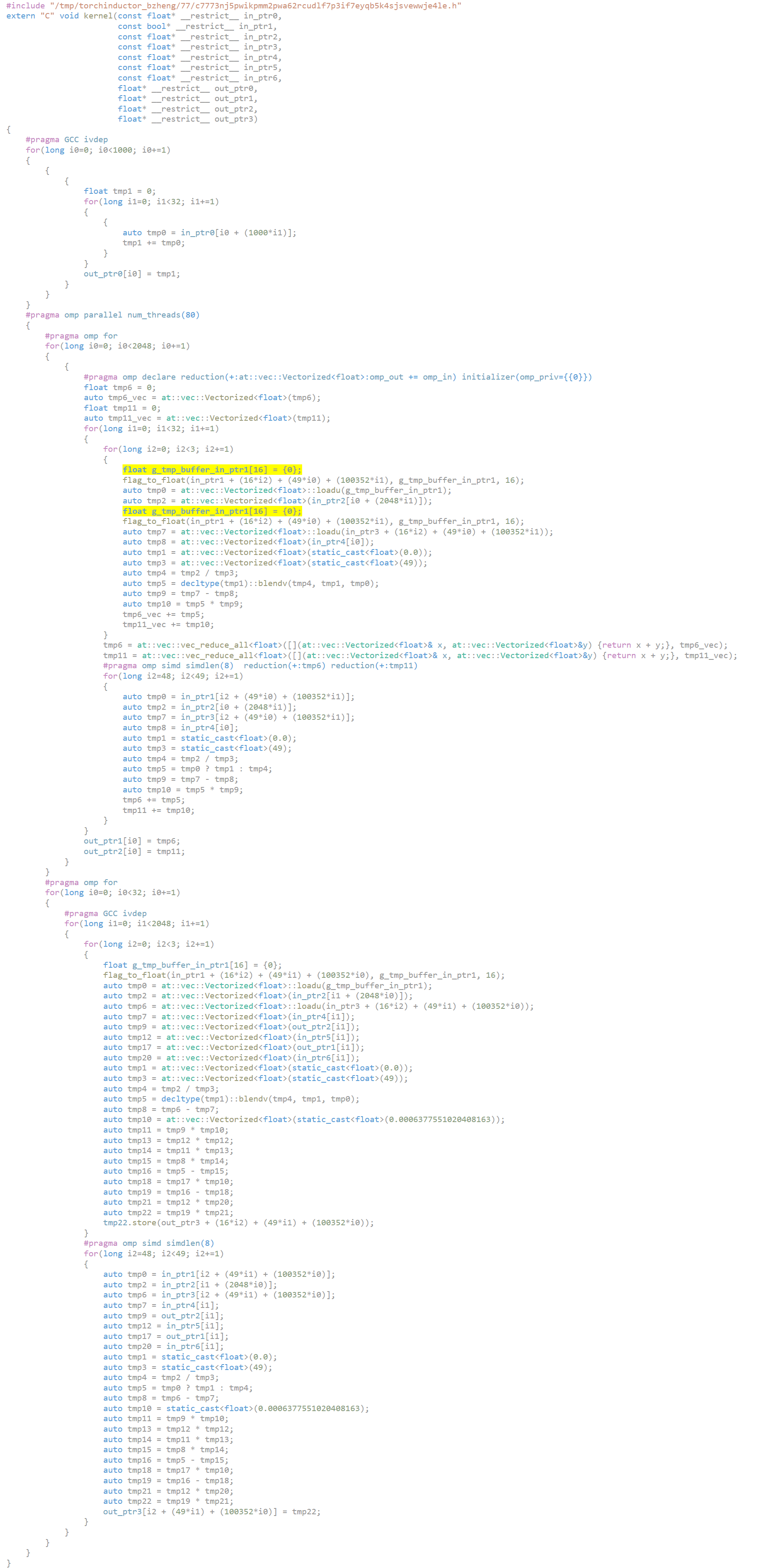
This PR is to optimize reduction implementation by `at::vec`. The main idea is as same as the aten implementation.
- Step1: Parallelize and vectorize the reduction implementation
- Step2: Invoke `at::vec::vec_reduce_all` to reduce the vector generated at step 1 to a single scalar
- Step3: Handle the tail elements
For the implementation, we create two kernels - `CppVecKernel` and `CppKernel`. The code block generation is as follows step by step.
- Gen the non-reduction loop - [Code](https://github.com/pytorch/pytorch/blob/gh/EikanWang/9/head/torch/_inductor/codegen/cpp.py#L1008-L1010)
- Gen the reduction initialization both for vectorization and non-vectorization kernel - [Code](https://github.com/pytorch/pytorch/blob/gh/EikanWang/9/head/torch/_inductor/codegen/cpp.py#L1015)
- Gen the reduction loop for the vectorization kernel - [Code](https://github.com/pytorch/pytorch/blob/gh/EikanWang/9/head/torch/_inductor/codegen/cpp.py#L1021-L1023)
- Gen the code to reduce the vector to scalar - [Code](https://github.com/pytorch/pytorch/blob/gh/EikanWang/9/head/torch/_inductor/codegen/cpp.py#L1033)
- Gen the reduction loop for the non-vectorization kernel - [Code](https://github.com/pytorch/pytorch/blob/gh/EikanWang/9/head/torch/_inductor/codegen/cpp.py#L1042)
- Do some post-reduction things like store reduction value - [Code](https://github.com/pytorch/pytorch/blob/gh/EikanWang/9/head/torch/_inductor/codegen/cpp.py#L1049)
```python
# Gen the non-reduction loop
for loop in CppVecKernel.NoneReductionLoop:
# Gen the reduction initialization both for vectorization and non-vectorization kernel
CppVecKernel.ReductionPrefix
# Gen the reduction loop for the vectorization kernel
for loop in CppVecKernel.ReductionLoop
CppVecKernel.Loads
CppVecKernel.Compute
CppVecKernel.Stores
# Gen the code to reduce the vector to scalar
CppVecKernel.ReductionSuffix
# Gen the reduction loop for the non-vectorization kernel
for loop in CppKernel.ReductionLoop
CppKernel.Loads
CppKernel.Compute
CppKernel.Stores
# The reduction is almost finished. To do some post-reduction things like store reduction value.
CppKernel.ReductionSuffix
```
The code snippet for maximum reduction exemplifies the idea. More detailed comments are inlined.
```C++
{
// Declare reduction for at::vec::Vectorized since it is not built-in data type.
#pragma omp declare reduction(+:at::vec::Vectorized<float>:omp_out += omp_in) initializer(omp_priv={{0}})
float tmp4 = 0;
// tmp4_vec is used to vectorize the sum reduction for tmp4
auto tmp4_vec = at::vec::Vectorized<float>(tmp4);
float tmp6 = 0;
// tmp6_vec is used to vectorize the sum reduction for tmp6
auto tmp6_vec = at::vec::Vectorized<float>(tmp6);
#pragma omp parallel num_threads(48)
{
// Parallelize the vectorized reduction
#pragma omp for reduction(+:tmp4_vec) reduction(+:tmp6_vec)
for(long i0=0; i0<192; i0+=1)
{
auto tmp0 = at::vec::Vectorized<float>::loadu(in_ptr0 + 8*i0);
auto tmp1 = at::vec::Vectorized<float>::loadu(in_ptr1 + 8*i0);
auto tmp2 = tmp0 - tmp1;
auto tmp3 = tmp2.abs();
auto tmp5 = tmp2 * tmp2;
tmp4_vec += tmp3;
tmp6_vec += tmp5;
}
// Reduce the tmp4_vec as a scalar and store at tmp4
tmp4 = at::vec::vec_reduce_all<float>([](at::vec::Vectorized<float>& x, at::vec::Vectorized<float>&y) {return x + y;}, tmp4_vec);
// Reduce the tmp6_vec as a scalar and store at tmp6
tmp6 = at::vec::vec_reduce_all<float>([](at::vec::Vectorized<float>& x, at::vec::Vectorized<float>&y) {return x + y;}, tmp6_vec);
// Handle the tail elements that could not be vectorized by aten.
#pragma omp for simd simdlen(4) reduction(+:tmp4) reduction(+:tmp6)
for(long i0=1536; i0<1536; i0+=1)
{
auto tmp0 = in_ptr0[i0];
auto tmp1 = in_ptr1[i0];
auto tmp2 = tmp0 - tmp1;
auto tmp3 = std::abs(tmp2);
auto tmp5 = tmp2 * tmp2;
tmp4 += tmp3;
tmp6 += tmp5;
}
}
out_ptr0[0] = tmp4;
out_ptr1[0] = tmp6;
}
```
Performance(Measured by operatorbench and the base line of speedup ratio is aten operator performance):
Softmax (1,16,384,384,dim=3) | Speedup ratio (simdlen=None) | Speedup ratio (simdlen=8) + this PR
-- | -- | --
24c | 0.37410838067524177 | 0.9036240100351164
4c | 0.24655829520907663 | 1.0255329993674518
1c | 0.21595768114988007 | 1.000587368005134
HW Configuration:
SKU: SKX Intel(R) Xeon(R) Platinum 8260 CPU @ 2.40GHz
MemTotal: 196708148 kB
MemFree: 89318532 kB
MemBandwidth: 112195.1MB/S
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87356
Approved by: https://github.com/jgong5, https://github.com/jansel
In this PR, we replace OMP SIMD with `aten::vec` to optimize TorchInductor vectorization performance. Take `res=torch.exp(torch.add(x, y))` as the example. The generated code is as follows if `config.cpp.simdlen` is 8.
```C++
extern "C" void kernel(const float* __restrict__ in_ptr0,
const float* __restrict__ in_ptr1,
float* __restrict__ out_ptr0,
const long ks0,
const long ks1)
{
#pragma omp parallel num_threads(48)
{
#pragma omp for
for(long i0=0; i0<((ks0*ks1) / 8); ++i0)
{
auto tmp0 = at::vec::Vectorized<float>::loadu(in_ptr0 + 8*i0);
auto tmp1 = at::vec::Vectorized<float>::loadu(in_ptr1 + 8*i0);
auto tmp2 = tmp0 + tmp1;
auto tmp3 = tmp2.exp();
tmp3.store(out_ptr0 + 8*i0);
}
#pragma omp for simd simdlen(4)
for(long i0=8*(((ks0*ks1) / 8)); i0<ks0*ks1; ++i0)
{
auto tmp0 = in_ptr0[i0];
auto tmp1 = in_ptr1[i0];
auto tmp2 = tmp0 + tmp1;
auto tmp3 = std::exp(tmp2);
out_ptr0[i0] = tmp3;
}
}
}
```
The major pipeline is as follows.
- Check whether the loop body could be vectorized by `aten::vec`. The checker consists of two parts. [One ](bf66991fc4/torch/_inductor/codegen/cpp.py (L702))is to check whether all the `ops` have been supported. The [other one](355326faa3/torch/_inductor/codegen/cpp.py (L672)) is to check whether the data access could be vectorized.
- [`CppSimdVecKernelChecker`](355326faa3/torch/_inductor/codegen/cpp.py (L655))
- Create the `aten::vec` kernel and original omp simd kernel. Regarding the original omp simd kernel, it serves for the tail loop when the loop is vectorized.
- [`CppSimdVecKernel`](355326faa3/torch/_inductor/codegen/cpp.py (L601))
- [`CppSimdVecOverrides`](355326faa3/torch/_inductor/codegen/cpp.py (L159)): The ops that we have supported on the top of `aten::vec`
- Create kernel
- [`aten::vec` kernel](355326faa3/torch/_inductor/codegen/cpp.py (L924))
- [`Original CPP kernel - OMP SIMD`](355326faa3/torch/_inductor/codegen/cpp.py (L929))
- Generate code
- [`CppKernelProxy`](355326faa3/torch/_inductor/codegen/cpp.py (L753)) is used to combine the `aten::vec` kernel and original cpp kernel
- [Vectorize the most inner loop](355326faa3/torch/_inductor/codegen/cpp.py (L753))
- [Generate code](355326faa3/torch/_inductor/codegen/cpp.py (L821))
Next steps:
- [x] Support reduction
- [x] Vectorize the tail loop with `aten::vec`
- [ ] Support BF16
- [ ] Optimize the loop condition and loop index calculation by replacing `div` with `add`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87068
Approved by: https://github.com/jgong5, https://github.com/jansel
Porting over [torchdynamo/#1633](https://github.com/pytorch/torchdynamo/pull/1633)
`torch/_inductor/codegen/triton.py` now defines `libdevice_<function>` variants
of some functions. You can request dispatch to those for
float64 dtypes when using `register_pointwise` by setting
`use_libdevice_for_f64=True`.
Other minor changes:
- In triton, sigmoid now codegens tl.sigmoid
- silu now comes from decomp, not lowering
- Some test skips no longer necessary, removed or made xfails
Switching to `tl.sigmoid` has exactly same performance.
Moving `silu` to decomp does not change anything, same triton code is generated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87189
Approved by: https://github.com/ngimel
{kind=link}
{kind=link}