Fixes https://github.com/pytorch/data/issues/538
- Improve the validation function to raise warning about unpickable function when either lambda or local function is provided to `DataPipe`.
- The inner function from `functools.partial` object is extracted as well for validation
- Mimic the behavior of `pickle` module for local lambda function: It would only raise Error for the local function rather than `lambda` function. So, we will raise warning about local function not lambda function.
```py
>>> import pickle
>>> def fn():
... lf = lambda x: x
... pickle.dumps(lf)
>>> pickle.dumps(fn)
AttributeError: Can't pickle local object 'fn.<locals>.<lambda>'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80140
Approved by: https://github.com/VitalyFedyunin, https://github.com/NivekT
Fixes#79828
In distributed environment, before this PR, DataLoader would create a Tensor holding the shared seed in RANK 0 and send the Tensor to other processes. However, when `NCCL` is used as the distributed backend, the Tensor is required to be moved to cuda before broadcasted from RANK 0 to other RANKs. And, this causes the Issue where DataLoader doesn't move the Tensor to cuda before sharing using `NCCL`.
After offline discussion with @mrshenli, we think the distributed Store is a better solution as the shared seed is just an integer value. Then, we can get rid of the dependency on NCCL and CUDA when sharing info between distributed processes for DataLoader.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79829
Approved by: https://github.com/VitalyFedyunin, https://github.com/NivekT
Fixes#78510
This PR adds support for using fractions with `random_split`. This should be completely backwards-compatible as the fractional-style splitting is only applied when the sum across the input lengths is lower than 1.0
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78877
Approved by: https://github.com/ejguan
1. Change the sharding strategy from sharding by worker first then by rank to sharding in the order of rank then workers.
2. Change to fetch Rank and World size in main process for the sake of `spawn`.
For the change 1:
Before this PR, for the case when dataset can not be evenly divided by `worker_num * world_size`, more data will be retrieved by workers in first RANKs.
Using the following example:
- dataset size: 100
- world_size: 4
- num_worker: 2
The number of data retrieved by each rank before this PR
- Rank 0: 26
- Rank 1: 26
- Rank 2: 24
- Rank 3: 24
The number of data retrieved by each rank after this PR
- Rank 0: 25
- Rank 1: 25
- Rank 2: 25
- Rank 3: 25
For the change 2:
Before this PR, `dist` functions are invoked inside worker processes. It's fine when the worker processes are forked from the parent process. All environment variables are inherited and exposed to these `dist` functions. However, when the worker processes are spawned, they won't be able to access to these environment variables, then the dataset won't be sharded by rank.
After this PR, `_sharding_worker_init_fn` should be working for both `spawn` and `fork` case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79041
Approved by: https://github.com/VitalyFedyunin, https://github.com/NivekT
Users were reporting errors of not being able to use collect_env with
older versions of python. This adds a test to ensure that we maintain
compat for this script with older versions of python
Signed-off-by: Eli Uriegas <eliuriegasfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78946
Approved by: https://github.com/janeyx99
Fixes https://github.com/pytorch/data/issues/426
This PR introduces two main changes:
- It ensures the `ShufflerDataPipe` would share the same seed across distributed processes.
- Users can reset `shuffle` for persistent workers per epoch.
Detail:
- `shared_seed` is shared across distributed and worker processes. It will seed a `shared_rng` to provide seeds to each `ShufflerDataPipe` in the pipeline
- `worker_loop` now accepts a new argument of `shared_seed` to accept this shared seed.
- The `shared_seed` is attached to `_ResumeIteration` for resetting seed per epoch for `persistent worker`
- I choose not to touch `base_seed` simply for BC issue
I used this [script](https://gist.github.com/ejguan/d88f75fa822cb696ab1bc5bc25844f47) to test the result with `world_size=4`. Please check the result in: https://gist.github.com/ejguan/6ee2d2de12ca57f9eb4b97ef5a0e300b
You can see there isn't any duplicated/missing element for each epoch. And, with the same seed, the order of data remains the same across epochs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78765
Approved by: https://github.com/VitalyFedyunin
Fixes https://github.com/pytorch/data/issues/426
This PR introduces two main changes:
- It ensures the `ShufflerDataPipe` would share the same seed across distributed processes.
- Users can reset `shuffle` for persistent workers per epoch.
Detail:
- `shared_seed` is shared across distributed and worker processes. It will seed a `shared_rng` to provide seeds to each `ShufflerDataPipe` in the pipeline
- `worker_loop` now accepts a new argument of `shared_seed` to accept this shared seed.
- The `shared_seed` is attached to `_ResumeIteration` for resetting seed per epoch for `persistent worker`
- I choose not to touch `base_seed` simply for BC issue
I used this [script](https://gist.github.com/ejguan/d88f75fa822cb696ab1bc5bc25844f47) to test the result with `world_size=4`. Please check the result in: https://gist.github.com/ejguan/6ee2d2de12ca57f9eb4b97ef5a0e300b
You can see there isn't any duplicated/missing element for each epoch. And, with the same seed, the order of data remains the same across epochs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78765
Approved by: https://github.com/VitalyFedyunin
Fixes#78236
An erronously shaped weights vector will result in the following output
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~/datarwe/pytorch/torch/utils/data/sampler.py in <module>
[274](file:///home/oliver/datarwe/pytorch/torch/utils/data/sampler.py?line=273) WeightedRandomSampler([1,2,3], 10)
----> [275](file:///home/oliver/datarwe/pytorch/torch/utils/data/sampler.py?line=274) WeightedRandomSampler([[1,2,3], [4,5,6]], 10)
~/datarwe/pytorch/torch/utils/data/sampler.py in __init__(self, weights, num_samples, replacement, generator)
[192](file:///home/oliver/datarwe/pytorch/torch/utils/data/sampler.py?line=191) weights = torch.as_tensor(weights, dtype=torch.double)
[193](file:///home/oliver/datarwe/pytorch/torch/utils/data/sampler.py?line=192) if len(weights.shape) != 1:
--> [194](file:///home/oliver/datarwe/pytorch/torch/utils/data/sampler.py?line=193) raise ValueError("weights should be a 1d sequence but given "
[195](file:///home/oliver/datarwe/pytorch/torch/utils/data/sampler.py?line=194) "weights have shape {}".format(tuple(weights.shape)))
[196](file:///home/oliver/datarwe/pytorch/torch/utils/data/sampler.py?line=195)
ValueError: weights should be a 1d sequence but given weights have shape (2, 3)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78585
Approved by: https://github.com/NivekT, https://github.com/ejguan
This is the first PR to make DataPipe deterministic.
Users should be able to use `torch.manual_seed(seed)` to control the shuffle order for the following cases:
- Directly over `DataPipe`
- For single-process DataLoader
- Multiprocessing DataLoader
Unfortunately, for distributed training, users have to run `apply_shuffle_seed` manually to make sure all distributed processes having the same order of shuffle.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77741
Approved by: https://github.com/VitalyFedyunin, https://github.com/NivekT
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76384
OSS issue discussion: https://github.com/pytorch/data/issues/346
This diff updates `mux` and `mux_longest` data pipe.
`mux`: Yields one element at a time from each of the input Iterable DataPipes (functional name: ``mux``). As in, one element from the 1st input DataPipe, then one element from the 2nd DataPipe in the next iteration, and so on. It ends when the shortest input DataPipe is exhausted.
`mux` example:
```
>>> from torchdata.datapipes.iter import IterableWrapper
>>> dp1, dp2, dp3 = IterableWrapper(range(3)), IterableWrapper(range(10, 15)), IterableWrapper(range(20, 25))
>>> list(dp1.mux(dp2, dp3))
[0, 10, 20, 1, 11, 21, 2, 12, 22]
```
Test Plan:
buck test mode/opt //caffe2/test:datapipe
https://www.internalfb.com/intern/testinfra/testrun/4785074706282345
Differential Revision: D36017945
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77145
Approved by: https://github.com/NivekT, https://github.com/ejguan
We don't have any coverage for meta tensor correctness for backwards
because torch function mode can only allow us to interpose on
Python torch API calls, but backwards invocations happen from C++.
To make this possible, I add torch_dispatch_meta test which runs the
tests with __torch_dispatch__
While doing this, I needed to generate fresh expected failure / skip
lists for the new test suite, and I discovered that my original
scaffolding for this purpose was woefully insufficient. So I rewrote
how the test framework worked, and at the same time rewrote the
__torch_function__ code to also use the new logic. Here's whats
new:
- Expected failure / skip is now done on a per function call basis,
rather than the entire test. This means that separate OpInfo
samples for a function don't affect each other.
- There are now only two lists: expect failure list (where the test
consistently fails on all runs) and skip list (where the test
sometimes passes and fails.
- We explicitly notate the dtype that failed. I considered detecting
when something failed on all dtypes, but this was complicated and
listing everything out seemed to be nice and simple. To keep the
dtypes short, I introduce a shorthand notation for dtypes.
- Conversion to meta tensors is factored into its own class
MetaConverter
- To regenerate the expected failure / skip lists, just run with
PYTORCH_COLLECT_EXPECT and filter on a specific test type
(test_meta or test_dispatch_meta) for whichever you want to update.
Other misc fixes:
- Fix max_pool1d to work with BFloat16 in all circumstances, by making
it dispatch and then fixing a minor compile error (constexpr doesn't
work with BFloat16)
- Add resolve_name for turning random torch API functions into string
names
- Add push classmethod to the Mode classes, so that you can more easily
push a mode onto the mode stack
- Add some more skips for missing LAPACK
- Added an API to let you query if there's already a registration for
a function, added a test to check that we register_meta for all
decompositions (except detach, that decomp is wrong lol), and then
update all the necessary sites to make the test pass.
Signed-off-by: Edward Z. Yang <ezyangfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77477
Approved by: https://github.com/zou3519
`torch.sparse.sampled_addmm` was incorrect for noncontiguous inputs on CUDA.
Unfortnately, it was overlooked in the tests that noncontiguous inputs
are not tested properly because 1x5, 5x1 shapes were used.
Block sparse triangular solver on CUDA could return incorrect results if
there's a zero on the diagonal in the sparse matrix. Now it returns nan.
Tests also revealed that unitriangular=True flag is not working
correctly on CPU in some cases. That part needs more investigation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76590
Approved by: https://github.com/cpuhrsch
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76384
OSS issue discussion: https://github.com/pytorch/data/issues/346
This diff updates `mux` and `mux_longest` data pipe.
`mux`: Yields one element at a time from each of the input Iterable DataPipes (functional name: ``mux``). As in, one element from the 1st input DataPipe, then one element from the 2nd DataPipe in the next iteration, and so on. It ends when the shortest input DataPipe is exhausted.
`mux` example:
```
>>> from torchdata.datapipes.iter import IterableWrapper
>>> dp1, dp2, dp3 = IterableWrapper(range(3)), IterableWrapper(range(10, 15)), IterableWrapper(range(20, 25))
>>> list(dp1.mux(dp2, dp3))
[0, 10, 20, 1, 11, 21, 2, 12, 22]
```
Test Plan:
buck test mode/dev //pytorch/data/test:tests -- --exact 'pytorch/data/test:tests - test_mux_longest_iterdatapipe (test_datapipe.TestDataPipe)'
https://www.internalfb.com/intern/testinfra/testrun/3096224791148107
Reviewed By: ejguan
Differential Revision: D35799965
fbshipit-source-id: 320e71a342ec27e6e9200624aad42f4b99f97c3a
(cherry picked from commit 741ed595275df6c05026ed6f0e78d7052328fb7d)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76333
The current PyTorch multi-head attention and transformer
implementations are slow. This should speed them up for inference.
ghstack-source-id: 154737857
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: cpuhrsch
Differential Revision: D35239925
fbshipit-source-id: 5a7eb8ff79bc6afb4b7d45075ddb2a24a6e2df28
Summary:
X-link: https://github.com/pytorch/data/pull/368
This is PR aims to expose the right data-relate API.
There are two more changes made in this PR to convert public api to private api
`check_lambda_fn` -> `_check_lambda_fn`
`deprecation_warning` -> `_deprecation_warning`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76143
Reviewed By: albanD, NivekT
Differential Revision: D35798311
Pulled By: ejguan
fbshipit-source-id: b13fded5c88a533c706702fb2070c918c839dca4
(cherry picked from commit 0b534b829a2e90e1e533951c6d334fdeaa9358b9)
Summary:
pin_memory, has optional device parameter to specify
which device you want to pin for. With this above change
the Dataloader will work only for CUDA backend. To add
support for other backend which supports pinned memory,
dataloader is updated with device as optional parameter.
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65402
Reviewed By: zou3519
Differential Revision: D32282204
Pulled By: VitalyFedyunin
fbshipit-source-id: e2e09876969af108d0db38af7c2d1b2f1cfa9858
(cherry picked from commit 3b76e151964fce442e27fe8fb5c37af930da4fa1)
Summary:
hip/hip_runtime.h and libamdhip64.so may be required to compile
extension such as torch_ucc. They are in $ROCM_HOME/hip by default,
and may not be symlinked to $ROCM_HOME/include and $ROCM_HOME/lib.
This commit defines $ROCM_HOME/hip as $HIP_HOME, and adds its include
and lib paths when building hipified extension.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75548
Test Plan:
## Verify OSS pytorch + TorchUCC on an AMD GPU machine (MI100)
- step 1. Install OSS pytorch
```
export ROCM_PATH=/opt/rocm-4.5.2
git clone https://github.com/pytorch/pytorch.git
cd pytorch
python3 tools/amd_build/build_amd.py
USE_NCCL=0 USE_RCCL=0 USE_KINETO=0 with-proxy python3 setup.py develop
USE_NCCL=0 USE_RCCL=0 USE_KINETO=0 with-proxy python3 setup.py install
```
- step2. Install torchUCC extension
```
# /opt/rocm-4.5.2/include/hip does not exist, need include /opt/rocm-4.5.2/hip/include at compile time
export ROCM_PATH=/opt/rocm-4.5.2
export RCCL_INSTALL_DIR=/opt/rccl-rocm-rel-4.4-rdc
git clone https://github.com/facebookresearch/torch_ucc.git
cd torch_ucc
UCX_HOME=$RCCL_INSTALL_DIR UCC_HOME=$RCCL_INSTALL_DIR WITH_CUDA=$ROCM_PATH python setup.py
```
Build log before fix (error "hip/hip_runtime.h: No such file or directory"): P493038915
Build log after fix: P493037572
Reviewed By: ezyang
Differential Revision: D35506098
Pulled By: minsii
fbshipit-source-id: 76cbb6d4eaa6549a00898c9d9ebaca47a55330e9
(cherry picked from commit d684c080edf1fbd293e3321151976812c1da8533)
Summary:
## Original commit message:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73368
debug_pkl file inside of pytorch's .pt file consists of a list of SourceRanges. Each SourceRange points to a Source which is a stack track, filename, and start, end numbers. Those are emitted in debug_pkl file as strings.
Since many SourceRange shares the same source, the string for trace can be deduped.
The newer format saves a set of unique traces in a tuple, then each SourceRange will save the offset of it's trace w.r.t. position in that tuple. (i.e. manually applying dictionary compression).
The above helps with smaller file size. On loading, if we copy each trace to Source as string the runtime memory would still blowup.
To mitigate this, we use SourceView directly instead of source which will take the reference of string inside of Deserializer and make that into string_view. This is safe because Deserializer is hold by Unpickler by shared_ptr, and Unpickler is also hold by shared_ptr by another Source object. That Source object will be alive during the model construction.
Test Plan:
## Original Test plan
unit test
Took original file (312271638_930.predictor.disagg.local); loaded with `torch.jit.load` save again with `torch.jit.save`. Unzip both, look at contents:
```
[qihan@devvm5585.vll0 ~]$ du archive -h
4.0K archive/xl_model_weights
3.7M archive/extra
8.0K archive/code/__torch__/caffe2/torch/fb/model_transform/splitting
8.0K archive/code/__torch__/caffe2/torch/fb/model_transform
8.0K archive/code/__torch__/caffe2/torch/fb
8.0K archive/code/__torch__/caffe2/torch
8.0K archive/code/__torch__/caffe2
20M archive/code/__torch__/torch/fx/graph_module
20M archive/code/__torch__/torch/fx
8.0K archive/code/__torch__/torch/classes
20M archive/code/__torch__/torch
20M archive/code/__torch__
20M archive/code
2.7M archive/constants
35M archive
[qihan@devvm5585.vll0 ~]$ du resaved -h
4.0K resaved/extra
8.0K resaved/code/__torch__/caffe2/torch/fb/model_transform/splitting
8.0K resaved/code/__torch__/caffe2/torch/fb/model_transform
8.0K resaved/code/__torch__/caffe2/torch/fb
8.0K resaved/code/__torch__/caffe2/torch
8.0K resaved/code/__torch__/caffe2
1.3M resaved/code/__torch__/torch/fx/graph_module
1.3M resaved/code/__torch__/torch/fx
8.0K resaved/code/__torch__/torch/classes
1.4M resaved/code/__torch__/torch
1.4M resaved/code/__torch__
1.4M resaved/code
2.7M resaved/constants
13M resaved
[qihan@devvm5585.vll0 ~]$
```
## Additional test:
`buck test mode/dev-tsan //caffe2/benchmarks/static_runtime:static_runtime_cpptest -- --exact 'caffe2/benchmarks/static_runtime:static_runtime_cpptest - StaticRuntime.to'` passes
test jest.fbios.startup_cold_start.local.simulator f333356873 -
Differential Revision: D35196883
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74869
Approved by: https://github.com/gmagogsfm
This PR is trying to solve the problem that delegate the API from the profiler layer to the `Iterator` returned from `IterDataPipe`.
We need this for internal usage `limit`, `resume`, etc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75275
Approved by: https://github.com/NivekT
Without this, `DataLoader2` will just add an `Shuffler` to the end of the datapipe if `shuffle=True`:
```py
from torch.utils.data.dataloader_experimental import DataLoader2
from torchdata.datapipes.iter import IterableWrapper, IterDataPipe, Shuffler
class Sorter(IterDataPipe):
def __init__(self, datapipe):
self.datapipe = datapipe
def __iter__(self):
return iter(sorted(self.datapipe))
data = list(range(1000))
dp = IterableWrapper(data)
dp = Shuffler(dp).set_shuffle(False)
dp = Sorter(dp)
dl2 = DataLoader2(dp, shuffle=True, batch_size=None)
assert list(dl2) == data # fails unless you hit a lucky random seed
```
This example is somewhat non-sensical, but demonstrates we cannot simply add a `Shuffler`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75014
Approved by: https://github.com/ejguan
Summary:
Fixes a bug where collect_env.py was not able to be run without having
torch installed
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74342
Reviewed By: malfet, janeyx99
Differential Revision: D34943464
Pulled By: seemethere
fbshipit-source-id: dbaa0004b88cb643a9c6426c9ea7c5be3d3c9ef5
(cherry picked from commit 4f39ebb823f88df0c3902db15deaffc6ba481cb3)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73991
Automatically generate `datapipe.pyi` via CMake and removing the generated .pyi file from Git. Users should have the .pyi file locally after building for the first time.
I will also be adding an internal equivalent diff for buck.
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D34868001
Pulled By: NivekT
fbshipit-source-id: 448c92da659d6b4c5f686407d3723933c266c74f
(cherry picked from commit 306dbc5f469e63bc141dac57ef310e6f0e16d9cd)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73396
Separating DataPipes from Dataset into different files. This makes the code more maintainable and simplifies some of the code generation.
I have also tried to move `datapipe.py` into `torch.utils.data.datapipes`, but that will lead to circular import and rewriting many import statements. Should I put more time and go down that path some more?
Fixes https://github.com/pytorch/data/issues/213
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D34481962
Pulled By: NivekT
fbshipit-source-id: 42fb26fe7fc334636852cfd8719fc807bdaa7912
(cherry picked from commit 81e76a64e297cb5c58caa951c554e49526173936)
Summary:
Working towards https://docs.google.com/document/d/10yx2-4gs0gTMOimVS403MnoAWkqitS8TUHX73PN8EjE/edit?pli=1#
This PR:
- Ensure that all the submodules are listed in a rst file (that ensure they are considered by the coverage tool)
- Remove some long deprecated code that just error out on import
- Remove the allow list altogether to ensure nothing gets added back there
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73983
Reviewed By: anjali411
Differential Revision: D34787908
Pulled By: albanD
fbshipit-source-id: 163ce61e133b12b2f2e1cbe374f979e3d6858db7
(cherry picked from commit c9edfead7a01dc45bfc24eaf7220d2a84ab1f62e)
Summary:
This diff is reverting D34455360 (61d6c43864)
D34455360 (61d6c43864) is making the following tests to fail and this revert diff is either the revert of the blame diff or the revert of the stack of diffs that need to be reverted to revert the blame diff
Tests affected:
- https://www.internalfb.com/intern/test/562950004334605/
Multisect link:
https://www.internalfb.com/intern/testinfra/multisect/756170
Test Plan: NA
Reviewed By: zhxchen17
Differential Revision: D34596156
fbshipit-source-id: a465bca0094db3caf6130c80f1ed49eea981359b
(cherry picked from commit ef5e5578c64ce9827570757fb016aafa9c782c6a)
I was working on an explanation of how to call into the "super"
implementation of some given ATen operation inside of __torch_dispatch__
(https://github.com/albanD/subclass_zoo/blob/main/trivial_tensors.py)
and I kept thinking to myself "Why doesn't just calling super() on
__torch_dispatch__ work"? Well, after this patch, it does! The idea
is if you don't actually unwrap the input tensors, you can call
super().__torch_dispatch__ to get at the original behavior.
Internally, this is implemented by disabling PythonKey and then
redispatching. This implementation of disabled_torch_dispatch is
not /quite/ right, and some reasons why are commented in the code.
There is then some extra work I have to do to make sure we recognize
disabled_torch_dispatch as the "default" implementation (so we don't
start slapping PythonKey on all tensors, including base Tensors),
which is modeled the same way as how disabled_torch_function is done.
Signed-off-by: Edward Z. Yang <ezyangfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73684
Approved by: albanD
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73368
debug_pkl file inside of pytorch's .pt file consists of a list of SourceRanges. Each SourceRange points to a Source which is a stack track, filename, and start, end numbers. Those are emitted in debug_pkl file as strings.
Since many SourceRange shares the same source, the string for trace can be deduped.
The newer format saves a set of unique traces in a tuple, then each SourceRange will save the offset of it's trace w.r.t. position in that tuple. (i.e. manually applying dictionary compression).
The above helps with smaller file size. On loading, if we copy each trace to Source as string the runtime memory would still blowup.
To mitigate this, we use SourceView directly instead of source which will take the reference of string inside of Deserializer and make that into string_view. This is safe because Deserializer is hold by Unpickler by shared_ptr, and Unpickler is also hold by shared_ptr by another Source object. That Source object will be alive during the model construction.
Test Plan:
unit test
Took original file (312271638_930.predictor.disagg.local); loaded with `torch.jit.load` save again with `torch.jit.save`. Unzip both, look at contents:
```
[qihan@devvm5585.vll0 ~]$ du archive -h
4.0K archive/xl_model_weights
3.7M archive/extra
8.0K archive/code/__torch__/caffe2/torch/fb/model_transform/splitting
8.0K archive/code/__torch__/caffe2/torch/fb/model_transform
8.0K archive/code/__torch__/caffe2/torch/fb
8.0K archive/code/__torch__/caffe2/torch
8.0K archive/code/__torch__/caffe2
20M archive/code/__torch__/torch/fx/graph_module
20M archive/code/__torch__/torch/fx
8.0K archive/code/__torch__/torch/classes
20M archive/code/__torch__/torch
20M archive/code/__torch__
20M archive/code
2.7M archive/constants
35M archive
[qihan@devvm5585.vll0 ~]$ du resaved -h
4.0K resaved/extra
8.0K resaved/code/__torch__/caffe2/torch/fb/model_transform/splitting
8.0K resaved/code/__torch__/caffe2/torch/fb/model_transform
8.0K resaved/code/__torch__/caffe2/torch/fb
8.0K resaved/code/__torch__/caffe2/torch
8.0K resaved/code/__torch__/caffe2
1.3M resaved/code/__torch__/torch/fx/graph_module
1.3M resaved/code/__torch__/torch/fx
8.0K resaved/code/__torch__/torch/classes
1.4M resaved/code/__torch__/torch
1.4M resaved/code/__torch__
1.4M resaved/code
2.7M resaved/constants
13M resaved
[qihan@devvm5585.vll0 ~]$
```
Reviewed By: gmagogsfm
Differential Revision: D34455360
fbshipit-source-id: 8cc716f9bba7183746b1b4ecc33a2de34ac503b9
(cherry picked from commit f1a04730fc9ac8fdab6c8e4c44cb5529e42090e4)
Summary:
- Target Sha1: ae108ef49aa5623b896fc93d4298c49d1750d9ba
- Make USE_XNNPACK a dependent option on cmake minimum version 3.12
- Print USE_XNNPACK under cmake options summary, and print the
availability from collet_env.py
- Skip XNNPACK based tests when XNNPACK is not available
- Add SkipIfNoXNNPACK wrapper to skip tests
- Update cmake version for xenial-py3.7-gcc5.4 image to 3.12.4
- This is required for the backwards compatibility test.
The PyTorch op schema is XNNPACK dependent. See,
aten/src/ATen/native/xnnpack/RegisterOpContextClass.cpp for
example. The nightly version is assumed to have USE_XNNPACK=ON,
so with this change we ensure that the test build can also
have XNNPACK.
- HACK: skipping test_xnnpack_integration tests on ROCM
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72642
Reviewed By: kimishpatel
Differential Revision: D34456794
Pulled By: digantdesai
fbshipit-source-id: 85dbfe0211de7846d8a84321b14fdb061cd6c037
(cherry picked from commit 6cf48e7b64d6979962d701b5d493998262cc8bfa)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72596
debug_pkl file inside of pytorch's .pt file consists of a list of SourceRanges. Each SourceRange points to a Source which is a stack track, filename, and start, end numbers. Those are emitted in debug_pkl file as strings.
Since many SourceRange shares the same source, the string for trace can be deduped.
The newer format saves a set of unique traces in a tuple, then each SourceRange will save the offset of it's trace w.r.t. position in that tuple. (i.e. manually applying dictionary compression).
The above helps with smaller file size. On loading, if we copy each trace to Source as string the runtime memory would still blowup.
To mitigate this, we use SourceView directly instead of source which will take the reference of string inside of Deserializer and make that into string_view. This is safe because Deserializer is hold by Unpickler by shared_ptr, and Unpickler is also hold by shared_ptr by another Source object. That Source object will be alive during the model construction.
Test Plan:
unit test
Took original file (312271638_930.predictor.disagg.local); loaded with `torch.jit.load` save again with `torch.jit.save`. Unzip both, look at contents:
```
[qihan@devvm5585.vll0 ~]$ du archive -h
4.0K archive/xl_model_weights
3.7M archive/extra
8.0K archive/code/__torch__/caffe2/torch/fb/model_transform/splitting
8.0K archive/code/__torch__/caffe2/torch/fb/model_transform
8.0K archive/code/__torch__/caffe2/torch/fb
8.0K archive/code/__torch__/caffe2/torch
8.0K archive/code/__torch__/caffe2
20M archive/code/__torch__/torch/fx/graph_module
20M archive/code/__torch__/torch/fx
8.0K archive/code/__torch__/torch/classes
20M archive/code/__torch__/torch
20M archive/code/__torch__
20M archive/code
2.7M archive/constants
35M archive
[qihan@devvm5585.vll0 ~]$ du resaved -h
4.0K resaved/extra
8.0K resaved/code/__torch__/caffe2/torch/fb/model_transform/splitting
8.0K resaved/code/__torch__/caffe2/torch/fb/model_transform
8.0K resaved/code/__torch__/caffe2/torch/fb
8.0K resaved/code/__torch__/caffe2/torch
8.0K resaved/code/__torch__/caffe2
1.3M resaved/code/__torch__/torch/fx/graph_module
1.3M resaved/code/__torch__/torch/fx
8.0K resaved/code/__torch__/torch/classes
1.4M resaved/code/__torch__/torch
1.4M resaved/code/__torch__
1.4M resaved/code
2.7M resaved/constants
13M resaved
[qihan@devvm5585.vll0 ~]$
```
Reviewed By: JasonHanwen
Differential Revision: D33994011
fbshipit-source-id: 8e6224c6e942e91c3403f686c8f0937d1002ed41
(cherry picked from commit a7014dd4029308c95007f362a57c31796d686647)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72896
Fixing the issue described here: https://github.com/pytorch/data/issues/214
There will be a follow-up PR in TorchData as well
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D34258669
Pulled By: NivekT
fbshipit-source-id: 6dd88250ed14ebe779915dc46139be7e012e9d1b
(cherry picked from commit 025b8ed98019e576bfef04c33a3f33ed1a426a66)
Summary:
Adding documentation about compiling extension with CUDA 11.5 and Windows
Example of failure: https://github.com/pytorch/pytorch/runs/4408796098?check_suite_focus=true
Note: Don't use torch/extension.h In CUDA 11.5 under windows in your C++ code:
Use aten instead of torch interface in all cuda 11.5 code under windows. It has been failing with errors, due to a bug in nvcc.
Example use:
>>> #include <ATen/ATen.h>
>>> at::Tensor SigmoidAlphaBlendForwardCuda(....)
Instead of:
>>> #include <torch/extension.h>
>>> torch::Tensor SigmoidAlphaBlendForwardCuda(...)
Currently open issue for nvcc bug: https://github.com/pytorch/pytorch/issues/69460
Complete Workaround code example: cb170ac024
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73013
Reviewed By: malfet, seemethere
Differential Revision: D34306134
Pulled By: atalman
fbshipit-source-id: 3c5b9d7a89c91bd1920dc63dbd356e45dc48a8bd
(cherry picked from commit 87098e7f17)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72866https://github.com/pytorch/pytorch/pull/71597 adds a wrapper `torch.jit.LoweredWrapper` and it breaks the model dump. Fix the model_dump in the notebook
ghstack-source-id: 149311636
Test Plan:
CI and test with N509022
Before:
{F701413403}
After:
{F701412963}
Reviewed By: iseeyuan
Differential Revision: D34247216
fbshipit-source-id: 695b02b03675fae596bb450441b327e4cdcffe9c
(cherry picked from commit d46a82a4c1)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72829
Make two functions more flexible and usable from a different repo.
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D34227912
Pulled By: NivekT
fbshipit-source-id: 873934ed33caf485de7f56e9c4a1d3f3fa1a92ef
(cherry picked from commit b990c5e4c7)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72667
Created by running
```
python -m libcst.tool codemod --no-format --jobs=1 convert_type_comments.ConvertTypeComments ~/fbsource/fbcode/caffe2/torch/utils/ --no-quote-annotations
```
and then manually cleaning up unreadable function headers (which is needed due to lack of autoformatting).
Test Plan:
Wait for CI - usually type annotations are safe to land, but the jit
compiler sometimes can choke if there's a problem.
Reviewed By: grievejia
Differential Revision: D34148011
fbshipit-source-id: 8f7c7a3b5ef78e0dea6d10ce70072f39e6d1ecc3
(cherry picked from commit 25a929ef8d)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72618
The major changes are in torch/utils/data/dataset.py
Let me know if anything is unclear. I'm open to suggestion.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D34119492
Pulled By: NivekT
fbshipit-source-id: 358cb6d33d18501f9042431350f872ebaa9b4070
(cherry picked from commit 53b484f60a)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72476
To render the change in documentation, please pull down this PR and build the doc in `TorchData`.
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D34078078
Pulled By: NivekT
fbshipit-source-id: f478d5a901f8364ab6de1fd4bf8a8ab1036b2231
(cherry picked from commit e00a9967e9)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72475
To render the change in documentation, please pull down this PR and build the doc in `TorchData`.
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D34078064
Pulled By: NivekT
fbshipit-source-id: 0d3d02d5d05ecd774251cf8d04c40413660446f1
(cherry picked from commit 9f604689a4)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72123
There is a bug to fix the typing system in DataPipe, which would take more than 1 week to fix. I will follow up on it later this month. As branch cut is today, add this PR to disable typing to make sure release works.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D33920610
Pulled By: ejguan
fbshipit-source-id: febff849ab2272fd3b1c5127a20f27eb82992d9c
(cherry picked from commit ee103e62e7)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71579Fixes#1551
As the comment in the code, register a function to terminate persistent workers.
By adding a reference of these workers in `atexit`, it would prevent Python interpreter kills these persistent worker processes before `pin_memorh_thread` exits.
And, if users explicitly kills DataLoader iterator, such function in `atexit` would be a no-op.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D33896537
Pulled By: ejguan
fbshipit-source-id: 36b57eac7523d8aa180180c2b61fc693ea4638ae
(cherry picked from commit 05add2ae0f)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/70103
I used an argument so it can be disabled. I called it `deterministic_order` because `sort` can be confusing, as it's actually sorted but by dir levels.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70435
Reviewed By: albanD
Differential Revision: D33899755
Pulled By: ejguan
fbshipit-source-id: e8a08f03a49120333b2d27f332cd21a3240a02a9
(cherry picked from commit 4616e43ec3)
Summary:
# Overview
Currently the cuda topk implementation uses only 1 block per slice, which limits the performance for big slices. This PR addresses this issue.
There are 2 parts in the topk calculation, find the kth value (`radixFindKthValues`) in each slice, then gather topk values (`gatherTopK`) based on the kth value. `radixFindKthValues` kernel now supports multiple blocks. `gatherTopK` may also need a multiple block version (separate PR?).
kthvalue, quantile, median could also use the same code (separate PR).
# Benchmark
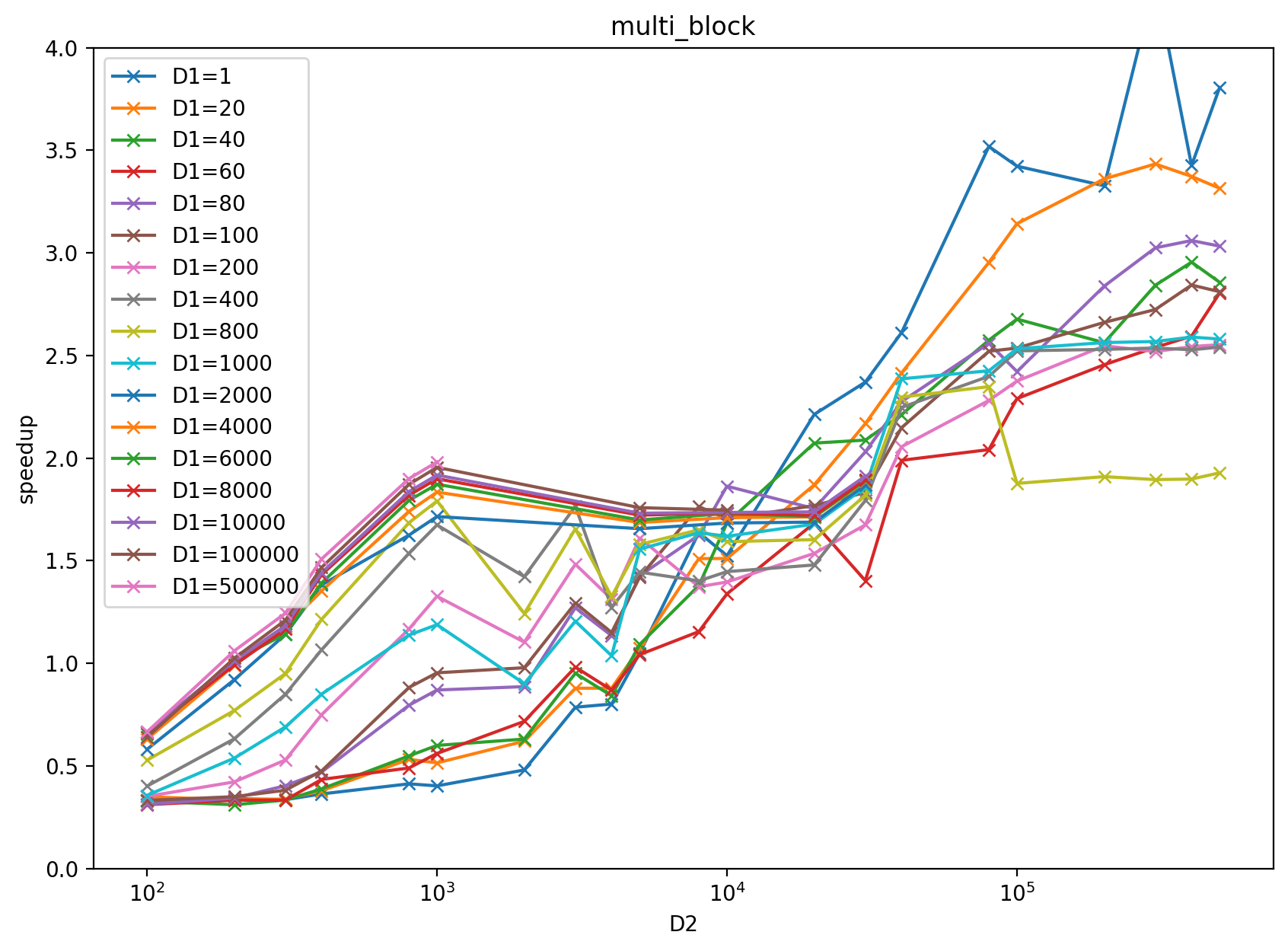
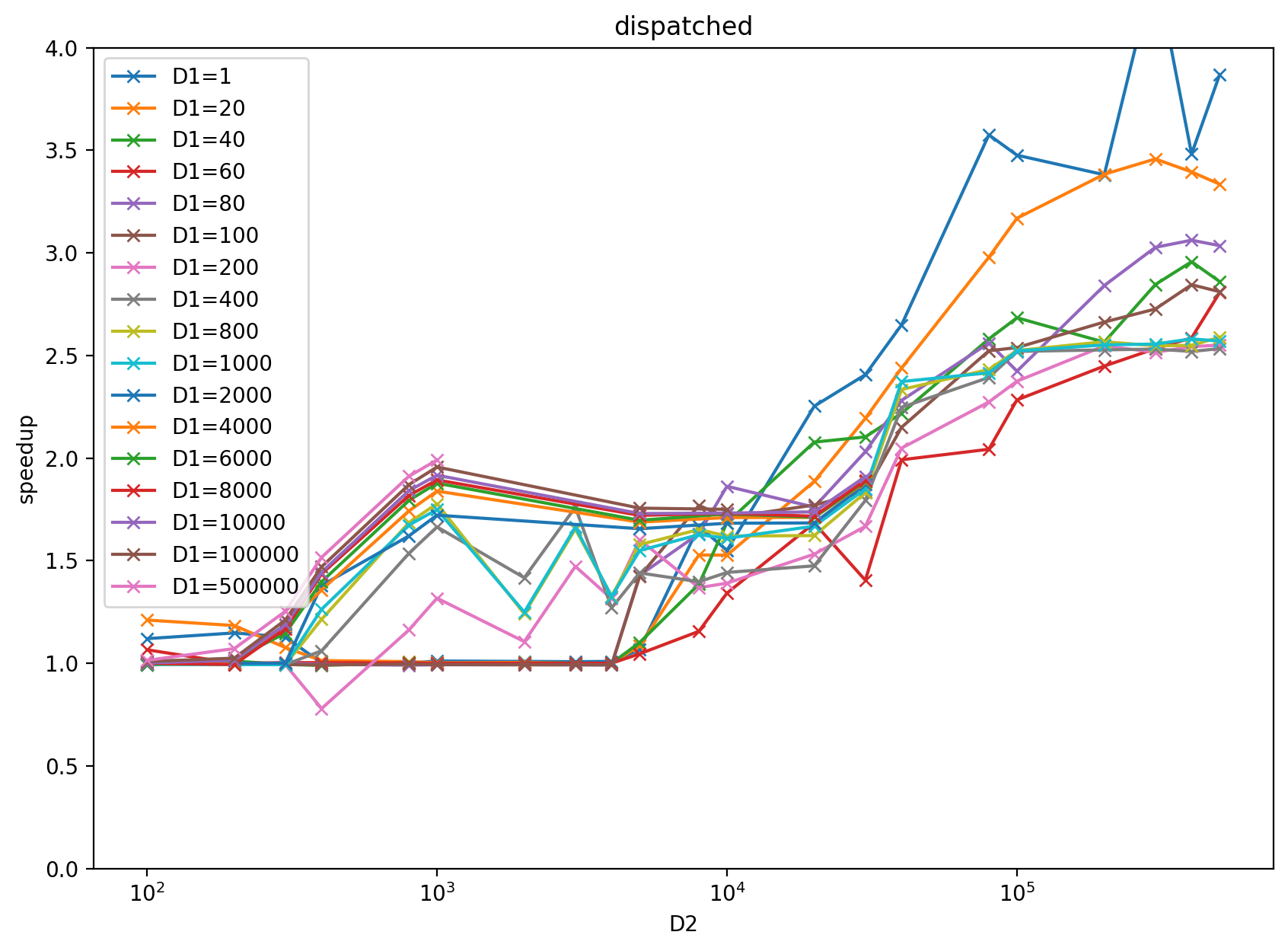
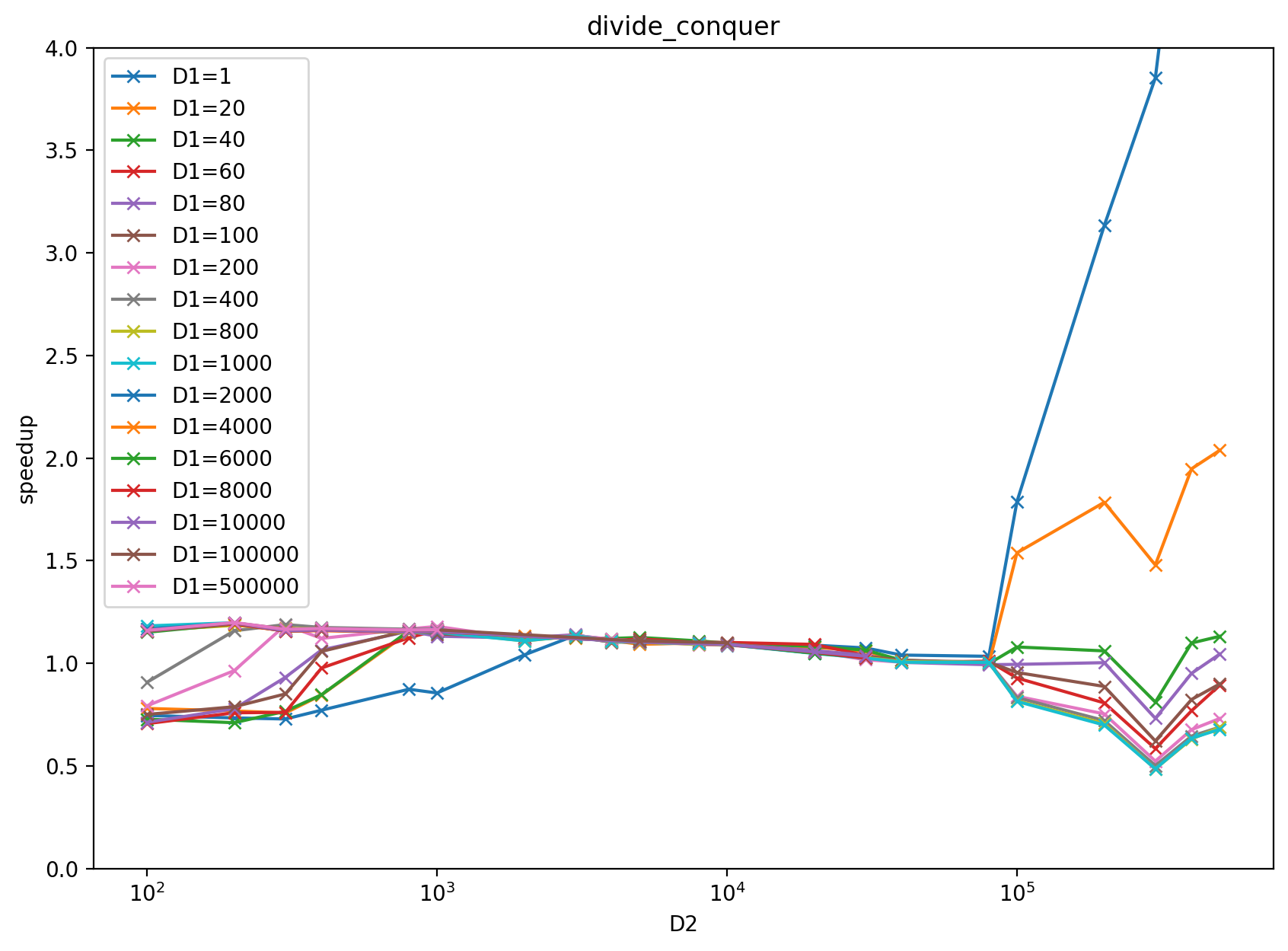
Benchmark result with input `x = torch.randn((D1 (2d884f2263), D2 (9b53d3194c)), dtype=torch.float32)` and `k = 2000` on RTX 3080: https://docs.google.com/spreadsheets/d/1BAGDkTCHK1lROtjYSjuu_nLuFkwfs77VpsVPymyO8Gk/edit?usp=sharing
benchmark plot: left is multiblock, right is dispatched based on heuristics result from the above google sheet.
<p class="img">
<img width=49% src="https://user-images.githubusercontent.com/9999318/150860547-7e450ed2-df09-4292-a02a-cb0e1040eebe.png">
<img width=49% src="https://user-images.githubusercontent.com/9999318/150860579-672b88ca-e500-4846-825c-65d31d126df4.png">
</p>
The performance of divide-and-conquer implementation at https://github.com/pytorch/pytorch/pull/39850 is not stable in terms of the D1 (2d884f2263), D2 (9b53d3194c) size increasing, for more detail please check the above google sheet.
<p>
<img width=49% src="https://user-images.githubusercontent.com/9999318/150860563-21d5a5a3-9d6a-4cef-9031-cac4d2d8edee.png">
</p>
# cubin binary size
The cubin binary size for TensorTopK.cubin (topk) and Sorting.cubin (kthvalue, quantile and etc) has been reduced by removing `#pragma unroll` at [SortingRadixSelect.cuh](https://github.com/pytorch/pytorch/pull/71081/files#diff-df06046dc4a2620f47160e1b16b8566def855c0f120a732e0d26bc1e1327bb90L321) and `largest` template argument without much performance regression.
The final binary size before and after the PR is
```
# master
-rw-rw-r-- 1 richard richard 18M Jan 24 20:07 TensorTopK.cu.1.sm_86.cubin
-rw-rw-r-- 1 richard richard 16M Jan 24 20:07 Sorting.cu.1.sm_86.cubin
# this PR
-rw-rw-r-- 1 richard richard 5.0M Jan 24 20:11 TensorTopK.cu.1.sm_86.cubin
-rw-rw-r-- 1 richard richard 2.5M Jan 24 20:11 Sorting.cu.1.sm_86.cubin
```
script to extract cubin
```
# build with REL_WITH_DEB_INFO=0
# at pytorch directory
cubin_path=build/caffe2/CMakeFiles/torch_cuda.dir/__/aten/src/ATen/native/cuda/cubin; mkdir -p $cubin_path; cd $cubin_path; find ../ -type f -name '*cu.o' -exec cuobjdump {} -xelf all \; ; ls -lh *.cubin -S | head -70
```
# benchmark script
```py
import torch
import time
import torch
import pandas as pd
import numpy as np
import torch.utils.benchmark as benchmark
torch.manual_seed(1)
dtype = torch.float
data = []
for d1 in [1, 20, 40, 60, 80, 100, 200, 400, 800, 1000, 2000, 4000, 6000, 8000, 10000, 100000, 500000]:
if d1 <= 1000:
D2 (9b53d3194c) = [100, 200, 300, 400, 800, 1000, 2000, 3000, 4000, 5000, 8000, 10000, 20000, 30000, 40000, 80000, 100000, 200000, 300000, 400000, 500000]
else:
D2 (9b53d3194c) = [100, 200, 300, 400, 800, 1000, 5000, 10000, 20000, 30000]
for d2 in D2 (9b53d3194c):
k = 2000 if d2 >= 2000 else d2 // 2
print(f"----------------- D1 (2d884f2263) = {d1}, D2 (9b53d3194c) = {d2} -----------------")
try:
x = torch.randn((d1, d2), dtype=dtype, device="cuda")
m = benchmark.Timer(
stmt='x.topk(k=k, dim=1, sorted=False, largest=True)',
globals={'x': x, 'k': k},
num_threads=1,
).blocked_autorange(min_run_time=1)
print(m)
time_ms = m.median * 1000
except RuntimeError: # OOM
time_ms = -1
data.append([d1, d2, k, time_ms])
df = pd.DataFrame(data=data, columns=['D1 (2d884f2263)', 'D2 (9b53d3194c)', 'k', 'time(ms)'])
print(df)
df.to_csv('benchmark.csv')
```
plot script could be found at: https://github.com/yueyericardo/misc/tree/master/share/topk-script
cc zasdfgbnm ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71081
Reviewed By: albanD
Differential Revision: D33823002
Pulled By: ngimel
fbshipit-source-id: c0482664e9d74f7cafc559a07c6f0b564c9e3ed0
(cherry picked from commit be367b8d07)
Summary:
This moves the warning to the legacy function where it belongs, improves the phrasing, and adds examples.
There may be more to do to make `from_dlpack` more discoverable as a follow-up, because in multiple issues/PR we discovered people wanted new things (e.g., a memoryview-like object, or `__array_interface__` support) that `from_dlpack` already provides.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70437
Reviewed By: albanD
Differential Revision: D33760552
Pulled By: mruberry
fbshipit-source-id: e8a61fa99d42331cc4bf3adfe494cab13ca6d499
(cherry picked from commit 880ad96659)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71579Fixes#1551
As the comment in the code, register a function to terminate persistent workers. Using `atexit` to make sure termination of persistent workers always happens at the end (after pin_memory_thread exits).
We need such mechanism because Python interpreter would clean up worker process before DataLoader iterator in some rare cases.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D33694867
Pulled By: ejguan
fbshipit-source-id: 0847f4d424a0cd6b3c0be8235d505415970254e8
(cherry picked from commit 18ad4621af)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71072
This PR replaces the old logic of loading frozen torch through cpython by directly loading zipped torch modules directly onto deploy interpreter. We use elf file to load the zip file as its' section and load it back in the interpreter executable. Then, we directly insert the zip file into sys.path of the each initialized interpreter. Python has implicit ZipImporter module that can load modules from zip file as long as they are inside sys.path.
Test Plan: buck test //caffe2/torch/csrc/deploy:test_deploy
Reviewed By: shunting314
Differential Revision: D32442552
fbshipit-source-id: 627f0e91e40e72217f3ceac79002e1d8308735d5
Summary:
Distributed sampler sets different indices for different processes. By doing this, it assumes that the data is the same across the board and in the same order. This may seem trivial, however, there are times that users don't guarantee the order items are gonna have, because they rely on something such as the order the filesystem lists a directory (which is not guaranteed and may vary on different computers), or the order a `set` is iterated.
I think it's better to make it clearer.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70104
Reviewed By: bdhirsh
Differential Revision: D33569539
Pulled By: rohan-varma
fbshipit-source-id: 68ff028cb360cadaee8c441256c1b027a57c7089
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71161
Users should import these DataPipes from [TorchData](https://github.com/pytorch/data) if they would like to use them. We will be checking for any downstream library usage before landing this PR.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D33532272
Pulled By: NivekT
fbshipit-source-id: 9dbfb21baf2d1183e0aa379049ad8304753e08a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71171
Editing two warnings to more accurately portray the deprecation plan for the DataPipes
cc VitalyFedyunin ejguan NivekT
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D33535785
Pulled By: NivekT
fbshipit-source-id: b902aaa3637ade0886c86a57b58544ff7993fd91
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70990
Releasing `decode` API for domains to let them implement custom `decode` DataPipe for now.
Test Plan: Imported from OSS
Reviewed By: NivekT
Differential Revision: D33477620
Pulled By: ejguan
fbshipit-source-id: d3c30ba55c327f4849d56f42d328a932a31777ed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70619
This Diff improves `hipify_python`, which is needed for AMD GPUs.
Change 1:
```
if (c == "," or ind == len(kernel_string) - 1) and closure == 0:
```
This is needed to deal with the following case (ex: https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/test/cuda_vectorized_test.cu#L111)
```
kernel<<<val, func()>>>(...)
// In this case, kernel_string is "val, func()"
// so closure gets 0 when ind == len(kernel_string) - 1.
```
Change 2:
```
mask_comments()
```
This is needed to deal with a case where "<<<" is included in a comment or a string literal (ex: https://github.com/pytorch/pytorch/blob/master/torch/csrc/deploy/interpreter/builtin_registry.cpp#L71)
```
abc = "<<<XYZ>>>"
// Though this <<<XYZ>>> is irrelevant to CUDA kernels,
// the current script attempts to hipify this and fails.
```
Test Plan:
This patch fixes errors I encountered by running
```
python3 tools/amd_build/build_amd.py
```
I confirmed, with Linux `diff`, that this patch does not change HIP code that was generated successfully with the original script.
Reviewed By: hyuen
Differential Revision: D33407743
fbshipit-source-id: bec822e040a154be4cda1c294536792ca8d596ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70367
This PR renames the `FileLoaderIterDataPipe` to `FileOpenerIterDataPipe`. For the sake of not breaking many CI tests immediately, it still preserves `FileLoader` as an alias. This will allow downstream libraries/users to migrate their use cases before we fully remove all references to `FileLoader` from PyTorch.
Fixes https://github.com/pytorch/data/issues/103. More detailed discussion about this decision is also in the linked issue.
cc VitalyFedyunin ejguan NivekT pmeier Nayef211
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D33301648
Pulled By: NivekT
fbshipit-source-id: 59278dcd44e372df0ba2001a4eecbf9792580d0b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70249
IMO, the `unbatch_level` argument is not needed here since users can simply can `.unbatch` before calling `.groupby` if needed. One small step closer to an unified API with other libraries.
Note that we may rename the functional name from `.groupby` to `.group` in the future. TBD.
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D33259104
Pulled By: NivekT
fbshipit-source-id: 490e3b6f5927f9ebe8772d5a5e4fbabe9665dfdf
Summary:
Remove all hardcoded AMD gfx targets
PyTorch build and Magma build will use rocm_agent_enumerator as
backup if PYTORCH_ROCM_ARCH env var is not defined
PyTorch extensions will use same gfx targets as the PyTorch build,
unless PYTORCH_ROCM_ARCH env var is defined
torch.cuda.get_arch_list() now works for ROCm builds
PyTorch CI dockers will continue to be built for gfx900 and gfx906 for now.
PYTORCH_ROCM_ARCH env var can be a space or semicolon separated list of gfx archs eg. "gfx900 gfx906" or "gfx900;gfx906"
cc jeffdaily sunway513 jithunnair-amd ROCmSupport KyleCZH
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61706
Reviewed By: seemethere
Differential Revision: D32735862
Pulled By: malfet
fbshipit-source-id: 3170e445e738e3ce373203e1e4ae99c84e645d7d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69508
Original Phabricator Diff: D32704467 (e032dae329)
Reland, fix is to not test traditional checkpoint when input does not require grad as that is unsupported as documented.
Original PR body:
Resubmission of https://github.com/pytorch/pytorch/pull/62964 with the
suggestions and tests discussed in
https://github.com/pytorch/pytorch/issues/65537.
Adds a `use_reentrant=False` flag to `checkpoint` function. When
`use_reentrant=True` is specified, a checkpointing implementation that uses
SavedVariableHooks instead of re-entrant autograd is used. This makes it more
composable with things such as `autograd.grad` as well as DDP (still need to
add thorough distributed testing).
As discussed in https://github.com/pytorch/pytorch/issues/65537, the tests that we need to add are:
- [x] Gradient hooks are called once
- [x] works when input does require grads but Tensor that require grads are captures (like first layer in a nn)
- [x] works for functions with arbitrary input/output objects
- [x] distributed tests (next PR)
Note that this is only for `torch.utils.checkpoint`, if this approach overall looks good, we will do something similar for `checkpoint_sequential`.
ghstack-source-id: 144948501
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D32902634
fbshipit-source-id: 2ee87006e5045e5471ff80c36a07fbecc2bea3fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69391
As part of the efforts to unify the APIs across different data backends (e.g. TorchData, TorchArrow), we are making changes to different DataPipes' APIs. In this PR, we are removing the input argument `nesting_level` from `FilterIterDataPipe`.
cc VitalyFedyunin ejguan NivekT
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D32849462
Pulled By: NivekT
fbshipit-source-id: 91cf1dc03dd3d3cbd7a9c6ccbd791ade91355f30
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69390
As part of the efforts to unify the APIs across different data backends (e.g. TorchData, TorchArrow), we are making changes to different DataPipes' APIs. In this PR, we are removing the input argument `nesting_level` from `MapperIterDataPipe`.
cc VitalyFedyunin ejguan NivekT
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D32849465
Pulled By: NivekT
fbshipit-source-id: 963ce70b84a7658331d126e5ed9fdb12273c8e1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69027
Resubmission of https://github.com/pytorch/pytorch/pull/62964 withe
suggestions and tests discussed in
https://github.com/pytorch/pytorch/issues/65537.
Adds a `use_reentrant=False` flag to `checkpoint` function. When
`use_reentrant=True` is specified, a checkpointing implementation that uses
SavedVariableHooks instead of re-entrant autograd is used. This makes it more
composable with things such as `autograd.grad` as well as DDP (still need to
add thorough distributed testing).
As discussed in https://github.com/pytorch/pytorch/issues/65537, we have added
the following tests:
-[ ] Gradient hooks are called once
ghstack-source-id: 144644859
Test Plan: CI
Reviewed By: pbelevich
Differential Revision: D32704467
fbshipit-source-id: 6eea1cce6b935ef5a0f90b769e395120900e4412
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68594
Based on my conversation with ejguan [here](https://github.com/pytorch/pytorch/pull/68197#pullrequestreview-809148827), we both believe that having the `unbatch_level` argument and functionality is making this DataPipe unnecessarily complicated, because users can call `.unbatch` before `.batch` if they would like to do so. That will likely be cleaner as well.
I also checked other libraries (for example, [TensorFlow](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#unbatch)), and I do not see them provide the ability the `unbatch` within the `batch` function either.
This PR simplifies the DataPipe by removing the argument.
cc VitalyFedyunin ejguan NivekT
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D32532594
Pulled By: NivekT
fbshipit-source-id: 7276ce76ba2a3f207c9dfa58803a48e320adefed
Summary:
`default_collate`, `default_convert`, and `pin_memory` convert sequences into lists. I believe they should keep the original type when possible (e.g., I have a class that inherits from `list`, which comes from a 3rd party library that I can't change, and provides extra functionality).
Note it's easy to do when the type supports an iterable in its creation but it's not always the case (e.g., `range`).
Even though this can be accomplished if using a custom `default_collate`/`default_convert`, 1) this is behavior they should support out-of-the-box IMHO, and 2) `pin_memory` still does it.
cc VitalyFedyunin ejguan NivekT
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68779
Reviewed By: wenleix
Differential Revision: D32651129
Pulled By: ejguan
fbshipit-source-id: 17c390934bacc0e4ead060469cf15dde815550b4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68707
This PR adds a path for block CSR matrices for `torch.addmm`. cuSPARSE interface is restricted to 32-bit indices and square blocks.
My plan is to make everything work and tests passing using an unsafe constructor first, keeping it all private. Then discuss & implement constructors with block information separately unlocking the functions for wider use. Documentation will come with the update to constructors.
cc nikitaved pearu cpuhrsch IvanYashchuk ngimel
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D32650366
Pulled By: cpuhrsch
fbshipit-source-id: 430a9627901781ee3d2e2496097b71ec17727d98
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68707
This PR adds a path for block CSR matrices for `torch.addmm`. cuSPARSE interface is restricted to 32-bit indices and square blocks.
My plan is to make everything work and tests passing using an unsafe constructor first, keeping it all private. Then discuss & implement constructors with block information separately unlocking the functions for wider use. Documentation will come with the update to constructors.
cc nikitaved pearu cpuhrsch IvanYashchuk ngimel
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D32633806
Pulled By: cpuhrsch
fbshipit-source-id: b98db0bd655cce651a5da457e78fca08619a5066
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68647Fixes#68539
When all data from source datapipe depletes, there is no need to yield the biggest group in the buffer.
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32562646
Pulled By: ejguan
fbshipit-source-id: ce91763656bc457e9c7d0af5861a5606c89965d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67783
Add `getstate_hook` to exclude primitive objects and callable when serialization when `exclude_primitive` is enabled for `traverse`.
For graph traversing, we don't have to handle the lambda and other stuff.
This is used by `OnDiskCacheHolder` to trace the DataPipe Graph.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D32146697
Pulled By: ejguan
fbshipit-source-id: 03b2ce981bb21066e807f57c167b77b2d0e0ce61
Summary:
The frexp function has been enabled in ROCm code. Updating PyTorch
to enable this functionality.
cc jeffdaily sunway513 jithunnair-amd ROCmSupport KyleCZH
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67226
Reviewed By: jbschlosser
Differential Revision: D31984606
Pulled By: ngimel
fbshipit-source-id: b58eb7f226f6eb3e17d8b1e2517a4ea7297dc1d5
{kind=link}
{kind=link}
{kind=link}