Continuation after https://github.com/pytorch/pytorch/pull/90163.
Here is a script I used to find all the non-existing arguments in the docstrings (the script can give false positives in presence of *args/**kwargs or decorators):
_Edit:_
I've realized that the indentation is wrong for the last `break` in the script, so the script only gives output for a function if the first docstring argument is wrong. I'll create a separate PR if I find more issues with corrected script.
``` python
import ast
import os
import docstring_parser
for root, dirs, files in os.walk('.'):
for name in files:
if root.startswith("./.git/") or root.startswith("./third_party/"):
continue
if name.endswith(".py"):
full_name = os.path.join(root, name)
with open(full_name, "r") as source:
tree = ast.parse(source.read())
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
all_node_args = node.args.args
if node.args.vararg is not None:
all_node_args.append(node.args.vararg)
if node.args.kwarg is not None:
all_node_args.append(node.args.kwarg)
if node.args.posonlyargs is not None:
all_node_args.extend(node.args.posonlyargs)
if node.args.kwonlyargs is not None:
all_node_args.extend(node.args.kwonlyargs)
args = [a.arg for a in all_node_args]
docstring = docstring_parser.parse(ast.get_docstring(node))
doc_args = [a.arg_name for a in docstring.params]
clean_doc_args = []
for a in doc_args:
clean_a = ""
for c in a.split()[0]:
if c.isalnum() or c == '_':
clean_a += c
if clean_a:
clean_doc_args.append(clean_a)
doc_args = clean_doc_args
for a in doc_args:
if a not in args:
print(full_name, node.lineno, args, doc_args)
break
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90505
Approved by: https://github.com/malfet, https://github.com/ZainRizvi
**Line 492: ANTIALIAS updated to Resampling.LANCZOS**
Removes the following Depreciation Warning:
`DeprecationWarning: ANTIALIAS is deprecated and will be removed in Pillow 10 (2023-07-01). `
`Use Resampling.LANCZOS instead.`
---
```
try:
ANTIALIAS = Image.Resampling.LANCZOS
except AttributeError:
ANTIALIAS = Image.ANTIALIAS
image = image.resize((scaled_width, scaled_height), ANTIALIAS)
```
Now Resampling.LANCZOS will be used unless it gives an AttributeError exception in which case it will revert back to using Image.ANTIALIAS.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85679
Approved by: https://github.com/albanD
Fix use-dict-literal pylint suggestions by changing `dict()` to `{}`. This PR should do the change for every Python file except test/jit/test_list_dict.py, where I think the intent is to test the constructor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83718
Approved by: https://github.com/albanD
### Description
Small code refactoring to make the code more pythonic by utilizing the Python `with` statement
### Issue
Not an issue
### Testing
This is a code refactoring
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82929
Approved by: https://github.com/malfet
### Description
<!-- What did you change and why was it needed? -->
The `graph` function takes a dependency on `torch.onnx.select_model_mode_for_export`, which was used because it implicitly patches `torch._C.Node` to allow for key access. This change removed the need for the patch and decoupled the tensorboard util from `torch.onnx`.
This is needed to unblock #82511 because we are removing the monkey patch
### Issue
<!-- Link to Issue ticket or RFP -->
### Testing
<!-- How did you test your change? -->
cc @ezyang @orionr @BowenBao
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82628
Approved by: https://github.com/ezyang
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72667
Created by running
```
python -m libcst.tool codemod --no-format --jobs=1 convert_type_comments.ConvertTypeComments ~/fbsource/fbcode/caffe2/torch/utils/ --no-quote-annotations
```
and then manually cleaning up unreadable function headers (which is needed due to lack of autoformatting).
Test Plan:
Wait for CI - usually type annotations are safe to land, but the jit
compiler sometimes can choke if there's a problem.
Reviewed By: grievejia
Differential Revision: D34148011
fbshipit-source-id: 8f7c7a3b5ef78e0dea6d10ce70072f39e6d1ecc3
(cherry picked from commit 25a929ef8d)
Summary:
During development it is common practice to put `type: ignore` comments on lines that are correct, but `mypy` doesn't recognize this. This often stems from the fact, that the used `mypy` version wasn't able to handle the used pattern.
With every new release `mypy` gets better at handling complex code. In addition to fix all the previously accepted but now failing patterns, we should also revisit all `type: ignore` comments to see if they are still needed or not. Fortunately, we don't need to do it manually: by adding `warn_unused_ignores = True` to the configuration, `mypy` will error out in case it encounters an `type: ignore` that is no longer needed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60006
Reviewed By: jbschlosser, malfet
Differential Revision: D29133237
Pulled By: albanD
fbshipit-source-id: 41e82edc5cd5affa7ccedad044b59b94dad4425a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59435
Sometimes we need to compare 10+ digits. Currenlty tensorboard only saves float32. Provide an option to save float64
Reviewed By: yuguo68
Differential Revision: D28856352
fbshipit-source-id: 05d12e6f79b6237b3497b376d6665c9c38e03cf7
Summary:
[distutils](https://docs.python.org/3/library/distutils.html) is on its way out and will be deprecated-on-import for Python 3.10+ and removed in Python 3.12 (see [PEP 632](https://www.python.org/dev/peps/pep-0632/)). There's no reason for us to keep it around since all the functionality we want from it can be found in `setuptools` / `sysconfig`. `setuptools` includes a copy of most of `distutils` (which is fine to use according to the PEP), that it uses under the hood, so this PR also uses that in some places.
Fixes#56527
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57040
Pulled By: driazati
Reviewed By: nikithamalgifb
Differential Revision: D28051356
fbshipit-source-id: 1ca312219032540e755593e50da0c9e23c62d720
Summary:
As this diff shows, currently there are a couple hundred instances of raw `noqa` in the codebase, which just ignore all errors on a given line. That isn't great, so this PR changes all existing instances of that antipattern to qualify the `noqa` with respect to a specific error code, and adds a lint to prevent more of this from happening in the future.
Interestingly, some of the examples the `noqa` lint catches are genuine attempts to qualify the `noqa` with a specific error code, such as these two:
```
test/jit/test_misc.py:27: print(f"{hello + ' ' + test}, I'm a {test}") # noqa E999
test/jit/test_misc.py:28: print(f"format blank") # noqa F541
```
However, those are still wrong because they are [missing a colon](https://flake8.pycqa.org/en/3.9.1/user/violations.html#in-line-ignoring-errors), which actually causes the error code to be completely ignored:
- If you change them to anything else, the warnings will still be suppressed.
- If you add the necessary colons then it is revealed that `E261` was also being suppressed, unintentionally:
```
test/jit/test_misc.py:27:57: E261 at least two spaces before inline comment
test/jit/test_misc.py:28:35: E261 at least two spaces before inline comment
```
I did try using [flake8-noqa](https://pypi.org/project/flake8-noqa/) instead of a custom `git grep` lint, but it didn't seem to work. This PR is definitely missing some of the functionality that flake8-noqa is supposed to provide, though, so if someone can figure out how to use it, we should do that instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56272
Test Plan:
CI should pass on the tip of this PR, and we know that the lint works because the following CI run (before this PR was finished) failed:
- https://github.com/pytorch/pytorch/runs/2365189927
Reviewed By: janeyx99
Differential Revision: D27830127
Pulled By: samestep
fbshipit-source-id: d6dcf4f945ebd18cd76c46a07f3b408296864fcb
Summary:
This PR adds fixes mypy issues on the current pytorch main branch. In special, it replaces occurrences of `np.bool/np.float` to `np.bool_/np.float64`, respectively:
```
test/test_numpy_interop.py:145: error: Module has no attribute "bool"; maybe "bool_" or "bool8"? [attr-defined]
test/test_numpy_interop.py:159: error: Module has no attribute "float"; maybe "float_", "cfloat", or "float64"? [attr-defined]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52090
Reviewed By: walterddr
Differential Revision: D26469596
Pulled By: malfet
fbshipit-source-id: e55a5c6da7b252469e05942e0d2588e7f92b88bf
Summary:
Very small PR to fix a typo.
### Description
Fixed 1 typo in the documentation of `torch/utils/tensorboard/writer.py` (replaced "_should in_" by "_should be in_")
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49648
Reviewed By: ngimel
Differential Revision: D25665831
Pulled By: mrshenli
fbshipit-source-id: a4e733515603bb9313c1267fdf2cfcc2bc2773c6
Summary:
Stumbled upon a little gem in the audio conversion for `SummaryWriter.add_audio()`: two Python `for` loops to convert a float array to little-endian int16 samples. On my machine, this took 35 seconds for a 30-second 22.05 kHz excerpt. The same can be done directly in numpy in 1.65 milliseconds. (No offense, I'm glad that the functionality was there!)
Would also be ready to extend this to support stereo waveforms, or should this become a separate PR?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44201
Reviewed By: J0Nreynolds
Differential Revision: D23831002
Pulled By: edward-io
fbshipit-source-id: 5c8f1ac7823d1ed41b53c4f97ab9a7bac33ea94b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40720
Add support for populating domain_discrete field in TensorBoard add_hparams API
Test Plan: Unit test test_hparams_domain_discrete
Reviewed By: edward-io
Differential Revision: D22291347
fbshipit-source-id: 78db9f62661c9fe36cd08d563db0e7021c01428d
Summary: Add support for populating domain_discrete field in TensorBoard add_hparams API
Test Plan: Unit test test_hparams_domain_discrete
Reviewed By: edward-io
Differential Revision: D22227939
fbshipit-source-id: d2f0cd8e5632cbcc578466ff3cd587ee74f847af
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40660
Support custom run_name since using timestamp as run_name can be confusing to people
Test Plan:
hp = {"lr": 0.1, "bool_var": True, "string_var": "hi"}
mt = {"accuracy": 0.1}
writer.add_hparams(hp, mt, run_name="run1")
writer.flush()
Reviewed By: edward-io
Differential Revision: D22157749
fbshipit-source-id: 3d4974381e3be3298f3e4c40e3d4bf20e49dfb07
Summary:
The root cause of incorrect rendering is that numbers are treated as a string if the data type is not specified. Therefore the data is sort based on the first digit.
closes https://github.com/pytorch/pytorch/issues/29906
cc orionr sanekmelnikov
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31544
Differential Revision: D21105403
Pulled By: natalialunova
fbshipit-source-id: a676ff5ab94c5bdb653615d43219604e54747e56
Summary:
cc orionr sanekmelnikov
Confirm that the function was removed already.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36495
Differential Revision: D21003122
Pulled By: natalialunova
fbshipit-source-id: 364b0790953980e02eb7ff8fa0b6218d7e34a0c3
Summary:
The function originally comes from 4279f99847/tensorflow/python/ops/summary_op_util.py (L45-L68)
As its comment says:
```
# In the past, the first argument to summary ops was a tag, which allowed
# arbitrary characters. Now we are changing the first argument to be the node
# name. This has a number of advantages (users of summary ops now can
# take advantage of the tf name scope system) but risks breaking existing
# usage, because a much smaller set of characters are allowed in node names.
# This function replaces all illegal characters with _s, and logs a warning.
# It also strips leading slashes from the name.
```
This function is only for compatibility with TF's operator name restrictions, and is therefore no longer valid in pytorch. By removing it, tensorboard summaries can use more characters in the names.
Before:
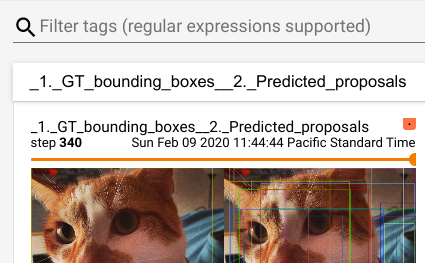
After:
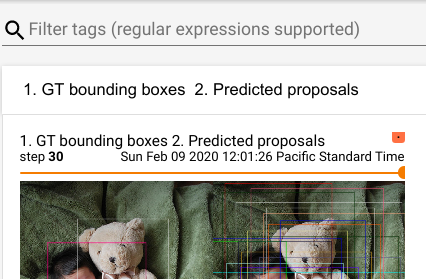
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33133
Differential Revision: D20089307
Pulled By: ezyang
fbshipit-source-id: 3552646dce1d5fa0bde7470f32d5376e67ec31c6
{kind=link}
{kind=link}
{kind=link}