Summary:
This diff introduces a set of changes that makes it possible for the host to get assertions from CUDA devices. This includes the introduction of
**`CUDA_KERNEL_ASSERT2`**
A preprocessor macro to be used within a CUDA kernel that, upon an assertion failure, writes the assertion message, file, line number, and possibly other information to UVM (Managed memory). Once this is done, the original assertion is triggered, which places the GPU in a Bad State requiring recovery. In my tests, data written to UVM appears there before the GPU reaches the Bad State and is still accessible from the host after the GPU is in this state.
Messages are written to a multi-message buffer which can, in theory, hold many assertion failures. I've done this as a precaution in case there are several, but I don't actually know whether that is possible and a simpler design which holds only a single message may well be all that is necessary.
**`TORCH_DSA_KERNEL_ARGS`**
This preprocess macro is added as an _argument_ to a kernel function's signature. It expands to supply the standardized names of all the arguments needed by `C10_CUDA_COMMUNICATING_KERNEL_ASSERTION` to handle device-side assertions. This includes, eg, the name of the pointer to the UVM memory the assertion would be written to. This macro abstracts the arguments so there is a single point of change if the system needs to be modified.
**`c10::cuda::get_global_cuda_kernel_launch_registry()`**
This host-side function returns a singleton object that manages the host's part of the device-side assertions. Upon allocation, the singleton allocates sufficient UVM (Managed) memory to hold information about several device-side assertion failures. The singleton also provides methods for getting the current traceback (used to identify when a kernel was launched). To avoid consuming all the host's memory the singleton stores launches in a circular buffer; a unique "generation number" is used to ensure that kernel launch failures map to their actual launch points (in the case that the circular buffer wraps before the failure is detected).
**`TORCH_DSA_KERNEL_LAUNCH`**
This host-side preprocessor macro replaces the standard
```
kernel_name<<<blocks, threads, shmem, stream>>>(args)
```
invocation with
```
TORCH_DSA_KERNEL_LAUNCH(blocks, threads, shmem, stream, args);
```
Internally, it fetches the UVM (Managed) pointer and generation number from the singleton and append these to the standard argument list. It also checks to ensure the kernel launches correctly. This abstraction on kernel launches can be modified to provide additional safety/logging.
**`c10::cuda::c10_retrieve_device_side_assertion_info`**
This host-side function checks, when called, that no kernel assertions have occurred. If one has. It then raises an exception with:
1. Information (file, line number) of what kernel was launched.
2. Information (file, line number, message) about the device-side assertion
3. Information (file, line number) about where the failure was detected.
**Checking for device-side assertions**
Device-side assertions are most likely to be noticed by the host when a CUDA API call such as `cudaDeviceSynchronize` is made and fails with a `cudaError_t` indicating
> CUDA error: device-side assert triggered CUDA kernel errors
Therefore, we rewrite `C10_CUDA_CHECK()` to include a call to `c10_retrieve_device_side_assertion_info()`. To make the code cleaner, most of the logic of `C10_CUDA_CHECK()` is now contained within a new function `c10_cuda_check_implementation()` to which `C10_CUDA_CHECK` passes the preprocessor information about filenames, function names, and line numbers. (In C++20 we can use `std::source_location` to eliminate macros entirely!)
# Notes on special cases
* Multiple assertions from the same block are recorded
* Multiple assertions from different blocks are recorded
* Launching kernels from many threads on many streams seems to be handled correctly
* If two process are using the same GPU and one of the processes fails with a device-side assertion the other process continues without issue
* X Multiple assertions from separate kernels on different streams seem to be recorded, but we can't reproduce the test condition
* X Multiple assertions from separate devices should be all be shown upon exit, but we've been unable to generate a test that produces this condition
Differential Revision: D37621532
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84609
Approved by: https://github.com/ezyang, https://github.com/malfet
Fixes#43144
This uses the Backend system added by [82682](https://github.com/pytorch/pytorch/pull/82682) to change allocators dynamically during the code execution. This will allow us to use RMM, use CUDA managed memory for some portions of the code that do not fit in GPU memory. Write static memory allocators to reduce fragmentation while training models and improve interoperability with external DL compilers/libraries.
For example, we could have the following allocator in c++
```c++
#include <sys/types.h>
#include <cuda_runtime_api.h>
#include <iostream>
extern "C" {
void* my_malloc(ssize_t size, int device, cudaStream_t stream) {
void *ptr;
std::cout<<"alloc "<< size<<std::endl;
cudaMalloc(&ptr, size);
return ptr;
}
void my_free(void* ptr) {
std::cout<<"free "<<std::endl;
cudaFree(ptr);
}
}
```
Compile it as a shared library
```
nvcc allocator.cc -o alloc.so -shared --compiler-options '-fPIC'
```
And use it from PyTorch as follows
```python
import torch
# Init caching
# b = torch.zeros(10, device='cuda')
new_alloc = torch.cuda.memory.CUDAPluggableAllocator('alloc.so', 'my_malloc', 'my_free')
old = torch.cuda.memory.get_current_allocator()
torch.cuda.memory.change_current_allocator(new_alloc)
b = torch.zeros(10, device='cuda')
# This will error since the current allocator was already instantiated
torch.cuda.memory.change_current_allocator(old)
```
Things to discuss
- How to test this, needs compiling external code ...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86786
Approved by: https://github.com/albanD
Enables:
test_bmm_cuda_float64
test_bmm_deterministic_cuda_float64
test_csr_matvec_cuda_complex128
test_csr_matvec_cuda_complex64
test_csr_matvec_cuda_float32
test_csr_matvec_cuda_float64
To enable the above tests had to add some more hip mappings for the hipification process.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78939
Approved by: https://github.com/pruthvistony, https://github.com/malfet
I got the following error on OSX, which doesn't have HIP.
As this file is supposed to compile with non-HIP builds,
I added this error to the errors to ignore.
```
Traceback (most recent call last):
File "test/test_profiler.py", line 31, in <module>
from torch.profiler._pattern_matcher import (Pattern, NamePattern,
File "/Users/jclow/pytorch3/torch/profiler/_pattern_matcher.py", line 9, in <module>
import torch.utils.benchmark as benchmark
File "/Users/jclow/pytorch3/torch/utils/benchmark/__init__.py", line 2, in <module>
from torch.utils.benchmark.utils.timer import * # noqa: F403
File "/Users/jclow/pytorch3/torch/utils/benchmark/utils/timer.py", line 8, in <module>
from torch.utils.benchmark.utils import common, cpp_jit
File "/Users/jclow/pytorch3/torch/utils/benchmark/utils/cpp_jit.py", line 13, in <module>
from torch.utils import cpp_extension
File "/Users/jclow/pytorch3/torch/utils/cpp_extension.py", line 19, in <module>
from .hipify import hipify_python
File "/Users/jclow/pytorch3/torch/utils/hipify/hipify_python.py", line 34, in <module>
from .cuda_to_hip_mappings import CUDA_TO_HIP_MAPPINGS
File "/Users/jclow/pytorch3/torch/utils/hipify/cuda_to_hip_mappings.py", line 34, in <module>
rocm_path = subprocess.check_output(["hipconfig", "--rocmpath"]).decode("utf-8")
File "/Users/jclow/opt/anaconda3/envs/pytorch3/lib/python3.8/subprocess.py", line 415, in check_output
return run(*popenargs, stdout=PIPE, timeout=timeout, check=True,
File "/Users/jclow/opt/anaconda3/envs/pytorch3/lib/python3.8/subprocess.py", line 493, in run
with Popen(*popenargs, **kwargs) as process:
File "/Users/jclow/opt/anaconda3/envs/pytorch3/lib/python3.8/subprocess.py", line 858, in __init__
self._execute_child(args, executable, preexec_fn, close_fds,
File "/Users/jclow/opt/anaconda3/envs/pytorch3/lib/python3.8/subprocess.py", line 1706, in _execute_child
raise child_exception_type(errno_num, err_msg, err_filename)
PermissionError: [Errno 13] Permission denied: 'hipconfig'
```
Differential Revision: [D38766067](https://our.internmc.facebook.com/intern/diff/D38766067)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83009
Approved by: https://github.com/malfet
### Description
Enables jiterator for ROCm builds. This includes necessary porting when hiprtc and nvrtc behavior differed. This also ported ROCm versus CUDA differences w.r.t. MAX_DIMS and NUM_THREADS from the non-jiterator code paths into jiterator.
### Testing
CI with ciflow/trunk label to force running ROCm workflows that are currently trunk-only.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77982
Approved by: https://github.com/ngimel
### Description
The hipify mappings file now parses the rocm version header file and can use this information to conditionalize the mappings. This is necessary while rocm packaging matures.
### Issue
#80849 updated the hipify mappings, but it wasn't backward compatible with ROCm versions prior to 5.2.
### Testing
Verified by building rocm pytorch using both the rocm 5.1 and 5.2 dockerfiles.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82258
Approved by: https://github.com/albanD
`torch.sparse.sampled_addmm` was incorrect for noncontiguous inputs on CUDA.
Unfortnately, it was overlooked in the tests that noncontiguous inputs
are not tested properly because 1x5, 5x1 shapes were used.
Block sparse triangular solver on CUDA could return incorrect results if
there's a zero on the diagonal in the sparse matrix. Now it returns nan.
Tests also revealed that unitriangular=True flag is not working
correctly on CPU in some cases. That part needs more investigation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76590
Approved by: https://github.com/cpuhrsch
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76333
The current PyTorch multi-head attention and transformer
implementations are slow. This should speed them up for inference.
ghstack-source-id: 154737857
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: cpuhrsch
Differential Revision: D35239925
fbshipit-source-id: 5a7eb8ff79bc6afb4b7d45075ddb2a24a6e2df28
Summary:
# Overview
Currently the cuda topk implementation uses only 1 block per slice, which limits the performance for big slices. This PR addresses this issue.
There are 2 parts in the topk calculation, find the kth value (`radixFindKthValues`) in each slice, then gather topk values (`gatherTopK`) based on the kth value. `radixFindKthValues` kernel now supports multiple blocks. `gatherTopK` may also need a multiple block version (separate PR?).
kthvalue, quantile, median could also use the same code (separate PR).
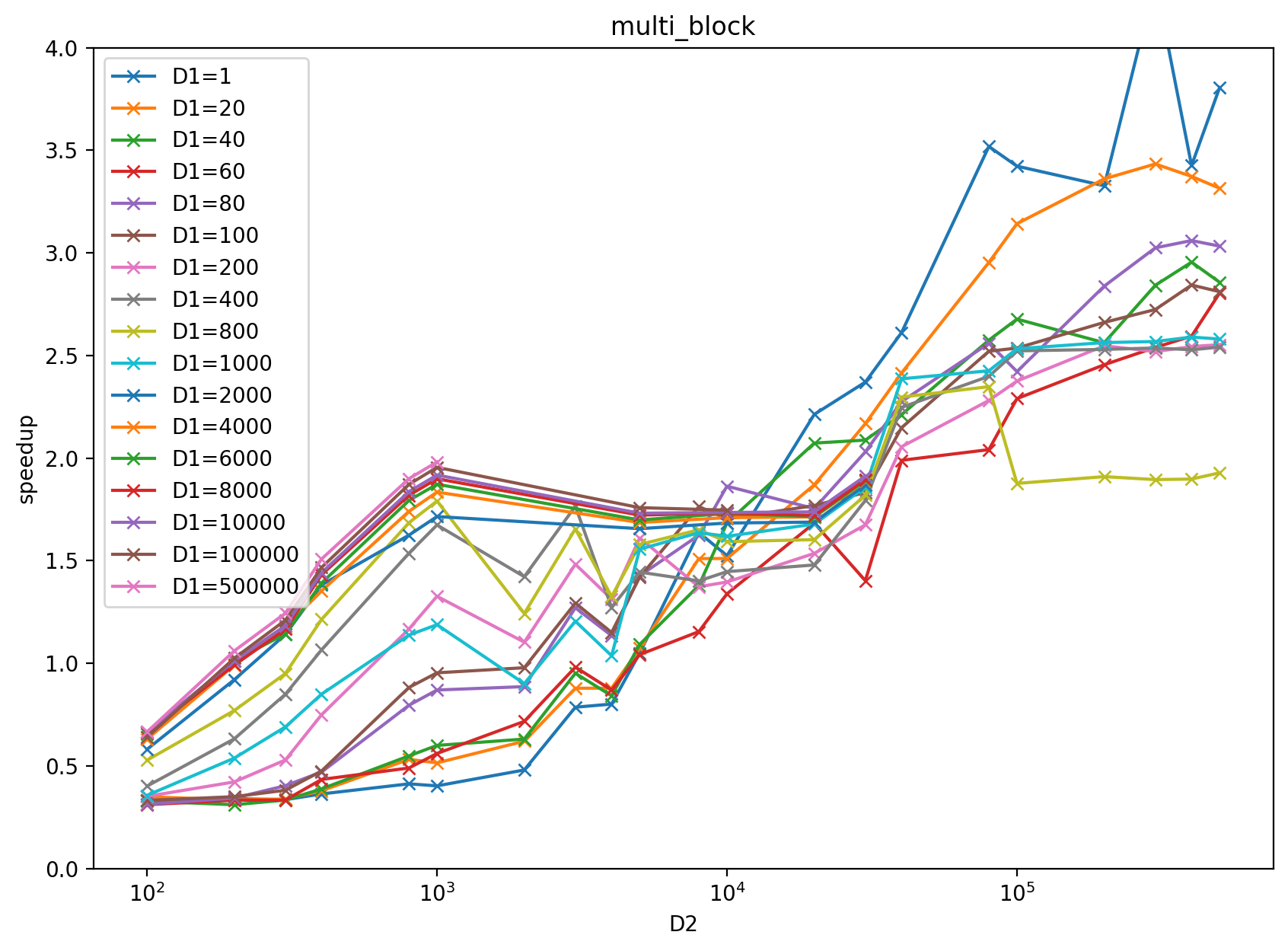
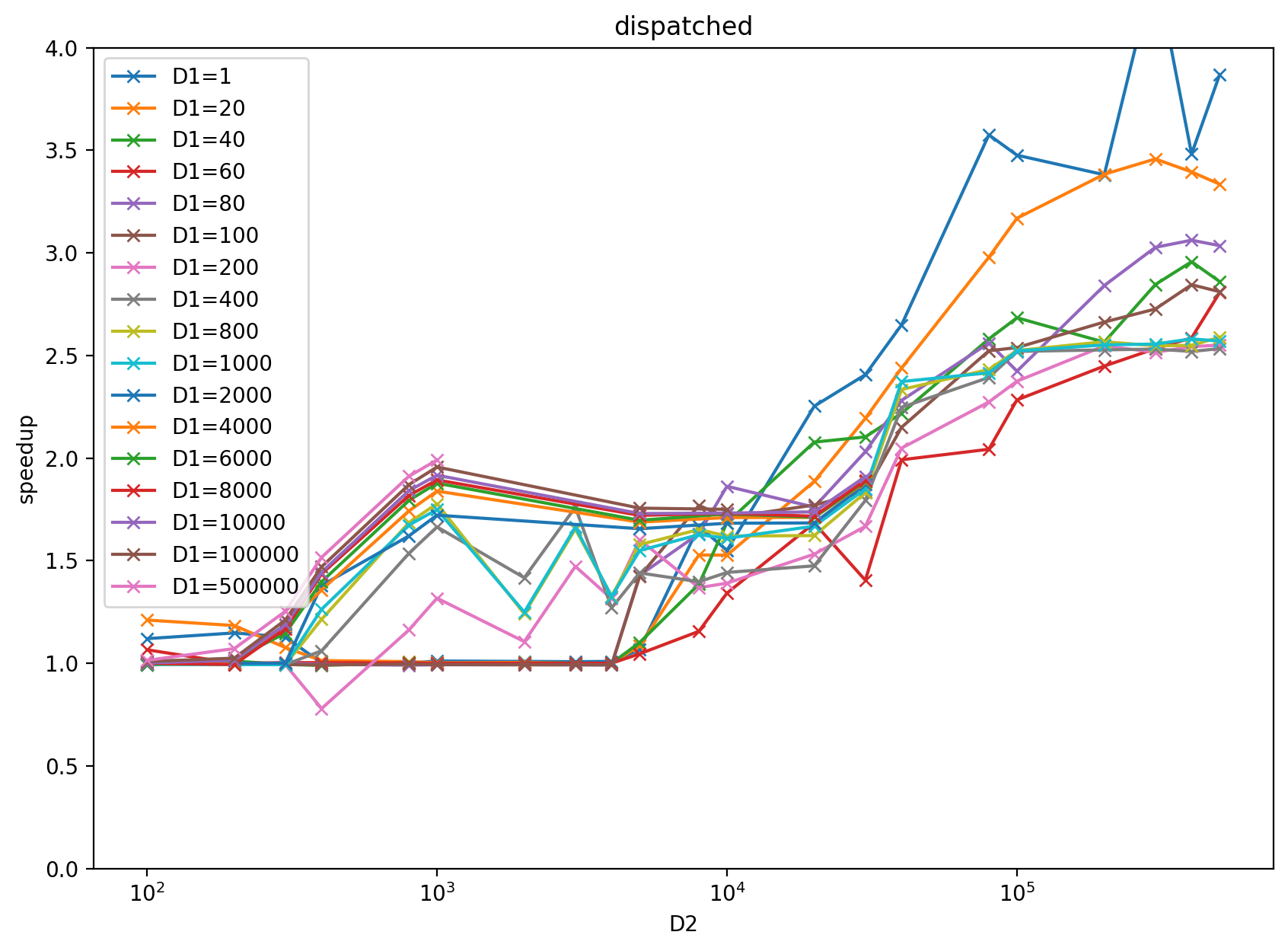
# Benchmark
Benchmark result with input `x = torch.randn((D1 (2d884f2263), D2 (9b53d3194c)), dtype=torch.float32)` and `k = 2000` on RTX 3080: https://docs.google.com/spreadsheets/d/1BAGDkTCHK1lROtjYSjuu_nLuFkwfs77VpsVPymyO8Gk/edit?usp=sharing
benchmark plot: left is multiblock, right is dispatched based on heuristics result from the above google sheet.
<p class="img">
<img width=49% src="https://user-images.githubusercontent.com/9999318/150860547-7e450ed2-df09-4292-a02a-cb0e1040eebe.png">
<img width=49% src="https://user-images.githubusercontent.com/9999318/150860579-672b88ca-e500-4846-825c-65d31d126df4.png">
</p>
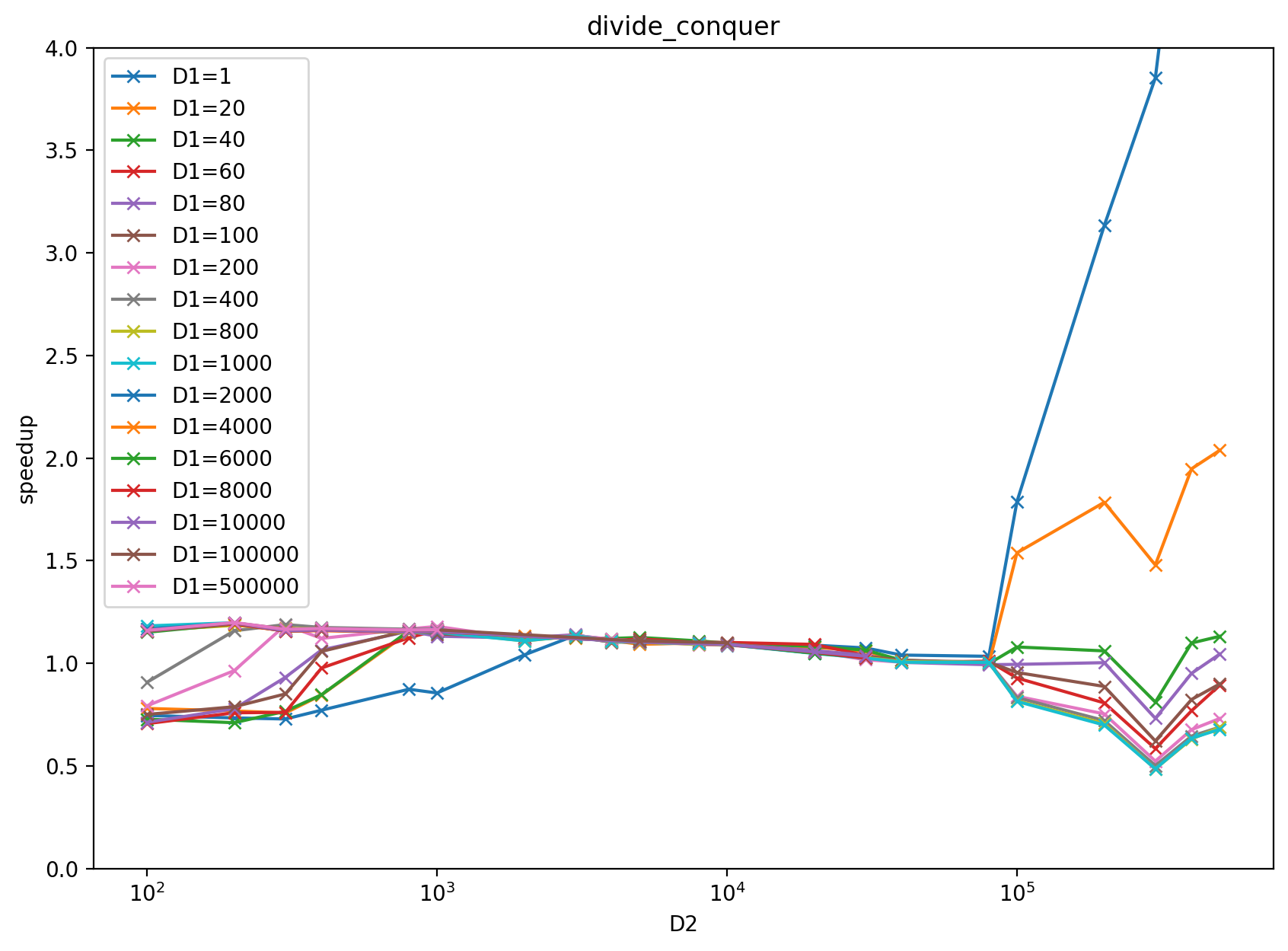
The performance of divide-and-conquer implementation at https://github.com/pytorch/pytorch/pull/39850 is not stable in terms of the D1 (2d884f2263), D2 (9b53d3194c) size increasing, for more detail please check the above google sheet.
<p>
<img width=49% src="https://user-images.githubusercontent.com/9999318/150860563-21d5a5a3-9d6a-4cef-9031-cac4d2d8edee.png">
</p>
# cubin binary size
The cubin binary size for TensorTopK.cubin (topk) and Sorting.cubin (kthvalue, quantile and etc) has been reduced by removing `#pragma unroll` at [SortingRadixSelect.cuh](https://github.com/pytorch/pytorch/pull/71081/files#diff-df06046dc4a2620f47160e1b16b8566def855c0f120a732e0d26bc1e1327bb90L321) and `largest` template argument without much performance regression.
The final binary size before and after the PR is
```
# master
-rw-rw-r-- 1 richard richard 18M Jan 24 20:07 TensorTopK.cu.1.sm_86.cubin
-rw-rw-r-- 1 richard richard 16M Jan 24 20:07 Sorting.cu.1.sm_86.cubin
# this PR
-rw-rw-r-- 1 richard richard 5.0M Jan 24 20:11 TensorTopK.cu.1.sm_86.cubin
-rw-rw-r-- 1 richard richard 2.5M Jan 24 20:11 Sorting.cu.1.sm_86.cubin
```
script to extract cubin
```
# build with REL_WITH_DEB_INFO=0
# at pytorch directory
cubin_path=build/caffe2/CMakeFiles/torch_cuda.dir/__/aten/src/ATen/native/cuda/cubin; mkdir -p $cubin_path; cd $cubin_path; find ../ -type f -name '*cu.o' -exec cuobjdump {} -xelf all \; ; ls -lh *.cubin -S | head -70
```
# benchmark script
```py
import torch
import time
import torch
import pandas as pd
import numpy as np
import torch.utils.benchmark as benchmark
torch.manual_seed(1)
dtype = torch.float
data = []
for d1 in [1, 20, 40, 60, 80, 100, 200, 400, 800, 1000, 2000, 4000, 6000, 8000, 10000, 100000, 500000]:
if d1 <= 1000:
D2 (9b53d3194c) = [100, 200, 300, 400, 800, 1000, 2000, 3000, 4000, 5000, 8000, 10000, 20000, 30000, 40000, 80000, 100000, 200000, 300000, 400000, 500000]
else:
D2 (9b53d3194c) = [100, 200, 300, 400, 800, 1000, 5000, 10000, 20000, 30000]
for d2 in D2 (9b53d3194c):
k = 2000 if d2 >= 2000 else d2 // 2
print(f"----------------- D1 (2d884f2263) = {d1}, D2 (9b53d3194c) = {d2} -----------------")
try:
x = torch.randn((d1, d2), dtype=dtype, device="cuda")
m = benchmark.Timer(
stmt='x.topk(k=k, dim=1, sorted=False, largest=True)',
globals={'x': x, 'k': k},
num_threads=1,
).blocked_autorange(min_run_time=1)
print(m)
time_ms = m.median * 1000
except RuntimeError: # OOM
time_ms = -1
data.append([d1, d2, k, time_ms])
df = pd.DataFrame(data=data, columns=['D1 (2d884f2263)', 'D2 (9b53d3194c)', 'k', 'time(ms)'])
print(df)
df.to_csv('benchmark.csv')
```
plot script could be found at: https://github.com/yueyericardo/misc/tree/master/share/topk-script
cc zasdfgbnm ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71081
Reviewed By: albanD
Differential Revision: D33823002
Pulled By: ngimel
fbshipit-source-id: c0482664e9d74f7cafc559a07c6f0b564c9e3ed0
(cherry picked from commit be367b8d07)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70619
This Diff improves `hipify_python`, which is needed for AMD GPUs.
Change 1:
```
if (c == "," or ind == len(kernel_string) - 1) and closure == 0:
```
This is needed to deal with the following case (ex: https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/test/cuda_vectorized_test.cu#L111)
```
kernel<<<val, func()>>>(...)
// In this case, kernel_string is "val, func()"
// so closure gets 0 when ind == len(kernel_string) - 1.
```
Change 2:
```
mask_comments()
```
This is needed to deal with a case where "<<<" is included in a comment or a string literal (ex: https://github.com/pytorch/pytorch/blob/master/torch/csrc/deploy/interpreter/builtin_registry.cpp#L71)
```
abc = "<<<XYZ>>>"
// Though this <<<XYZ>>> is irrelevant to CUDA kernels,
// the current script attempts to hipify this and fails.
```
Test Plan:
This patch fixes errors I encountered by running
```
python3 tools/amd_build/build_amd.py
```
I confirmed, with Linux `diff`, that this patch does not change HIP code that was generated successfully with the original script.
Reviewed By: hyuen
Differential Revision: D33407743
fbshipit-source-id: bec822e040a154be4cda1c294536792ca8d596ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68707
This PR adds a path for block CSR matrices for `torch.addmm`. cuSPARSE interface is restricted to 32-bit indices and square blocks.
My plan is to make everything work and tests passing using an unsafe constructor first, keeping it all private. Then discuss & implement constructors with block information separately unlocking the functions for wider use. Documentation will come with the update to constructors.
cc nikitaved pearu cpuhrsch IvanYashchuk ngimel
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D32650366
Pulled By: cpuhrsch
fbshipit-source-id: 430a9627901781ee3d2e2496097b71ec17727d98
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68707
This PR adds a path for block CSR matrices for `torch.addmm`. cuSPARSE interface is restricted to 32-bit indices and square blocks.
My plan is to make everything work and tests passing using an unsafe constructor first, keeping it all private. Then discuss & implement constructors with block information separately unlocking the functions for wider use. Documentation will come with the update to constructors.
cc nikitaved pearu cpuhrsch IvanYashchuk ngimel
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D32633806
Pulled By: cpuhrsch
fbshipit-source-id: b98db0bd655cce651a5da457e78fca08619a5066
Summary:
The frexp function has been enabled in ROCm code. Updating PyTorch
to enable this functionality.
cc jeffdaily sunway513 jithunnair-amd ROCmSupport KyleCZH
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67226
Reviewed By: jbschlosser
Differential Revision: D31984606
Pulled By: ngimel
fbshipit-source-id: b58eb7f226f6eb3e17d8b1e2517a4ea7297dc1d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67323
Applied patch proposed by Jeff https://github.com/pytorch/pytorch/pull/63948#issuecomment-952166982.
In PyTorch, we map cuBLAS->rocBLAS and cuSPARSE->hipSPARSE. Note the prefix, roc versus hip.
The 'hip' APIs offer a more direct CUDA-friendly mapping, but calling rocBLAS directly has better performance.
Unfortunately, the `roc*` types and `hip*` types differ, i.e., `rocblas_float_complex` versus `hipComplex`.
In the case of SPARSE, we must use the hip types for complex instead of the roc types,
but the pytorch mappings assume roc. Therefore, we create a new SPARSE mapping that has a higher priority.
Its mappings will trigger first, and only when a miss occurs will the lower-priority pytorch mapping take place.
When a file contains "sparse" in the filename, a mapping marked with API_SPARSE is preferred over other choices.
cc jeffdaily sunway513 jithunnair-amd ROCmSupport KyleCZH
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D31969246
Pulled By: cpuhrsch
fbshipit-source-id: 4ce1b35eaf9ef0d146a0955ce70c354ddd8f4669
Summary:
- [x] Fixed the Pyre type checking errors in `torch/utils/hipify/hipify_python.py`:
```
torch/utils/hipify/hipify_python.py:196:8 Incompatible variable type [9]: clean_ctx is declared to have type `GeneratedFileCleaner` but is used as type `None`.
torch/utils/hipify/hipify_python.py:944:4 Incompatible variable type [9]: clean_ctx is declared to have type `GeneratedFileCleaner` but is used as type `None`.
```
Fixing the issue: https://github.com/MLH-Fellowship/pyre-check/issues/78
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66164
Reviewed By: onionymous
Differential Revision: D31411443
Pulled By: 0xedward
fbshipit-source-id: c69f8fb839ad1d5ba5e4a223e1322ae7207e1574
Summary:
This PR enables Half, BFloat16, ComplexFloat, and ComplexDouble support for matrix-matrix multiplication of COO sparse matrices.
The change is applied only to CUDA 11+ builds.
`cusparseSpGEMM` also supports `CUDA_C_16F` (complex float16) and `CUDA_C_16BF` (complex bfloat16). PyTorch also supports the complex float16 dtype (`ScalarType::ComplexHalf`), but there is no convenient dispatch, so this dtype is omitted in this PR.
cc nikitaved pearu cpuhrsch IvanYashchuk ezyang anjali411 dylanbespalko mruberry Lezcano
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59980
Reviewed By: ngimel
Differential Revision: D30994115
Pulled By: cpuhrsch
fbshipit-source-id: 4f55b99e8e25079d6273b4edf95ad6fa85aeaf24
Summary:
This PR enables Half, BFloat16, ComplexFloat, and ComplexDouble support for matrix-matrix multiplication of COO sparse matrices.
The change is applied only to CUDA 11+ builds.
`cusparseSpGEMM` also supports `CUDA_C_16F` (complex float16) and `CUDA_C_16BF` (complex bfloat16). PyTorch also supports the complex float16 dtype (`ScalarType::ComplexHalf`), but there is no convenient dispatch, so this dtype is omitted in this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59980
Reviewed By: ngimel
Differential Revision: D29699456
Pulled By: cpuhrsch
fbshipit-source-id: 407ae53392acb2f92396a62a57cbaeb0fe6e950b
Summary:
- HIP_VERSION semantic versioning will change in ROCm4.3. The changes essentially remove the dependency on HIP_VERSION provided in the hip header to keep code compatible with older and newer versions of ROCm.
- TORCH_HIP_VERSION is derived from HIP_VERSION_MAJOR and HIP_VERSION_MINOR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62786
Reviewed By: bdhirsh
Differential Revision: D30281682
Pulled By: seemethere
fbshipit-source-id: e41e69fb9e13de5ddd1af99ba5bbdcbb7b64b673
Summary:
This is a first step towards creating context manager that errors out on synchronizing calls.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61889
Reviewed By: albanD
Differential Revision: D29805280
Pulled By: ngimel
fbshipit-source-id: b66400fbe0941b7daa51e6b30abe27b9cccd4e8a
Summary:
Enables an important performance optimization for ROCm, in light of the discussion in https://github.com/pytorch/pytorch/issues/41028.
CC jithunnair-amd sunway513
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60607
Reviewed By: jbschlosser
Differential Revision: D29409894
Pulled By: ngimel
fbshipit-source-id: effca258a0f37eaefa35674a7fd19459ca7dc95b
Summary:
Previous is https://github.com/pytorch/pytorch/issues/57781
We add now two CUDA bindings to avoid using ctypes to fix a windows issue.
However, we use ctypes to allocate the stream and create its pointer
(we can do this with a 0-dim tensor too if it feels better).
CC. ezyang rgommers ngimel mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59527
Reviewed By: albanD
Differential Revision: D29053062
Pulled By: ezyang
fbshipit-source-id: 661e7e58de98b1bdb7a0871808cd41d91fe8f13f
Summary:
This is required in https://github.com/pytorch/pytorch/pull/57110#issuecomment-828357947
We need to provide means to synchronize on externally allocated streams for dlpack support in python array data api.
cc mruberry rgommers leofang asi1024 kmaehashi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57781
Reviewed By: mrshenli
Differential Revision: D28326365
Pulled By: ezyang
fbshipit-source-id: b67858c8033949951b49a3d319f649884dfd0a91
Summary:
Some machines don't have a versionless `python` on their PATH, which breaks these existing shebangs.
I'm assuming that all the existing versionless `python` shebangs are meant to be `python3` and not `python2`; please let me know if my assumption was incorrect for any of these.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58275
Test Plan: CI.
Reviewed By: zhouzhuojie
Differential Revision: D28428143
Pulled By: samestep
fbshipit-source-id: 6562be3d12924db72a92a0207b060ef740f61ebf
{kind=link}
{kind=link}
{kind=link}