Hi, we noticed in our team that by using CyclicLR, there is a problem with memory clearance on GPU (probably it will be the case without the GPU as well, but that was our use case) After initializing CyclicLR, GPU memory is not cleared even after the model, optimizer and scheduler are out of scope (e.g. reference count is zero). This is because `__init__` method inside `CyclicLR` creates reference to its own methods and it will not get removed until `gc.collect()` is called manually. This is a problem if people want to test multiple models in one run of a script, after testing the first model, second one will fail on `CUDA out of memory error` because the first one is not cleared from the memory.
I propose a simple fix by using `weakref`, similarly as in `_LRScheduler` base class, but if you have any comments I am happy to change it.
Here is the code to reproduce the bug:
```
import torch
import weakref
from transformers import DetrForObjectDetection
class X:
def __init__(self, optimizer):
self.optimizer = optimizer
# Will cause cyclic reference.
self.func = self.dummy
# Will work as expected, memory cleared after instance count is zero.
# self.func = weakref.WeakMethod(self.dummy)
def dummy(self, x):
return 1.
def test():
model = DetrForObjectDetection.from_pretrained('facebook/detr-resnet-50')
model.to('cuda')
optimizer = torch.optim.Adam(model.parameters())
x = X(optimizer)
test()
print(f'{torch.cuda.memory_reserved()}, {torch.cuda.memory_allocated()}') # Should print (<some memory>, 0), but with cyclic reference, it will print (<some memory>, <some memory>).
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85462
Approved by: https://github.com/albanD
Hello there 👋
As discussed in #84485, this PR enables more flexibility on the optimizers that are wrapped by LR schedulers in PyTorch. Currently, it is incompatible with optimizers that have a number of betas different than 2. This PR fixes that with minimal modifications.
Fixes#84485
Any feedback is welcome!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84486
Approved by: https://github.com/Lezcano, https://github.com/soulitzer
This is a new version of #15648 based on the latest master branch.
Unlike the previous PR where I fixed a lot of the doctests in addition to integrating xdoctest, I'm going to reduce the scope here. I'm simply going to integrate xdoctest, and then I'm going to mark all of the failing tests as "SKIP". This will let xdoctest run on the dashboards, provide some value, and still let the dashboards pass. I'll leave fixing the doctests themselves to another PR.
In my initial commit, I do the bare minimum to get something running with failing dashboards. The few tests that I marked as skip are causing segfaults. Running xdoctest results in 293 failed, 201 passed tests. The next commits will be to disable those tests. (unfortunately I don't have a tool that will insert the `#xdoctest: +SKIP` directive over every failing test, so I'm going to do this mostly manually.)
Fixes https://github.com/pytorch/pytorch/issues/71105
@ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82797
Approved by: https://github.com/ezyang
What was happening is that when we have multiple learning rate schedulers, the order in which they are being initialized is not being taken into account. This is a problem if they were being initialized in sequential order (as one might intuitively do).
Each scheduler calls `step()` on initialization and sets the `lr` in its optimizer's `params_groups`. However, this means that step 0 will be using the `lr` that was set by the very last scheduler (in the case of initializing schedulers sequentially) instead of the first scheduler.
The fix in this PR, addresses the above bug by performing a call to the appropriate scheduler on initialization after decrementing the `last_epoch` values in order to keep them the same post-step. This will ensure that the correct scheduler is the one setting the `lr` values for the optimizer's `param_groups`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72856
Approved by: https://github.com/jbschlosser
### Goal
Fixes https://github.com/pytorch/pytorch/issues/79720
### Approach
replace `Chains list of learning rate schedulers. It takes a list of chainable learning rate schedulers and performs consecutive step() functions` **`belong`** `to them by just one call.` with `Chains list of learning rate schedulers. It takes a list of chainable learning rate schedulers and performs consecutive step() functions` **`belonging`** `to them by just one call.`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79775
Approved by: https://github.com/albanD
Fixes#60265
The initial LR for this scheduler is not consistent when a new instance is created with `last_epoch != -1`
Maybe we can refactor the testing code to test `last_epoch != -1` in schedulers that can recreate their state from the current epoch?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60339
Approved by: https://github.com/albanD
Summary:
- ~optimizer isn't required for `SequentialLR` since it's already present in the schedulers. Trying to match the signature of it with `ChainedScheduler`.~
- ~`verbose` isn't really used anywhere so removed it.~
updated missing docs and added a small check
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69817
Reviewed By: ngimel
Differential Revision: D33069589
Pulled By: albanD
fbshipit-source-id: f015105a35a2ca39fe94c70acdfd55cdf5601419
Summary:
Fixes https://github.com/pytorch/pytorch/issues/67601.
As simple a fix as I could make it. I even managed to delete some testing code!
I checked calling `super()` and, as I had feared, it doesn't work out the box, so perhaps that ought to be revisited later.
As it stands, https://github.com/pytorch/pytorch/issues/20124, still applies to the chained scheduler, but I think this change is still an improvement.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68010
Reviewed By: zou3519
Differential Revision: D32278139
Pulled By: albanD
fbshipit-source-id: 4c6f9f1b2822affdf63a6d22ddfdbcb1c6afd579
Summary:
The final learning rate should be 0.05 like the lr used as the argument for the optimizer and not 0.005.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67840
Reviewed By: jbschlosser
Differential Revision: D32187091
Pulled By: albanD
fbshipit-source-id: 8aff691bba3896a847d7b9d9d669a65f67a6f066
Summary:
## {emoji:1f41b} Bug
'CosineAnnealingWarmRestarts' object has no attribute 'T_cur'.
In the Constructor of the CosineAnnealingWarmRestarts, we're calling the constructor of the Parent class (_LRScheduler) which inturn calls the step method of the CosineAnnealingWarmRestarts.
The called method tries to update the object's attribute 'T_cur' which is not defined yet. So it raises the error.
This only holds, when we give the value for last_epoch argument as 0 or greater than 0 to the 'CosineAnnealingWarmRestarts', while initializing the object.

## To Reproduce
Steps to reproduce the behavior:
1. Give the value for the last_epoch argument as zero OR
1. Give the value for the last_epoch argument as a Positive integer.
## Expected behavior
I only expected the 'CosineAnnealingWarmRestarts' object to be initialized.
## Environment
PyTorch version: 1.9.0+cpu
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.2 LTS (x86_64)
GCC version: (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0
Clang version: Could not collect
CMake version: version 3.21.2
Libc version: glibc-2.31
Python version: 3.8.10 [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.8.0-59-generic-x86_64-with-glibc2.29
Is CUDA available: False
CUDA runtime version: No CUDA
## Additional context
We can able to solve this bug by moving the line 'self.T_cur = self.last_epoch' above the 'super(CosineAnnealingWarmRestarts,self).__init__()' line. Since we've initialized the "self.T_cur" to the object.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64758
Reviewed By: ezyang
Differential Revision: D31113694
Pulled By: jbschlosser
fbshipit-source-id: 98c0e292291775895dc3566fda011f2d6696f721
Summary:
Partially resolves https://github.com/pytorch/vision/issues/4281
In this PR we are proposing a new scheduler --SequentialLR-- which enables list of different schedulers called in different periods of the training process.
The main motivation of this scheduler is recently gained popularity of warming up phase in the training time. It has been shown that having a small steps in initial stages of training can help convergence procedure get faster.
With the help of SequentialLR we mainly enable to call a small constant (or linearly increasing) learning rate followed by actual target learning rate scheduler.
```PyThon
scheduler1 = ConstantLR(optimizer, factor=0.1, total_iters=2)
scheduler2 = ExponentialLR(optimizer, gamma=0.9)
scheduler = SequentialLR(optimizer, schedulers=[scheduler1, scheduler2], milestones=[5])
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
```
which this code snippet will call `ConstantLR` in the first 5 epochs and will follow up with `ExponentialLR` in the following epochs.
This scheduler could be used to provide call of any group of schedulers next to each other. The main consideration we should make is every time we switch to a new scheduler we assume that new scheduler starts from the beginning- zeroth epoch.
We also add Chained Scheduler to `optim.rst` and `lr_scheduler.pyi` files here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64037
Reviewed By: albanD
Differential Revision: D30841099
Pulled By: iramazanli
fbshipit-source-id: 94f7d352066ee108eef8cda5f0dcb07f4d371751
Summary:
Partially unblocks https://github.com/pytorch/vision/issues/4281
Previously we have added WarmUp Schedulers to PyTorch Core in the PR : https://github.com/pytorch/pytorch/pull/60836 which had two mode of execution - linear and constant depending on warming up function.
In this PR we are changing this interface to more direct form, as separating linear and constant modes to separate Schedulers. In particular
```Python
scheduler1 = WarmUpLR(optimizer, warmup_factor=0.1, warmup_iters=5, warmup_method="constant")
scheduler2 = WarmUpLR(optimizer, warmup_factor=0.1, warmup_iters=5, warmup_method="linear")
```
will look like
```Python
scheduler1 = ConstantLR(optimizer, warmup_factor=0.1, warmup_iters=5)
scheduler2 = LinearLR(optimizer, warmup_factor=0.1, warmup_iters=5)
```
correspondingly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64395
Reviewed By: datumbox
Differential Revision: D30753688
Pulled By: iramazanli
fbshipit-source-id: e47f86d12033f80982ddf1faf5b46873adb4f324
Summary:
In this PR we are introducing ChainedScheduler which initially proposed in the discussion https://github.com/pytorch/pytorch/pull/26423#discussion_r329976246 .
The idea is to provide a user friendly chaining method for schedulers, especially for the cases many of them are involved and we want to have a clean and easy to read interface for schedulers. This method will be even more crucial once CompositeSchedulers and Schedulers for different type of parameters are involved.
The immediate application of Chained Scheduler is expected to happen in TorchVision Library to combine WarmUpLR and MultiStepLR https://github.com/pytorch/vision/blob/master/references/video_classification/scheduler.py#L5 . However, it can be expected that in many other use cases also this method could be applied.
### Example
The usage is as simple as below:
```python
sched=ChainedScheduler([ExponentialLR(self.opt, gamma=0.9),
WarmUpLR(self.opt, warmup_factor=0.2, warmup_iters=4, warmup_method="constant"),
StepLR(self.opt, gamma=0.1, step_size=3)])
```
Then calling
```python
sched.step()
```
would trigger step function for all three schedulers consecutively
Partially resolves https://github.com/pytorch/vision/issues/4281
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63491
Reviewed By: datumbox, mruberry
Differential Revision: D30576180
Pulled By: iramazanli
fbshipit-source-id: b43f0749f55faab25079641b7d91c21a891a87e4
Summary:
It has been discussed in the https://github.com/pytorch/pytorch/pull/60836#issuecomment-899084092 that we have observed an obstacle to chain some type of learning rate schedulers. In particular we observed
* some of the learning rate schedulers returns initial learning rates at epoch 0 as
```
return self.base_lrs`
```
* This can be a problem when two schedulers called as chained as
```
scheduler1.step()
scheduler2.step()
```
in particular, we completely ignore the effect of scheduler1 at epoch 0. This could not be an issue if at epoch 0, scheduler1 was ineffective as in many schedulers, however for schedulers as WarmUp Schedulers, where at epoch 0 schedulers multiplicative value is smaller than 1 this could lead to undesired behaviors.
The following code snippet illustrates the problem better
## Reproducing the bug
```python
import torch
from torch.nn import Parameter
from torch.optim import SGD
from torch.optim.lr_scheduler import WarmUpLR, ExponentialLR
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 1.0)
scheduler1 = WarmUpLR(optimizer, warmup_factor=0.1, warmup_iters=5, warmup_method="constant")
scheduler2 = ExponentialLR(optimizer, gamma=0.9)
for epoch in range(10):
print(epoch, scheduler2.get_last_lr()[0])
optimizer.step()
scheduler1.step()
scheduler2.step()
```
### Current Result
```
0 1.0
1 0.9
2 0.81
3 0.7290000000000001
4 0.6561000000000001
5 5.904900000000001
6 5.314410000000001
7 4.782969000000001
8 4.304672100000001
9 3.874204890000001
```
### Expected Result
```
0 1.0
1 0.9
2 0.81
3 0.7290000000000001
4 0.6561000000000001
5 0.5904900000000001
6 0.5314410000000001
7 0.4782969000000001
8 0.4304672100000001
9 0.3874204890000001
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63457
Reviewed By: datumbox
Differential Revision: D30424160
Pulled By: iramazanli
fbshipit-source-id: 3e15af8d278c872cd6f53406b55f4d3ce5002867
Summary:
Warm up of learning rate scheduling has initially been discussed by Priya et. al. in the paper: https://arxiv.org/pdf/1706.02677.pdf .
In the section 2.2 of the paper they discussed and proposed idea of warming up learning schedulers in order to prevent big variance / noise in the learning rate. Then idea has been further discussed in the following papers:
* Akilesh Gotmare et al. https://arxiv.org/abs/1810.13243
* Bernstein et al http://proceedings.mlr.press/v80/bernstein18a/bernstein18a.pdf
* Liyuan Liu et al: https://arxiv.org/pdf/1908.03265.pdf
There are two type of popularly used learning rate warm up ideas
* Constant warmup (start with very small constant learning rate)
* Linear Warmup ( start with small learning rate and gradually increase)
In this PR we are adding warm up as learning rate scheduler. Note that learning rates are chainable, which means that we can merge warmup scheduler with any other learning rate scheduler to make more sophisticated learning rate scheduler.
## Linear Warmup
Linear Warmup is multiplying learning rate with pre-defined constant - warmup_factor in the first epoch (epoch 0). Then targeting to increase this multiplication constant to one in warmup_iters many epochs. Hence we can derive the formula at i-th step to have multiplication constant equal to:
warmup_factor + (1-warmup_factor) * i / warmup_iters
Moreover, the fraction of this quantity at point i to point i-1 will give us
1 + (1.0 - warmup_factor) / [warmup_iters*warmup_factor+(i-1)*(1-warmup_factor)]
which is used in get_lr() method in our implementation. Below we provide an example how to use linear warmup scheduler and to give an example to show how does it works.
```python
import torch
from torch.nn import Parameter
from torch.optim import SGD
from torch.optim.lr_scheduler import WarmUpLR
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler = WarmUpLR(optimizer, warmup_factor=0.1, warmup_iters=10, warmup_method="linear")
for epoch in range(15):
print(epoch, scheduler.get_last_lr()[0])
optimizer.step()
scheduler.step()
```
```
0 0.010000000000000002
1 0.019000000000000003
2 0.028000000000000008
3 0.03700000000000001
4 0.04600000000000001
5 0.055000000000000014
6 0.06400000000000002
7 0.07300000000000002
8 0.08200000000000003
9 0.09100000000000004
10 0.10000000000000005
11 0.10000000000000005
12 0.10000000000000005
13 0.10000000000000005
14 0.10000000000000005
```
## Constant Warmup
Constant warmup has straightforward idea, to multiply learning rate by warmup_factor until we reach to epoch warmup_factor, then do nothing for following epochs
```python
import torch
from torch.nn import Parameter
from torch.optim import SGD
from torch.optim.lr_scheduler import WarmUpLR
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler = WarmUpLR(optimizer, warmup_factor=0.1, warmup_iters=5, warmup_method="constant")
for epoch in range(10):
print(epoch, scheduler.get_last_lr()[0])
optimizer.step()
scheduler.step()
```
```
0 0.010000000000000002
1 0.010000000000000002
2 0.010000000000000002
3 0.010000000000000002
4 0.010000000000000002
5 0.10000000000000002
6 0.10000000000000002
7 0.10000000000000002
8 0.10000000000000002
9 0.10000000000000002
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60836
Reviewed By: saketh-are
Differential Revision: D29537615
Pulled By: iramazanli
fbshipit-source-id: d910946027acc52663b301f9c56ade686e62cb69
Summary:
Fixes https://github.com/pytorch/pytorch/issues/46405, https://github.com/pytorch/pytorch/issues/43352
I updated the docstring in the local file (function level comments). Do I also need to edit somewhere else or recompile docstrings?
Also, though I didn't change any types here, how is typing (for IDE type checking) documentation generated / used)?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46813
Reviewed By: ezyang
Differential Revision: D24923112
Pulled By: vincentqb
fbshipit-source-id: be7818e0d4593bfc5d74023b9c361ac2a538589a
Summary:
Fixes https://github.com/pytorch/pytorch/issues/40362
The new `three_phase` option provides a way of constructing schedules according to the scheme recommended in [Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates](https://arxiv.org/abs/1708.07120).
Note that this change maintains backwards compatibility, and as a result the default behaviour of OneCycleLR remains quite counter-intuitive.
vincentqb
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42715
Reviewed By: heitorschueroff
Differential Revision: D24289744
Pulled By: vincentqb
fbshipit-source-id: e4aad87880716bb14613c0aa8631e43b04a93e5c
Summary:
The subclass sets "self.last_epoch" when this is set in the parent class's init function. Why would we need to set last_epoch twice? I think calling "super" resets last_epoch anyway, so I am not sure why we would want to include this in the subclass. Am I missing something?
For the record, I am just a Pytorch enthusiast. I hope my question isn't totally silly.
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44613
Reviewed By: albanD
Differential Revision: D23691770
Pulled By: mrshenli
fbshipit-source-id: 080d9acda86e1a2bfaafe2c6fcb8fc1544f8cf8a
Summary:
When an error is raised and `__exit__` in a context manager returns `True`, the error is suppressed; otherwise the error is raised. No return value should be given to maintain the default behavior of context manager.
Fixes https://github.com/pytorch/pytorch/issues/32639. The `get_lr` function was overridden with a function taking an epoch parameter, which is not allowed. However, the relevant error was not being raised.
```python
In [1]: import torch
...:
...: class MultiStepLR(torch.optim.lr_scheduler._LRScheduler):
...: def __init__(self, optimizer, gamma, milestones, last_epoch = -1):
...: self.init_lr = [group['lr'] for group in optimizer.param_groups]
...: self.gamma = gamma
...: self.milestones = milestones
...: super().__init__(optimizer, last_epoch)
...:
...: def get_lr(self, step):
...: global_step = self.last_epoch #iteration number in pytorch
...: gamma_power = ([0] + [i + 1 for i, m in enumerate(self.milestones) if global_step >= m])[-1]
...: return [init_lr * (self.gamma ** gamma_power) for init_lr in self.init_lr]
...:
...: optimizer = torch.optim.SGD([torch.rand(1)], lr = 1)
...: scheduler = MultiStepLR(optimizer, gamma = 1, milestones = [10, 20])
```
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-1-7fad6ba050b0> in <module>
14
15 optimizer = torch.optim.SGD([torch.rand(1)], lr = 1)
---> 16 scheduler = MultiStepLR(optimizer, gamma = 1, milestones = [10, 20])
<ipython-input-1-7fad6ba050b0> in __init__(self, optimizer, gamma, milestones, last_epoch)
6 self.gamma = gamma
7 self.milestones = milestones
----> 8 super().__init__(optimizer, last_epoch)
9
10 def get_lr(self, step):
~/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/optim/lr_scheduler.py in __init__(self, optimizer, last_epoch)
75 self._step_count = 0
76
---> 77 self.step()
78
79 def state_dict(self):
~/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/optim/lr_scheduler.py in step(self, epoch)
141 print("1a")
142 # try:
--> 143 values = self.get_lr()
144 # except TypeError:
145 # raise RuntimeError
TypeError: get_lr() missing 1 required positional argument: 'step'
```
May be related to https://github.com/pytorch/pytorch/issues/32898.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32997
Differential Revision: D19737731
Pulled By: vincentqb
fbshipit-source-id: 5cf84beada69b91f91e36b20c3278e9920343655
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27254
`MultiplicativeLR` consumes a function providing the multiplicative factor at each epoch. It mimics `LambdaLR` in its syntax.
Test Plan: Imported from OSS
Differential Revision: D17728088
Pulled By: vincentqb
fbshipit-source-id: 1c4a8e19a4f24c87b5efccda01630c8a970dc5c9
{kind=link}
{kind=link}
{kind=link}
{kind=link}
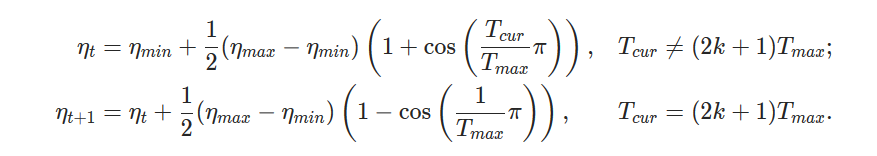{kind=link}
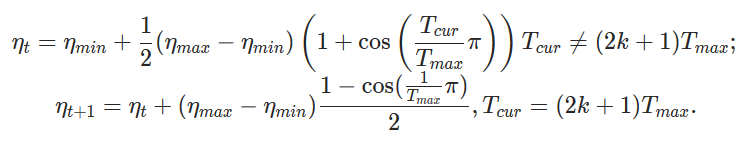{kind=link}
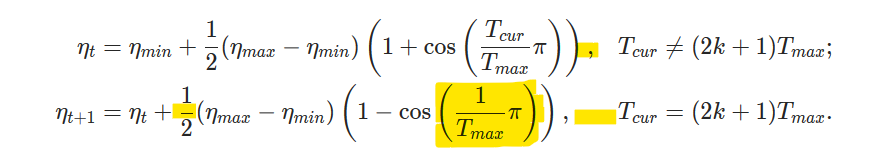{kind=link}