Before this PR, if a user runs DDP with `device_ids` specified and with a `PackedSequence` input, then the execution will error with something like:
```
raise ValueError(
ValueError: batch_sizes should always be on CPU. Instances of PackedSequence should never be created manually. They should be instantiated by
functions like pack_sequence and pack_padded_sequences in nn.utils.rnn. https://pytorch.org/docs/stable/nn.html...
```
This is because the DDP forward calls `_to_kwargs()`, which calls `_recursive_to()`, which moves the inputs to GPU. However, `_is_namedtuple(packed_sequence)` returns `True`, leading to the branch `return [type(obj)(*args) for args in zip(*map(to_map, obj))]`, which tries to construct a `PackedSequence` directly via `type(obj)(*args)`, leading to the error.
Repro for `_is_namedtuple(packed_sequence)` returning `True`:
```
import random
import torch
import torch.nn.utils.rnn as rnn_utils
from torch.nn.parallel.scatter_gather import _is_namedtuple
def _ordered_sequence(tensor_type):
seqs = [tensor_type(random.randint(1, 256))
for _ in range(32)]
seqs = [s.random_(-128, 128) for s in seqs]
ordered = sorted(seqs, key=len, reverse=True)
return ordered
def _padded_sequence(tensor_type):
ordered = _ordered_sequence(tensor_type)
lengths = [len(i) for i in ordered]
padded_tensor = rnn_utils.pad_sequence(ordered)
return padded_tensor, lengths
padded, lengths = _padded_sequence(torch.Tensor)
packed = rnn_utils.pack_padded_sequence(
padded, lengths, enforce_sorted=False)
print(type(packed), packed.data.device)
print(_is_namedtuple(packed))
```
Test Plan:
```
python test/distributed/test_c10d_nccl.py -k test_ddp_packed_sequence
```
Without the fix, the added unit test fails with the expected error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86614
Approved by: https://github.com/rohan-varma
This deprecates `FlattenParamsWrapper`'s usage for "unflattening" the original parameters. After this PR, FPW only serves to register and de-register its `FlatParameter` for the parent `FullyShardedDataParallel` instance.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86117
Approved by: https://github.com/zhaojuanmao
This PR renames `param_dtype` and `reduce_dtype` in `HandleConfig` to `low_prec_param_dtype` and `low_prec_reduce_dtype` to emphasize that they are meant to be of the low precision (if not `None`).
(In my mind, mixed precision refers to the paradigm of using both full and low precision together during training. "Reduced" and "low precision" mean the same thing, but I prefer the term "low precision" in the code since it is shorter. A particular dtype can be a low precision dtype or a full precision dtype.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86512
Approved by: https://github.com/zhaojuanmao
This adds `summon_full_params(with_grads=True)` for `use_orig_params=True` and `offload_to_cpu=False`. Filling in the `use_orig_params=False` case requires some already-planned refactoring, and the `offload_to_cpu=True` case needs some additional work as well.
Adding this is helpful for debugging `use_orig_params=True` to make sure gradients are being updated correctly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85738
Approved by: https://github.com/rohan-varma
**Overview**
This PR adds the option to use the original parameters via `use_orig_params=True` in the FSDP constructor.
- This exposes the original parameters rather than the `FlatParameter`s from `named_parameters()`, which means that the optimizer runs on the original parameters. Hence, users may assign original parameters from the same `FlatParameter` to different parameter groups.
- This enables decoupling the original parameter variables from their storage without changing the variables themselves, which is critical for our upcoming execution-order-based non-recursive wrapping policy.
For more detailed design explanation, refer to the Quip shared internally.
**Follow-Ups**
See 85831 (removing link to avoid spamming the issue whenever I update this PR).
`test_fsdp_use_orig_params.py` adds ~4 min 46 seconds to the TTS on the AWS cluster.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84911
Approved by: https://github.com/rohan-varma
Summary:
The flow logic around torch.dist imports results in large number of pyre errors (100's); would be preferable to just raise on importing as opposed to silently fail.
Con: Some percentage (MacOS?) of users may have notebooks that imports PT-D, although would think small, since any attempt to call parts of the library would just fail...
TODO: assuming ok, will remove the 10's-100's of unused pyre ignores no longer required.
Test Plan: existing unit tests
Differential Revision: D39842273
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85781
Approved by: https://github.com/mrshenli
Summary: The "kill worker process" event was logged to Scuba only when the worker process was really reaped. We want to add a new event "timer expired", no matter the worker process will be reaped or not. This will help collect data before we enable the JustKnob to kill the worker process on timeout.
Test Plan:
### Unit Test
```
buck test mode/dev-nosan //caffe2/test/distributed/elastic/agent/server/test:local_agent_test
```
```
Test Session: https://www.internalfb.com/intern/testinfra/testrun/7318349508929624
RE: reSessionID-ea464c43-54e7-44f2-942b-14ea8aa98c74 Up: 10.5 KiB Down: 1.1 MiB
Jobs completed: 100. Time elapsed: 3206.9s. Cache hits: 91%. Commands: 11 (cached: 10, remote: 1, local: 0)
Tests finished: Pass 55. Fail 0. Fatal 0. Skip 0. 0 builds failed
```
--------
```
buck test mode/dev-nosan //caffe2/test/distributed/elastic/agent/server/test/fb:local_agent_fb_internal_test
```
```
Test Session: https://www.internalfb.com/intern/testinfra/testrun/6473924579130483
RE: reSessionID-231a47b7-a43d-4c0f-9f73-64713ffcbbd3 Up: 5.7 MiB Down: 1.9 GiB
Jobs completed: 182156. Time elapsed: 282.4s. Cache hits: 99%. Commands: 72112 (cached: 72107, remote: 1, local: 4)
Tests finished: Pass 2. Fail 0. Fatal 0. Skip 0. 0 builds failed
```
Differential Revision: D39903376
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85861
Approved by: https://github.com/d4l3k
For the rate limiter, I initially implemented the approach of only dequeueing a single event, but there was concern about blocking the CPU _every_ iteration. The landed approach instead blocks every `_max_num_inflight_all_gathers` iterations and flushes the entire queue.
However, upon further analysis, the approach of dequeueing a single event should be more performant with the same memory usage -- as the name suggests, both have `_max_num_inflight_all_gathers` concurrently inflight all-gathers. The cost of blocking the CPU thread is not important compared to the duration the CPU thread is actually blocked. This PR's approach reduces the latter quantity.
**Fast Communication; Slow Computation**
<img width="1235" alt="Screen Shot 2022-10-04 at 4 15 13 PM" src="https://user-images.githubusercontent.com/31054793/193917536-f1491803-9578-45ea-ba6e-e735c1bf7784.png">
**Slow Communication; Fast Computation**
<img width="718" alt="Screen Shot 2022-10-04 at 4 34 15 PM" src="https://user-images.githubusercontent.com/31054793/193921508-f2a4fd22-2b03-4a8e-b6ca-634c584c70e2.png">
**T5-11B**
2 nodes / 16 40 GB A100s with EFA and batch size 6:
- [Old] 5.81 s / batch; 24 and 20 CUDA malloc retries on local rank 0s; 35.234 GB peak active; 38.806 GB peak reserved
- [New] 5.10 s / batch; 25 and 29 CUDA malloc retries on local rank 0s; 35.234 GB peak active; 38.868 GB peak reserved
4 nodes / 32 40 GB A100s with EFA and batch size 7:
- [Old] 5.21 s / batch; 0, 0, 0, 0 CUDA malloc retries on local rank 0s; 33.695 GB peak active; 38.494 GB peak reserved
- [New] 4.93 s / batch; 1, 0, 0, 0 CUDA malloc retries on local rank 0s; 33.678 GB peak active; 38.792 GB peak reserved
The new version changes the fragmentation in the allocator. It is possible that by blocking the CPU thread more in the old approach, the initial blocks used to serve the all-gather stream allocations are different compared to the new approach. Even though the number of CUDA malloc retries increases slightly, the net result is a speedup with the new approach.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86165
Approved by: https://github.com/zhaojuanmao
This PR refactors the prefetching implementation to enable a module to prefetch more than one all-gather.
- The motivation is for backward prefetching, but forward prefetching is included in the change as well.
- The prefetching limit is a _limit_. In some edge cases (e.g. dynamic graph or first/last module), the limit may not be reached.
- The prefetching limit is kept as internal in this PR -- it is set as local variables `backward_prefetch_limit` and `forward_prefetch_limit` in the `FullyShardedDataParallel` constructor and passed to the `_ExecOrderData()` constructor.
- This PR additionally includes some clean up for forward prefetching but does not change any semantics assuming static graph.
If we increase the `backward_prefetch_limit` to `2`, then a typical pattern may be that the first module in the pre-backward prefetches 2, but every next module only prefetches 1 since its first target was already prefetched by the previous. If we did not do this behavior, then with more modules, the prefetching would run further and further ahead.
**`_handles_prefetched`**
- This is used to avoid multiple modules prefetching the same handles keys.
- `_handles_prefetched[handles_key]` is set to `True` when the prefetch for `handles_key` happens from the CPU thread (`_prefetch_handles()`).
- `_handles_prefetched[handles_key]` is set to `False` when any handle in `handles_key` is resharded (`_reshard()`).
- `_handles_prefetched` is cleared at the end of the backward (`_wait_for_post_backward()`).
**`_needs_pre_backward_unshard`**
- This is used to determine if a handles key should be backward prefetched at all.
- `_needs_pre_backward_unshard[handles_key]` is set to `False` in the post-forward (`_register_pre_backward_hooks()`).
- `_needs_pre_backward_unshard[handles_key]` is set to `True` in the post-forward if the forward outputs include tensors that require gradient (`_register_pre_backward_hook()`).
- `_needs_pre_backward_unshard[handles_key]` is set to `False` in the pre-backward hook, after unsharding (`_pre_backward_hook()`).
**`_needs_pre_forward_unshard`**
- This is used to determine if a handles key should be forward prefetched at all.
- `_needs_pre_forward_unshard[handles_key]` is set to `True` in the root's pre-forward (`_fsdp_root_pre_forward()`).
- `_needs_pre_forward_unshard[handles_key]` is set to `False` in the pre-forward unshard (`_pre_forward_unshard()`).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86198
Approved by: https://github.com/zhaojuanmao
Optimizer state_dict currently move tensors to CPU() immediately after allgather(). However, for sharded optimizer state_dict, this moving is duplicated. We should wait until all the sharding are done. This PR may slightly reduce the performance of full optimizer state_dict as it has to allocate more memory than w/o this PR. But the benchmark shows the memory allocation is pretty light.
Differential Revision: [D39855912](https://our.internmc.facebook.com/intern/diff/D39855912/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D39855912/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85761
Approved by: https://github.com/rohan-varma
### Deprecation reasons:
- For most users training is on one GPU per process so these APIs are rarely used
- They added one more API dimension
- They can be expressed in a composed manner
- They are not abstracted – specific to GPU
- They caused backend APIs and implementations to have nested `std::vector<std::vector<Tensor>>`, which is hard to read or maintain
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85961
Approved by: https://github.com/XilunWu, https://github.com/H-Huang
- We consider that general users need not to use the `*_coalesced` APIs unless there is an extreme concern about performance.
- We are investigating using a context manager named `coalescing_manager` which wrap around multiple individual collectives to compose the coalescing hint, rather than giving each collective a *_coalesced variant.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85959
Approved by: https://github.com/XilunWu, https://github.com/H-Huang
We should remove this arg when release after 1.13 rolls around, enhance warning to indicate it will be gone. We can do this as FSDP is still beta and can be BC breaking until we stabilize the API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85963
Approved by: https://github.com/awgu
This adds `FSDPExtensions` to enable TP + FSDP composability. To be agnostic to both `ShardedTensor` and `DistributedTensor`, the design relies on customizable hooks.
Some notes:
- I preferred the `_ext` prefix (short for "extension") over `_param_extension` simply because it is shorter. It should not matter much because it is purely internal facing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85039
Approved by: https://github.com/kumpera, https://github.com/fegin
### Description
- This PR renames `_all_gather_base` to `all_gather_into_tensor` so that it is clearer in meaning.
- The `all_gather_into_tensor` API differs from the `all_gather` API in the output it accepts -- a single, large tensor instead of a list of tensors.
- This PR also adds deprecation warning to `_all_gather_base`.
### Issue
`_all_gather_base` was implemented in https://github.com/pytorch/pytorch/pull/33924 to avoid unnecessary flattening. There was previous effort (#82639) to merge `_all_gather_base` with the existing `all_gather` API by detecting the parameter type passed in for the output.
There are, however, two "blockers" that make the merge difficult:
(i) The merge leads to backward compatibility break. We would need to change the parameter name `tensor_list` in `all_gather` to a general name `output` that can cover both tensor and tensor list.
(ii) Recently, the `all_gather` API has added uneven tensor support, utilizing the tensor boundaries implied by the list. We are, however, not sure to add such support to the `_all_gather_base` function, because that would require users to pass in additional tensor boundary information.
In view of the above, we decided to productize `_all_gather_base` as a separate function, but with a clearer name.
### Testing
Added tests:
- `test_all_gather_into_cat_tensor_cuda` -- output form as with `torch.cat`. For example:
```
>>> tensor_in
tensor([1, 2], device='cuda:0') # Rank 0
tensor([3, 4], device='cuda:1') # Rank 1
>>> tensor_out
tensor([1, 2, 3, 4], device='cuda:0') # Rank 0
tensor([1, 2, 3, 4], device='cuda:1') # Rank 1
```
- `test_all_gather_into_stack_tensor_cuda` -- output form as with `torch.stack`. For example:
```
>>> tensor_out2
tensor([[1, 2],
[3, 4]], device='cuda:0') # Rank 0
tensor([[1, 2],
[3, 4]], device='cuda:1') # Rank 1
```
The output form is determined by the shape of the output tensor passed by the user, no flag used.
Cc @rohan-varma @mrshenli @crcrpar @ptrblck @H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85686
Approved by: https://github.com/rohan-varma, https://github.com/crcrpar
Move a bunch of globals to instance methods and replace all use to them.
We move all PG related globals under World and use a singleton instance under _world.
This creates an undocumented extension point to inject full control of how how c10d
state behaves.
One simple hack is to change _world to an implementation that uses a threadlocal
and enable per-thread PGs.
It almost get DDP working and the PG is missing an implementation of all_reduce.
This enables notebook usage of PTD, which is a big deal for learning it:
https://gist.github.com/kumpera/32cb051fa26b8cad8bdf671f968dcd68
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84153
Approved by: https://github.com/rohan-varma
- Support storing SymFloat in IValue
- Add SymFloat to JIT type system (erases to float)
- Printing support for SymFloat
- add/sub/mul/truediv operator support for SymFloat
- Support truediv on integers, it returns a SymFloat
- Support parsing SymFloat from Python object
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85411
Approved by: https://github.com/albanD
- This implements explicit forward prefetching following the static 1st iteration's pre-forward order when `forward_prefetch=True` in the FSDP constructor.
- This has the same unit test coverage as the original `forward_prefetch`.
- I checked via print statements that the prefetches are happening, but since I cannot get a good CPU bound workload, it is hard to tell via traces that the prefetch is working.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85177
Approved by: https://github.com/zhaojuanmao
This is a short-term quick fix to accommodate using the existing optimizer state APIs without passing `optim_input`. It preserves the existing `optim_input` code path but if `optim_input` is `None` while `optim` is not, then the APIs will use the new code path that relies on `self.param_groups` to get the information previously provided by `optim_input`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84201
Approved by: https://github.com/rohan-varma
Differential Revision: [D39565189](https://our.internmc.facebook.com/intern/diff/D39565189)
Rehash of a similar PR from a month ago that got stale. Adds a config to FSDP MP so that gradients can be kept in lower precision, to support optimizers such as AnyPrecisionOptimizer which would like to keep grads in bf16.
To do this, for sharded cases, we cannot simply omit the cast back to the full precision param dtype, otherwise when setting `p.grad = p._saved_grad_shard` in finalize_params, autograd will throw an error indicating that the grad dtype should match the param dtype when it is being set.
As a workaround, we re-cast after setting this. Although, this means that for cases that use gradient accumulation, p._saved_grad_shard will be of the reduced dtype because it is set to p.grad in `_prep_grad_for_backward`. As a result, add a check + recast here as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85134
Approved by: https://github.com/awgu
For both exposing the original parameters and for TP integration, we cannot only rely on `isinstance(param, FlatParameter)` to ignore already-flattened parameters in `.named_parameters()`. As a simple workaround, we can mark original parameters or `ShardedTensor`s with an attribute `_fsdp_flattened` (saved as a string variable `FSDP_FLATTENED`) to indicate that the parameter/tensor has already been flattened. This issue only arises for recursive/nested FSDP wrapping.
This PR also changes `isinstance(param, FlatParameter)` checks to `type(param) is FlatParameter` because all tensor subclasses that have `_is_param == True` will return `True` for `isinstance(param, <any subclass with _is_param == True>)`. This means that a `ShardedTensor` parameter will return `True` for `isinstance(st, FlatParameter)`, which is not what we want.
5271494ef2/torch/nn/parameter.py (L8-L10)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85038
Approved by: https://github.com/rohan-varma
While passing tensors with different dtypes don't crash, they don't produce sensible results.
We see data tearing instead of casting.
It's not clear we want to support transparent casting so, for now, we fail when such input is presented.
Fixes#84525
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84664
Approved by: https://github.com/rohan-varma
Fixes#84865
Previous `torch.distributed.reduce_scatter`:
```
def reduce_scatter(output, input_list, op=ReduceOp.SUM, group=None, async_op=False):
"""
Reduces, then scatters a list of tensors to all processes in a group.
Args:
output (Tensor): Output tensor.
input_list (list[Tensor]): List of tensors to reduce and scatter.
group (ProcessGroup, optional): The process group to work on. If None,
the default process group will be used.
async_op (bool, optional): Whether this op should be an async op.
```
Fixed:
```
def reduce_scatter(output, input_list, op=ReduceOp.SUM, group=None, async_op=False):
"""
Reduces, then scatters a list of tensors to all processes in a group.
Args:
output (Tensor): Output tensor.
input_list (list[Tensor]): List of tensors to reduce and scatter.
op (optional): One of the values from
``torch.distributed.ReduceOp``
enum. Specifies an operation used for element-wise reductions
group (ProcessGroup, optional): The process group to work on. If None,
the default process group will be used.
async_op (bool, optional): Whether this op should be an async op.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84983
Approved by: https://github.com/H-Huang
This fixes the activation offload for checkpoint wrapper, which was previously broken. It was broken because it was tightly coupled with activation checkpoint, i.e. we did:
```
with save_on_cpu:
checkpoint(module_forward())
```
which would not offload any activation tensors to CPU, as those activations would already be not saved by autograd due to the checkpoint implementation taking priority.
Now, if `offload_to_cpu` is specified, we only do `save_on_cpu` and no checkpoint, so all intermediate tensors are offloaded to CPU instead of checkpointed.
These wrappers can be composed, i.e. if we have
`(Linear, Linear) -> (Linear, Linear) -> (Linear, Linear)`
we can do
`Offload( checkpoint(Linear, Linear) -> checkpoint(Linear, Linear) -> checkpoint(Linear, Linear))`
and inner tensors would be checkpointed while outers will be offloaded.
Differential Revision: [D39448882](https://our.internmc.facebook.com/intern/diff/D39448882/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84907
Approved by: https://github.com/awgu
We don't need eager mode support (automatic wait on read) for now.
Removing that to simply the code. We can always add this back if
necessary in the future.
Note that, we still need the eager mode code in `__torch_dispatch__`,
as `make_fx` will also run the ops in eager mode to get the output.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84978
Approved by: https://github.com/wanchaol
**Overview**
This PR adds a `bool` argument `limit_all_gathers` to the FSDP constructor, defaulted to `False`.
- Setting `limit_all_gathers=True` limits the max number of inflight all-gathers to 2 (an empirically chosen constant), preventing a fast CPU thread from over-allocating blocks to the all-gather stream.
- When experiencing a high number of CUDA malloc retries, the limiter can help reduce the number and hence lead to QPS improvement.
**Exploration**
I experimented with both a count-based limiter and size-based limiter (where the size is based on the inflight all-gather size in bytes).
- The size-based limiter did not provide any advantage, only confusing the developer and user alike on what threshold to set.
- For the count-based approach, I decided not to expose the max number of inflight all-gathers to the user since values other than 2 do not show improvements and exposing the knob may confuse users.
**T5-11B**
T5-11B evidences the performance gain from enabling the limiter and that a limit of 2 is a reasonable choice. This is run on an AWS cluster with 8 A100s per node and EFA. For both 2 and 4 nodes, we scale the batch size maximally before hitting OOM, which is a common practice.
<p float="left">
<img src="https://user-images.githubusercontent.com/31054793/188936036-04427da9-f492-4e50-9b35-ff64665d9815.png" width="400" />
<img src="https://user-images.githubusercontent.com/31054793/188936045-f44e659f-1e18-4ea7-8c78-0fce4ff8fb48.png" width="400" />
</p>
For 2 nodes, the limit of 2 yields 3.01x QPS improvement, and for 4 nodes, the limit of 2 yields 2.87x QPS improvement.
We need more data points, but the limiter may simplify the batch size scaling workflow. Normally, a practitioner may scale until hitting OOM and back off until there are few CUDA malloc retries. However, now the practitioner may be able to scale until hitting OOM and simply turn on the limiter to reduce the number of retries instead of backing off.
Differential Revision: [D39331201](https://our.internmc.facebook.com/intern/diff/D39331201)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83917
Approved by: https://github.com/zhaojuanmao
### Additional Constructor Changes
- `self.sharding_strategy`
- If the world size is 1, I clamp the sharding strategy to `NO_SHARD`, regardless of the passed-in sharding strategy, since the behavior is fully equivalent. This absolves the need for `p._is_sharded or self.world_size == 1` checks in the core code. Once we fully shift the paradigm to using handles, this should result in a clear net positive. However, for now, we still have some places where we interface directly with the `FlatParameter`, in which case we have some temporary hacky code.
- `HandleConfig`
- As a part of the new design abstraction, much logic is lowered to the `FlatParamHandle`. This requires the handle be aware of mixed precision, CPU offloading, sharding strategy, and the process group (for world size > 1). To be less error-prone, I re-defined the `dataclass`s and `enum`s for the handle. These can be removed and coalesced with the existing ones.
- The drawback is that the `FlattenParamsWrapper` constructor now takes in the `HandleConfig` to forward it to the `FlatParamHandle` constructor. I tolerate this since we plan to retire the FPW. For now, the handle's process group attributes are set later when we call `handle.shard()`.
- We will dive into this logic lowering later. For now, the idea is we need to pass some extra info to the handle, which must go through the FPW.
- `FullyShardedDataParallel._shard_parameters()` -> `FlatParamHandle.shard()`
- [Important] Generalizing attributes to remove the 1 `FullyShardedDataParallel` : 1 `FlatParameter` assumption
- **Before:** `_fsdp_graph_order`, `_pre_backward_hook_full_params_prefetched`, `_forward_full_params_prefetched`, `reshard_after_forward` are with respect to 1 `FullyShardedDataParallel`
- **After:** (1) We use `FlatParamHandle` in place of `FullyShardedDataParallel`. (2) The atomic unit for forward and pre-backward is a _group_ of handles involved in the same module's forward/pre-backward. This is represented as `Tuple[FlatParamHandle, ...]`. For now, this is **always a singleton tuple**, but this shift enables a module having multiple FSDP parameters (which we have use cases for).
- `_reset_lazy_init()` attributes
- The prefetched flags are merged into `self._handles_prefetched`, which is directly defined in the constructor. `reshard_after_forward` is retired since it can be fully determined by other attributes (`_is_root` and `sharding_strategy`).
## FSDP Runtime: Unshard
The first step is to read the existing `_rebuild_full_params()`. A few notable observations:
- It returns `Tuple[Tensor, bool]`. The first element is the _padded unsharded flattened parameter_, and the second element is whether we can free it upon exiting `summon_full_params()`. This return value is **only used in `summon_full_params()`**.
- If parameter mixed precision is enabled and the `FlatParameter` is already unsharded, then the low precision shard (`_mp_shard`) is still re-allocated on GPU. (It is freed at the end of the method.)
- If CPU offloading is enabled and the `FlatParameter` is already unsharded, then there is a no-op `p.data = p.data.to(self.compute_device, non_blocking=True)`.
- Inside `summon_full_params()`, `mixed_precision_cast_ran` is always `False`. Therefore, the return value for the `not p._is_sharded and mixed_precision_cast_ran` branch is unused.
-`summon_full_params()` can only be called (before forward or after backward) or (between forward and backward). Given this, I cannot think of a case where we call `summon_full_params()`, the `FlatParameter` is already unsharded, but `reshard_after_forward` is `True`. The `FlatParameter` should be sharded (before forward or after backward), and the `FlatParameter` may only be unsharded (between forward and backward) if `reshard_after_forward` is `False`.
- If parameter mixed precision is enabled and the sharding strategy is a sharded one, then inside `summon_full_params()`, the `FlatParameter` is unsharded in full precision. This involves allocating a new padded unsharded flattened parameter on GPU in full precision since `_full_param_padded` is in the low precision.
Some comments:
- Ideally, we reduce the complexity of the core code path: i.e. unshard for forward and pre-backward. If the return value is only used for `summon_full_params()`, we should consider if we can compartmentalize that logic.
- The branching is complex, and some return values are never used, where this fact is not immediately obvious. We should see if we can reduce the branch complexity.
Disclaimer: The difference in attribute semantics between `NO_SHARD` and the sharded strategies makes it challenging to unify the cases. This PR does not attempt to address that since it requires more design thought. However, it does attempt to reduce the complexity for the sharded strategies.
### Unshard: Core Code Path
Let us trace through the new logical unshard.
1. `FullyShardedDataParallel._unshard(self, handles: List[FlatParamHandle], prepare_gradient: bool)`
- This iterates over the handles and calls `handle.pre_unshard()`, `handle.unshard()`, and `handle.post_unshard(prepare_gradient)` in the all-gather stream.
2. `FlatParamHandle.needs_unshard(self)`
- We take an aside to look at this key subroutine.
- For `NO_SHARD`, this returns `False`.
- For sharded strategies, this checks if the padded unsharded flattened parameter is allocated. The padded unsharded flattened parameter is the base tensor for the unpadded unsharded flattened parameter, which is a view into the padded one. Thus, the padded one's allocation fully determines if the `FlatParameter` is unsharded.
- For sharded strategies, to accommodate the parameter mixed precision + `summon_full_params()` case, we introduce `_full_prec_full_param_padded`, which is the padded unsharded flattened parameter in full precision. The helper `_get_padded_unsharded_flat_param()` takes care of this casing and returns the padded unsharded flattened parameter. Instead of allocating a new tensor each time, we manually manage `_full_prec_full_param_padded`'s storage just like for `_full_param_padded`.
3. `FlatParamHandle.pre_unshard(self)`
- For sharded strategies, the postcondition is that the handle's `FlatParameter` points to the tensor to all-gather. This should be on the communication device and in the desired precision. The allocation and usage of the low precision shard for parameter mixed precision and the CPU -> GPU copy for CPU offloading both classify naturally in the pre-unshard.
- For sharded strategies, if the `FlatParameter` does not need to be unsharded, `pre_unshard()` is a no-op. This avoids unnecessarily allocating and freeing the low precision shard.
- For `NO_SHARD`, we simply preserve the existing semantics.
4. `FlatParamHandle.unshard(self)`
- If the handle was resharded without freeing the padded unsharded flattened parameter (e.g. `summon_full_params()` between forward and backward when `reshard_after_forward=False`), then the `FlatParameter` points to the sharded flattened parameter. We need to switch to using the unsharded parameter. This is a design choice. Alternatively, we may not switch to using the sharded flattened parameter in `reshard()` if we do not free the padded unsharded flattened parameter. However, the postcondition that the `FlatParameter` points to the sharded flattened parameter after `reshard()` is helpful logically, so I prefer this approach.
- Otherwise, this allocates the padded unsharded flattened parameter, all-gathers, and switches to using the unpadded unsharded flattened parameter.
- In the future, we may add an option to `unshard()` that additionally all-gathers the gradient.
5. `FlatParamHandle.post_unshard(self, prepare_gradient: bool)`
- For sharded strategies, if using parameter mixed precision, this frees the low precision shard. More generally, this should free any sharded allocations made in `pre_unshard()` since the all-gather has been launched. If using CPU offloading, the GPU copy of the local shard goes out of scope after `unshard()` and is able to be garbage collected. **We should understand if there is any performance difference between manually freeing versus deferring to garbage collection since our usage is inconsistent.** For now, I preserve the existing semantics here.
- `prepare_gradient` is meant to be set to `True` for the pre-backward unshard and `False` for the forward unshard. This runs the equivalent logic of `_prep_grads_for_backward()`.
- This post-unshard logic (notably the gradient preparation) now runs in the all-gather stream, which is fine because we always have the current stream wait for the all-gather stream immediately after `FullyShardedDataParallel._unshard()`. IIUC, we do not need to call `_mp_shard.record_stream(current_stream)` (where `current_stream` is the default stream) because `_mp_shard` is allocated and freed in the same (all-gather) stream.
- A postcondition is that the `FlatParameter` is on the compute device. It should also have the unpadded unsharded size (though I do not have a check for this at the moment).
### Unshard: `summon_full_params()`
Now that we see how the logical unshard has been reorganized for the core code path, let us dive into `summon_full_params()`.
The two constraints are:
1. If using parameter mixed precision, we should unshard in full precision.
2. We must determine if we should free the padded unsharded flattened parameter upon exiting.
The first constraint is addressed as described before in the core unshard code path, so it remains to explore the second constraint.
I propose a simple rule: **We free iff we actually unshard the `FlatParameter` in `summon_full_params()`** (i.e. it was not already unsharded). We perform a case analysis:
**Parameter mixed precision enabled:**
* `NO_SHARD`: `flat_param.data` points to `flat_param._local_shard`, which is the full precision unsharded flattened parameter. This is **not safe to free**.
* `FULL_SHARD` / `SHARD_GRAD_OP`: We force full precision and all-gather to `_full_prec_full_param_padded`. We do not support `nested summon_full_params()`, so `_full_prec_full_param_padded` must be unallocated. We unshard, and it is **safe to free**.
**Parameter mixed precision disabled:**
* `NO_SHARD`: This is the same as with mixed precision enabled. This is **not safe to free**.
* `FULL_SHARD` / `SHARD_GRAD_OP`: We all-gather to `_full_param_padded`. It may already be unsharded.
* Already unsharded: The unshard is a no-op. This is **not safe to free**.
* For `FULL_SHARD`, this can happen for the root FSDP instance after `forward()` but before backward.
* For `SHARD_GRAD_OP`, this can happen for all FSDP instances after `forward()` but before backward.
* Needs unshard: We unshard. This is **safe to free**.
Therefore, we see that it is not safe to free when using `NO_SHARD` and when using a sharded strategy but the `FlatParameter` is already unsharded. This is precisely the proposed rule.
There were two notable edge cases that the existing code did not address.
1. The existing code tests if the `FlatParameter` is already unsharded by checking the allocation status of `_full_param_padded`. When using parameter mixed precision, this is the incorrect tensor to check. If `_full_param_padded` is allocated (e.g. when `reshard_after_forward=False` and calling `summon_full_params()` between forward and backward), the already-unsharded check is a false positive, and `summon_full_params()` does not correctly force full precision. https://github.com/pytorch/pytorch/issues/83068
- This PR's `needs_unshard()` check correctly routes to the appropriate padded unsharded flattened parameter depending on the calling context (i.e. if it needs to force full precision or not).
2. The existing code does not free the GPU copy of the padded unsharded flattened parameter when calling `summon_full_params(offload_to_cpu=True)`. It unshards the `FlatParameter`, moves the padded unsharded flattened parameter to CPU, and sets the `FlatParameter` data to be the appropriate unpadded view into the padded unsharded flattened parameter on CPU. However, `_full_param_padded` still points to the all-gathered padded unsharded flattened parameter on GPU, which is kept in memory. https://github.com/pytorch/pytorch/issues/83076
- This PR frees the GPU copy and reallocates it upon exiting `summon_full_params()`. This is essential for avoiding peak GPU memory usage from increasing as we recurse through the module tree. There may be some cases where we can avoid reallocation altogether, but that can be addressed in a follow-up PR.
- This PR offloads the *unpadded* unsharded flattened parameter to CPU directly instead of the *padded* one. As far as I can tell, there is no need to include the padding since unflattening the original parameters does not require the padding.
- The relevant code is in the context manager `FlatParamHandle.to_cpu()`.
### Unshard: Mixed-Precision Stream
This PR removes the mixed precision stream usage. As is, I do not think there is any extra overlap being achieved by the stream usage.
The low precision shard is allocated and copied to in the mixed precision stream ([code](1f99bdfcc4/torch/distributed/fsdp/fully_sharded_data_parallel.py (L1401-L1412))), and the current stream (in this case the all-gather stream) waits for the mixed precision stream ([code](1f99bdfcc4/torch/distributed/fsdp/fully_sharded_data_parallel.py (L1414))). However, we immediately schedule an all-gather that communicates that exact low precision shard ([code](1f99bdfcc4/torch/distributed/fsdp/fully_sharded_data_parallel.py (L3338))) with no other meaningful computation between. If we remove the mixed precision stream, the low precision shard is allocated and copied to in the all-gather stream (including the non-blocking CPU -> GPU copy if using CPU offloading).
Under this PR's design, we may consider a "pre-unshard" stream for all logical pre-unshard data transfers if we want to overlap in the future. IIUC, the overlap opportunity exists if there are multiple `FlatParameter`s per module, and we only have the all-gather stream wait for the data transfer corresponding to the local shard it communicates, not the others.
If we agree on removing the mixed-precision stream for now, I will remember to delete it from `_init_streams()`.
## FSDP Runtime: Reshard
Like with unshard, the first step is the look at the existing `_free_full_params()` and `_use_param_local_shard()`. A few notable observations:
- For only `NO_SHARD`, `_free_full_params()` includes a call to `_free_mp_shard()`.
- For `summon_full_params()`, there is a separate `_free_full_params_and_use_local_shard()` that duplicates the main logic of `_free_full_params()` and calls `_use_param_local_shard()`.
- In `forward()`, if `reshard_after_forward=True`, we call `_free_full_params()` and then `_free_mp_shard()`. Hence, for `NO_SHARD`, the `_free_mp_shard()` is a no-op.
- In the post-backward hook, we typically call `_free_full_params()` and `_free_mp_shard()`. The `_free_mp_shard()` is a no-op for `NO_SHARD` and if `reshard_after_forward=True`.
Some comments:
- The code certainly works, but some of the no-ops are subtle. When possible, we should make it clear when calls are no-ops or not. It is good that the existing code documents that `_free_mp_shard()` is a no-op in the post-backward hook when `reshard_after_forward=True`. However, there are still some non-obvious no-ops (around `NO_SHARD`).
- We should see if we can avoid the duplicate `_free_full_params_and_use_local_shard()`.
Let us trace through the logical reshard:
1. `FullyShardedDataParallel._reshard(self, handles: List[FlatParamHandle], free_unsharded_flat_params: List[bool])`
- The two args should have the same length since they are to be zipped.
- The goal of having `free_unsharded_flat_params` is that the caller should be explicit about whether the (padded) unsharded flattened parameter should be freed. The low precision shard is always meant to be freed (as early as possible), so there is no corresponding `List[bool]`.
2. `FlatParamHandle.reshard(self, free_unsharded_flat_param: bool)`
- This frees the (padded) unsharded flattened parameter if `free_unsharded_flat_param` and switches to using the sharded flattened parameter.
- Echoing back to forcing full precision in `summon_full_params()`, `_free_unsharded_flat_param()` frees the correct tensor by using `_get_padded_unsharded_flat_parameter()`.
3. `FlatParamHandle.post_reshard(self)`
- I am not fully content with the existence of this method, but this seems to be an unavoidable consequence of `NO_SHARD`. Perhaps, this may be useful in the future for other reasons though.
- Right now, this method is only meaningful for `NO_SHARD` + parameter mixed precision + outside `summon_full_params()`. `_mp_shard` is not freed in the post-unshard since it is also the low precision _unsharded_ flattened parameter, so we must delay the free until the the post-reshard.
Below the `FlatParamHandle.reshard()` and `post_reshard()` layer, there should not be any no-ops.
One final comment I will mention is that I like the `pre_unshard()`, `unshard()`, `post_unshard()`, and `reshard()`, `post_reshard()` organization because it makes it clear what the boundaries are and their temporal relationship. Through that, we can set pre- and post-conditions. Furthermore, we can eventually convert logic to hooks that may be registered on the `FlatParamHandle` (for `pre_unshard()`, `post_unshard()`, and `post_reshard()`). This may improve the customizability of FSDP.
## FSDP Runtime: `forward()`
- This PR reorganizes `forward()` in preparation for non-recursive wrapping, which uses pre-forward and post-forward hooks that expect the signature `hook(module, input)`. For FSDP, the `module` and `input` arguments are not used.
- This PR creates a new method `_fsdp_root_pre_forward()` to handle the logic only the root FSDP should run.
## FSDP Prefetching
Finally, we dive into the prefetching changes. Some highlights:
1. This PR unifies the execution order validation and prefetching implementations.
- Both involve the execution order and can be unified to share some boilerplate.
2. Execution order validation only runs when the distributed debug level is `INFO`.
- We have yet to have one success case where we actually catch an unintended source of dynamism. The warning is also too verbose. Hence, we are gating it by the `INFO` level.
3. This PR moves prefetching to be with respect to groups of handles (as mentioned in the constructor comment).
- This is essential for supporting prefetching with non-recursive wrapping.
4. This PR does not include "bubbles", i.e. modules with no handles, in the recorded execution order(s). This deviates from the existing implementation.
- This makes prefetching possibly more aggressive (when there are such bubbles), but it should not have significant performance implications either way.
5. This PR changes backward prefetching to reset the post-forward order each iteration (as intended).
6. This PR changes forward prefetching to use the first iteration's pre-forward order instead of the first iteration's post-forward order. (We can discuss whether we want this in this PR or not. Otherwise, I can keep it as using the post-forward order to preserve the existing semantics.) This PR also removes the `all_gather_stream.wait_stream(current_stream)` before forward prefetching because it does not help with high GPU reserved memory. We can add that back if desired.
### Appendix
#### Reverse Post-Forward Order Is Not Always the Pre-Backward Order
The existing PT-D FSDP pre-backward prefetching uses the reverse post-forward order.
<details>
<summary>Model Code</summary>
```
class Model(nn.Module):
def __init__(self):
super().__init__()
self.block1 = nn.Sequential(
nn.Conv2d(3, 4, kernel_size=3),
nn.BatchNorm2d(4),
nn.ReLU(inplace=True),
)
self.block2 = nn.Sequential(
nn.Conv2d(4, 4, kernel_size=3),
nn.BatchNorm2d(4),
nn.ReLU(inplace=False),
)
self.block3 = nn.Linear(12, 8)
self.head = nn.Sequential(
nn.AdaptiveAvgPool2d(output_size=(1, 1)),
nn.Flatten(),
nn.Linear(4, 10),
)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
return self.head(x)
model = Model().cuda()
fsdp_kwargs = {}
model.block1[1] = FSDP(model.block1[1], **fsdp_kwargs) # BN2d
model.block2[1] = FSDP(model.block2[1], **fsdp_kwargs) # BN2d
model.block1 = FSDP(model.block1, **fsdp_kwargs)
model.block2 = FSDP(model.block2, **fsdp_kwargs)
model.block3 = FSDP(model.block3, **fsdp_kwargs)
model = FSDP(model, **fsdp_kwargs)
```
</details>
<details>
<summary>Execution Orders </summary>
```
Pre-backward hook for ('head.2.weight', 'head.2.bias') 140339520587136 (model)
Pre-backward hook for ('weight', 'bias') 140339461194656 (block3)
Pre-backward hook for ('0.weight', '0.bias') 140339520589776 (block2)
Pre-backward hook for ('weight', 'bias') 140339520587664 (block2 BN)
Pre-backward hook for ('weight', 'bias') 140339520586656 (block1 BN)
Pre-backward hook for ('0.weight', '0.bias') 140339520588768 (block1)
Pre-forward order:
('head.2.weight', 'head.2.bias') 140339520587136 (model)
('0.weight', '0.bias') 140339520588768 (block1)
('weight', 'bias') 140339520586656 (block1 BN)
('0.weight', '0.bias') 140339520589776 (block2)
('weight', 'bias') 140339520587664 (block2 BN)
('weight', 'bias') 140339461194656 (block3)
Reverse post-forward order:
('head.2.weight', 'head.2.bias') 140339520587136 (model)
('weight', 'bias') 140339461194656 (block3)
('0.weight', '0.bias') 140339520589776 (block2)
('weight', 'bias') 140339520587664 (block2 BN)
('0.weight', '0.bias') 140339520588768 (block1)
('weight', 'bias') 140339520586656 (block1 BN)
```
</details>
Differential Revision: [D39293429](https://our.internmc.facebook.com/intern/diff/D39293429)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83665
Approved by: https://github.com/zhaojuanmao
We are removing the `forward_prefetch` option. By the nature of async GPU kernel execution, launching the CPU kernel for the next layer's all-gather early does not actually improve performance. Moreover, the existing `forward_prefetch` uses the post-forward order instead of the pre-forward order, which leads to mis-targeted prefetched all-gathers.
Differential Revision: [D39454217](https://our.internmc.facebook.com/intern/diff/D39454217)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84600
Approved by: https://github.com/zhaojuanmao
**Background:**
Optimizer states are of the type `Dict[int, Dict[str, torch.Tensor]]` and the order of `dict.items()` is the creation order of keys. Without checkpoint (state_dict/load_state_dict), the creation order of keys depends on the implementation of the optimizer (e.g., Adam seems to creates `exp_avg` then `exp_avg_sq`). However, when loading states from a checkpoint, since the optimizer state are lazily initialized, the order depends on the user code (reading state_dict from IO). See the following example:
```
optimizer_state_dict = USER_CODE_TO_READ_STATE_FROM_IO()
optimizer.load_state_dict(optimizer_state_dict)
```
The key order of `optimizer_state_dict` depends on `USER_CODE_TO_READ_STATE_FROM_IO` and there is no guarantee that the order is the same across ranks.
**What Can Go Wrong?**
After the first checkpoint load, the key order of optimizer may not be the same on different ranks. When users try to save another checkpoint, user will call `_unflatten_optim_state()` to save the optimizer states. Inside `_unflatten_optim_state()`, `dict.itmes()` will be called to iterate all the local optimizer state and `all_gather()` will be used to gather the local states. Since the order may be different across ranks, the gathered states are not correct.
We have seen some models get NaN loss after the second checkpoint load because of this issue.
**What This PR Does?**
This PR implements a `sorted_items()` to return sorted `(key, value)` pairs. We can do this because the key is either an integer or a string.
Differential Revision: [D39315184](https://our.internmc.facebook.com/intern/diff/D39315184/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84654
Approved by: https://github.com/awgu
### Overview
This PR retires `self.device_id` by coalescing it with `self.compute_device` and more generally cleans up the FSDP constructor.
### Existing FSDP Constructor Semantics (In Order)
1. Compute the ignored parameters/modules from `ignored_modules` and the buffer names (to avoid cloning in `state_dict()`)
2. Recursively auto wrap if needed
5. Define process group attributes
6. Determine `device_id`
7. Materialize the wrapped module if using meta device or `torchdistX` deferred initialization
8. Move the module if needed (based on `self.device_id`)
9. Determine `compute_device`
10. Define `training_state`, gradient divide factors, FSDP feature-related attributes (`cpu_offload`, `forward_prefetch`, `backward_prefetch`, `sharding_strategy`, `mixed_precision`), `_orig_buffer_dtypes`
11. Determine the parameters to flatten
12. Sync module states if `sync_module_states`
13. Initialize the `FlattenParamsWrapper` with the parameters to flatten and the wrapped module, which constructs the `FlatParameter`
14. Shard the `FlatParameter` (in-place)
15. Define `_is_root`, shared attributes (`_streams`, `_fsdp_graph_order`), prefetching attributes (`_my_fsdp_idx_in_graph`, `_pre_backward_hook_full_params_prefetched`, `_forward_full_params_prefetched`), `reshard_after_forward` -- all of this is done in `_reset_lazy_init()`
16. Define `_require_backward_grad_sync` to configure `no_sync()`
17. Define state dict attributes (`_state_dict_type`, `_state_dict_config`) and register state dict hooks
18. Define backward pass flags (`_pre_backward_hook_has_run`, `_need_rebuild_full_params`)
19. Move `FlatParameter`s to CPU if `cpu_offload.offload_params`
20. Define `_exec_order_data` for execution order validation
21. Define communication hook attributes (`communication_hook`, `communication_hook_state`, `_hook_registered`)
### Notable Changes
- `self.mixed_precision`
- **Before:** `self.mixed_precision` itself could be `None`. Equivalently, `self.mixed_precision` could be `MixedPrecision(None, None, None)`. Both would disable mixed precision completely.
- **After:** `self.mixed_precision` itself is never `None`. We only have `MixedPrecision(None, None, None)` (default construction of the `dataclass`) to disable mixed precision. This catches the issue that for `test_summon_full_params.py`, we were passing `MixedPrecision(None, None, None)` when we wanted to actually enable mixed precision.
- `cpu_offload.offload_params=True` + `device_id`
- **Before:** For nested FSDP and `device_id` specified, `FlatParameter`s already offloaded to CPU are moved back to GPU and not re-offloaded to CPU.
- **After:** The nested `FlatParameter`s are re-offloaded to CPU. This is a temporary hack. The ideal solution removes the `module = module.to(<GPU device>)` in the first place and only moves the relevant parameters. Because the `module.to()` implementation has some complexity, I did not want to remove that call in this PR.
- `device_id` and `compute_device`
- **Before:** `self.device_id` is either `None` or equal to `self.compute_device`. `self.device_id` is not used after the FSDP constructor.
- **After:** `self.device_id` is removed and instead coalesced with `self.compute_device`. The only semantic change is that `test_module_device_mismatches_device_id()` errors earlier (but importantly, still errors).
- This PR also uses a helper method `_get_orig_params()`, which is more robust and may avoid issues like https://github.com/pytorch/pytorch/issues/82891 without having to gate higher-level logic.
- `_reset_lazy_init()` attributes
- **Before:** Some attributes were being _defined_ in `_reset_lazy_init()` (which may not be obvious to all devs).
- **After:** For this PR, we define these attributes in the constructor but leave `_reset_lazy_init()` as is. In the follow-ups, this gets further refactored.
- Otherwise, I simply moved some logic into their own methods and reorganized the attribute definitions to be grouped logically.
### Follow-Ups
1. What should the specification be for `device_id` + `ignored_modules`?
2. Investigate removing the `module = module.to(<GPU device>)` in favor of moving per parameter.
3. Should we call `_reset_lazy_init()` in `register_comm_hook()`?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83663
Approved by: https://github.com/zhaojuanmao, https://github.com/rohan-varma
Those functions enable membership introspection into a ProcessGroup. A common scenario
that needs this is library code that consumes a PG but doesn't create it, which means
it likely doesn't know the global ranks used to create it.
Translating from local to global is necessary when using c10d collectives like broadcast
so if your library code adopts the convention of using local rank 0, it needs
to the following:
```python
import torch.distributed as dist
my_pg: dist.ProcessGroup = ...
def my_library_bcast(tensor)
dist.broadcast(tensor, src=dist.get_global_rank(my_pg, local_rank=0), my_pg)
```
This implements some of the helpers needed to implement the `clone` API from: https://github.com/pytorch/pytorch/issues/81291
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82134
Approved by: https://github.com/rohan-varma
Since exec order warning can result in very long module name print out, gating this only to be printing in debug mode. Oftentimes such as in multiModal training, there is not a lot we can do about this warning since some modules go unused in certain iterations.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83868
Approved by: https://github.com/awgu
Change StorageReader and StorageWriter to follow the new SavePlanner / LoadPlanner design.
Add optional planner param to load_state_dict and save_state_dict and implement the new protocol.
This includes a small rework of FileSystem layer to support single file per rank and making fsync optional to match torch.save behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83781
Approved by: https://github.com/wanchaol, https://github.com/fduwjj
There are a couple issues / assumptions within FSDP today that this PR attempts to fix:
- In wait_for_post_backward, we assume that if a param required grad, its post backward was called, but this is not true, i.e. if its output did not participate in grad computation, it would not have called post backward. To fix this we simply removed those assertions.
- There is a deeper issue where in `_finalize_params`, we could end up assigning a grad of the sharded shape to an unsharded parameter gradient field, which would raise a shape error. This can happen for example if a parameter's usage transitions from used --> unused. In this case, when the parameter was used, it would have had a gradient, then user could have possibly called `zero_grad()` and p.grad would not be `None`. This in `_prep_grad_for_backward`, we would assign a `_saved_grad_shard` to this gradient field which would be the sharded shape. In `_finalize_param`, our parameter would be unsharded (since post_backward was not called), but we'd try to assign, raising the shape issue. This issue is fixed by checking `_post_backward_called`. If this is False, we simply skip the assignment because there is no new gradient to update.
- A final issue as mentioned above is that if post_backward is not called, we never reshard the full param. This is fixed by checking if we haven't resharded (basically if post_backward_called == False), and if so, performing a reshard.
A few things to note:
- This logic may have to be revisited when non-recursive wrapping lands as there are multiple FlatParams per FSDP unit
- This logic may not work when post_backward_hook fires but p.grad is None, i.e. the short-circuiting here: f534b2c627/torch/distributed/fsdp/fully_sharded_data_parallel.py (L2884). As a quick fix, we could just move `_post_backward_called` flag change to after this, or just perform a reshard before returning early. I am not sure how to repro a case where p.grad == None but we call the post-backward hook, https://github.com/pytorch/pytorch/issues/83197 might be a possibility, but I think it is fine to not support this yet.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83195
Approved by: https://github.com/awgu
Summary:
This diff implements a named pipe based watchdog timer (`FileTimerClient` and `FileTimerServer`). This is similar to the existing `LocalTimerClient` and `LocalTimerServer` (https://fburl.com/code/j4b9pyya).
The motivation is from the need of handling various timeout issues. The training process occasionally get stuck. We need a proper watchdog to monitor the liveness of the training processes. This timer allows the TorchElastic agent (as the watchdog) to monitor the progress of the training processes that it spawned. If a timeout occurred, he TorchElastic agent can take some action to kill the stuck process and creating a core dump for it.
`LocalTimerClient` and `LocalTimerServer` require a `multiprocessing.Queue()` to work. So they can only be used between `multiprocessing` parent and child processes.
`FileTimerClient` and `FileTimerServer` does not have such limitation.
Test Plan:
### Unit Test
```
buck test mode/opt caffe2/test/distributed/elastic/timer:file_based_timer_test
```
```
RemoteExecution session id: reSessionID-06d70a77-043c-4d9d-b0f2-94c24460740a-tpx
Started reporting to test run: https://www.internalfb.com/intern/testinfra/testrun/844425186732666
✓ ListingSuccess: caffe2/test/distributed/elastic/timer:file_based_timer_test : 12 tests discovered (2.177)
✓ Pass: caffe2/test/distributed/elastic/timer:file_based_timer_test - test_happy_path (file_based_local_timer_test.FileTimerTest) (2.463)
✓ Pass: caffe2/test/distributed/elastic/timer:file_based_timer_test - test_expired_timers (file_based_local_timer_test.FileTimerServerTest) (1.889)
✓ Pass: caffe2/test/distributed/elastic/timer:file_based_timer_test - test_send_request_release (file_based_local_timer_test.FileTimerServerTest) (1.700)
✓ Pass: caffe2/test/distributed/elastic/timer:file_based_timer_test - test_valid_timers (file_based_local_timer_test.FileTimerServerTest) (1.873)
✓ Pass: caffe2/test/distributed/elastic/timer:file_based_timer_test - test_watchdog_call_count (file_based_local_timer_test.FileTimerServerTest) (1.715)
✓ Pass: caffe2/test/distributed/elastic/timer:file_based_timer_test - test_watchdog_empty_queue (file_based_local_timer_test.FileTimerServerTest) (1.609)
✓ Pass: caffe2/test/distributed/elastic/timer:file_based_timer_test - test_exception_propagation (file_based_local_timer_test.FileTimerTest) (1.633)
✓ Pass: caffe2/test/distributed/elastic/timer:file_based_timer_test - test_multiple_clients_interaction (file_based_local_timer_test.FileTimerTest) (2.189)
✓ Pass: caffe2/test/distributed/elastic/timer:file_based_timer_test - test_get_timer_recursive (file_based_local_timer_test.FileTimerTest) (2.295)
✓ Pass: caffe2/test/distributed/elastic/timer:file_based_timer_test - test_no_client (file_based_local_timer_test.FileTimerTest) (1.753)
✓ Pass: caffe2/test/distributed/elastic/timer:file_based_timer_test - test_timer (file_based_local_timer_test.FileTimerTest) (2.151)
✓ Pass: caffe2/test/distributed/elastic/timer:file_based_timer_test - test_client_interaction (file_based_local_timer_test.FileTimerTest) (1.895)
Summary
Pass: 12
ListingSuccess: 1
Finished test run: https://www.internalfb.com/intern/testinfra/testrun/844425186732666
```
Differential Revision: D38604238
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83695
Approved by: https://github.com/d4l3k
Fix use-dict-literal pylint suggestions by changing `dict()` to `{}`. This PR should do the change for every Python file except test/jit/test_list_dict.py, where I think the intent is to test the constructor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83718
Approved by: https://github.com/albanD
@awgu pointed out these checks aren't really doing anything, as they just make sure we're setting training state in certain ways throughout FSDP and is sort of arbitrary. So, removing them to avoid confusion.
We still keep the checking around `_post_backward_called` because this is needed in `finalize_params` for now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83150
Approved by: https://github.com/awgu
The planners come with default implementations in default_planner.py.
The default planners expose their core functionality as separate functions
to make it easy for other checkpoint implementations to use this functionality.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83419
Approved by: https://github.com/wanchaol
Fixes https://github.com/pytorch/pytorch/issues/79114
An implementation of a FSDP communication hook interface for a sharded strategies:
- Added `reduce_scatter_hook` to default hooks. Note the difference of `reduce_scatter` from `all_reduce`, it requires 2 tensors:`input_gradient` and `output` variables and stores result in `output`, which is further used as a summed gradient shard.
- Adjusted FSDP logic to return `reduce_scatter_hook` as a default communication hook for sharded strategies, `DefaultState` is the same for sharded and non-sharded strategies.
- Adjusted low-precision hooks to work with both `all_reduce` and `reduce_scatter` depending on whether `output` tensor is provided or not.
Test plan:
Added all existing sharded strategies as an input parameters to existing tests.
For`test_default_communication_hook_behaviour` double checked how a linear layer is sharded across workers. This test creates a simple net ``1 X N``, where ``N`` - is the number of workers. For sharded cases, ``N`` parameters are sharded across ``N`` workers. This test checks that after backward, each worker has a proper value in it's chunk of the gradient, or the whole gradient on every worker is equal to an expected value.
Checked that low-precision tests work for sharded cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83254
Approved by: https://github.com/rohan-varma, https://github.com/awgu
FSDP originally uses `_init_from_local_shards_and_global_metadata()` to create a ShardedTensor for sharded_state_dict(). We have seen some non-trivial overhead if the number of tensors is large. Using `_init_from_local_shards_and_global_metadata ` can significantly reduce the overhead. For a model with ~250 tensors in the state_dict trained with 16 GPUs, the original `sharded_state_dict` takes ~1.7 seconds and this PR reduces the overhead to ~0.6 seconds.
Differential Revision: [D38452170](https://our.internmc.facebook.com/intern/diff/D38452170/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82911
Approved by: https://github.com/awgu
These two ops (Embedding and EmbeddingBag for ShardedTensor) especially for row-wise sharding is very inefficient and hard to fit in the concept of future design. So this PR is trying to:
1. Remove all unnecessary collective communications. Only one gather and one reduce(or reduce scatter) is needed.
2. Use auto-grad enabled collectives so that we can use these ops in real model training.
3. Some minor code cleaning
4. Treat input differently when it's replicated tensor. (Will add more for this for the next few PRs).
Differential Revision: [D37965687](https://our.internmc.facebook.com/intern/diff/D37965687/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81853
Approved by: https://github.com/wanchaol
This is a new version of #15648 based on the latest master branch.
Unlike the previous PR where I fixed a lot of the doctests in addition to integrating xdoctest, I'm going to reduce the scope here. I'm simply going to integrate xdoctest, and then I'm going to mark all of the failing tests as "SKIP". This will let xdoctest run on the dashboards, provide some value, and still let the dashboards pass. I'll leave fixing the doctests themselves to another PR.
In my initial commit, I do the bare minimum to get something running with failing dashboards. The few tests that I marked as skip are causing segfaults. Running xdoctest results in 293 failed, 201 passed tests. The next commits will be to disable those tests. (unfortunately I don't have a tool that will insert the `#xdoctest: +SKIP` directive over every failing test, so I'm going to do this mostly manually.)
Fixes https://github.com/pytorch/pytorch/issues/71105
@ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82797
Approved by: https://github.com/ezyang
- Modifies the current cmake build definitions to use `find_package` to find UCX and UCC installed in the system
- Install UCX and UCC in CUDA dockers
- Build PyTorch with `USE_UCC=1` in pipelines
- Currently, we are not running unit tests with the UCC PG. Those tests will be added in future PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81583
Approved by: https://github.com/vtlam, https://github.com/malfet
Allow checkpoint_wrapper to take in the checkpoint functional impl. This decouples it from torch.utils.checkpoint and allows other checkpoint implementations to be used.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83035
Approved by: https://github.com/awgu
Summary:
`batch_isend_irecv` previously required the use of `torch.cuda.synchronize` to avoid data race conditions. This was because the ncclStreams were recorderd in the returned ncclWork object _before_ a ncclGroupEnd by the `_batch_p2p_manager` was issued. Thus, the `req.wait()` was effectively waiting on nothing, leading to the later operators working on incorrect intermediate data.
This fix:
- keeps track of ncclStreams to wait on, and records them in the work objects after the batch manager issues a ncclGroupEnd
- renames the `_batch_p2p_manager` to `_coalescing_manager` for generality
- removes the explicit check for NCCL backend inside `_batch_p2p_manager` in distributed_c10.py and moves the manager start/end to ProcessGroup.hpp, in order to transparently work with all process groups
Test Plan: Modified the unittest for `batch_isend_irecv` to check that received tensors are the same as expected tensors. Verified that the test fails before the change, and passes after the change.
Differential Revision: D38100789
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82450
Approved by: https://github.com/kwen2501
See https://github.com/pytorch/pytorch/issues/82891 for full context.
When we init FSDP with device_id + CPU offload, we could potentially hit a crash when an outer FSDP unit does not manage any params. What was happening is that it would end up getting a flat param of a child FSDP module, check the device of this, see it is CPU, and throw an error.
The fix is to avoid this check if we hit a flat param. Also fixes up the documentation of the function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82892
Approved by: https://github.com/awgu
This PR implements the following changes.
Move to new checkpoint metadata format with split between logical and storage data.
This is a step in the direction of supporting extensible checkpointing as it moves us away from the hardcoded storage model enforced by the FileSystem storage layer.
Change CheckpointException to include exception traceback. Exception tracebacks are not serializable so we need to take care of that otherwise we provide horribly bad errors to users.
Finally, remove `validate_state_dict` as it lost its usefulness. Loading is becoming more and more flexible to the point that the only reasonable way to verify if it's possible to load a given configuration is to actually try it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82078
Approved by: https://github.com/wanchaol, https://github.com/fduwjj
### Description
Across PyTorch's docstrings, both `callable` and `Callable` for variable types. The Callable should be capitalized as we are referring to the `Callable` type, and not the Python `callable()` function.
### Testing
There shouldn't be any testing required.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82487
Approved by: https://github.com/albanD
MetadataIndex simplifies indexing into state dict and Metadata.
This includes a find_state_dict_object helper that searcher into a state dict.
This PR doesn't include search over Metadata at it requires changes that will land
in a subsequent PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81909
Approved by: https://github.com/wanchaol
Introduce _DistWrapper class that wraps a process group and provides functional
variants of collectives. It works without c10d enabled and is exception
robust.
Introduce tensor_narrow_n that handle narrowing over multiple dimentions.
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81828
Approved by: https://github.com/wanchaol
This removes the `_orig_size` attribute that is initialized in `fully_sharded_data_parallel.py` since it represents the same quantity as `_unsharded_size` in `flat_param.py`. Since the quantity is not sharding dependent, we keep its initialization in `FlatParameter.init_metadata()` instead of in `FullyShardedDataParallel._shard_parameters()`.
Differential Revision: [D37726062](https://our.internmc.facebook.com/intern/diff/D37726062)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79984
Approved by: https://github.com/rohan-varma
**Overview**
This PR introduces `FlatParamHandle` to enable non-recursive FSDP wrapping. The class absorbs the unflattening/flattening logic from `FlattenParamsWrapper` but does not require wrapping a particular `nn.Module`.
## Discussion
### Introducing `FlatParamHandle`
There is flexibility in the design space for how to allocate attributes and methods to `FlatParameter` versus a wrapping class like `FlatParamHandle` or `FlattenParamsWrapper`. Several points in the design space provide the same functionality, so deciding on an allocation is arguably stylistic, though then preference should be given to cleaner designs.
The forefront consideration is that a `FlatParameter`'s metadata should be initialized once, while its data may be reloaded via checkpointing. This motivates decoupling the metadata initialization from the `FlatParameter` constructor, which should instead only handle the parameter data. Thus, we have both a `FlatParamHandle` managing a `FlatParameter` and the `FlatParameter` itself.
```
class FlatParamHandle:
def __init__(self, module: nn.Module, params: Sequence[nn.Parameter]):
# Calls `_init_flat_param()`
def _init_flat_param(self, module: nn.Module, params: Sequence[nn.Parameter]):
# Calls `flatten_params()` and initializes metadata
@staticmethod
def flatten_params(params: Sequence[torch.Tensor], requires_grad: bool) -> FlatParameter:
# Also may be used for checkpoint reloading
class FlatParameter(nn.Parameter):
# Constructor is not overridden
```
Under this separation with `FlatParameter` as solely as a data container, we keep methods manipulating `FlatParameter` on the `FlatParamHandle`. Because `FlatParameter`'s constructor is not overridden, we should be able to replace it with another tensor type e.g. `ShardedTensor` with minimal changes.
### Compatibility with `FlattenParamsWrapper`
To ensure backward compatibility, `FlattenParamsWrapper` now holds a `FlatParamHandle`. Existing logic from `FlattenParamsWrapper` simply routes to the handle now.
A `FullyShardedDataParallel` instance holds references to all of its handles.
- For the recursive-wrapping paradigm, there is at most one handle, which is from its `FlattenParamsWrapper` if it manages parameters.
- For the non-recursive wrapping paradigm, there may be multiple handles, all owned by the single (root) `FullyShardedDataParallel` instance.
## For Reviewers
### `FlatParameter` Construction
In the existing implementation, a `FlatParameter`'s metadata was partially initialized in its constructor (e.g. `_param_numels`, `_param_shapes`) and partially initialized by the owning `FlattenParamsWrapper` (e.g. `_param_infos`, `_shared_param_infos`). The latter part was needed due to requiring module information. With this PR, the metadata initialization is consolidated in `FlatParamHandle`.
- During model construction, a `FlatParameter` should be initialized via the handle constructor`FlatParamHandle(params, module)`.
- During sharded checkpoint loading, a `FlatParameter` should be initialized via the static method `FlatParamHandle.flatten_params(new_params)`.
- The checkpointing implementation is responsible for checking that `new_params` used to construct the `FlatParameter` data to load is consistent with the existing `FlatParameter`'s metadata.
These are the only two cases for `FlatParameter` construction right now, so there is no real functionality regression by not recomputing some of the metadata in the `FlatParameter` constructor. The `nn.Module.state_dict()` is implemented using in-place `copy_()`, so the new loaded `FlatParameter`'s metadata *should* match the existing `FlatParameter`'s metadata for correctness anyway. (I.e. we do not support a usage where we reload a `FlatParameter` with differing metadata into an existing `FlatParameter`.)
### BC Breaking
- `ShardMetadata` -> `FlatParamShardMetadata` to avoid name conflict with `ShardedTensor`
- `metadata()` -> removed (unused)
- `FlatParameter` attributes
- `_param_numels` -> `_numels`
- `_param_shapes` -> `_shapes`
- `_param_names` -> `_prefixed_param_names`
- `full_numel` -> `_unsharded_size.numel()`
- `_param_indice_in_shard` -> `_shard_indices`
- `_sharded_param_offsets` -> `_shard_param_offsets`
- `num_padded` -> `_shard_numel_padded`
- `param_offsets` -> not saved; directly constructed in `_get_flat_param_offsets()` and used once
- `FlattenParamsWrapper` `param_list` argument -> `params` for consistency with `FlatParameter`
## Follow-Ups
- The current `FlatParameter`'s `data` represents either the sharded unflattened parameter, unsharded unflattened parameter, or reduced-precision sharded unflattened parameter, depending dynamically on the runtime context. When its `data` represents one quantity, the other quantities are still saved as attributes on the `FlatParameter` (e.g. `_local_shard`, `_full_param_padded`, `_mp_shard`). `FullyShardedDataParallel` directly manipulates the `data`.
We should investigate the tradeoffs of having those attributes on the `FlatParameter` versus moving them to the `FlatParamHandle`. The motivation for the latter is to define a clean interface for `FullyShardedDataParallel` to manage parameter data in preparation for generalizing to multiple parameter groups, to managing non-`FlatParameter`s, and to supporting non-CUDA devices. (More explicitly, `FullyShardedDataParallel`'s parameter *variables* would be set to different `Tensor` variables, none of which own another, instead of `FullyShardedDataParallel`'s parameter variables' *data* being set to different `Tensor` variables, all owned by the `FlatParameter`, and the data management would be folded into handle, hidden from `FullyShardedDataParallel`.)
- We should investigate if we can coalesce the remaining logic in `FlattenParamsWrapper` into `FullyShardedDataParallel` and remove `FlattenParamsWrapper`.
- We may want to move the mixed precision logic to the handle instead of the `FullyShardedDataParallel` instance to enable per-`FlatParameter` mixed precision instead of per-`FullyShardedDataParallel`. Otherwise, the non-recursive wrapping path is bound to all-or-nothing mixed precision.
Differential Revision: [D37250558](https://our.internmc.facebook.com/intern/diff/D37250558)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79652
Approved by: https://github.com/zhaojuanmao, https://github.com/fegin, https://github.com/rohan-varma
Recently, `register_comm_hook` was introduced to `FSDP`, which at the moment supports only `NO_SHARD` strategy and has a default `all_reduce` hook implemented. This PR adds two lower precision hooks to an existing default hook.
I've also made slight adjustments to existing implementation of an `all_reduce` hook including:
`AllReduceState` ->` DefaultState `, motivation: `AllReduceState` is not specific to all_reduce. Gradients' pre- and post-division factors are also useful for other hooks, that require pre- and post-division, e.g. `fp16_hook` and `bf16_hook`.
I've put all 3 hooks into `default_hooks.py`
Additionally, `FSDP` supports `MixedPrecision` and, theoretically, it is possible to specify MixedPrecision for gradients and attach a lower precision hook to the model. To avoid double-casting, I've added a couple of checks to `fully_sharded_data_parallel`, i.e. casting to precision and back is performed by a lower precision hook only. I think, as a next step, it would be nice to ensure that user can't have both lower precision hook and MixedPrecision(reduce_dtype=<precision>) specified, but I am happy to discuss this and adjust current implementation.
As a test, I create two models: one with a lower precision hook and one with a `MixedPrecision(reduce_dtype=<precision>)` specified, perform one forward/backward and optimizer step and compare gradients.
PS. first version of this PR was reverted, because added unittests didn't include NCCL version checks for `bf16_hook` (thus failed on trunk). In this version, I've added appropriate checks for tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81711
Approved by: https://github.com/rohan-varma
Summary: Refractor error_handler.py
Test Plan:
In the previous diff, I added a unit test which showcases the failed case. With this diff, we can see that the override works as expected.
Also added few additional tests for test coverage
Reviewed By: wilson100hong
Differential Revision: D37677402
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81408
Approved by: https://github.com/d4l3k
Recently, `register_comm_hook` was introduced to `FSDP`, which at the moment supports only `NO_SHARD` strategy and has a default `all_reduce` hook implemented. This PR adds two lower precision hooks to an existing default hook.
I've also made slight adjustments to existing implementation of an `all_reduce` hook including:
- `AllReduceState` -> `DefaultState` , motivation: `AllReduceState` is not specific to `all_reduce`. Gradients' pre- and post-division factors are also useful for other hooks, that require pre- and post-division, e.g. fp16_hook and bf16_hook.
- I've put all 3 hooks into `default_hooks.py`
Additionally, `FSDP` supports `MixedPrecision` and, theoretically, it is possible to specify `MixedPrecision` for gradients and attach a lower precision hook to the model. To avoid double-casting, I've added a couple of checks to `fully_sharded_data_parallel`, i.e. casting to precision and back is performed by a lower precision hook only. I think, as a next step, it would be nice to ensure that user can't have both lower precision hook and `MixedPrecision(reduce_dtype=<precision>)` specified, but I am happy to discuss this and adjust current implementation.
As a test, I create two models: one with a lower precision hook and one with a `MixedPrecision(reduce_dtype=<precision>)` specified, perform one forward/backward and optimizer step and compare gradients.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80557
Approved by: https://github.com/rohan-varma
Summary:
This diff integrates UCC process group as a native component of Pytorch Distributed core. It is based on the existing torch-ucc (https://github.com/facebookresearch/torch_ucc) as the wrapper for UCC collective communication library.
The environment and cmake variables are named in mirroring to the existing process groups such as NCCL and Gloo. Specifically,
- USE_UCC: enables UCC PG. This defaults to OFF, so there is no breakage of existing builds that do not have UCX/UCC external libraries.
- USE_SYSTEM_UCC: uses external UCX and UCC shared libraries that are set accordingly with UCX_HOME and UCC_HOME.
Currently, this diff only supports USE_SYSTEM_UCC=ON, i.e., requiring users to specify external libraries for UCX and UCC. In subsequent diffs, we will add UCX and UCC repos as third-party dependencies in pytorch/third-party.
Test Plan:
Passed Torch-UCC tests that invoke UCC process group. For example:
$ sh test/start_test.sh test/torch_allreduce_test.py --backend gloo --use-cuda
...
Test allreduce: succeeded
Differential Revision: D36973688
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79918
Approved by: https://github.com/kwen2501, https://github.com/kingchc
This support allows one to get the parameter execution order at the FSDP module construction time rather than at runtime for some models, under which case the preparation step can be removed. This will be used in the non-recursive wrapping policy later on.
Note that this support is based on the assumption that the tracer provided by the user will be able to successfully trace the forward pass.
### Advantage of using `torch.fx` to get the parameter order rather than using backward hook:
When using backward hook, the parameter execution order will be the reversed ordering of the parameter gradient ready order. One problem is that we are not able to get the number of times each parameter is used inside the forward function. For example, consider the following forward function,
```python
def forward(self, x):
z = self.relu(self.layer0(x))
z = self.relu(self.layer2(z))
z = self.relu(self.layer1(z))
z = self.relu(self.layer0(x))
return z
```
Based on the parameter gradient ready order, the current parameter execution order for the example is `[layer0.weight, layer2.weight, layer1.weight]`. However, we don't get the information that layer0 is called twice.
Using `torch.fx`, we can get a more detailed parameter execution order: [layer0.weight, layer2.weight, layer1.weight, layer0.weight]. This allows us to implement more scheduling algorithms that could be useful in multiple regimes. For example, since we know that `layer0` will be called twice, we can delay the resharding of `layer0.weight` to the end, which would costs more memory but faster.
### Example of API usage
The execution information is recorded via calling `tracer.trace` in the `_patch_tracer` context manager:
```python
tracer = torch.fx.Tracer() # or an instance of Tracer's children class
execution_info = _init_execution_info(model)
with _patch_tracer(
tracer=tracer, root_module=model, execution_info=execution_info
):
tracer.trace(model, concrete_args=...)
```
The execution information will be recorded in `execution_info.module_forward_order` and `execution_info.module_to_execution_infos`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80294
Approved by: https://github.com/mrshenli, https://github.com/zhaojuanmao
Remove `_checkpoint_wrapped_module` prefixes when creating keys for optimizer state_dict.
Having these does not actually create an issue for optim_state_dict save / load, but we'd like to strip these keys out for downstream code that consumes these APIs typically expecting checkpointing prefixes to not exist (as checkpointing should be a transparent operation which should not change module / parameter names).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80480
Approved by: https://github.com/awgu, https://github.com/fegin
Fixes#75666
Current PR adds the functionality for `PostLocalSGD` communication hook and tests that communication hook can be properly saved and restored. Similar to https://github.com/pytorch/pytorch/pull/79334, where serialization was added to `PowerSGD`.
``__getstate__``
Returns:
```
``Dict[str, Any]`` which will be pickled and saved.
``process_group`` and ``subgroup`` are not serializable and excluded from
a returned state.
```
``__setstate__``
```
Takes provided ``state`` and retrieves ``PostLocalSGDState``.
``process_group`` and ``subgroup`` are set to default process_group and subgroup respectively.
Default subgroup is equivalent to the subgroup on each node.
```
Small adjustment to `PowerSGD`'s warning message.
Refactored unittest, i.e. separated parity and log checks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80435
Approved by: https://github.com/awgu
This TODO is no longer needed, as we use `_register_fused_optim` to register the overlapped optimizer in DDP. Also, remove comment about API being experimental, as this API is no longer going to be used by end user.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80453
Approved by: https://github.com/awgu
Currently, pre- and post-division steps in `FullyShardedDataParallel._post_backward_hook` state the following:
> Average grad by world_size for consistency with PyTorch DDP.
This is not matching what is actually going on, i.e. pre-divide factor may be equal to `world_size` and may not.
For example, for `world_size = 3 `, `predivide_factor=2`
This PR clarifies pre- and post-division in the code
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80456
Approved by: https://github.com/rohan-varma
Fixes#79114
An implementation of a FSDP communication hook interface for a NO_SHARD strategy:
- `FullyShardedDataParallel.register_comm_hook(self, state: object, hook: callable)` checks current sharding strategy. If it is other that NO_SHARD, raises a runtime error. Otherwise, sets and shares a specified hook and its state with all submodules
- When FSDP is ready to communicate a gradient, checks if there is a registered hook, and calls it instead of all_reduce. Additionally, gradient pre and post devision are not performed if a hook is registered.
To test the interface, I've implemented a communication hook, that calls for `all_reduce`.
A unittest:
- checks that is a sharding strategy is anything but NO_SHARD, a runtime error is raised
- checks that for a NO_SHARD case, model with registered all_reduce hook and without a hook work the same.
- checks for 2 types of FSDP models: with the wrapped first layer and without. (to make sure submodules have a hook registered)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79833
Approved by: https://github.com/rohan-varma, https://github.com/awgu
In some use cases, FSDP runs into an issue where a training state assert in `_wait_for_post_backward` erroneously fires. Digging into the root cause, this is because `_post_backward_hook` which sets the module's training state to backward_post is never actually called, since no param in that module had gradient computed for it. Similar to DDP, this can happen when not all module outputs are used in loss computation, or module did not participate in forward at all.
Fix this by tracking a variable `_post_backward_called` to track whether the hook is actually called or not.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80245
Approved by: https://github.com/awgu
For ignored modules' parameters, we should also clean their parameter names since they will have the FSDP-specific prefixes.
This change only affects the prefixed parameter name keys in `full_optim_state_dict()` (i.e. optim state dict saving). Not having this change does not actually violate the correctness of the optim state dict save-load flow because it only requires that the keys are unique and internally consistent.
Either way, this PR explicitly adds the specification now that the parameter keys in the optim state dict should match the keys of full model state dict.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79955
Approved by: https://github.com/rohan-varma
This is the first PR for a wrapping policy that wraps parameters and performs the communication scheduling based on the parameter execution order in the forward pass (also called non-recursive wrapping policy).
This PR includes:
- The basic API for using this policy,
- A helper function to get the parameter execution order in the first forward and backward pass.
Other parts will be implemented in future PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79238
Approved by: https://github.com/zhaojuanmao, https://github.com/awgu
Fix a potential small bug in FSDP pre_backward_hook params prefetch.
In `_pre_backward_hook`, `self._need_prefetch_full_params(self.training_state)` is used to decide whether the params of the next backward pass needs to be pre-fetched, and currently it is also used to check whether we want to perform synchronization in the current backward pass before `_rebuild_full_params`.
For some edge cases, using this to check whether to perform synchronization is not current. One example is when `self._my_fsdp_idx_in_graph = 0`, which means this is the last backward pass. In this way, we have `self._need_prefetch_full_params(self.training_state)=False` since there is no backward pass after it, and currently synchronization will not be done before `_rebuild_full_params`.
But the params of this layer is prefetched at the previous layer, thus a synchronization needs to be done.
To fix this, we just needs to check whether to do the synchronization using another flag rather than `self._need_prefetch_full_params(self.training_state)`, and that is what this PR does.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78851
Approved by: https://github.com/zhaojuanmao
This PR addresses issue address #75666.
Stateful communication hook now can be saved and reloaded to resume training.
Current PR adds the functionality for PowerSGD communication hook and tests that communication hook can be properly saved and restored.
PowerSGD implementation uses ``__slots__``, as a result introduced __getstate__ and __setstate__ methods are implemented to work with `__slots__` and not` __dict__`.
`__getstate__ `
Returns:
A dictionary that represents a ``PowerSGDState`` which will be pickled and saved.
``process_group`` is non-serializable and excluded from a returned state.
`__setstate__`
Takes a provided ``state`` and retrieves ``PowerSGDState``.
``process_group`` is set to default with a proper warning issued to a user.
Unit test
A hook-independent `_test_hook_pickling` is added with this PR, as well as `test_ddp_hook_pickling_powerSGD`, which tests `powerSGD`’s ability to be saved and reloaded.
Currently, the test creates a ddp model with a provided hook, trains it for 10 epochs and saves model’s state and hook’s state.
During reloading, unit test makes sure that a warning was logged (only one warning and the proper one). It then proceeds to check that reloaded hook and original hook are the same. Finally, it checks that a hook’s state was properly initialized:
- it compares slot values (all, but 2: `process_group` and `rng`) for original and reloaded state
- it checks that process group was set to a default group
- it checks that a random state was restored properly with np.testing.assert_array_equal, because `rng` is an instance of `np.random.RandomState`, represented by a tuple. One of entries is of `ndarray dtype[uint32]` type and `np.testing.assert_array_equal` is used for assertion.
Future To-Do:
- Implement similar __getstate__ and __setstate__ for other stateful communication hooks
- Add appropriate tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79334
Approved by: https://github.com/rohan-varma, https://github.com/awgu
This fixes all object collectives under NCCL and adds some automated tests for them.
This PR *does not* fix sending tensors using object collectives.
It simplifies device handling by computing the appropriate one earlier and then ensuring all tensor ops happen on it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79034
Approved by: https://github.com/rohan-varma
Near term fix for https://github.com/pytorch/pytorch/issues/76368.
Q. Why does the user need to request `capturable=True` in the optimizer constructor? Why can't capture safety be completely automatic?
A. We need to set up capture-safe (device-side) state variables before capture. If we don't, and step() internally detects capture is underway, it's too late: the best we could do is create a device state variable and copy the current CPU value into it, which is not something we want baked into the graph.
Q. Ok, why not just do the capture-safe approach with device-side state variables all the time?
A. It incurs several more kernel launches per parameter, which could really add up and regress cpu overhead for ungraphed step()s. If the optimizer won't be captured, we should allow step() to stick with its current cpu-side state handling.
Q. But cuda RNG is a stateful thing that maintains its state on the cpu outside of capture and replay, and we capture it automatically. Why can't we do the same thing here?
A. The graph object can handle RNG generator increments because its capture_begin, capture_end, and replay() methods can see and access generator object. But the graph object has no explicit knowledge of or access to optimizer steps in its capture scope. We could let the user tell the graph object what optimizers will be stepped in its scope, ie something like
```python
graph.will_use_optimizer(opt)
graph.capture_begin()
...
```
but that seems clunkier than an optimizer constructor arg.
I'm open to other ideas, but right now I think constructor arg is necessary and the least bad approach.
Long term, https://github.com/pytorch/pytorch/issues/71274 is a better fix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77862
Approved by: https://github.com/ezyang
Co-authored with: @awgu
When `state_dict` has a prefix attached to it, the current logic for ignoring parameters and buffers does not work since it doesn't account for this prefix. To fix this, we make the following changes:
- clean the key if it starts with prefix. Note that all keys may not start with prefix, i.e. if the current module's state_dict_post_hook is running and previous module `state_dict` has already been computed and previous module is on the same level of hierarchy as the current module.
- This prefixing makes it so that it is not current to override child module's ignored params and buffers with the root FSDP instance's (this wouldn't work if child FSDP instances had ignored modules, and root didn't, for example). We fix this by having each parent know about the ignored modules of their children, and computing fully qualified names for ignored params and buffers.
- This means that each for a particular FSDP instance, that instance knows about the names of itself and its children (in fully qualified form) that it needs to ignore. It wouldn't know about parent ignored params and buffers, but it doesn't need to store this data.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78278
Approved by: https://github.com/awgu
After offline discussion, decided that by default moving CPU module to GPU is a bit too risky due to possible OOM during init issue.
Theoretically, we should not OOM because it is required for module that is being wrapped by FSDP to fit into GPU, i.e. during forward. But possibly can be temporary GPU tensors etc allocated during __init___ that break this assumption, it is better for now to allow users a way to init on CPU if needed.
We still warn to use `device_id` for faster init if model is on CPU.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77720
Approved by: https://github.com/zhaojuanmao
Introduce error handling across all ranks when loading and saving checkpoints.
This makes it a lot simpler for users to handle failures and, as a positive side-effect, coordination of when it successfully finished.
This change requires 3 collectives when saving and 1 when loading.
All those collectives carry a small payload so they will be latency bound and write time should dominate it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77091
Approved by: https://github.com/pritamdamania87, https://github.com/wanchaol
This PR does a number of things:
- Move linalg.vector_norm to structured kernels and simplify the logic
- Fixes a number of prexisting issues with the dtype kwarg of these ops
- Heavily simplifies and corrects the logic of `linalg.matrix_norm` and `linalg.norm` to be consistent with the docs
- Before the `_out` versions of these functions were incorrect
- Their implementation is now as efficient as expected, as it avoids reimplementing these operations whenever possible.
- Deprecates `torch.frobenius_norm` and `torch.nuclear_norm`, as they were exposed in the API and they are apparently being used in mobile (??!!) even though they were not documented and their implementation was slow.
- I'd love to get rid of these functions already, but I guess we have to go through their deprecation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76547
Approved by: https://github.com/mruberry
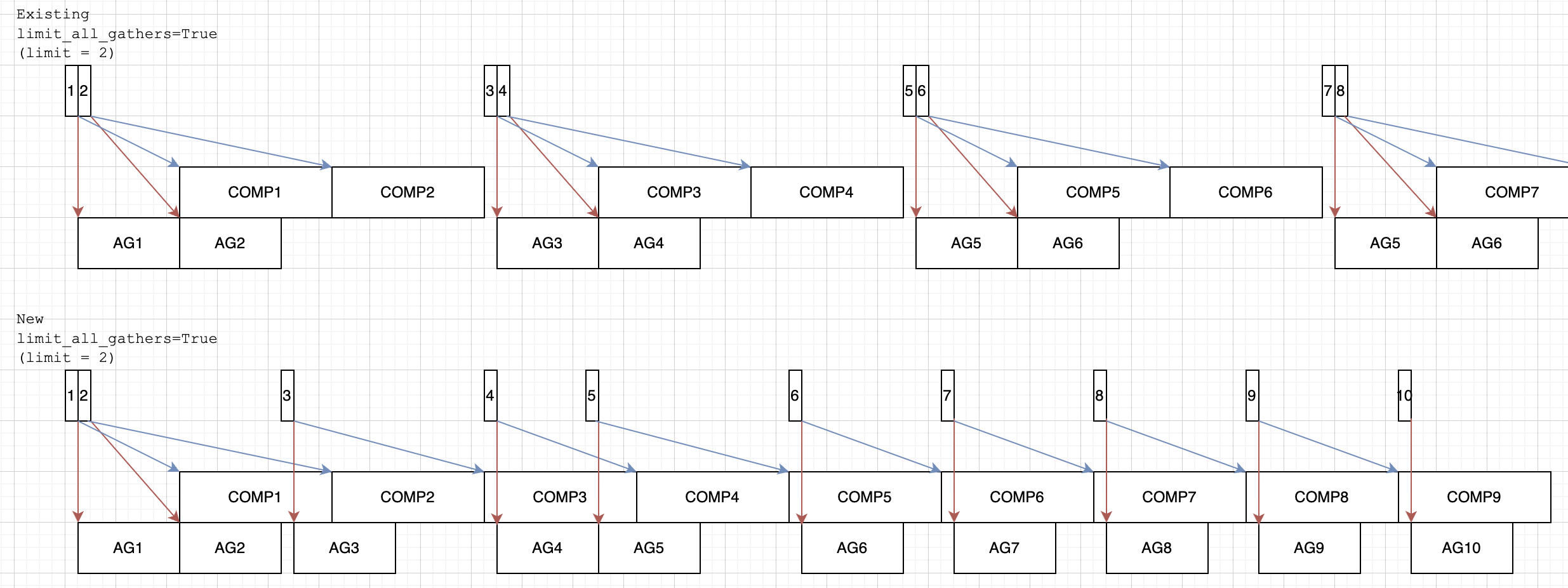{kind=link}
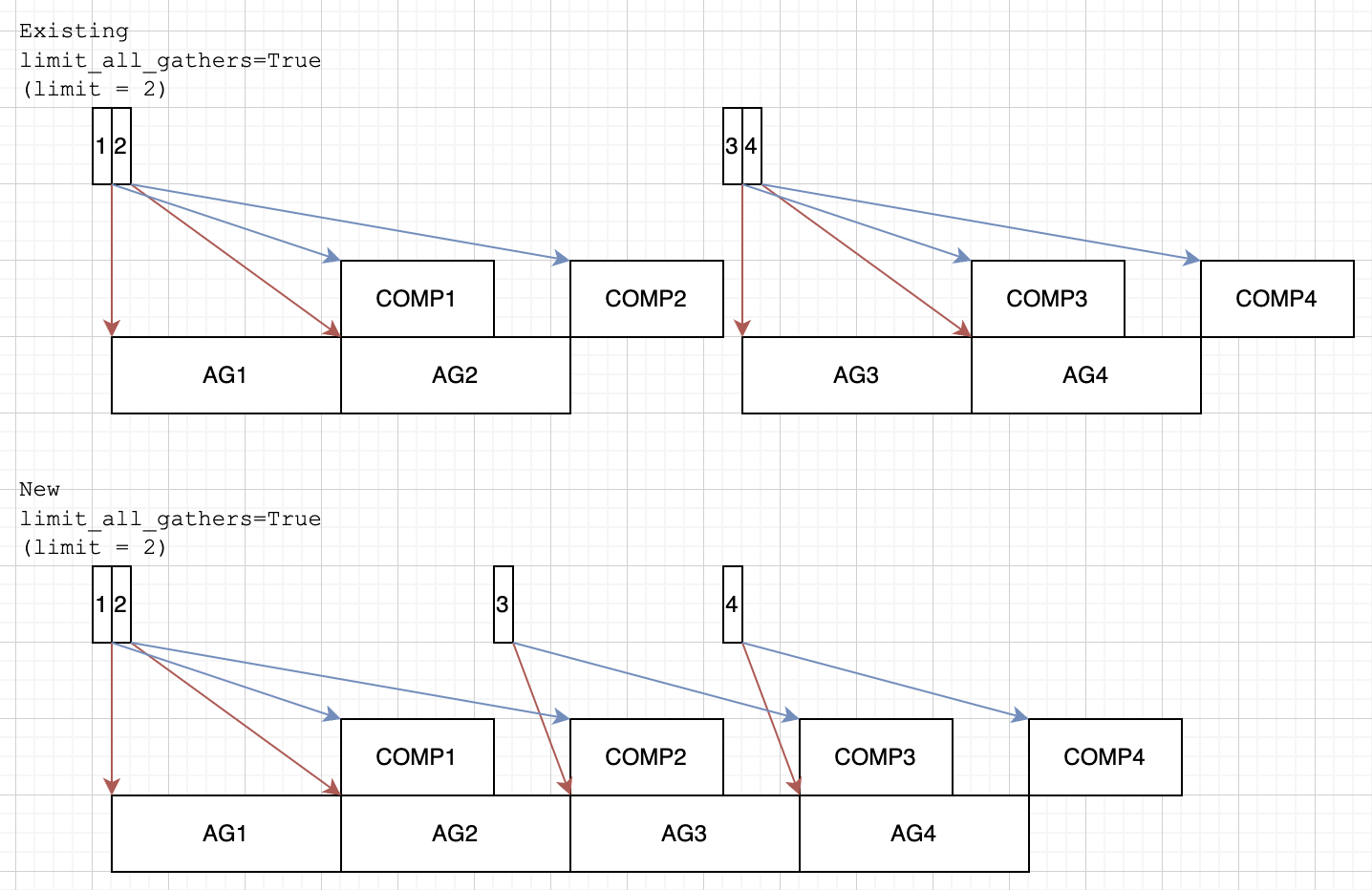{kind=link}
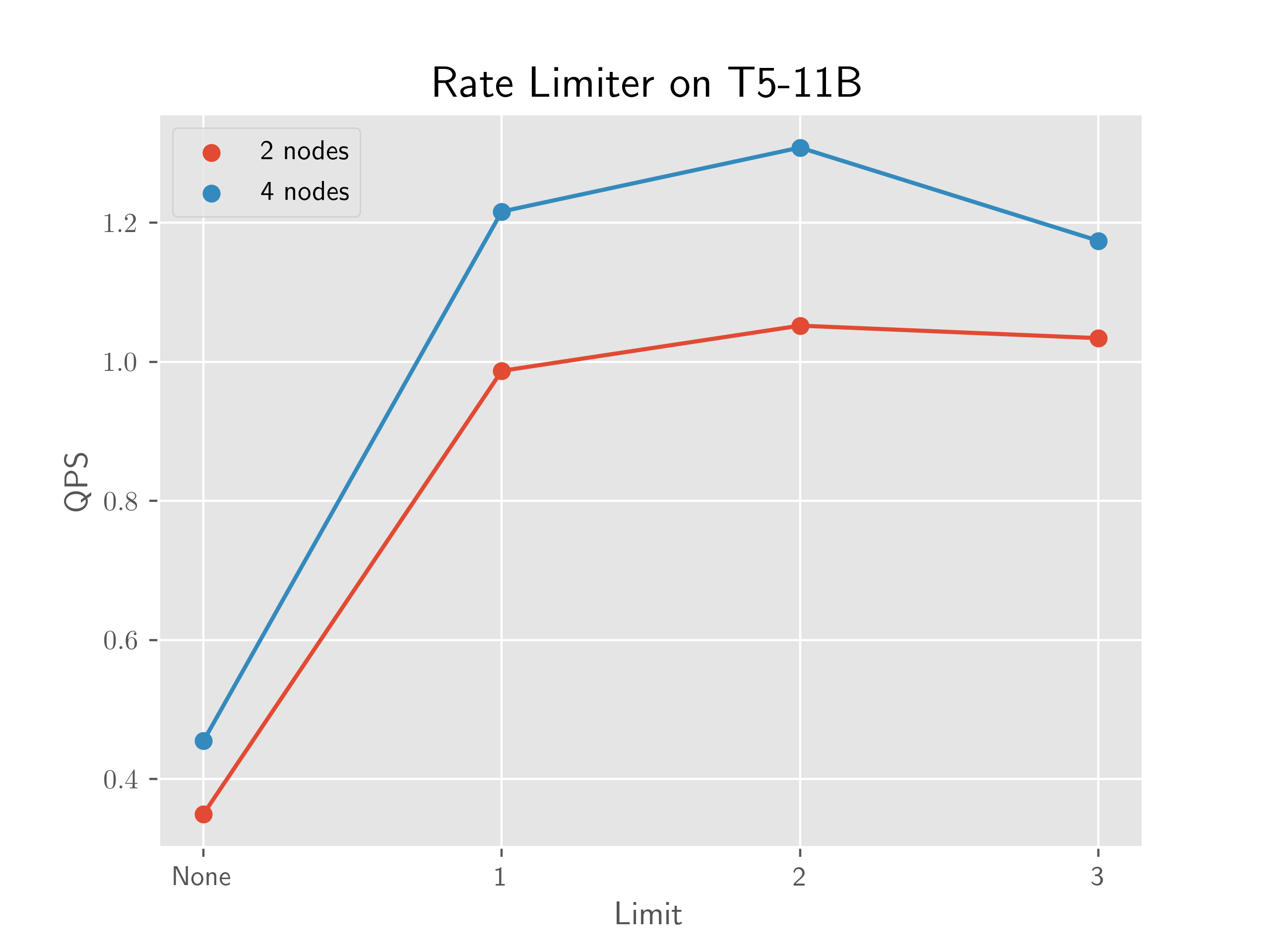{kind=link}
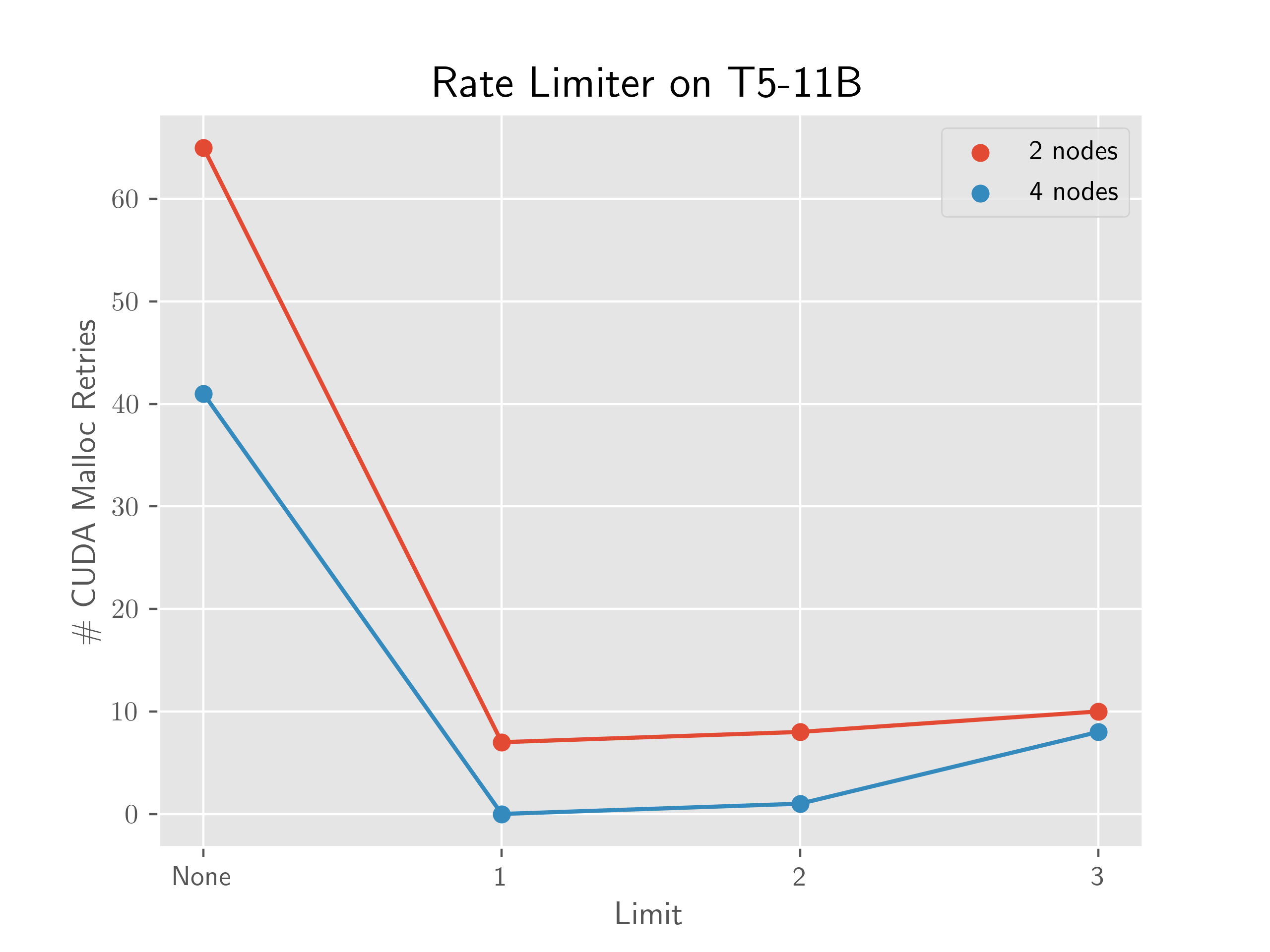{kind=link}