This lowers the `reduce_dtype` retrieval to the `handle` instead of the `state` in preparation for `fully_shard`, and this adds a guard to avoid a no-op `to()` call.
Note that this change pretty much gets overridden in following PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90615
Approved by: https://github.com/rohan-varma
Use register_state_dict_pre_hook in FSDP to simplify state_dict implementations & remove hacks. This removes `def state_dict` entirely and paves the path for composable API as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90436
Approved by: https://github.com/fegin
This saves a data structure `_stream_to_name: Dict[torch.cuda.Stream, str]` that maps each FSDP stream to its name. This can help in debugging by checking `_stream_to_name[torch.cuda.current_stream()]` to see if it is `"default"` or `"unshard"` in the post-backward hook for example.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90611
Approved by: https://github.com/rohan-varma
Adds 2 new hybrid sharding strategy to FSDP:
1. HYBRID_SHARD: applies zero-3 style sharding within a node, and data parallel across
2. HYBRID_SHARD_ZERO2: applies zero-2 style sharding within a node, and data parallel across
These are useful for medium sized models and aim to decrease communication volume, tests and benchmarks will be run to understand which workloads are optimal under which sharding strategy.
Hybrid sharding in general works by sharding the model using a process group within a single node, and creating intra-node process groups for replication / data parallelism. The user either needs to pass in a tuple of these process groups, or None, and we generate the process groups appropriately.
** Acknowledgements **
- @awgu 's excellent prototype: 5ad3a16d48
- @liangluofb For ideation, feedback, and initial implementation and experimentation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89915
Approved by: https://github.com/awgu
- This PR introduces a new concept, the _communication module_ (denoted `comm_module`), that represents the module responsible for the unshard/reshard pair for a `FlatParamHandle`. This is well-defined because the current design assumes that each `FlatParamHandle` only has _one_ unshard/reshard pair for either the forward or backward pass.
- For the wrapper code path, the `comm_module` is exactly the module already being passed to the `FlatParamHandle` constructor.
- For the composable code path, the `comm_module` is not necessarily the module already being passed to the `FlatParamHandle`. This is because the module already being passed is always the local FSDP root module to give complete FQNs, instead of local FQNs. Distinguishing the communication module from the local FSDP root module can provide more flexibility for non-recursive wrapping designs in the future.
- This PR adds a unit test `test_unshard_reshard_order` that explicitly checks that `_unshard` and `_reshard` are called in the exactly the same order across the two code paths.
- This PR does not fix `test_checkpoint_fsdp_submodules_use_reentrant`. However, the error message changes, so this PR accommodates that.
- The error is now the same as if we used the equivalent wrapper FSDP:
```
test_model.u1 = FSDP(test_model.u1, use_orig_params=True)
test_model.u2 = FSDP(test_model.u2, use_orig_params=True)
```
- The error is also the same as if we used wrapper FSDP with `use_orig_params=False`, so it is not unique to `use_orig_params=True`.
---
**`comm_module` Example**
```
model = Model(
seq1: nn.Sequential(
nn.Linear
nn.ReLU
nn.Linear
nn.ReLU
)
seq2: nn.Sequential(
nn.Linear
nn.ReLU
nn.Linear
nn.ReLU
)
)
policy = ModuleWrapPolicy({nn.Sequential})
fully_shard(model, policy=policy)
FullyShardedDataParallel(model, auto_wrap_policy=policy)
```
- This policy constructs two `FlatParamHandle`s, one for `seq1` and one for `seq2`.
- `FullyShardedDataParallel` will pass `seq1` and `seq2` as the `module` argument to the two `FlatParamHandle`s, respectively.
- `fully_shard()` will pass `model` as the `module` argument to every `FlatParamHandle`.
- `FullyShardedDataParallel` will pass `seq1` and `seq2` as the `comm_module` argument to the two `FlatParamHandle`s, respectively.
- `fully_shard()` will pass `seq1` and `seq2` as the `comm_module` argument to the two `FlatParamHandle`s, respectively.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90387
Approved by: https://github.com/mrshenli
**Motivation:**
Add a helper to map from the FQN to the corresponding flat_param. The helper will directly get flat_param from fsdp_state and flat_handler as flat_param is not registered to the module if `use_orig_params` is True.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89899
Approved by: https://github.com/awgu
I need to rebase later after Shen's PRs land.
The idea is to only register the pre/post-forward hook on the _root modules_ among the modules that consume a `FlatParameter`. (Yes, the term _root module_ is heavily overloaded. We may want to clarify that at some point. Here, _root_ is being used in the graph sense, meaning parent-less, and the scope is only among the modules consuming a `FlatParameter`.)
This avoids unnecessary pre/post-forward hooks running, which would lead to errors because the unshard is not truly idempotent.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90201
Approved by: https://github.com/mrshenli, https://github.com/rohan-varma
Summary:
This diff is reverting D41682843
D41682843 has been identified to be causing the following test or build failures:
Tests affected:
- https://www.internalfb.com/intern/test/281475048939643/
Here's the Multisect link:
https://www.internalfb.com/intern/testinfra/multisect/1444954
Here are the tasks that are relevant to this breakage:
T93770103: 5 tests started failing for oncall assistant_multimodal in the last 2 weeks
We're generating a revert to back out the changes in this diff, please note the backout may land if someone accepts it.
Test Plan: NA
Reviewed By: zyan0, atuljangra, YazhiGao
Differential Revision: D41710749
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90132
Approved by: https://github.com/awgu
For PyTorch FSDP, the only way that gradients are in low precision is if `keep_low_precision_grads=True` or if the user turns on AMP. This PR adds tests for the former and improves the documentation for `clip_grad_norm_()`, especially around these non-full-precision cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90028
Approved by: https://github.com/rohan-varma
For any `flat_param.data = flat_param.to(...)` or `flat_param.grad.data = flat_param.grad.to(...)`, we must also refresh sharded parameter/gradient views, respectively, if the storage changes.
For `keep_low_precision_grads=True` and a sharded strategy, we cast the gradient back to the low precision using `.data` to bypass the PyTorch check that a parameter and its gradient have the same dtype. For `use_orig_params=True` before this PR, the gradient would incorrectly still be in full precision, not low precision, since we did not refresh views (this can actually be considered a memory leak since we have two copies of the gradient now, one in low precision and one in full precision). This PR refreshes the views.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90027
Approved by: https://github.com/mrshenli
This was separated out from the previous PR to decouple. Since not all builds include `torch.distributed`, we should define the globals in the dynamo file and import to distributed instead of vice versa. Unlike the version from the previous PR, this PR prefixes the globals with `_` to future proof against `_dynamo/` eventually becoming public.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89913
Approved by: https://github.com/wconstab
This PR attemps to fix the following pyre error:
```
Incompatible parameter type [6]: In call
`dist.fsdp.fully_sharded_data_parallel.FullyShardedDataParallel.__init__`,
for 7th parameter `auto_wrap_policy` expected
`Optional[typing.Callable[..., typing.Any]]` but got
`Optional[_FSDPPolicy]`.
```
Besides, this also removes the type inconsistency in code and docstring.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89930
Approved by: https://github.com/awgu
I made a pass over Linjian's `_symbolic_trace.py` and tidied it up a bit. Aside from simple stylistic changes, this PR makes the following changes:
- Save `visited_params: Set[nn.Parameter]` to avoid linear overhead to check a parameter already being visited when appending to the parameter execution order list (`param_forward_order`)
- Move the tracer patching logic to a class `_ExecOrderTracer` to have a reference to `self.exec_info` without having a fragmented 2-step initialization (like the old `_init_execution_info(root_module)` plus `_patch_tracer(tracer, root_module, execution_info)`)
- Define `_ParamUsageInfo` to formalize the `Tuple[nn.Module, List[str, nn.Parameter]]` elements being mapped to in the execution info `dict`, and clarify the documentation regarding what this represents
- Change the unit test to use `TestCase`, not `FSDPTest`, to avoid initializing a process group
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89917
Approved by: https://github.com/zhaojuanmao, https://github.com/fegin
This PR makes two minor changes: It (1) moves the recently-added module annotation logic for dynamo support to a separate file `torch/distributed/fsdp/_dynamo_utils.py` and ~~(2) saves the annotated attribute names to global variables `FSDP_MANAGED_MODULE` and `FSDP_USE_ORIG_PARAMS`~~.
Update: Since the distributed package may not be included in some builds, it is not safe to import from `torch.distributed...` to a file in `_dynamo/`. I will not include change (2) in this PR. The alternative is to define those globals (privately) in the dynamo file and import from there in the FSDP file.
- The first change is mainly a personal choice, where I wanted to avoid the dynamo explanation from dominating the FSDP constructor space-wise. I added the `(see function for details)` to the inline comment to forward interested readers.
- The second change follows the custom we have taken in the past for such attributes (e.g. `FSDP_FLATTENED`). My understanding (in the past as well as currently) is that this is a good practice.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89890
Approved by: https://github.com/wconstab
To reuse memory when allocating the unsharded `FlatParameter` in the unshard stream, we only need to block the CPU thread on the preceding free event (i.e. `event.synchronize()`) before allocating the unsharded memory, which happens in `handle.unshard()`. Notably, this can be done after the pre-unshard logic, which at most performs _sharded_ allocations (low precision shard or H2D sharded `FlatParameter` copy) in its own pre-unshard stream. This enables the pre-unshard to overlap with any pending ops.
With this change, I believe that we should use `limit_all_gathers=True` all the time to stay true to FSDP's proposed memory semantics.
If a user wants to set `limit_all_gathers=False`, that would mean that he/she wants to overlap ops that are issued after the unshard logic's all-gather with ops that are pending at the time when FSDP _would_ block the CPU thread via `event.synchronize()`.
- If the user is willing to not reuse memory for that all-gather, then the user may as well have applied `NO_SHARD` and optionally ZeRO-1 (if this niche is important, then maybe we should consider hardening ZeRO-1). This is because now the unsharded memory for the all-gather additionally contributes to peak memory since it cannot reuse memory.
- If the user wanted to reuse memory for that all-gather, then we needed to block the CPU thread. There is no way around that given the caching allocator semantics.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89057
Approved by: https://github.com/mrshenli
We do not need to have the pre-unshard and unshard streams wait for the computation stream because we are not using the pre-unshard or unshard streams in `clip_grad_norm_()`.
The other change is simply avoiding a loop to get `grads`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89308
Approved by: https://github.com/mrshenli
**Overview**
This PR removes an outdated TODO:
```
# TODO (awgu): When exposing the original parameters, we need to also
# use this attribute to prevent re-synchronizing parameters.
```
**Justification**
We only pass `managed_params` to `_sync_module_params_and_buffers()`, where `managed_params` is defined as
```
managed_params = list(_get_orig_params(root_module, state._ignored_params))
```
This `_get_orig_params()` call excludes parameters already flattened by FSDP. Thus, `_sync_module_params_and_buffers()` will not re-sync already-synchronized parameters. Each parameter appears in `managed_params` for some FSDP instance exactly once and hence is only synchronized once.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89217
Approved by: https://github.com/mrshenli
The issue for `test_2d_parallel.py` is that `DTensor` does not support the idiom `param.data = view` where `view` is a `DTensor`. To work around this, we do not preserve the parameter variable `param` and instead create a new parameter variable altogether via `nn.Parameter(view)`. Preserving the parameter variable when unsharded was not a strict requirement -- it just made sense to do that if we are already doing that when _sharded_, where it _is_ a strict requirement to support the optimizer step. The sharded case is not an issue for 2D because sharded implies local tensor, not `DTensor`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89845
Approved by: https://github.com/zhaojuanmao
This assert was accidentally made stricter when transitioning from per-FSDP-instance training state to per-handle training state. This PR relaxes it again, which should restore compatibility for some reentrant AC plus FSDP cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89791
Approved by: https://github.com/zhaojuanmao
- This is a strict requirement given the way dynamo+FSDP is implemented,
but isn't convenient to assert.
- By plumbing use_orig_param field on all wrapped modules, we can
do this assertion inside dynamo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89523
Approved by: https://github.com/awgu
### Summary
Making dynamo treat the nn.Modules inside FSDP wrappers as 'Unspecialized'
results in dynamo-produced graphs where nn.module parameters are inputs
to the graph rather than attributes of the outer graphmodule.
This helps in FSDP since it forces dynamo to pick the latest copy
of the parameters off the user's nn.Module (which FSDP mutates every pre_forward),
solving the ordering issue in backward.
### Details
Imagine this toy model
```
class MyModule(torch.nn.Module):
def __init__(self, a, b):
super(MyModule, self).__init__()
self.net = nn.Sequential(
nn.Linear(a, b),
nn.ReLU(),
)
def forward(self, x):
return self.net(x)
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net = nn.Sequential(
*[MyModule(10, 10000)]
+ [MyModule(10000, 1000)]
+ [MyModule(1000, 5)]
)
def forward(self, x):
return self.net(x)
```
Where FSDP is recursively wrapped around each `MyModule`, then dynamo-compiled, with dynamo already configured to skip/break in FSDP code. You'd expect to get 3 compiled AOT functions, corresponding to the contents of `MyModule`, and then see FSDP's communication ops happen inbetween them (eagerly). This almost happens (everything works out fine in forward), but in backward there is an ordering issue.
FSDP creates a flat buffer for all the parameters that are bucketed together, and then creates views into this buffer to replace the original parameters. On each iteration of forward, it creates a new view after 'filling' the flatbuffer with data from an all-gather operation, to 'unshard' the parameters from remote devices. Dynamo traces the first such view and stores it in a compiled graphmodule.
During tracing, we see (1) view created for first MyModule, (2) compile first MyModule, (3) ... for the rest of layers
Then during runtime, we see (A) view created for first MyModule (and orphaned), (B) execute first compiled MyModule, using old view, ...
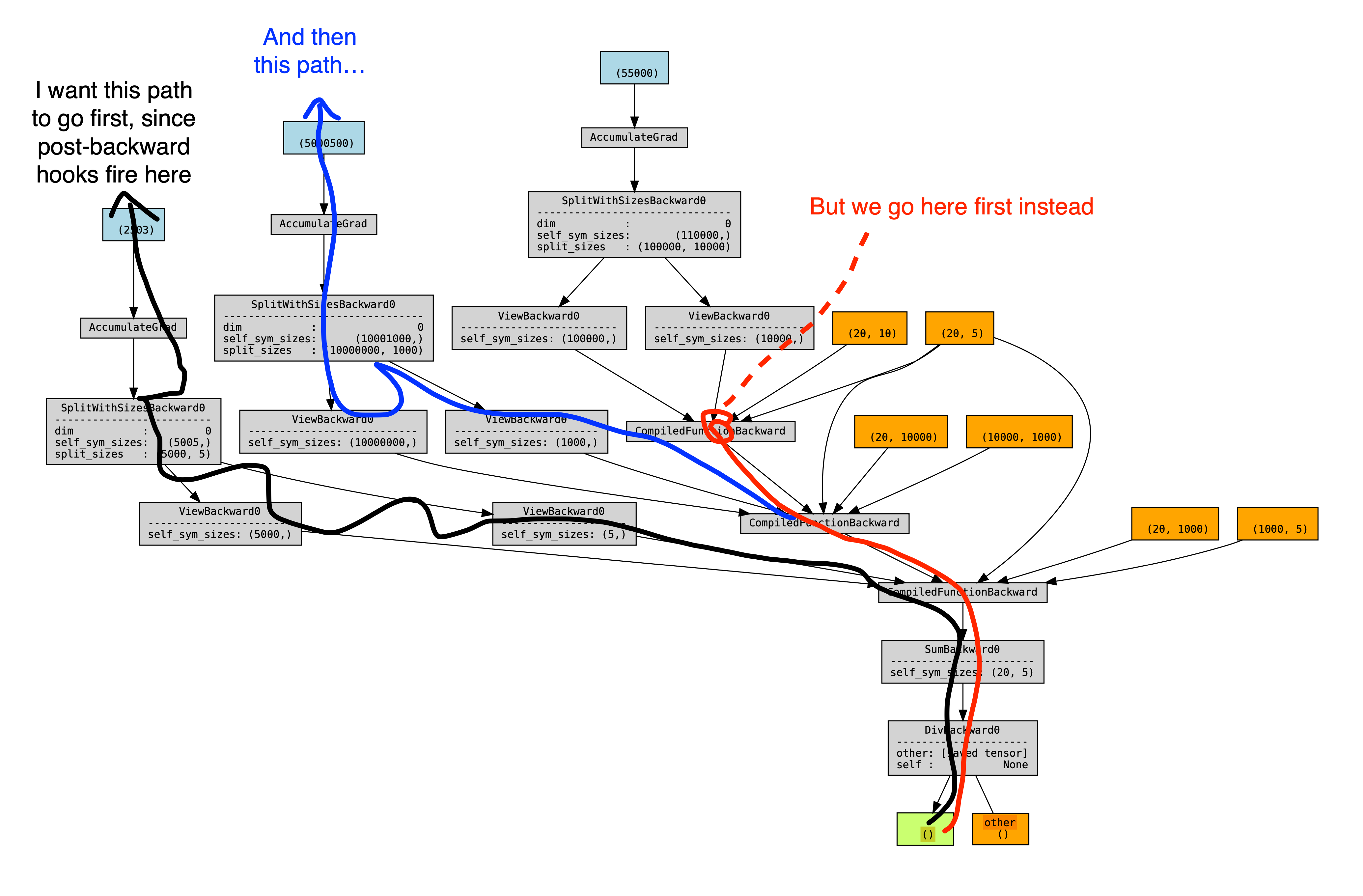
This is a problem, because we want backward hooks to run right after each compiled-backward, but autograd executes those hooks in an order mirroring their execution order during forward. Since we are forever using the views created during steps (1, 3, .. N), which all happen before the steps (A, B, ...), this means that all the hooks will happen after all the compiled backwards. An illustration of the problem - a torchviz graph showing the 2 possible orderings of autograd, and a profile showing the view-backwards ops happening after all the compiled backwards, and before all the backward hooks.
<img width="2069" alt="image" src="https://user-images.githubusercontent.com/4984825/202828002-32dbbd15-8fc3-4281-93e9-227ab5e32683.png">
<img width="2069" alt="image" src="https://user-images.githubusercontent.com/4984825/202828632-33e40729-9a7f-4e68-9ce1-571e3a8dd2dd.png">
A solution is to make dynamo not specialize on these nn modules. It is worth pointing out that this nn.module specialization is de-facto failing, as we are modifying .parameters and this bypasses dynamo's __setattr__ monkeypatch, which should have automatically kicked us out to Unspecialized and forced a recompile.
After unspecializing, the new views (created during steps A, C, ...) are actually _used_ at runtime by the module, making their creation order interleaved, making autograd execute their backwards interleaved.
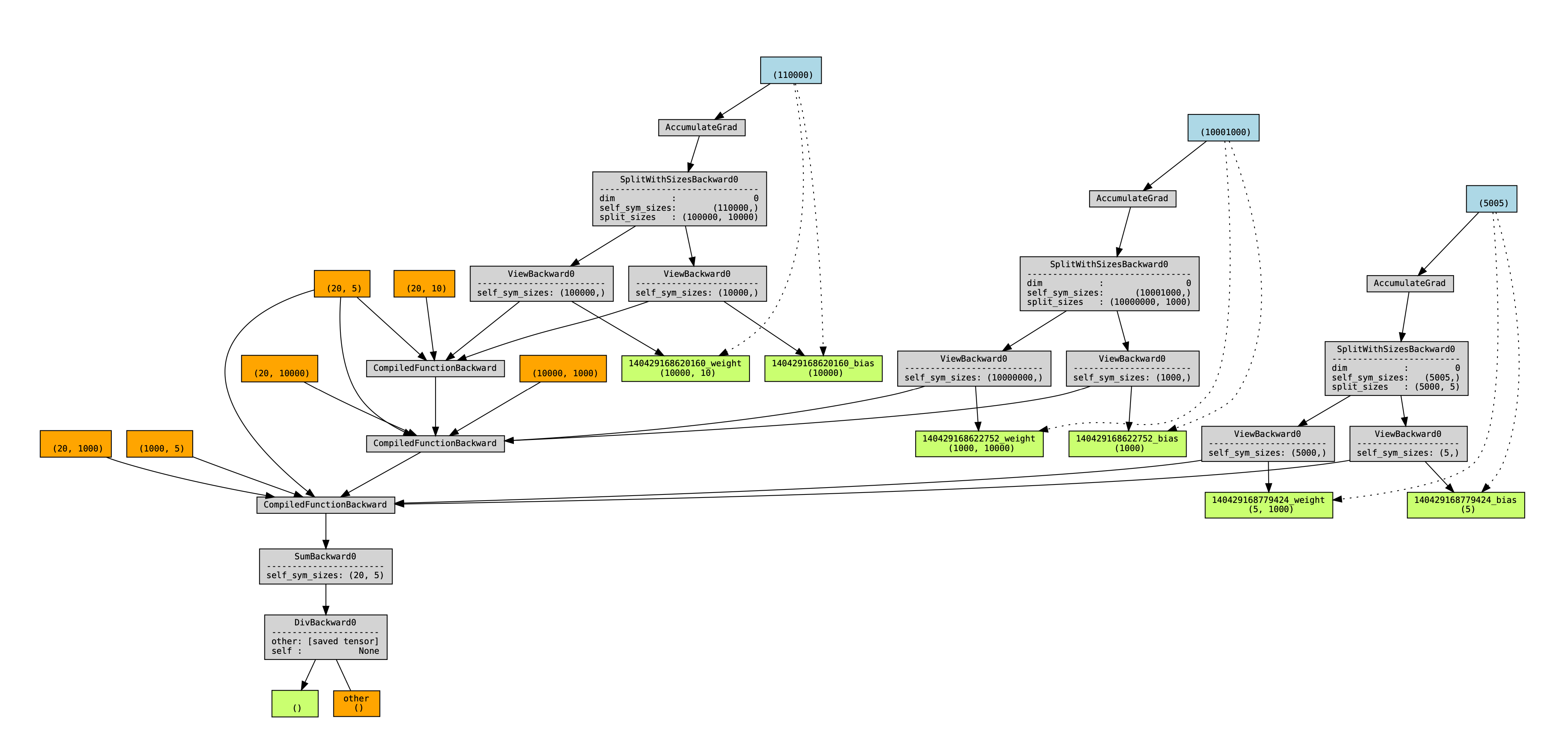
The new torchviz graph (this time with names added for the view tensors):
<img width="2043" alt="image" src="https://user-images.githubusercontent.com/4984825/202828480-d30005ba-0d20-45d8-b647-30b7ff5e91d3.png">
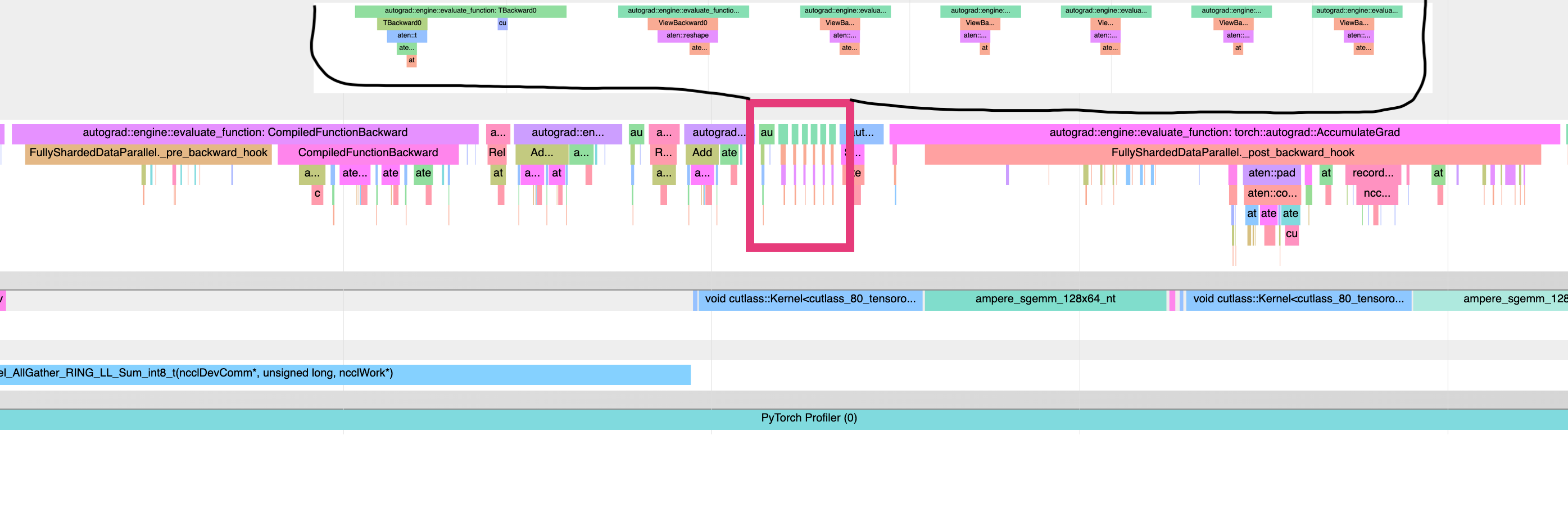
And a new profile showing the interleaving of compiled backwards and hooks, allowing overlapping of reduce-scatter.
<img width="2293" alt="image" src="https://user-images.githubusercontent.com/4984825/202828533-bb20a041-19b8-499c-b3cf-02808933df47.png">
@jansel @davidberard98 @aazzolini @mrshenli @awgu @ezyang @soumith @voznesenskym @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89330
Approved by: https://github.com/davidberard98
This ensures that all elements of `FlatParameter._params` and `FlatParameter._shared_params` are `nn.Parameter`s (as expected). This was violated by the local tensor of a `DTensor` when using 2D parallelism. To fix the breakage, we simply wrap with `nn.Parameter` if needed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89782
Approved by: https://github.com/fduwjj
- This PR registers the FSDP root pre-forward hook as a module forward pre-hook following the recently added support for kwargs for those hooks.
- This PR also passes `prepend=True` for the normal (not root) pre-forward hook. This is not strictly required for this PR, but I believe it is needed for composability with activation checkpointing. (We want to run FSDP logic on the outside and AC logic on the inside, just like how we recommend `FSDP(AC(module))` for the wrapper versions.)
Fun fact: I originally chose the `[FSDP()]` prefix in the PR titles when we still referred to composable FSDP as functional-like FSDP, in which case `FSDP()` approximated "functional FSDP". I am preserving this usage to make searching for PRs relating to composable FSDP easier.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89572
Approved by: https://github.com/mrshenli
This PR fixes `FSDP.clip_grad_norm_()` for `NO_SHARD`, which previously "double-counted" each gradient `world_size`-many times.
This does not address any discrepancies between `FULL_SHARD` and DDP. (Note that the unit tests do show parity between `FULL_SHARD` and DDP when using `FSDP.clip_grad_norm_()` and `nn.utils.clip_grad_norm_()` respectively on one iteration.)
The added unit test code path tests mixing nested FSDP instances with both `FULL_SHARD` and `NO_SHARD` to ensure that the `local_sharded_norm` and `local_nonsharded_norm` computations are interoperating correctly. I want to test non-FSDP root instance in the future, but this is BC breaking since we need to make `clip_grad_norm_()` a static method, which would require a different method call syntax (`FSDP.clip_grad_norm_(root_module, ...)` vs. `root_module.clip_grad_norm_(...)`).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88955
Approved by: https://github.com/zhaojuanmao
**BC Breaking Change**
This renames `unwrapped_params` to `nonwrapped_numel`. I prefer `nonwrapped` over `unwrapped` because "unwrap" suggests that some wrapping has been undone. I prefer `numel` over `params` because that is unit of measurement; I think we should keep "params" to refer to `nn.Parameter`s themselves.
This only breaks anything that passes `unwrapped_params` as a keyword argument, but I did not see anything that did that (except the one internal benchmark file but that does not actually depend on our `pytorch` code).
In a follow-up, I want to rename `min_num_params` to `min_nonwrapped_numel` in `size_based_auto_wrap_policy`, which is also BC breaking. Again, this is to differentiate between "params" being `nn.Parameter`s and "numel" being the unit for `param.numel()`.
**Overview**
This PR introduces `ModuleWrapPolicy` as a lightweight layer over the existing `transformer_auto_wrap_policy`. The most common auto wrapping paradigm is:
```
module_classes: Set[Type[nn.Module]] = ...
auto_wrap_policy = functools.partial(
transformer_auto_wrap_policy,
transformer_layer_cls=module_classes,
)
fsdp_model = FSDP(model, auto_wrap_policy=auto_wrap_policy, ...)
```
Now, users can instead write:
```
auto_wrap_policy = ModuleWrapPolicy(module_classes)
fsdp_model = FSDP(model, auto_wrap_policy=auto_wrap_policy, ...)
```
This hides the unused arguments expected from the callable (`recurse` and `unwrapped_params`/`nonwrapped_numel`).
`ModuleWrapPolicy` inherits from an abstract base class `FSDPPolicy` that expects a `policy` property. This decouples the construct of such `FSDPPolicy` classes and their actual `policy`, which must abide by the `_recursive_wrap` interface. Any existing auto wrap policy can be rewritten as a class that inherits from `FSDPPolicy`, so this approach is fully backward compatible from a functionality perspective.
I call this base class `FSDPPolicy` to generalize over the cases where we may not want to actually perform any nested wrapping. In reality, the policy is meant for constructing `FlatParameter`s, which just happened to be induced by a nested wrapping before. Given this, I am changing the constructor argument in `fully_shard()` to simply `policy` instead of `auto_wrap_policy`.
This PR migrates usages of `transformer_auto_wrap_policy` within our unit test suite to `ModuleWrapPolicy` as much as possible.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88450
Approved by: https://github.com/zhaojuanmao
Dynamo+AotAutograd needs a way to wrap all tensors (whether
inputs or params/buffers) in FakeTensor wrappers, and
FSDP's mangling of parameters hides them from this wrapping.
This PR unblocks running hf_bert and hf_T5 with FSDP under dynamo, whether using recursive wrapping around transformer layers or only applying FSDP around the whole model. Perf/memory validation and possibly optimization is the next step.
`python benchmarks/dynamo/distributed.py --torchbench_model hf_Bert --fsdp --dynamo aot_eager`
`python benchmarks/dynamo/distributed.py --torchbench_model hf_Bert --fsdp --dynamo aot_eager --fsdp_wrap`
`python benchmarks/dynamo/distributed.py --torchbench_model hf_T5 --fsdp --dynamo aot_eager`
`python benchmarks/dynamo/distributed.py --torchbench_model hf_T5 --fsdp --dynamo aot_eager --fsdp_wrap`
The problem:
Dynamo (Actually aot_autograd) trips up with FSDP becuase it must
wrap all input tensors in FakeTensor wrappers, and it only knows
to wrap graph inputs or named_(parameters, buffers). FSDP's
pre_forward hook sets views (which are not nn.param) into the flatparam
as attrs on the module with the same name as the original param, but
they will not show up in named_parameters.
- in use_orig_params mode, FSDP still de-registers
params during pre-forward hook, then re-registers them
post-forward
- during forward (between the hooks), the params are setattr'd
on the module as regular view tensors, not nn.Parameters
- note: use_orig_params is the recommended way to use FSDP,
and use_orig_params=False is being deprecated. So i only consider
use_orig_params=True for this enablement
The solution:
- adding them to named_buffers is not possible because it interferes
with how FSDP's `_apply` works
- since they are not actual nn.parameters, register_parameter will
complain about registering them
- simply seting `module._parameters[name] = view` seems to be a viable
workaround, despite being hacky, and FSDP code does modify _parameters
directly already.
Note: Manual checkpointing still isn't working with FSDP+dynamo,
so that will have to be addressed in a follow up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88781
Approved by: https://github.com/ezyang, https://github.com/awgu
**What**
This PR completely removes the `FullyShardedDataParallel` dependency from `_state_dict_utils` -- `_state_dict_utils` now depends only on `_FSDPState` and all the utils modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88637
Approved by: https://github.com/awgu
**What**
`_summon_full_parameters` is required for state_dict. To enable composable FSDP state_dict, `_summon_full_params` must be accessible without FullyShardedDataParall. This PR move the core logic of `_summon_full_params` to `_unshard_params_utils`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88636
Approved by: https://github.com/awgu
**What This PR Does**
_state_dict_utils currently accesses the FSDP states through module. To enable composable FSDP state_dict, these accesses need to go through _FSDPState. module is still required for most APIs as state_dict has to access per-module information.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88635
Approved by: https://github.com/awgu
This is one step toward the ultimate goal: remove the overwritten state_dict in FSDP. All the logic should be either in `pre_state_dict_hook` or `post_state_dict_hook`.
Since current `nn.Module` does not support `pre_state_dict_hook`, this PR mimic `pre_state_dict_hook` by calling the pre hook inside post the hook, effectively ditching all the work done by `nn.Module.state_dict`. Once `pre_state_dict_hook` is supported by `nn.Module`, these pre hook calls can be moved out from the post hooks and be registered to `nn.Module.pre_state_dict_hook`.
The major issue of this temporary solution is that `post_state_dict_hook` is called from the leaf node to the root node. This makes the `module._lazy_init()` invalid as FSDP assumes `_lazy_init()` to be called from the root. As a result, `FSDP.state_dict` currently contains only one logic -- calling `module._lazy_init()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87900
Approved by: https://github.com/rohan-varma
- Calling `F.pad()` issues a pad kernel from the CPU even if there is no padding needed, which can incur some non-negligible overhead. This PR removes that unnecessary call for the no-padding case.
- This PR also does not zero the newly-allocated sharded gradient tensor before the reduce-scatter if `use_orig_params=True` because there is no need. The reduce-scatter will fill the tensor anyway, and we do not care about the values in the padding. For `use_orig_params=False`, the padding is exposed to the user, so we preserve the existing semantics of zeroing it. I left a to-do to follow-up since we may optimize that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88769
Approved by: https://github.com/zhaojuanmao
{kind=link}
{kind=link}
{kind=link}
{kind=link}