- Add `full` nvprim to support factory functions because the full reference uses `empty` and `fill` while we have a full factory function.
- Change `full_like` reference to call `full` to avoid defining another nvprim.
- Enable support for new_zeros to enable `cudnn_batch_norm` decomposition.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89230
Approved by: https://github.com/kevinstephano, https://github.com/mruberry
… as equivalent replacements for std::is_pod and std::is_pod_v because they are deprecated in C++20.
When consuming libtorch header files in a project that uses C++20, there are warnings about std::is_pod being deprecated. This patch fixes that issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88918
Approved by: https://github.com/ezyang
Summary: `ExprGroup::getMergeCandidates()` had a logic bug. The vector being initialized had its arguments mis-ordered. This didn't trigger a build warning because the warning about implicit cast from an integral type to `bool` wasn't enabled.
Test Plan: `buck test fbsource//arvr/mode/win/vs2019/cuda11/opt fbsource//arvr/mode/hybrid_execution //arvr/libraries/neural_net_inference/TorchScript/...`
Differential Revision: D41488939
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89551
Approved by: https://github.com/davidberard98, https://github.com/jjsjann123
Update previous recursive logic.
Continue setting training attribute only if the slot is an object and a module.
For the corresponding JIT module, they get the module list first and set module one by one. there is method to get all modules iteratively, instead of recursively.
This change patch one fix to set training attribute for `model_f269583363.ptl`. Another patch is needed, because current lite interpreter doesn't have the correct type when loading object with setstate.
Differential Revision: [D41466417](https://our.internmc.facebook.com/intern/diff/D41466417/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89488
Approved by: https://github.com/iseeyuan
Summary:
This PR deprecates the `compute_dtype` field on observers, and replaces
it with the `is_dynamic` field on observers. This is better aligned
with the reference model spec.
Test plan:
```
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85431
Approved by: https://github.com/jerryzh168
Summary: This permute copy change seems to be causing huge regressions on machines without AVX512. Revert to mitigate. This shouldn't be problematic since the improvement from changing it was super small anyways.
Differential Revision: D41450088
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89463
Approved by: https://github.com/hlu1
Handling constant data for xnnpack delegation. This allows us to handle new modules like such:
```
class Module(torch.nn.Module):
def __init__(self):
super().__init__()
self._constant = torch.ones(4, 4, 4)
def forward(self, x):
return x + self._constant
```
this is the precursor work to handling convolution, as we need to serialize constant data(weights)
Differential Revision: [D41050349](https://our.internmc.facebook.com/intern/diff/D41050349/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89445
Approved by: https://github.com/digantdesai
`setType` API is not respected in current exporter because the graph-level shape type inference simply overrides every NOT ONNX Op shape we had from node-level shape type inference. To address this issue, this PR (1) makes custom Op with `setType` **reliable** in ConstantValueMap to secure its shape/type information in pass: _C._jit_pass_onnx. (2) If an invalid Op with shape/type in pass: _C._jit_pass_onnx_graph_shape_type_inference(graph-level), we recognize it as reliable.
1. In #62856, The refactor in onnx.cpp made regression on custom Op, as that was the step we should update custom Op shape/type information into ConstantValueMap for remaining Ops.
2. Add another condition besides IsValidONNXNode for custom Op setType in shape_type_inference.cpp. If all the node output has shape (not all dynamic), we say it's custom set type.
3. ~However, this PR won't solve the [issue](https://github.com/pytorch/pytorch/issues/87738#issuecomment-1292831219) that in the node-level shape type inference, exporter invokes the warning in terms of the unknow custom Op, since we process its symbolic_fn after this warning, but it would have shape/type if setType is used correctly. And that will be left for another issue to solve. #84661~ Add `no_type_warning` in UpdateReliable() and it only warns if non ONNX node with no given type appears.
Fixes#81693Fixes#87738
NOTE: not confident of this not breaking anything. Please share your thoughts if there is a robust test on your mind.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88622
Approved by: https://github.com/BowenBao
Introduce `_eval_no_call` method, that evaluates statement only if it
does not contain any calls(done by examining the bytecode), thus preventing command injection exploit
Added simple unit test to check for that
`torch.jit.annotations.get_signature` would not result in calling random
code.
Although, this code path exists for Python-2 compatibility, and perhaps
should be simply removed.
Fixes https://github.com/pytorch/pytorch/issues/88868
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89189
Approved by: https://github.com/suo
Here we pass XNNExecutor* to compile model so that XNNExecutor can be allocated by runtime. This signature change is for executorch:
```
XNNExecutor compileModel(void* buffer) --> void compileModel(void* buffer, XNNExecutor* executor)
```
The intended usecase for allocating Executor and Compiling the serialized flatbuffer:
```
XNNExecutor* executor = runtime_allocator->allocateList<jit::xnnpack::delegate::XNNExecutor>(1);
XNNCompiler::compileModel(processed.buffer, executor);
```
Differential Revision: [D41208387](https://our.internmc.facebook.com/intern/diff/D41208387/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89090
Approved by: https://github.com/digantdesai
As title, add three things to the schema
1. debug handle for each node
2. file identifier, so we can sanity check we are getting the xnnpack schema flatbuffers file, instead of other random binary
3. extension, so the dumped binary will end up with its own extension like `myschema.xnnpack` (maybe can have a better name) instead of the default extension `.bin`
Differential Revision: [D40906970](https://our.internmc.facebook.com/intern/diff/D40906970/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89033
Approved by: https://github.com/mcr229
Bug:
Previously, `initOutputLayouts()` was called after creating a graph and before merging other nodes. It is a vector with one element. So when a graph contains multiple outputs, e.g. using AOTAutograd compile in my case, layout_propagation pass try to access out of range elements in the vector. Then it comes to the second bug in `useOpaqueLayout()`, the out of range checks the index with the updated output size instead of the size of the vector. Then used `[]` to access the element, which is out of range.
Fixes the above two issues:
1. check the offset is within range with the size of `attr::output_layouts` vector instead of another variable. This check catches the error now.
2. change the place to initial `attr::output_layouts` after node merging. The graph may change with node merging. Thus we moved the initialization in layout_propagation with the complete graph.
Added test time:
`Ran 1 test in 0.383s`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88496
Approved by: https://github.com/jgong5, https://github.com/sanchitintel
* Reflect required arguments in method signature for each diagnostic rule. Previous design accepts arbitrary sized tuple which is hard to use and prone to error.
* Removed `DiagnosticTool` to keep things compact.
* Removed specifying supported rule set for tool(context) and checking if rule of reported diagnostic falls inside the set, to keep things compact.
* Initial overview markdown file.
* Change `full_description` definition. Now `text` field should not be empty. And its markdown should be stored in `markdown` field.
* Change `message_default_template` to allow only named fields (excluding numeric fields). `field_name` provides clarity on what argument is expected.
* Added `diagnose` api to `torch.onnx._internal.diagnostics`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87830
Approved by: https://github.com/abock
This is the on-device runtime work. We modify the compile and execute from our hacky solution from before to what will actually be running at runtime.
First we rebuild our graph from the serialized flatbuffer string. We also introduce a runtime wrapper that inherits CustomClassHolder that allows us to forward along the built xnngraph runtime to our execute function
Once the subgraph object has been rebuilt by our we pass it along to the runtime wrapper for us to forward along to execute
At execute we prep the input/outputs and invoke the runtime using our runtime wrapper. Finally we forward those results to our execution
Differential Revision: [D39413031](https://our.internmc.facebook.com/intern/diff/D39413031/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D39413031/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88780
Approved by: https://github.com/digantdesai
# Executor Class
Executor object used to wrap our xnn_runtime object. The ideal flow of this object looks as such:
```
executor.set_inputs(vector<tensor> inputs, vector<tensor> outputs)
executor.forward()
```
This will likely be returned by our delegate compile and given over to execute in order to run inference using the xnn runtime
##### Executorch Considerations
```
#include <ATen/Functions.h>
#include <ATen/Utils.h>
```
These Aten functions are included in order to use at::Tensor when setting the inputs, this will change when used for Executorch because we will be switching from at::Tensor to whatever tensor abstraction is used for ET. Seems like they have the same call for `.data_ptr<float>()`, so realistically all logic here will be the same.
ATen/Utils is used for TORCH_CHECK. We will switch to ET_CHECK_MESSAGE for executorch.
Differential Revision: [D40733121](https://our.internmc.facebook.com/intern/diff/D40733121/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88778
Approved by: https://github.com/digantdesai
As of LLVM 15 typed pointers are going away:
https://llvm.org/docs/OpaquePointers.html. Thus
`getPointerElementType` is no longer legal, since pointers are all
opaque. I don't totally remember why we use it so prolifically, or
whether there's an easy change to get rid of it, or whether we'd need
a significant refactor to carry around `Type`s alongside `Value`s.
But in any case, NNC is deprecated (see: TorchInductor) and will
hopefully be gone before LLVM 16 is a thing. For now, we can apply
the hack of turning off opaque pointer mode on the LLVMContext.
Differential Revision: [D41176215](https://our.internmc.facebook.com/intern/diff/D41176215)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88798
Approved by: https://github.com/desertfire
Fixes#81690
TODO:
* [x] C++ Unpickler Fix (locally tested pickled in Python and unpickled in C++)
* [x] C++ Pickler Fix (locally tested pickled in C++ and unpickled in Python)
* [x] Do quant_tensor, sparse_tensor, etc require similar changes? (Sparse and Quant don't need this)
* [x] Add Comments
* [x] How to make sure C++ and Python are in sync? (Functions in `pickler.h` help in getting and setting Tensor Metadata (math-bits for now) on a tensor. They are the only place which should handle this.)
Notes:
Quant Tensor don't support complex dtypes and for float they segfault with `_neg_view` : https://github.com/pytorch/pytorch/issues/88484
Sparse Tensor:
```python
>>> a = torch.tensor([[0, 2.], [3j, 0]]).to_sparse()
>>> a.conj().is_conj()
False
>>> a._neg_view()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NotImplementedError: Cannot access storage of SparseTensorImpl
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88182
Approved by: https://github.com/ezyang, https://github.com/anjali411
This build uses the wrong BUILD_ENVIRONMENT `pytorch-linux-focal-py3`, thus it hasn't been run for a long time (forgotten). The name was probably the old name of the build environment we used in the past. The convention today doesn't have the `pytorch-` prefix. There is a TODO for this:
> TODO: this condition is never (BUILD_ENVIRONMENT doesn't start with pytorch-), need to fix this.
This is done as part of [T131829540](https://www.internalfb.com/intern/tasks/?t=131829540), where we want
`static_runtime_benchmark` build and test jobs to run in OSS CI to avoid breaking internal
* I also fix some compiler warning errors `-Werror=sign-compare`, `-Werror,-Wunused-const-variable`, and gcc7 compatibility issue along the way because this hasn't been run for a long time.
* Reviving this test also reveals a small bug in `PrepackWeights` test in `test_static_runtime.cc` added recently in https://github.com/pytorch/pytorch/pull/85289. The test refers to an internal ops and should only be run internally. This has been fixed by https://github.com/pytorch/pytorch/pull/87799 (To be merged)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87660
Approved by: https://github.com/malfet
Summary:
D40798763 broke this op. Unfortunately, it wasn't caught at land time due to the recent OSS Static Runtime test problems.
The problem is C++ overload resolution. After D40798763, the int that we were passing to `at::native::tensor_split` was getting implicitly converted to `IntArrayRef`. Fix this by converting the int to a `SymInt` and calling the correct overload.
Test Plan:
```
buck2 test caffe2/benchmarks/static_runtime:static_runtime_cpptest -- Tensor_Split --run-disabled
```
Differential Revision: D40862394
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88113
Approved by: https://github.com/hlu1
Syncing nvfuser devel branch to upstream master. https://github.com/csarofeen/pytorch/
Codegen changes include:
* codegen improvement:
i. allow non-root trivial reductions, allow empty/no-op fusion
ii. fixes vectorization checks and size calculation
iii. bank conflict handle improvement
iv. enables transpose scheduler
* misc:
i. CI tests failure fixes
ii. cpp tests file clean up
iii. trivial forwarding supports added in codegen runtime
iv. added factory methods support in codegen
Commits that's in this PR from the devel branch:
```
7117a7e37ebec372d9e802fdfb8abb7786960f4a patching nvfuser conv cudnn test numerics mismatch (#2048)
65af1a4e7013f070df1ba33701f2d524de79d096 Inserting sync for redundant parallel types is already done at the (#2023)
6ac74d181689c8f135f60bfc1ec139d88941c98c Fix sync map (#2047)
f5bca333355e2c0033523f3402de5b8aac602c00 Bank conflict checker improvements (#2032)
d2ca7e3fd203537946be3f7b435303c60fa7f51e Minor update on cp.async code generation. (#1901)
d36cf61f5570c9c992a748126287c4e7432228e0 Test file cleanup (#2040)
0b8e83f49c2ea9f04a4aad5061c1e7f4268474c6 Allow non-root trivial reductions (#2037)
a2dfe40b27cd3f5c04207596f0a1818fbd5e5439 Fix vectorize size calculation (#2035)
e040676a317fe34ea5875276270c7be88f6eaa56 Use withPredicate to replace setPredicate to maintain Exprs immutable (#2025)
197221b847ad5eb347d7ec1cf2706733aacbf97c removing ci workflow (#2034)
40e2703d00795526e7855860aa00b9ab7160755f Reduction rand like patch (#2031)
bc772661cbdb3b711d8e9854ae9b8b7052e3e4a3 Add utility for checking bank conflict of shared memory (#2029)
ddd1cf7695f3fb172a0e4bcb8e4004573617a037 Add back FusionReductionWithTrivialReduction_CUDA (#2030)
fbd97e5ef15fa0f7573800e6fbb5743463fd9e57 Revert "Cleanup trivial reduction workarounds (#2006)" (#2024)
bca20c1dfb8aa8d881fc7973e7579ce82bc6a894 Cleanup trivial reduction workarounds (#2006)
e4b65850eee1d70084105bb6e1f290651adde23e Trivial forwarding (#1995)
1a0e355b5027ed0df501989194ee8f2be3fdd37a Fix contiguity analysis of predicates to match updated contiguity. (#1991)
a4effa6a5f7066647519dc56e854f4c8a2efd2a7 Enable output allocation cache (#2010)
35440b7953ed8da164a5fb28f87d7fd760ac5e00 Patching bn inference (#2016)
0f9f0b4060dc8ca18dc65779cfd7e0776b6b38e8 Add matmul benchmark (#2007)
45045cd05ea268f510587321dbcc8d7c2977cdab Enable tests previously disabled due to an aliasing bug (#2005)
967aa77d2c8e360c7c01587522eec1c1d377c87e Contiguous indexing for View operations (#1990)
a43cb20f48943595894e345865bc1eabf58a5b48 Make inlining even more modular (#2004)
dc458358c0ac91dfaf4e6655a9b3fc206fc0c897 Test util cleanup (#2003)
3ca21ebe4d213f0070ffdfa4ae5d7f6cb0b8e870 More strict validation (#2000)
a7a7d573310c4707a9f381831d3114210461af01 Fix build problem (#1999)
fc235b064e27921fa9d6dbb9dc7055e5bae1c222 Just fixes comments (#1998)
482386c0509fee6edb2964c5ae72074791f3e43a cleanup (#1997)
4cbe0db6558a82c3097d281eec9c85ad2ea0893a Improve divisible split detection (#1970)
42ccc52bdc18bab0330f4b93ed1399164e2980c9 Minor build fix. (#1996)
fcf8c091f72d46f3055975a35afd06263324ede6 Cleanup of lower_utils.cpp: Isolate out GpuLower usage (#1989)
15f2f6dba8cbf408ec93c344767c1862c30f7ecc Move ConcretizedBroadcastDomains to shared_ptr in GpuLower. (#1988)
8f1c7f52679a3ad6acfd419d28a2f4be4a7d89e2 Minor cleanup lower_unroll.cpp (#1994)
1d9858c80319ca7f0037db7de5f04e47f540d76c Minor cleanup (#1992)
f262d9cab59f41c669f53799c6d4a6b9fc4267eb Add support for uniform RNG (#1986)
eb1dad10c73f855eb1ecb20a8b1f7b6edb0c9ea3 Remove non-const functions, remove GpuLower instance on build, pass in ca_map. (#1987)
634820c5e3586c0fe44132c51179b3155be18072 Add support for some empty fusion (#1981)
eabe8d844ad765ee4973faa4821d451ef71b83c3 Segment self mapping fusions (#1954)
e96aacfd9cf9b3c6d08f120282762489bdf540c8 Enable Transpose operation (#1882)
425dce2777420248e9f08893765b5402644f4161 Add a null scheduler that helps segmenting away no-op schedules (#1835)
306d4a68f127dd1b854b749855e48ba23444ba60 Fix canScheduleCompileTime check of transpose scheduler (#1969)
b1bd32cc1b2ae7bbd44701477bddbcfa6642a9be Minor fix (#1967)
bd93578143c1763c1e00ba613a017f8130a6b989 Enable transpose scheduler (#1927)
b7a206e93b4ac823c791c87f12859cf7af264a4c Move scheduler vectorize utilities into their own file (#1959)
d9420e4ca090489bf210e68e9912bb059b895baf View scheduling (#1928)
c668e13aea0cf21d40f95b48e0163b812712cdf2 Upstream push ci fixes (#1965)
c40202bb40ce955955bb97b12762ef3b6b612997 Fix dump effective bandwidth (#1962)
93505bcbb90a7849bd67090fe5708d867e8909e4 WAR on index mapping when exact and permissive maps differ (#1960)
45e95fd1d3c773ee9b2a21d79624c279d269da9f Allow splitting inner-most ID to create virtual innermost ID in transpose scheduler (#1930)
a3ecb339442131f87842eb56955e4f17c544e99f Improve the comments at the beginning of index_compute.h (#1946)
f7bc3417cc2923a635042cc6cc361b2f344248d6 Remove unused variables (#1955)
df3393adbb5cb0309d091f358cfa98706bd4d313 Some cleanup (#1957)
7d1d7c8724ab5a226fad0f5a80feeac04975a496 TVDomainGuard factory (#1953)
357ba224c0fb41ed3e4e8594d95599c973f4a0ca Fill allocation with nan on tests (#1956)
8eafc54685d406f5ac527bcbacc475fda4492d7a Fix detection of unmappable root domains (#1952)
90a51f282601ba8ebd4c84b9334efd7762a234bc Some indexing cleanups, Add eye support (#1940)
ddc01e4e16428aec92f9c84d698f959b6436a971 Exclude unsupported data types (#1951)
992e17c0688fe690c51b50e81a75803621b7e6aa test the groups the same order as they are merged (#1949)
208262b75d1fed0597a0329d61d57bc8bcd7ff14 Move detection of self mapping IDs to IterDomainGraph from (#1941)
ac4de38c6ee53b366e85fdfe408c3642d32b57df Merge pull request #1945 from csarofeen/master_merge_0828
631094891a96f715d8c9925fb73d41013ca7f2e3 Add full, full_like, zeros, zeros_like, ones, ones_like (#1943)
aab10bce4541204c46b91ff0f0ed9878aec1bfc4 Merge remote-tracking branch 'upstream/viable/strict' into HEAD
4c254c063bb55887b45677e3812357556a7aa80d Fix arange when step is negative (#1942)
89330aa23aa804340b2406ab58899d816e3dc3d2 Tensor factories must set the output shape as its input (#1939)
```
RUN_TORCHBENCH: nvfuser
Differential Revision: [D40869846](https://our.internmc.facebook.com/intern/diff/D40869846)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87779
Approved by: https://github.com/davidberard98
Summary:
https://www.internalfb.com/code/fbsource/[c0e4da0b5c7fff3b4e31e4611033c30cabdc6aef]/fbcode/caffe2/torch/csrc/jit/backends/backend_detail.cpp?lines=268-276
seems like the torchscript addition of
`$unpack, = self.__backend.execute( ... `
the comma after unpack forces the result of execute to have only one item. So for this fix now when the size of the outputs > 1, execute returns a List List of outputs (basically put the outputs in another list before putting it into the list we return)
```
[[output1, output2, output3, ...]]
```
instead of
```
[output1, output2, output3, ...]
```
Do we want to fix this in backend_detail? Or should we make the change in our delegate to accomadate the torchscript? Proposing this q here. Requesting cccclai, kimishpatel for approval here
Test Plan: unblocked models for chengxiangyin and models in pytorch playground all passing unit tests
Reviewed By: kimishpatel, cccclai
Differential Revision: D40328684
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88345
Approved by: https://github.com/jmdetloff, https://github.com/Skylion007
{kind=link}
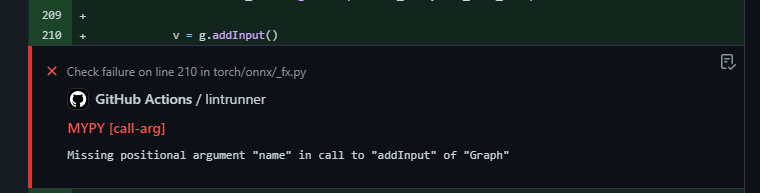{kind=link}