Summary: This diff merges both previous implementations of constructors for nested tensors, the one from lists of tensors and the one with arbitrary python lists, adn implements it in pytorch core so no extensions are needed to construct NT.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88213
Approved by: https://github.com/cpuhrsch
Summary:
This header is being included from both aten/native and torch/csrc, but
some of our build configurations don't allow direct dependencies from
torch/csrc to atent/native, so put the header in aten where it's always
accessible.
Resolves https://github.com/pytorch/pytorch/issues/81198
Test Plan:
CI.
```
./scripts/build_android.sh
env ANDROID_ABI="x86_64" ANDROID_NDK=".../ndk-bundle" CMAKE_CXX_COMPILER_LAUNCHER=ccache CMAKE_C_COMPILER_LAUNCHER=ccache USE_VULKAN=0 ./scripts/build_android.sh
echo '#include <torch/torch.h>' > test.cpp
g++ -E -I $PWD/build_android/install/include/ -I $PWD/build_android/install/include/torch/csrc/api/include test.cpp >/dev/null
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82379
Approved by: https://github.com/ezyang, https://github.com/malfet
We define specializations for pybind11 defined templates
(in particular, PYBIND11_DECLARE_HOLDER_TYPE) and consequently
it is important that these specializations *always* be #include'd
when making use of pybind11 templates whose behavior depends on
these specializations, otherwise we can cause an ODR violation.
The easiest way to ensure that all the specializations are always
loaded is to designate a header (in this case, torch/csrc/util/pybind.h)
that ensures the specializations are defined, and then add a lint
to ensure this header is included whenever pybind11 headers are
included.
The existing grep linter didn't have enough knobs to do this
conveniently, so I added some features. I'm open to suggestions
for how to structure the features better. The main changes:
- Added an --allowlist-pattern flag, which turns off the grep lint
if some other line exists. This is used to stop the grep
lint from complaining about pybind11 includes if the util
include already exists.
- Added --match-first-only flag, which lets grep only match against
the first matching line. This is because, even if there are multiple
includes that are problematic, I only need to fix one of them.
We don't /really/ need this, but when I was running lintrunner -a
to fixup the preexisting codebase it was annoying without this,
as the lintrunner overall driver fails if there are multiple edits
on the same file.
I excluded any files that didn't otherwise have a dependency on
torch/ATen, this was mostly caffe2 and the valgrind wrapper compat
bindings.
Note the grep replacement is kind of crappy, but clang-tidy lint
cleaned it up in most cases.
See also https://github.com/pybind/pybind11/issues/4099
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82552
Approved by: https://github.com/albanD
unflatten now has a free function version in torch.flatten in addition to
the method in torch.Tensor.flatten.
Updated docs to reflect this and polished them a little.
For consistency, changed the signature of the int version of unflatten in
native_functions.yaml.
Some override tests were failing because unflatten has unusual
characteristics in terms of the .int and .Dimname versions having
different number of arguments so this required some changes
to test/test_override.py
Removed support for using mix of integer and string arguments
when specifying dimensions in unflatten.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81399
Approved by: https://github.com/Lezcano, https://github.com/ngimel
This PR heavily simplifies the code of `linalg.solve`. At the same time,
this implementation saves quite a few copies of the input data in some
cases (e.g. A is contiguous)
We also implement it in such a way that the derivative goes from
computing two LU decompositions and two LU solves to no LU
decompositions and one LU solves. It also avoids a number of unnecessary
copies the derivative was unnecessarily performing (at least the copy of
two matrices).
On top of this, we add a `left` kw-only arg that allows the user to
solve `XA = B` rather concisely.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74046
Approved by: https://github.com/nikitaved, https://github.com/IvanYashchuk, https://github.com/mruberry
```Python
chebyshev_polynomial_v(input, n, *, out=None) -> Tensor
```
Chebyshev polynomial of the third kind $V_{n}(\text{input})$.
```Python
chebyshev_polynomial_w(input, n, *, out=None) -> Tensor
```
Chebyshev polynomial of the fourth kind $W_{n}(\text{input})$.
```Python
legendre_polynomial_p(input, n, *, out=None) -> Tensor
```
Legendre polynomial $P_{n}(\text{input})$.
```Python
shifted_chebyshev_polynomial_t(input, n, *, out=None) -> Tensor
```
Shifted Chebyshev polynomial of the first kind $T_{n}^{\ast}(\text{input})$.
```Python
shifted_chebyshev_polynomial_u(input, n, *, out=None) -> Tensor
```
Shifted Chebyshev polynomial of the second kind $U_{n}^{\ast}(\text{input})$.
```Python
shifted_chebyshev_polynomial_v(input, n, *, out=None) -> Tensor
```
Shifted Chebyshev polynomial of the third kind $V_{n}^{\ast}(\text{input})$.
```Python
shifted_chebyshev_polynomial_w(input, n, *, out=None) -> Tensor
```
Shifted Chebyshev polynomial of the fourth kind $W_{n}^{\ast}(\text{input})$.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78304
Approved by: https://github.com/mruberry
Adds:
```Python
bessel_j0(input, *, out=None) -> Tensor
```
Bessel function of the first kind of order $0$, $J_{0}(\text{input})$.
```Python
bessel_j1(input, *, out=None) -> Tensor
```
Bessel function of the first kind of order $1$, $J_{1}(\text{input})$.
```Python
bessel_j0(input, *, out=None) -> Tensor
```
Bessel function of the second kind of order $0$, $Y_{0}(\text{input})$.
```Python
bessel_j1(input, *, out=None) -> Tensor
```
Bessel function of the second kind of order $1$, $Y_{1}(\text{input})$.
```Python
modified_bessel_i0(input, *, out=None) -> Tensor
```
Modified Bessel function of the first kind of order $0$, $I_{0}(\text{input})$.
```Python
modified_bessel_i1(input, *, out=None) -> Tensor
```
Modified Bessel function of the first kind of order $1$, $I_{1}(\text{input})$.
```Python
modified_bessel_k0(input, *, out=None) -> Tensor
```
Modified Bessel function of the second kind of order $0$, $K_{0}(\text{input})$.
```Python
modified_bessel_k1(input, *, out=None) -> Tensor
```
Modified Bessel function of the second kind of order $1$, $K_{1}(\text{input})$.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78451
Approved by: https://github.com/mruberry
Adds:
```Python
chebyshev_polynomial_t(input, n, *, out=None) -> Tensor
```
Chebyshev polynomial of the first kind $T_{n}(\text{input})$.
If $n = 0$, $1$ is returned. If $n = 1$, $\text{input}$ is returned. If $n < 6$ or $|\text{input}| > 1$ the recursion:
$$T_{n + 1}(\text{input}) = 2 \times \text{input} \times T_{n}(\text{input}) - T_{n - 1}(\text{input})$$
is evaluated. Otherwise, the explicit trigonometric formula:
$$T_{n}(\text{input}) = \text{cos}(n \times \text{arccos}(x))$$
is evaluated.
## Derivatives
Recommended $k$-derivative formula with respect to $\text{input}$:
$$2^{-1 + k} \times n \times \Gamma(k) \times C_{-k + n}^{k}(\text{input})$$
where $C$ is the Gegenbauer polynomial.
Recommended $k$-derivative formula with respect to $\text{n}$:
$$\text{arccos}(\text{input})^{k} \times \text{cos}(\frac{k \times \pi}{2} + n \times \text{arccos}(\text{input})).$$
## Example
```Python
x = torch.linspace(-1, 1, 256)
matplotlib.pyplot.plot(x, torch.special.chebyshev_polynomial_t(x, 10))
```
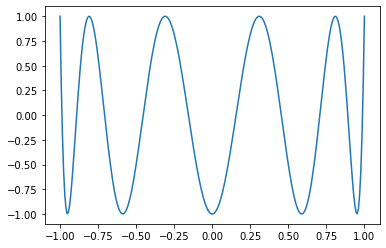
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78196
Approved by: https://github.com/mruberry
`nn.Transformer` is not possible to be used to implement BERT, while `nn.TransformerEncoder` does. So this PR moves the sentence 'Users can build the BERT model with corresponding parameters.' from `nn.Transformer` to `nn.TransformerEncoder`.
Fixes#68053
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78337
Approved by: https://github.com/jbschlosser
Euler beta function:
```Python
torch.special.beta(input, other, *, out=None) → Tensor
```
`reentrant_gamma` and `reentrant_ln_gamma` implementations (using Stirling’s approximation) are provided. I started working on this before I realized we were missing a gamma implementation (despite providing incomplete gamma implementations). Uses the coefficients computed by Steve Moshier to replicate SciPy’s implementation. Likewise, it mimics SciPy’s behavior (instead of the behavior in Cephes).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78031
Approved by: https://github.com/mruberry
This PR modifies `lu_unpack` by:
- Using less memory when unpacking `L` and `U`
- Fuse the subtraction by `-1` with `unpack_pivots_stub`
- Define tensors of the correct types to avoid copies
- Port `lu_unpack` to be a strucutred kernel so that its `_out` version
does not incur on extra copies
Then we implement `linalg.lu` as a structured kernel, as we want to
compute its derivative manually. We do so because composing the
derivatives of `torch.lu_factor` and `torch.lu_unpack` would be less efficient.
This new function and `lu_unpack` comes with all the things it can come:
forward and backward ad, decent docs, correctness tests, OpInfo, complex support,
support for metatensors and support for vmap and vmap over the gradients.
I really hope we don't continue adding more features.
This PR also avoids saving some of the tensors that were previously
saved unnecessarily for the backward in `lu_factor_ex_backward` and
`lu_backward` and does some other general improvements here and there
to the forward and backward AD formulae of other related functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67833
Approved by: https://github.com/IvanYashchuk, https://github.com/nikitaved, https://github.com/mruberry
This functionality does not seem to be used
and there are some requests to update dependency.
Add `third_party` to torch_cpu include directories if compiling with
Caffe2 support, as `caffe2/quantization/server/conv_dnnlowp_op.cc` depends on `third_party/fbgemm/src/RefImplementations.h`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75394
Approved by: https://github.com/janeyx99, https://github.com/seemethere
This PR adds a function for computing the LDL decomposition and a function that can solve systems of linear equations using this decomposition. The result of `torch.linalg.ldl_factor_ex` is in a compact form and it's required to use it only through `torch.linalg.ldl_solve`. In the future, we could provide `ldl_unpack` function that transforms the compact representation into explicit matrices.
Fixes https://github.com/pytorch/pytorch/issues/54847.
cc @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69828
Approved by: https://github.com/Lezcano, https://github.com/mruberry, https://github.com/albanD
Closes#44459
This migrates the python implementation of `_pad_circular` to ATen and
removes the old C++ implementation that had diverged from python.
Note that `pad` can't actually use this until the
forward-compatibility period is over.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73410
Approved by: https://github.com/ezyang
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73378
1) ran check_for_c10_loops.py to automatically update all files (*.h, *.hpp, *.cpp) under fbcode/caffe2/torch (this is the path in the check_for_c10_loops.py, slightly different from the task description where the path mentioned was fbcode/caffe2. since current commit already contains 27 files, will use a separate commit for additional files).
2) manually reviewed each change, and reverted a few files:
(a) select_keys.cpp, bucketize_calibration.cpp, index_mmh and TCPStore.cpp: iterator modified in loop
(b) qlinear_4bit_ops.cpp and id_list_feature_merge_conversion.cpp: condition containing multiple expressions.
Test Plan:
Doing the following (still in progress, will address issues as they appear):
buck build ...
buck test ...
Reviewed By: r-barnes
Differential Revision: D34435473
fbshipit-source-id: b8d3c94768b02cf71ecb24bb58d29ee952f672c2
(cherry picked from commit fa9b0864f3761a501868fe0373204b12fdfc2b32)
Summary:
With this change, the optimizer is almost twice as fast as before. As the result of the first call is never used, it looks like a copy paste error and therefore can be removed. In addition, this duplicate call is not present in the Python implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72773
Reviewed By: samdow
Differential Revision: D34214312
Pulled By: albanD
fbshipit-source-id: 4f4de08633c7236f3ccce8a2a74e56500003281b
(cherry picked from commit 4a63f812ab)
{kind=link}
{kind=link}