Summary: biggest issue was that the constructors for the fake_quantize
classes use custom partials that live in the observer module and so
the module for these needed to be set correctly in the constructor class
method
Test Plan: python test/test_public_bindings.py
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86022
Approved by: https://github.com/jerryzh168
The scheduler updates the levels of sparsity based on https://arxiv.org/abs/1710.01878.
## Implementation
The update rule is defined as:
$$
\begin{aligned}
s_t &= s_f + (s_i - s_f)\left( 1 - \frac{t - t_0}{n\Delta t} \right)^3 \\
\mbox{for} ~ t &\in \left\\{ t_0, t_0+\Delta t, \dots, t_0 + n\Delta t \right\\} \end{aligned}
$$
There is a minor difference compared to the original paper. By providing `initially_zero` argument, one can set the level of sparsity before step $t_0$: If `False`, the sparsity level before $t_0$ is set to $s_i$, otherwise 0.
## Tests
```
python test/test_ao_sparsity.py -- TestCubicScheduler
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85232
Approved by: https://github.com/junesg, https://github.com/jerryzh168
**Summary:** This commit enforces the following constraints on the
QNNPACK BackendConfig:
- `quant_min_lower_bound` = -127 for qint8 weight
- `quant_max_upper_bound` = 127 for qint8 weight
- `scale_min_lower_bound` = 2 ** -12 for qint8 activations and weight
These constraints will enable users to use this BackendConfig with
faster XNNPACK quantized ops. They are also consistent with the
existing settings in `default_symmetric_qnnpack_qconfig` and its
per_channel and QAT variants. For more detail on why these exact
values were chosen, please see the description of
https://github.com/pytorch/pytorch/pull/74396.
Note that there are currently no restrictions on the qscheme in
DTypeConfig. This should be added in the future to further enforce
the restriction that the weights must be quantized with either
per_tensor_symmetric or per_channel_symmetric.
Existing default QConfigs such as `get_default_qconfig("qnnpack")`
and `get_default_qat_qconfig("qnnpack")` will continue to be
supported, but only for the existing dtypes, e.g. quint8 activations
for weighted ops like linear and conv. In the future, we should
revisit whether to enable XNNPACK ops using these QConfigs as well.
**Test Plan:**
python test/test_quantization.py TestQuantizeFx.test_qnnpack_backend_config
**Reviewers:** jerryzh168, vkuzo
**Subscribers:** jerryzh168, vkuzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85863
Approved by: https://github.com/jerryzh168
Summary: `per_channel_weight_observer_range_neg_127_to_127` now correctly uses `PerChannelMinMaxObserver` instead of `MinMaxObserver`
Test Plan:
Adds a new test `quantization.core.test_top_level_apis
` to instansiate and run `forward()` on all `default` observers
Differential Revision: D39916482
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85883
Approved by: https://github.com/salilsdesai
**Summary:** This commit adds the following constraints to
BackendConfig:
quant_min_lower_bound
quant_max_upper_bound
scale_min_lower_bound
scale_max_upper_bound
This is motivated by QNNPACK constraints on qint8 weight
values and the min scale value. Actually enforcing these
constraints in the QNNPACK BackendConfig will follow in a
future commit.
Today, users can also specify the above constraints through
QConfigs, and these settings may not necessarily match the
ones specified in the BackendConfig. In this case, we will
handle the discrepancy as follows:
(1) Require QConfig quant ranges to fall within the backend's
(2) Require QConfig min scale value (eps) >= backend's
(3) Require QConfig to specify quant range if the backend
specified one
(4) Require QConfig to specify min scale value (eps) if the
backend specified one
Public API changes:
* Previous API, still supported after this commit:
```
dtype_config = DTypeConfig(
input_dtype=torch.quint8,
output_dtype=torch.quint8,
weight_dtype=torch.qint8,
bias_dtype=torch.float,
)
```
* New API:
```
dtype_config = DTypeConfig(
input_dtype=DTypeWithConstraints(
dtype=torch.quint8,
quant_min_lower_bound=0,
quant_max_upper_bound=127,
scale_min_lower_bound=2 ** -12,
),
output_dtype=DTypeWithConstraints(
dtype=torch.quint8,
quant_min_lower_bound=0,
quant_max_upper_bound=127,
scale_min_lower_bound=2 ** -12,
),
weight_dtype=DTypeWithConstraints(
dtype=torch.qint8,
quant_min_lower_bound=-128,
quant_max_upper_bound=127,
scale_min_lower_bound=2 ** -12,
),
bias_dtype=torch.float,
)
```
* Additionally, the following `DTypeConfig` attributes
have new types with helper getters:
```
# These have type DTypeWithConstraints
dtype_config.input_dtype
dtype_config.output_dtype
dtype_config.weight_dtype
# These return Optional[torch.dtype]
dtype_config.get_input_dtype()
dtype_config.get_output_dtype()
dtype_config.get_weight_dtype()
```
Note that scale_max is currently not used because there is
no existing mechanism to enforce this on the observer. In the
future, we can validate this as well if there is a use case.
**Test Plan:**
python test/test_quantization.py
TestBackendConfig.test_dtype_with_constraints
python test/test_quantization.py
TestQuantizeFx.test_backend_config_scale_min
python test/test_quantization.py
TestQuantizeFx.test_backend_config_quantization_range
**Reviewers:** jerryzh168, vkuzo
**Subscribers:** jerryzh168, vkuzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85200
Approved by: https://github.com/jerryzh168
Summary: This commit adds the initial BackendConfig for backends
PyTorch lowers to through the Executorch stack. This initial
version is only intended to cover the following set of ops:
quantized::linear_dynamic,
quantized::add,
quantized::batch_norm2d,
quantized::conv2d.new,
quantized::linear,
quantized::conv2d_relu.new,
aten::relu_,
aten::_adaptive_avg_pool2d,
aten::_reshape_alias_copy,
aten::squeeze.dim,
aten::permute
For now, the `BackendPatternConfig` for each of these ops is
the same as the ones for the corresponding ops in the FBGEMM
`BackendConfig`, though this may change in the future.
Reviewers: jerryzh168, vkuzo
Subscribers: jerryzh168, vkuzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85527
Approved by: https://github.com/jerryzh168
**Summary:** This commit enables the custom module LSTM path for
FX graph mode static quantization. This has the same flow as eager
mode, which was already previously supported:
```
torch.nn.LSTM
| (prepare_fx)
v
torch.ao.nn.quantizable.LSTM
| (convert_fx)
v
torch.ao.nn.quantized.LSTM
```
The main reason why custom module LSTM is not supported in FX
graph mode quantization today is because its inputs and outputs
are nested tuples, and existing constructs such as observers,
"quantize" nodes, and "dequantize" nodes do not understand how
to handle complex structures.
Note that the approach taken in this commit is only intended to
be a short-term solution highly tailored to the input and output
formats of custom module LSTM. In the future, for the longer-term
solution, we should design a more general QConfig that allows users
to specify complex input and output formats, and enable FX graph
mode quantization to understand arbitrary nested structures and
automatically infer how to transform the graph accordingly.
**Context:**
Today, in FX graph mode static quantization, custom modules are
assumed to have quantized inputs and quantized outputs, with the
exact dtypes derived from the associated QConfig (default quint8).
Since custom modules are currently not handled through the reference
model flow, their observer replacement logic are a little different
from normal operators:
```
# (1) Original model
input -> custom_module -> output
# (2) Observed model (after prepare)
input -> obs0 -> custom_module -> obs1 -> output
# (3) Quantized model (after convert)
input -> quant -> quantized_custom_module -> dequant -> output
```
In the last step, input observers are replaced with "quantize"
and output observers are replaced with "dequantize", in contrast
to other non-custom-module patterns where observers are replaced
with "quantize-dequantize" pairs instead. Note that, conceptually,
the output observer `obs1` is really just a DeQuantStub, since no
observation is actually needed.
**Custom module LSTM:**
The reason why custom module LSTM cannot be handled in the same
way is because, unlike other custom modules, its inputs and outputs
are nested tuples instead of single tensors. This is how the existing
custom module code would try to handle LSTMs:
```
# (1) Original model
# input format: (input, (hidden0, hidden1))
# output format: (output, (hidden0, hidden1))
input -> lstm -> output
hidden0 -/ \-> hidden0
hidden1 -/ \-> hidden1
# (2) Observed model (after prepare)
input -> obs0 -> lstm -> obs1 # fails
hidden0 -/ # missing observer
hidden1 -/ # missing observer
```
However, this fails today because 1) we assume there is only one input
to the custom module, and so we never end up quantizing `hidden0` and
`hidden1`, and 2) the output observer `obs1` is fed a tuple, which it
does not understand how to handle.
**Short-term fix:**
This commit addresses the above by specifically handling the input
and output structures used by custom module LSTM. For the inputs,
we manually insert observers for `hidden0` and `hidden1` to ensure
all input tensors are quantized.
For the outputs, we split the tuple into its internal nodes, attach
a DeQuantStub to each node, and recombine these DeQuantStubs
according to the original structure. Finally, we must also reroute
consumers of the original LSTM tuple (and its internal nodes, e.g.
`lstm[0]`) to these DeQuantStubs:
```
# (1) Original model
input -> lstm -> output -> linear0
hidden0 -/ \-> hidden0 -> linear1
hidden1 -/ \-> hidden1 -> linear2
# (2) Observed model (after prepare)
input -> obs0 -> lstm -> output -> dqstub -> linear0 -> obs3
hidden0 -> obs1 -/ \-> hidden0 -> dqstub -> linear1 -> obs4
hidden1 -> obs2 -/ \-> hidden1 -> dqstub -> linear2 -> obs5
# (3) Reference model (after convert)
input -> quant -> qlstm -> output -> dequant -> linear0 -> quant -> dequant
hidden0 -> quant -/ \-> hidden0 -> dequant -> linear1 -> quant -> dequant
hidden1 -> quant -/ \-> hidden1 -> dequant -> linear2 -> quant -> dequant
# (4) Quantized model (after lowering)
input -> quant -> qlstm -> output -> quantized_linear0 -> dequant
hidden0 -> quant -/ \-> hidden0 -> quantized_linear1 -> dequant
hidden1 -> quant -/ \-> hidden1 -> quantized_linear2 -> dequant
```
Note that we choose to insert DeQuantStubs here instead of observers
because these will ultimately be replaced by "dequantize" nodes. This
matches the general custom module behavior, where output observers
are replaced only with "dequantize" nodes (as opposed to the normal
"quantize-dequantize" pair), since custom module outputs are assumed
to already be quantized. Using DeQuantStubs instead of observers also
simplifies the "dequantize" insertion logic. In the future, we should use
DeQuantStubs in place of output observers for custom modules in general.
**Test plan:**
python test/test_quantization.py TestQuantizeFx.test_static_lstm
python test/test_quantization.py
TestQuantizeFx.test_static_lstm_consume_tuple
**Reviewers:** jerryzh168, vkuzo
**Subscribers:** jerryzh168, vkuzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85068
Approved by: https://github.com/jerryzh168
The `WeightNormSparsifier` currently only supports L2-norm. This allows the users specify the function that is applied to compute the norm. In addition, L1-norm is also added, as an `.abs` function.
## Implementation details
- The functions that are referred to as "norms", are not strictly such. For example, L2-norm of `x` is computed as `F.avg_pool(x * x, ...)`. Similarly, L1-norm of `x` is computed as `F.avg_pool(x.abs(), ...)`.
- When passing callable functions for the norm, the above assumption must hold: `F.avg_pool(norm_fn(x), ...)` will be applied.
## Example:
```python
>>> # L3-norm
>>> l3 = lambda T: T * T * T
>>> sparsifier = WeightNormSparsifier(norm=l3)
>>>
>>> # L0-norm
>>> l0 = lambda T: (torch.logical_or(torch.zeros(T.shape), T != 0).to(T.dtype)
>>> sparsifier = WeightNormSparsifier(norm=l0)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85236
Approved by: https://github.com/jcaip
Summary:
This is a developer-oriented design doc/README for FX Graph Mode Quantization, the goal for the doc is for new developers of
FX Graph Mode Quantization to get familiarized with the high level algorithm of FX Graph Mode Quantization and ramp up quickly
Test Plan:
no test needed
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85070
Approved by: https://github.com/vkuzo
Summary:
Before this PR, the `dtype` attribute of observers was not clearly
defined. It originally meant `interface_dtype` in the eager mode
workflow, which is how the codebase before this PR is using it.
In the new reference model spec, `dtype` attribute of an observer
represents the `dtype` value which needs to be passed into a `quantize`
function in the reference model spec. This PR aligns the codebase
to this definition of dtype. In detail:
1. change util functions to interpret `dtype` using the reference model definition
2. change `prepare` to interpret `dtype` using the reference model definition
3. change observers for dynamic quantization to interpret `dtype` using the reference
model definition.
A future PR (left out of this one to keep LOC small) will deprecate the
`compute_dtype` field and instead expose `is_dynamic` on observers.
"
Test plan:
```
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
```
Differential Revision: [D39675209](https://our.internmc.facebook.com/intern/diff/D39675209)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85345
Approved by: https://github.com/z-a-f, https://github.com/jerryzh168
Summary:
- `remove_quant_dequant_pairs` removes ops when a `quant` is followed by a `dequant`
- It looks like the quantized implementation of `layer_norm` only supports float weights, so updated the default qconfig to avoid quantizing the weight param.
- Fixes broken test, `test_norm_weight_bias`. This was the only test that broke, because the default qconfig dict we pass in quantizes the weight. I just pulled the native qconfig object and converted it to a dict.
- Adds in qconfig and backend config support for layernorm
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
python test/test_quantization.py TestQuantizeFxModels
```
Reviewers:
Subscribers:
Tasks: Fixes https://github.com/pytorch/pytorch/issues/83110
Tags: quant, fx
Differential Revision: [D39395141](https://our.internmc.facebook.com/intern/diff/D39395141)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84203
Approved by: https://github.com/jerryzh168
Summary:
Adds `extra_repr` to `HistogramObserver`. This is useful when debugging
PTQ models because it allows to quickly check whether a `HistogramObserver`
has received data or not.
Test plan:
```
>>> import torch
>>> obs = torch.ao.quantization.HistogramObserver()
>>> obs(torch.randn(1, 3, 224, 224))
...
>>> print(obs)
// before - hard to tell if observer has seen data
HistogramObserver()
// after
HistogramObserver(min_val=-4.778339862823486, max_val=4.311892986297607)
>>>
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84760
Approved by: https://github.com/andrewor14
Summary:
Some more clarifications for the arguments, including linking to object docs (QConfigMapping, BackendConfig) and adding types
in the doc
Test Plan:
```
cd docs
make html
```
and
visual inspection for the generated docs
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84587
Approved by: https://github.com/vkuzo
Some of the subpackages were not included in the 'torch.nn.quantized'.
That would cause some specific cases fail.
For example, `from torch.nn.quantized import dynamic` would work,
but `import torch; torch.nn.quantized.dynamic` would fail.
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84141
Approved by: https://github.com/andrewor14
Summary:
- Finishes the second part of https://github.com/pytorch/pytorch/pull/83263
- Removes WEIGHT_INDEX_DICT and BIAS_INDEX_DICT from utils.py
- Moves two funcitons, `node_arg_is_weight` and `node_arg_is_bias` into utils.py from prepare.py
convert.py and _equalize.py now use node_arg_is_weight instead of the dictionaries
- Adds in quantization support for `F.groupnorm`.
Add in missing BackendPatternConfigs for layernorm, instancenorm, and groupnorm
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
```
Reviewers:
Subscribers:
Tasks:
Tags:
ghstack-source-id: 2b157e0dc4f1553be1f4813b4693db952e6fc558
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83848Fixes#83093
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83853
Approved by: https://github.com/jerryzh168, https://github.com/andrewor14
Summary:
After inserting quant dequant nodes in the graph, we need
1. Insert packed param creation and quantized op
2. Create packed_params attribute in the top module. For this we need
graph that inlined except for calculate_qparams method calls. But they
can be inlined too. So perhaps we need to make sure no other callmethods
exist.
3. Insert SetAttr for the packed param
4. Insert GetAttr for the packed param
5. Use GetAttr output for quantized op where applicable, e.g.
linear_dynamic
The above is added to quantize_<method-name> method created inprevious
step. Once the above steps are done clone the method into
quantized_<method-name>
Modify quantize_<method-name>:
1. Remove all outputs from the method.
2. Run dce
3. Remove all inputs from the method except self.
Modify quantized_<method-name>:
1. Remove all packed_param setAttr nodes.
2. Run dce.
This should result in removal of all nodes that generate packed param.
Test Plan: To be written
Reviewers:
Subscribers:
Tasks:
Tags:
Differential Revision: [D38771416](https://our.internmc.facebook.com/intern/diff/D38771416)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83571
Approved by: https://github.com/jerryzh168
Summary:
This diff adds a way to:
- clone previously observed method
- Add calls to observer's calculate_qparams methods
- Extract the scale and zero point
- Use them to insert quant dequant nodes
Now for forward method we have
- observe_forward
- quantize_forward
observe_forward is used post training to observer statistics. In the
case of dynamic PTQ this requires just running that method once to
update weight observer statistics.
quantize_forward method will be used to use the observer
statistics to calculate quantization parameters and apply that to quant
dequant op.
Subsequent diffs will replace dequant + op with their quantized op
counter parts and replace quantize ops with relevant packed params class
where possible
Test Plan:
To be written
Reviewers:
Subscribers:
Tasks:
Tags:
Differential Revision: [D38771419](https://our.internmc.facebook.com/intern/diff/D38771419)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83570
Approved by: https://github.com/jerryzh168
Summary:
TO support on device quantization this diff introduces observer
insertion. Specifically observers are inserted by adding new method with
prefix observ_.
Intent is that post training, this method will be run to record
statistics
Test Plan:
test_ondevice_quantization.py
Reviewers:
Subscribers:
Tasks:
Tags:
Differential Revision: [D38771417](https://our.internmc.facebook.com/intern/diff/D38771417)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83568
Approved by: https://github.com/jerryzh168
Context: In order to avoid the cluttering of the `torch.nn` namespace
the quantized modules namespace is moved to `torch.ao.nn`.
The list of the `nn.quantized` files that are being migrated:
- [X] `torch.nn.quantized` → `torch.ao.nn.quantized`
- [X] `torch.nn.quantized.functional` → `torch.ao.nn.quantized.functional`
- [X] `torch.nn.quantized.modules` → `torch.ao.nn.quantized.modules`
- [X] `torch.nn.quantized.dynamic` → `torch.ao.nn.quantized.dynamic`
- [X] `torch.nn.quantized._reference` → `torch.ao.nn.quantized._reference`
- [X] `torch.nn.quantizable` → `torch.ao.nn.quantizable`
- [X] [Current PR] `torch.nn.qat` → `torch.ao.nn.qat`
- [X] `torch.nn.qat.modules` → `torch.ao.nn.qat.modules`
- [X] `torch.nn.qat.dynamic` → `torch.ao.nn.qat.dynamic`
- [ ] `torch.nn.intrinsic` → `torch.ao.nn.intrinsic`
- [ ] `torch.nn.intrinsic.modules` → `torch.ao.nn.intrinsic.modules`
- [ ] `torch.nn.intrinsic.qat` → `torch.ao.nn.intrinsic.qat`
- [ ] `torch.nn.intrinsic.quantized` → `torch.ao.nn.intrinsic.quantized`
- [ ] `torch.nn.intrinsic.quantized.modules` → `torch.ao.nn.intrinsic.quantized.modules`
- [ ] `torch.nn.intrinsic.quantized.dynamic` → `torch.ao.nn.intrinsic.quantized.dynamic`
Majority of the files are just moved to the new location.
However, specific files need to be double checked:
- None
Differential Revision: [D36861197](https://our.internmc.facebook.com/intern/diff/D36861197/)
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D36861197/)!
Differential Revision: [D36861197](https://our.internmc.facebook.com/intern/diff/D36861197)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78716
Approved by: https://github.com/jerryzh168
Context: In order to avoid the cluttering of the `torch.nn` namespace
the quantized modules namespace is moved to `torch.ao.nn`.
The list of the `nn.quantized` files that are being migrated:
- [X] `torch.nn.quantized` → `torch.ao.nn.quantized`
- [X] `torch.nn.quantized.functional` → `torch.ao.nn.quantized.functional`
- [X] `torch.nn.quantized.modules` → `torch.ao.nn.quantized.modules`
- [X] `torch.nn.quantized.dynamic` → `torch.ao.nn.quantized.dynamic`
- [X] `torch.nn.quantized._reference` → `torch.ao.nn.quantized._reference`
- [X] [Current PR] `torch.nn.quantizable` → `torch.ao.nn.quantizable`
- [ ] `torch.nn.qat` → `torch.ao.nn.qat`
- [ ] `torch.nn.qat.modules` → `torch.ao.nn.qat.modules`
- [ ] `torch.nn.qat.dynamic` → `torch.ao.nn.qat.dynamic`
- [ ] `torch.nn.intrinsic` → `torch.ao.nn.intrinsic`
- [ ] `torch.nn.intrinsic.modules` → `torch.ao.nn.intrinsic.modules`
- [ ] `torch.nn.intrinsic.qat` → `torch.ao.nn.intrinsic.qat`
- [ ] `torch.nn.intrinsic.quantized` → `torch.ao.nn.intrinsic.quantized`
- [ ] `torch.nn.intrinsic.quantized.modules` → `torch.ao.nn.intrinsic.quantized.modules`
- [ ] `torch.nn.intrinsic.quantized.dynamic` → `torch.ao.nn.intrinsic.quantized.dynamic`
Majority of the files are just moved to the new location.
However, specific files need to be double checked:
- `torch/ao/nn/__init__.py` → Changing the imports to lazy.
Differential Revision: [D36861090](https://our.internmc.facebook.com/intern/diff/D36861090/)
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D36861090/)!
Differential Revision: [D36861090](https://our.internmc.facebook.com/intern/diff/D36861090)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78717
Approved by: https://github.com/jerryzh168
Context: In order to avoid the cluttering of the `torch.nn` namespace
the quantized modules namespace is moved to `torch.ao.nn`.
The list of the `nn.quantized` files that are being migrated:
- [ ] `torch.nn.quantized` → `torch.ao.nn.quantized`
- [X] `torch.nn.quantized.functional` → `torch.ao.nn.quantized.functional`
- [X] `torch.nn.quantized.modules` → `torch.ao.nn.quantized.modules`
- [X] `torch.nn.quantized.dynamic` → `torch.ao.nn.quantized.dynamic`
- [X] [Current PR] `torch.nn.quantized._reference` → `torch.ao.nn.quantized._reference`
- [ ] `torch.nn.quantizable` → `torch.ao.nn.quantizable`
- [ ] `torch.nn.qat` → `torch.ao.nn.qat`
- [ ] `torch.nn.qat.modules` → `torch.ao.nn.qat.modules`
- [ ] `torch.nn.qat.dynamic` → `torch.ao.nn.qat.dynamic`
- [ ] `torch.nn.intrinsic` → `torch.ao.nn.intrinsic`
- [ ] `torch.nn.intrinsic.modules` → `torch.ao.nn.intrinsic.modules`
- [ ] `torch.nn.intrinsic.qat` → `torch.ao.nn.intrinsic.qat`
- [ ] `torch.nn.intrinsic.quantized` → `torch.ao.nn.intrinsic.quantized`
- [ ] `torch.nn.intrinsic.quantized.modules` → `torch.ao.nn.intrinsic.quantized.modules`
- [ ] `torch.nn.intrinsic.quantized.dynamic` → `torch.ao.nn.intrinsic.quantized.dynamic`
Majority of the files are just moved to the new location.
However, specific files need to be double checked:
- None
Differential Revision: [D36860927](https://our.internmc.facebook.com/intern/diff/D36860927/)
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D36860927/)!
Differential Revision: [D36860927](https://our.internmc.facebook.com/intern/diff/D36860927)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78715
Approved by: https://github.com/jerryzh168
Context: In order to avoid the cluttering of the `torch.nn` namespace
the quantized modules namespace is moved to `torch.ao.nn`.
The list of the `nn.quantized` files that are being migrated:
- [ ] `torch.nn.quantized` → `torch.ao.nn.quantized`
- [X] `torch.nn.quantized.functional` → `torch.ao.nn.quantized.functional`
- [X] `torch.nn.quantized.modules` → `torch.ao.nn.quantized.modules`
- [X] [Current PR] `torch.nn.quantized.dynamic` → `torch.ao.nn.quantized.dynamic`
- [ ] `torch.nn.quantized._reference` → `torch.ao.nn.quantized._reference`
- [ ] `torch.nn.quantizable` → `torch.ao.nn.quantizable`
- [ ] `torch.nn.qat` → `torch.ao.nn.qat`
- [ ] `torch.nn.qat.modules` → `torch.ao.nn.qat.modules`
- [ ] `torch.nn.qat.dynamic` → `torch.ao.nn.qat.dynamic`
- [ ] `torch.nn.intrinsic` → `torch.ao.nn.intrinsic`
- [ ] `torch.nn.intrinsic.modules` → `torch.ao.nn.intrinsic.modules`
- [ ] `torch.nn.intrinsic.qat` → `torch.ao.nn.intrinsic.qat`
- [ ] `torch.nn.intrinsic.quantized` → `torch.ao.nn.intrinsic.quantized`
- [ ] `torch.nn.intrinsic.quantized.modules` → `torch.ao.nn.intrinsic.quantized.modules`
- [ ] `torch.nn.intrinsic.quantized.dynamic` → `torch.ao.nn.intrinsic.quantized.dynamic`
Majority of the files are just moved to the new location.
However, specific files need to be double checked:
- [Documentation](docs/source/quantization-support.rst) @vkuzo
- [Public API test list](test/allowlist_for_publicAPI.json) @peterbell10
- [BC test](test/quantization/bc/test_backward_compatibility.py) @vkuzo
- [IR emitter](torch/csrc/jit/frontend/ir_emitter.cpp) @jamesr66a
- [JIT serialization](torch/csrc/jit/serialization/import_source.cpp) @IvanKobzarev @jamesr66a
Differential Revision: [D36860660](https://our.internmc.facebook.com/intern/diff/D36860660/)
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D36860660/)!
Differential Revision: [D36860660](https://our.internmc.facebook.com/intern/diff/D36860660)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78714
Approved by: https://github.com/jerryzh168
Motivation: each quantization observer only supports a limit qschemes, we need to do this check at the initiation step, rather than at the running step, such as MinMaxObserver with set qscheme with **torch.per_channel_affine**, there will have a runtime error at the running the calibration step:
```
AttributeError: 'MinMaxObserver' object has no attribute 'ch_axis'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80126
Approved by: https://github.com/jerryzh168
Fix use-dict-literal pylint suggestions by changing `dict()` to `{}`. This PR should do the change for every Python file except test/jit/test_list_dict.py, where I think the intent is to test the constructor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83718
Approved by: https://github.com/albanD
Summary:
att, probably missed the op during migration to the reference flow
Test Plan:
python test/test_quantization.py TestQuantizeFxOps.test_qmatmul
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83885
Approved by: https://github.com/andrewor14
Summary: Previously we use a single BackendConfig
(get_native_backend_config) for both the FBGEMM and QNNPACK
backends. However, these two backends have subtle differences
in terms of their requirements that cannot be satisfied using
a single BackendConfig. Therefore, this commit is the first step
torwards decoupling the two backends. The real change in
functionality will come in a future commit after DTypeConfig
supports quant_min/quant_max and scale_min/scale_max. Existing
uses of `get_native_backend_config` should not be affected.
Public facing changes:
```
from torch.ao.quantization.backend_config import (
get_fbgemm_backend_config,
get_qnnpack_backend_config,
)
fbgemm_backend_config = get_fbgemm_backend_config()
qnnpack_backend_config = get_qnnpack_backend_config()
```
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Reviewers: jerryzh168
Subscribers: jerryzh168
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83566
Approved by: https://github.com/jerryzh168
Context: In order to avoid the cluttering of the `torch.nn` namespace
the quantized modules namespace is moved to `torch.ao.nn`.
The list of the `nn.quantized` files that are being migrated:
- [X] `torch.nn.quantized` → `torch.ao.nn.quantized`
- [X] `torch.nn.quantized.functional` → `torch.ao.nn.quantized.functional`
- [X] `torch.nn.quantized.modules` → `torch.ao.nn.quantized.modules`
- [X] `torch.nn.quantized.dynamic` → `torch.ao.nn.quantized.dynamic`
- [X] `torch.nn.quantized._reference` → `torch.ao.nn.quantized._reference`
- [X] `torch.nn.quantizable` → `torch.ao.nn.quantizable`
- [X] [Current PR] `torch.nn.qat` → `torch.ao.nn.qat`
- [X] `torch.nn.qat.modules` → `torch.ao.nn.qat.modules`
- [X] `torch.nn.qat.dynamic` → `torch.ao.nn.qat.dynamic`
- [ ] `torch.nn.intrinsic` → `torch.ao.nn.intrinsic`
- [ ] `torch.nn.intrinsic.modules` → `torch.ao.nn.intrinsic.modules`
- [ ] `torch.nn.intrinsic.qat` → `torch.ao.nn.intrinsic.qat`
- [ ] `torch.nn.intrinsic.quantized` → `torch.ao.nn.intrinsic.quantized`
- [ ] `torch.nn.intrinsic.quantized.modules` → `torch.ao.nn.intrinsic.quantized.modules`
- [ ] `torch.nn.intrinsic.quantized.dynamic` → `torch.ao.nn.intrinsic.quantized.dynamic`
Majority of the files are just moved to the new location.
However, specific files need to be double checked:
- None
Differential Revision: [D36861197](https://our.internmc.facebook.com/intern/diff/D36861197/)
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D36861197/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78716
Approved by: https://github.com/jerryzh168
Context: In order to avoid the cluttering of the `torch.nn` namespace
the quantized modules namespace is moved to `torch.ao.nn`.
The list of the `nn.quantized` files that are being migrated:
- [X] `torch.nn.quantized` → `torch.ao.nn.quantized`
- [X] `torch.nn.quantized.functional` → `torch.ao.nn.quantized.functional`
- [X] `torch.nn.quantized.modules` → `torch.ao.nn.quantized.modules`
- [X] `torch.nn.quantized.dynamic` → `torch.ao.nn.quantized.dynamic`
- [X] `torch.nn.quantized._reference` → `torch.ao.nn.quantized._reference`
- [X] [Current PR] `torch.nn.quantizable` → `torch.ao.nn.quantizable`
- [ ] `torch.nn.qat` → `torch.ao.nn.qat`
- [ ] `torch.nn.qat.modules` → `torch.ao.nn.qat.modules`
- [ ] `torch.nn.qat.dynamic` → `torch.ao.nn.qat.dynamic`
- [ ] `torch.nn.intrinsic` → `torch.ao.nn.intrinsic`
- [ ] `torch.nn.intrinsic.modules` → `torch.ao.nn.intrinsic.modules`
- [ ] `torch.nn.intrinsic.qat` → `torch.ao.nn.intrinsic.qat`
- [ ] `torch.nn.intrinsic.quantized` → `torch.ao.nn.intrinsic.quantized`
- [ ] `torch.nn.intrinsic.quantized.modules` → `torch.ao.nn.intrinsic.quantized.modules`
- [ ] `torch.nn.intrinsic.quantized.dynamic` → `torch.ao.nn.intrinsic.quantized.dynamic`
Majority of the files are just moved to the new location.
However, specific files need to be double checked:
- None
Differential Revision: [D36861090](https://our.internmc.facebook.com/intern/diff/D36861090/)
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D36861090/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78717
Approved by: https://github.com/jerryzh168
Context: In order to avoid the cluttering of the `torch.nn` namespace
the quantized modules namespace is moved to `torch.ao.nn`.
The list of the `nn.quantized` files that are being migrated:
- [ ] `torch.nn.quantized` → `torch.ao.nn.quantized`
- [X] `torch.nn.quantized.functional` → `torch.ao.nn.quantized.functional`
- [X] `torch.nn.quantized.modules` → `torch.ao.nn.quantized.modules`
- [X] `torch.nn.quantized.dynamic` → `torch.ao.nn.quantized.dynamic`
- [X] [Current PR] `torch.nn.quantized._reference` → `torch.ao.nn.quantized._reference`
- [ ] `torch.nn.quantizable` → `torch.ao.nn.quantizable`
- [ ] `torch.nn.qat` → `torch.ao.nn.qat`
- [ ] `torch.nn.qat.modules` → `torch.ao.nn.qat.modules`
- [ ] `torch.nn.qat.dynamic` → `torch.ao.nn.qat.dynamic`
- [ ] `torch.nn.intrinsic` → `torch.ao.nn.intrinsic`
- [ ] `torch.nn.intrinsic.modules` → `torch.ao.nn.intrinsic.modules`
- [ ] `torch.nn.intrinsic.qat` → `torch.ao.nn.intrinsic.qat`
- [ ] `torch.nn.intrinsic.quantized` → `torch.ao.nn.intrinsic.quantized`
- [ ] `torch.nn.intrinsic.quantized.modules` → `torch.ao.nn.intrinsic.quantized.modules`
- [ ] `torch.nn.intrinsic.quantized.dynamic` → `torch.ao.nn.intrinsic.quantized.dynamic`
Majority of the files are just moved to the new location.
However, specific files need to be double checked:
- None
Differential Revision: [D36860927](https://our.internmc.facebook.com/intern/diff/D36860927/)
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D36860927/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78715
Approved by: https://github.com/jerryzh168
Context: In order to avoid the cluttering of the `torch.nn` namespace
the quantized modules namespace is moved to `torch.ao.nn`.
The list of the `nn.quantized` files that are being migrated:
- [ ] `torch.nn.quantized` → `torch.ao.nn.quantized`
- [X] `torch.nn.quantized.functional` → `torch.ao.nn.quantized.functional`
- [X] `torch.nn.quantized.modules` → `torch.ao.nn.quantized.modules`
- [X] [Current PR] `torch.nn.quantized.dynamic` → `torch.ao.nn.quantized.dynamic`
- [ ] `torch.nn.quantized._reference` → `torch.ao.nn.quantized._reference`
- [ ] `torch.nn.quantizable` → `torch.ao.nn.quantizable`
- [ ] `torch.nn.qat` → `torch.ao.nn.qat`
- [ ] `torch.nn.qat.modules` → `torch.ao.nn.qat.modules`
- [ ] `torch.nn.qat.dynamic` → `torch.ao.nn.qat.dynamic`
- [ ] `torch.nn.intrinsic` → `torch.ao.nn.intrinsic`
- [ ] `torch.nn.intrinsic.modules` → `torch.ao.nn.intrinsic.modules`
- [ ] `torch.nn.intrinsic.qat` → `torch.ao.nn.intrinsic.qat`
- [ ] `torch.nn.intrinsic.quantized` → `torch.ao.nn.intrinsic.quantized`
- [ ] `torch.nn.intrinsic.quantized.modules` → `torch.ao.nn.intrinsic.quantized.modules`
- [ ] `torch.nn.intrinsic.quantized.dynamic` → `torch.ao.nn.intrinsic.quantized.dynamic`
Majority of the files are just moved to the new location.
However, specific files need to be double checked:
- [Documentation](docs/source/quantization-support.rst) @vkuzo
- [Public API test list](test/allowlist_for_publicAPI.json) @peterbell10
- [BC test](test/quantization/bc/test_backward_compatibility.py) @vkuzo
- [IR emitter](torch/csrc/jit/frontend/ir_emitter.cpp) @jamesr66a
- [JIT serialization](torch/csrc/jit/serialization/import_source.cpp) @IvanKobzarev @jamesr66a
Differential Revision: [D36860660](https://our.internmc.facebook.com/intern/diff/D36860660/)
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D36860660/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78714
Approved by: https://github.com/jerryzh168
Summary:
att, it seems more appropriate to name it qconfig_mapping_utils, also we probably want to move
the functions in torch/ao/quantization/qconfig_mapping_utils.py to torch/ao/quantization/fx/qconfig_mapping_utils.py as well
Test Plan:
python test/test_quantization.py TestQuantizeFx
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83369
Approved by: https://github.com/andrewor14
Summary: This adds the capability to generate a QConfigMapping based on
the suggestions of the ModelReport API for the user to use. The only
dependency of this feature is that the calibration is run before the
generation of the QConfigMapping and there is no dependency on the
report generation other than that the observers cannot be removed before
this is called. This maps module fqns to EqualizationQConfigs instead of regular
QConfigs.
Example Usage (after callibration):
```
quantization_mapping = mod_report.generate_qconfig_mapping()
equalization_mapping = mod_report.generate_equalization_mapping()
prepared_model = quantize_fx.prepare_fx(model, mapping, example_input, _equalization_config=equalization_mapping)
quantized_model = quantize_fx.convert_fx(prepared)
```
This was tested by ensuring that the suggestions generated in the QConfigMapping are:
1. Correct according to the set backend and data passed through
2. Able to be prepared and converted as a proper config (is a valid config)
The test for this is a part of the TestFxModelReportClass test suite.
Test Plan: python test/test_quantization.py TestFxModelReportClass.test_equalization_mapping_generation
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83698
Approved by: https://github.com/jerryzh168
Summary:
Now we have a separate file to define BackendConfig related classes, we can move ObservationType to that file as well
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
python test/test_quantization.py TestQuantizeFxModels
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83368
Approved by: https://github.com/andrewor14
Summary: This adds the capability to generate a QConfigMapping based on
the suggestions of the ModelReport API for the user to use. The only
dependency of this feature is that the callibration is run before the
generation of the QConfigMapping and there is no dependency on the
report generation other than that the observers cannot be removed before
this is called.
Example Usage (after callibration):
```
mapping = mod_report.generate_qconfig_mapping()
prepared_model = quantize_fx.prepare_fx(model, mapping, example_input)
quantized_model = quantize_fx.convert_fx(prepared)
```
This was tested by ensuring that the suggestions generated in the
QConfigMapping are:
1. Correct according to the set backend and data passed through
2. Able to be prepared and converted as a proper config (is a valid
config)
The test for this is a part of the TestFxModelReportClass test suite.
Test Plan: python test/test_quantization.py TestFxModelReportClass.test_qconfig_mapping_generation
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83688
Approved by: https://github.com/jerryzh168
Context: In order to avoid the cluttering of the `torch.nn` namespace
the quantized modules namespace is moved to `torch.ao.nn`.
The list of the `nn.quantized` files that are being migrated:
- [ ] `torch.nn.quantized` → `torch.ao.nn.quantized`
- [X] [Current PR] `torch.nn.quantized.functional` → `torch.ao.nn.quantized.functional`
- [ ] `torch.nn.quantized.modules` → `torch.ao.nn.quantized.modules`
- [ ] `torch.nn.quantized.dynamic` → `torch.ao.nn.quantized.dynamic`
- [ ] `torch.nn.quantized._reference` → `torch.ao.nn.quantized._reference`
- [ ] `torch.nn.quantizable` → `torch.ao.nn.quantizable`
- [ ] `torch.nn.qat` → `torch.ao.nn.qat`
- [ ] `torch.nn.qat.modules` → `torch.ao.nn.qat.modules`
- [ ] `torch.nn.qat.dynamic` → `torch.ao.nn.qat.dynamic`
- [ ] `torch.nn.intrinsic` → `torch.ao.nn.intrinsic`
- [ ] `torch.nn.intrinsic.modules` → `torch.ao.nn.intrinsic.modules`
- [ ] `torch.nn.intrinsic.qat` → `torch.ao.nn.intrinsic.qat`
- [ ] `torch.nn.intrinsic.quantized` → `torch.ao.nn.intrinsic.quantized`
- [ ] `torch.nn.intrinsic.quantized.modules` → `torch.ao.nn.intrinsic.quantized.modules`
- [ ] `torch.nn.intrinsic.quantized.dynamic` → `torch.ao.nn.intrinsic.quantized.dynamic`
Majority of the files are just moved to the new location.
However, specific files need to be double checked:
- [Documentation](docs/source/quantization-support.rst) @vkuzo
- [Public API test list](test/allowlist_for_publicAPI.json) @peterbell10
Differential Revision: [D36792967](https://our.internmc.facebook.com/intern/diff/D36792967/)
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D36792967/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78712
Approved by: https://github.com/jerryzh168
Summary:
CommonQuantizeHandler This was added previously to make some of the refactor to use reference quantized model flow easier, now we have
fully migrated to use reference quantized model flow, it's no longer needed, so we can remove it
Also updated some comments
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
python test/test_quantization.py TestQuantizeFxModels
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83360
Approved by: https://github.com/andrewor14
Summary:
This change adds in input_type_to_index mappings to the backend patterns for `nn.functional.linear`, `nn.functional.conv1d`, `nn.functional.conv1d`, and `nn.functional.conv3d`.
This let's us remove `WEIGHT_INDEX_DICT` and `BIAS_INDEX_DICT` from `prepare.py`.
Instead we pass around `backend_config` and check wether an arg is weight/bias agains that config
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
```
Reviewers:
@andrewor14
Subscribers:
Tasks:
Tags: quant, fx
Differential Revision: [D38705516](https://our.internmc.facebook.com/intern/diff/D38705516)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83263
Approved by: https://github.com/andrewor14
This is a new version of #15648 based on the latest master branch.
Unlike the previous PR where I fixed a lot of the doctests in addition to integrating xdoctest, I'm going to reduce the scope here. I'm simply going to integrate xdoctest, and then I'm going to mark all of the failing tests as "SKIP". This will let xdoctest run on the dashboards, provide some value, and still let the dashboards pass. I'll leave fixing the doctests themselves to another PR.
In my initial commit, I do the bare minimum to get something running with failing dashboards. The few tests that I marked as skip are causing segfaults. Running xdoctest results in 293 failed, 201 passed tests. The next commits will be to disable those tests. (unfortunately I don't have a tool that will insert the `#xdoctest: +SKIP` directive over every failing test, so I'm going to do this mostly manually.)
Fixes https://github.com/pytorch/pytorch/issues/71105
@ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82797
Approved by: https://github.com/ezyang
Summary: This creates the framework in the ModelReport API for the
generation of QConfigs by the ModelReport instance based on suggestions.
This functionality will eventually be added into the report generation
or be something that complements it, but for now it will be an
independent call for API stability and to be able to better modularize
the features as it stabilizes.
This also adds the framework for the relavent test function and a note
in the README at what future changes are planned for this new method in
the ModelReport API.
Test Plan: python test/test_quantization.py TestFxModelReportClass.test_qconfig_generation
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83091
Approved by: https://github.com/HDCharles
Summary: I added some additional tasks to further improve the
ModelReport API to the README. These are tasks that I will try to
complete in the next few weeks but also can help to provide future
direction later.
Test Plan: No code added
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83088
Approved by: https://github.com/andrewor14
Implementation of `post_training_sparse_quantize` that takes in a model
and applies sparsification and quantization to only `embeddings` & `embeddingbags`.
The quantization step can happen before or after sparsification depending on the `sparsify_first` argument.
Test Plan:
```python test/test_ao_sparsity.py TestQuantizationUtils```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82759
Approved by: https://github.com/z-a-f
Summary: Before, the line plot for the ModelReportVisualizer used to
plot a different line for each channel. However, for models that have a
lot of channels, this can get really hard to read and parse and doesn't
provide much valuable information.
Now, we just have a single value per module that is the average of the
500 channels.
We also considered plotting 3 lines (a min line, a max line, and an
average line) but the issue was that large outliers could result in one
of the lines completely messing up the scale and the other two not being
visible. As a result, it made sense to do an average and let the user
use the report data to generate the other two if they wished to do so.
This was tested visually in a ipynb notebook
Test Plan: Tested visually in a ipynb notebook
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82918
Approved by: https://github.com/jerryzh168
Summary: There was an issue with per-channel visualizations in the
ModelReportVisualizer that in specific scenarios in which there were
only per-channel features for a module, it would fail to specifically
get the channel by channel info.
After digging through the code, the core reason was a for loop that was
enumerating on the `tensor_table` (tensor level info) even in the
scenario in which we only had per-channel info.
This was fixed, and tested in a Bento to ensure expected functionality.
Test Plan: Tested visually
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82917
Approved by: https://github.com/jerryzh168
Summary: This adds information on how the ModelReportVisualizer
integrates into the ModelReport API into the README file for the
ModelReport folder. It updates the high level usage flow, includes
information on the API, some of the important public methods and what
they do, as well as updates to the folder structure to include the new
`model_report_visualizer.py` file as well as updating the tests section
to highlight that there are high level tests for the
ModelReportVisualizer as well.
There really aren't any direct tests for this since it's just updates to
a README, but the tests for the ModelReportVisualizer are relavent and
were run to make sure table generation was still properly occuring.
Test Plan: python test/test_quantization.py TestFxModelReportVisualizer
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82796
Approved by: https://github.com/jerryzh168
Summary: After working on a tutorial and spending more time
experimenting with the input-weight equalization recommendation feature,
I realized that having half as the number of channels to benefit from
input-weight was too high, and that it should be a bit more lenient.
Based on the example I played around with in an internal tutorial, I
found that somewhere in the 0.3 - 0.4 threshold made more sense. In the
future, more in-depth testing and experimenting with more models may
help further fine-tune this fraction of channels that would benefit.
Test Plan: python test/test_quantization.py TestFxDetectInputWeightEqualization
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82795
Approved by: https://github.com/jerryzh168
Summary: This fixes a punctuation issue with the Dynamic Static Detector
that was missing a period when suggesting to use a dynamic quantize per
tensor layer.
Quick grammer fix and no other changes to code.
Test Plan: python test/test_quantization.py TestFxModelReportDetectDynamicStatic
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82794
Approved by: https://github.com/jerryzh168
### Summary
Refactors quantization levels visualization function to include alpha qparam in parameters of `float_to_apot` function call (due to `float_to_apot` function update). Also adds additional detail to the documentation for `quant_levels_visualization`.
### Test Plan
Print visualization by calling `quant_levels_visualization` function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82790
Approved by: https://github.com/jerryzh168
Summary:
Add a global custon module support list for the users to specify the modules they want the equalization process support.
To use this list, import it from the _equalize.py file and append module in it.
Unittest passed to check global support list:
https://pxl.cl/28RKG
Test Plan: buck1 test mode/dev //on_device_ai/odai/tests/transforms:test_transforms -- --exact 'on_device_ai/odai/tests/transforms:test_transforms - test_custom_support_list (on_device_ai.odai.tests.transforms.test_input_weight_for_turing.TestInputWeight)'
Reviewed By: jerryzh168
Differential Revision: D38264244
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82606
Approved by: https://github.com/HDCharles
### Summary
This PR modifies the bitshift implementation of matrix multiplication for LinearAPoT in `bitshift_mul` to support all input values of k. It also fixes the row/col dimension assignment for the `mat_mul `method
### Test Plan
Run unit tests with: `python test/quantization/core/experimental/test_linear.py`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82409
Approved by: https://github.com/dzdang
Summary: The primary issue was that fusion and matching had to be
updated to handle parametrized modules
Test Plan: python test/test_ao_sparsity.py TestFxComposability
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81993
Approved by: https://github.com/jerryzh168
The readme file contains an overview of the base data scheduler.
Consists of code snippets and instructions on how to create your own custom
data scheduler and how to use during training a model.
Test Plan: None
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82131
Approved by: https://github.com/z-a-f
Summary: sparse_prepare automatically composes with quantized prepare
even in cases with fusion. However, the convert step needed to be updated to handle parametrized
modules.
Test Plan: python test/test_ao_sparsity.py TestFxComposability
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81992
Approved by: https://github.com/jerryzh168
The README contains introduction and details on the activation sparsifier. It also contains
code snippets and examples on using the activation sparsifier.
Test Plan: None
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81814
Approved by: https://github.com/z-a-f
The readme file contains an overview of the base data sparsifier, it's implementation details.
Also, consists of code snippets and instructions on how to create your own custom
data sparsifier.
Test Plan: None
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82130
Approved by: https://github.com/z-a-f
Bug: The config and mask were being recreated while replacing data on the data sparsifier.
Fix: Introduced an argument `reuse_mask` which when set `True` uses the old mask. If new config is not
specified, the data sparsifier by default uses the old config with the new data.
Also, added unit tests to check this bug.
Test Plan:
```python test/test_ao_sparsity.py TestBaseDataSparsifier```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82129
Approved by: https://github.com/z-a-f
The stored mask is dumped as `torch.sparse_coo` while serializing. While restoring the state,
the mask is converted to a dense tensor again.
Test Plan:
```python test/test_ao_sparsity.py TestActivationSparsifier```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82181
Approved by: https://github.com/z-a-f
The stored mask is dumped as `torch.sparse_coo` while serializing. While restoring the state,
the mask is converted to a dense tensor again.
Test Plan:
```python test/test_ao_sparsity.py TestBaseDataSparsifier```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82180
Approved by: https://github.com/z-a-f
### Summary
Modify APoT dequantize method to correctly add dequantized values to result numpy array and retain original tensor dimensions
### Test Plan
Run unit tests with: `python test/quantization/core/experimental/test_quantizer.py`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82126
Approved by: https://github.com/HDCharles
Summary: This adds the capability to visualize the histogram in the
ModelReportVisualizer. You can visualize the histogram of a single
feature for a single layer, (for example you want to see the
distribution of some data across all channels), or for some feature
across multiple layers of a similar kind. All channel data is merged
together to plot one large distribution. The user gets to decide the
number of bins the histogram has and it will create those many equally
spaced bins.
Expected Usage
```
mod_rep_visualizer.generate_histogram_visualization(<feature_name>,<module_name>)
```
You can also filter the modules so that only modules with a certain
substring will have their features represented in the plot.
> ** This is intended to be used in a `.ipynb` style notebook**
The tests for this were just visual inspection for two reasons:
1.) This method does not return anything, it just generates the
visualization plot
2.) All the data to create the plot visualization is gotten from
`generate_filtered_tables` which is already tested, so testing all that
for this again would be redundant.
Example Image outputs are pasted below in the PR thread.
Test Plan: Visual Test
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81975
Approved by: https://github.com/jerryzh168
Summary: This adds the capability to visualize the line plot in the
ModelReportVisualizer. You can visualize line plots of single feature,
and this feature can either be a per-tensor or per-channel feature. If
the feature is per tensor, then the idx of the module is printed as the
x axis and the values of the feature as the y. If the feature is per
channel, then **an** (the first one) idx of the module will the value on
the x axis and the corresponding feature val in the y axis, and there
will be a seperate line for each channel, and a legend denoting which
line belongs to which channel.
Expected Usage
```
mod_rep_visualizer.generate_plot_visualization(<feature_name>)
```
You can also filter the modules so that only modules with a certain
substring will have their features represented in the plot.
> ** This is intended to be used in a `.ipynb` style notebook**
The tests for this were just visual inspection for two reasons:
1.) This method does not return anything, it just generates the
visualization plot
2.) All the data to create the plot visualization is gotten from
`generate_filtered_tables` which is already tested, so testing all that
for this again would be redundant.
Example Image outputs are pasted below in the PR thread.
Test Plan: Visual Test
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81974
Approved by: https://github.com/jerryzh168
Summary: This adds the capability to visualize the table of information
in the ModelReportVisualizer. This allows the user to filter based on
module name pattern match or feature name pattern match and the
implemented method `generate_table_visualization` prints out the table
in a string format that is easy to parse.
Expected Usage
```
mod_rep_visualizer.generate_table_visualization()
```
Can also pass in optional filters as well if needed.
The tests for this were just visual inspection for two reasons:
1.) This method does not return anything, it just generates the
visualization
2.) All the data to create the table visualization is gotten from
`generate_filtered_tables` which is already tested, so testing all that
for this again would be redundant.
Example Printed Output
```
Tensor Level Information
idx layer_fqn input_activation_global_max input_activation_global_min input_weight_channel_axis input_weight_threshold outlier_detection_channel_axis outlier_detection_ratio_threshold outlier_detection_reference_percentile weight_global_max weight_global_min
----- ------------- ----------------------------- ----------------------------- --------------------------- ------------------------ -------------------------------- ----------------------------------- ---------------------------------------- ------------------- -------------------
1 block1.linear 1.9543 -1.33414 1 0.5 1 3.5 0.95 0.380521 -0.568476
2 block2.linear 1.81486 0 1 0.5 1 3.5 0.95 0.521438 -0.0256195
Channel Level Information
idx layer_fqn channel constant_batch_counts input_activation_per_channel_max input_activation_per_channel_min input_weight_channel_comparison_metrics input_weight_equalization_recommended outlier_detection_batches_used outlier_detection_is_sufficient_batches outlier_detection_percentile_ratios outliers_detected weight_per_channel_max weight_per_channel_min
----- ------------- --------- ----------------------- ---------------------------------- ---------------------------------- ----------------------------------------- --------------------------------------- -------------------------------- ----------------------------------------- ------------------------------------- ------------------- ------------------------ ------------------------
1 block1.linear 0 0 1.9543 -1.33414 0.956912 True 1 True 1.77489 False 0.300502 -0.568476
2 block1.linear 1 0 1.14313 -0.756184 1.04378 True 1 True 2.07887 False 0.336131 -0.261025
3 block1.linear 2 0 0.653274 -0.937748 1.10837 True 1 True 1.00712 False 0.380521 -0.183536
4 block2.linear 0 0 1.81486 0 0.542731 True 1 True 1.78714 False 0.13552 -0.0256195
5 block2.linear 1 0 1.72578 0 0.505475 True 1 True 1.40475 False 0.485536 0.352621
6 block2.linear 2 0 1.7284 0 0.909304 True 1 True 1.40392 False 0.521438 0.0906605
```
Test Plan: Visual Test
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81973
Approved by: https://github.com/jerryzh168
Summary: This adds the ability to generate and display the collected
statistics in a table format for the ModelReportVisualizer. The output
of this is a dictionary containing two keys, mapping to a tensor stats
table and channel stats table respectively.
The two ways you can filter is by module_fqn, by only including modules
with the `module_fqn_filter` substring, or by feature filter, which only includes
features that contain the `feature_filter` substring.
Expected Use:
```
table_dict = mod_rep_visualizer.generate_filtered_tables()
tensor_table = table_dict[ModelReportVisualizer.TABLE_TENSOR_KEY]
channel_table = table_dict[ModelReportVisualizer.TABLE_CHANNEL_KEY]
```
Headers for the Tensor level info:
```
idx layer_fqn feature_1 feature_2 feature_3 .... feature_n
---- --------- --------- --------- --------- ---------
```
Headers for the channel level info:
```
idx layer_fqn channel feature_1 feature_2 feature_3 .... feature_n
---- --------- ------- --------- --------- --------- ---------
```
The reason we split this up into two tables is because with the design
where everything is in one table, it is ambiguous and easy to mix up
whether a tensor level stat is actually tensor level stat or might be a
per channel stat since we would have a row for each channel.
Also changed some of the framework to abstract out the finding of the
tables to the actual visualization to make the API much easier for the
user to digest and parse.
Test Plan: python test/test_quantization.py TestFxModelReportVisualizer.test_generate_table
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81673
Approved by: https://github.com/jerryzh168
The README contains the results of the benchmarking exercise and area of future work.
It also contains instructions to run the benchmarking scripts to reproduce the results.
Also, contains other information such as requirements, machine config etc.
Test Plan: None
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81781
Approved by: https://github.com/z-a-f
The objective is to check if introducing torch sparse coo in the sparse dlrm model improves the inference time
over different sparsity levels.
The ```evaluate_forward_time.py``` makes use of the ```sparse_model_metadata.csv``` file dumped by the
```evaluate_disk_savings.py```. Records forward time for the sparse dlrm model using sparse coo
tensors and without using sparse coo tensors and dumps it into a csv file ```dlrm_forward_time_info.csv```
**Results**: The dlrm model with sparse coo tensor is slower (roughly 2x).
After running, `evaluate_memory_savings.py`, run: `python evaluate_forward_time.py --raw_data_file=<path_to_raw_data_txt_file> --processed_data_file=<path_to_kaggleAdDisplayChallenge_processed.npz> --sparse_model_metadata=<path_to_sparse_model_metadata_csv>`
Dependencies: DLRM Repository (https://github.com/facebookresearch/dlrm)
Test Plan: None
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81780
Approved by: https://github.com/z-a-f
The objective is to perform evaluation of the model quality after sparsifying the embeddings of the dlrm model.
The ```evaluation_model_metrics.py``` makes use of the ```sparse_model_metadata.csv``` file dumped by the
```evaluate_disk_savings.py```. The model metrics such as accuracy, auc, f1 etc are calculated on the test-dataset
for various sparsity levels, block shapes and norms available on the metadata csv file.
**Results**: The model accuracy decreases slowly with sparsity levels. Even at 90% sparsity levels, the model accuracy decreases only by 2%.
After running `evaluate_memory_savings.py`, run: `python evaluate_model_metrics.py --raw_data_file=<path_to_raw_data_txt_file> --processed_data_file=<path_to_kaggleAdDisplayChallenge_processed.npz> --sparse_model_metadata=<path_to_sparse_model_metadata_csv>`
Dependencies: DLRM Repository (https://github.com/facebookresearch/dlrm)
Test Plan: None
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81779
Approved by: https://github.com/z-a-f
The objective is to sparsify the embeddings of the dlrm model and observe the disk savings.
The model is sparsified and dumped to disk and then zipped.
The embeddings are pruned to different sparsity levels (0.0 - 1.0), for multiple block shapes ((1,1) and (1,4))
and optimization functions (L1, L2).
The user trying to reproduce the results is required to clone the dlrm repository and copy the files to dlrm directory.
Then train the dlrm model as per the instructions on the github page and then run this script.
**Results**: Introducing sparsity in the embeddings reduces file size after compression. The compressed model size goes
down from 1.9 GB to 150 MB after 100% sparsity.
Dependencies: DLRM Repository (https://github.com/facebookresearch/dlrm)
After Setup, Run: `python evaluate_disk_savings.py --model_path=<path_to_model_checkpoint> --sparsified_model_dump_path=<path_to_dump_sparsified_models>`
Test Plan: None
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81778
Approved by: https://github.com/z-a-f
Summary: Following https://github.com/pytorch/pytorch/pull/78452
and https://github.com/pytorch/pytorch/pull/79066, this commit
is part 1 of the broader effort to replace `backend_config_dict`
with a python config object, a more formal and robust API that
leads to better user experience. Note that there is no change in
behavior in this commit by itself. A future commit (part 2) will
replace all existing usages of `backend_config_dict` with the
`BackendConfig` object added in this commit.
Test Plan:
python test/test_quantization.py TestBackendConfig
Reviewers: jerryzh168
Subscribers: jerryzh168
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81469
Approved by: https://github.com/jerryzh168
Implemented dumping and loading of state_dicts and __get_state__ and __set_state__ functions.
hook and layer are removed from the data_groups dictionary before serializing.
In the future, might have to treat functions differently before serializing. Currently, it is being
treated similar to other types while serializing.
Test Plan:
```python test/test_ao_sparsity.py TestActivationSparsifier```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80890
Approved by: https://github.com/z-a-f
Unregisters aggreagate hook that was applied earlier and registers sparsification hooks.
The sparsification hook will apply the mask to the activations before it is fed into the
attached layer.
Test Plan:
```python test/test_ao_sparsity.py TestActivationSparsifier```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80889
Approved by: https://github.com/z-a-f
The step() internally calls the update_mask() function for each layer
The update_mask() applies reduce_fn and mask_fn to compute the sparsification mask.
Note:
the reduce_fn and mask_fn is called for each feature, dim over the data
Test Plan:
```python test/test_ao_sparsity.py TestActivationSparsifier```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80888
Approved by: https://github.com/z-a-f
The register_layer() attaches a pre-forward hook to the layer to aggregate
activations over time. The mask shape is also inferred here.
The get_mask() returns the computed mask associated to the attached layer.
The mask is
- a torch tensor is features for that layer is None.
- a list of torch tensors for each feature, otherwise
Test Plan:
```python test/test_ao_sparsity.py TestActivationSparsifier```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80887
Approved by: https://github.com/z-a-f
The Activation sparsifier class aims to sparsify/prune activations in a neural
network. The idea is to attach the sparsifier to a layer (or layers) and it
zeroes out the activations based on the mask_fn (or sparsification function)
input by the user.
The mask_fn is applied once all the inputs are aggregated and reduced i.e.
mask = mask_fn(reduce_fn(aggregate_fn(activations)))
Note::
The sparsification mask is computed on the input **before it goes through the attached layer**.
Test Plan:
```python test/test_ao_sparsity.py TestActivationSparsifier```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80886
Approved by: https://github.com/HDCharles
Summary: This updates the DynamicStatic Detector to also provide insight
into whether Conv layers should use dynamic or static quantization.
Before, this was not included because as of now, Dynamic quantization is
not supported for Conv layers, but this adds a check for Conv layers and
if dynamic is recommended, it will also give a disclaimer that it is not
currently supported but will be in the future.
Test Plan: python test/test_quantization.py TestFxModelReportDetectDynamicStatic
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81972
Approved by: https://github.com/jerryzh168
Summary: The current implementation of the InputWeightEqualization
detector broke when it was tested on MobileNetV2, and the reason for
this is that it wasn't able to properly handle groups in Conv layers,
and there also had to be some minor reshaping of the weights to handle
this as well.
In addition, the output was correspondingly tuned so that instead of
giving on output for each channel on each layer, it gives a single
suggestion per module and just lets it know how many of the channels
could benefit from input-weight equalization, and suggests it if it's
more than half.
There was also the realization that the test class didn't do a good job
of testing different dimensions for the batch vs. height vs. width, so
this was updated to be more comprehensive as well.
Test Plan: python test/test_quantization TestFxDetectInputWeightEqualization
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81971
Approved by: https://github.com/jerryzh168
This callback aims to sparsify the model inside lightning module after training.
**Note that the model is copied and then sparsified, so the existing model is not modified**
The sparsified model can be used for comparison and can be accessed using
<callback_obj>.sparsified
Test Plan:
```python torch/ao/sparsity/_experimental/data_sparsifier/lightning/tests/test_callbacks.py TestTrainingAwareCallback```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80371
Approved by: https://github.com/z-a-f
Lightning callback that enables post-training sparsity.
This callback aims to sparsify the model inside lightning module after training.
**Note that the model is copied and then sparsified, so the existing model is not modified**
The sparsified model can be used for comparison and can be accessed using <callback_obj>.sparsified
Test Plan
```python torch/ao/sparsity/_experimental/data_sparsifier/lightning/tests/test_callbacks.py TestPostTrainingCallback```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80370
Approved by: https://github.com/z-a-f
Add prelu op and module for quantized CPU backend.
The PR includes:
- Quantized version of prelu op
- Native prelu kernel for quantized CPU
- Prelu modules in `nn` and `nn.quantized`
- FX support for prelu
- Unit tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73491
Approved by: https://github.com/jerryzh168
Summary: Added the functionality to be able to get the feature names and
module_fqns from the ModelReportVisualizer class. The purpose of this
addition is so that users can see the exact set of module_fqns or
feature names that they can filter based on, and use this information to
perform their filtering.
Test Plan: python test/test_quantization.py
TestFxModelReportVisualizer.test_get_modules_and_features
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81647
Approved by: https://github.com/andrewor14
Summary: We created a ModelReportVisualizer class, and the primary
way it is envisioned that it is accessed is:
```
model_report_visualizer = model_reporter.generate_visualizer()
```
This method only works after reports have been generated and it takes in
the generated reports and reformats them to be ordered by module, into
the format required by the ModelReportVisualization. It then generates
the visualizer instance and returns that to the user.
Test Plan: python test/test_quantization.py TestFxModelReportClass.test_generate_visualizer
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81589
Approved by: https://github.com/andrewor14
Summary: This introduces the skeleton for the ModelReportVisualizer
class. This class helps visualize the information generated by the
ModelReport class `generate_report()` output. This class aims to provide
visualizations in a table, plot (line graph) and histogram view.
This also introduces an empty test class for testing visualizations. As
implementations start occuring for this class, tests will also be
approrpriately added.
This includes the high level descriptions for each of the methods as
well. Expected use cases will be added to the class description in a
future commit as that gets finalized.
Test Plan: python test/test_quantization.py TestFxModelReportVisualizer
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81523
Approved by: https://github.com/andrewor14
Summary: Currently, the ModelReport API only takes in detectors at the
beginning and for each of its methods, you have to pass in the model
each time, which doesn't really make sense because:
1. you will always want to be working on the same model
2. passing in a different model could break things, so more
fault-tolerant if we keep the model internally and make calls on it
Therefore, now the model will be passed in in intialization, and will
just be used for the rest of the operations with the local link.
All the ModelReport tests have been adjusted to account for this, and
this change must pass all the tests to ensure a successful API
transition.
If you wish to see how the updated API looks, the Expected Usage in the
ModelReport clas description has been updated to reflect the changes.
The README has also been updated with these changes as well.
Test Plan: python test/test_quantization.py TestFxModelReportClass
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81588
Approved by: https://github.com/jerryzh168
Summary: Currently, all the detectors have pretty accurate naming
schemes that give an idea of what they do. However, since now there are
more and more detectors being developed, there is a need to make sure
that the naming scheme for detectors are consistent for their keys.
This updates the keys of the returned dictionary keys to better
highlight if something is an activation stat or weight stat, etc.
Test Plan:
python test/test_quantization.py TestFxModelReportDetector
python test/test_quantization.py TestFxModelReportObserver
python test/test_quantization.py TestFxModelReportDetectDynamicStatic
python test/test_quantization.py TestFxModelReportClass
python test/test_quantization.py TestFxDetectInputWeightEqualization
python test/test_quantization.py TestFxDetectOutliers
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81587
Approved by: https://github.com/jerryzh168
Summary: Currently the InputWeightEqualizationDetector has a
multi-layered output.
Example
```
{'block1.linear': {'channel_axis_selected': 1,
'channel_comparison_metrics': tensor([0.8736, 0.6594, 0.2916], grad_fn=<DivBackward0>),
'input_range_info': {'global_max': tensor(9.),
'global_min': tensor(-10.),
'per_channel_max': tensor([9., 9., 9.]),
'per_channel_min': tensor([-10., -10., -10.])},
'input_weight_equalization_recommended': [True,
False,
False],
'threshold': 0.8,
'weight_range_info': {'global_max': tensor(0.5618, grad_fn=<UnbindBackward0>),
'global_min': tensor(-0.2211, grad_fn=<UnbindBackward0>),
'per_channel_max': tensor([0.3764, 0.5618, 0.2894], grad_fn=<NotImplemented>),
'per_channel_min': tensor([-0.2211, 0.2213, 0.2228], grad_fn=<NotImplemented>)}},
}
```
With all the levels, it can be hard to parse the information for
anything, especially the planned visualization feature where the data
has to be reorganized. Therefore, to make it standardized across all
detectors, all outputs will be limited to one level.
The new format is:
```
{'block1.linear': { 'channel_axis_selected': 1,
'channel_comparison_metrics': tensor([0.5705, 0.9457, 0.8891], grad_fn=<DivBackward0>),
'activation_global_max': tensor(9.),
'activation_global_min': tensor(-10.),
'activation_per_channel_max': tensor([9., 9., 9.]),
'activation_per_channel_min': tensor([-10., -10., -10.]),
'input_weight_equalization_recommended': [False, True, True],
'threshold': 0.8,
'weight_global_max': tensor(0.4258, grad_fn=<UnbindBackward0>),
'weight_global_min': tensor(-0.4958, grad_fn=<UnbindBackward0>),
'weight_per_channel_max': tensor([0.1482, 0.3285, 0.4258], grad_fn=<NotImplemented>),
'weight_per_channel_min': tensor([-0.1517, -0.4958, -0.3027], grad_fn=<NotImplemented>)},
}
```
The README will also be updated to reflect this change.
Test Plan: python test/test_quantization.py TestFxDetectInputWeightEqualization
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81586
Approved by: https://github.com/jerryzh168
Summary: Currently, the PerChannelDetector has a multi-layered output.
Example:
```
{'backend': 'qnnpack',
'per_channel_status': {'block1.linear': {'per_channel_supported': True,
'per_channel_used': False},
'block2.linear': {'per_channel_supported': True,
'per_channel_used': False}}}
```
The issue with this is that when it comes to future features such as
visualizations where we need to go through this dictionary, it can be
hard because of the variable number of layers.
This changes the output format of the PerChannelDetector to have a
standard format.
Ex.)
```
{'block1.linear': {'backend': 'qnnpack',
'per_channel_supported': True,
'per_channel_used': False},
'block2.linear': {'backend': 'qnnpack',
'per_channel_supported': True,
'per_channel_used': False}}
```
Test Plan: python test/test_quantization.py TestFxModelReportDetector
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81585
Approved by: https://github.com/HDCharles
Summary: There were accidently two lines added after a return statement
in the OutlierDetecor insertion that was not caught by either the linter
nor the tests nor i, that were harmless, but some odd merge issue. This
removes those two lines.
Test Plan: python test/test_quantization.py TestFxDetectOutliers
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81499
Approved by: https://github.com/kit1980
Summary: This adds a README for the ModelReport functionality that
contains an overview of the class, what it does,
and how it works, an example of usage, information on how to implement a
new detector (since this is how core functionality is added), folder
structure information, and finally information on tests and where they
are located.
The ModelReport class is still in development and will, in the future,
get additional features such as visualizations, and the README will be
updated with this information as it is added.
Test Plan: Just a new README, no code is added, README will be reviewed
for accuracy and ease of use/ easiness to read.
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81369
Approved by: https://github.com/jerryzh168
Summary: Before for the detectors, the
determine_observer_insert_points() function for all of them would have
hard coded strings as the keys for the dictionary that would be returned
to the ModelReport instance, and those same hard-coded keys would be
used to actually extract information from them. Since all detectors used
the same string keys, these were just made default variables at the top
of the detector.py file, and all detectors just used those. The same
ones are imported and now used in ModelReport file as well. This way,
there is less of a chance of an error because of incorrectly typed
strings.
The test plan primarily tests the ModelReport class because this uses
the same new vars as well for the strings and is the primary one calling
each of the detector instances' determine_observer_insert_points()
Test Plan: python test/test_quantization.py TestFxModelReportClass
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81382
Approved by: https://github.com/jerryzh168
Summary: Before, all the function calls for the ModelReport object were
dependent on the Fx Graph Mode workflow. However, in reality, this was
not true and the only requirement that was needed was for the model to
be a traceable GraphModule. This also helped keep the ModelReport class
as detached from the Fx Workflow as possible so that it can be used as a
more all purpose tool in the future.
This updated all the references to make sure that it wasn't specifically
referencing that a Fx Graph Mode workflow is needed, and is instead more
general since all we really need is a traceable model.
Test Plan: python test/test_quantization.py TestFxModelReportClass
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81252
Approved by: https://github.com/jerryzh168
Summary: This adds a example usage description to the ModelReport class
so that people can see how it can be used right in the class
documentation without having to consult external sources. The example
usage depicts how it can be used using the QuantizationTracer, which was
a decision taken to illustrate how there is no strict requirement on
using this tool with only Fx Graph Mode workflow.
Test Plan: python test/test_quantization.py TestFxModelReportClass
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81251
Approved by: https://github.com/jerryzh168
Summary: A huge part of the work for the Outlier detector was figuring
out what a good nth percentile to compare against the 100th percentile
was while also figuring out what a good comparision ratio would be. This
commit adds the link to a collab to the documentation of the function so
that people can go and see what the calculations used to determine those
values are and realize that they are not just randomly thrown in there.
At a high level, this collab contains work that includes:
- Figuring out whether to use interpolation or lower as the rule for
finding quantile between two indices
- Figuring out what a good value for reference_percentile is
- Figuring out what a good value for ratio_threshold is
Test Plan: python test/test_quantization.py TestFxDetectOutliers
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81250
Approved by: https://github.com/jerryzh168
Summary: The current Outlier detector does a good job of finding whether
data distributions passing through layers have outliers. However,
suppose we have a completely constant channel. The outlier detector
would not detect it as an outlier, but that is still something we want
to highlight because a constant channel usually is a result of a bad
configuration or something really wrong with the data.
To address this there are two additions to the outlier detector that
this commit makes:
- The first is to add whether there are any constant batches at all and
let the user know in the text report
- The second is to let the user know the number of total constant
batches found for each channel, so they can figure out if there are any
unnecessary channels present.
The exisiting outlier detector tests were modified to do a quick check
for this feature.
Test Plan: python test/test_quantization.py TestFxDetectOutliers
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81249
Approved by: https://github.com/andrewor14
Summary: The outlier detector has a feature where it's able to notify
the user if below the whole set of batches that passed through were used
in Outlier calculation, which mainly happens as a result of 0-errors.
This changes the code so that instead of comparing against a value like
30 as we were before, we now let the user pass in an optional fractional
value and if the ratio of the batches used was below that value, the
detector alerts the user.
Test Plan: python test/test_quantization.py TestFxDetectOutliers
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81174
Approved by: https://github.com/andrewor14
Summary: This adds the implementation for the report generation for the
Outlier Detector class. This includes both the generation of a
dictionary containing each module that had an observer attached and any
relavent stats collected by the observer that can help shed light on
outlier relavent data or computed metrics. It also includes a string
denoting specific modules that had outliers and gives a bit of insight
into what channels they are contained in.
This contains both the implementation for the report generation for the
outlier detector as well as a test class to test the report generation
functionality.
Test Plan: python test/test_quantization.py TestFxDetectOutliers
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80937
Approved by: https://github.com/andrewor14
The previous implementation was using loops to compute the sparsity within a block in a mask, as well as across the mask blocks. This implements the vectorized version.
## Vectorization:
A high level overview of the vectorization procedure falls into a two step process:
### Tensor-level masking
A tensor-level masking is a mask generation routine that has a granularity of `sparse_block_shape`. That means that only patches of that shape can be considered sparse/dense. To vectorize:
1. Reshape the data such that one of the dimensions represents the patches of sparse_block_shape.
2. Create a mask of the same shape as the reshaped data
3. Find the smallest `k` elements in the the data, given the dimension of the sparse "patches". `k` represents a derived paramter specifying the sparsity level.
4. Apply the 0/1 to the patches in the mask
5. Reshape the mask back to the original dimensions
Note: because the shape of the mask might not be multiple of the sparse_block_shape, we nudge the sshape of the mask, and truncate it afterwards.
## Block-level masking
A block-level masking is a mask generation routine that concerns itself only with sparsity within a patch of shape `sparse_block_shape`. This is useful when block sparsity allows partial block sparsification.
To vectorize:
Overall the block-level masking follows the same routine as the tensor-level algorithm described above. One distinction is that when reshaping the data/mask tensors we aim for creating a dimension that captures the internals of each patch. For example, if a `sparse_block_shape` is `(2, 2)`, we want to reshape the data/mask into `(2, 2, -1)`. That allows us to sort the internal elements on the last axis, and zero-out the ones that obey the sparse logic.
Differential Revision: [D37352494](https://our.internmc.facebook.com/intern/diff/D37352494/)
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D37352494/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80059
Approved by: https://github.com/jerryzh168
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/78117
Fixes: https://github.com/pytorch/pytorch/issues/73463
This PR adds a normalization pass that normalizes all the args to keyword args in positional order and fixes lowering code that previously
only uses node.args to use both args and kwargs instead.
Also tried to add a test for F.conv2d, but since conv2d matches multiple schemas we are doing an extra schema match, and because we are using symbolic values
in `transform`, we don't have a schema match, so F.conv2d still fails with runtime errors. we can resolve this issue later when there is a need.
Another thing I'm considering is to do the normalization with real inputs instead of symbolic inputs and not rely on operator_schemas (which is based on torchscript),
and rely on inspect.signature, I tried this briefly but didn't get too far, it looks like we cannot get the python signature for `torch._C._nn.linear`, it might be possible to fix as well, but will need follow up discussions.
The goal for this PR is just to introduce normalization in our codebase so that we can adapt some downstream code to this, and also fix the F.linear issue.
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_normalize_args
Reviewers:
Subscribers:
Tasks:
Tags:
Differential Revision: [D37163228](https://our.internmc.facebook.com/intern/diff/D37163228)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79095
Approved by: https://github.com/andrewor14
Summary: Previously, we automatically moved the model to CPU in
torch.ao.quantization.fx.convert to work around the issue where
certain functions called by convert expect CPU arguments. This
commit pushes this responsibility to the caller since it is the
user's decision of which device to use.
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
BC-breaking Notes:
Before:
```
model = resnet18(...)
model = prepare_fx(model, qconfig_mapping, example_inputs)
... # calibrate
model = convert_fx(model)
```
After:
```
model = resnet18(...)
model.cpu()
model = prepare_fx(model, qconfig_mapping, example_inputs)
... # calibrate
model = convert_fx(model)
```
Reviewers: jerryzh168
Subscribers: jerryzh168
Differential Revision: [D37528830](https://our.internmc.facebook.com/intern/diff/D37528830)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80555
Approved by: https://github.com/jerryzh168
Summary: This adds the implementation for observer insertion point
selection for the OutlierDetector. For this detector, the insertion
points are to insert a ModelReportObserver before any leaf level module
to study the distribution of data that passes into the module to detect
outliers.
This commit contains the implementation of the observer insertion as
well as the relavent test case. Some code from the
InputWeightEqualization was abstracted and made more modular so the same
helper function could be used for multiple outlier class tests.
As a part of the work for this, there was testing done to determine what
a good default ratio threshold and reference percentile would be, and
the work to determine this (based on a normal distribution) was then
analyzed to find good paramters.
We still want to keep thresholds and reference percentile as something
the user can input because these were based on a normal distribution,
and it can definately vary depending on the type of data a user has.
Test Plan: python test/test_quantization.py TestFxDetectOutliers
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80880
Approved by: https://github.com/andrewor14
Issue:
Previously, the L1/L2 norm data sparsifier was not supported with
1D tensors or parameters.
Fix:
If the tensor is 1D, then unsqueeze it to make it look 2D and
perform the rest as usual. Also, added some 1D tensor in the
unit test to test this issue.
Test Plan:
```python test/test_ao_sparsity.py TestNormDataSparsifiers```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80465
Approved by: https://github.com/z-a-f
Issue:
Previously, the data was not "attached" to the data sparsifier. Meaning
the data sparsifier created a copy of the actual data inside it's container. So,
when the data was modified outside of the sparsifier, the changes was not reflected
in the sparsifier.
Fix:
Use register_buffer() instead of nn.Parameter(..) to store the data inside the container.
Also, added a unit-test to reference this issue.
Test Plan:
```python test/test_ao_sparsity.py TestBaseDataSparsifier```
```python test/test_ao_sparsity.py TestNormDataSparsifiers```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80394
Approved by: https://github.com/z-a-f
Summary:
Some of the util functions in FX graph mode quantization throw warnings
such as:
```
/Users/vasiliy/pytorch/torch/ao/quantization/fx/utils.py:410: UserWarning: To copy construct from
a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().
requires_grad_(True), rather than torch.tensor(sourceTensor).
```
This PR fixes the warnings by moving the code to the recommended syntax if the
value is a tensor.
Test plan:
```
python test/test_quantization.py -k test_conv_linear_reference
// warning appeared before this PR and disappeared after this PR
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80883
Approved by: https://github.com/jerryzh168
### Summary:
This PR moves the clamping functionality from `quantize` to `float_to_apot` util function to align with the uniform quantize workflow in the codebase.
### Test Plan:
Run unit tests with:
python pytorch/test/quantization/core/experimental/test_quantizer.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80885
Approved by: https://github.com/dzdang
Summary: This adds the class framework for the ModelReport
OutlierDetector. This detector will be in charge of looking at
activation data and figuring out whether there are significant oultiers
present in them. It will average this data across batches to make a
recommendation / warning if significant outliers are found.
This commit contains just the class framework and a base test class.
Implementations will follow in following commits.
Test Plan: python test/test_quantization.py TestFxDetectOutliers
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80743
Approved by: https://github.com/HDCharles
Add prelu op and module for quantized CPU backend.
The PR includes:
- Quantized version of prelu op
- Native prelu kernel for quantized CPU
- Prelu modules in `nn` and `nn.quantized`
- FX support for prelu
- Unit tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73491
Approved by: https://github.com/jerryzh168
Summary:
Currently we expect the users to provide custom modules for LSTM and MHA. However, as we almost always ask the users to use those modules in the custom context, it is better to make this behavior default. In this case we try to align with the base quantization API, if the user specifies a custom_config_dict then that is used, however if the value is left as None then the default is used. If a user would like to both use the default and modify it, they have to do so manually, however the default is accessible by get_default_custom_config_dict
Additionally, the NS which uses prepare to insert custom observers for
its purposes had to be slightly modified to pass in an empty
custom_config_dict in order to avoid modifying the custom modules.
due to weird CI issues with previous PR,
previous discussion can be found: https://github.com/pytorch/pytorch/pull/71192
Test Plan:
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79960
Approved by: https://github.com/z-a-f
Summary: This commit adds qconfigs with special observers for fixed
qparams ops in get_default_qconfig_mapping and
get_default_qat_qconfig_mapping. For correctness, we also require
users to use these special observers if we detect these fixed
qparams ops in prepare.
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Reviewers: jerryzh168, vkuzo
Subscribers: jerryzh168, vkuzo
Differential Revision: [D37396379](https://our.internmc.facebook.com/intern/diff/D37396379)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80184
Approved by: https://github.com/jerryzh168
Summary: This PR removes the is_reference flag from the existing
convert_fx API and replaces it with a new convert_to_reference
function. This separates (1) converting the prepared model to a
reference model from (2) lowering the reference model to a quantized
model, enabling users to call their custom lowering function for
custom backends. For the native fbgemm backend, for example, the
following are equivalent:
```
from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx
prepared = prepare_fx(model, ...)
quantized = convert_fx(prepared, ...)
```
```
from torch.ao.quantization.fx import lower_to_fbgemm
from torch.ao.quantization.quantize_fx import (
prepare_fx,
convert_to_reference
)
prepared = prepare_fx(model, ...)
reference = convert_to_reference(prepared, ...)
quantized = lower_to_fbgemm(reference, ...)
```
Note that currently `lower_to_fbgemm` takes in two other arguments
that are difficult for users to provide. A future commit will remove
these arguments to make the helper function more user friendly.
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Reviewers: jerryzh168, vkuzo
Subscribers: jerryzh168, vkuzo
Differential Revision: [D37359946](https://our.internmc.facebook.com/intern/diff/D37359946)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80091
Approved by: https://github.com/jerryzh168
### Summary:
This PR implements APoT fake quantization for the purpose of quantization aware training. This implements `calculate_qparams` and `forward `methods to be used in fake quantization.
### Test Plan:
Run unit tests with: `python pytorch/test/quantization/core/experimental/test_fake_quantize.py`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79845
Approved by: https://github.com/dzdang
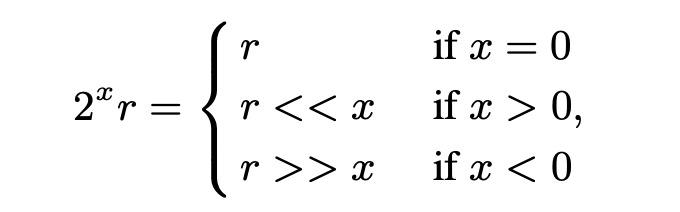{kind=link}