XiaobingSuper
4ca2fc485c
inductor(CPU): add Conv+binary+unary fusion filter ( #90259 )
...
For Conv+binary+unary fusion, we only support conv+add+relu, this PR adds a such check to fix TIMM failed models.
TODO: enable more Conv+binary+unary fusion to improve TIMM models' performance.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90259
Approved by: https://github.com/EikanWang , https://github.com/jgong5 , https://github.com/jansel
2022-12-12 06:04:55 +00:00
Bert Maher
b95ea4f149
[pt2] Reset dynamo log level when exiting inductor debug context ( #90473 )
...
When entering an inductor debug context we increase the log level of
dynamo; I guess this makes sense, since if we're debugging inductor, and
inductor calls into dynamo, we probably want visibility into what dynamo is
doing.
But when we exit that context, we probably want to go back to whatever level of
dynamo-specific logging was in place before. Dynamo generates lots of debug
info (guards, bytecode), and it's a lot to sift through if you're not
specifically interested in it.
Differential Revision: [D41841879](https://our.internmc.facebook.com/intern/diff/D41841879/ )
Differential Revision: [D41841879](https://our.internmc.facebook.com/intern/diff/D41841879 )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90473
Approved by: https://github.com/mlazos , https://github.com/jansel
2022-12-12 04:39:37 +00:00
Bert Maher
d3d85e1c3b
Emit torch.cuda.synchronize() after every kernel call in inductor ( #90472 )
...
Debugging illegal memory access is hard; even CUDA_LAUNCH_BLOCKING=1
and using C10_CUDA_KERNEL_LAUNCH_CHECK doesn't guarantee a useful stack trace.
doesn't necessarily guarantee that you'll get a stack trace pointing to the
right kernel. This diff adds a config option to force a CUDA synchronize after
every kernel call in inductor, for debugging those tricky cases.
Differential Revision: [D41744967](https://our.internmc.facebook.com/intern/diff/D41744967/ )
Differential Revision: [D41744967](https://our.internmc.facebook.com/intern/diff/D41744967 )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90472
Approved by: https://github.com/jansel
2022-12-12 04:35:10 +00:00
Edward Z. Yang
b68dead20c
Keep track of source name on all allocated SymInts ( #90295 )
...
Wow, I had to sweat so much to get this PR out lol.
This PR enforces the invariant that whenever we allocate SymInts as part of fakeification, the SymInt is associated with a Source, and in fact we store the string source name on SymbolWithSourceName. We use 'sname' as the shorthand for source name, as 'name' is already used by sympy to name symbols.
In order to store source names, we have to plumb source names from Dynamo to PyTorch. This made doing this PR a bit bone crushing, because there are many points in the Dynamo codebase where we are improperly converting intermediate tensors into fake tensors, where there is no source (and there cannot be, because it's a frickin' intermediate tensor). I've fixed all of the really awful cases in earlier PRs in the stack. This PR is just plumbing in source names from places where we do have it.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90295
Approved by: https://github.com/voznesenskym
2022-12-10 13:17:34 +00:00
blzheng
f9aa099074
[Inductor] fix issue: redeclaration of float g_tmp_buffer_xxx ( #90270 )
...
This pr is to fix the issue: redeclaration of 'float g_tmp_buffer_in_ptr1[16] = {0};'
If a bool or uint8 tensor is used by multiple op, this tensor will be loaded multiple times. On load, it writes the declaration of this variable, i.e., `self.loads.writeline(f"float {g_tmp_buf}[{nelements}] = {{0}};")`, which will introduce redeclaration error.

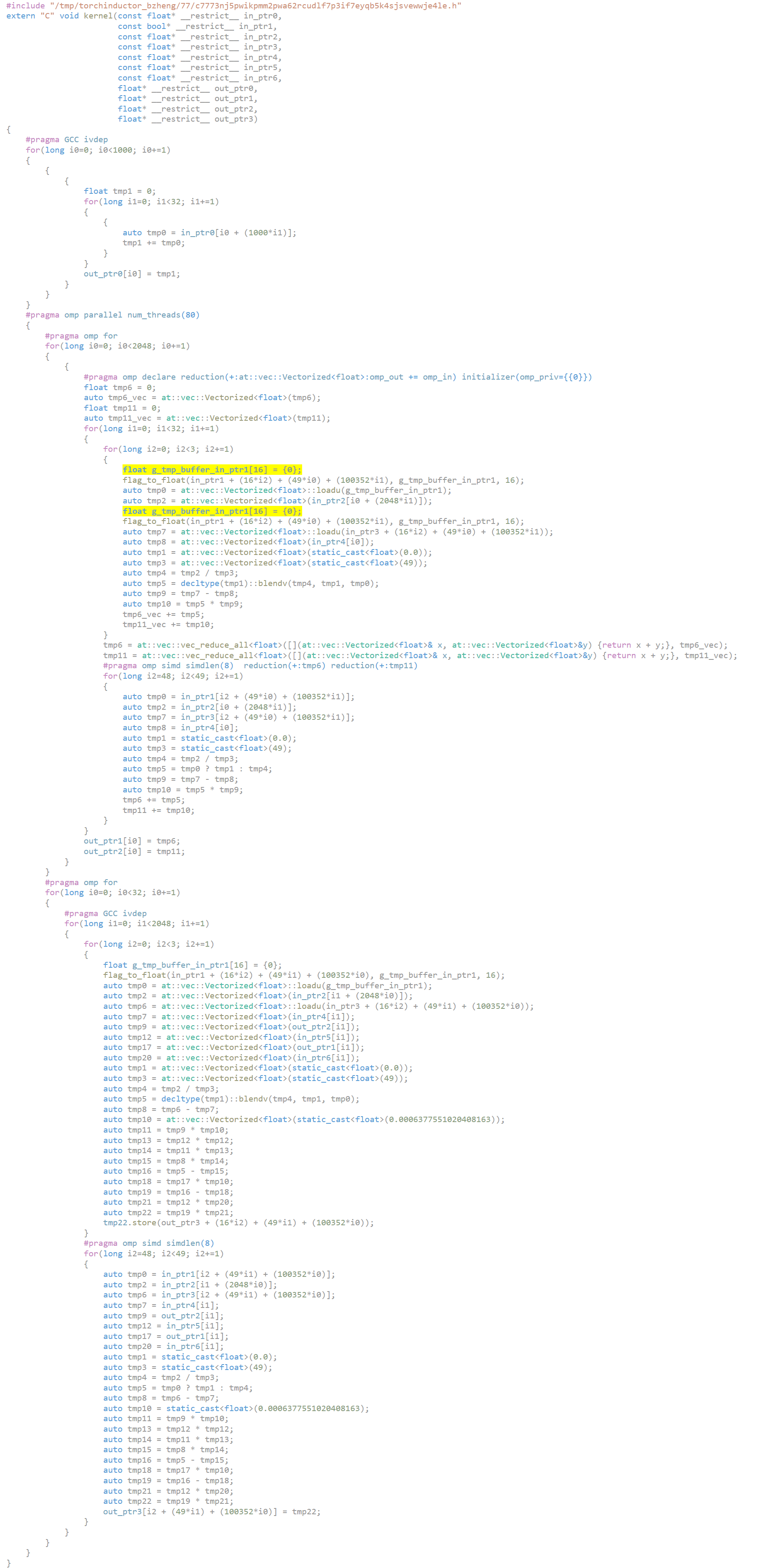
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90270
Approved by: https://github.com/EikanWang , https://github.com/jgong5 , https://github.com/desertfire , https://github.com/jansel
2022-12-10 12:59:30 +00:00
Jiawen Liu
4a1633ca69
[Inductor] GEMM Shape Padding Optimization ( #90425 )
...
Summary:
Optimize the shape padding in the following perspectives:
- Add BFloat16 support for AMP training and Float16 support for inference
- Optimize microbenchmark to avoid peak memory issue, and include profiling memory ops to make more accurate decision
- Add a flag to turn off/on padding dims N and M in `torch.bmm` due to expensive memory copy of `.contiguous` to avoid peak memory issues in internal models
Test Plan: CI
Differential Revision: D41724868
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90425
Approved by: https://github.com/jianyuh
2022-12-09 22:48:02 +00:00
PyTorch MergeBot
b2795d3c4e
Revert "[inductor] New approach for computing triton load/store masks ( #89566 )"
...
This reverts commit c6c2de586dhttps://github.com/pytorch/pytorch/pull/89566 on behalf of https://github.com/clee2000 due to broke test_invalid_operand_issue1_cuda in inductor/test_torchinductor on https://github.com/pytorch/pytorch/actions/runs/3657444733/jobs/6181700572
2022-12-09 19:36:25 +00:00
Michael Lazos
730e44bbc7
Add logging for aot autograd and unified debug flag ( #88987 )
...
- Adds `log_level` to aot's config
- Outputs log to `<graph_name>_<log_level>.log` in aot_torchinductor subfolder of the debug directory
- Modifies the Inductor debug context to use the graph name when naming the folder instead of the os pid
- Adds `TORCH_COMPILE_DEBUG` flag to enable it, (as well as separate dynamo and inductor logs)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88987
Approved by: https://github.com/Chillee
2022-12-09 17:28:10 +00:00
Bin Bao
282dfe8ba4
[inductor][Reland] Use decomposition for _to_copy ( #90494 )
...
Summary: also contains a fix for https://github.com/pytorch/pytorch/issues/89633
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90494
Approved by: https://github.com/ngimel
2022-12-09 16:51:50 +00:00
PyTorch MergeBot
6581063583
Revert "Dynamo, FX, Inductor Progress Bars ( #88384 )"
...
This reverts commit db0ce4acf3https://github.com/pytorch/pytorch/pull/88384 on behalf of https://github.com/malfet due to Broke test_public_bindings across the board
2022-12-09 16:32:25 +00:00
Fabio Rocha
c6c2de586d
[inductor] New approach for computing triton load/store masks ( #89566 )
...
This PR changes the way masks for loads/stores are computed in triton backend of inductor.
New approach is to iterate over all variables used in indexing expression and add the corresponding mask variables to the set that will be used. For indexing variables like `x0`, `y1` and `r3` it adds `xmask`, `ymask` and `rmask` respectively.
For indexing variables like `tmp5` (i.e., indirect indexing), it uses the new `mask_vars` attribute of the corresponding `TritonCSEVariable` object, which is populated when variable is created.
I started working on this with the aim of fixing https://github.com/pytorch/torchdynamo/issues/1654 , which meanwhile was fixed by #89524 with a different approach, making this change less necessary. However note that #89524 fixes the issue by broadcasting the indices that are being loaded to a larger size, while this approach fixes it by making the mask have only the necessary terms.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89566
Approved by: https://github.com/jansel , https://github.com/ngimel
2022-12-09 12:43:19 +00:00
Mark Saroufim
db0ce4acf3
Dynamo, FX, Inductor Progress Bars ( #88384 )
...
There are 3 progress bars each gated behind their own config, all off by default for now
1. Dynamo: Macro level config for dynamo, AOT, inductor
2. FX: Progress bar for each pass, with their names
3. Inductor
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88384
Approved by: https://github.com/wconstab , https://github.com/mlazos
2022-12-09 04:32:31 +00:00
PyTorch MergeBot
e89685b0b5
Revert "[inductor] Use decomposition for _to_copy ( #90314 )"
...
This reverts commit 3fdb5f2ddahttps://github.com/pytorch/pytorch/pull/90314 on behalf of https://github.com/desertfire due to regresses performance on hf_Bert
2022-12-08 18:29:06 +00:00
Bin Bao
d2ee94231e
[inductor] Fallback for index with None in the middle of indices ( #90022 )
...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90022
Approved by: https://github.com/ngimel
2022-12-08 16:18:57 +00:00
Bin Bao
3fdb5f2dda
[inductor] Use decomposition for _to_copy ( #90314 )
...
Summary: also contains a fix for https://github.com/pytorch/pytorch/issues/89633
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90314
Approved by: https://github.com/ngimel
2022-12-08 15:25:44 +00:00
PyTorch MergeBot
22a249e44e
Revert "[Inductor] More robust stride and offset extraction from index expressions ( #90184 )"
...
This reverts commit 71f27f7688https://github.com/pytorch/pytorch/pull/90184 on behalf of https://github.com/ngimel due to catastrophically regresses performance
2022-12-08 05:04:15 +00:00
Edward Z. Yang
37892041a1
Always compile tiny graphs with AOTAutograd ( #89775 )
...
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89775
Approved by: https://github.com/anjali411 , https://github.com/bdhirsh
2022-12-08 03:41:29 +00:00
Nikita Shulga
36ac095ff8
Migrate PyTorch to C++17 ( #85969 )
...
With CUDA-10.2 gone we can finally do it!
This PR mostly contains build system related changes, invasive functional ones are to be followed.
Among many expected tweaks to the build system, here are few unexpected ones:
- Force onnx_proto project to be updated to C++17 to avoid `duplicate symbols` error when compiled by gcc-7.5.0, as storage rule for `constexpr` changed in C++17, but gcc does not seem to follow it
- Do not use `std::apply` on CUDA but rely on the built-in variant, as it results in test failures when CUDA runtime picks host rather than device function when `std::apply` is invoked from CUDA code.
- `std::decay_t` -> `::std::decay_t` and `std::move`->`::std::move` as VC++ for some reason claims that `std` symbol is ambigious
- Disable use of `std::aligned_alloc` on Android, as its `libc++` does not implement it.
Some prerequisites:
- https://github.com/pytorch/pytorch/pull/89297
- https://github.com/pytorch/pytorch/pull/89605
- https://github.com/pytorch/pytorch/pull/90228
- https://github.com/pytorch/pytorch/pull/90389
- https://github.com/pytorch/pytorch/pull/90379
- https://github.com/pytorch/pytorch/pull/89570
- https://github.com/facebookincubator/gloo/pull/336
- https://github.com/facebookincubator/gloo/pull/343
- 919676fb32https://github.com/pytorch/pytorch/issues/56055
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85969
Approved by: https://github.com/ezyang , https://github.com/kulinseth
2022-12-08 02:27:48 +00:00
Bin Bao
d7c30e11c6
[inductor] Remove .to from lowering ( #90280 )
...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90280
Approved by: https://github.com/ngimel
2022-12-08 00:40:41 +00:00
YJ Shi
2b0b4bb6fd
[Dynamo] Fix llvm target for meta schedule & add torch to tvm ndarray helper func ( #90214 )
...
Fixes #90213 . Also a torch.tensor to tvm.nd.array helper function is added to avoid data copy with dlpack.
@jansel @Chillee
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90214
Approved by: https://github.com/wconstab
2022-12-07 19:23:56 +00:00
Peter Bell
e6a7278753
Give std/var correction overloads proper defaults ( #56398 )
...
The correction overloads defaults were left off for forward
compatibility reasons, but this FC window expired well over a year ago
at this point.
Differential Revision: [D29625593](https://our.internmc.facebook.com/intern/diff/D29625593 )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56398
Approved by: https://github.com/mruberry
2022-12-07 15:15:00 +00:00
Bert Maher
26d1dbc4f8
[inductor] More correct check for fbcode environment ( #90312 )
...
Summary:
importing torch.fb seemed like a good idea, but we don't always have
torch.fb inside fbcode. Testing for torch.version.git_version is more
reliable, since we'll never have a git_version inside fbcode, which is an hg
repo.
Test Plan: `buck2 run mode/dev-nosan //caffe2/test/inductor:smoke`
Reviewed By: soumith, jansel
Differential Revision: D41777058
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90312
Approved by: https://github.com/soumith
2022-12-07 04:50:11 +00:00
Ram Rachum
351d73b97f
Fix exception causes all over the codebase ( #90271 )
...
This is the continuation to #90134 and hopefully the final PR in this series.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90271
Approved by: https://github.com/kit1980
2022-12-07 04:29:00 +00:00
Peter Bell
71f27f7688
[Inductor] More robust stride and offset extraction from index expressions ( #90184 )
...
Currently the stride and offset are determined by substituting 1 and 0 for
different indices, which will fail for any expression that doesn't match the
expected stride calculation. Instead, this uses `sympy.match` and returns `None`
for any variables used in non-standard index calculation, e.g. `torch.roll`
which uses `ModularIndexing`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90184
Approved by: https://github.com/jansel
2022-12-07 01:43:21 +00:00
Peter Bell
4f44877983
[Inductor] Add test for Scheduler fusions ( #90014 )
...
Currently there is `test_vertical_fusion1` which fuses entirely during
the lowering stage and no buffers are realized. This adds
`test_scheduler_vertical_fusion1` which is the same test but with
several intermediate calculations realized so the scheduler is left
to do the fusion.
To support the test, this PR also adds:
- `metrics.ir_nodes_pre_fusion` which when compared with
`generated_kernel_count` tells us how many nodes were fused.
- `torch._test_inductor_realize` which is an identity operator in
eager, but under inductor also forces the input to be realized.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90014
Approved by: https://github.com/jansel
2022-12-07 01:33:25 +00:00
William Wen
d224ac7f77
Remove logging.CODE ( #90234 )
...
Fixes https://github.com/pytorch/torchdynamo/issues/1932
Discussed with @mlazos: if we still want to separate streams for code logging and the rest of info, we can use a separate logger object with a unique name.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90234
Approved by: https://github.com/ezyang
2022-12-06 22:24:43 +00:00
Natalia Gimelshein
a88400e0cc
pad low precision matmuls when requested ( #90235 )
...
Matmul padding is beneficial not only for fp32, fp16/bf16 with amp can benefit as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90235
Approved by: https://github.com/jiawenliu64
2022-12-06 04:13:24 +00:00
XiaobingSuper
2597d5d722
TorchDynamo: always convert flexiblelayout to be FixedLayout when given a stride_order ( #89904 )
...
For convolution, we always call **require_stride_order** to convert the input to the target stride order, if the original input's layout is flexiblelayout, there always have a memory copy because the **is_stride_order_storage_and_layout** only checks the init stride order, I think for flexiblelayout, means it's layout can be changed, if the user gives a stride order, I think we always need to convert the flexiblelayout to be FixedLayout using given strider order.
Given a CV user case, the max_pooling's output is used by two convolutions, there has two memory copies:
```
kernel_cpp_0 = async_compile.cpp('''
#include "/tmp/torchinductor_xiaobing/77/c7773nj5pwikpmm2pwa62rcudlf7p3if7eyqb5k4sjsvewwje4le.h"
extern "C" void kernel(const float* __restrict__ in_ptr0,
float* __restrict__ out_ptr0,
float* __restrict__ out_ptr1,
float* __restrict__ out_ptr2)
{
#pragma GCC ivdep
for(long i0=0; i0<128; i0+=1)
{
#pragma GCC ivdep
for(long i1=0; i1<3; i1+=1)
{
#pragma GCC ivdep
for(long i2=0; i2<3; i2+=1)
{
#pragma GCC ivdep
for(long i3=0; i3<3; i3+=1)
{
{
{
auto tmp0 = in_ptr0[i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp1 = in_ptr0[3 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp3 = in_ptr0[6 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp5 = in_ptr0[21 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp7 = in_ptr0[24 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp9 = in_ptr0[27 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp11 = in_ptr0[42 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp13 = in_ptr0[45 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp15 = in_ptr0[48 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp2 = (tmp0 != tmp0) ? tmp0 : std::max(tmp1, tmp0);
auto tmp4 = (tmp2 != tmp2) ? tmp2 : std::max(tmp3, tmp2);
auto tmp6 = (tmp4 != tmp4) ? tmp4 : std::max(tmp5, tmp4);
auto tmp8 = (tmp6 != tmp6) ? tmp6 : std::max(tmp7, tmp6);
auto tmp10 = (tmp8 != tmp8) ? tmp8 : std::max(tmp9, tmp8);
auto tmp12 = (tmp10 != tmp10) ? tmp10 : std::max(tmp11, tmp10);
auto tmp14 = (tmp12 != tmp12) ? tmp12 : std::max(tmp13, tmp12);
auto tmp16 = (tmp14 != tmp14) ? tmp14 : std::max(tmp15, tmp14);
out_ptr0[i3 + (3*i2) + (9*i1) + (27*i0)] = tmp16;
}
}
}
}
}
}
#pragma GCC ivdep
for(long i0=0; i0<128; i0+=1)
{
#pragma GCC ivdep
for(long i1=0; i1<3; i1+=1)
{
#pragma GCC ivdep
for(long i2=0; i2<9; i2+=1)
{
{
{
auto tmp0 = out_ptr0[i1 + (3*i2) + (27*i0)];
out_ptr1[i1 + (3*i2) + (27*i0)] = tmp0;
out_ptr2[i1 + (3*i2) + (27*i0)] = tmp0;
}
}
}
}
}
}
''')
async_compile.wait(globals())
del async_compile
def call(args):
arg0_1, arg1_1, arg2_1, arg3_1, arg4_1 = args
args.clear()
buf0 = empty_strided((128, 3, 3, 3), (27, 1, 9, 3), device='cpu', dtype=torch.float32)
buf2 = empty_strided((128, 3, 3, 3), (27, 1, 9, 3), device='cpu', dtype=torch.float32)
buf4 = empty_strided((128, 3, 3, 3), (27, 1, 9, 3), device='cpu', dtype=torch.float32)
kernel_cpp_0(c_void_p(arg4_1.data_ptr()), c_void_p(buf0.data_ptr()), c_void_p(buf2.data_ptr()), c_void_p(buf4.data_ptr()))
del arg4_1
del buf0
buf3 = torch.ops.mkldnn._convolution_pointwise(buf2, arg0_1, arg1_1, (0, 0), (1, 1), (1, 1), 1, 'none', [], '')
assert_size_stride(buf3, (128, 3, 3, 3), (27, 1, 9, 3))
del arg0_1
del arg1_1
del buf2
buf5 = torch.ops.mkldnn._convolution_pointwise(buf4, arg2_1, arg3_1, (0, 0), (1, 1), (1, 1), 1, 'none', [], '')
assert_size_stride(buf5, (128, 3, 3, 3), (27, 1, 9, 3))
del arg2_1
del arg3_1
return (buf3, buf5, )
```
After this PR, the generated code will remove the redundant memory copy:
```
kernel_cpp_0 = async_compile.cpp('''
#include "/tmp/torchinductor_xiaobing/77/c7773nj5pwikpmm2pwa62rcudlf7p3if7eyqb5k4sjsvewwje4le.h"
extern "C" void kernel(const float* __restrict__ in_ptr0,
float* __restrict__ out_ptr0)
{
#pragma GCC ivdep
for(long i0=0; i0<128; i0+=1)
{
#pragma GCC ivdep
for(long i1=0; i1<3; i1+=1)
{
#pragma GCC ivdep
for(long i2=0; i2<3; i2+=1)
{
#pragma GCC ivdep
for(long i3=0; i3<3; i3+=1)
{
{
{
auto tmp0 = in_ptr0[i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp1 = in_ptr0[3 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp3 = in_ptr0[6 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp5 = in_ptr0[21 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp7 = in_ptr0[24 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp9 = in_ptr0[27 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp11 = in_ptr0[42 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp13 = in_ptr0[45 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp15 = in_ptr0[48 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp2 = (tmp0 != tmp0) ? tmp0 : std::max(tmp1, tmp0);
auto tmp4 = (tmp2 != tmp2) ? tmp2 : std::max(tmp3, tmp2);
auto tmp6 = (tmp4 != tmp4) ? tmp4 : std::max(tmp5, tmp4);
auto tmp8 = (tmp6 != tmp6) ? tmp6 : std::max(tmp7, tmp6);
auto tmp10 = (tmp8 != tmp8) ? tmp8 : std::max(tmp9, tmp8);
auto tmp12 = (tmp10 != tmp10) ? tmp10 : std::max(tmp11, tmp10);
auto tmp14 = (tmp12 != tmp12) ? tmp12 : std::max(tmp13, tmp12);
auto tmp16 = (tmp14 != tmp14) ? tmp14 : std::max(tmp15, tmp14);
out_ptr0[i3 + (3*i2) + (9*i1) + (27*i0)] = tmp16;
}
}
}
}
}
}
}
''')
async_compile.wait(globals())
del async_compile
def call(args):
arg0_1, arg1_1, arg2_1, arg3_1, arg4_1 = args
args.clear()
buf0 = empty_strided((128, 3, 3, 3), (27, 1, 9, 3), device='cpu', dtype=torch.float32)
kernel_cpp_0(c_void_p(arg4_1.data_ptr()), c_void_p(buf0.data_ptr()))
del arg4_1
buf2 = torch.ops.mkldnn._convolution_pointwise(buf0, arg0_1, arg1_1, (0, 0), (1, 1), (1, 1), 1, 'none', [], '')
assert_size_stride(buf2, (128, 3, 3, 3), (27, 1, 9, 3))
del arg0_1
del arg1_1
buf3 = torch.ops.mkldnn._convolution_pointwise(buf0, arg2_1, arg3_1, (0, 0), (1, 1), (1, 1), 1, 'none', [], '')
assert_size_stride(buf3, (128, 3, 3, 3), (27, 1, 9, 3))
del arg2_1
del arg3_1
return (buf2, buf3, )
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89904
Approved by: https://github.com/jansel
2022-12-06 03:07:53 +00:00
Natalia Gimelshein
1ea20cdb33
workaround for indexing formulas with negative terms ( #89933 )
...
Fixes https://github.com/pytorch/torchdynamo/issues/1928
For `ModularIndexing` we generate indexing code with `//` and `%` operators. When `ModularIndexing` base is negative (that can happen after valid simplifications), `//` in triton produces wrong results https://github.com/openai/triton/issues/619/ . For `//` op coming from pytorch, we have codegen workarounds, but I'm reluctant to apply these workarounds to very common indexing computation patterns, both for code readability and perf considerations.
Similarly, we replace `ModularIndexing` with `IndexingDiv` when we can prove that base is small, but those assumptions break when `ModularIndexing` base is negative (`ModularIndexing` is always positive, `IndexingDiv` isn't).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89933
Approved by: https://github.com/jansel
2022-12-05 19:12:29 +00:00
Michael Voznesensky
5423c2f0e2
Light refactor to how we get shape_env for graph lowering ( #90139 )
...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90139
Approved by: https://github.com/ezyang
2022-12-05 18:35:30 +00:00
Nikita Karetnikov
226e803ecb
[Inductor] handle non-positive exponents in Pow ( #90146 )
...
Fixes #90125 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90146
Approved by: https://github.com/ezyang , https://github.com/jansel
2022-12-05 09:16:35 +00:00
Michael Voznesensky
41c3b41b92
Use dynamo fake tensor mode in aot_autograd, move aot_autograd compilation to lowering time [Merger of 89672 and 89773] ( #90039 )
...
After all of the preparatory commits, this is a subset of the
changes in https://github.com/pytorch/pytorch/pull/89392 that actually
change us to propagating fake tensors to backends.
Signed-off-by: Edward Z. Yang <ezyangfb.com>
This is the merger of Ed's PR #89672 , which is a rewrite of an older PR of mine (#89392 ), with CI Fixes on top of it (#89773 )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90039
Approved by: https://github.com/ezyang
2022-12-05 01:56:50 +00:00
PyTorch MergeBot
4648baa911
Revert "Use dynamo fake tensor mode in aot_autograd, move aot_autograd compilation to lowering time [Merger of 89672 and 89773] ( #90039 )"
...
This reverts commit ef0c7ec958https://github.com/pytorch/pytorch/pull/90039 on behalf of https://github.com/clee2000 due to broke xla tests ef0c7ec958https://github.com/pytorch/pytorch/actions/runs/3606308473/jobs/6077646142
2022-12-04 21:57:30 +00:00
Richard Zou
4068c5467d
[Reland] Move functorch/_src to torch/_functorch ( #88756 ) ( #90091 )
...
This will be the last disruptive functorch internals change.
Why are we moving these files?
- As a part of rationalizing functorch we are moving the code in
functorch/_src to torch/_functorch
- This is so that we can offer the functorch APIs as native PyTorch APIs
(coming soon) and resolve some internal build issues.
Why are we moving all of these files at once?
- It's better to break developers all at once rather than many times
Test Plan:
- wait for tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90091
Approved by: https://github.com/anijain2305 , https://github.com/ezyang
2022-12-03 14:17:15 +00:00
Michael Voznesensky
ef0c7ec958
Use dynamo fake tensor mode in aot_autograd, move aot_autograd compilation to lowering time [Merger of 89672 and 89773] ( #90039 )
...
After all of the preparatory commits, this is a subset of the
changes in https://github.com/pytorch/pytorch/pull/89392 that actually
change us to propagating fake tensors to backends.
Signed-off-by: Edward Z. Yang <ezyangfb.com>
This is the merger of Ed's PR #89672 , which is a rewrite of an older PR of mine (#89392 ), with CI Fixes on top of it (#89773 )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90039
Approved by: https://github.com/ezyang
2022-12-03 01:19:55 +00:00
Elias Ellison
acd68f9097
[Reland] dont clone args ( #89766 )
...
Reland of https://github.com/pytorch/pytorch/pull/89519 .
Improves first memory compression on pytorch struct from .55 -> .73. However, it doesn't totally eliminate the overhead from autotuning because of the 250mb cache clearing in triton benchmarking.
Reland bc previously we weren't accounting for inplace buffer reuse correctly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89766
Approved by: https://github.com/jansel
2022-12-02 17:20:40 +00:00
Jean Schmidt
f62e54df8f
Reland "Dynamo, FX, Inductor Progress Bars ( #88384 )" … ( #90055 )
...
This commit had inconsistent internal land and pr merged. This caused merge conflicts that required revert in both places, normalize the internal commit stack, and then re-land properly.
Original commit: #88384 (011452a2a1#90018 (8566aa7c0b4bdca50bf85ca14705b4304de030b3)
Revert of the inconsistent revert to restore healthy state (or re-land of the original commit): cf3c3f2280#90055 (TBD)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90055
Approved by: https://github.com/DanilBaibak , https://github.com/malfet
2022-12-02 13:28:00 +00:00
PyTorch MergeBot
cf3c3f2280
Revert "Revert "Dynamo, FX, Inductor Progress Bars ( #88384 )" ( #90018 )"
...
This reverts commit bcf4292f04https://github.com/pytorch/pytorch/pull/90018 on behalf of https://github.com/jeanschmidt due to landed internal commit does not match with this one, causing merge conflict and preventing import and land new commits
2022-12-02 09:57:31 +00:00
Wang, Eikan
0bde810572
Add more debug information for Inductor ( #90008 )
...
- Add graph index to the profile information of the Inductor kernel for better debugability.
The generated code for different graphs could produce kernels with the same name. The side effect is that it is hard to identify the portion of E2E performance for these kernels because the profiler will aggregate the performance with the same kernel name regardless of different graphs. Hence, this PR added the graph index to the profile information to address this limitation.
- Label arbitrary code ranges for `eager` and `opt` modes for better debugability
The profile information of dynamo benchmarks mixes the eager mode and opt mode. It is hard to separate the range for different modes. This PR added eager and opt marks to the profile information to address this limitation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90008
Approved by: https://github.com/jgong5 , https://github.com/jansel
2022-12-02 09:34:48 +00:00
Elias Ellison
6addc8d923
[Inductor] add expm1 lowering ( #89961 )
...
Improves perf of inductor no-cudagraphs on nvidia-deeprecommender from 0.88 -> .96. I am looking into disabling implicit fallbacks for benchmark models in another pr.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89961
Approved by: https://github.com/ngimel
2022-12-02 04:29:54 +00:00
XiaobingSuper
42f27c322b
TorchDynamo: don't compute index for max_pooling when return_index is false ( #89838 )
...
For max_pooling, if return_index is **False**, we don't need compute the index.
Before:
```
extern "C" void kernel(const float* __restrict__ in_ptr0,
float* __restrict__ out_ptr0)
{
#pragma GCC ivdep
for(long i0=0; i0<128; i0+=1)
{
#pragma GCC ivdep
for(long i1=0; i1<3; i1+=1)
{
#pragma GCC ivdep
for(long i2=0; i2<3; i2+=1)
{
#pragma GCC ivdep
for(long i3=0; i3<3; i3+=1)
{
{
{
auto tmp0 = in_ptr0[i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp2 = in_ptr0[3 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp7 = in_ptr0[6 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp12 = in_ptr0[21 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp17 = in_ptr0[24 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp22 = in_ptr0[27 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp27 = in_ptr0[42 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp32 = in_ptr0[45 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp37 = in_ptr0[48 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp1 = static_cast<long>((2*i2) + (14*i1));
auto tmp3 = static_cast<long>(1 + (2*i2) + (14*i1));
auto tmp4 = tmp2 > tmp0;
auto tmp5 = tmp4 ? tmp3 : tmp1;
auto tmp6 = (tmp0 != tmp0) ? tmp0 : std::max(tmp2, tmp0);
auto tmp8 = static_cast<long>(2 + (2*i2) + (14*i1));
auto tmp9 = tmp7 > tmp6;
auto tmp10 = tmp9 ? tmp8 : tmp5;
auto tmp11 = (tmp6 != tmp6) ? tmp6 : std::max(tmp7, tmp6);
auto tmp13 = static_cast<long>(7 + (2*i2) + (14*i1));
auto tmp14 = tmp12 > tmp11;
auto tmp15 = tmp14 ? tmp13 : tmp10;
auto tmp16 = (tmp11 != tmp11) ? tmp11 : std::max(tmp12, tmp11);
auto tmp18 = static_cast<long>(8 + (2*i2) + (14*i1));
auto tmp19 = tmp17 > tmp16;
auto tmp20 = tmp19 ? tmp18 : tmp15;
auto tmp21 = (tmp16 != tmp16) ? tmp16 : std::max(tmp17, tmp16);
auto tmp23 = static_cast<long>(9 + (2*i2) + (14*i1));
auto tmp24 = tmp22 > tmp21;
auto tmp25 = tmp24 ? tmp23 : tmp20;
auto tmp26 = (tmp21 != tmp21) ? tmp21 : std::max(tmp22, tmp21);
auto tmp28 = static_cast<long>(14 + (2*i2) + (14*i1));
auto tmp29 = tmp27 > tmp26;
auto tmp30 = tmp29 ? tmp28 : tmp25;
auto tmp31 = (tmp26 != tmp26) ? tmp26 : std::max(tmp27, tmp26);
auto tmp33 = static_cast<long>(15 + (2*i2) + (14*i1));
auto tmp34 = tmp32 > tmp31;
auto tmp35 = tmp34 ? tmp33 : tmp30;
auto tmp36 = (tmp31 != tmp31) ? tmp31 : std::max(tmp32, tmp31);
auto tmp38 = static_cast<long>(16 + (2*i2) + (14*i1));
auto tmp39 = tmp37 > tmp36;
auto tmp40 = tmp39 ? tmp38 : tmp35;
auto tmp41 = (tmp36 != tmp36) ? tmp36 : std::max(tmp37, tmp36);
out_ptr0[i3 + (3*i2) + (9*i1) + (27*i0)] = tmp41;
}
}
}
}
}
}
}
''')
```
After:
```
extern "C" void kernel(const float* __restrict__ in_ptr0,
float* __restrict__ out_ptr0)
{
#pragma GCC ivdep
for(long i0=0; i0<128; i0+=1)
{
#pragma GCC ivdep
for(long i1=0; i1<3; i1+=1)
{
#pragma GCC ivdep
for(long i2=0; i2<3; i2+=1)
{
#pragma GCC ivdep
for(long i3=0; i3<3; i3+=1)
{
{
{
auto tmp0 = in_ptr0[i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp1 = in_ptr0[3 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp3 = in_ptr0[6 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp5 = in_ptr0[21 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp7 = in_ptr0[24 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp9 = in_ptr0[27 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp11 = in_ptr0[42 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp13 = in_ptr0[45 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp15 = in_ptr0[48 + i3 + (6*i2) + (42*i1) + (147*i0)];
auto tmp2 = (tmp0 != tmp0) ? tmp0 : std::max(tmp1, tmp0);
auto tmp4 = (tmp2 != tmp2) ? tmp2 : std::max(tmp3, tmp2);
auto tmp6 = (tmp4 != tmp4) ? tmp4 : std::max(tmp5, tmp4);
auto tmp8 = (tmp6 != tmp6) ? tmp6 : std::max(tmp7, tmp6);
auto tmp10 = (tmp8 != tmp8) ? tmp8 : std::max(tmp9, tmp8);
auto tmp12 = (tmp10 != tmp10) ? tmp10 : std::max(tmp11, tmp10);
auto tmp14 = (tmp12 != tmp12) ? tmp12 : std::max(tmp13, tmp12);
auto tmp16 = (tmp14 != tmp14) ? tmp14 : std::max(tmp15, tmp14);
out_ptr0[i3 + (3*i2) + (9*i1) + (27*i0)] = tmp16;
}
}
}
}
}
}
}
''')
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89838
Approved by: https://github.com/jgong5 , https://github.com/jansel
2022-12-02 04:15:45 +00:00
Nikita Shulga
f623b123f0
[Inductor] Do not install g++12 by default ( #90038 )
...
Unless `TORCH_INDUCTOR_INSTALL_GXX` environment variable is define
(which is the case for CI)
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90038
Approved by: https://github.com/albanD
2022-12-02 04:13:58 +00:00
XiaobingSuper
b058a02786
TorchDynamo: enable convolution bn folding for functional bn ( #89746 )
...
Motivation: for Timm model, there is always use customer-defined BN which using F.batch_norm: https://github.com/rwightman/pytorch-image-models/blob/main/timm/models/layers/norm_act.py#L26 , and the fx graph will be like:
```
------------- ---------------------- --------------------------------------- --------------------------------------------------------------------------------------------------------- --------
placeholder x x () {}
call_module self_conv self_conv (x,) {}
get_attr self_bn_running_mean_1 self_bn_running_mean () {}
get_attr self_bn_running_var self_bn_running_var () {}
get_attr self_bn_weight self_bn_weight () {}
get_attr self_bn_bias self_bn_bias () {}
call_function batch_norm <function batch_norm at 0x7f07196cdf70> (self_conv, self_bn_running_mean_1, self_bn_running_var, self_bn_weight, self_bn_bias, False, 0.1, 1e-05) {}
call_module self_bn_drop self_bn_drop (batch_norm,)
```
the original conv+bn folding path doesn't work for **F.batch_norm**, but for **F.batch_norm** case, if its' parameters are const(attr of the module and will not be updated), we can also do the const folding's optimization. This PR will enable it and will improve the Timm models' performance.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89746
Approved by: https://github.com/jgong5 , https://github.com/jansel
2022-12-02 04:13:34 +00:00
Animesh Jain
d09c52e4fd
[inductor] Deterministic kernel names ( #89713 )
...
`node.origins` is a set and does not have an order. Therefore, inductor w and w/o cudagraphs experiments generate different kernel names, making it hard to debug.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89713
Approved by: https://github.com/soumith , https://github.com/mlazos , https://github.com/ngimel
2022-12-02 02:37:36 +00:00
Soumith Chintala
6f5945e4bb
triton supports devices < 7.0, not 6.0 ( #90020 )
...
triton is still buggy with Pascal devices, so make the error checker reflect that.
Also, this < 6.0 never worked, as the `has_triton` definition in utils.py was checking >= 7.0.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90020
Approved by: https://github.com/yanboliang , https://github.com/anijain2305
2022-12-01 22:01:41 +00:00
Nikita Shulga
768bd3fb4a
Add torch.compile implementation ( #89607 )
...
`torch.compile` can be used either as decorator or to optimize model directly, for example:
```
@torch.compile
def foo(x):
return torch.sin(x) + x.max()
```
or
```
mod = torch.nn.ReLU()
optimized_mod = torch.compile(mod, mode="max-autotune")
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89607
Approved by: https://github.com/soumith
2022-12-01 20:17:52 +00:00
Eli Uriegas
bcf4292f04
Revert "Dynamo, FX, Inductor Progress Bars ( #88384 )" ( #90018 )
...
This breaks in environments that use the fake tqdm 015b05af18/torch/hub.py (L26)https://github.com/pytorch/pytorch/pull/88384#issuecomment-1334272489
This reverts commit 011452a2a1https://github.com/pytorch/pytorch/pull/90018
Approved by: https://github.com/drisspg , https://github.com/dbort
2022-12-01 20:17:07 +00:00
Bert Maher
6317311e61
[inductor] Disable parallel compilation inside fbcode ( #89926 )
...
Forking python processes using `multiprocessing` doesn't play nicely
with certain aspects of FB infra, so let's disable it until we find a better
solution.
Differential Revision: [D41618774](https://our.internmc.facebook.com/intern/diff/D41618774/ )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89926
Approved by: https://github.com/desertfire
2022-12-01 02:33:45 +00:00
Wu, Chunyuan
a6caa9c54b
Add a cpp wrapper for Inductor ( #88167 )
...
## Description
Implements https://github.com/pytorch/torchdynamo/issues/1556 .
This PR adds a cpp wrapper to invoke the generated kernels. The cpp wrapper is turned off by default and can be turned on by setting:
```python
from torch._inductor import config
config.cpp_wrapper = True
```
### Example
The main part of the generated code:
```python
from torch.utils.cpp_extension import load_inline
wrapper = (
'''
#include <dlfcn.h>
#include <assert.h>
std::tuple<at::Tensor, at::Tensor> call_0(std::tuple<at::Tensor, at::Tensor> args) {
at::Tensor arg0_1, arg1_1;
std::tie(arg0_1, arg1_1) = args;
auto buf0 = at::empty_strided({8, 8}, {8, 1}, at::ScalarType::Float);
auto buf1 = at::empty_strided({8, 8}, {1, 8}, at::ScalarType::Float);
auto kernel0_lib = dlopen("/tmp/torchinductor_user/kn/ckn7ubcn2qbkme2vx5r6antnh5sv6d3o3t6qwdfgfoupnxty6pnm.so", RTLD_NOW);
assert(kernel0_lib != nullptr);
void (*kernel0)(const float*,const float*,float*,float*);
*(void **) (&kernel0) = dlsym(kernel0_lib, "kernel");
kernel0((float*)(arg0_1.data_ptr()), (float*)(arg1_1.data_ptr()), (float*)(buf0.data_ptr()), (float*)(buf1.data_ptr()));
arg0_1.reset();
arg1_1.reset();
return std::make_tuple(buf0, buf1); }''' )
module = load_inline(
name='inline_extension_c64wpbccpbre3th2k6oxwrjy5bhvxnmkdxkhcfxlsw7xpsg4eabu',
cpp_sources=[wrapper],
functions=['call_0'],
extra_cflags=['-fPIC -Wall -std=c++14 -Wno-unused-variable -march=native -O3 -ffast-math -fno-finite-math-only -fopenmp'],
extra_ldflags=['-shared -lgomp'],
extra_include_paths=['-I/home/user/pytorch/torch/include -I/home/user/pytorch/torch/include/torch/csrc/api/include -I/home/user/pytorch/torch/include/TH -I/home/user/pytorch/torch/include/THC -I/home/user/miniconda3/envs/pytorch/include/python3.7m'])
def _wrap_func(f):
def g(args):
return f(args)
return g
call = _wrap_func(module.call_0)
```
### Next steps
The below items will be addressed in upcoming PRs.
- [x] Support Reduction: #88561
- [x] Support None: #88560
- [ ] Support ExternKernel
- [x] ATen GEMM-related OPs: #88667
- [ ] ATen Conv
- [ ] Conv/GEMM fusion OPs
- [x] Cache the kernel loading part: #89742
- [ ] De-allocate input buffers when possible by leveraging CPython APIs
- [ ] Support Constant
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88167
Approved by: https://github.com/jgong5 , https://github.com/jansel , https://github.com/desertfire
2022-11-30 13:40:47 +00:00
Animesh Jain
68805b08d1
[benchmarks][dynamo] Trying CI - Set train() for TIMM models accuracy tests ( #89780 )
...
Moving to train mode for TIMM models and also raising batch size for accuracy testing.
Raising batch size seems to remove a lot of noise/instability coming from batch_norm decomposition.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89780
Approved by: https://github.com/ngimel
2022-11-30 12:57:35 +00:00
{kind=link}
{kind=link}