The big idea is to add `create_unbacked_symfloat` and `create_unbacked_symint` to ShapeEnv, allowing you to allocate symbolic floats/ints corresponding to data you don't know about at compile time. Then, instead of immediately erroring out when you try to call local_scalar_dense on a FakeTensor, we instead create a fresh symint/symfloat and return that.
There a bunch of odds and ends that need to be handled:
* A number of `numel` calls converted to `sym_numel`
* When we finally return from item(), we need to ensure we actually produce a SymInt/SymFloat when appropriate. The previous binding code assumed that you would have to get a normal Python item. I add a pybind11 binding for Scalar (to PyObject only) and refactor the code to use that. There is some trickiness where you are NOT allowed to go through c10::SymInt if there isn't actually any SymInt involved. See comment.
* One of our unit tests tripped an implicit data dependent access which occurs when you pass a Tensor as an argument to a sizes parameter. This is also converted to support symbolic shapes
* We now support tracking bare SymInt/SymFloat returns in proxy tensor mode (this was already in symbolic-shapes branch)
* Whenever we allocate an unbacked symint, we record the stack trace it was allocated at. These get printed when you attempt data dependent access on the symint (e.g., you try to guard on it)
* Subtlety: unbacked symints are not necessarily > 1. I added a test for this.
These unbacked symints are not very useful right now as you will almost always immediately raise an error later when you try to guard on them. The next logical step is adding an assertion refinement system that lets ShapeEnv learn facts about unbacked symints so it can do a better job eliding guards that are unnecessary.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90624
Approved by: https://github.com/Skylion007, https://github.com/voznesenskym
Retry of #89595. Accidentally closed.
## Forked `BaseCppType`
Created a module for Executorch: `torchgen.executorch`.
In `torchgen.executorch.api.types.types`:
* Define `BaseCppType` with `torch::executor` namespace.
In `torchgen.executorch.api.et_cpp`:
* Help generate `NamedCType` for `ExecutorchCppSignature` arguments.
In `torchgen.executorch.api.types.signatures`:
* Define the signature using these types. (`ExecutorchCppSignature`)
In `torchgen.executorch.api.types.__init__`:
* Suppress flake8 error for `import *`.
Differential Revision: [D41501836](https://our.internmc.facebook.com/intern/diff/D41501836/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90591
Approved by: https://github.com/iseeyuan
Summary:
This diff introduces a set of changes that makes it possible for the host to get assertions from CUDA devices. This includes the introduction of
**`CUDA_KERNEL_ASSERT2`**
A preprocessor macro to be used within a CUDA kernel that, upon an assertion failure, writes the assertion message, file, line number, and possibly other information to UVM (Managed memory). Once this is done, the original assertion is triggered, which places the GPU in a Bad State requiring recovery. In my tests, data written to UVM appears there before the GPU reaches the Bad State and is still accessible from the host after the GPU is in this state.
Messages are written to a multi-message buffer which can, in theory, hold many assertion failures. I've done this as a precaution in case there are several, but I don't actually know whether that is possible and a simpler design which holds only a single message may well be all that is necessary.
**`TORCH_DSA_KERNEL_ARGS`**
This preprocess macro is added as an _argument_ to a kernel function's signature. It expands to supply the standardized names of all the arguments needed by `C10_CUDA_COMMUNICATING_KERNEL_ASSERTION` to handle device-side assertions. This includes, eg, the name of the pointer to the UVM memory the assertion would be written to. This macro abstracts the arguments so there is a single point of change if the system needs to be modified.
**`c10::cuda::get_global_cuda_kernel_launch_registry()`**
This host-side function returns a singleton object that manages the host's part of the device-side assertions. Upon allocation, the singleton allocates sufficient UVM (Managed) memory to hold information about several device-side assertion failures. The singleton also provides methods for getting the current traceback (used to identify when a kernel was launched). To avoid consuming all the host's memory the singleton stores launches in a circular buffer; a unique "generation number" is used to ensure that kernel launch failures map to their actual launch points (in the case that the circular buffer wraps before the failure is detected).
**`TORCH_DSA_KERNEL_LAUNCH`**
This host-side preprocessor macro replaces the standard
```
kernel_name<<<blocks, threads, shmem, stream>>>(args)
```
invocation with
```
TORCH_DSA_KERNEL_LAUNCH(blocks, threads, shmem, stream, args);
```
Internally, it fetches the UVM (Managed) pointer and generation number from the singleton and append these to the standard argument list. It also checks to ensure the kernel launches correctly. This abstraction on kernel launches can be modified to provide additional safety/logging.
**`c10::cuda::c10_retrieve_device_side_assertion_info`**
This host-side function checks, when called, that no kernel assertions have occurred. If one has. It then raises an exception with:
1. Information (file, line number) of what kernel was launched.
2. Information (file, line number, message) about the device-side assertion
3. Information (file, line number) about where the failure was detected.
**Checking for device-side assertions**
Device-side assertions are most likely to be noticed by the host when a CUDA API call such as `cudaDeviceSynchronize` is made and fails with a `cudaError_t` indicating
> CUDA error: device-side assert triggered CUDA kernel errors
Therefore, we rewrite `C10_CUDA_CHECK()` to include a call to `c10_retrieve_device_side_assertion_info()`. To make the code cleaner, most of the logic of `C10_CUDA_CHECK()` is now contained within a new function `c10_cuda_check_implementation()` to which `C10_CUDA_CHECK` passes the preprocessor information about filenames, function names, and line numbers. (In C++20 we can use `std::source_location` to eliminate macros entirely!)
# Notes on special cases
* Multiple assertions from the same block are recorded
* Multiple assertions from different blocks are recorded
* Launching kernels from many threads on many streams seems to be handled correctly
* If two process are using the same GPU and one of the processes fails with a device-side assertion the other process continues without issue
* X Multiple assertions from separate kernels on different streams seem to be recorded, but we can't reproduce the test condition
* X Multiple assertions from separate devices should be all be shown upon exit, but we've been unable to generate a test that produces this condition
Differential Revision: D37621532
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84609
Approved by: https://github.com/ezyang, https://github.com/malfet
Currently there is `test_vertical_fusion1` which fuses entirely during
the lowering stage and no buffers are realized. This adds
`test_scheduler_vertical_fusion1` which is the same test but with
several intermediate calculations realized so the scheduler is left
to do the fusion.
To support the test, this PR also adds:
- `metrics.ir_nodes_pre_fusion` which when compared with
`generated_kernel_count` tells us how many nodes were fused.
- `torch._test_inductor_realize` which is an identity operator in
eager, but under inductor also forces the input to be realized.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90014
Approved by: https://github.com/jansel
When not using ordered dictionary, it can result in parameter values have
different order for each specialization. This can result shader names which are
not consistent in their naming and meaning of the template parameter values
that appear in the meaning of their names.
For example if you have:
conv2d_pw:
default_values:
- X: 1
- Y: 2
parameter_values:
- Y: 3
Default parameter value can generate shader with 'my_shader_1x2' where 1x2 is
for X, Y parameters respectively. Then,
for non default values, of which there is only 1, we have Y=3 and with existing
implementation you can end up genreating shader with 'my_shader_3x1'. Here 3 is
for Y and 1 is for X. This leads to confusing shader names.
THis diff fixes this by
1. using ordered dict.
2. non default values are updated by first copying default values and then
updating them.
Differential Revision: [D41006639](https://our.internmc.facebook.com/intern/diff/D41006639/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89951
Approved by: https://github.com/salilsdesai
Add dynamo smoke tests to CI, which checks for python/torch/cuda versions and runs simple dynamo examples on a few backends, including inductor. Smoke tests will run on dynamo and inductor shards.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89302
Approved by: https://github.com/malfet
This PR extends the `Tensor.to_sparse()` method to `Tensor.to_sparse(layout=None, blocksize=None)` in a BC manner (`layout=None` means `layout=torch.sparse_coo`).
In addition, the PR adds support for the following conversions:
- non-hybrid/hybrid COO tensor to CSR or CSC or a COO tensor
- short, bool, byte, char, bfloat16, int, long, half CSR tensor to a BSR tensor
and fixes the following conversions:
- hybrid COO to COO tensor
- non-batch/batch hybrid BSR to BSR or BSC tensor
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89502
Approved by: https://github.com/amjames, https://github.com/cpuhrsch
Using the same repro from the issue (but with BatchNorm2D)
Rectifies native_batch_norm schema by splitting the schema into 2:
1. one will have NON-optional alias-able running_mean and running_var inputs
2. the other will just not have those parameters at all (no_stats variation)
**Calling for name suggestions!**
## test plan
I've added tests in test_functionalization.py as well as an entry in common_method_invocations.py for `native_batch_norm_legit`
CI should pass.
## next steps
Because of bc/fc reasons, we reroute native_batch_norm to call our new schemas ONLY through the python dispatcher, but in 2 weeks or so, we should make `native_batch_norm_legit` the official batch_norm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88697
Approved by: https://github.com/albanD
I have found the reason why uploading tests stats fails for rerun disabled workflow, for example https://github.com/pytorch/pytorch/actions/runs/3522896778/jobs/5917765699. The problem is that the pytest XML file is now too big to be processed quickly (x50 bigger). Unlike unittest, `pytest-flakefinder` used by rerun disabled tests for test_ops includes skipped messages multiple times (50 times by default, retrying and skipping). This slows down the upload test stats script too much (O(n)) because it tries to gather all the stats. On the other hand, `check_disabled_tests` doesn't suffer from the same issue because it ignores all these skipped messages.
This is a quick fix to skip test reports from rerun disabled tests workflow when trying to upload test stats.
I'll try to fix this properly later in the way we use pytest-flakefinder. From what I see, a zipped test report from rerun disabled test is only few MB ([example](https://gha-artifacts.s3.amazonaws.com/pytorch/pytorch/3521687954/1/artifact/test-reports-test-default-1-2-linux.2xlarge_9636028803.zip)), but will balloon up to a much bigger XML file after extracting from a dozen to a few hundred MB (text). The size of the zipped file is not a big immediate problem
### Testing
[3521687954](https://github.com/pytorch/pytorch/actions/runs/3521687954) is an example workflow with rerun disabled tests and mem leak check. The script can now finish when running locally:
* `upload_test_stats` finishes around 3+ minutes
```
time python -m tools.stats.upload_test_stats --workflow-run-id 3521687954 --workflow-run-attempt 1 --head-branch master
...
Writing 8925 documents to S3
Done!
Writing 1760 documents to S3
Done!
Writing 1675249 documents to S3
Done!
python3 -m tools.stats.upload_test_stats --workflow-run-id 3521687954 1 185.69s user 12.89s system 75% cpu 4:22.82 total
```
* `check_disabled_tests` finishes within 3 minutes
```
time python -m tools.stats.check_disabled_tests --workflow-run-id 3521687954 --workflow-run-attempt 1 --repo pytorch/pytorch
...
python -m tools.stats.check_disabled_tests --workflow-run-id 3521687954 1 154.19s user 4.17s system 97% cpu 2:42.50 total
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89548
Approved by: https://github.com/clee2000
The idea is to add a custom handler to Functionalize key in Python
dispatcher that runs the functionalized version along side a non
functionalized version, and checks that their outputs agree in the
end. (Technically, for metadata mutation we should also check the
inputs, but for now we're relying on those functions returning self.)
I turned this on for test_functionalize.py (new TestCrossRefFunctionalize)
and found a bunch of failures that look legit.
This probably doesn't interact that nicely if you're also tracing at
the same time, probably need more special logic for that (directly,
just disabling tracing for when we create the nested fake tensor mode,
but IDK if there's a more principled way to organize this.)
There are some misc fixups which I can split if people really want.
- xfail_inherited_tests moved to test common_utils
- Bindings for _dispatch_tls_set_dispatch_key_included,
_dispatch_tls_is_dispatch_key_included and _functionalization_reapply_views_tls
- Type stubs for _enable_functionalization, _disable_functionalization
- all_known_overloads utility to let you iterate over all OpOverloads
in all namespaces. Iterator support on all torch._ops objects to let
you iterate over their members.
- suspend_functionalization lets you temporarily disable functionalization mode
in a context
- check_metadata_matches for easily comparing outputs of functions and see
if they match (TODO: there are a few copies of this logic, consolidate!)
- _fmt for easily printing the metadata of a tensor without its data
- _uncache_dispatch for removing a particular dispatch key from the cache,
so that we force it to regenerate
- check_significant_strides new kwarg only_cuda to let you also do stride
test even when inputs are not CUDA
- Functionalize in torch._C.DispatchKey
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89498
Approved by: https://github.com/malfet
Analyze and upload disabled tests rerun to S3. Note that this only picks up `test-reports` from `rerun_disable_tests` workflows.
### Testing
Running the script manually `python -m tools.stats.check_disabled_tests --workflow-run-id 3473068035 --workflow-run-attempt 1 --repo pytorch/pytorch` and see the files successfully uploaded to s3://ossci-raw-job-status/rerun_disabled_tests/3473068035/1
Rockset collection created https://console.rockset.com/collections/details/commons.rerun_disabled_tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89083
Approved by: https://github.com/clee2000
# Registers the derivative for mem efficient backward
- Use gradcheck to test correctness. The kernel is not implemented for fp64 so run checks with bumped tolerances in fp32
- I also made updates based off of Xformer main branch and flash-attention cutlass branch.
- This will enable the fused backward to be called for scaled dot product attention
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88856
Approved by: https://github.com/cpuhrsch
# Registers the derivative for mem efficient backward
- Use gradcheck to test correctness. The kernel is not implemented for fp64 so run checks with bumped tolerances in fp32
- I also made updates based off of Xformer main branch and flash-attention cutlass branch.
- This will enable the fused backward to be called for scaled dot product attention
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88856
Approved by: https://github.com/cpuhrsch
* Reflect required arguments in method signature for each diagnostic rule. Previous design accepts arbitrary sized tuple which is hard to use and prone to error.
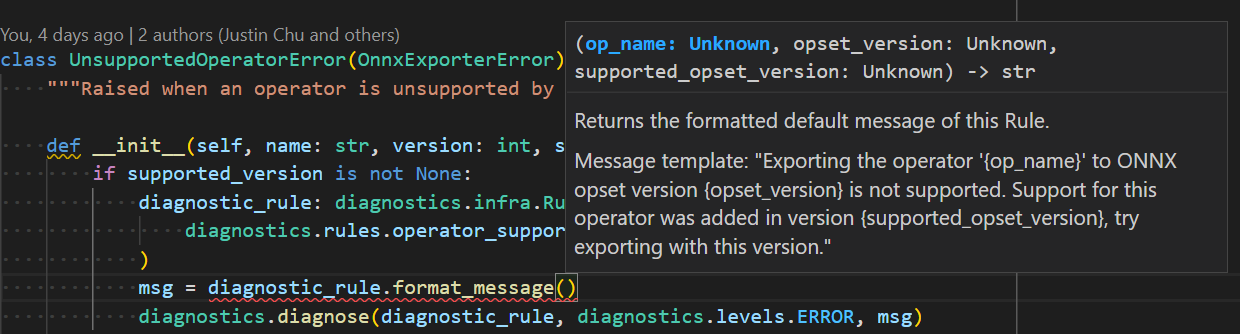
* Removed `DiagnosticTool` to keep things compact.
* Removed specifying supported rule set for tool(context) and checking if rule of reported diagnostic falls inside the set, to keep things compact.
* Initial overview markdown file.
* Change `full_description` definition. Now `text` field should not be empty. And its markdown should be stored in `markdown` field.
* Change `message_default_template` to allow only named fields (excluding numeric fields). `field_name` provides clarity on what argument is expected.
* Added `diagnose` api to `torch.onnx._internal.diagnostics`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87830
Approved by: https://github.com/abock
This diff adds the option to use a Buffer to store data for a `vTensor` by passing `StorageType::BUFFER` to the constructor of `vTensor`. To enable this change, the construction of `vTensor` and `vTensorStorage` had to be slightly refactored to properly support strides. To summarize the changes:
* `vTensorStorage` now contains no Tensor metadata (such as tensor sizes, strides, and `TensorOptions`) - it now only contains the image extents (if texture storage is used) and the buffer length. Tensor metadata is now managed by `vTensor`. The reason for this is to allow multiple `vTensor` objects to point to the same `vTensorStorage` but with different metadata which may be a useful feature now that Buffer storage is enabled.
* `vTensor` will now compute the strides upon construction based on the requested sizes and memory layout if Buffer storage is requested. Previously, strides were faked by setting them all to 0 as strides do not apply to image textures (this behavior is preserved for texture storage).
Differential Revision: [D40604163](https://our.internmc.facebook.com/intern/diff/D40604163/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87622
Approved by: https://github.com/digantdesai
Along the way, I undid making sparse/dense dim symint (they're
dimensions, so they should be static.)
Also symintify set_indices_and_values_unsafe
There is a little bit of a nontrivial infra change here: previously, we didn't populate the strides field on sparse tensors. It is now populated with "empty" strides, and this meant that sparse tensors were falsely reporting they were non-overlapping dense/contiguous. I added in a hack to work around this case.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88573
Approved by: https://github.com/anjali411
Summary: This diff merges both previous implementations of constructors for nested tensors, the one from lists of tensors and the one with arbitrary python lists, adn implements it in pytorch core so no extensions are needed to construct NT.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88213
Approved by: https://github.com/cpuhrsch
tbh at this point it might be easier to make a new workflow and copy the relevant jobs...
Changes:
* Disable cuda mem leak check except for on scheduled workflows
* Make pull and trunk run on a schedule which will run the memory leak check
* Periodic will always run the memory leak check -> periodic does not have parallelization anymore
* Concurrency check changed to be slightly more generous
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88373
Approved by: https://github.com/ZainRizvi, https://github.com/huydhn
During build, users commonly see a message like
```
fatal: no tag exactly matches 'd8b4f33324b1eb6c1103874764116fb68e0d0af4'
```
which is usually ignored when builds succeed, but has confused users when build fails (due to a different issue). This PR removes the red herring, since this usually prints for local development when tags are not found.
We catch the exception anyway and handle it under the hood, so we don't need to print it and confuse the user.
Test plan:
Note that builds on trunk current have this line, cmd-F 'fatal: no tag exactly matches' in https://github.com/pytorch/pytorch/actions/runs/3379162092/jobs/5610355820.
Then check in the PR build to see that the line no longer appears.
I also tagged my commit locally and printed what tag would be--this code and the old code printed the same results for what tag would be.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88335
Approved by: https://github.com/seemethere
We would like to be able to parameterize kernels such that a parameterized
algorithm can be implemented via templates. We can then profile performance of
a kernel with different parameter values. This enables us to determine what
parameters may work the best for a given kernel or a given device.
In this diff one such kernel added in 1x1 conv which parameters across size of
the tile being produced by each invocation.
Few other options for parameters can be:
- One can imagine dtype can also be a parameter such that we can do compute in
fp16 or int8/int16.
- Register blocking for input channels
Differential Revision: [D40280336](https://our.internmc.facebook.com/intern/diff/D40280336/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D40280336/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88323
Approved by: https://github.com/jmdetloff
Summary:
Sometimes we want to extend an existing custom namespace library, instead of creating a new one,
but we don't have a namespace config right now, so we hardcode some custom libraries defined
in pytorch today, i.e. quantized and quantized_decomposed
Test Plan:
ci
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88229
Approved by: https://github.com/ezyang
XPU would support channels last format for group norm operator, however, Pytorch converts all input tensor to contiguous format, which includes channels last tensor. Need Pytorch pass down this memory format hint to us.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87680
Approved by: https://github.com/albanD
This is exclusively used by macOS, ROCM (and any other future workflows) that don't have direct access to S3 to upload their artifacts
### Testing
Running the script locally with the personal GITHUB_TOKEN:
```
python3 -m tools.stats.upload_artifacts --workflow-run-id 3342375847 --workflow-run-attempt 1 --repo pytorch/pytorch
Using temporary directory: /var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb
Downloading sccache-stats-macos-12-py3-arm64-runattempt1-9155493770
Downloading sccache-stats-macos-12-py3-lite-interpreter-x86-64-runattempt1-9155493303
Downloading sccache-stats-macos-12-py3-x86-64-runattempt1-9155493627
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/sccache-stats-macos-12-py3-arm64-runattempt1-9155493770 to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/sccache-stats-macos-12-py3-arm64-9155493770
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/sccache-stats-macos-12-py3-lite-interpreter-x86-64-runattempt1-9155493303 to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/sccache-stats-macos-12-py3-lite-interpreter-x86-64-9155493303
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/sccache-stats-macos-12-py3-x86-64-runattempt1-9155493627 to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/sccache-stats-macos-12-py3-x86-64-9155493627
Downloading test-jsons-runattempt1-test-default-1-2-linux.rocm.gpu_9155913429.zip
Downloading test-jsons-runattempt1-test-default-1-2-macos-12_9155944815.zip
Downloading test-jsons-runattempt1-test-default-1-2-macos-m1-12_9155888061.zip
Downloading test-jsons-runattempt1-test-default-2-2-linux.rocm.gpu_9155913500.zip
Downloading test-jsons-runattempt1-test-default-2-2-macos-12_9155944892.zip
Downloading test-jsons-runattempt1-test-default-2-2-macos-m1-12_9155888182.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-jsons-runattempt1-test-default-1-2-linux.rocm.gpu_9155913429.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-jsons-test-default-1-2-linux.rocm.gpu_9155913429.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-jsons-runattempt1-test-default-1-2-macos-12_9155944815.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-jsons-test-default-1-2-macos-12_9155944815.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-jsons-runattempt1-test-default-1-2-macos-m1-12_9155888061.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-jsons-test-default-1-2-macos-m1-12_9155888061.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-jsons-runattempt1-test-default-2-2-linux.rocm.gpu_9155913500.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-jsons-test-default-2-2-linux.rocm.gpu_9155913500.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-jsons-runattempt1-test-default-2-2-macos-12_9155944892.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-jsons-test-default-2-2-macos-12_9155944892.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-jsons-runattempt1-test-default-2-2-macos-m1-12_9155888182.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-jsons-test-default-2-2-macos-m1-12_9155888182.zip
Downloading test-reports-runattempt1-test-default-1-2-linux.rocm.gpu_9155913429.zip
Downloading test-reports-runattempt1-test-default-1-2-macos-12_9155944815.zip
Downloading test-reports-runattempt1-test-default-1-2-macos-m1-12_9155888061.zip
Downloading test-reports-runattempt1-test-default-2-2-linux.rocm.gpu_9155913500.zip
Downloading test-reports-runattempt1-test-default-2-2-macos-12_9155944892.zip
Downloading test-reports-runattempt1-test-default-2-2-macos-m1-12_9155888182.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-reports-runattempt1-test-default-1-2-linux.rocm.gpu_9155913429.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-reports-test-default-1-2-linux.rocm.gpu_9155913429.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-reports-runattempt1-test-default-1-2-macos-12_9155944815.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-reports-test-default-1-2-macos-12_9155944815.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-reports-runattempt1-test-default-1-2-macos-m1-12_9155888061.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-reports-test-default-1-2-macos-m1-12_9155888061.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-reports-runattempt1-test-default-2-2-linux.rocm.gpu_9155913500.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-reports-test-default-2-2-linux.rocm.gpu_9155913500.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-reports-runattempt1-test-default-2-2-macos-12_9155944892.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-reports-test-default-2-2-macos-12_9155944892.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-reports-runattempt1-test-default-2-2-macos-m1-12_9155888182.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-reports-test-default-2-2-macos-m1-12_9155888182.zip
Downloading usage-log-runattempt1-test-default-1-2-linux.rocm.gpu_9155913429.zip
Downloading usage-log-runattempt1-test-default-1-2-macos-12_9155944815.zip
Downloading usage-log-runattempt1-test-default-1-2-macos-m1-12_9155888061.zip
Downloading usage-log-runattempt1-test-default-2-2-linux.rocm.gpu_9155913500.zip
Downloading usage-log-runattempt1-test-default-2-2-macos-12_9155944892.zip
Downloading usage-log-runattempt1-test-default-2-2-macos-m1-12_9155888182.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/usage-log-runattempt1-test-default-1-2-linux.rocm.gpu_9155913429.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/usage-log-test-default-1-2-linux.rocm.gpu_9155913429.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/usage-log-runattempt1-test-default-1-2-macos-12_9155944815.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/usage-log-test-default-1-2-macos-12_9155944815.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/usage-log-runattempt1-test-default-1-2-macos-m1-12_9155888061.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/usage-log-test-default-1-2-macos-m1-12_9155888061.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/usage-log-runattempt1-test-default-2-2-linux.rocm.gpu_9155913500.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/usage-log-test-default-2-2-linux.rocm.gpu_9155913500.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/usage-log-runattempt1-test-default-2-2-macos-12_9155944892.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/usage-log-test-default-2-2-macos-12_9155944892.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/usage-log-runattempt1-test-default-2-2-macos-m1-12_9155888182.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/usage-log-test-default-2-2-macos-m1-12_9155888182.zip
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87827
Approved by: https://github.com/clee2000
Meta tensor does a lot of work to make sure tensors "look" similar
to the original parts; e.g., if the original was a non-leaf, meta
converter ensures the meta tensor is a non-leaf too. Fake tensor
destroyed some of these properties when it wraps it in a FakeTensor.
This patch pushes the FakeTensor constructor into the meta converter
itself, so that we first create a fake tensor, and then we do various
convertibility bits to it to make it look right.
The two tricky bits:
- We need to have no_dispatch enabled when we allocate the initial meta
tensor, or fake tensor gets mad at us for making a meta fake tensor.
This necessitates the double-callback structure of the callback
arguments: the meta construction happens *inside* the function so
it is covered by no_dispatch
- I can't store tensors for the storages anymore, as that will result
in a leak. But we have untyped storage now, so I just store untyped
storages instead.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
cc @jansel @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87943
Approved by: https://github.com/eellison, https://github.com/albanD
This refactor was prompted by challenges handling mixed int/float
operations in C++. A previous version of this patch
added overloads for each permutation of int/float and was unwieldy
https://github.com/pytorch/pytorch/pull/87722/ This PR takes a different
approach.
The general outline of the patch is to combine the C++ types SymIntNode
and SymFloatNode into a single type, SymNode. This is type erased; we
no longer know statically at C++ if we have an int/float and have to test
it with the is_int()/is_float() virtual methods. This has a number of
knock on effects.
- We no longer have C++ classes to bind to Python. Instead, we take an
entirely new approach to our Python API, where we have a SymInt/SymFloat
class defined entirely in Python, which hold a SymNode (which corresponds
to the C++ SymNode). However, SymNode is not pybind11-bound; instead,
it lives as-is in Python, and is wrapped into C++ SymNode using PythonSymNode
when it goes into C++. This implies a userland rename.
In principle, it is also possible for the canonical implementation of SymNode
to be written in C++, and then bound to Python with pybind11 (we have
this code, although it is commented out.) However, I did not implement
this as we currently have no C++ implementations of SymNode.
Because we do return SymInt/SymFloat from C++ bindings, the C++ binding
code needs to know how to find these classes. Currently, this is done
just by manually importing torch and getting the attributes.
- Because SymInt/SymFloat are easy Python wrappers, __sym_dispatch__ now
takes SymInt/SymFloat, rather than SymNode, bringing it in line with how
__torch_dispatch__ works.
Some miscellaneous improvements:
- SymInt now has a constructor that takes SymNode. Note that this
constructor is ambiguous if you pass in a subclass of SymNode,
so an explicit downcast is necessary. This means toSymFloat/toSymInt
are no more. This is a mild optimization as it means rvalue reference
works automatically.
- We uniformly use the caster for c10::SymInt/SymFloat, rather than
going the long way via the SymIntNode/SymFloatNode.
- Removed some unnecessary toSymInt/toSymFloat calls in normalize_*
functions, pretty sure this doesn't do anything.
- guard_int is now a free function, since to guard on an int you cannot
assume the method exists. A function can handle both int and SymInt
inputs.
- We clean up the magic method definition code for SymInt/SymFloat/SymNode.
ONLY the user classes (SymInt/SymFloat) get magic methods; SymNode gets
plain methods; this is to help avoid confusion between the two types.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
cc @jansel @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87817
Approved by: https://github.com/albanD, https://github.com/anjali411
I missed the fine print in https://github.com/actions/setup-python/blob/main/README.md#caching-packages-dependencies when setting up the cache using setup-python GHA
> Restored cache will not be used if the requirements.txt file is not updated for a long time and a newer version of the dependency is available which can lead to an increase in total build time.
The latter part is important because it implies that even with the cache, pip will still try to check if a newer version exists and that part can be flaky, i.e. https://github.com/pytorch/pytorch/actions/runs/3313764038/jobs/5472180293
This undesired behavior can be turned off by setting the advance option `check-latest` to false https://github.com/actions/setup-python/blob/main/docs/advanced-usage.md#check-latest-version. Per my understanding, this should tell pip install in these workflows to use the local cached copy of the package avoiding the need to query pypi every single time.
`check-latest` was added quite recently https://github.com/actions/setup-python/pull/406, so `actionlint-1.6.15` fails to recognize it. Thus, this PR also upgrades `actionlint` to the latest 1.6.21 to pass the linter check. Here is an example error from 1.6.15 from https://github.com/pytorch/pytorch/actions/runs/3315388073/jobs/5475918454:
```
>>> Lint for .github/workflows/lint.yml:
Error (ACTIONLINT) [action]
input "check-latest" is not defined in action "actions/setup-python@v4".
available inputs are "architecture", "cache", "cache-dependency-path",
"python-version", "python-version-file", "token"
25 | with:
26 | python-version: 3.8
27 | architecture: x64
>>> 28 | check-latest: false
29 | cache: pip
30 | cache-dependency-path: |
31 | **/.github/requirements-gha-cache.txt
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87621
Approved by: https://github.com/ZainRizvi
{kind=link}