**Summary**
The update includes API changes and optimzations to reduce framework overhead, which will benefit all mkldnn (onednn) ops in JIT mode and inductor CPU backend, etc. These benefits will be seen after switching to new ideep API by future PRs.
**Test plan**
For correctness, all UTs that call mkldnn ops, including test_ops.py, test_mkldnn*.py, test_quantization.py, etc.
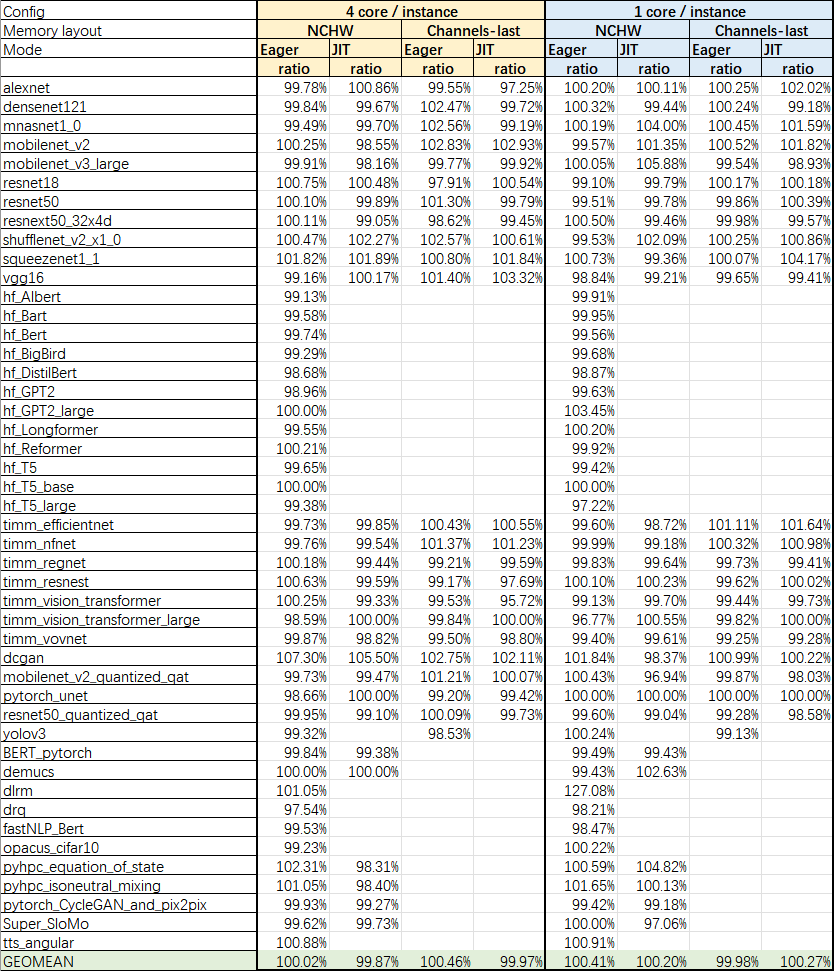
For performance, TorchBench has been run and no regression is found. Results are shown below.
- Intel (R) Xeon (R) IceLake with 40 cores
- Use multi-instance
- Using tcmalloc & Intel OMP
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87966
Approved by: https://github.com/jgong5, https://github.com/XiaobingSuper
I am one of the maintainers of pybind11, and a frequent PyTorch user. We added quite a lot of bugfixes and performance improvements in 2.10.1 (see the changelog for full details) and I wanted to upstream them to PyTorch.
Our releases is tested throughout Google's codebase including on their global builds of PyTorch so there should be no surprises.
The main new feature is optin in Eigen Tensor to Numpy casters.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88332
Approved by: https://github.com/soumith
Summary:
When building 3d photo sdk generator package in arvr/mode/mac and arvr/mode/mac-arm modes, we got several issues with aten cpu and xnnpack libraries.
The reason is that those packages are using platform-* properties (platform-deps, platform-srcs...) which are not compatible with arvr modes.
This diff fixes those issues by using `select` for non-platform properties when is_arvr_mode() is true, while keeping those platform ones for non-arvr modes.
Test Plan:
```
buck build //arvr/projects/compphoto/photo3d_sdk/unity/plugin:generator_plugin_shared arvr/mode/mac-arm/dev
buck build //arvr/projects/compphoto/photo3d_sdk/unity/plugin:generator_plugin_shared arvr/mode/mac-arm/opt
buck build //arvr/projects/compphoto/photo3d_sdk/unity/plugin:generator_plugin_shared arvr/mode/mac/dev
buck build //arvr/projects/compphoto/photo3d_sdk/unity/plugin:generator_plugin_shared arvr/mode/mac/opt
```
and sandcastle builds
Differential Revision: D40028669
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87125
Approved by: https://github.com/kimishpatel
## BFloat16 dtype support for faster inference with TorchScript using oneDNN Graph
Intel Xeon Cooper Lake platform & beyond support the `AVX512_BF16` ISA, which is essentially native BFloat16 support.
oneDNN Graph delivers high inference performance with BFloat16 on such machines.
While oneDNN Graph can still be used with BFloat16 on older machines that lack `avx512_bf16` ISA but support `avx512bw`, `avx512vl` & `avx512dq` ISAs, the BF16 performance on these older machines will be significantly poorer (probably even poorer than Float32), as they lack native BF16 support.
Currently, [AMP support for eager mode & JIT mode is divergent in PyTorch](https://github.com/pytorch/pytorch/issues/75956).
So, for using oneDNN Graph with BFloat16, eager-mode AMP should be leveraged by turning off AMP for JIT mode, using `torch._C._jit_set_autocast_mode(False)` in python code, so as to avoid conflicts.
Please use the following environment variable to view JIT logs -
`PYTORCH_JIT_LOG_LEVEL=">>graph_helper:>>graph_fuser:>>kernel:>>interface"`
## Changes being made in this PR
1. This PR does NOT change the `oneDNN` commit or the `ideep` files. While the `ideep` commit is being updated, only files pertaining to oneDNN Graph are being updated. oneDNN Graph is being upgraded to version 0.5.2 (alpha patch release 2).
To put things into perspective, `ideep` is a git submodule of PyTorch. `oneDNN Graph` is a git submodule of `ideep` (`ideep/mkl-dnn`), and oneDNN is a git submodule of oneDNN Graph (`ideep/mkl-dnn/third_party/oneDNN`).
2. Unit-tests are being updated. We now use the [existing dtypes decorator](https://github.com/pytorch/pytorch/blob/master/torch/testing/_internal/common_device_type.py#L123-L131).
3. Suggestions made by @eellison in the [FP32 PR](https://github.com/pytorch/pytorch/pull/68111#pullrequestreview-896719477) are being incorporated/addressed -
| Action-item | Status |
| :--- | ---: |
|checkInputCompatibility follow up | Fixed |
|the mayConvertScalarInputToTensor logic we can consider | Added type promotion code |
|fix up fixConvOptionalBias| The current approach seems correct |
|Use opinfo tests| using dtypes decorator. Will use `OpInfo` in a subsequent PR, if that'd be possible. Should we create a list of ops from opDB that are supported by oneDNN Graph, and add it to `common_methods_invocations.py`? |
|inferDevice torch_check call | not necessary now, perhaps, as only CPU is supported, for now? We'd add it by the beta release of oneDNN Graph, though, so that by then, users might be able to use other fusers with oneDNN Graph (NNC/TensorExpr are already compatible with the oneDNN Graph fuser). We can still add it, if you'd insist. |
|not checking shapes of input mkldnn tensor to llga guard | Those checks should not be present because oneDNN Graph may use blocked or channels-last layout, so those strides would be different. They're only skipped if an LLGA subgraph's output is input to another LLGA subgraph, which enables LLGA to choose an optimal layout between them. |
|fix test failures with respect to unsupported inputs | We'll address them with the upcoming release of oneDNN Graph beta version|
4. More PyTorch ops are being been mapped to oneDNN Graph
## Example of using oneDNN Graph with BFloat16
```python
# Assuming we have a model of the name 'model'
example_input = torch.rand(1, 3, 224, 224)
# enable oneDNN Graph
torch.jit.enable_onednn_fusion(True)
# Disable AMP for JIT
torch._C._jit_set_autocast_mode(False)
with torch.no_grad(), torch.cpu.amp.autocast():
model = torch.jit.trace(model, (example_input))
model = torch.jit.freeze(model)
# 2 warm-ups (2 for tracing/scripting with an example, 3 without an example)
model(example_input)
model(example_input)
# speedup would be observed in subsequent runs.
model(example_input)
```
## TorchBench based Benchmarks
**URL:** https://github.com/sanchitintel/benchmark/tree/onednn_graph_benchmark (instructions present at URL).
**Batch-size(s):** TorchBench-default for each model
**Baseline :** PyTorch JIT OFI FP32
**Machine:** Intel(R) Xeon(R) Platinum 8371HC (Cooper Lake)
**Sockets used**: 1
**Number of cores on one socket**: 26
Intel OpenMP & tcmalloc were preloaded
#### Benchmark results with single thread
| name | latency of PyTorch JIT OFI FP32 (s) | Latency of oneDNN Graph BF16 (s) | % change |
| :--- | ---: | ---: | ---: |
| test_eval[alexnet-cpu-jit] | 1.063851 | 0.509820 | -52.1% |
| test_eval[mnasnet1_0-cpu-jit] | 0.218435 | 0.107100 | -51.0% |
| test_eval[mobilenet_v2-cpu-jit] | 0.114467 | 0.058359 | -49.0% |
| test_eval[mobilenet_v3_large-cpu-jit] | 0.233873 | 0.117614 | -49.7% |
| test_eval[resnet18-cpu-jit] | 0.160584 | 0.075854 | -52.8% |
| test_eval[resnet50-cpu-jit] | 1.652846 | 0.713373 | -56.8% |
| test_eval[resnext50_32x4d-cpu-jit] | 0.471174 | 0.209431 | -55.6% |
|test_eval[shufflenet_v2_x1_0-cpu-jit] | 0.310306 | 0.167090 | -46.2% |
| test_eval[squeezenet1_1-cpu-jit] | 0.161247 | 0.045684 | -71.7% |
| test_eval[timm_efficientnet-cpu-jit] | 1.643772 | 0.800099 | -51.3% |
| test_eval[timm_regnet-cpu-jit] | 5.732272 | 2.333417 | -59.3% |
| test_eval[timm_resnest-cpu-jit] | 1.366464 | 0.715252 | -47.7% |
| test_eval[timm_vision_transformer-cpu-jit] | 0.508521 | 0.271598 | -46.6% |
| test_eval[timm_vovnet-cpu-jit] | 2.756692 | 1.125033 | -59.2% |
| test_eval[vgg16-cpu-jit] | 0.711533 | 0.312344 | -56.1% |
#### Benchmark results with 26 threads:
| name | latency of PyTorch JIT OFI FP32 (s) | Latency of oneDNN Graph BF16 (s) | % change |
| :--- | ---: | ---: | ---: |
| test_eval[alexnet-cpu-jit] | 0.062871 | 0.034198 | -45.6% |
| test_eval[mnasnet1_0-cpu-jit] | 0.022490 | 0.008172 | -63.7% |
| test_eval[mobilenet_v2-cpu-jit] | 0.012730 | 0.005866 | -53.9% |
| test_eval[mobilenet_v3_large-cpu-jit] | 0.025948 | 0.010346 | -60.1% |
| test_eval[resnet18-cpu-jit] | 0.011194 | 0.005726 | -48.9% |
| test_eval[resnet50-cpu-jit] | 0.124662 | 0.045599 | -63.4% |
| test_eval[resnext50_32x4d-cpu-jit] | 0.034737 | 0.015214 | -56.2% |
|test_eval[shufflenet_v2_x1_0-cpu-jit] | 0.028820 | 0.012517 | -56.6% |
| test_eval[squeezenet1_1-cpu-jit] | 0.012557 | 0.003876 | -69.1% |
| test_eval[timm_efficientnet-cpu-jit] | 0.203177 | 0.051879 | -74.5% |
| test_eval[timm_regnet-cpu-jit] | 0.452050 | 0.151113 | -66.6% |
| test_eval[timm_resnest-cpu-jit] | 0.117072 | 0.052848 | -54.9% |
| test_eval[timm_vision_transformer-cpu-jit] | 0.046048 | 0.023275 | -49.5% |
| test_eval[timm_vovnet-cpu-jit] | 0.213187 | 0.077482 | -63.7% |
| test_eval[vgg16-cpu-jit] | 0.044726 | 0.021998 | -50.8% |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85591
Approved by: https://github.com/jgong5, https://github.com/frank-wei, https://github.com/chunyuan-w
# Summary:
- I added a new submodule Cutlass pointing to 2.10 release. The inclusion of flash_attention code should be gated by the flag: USE_FLASH_ATTENTION. This is defaulted to off resulting in flash to not be build anywhere. This is done on purpose since we don't have A100 machines to compile and test on.
- Only looked at CMake did not attempt bazel or buck yet.
- I included the mha_fwd from flash_attention that has ben refactored to use cutlass 2.10. There is currently no backwards kernel on this branch. That would be a good follow up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81434
Approved by: https://github.com/cpuhrsch
Summary:
enabling AT_POCKETFFT_ENABLED@ flag and adding the appropriate dependencies to aten-cpu
moved mkl files from
`aten_cpu_source_non_codegen_list` to
`aten_native_source_non_codegen_list`
Test Plan:
After building testing binaries for both android and ios targets
### iOS
`fbcode/aibench/specifications/frameworks/pytorch/ios/build.sh`
Submitted benchmarks with the new binaries supporting pocketfft here:
https://www.internalfb.com/intern/aibench/details/245253003946591
### Android
`fbcode/aibench/specifications/frameworks/pytorch/android/arm64/build.sh`
Submitted Benchmarks with the new binaries supporting pocket fft here:
https://www.internalfb.com/intern/aibench/details/406253690682941
### Build Size Impact
Success: igios-pika on D37790257-V7
☷[pocket fft] turning on pocketfft flag☷
Diff: https://fburl.com/diff/exkploof
Unigraph Explorer: https://fburl.com/mbex/aipdzaqo
Changes for variation [arm64 + 3x assets]:
```Compressed : -473 B (-0.00%) => 86.69 MiB
Uncompressed: +2.4 KiB (+0.00%) => 187.71 MiB
```
Reviewed By: kimishpatel
Differential Revision: D37790257
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81670
Approved by: https://github.com/kit1980
Fixes#81181 by creating a temporary LICENCE file that has all the third-party licenses concatenated together when creating a wheel. Also update the `third_party/LICENSES_BUNDLED.txt` file.
The `third_party/LICENSES_BUNDLED.txt` file is supposed to be tested via `tests/test_license.py`, but the test is not running?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81500
Approved by: https://github.com/rgommers, https://github.com/seemethere
{kind=link}
{kind=link}
{kind=link}
{kind=link}