This will be the last disruptive functorch internals change.
Why are we moving these files?
- As a part of rationalizing functorch we are moving the code in
functorch/_src to torch/_functorch
- This is so that we can offer the functorch APIs as native PyTorch APIs
(coming soon) and resolve some internal build issues.
Why are we moving all of these files at once?
- It's better to break developers all at once rather than many times
Test Plan:
- wait for tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90091
Approved by: https://github.com/anijain2305, https://github.com/ezyang
- Add graph index to the profile information of the Inductor kernel for better debugability.
The generated code for different graphs could produce kernels with the same name. The side effect is that it is hard to identify the portion of E2E performance for these kernels because the profiler will aggregate the performance with the same kernel name regardless of different graphs. Hence, this PR added the graph index to the profile information to address this limitation.
- Label arbitrary code ranges for `eager` and `opt` modes for better debugability
The profile information of dynamo benchmarks mixes the eager mode and opt mode. It is hard to separate the range for different modes. This PR added eager and opt marks to the profile information to address this limitation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90008
Approved by: https://github.com/jgong5, https://github.com/jansel
Moving to train mode for TIMM models and also raising batch size for accuracy testing.
Raising batch size seems to remove a lot of noise/instability coming from batch_norm decomposition.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89780
Approved by: https://github.com/ngimel
This will be the last disruptive functorch internals change.
Why are we moving these files?
- As a part of rationalizing functorch we are moving the code in
functorch/_src to torch/_functorch
- This is so that we can offer the functorch APIs as native PyTorch APIs
(coming soon) and resolve some internal build issues.
Why are we moving all of these files at once?
- It's better to break developers all at once rather than many times
Test Plan:
- wait for tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88756
Approved by: https://github.com/ezyang
Performance benchmarks on 6 popular models from 1-64 GPUs compiled with
torchinductor show performance gains or parity with eager, and showed
regressions without DDPOptimizer. *Note: resnet50 with small batch size shows a regression with optimizer, in part due to failing to compile one subgraph due to input mutation, which will be fixed.
(hf_Bert, hf_T5_large, hf_T5, hf_GPT2_large, timm_vision_transformer, resnet50)
Correctness checks are implemented in CI (test_dynamo_distributed.py),
via single-gpu benchmark scripts iterating over many models
(benchmarks/dynamo/torchbench.py/timm_models.py/huggingface.py),
and via (multi-gpu benchmark scripts in torchbench)[https://github.com/pytorch/benchmark/tree/main/userbenchmark/ddp_experiments].
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88523
Approved by: https://github.com/davidberard98
### Summary
Making dynamo treat the nn.Modules inside FSDP wrappers as 'Unspecialized'
results in dynamo-produced graphs where nn.module parameters are inputs
to the graph rather than attributes of the outer graphmodule.
This helps in FSDP since it forces dynamo to pick the latest copy
of the parameters off the user's nn.Module (which FSDP mutates every pre_forward),
solving the ordering issue in backward.
### Details
Imagine this toy model
```
class MyModule(torch.nn.Module):
def __init__(self, a, b):
super(MyModule, self).__init__()
self.net = nn.Sequential(
nn.Linear(a, b),
nn.ReLU(),
)
def forward(self, x):
return self.net(x)
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net = nn.Sequential(
*[MyModule(10, 10000)]
+ [MyModule(10000, 1000)]
+ [MyModule(1000, 5)]
)
def forward(self, x):
return self.net(x)
```
Where FSDP is recursively wrapped around each `MyModule`, then dynamo-compiled, with dynamo already configured to skip/break in FSDP code. You'd expect to get 3 compiled AOT functions, corresponding to the contents of `MyModule`, and then see FSDP's communication ops happen inbetween them (eagerly). This almost happens (everything works out fine in forward), but in backward there is an ordering issue.
FSDP creates a flat buffer for all the parameters that are bucketed together, and then creates views into this buffer to replace the original parameters. On each iteration of forward, it creates a new view after 'filling' the flatbuffer with data from an all-gather operation, to 'unshard' the parameters from remote devices. Dynamo traces the first such view and stores it in a compiled graphmodule.
During tracing, we see (1) view created for first MyModule, (2) compile first MyModule, (3) ... for the rest of layers
Then during runtime, we see (A) view created for first MyModule (and orphaned), (B) execute first compiled MyModule, using old view, ...
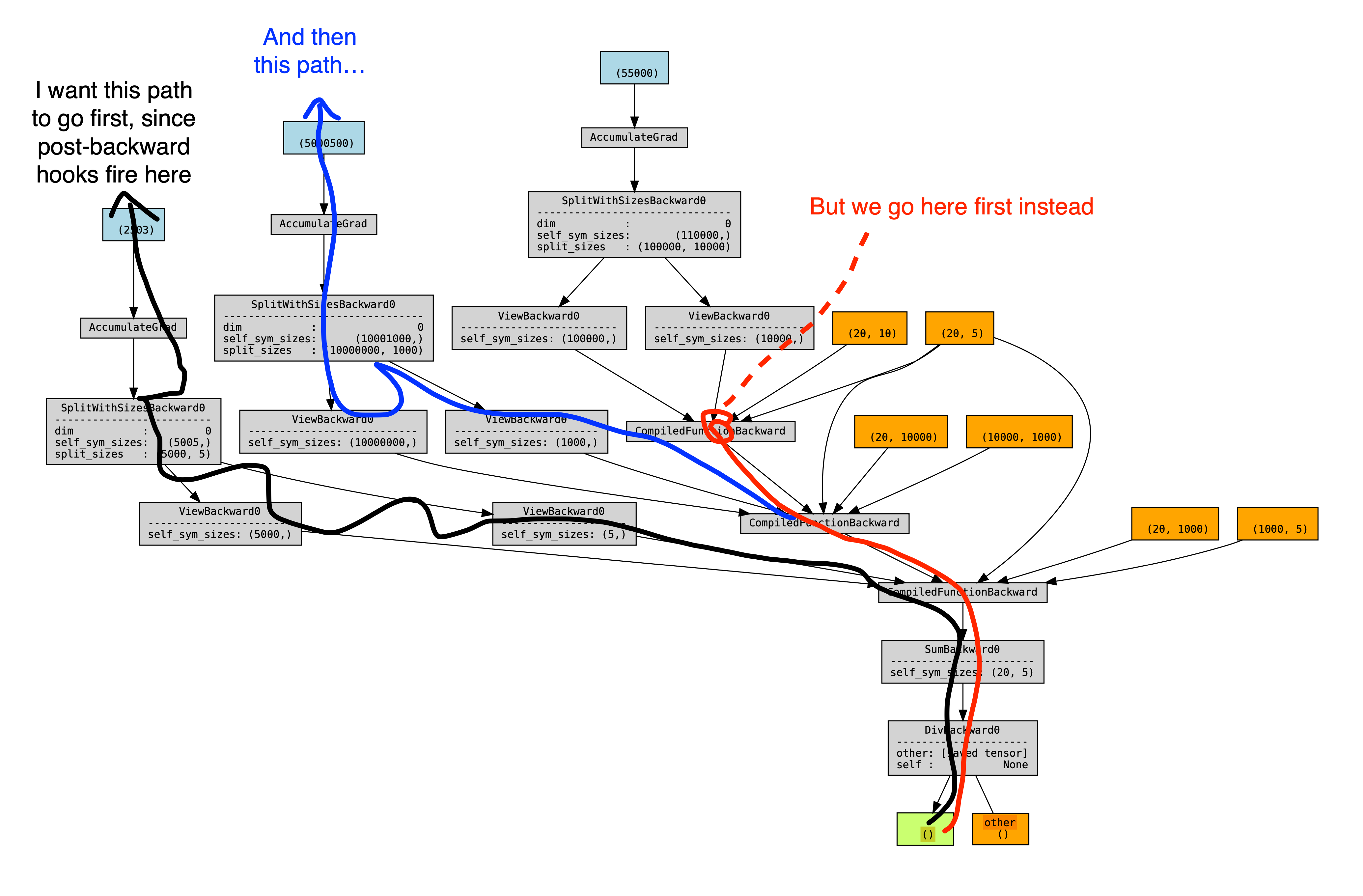
This is a problem, because we want backward hooks to run right after each compiled-backward, but autograd executes those hooks in an order mirroring their execution order during forward. Since we are forever using the views created during steps (1, 3, .. N), which all happen before the steps (A, B, ...), this means that all the hooks will happen after all the compiled backwards. An illustration of the problem - a torchviz graph showing the 2 possible orderings of autograd, and a profile showing the view-backwards ops happening after all the compiled backwards, and before all the backward hooks.
<img width="2069" alt="image" src="https://user-images.githubusercontent.com/4984825/202828002-32dbbd15-8fc3-4281-93e9-227ab5e32683.png">
<img width="2069" alt="image" src="https://user-images.githubusercontent.com/4984825/202828632-33e40729-9a7f-4e68-9ce1-571e3a8dd2dd.png">
A solution is to make dynamo not specialize on these nn modules. It is worth pointing out that this nn.module specialization is de-facto failing, as we are modifying .parameters and this bypasses dynamo's __setattr__ monkeypatch, which should have automatically kicked us out to Unspecialized and forced a recompile.
After unspecializing, the new views (created during steps A, C, ...) are actually _used_ at runtime by the module, making their creation order interleaved, making autograd execute their backwards interleaved.
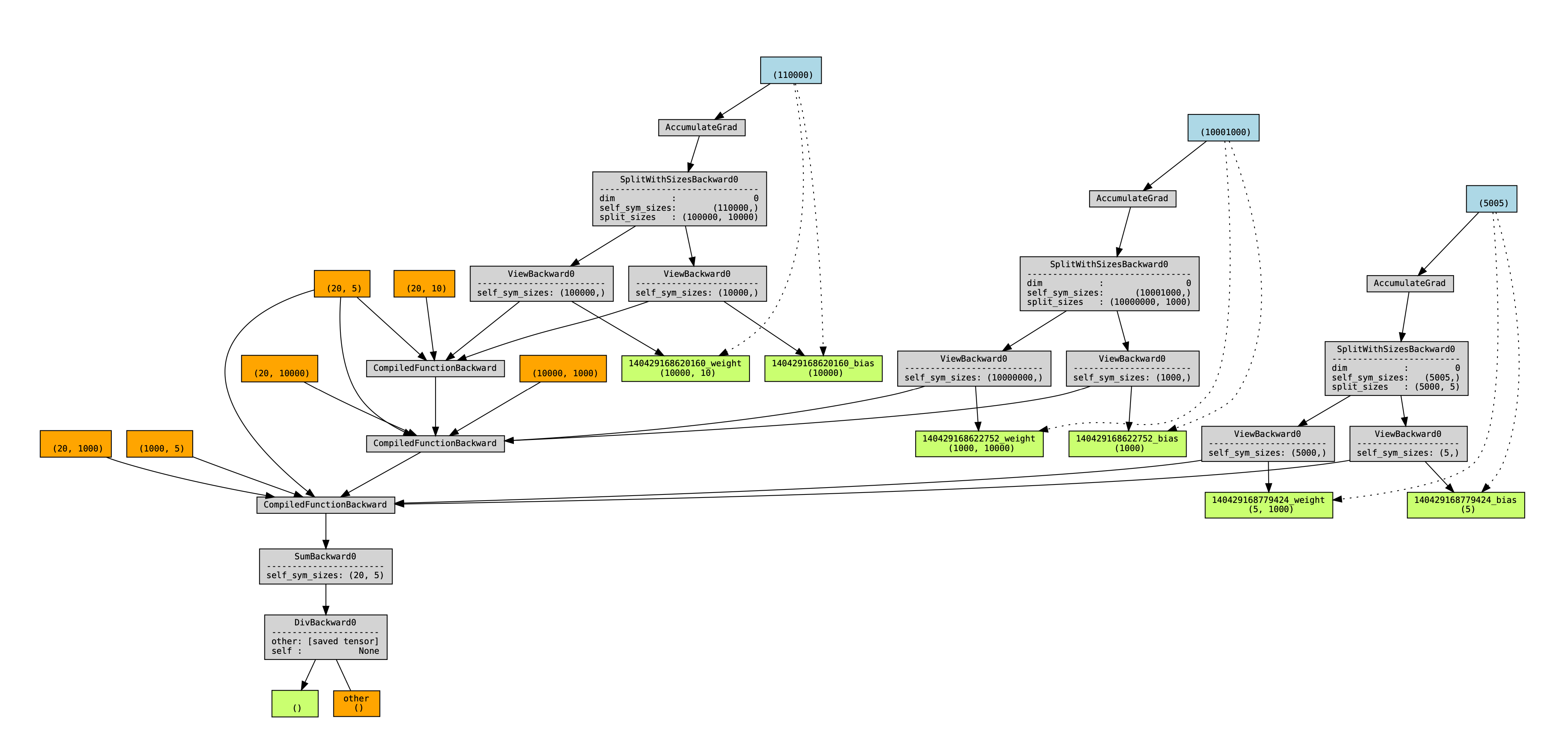
The new torchviz graph (this time with names added for the view tensors):
<img width="2043" alt="image" src="https://user-images.githubusercontent.com/4984825/202828480-d30005ba-0d20-45d8-b647-30b7ff5e91d3.png">
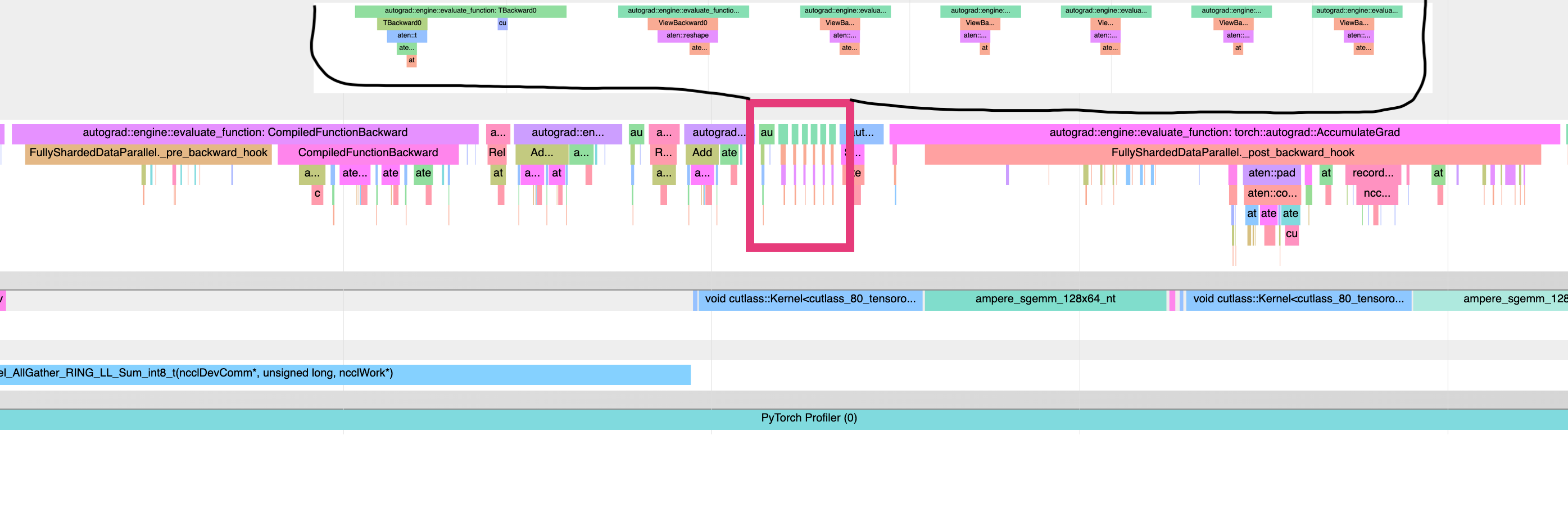
And a new profile showing the interleaving of compiled backwards and hooks, allowing overlapping of reduce-scatter.
<img width="2293" alt="image" src="https://user-images.githubusercontent.com/4984825/202828533-bb20a041-19b8-499c-b3cf-02808933df47.png">
@jansel @davidberard98 @aazzolini @mrshenli @awgu @ezyang @soumith @voznesenskym @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89330
Approved by: https://github.com/davidberard98
Summary stat diff was reporting diff between previous day and the day before that, instead of today and previous day. Issue was because summary stats were not uploaded to the archive before the summary stat differ was run.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89789
Approved by: https://github.com/anijain2305
Disabling Gradscaler because
1) Benchmark setup runs 2 iterations of fwd-bwd. So, not useful.
2) Current setup shares grad_scaler for eager and dynamo model,
which is bad as Gradscaler has state and can adjust the scaling
factor between eager and dynamo run, making accuracy check
harder.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89741
Approved by: https://github.com/ngimel
Summary: This permute copy change seems to be causing huge regressions on machines without AVX512. Revert to mitigate. This shouldn't be problematic since the improvement from changing it was super small anyways.
Differential Revision: D41450088
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89463
Approved by: https://github.com/hlu1
In #87741 we added the inference support for dynamo/torchxla integration. Later on in #88449 we attempt to add the training support. That attempt is not smooth because
- we try 2 things together
1. let dynamo trace the model on xla rather than eager
2. enable training
- It turns out neither of these two tasks are trivial enough.
Furthermore, item 2 (enable training) depends on item 1 (tracing on xla). We enable training via AOTAutograd. AOTAutograd lift all model parameters/buffers as graph inputs. Without item 1 being done, we would need copy all graph inputs (including model parameters/buffers) from eager device to xla devices. That hurts performance a lot. Have a cache to map eager parameter to XLA parameter does not solve the problem since the update on either will not sync automatically to the other. They will easily go out of sync.
This PR let dynamo trace the model on XLA rather than eager. This is a preparation step to enabling training.
Also, tracing on XLA makes the data movement more efficient. We see 1.5x geomean speedup compared to previous 1.38x.
```
+-------------------------+--------------------+-------------------------+
| Model | XLA (trace once) | XLA (trace everytime) |
+=========================+====================+=========================+
| resnet18 | 1.38 | 1.008 |
+-------------------------+--------------------+-------------------------+
| resnet50 | 1.227 | 0.998 |
+-------------------------+--------------------+-------------------------+
| resnext50_32x4d | 1.544 | 1.008 |
+-------------------------+--------------------+-------------------------+
| alexnet | 1.085 | 1.045 |
+-------------------------+--------------------+-------------------------+
| mobilenet_v2 | 2.028 | 1.013 |
+-------------------------+--------------------+-------------------------+
| mnasnet1_0 | 1.516 | 0.995 |
+-------------------------+--------------------+-------------------------+
| squeezenet1_1 | 0.868 | 1.01 |
+-------------------------+--------------------+-------------------------+
| vgg16 | 1.099 | 1.008 |
+-------------------------+--------------------+-------------------------+
| BERT_pytorch | 3.26 | 1.027 |
+-------------------------+--------------------+-------------------------+
| timm_vision_transformer | 2.182 | 1.015 |
+-------------------------+--------------------+-------------------------+
| geomean | 1.50389 | 1.01261 |
+-------------------------+--------------------+-------------------------+
```
Example command
```
GPU_NUM_DEVICES=1 python benchmarks/dynamo/torchbench.py --randomize-input --performance --trace-on-xla --only resnet18 --backend=torchxla_trace_once
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88904
Approved by: https://github.com/wconstab, https://github.com/JackCaoG, https://github.com/jansel
Summary:
This Diff ports the torchbench.py script from torchdynamo to torchbench to support the development of internal models.
Currently, only works with the `--only` option, and can only test one model at a time.
Note that the noisy logs are from upstream model code, not the benchmark code.
In the internal environment, `torch._dynamo.config.base_dir` is not writable, so we add an option to specify the output directory.
Test Plan:
```
$ buck2 run mode/opt //caffe2/benchmarks/dynamo:torchbench -- --performance --only ads_dhen_5x --part over --output-directory /tmp/tb-test/
cuda eval ads_dhen_5x
1/ 1 +0 frames 2s 1 graphs 1 graph calls 412/ 411 = 100% ops 100% time
```
```
$ buck2 run mode/opt //caffe2/benchmarks/dynamo:torchbench -- --performance --only cmf_10x --part over --output-directory /tmp/tb-test/
cuda eval cmf_10x
1/ 1 +0 frames 1s 1 graphs 1 graph calls 306/ 305 = 100% ops 100% time
```
Reviewed By: jansel
Differential Revision: D41294311
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89239
Approved by: https://github.com/jansel
Mainly wanted to confirm torchrun works fine with dynamo/ddp,
but it is also a better system than manually launching processes.
Partially addresses issue #1779
New run commands
------------
single process:
python benchmarks/dynamo/distributed.py [args]
multi-gpu (e.g. 2 gpu on one host):
torchrun --nproc_per_node 2 benchmarks/dynamo/distributed.py [args]
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89149
Approved by: https://github.com/aazzolini
A number of dashboard improvements:
- Add accuracy failures to warnings section
- Add regression detection to all metrics (speedup, compile time, peak memory), not just accuracy
- Add testing flag to update-dashboard to prevent image/comment uploads
- Add section for comparing summary statistics (passrate, speedup) between 2 most recent reports
- Show names of reports for summary stats diff and regression detection sections
- Remove metric graphs from the comment (they can still be found in the generated text file)
Sample comment: https://github.com/pytorch/torchdynamo/issues/1831#issuecomment-1317565972
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89155
Approved by: https://github.com/anijain2305
Sometimes it's really convenient to run simple models thru the torchbench.py script rather than those from pytorch/benchmark. This PR add the ability to run any model from a specified path by overloading the --only argument.
This PR is split out from #88904
Here is the usage:
Specify the path and class name of the model in format like:
--only=path:<MODEL_FILE_PATH>,class:<CLASS_NAME>
Due to the fact that dynamo changes current working directory,
the path should be an absolute path.
The class should have a method get_example_inputs to return the inputs
for the model. An example looks like
```
class LinearModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(10, 10)
def forward(self, x):
return self.linear(x)
def get_example_inputs(self):
return (torch.randn(2, 10),)
```
Test command:
```
# python benchmarks/dynamo/torchbench.py --performance --only=path:/pytorch/myscripts/model_collection.py,class:LinearModel --backend=eager
WARNING:common:torch.cuda.is_available() == False, using CPU
cpu eval LinearModel 0.824x p=0.00
```
Content of model_collection.py
```
from torch import nn
import torch
class LinearModel(nn.Module):
"""
AotAutogradStrategy.compile_fn ignore graph with at most 1 call nodes.
Make sure this model calls 2 linear layers to avoid being skipped.
"""
def __init__(self, nlayer=2):
super().__init__()
layers = []
for _ in range(nlayer):
layers.append(nn.Linear(10, 10))
self.layers = nn.Sequential(*layers)
def forward(self, x):
return self.layers(x)
def get_example_inputs(self):
return (torch.randn(2, 10),)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89028
Approved by: https://github.com/jansel
Fix dashboard comment failure due to the following trace:
```
Traceback (most recent call last):
File "/scratch/anijain/dashboard/work/pytorch/benchmarks/dynamo/runner.py", line 1180, in <module>
DashboardUpdater(args).update()
File "/scratch/anijain/dashboard/work/pytorch/benchmarks/dynamo/runner.py", line 1119, in update
self.comment_on_gh(comment)
File "/scratch/anijain/dashboard/work/pytorch/benchmarks/dynamo/runner.py", line 1096, in comment_on_gh
subprocess.check_call(
File "/scratch/anijain/dashboard/env/lib/python3.9/subprocess.py", line 368, in check_call
retcode = call(*popenargs, **kwargs)
File "/scratch/anijain/dashboard/env/lib/python3.9/subprocess.py", line 349, in call
with Popen(*popenargs, **kwargs) as p:
File "/scratch/anijain/dashboard/env/lib/python3.9/subprocess.py", line 951, in __init__
self._execute_child(args, executable, preexec_fn, close_fds,
File "/scratch/anijain/dashboard/env/lib/python3.9/subprocess.py", line 1821, in _execute_child
raise child_exception_type(errno_num, err_msg, err_filename)
OSError: [Errno 7] Argument list too long: '/data/home/anijain/miniconda/bin/gh'
srun: error: a100-st-p4d24xlarge-27: task 0: Exited with exit code 1
```
That is, we were trying to execute a gh command in the OS that was too long.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89002
Approved by: https://github.com/davidberard98
Hello @wconstab! As you saw, `transformer_auto_wrap_policy()` is a misnomer and actually works for any module classes. The PR before this one tries to add a class `ModuleWrapPolicy` that takes in the `module_classes` in its constructor and works just like `transformer_auto_wrap_policy()` without requiring the `functools.partial()`. I hope you do not mind if we update the dynamo benchmarks util file with this migration.
The PR before this one might require some back and forth within FSDP devs, so I apologize for any consequent updates to this PR, which in itself is an easy change. I will request review once we know the previous PR is good for land.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88453
Approved by: https://github.com/wconstab
{kind=link}
{kind=link}
{kind=link}
{kind=link}