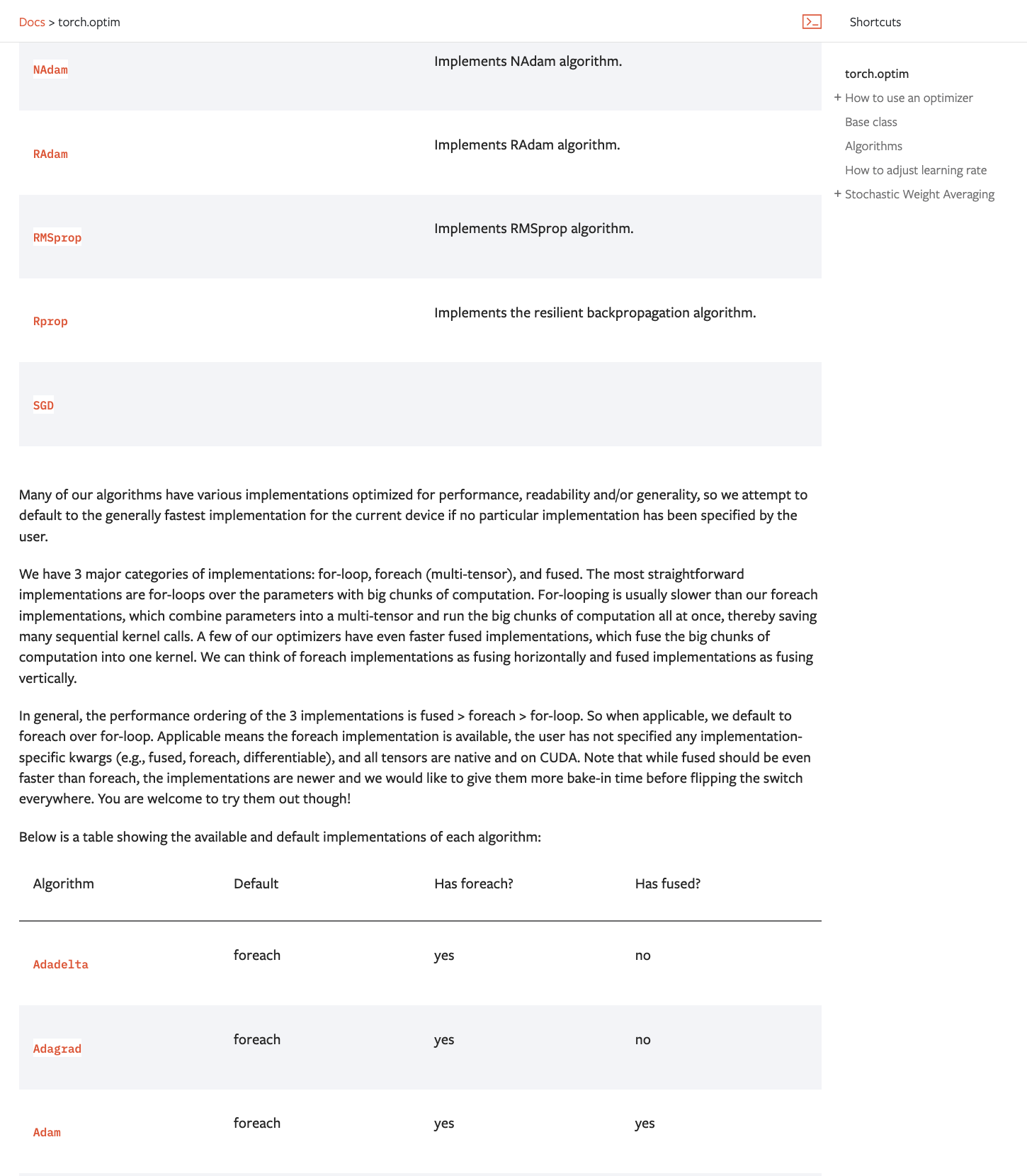
According to the documentation, decay is a number in [0,1] range,[ i.e.](https://pytorch.org/docs/stable/optim.html)
```
Decay is a parameter between 0 and 1 that controls how fast the averaged parameters are decayed. If not provided to get_ema_multi_avg_fn, the default is 0.999.
```
An inspection of `swa_utils.py` indicates there are no checks for invalid values of `decay`. Adding asserts as suggested in this PR ensures valid compute range (one way to enforce correct behavior, there are perhaps more suitable ones). Papers `torch` cites for reference idea/implementation also consider exclusively this range (e.g., https://arxiv.org/pdf/2310.04415).
Fixes https://github.com/pytorch/pytorch/issues/133772
Pull Request resolved: https://github.com/pytorch/pytorch/pull/133773
Approved by: https://github.com/janeyx99
A proposal addressing Issue #1489: **Optimizer should track parameter names and not id.**
(also mentioned in here: [[RFC] Introducing FQNs/clarity eyeglasses to optim state_dict](https://dev-discuss.pytorch.org/t/rfc-introducing-fqns-clarity-to-optim-state-dict/1552)
## Summary
This PR introduces a backward-compatible enhancement where optimizers track parameter names instead of just their id.
Optimizers can be initialized with `named_parameters()` as:
```python
optimizer = optim.SGD(model.named_parameters(), lr=0.01, momentum=0.9)
```
This allows for greater clarity and ease when handling optimizers, as the parameters' names are preserved within the optimizer’s `state_dict` as:
```
state_dict =
{
'state': {
0: {'momentum_buffer': tensor(...), ...},
1: {'momentum_buffer': tensor(...), ...},
},
'param_groups': [
{
'lr': 0.01,
'weight_decay': 0,
...
'params': [0,1]
'param_names' ['layer.weight', 'layer.bias'] (optional)
}
]
}
```
Loading `state_dict` is not changed (backward-compatible) and the `param_names` key will be ignored.
## Key Features
#### Named Parameters in Optimizer Initialization:
Optimizers can accept the output of `model.named_parameters()` during initialization, allowing them to store parameter names directly.
#### Parameter Names in `state_dict`:
The parameter names are saved as a list in the optimizer’s `state_dict` with key `param_names`, alongside the `params` indices, ensuring seamless tracking of both names and parameters.
## Backward Compatibility
#### No Breaking Changes:
This change is fully backward-compatible. The added `param_names` key in the optimizer's `state_dict` is ignored when loading a state to the optimizer.
#### Customization with Hooks:
For more control, the loaded state_dict can be modified using a custom `register_load_state_dict_pre_hook`, providing flexibility for different design needs.
## Documentation Updates
Please refer to the documentation changes for more details on how this feature is implemented and how it can be used effectively.
## Solution Example:
A suggested solution to the problem mentioned in #1489, for the same parameters but in a different order.
The following `register_load_state_dict_pre_hook` should be added to the optimizer before loading to enable loading the state dict :
```python
def adapt_state_dict_ids(optimizer, state_dict):
# assuming a single param group.
current_state_group = optimizer.state_dict()['param_groups'][0]
loaded_state_group = state_dict['param_groups'][0]
# same number of params, same names, only different ordering
current_state_name_to_id_mapping = {} # mapping -- param_name: id
for i, name in enumerate(current_state_group['param_names']):
current_state_name_to_id_mapping[name] = current_state_group['params'][i]
# changing the ids of the loaded state dict to match the order of the given state dict.
for i, name in enumerate(current_state_group['param_names']):
loaded_state_group['params'][i] = current_state_name_to_id_mapping[name]
return state_dict
```
In this code, the loaded `state_dict` ids are adapted to match the order of the current optimizer `state_dict`.
Both the previous and the current optimizers are required to be initiated with `named_parameters()` to have the 'param_names' key in the dict.
### Note
This is my first contribution to PyTorch, and I wish to receive feedback or suggestions for improvement.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/134107
Approved by: https://github.com/janeyx99
Co-authored-by: Jane (Yuan) Xu <31798555+janeyx99@users.noreply.github.com>
Link various classes and functions of the `optim.swa.util` to make doc content accessible from the `torch.optim` doc.
Currently, if you click the link,
https://pytorch.org/docs/stable/optim.html#module-torch.optim.swa_utils it goes to a blank, bottom of the page section of `torch.optim`.
Also,
`torch.optim.swa_utils.AveragedModel` and `torch.optim.swa_utils.SWALR` classes as well as `torch.optim.swa_utils.update_bn()` and `optim.swa_utils.get_ema_multi_avg_fn` are not linked to doc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/133393
Approved by: https://github.com/janeyx99
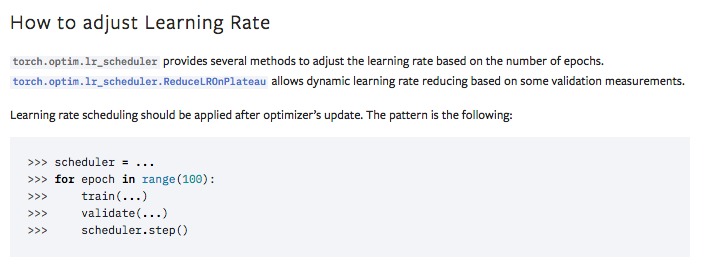
The `LRScheduler` class provides methods to adjusts the learning rate during optimization (as updated in this PR). Also, as a note, all the classes of lr_scheduluer are already provided in the `How to adjust learning rate` section.
Fixes#127884
Pull Request resolved: https://github.com/pytorch/pytorch/pull/133243
Approved by: https://github.com/janeyx99
#109581
At this point, the vanilla implementation (the default) is good.
Docs: https://docs-preview.pytorch.org/pytorch/pytorch/129905/generated/torch.optim.Adafactor.html#torch.optim.Adafactor
Specifically, the impl in this PR, which attempts to replicate the paper,
```
optim = torch.optim.Adafactor([weight])
```
is close enough to https://pytorch-optimizers.readthedocs.io/en/latest/optimizer/#pytorch_optimizer.AdaFactor
```
optim_c = AdaFactor([weight], betas=(0, 0.999), scale_parameter=False)
```
is close enough to https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/Adafactor
```
optim = keras.optimizers.Adafactor(learning_rate=0.01)
```
The three results respectively for the same randomly generated weights:
```
# ours
tensor([[ 0.3807594, -0.3912092],
[ 0.0762539, 0.5377805],
[ 0.2459473, 0.4662207]])
# pytorch-optimizer
tensor([[ 0.3807592, -0.3912172],
[ 0.0762507, 0.5377818],
[ 0.2459457, 0.4662213]])
# keras
array([[ 0.38076326, -0.39121315],
[ 0.0762547 , 0.5377859 ],
[ 0.24594972, 0.46622536]], dtype=float32)
```
This gives me confidence to move forward in speeding up the implementation now that a baseline has been established. If you're curious about differences:
* keras assigns step_size (rho_t in their code) to `min(lr, 1 / sqrt(step)` whereas the OG impl uses a hardcoded 0.01 instead of lr. We do the same thing as keras, but our lr default is 0.01.
* We differ from the pytorch-optimizers default in that our default will not track momentum (thus `beta1=0`) and we do not apply parameter scaling.
<details>
Keras collab: https://colab.research.google.com/drive/1i3xF8ChL7TWKJGV_5v_5nMhXKnYmQQ06?usp=sharing
My script repro:
```
import torch
from pytorch_optimizer import AdaFactor
torch.set_printoptions(precision=7)
weight = torch.tensor([[ 0.37697506, -0.39500135],
[ 0.07246649, 0.53399765],
[ 0.24216151, 0.46243715]], dtype=torch.float32)
# bias = torch.tensor([0, 0], dtype=torch.float32)
weight.grad = torch.tensor([[-0.5940447, -0.7743838],
[-0.5940447, -0.7743838],
[-0.5940447, -0.7743838]], dtype=torch.float32)
# bias.grad = torch.tensor([-2.5027974, 1.5422692], dtype=torch.float32)
weight_c = weight.clone()
weight_c.grad = weight.grad.clone()
optim = torch.optim.Adafactor([weight])
optim.step()
print(weight)
optim_c = AdaFactor([weight_c], betas=(0, 0.999), scale_parameter=False)
optim_c.step()
print(weight_c)
```
<details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/129905
Approved by: https://github.com/albanD
I'd like to discuss the criteria that we regard an implementation as stable. If there is no existing standard, my initial proposal would be a 6 month period after the commit to regard it as stable. As a result, now Adam and AdamW on CUDA would be considered as stable, while the rest are of beta.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/129006
Approved by: https://github.com/malfet
Add non-package python modules to the public API checks.
The original change is to remove the `ispkg` check in this line
https://github.com/pytorch/pytorch/blob/main/docs/source/conf.py#L518
Everything else is to add the appropriate modules to the rst files, make sure every module we provide can be imported (fixed by either making optional dependencies optional or just deleting files that have been un-importable for 3 years), make API that are both modules and functions (like torch.autograd.gradcheck) properly rendered on the docs website without confusion and add every non-documented API to the allow list (~3k of them).
Next steps will be to try and fix these missing docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/110568
Approved by: https://github.com/zou3519
This PR proposes an optimized way to do Exponential Moving Average (EMA), which is faster than the current way using `swa_utils.AveragedModel` described in https://pytorch.org/docs/stable/optim.html#custom-averaging-strategies.
This implementation is asynchronous, and is built as an optimizer wrapper so that the EMA weight update happens without any additional CPU/GPU sync, just after optimizer steps, and with limited code changes.
Example usage:
```
model = Model().to(device)
opt = torch.optim.Adam(model.parameters())
opt = EMAOptimizer(opt, device, 0.9999)
for epoch in range(epochs):
training_loop(model, opt)
regular_eval_accuracy = evaluate(model)
with opt.swap_ema_weights():
ema_eval_accuracy = evaluate(model)
```
Here are some benchmarks (time per iteration) on various torchvision models:
|model|this PR iteration time |swa_utils.AveragedModel iteration time| iteration speedup |
|-----|-----------------------------|-----------------------|---------------------------------------------|
| | | | |
|regnet_x_1_6gf|62.73 |67.998 |1.08 |
|regnet_x_3_2gf|101.75 |109.422 |1.08 |
|regnet_x_400mf|25.13 |32.005 |1.27 |
|regnet_x_800mf|33.01 |37.466 |1.13 |
|regnet_x_8gf|128.13 |134.868 |1.05 |
|regnet_y_16gf|252.91 |261.292 |1.03 |
|regnet_y_1_6gf|72.14 |84.22 |1.17 |
|regnet_y_3_2gf|99.99 |109.296 |1.09 |
|regnet_y_400mf|29.53 |36.506 |1.24 |
|regnet_y_800mf|37.82 |43.634 |1.15 |
|regnet_y_8gf|196.63 |203.317 |1.03 |
|resnet101|128.80 |137.434 |1.07 |
|resnet152|182.85 |196.498 |1.07 |
|resnet18|29.06 |29.975 |1.03 |
|resnet34|50.73 |53.443 |1.05 |
|resnet50|76.88 |80.602 |1.05 |
|resnext101_32x8d|277.29 |280.759 |1.01 |
|resnext101_64x4d|269.56 |281.052 |1.04 |
|resnext50_32x4d|100.73 |101.102 |1.00 |
|shufflenet_v2_x0_5|10.56 |15.419 |1.46 |
|shufflenet_v2_x1_0|13.11 |18.525 |1.41 |
|shufflenet_v2_x1_5|18.05 |23.132 |1.28 |
|shufflenet_v2_x2_0|25.04 |30.008 |1.20 |
|squeezenet1_1|14.26 |14.325 |1.00 |
|swin_b|264.52 |274.613 |1.04 |
|swin_s|180.66 |188.914 |1.05 |
|swin_t|108.62 |112.632 |1.04 |
|swin_v2_s|220.29 |231.153 |1.05 |
|swin_v2_t|127.27 |133.586 |1.05 |
|vgg11|95.52 |103.714 |1.09 |
|vgg11_bn|106.49 |120.711 |1.13 |
|vgg13|132.94 |147.063 |1.11 |
|vgg13_bn|149.73 |165.256 |1.10 |
|vgg16|158.19 |172.865 |1.09 |
|vgg16_bn|177.04 |192.888 |1.09 |
|vgg19|184.76 |194.194 |1.05 |
|vgg19_bn|203.30 |213.334 |1.05 |
|vit_b_16|217.31 |219.748 |1.01 |
|vit_b_32|69.47 |75.692 |1.09 |
|vit_l_32|223.20 |258.487 |1.16 |
|wide_resnet101_2|267.38 |279.836 |1.05 |
|wide_resnet50_2|145.06 |154.918 |1.07 |
You can see that in all cases it is faster than using `AveragedModel`. In fact in many cases, adding EMA does not add any overhead since the computation is hidden behind the usual iteration flow.
This is a similar implementation to the one currently in [NVIDIA NeMo](https://github.com/NVIDIA/NeMo).
If the team is interested in merging this, let me know and I'll add some documentation similar to `swa_utils` and tests.
Credits to @szmigacz for the implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94820
Approved by: https://github.com/janeyx99
Summary:
Partially resolves https://github.com/pytorch/vision/issues/4281
In this PR we are proposing a new scheduler --SequentialLR-- which enables list of different schedulers called in different periods of the training process.
The main motivation of this scheduler is recently gained popularity of warming up phase in the training time. It has been shown that having a small steps in initial stages of training can help convergence procedure get faster.
With the help of SequentialLR we mainly enable to call a small constant (or linearly increasing) learning rate followed by actual target learning rate scheduler.
```PyThon
scheduler1 = ConstantLR(optimizer, factor=0.1, total_iters=2)
scheduler2 = ExponentialLR(optimizer, gamma=0.9)
scheduler = SequentialLR(optimizer, schedulers=[scheduler1, scheduler2], milestones=[5])
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
```
which this code snippet will call `ConstantLR` in the first 5 epochs and will follow up with `ExponentialLR` in the following epochs.
This scheduler could be used to provide call of any group of schedulers next to each other. The main consideration we should make is every time we switch to a new scheduler we assume that new scheduler starts from the beginning- zeroth epoch.
We also add Chained Scheduler to `optim.rst` and `lr_scheduler.pyi` files here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64037
Reviewed By: albanD
Differential Revision: D30841099
Pulled By: iramazanli
fbshipit-source-id: 94f7d352066ee108eef8cda5f0dcb07f4d371751
Summary:
Partially unblocks https://github.com/pytorch/vision/issues/4281
Previously we have added WarmUp Schedulers to PyTorch Core in the PR : https://github.com/pytorch/pytorch/pull/60836 which had two mode of execution - linear and constant depending on warming up function.
In this PR we are changing this interface to more direct form, as separating linear and constant modes to separate Schedulers. In particular
```Python
scheduler1 = WarmUpLR(optimizer, warmup_factor=0.1, warmup_iters=5, warmup_method="constant")
scheduler2 = WarmUpLR(optimizer, warmup_factor=0.1, warmup_iters=5, warmup_method="linear")
```
will look like
```Python
scheduler1 = ConstantLR(optimizer, warmup_factor=0.1, warmup_iters=5)
scheduler2 = LinearLR(optimizer, warmup_factor=0.1, warmup_iters=5)
```
correspondingly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64395
Reviewed By: datumbox
Differential Revision: D30753688
Pulled By: iramazanli
fbshipit-source-id: e47f86d12033f80982ddf1faf5b46873adb4f324
Summary:
Warm up of learning rate scheduling has initially been discussed by Priya et. al. in the paper: https://arxiv.org/pdf/1706.02677.pdf .
In the section 2.2 of the paper they discussed and proposed idea of warming up learning schedulers in order to prevent big variance / noise in the learning rate. Then idea has been further discussed in the following papers:
* Akilesh Gotmare et al. https://arxiv.org/abs/1810.13243
* Bernstein et al http://proceedings.mlr.press/v80/bernstein18a/bernstein18a.pdf
* Liyuan Liu et al: https://arxiv.org/pdf/1908.03265.pdf
There are two type of popularly used learning rate warm up ideas
* Constant warmup (start with very small constant learning rate)
* Linear Warmup ( start with small learning rate and gradually increase)
In this PR we are adding warm up as learning rate scheduler. Note that learning rates are chainable, which means that we can merge warmup scheduler with any other learning rate scheduler to make more sophisticated learning rate scheduler.
## Linear Warmup
Linear Warmup is multiplying learning rate with pre-defined constant - warmup_factor in the first epoch (epoch 0). Then targeting to increase this multiplication constant to one in warmup_iters many epochs. Hence we can derive the formula at i-th step to have multiplication constant equal to:
warmup_factor + (1-warmup_factor) * i / warmup_iters
Moreover, the fraction of this quantity at point i to point i-1 will give us
1 + (1.0 - warmup_factor) / [warmup_iters*warmup_factor+(i-1)*(1-warmup_factor)]
which is used in get_lr() method in our implementation. Below we provide an example how to use linear warmup scheduler and to give an example to show how does it works.
```python
import torch
from torch.nn import Parameter
from torch.optim import SGD
from torch.optim.lr_scheduler import WarmUpLR
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler = WarmUpLR(optimizer, warmup_factor=0.1, warmup_iters=10, warmup_method="linear")
for epoch in range(15):
print(epoch, scheduler.get_last_lr()[0])
optimizer.step()
scheduler.step()
```
```
0 0.010000000000000002
1 0.019000000000000003
2 0.028000000000000008
3 0.03700000000000001
4 0.04600000000000001
5 0.055000000000000014
6 0.06400000000000002
7 0.07300000000000002
8 0.08200000000000003
9 0.09100000000000004
10 0.10000000000000005
11 0.10000000000000005
12 0.10000000000000005
13 0.10000000000000005
14 0.10000000000000005
```
## Constant Warmup
Constant warmup has straightforward idea, to multiply learning rate by warmup_factor until we reach to epoch warmup_factor, then do nothing for following epochs
```python
import torch
from torch.nn import Parameter
from torch.optim import SGD
from torch.optim.lr_scheduler import WarmUpLR
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler = WarmUpLR(optimizer, warmup_factor=0.1, warmup_iters=5, warmup_method="constant")
for epoch in range(10):
print(epoch, scheduler.get_last_lr()[0])
optimizer.step()
scheduler.step()
```
```
0 0.010000000000000002
1 0.010000000000000002
2 0.010000000000000002
3 0.010000000000000002
4 0.010000000000000002
5 0.10000000000000002
6 0.10000000000000002
7 0.10000000000000002
8 0.10000000000000002
9 0.10000000000000002
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60836
Reviewed By: saketh-are
Differential Revision: D29537615
Pulled By: iramazanli
fbshipit-source-id: d910946027acc52663b301f9c56ade686e62cb69
Summary:
Fixes : https://github.com/pytorch/pytorch/issues/24892
In the paper : https://arxiv.org/pdf/1908.03265.pdf Liyuan Liu et al. suggested a new optimization algorithm with an essence of similar to Adam Algorithm.
It has been discussed in the paper that, without warmup heuristic, in the early stage of adaptive optimization / learning algorithms sometimes we can get undesirable large variance which can slow overall convergence process.
Authors proposed the idea of rectification of variance of adaptive learning rate when it is expected to be high.
Differing from the paper, we selected variance tractability cut-off as 5 instead of 4. This adjustment is common practice, and could be found in the code-repository and also tensorflow swift optim library as well :
2f03dd1970/radam/radam.py (L156)f51ee4618d/Sources/TensorFlow/Optimizers/MomentumBased.swift (L638)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58968
Reviewed By: vincentqb
Differential Revision: D29310601
Pulled By: iramazanli
fbshipit-source-id: b7bd487f72f1074f266687fd9c0c6be264a748a9
Summary:
Fixes : https://github.com/pytorch/pytorch/issues/5804
In the paper : https://openreview.net/forum?id=OM0jvwB8jIp57ZJjtNEZ Timothy Dozat suggested a new optimization algorithm with an essence of combination of NAG and Adam algorithms.
It is known that the idea of momentum can be improved with the Nesterov acceleration in optimization algorithms, and Dozat is investigating to apply this idea to momentum component of Adam algorithm. Author provided experiment evidence in their work to show excellence of the idea.
In this PR we are implementing the proposed algorithm NAdam in the mentioned paper. Author has a preliminary work http://cs229.stanford.edu/proj2015/054_report.pdf where he shows the decay base constant should be taken as 0.96 which we also followed the same phenomenon here in this implementation similar to Keras. Moreover, implementation / coding practice have been followed similar to Keras in some other places as well:
f9d3868495/tensorflow/python/keras/optimizer_v2/nadam.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59009
Reviewed By: gchanan, vincentqb
Differential Revision: D29220375
Pulled By: iramazanli
fbshipit-source-id: 4b4bb4b15f7e16f7527f368bbf4207ed345751aa
Summary:
Fixes : https://github.com/pytorch/pytorch/issues/24892
In the paper : https://arxiv.org/pdf/1908.03265.pdf Liyuan Liu et al. suggested a new optimization algorithm with an essence of similar to Adam Algorithm.
It has been discussed in the paper that, without warmup heuristic, in the early stage of adaptive optimization / learning algorithms sometimes we can get undesirable large variance which can slow overall convergence process.
Authors proposed the idea of rectification of variance of adaptive learning rate when it is expected to be high.
Differing from the paper, we selected variance tractability cut-off as 5 instead of 4. This adjustment is common practice, and could be found in the code-repository and also tensorflow swift optim library as well :
2f03dd1970/radam/radam.py (L156)f51ee4618d/Sources/TensorFlow/Optimizers/MomentumBased.swift (L638)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58968
Reviewed By: gchanan
Differential Revision: D29241736
Pulled By: iramazanli
fbshipit-source-id: 288b9b1f3125fdc6c7a7bb23fde1ea5c201c0448
Summary:
In the optimizer documentation, many of the learning rate schedulers [examples](https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate) are provided according to a generic template. In this PR we provide a precise simple use case example to show how to use learning rate schedulers. Moreover, in a followup example we show an example how to chain two schedulers next to each other.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56705
Reviewed By: ezyang
Differential Revision: D27966704
Pulled By: iramazanli
fbshipit-source-id: f32b2d70d5cad7132335a9b13a2afa3ac3315a13
Summary:
Related to https://github.com/pytorch/pytorch/issues/52256
Use autosummary instead of autofunction to create subpages for optim and cuda functions/classes.
Also fix some minor formatting issues in optim.LBFGS and cuda.stream docstings
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55673
Reviewed By: jbschlosser
Differential Revision: D27747741
Pulled By: zou3519
fbshipit-source-id: 070681f840cdf4433a44af75be3483f16e5acf7d
Summary:
Context: https://github.com/pytorch/pytorch/pull/53299#discussion_r587882857
These are the only hand-written parts of this diff:
- the addition to `.github/workflows/lint.yml`
- the file endings changed in these four files (to appease FB-internal land-blocking lints):
- `GLOSSARY.md`
- `aten/src/ATen/core/op_registration/README.md`
- `scripts/README.md`
- `torch/csrc/jit/codegen/fuser/README.md`
The rest was generated by running this command (on macOS):
```
git grep -I -l ' $' -- . ':(exclude)**/contrib/**' ':(exclude)third_party' | xargs gsed -i 's/ *$//'
```
I looked over the auto-generated changes and didn't see anything that looked problematic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53406
Test Plan:
This run (after adding the lint but before removing existing trailing spaces) failed:
- https://github.com/pytorch/pytorch/runs/2043032377
This run (on the tip of this PR) succeeded:
- https://github.com/pytorch/pytorch/runs/2043296348
Reviewed By: walterddr, seemethere
Differential Revision: D26856620
Pulled By: samestep
fbshipit-source-id: 3f0de7f7c2e4b0f1c089eac9b5085a58dd7e0d97
Summary:
The `i` variable in `Line 272` may cause ambiguity in understanding. I think it should be named as `epoch` variable.
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45944
Reviewed By: agolynski
Differential Revision: D24219486
Pulled By: vincentqb
fbshipit-source-id: 2af0408594613e82a1a1b63971650cabde2b576e
Summary:
This PR adds a description of `torch.optim.swa_utils` added in https://github.com/pytorch/pytorch/pull/35032 to the docs at `docs/source/optim.rst`. Please let me know what you think!
vincentqb andrewgordonwilson
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41228
Reviewed By: ngimel
Differential Revision: D22609451
Pulled By: vincentqb
fbshipit-source-id: 8dd98102c865ae4a074a601b047072de8cc5a5e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27254
`MultiplicativeLR` consumes a function providing the multiplicative factor at each epoch. It mimics `LambdaLR` in its syntax.
Test Plan: Imported from OSS
Differential Revision: D17728088
Pulled By: vincentqb
fbshipit-source-id: 1c4a8e19a4f24c87b5efccda01630c8a970dc5c9
Summary:
# What is this?
This is an implementation of the AdamW optimizer as implemented in [the fastai library](803894051b/fastai/callback.py) and as initially introduced in the paper [Decoupled Weight Decay Regularization](https://arxiv.org/abs/1711.05101). It decouples the weight decay regularization step from the optimization step during training.
There have already been several abortive attempts to push this into pytorch in some form or fashion: https://github.com/pytorch/pytorch/pull/17468, https://github.com/pytorch/pytorch/pull/10866, https://github.com/pytorch/pytorch/pull/3740, https://github.com/pytorch/pytorch/pull/4429. Hopefully this one goes through.
# Why is this important?
Via a simple reparameterization, it can be shown that L2 regularization has a weight decay effect in the case of SGD optimization. Because of this, L2 regularization became synonymous with the concept of weight decay. However, it can be shown that the equivalence of L2 regularization and weight decay breaks down for more complex adaptive optimization schemes. It was shown in the paper [Decoupled Weight Decay Regularization](https://arxiv.org/abs/1711.05101) that this is the reason why models trained with SGD achieve better generalization than those trained with Adam. Weight decay is a very effective regularizer. L2 regularization, in and of itself, is much less effective. By explicitly decaying the weights, we can achieve state-of-the-art results while also taking advantage of the quick convergence properties that adaptive optimization schemes have.
# How was this tested?
There were test cases added to `test_optim.py` and I also ran a [little experiment](https://gist.github.com/mjacar/0c9809b96513daff84fe3d9938f08638) to validate that this implementation is equivalent to the fastai implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21250
Differential Revision: D16060339
Pulled By: vincentqb
fbshipit-source-id: ded7cc9cfd3fde81f655b9ffb3e3d6b3543a4709
Summary:
This implements a cyclical learning rate (CLR) schedule with an optional inverse cyclical momentum. More info about CLR: https://github.com/bckenstler/CLR
This is finishing what #2016 started. Resolves#1909.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18001
Differential Revision: D14451845
Pulled By: sampepose
fbshipit-source-id: 8f682e0c3dee3a73bd2b14cc93fcf5f0e836b8c9
{kind=link}
{kind=link}