Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60959
Add TorchVitals for Dataloader, this indicates that the data loader was enabled.
This is a no-op if TORCH_VITALS environment variable is not set.
Test Plan: buck test mode/dbg caffe2/test:torch -- --regex vitals
Reviewed By: VitalyFedyunin
Differential Revision: D29445146
fbshipit-source-id: d5778fff3dafb3c0463fec7a498bff4905597518
Summary:
Based from https://github.com/pytorch/pytorch/pull/50466
Adds the initial implementation of `torch.cov` similar to `numpy.cov`. For simplicity, we removed support for many parameters in `numpy.cov` that are either redundant such as `bias`, or have simple workarounds such as `y` and `rowvar`.
cc PandaBoi
closes https://github.com/pytorch/pytorch/issues/19037
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58311
Reviewed By: jbschlosser
Differential Revision: D29431651
Pulled By: heitorschueroff
fbshipit-source-id: 167dea880f534934b145ba94291a9d634c25b01b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58059
Add CUDA.used vital sign which is true only if CUDA was "used" which technically means the context was created.
Also adds the following features:
- Force vitals to be written even if vitals are disabled, to enable testing when the env variable is not set from the start of execution
- Add a read_vitals call for python to read existing vital signs.
Test Plan: buck test mode/dbg caffe2/test:torch -- --regex basic_vitals
Reviewed By: xuzhao9
Differential Revision: D28357615
fbshipit-source-id: 681bf9ef63cb1458df9f1c241d301a3ddf1e5252
Summary:
Currently foreach `addcmul` and `addcdiv` cast scalar to float so that actual math is done in FP32 when tensor dtype is Float16/BFloat16 while regular `addcmul` and `addcdiv`, not.
### Reproducible steps to see the behavioral difference
```ipython
In [1]: import torch; torch.__version__
Out[1]: '1.9.0'
In [2]: a, b, c = torch.tensor([60000.0], device='cuda', dtype=torch.half), torch.tensor([60000.0], device='cuda', dtype=torch.half), torch.tensor([-1.0], device='cuda', dtype=torch.half)
In [4]: torch.addcmul(a, b, c, value=2)
Out[4]: tensor([-inf], device='cuda:0', dtype=torch.float16)
In [5]: torch._foreach_addcmul([a], [b], [c], value=2)[0]
Out[5]: tensor([-60000.], device='cuda:0', dtype=torch.float16)
```
### How foreach casts?
Foreach addcmul and addcdiv cast scalar to `opmath_t` (almost equivalent to acc_type) here: 42c8439b6e/aten/src/ATen/native/cuda/ForeachPointwiseOp.cu (L30) and cast inputs and results here:
42c8439b6e/aten/src/ATen/native/cuda/ForeachFunctors.cuh (L133-L135)
Related to https://github.com/pytorch/pytorch/issues/58833#60227https://github.com/pytorch/pytorch/issues/60454
cc ptrblck mcarilli ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60715
Reviewed By: albanD
Differential Revision: D29385715
Pulled By: ngimel
fbshipit-source-id: 8bb2db19ab66fc99d686de056a6ee60f9f71d603
Summary:
Fixes https://github.com/pytorch/pytorch/issues/56036
Fixes https://github.com/pytorch/pytorch/issues/56130
* All the interior points are computed using second order accurate central differences method for gradient operator. However, currently we only have first order method computation for edge points. In this PR we are adding second order methods for edge points as well.
* Currently, there is no detailed description of how gradient operator computed using second order method, and how to use parameters correctly. We add detailed explanation of meaning of each parameter, and return of the gradient operator, meanwhile giving description of the second-order computation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58165
Reviewed By: mruberry
Differential Revision: D29305321
Pulled By: iramazanli
fbshipit-source-id: 0e0e418eed801c8510b8babe2ad3d064479fb4d6
Summary:
Fixes https://github.com/pytorch/pytorch/issues/27655
This PR adds a C++ and Python version of ReflectionPad3d with structured kernels. The implementation uses lambdas extensively to better share code from the backward and forward pass.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59791
Reviewed By: gchanan
Differential Revision: D29242015
Pulled By: jbschlosser
fbshipit-source-id: 18e692d3b49b74082be09f373fc95fb7891e1b56
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59014Fixes#48401
`assert_no_overlap` currently has a false-negative where it recognizes
the transpose of a contiguous tensor as fully overlapping. This happens because
the memory regions do fully overlap, but of course the strides are different so
the actual elements don't all overlap.
This goes slightly in the other direction, by requiring strides to exactly
match we get false-positives for some unusual situations, e.g.
```
torch.add(a, a, out=a.view([1, *a.shape]))
```
Or replacing strides of length-1 dimensions, etc. However, I think these are
sufficiently obscure that it's okay to error and the common cases like
inplace operations still work as before.
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D29040928
Pulled By: ngimel
fbshipit-source-id: 5a636c67536a3809c83f0d3117d2fdf49c0a45e6
Summary:
Based from https://github.com/pytorch/pytorch/pull/50466
Adds the initial implementation of `torch.cov` similar to `numpy.cov`. For simplicity, we removed support for many parameters in `numpy.cov` that are either redundant such as `bias`, or have simple workarounds such as `y` and `rowvar`.
cc PandaBoi
TODO
- [x] Improve documentation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58311
Reviewed By: mruberry
Differential Revision: D28994140
Pulled By: heitorschueroff
fbshipit-source-id: 1890166c0a9c01e0a536acd91571cd704d632f44
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59596
Parallelize batch matmul across batch dim. This was found to improve perf for
some usecases on mobile.
ghstack-source-id: 130989569
Test Plan: CI unit tests
Reviewed By: albanD
Differential Revision: D26833417
fbshipit-source-id: 9b84d89d29883a6c9d992d993844dd31a25f76b1
Summary:
Implements an idea by ngimel to improve the performance of `torch.flip` via a clever hack into TI to bypass the fact that TI is not designed to work with negative indices.
Something that might be added is vectorisation support on CPU, given how simple the implementation is now.
Some low-hanging fruits that I did not implement:
- Write it as a structured kernel
- Migrate the tests to opinfos
- Have a look at `cumsum_backward` and `cumprod_backward`, as I think that they could be implemented faster with `flip`, now that `flip` is fast.
**Edit**
This operation already has OpInfos and it cannot be migrated to a structured kernel because it implements quantisation
Summary of the PR:
- x1.5-3 performance boost on CPU
- x1.5-2 performance boost on CUDA
- Comparable performance across dimensions, regardless of the strides (thanks TI)
- Simpler code
<details>
<summary>
Test Script
</summary>
```python
from itertools import product
import torch
from torch.utils.benchmark import Compare, Timer
def get_timer(size, dims, num_threads, device):
x = torch.rand(*size, device=device)
timer = Timer(
"torch.flip(x, dims=dims)",
globals={"x": x, "dims": dims},
label=f"Flip {device}",
description=f"dims: {dims}",
sub_label=f"size: {size}",
num_threads=num_threads,
)
return timer.blocked_autorange(min_run_time=5)
def get_params():
sizes = ((1000,)*2, (1000,)*3, (10000,)*2)
for size, device in product(sizes, ("cpu", "cuda")):
threads = (1, 2, 4) if device == "cpu" else (1,)
list_dims = [(0,), (1,), (0, 1)]
if len(size) == 3:
list_dims.append((0, 2))
for num_threads, dims in product(threads, list_dims):
yield size, dims, num_threads, device
def compare():
compare = Compare([get_timer(*params) for params in get_params()])
compare.trim_significant_figures()
compare.colorize()
compare.print()
compare()
```
</details>
<details>
<summary>
Benchmark PR
</summary>
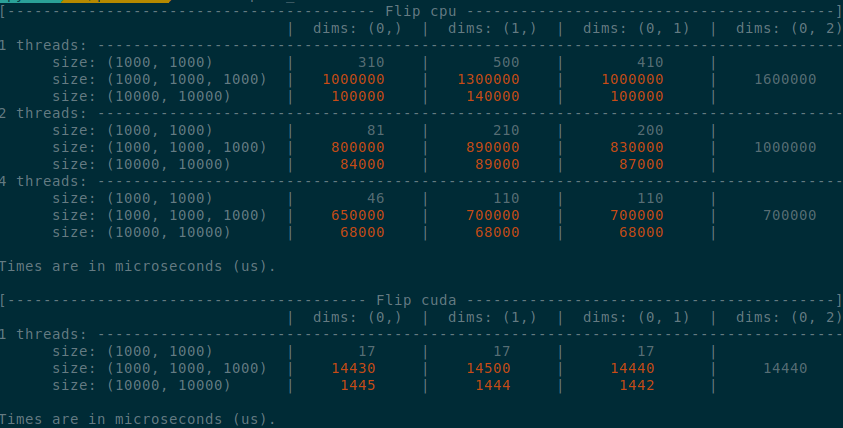
</details>
<details>
<summary>
Benchmark master
</summary>
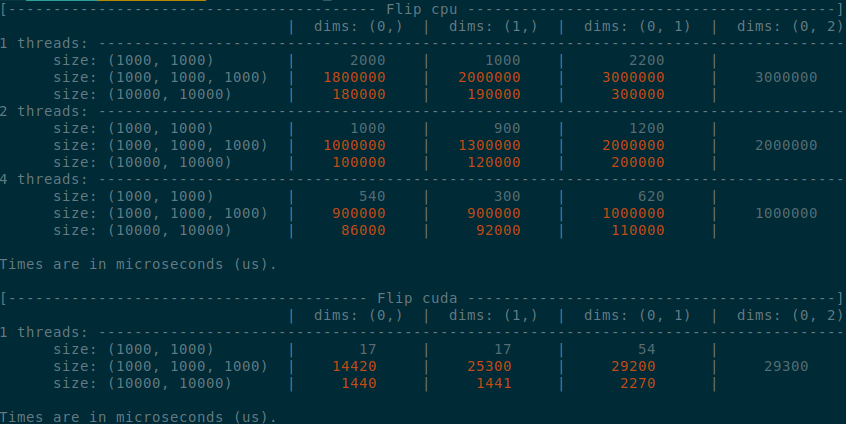
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58747
Reviewed By: agolynski
Differential Revision: D28877076
Pulled By: ngimel
fbshipit-source-id: 4fa6eb519085950176cb3a9161eeb3b6289ec575
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56017Fixes#55686
This patch is seemingly straightforward but some of the changes are very
subtle. For the general algorithmic approach, please first read the
quoted issue. Based on the algorithm, there are some fairly
straightforward changes:
- New boolean on TensorImpl tracking if we own the pyobj or not
- PythonHooks virtual interface for requesting deallocation of pyobj
when TensorImpl is being released and we own its pyobj, and
implementation of the hooks in python_tensor.cpp
- Modification of THPVariable to MaybeOwned its C++ tensor, directly
using swolchok's nice new class
And then, there is python_variable.cpp. Some of the changes follow the
general algorithmic approach:
- THPVariable_NewWithVar is simply adjusted to handle MaybeOwned and
initializes as owend (like before)
- THPVariable_Wrap adds the logic for reverting ownership back to
PyObject when we take out an owning reference to the Python object
- THPVariable_dealloc attempts to resurrect the Python object if
the C++ tensor is live, and otherwise does the same old implementation
as before
- THPVariable_tryResurrect implements the resurrection logic. It is
modeled after CPython code so read the cited logic and see if
it is faithfully replicated
- THPVariable_clear is slightly updated for MaybeOwned and also to
preserve the invariant that if owns_pyobj, then pyobj_ is not null.
This change is slightly dodgy: the previous implementation has a
comment mentioning that the pyobj nulling is required to ensure we
don't try to reuse the dead pyobj. I don't think, in this new world,
this is possible, because the invariant says that the pyobj only
dies if the C++ object is dead too. But I still unset the field
for safety.
And then... there is THPVariableMetaType. colesbury explained in the
issue why this is necessary: when destructing an object in Python, you
start off by running the tp_dealloc of the subclass before moving up
to the parent class (much in the same way C++ destructors work). The
deallocation process for a vanilla Python-defined class does irreparable
harm to the PyObject instance (e.g., the finalizers get run) making it
no longer valid attempt to resurrect later in the tp_dealloc chain.
(BTW, the fact that objects can resurrect but in an invalid state is
one of the reasons why it's so frickin' hard to write correct __del__
implementations). So we need to make sure that we actually override
the tp_dealloc of the bottom most *subclass* of Tensor to make sure
we attempt a resurrection before we start finalizing. To do this,
we need to define a metaclass for Tensor that can override tp_dealloc
whenever we create a new subclass of Tensor. By the way, it was totally
not documented how to create metaclasses in the C++ API, and it took
a good bit of trial error to figure it out (and the answer is now
immortalized in https://stackoverflow.com/q/67077317/23845 -- the things
that I got wrong in earlier versions of the PR included setting
tp_basicsize incorrectly, incorrectly setting Py_TPFLAGS_HAVE_GC on
the metaclass--you want to leave it unset so that it inherits, and
determining that tp_init is what actually gets called when you construct
a class, not tp_call as another not-to-be-named StackOverflow question
suggests).
Aside: Ordinarily, adding a metaclass to a class is a user visible
change, as it means that it is no longer valid to mixin another class
with a different metaclass. However, because _C._TensorBase is a C
extension object, it will typically conflict with most other
metaclasses, so this is not BC breaking.
The desired new behavior of a subclass tp_dealloc is to first test if
we should resurrect, and otherwise do the same old behavior. In an
initial implementation of this patch, I implemented this by saving the
original tp_dealloc (which references subtype_dealloc, the "standard"
dealloc for all Python defined classes) and invoking it. However, this
results in an infinite loop, as it attempts to call the dealloc function
of the base type, but incorrectly chooses subclass type (because it is
not a subtype_dealloc, as we have overridden it; see
b38601d496/Objects/typeobject.c (L1261) )
So, with great reluctance, I must duplicate the behavior of
subtype_dealloc in our implementation. Note that this is not entirely
unheard of in Python binding code; for example, Cython
c25c3ccc4b/Cython/Compiler/ModuleNode.py (L1560)
also does similar things. This logic makes up the bulk of
THPVariable_subclass_dealloc
To review this, you should pull up the CPython copy of subtype_dealloc
b38601d496/Objects/typeobject.c (L1230)
and verify that I have specialized the implementation for our case
appropriately. Among the simplifications I made:
- I assume PyType_IS_GC, because I assume that Tensor subclasses are
only ever done in Python and those classes are always subject to GC.
(BTW, yes! This means I have broken anyone who has extend PyTorch
tensor from C API directly. I'm going to guess no one has actually
done this.)
- I don't bother walking up the type bases to find the parent dealloc;
I know it is always THPVariable_dealloc. Similarly, I can get rid
of some parent type tests based on knowledge of how
THPVariable_dealloc is defined
- The CPython version calls some private APIs which I can't call, so
I use the public PyObject_GC_UnTrack APIs.
- I don't allow the finalizer of a Tensor to change its type (but
more on this shortly)
One alternative I discussed with colesbury was instead of copy pasting
the subtype_dealloc, we could transmute the type of the object that was
dying to turn it into a different object whose tp_dealloc is
subtype_dealloc, so the stock subtype_dealloc would then be applicable.
We decided this would be kind of weird and didn't do it that way.
TODO:
- More code comments
- Figure out how not to increase the size of TensorImpl with the new
bool field
- Add some torture tests for the THPVariable_subclass_dealloc, e.g.,
involving subclasses of Tensors that do strange things with finalizers
- Benchmark the impact of taking the GIL to release C++ side tensors
(e.g., from autograd)
- Benchmark the impact of adding a new metaclass to Tensor (probably
will be done by separating out the metaclass change into its own
change)
- Benchmark the impact of changing THPVariable to conditionally own
Tensor (as opposed to unconditionally owning it, as before)
- Add tests that this actually indeed preserves the Python object
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D27765125
Pulled By: ezyang
fbshipit-source-id: 857f14bdcca2900727412aff4c2e2d7f0af1415a
Summary:
1) remove pushing back to strides vector for 1D tensors, those strides are never used in the loop anyway
2) avoid calling get_data_ptrs unless necessary
3) don't call into assert_no_partial_overlap if tensorImpls are the same (assert_no_partial_overlap has this comparison too, but after a couple of nested function calls)
4) is_non_overlapping_and_dense instead of is_contiguous in memory overlap (which, for some reason, is faster than is_contiguous, though I hoped after is_contiguous is non-virtualized, it should be the same).
Altogether, brings instruction count down from ~110K to 102735 for the following binary inplace benchmark:
```
In [2]: timer = Timer("m1.add_(b);", setup="at::Tensor m1=torch::empty({1}); at::Tensor b = torch::empty({1});", language="c++", timer=timeit.default_timer)
...: stats=timer.collect_callgrind(number=30, repeats=3)
...: print(stats[1].as_standardized().stats(inclusive=False))
```
similar improvements for unary inplace.
Upd: returned stride packing for now, counts is now 104295, so packing is worth ~ 52 instructions, we should think about how to remove it safely.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58810
Reviewed By: bhosmer
Differential Revision: D28664514
Pulled By: ngimel
fbshipit-source-id: 2e03cf90b37a411d9994a7607402645f1d8f3c93
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58881
recently added new parameter to the function with PR: https://github.com/pytorch/pytorch/pull/58417
However, this introduced ambiguity when making call below:
some_tensor.repeat_interleave(some_integer_value)
Making it optional to avoid the issue.
Reviewed By: ezyang, ngimel
Differential Revision: D28653820
fbshipit-source-id: 5bc0b1f326f069ff505554b51e3b24d60e69c843
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58417
Same as title.
Test Plan:
Rely on CI signal.
Update unit test to exercise new code path as well.
Reviewed By: ngimel
Differential Revision: D28482927
fbshipit-source-id: 3ec8682810ed5c8547b1e8d3869924480ce63dcd
Summary:
This adds the methods `Tensor.cfloat()` and `Tensor.cdouble()`.
I was not able to find the tests for `.float()` functions. I'd be happy to add similar tests for these functions once someone points me to them.
Fixes https://github.com/pytorch/pytorch/issues/56014
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58137
Reviewed By: ejguan
Differential Revision: D28412288
Pulled By: anjali411
fbshipit-source-id: ff3653cb3516bcb3d26a97b9ec3d314f1f42f83d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58144
reland D28291041 (14badd9929), which was reverted due to a type error from Tuple[torch.Tensor], seems that mypy requires Tuple[torch.Tensor, torch.Tensor, torch.Tensor]
Test Plan:
buck test mode/opt //caffe2/test:torch_cuda -- test_index_copy_deterministic
✓ ListingSuccess: caffe2/test:torch_cuda - main (9.229)
✓ Pass: caffe2/test:torch_cuda - test_index_copy_deterministic_cuda (test_torch.TestTorchDeviceTypeCUDA) (25.750)
✓ Pass: caffe2/test:torch_cuda - main (25.750)
Reviewed By: ngimel
Differential Revision: D28383178
fbshipit-source-id: 38896fd6ddd670cfcce36e079aee7ad52adc2a28
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57544
Instead of removing tp_new from the superclass (which causes
super().__new__ to not work), I now still install tp_new on the
superclass, but verify that you are not trying to directly
construct _TensorBase.
Fixes https://github.com/pytorch/pytorch/issues/57421
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D28189475
Pulled By: ezyang
fbshipit-source-id: 9397a3842a77f5428d182dd62244b42425bca827
Summary:
This PR also removes qr and eig tests from test/test_torch.py. They were not skipped if compiled without LAPACK and they are now replaced with OpInfos.
Fixes https://github.com/pytorch/pytorch/issues/55929
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56284
Reviewed By: ejguan
Differential Revision: D27827077
Pulled By: mruberry
fbshipit-source-id: 1dceb955810a9fa34bb6baaccbaf0c8229444d3a
Summary:
Fixes https://github.com/pytorch/pytorch/issues/55090
I included the header directly, but I am not sure if we should add this as a git submodule, what do you guys think?
Also regarding the implementation, in ATen lanes seems not to be supported, but from CuPy complex types are exported with 2 lanes, I am not sure wether this is correct or not. However, in PyTorch this seems to be working properly, so I forgive 2 lanes for complex datatypes.
TODO: add tests for complex and bfloat
Easy test script against cupy
```python
import cupy
import torch
from torch.utils.dlpack import to_dlpack
from torch.utils.dlpack import from_dlpack
# Create a PyTorch tensor.
tx1 = torch.tensor(
[2 + 1j, 3 + 2j, 4 + 3j, 5 + 4j], dtype=torch.complex128
).cuda()
# Convert it into a DLPack tensor.
dx = to_dlpack(tx1)
# Convert it into a CuPy array.
cx = cupy.fromDlpack(dx)
# Convert it back to a PyTorch tensor.
tx2 = from_dlpack(cx.toDlpack())
torch.testing.assert_allclose(tx1, tx2)
```
Thanks to leofang who updated CuPy's dlpack version and his PR served me as the guide for this one.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55365
Reviewed By: ngimel
Differential Revision: D27724923
Pulled By: mruberry
fbshipit-source-id: 481eadb882ff3dd31e7664e08e8908c60a960f66
{kind=link}
{kind=link}