Summary:
This is a minimalist PR to add MKL-DNN tensor per discussion from Github issue: https://github.com/pytorch/pytorch/issues/16038
Ops with MKL-DNN tensor will be supported in following-up PRs to speed up imperative path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17748
Reviewed By: dzhulgakov
Differential Revision: D14614640
Pulled By: bddppq
fbshipit-source-id: c58de98e244b0c63ae11e10d752a8e8ed920c533
Summary:
Per our offline discussion, allow Tensors, ints, and floats to be casted to be bool when used in a conditional
Fix for https://github.com/pytorch/pytorch/issues/18381
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18755
Reviewed By: driazati
Differential Revision: D14752476
Pulled By: eellison
fbshipit-source-id: 149960c92afcf7e4cc4997bccc57f4e911118ff1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18230
Implementing minimum qtensor API to unblock other workstreams in quantization
Changes:
- Added Quantizer which represents different quantization schemes
- Added qint8 as a data type for QTensor
- Added a new ScalarType QInt8
- Added QTensorImpl for QTensor
- Added following user facing APIs
- quantize_linear(scale, zero_point)
- dequantize()
- q_scale()
- q_zero_point()
Reviewed By: dzhulgakov
Differential Revision: D14524641
fbshipit-source-id: c1c0ae0978fb500d47cdb23fb15b747773429e6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18628
ghimport-source-id: d94b81a6f303883d97beaae25344fd591e13ce52
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18629 Provide flake8 install instructions.
* **#18628 Delete duplicated technical content from contribution_guide.rst**
There's useful guide in contributing_guide.rst, but the
technical bits were straight up copy-pasted from CONTRIBUTING.md,
and I don't think it makes sense to break the CONTRIBUTING.md
link. Instead, I deleted the duplicate bits and added a cross
reference to the rst document.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14701003
fbshipit-source-id: 3bbb102fae225cbda27628a59138bba769bfa288
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18598
ghimport-source-id: c74597e5e7437e94a43c163cee0639b20d0d0c6a
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18598 Turn on F401: Unused import warning.**
This was requested by someone at Facebook; this lint is turned
on for Facebook by default. "Sure, why not."
I had to noqa a number of imports in __init__. Hypothetically
we're supposed to use __all__ in this case, but I was too lazy
to fix it. Left for future work.
Be careful! flake8-2 and flake8-3 behave differently with
respect to import resolution for # type: comments. flake8-3 will
report an import unused; flake8-2 will not. For now, I just
noqa'd all these sites.
All the changes were done by hand.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14687478
fbshipit-source-id: 30d532381e914091aadfa0d2a5a89404819663e3
Summary:
Changelog:
- Renames `btriunpack` to `lu_unpack` to remain consistent with the `lu` function interface.
- Rename all relevant tests, fix callsites
- Create a tentative alias for `lu_unpack` under the name `btriunpack` and add a deprecation warning to not promote usage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18529
Differential Revision: D14683161
Pulled By: soumith
fbshipit-source-id: 994287eaa15c50fd74c2f1c7646edfc61e8099b1
Summary:
Changelog:
- Renames `btrifact` and `btrifact_with_info` to `lu`to remain consistent with other factorization methods (`qr` and `svd`).
- Now, we will only have one function and methods named `lu`, which performs `lu` decomposition. This function takes a get_infos kwarg, which when set to True includes a infos tensor in the tuple.
- Rename all tests, fix callsites
- Create a tentative alias for `lu` under the name `btrifact` and `btrifact_with_info`, and add a deprecation warning to not promote usage.
- Add the single batch version for `lu` so that users don't have to unsqueeze and squeeze for a single square matrix (see changes in determinant computation in `LinearAlgebra.cpp`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18435
Differential Revision: D14680352
Pulled By: soumith
fbshipit-source-id: af58dfc11fa53d9e8e0318c720beaf5502978cd8
Summary:
This implements a cyclical learning rate (CLR) schedule with an optional inverse cyclical momentum. More info about CLR: https://github.com/bckenstler/CLR
This is finishing what #2016 started. Resolves#1909.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18001
Differential Revision: D14451845
Pulled By: sampepose
fbshipit-source-id: 8f682e0c3dee3a73bd2b14cc93fcf5f0e836b8c9
Summary:
There are a number of pages in the docs that serve insecure content. AFAICT this is the sole source of that.
I wasn't sure if docs get regenerated for old versions as part of the automation, or if those would need to be manually done.
cf. https://github.com/pytorch/pytorch.github.io/pull/177
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18508
Differential Revision: D14645665
Pulled By: zpao
fbshipit-source-id: 003563b06048485d4f539feb1675fc80bab47c1b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18507
ghimport-source-id: 1c3642befad2da78a7e5f39d6d58732b85c76267
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18507 Upgrade flake8-bugbear to master, fix the new lints.**
It turns out Facebobok is internally using the unreleased master
flake8-bugbear, so upgrading it grabs a few more lints that Phabricator
was complaining about but we didn't get in open source.
A few of the getattr sites that I fixed look very suspicious (they're
written as if Python were a lazy language), but I didn't look more
closely into the matter.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14633682
fbshipit-source-id: fc3f97c87dca40bbda943a1d1061953490dbacf8
Summary:
This depend on https://github.com/pytorch/pytorch/pull/16039
This prevent people (reviewer, PR author) from forgetting adding things to `tensors.rst`.
When something new is added to `_tensor_doc.py` or `tensor.py` but intentionally not in `tensors.rst`, people should manually whitelist it in `test_docs_coverage.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16057
Differential Revision: D14619550
Pulled By: ezyang
fbshipit-source-id: e1c6dd6761142e2e48ec499e118df399e3949fcc
Summary:
This PR adds a Global Site Tag to the site.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17690
Differential Revision: D14620816
Pulled By: zou3519
fbshipit-source-id: c02407881ce08340289123f5508f92381744e8e3
Summary:
`SobolEngine` is a quasi-random sampler used to sample points evenly between [0,1]. Here we use direction numbers to generate these samples. The maximum supported dimension for the sampler is 1111.
Documentation has been added, tests have been added based on Balandat 's references. The implementation is an optimized / tensor-ized implementation of Balandat 's implementation in Cython as provided in #9332.
This closes#9332 .
cc: soumith Balandat
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10505
Reviewed By: zou3519
Differential Revision: D9330179
Pulled By: ezyang
fbshipit-source-id: 01d5588e765b33b06febe99348f14d1e7fe8e55d
Summary:
This is to fix#16141 and similar issues.
The idea is to track a reference to every shared CUDA Storage and deallocate memory only after a consumer process deallocates received Storage.
ezyang Done with cleanup. Same (insignificantly better) performance as in file-per-share solution, but handles millions of shared tensors easily. Note [ ] documentation in progress.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16854
Differential Revision: D13994490
Pulled By: VitalyFedyunin
fbshipit-source-id: 565148ec3ac4fafb32d37fde0486b325bed6fbd1
Summary:
* Adds more headers for easier scanning
* Adds some line breaks so things are displayed correctly
* Minor copy/spelling stuff
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18234
Reviewed By: ezyang
Differential Revision: D14567737
Pulled By: driazati
fbshipit-source-id: 046d991f7aab8e00e9887edb745968cb79a29441
Summary:
Changelog:
- Renames `trtrs` to `triangular_solve` to remain consistent with `cholesky_solve` and `solve`.
- Rename all tests, fix callsites
- Create a tentative alias for `triangular_solve` under the name `trtrs`, and add a deprecation warning to not promote usage.
- Move `isnan` to _torch_docs.py
- Remove unnecessary imports
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18213
Differential Revision: D14566902
Pulled By: ezyang
fbshipit-source-id: 544f57c29477df391bacd5de700bed1add456d3f
Summary:
Fixes Typo and a Link in the `docs/source/community/contribution_guide.rst`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18237
Differential Revision: D14566907
Pulled By: ezyang
fbshipit-source-id: 3a75797ab6b27d28dd5566d9b189d80395024eaf
Summary:
Changelog:
- Renames `gesv` to `solve` to remain consistent with `cholesky_solve`.
- Rename all tests, fix callsites
- Create a tentative alias for `solve` under the name `gesv`, and add a deprecated warning to not promote usage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18060
Differential Revision: D14503117
Pulled By: zou3519
fbshipit-source-id: 99c16d94e5970a19d7584b5915f051c030d49ff5
Summary:
Fix a very common typo in my name.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17949
Differential Revision: D14475162
Pulled By: ezyang
fbshipit-source-id: 91c2c364c56ecbbda0bd530e806a821107881480
Summary: Adding new documents to the PyTorch website to describe how PyTorch is governed, how to contribute to the project, and lists persons of interest.
Reviewed By: orionr
Differential Revision: D14394573
fbshipit-source-id: ad98b807850c51de0b741e3acbbc3c699e97b27f
Summary:
as title
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17476
Differential Revision: D14218312
Pulled By: suo
fbshipit-source-id: 64df096a3431a6f25cd2373f0959d415591fed15
Summary:
Based on https://github.com/pytorch/pytorch/pull/12413, with the following additional changes:
- Inside `native_functions.yml` move those outplace operators right next to everyone's corresponding inplace operators for convenience of checking if they match when reviewing
- `matches_jit_signature: True` for them
- Add missing `scatter` with Scalar source
- Add missing `masked_fill` and `index_fill` with Tensor source.
- Add missing test for `scatter` with Scalar source
- Add missing test for `masked_fill` and `index_fill` with Tensor source by checking the gradient w.r.t source
- Add missing docs to `tensor.rst`
Differential Revision: D14069925
Pulled By: ezyang
fbshipit-source-id: bb3f0cb51cf6b756788dc4955667fead6e8796e5
Summary:
one_hot docs is missing [here](https://pytorch.org/docs/master/nn.html#one-hot).
I dug around and could not find a way to get this working properly.
Differential Revision: D14104414
Pulled By: zou3519
fbshipit-source-id: 3f45c8a0878409d218da167f13b253772f5cc963
Summary:
This prevent people (reviewer, PR author) from forgetting adding things to `torch.rst`.
When something new is added to `_torch_doc.py` or `functional.py` but intentionally not in `torch.rst`, people should manually whitelist it in `test_docs_coverage.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16039
Differential Revision: D14070903
Pulled By: ezyang
fbshipit-source-id: 60f2a42eb5efe81be073ed64e54525d143eb643e
Summary:
This PR is a simple fix for the mistake in the first note for `torch.device` in the "tensor attributes" doc.

```
>>> # You can substitute the torch.device with a string
>>> torch.randn((2,3), 'cuda:1')
```
Above code will cause error like below:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-53-abdfafb67ab1> in <module>()
----> 1 torch.randn((2,3), 'cuda:1')
TypeError: randn() received an invalid combination of arguments - got (tuple, str), but expected one of:
* (tuple of ints size, torch.Generator generator, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
* (tuple of ints size, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
```
Simply adding the argument name `device` solves the problem: `torch.randn((2,3), device='cuda:1')`.
However, another concern is that this note seems redundant as **there is already another note covering this usage**:
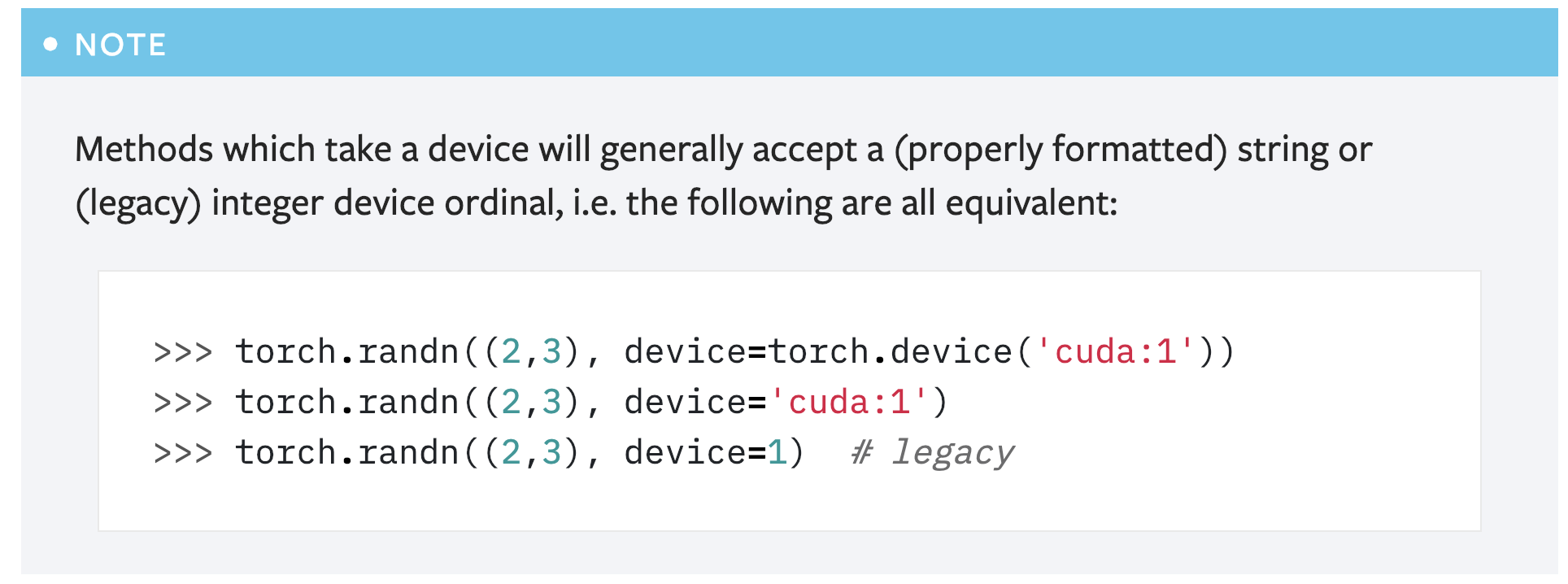
So maybe it's better to just remove this note?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16839
Reviewed By: ezyang
Differential Revision: D13989209
Pulled By: gchanan
fbshipit-source-id: ac255d52528da053ebfed18125ee6b857865ccaf
Summary:
Some batched updates:
1. bool is a type now
2. Early returns are allowed now
3. The beginning of an FAQ section with some guidance on the best way to do GPU training + CPU inference
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16866
Differential Revision: D13996729
Pulled By: suo
fbshipit-source-id: 3b884fd3a4c9632c9697d8f1a5a0e768fc918916
Summary:
Now that `cuda.get/set_rng_state` accept `device` objects, the default value should be an device object, and doc should mention so.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14324
Reviewed By: ezyang
Differential Revision: D13528707
Pulled By: soumith
fbshipit-source-id: 32fdac467dfea6d5b96b7e2a42dc8cfd42ba11ee
Summary:
Changelog:
- Renames `potrs` to `cholesky_solve` to remain consistent with Tensorflow and Scipy (not really, they call their function chol_solve)
- Default argument for upper in cholesky_solve is False. This will allow a seamless interface between `cholesky` and `cholesky_solve`, since the `upper` argument in both function are the same.
- Rename all tests
- Create a tentative alias for `cholesky_solve` under the name `potrs`, and add deprecated warning to not promote usage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15334
Differential Revision: D13507724
Pulled By: soumith
fbshipit-source-id: b826996541e49d2e2bcd061b72a38c39450c76d0
Summary:
Some of the codeblocks were showing up as normal text and the "unsupported modules" table was formatted incorrectly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15227
Differential Revision: D13468847
Pulled By: driazati
fbshipit-source-id: eb7375710d4f6eca1d0f44dfc43c7c506300cb1e
Summary:
Documents what is supported in the script standard library.
* Adds `my_script_module._get_method('forward').schema()` method to get function schema from a `ScriptModule`
* Removes `torch.nn.functional` from the list of builtins. The only functions not supported are `nn.functional.fold` and `nn.functional.unfold`, but those currently just dispatch to their corresponding aten ops, so from a user's perspective it looks like they work.
* Allow printing of `IValue::Device` by getting its string representation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14912
Differential Revision: D13385928
Pulled By: driazati
fbshipit-source-id: e391691b2f87dba6e13be05d4aa3ed2f004e31da
Summary:
Tracing records variable names and we have new types and stuff in the IR, so this updates the graph printouts in the docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14914
Differential Revision: D13385101
Pulled By: jamesr66a
fbshipit-source-id: 6477e4861f1ac916329853763c83ea157be77f23
Summary:
Added a few examples and explains to how publish/load models.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14862
Differential Revision: D13384790
Pulled By: ailzhang
fbshipit-source-id: 008166e84e59dcb62c0be38a87982579524fb20e
Summary:
pytorch_theme.css is no longer necessary for the cpp or html docs site build. The new theme styles are located at https://github.com/pytorch/pytorch_sphinx_theme. The Lato font is also no longer used in the new theme.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14779
Differential Revision: D13356125
Pulled By: ezyang
fbshipit-source-id: c7635eb7512c7dcaddb9cad596ab3dbc96480144
Summary:
When I wrote the frontend API, it is designed on not letting users use the default_group directly on any functions. It should really be private.
All collectives are supposed to either use group.WORLD, or anything that comes out of new_group. That was the initial design.
We need to make a TODO on removing group.WORLD one day. It exists for backward compatibility reasons and adds lots of complexity.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14767
Reviewed By: pietern
Differential Revision: D13330655
Pulled By: teng-li
fbshipit-source-id: ace107e1c3a9b3910a300b22815a9e8096fafb1c
Summary:
* s/environmental/environment/g
* Casing (CUDA, InfiniBand, Ethernet)
* Don't embed torch.multiprocessing.spawn but link to it (not part of the package)
* spawn _function_ instead of _utility_ (it's mentioned after the launch utility which is a proper utility)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14605
Differential Revision: D13273480
Pulled By: pietern
fbshipit-source-id: da6b4b788134645f2dcfdd666d1bbfc9aabd97b1
Summary:
Removed an incorrect section. We don't support this. I wrote this from my memory :(
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14530
Differential Revision: D13253471
Pulled By: teng-li
fbshipit-source-id: c3f1ffc6c98ef8789157e885776e0b775ec47b15
Summary:
Add to the Tensor doc info about `.device`, `.is_cuda`, `.requires_grad`, `.is_leaf` and `.grad`.
Update the `register_backward_hook` doc with a warning stating that it does not work in all cases.
Add support in the `_add_docstr` function to add docstring to attributes.
There is an explicit cast here but I am not sure how to handle it properly. The thing is that the doc field for getsetdescr is written as being a const char * (as all other doc fields in descriptors objects) in cpython online documentation. But in the code, it is the only one that is not const.
I assumed here that it is a bug in the code because it does not follow the doc and the convention of the others descriptors and so I cast out the const.
EDIT: the online doc I was looking at is for 3.7 and in that version both the code and the doc are const. For older versions, both are non const.
Please let me know if this should not be done. And if it should be done if there is a cleaner way to do it !
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14339
Differential Revision: D13243266
Pulled By: ezyang
fbshipit-source-id: 75b7838f7cd6c8dc72b0c61950e7a971baefaeeb
Summary:
- to fix#12241
- add `_sparse_sum()` to ATen, and expose as `torch.sparse.sum()`, not support `SparseTensor.sum()` currently
- this PR depends on #11253, and will need to be updated upon it lands
- [x] implement forward
- [x] implement backward
- performance [benchmark script](https://gist.github.com/weiyangfb/f4c55c88b6092ef8f7e348f6b9ad8946#file-sparse_sum_benchmark-py):
- sum all dims is fastest for sparse tensor
- when input is sparse enough nnz = 0.1%, sum of sparse tensor is faster than dense in CPU, but not necessary in CUDA
- CUDA backward is comparable (<2x) between `sum several dims` vs `sum all dims` in sparse
- CPU backward uses binary search is still slow in sparse, takes `5x` time in `sum [0, 2, 3] dims` vs `sum all dims`
- optimize CUDA backward for now
- using thrust for sort and binary search, but runtime not improved
- both of CPU and CUDA forward are slow in sparse (`sum several dims` vs `sum all dims`), at most `20x` slower in CPU, and `10x` in CUDA
- improve CPU and CUDA forward kernels
(nnz, sizes, sum_dims, keepdim, sum all or dims, bk=backward) | CPU (sparse vs dense) | CUDA(sparse vs dense)
-- | -- | --
(1000, [1000, 1000, 2, 2], [0, 1], False, sumAll) | 8.77 µs vs 72.9 µs | 42.5 µs vs 108 µs
(1000, [1000, 1000, 2, 2], [0, 1], False, sumD) | 112 µs vs 4.47 ms | 484 µs vs 407 µs
(1000, [1000, 1000, 2, 2], [0, 1], False, sumAll, bk) | 141 µs vs 148 µs | 647 µs vs 231 µs
(1000, [1000, 1000, 2, 2], [0, 1], False, sumD, bk) | 235 µs vs 1.23 ms | 781 µs vs 213 µs
(1000, [1000, 1000, 2, 2], [2, 3], False, sumD) | 48.5 µs vs 360 µs | 160 µs vs 2.03 ms
(1000, [1000, 1000, 2, 2], [2, 3], False, sumD, bk) | 258 µs vs 1.22 ms | 798 µs vs 224 µs
(1000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD) | 204 µs vs 882 µs | 443 µs vs 133 µs
(1000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD, bk) | 709 µs vs 1.15 ms | 893 µs vs 202 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumAll) | 39.8 µs vs 81 µs | 42.4 µs vs 113 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumD) | 747 µs vs 4.7 ms | 2.4 ms vs 414 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumAll, bk) | 1.04 ms vs 126 µs | 5.03 ms vs 231 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumD, bk) | 1.12 ms vs 1.24 ms | 5.99 ms vs 213 µs
(10000, [1000, 1000, 2, 2], [2, 3], False, sumD) | 133 µs vs 366 µs | 463 µs vs 2.03 ms
(10000, [1000, 1000, 2, 2], [2, 3], False, sumD, bk) | 1.56 ms vs 1.22 ms | 6.11 ms vs 229 µs
(10000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD) | 1.53 ms vs 799 µs | 824 µs vs 134 µs
(10000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD, bk) | 5.15 ms vs 1.09 ms | 7.02 ms vs 205 µs
- after improving CPU and CUDA forward kernels
- in `(1000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD)` forward, CPU takes ~~`171 µs`~~, in which `130 µs` is spent on `coalesce()`, for CUDA, total time is ~~`331 µs`~~, in which `141 µs` is spent on `coalesce()`, we need to reduce time at other places outside `coalesce()`.
- after a few simple tweaks, now in the forward, it is at most `10x` slower in CPU, and `7x` in CUDA. And time takes in `sum dense dims only [2, 3]` is `~2x` of `sum all dims`. Speed of `sum all sparse dims [0, 1]` is on bar with `sum all dims`
(nnz, sizes, sum_dims, keepdim, sum all or dims, bk=backward) | CPU (sparse vs dense) | CUDA(sparse vs dense)
-- | -- | --
(1000, [1000, 1000, 2, 2], [0, 1], False, sumAll) | 7 µs vs 69.5 µs | 31.5 µs vs 61.6 µs
(1000, [1000, 1000, 2, 2], [0, 1], False, sumD) | 11.3 µs vs 4.72 ms | 35.2 µs vs 285 µs
(1000, [1000, 1000, 2, 2], [0, 1], False, sumAll, bk) | 197 µs vs 124 µs | 857 µs vs 134 µs
(1000, [1000, 1000, 2, 2], [0, 1], False, sumD, bk) | 124 µs vs 833 µs | 796 µs vs 106 µs
(1000, [1000, 1000, 2, 2], [2, 3], False, sumD) | 20.5 µs vs 213 µs | 39.4 µs vs 1.24 ms
(1000, [1000, 1000, 2, 2], [2, 3], False, sumD, bk) | 131 µs vs 830 µs | 881 µs vs 132 µs
(1000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD) | 95.8 µs vs 409 µs | 246 µs vs 87.2 µs
(1000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD, bk) | 624 µs vs 820 µs | 953 µs vs 124 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumAll) | 45.3 µs vs 72.9 µs | 33.9 µs vs 57.2 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumD) | 81.4 µs vs 4.49 ms | 39.7 µs vs 280 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumAll, bk) | 984 µs vs 111 µs | 6.41 ms vs 121 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumD, bk) | 1.45 ms vs 828 µs | 6.77 ms vs 113 µs
(10000, [1000, 1000, 2, 2], [2, 3], False, sumD) | 74.9 µs vs 209 µs | 37.7 µs vs 1.23 ms
(10000, [1000, 1000, 2, 2], [2, 3], False, sumD, bk) | 1.48 ms vs 845 µs | 6.96 ms vs 132 µs
(10000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD) | 1.14 ms vs 411 µs | 252 µs vs 87.8 µs
(10000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD, bk) | 4.53 ms vs 851 µs | 7.12 ms vs 128 µs
- time takes in CUDA backward of sparse is super long with large variance (in case of nnz=10000, it normally takes 6-7ms). To improve backward of sparse ops, we will need to debug at places other than CUDA kernels. here is a benchmark of `torch.copy_()`:
```
>>> d = [1000, 1000, 2, 2]
>>> nnz = 10000
>>> I = torch.cat([torch.randint(0, d[0], size=(nnz,)),
torch.randint(0, d[1], size=(nnz,))], 0).reshape(2, nnz)
>>> V = torch.randn(nnz, d[2], d[3])
>>> size = torch.Size(d)
>>> S = torch.sparse_coo_tensor(I, V, size).coalesce().cuda()
>>> S2 = torch.sparse_coo_tensor(I, V, size).coalesce().cuda().requires_grad_()
>>> data = S2.clone()
>>> S.copy_(S2)
>>> y = S * 2
>>> torch.cuda.synchronize()
>>> %timeit y.backward(data, retain_graph=True); torch.cuda.synchronize()
7.07 ms ± 3.06 ms per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12430
Differential Revision: D12878313
Pulled By: weiyangfb
fbshipit-source-id: e16dc7681ba41fdabf4838cf05e491ca9108c6fe
Summary:
The doc covers pretty much all we have had on distributed for PT1 stable release, tracked in https://github.com/pytorch/pytorch/issues/14080
Tested by previewing the sphinx generated webpages. All look good.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14444
Differential Revision: D13227675
Pulled By: teng-li
fbshipit-source-id: 752f00df096af38dd36e4a337ea2120ffea79f86
Summary:
This issue was noticed, and fix proposed, by raulpuric.
Checkpointing is implemented by rerunning a forward-pass segment for each checkpointed segment during backward. This can result in the RNG state advancing more than it would without checkpointing, which can cause checkpoints that include dropout invocations to lose end-to-end bitwise accuracy as compared to non-checkpointed passes.
The present PR contains optional logic to juggle the RNG states such that checkpointed passes containing dropout achieve bitwise accuracy with non-checkpointed equivalents.** The user requests this behavior by supplying `preserve_rng_state=True` to `torch.utils.checkpoint` or `torch.utils.checkpoint_sequential`.
Currently, `preserve_rng_state=True` may incur a moderate performance hit because restoring MTGP states can be expensive. However, restoring Philox states is dirt cheap, so syed-ahmed's [RNG refactor](https://github.com/pytorch/pytorch/pull/13070#discussion_r235179882), once merged, will make this option more or less free.
I'm a little wary of the [def checkpoint(function, *args, preserve_rng_state=False):](https://github.com/pytorch/pytorch/pull/14253/files#diff-58da227fc9b1d56752b7dfad90428fe0R75) argument-passing method (specifically, putting a kwarg after a variable argument list). Python 3 seems happy with it.
Edit: It appears Python 2.7 is NOT happy with a [kwarg after *args](https://travis-ci.org/pytorch/pytorch/builds/457706518?utm_source=github_status&utm_medium=notification). `preserve_rng_state` also needs to be communicated in a way that doesn't break any existing usage. I'm open to suggestions (a global flag perhaps)?
**Batchnorm may still be an issue, but that's a battle for another day.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14253
Differential Revision: D13166665
Pulled By: soumith
fbshipit-source-id: 240cddab57ceaccba038b0276151342344eeecd7
Summary:
Update range documentation to show that we don't support start or increment parameters
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13730
Differential Revision: D12982016
Pulled By: eellison
fbshipit-source-id: cc1462fc1af547ae80c6d3b87999b7528bade8af
Summary:
The stylesheet at docs/source/_static/css/pytorch_theme.css is no longer necessary for the html docs build. The new html docs theme styles are located at https://github.com/pytorch/pytorch_sphinx_theme.
The Lato font is also no longer used in the new theme.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13699
Differential Revision: D12967448
Pulled By: soumith
fbshipit-source-id: 7de205162a61e3acacfd8b499660d328ff3812ec
Summary:
Also add docs for get_backend, Backend, and reduce_op
fixes#11803
cc The controller you requested could not be found. pietern apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11830
Differential Revision: D9927991
Pulled By: SsnL
fbshipit-source-id: a2ffb70826241ba84264f36f2cb173e00b19af48
Summary:
This PR performs a renaming of the function `potrf` responsible for the Cholesky
decomposition on positive definite matrices to `cholesky` as NumPy and TF do.
Billing of changes
- make potrf cname for cholesky in Declarations.cwrap
- modify the function names in ATen/core
- modify the function names in Python frontend
- issue warnings when potrf is called to notify users of the change
Reviewed By: soumith
Differential Revision: D10528361
Pulled By: zou3519
fbshipit-source-id: 19d9bcf8ffb38def698ae5acf30743884dda0d88
Summary:
[Edit: after applied colesbury 's suggestions]
* Hub module enable users to share code + pretrained weights through github repos.
Example usage:
```
hub_model = hub.load(
'ailzhang/vision:hub', # repo_owner/repo_name:branch
'wrapper1', # entrypoint
1234, # args for callable [not applicable to resnet18]
pretrained=True) # kwargs for callable
```
* Protocol on repo owner side: example https://github.com/ailzhang/vision/tree/hub
* The "published" models should be at least in a branch/tag. It can't be a random commit.
* Repo owner should have the following field defined in `hubconf.py`
* function/entrypoint with function signature `def wrapper1(pretrained=False, *args, **kwargs):`
* `pretrained` allows users to load pretrained weights from repo owner.
* `args` and `kwargs` are passed to the callable `resnet18`, repo owner should clearly specify their help message in the docstring
```
def wrapper1(pretrained=False, *args, **kwargs):
"""
pretrained (bool): a recommended kwargs for all entrypoints
args & kwargs are arguments for the function
"""
from torchvision.models.resnet import resnet18
model = resnet18(*args, **kwargs)
checkpoint = 'https://download.pytorch.org/models/resnet18-5c106cde.pth'
if pretrained:
model.load_state_dict(model_zoo.load_url(checkpoint, progress=False))
return model
```
* Hub_dir
* `hub_dir` specifies where the intermediate files/folders will be saved. By default this is `~/.torch/hub`.
* Users can change it by either setting the environment variable `TORCH_HUB_DIR` or calling `hub.set_dir(PATH_TO_HUB_DIR)`.
* By default, we don't cleanup files after loading so that users can use cache next time.
* Cache logic :
* We used the cache by default if it exists in `hub_dir`.
* Users can force a fresh reload by calling `hub.load(..., force_reload=True)`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12228
Differential Revision: D10511470
Pulled By: ailzhang
fbshipit-source-id: 12ac27f01d33653f06b2483655546492f82cce38
Summary:
Here is my stab at ```dense.to_sparse```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12171
Differential Revision: D10859078
Pulled By: weiyangfb
fbshipit-source-id: 5df72f72ba4f8f10e283402ff7731fd535682664
Summary:
include atomicAdd commentary as this is less well known
There is some discussion in #12207
Unfortunately, I cannot seem to get the ..include working in `_tensor_docs.py` and `_torch_docs.py`. I could use a hint for that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12217
Differential Revision: D10419739
Pulled By: SsnL
fbshipit-source-id: eecd04fb7486bd9c6ee64cd34859d61a0a97ec4e
Summary:
This PR gets rid of unnecessary copy of weight gradients in cudnn rnn. Also removes unnecessary check for input size when deciding whether to use persistent rnn, and adds doc string explaining when persistent rnn can be used. cc ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12600
Differential Revision: D10359981
Pulled By: soumith
fbshipit-source-id: 0fce11b527d543fabf21e6e9213fb2879853d7fb
Summary:
- This was one of the few functions left out from the list of functions in
NumPy's `linalg` module
- `multi_mm` is particularly useful for DL research, for quick analysis of
deep linear networks
- Added tests and doc string
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12380
Differential Revision: D10357136
Pulled By: SsnL
fbshipit-source-id: 52b44fa18d6409bdeb76cbbb164fe4e88224458e
Summary:
- fix https://github.com/pytorch/pytorch/issues/12120
- add `torch.argsort`, `torch.pdist`, `broadcast_tensors` to *.rst files
- add parameter dim to `torch.unique` doc
- fix table and args for `torch.norm`
- test plan: make html and check docs in browser
gchanan
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12126
Differential Revision: D10087006
Pulled By: weiyangfb
fbshipit-source-id: 25f65c43d14e02140d0da988d8742c7ade3d8cc9
Summary:
goldsborough Modify the docs to match the changes made in #4999
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12158
Differential Revision: D10103964
Pulled By: SsnL
fbshipit-source-id: 1b8692da86aca1a52e8d2e6cea76a5ad1f71e058
Summary:
Couple questions:
1) I used the log1p implementation in #8969 as a guide especially for testing. I'm not sure what the ```skipIfROCM``` annotation is for, so unsure if i need it for my test.
2) I implemented the branching logic in the narrow function itself; is this the right place to do so? I noticed that there a number of places where sparse-specific logic is handled with just an if statement in this file. Or should I implement a separate dispatch in native_functions.yml as in the log1p?
And of course, happy to make any any other updates/changes that I may have missed as well. This is my first PR to the project.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11342
Differential Revision: D9978430
Pulled By: weiyangfb
fbshipit-source-id: e73dc20302ab58925afb19e609e31f4a38c634ad
Summary:
Deleted this section by mistake in last PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11938
Reviewed By: SsnL
Differential Revision: D9993258
Pulled By: brianjo
fbshipit-source-id: 2552178cebd005a1105a22930c4d128c67247378
Summary:
A couple fixes I deem necessary to the TorchScript C++ API after writing the tutorial:
1. When I was creating the custom op API, I created `torch/op.h` as the one-stop header for creating custom ops. I now notice that there is no good header for the TorchScript C++ story altogether, i.e. when you just want to load a script module in C++ without any custom ops necessarily. The `torch/op.h` header suits that purpose just as well of course, but I think we should rename it to `torch/script.h`, which seems like a great name for this feature.
2. The current API for the CMake we provided was that we defined a bunch of variables like `TORCH_LIBRARY_DIRS` and `TORCH_INCLUDES` and then expected users to add those variables to their targets. We also had a CMake function that did that for you automatically. I now realized a much smarter way of doing this is to create an `IMPORTED` target for the libtorch library in CMake, and then add all this stuff to the link interface of that target. Then all downstream users have to do is `target_link_libraries(my_target torch)` and they get all the proper includes, libraries and compiler flags added to their target. This means we can get rid of the CMake function and all that stuff. orionr AFAIK this is a much, much better way of doing all of this, no?
3. Since we distribute libtorch with `D_GLIBCXX_USE_CXX11_ABI=0`, dependent libraries must set this flag too. I now add this to the interface compile options of this imported target.
4. Fixes to JIT docs.
These could likely be 4 different PRs but given the release I wouldn't mind landing them all asap.
zdevito dzhulgakov soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11682
Differential Revision: D9839431
Pulled By: goldsborough
fbshipit-source-id: fdc47b95f83f22d53e1995aa683e09613b4bfe65
Summary:
This adds a Note on making experiments reproducible.
It also adds Instructions for building the Documentation to `README.md`. Please ping if I missed any requirements.
I'm not sure what to do about the submodule changes. Please advise.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11329
Differential Revision: D9784939
Pulled By: ezyang
fbshipit-source-id: 5c5acbe343d1fffb15bdcb84c6d8d925c2ffcc5e
Summary:
Ping ezyang
This addresses your comment in #114. Strangely, when running the doc build (`make html`) none of my changes are actually showing, could you point out what I'm doing wrong?
Once #11329 is merged it might make sense to link to the reproducibility note everywhere.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11434
Differential Revision: D9751208
Pulled By: ezyang
fbshipit-source-id: cc672472449564ff099323c39603e8ff2b2d35c9
Summary:
I'm 80% sure that this fixes the math bug. But I can't repro locally so I don't know.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11472
Differential Revision: D9755328
Pulled By: SsnL
fbshipit-source-id: 130be664d3c6ceee3c0c166c1a86fc9ec3b79d74
Summary:
vishwakftw Your patch needed some updates because the default native function dispatches changed from `[function, method]` to `[function]`. The CI was run before that change happened so it still shows green, but the internal test caught it.
I did some changes when rebasing and updating so I didn't just force push to your branch. Let's see if this passes CI and internal test. If it does, let me know if you want me to force push to your branch or use this PR instead.
Note to reviewers: patch was already approved at #10068 .
cc yf225
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11421
Differential Revision: D9733407
Pulled By: SsnL
fbshipit-source-id: cf2ed293bb9942dcc5158934ff4def2f63252599
Summary:
In addition to documentation, this cleans up a few error message formats.
It also adds infra to find which operators are supported by the JIT automatically, which is then used in the generation of the docs.
The wording and formatting of the docs is not yet polished, but having this will allow our document writers to make faster progress.
Followup PRs will polish the docs and fix formatting issues.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11357
Differential Revision: D9721277
Pulled By: zdevito
fbshipit-source-id: 153a0d5be1efb314511bcfc0cec48643d78ea48b
Summary:
This PR cleans up the `at::Tensor` class by removing all methods that start with an underscore in favor of functions in the `at::` namespace. This greatly cleans up the `Tensor` class and makes it clearer what is the public and non-public API.
For this I changed `native_functions.yaml` and `Declarations.cwrap` to make all underscore methods `variant: function` (or add such a statement to begin with), and then fixed all code locations using the underscore methods.
ezyang colesbury gchanan
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11152
Differential Revision: D9683607
Pulled By: goldsborough
fbshipit-source-id: 97f869f788fa56639c05a439e2a33be49f10f543
Summary:
Since we don't need `torch.autograd.Variable` anymore, I removed `torch.autograd.Variable` from `onnx.rst`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10810
Differential Revision: D9500960
Pulled By: zou3519
fbshipit-source-id: 1bc820734c96a8c7cb5d804e6d51a95018db8e7f
Summary:
The CPU and CUDA variants are a direct transposition of Graves et al.'s description of the algorithm with the
modification that is is in log space.
The there also is a binding for the (much faster) CuDNN implementation.
This could eventually fix#3420
I still need to add tests (TestNN seems much more elaborate than the other testing) and fix the bugs than invariably turn up during the testing. Also, I want to add some more code comments.
I could use feedback on all sorts of things, including:
- Type handling (cuda vs. cpu for the int tensors, dtype for the int tensors)
- Input convention. I use log probs because that is what the gradients are for.
- Launch parameters for the kernels
- Errors and obmissions and anything else I'm not even aware of.
Thank you for looking!
In terms of performance it looks like it is superficially comparable to WarpCTC (and thus, but I have not systematically investigated this).
I have read CuDNN is much faster than implementations because it does *not* use log-space, but also the gathering step is much much faster (but I avoided trying tricky things, it seems to contribute to warpctc's fragility). I might think some more which existing torch function (scatter or index..) I could learn from for that step.
Average timings for the kernels from nvprof for some size:
```
CuDNN:
60.464us compute_alphas_and_betas
16.755us compute_grads_deterministic
Cuda:
121.06us ctc_loss_backward_collect_gpu_kernel (= grads)
109.88us ctc_loss_gpu_kernel (= alphas)
98.517us ctc_loss_backward_betas_gpu_kernel (= betas)
WarpCTC:
299.74us compute_betas_and_grad_kernel
66.977us compute_alpha_kernel
```
Of course, I still have the (silly) outer blocks loop rather than computing consecutive `s` in each thread which I might change, and there are a few other things where one could look for better implementations.
Finally, it might not be unreasonable to start with these implementations, as the performance of the loss has to be seen in the context of the entire training computation, so this would likely dilute the relative speedup considerably.
My performance measuring testing script:
```
import timeit
import sys
import torch
num_labels = 10
target_length = 30
input_length = 50
eps = 1e-5
BLANK = 0#num_labels
batch_size = 16
torch.manual_seed(5)
activations = torch.randn(input_length, batch_size, num_labels + 1)
log_probs = torch.log_softmax(activations, 2)
probs = torch.exp(log_probs)
targets = torch.randint(1, num_labels+1, (batch_size * target_length,), dtype=torch.long)
targets_2d = targets.view(batch_size, target_length)
target_lengths = torch.tensor(batch_size*[target_length])
input_lengths = torch.tensor(batch_size*[input_length])
activations = log_probs.detach()
def time_cuda_ctc_loss(grout, *args):
torch.cuda.synchronize()
culo, culog_alpha = torch._ctc_loss(*args)
g, = torch.autograd.grad(culo, args[0], grout)
torch.cuda.synchronize()
def time_cudnn_ctc_loss(groupt, *args):
torch.cuda.synchronize()
culo, cugra= torch._cudnn_ctc_loss(*args)
g, = torch.autograd.grad(culo, args[0], grout)
torch.cuda.synchronize()
def time_warp_ctc_loss(grout, *args):
torch.cuda.synchronize()
culo = warpctc.ctc_loss(*args, blank_label=BLANK, size_average=False, length_average=False, reduce=False)
g, = torch.autograd.grad(culo, args[0], grout)
torch.cuda.synchronize()
if sys.argv[1] == 'cuda':
lpcu = log_probs.float().cuda().detach().requires_grad_()
args = [lpcu, targets_2d.cuda(), input_lengths.cuda(), target_lengths.cuda(), BLANK]
grout = lpcu.new_ones((batch_size,))
torch.cuda.synchronize()
print(timeit.repeat("time_cuda_ctc_loss(grout, *args)", number=1000, globals=globals()))
elif sys.argv[1] == 'cudnn':
lpcu = log_probs.float().cuda().detach().requires_grad_()
args = [lpcu, targets.int(), input_lengths.int(), target_lengths.int(), BLANK, True]
grout = lpcu.new_ones((batch_size,))
torch.cuda.synchronize()
print(timeit.repeat("time_cudnn_ctc_loss(grout, *args)", number=1000, globals=globals()))
elif sys.argv[1] == 'warpctc':
import warpctc
activations = activations.cuda().detach().requires_grad_()
args = [activations, input_lengths.int(), targets.int(), target_lengths.int()]
grout = activations.new_ones((batch_size,), device='cpu')
torch.cuda.synchronize()
print(timeit.repeat("time_warp_ctc_loss(grout, *args)", number=1000, globals=globals()))
```
I'll also link to a notebook that I used for writing up the algorithm in simple form and then test the against implementations against it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9628
Differential Revision: D8952453
Pulled By: ezyang
fbshipit-source-id: 18e073f40c2d01a7c96c1cdd41f6c70a06e35860
Summary:
This implements the two-parameter Weibull distribution, with scale $\lambda$ and shape $k$ parameters as described on [Wikipedia](https://en.wikipedia.org/wiki/Weibull_distribution).
**Details**
- We implement as a transformed exponential distribution, as described [here](https://en.wikipedia.org/wiki/Weibull_distribution#Related_distributions).
- The `weibull_min` variance function in scipy does not yet support a vector of distributions, so our unit test uses a scalar distribution instead of a vector.
Example of the bug:
```
>>> sp.stats.expon(np.array([0.5, 1, 2])).var() # fine
array([1., 1., 1.])
>>> sp.stats.weibull_min(c=np.array([0.5, 1, 2])).var() # buggy
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.7/site-packages/scipy/stats/_distn_infrastructure.py", line 490, in var
return self.dist.var(*self.args, **self.kwds)
File "/usr/local/lib/python3.7/site-packages/scipy/stats/_distn_infrastructure.py", line 1242, in var
res = self.stats(*args, **kwds)
File "/usr/local/lib/python3.7/site-packages/scipy/stats/_distn_infrastructure.py", line 1038, in stats
if np.isinf(mu):
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9454
Differential Revision: D8863574
Pulled By: SsnL
fbshipit-source-id: 1ad3e175b469eee2b6af98e7b379ea170d3d9787
Summary:
This pull request implements low rank multivariate normal distribution where the covariance matrix has the from `W @ W.T + D`. Here D is a diagonal matrix, W has shape n x m where m << n. It used "matrix determinant lemma" and "Woodbury matrix identity" to save computational cost.
During the way, I also revise MultivariateNormal distribution a bit. Here are other changes:
+ `torch.trtrs` works with cuda tensor. So I tried to use it instead of `torch.inverse`.
+ Use `torch.matmul` instead of `torch.bmm` in `_batch_mv`. The former is faster and simpler.
+ Use `torch.diagonal` for `_batch_diag`
+ Reimplement `_batch_mahalanobis` based on `_batch_trtrs_lower`.
+ Use trtrs to compute term2 of KL.
+ `variance` relies on `scale_tril` instead of `covariance_matrix`
TODO:
- [x] Resolve the fail at `_gradcheck_log_prob`
- [x] Add test for KL
cc fritzo stepelu apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/8635
Differential Revision: D8951893
Pulled By: ezyang
fbshipit-source-id: 488ee3db6071150c33a1fb6624f3cfd9b52760c3
Summary:
fixes#4176 cc vishwakftw
I didn't do `:math:` and `\neg` because I am using double ticks so they render more similarly with `:attr:`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9630
Differential Revision: D8933022
Pulled By: SsnL
fbshipit-source-id: 31d8551f415b624c2ff66b25d886f20789846508
Summary:
dlpacks deserve documentation. :)
I wonder whether it might make sense to merge the various small torch.utils pages (and include a link for the larger ones, e.g. data) to enhance the structure in the docs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9343
Differential Revision: D8801227
Pulled By: soumith
fbshipit-source-id: 2980d271971743b86f052bec5a2cb4d146a90d9b
Summary:
Commits:
1. In extension doc, get rid of all references of `Variable` s (Closes#6947 )
+ also add minor improvements
+ also added a section with links to cpp extension :) goldsborough
+ removed mentions of `autograd.Function.requires_grad` as it's not used anywhere and hardcoded to `return_Py_True`.
2. Fix several sphinx warnings
3. Change `*` in equations in `module/conv.py` to `\times`
4. Fix docs for `Fold` and `Unfold`.
+ Added better shape check for `Fold` (it previously may give bogus result when there are not enough blocks). Added test for the checks.
5. Fix doc saying `trtrs` not available for CUDA (#9247 )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9239
Reviewed By: soumith
Differential Revision: D8762492
Pulled By: SsnL
fbshipit-source-id: 13cd91128981a94493d5efdf250c40465f84346a
Summary:
This PR addresses #5823.
* fix docstring: upsample doesn't support LongTensor
* Enable float scale up & down sampling for linear/bilinear/trilinear modes. (following SsnL 's commit)
* Enable float scale up & down sampling for nearest mode. Note that our implementation is slightly different from TF that there's actually no "align_corners" concept in this mode.
* Add a new interpolate function API to replace upsample. Add deprecate warning for upsample.
* Add an area mode which is essentially Adaptive_average_pooling into resize_image.
* Add test cases for interpolate in test_nn.py
* Add a few comments to help understand *linear interpolation code.
* There is only "*cubic" mode missing in resize_images API which is pretty useful in practice. And it's labeled as hackamonth here #1552. I discussed with SsnL that we probably want to implement all new ops in ATen instead of THNN/THCUNN. Depending on the priority, I could either put it in my queue or leave it for a HAMer.
* After the change, the files named as *Upsampling*.c works for both up/down sampling. I could rename the files if needed.
Differential Revision: D8729635
Pulled By: ailzhang
fbshipit-source-id: a98dc5e1f587fce17606b5764db695366a6bb56b
Summary:
Closes#9147
Added a test to prevent regression in test_torch
Added entries in docs
cc ezyang weiyangfb
Closes https://github.com/pytorch/pytorch/pull/9156
Differential Revision: D8732095
Pulled By: soumith
fbshipit-source-id: 7a6892853cfc0ccb0142b4fd25015818849adf61
* docs: enable redirect link to work for each specific page
* docs: add canonical_url for search engines
closes#7222
* docs: update redirect link to canonical_url
* Implement adaptive softmax
* fix test for python 2
* add return_logprob flag
* add a test for cross-entropy path
* address review comments
* Fix docs
* pytorch 0.4 fixes
* address review comments
* don't use no_grad when computing log-probs
* add predict method
* add test for predict
* change methods order
* get rid of hardcoded int values
* Add an optional bias term to the head of AdaptiveSoftmax
* Implement torch.as_tensor, similar to numpy.asarray.
torch.as_tensor behaves like torch.tensor except it avoids copies if possible; so also somewhat like tensor.new but without the size overloads.
I didn't add a requires_grad field, because we haven't decided on the semantics such as as_param.
* Remove requires_grad for doc.
* initial commit for spectral norm
* fix comment
* edit rst
* fix doc
* remove redundant empty line
* fix nit mistakes in doc
* replace l2normalize with F.normalize
* fix chained `by`
* fix docs
fix typos
add comments related to power iteration and epsilon
update link to the paper
make some comments specific
* fix typo
Adds ability to JIT compile C++ extensions from strings
>>> from torch.utils.cpp_extension import load_inline
>>> source = '''
at::Tensor sin_add(at::Tensor x, at::Tensor y) {
return x.sin() + y.sin();
}
'''
>>> module = load_inline(name='inline_extension', cpp_sources=source, functions='sin_add')
Fixes#7012
* Inline JIT C++ Extensions
* jit_compile_sources -> jit_compile
* Split up test into CUDA and non-CUDA parts
* Documentation fixes
* Implement prologue and epilogue generation
* Remove extra newline
* Only create the CUDA source file when cuda_sources is passed
* More factory functions
Changes:
- Added the remaining factory and factory-like functions
- Better argument reuse via string templates
- Link under torch.rst's Creation Ops to the randomized creation ops
* Add double tick around False
* fix flake8
* Fix False
* Clarify comment: hopefully it is clearer now
* start at generic trilinear
* Implement einsum (fixes#1889)
This provides a simple implementation of einsum. It is built on
top of the work for computing bilinear (#6110).
It uses a naive left-to-right resolution at the moment.
Autograd is able to differentiate by itself.
The obvious unsupported feature is taking diagonals (einsum('ii->i',(a,)).
* add tests and docs
* fix flake8
* clean diff
* rebase on current master to resolve conflicting String wrapping
* clean up after rebase
* better commentary in einsum and sumproduct_pair
* don't say fixme if it's fixed and rename num_outputs to num_output_dims
* adapt python wrapper to use std::string instead of String to avoid typedef at::String
* typos and some vector to array conversion
* fix accidental python<->python3 change
* really fix bad rebase
* Codemod to update our codebase to 0.4 standard
* Update some of the test scri[ts
* remove Variable in test_clip_grad_value
* fix _symbolic_override_wrapper_maker
Changes:
- Deleted docs for old constructor. Add link to new `torch.tensor` ctor
- Add docs for `torch.tensor`
- Add some info on dtypes to the top of `tensors.rst`.
Introducing two updates.
1. Add param to He initialization scheme in torch.nn.init
Problem solved:
The function calculate_gain can take an argument to specify the type of non-linearity used. However, it wasn't possible to pass this argument directly to the He / Kaiming weight initialization function.
2. Add util to clip gradient value in torch.nn.utils.clip_grad
Problem solved:
DL libraries typically provide users with easy access to functions for clipping the gradients both using the norm and a fixed value. However, the utils clip_grad.py only had a function to clip the gradient norm.
* add param to He initialization scheme in torch.nn.init
* add util to clip gradient value in torch/nn/utils/clip_grad.py
* update doc in torch.nn.utils.clip_grad
* update and add test for torch.nn.utils.clip_grad
* update function signature in torch.nn.utils.clip_grad to match suffix_ convention
* ensure backward compatibility in torch.nn.utils.clip_grad
* remove DeprecationWarning in torch.nn.utils.clip_grad
* extend test and implementation of torch.nn.utils.clip_grad
* update test and implementation torch.nn.utils.clip_grad
* Add device docs; match constructor parameter names with attribute names.
* Use double quotes for strings.
* Update printing.
* Separate device ordinal-only construction into a separate note.
* Use current device.
* Split set_default_tensor_type(dtype) into set_default_dtype(dtype).
* Fix flake8.
The difference between this one and set_default_tensor_type is that it only sets scalar type what determines the type + device of a tensor returned from a factory function with defaults is the default tensor type + the current device (if the default tensor type is cuda). This just changes the scalar type of the default tensor type.
We do eventually want to deprecate set_default_tensor_type; it is not clear how to do that in a sensible and backwards compatible way.
* added randint function in ATEN yaml as well as Tensorfactories.cpp
* corrected randint
* randint with overloading complete,getting tuple of ints behaviour though
* done randintlike and randint_out
Left : adding docs and test, and remove the bug on size = (5)
* Removed my error messages, ThRandomTensor will handle all exceptions
* added docs and tests, corrected a mistake
Tested with manual seeds in some test cases as well. Seems fine to me (check documentation though)
* corrected indentation to spaces, and improved sizes argument description
* made documentation argument description shorter
* added whitespace after ',' in torch docs
* addes spaces in documentation
* added more tests (including bounds and overloading features)
* added whitespaces in test_torch
* removed trailing whitespaces
* removed whitespace from a blank line
* removed positive requirement from docs. Added dtype argument and gave eg
* made randint over randn in all files
* changed to data type for dtype in docs for randint
* added autofunction entry for randint in torch.rst
* change irfft signal_sizes arg to be the last
* add docs for fft, ifft, rfft, irfft; update doc for stft
* fix typo in window function docs
* improve gradcheck error message
* implement backward of fft, ifft, rfft, irfft
* add grad tests for fft, ifft, rfft, irfft
* fix nits and typos from #6118
* address comments
* Autograd container for trading compute for memory
* add a unit test for checkpoint
* address comments
* address review comments
* adding some docs for the checkpoint api
* more comments
* more comments
* repro bug
* Fix a subtle bug/apply some review comments
* Update checkpoint.py
* Run everything in grad mode
* fix flake and chunk=1
* use imperative backward as per discussion
* remove Variable and also add models and test for models
* Add a simple thread local variable to check for autograd grad mode
* remove models and models test after debugging
* address review comments
* address more comments
* address more comments
Part of #5738. Warns users that they're not viewing the latest stable
release docs.
We should remember to delete this when cutting out 0.4.0 release docs. (we'd just delete the div in pytorch.github.io)
Fixes#6312.
Changed bottleneck's arg parser to user argparse.REMAINDER. This lets
the user specify args as `python -m torch.utils.bottleneck script.py
[args]` (previously, a -- was needed after `bottleneck` and before
`script.py`).
* Implemented log2 and log10
* Re-add incorrectly removed files
* Fix minor bugs
* Fix log1p docs
* Add a try-except for python2 math module in log2 test
* Revert changes made to aten/doc/*
* Fix docstring errors
* Fix windows build
* Add max_values and argmax convenience functions to ATen
* Add documentation for torch.argmax/argmin and skip max_values
* Add tests for argmax/argmin
* Dont default the dim argument
* Use dim=0 in test_torch.py for argmax tests
* Implement argmin() and argmax() without dim
* Call .contiguous() before .view(-1)
This PR enables users to print extra information of their subclassed nn.Module.
Now I simply insert the user-defined string at the ending of module name, which should be discussed in this PR.
Before this PR, users should redefine the __repr__ and copy&paste the source code from Module.
* Add support for extra information on Module
* Rewrite the repr method of Module
* Fix flake8
* Change the __repr__ to get_extra_repr in Linear
* Fix extra new-line for empty line
* Add test for __repr__ method
* Fix bug of block string indent
* Add indent for multi-line repr test.
* Address review comments
* Update tutorial for creating nn.Module
* Fix flake8, add extra_repr of bilinear
* Refactor DropoutNd
* Change to extra_repr in some Modules
* Fix flake8
* Refactor padding modules
* Refactor pooling module
* Fix typo
* Change to extra_repr
* Fix bug for GroupNorm
* Fix bug for LayerNorm
* Deprecate ctx.saved_variables via python warning.
Advises replacing saved_variables with saved_tensors.
Also replaces all instances of ctx.saved_variables with ctx.saved_tensors in the
codebase.
Test by running:
```
import torch
from torch.autograd import Function
class MyFunction(Function):
@staticmethod
def forward(ctx, tensor1, tensor2):
ctx.save_for_backward(tensor1, tensor2)
return tensor1 + tensor2
@staticmethod
def backward(ctx, grad_output):
var1, var2 = ctx.saved_variables
return (grad_output, grad_output)
x = torch.randn((3, 3), requires_grad=True)
y = torch.randn((3, 3), requires_grad=True)
model = MyFunction()
model.apply(x, y).sum().backward()
```
and assert the warning shows up.
* Address comments
* Add deprecation test for saved_variables
* Implement torch.util.bottleneck
This is a tool that is intended to be used as initial exploratory
debugging of bottlenecks in user scripts. Run it with
python -m torch.utils.bottleneck /path/to/source/script.py
* Refactor and address comments
* Fix tests
* Allow passing of args to the profiled script
* Replace Variable
* Implement torch.reshape and Tensor.reshape
This implements reshape which has similar semantics to numpy.reshape. It
will return a view of the source tensor if possible. Otherwise, it
returns a copy.
* Remove in-place reshape_ that was an alias for resize_
* Update documentation
* Improvize documentation
1. Add formula for erf, erfinv
2. Make exp, expm1 similar to log, log1p
3. Symbol change in ge, le, ne, isnan
* Fix minor nit in the docstring
* More doc improvements
1. Added some formulae
2. Complete scanning till "Other Operations" in Tensor docs
* Add more changes
1. Modify all torch.Tensor wherever required
* Fix Conv docs
1. Fix minor nits in the references for LAPACK routines
* Improve Pooling docs
1. Fix lint error
* Improve docs for RNN, Normalization and Padding
1. Fix flake8 error for pooling
* Final fixes for torch.nn.* docs.
1. Improve Loss Function documentation
2. Improve Vision Layers documentation
* Fix lint error
* Improve docstrings in torch.nn.init
* Fix lint error
* Fix minor error in torch.nn.init.sparse
* Fix Activation and Utils Docs
1. Fix Math Errors
2. Add explicit clean to Makefile in docs to prevent running graph generation script
while cleaning
3. Fix utils docs
* Make PYCMD a Makefile argument, clear up prints in the build_activation_images.py
* Fix batch norm doc error
Questions/possible future works:
How to template-ize to extend support beyond LongTensor?
How to check if autograd works (and if not, how to add explicit gradient)?
CUDA support?
Testing command:
DEBUG=1 NO_CUDA=1 MACOSX_DEPLOYMENT_TARGET=10.9 CC=clang CXX=clang++ python setup.py build && DEBUG=1 NO_CUDA=1 MACOSX_DEPLOYMENT_TARGET=10.9 CC=clang CXX=clang++ python setup.py develop && python3 test/test_torch.py
Partially fixes#2031
* Initial commit for unique op
* Working unique with test
* Make inverse indices shape conform to input
* flake8 whitespace removal
* address review comment nits
* Expose fn and add docs. Explicitly declare no gradients
* Trial generic dispatch implementation
* Add tests for generics
* flake8 whitespace
* Add basic CUDA error throwing and templateize set
* Explicit contiguous and AT_DISPATCH_ALL_TYPES return
* Remove extraneous numpy conversion
* Refactor out .data calls
* Refactored to variable return length API with wrapper fn as opposed to returning a 0-length tensor, per off-line reviewer comments
* Remove A
* Don't use hidden torch._unique() in test
* Fix documentations
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}