Fixes https://github.com/pytorch/pytorch/issues/118129
Suppressions automatically added with
```
import re
with open("error_file.txt", "r") as f:
errors = f.readlines()
error_lines = {}
for error in errors:
match = re.match(r"(.*):(\d+):\d+: error:.*\[(.*)\]", error)
if match:
file_path, line_number, error_type = match.groups()
if file_path not in error_lines:
error_lines[file_path] = {}
error_lines[file_path][int(line_number)] = error_type
for file_path, lines in error_lines.items():
with open(file_path, "r") as f:
code = f.readlines()
for line_number, error_type in sorted(lines.items(), key=lambda x: x[0], reverse=True):
code[line_number - 1] = code[line_number - 1].rstrip() + f" # type: ignore[{error_type}]\n"
with open(file_path, "w") as f:
f.writelines(code)
```
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Co-authored-by: Catherine Lee <csl@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/118533
Approved by: https://github.com/Skylion007, https://github.com/zou3519
Fixes https://github.com/pytorch/pytorch/issues/118129
Suppressions automatically added with
```
import re
with open("error_file.txt", "r") as f:
errors = f.readlines()
error_lines = {}
for error in errors:
match = re.match(r"(.*):(\d+):\d+: error:.*\[(.*)\]", error)
if match:
file_path, line_number, error_type = match.groups()
if file_path not in error_lines:
error_lines[file_path] = {}
error_lines[file_path][int(line_number)] = error_type
for file_path, lines in error_lines.items():
with open(file_path, "r") as f:
code = f.readlines()
for line_number, error_type in sorted(lines.items(), key=lambda x: x[0], reverse=True):
code[line_number - 1] = code[line_number - 1].rstrip() + f" # type: ignore[{error_type}]\n"
with open(file_path, "w") as f:
f.writelines(code)
```
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/118533
Approved by: https://github.com/Skylion007, https://github.com/zou3519
After #84624, aten::linalg_vector_norm started being used instead of aten::norm. In the ONNX exporter, the latter leveraged Reduce{L1,L2} when p={1,2}, which resulted in more optimized code in the ONNX Runtime
This PR extends aten::linal_vector_norm to also use Reduce{L1,L2} when ord={1,2}, producing an equivalent ONNX subgraph
This PR is a WIP. Pending work include checking argument equivalence between `aten::norm` and `aten::linalg_vector_norm` and maybe re-enable tests disabled by #84624
Pull Request resolved: https://github.com/pytorch/pytorch/pull/113173
Approved by: https://github.com/justinchuby
Fixes#110597
Summary:
* Generic code: The `torch._C.Value.node().mustBeNone()` is encapsulated into the high-level API `JitScalarType.from_value` ; `_is_none` was also extended to allow either `None` or `torch._C.Value.node.mustBeNone()`, so users don't manually call into TorchScript API when implementing operators
* Specific to `new_zeros` (and ops of ` *_like` and `new_*`): When checking `dtype`, we always must use ` _is_none`, which will call proposed by #110935
Pull Request resolved: https://github.com/pytorch/pytorch/pull/110956
Approved by: https://github.com/justinchuby, https://github.com/BowenBao
This commit improves the export of aten::slice() to ONNX in the following ways:
1. The step size can be an input tensor rather than a constant.
2. Fixes a bug where using a 1-D, 1-element torch tensor as an index created a broken ONNX model.
This commit also adds tests for the new functionality.
Fixes#104314
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104385
Approved by: https://github.com/thiagocrepaldi
This PR conditionally inserts a cast operator after a reduction operation to match the specified dtype in the exported ONNX model. The code changes affect **opset9**, and **opset13**.
I understand there's an [automatic upcast to int64](c91a41fd68/torch/onnx/symbolic_opset9.py (L783)) before reduction most likely to prevent overflow so I left that alone and only conditionally add casting back to desired dtype.
## Test int32
```
import torch
import onnx
a = torch.tensor([10, 20, 30, 80], dtype=torch.int32)
def test():
class SumInt32(torch.nn.Module):
def forward(self, a):
return torch.sum(a, dtype=torch.int32)
sumi = SumInt32().eval()
assert sumi(a).dtype == torch.int32
print("Torch model output type matches input type")
torch.onnx.export(sumi, (a), "/tmp/sumi_int32.onnx", opset_version=12)
model = onnx.load("/tmp/sumi_int32.onnx")
assert model.graph.output[0].type.tensor_type.elem_type == onnx.TensorProto.INT32
print("ONNX model output type matches input type")
test()
```
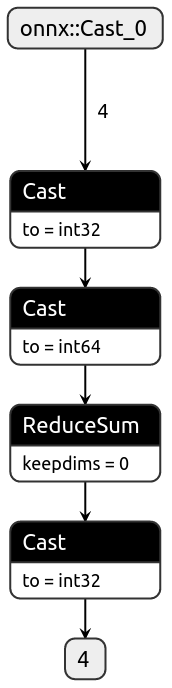
## Test int64
```
import onnx
import torch
a = torch.tensor([10, 20, 30, 80], dtype=torch.int64)
def test():
class SumInt64(torch.nn.Module):
def forward(self, a):
return torch.sum(a, dtype=torch.int64)
sumi = SumInt64().eval()
assert sumi(a).dtype == torch.int64
print("Torch model output type matches input type")
torch.onnx.export(sumi, (a), "/tmp/sumi_int64.onnx", opset_version=12)
model = onnx.load("/tmp/sumi_int64.onnx")
assert model.graph.output[0].type.tensor_type.elem_type == onnx.TensorProto.INT64
print("ONNX model output type matches input type")
test()
```
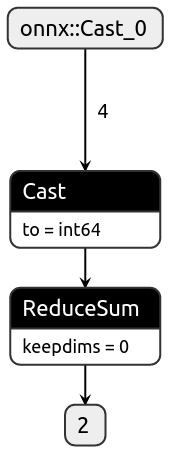
Fixes https://github.com/pytorch/pytorch/issues/100097
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100700
Approved by: https://github.com/thiagocrepaldi
This commit fixes a bug where the ONNX exporter for circular padding queried the input tensor shape in order to get the correct 'end' index for a slice node. This doesn't work when the axis in question is has dynamic size. The commit fixes this by setting the 'end' index to INT_MAX, which is the recommended way of slicing to the end of a dimension with unknown size per ONNX spec.
See https://onnx.ai/onnx/operators/onnx__Slice.html
Also adds a regression test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95647
Approved by: https://github.com/BowenBao
* CI Test environment to install onnx and onnx-script.
* Add symbolic function for `bitwise_or`, `convert_element_type` and `masked_fill_`.
* Update symbolic function for `slice` and `arange`.
* Update .pyi signature for `_jit_pass_onnx_graph_shape_type_inference`.
Co-authored-by: Wei-Sheng Chin <wschin@outlook.com>
Co-authored-by: Ti-Tai Wang <titaiwang@microsoft.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94564
Approved by: https://github.com/abock
When TorchScript Value has an optional tensor, `dtype()` or `scalarType()` is not available and raise (by design).
The symbolic `_op_with_optional_float_cast` must check whether the tensor is otpional or not before calling the scalar type resolution API. This PR fixes that
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94427
Approved by: https://github.com/abock, https://github.com/shubhambhokare1
#84624 introduces an update on `torch.norm` [dispatch logic](eaa43d9f25/torch/functional.py (L1489)) which now depends on `layout`. Resulting in regressions to export related operators from TorchScript.
This PR resolves the regression by partially supporting a subset use case of `prim::layout` (only `torch.strided`), `aten::__contains__` (only constants) operators. It requires much more effort to properly support other layouts, e.g. `torch.sparse_coo`. Extending JIT types, and supporting related family of ops like `aten::to_sparse`. This is out of the scope of this PR.
Fixes#83661
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91660
Approved by: https://github.com/justinchuby, https://github.com/kit1980
This change introduces a mechanism to test onnx export based on sample inputs registered in OpInfo, similar to how MPS and other components of pytorch are tested. It provides test coverage on ops and dtypes previously unattainable with manually created test models. This is the best way for us to discover gaps in the exporter support, especially for ops with partial existing support.
This test is adapted from https://github.com/pytorch/pytorch/blob/master/test/test_mps.py
This PR also
- Update sqrt to support integer inputs to match pytorch behavior
- Add pytest-subtests for unittest subtests support in the new test file
I only enabled very few ops: `t`, `ceil` and `sqrt` because otherwise too many things will fail due to (1) unsupported dtypes in the exporter (2) unimplemented dtype support in onnxruntime (3) unexpected input to verification.verify.
Subsequent PRs should improve `verification.verify` first for it to accept any legal input to a pytorch model, then incrementally fix the symbolic functions to enable more test cases.
Fixes#85363
Design #88118
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86182
Approved by: https://github.com/BowenBao
Prior to this change, the symbolic_fn `layer_norm` (before ONNX version 17) always lose precision when eps is smaller than Float type, while PyTorch always take eps as Double. This PR adds `onnx::Cast` into eps related operations to prevent losing precision during the calculation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89869
Approved by: https://github.com/BowenBao
Preparation for the next PR in this stack: #89559.
I replaced
- `self.assertTrue(torch.equal(...))` with `self.assertEqual(..., rtol=0, atol=0, exact_device=True)`,
- the same for `self.assertFalse(...)` with `self.assertNotEqual(...)`, and
- `assert torch.equal(...)` with `torch.testing.assert_close(..., rtol=0, atol=0)` (note that we don't need to set `check_device=True` here since that is the default).
There were a few instances where the result of `torch.equal` is used directly. In that cases I've replaced with `(... == ...).all().item()` while sometimes also dropping the `.item()` depending on the context.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89527
Approved by: https://github.com/mruberry
Fixes https://github.com/pytorch/pytorch/issues/84365 and more
This PR addresses not only the issue above, but the entire family of issues related to `torch._C.Value.type()` parsing when `scalarType()` or `dtype()` is not available.
This issue exists before `JitScalarType` was introduced, but the new implementation refactored the bug in because the new api `from_name` and `from_dtype` requires parsing `torch._C.Value.type()` to get proper inputs, which is exactly the root cause for this family of bugs.
Therefore `from_name` and `from_dtype` must be called when the implementor knows the `name` and `dtype` without parsing a `torch._C.Value`. To handle the corner cases hidden within `torch._C.Value`, a new `from_value` API was introduced and it should be used in favor of the former ones for most cases. The new API is safer and doesn't require type parsing from user, triggering JIT asserts in the core of pytorch.
Although CI is passing for all tests, please review carefully all symbolics/helpers refactoring to make sure the meaning/intetion of the old call are not changed in the new call
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87245
Approved by: https://github.com/justinchuby, https://github.com/BowenBao
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}