This refactors the stack trace facility specific to memory profiling
in python+cuda to make a generic facility to generate combined stack
traces.
The generic facility (combined_traceback.h) does not require
python to be around to work, but will return python stacks if it is
present.
This facility is then used to add support for stack trace gathering in memory profiling that
happens directly from C++.
It is also used to expose a python API for gathering and symbolizing
combineds stacks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95541
Approved by: https://github.com/ezyang
Adds the ability to quickly generate stack traces for C++,
and combine Python, TorchScript, and C++ frames into a single trace.
This makes it possible for the memory tracer to record allocations inside
C++ code (e.g. convolution temporaries, backward operators).
The unwinder code is ~10x faster than execinfo.h's backward because it
cache fast unwinder routines for instruction pointers that have already been seen.
It is also only 1.2--2x slower than copying the entire stack (the approach perf takes),
while using 2 orders of magnitude less space per stack.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95357
Approved by: https://github.com/bertmaher
Applies the remaining flake8-comprehension fixes and checks. This changes replace all remaining unnecessary generator expressions with list/dict/set comprehensions which are more succinct, performant, and better supported by our torch.jit compiler. It also removes useless generators such as 'set(a for a in b)`, resolving it into just the set call.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94676
Approved by: https://github.com/ezyang
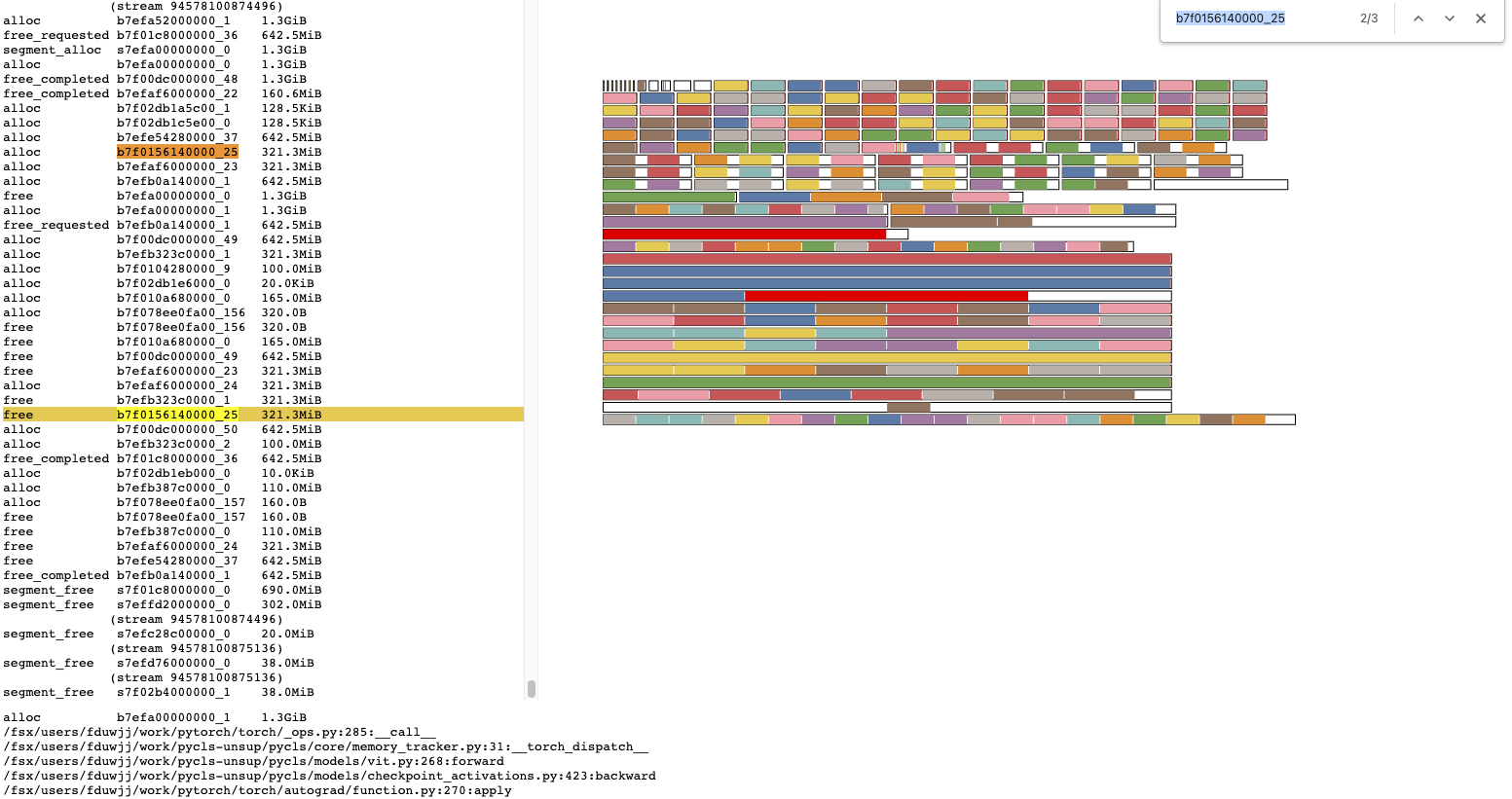
This adds a d3-based interactive visualization for exploring the memory
allocation traces that the caching allocator can capture. This visualization
code can also be attached to kineto trace information in the future to also
provide visualization for the memory events captured there, which come with
addition information about the graph.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90348
Approved by: https://github.com/robieta
We currently can take snapshots of the state of the allocated cuda memory, but we do not have a way to correlate these snapshots with the actions the allocator that were taken between snapshots. This PR adds a simple fixed-sized buffer that records the major actions that the allocator takes (ALLOC, FREE, SEGMENT_ALLOC, SEGMENT_FREE, OOM, SNAPSHOT) and includes these with the snapshot information. Capturing period snapshots with a big enough trace buffer makes it possible to see how the allocator state changes over time.
We plan to use this functionality to guide how settings in the allocator can be adjusted and eventually have a more robust overall algorithm.
As a component of this functionality, we also add the ability to get a callback when the allocator will throw an OOM, primarily so that snapshots can be taken immediately to see why the program ran out of memory (most programs have some C++ state that would free tensors before the OutOfMemory exception can be caught).
This PR also updates the _memory_viz.py script to pretty-print the trace information and provide a better textual summary of snapshots distinguishing between internal and external fragmentation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86241
Approved by: https://github.com/ngimel
Record stack trace information for each allocated segment in the allocator.
It takes around 1.5us to record 50 stack frames of context.
Since invoking a Pytorch operator is around 8us, this adds minimal overhead but we still leave it disabled by default so that we can test it more on real workloads first.
Stack information is kept both for allocated blocks and the last allocation used inactive blocks. We could potential keep around the _first_ allocation that caused the block to get allocated from cuda as well.
Potential Followups:
* stack frame entries are small (16 bytes), but the list of Frames is not compressed eventhough most frames will share some entries. So far this doesn't produce huge dumps (7MB for one real workload that uses all memory on the GPU), but it can be much smaller through compression.
* Code to format the information is slow (a few seconds) because it uses python and FlameGraph.pl
* Things allocated during the backward pass have no stack frames because they are run on another C++ thread.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82146
Approved by: https://github.com/albanD
{kind=link}