The strategy for supporting functools partials is relatively straightforward.
There are 2 cases we need to support:
**1) Functools partials as input**
In this case, we are first seeing the functools partial and it is guaranteed to have a source. As such, the args, keywords, and func of the functools partial are passed through VariableBuilder. As this is the first time we are seeing these objects (as it is an input), we re-enter VariableBuilder with a source referencing the args, keywords, and func as attributes of the input to produce:
- func: A callable VariableTracker (UDF, TorchVariable, etc) depending on the value of `func`
- args: List[VariableTracker] - note, not ListVariableTracker!
- keywords: Dict[str, VariableTracker]
A major benefit of this structure is that it very elegantly matches the args to `call_function`.
We then compose a FunctoolsPartialVariable from the VariableTrackers made above.
**2) Functools partials created within compile**
In this case, we already have all the args as known VTs, and thus just compose a FunctoolsPartialVariable as we do for case (1).
For both (1) and (2) - we propagate all guards from the func, args, and keyword VTs to the FunctoolsPartialVariable
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108846
Approved by: https://github.com/ezyang, https://github.com/jansel
Summary:
Original commit changeset: 33650f7cb0fb
Original Phabricator Diff: D48833682
Test Plan: See T162942232 for how we figured out that this diff caused significant numeric difference.
Reviewed By: voznesenskym
Differential Revision: D49082219
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108823
Approved by: https://github.com/xw285cornell
Summary: Currently node metadata "nn_module_stack" is only being used by export. For some export model, we still want to retain nn_module_stack for unspecialized module for various purposes. This diff add a path to also record nn_module_stack when unspecialized module has a source available.
Test Plan: test_export_nn_module_stack_patched_module
Differential Revision: D48841193
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108281
Approved by: https://github.com/yanboliang, https://github.com/tugsbayasgalan
before the PR, running super(MyConv1d, self).forward or super(MyConvTranspose, self).foward, dynamo will create a graph break when executing NNModuleVariable.call_method and raise unimplemented error for name=_conv_forward / _output_padding. see issue for full detail: https://github.com/pytorch/pytorch/issues/101155
after the PR, for torch.nn.conv module with function name _conv_forward / _output_padding, we inline the function with tx.inline_user_function_return
code refactor: added NNModuleVariable._inline_user_function_return_helper to consolidaste tx.inline_user_function_return into 1 place to keep code dry. after factor, there are 2 uncolidated inline_user_function_return with different ```fn``` and ```source``` logic. the code is still dry. For local testing, they are covered by test_modulelist, test_moduledict, test_conv_call_super_forward_directly and test_conv_transpose_call_super_forward_directly in test_modules.py
Differential Revision: [D46494460](https://our.internmc.facebook.com/intern/diff/D46494460)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102509
Approved by: https://github.com/yanboliang
Opening this so I can discuss with @albanD
I built a proof of concept of an in place API for an nn.Module that allows us to save and load a torch.compiled model with no issues https://github.com/msaroufim/mlsys-experiments/blob/main/save-compiled-model.py
So users can run` model.compile()` and then run `torch.save(model, "model.pt")` and `torch.load(model, "model.pt)` with no issues unlike the rather strange current suggestion we give to users which is `opt_mod = torch.compile(mod); torch.save(mod, "model.pt")`
Right now I'm trying to extend this to work for nn.modules more generally
TODO: Failing tests
* [x] torch.jit.load -> issue was because of aliasing `__call__` to `_call_impl`, _call_impl used to be skipped when now it lo longer is so expanded the skip check. I added an explicit `torch.jit.load()` test now which @davidberard98 suggested
* [x] functorch seems to be a flake - ran locally and it worked `pytest functorch/test_eager_transforms.py`
* [x] a test infra flake - `test_testing.py::TestImports::test_no_mutate_global_logging_on_import_path_functorch`
* [x] It seems like I broke inlining in dynamo though `python -m pytest test/dynamo/test_dynamic_shapes.py -k test_issue175` chatting with Voz about it but still not entirely sure how to fix - found a workaround after chatting with @yanboliang
* [x] `pytest test/dynamo/test_modules.py` and `test/dynamo/test_dynamic_shapes` `test/dynamo/test_misc.py` seem to be failing in CI but trying it out locally they all pass tests passed with 0 failures
* [x] `pytest test/profiler/test_profiler_tree.py ` these tests have ProfilerTrees explicitly printed and will now break if __call__ is not in tree - ran with `EXPECT_ACCEPT=1`
* [x] `pytest test/test_torch.py::TestTorch::test_typed_storage_deprecation_warning` a flake, ran this locally and it works fine
* [x] I reverted my changes to `_dynamo/nn_module.py` since it looks like @wconstab is now directly handling `_call_impl` there but this is triggering an infinite inlining which is crashing
* [x] Tried out to instead override `__call__`, python doesnt like this though https://github.com/pytorch/pytorch/pull/97565#issuecomment-1524570439
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97565
Approved by: https://github.com/aaronenyeshi, https://github.com/albanD, https://github.com/voznesenskym
Opening this so I can discuss with @albanD
I built a proof of concept of an in place API for an nn.Module that allows us to save and load a torch.compiled model with no issues https://github.com/msaroufim/mlsys-experiments/blob/main/save-compiled-model.py
So users can run` model.compile()` and then run `torch.save(model, "model.pt")` and `torch.load(model, "model.pt)` with no issues unlike the rather strange current suggestion we give to users which is `opt_mod = torch.compile(mod); torch.save(mod, "model.pt")`
Right now I'm trying to extend this to work for nn.modules more generally
TODO: Failing tests
* [x] torch.jit.load -> issue was because of aliasing `__call__` to `_call_impl`, _call_impl used to be skipped when now it lo longer is so expanded the skip check. I added an explicit `torch.jit.load()` test now which @davidberard98 suggested
* [x] functorch seems to be a flake - ran locally and it worked `pytest functorch/test_eager_transforms.py`
* [x] a test infra flake - `test_testing.py::TestImports::test_no_mutate_global_logging_on_import_path_functorch`
* [x] It seems like I broke inlining in dynamo though `python -m pytest test/dynamo/test_dynamic_shapes.py -k test_issue175` chatting with Voz about it but still not entirely sure how to fix - found a workaround after chatting with @yanboliang
* [x] `pytest test/dynamo/test_modules.py` and `test/dynamo/test_dynamic_shapes` `test/dynamo/test_misc.py` seem to be failing in CI but trying it out locally they all pass tests passed with 0 failures
* [x] `pytest test/profiler/test_profiler_tree.py ` these tests have ProfilerTrees explicitly printed and will now break if __call__ is not in tree - ran with `EXPECT_ACCEPT=1`
* [x] `pytest test/test_torch.py::TestTorch::test_typed_storage_deprecation_warning` a flake, ran this locally and it works fine
* [x] I reverted my changes to `_dynamo/nn_module.py` since it looks like @wconstab is now directly handling `_call_impl` there but this is triggering an infinite inlining which is crashing
* [x] Tried out to instead override `__call__`, python doesnt like this though https://github.com/pytorch/pytorch/pull/97565#issuecomment-1524570439
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97565
Approved by: https://github.com/aaronenyeshi, https://github.com/albanD
**TL;DR**: This PR fixes handling for lazy modules where `cls_to_become is None`. In those cases, we should leave the type of the lazy module as the old value.
**Details**:
Lazy modules are intended to be initialized at execution; some of them are also supposed to switch to a different type after they have been initialized. However, not all are supposed to switch; see this logic from `nn/modules/lazy.py`
```python
def _infer_parameters(self, ...):
...
if module.cls_to_become is not None:
module.__class__ = module.cls_to_become
```
i.e., we should leave the module type as the old value if `module.cls_to_become is None`. This PR updates dynamo's handling to match this behavior.
Test `test_lazy_module_no_cls_to_become` added to `test/dynamo/test_module.py`.
Differential Revision: [D45253698](https://our.internmc.facebook.com/intern/diff/D45253698)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99943
Approved by: https://github.com/jansel
Before this PR, if users call ```Conv2d(x)```, dynamo handles it well(no graph break) and puts a ```call_module``` op in the FX graph. However, if users explicitly call ```Conv2d.forward(x)``` in another ```forward``` function, the inlining would be failed(caused graph break). This PR fixed this issue by translating the explicit ```Conv2d.forward(x)``` to ```Conv2d(x)```.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99015
Approved by: https://github.com/jansel, https://github.com/wconstab
Allowed modules are stuck into dynamo's fx graph as call_module
nodes, without dynamo doing any tracing of the module. This means
during AOT trace time, hooks will fire during tracing when the
call_module is executed, but the hooks themselves will disappear
after that and not be present in the compiled program.
(worse, if they performed any tensor operations, those would get
traced so you could end up with part of the hook's functionality).
To circumvent this, there are two options for 'allowed modules' with hooks.
1) don't treat them as 'allowed' - trace into them
2) graph-break, so the module is no longer part of the dynamo trace at all
(1) will fail for users that opted into allowed modules becuase they know
their module has problems being traced by dynamo.
(2) causes graph breaks on common modules such as nn.Linear, just because they
are marked as 'allowed'.
It would help matters if we could differentiate between types of allowed modules
(A) allowed to avoid overheads - used for common ops like nn.Linear
(B) allowed to avoid dynamo graphbreaks caused by unsupported code
Ideally, we'd use method (1) for group (A) and (2) for (B).
For now, graph-break on all cases of allowed modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97184
Approved by: https://github.com/jansel
This fixes a regression added in the following PR to graph-break on allowed modules with hooks, but has its own problems.
- following #97184 PR makes 'allowed modules' with hooks graph-break, and lazy modules
are allowed. (should we just make lazy modules not allowed ?)
- graph-breaks at lazy modules fail the lazy module unit tests which assert no graphbreaks
- this PR attempts to always 'initialize' lazy modules before tracing/calling into their __call__,
and initializing a lazy module should delete all its hooks after firing them once, making
the above issue go away
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98516
Approved by: https://github.com/yanboliang, https://github.com/jansel
Tweak dynamo behavior in 2 places when calling nn.Modules,
to route the call to __call__ instead of .forward(), since
__call__ is the codepath that eager users hit and will dispatch
to hooks correctly.
(1) inside NNModuleVariable.call_function, which covers the common case
of calling a module from code dynamo is already tracing
(2) at the OptimizedModule layer, which is the entrypoint
into a top-level nn.Module dynamo is about to compile
This exposes a new bug: NNModuleVariable used to special-case calling
module.forward() (which is a method) as a UserFunctionVariable with an extra
'self' arg. After tracing into module.__call__, there is no longer a special
case for the eventual call into .forward, and it gets wrapped in a
UserDefinedObjectVariable following standard behavior of ._wrap(). UDOV can't be
called, so this broke some tests.
- Fix: add a new special case in _wrap() that treats methods as a UserDefinedMethod
instead of UserDefinedObjectVariable. Now, the forward method can be called.
Also, fix NNModuleVar.call_method routing forward back to __call__
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92125
Approved by: https://github.com/ezyang, https://github.com/jansel, https://github.com/voznesenskym
After some thoughts, I find it difficult to come up with a robust naming convention that satisfies the following constraints at the same time: 1. the new name should be a valid nn.Moule attribute (as required by minifier and it's a good thing to have in general) 2. it can cover various cases such as GetItemSource, GetAttrSource 3. it's easy to recover the original path 4. robust to users' naming scheme.
Thanks to @yanboliang for pointing out the original access path is preserved in Source, now we just need to add an additonal value source.name() to node.meta["nn_module_stack"] to get the access path in original module.
We also address some TODO in quantization, which relies on the original naming convention in nn_module_stack.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94945
Approved by: https://github.com/jansel, https://github.com/yanboliang
Currently, when unrolling an nn.Sequential, we use an integer to represent its submodule's name. This produces some difficulty in tracking the origin of the parameters in the export path:
```python
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
```
Currently, the submodules will have names such as model.0, model.1 instead of model.conv1, model.relu1. This discrepency causes it difficult to track the origin of paramers because they are represented as model.conv1.foo and model.relu1.foo in model.named_parameters().
We replace enumerate() with named_children() to keep submodule's name.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94913
Approved by: https://github.com/jansel
**Summary**: torch.nn.Module implementations previously did not support custom implementations of `__getattr__`; if a torch.nn.Module subclass implemented `__getattr__` and we tried to access an attribute that was expected to be present in `__getattr__`, dynamo would not check `__getattr__` and would error out with an AttributeError. This PR copies the functionality from UserDefinedObjectVariable into torch.nn.Module so that it also supports `__getattr__`
Example of a module which previously would fail:
```python
class MyMod(torch.nn.Module):
def __init__(self):
super().__init__()
self.custom_dict = {"queue": [torch.rand((2, 2)) for _ in range(3)]}
self.other_attr = torch.rand((2, 2))
def __getattr__(self, name):
custom_dict = self.custom_dict
if name in custom_dict:
return custom_dict[name]
return super().__getattr__(name)
def forward(self, x):
return x @ self.other_attr + self.queue[-1]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94658
Approved by: https://github.com/yanboliang, https://github.com/jansel
Summary:
This PR supports the following feature for QConfigMapping:
```
qconfig_mapping = QConfigMapping().set_object_type(torch.nn.Conv2d, qconfig)
backend_config = get_qnnpack_pt2e_backend_config()
m = prepare_pt2e(m, qconfig_mapping, example_inputs, backend_config)
```
which means users want to set the qconfig for all calls to `torch.nn.Conv2d` to use `qconfig`, note this is only verified for the case when the module is broken down to a single aten op right now, e.g. torch.nn.Conv2d will be torch.ops.aten.convolution op when traced through. will need to support more complicated modules that is broken down to multiple operators later, e.g. (MaxPool)
Test Plan:
python test/test_quantization.py TestQuantizePT2E.test_qconfig_module_type
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92355
Approved by: https://github.com/jcaip
**Motivation**
When adding support for default args (#90575), a lot of VariableTrackers missing sources were encountered. Currently, in a lot of cases it seems OK to skip the source for VariableTrackers created (especially during inlining), but that assumption breaks down when inlining functions with default arguments.
**Summary** of changes
- propagate the self.source of the VariableBuilder to the new variables being built, which seems like it was an omission previously
- Add SuperSource to track usages of super(), so that SuperVariables can support function calls with default args
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91729
Approved by: https://github.com/ezyang
### Summary
Making dynamo treat the nn.Modules inside FSDP wrappers as 'Unspecialized'
results in dynamo-produced graphs where nn.module parameters are inputs
to the graph rather than attributes of the outer graphmodule.
This helps in FSDP since it forces dynamo to pick the latest copy
of the parameters off the user's nn.Module (which FSDP mutates every pre_forward),
solving the ordering issue in backward.
### Details
Imagine this toy model
```
class MyModule(torch.nn.Module):
def __init__(self, a, b):
super(MyModule, self).__init__()
self.net = nn.Sequential(
nn.Linear(a, b),
nn.ReLU(),
)
def forward(self, x):
return self.net(x)
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net = nn.Sequential(
*[MyModule(10, 10000)]
+ [MyModule(10000, 1000)]
+ [MyModule(1000, 5)]
)
def forward(self, x):
return self.net(x)
```
Where FSDP is recursively wrapped around each `MyModule`, then dynamo-compiled, with dynamo already configured to skip/break in FSDP code. You'd expect to get 3 compiled AOT functions, corresponding to the contents of `MyModule`, and then see FSDP's communication ops happen inbetween them (eagerly). This almost happens (everything works out fine in forward), but in backward there is an ordering issue.
FSDP creates a flat buffer for all the parameters that are bucketed together, and then creates views into this buffer to replace the original parameters. On each iteration of forward, it creates a new view after 'filling' the flatbuffer with data from an all-gather operation, to 'unshard' the parameters from remote devices. Dynamo traces the first such view and stores it in a compiled graphmodule.
During tracing, we see (1) view created for first MyModule, (2) compile first MyModule, (3) ... for the rest of layers
Then during runtime, we see (A) view created for first MyModule (and orphaned), (B) execute first compiled MyModule, using old view, ...
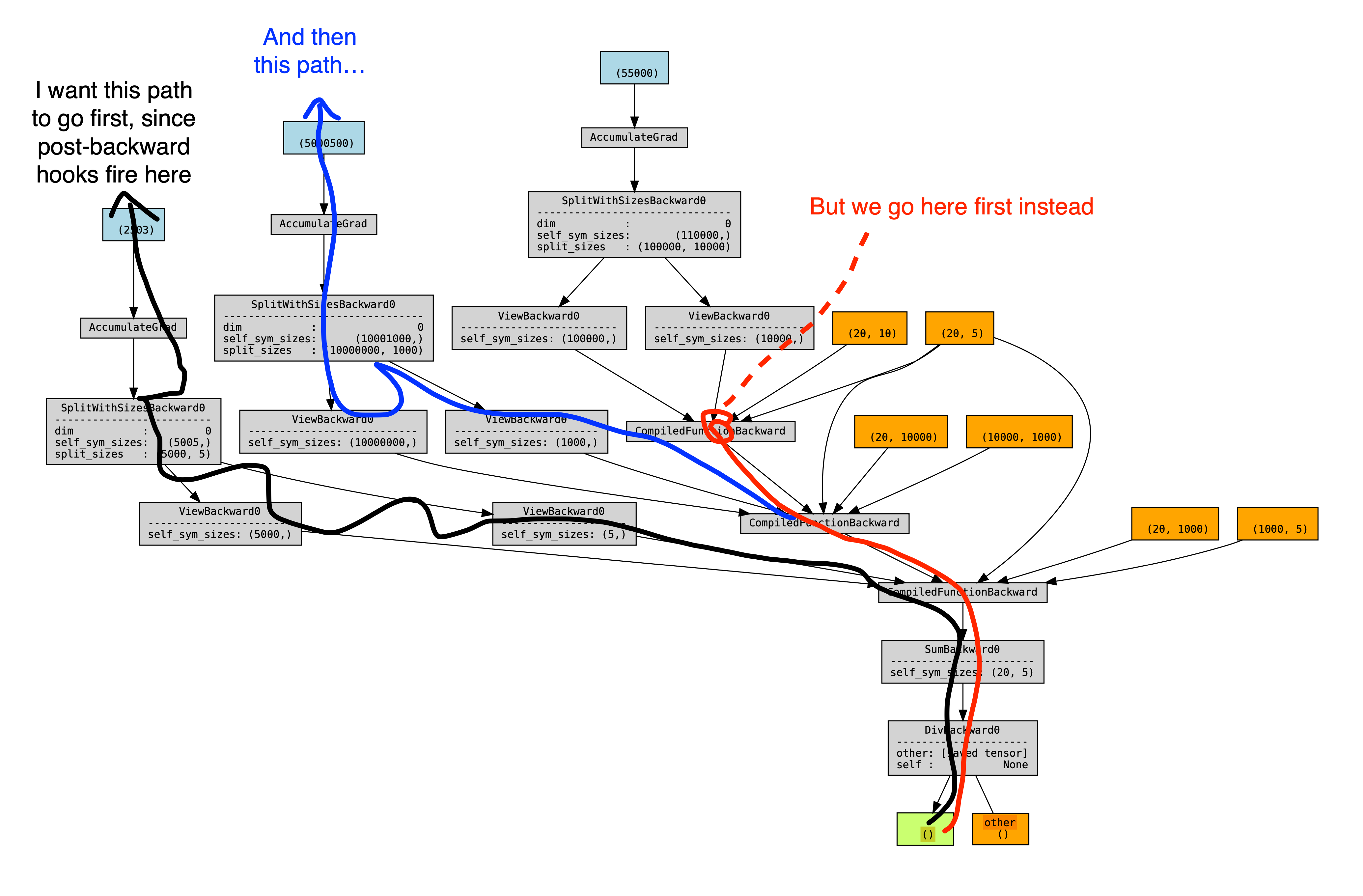
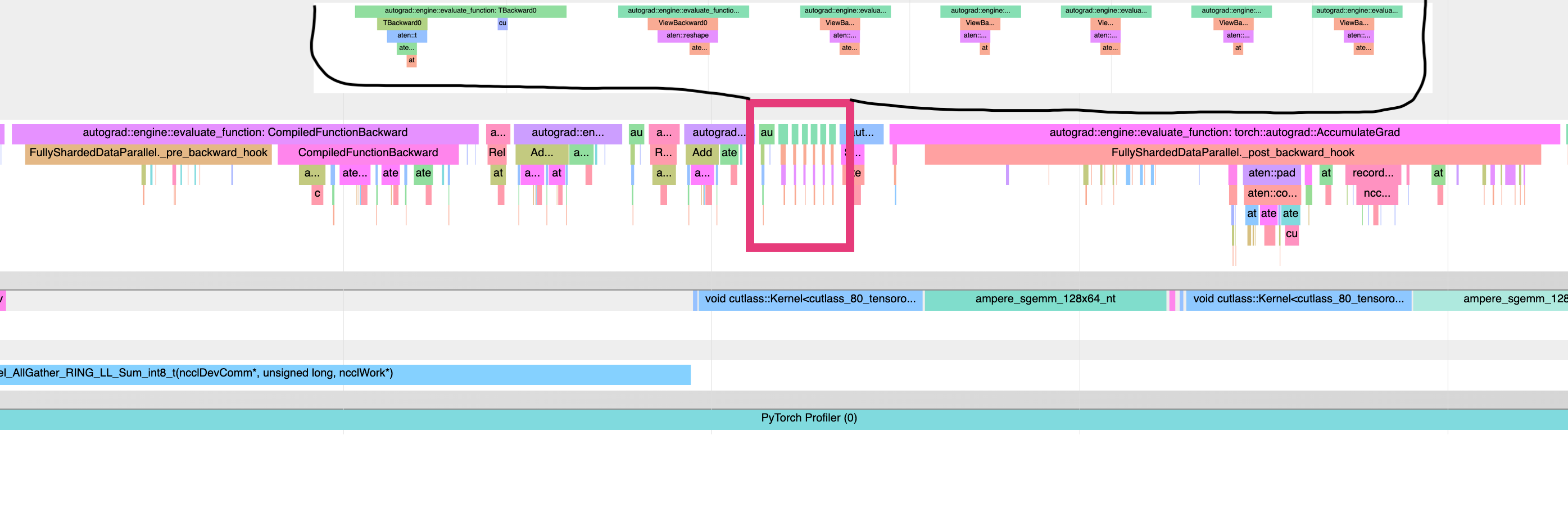
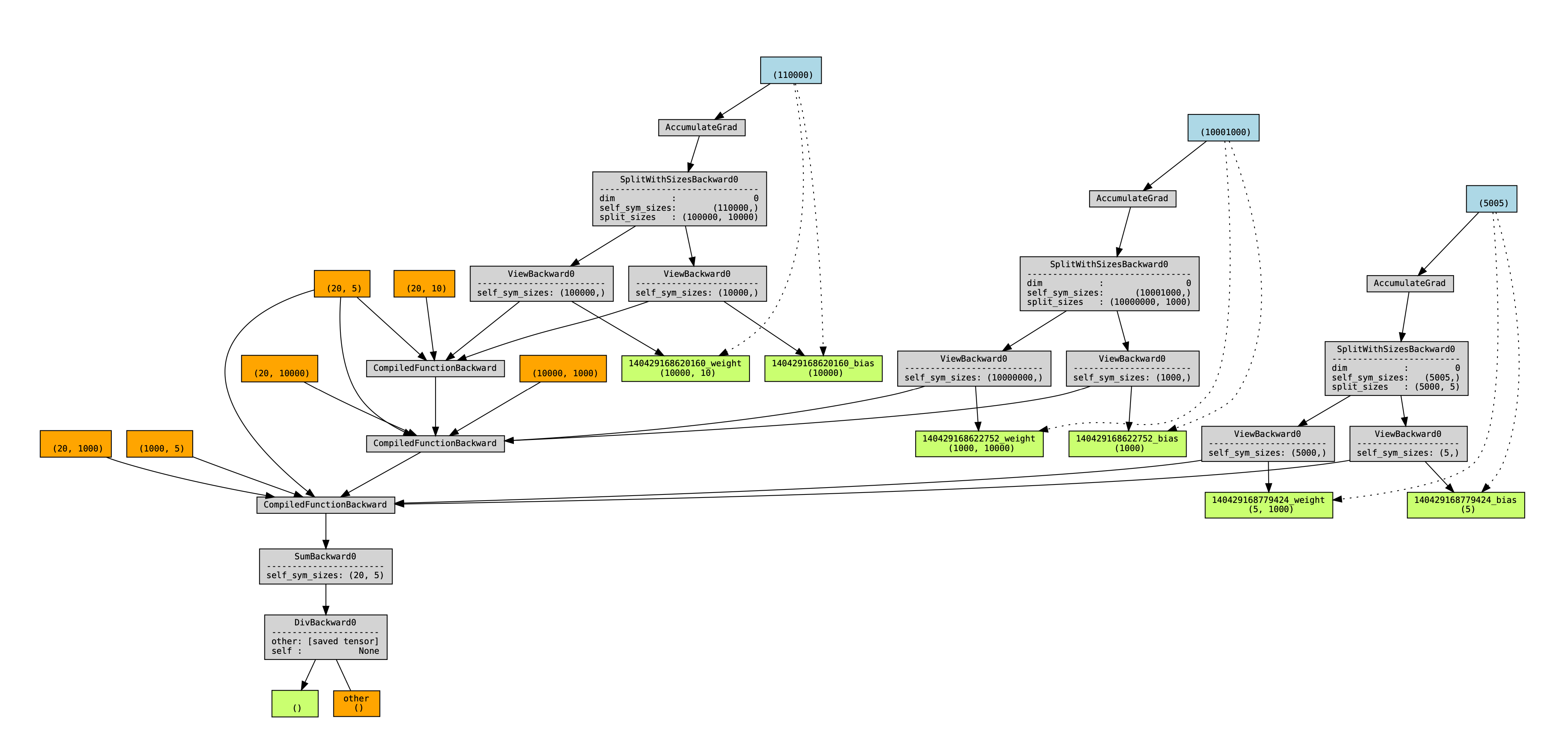
This is a problem, because we want backward hooks to run right after each compiled-backward, but autograd executes those hooks in an order mirroring their execution order during forward. Since we are forever using the views created during steps (1, 3, .. N), which all happen before the steps (A, B, ...), this means that all the hooks will happen after all the compiled backwards. An illustration of the problem - a torchviz graph showing the 2 possible orderings of autograd, and a profile showing the view-backwards ops happening after all the compiled backwards, and before all the backward hooks.
<img width="2069" alt="image" src="https://user-images.githubusercontent.com/4984825/202828002-32dbbd15-8fc3-4281-93e9-227ab5e32683.png">
<img width="2069" alt="image" src="https://user-images.githubusercontent.com/4984825/202828632-33e40729-9a7f-4e68-9ce1-571e3a8dd2dd.png">
A solution is to make dynamo not specialize on these nn modules. It is worth pointing out that this nn.module specialization is de-facto failing, as we are modifying .parameters and this bypasses dynamo's __setattr__ monkeypatch, which should have automatically kicked us out to Unspecialized and forced a recompile.
After unspecializing, the new views (created during steps A, C, ...) are actually _used_ at runtime by the module, making their creation order interleaved, making autograd execute their backwards interleaved.
The new torchviz graph (this time with names added for the view tensors):
<img width="2043" alt="image" src="https://user-images.githubusercontent.com/4984825/202828480-d30005ba-0d20-45d8-b647-30b7ff5e91d3.png">
And a new profile showing the interleaving of compiled backwards and hooks, allowing overlapping of reduce-scatter.
<img width="2293" alt="image" src="https://user-images.githubusercontent.com/4984825/202828533-bb20a041-19b8-499c-b3cf-02808933df47.png">
@jansel @davidberard98 @aazzolini @mrshenli @awgu @ezyang @soumith @voznesenskym @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89330
Approved by: https://github.com/davidberard98
I'm not sure why this never caused problems before. The error
manifests as `TypeError: 'MyModule' object is not subscriptable`
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89625
Approved by: https://github.com/albanD
{kind=link}
{kind=link}
{kind=link}
{kind=link}