Give context about failures ~and include it in the test report~! Unfortunately I cannot include it easily in the test report through the addExpectedFailures :c as tracebacks are not something I can instantiate. (see revert comment)
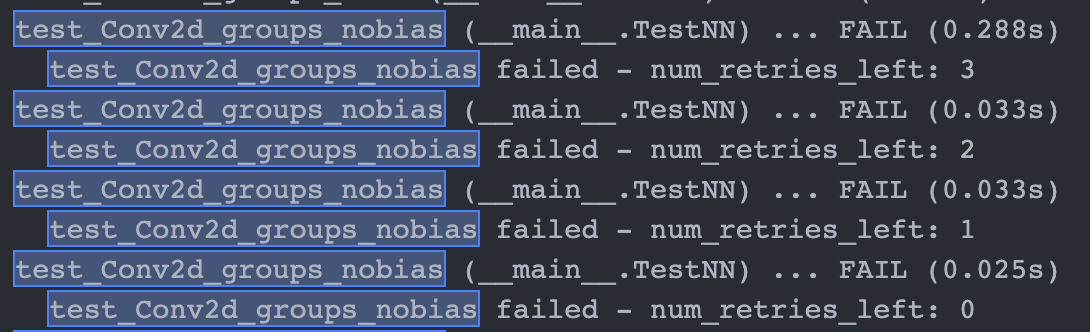
Current way doesn't print the stack traces, which has been fine because we don't hide the signal and it shows up at the end:
<img width="545" alt="image" src="https://user-images.githubusercontent.com/31798555/168878182-914edc39-369f-40bc-8b35-9d5cd47a6b1c.png">
However, when we want to hide the signal, we'd like to print the stack traces for each failed attempt, as it won't be shown at the end.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77664
Approved by: https://github.com/suo
This functionality does not seem to be used
and there are some requests to update dependency.
Add `third_party` to torch_cpu include directories if compiling with
Caffe2 support, as `caffe2/quantization/server/conv_dnnlowp_op.cc` depends on `third_party/fbgemm/src/RefImplementations.h`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75394
Approved by: https://github.com/janeyx99, https://github.com/seemethere
Adds a prototype tracer with no caching support and the `ElementwiseUnaryPythonRefInfo` class. A reference for `floor` is added to test the latter, and the elementwise binary reference inputs are extended to also return noncontiguous inputs. The SampleInput transform operation has been updated to return an actual SampleInput instead of a tuple to facilitate uniform handling of (transformed) SampleInputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76388
Approved by: https://github.com/ngimel
As per title.
### When running `python run_test.py -h`
It used to show:
- The general unittest parser help that we print via a second thread 35545d85dc/torch/testing/_internal/common_utils.py (L467-L470)
- The common_utils's parser help
<details><summary>Full result</summary>
<p>
```bash
$ python run_test.py -h
usage: run_test.py [-h] [-v] [-q] [--locals] [-f] [-c] [-b] [-k TESTNAMEPATTERNS] [tests [tests ...]]
positional arguments:
tests a list of any number of test modules, classes and test methods.
optional arguments:
-h, --help show this help message and exit
-v, --verbose Verbose output
-q, --quiet Quiet output
--locals Show local variables in tracebacks
-f, --failfast Stop on first fail or error
-c, --catch Catch Ctrl-C and display results so far
-b, --buffer Buffer stdout and stderr during tests
-k TESTNAMEPATTERNS Only run tests which match the given substring
Examples:
run_test.py - run default set of tests
run_test.py MyTestSuite - run suite 'MyTestSuite'
run_test.py MyTestCase.testSomething - run MyTestCase.testSomething
run_test.py MyTestCase - run all 'test*' test methods
in MyTestCase
usage: run_test.py [-h] [--subprocess] [--seed SEED] [--accept] [--jit_executor JIT_EXECUTOR] [--repeat REPEAT] [--test_bailouts]
[--save-xml [SAVE_XML]] [--discover-tests] [--log-suffix LOG_SUFFIX] [--run-parallel RUN_PARALLEL]
[--import-slow-tests [IMPORT_SLOW_TESTS]] [--import-disabled-tests [IMPORT_DISABLED_TESTS]]
optional arguments:
-h, --help show this help message and exit
--subprocess whether to run each test in a subprocess
--seed SEED
--accept
--jit_executor JIT_EXECUTOR
--repeat REPEAT
--test_bailouts
--save-xml [SAVE_XML]
--discover-tests
--log-suffix LOG_SUFFIX
--run-parallel RUN_PARALLEL
--import-slow-tests [IMPORT_SLOW_TESTS]
--import-disabled-tests [IMPORT_DISABLED_TESTS]
```
</p>
</details>
It now prints:
- The general unittest parser help the same way. Should we remove this? We can't merge them unfortunately as inittest does not accept parent / does not expose the parser for us to take it as a parent.
- The combined common_utils + run_test parsers help
<details><summary>Full result</summary>
<p>
```bash
$ python run_test.py -h
usage: run_test.py [-h] [-v] [-q] [--locals] [-f] [-c] [-b] [-k TESTNAMEPATTERNS] [tests [tests ...]]
positional arguments:
tests a list of any number of test modules, classes and test methods.
optional arguments:
-h, --help show this help message and exit
-v, --verbose Verbose output
-q, --quiet Quiet output
--locals Show local variables in tracebacks
-f, --failfast Stop on first fail or error
-c, --catch Catch Ctrl-C and display results so far
-b, --buffer Buffer stdout and stderr during tests
-k TESTNAMEPATTERNS Only run tests which match the given substring
Examples:
run_test.py - run default set of tests
run_test.py MyTestSuite - run suite 'MyTestSuite'
run_test.py MyTestCase.testSomething - run MyTestCase.testSomething
run_test.py MyTestCase - run all 'test*' test methods
in MyTestCase
Ignoring disabled issues: []
usage: run_test.py [-h] [--subprocess] [--seed SEED] [--accept] [--jit_executor JIT_EXECUTOR] [--repeat REPEAT] [--test_bailouts]
[--save-xml [SAVE_XML]] [--discover-tests] [--log-suffix LOG_SUFFIX] [--run-parallel RUN_PARALLEL]
[--import-slow-tests [IMPORT_SLOW_TESTS]] [--import-disabled-tests [IMPORT_DISABLED_TESTS]] [-v] [--jit]
[--distributed-tests] [-core] [-pt] [-c] [-i TESTS [TESTS ...]] [-x TESTS [TESTS ...]] [-f TESTS] [-l TESTS]
[--bring-to-front TESTS [TESTS ...]] [--ignore-win-blocklist] [--continue-through-error]
[--export-past-test-times [EXPORT_PAST_TEST_TIMES]] [--shard SHARD SHARD] [--exclude-jit-executor]
[--exclude-distributed-tests] [--run-specified-test-cases [RUN_SPECIFIED_TEST_CASES]]
[--use-specified-test-cases-by {include,bring-to-front}] [--dry-run]
[additional_unittest_args [additional_unittest_args ...]]
Run the PyTorch unit test suite
positional arguments:
additional_unittest_args
additional arguments passed through to unittest, e.g., python run_test.py -i sparse -- TestSparse.test_factory_size_check
optional arguments:
-h, --help show this help message and exit
--subprocess whether to run each test in a subprocess
--seed SEED
--accept
--jit_executor JIT_EXECUTOR
--repeat REPEAT
--test_bailouts
--save-xml [SAVE_XML]
--discover-tests
--log-suffix LOG_SUFFIX
--run-parallel RUN_PARALLEL
--import-slow-tests [IMPORT_SLOW_TESTS]
--import-disabled-tests [IMPORT_DISABLED_TESTS]
-v, --verbose print verbose information and test-by-test results
--jit, --jit run all jit tests
--distributed-tests, --distributed-tests
run all distributed tests
-core, --core Only run core tests, or tests that validate PyTorch's ops, modules,and autograd. They are defined by CORE_TEST_LIST.
-pt, --pytest If true, use `pytest` to execute the tests. E.g., this runs TestTorch with pytest in verbose and coverage mode: python run_test.py -vci torch -pt
-c, --coverage enable coverage
-i TESTS [TESTS ...], --include TESTS [TESTS ...]
select a set of tests to include (defaults to ALL tests). tests must be a part of the TESTS list defined in run_test.py
-x TESTS [TESTS ...], --exclude TESTS [TESTS ...]
select a set of tests to exclude
-f TESTS, --first TESTS
select the test to start from (excludes previous tests)
-l TESTS, --last TESTS
select the last test to run (excludes following tests)
--bring-to-front TESTS [TESTS ...]
select a set of tests to run first. This can be used in situations where you want to run all tests, but care more about some set, e.g. after making a change to a specific component
--ignore-win-blocklist
always run blocklisted windows tests
--continue-through-error
Runs the full test suite despite one of the tests failing
--export-past-test-times [EXPORT_PAST_TEST_TIMES]
dumps test times from previous S3 stats into a file, format JSON
--shard SHARD SHARD runs a shard of the tests (taking into account other selections), e.g., --shard 2 3 will break up the selected tests into 3 shards and run the tests in the 2nd shard (the first number should not exceed the second)
--exclude-jit-executor
exclude tests that are run for a specific jit config
--exclude-distributed-tests
exclude distributed tests
--run-specified-test-cases [RUN_SPECIFIED_TEST_CASES]
load specified test cases file dumped from previous OSS CI stats, format CSV. If all test cases should run for a <test_module> please add a single row:
test_filename,test_case_name
...
<test_module>,__all__
...
how we use the stats will be based on option "--use-specified-test-cases-by".
--use-specified-test-cases-by {include,bring-to-front}
used together with option "--run-specified-test-cases". When specified test case file is set, this option allows the user to control whether to only run the specified test modules or to simply bring the specified modules to front and also run the remaining modules. Note: regardless of this option, we will only run the specified test cases within a specified test module. For unspecified test modules with the bring-to-front option, all test cases will be run, as one may expect.
--dry-run Only list the test that will run.
where TESTS is any of: benchmark_utils/test_benchmark_utils, distributed/_shard/sharded_optim/test_sharded_optim, distributed/_shard/sharded_tensor/ops/test_binary_cmp, distributed/_shard/sharded_tensor/ops/test_elementwise_ops, distributed/_shard/sharded_tensor/ops/test_embedding, distributed/_shard/sharded_tensor/ops/test_embedding_bag, distributed/_shard/sharded_tensor/ops/test_init, distributed/_shard/sharded_tensor/ops/test_linear, distributed/_shard/sharded_tensor/ops/test_math_ops, distributed/_shard/sharded_tensor/test_megatron_prototype, distributed/_shard/sharded_tensor/test_partial_tensor, distributed/_shard/sharded_tensor/test_sharded_tensor, distributed/_shard/sharded_tensor/test_sharded_tensor_reshard, distributed/_shard/sharding_spec/test_sharding_spec, distributed/_shard/test_replicated_tensor, distributed/algorithms/test_join, distributed/elastic/events/lib_test, distributed/elastic/metrics/api_test, distributed/elastic/multiprocessing/api_test, distributed/elastic/timer/api_test, distributed/elastic/timer/local_timer_example, distributed/elastic/timer/local_timer_test, distributed/elastic/utils/distributed_test, distributed/elastic/utils/logging_test, distributed/elastic/utils/util_test, distributed/fsdp/test_flatten_params_wrapper, distributed/fsdp/test_fsdp_apply, distributed/fsdp/test_fsdp_checkpoint, distributed/fsdp/test_fsdp_clip_grad_norm, distributed/fsdp/test_fsdp_comm, distributed/fsdp/test_fsdp_core, distributed/fsdp/test_fsdp_freezing_weights, distributed/fsdp/test_fsdp_grad_acc, distributed/fsdp/test_fsdp_ignored_modules, distributed/fsdp/test_fsdp_input, distributed/fsdp/test_fsdp_memory, distributed/fsdp/test_fsdp_mixed_precision, distributed/fsdp/test_fsdp_multiple_forward, distributed/fsdp/test_fsdp_multiple_wrapping, distributed/fsdp/test_fsdp_optim_state, distributed/fsdp/test_fsdp_overlap, distributed/fsdp/test_fsdp_pure_fp16, distributed/fsdp/test_fsdp_state_dict, distributed/fsdp/test_fsdp_summon_full_params, distributed/fsdp/test_fsdp_traversal, distributed/fsdp/test_fsdp_uneven, distributed/fsdp/test_shard_utils, distributed/fsdp/test_utils, distributed/fsdp/test_wrap, distributed/nn/jit/test_instantiator, distributed/optim/test_zero_redundancy_optimizer, distributed/pipeline/sync/skip/test_api, distributed/pipeline/sync/skip/test_gpipe, distributed/pipeline/sync/skip/test_inspect_skip_layout, distributed/pipeline/sync/skip/test_leak, distributed/pipeline/sync/skip/test_portal, distributed/pipeline/sync/skip/test_stash_pop, distributed/pipeline/sync/skip/test_tracker, distributed/pipeline/sync/skip/test_verify_skippables, distributed/pipeline/sync/test_balance, distributed/pipeline/sync/test_bugs, distributed/pipeline/sync/test_checkpoint, distributed/pipeline/sync/test_copy, distributed/pipeline/sync/test_deferred_batch_norm, distributed/pipeline/sync/test_dependency, distributed/pipeline/sync/test_inplace, distributed/pipeline/sync/test_microbatch, distributed/pipeline/sync/test_phony, distributed/pipeline/sync/test_pipe, distributed/pipeline/sync/test_pipeline, distributed/pipeline/sync/test_stream, distributed/pipeline/sync/test_transparency, distributed/pipeline/sync/test_worker, distributed/rpc/cuda/test_tensorpipe_agent, distributed/rpc/test_faulty_agent, distributed/rpc/test_tensorpipe_agent, distributed/test_c10d_common, distributed/test_c10d_gloo, distributed/test_c10d_nccl, distributed/test_c10d_spawn_gloo, distributed/test_c10d_spawn_nccl, distributed/test_data_parallel, distributed/test_distributed_spawn, distributed/test_launcher, distributed/test_nccl, distributed/test_pg_wrapper, distributed/test_store, distributions/test_constraints, distributions/test_distributions, lazy/test_bindings, lazy/test_extract_compiled_graph, lazy/test_ts_opinfo, test_ao_sparsity, test_autocast, test_autograd, test_binary_ufuncs, test_bundled_inputs, test_complex, test_cpp_api_parity, test_cpp_extensions_aot_ninja, test_cpp_extensions_aot_no_ninja, test_cpp_extensions_jit, test_cuda, test_cuda_primary_ctx, test_dataloader, test_datapipe, test_deploy, test_deploy, test_dispatch, test_expanded_weights, test_foreach, test_function_schema, test_functional_autograd_benchmark, test_functional_optim, test_functionalization, test_futures, test_fx, test_fx_experimental, test_hub, test_import_stats, test_indexing, test_jit, test_jit_autocast, test_jit_cuda_fuser, test_jit_disabled, test_jit_fuser_legacy, test_jit_fuser_te, test_jit_legacy, test_jit_profiling, test_license, test_linalg, test_logging, test_masked, test_mkldnn, test_mobile_optimizer, test_model_dump, test_module_init, test_modules, test_monitor, test_multiprocessing, test_multiprocessing_spawn, test_namedtensor, test_namedtuple_return_api, test_native_functions, test_nestedtensor, test_nn, test_numba_integration, test_numpy_interop, test_openmp, test_ops, test_ops_gradients, test_ops_jit, test_optim, test_overrides, test_package, test_per_overload_api, test_profiler, test_pruning_op, test_public_bindings, test_python_dispatch, test_pytree, test_quantization, test_reductions, test_scatter_gather_ops, test_serialization, test_set_default_mobile_cpu_allocator, test_shape_ops, test_show_pickle, test_sort_and_select, test_sparse, test_sparse_csr, test_spectral_ops, test_stateless, test_tensor_creation_ops, test_tensorboard, test_tensorexpr, test_tensorexpr_pybind, test_testing, test_torch, test_type_hints, test_type_info, test_type_promotion, test_unary_ufuncs, test_utils, test_view_ops, test_vmap, test_vulkan, test_xnnpack_integration
```
</p>
</details>
### When running anything else (for example `python test_autograd.py -h`)
It did not change and still does:
- The general unittest parser help that we print via a second thread
- The common_utils's parser help
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76152
Approved by: https://github.com/malfet, https://github.com/seemethere
Currently `torch.onnx.export(.., operator_export_type=OperatorExportTypes.ONNX_ATEN_FALLBACK)` only issues ATen ops through explicit requests (e.g. `g.at()`) calls inside each op symbolic function. This is done based on specific conditions such as `operator_export_type==OperatorExportTypes.ONNX_ATEN_FALLBACK)` or `is_caffe2_aten_fallback()`
This PR extends the ATen fallback mechanism for scenarios when the symbolic function raises `RuntimeError` during export. The idea is that partial implementation of existing ONNX ops can fallback to ATen as a last resort. That is valuable because each operator can have many input combinations and not all are always implemented.
A minor fix was done to make sure the `overload_name` attribute is added to explicit ATen op fallback requests when a symbolic is not registered to a particular op.
ps: The behavior for builds with BUILD_CAFFE2=1 is not changed to ensure BC.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74759
Approved by: https://github.com/garymm, https://github.com/msaroufim
crossref is a new strategy for performing tests when you want
to run a normal PyTorch API call, separately run some variation of
the API call (e.g., same thing but all the arguments are meta tensors)
and then cross-reference the results to see that they are consistent.
Any logic you add to CrossRefMode will get run on *every* PyTorch API
call that is called in the course of PyTorch's test suite. This can
be a good choice for correctness testing if OpInfo testing is not
exhaustive enough.
For now, the crossref test doesn't do anything except verify that
we can validly push a mode onto the torch function mode stack for all
functions.
Signed-off-by: Edward Z. Yang <ezyangfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75988
Approved by: https://github.com/seemethere
This PR introduces 3 BC changes:
First, this PR propagates `BUILD_CAFFE2` flag to `libtorch` and `libtorch_python`, which is necessary for non-caffe2 ONNX runtimes when using `ONNX_ATEN_FALLBACK` operator export type.
Second, as a complement of https://github.com/pytorch/pytorch/pull/68490, this PR refactors Caffe2's Aten ops symbolics to consider not only the `operator_export_type` (aka `ONNX_ATEN_FALLBACK`) to emit Caffe2 Aten ops, but also whether `BUILD_CAFFE2` (which is called `torch.onnx._CAFFE2_ATEN_FALLBACK` in python binding) is set.
Lastly, it renames `onnx::ATen` to `aten::ATen` for ONNX spec consistency in a BC fashion.
ONNX doesn't have `ATen` op on its spec, but PyTorch ONNX converter emits them. Non-Caffe2 backend engines would be mislead by such operator's name/domain. A non-ideal workaround would be to have Aten ops handled based on its name and ignore the (non-complaint) domain. Moreover, users could incorrectly file bugs to either ONNX or ONNX Runtime when they inspect the model and notice the presence of an unspecified ONNX operator.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73954
Approved by: https://github.com/BowenBao, https://github.com/malfet, https://github.com/garymm, https://github.com/jiafatom
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73875
Previously we had a few settings:
- getExecutor - which toggled between Profiling Executor and Legacy
- getGraphOptimize - if true, overrides PE/Legacy to run with simple executor (no optimizations)
and then...
- getProfilingMode - which would set PE to 0 specializtions.
The last mode is redundant with getGraphOptimize, we should just remove it and use getGraphOptimize in these cases. It would lead to potentially invalid combinations of logic - what does mean if getProfilingMode is true but getExecutor is set to false ? This would lead to a bug in specialize_autograd_zero in this case, see: https://github.com/pytorch/pytorch/blob/master/torch%2Fcsrc%2Fjit%2Fpasses%2Fspecialize_autogradzero.cpp#L93.
The tests here are failing but get fixed with the PR above it, so i'll squash for landing.
Test Plan: Imported from OSS
Reviewed By: cpuhrsch
Differential Revision: D34938130
Pulled By: eellison
fbshipit-source-id: 1a9c0ae7f6d1cfddc2ed3499a5af611053ae5e1b
(cherry picked from commit cf69ce3d155ba7d334022c42fb2cee54bb088c23)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74641
This makes dns hostname lookup failures retryable since in some environments such as Kubernetes they're not guaranteed to be resolvable until the job starts. Retrying this eliminates the race condition.
This also fixes `sandcastle_skip_if` when used on the class instead of the method. Previously they wouldn't inherit from TestCase so just wouldn't run under buck at all.
Fixes https://github.com/pytorch/pytorch/issues/73682
Test Plan:
Added a unit test
```
buck test //caffe2/test/distributed:test_store
```
Reviewed By: aivanou
Differential Revision: D35092284
fbshipit-source-id: d40bf187e52c41f551e4fe41c536b2b0015588ee
(cherry picked from commit f8908309d8ee64c25ee466a6b4922f34f2b7618e)
Summary:
Issue: https://github.com/pytorch/pytorch/issues/69014 (skip reason is not printed for tests running in CI)
Cause: locally tests are fired with testrunner that is built into unittest. When IN_CI env variable is true - tests are fired with xml test runner from unittest-xml-reporting. They have different summary printing properties
Solution: patching printing logic in unittest-xml-reporting when a test is skipped
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74451
Test Plan: examine CI run
Reviewed By: janeyx99
Differential Revision: D35050675
Pulled By: tenpercent
fbshipit-source-id: e3421687d68932079ba156153abeefee368b2fb3
(cherry picked from commit e2356d8ecc618dad9c7c556d40b47c1a6c53f68a)
This PR extends our OpInfo test architecture with "reference inputs," an optional expansion of typical sample inputs that allows for more thorough testing. Currently only the elementwise binary operations implement an extended set of reference inputs. This PR also cleans up some smaller OpInfo-related issues, including several bugs, and it identified https://github.com/pytorch/pytorch/issues/74279.
A reference inputs function can be specified for an OpInfo by filling in its "reference_inputs_func" metadata. If this is done it's recommended that the reference inputs function first call the sample inputs function, then produce additional sample inputs. See `reference_inputs_elementwise_binary` for an example of this pattern.
In addition to implementing reference inputs for the elementwise binary operations, this PR improves their consistency and simplifies how their metadata is represented. The great majority now use a generic sample input function, and those that want extensions start by calling the generic sample input function and then adding additional samples. This removes many older sample input functions. The BinaryUfuncInfo subclass also now allows specifying scalar support more precisely, and reference inputs and error inputs are generated based on this metadata to ensure it's correct.
cc @kshitij12345 @pmeier @zou3519 @Chillee
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74280
Approved by: https://github.com/ngimel
Summary:
- Target Sha1: ae108ef49aa5623b896fc93d4298c49d1750d9ba
- Make USE_XNNPACK a dependent option on cmake minimum version 3.12
- Print USE_XNNPACK under cmake options summary, and print the
availability from collet_env.py
- Skip XNNPACK based tests when XNNPACK is not available
- Add SkipIfNoXNNPACK wrapper to skip tests
- Update cmake version for xenial-py3.7-gcc5.4 image to 3.12.4
- This is required for the backwards compatibility test.
The PyTorch op schema is XNNPACK dependent. See,
aten/src/ATen/native/xnnpack/RegisterOpContextClass.cpp for
example. The nightly version is assumed to have USE_XNNPACK=ON,
so with this change we ensure that the test build can also
have XNNPACK.
- HACK: skipping test_xnnpack_integration tests on ROCM
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72642
Reviewed By: kimishpatel
Differential Revision: D34456794
Pulled By: digantdesai
fbshipit-source-id: 85dbfe0211de7846d8a84321b14fdb061cd6c037
(cherry picked from commit 6cf48e7b64d6979962d701b5d493998262cc8bfa)
Summary:
Rest of the tests from CUDA testuite is skipped after GPU context corruption is encountered.
For tests decorated with `expectedFailure` creates false impression that entire testsuite is passing.
Remedy it by suppressing the exception and printing the warning about unexpected success if `should_stop_early` is true
Also, prints warning when this happens (to make attribution easier) as well as when this condition is detected.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72016
Test Plan:
`python test_ops.py -v -k test_fn_fwgrad_bwgrad_gradient`
Before the change:
```
test_fn_fwgrad_bwgrad_gradient_cpu_complex128 (__main__.TestGradientsCPU) ... ok
test_fn_fwgrad_bwgrad_gradient_cpu_float64 (__main__.TestGradientsCPU) ... ok
test_fn_fwgrad_bwgrad_gradient_cuda_complex128 (__main__.TestGradientsCUDA) ... expected failure
----------------------------------------------------------------------
Ran 3 tests in 0.585s
OK (expected failures=1)
```
After the change:
```
test_fn_fwgrad_bwgrad_gradient_cpu_complex128 (__main__.TestGradientsCPU) ... ok
test_fn_fwgrad_bwgrad_gradient_cpu_float64 (__main__.TestGradientsCPU) ... ok
test_fn_fwgrad_bwgrad_gradient_cuda_complex128 (__main__.TestGradientsCUDA) ... /home/conda/miniconda3/lib/python3.9/site-packages/torch/testing/_internal/common_utils.py:1670: UserWarning: TEST SUITE EARLY TERMINATION due to torch.cuda.synchronize() failed with CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
warn(f"TEST SUITE EARLY TERMINATION due to torch.cuda.synchronize() failed with {rte}")
/home/conda/miniconda3/lib/python3.9/site-packages/torch/testing/_internal/common_device_type.py:382: UserWarning: Suppressed expected failure that resulted in fatal error
warn("Suppressed expected failure that resulted in fatal error")
unexpected success
----------------------------------------------------------------------
Ran 3 tests in 0.595s
FAILED (unexpected successes=1)
```
And `stderr` from XML file contains requested info:
```
/home/conda/miniconda3/lib/python3.9/site-packages/torch/testing/_internal/common_utils.py:1670: UserWarning: TEST SUITE EARLY TERMINATION due to torch.cuda.synchronize() failed with CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
warn(f"TEST SUITE EARLY TERMINATION due to torch.cuda.synchronize() failed with {rte}")
/home/conda/miniconda3/lib/python3.9/site-packages/torch/testing/_internal/common_device_type.py:382: UserWarning: Suppressed expected failure that resulted in fatal error
warn("Suppressed expected failure that resulted in fatal error")
```
Fixes https://github.com/pytorch/pytorch/issues/71973
Reviewed By: janeyx99, ngimel
Differential Revision: D33854287
Pulled By: malfet
fbshipit-source-id: dd0f5a4d2fcd21ebb7ee50ce4ec4914405a812d0
(cherry picked from commit 0c0baf3931)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67996
This is necessary for most matrix decompositions in `linalg`.
cc mruberry
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D33774418
Pulled By: mruberry
fbshipit-source-id: 576f2dda9d484808b4acf0621514c0ffe26834e6
(cherry picked from commit fb07c50aa9)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70253
I included a derivation of the formula in the complex case, as it is
particularly tricky. As far as I know, this is the first time this formula
is derived in the literature.
I also implemented a more efficient and more accurate version of svd_backward.
More importantly, I also added a lax check in the complex case making sure the loss
function just depends on the subspaces spanned by the pairs of singular
vectors, and not their joint phase.
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: mikaylagawarecki
Differential Revision: D33751982
Pulled By: mruberry
fbshipit-source-id: c2a4a92a921a732357e99c01ccb563813b1af512
(cherry picked from commit 391319ed8f)
Summary:
Hi,
The PR fixes https://github.com/pytorch/pytorch/issues/71096. It aims to scan all the test files and replace ` ALL_TENSORTYPES` and `ALL_TENSORTYPES2` with `get_all_fp_dtypes`.
I'm looking forward to your viewpoints!
Thanks!
cc: janeyx99 kshitij12345
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71153
Reviewed By: jbschlosser, mruberry
Differential Revision: D33533346
Pulled By: anjali411
fbshipit-source-id: 75e79ca2756c1ddaf0e7e0289257fca183a570b3
(cherry picked from commit da54b54dc5)
Summary:
Allows disabling issues to disable all parametrized tests with dtypes.
Tested locally with:
1. .pytorch-disabled-tests.json as
```
{"test_bitwise_ops (__main__.TestBinaryUfuncs)": ["https://github.com/pytorch/pytorch/issues/99999", ["mac"]]}
```
and running `python test_binary_ufuncs.py --import-disabled-tests -k test_bitwise_ops` yields all tests skipped.
2. .pytorch-disabled-tests.json as
```
{"test_bitwise_ops_cpu_int16 (__main__.TestBinaryUfuncsCPU)": ["https://github.com/pytorch/pytorch/issues/99999", ["mac"]]}
```
and running `python test_binary_ufuncs.py --import-disabled-tests -k test_bitwise_ops` yields only `test_bitwise_ops_cpu_int16` skipped.
NOTE: this only works with dtype parametrization, not all prefixes, e.g., disabling `test_async_script` would NOT disable `test_async_script_capture`. This is the most intuitive behavior, I believe, but I can be convinced otherwise.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71499
Reviewed By: mruberry
Differential Revision: D33742723
Pulled By: janeyx99
fbshipit-source-id: 98a84f9e80402978fa8d22e0f018e6c6c4339a72
(cherry picked from commit 3f778919ca)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68183
We do so in favour of
`make_fullrank_matrices_with_distinct_singular_values` as this latter
one not only has an even longer name, but also generates inputs
correctly for them to work with the PR that tests noncontig inputs
latter in this stack.
We also heavily simplified the generation of samples for the SVD, as it was
fairly convoluted and it was not generating the inputs correclty for
the noncontiguous test.
To do the transition, we also needed to fix the following issue, as it was popping
up in the tests:
Fixes https://github.com/pytorch/pytorch/issues/66856
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D32684853
Pulled By: mruberry
fbshipit-source-id: e88189c8b67dbf592eccdabaf2aa6d2e2f7b95a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D32834069
Pulled By: mruberry
fbshipit-source-id: 51ef12535fa91d292f419acf83b800b86ee9c7eb
{kind=link}