vfdev
d2abf3f981
Added antialias flag to interpolate (CPU only, bicubic) ( #68819 )
...
Summary:
Description:
- Added antialias flag to interpolate (CPU only)
- forward and backward for bicubic mode
- added tests
Previous PR for bilinear, https://github.com/pytorch/pytorch/pull/65142
### Benchmarks
<details>
<summary>
Forward pass, CPU. PTH interpolation vs PIL
</summary>
Cases:
- PTH RGB 3 Channels, float32 vs PIL RGB uint8 (apples vs pears)
- PTH 1 Channel, float32 vs PIL 1 Channel Float
Code: https://gist.github.com/vfdev-5/b173761a567f2283b3c649c3c0574112
```
Torch config: PyTorch built with:
- GCC 9.3
- C++ Version: 201402
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- CPU capability usage: AVX2
- CUDA Runtime 11.1
- NVCC architecture flags: -gencode;arch=compute_61,code=sm_61
- CuDNN 8.0.5
- Build settings: BUILD_TYPE=Release, CUDA_VERSION=11.1, CUDNN_VERSION=8.0.5, CXX_COMPILER=/usr/bin/c++, CXX_FLAGS= -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_PYTORCH_QNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.11.0, USE_CUDA=1, USE_CUDNN=1, USE_EIGEN_FOR_BLAS=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=OFF, USE_MKLDNN=OFF, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=0, USE_OPENMP=ON, USE_ROCM=OFF,
Num threads: 1
[------------------- Downsampling (bicubic): torch.Size([1, 3, 906, 438]) -> (320, 196) -------------------]
| Reference, PIL 8.4.0, mode: RGB | 1.11.0a0+gitb0bdf58
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 4.5 | 5.2
channels_last non-contiguous torch.float32 | 4.5 | 5.3
Times are in milliseconds (ms).
[------------------- Downsampling (bicubic): torch.Size([1, 3, 906, 438]) -> (460, 220) -------------------]
| Reference, PIL 8.4.0, mode: RGB | 1.11.0a0+gitb0bdf58
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 5.7 | 6.4
channels_last non-contiguous torch.float32 | 5.7 | 6.4
Times are in milliseconds (ms).
[------------------- Downsampling (bicubic): torch.Size([1, 3, 906, 438]) -> (120, 96) --------------------]
| Reference, PIL 8.4.0, mode: RGB | 1.11.0a0+gitb0bdf58
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 3.0 | 4.0
channels_last non-contiguous torch.float32 | 2.9 | 4.1
Times are in milliseconds (ms).
[------------------ Downsampling (bicubic): torch.Size([1, 3, 906, 438]) -> (1200, 196) -------------------]
| Reference, PIL 8.4.0, mode: RGB | 1.11.0a0+gitb0bdf58
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 14.7 | 17.1
channels_last non-contiguous torch.float32 | 14.8 | 17.2
Times are in milliseconds (ms).
[------------------ Downsampling (bicubic): torch.Size([1, 3, 906, 438]) -> (120, 1200) -------------------]
| Reference, PIL 8.4.0, mode: RGB | 1.11.0a0+gitb0bdf58
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 3.5 | 3.9
channels_last non-contiguous torch.float32 | 3.5 | 3.9
Times are in milliseconds (ms).
[---------- Downsampling (bicubic): torch.Size([1, 1, 906, 438]) -> (320, 196) ---------]
| Reference, PIL 8.4.0, mode: F | 1.11.0a0+gitb0bdf58
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 2.4 | 1.8
Times are in milliseconds (ms).
[---------- Downsampling (bicubic): torch.Size([1, 1, 906, 438]) -> (460, 220) ---------]
| Reference, PIL 8.4.0, mode: F | 1.11.0a0+gitb0bdf58
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 3.1 | 2.2
Times are in milliseconds (ms).
[---------- Downsampling (bicubic): torch.Size([1, 1, 906, 438]) -> (120, 96) ----------]
| Reference, PIL 8.4.0, mode: F | 1.11.0a0+gitb0bdf58
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 1.6 | 1.4
Times are in milliseconds (ms).
[--------- Downsampling (bicubic): torch.Size([1, 1, 906, 438]) -> (1200, 196) ---------]
| Reference, PIL 8.4.0, mode: F | 1.11.0a0+gitb0bdf58
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 7.9 | 5.7
Times are in milliseconds (ms).
[--------- Downsampling (bicubic): torch.Size([1, 1, 906, 438]) -> (120, 1200) ---------]
| Reference, PIL 8.4.0, mode: F | 1.11.0a0+gitb0bdf58
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 1.7 | 1.3
Times are in milliseconds (ms).
```
</details>
Code is moved from torchvision: https://github.com/pytorch/vision/pull/3810 and https://github.com/pytorch/vision/pull/4208
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68819
Reviewed By: mikaylagawarecki
Differential Revision: D33339117
Pulled By: jbschlosser
fbshipit-source-id: 6a0443bbba5439f52c7dbc1be819b75634cf67c4
2021-12-29 14:04:43 -08:00
srijan789
73b5b6792f
Adds reduction args to signature of F.multilabel_soft_margin_loss docs ( #70420 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/70301
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70420
Reviewed By: gchanan
Differential Revision: D33336924
Pulled By: jbschlosser
fbshipit-source-id: 18189611b3fc1738900312efe521884bced42666
2021-12-28 09:48:05 -08:00
George Qi
7c690ef1c2
FractionalMaxPool3d with no_batch_dim support ( #69732 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/69732
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D33280090
Pulled By: george-qi
fbshipit-source-id: aaf90a372b6d80da0554bad28d56436676f9cb89
2021-12-22 14:30:32 -08:00
rohitgr7
78bea1bb66
update example in classification losses ( #69816 )
...
Summary:
Just updated a few examples that were either failing or raising deprecated warnings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69816
Reviewed By: bdhirsh
Differential Revision: D33217585
Pulled By: albanD
fbshipit-source-id: c6804909be74585c8471b8166b69e6693ad62ca7
2021-12-21 02:46:48 -08:00
kshitij12345
e8d5c7cf7f
[nn] mha : no-batch-dim support (python) ( #67176 )
...
Summary:
Reference: https://github.com/pytorch/pytorch/issues/60585
* [x] Update docs
* [x] Tests for shape checking
Tests take roughly 20s on system that I use. Below is the timings for slowest 20 tests.
```
pytest test/test_modules.py -k _multih --durations=20
============================================================================================== test session starts ===============================================================================================
platform linux -- Python 3.10.0, pytest-6.2.5, py-1.10.0, pluggy-1.0.0
rootdir: /home/kshiteej/Pytorch/pytorch_no_batch_mha, configfile: pytest.ini
plugins: hypothesis-6.23.2, repeat-0.9.1
collected 372 items / 336 deselected / 36 selected
test/test_modules.py ..............ssssssss.............. [100%]
================================================================================================ warnings summary ================================================================================================
../../.conda/envs/pytorch-cuda-dev/lib/python3.10/site-packages/torch/backends/cudnn/__init__.py:73
test/test_modules.py::TestModuleCUDA::test_factory_kwargs_nn_MultiheadAttention_cuda_float32
/home/kshiteej/.conda/envs/pytorch-cuda-dev/lib/python3.10/site-packages/torch/backends/cudnn/__init__.py:73: UserWarning: PyTorch was compiled without cuDNN/MIOpen support. To use cuDNN/MIOpen, rebuild PyTorch making sure the library is visible to the build system.
warnings.warn(
-- Docs: https://docs.pytest.org/en/stable/warnings.html
============================================================================================== slowest 20 durations ==============================================================================================
8.66s call test/test_modules.py::TestModuleCUDA::test_gradgrad_nn_MultiheadAttention_cuda_float64
2.02s call test/test_modules.py::TestModuleCPU::test_gradgrad_nn_MultiheadAttention_cpu_float64
1.89s call test/test_modules.py::TestModuleCUDA::test_grad_nn_MultiheadAttention_cuda_float64
1.01s call test/test_modules.py::TestModuleCUDA::test_factory_kwargs_nn_MultiheadAttention_cuda_float32
0.51s call test/test_modules.py::TestModuleCPU::test_grad_nn_MultiheadAttention_cpu_float64
0.46s call test/test_modules.py::TestModuleCUDA::test_forward_nn_MultiheadAttention_cuda_float32
0.45s call test/test_modules.py::TestModuleCUDA::test_non_contiguous_tensors_nn_MultiheadAttention_cuda_float64
0.44s call test/test_modules.py::TestModuleCUDA::test_non_contiguous_tensors_nn_MultiheadAttention_cuda_float32
0.21s call test/test_modules.py::TestModuleCUDA::test_pickle_nn_MultiheadAttention_cuda_float64
0.21s call test/test_modules.py::TestModuleCUDA::test_pickle_nn_MultiheadAttention_cuda_float32
0.18s call test/test_modules.py::TestModuleCUDA::test_forward_nn_MultiheadAttention_cuda_float64
0.17s call test/test_modules.py::TestModuleCPU::test_non_contiguous_tensors_nn_MultiheadAttention_cpu_float32
0.16s call test/test_modules.py::TestModuleCPU::test_non_contiguous_tensors_nn_MultiheadAttention_cpu_float64
0.11s call test/test_modules.py::TestModuleCUDA::test_factory_kwargs_nn_MultiheadAttention_cuda_float64
0.08s call test/test_modules.py::TestModuleCPU::test_pickle_nn_MultiheadAttention_cpu_float32
0.08s call test/test_modules.py::TestModuleCPU::test_pickle_nn_MultiheadAttention_cpu_float64
0.06s call test/test_modules.py::TestModuleCUDA::test_repr_nn_MultiheadAttention_cuda_float64
0.06s call test/test_modules.py::TestModuleCUDA::test_repr_nn_MultiheadAttention_cuda_float32
0.06s call test/test_modules.py::TestModuleCPU::test_forward_nn_MultiheadAttention_cpu_float32
0.06s call test/test_modules.py::TestModuleCPU::test_forward_nn_MultiheadAttention_cpu_float64
============================================================================================ short test summary info =============================================================================================
=========================================================================== 28 passed, 8 skipped, 336 deselected, 2 warnings in 19.71s ===========================================================================
```
cc albanD mruberry jbschlosser walterddr
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67176
Reviewed By: dagitses
Differential Revision: D33094285
Pulled By: jbschlosser
fbshipit-source-id: 0dd08261b8a457bf8bad5c7f3f6ded14b0beaf0d
2021-12-14 13:21:21 -08:00
Pearu Peterson
48771d1c7f
[BC-breaking] Change dtype of softmax to support TorchScript and MyPy ( #68336 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/68336
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D32470965
Pulled By: cpuhrsch
fbshipit-source-id: 254b62db155321e6a139bda9600722c948f946d3
2021-11-18 11:26:14 -08:00
Richard Zou
f9ef807f4d
Replace empty with new_empty in nn.functional.pad ( #68565 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68565
This makes it so that we can now vmap over nn.functional.pad (circular
variant). Previously we could not because we were effectively doing
`out.copy_(input)` where the out was created with empty.
This also has the added side effect of cleaning up the code.
Test Plan:
- I tested this using functorch.vmap and can confirm that vmap now
works.
- Unfortunately this doesn't work with the vmap in core so I cannot add
a test for this here.
Reviewed By: albanD
Differential Revision: D32520188
Pulled By: zou3519
fbshipit-source-id: 780a7e8207d7c45fcba645730a5803733ebfd7be
2021-11-18 06:06:50 -08:00
vfdev-5
3da2e09c9b
Added antialias flag to interpolate (CPU only, bilinear) ( #65142 )
...
Summary:
Description:
- Added antialias flag to interpolate (CPU only)
- forward and backward for bilinear mode
- added tests
### Benchmarks
<details>
<summary>
Forward pass, CPU. PTH interpolation vs PIL
</summary>
Cases:
- PTH RGB 3 Channels, float32 vs PIL RGB uint8 (apply vs pears)
- PTH 1 Channel, float32 vs PIL 1 Channel Float
Code: https://gist.github.com/vfdev-5/b173761a567f2283b3c649c3c0574112
```
# OMP_NUM_THREADS=1 python bench_interp_aa_vs_pillow.py
Torch config: PyTorch built with:
- GCC 9.3
- C++ Version: 201402
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- CPU capability usage: AVX2
- CUDA Runtime 11.1
- NVCC architecture flags: -gencode;arch=compute_75,code=sm_75
- CuDNN 8.0.5
- Build settings: BUILD_TYPE=Release, CUDA_VERSION=11.1, CUDNN_VERSION=8.0.5, CXX_COMPILER=/usr/bin/c++, CXX_FLAGS= -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_PYTORCH_QNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.10.0, USE_CUDA=1, USE_CUDNN=1, USE_EIGEN_FOR_BLAS=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=OFF, USE_MKLDNN=OFF, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=0, USE_OPENMP=ON,
Num threads: 1
[------------------------ Downsampling: torch.Size([1, 3, 906, 438]) -> (320, 196) ------------------------]
| Reference, PIL 8.3.2, mode: RGB | 1.10.0a0+git1e87d91
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 2.9 | 3.1
channels_last non-contiguous torch.float32 | 2.6 | 3.6
Times are in milliseconds (ms).
[------------------------ Downsampling: torch.Size([1, 3, 906, 438]) -> (460, 220) ------------------------]
| Reference, PIL 8.3.2, mode: RGB | 1.10.0a0+git1e87d91
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 3.4 | 4.0
channels_last non-contiguous torch.float32 | 3.4 | 4.8
Times are in milliseconds (ms).
[------------------------ Downsampling: torch.Size([1, 3, 906, 438]) -> (120, 96) -------------------------]
| Reference, PIL 8.3.2, mode: RGB | 1.10.0a0+git1e87d91
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 1.6 | 1.8
channels_last non-contiguous torch.float32 | 1.6 | 1.9
Times are in milliseconds (ms).
[----------------------- Downsampling: torch.Size([1, 3, 906, 438]) -> (1200, 196) ------------------------]
| Reference, PIL 8.3.2, mode: RGB | 1.10.0a0+git1e87d91
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 9.0 | 11.3
channels_last non-contiguous torch.float32 | 8.9 | 12.5
Times are in milliseconds (ms).
[----------------------- Downsampling: torch.Size([1, 3, 906, 438]) -> (120, 1200) ------------------------]
| Reference, PIL 8.3.2, mode: RGB | 1.10.0a0+git1e87d91
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 2.1 | 1.8
channels_last non-contiguous torch.float32 | 2.1 | 3.4
Times are in milliseconds (ms).
[--------------- Downsampling: torch.Size([1, 1, 906, 438]) -> (320, 196) --------------]
| Reference, PIL 8.3.2, mode: F | 1.10.0a0+git1e87d91
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 1.2 | 1.0
Times are in milliseconds (ms).
[--------------- Downsampling: torch.Size([1, 1, 906, 438]) -> (460, 220) --------------]
| Reference, PIL 8.3.2, mode: F | 1.10.0a0+git1e87d91
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 1.4 | 1.3
Times are in milliseconds (ms).
[--------------- Downsampling: torch.Size([1, 1, 906, 438]) -> (120, 96) ---------------]
| Reference, PIL 8.3.2, mode: F | 1.10.0a0+git1e87d91
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 719.9 | 599.9
Times are in microseconds (us).
[-------------- Downsampling: torch.Size([1, 1, 906, 438]) -> (1200, 196) --------------]
| Reference, PIL 8.3.2, mode: F | 1.10.0a0+git1e87d91
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 3.7 | 3.5
Times are in milliseconds (ms).
[-------------- Downsampling: torch.Size([1, 1, 906, 438]) -> (120, 1200) --------------]
| Reference, PIL 8.3.2, mode: F | 1.10.0a0+git1e87d91
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 834.4 | 605.7
Times are in microseconds (us).
```
</details>
Code is moved from torchvision: https://github.com/pytorch/vision/pull/4208
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65142
Reviewed By: mrshenli
Differential Revision: D32432405
Pulled By: jbschlosser
fbshipit-source-id: b66c548347f257c522c36105868532e8bc1d4c6d
2021-11-17 09:10:15 -08:00
vfdev-5
6adbe044e3
Added nearest-exact interpolation mode ( #64501 )
...
Summary:
Added "nearest-exact" interpolation mode to fix the issues: https://github.com/pytorch/pytorch/issues/34808 and https://github.com/pytorch/pytorch/issues/62237 .
Description:
As we can not fix "nearest" mode without large impact on already trained model [it was suggested](https://github.com/pytorch/pytorch/pull/64501#pullrequestreview-749771815 ) to introduce new mode instead of fixing exising "nearest" mode.
- New mode "nearest-exact" performs index computation for nearest interpolation to match scikit-image, pillow, TF2 and while "nearest" mode still match opencv INTER_NEAREST, which appears to be buggy, see https://ppwwyyxx.com/blog/2021/Where-are-Pixels/#Libraries .
"nearest":
```
input_index_f32 = output_index * scale
input_index = floor(input_index_f32)
```
"nearest-exact"
```
input_index_f32 = (output_index + 0.5) * scale - 0.5
input_index = round(input_index_f32)
```
Comparisions with other libs: https://gist.github.com/vfdev-5/a5bd5b1477b1c82a87a0f9e25c727664
PyTorch version | 1.9.0 "nearest" | this PR "nearest" | this PR "nearest-exact"
---|---|---|---
Resize option: | |
OpenCV INTER_NEAREST result mismatches | 0 | 0 | 10
OpenCV INTER_NEAREST_EXACT result mismatches | 9 | 9 | 9
Scikit-Image result mismatches | 10 | 10 | 0
Pillow result mismatches | 10 | 10 | 7
TensorFlow result mismatches | 10 | 10 | 0
Rescale option: | | |
size mismatches (https://github.com/pytorch/pytorch/issues/62396 ) | 10 | 10 | 10
OpenCV INTER_NEAREST result mismatches | 3 | 3| 5
OpenCV INTER_NEAREST_EXACT result mismatches | 3 | 3| 4
Scikit-Image result mismatches | 4 | 4 | 0
Scipy result mismatches | 4 | 4 | 0
TensorFlow: no such option | - | -
Versions:
```
skimage: 0.19.0.dev0
opencv: 4.5.4-dev
scipy: 1.7.2
Pillow: 8.4.0
TensorFlow: 2.7.0
```
Implementations in other libs:
- Pillow:
- ee079ae67e/src/libImaging/Geometry.c (L889-L899)ee079ae67e/src/libImaging/Geometry.c (L11)38fae50c3f/skimage/transform/_warps.py (L180-L188)47bb6febaa/scipy/ndimage/src/ni_interpolation.c (L775-L779)47bb6febaa/scipy/ndimage/src/ni_interpolation.c (L479)https://github.com/pytorch/pytorch/pull/64501
Reviewed By: anjali411
Differential Revision: D32361901
Pulled By: jbschlosser
fbshipit-source-id: df906f4d25a2b2180e1942ffbab2cc14600aeed2
2021-11-15 14:28:19 -08:00
Junjie Wang
301369a774
[PyTorch][Fix] Pass the arguments of embedding as named arguments ( #67574 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67574
When adding the optional params for sharded embedding op. Found that we cannot get these params from `__torch_function__` override. The reason is that we don't pass them via keyword arguments. So maybe we want to change them to kwargs?
ghstack-source-id: 143029375
Test Plan: CI
Reviewed By: albanD
Differential Revision: D32039152
fbshipit-source-id: c7e598e49eddbabff6e11e3f8cb0818f57c839f6
2021-11-11 15:22:10 -08:00
Kushashwa Ravi Shrimali
9e7b314318
OpInfo for nn.functional.conv1d ( #67747 )
...
Summary:
This PR adds OpInfo for `nn.functional.conv1d`. There is a minor typo fix in the documentation as well.
Issue tracker: https://github.com/pytorch/pytorch/issues/54261
cc: mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67747
Reviewed By: malfet
Differential Revision: D32309258
Pulled By: mruberry
fbshipit-source-id: add21911b8ae44413e033e19398f398210737c6c
2021-11-11 09:23:04 -08:00
Natalia Gimelshein
8dfbc620d4
don't hardcode mask type in mha ( #68077 )
...
Summary:
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68077
Reviewed By: zou3519
Differential Revision: D32292410
Pulled By: ngimel
fbshipit-source-id: 67213cf5474dc3f83e90e28cf5a823abb683a6f9
2021-11-10 09:41:21 -08:00
vfdev-5
49bf24fc83
Updated error message for nn.functional.interpolate ( #66417 )
...
Summary:
Description:
- Updated error message for nn.functional.interpolate
Fixes https://github.com/pytorch/pytorch/issues/63845
cc vadimkantorov
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66417
Reviewed By: albanD
Differential Revision: D31924761
Pulled By: jbschlosser
fbshipit-source-id: ca74c77ac34b4f644aa10440b77b3fcbe4e770ac
2021-10-26 10:33:24 -07:00
kshitij12345
828a9dcc04
[nn] MarginRankingLoss : no batch dim ( #64975 )
...
Summary:
Reference: https://github.com/pytorch/pytorch/issues/60585
cc albanD mruberry jbschlosser walterddr
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64975
Reviewed By: albanD
Differential Revision: D31906528
Pulled By: jbschlosser
fbshipit-source-id: 1127242a859085b1e06a4b71be19ad55049b38ba
2021-10-26 09:03:31 -07:00
Mikayla Gawarecki
5569d5824c
Fix documentation of arguments for torch.nn.functional.Linear ( #66884 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66884
Addressing docs fix mentioned in issue 64978 on Github
ghstack-source-id: 141093449
Test Plan: https://pxl.cl/1Rxkz
Reviewed By: anjali411
Differential Revision: D31767303
fbshipit-source-id: f1ca10fed5bb768749bce3ddc240bbce1dfb3f84
2021-10-20 12:02:58 -07:00
vfdev
62ca5a81c0
Exposed recompute_scale_factor into nn.Upsample ( #66419 )
...
Summary:
Description:
- Exposed recompute_scale_factor into nn.Upsample such that recompute_scale_factor=True option could be used
Context: https://github.com/pytorch/pytorch/pull/64501#discussion_r710205190
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66419
Reviewed By: gchanan
Differential Revision: D31731276
Pulled By: jbschlosser
fbshipit-source-id: 2118489e6f5bc1142f2a64323f4cfd095a9f3c42
2021-10-20 07:59:25 -07:00
kshitij12345
1db50505d5
[nn] MultiLabelSoftMarginLoss : no batch dim support ( #65690 )
...
Summary:
Reference: https://github.com/pytorch/pytorch/issues/60585
cc albanD mruberry jbschlosser walterddr
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65690
Reviewed By: zou3519
Differential Revision: D31731162
Pulled By: jbschlosser
fbshipit-source-id: d26f27555f78afdadd49126e0548a8bfda50cc5a
2021-10-18 15:30:01 -07:00
Kushashwa Ravi Shrimali
909694fd88
Fix nn.functional.max_poolNd dispatch (for arg: return_indices) ( #62544 )
...
Summary:
Please see https://github.com/pytorch/pytorch/issues/62545 for context.
The order of `return_indices, ceil_mode` is different for `nn.functional.max_poolNd` functions to what seen with `torch.nn.MaxPoolNd` (modular form). While this should be resolved in the future, it was decided to first raise a warning that the behavior will be changed in the future. (please see https://github.com/pytorch/pytorch/pull/62544#issuecomment-893770955 for more context)
This PR thus raises appropriate warnings and updates the documentation to show the full signature (along with a note) for `torch.nn.functional.max_poolNd` functions.
**Quick links:**
(_upstream_)
* Documentation of [`nn.functional.max_pool1d`](https://pytorch.org/docs/1.9.0/generated/torch.nn.functional.max_pool1d.html ), [`nn.functional.max_pool2d`](https://pytorch.org/docs/stable/generated/torch.nn.functional.max_pool2d.html ), and [`nn.functional.max_pool3d`](https://pytorch.org/docs/stable/generated/torch.nn.functional.max_pool3d.html ).
(_this branch_)
* Documentation of [`nn.functional.max_pool1d`](https://docs-preview.pytorch.org/62544/generated/torch.nn.functional.max_pool1d.html?highlight=max_pool1d ), [`nn.functional.max_pool2d`](https://docs-preview.pytorch.org/62544/generated/torch.nn.functional.max_pool2d.html?highlight=max_pool2d#torch.nn.functional.max_pool2d ), and [`nn.functional.max_pool3d`](https://docs-preview.pytorch.org/62544/generated/torch.nn.functional.max_pool3d.html?highlight=max_pool3d#torch.nn.functional.max_pool3d ).
cc mruberry jbschlosser
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62544
Reviewed By: gchanan
Differential Revision: D31179038
Pulled By: jbschlosser
fbshipit-source-id: 0a2c7215df9e132ce9ec51448c5b3c90bbc69030
2021-10-18 08:34:38 -07:00
Natalia Gimelshein
4a50b6c490
fix cosine similarity dimensionality check ( #66191 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/66086
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66191
Reviewed By: dagitses, malfet
Differential Revision: D31436997
Pulled By: ngimel
fbshipit-source-id: 363556eea4e1696d928ae08320d298451c286b10
2021-10-06 15:44:51 -07:00
John Clow
36485d36b6
Docathon: Add docs for nn.functional.*d_max_pool ( #63264 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63264
Adding docs to max_pool to resolve docathon issue #60904
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D31071491
Pulled By: Gamrix
fbshipit-source-id: f4f6ec319c62ff1dfaeed8bb6bb0464b9514a7e9
2021-09-23 11:59:50 -07:00
kshitij12345
a012216b96
[nn] Fold : no batch dim ( #64909 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/64907
Reference: https://github.com/pytorch/pytorch/issues/60585
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64909
Reviewed By: cpuhrsch, heitorschueroff
Differential Revision: D30991087
Pulled By: jbschlosser
fbshipit-source-id: 91a37e0b1d51472935ff2308719dfaca931513f3
2021-09-23 08:37:32 -07:00
Samantha Andow
c7c711bfb8
Add optional tensor arguments to ( #63967 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/63435
Adds optional tensor arguments to check handling torch function checks. The only one I didn't do this for in the functional file was `multi_head_attention_forward` since that already took care of some optional tensor arguments but not others so it seemed like arguments were specifically chosen
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63967
Reviewed By: albanD
Differential Revision: D30640441
Pulled By: ezyang
fbshipit-source-id: 5ef9554d2fb6c14779f8f45542ab435fb49e5d0f
2021-08-30 19:21:26 -07:00
Thomas J. Fan
d3bcba5f85
ENH Adds label_smoothing to cross entropy loss ( #63122 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/7455
Partially resolves pytorch/vision#4281
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63122
Reviewed By: iramazanli
Differential Revision: D30586076
Pulled By: jbschlosser
fbshipit-source-id: 06afc3aa1f8b9edb07fe9ed68c58968ad1926924
2021-08-29 23:33:04 -07:00
Sameer Deshmukh
809e1e7457
Allow TransformerEncoder and TransformerDecoder to accept 0-dim batch sized tensors. ( #62800 )
...
Summary:
This issue fixes a part of https://github.com/pytorch/pytorch/issues/12013 , which is summarized concretely in https://github.com/pytorch/pytorch/issues/38115 .
This PR allows TransformerEncoder and Decoder (alongwith the inner `Layer` classes) to accept inputs with 0-dimensional batch sizes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62800
Reviewed By: VitalyFedyunin
Differential Revision: D30303240
Pulled By: jbschlosser
fbshipit-source-id: 8f8082a6f2a9f9d7ce0b22a942d286d5db62bd12
2021-08-13 16:11:57 -07:00
Thomas J. Fan
c5f3ab6982
ENH Adds no_batch_dim to FractionalMaxPool2d ( #62490 )
...
Summary:
Towards https://github.com/pytorch/pytorch/issues/60585
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62490
Reviewed By: bdhirsh
Differential Revision: D30287143
Pulled By: jbschlosser
fbshipit-source-id: 1b9dd932157f571adf3aa2c98c3c6b56ece8fa6e
2021-08-13 08:48:40 -07:00
Sameer Deshmukh
9e7b6bb69f
Allow LocalResponseNorm to accept 0 dim batch sizes ( #62801 )
...
Summary:
This issue fixes a part of https://github.com/pytorch/pytorch/issues/12013 , which is summarized concretely in https://github.com/pytorch/pytorch/issues/38115 .
This PR allows `LocalResponseNorm` to accept tensors with 0 dimensional batch size.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62801
Reviewed By: zou3519
Differential Revision: D30165282
Pulled By: jbschlosser
fbshipit-source-id: cce0b2d12dbf47dc8ed6247c267bf2f2305f858a
2021-08-10 06:54:52 -07:00
Natalia Gimelshein
e6a3154519
Allow broadcasting along non-reduction dimension for cosine similarity ( #62912 )
...
Summary:
Checks introduced by https://github.com/pytorch/pytorch/issues/58559 are too strict and disable correctly working cases that people were relying on.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62912
Reviewed By: jbschlosser
Differential Revision: D30165827
Pulled By: ngimel
fbshipit-source-id: f9229a9fc70142fe08a42fbf2d18dae12f679646
2021-08-06 19:17:04 -07:00
James Reed
5542d590d4
[EZ] Fix type of functional.pad default value ( #62095 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/62095
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D29879898
Pulled By: jamesr66a
fbshipit-source-id: 903d32eca0040f176c60ace17cadd36cd710345b
2021-08-03 17:47:20 -07:00
Joel Schlosser
a42345adee
Support for target with class probs in CrossEntropyLoss ( #61044 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/11959
Alternative approach to creating a new `CrossEntropyLossWithSoftLabels` class. This PR simply adds support for "soft targets" AKA class probabilities to the existing `CrossEntropyLoss` and `NLLLoss` classes.
Implementation is dumb and simple right now, but future work can add higher performance kernels for this case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61044
Reviewed By: zou3519
Differential Revision: D29876894
Pulled By: jbschlosser
fbshipit-source-id: 75629abd432284e10d4640173bc1b9be3c52af00
2021-07-29 10:04:41 -07:00
Thomas J. Fan
7c588d5d00
ENH Adds no_batch_dim support for pad 2d and 3d ( #62183 )
...
Summary:
Towards https://github.com/pytorch/pytorch/issues/60585
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62183
Reviewed By: ejguan
Differential Revision: D29942250
Pulled By: jbschlosser
fbshipit-source-id: d1df4ddcb90969332dc1a2a7937e66ecf46f0443
2021-07-28 11:10:44 -07:00
Thomas J. Fan
71a6ef17a5
ENH Adds no_batch_dim tests/docs for Maxpool1d & MaxUnpool1d ( #62206 )
...
Summary:
Towards https://github.com/pytorch/pytorch/issues/60585
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62206
Reviewed By: ejguan
Differential Revision: D29942341
Pulled By: jbschlosser
fbshipit-source-id: a3fad774cee30478f7d6cdd49d2eec31be3fc518
2021-07-28 10:15:32 -07:00
Thomas J. Fan
1ec6205bd0
ENH Adds no_batch_dim support for maxpool and unpool for 2d and 3d ( #61984 )
...
Summary:
Towards https://github.com/pytorch/pytorch/issues/60585
(Interesting how the maxpool tests are currently in `test/test_nn.py`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61984
Reviewed By: suo
Differential Revision: D29883846
Pulled By: jbschlosser
fbshipit-source-id: 1e0637c96f8fa442b4784a9865310c164cbf61c8
2021-07-23 16:14:10 -07:00
Joel Schlosser
f4ffaf0cde
Fix type promotion for cosine_similarity() ( #62054 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/61454
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62054
Reviewed By: suo
Differential Revision: D29881755
Pulled By: jbschlosser
fbshipit-source-id: 10499766ac07b0ae3c0d2f4c426ea818d1e77db6
2021-07-23 15:20:48 -07:00
Thomas J. Fan
48af9de92f
ENH Enables No-batch for *Pad1d Modules ( #61060 )
...
Summary:
Toward https://github.com/pytorch/pytorch/issues/60585
This PR adds a `single_batch_reference_fn` that uses the single batch implementation to check no-batch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61060
Reviewed By: mrshenli
Differential Revision: D29739823
Pulled By: jbschlosser
fbshipit-source-id: d90d88a3671177a647171801cc6ec7aa3df35482
2021-07-21 07:12:41 -07:00
Joel Schlosser
4d842d909b
Revert FC workaround for ReflectionPad3d ( #61308 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/61248
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61308
Reviewed By: iramazanli
Differential Revision: D29566849
Pulled By: jbschlosser
fbshipit-source-id: 8ab443ffef7fd9840d64d71afc2f2d2b8a410ddb
2021-07-12 14:19:07 -07:00
vfdev
68f9819df4
Typo fix ( #41121 )
...
Summary:
Description:
- Typo fix in the docstring
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41121
Reviewed By: heitorschueroff
Differential Revision: D29660228
Pulled By: ezyang
fbshipit-source-id: fc2b55683ec5263ff55c3b6652df3e6313e02be2
2021-07-12 12:43:47 -07:00
kshitij12345
3faf6a715d
[special] migrate log_softmax ( #60512 )
...
Summary:
Reference: https://github.com/pytorch/pytorch/issues/50345
Rendered Docs: https://14335157-65600975-gh.circle-artifacts.com/0/docs/special.html#torch.special.log_softmax
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60512
Reviewed By: iramazanli
Differential Revision: D29626262
Pulled By: mruberry
fbshipit-source-id: c42d4105531ffb004f11f1ba6ae50be19bc02c91
2021-07-12 11:01:25 -07:00
Natalia Gimelshein
5b118a7f23
Don't reference reflection_pad3d in functional.py ( #60837 )
...
Summary:
To work around FC issue
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60837
Reviewed By: jbschlosser
Differential Revision: D29421142
Pulled By: ngimel
fbshipit-source-id: f5c1d9c324173b628e286f9005edf7109162066f
2021-06-27 20:54:32 -07:00
lezcano
4e347f1242
[docs] Fix backticks in docs ( #60474 )
...
Summary:
There is a very common error when writing docs: One forgets to write a matching `` ` ``, and something like ``:attr:`x`` is rendered in the docs. This PR fixes most (all?) of these errors (and a few others).
I found these running ``grep -r ">[^#<][^<]*\`"`` on the `docs/build/html/generated` folder. The regex finds an HTML tag that does not start with `#` (as python comments in example code may contain backticks) and that contains a backtick in the rendered HTML.
This regex has not given any false positive in the current codebase, so I am inclined to suggest that we should add this check to the CI. Would this be possible / reasonable / easy to do malfet ?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60474
Reviewed By: mrshenli
Differential Revision: D29309633
Pulled By: albanD
fbshipit-source-id: 9621e0e9f87590cea060dd084fa367442b6bd046
2021-06-24 06:27:41 -07:00
Thomas J. Fan
4e51503b1f
DOC Improves input and target docstring for loss functions ( #60553 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/56581
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60553
Reviewed By: VitalyFedyunin
Differential Revision: D29343797
Pulled By: jbschlosser
fbshipit-source-id: cafc29d60a204a21deff56dd4900157d2adbd91e
2021-06-23 20:20:29 -07:00
Thomas J. Fan
c16f87949f
ENH Adds nn.ReflectionPad3d ( #59791 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/27655
This PR adds a C++ and Python version of ReflectionPad3d with structured kernels. The implementation uses lambdas extensively to better share code from the backward and forward pass.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59791
Reviewed By: gchanan
Differential Revision: D29242015
Pulled By: jbschlosser
fbshipit-source-id: 18e692d3b49b74082be09f373fc95fb7891e1b56
2021-06-21 10:53:14 -07:00
Saketh Are
bbd58d5c32
fix :attr: rendering in F.kl_div ( #59636 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59636
Fixes #57538
Test Plan:
Rebuilt docs to verify the fix:
{F623235643}
Reviewed By: zou3519
Differential Revision: D28964825
fbshipit-source-id: 275c7f70e69eda15a807e1774fd852d94bf02864
2021-06-09 12:20:14 -07:00
Thomas J. Fan
8693e288d7
DOC Small rewrite of interpolate recompute_scale_factor docstring ( #58989 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/55909
This PR looks to improve the documentation to describe the following behavior:
8130f2f67a/torch/nn/functional.py (L3673-L3685)https://github.com/pytorch/pytorch/pull/58989
Reviewed By: ejguan
Differential Revision: D28931879
Pulled By: jbschlosser
fbshipit-source-id: d1140ebe1631c5ec75f135c2907daea19499f21a
2021-06-07 12:40:05 -07:00
Joel Schlosser
ef32a29c97
Back out "[pytorch][PR] ENH Adds dtype to nn.functional.one_hot" ( #59080 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59080
Original commit changeset: 3686579517cc
Test Plan: None; reverting diff
Reviewed By: albanD
Differential Revision: D28746799
fbshipit-source-id: 75a7885ab0bf3abadde9a42b56d479f71f57c89c
2021-05-27 15:40:52 -07:00
Adnios
09a8f22bf9
Add mish activation function ( #58648 )
...
Summary:
See issus: https://github.com/pytorch/pytorch/issues/58375
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58648
Reviewed By: gchanan
Differential Revision: D28625390
Pulled By: jbschlosser
fbshipit-source-id: 23ea2eb7d5b3dc89c6809ff6581b90ee742149f4
2021-05-25 10:36:21 -07:00
Thomas J. Fan
a7f4f80903
ENH Adds dtype to nn.functional.one_hot ( #58090 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/33046
Related to https://github.com/pytorch/pytorch/issues/53785
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58090
Reviewed By: zou3519
Differential Revision: D28640893
Pulled By: jbschlosser
fbshipit-source-id: 3686579517ccc75beaa74f0f6d167f5e40a83fd2
2021-05-24 13:48:25 -07:00
Basil Hosmer
90f05c005d
refactor multi_head_attention_forward ( #56674 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56674
`torch.nn.functional.multi_head_attention_forward` supports a long tail of options and variations of the multihead attention computation. Its complexity is mostly due to arbitrating among options, preparing values in multiple ways, and so on - the attention computation itself is a small fraction of the implementation logic, which is relatively simple but can be hard to pick out.
The goal of this PR is to
- make the internal logic of `multi_head_attention_forward` less entangled and more readable, with the attention computation steps easily discernible from their surroundings.
- factor out simple helpers to perform the actual attention steps, with the aim of making them available to other attention-computing contexts.
Note that these changes should leave the signature and output of `multi_head_attention_forward` completely unchanged, so not BC-breaking. Later PRs should present new multihead attention entry points, but deprecating this one is out of scope for now.
Changes are in two parts:
- the implementation of `multi_head_attention_forward` has been extensively resequenced, which makes the rewrite look more total than it actually is. Changes to argument-processing logic are largely confined to a) minor perf tweaks/control flow tightening, b) error message improvements, and c) argument prep changes due to helper function factoring (e.g. merging `key_padding_mask` with `attn_mask` rather than applying them separately)
- factored helper functions are defined just above `multi_head_attention_forward`, with names prefixed with `_`. (A future PR may pair them with corresponding modules, but for now they're private.)
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D28344707
Pulled By: bhosmer
fbshipit-source-id: 3bd8beec515182c3c4c339efc3bec79c0865cb9a
2021-05-11 10:09:56 -07:00
Harish Shankam
ad31aa652c
Fixed the error in conv1d example ( #57356 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/51225
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57356
Reviewed By: albanD
Differential Revision: D28173174
Pulled By: malfet
fbshipit-source-id: 5e813306f2e2f7e0412ffaa5d147441134739e00
2021-05-06 07:02:37 -07:00
Joel Schlosser
7d2a9f2dc9
Fix instance norm input size validation + test ( #56659 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/45687
Fix changes the input size check for `InstanceNorm*d` to be more restrictive and correctly reject sizes with only a single spatial element, regardless of batch size, to avoid infinite variance.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56659
Reviewed By: pbelevich
Differential Revision: D27948060
Pulled By: jbschlosser
fbshipit-source-id: 21cfea391a609c0774568b89fd241efea72516bb
2021-04-23 10:53:39 -07:00
M.L. Croci
1f0223d6bb
Fix bug in gaussian_nll_loss ( #56469 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53964 . cc albanD almson
## Major changes:
- Overhauled the actual loss calculation so that the shapes are now correct (in functional.py)
- added the missing doc in nn.functional.rst
## Minor changes (in functional.py):
- I removed the previous check on whether input and target were the same shape. This is to allow for broadcasting, say when you have 10 predictions that all have the same target.
- I added some comments to explain each shape check in detail. Let me know if these should be shortened/cut.
Screenshots of updated docs attached.
Let me know what you think, thanks!
## Edit: Description of change of behaviour (affecting BC):
The backwards-compatibility is only affected for the `reduction='none'` mode. This was the source of the bug. For tensors with size (N, D), the old returned loss had size (N), as incorrect summation was happening. It will now have size (N, D) as expected.
### Example
Define input tensors, all with size (2, 3).
`input = torch.tensor([[0., 1., 3.], [2., 4., 0.]], requires_grad=True)`
`target = torch.tensor([[1., 4., 2.], [-1., 2., 3.]])`
`var = 2*torch.ones(size=(2, 3), requires_grad=True)`
Initialise loss with reduction mode 'none'. We expect the returned loss to have the same size as the input tensors, (2, 3).
`loss = torch.nn.GaussianNLLLoss(reduction='none')`
Old behaviour:
`print(loss(input, target, var)) `
`# Gives tensor([3.7897, 6.5397], grad_fn=<MulBackward0>. This has size (2).`
New behaviour:
`print(loss(input, target, var)) `
`# Gives tensor([[0.5966, 2.5966, 0.5966], [2.5966, 1.3466, 2.5966]], grad_fn=<MulBackward0>)`
`# This has the expected size, (2, 3).`
To recover the old behaviour, sum along all dimensions except for the 0th:
`print(loss(input, target, var).sum(dim=1))`
`# Gives tensor([3.7897, 6.5397], grad_fn=<SumBackward1>.`
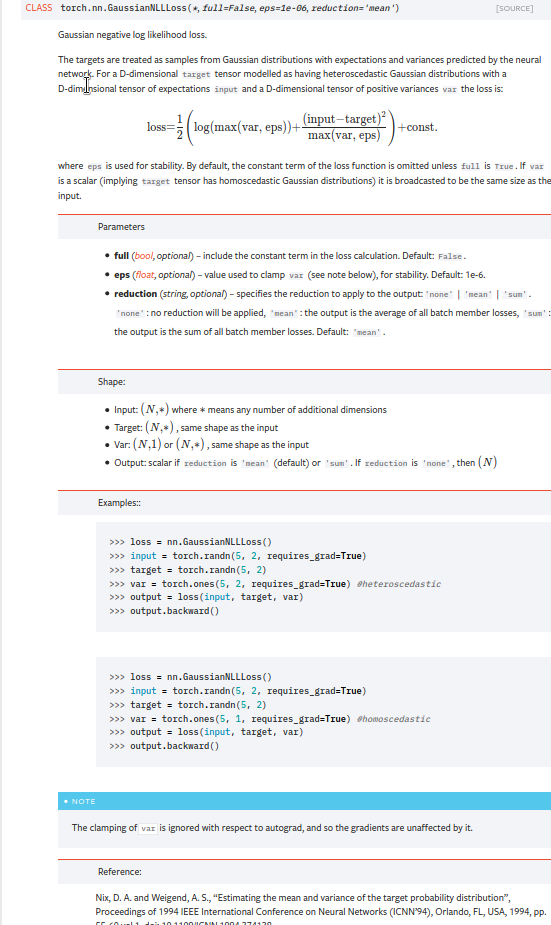
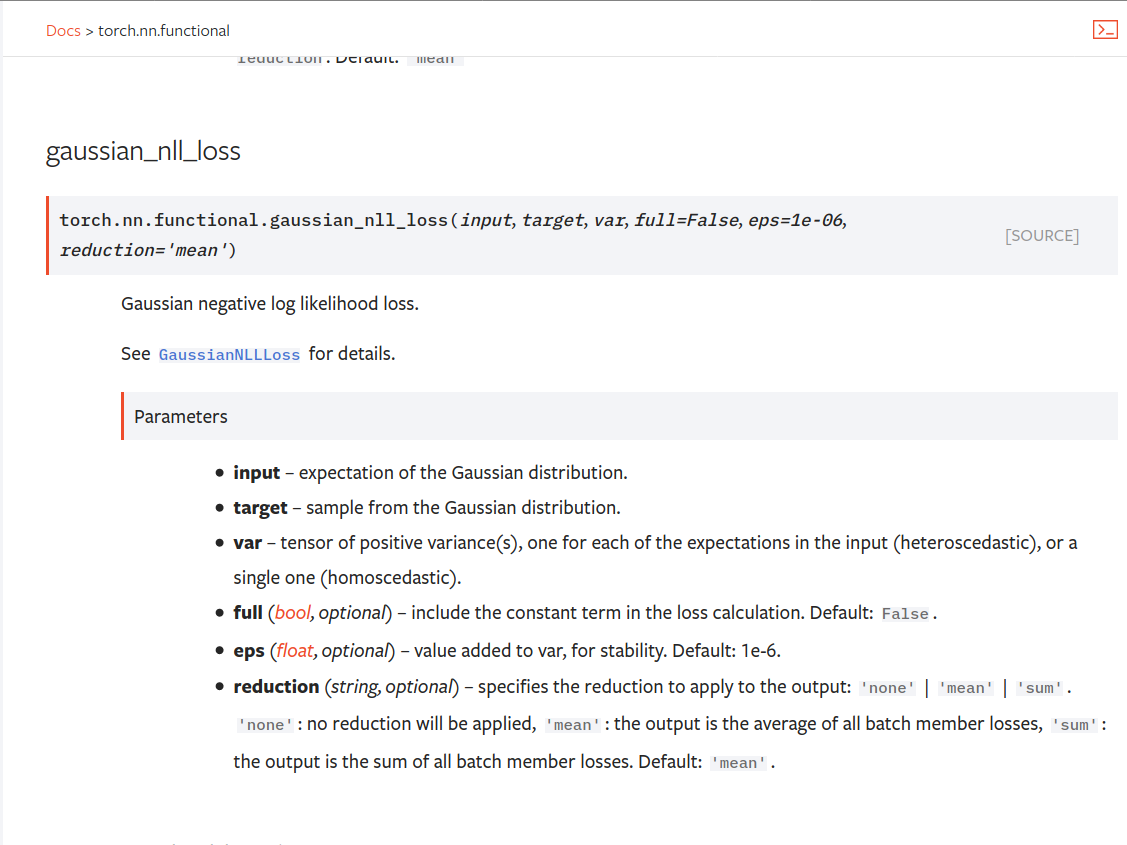
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56469
Reviewed By: jbschlosser, agolynski
Differential Revision: D27894170
Pulled By: albanD
fbshipit-source-id: 197890189c97c22109491c47f469336b5b03a23f
2021-04-22 07:43:48 -07:00
{kind=link}
{kind=link}