Fixes #ISSUE_NUMBER
1、add checkpoint support for custom device
2、add a device argument, I want to add a device="cuda" parameter to the func `forward` of `CheckpointFunction`, and I can specify the device type when using it, but the func `apply` of `torch.autograd.Function` does not support `kwargs`, so I added a variable named `_device`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99626
Approved by: https://github.com/soulitzer
Description:
- As suggested by Nikita, created `torch.backends.cpu` submodule and exposed `get_cpu_capability`.
- In torchvision Resize method we want to know current cpu capability in order to pick appropriate codepath depending on cpu capablities
Newly coded vectorized resize of uint8 images on AVX2 supported CPUs is now faster than older way (uint8->float->resize->uint8). However, on non-avx hardware (e.g. Mac M1) certain configs are slower using native uint8.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100164
Approved by: https://github.com/albanD, https://github.com/malfet
Summary
* Introduce `DiagnosticContext` to `torch.onnx.dynamo_export`.
* Remove `DiagnosticEngine` in preparations to update 'diagnostics' in `dynamo_export` to drop dependencies on global diagnostic context. No plans to update `torch.onnx.export` diagnostics.
Next steps
* Separate `torch.onnx.export` diagnostics and `torch.onnx.dynamo_export` diagnostics.
* Drop dependencies on global diagnostic context. https://github.com/pytorch/pytorch/pull/100219
* Replace 'print's with 'logger.log'.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99668
Approved by: https://github.com/justinchuby, https://github.com/abock
This PR proposes an optimized way to do Exponential Moving Average (EMA), which is faster than the current way using `swa_utils.AveragedModel` described in https://pytorch.org/docs/stable/optim.html#custom-averaging-strategies.
This implementation is asynchronous, and is built as an optimizer wrapper so that the EMA weight update happens without any additional CPU/GPU sync, just after optimizer steps, and with limited code changes.
Example usage:
```
model = Model().to(device)
opt = torch.optim.Adam(model.parameters())
opt = EMAOptimizer(opt, device, 0.9999)
for epoch in range(epochs):
training_loop(model, opt)
regular_eval_accuracy = evaluate(model)
with opt.swap_ema_weights():
ema_eval_accuracy = evaluate(model)
```
Here are some benchmarks (time per iteration) on various torchvision models:
|model|this PR iteration time |swa_utils.AveragedModel iteration time| iteration speedup |
|-----|-----------------------------|-----------------------|---------------------------------------------|
| | | | |
|regnet_x_1_6gf|62.73 |67.998 |1.08 |
|regnet_x_3_2gf|101.75 |109.422 |1.08 |
|regnet_x_400mf|25.13 |32.005 |1.27 |
|regnet_x_800mf|33.01 |37.466 |1.13 |
|regnet_x_8gf|128.13 |134.868 |1.05 |
|regnet_y_16gf|252.91 |261.292 |1.03 |
|regnet_y_1_6gf|72.14 |84.22 |1.17 |
|regnet_y_3_2gf|99.99 |109.296 |1.09 |
|regnet_y_400mf|29.53 |36.506 |1.24 |
|regnet_y_800mf|37.82 |43.634 |1.15 |
|regnet_y_8gf|196.63 |203.317 |1.03 |
|resnet101|128.80 |137.434 |1.07 |
|resnet152|182.85 |196.498 |1.07 |
|resnet18|29.06 |29.975 |1.03 |
|resnet34|50.73 |53.443 |1.05 |
|resnet50|76.88 |80.602 |1.05 |
|resnext101_32x8d|277.29 |280.759 |1.01 |
|resnext101_64x4d|269.56 |281.052 |1.04 |
|resnext50_32x4d|100.73 |101.102 |1.00 |
|shufflenet_v2_x0_5|10.56 |15.419 |1.46 |
|shufflenet_v2_x1_0|13.11 |18.525 |1.41 |
|shufflenet_v2_x1_5|18.05 |23.132 |1.28 |
|shufflenet_v2_x2_0|25.04 |30.008 |1.20 |
|squeezenet1_1|14.26 |14.325 |1.00 |
|swin_b|264.52 |274.613 |1.04 |
|swin_s|180.66 |188.914 |1.05 |
|swin_t|108.62 |112.632 |1.04 |
|swin_v2_s|220.29 |231.153 |1.05 |
|swin_v2_t|127.27 |133.586 |1.05 |
|vgg11|95.52 |103.714 |1.09 |
|vgg11_bn|106.49 |120.711 |1.13 |
|vgg13|132.94 |147.063 |1.11 |
|vgg13_bn|149.73 |165.256 |1.10 |
|vgg16|158.19 |172.865 |1.09 |
|vgg16_bn|177.04 |192.888 |1.09 |
|vgg19|184.76 |194.194 |1.05 |
|vgg19_bn|203.30 |213.334 |1.05 |
|vit_b_16|217.31 |219.748 |1.01 |
|vit_b_32|69.47 |75.692 |1.09 |
|vit_l_32|223.20 |258.487 |1.16 |
|wide_resnet101_2|267.38 |279.836 |1.05 |
|wide_resnet50_2|145.06 |154.918 |1.07 |
You can see that in all cases it is faster than using `AveragedModel`. In fact in many cases, adding EMA does not add any overhead since the computation is hidden behind the usual iteration flow.
This is a similar implementation to the one currently in [NVIDIA NeMo](https://github.com/NVIDIA/NeMo).
If the team is interested in merging this, let me know and I'll add some documentation similar to `swa_utils` and tests.
Credits to @szmigacz for the implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94820
Approved by: https://github.com/janeyx99
Allowed modules are stuck into dynamo's fx graph as call_module
nodes, without dynamo doing any tracing of the module. This means
during AOT trace time, hooks will fire during tracing when the
call_module is executed, but the hooks themselves will disappear
after that and not be present in the compiled program.
(worse, if they performed any tensor operations, those would get
traced so you could end up with part of the hook's functionality).
To circumvent this, there are two options for 'allowed modules' with hooks.
1) don't treat them as 'allowed' - trace into them
2) graph-break, so the module is no longer part of the dynamo trace at all
(1) will fail for users that opted into allowed modules becuase they know
their module has problems being traced by dynamo.
(2) causes graph breaks on common modules such as nn.Linear, just because they
are marked as 'allowed'.
It would help matters if we could differentiate between types of allowed modules
(A) allowed to avoid overheads - used for common ops like nn.Linear
(B) allowed to avoid dynamo graphbreaks caused by unsupported code
Ideally, we'd use method (1) for group (A) and (2) for (B).
For now, graph-break on all cases of allowed modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97184
Approved by: https://github.com/jansel
Summary
* Introduce input/output adapter. Due to design differences, input/output format
between PyTorch model and exported ONNX model are often not the same. E.g., `None`
inputs are allowed for PyTorch model, but are not supported by ONNX. Nested constructs
of tensors are allowed for PyTorch model, but only flattened tensors are supported by ONNX,
etc. The new input/output adapter is exported with the model. Providing an interface to
automatically convert and validate inputs/outputs format.
* As suggested by #98251,
provide extension for unwrapping user defined python classes for `dynamo.export` based
exporter. Unblock huggingface models.
* Re-wire tests to run through `DynamoExporter` w/ `dynamo_export` api. Kept
`DynamoOptimizeExporter` in the tests for now for coverage of this change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98421
Approved by: https://github.com/justinchuby, https://github.com/titaiwangms, https://github.com/thiagocrepaldi
This PR makes basic nnmodule forward hooks work by default, without any overhead. But it leaves silent correctness issues if users modify/remove their hooks later, thus also emits a warning.
- the usual case is to not use hooks, so avoid guard overhead here
- registering any hook before compile will trigger a warning about hook support
- registering a hook later (or removing one) requires user knowledge and opting in,
currently this isn't warnable (but maybe we can observe compiled nnmodules to make it
warnable).
Why skip hook guards by default instead of not tracing __call__/hooks by default?
- avoid having a mode flag that alters dynamo tracing behavior (harder to test both codepaths
in CI with full coverage)
- the most basic hook usecase (registering a hook before compile, and never removing it)
will work by default with this PR, while it would require enablement and incur overhead
in the 'not tracing __call__' proposal.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98371
Approved by: https://github.com/jansel
This is the first phase of the new ONNX exporter API for exporting from TorchDynamo and FX, and represents the beginning of a new era for exporting ONNX from PyTorch.
The API here is a starting point upon which we will layer more capability and expressiveness in subsequent phases. This first phase introduces the following into `torch.onnx`:
```python
dynamo_export(
model: torch.nn.Module,
/,
*model_args,
export_options: Optional[ExportOptions] = None,
**model_kwargs,
) -> ExportOutput:
...
class ExportOptions:
opset_version: Optional[int] = None
dynamic_shapes: Optional[bool] = None
logger: Optional[logging.Logger] = None
class ExportOutputSerializer(Protocol):
def serialize(
self,
export_output: ExportOutput,
destination: io.BufferedIOBase,
) -> None:
...
class ExportOutput:
model_proto: onnx.ModelProto
def save(
self,
destination: Union[str, io.BufferedIOBase],
*,
serializer: Optional[ExportOutputSerializer] = None,
) -> None:
...
```
In addition to the API in the first commit on this PR, we have a few experiments for exporting Dynamo and FX to ONNX that this PR rationalizes through the new Exporter API and adjusts tests to use the new API.
- A base `FXGraphModuleExporter` exporter from which all derive:
- `DynamoExportExporter`: uses dynamo.export to acquire FX graph
- `DynamoOptimizeExporter`: uses dynamo.optimize to acquire FX graph
- `FXSymbolicTraceExporter`: uses FX symbolic tracing
The `dynamo_export` API currently uses `DynamoOptimizeExporter`.
### Next Steps (subsequent PRs):
* Combine `DynamoExportExporter` and `DynamoOptimizeExporter` into a single `DynamoExporter`.
* Make it easy to test `FXSymbolicTraceExporter` through the same API; eventually `FXSymbolicTraceExporter` goes away entirely when the Dynamo approach works for large models. We want to keep `FXSymbolicTraceExporter` around for now for experimenting and internal use.
* Parameterize (on `ExportOptions`) and consolidate Dynamo exporter tests.
- This PR intentionally leaves the existing tests unchanged as much as possible except for the necessary plumbing.
* Subsequent API phases:
- Diagnostics
- Registry, dispatcher, and Custom Ops
- Passes
- Dynamic shapes
Fixes#94774
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97920
Approved by: https://github.com/justinchuby, https://github.com/titaiwangms, https://github.com/thiagocrepaldi, https://github.com/shubhambhokare1
Fixes https://github.com/pytorch/pytorch/issues/97260
We got some feedback that the page reads like "in order to save an input
for backward, you must return it as an output of the
autograd.Function.forward".
Doing so actually raises an error (on master and as of 2.1), but results
in an ambiguous situation on 2.0.0. To avoid more users running into
this, we clarify the documentation so it doesn't read like the above
and clearly mentions that you can save things from the inputs or
outputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98020
Approved by: https://github.com/soulitzer, https://github.com/kshitij12345
Chatted with @stas00 on slack and here are some great improvements he suggested to the compile docs
- [x] Rename `dynamo` folder to `compile`
- [x] Link `compile` docstring on `torch.html` to main index page for compile
- [x] Create a new index page that describes why people should care
- [x] easy perf, memory reduction, 1 line
- [x] Short benchmark table
- [x] How to guide
- [x] TOC that links to the more technical pages folks have written, make the existing docs we have a Technical overview
- [x] Highlight the new APIs for `torch._inductor.list_options()` and `torch._inductor.list_mode_options()` - clarify these are inductor specific and add more prose around which ones are most interesting
He also highlighted an interesting way to think about who is reading this doc we have
- [x] End users, that just want things to run fast
- [x] Library maintainers wrapping torch.compile which would care for example about understanding when in their code they should compile a model, which backends are supported
- [x] Debuggers who needs are somewhat addressed by the troubleshooting guide and faq but those could be dramatically reworked to say what we expect to break
And in a seperate PR I'll work on the below with @SherlockNoMad
- [ ] Authors of new backends that care about how to plug into dynamo or inductor layer so need to explain some more internals like
- [ ] IR
- [ ] Where to plugin, dynamo? inductor? triton?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96706
Approved by: https://github.com/svekars
Fixes#95796
### Implementation
Adds python implementation for `nn.ZeroPad1d` and `nn.ZeroPad3d` in `torch/nn/modules/padding.py`.
Adds cpp implementation for `nn::ZeroPad1d` and `nn::ZeroPad3d` in the following 3 files, refactored with templates similarly to `nn::ConstantPad`'s implementation: <br>
- `torch/crsc/api/include/torch/nn/modules/padding.h`
- `torch/csrc/api/include/torch/nn/options/padding.h`
- `torch/csrc/api/src/nn/modules/padding.cpp`
Also added relevant definitions in `torch/nn/modules/__init__.py`.
### Testing
Adds the following tests:
- cpp tests of similar length and structure as `ConstantPad` and the existing `ZeroPad2d` impl in `test/cpp/api/modules.cpp`
- cpp API parity tests in `torch/testing/_internal/common_nn.py`
- module init tests in `test/test_module_init.py`
Also added relevant definitions in `test/cpp_api_parity/parity-tracker.md`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96295
Approved by: https://github.com/soulitzer
This should be self containable to merge but other stuff that's been bugging me is
* Instructions on debugging IMA issues
* Dynamic shape instructions
* Explaining config options better
Will look at adding a config options doc
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95802
Approved by: https://github.com/svekars
Fixed following errors in contribution guide.
"deep neural networks using a **on** tape-based autograd systems." to "deep neural networks **using a tape-based** autograd systems."
"the best entrance **point** and are great places to start." to "the best entrance **points** and are great places to start."
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95454
Approved by: https://github.com/ezyang
Fixes https://github.com/pytorch/serve/issues/1937
A fairly common query I see folks running while using pytorch is
`nvidia-smi --format=csv,noheader,nounits --query-gpu=utilization.gpu,utilization.memory,memory.total,memory.used,temperature.gpu,power.draw,clocks.current.sm,clocks.current.memory -l 10`
Existing metrics we have
* For kernel utilization`torch.cuda.utilization()`
* For memory utilization we have them under `torch.cuda.memory` the memory allocated with `torch.cuda.memory.memory_allocated()`
* For total available memory we have `torch.cuda.get_device_properties(0).total_memory`
Which means the only metrics we're missing are
* Temperature: now in `torch.cuda.temperature()`
* Power draw: now in `torch.cuda.power()`
* Clock speed: now in `torch.cuda.clock_speed()`
With some important details on each
* Clock speed settings: I picked the SM clock domain which is documented here https://docs.nvidia.com/deploy/nvml-api/group__nvmlDeviceEnumvs.html#group__nvmlDeviceEnumvs_1g805c0647be9996589fc5e3f6ff680c64
* Temperature: I use `pynvml.nvmlDeviceGetTemperature(handle, 0)` where 0 refers to the GPU die temperature
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91717
Approved by: https://github.com/ngimel
Corrected the grammar of a sentence in "Implementing Features or Fixing Bugs" section of the contribution guide.
**Before:**
Issues that are labeled first-new-issue, low, or medium priority provide the best entrance point are great places to start.
**After:**
Issues that are labeled first-new-issue, low, or medium priority provide the best entrance point _and_ are great places to start.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93014
Approved by: https://github.com/albanD, https://github.com/kit1980
Fixes#91824
This PR add a new dynamo backend registration mechanism through ``entry_points``. The ``entry_points`` of a package is provides a way for the package to reigster a plugin for another one.
The docs of the new mechanism:
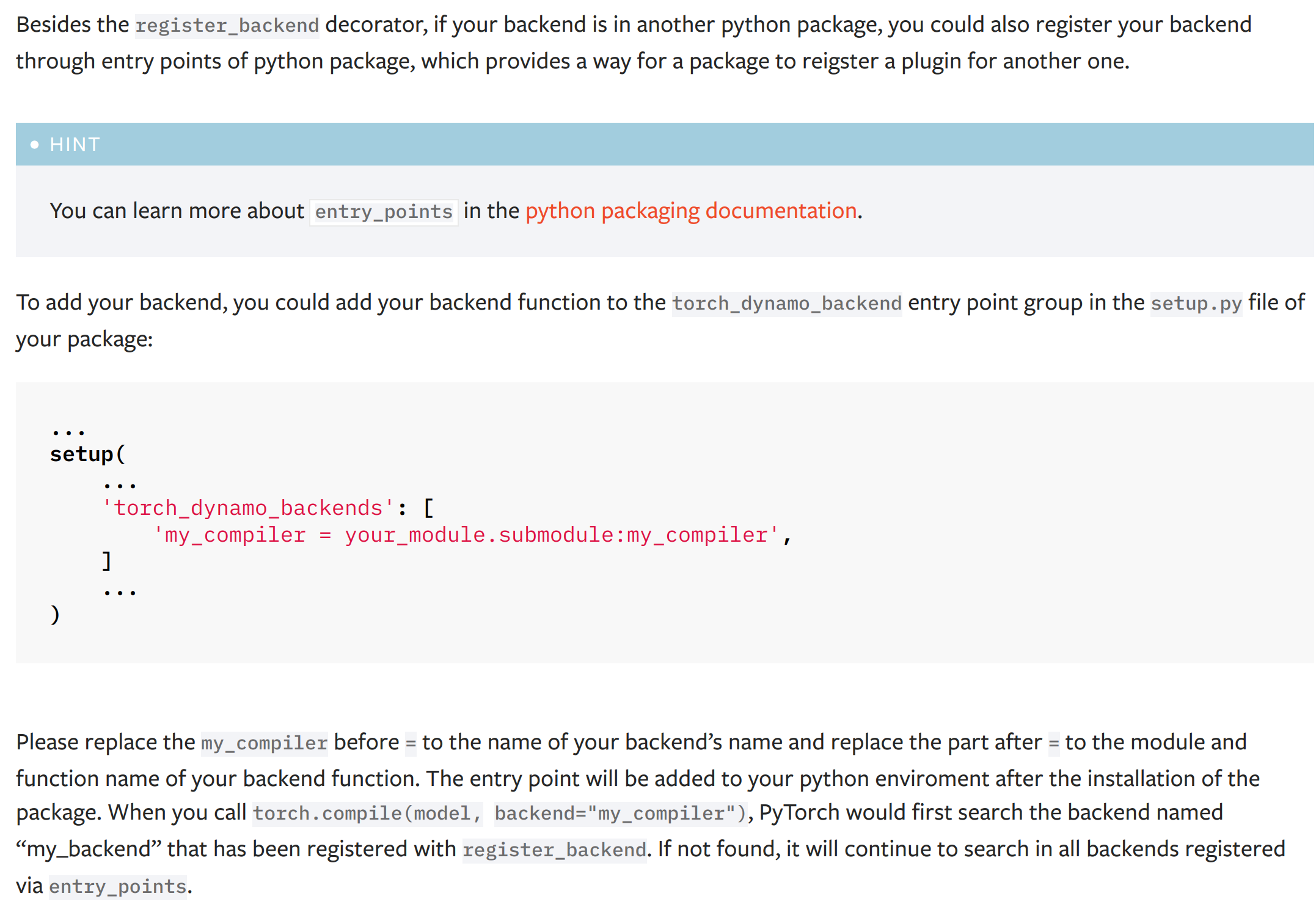
(the typo '...named "my_backend" that has been..." has been fixed to '...named "my_compiler" that has been...')
# Discussion
## About the test
I did not add a test for this PR as it is hard either to install a fack package during a test or manually hack the entry points function by replacing it with a fake one. I have tested this PR offline with the hidet compiler and it works fine. Please let me know if you have any good idea to test this PR.
## About the dependency of ``importlib_metadata``
This PR will add a dependency ``importlib_metadata`` for the python < 3.10 because the modern usage of ``importlib`` gets stable at this python version (see the documentation of the importlib package [here](https://docs.python.org/3/library/importlib.html)). For python < 3.10, the package ``importlib_metadata`` implements the feature of ``importlib``. The current PR will hint the user to install this ``importlib_metata`` if their python version < 3.10.
## About the name and docs
Please let me know how do you think the name ``torch_dynamo_backend`` as the entry point group name and the documentation of this registration mechanism.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93873
Approved by: https://github.com/malfet, https://github.com/jansel
- To check for Memory Leaks in `test_mps.py`, set the env-variable `PYTORCH_TEST_MPS_MEM_LEAK_CHECK=1` when running test_mps.py (used CUDA code as reference).
- Added support for the following new python interfaces in MPS module:
`torch.mps.[empty_cache(), set_per_process_memory_fraction(), current_allocated_memory(), driver_allocated_memory()]`
- Renamed `_is_mps_on_macos_13_or_newer()` to `_mps_is_on_macos_13_or_newer()`, and `_is_mps_available()` to `_mps_is_available()` to be consistent in naming with prefix `_mps`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94646
Approved by: https://github.com/malfet
- This PR is a prerequisite for the upcoming Memory Leak Detection PR.
- Enable global manual seeding via `torch.manual_seed()` + test case
- Add `torch.mps.synchronize()` to wait for MPS stream to finish + test case
- Enable the following python interfaces for MPS:
`torch.mps.[get_rng_state(), set_rng_state(), synchronize(), manual_seed(), seed()]`
- Added some test cases in test_mps.py
- Added `mps.rst` to document the `torch.mps` module.
- Fixed the failure with `test_public_bindings.py`
Description of new files added:
- `torch/csrc/mps/Module.cpp`: implements `torch._C` module functions for `torch.mps` and `torch.backends.mps`.
- `torch/mps/__init__.py`: implements Python bindings for `torch.mps` module.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94417
Approved by: https://github.com/albanD
- This PR is a prerequisite for the upcoming Memory Leak Detection PR.
- Enable global manual seeding via `torch.manual_seed()` + test case
- Add `torch.mps.synchronize()` to wait for MPS stream to finish + test case
- Enable the following python interfaces for MPS:
`torch.mps.[get_rng_state(), set_rng_state(), synchronize(), manual_seed(), seed()]`
- Added some test cases in test_mps.py
- Added `mps.rst` to document the `torch.mps` module.
- Fixed the failure with `test_public_bindings.py`
Description of new files added:
- `torch/csrc/mps/Module.cpp`: implements `torch._C` module functions for `torch.mps` and `torch.backends.mps`.
- `torch/mps/__init__.py`: implements Python bindings for `torch.mps` module.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94417
Approved by: https://github.com/albanD
# Summary
- Adds type hinting support for SDPA
- Updates the documentation adding warnings and notes on the context manager
- Adds scaled_dot_product_attention to the non-linear activation function section of nn.functional docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94008
Approved by: https://github.com/cpuhrsch
Preferring dash over underscore in command-line options. Add `--command-arg-name` to the argument parser. The old arguments with underscores `--command_arg_name` are kept for backward compatibility.
Both dashes and underscores are used in the PyTorch codebase. Some argument parsers only have dashes or only have underscores in arguments. For example, the `torchrun` utility for distributed training only accepts underscore arguments (e.g., `--master_port`). The dashes are more common in other command-line tools. And it looks to be the default choice in the Python standard library:
`argparse.BooleanOptionalAction`: 4a9dff0e5a/Lib/argparse.py (L893-L895)
```python
class BooleanOptionalAction(Action):
def __init__(...):
if option_string.startswith('--'):
option_string = '--no-' + option_string[2:]
_option_strings.append(option_string)
```
It adds `--no-argname`, not `--no_argname`. Also typing `_` need to press the shift or the caps-lock key than `-`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94505
Approved by: https://github.com/ezyang, https://github.com/seemethere
Changes:
1. `typing_extensions -> typing-extentions` in dependency. Use dash rather than underline to fit the [PEP 503: Normalized Names](https://peps.python.org/pep-0503/#normalized-names) convention.
```python
import re
def normalize(name):
return re.sub(r"[-_.]+", "-", name).lower()
```
2. Import `Literal`, `Protocal`, and `Final` from standard library as of Python 3.8+
3. Replace `Union[Literal[XXX], Literal[YYY]]` to `Literal[XXX, YYY]`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94490
Approved by: https://github.com/ezyang, https://github.com/albanD
The previous sentence seemed to imply that sparse may not always be helpful, ie, your execution time may increase when using sparse. But the docs mentioned otherwise.
A simple re-ordering of two words in the documentation to better align with the contextual sentiment.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93258
Approved by: https://github.com/cpuhrsch
We want to make TorchRec sharded models TorchScriptable.
TorchRec sharded models uses generic types Awaitable[W] and LazyAwaitable[W] (https://github.com/pytorch/torchrec/blob/main/torchrec/distributed/types.py#L212).
In sharded model those types are used instead of contained type W, having the initialization function that produces object of type W.
At the moment when the first attribute of W is requested - `LazyAwaitable[W]` will call its initialization function (on the same stack), cache the result inside and work transparently as an object of W. So we can think about it as a delayed object initialization.
To support this behavior in TorchScript - we propose a new type to TorchScript - `Await`.
In eager mode it works the same as `LazyAwaitable[W]` in TorchRec, being dynamically typed - acting as a type `W` while it is `Await[W]`.
Within torchscript it is `Await[W]` and can be only explicitly converted to W, using special function `torch.jit.awaitable_wait(aw)`.
Creation of this `Await[W]` is done via another special function `torch.jit.awaitable(func, *args)`.
The semantic is close to `torch.jit.Future`, fork, wait and uses the same jit mechanics (inline fork Closures) with the difference that it does not start this function in parallel on fork. It only stores as a lambda inside IValue that will be called on the same thread when `torch.jit.awaitable_wait` is called.
For example (more examples in this PR `test/jit/test_await.py`)
```
def delayed(z: Tensor) -> Tensor:
return Tensor * 3
@torch.jit.script
def fn(x: Tensor):
aw: Await[int] = torch.jit._awaitable(delayed, 99)
a = torch.eye(2)
b = torch.jit._awaitable_wait(aw)
return a + b + x
```
Functions semantics:
`_awaitable(func -> Callable[Tuple[...], W], *args, **kwargs) -> Await[W]`
Creates Await object, owns args and kwargs. Once _awaitable_wait calls, executes function func and owns the result of the function. Following _awaitable_wait calls will return this result from the first function call.
`_awaitable_wait(Await[W]) -> W`
Returns either cached result of W if it is not the first _awaitable_wait call to this Await object or calls specified function if the first.
`_awaitable_nowait(W) -> Await[W]`
Creates trivial Await[W] wrapper on specified object To be type complaint for the corner cases.
Differential Revision: [D42502706](https://our.internmc.facebook.com/intern/diff/D42502706)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90863
Approved by: https://github.com/davidberard98
We have known for a while that we should in principle support SymBool as a separate concept from SymInt and SymFloat ( in particular, every distinct numeric type should get its own API). However, recent work with unbacked SymInts in, e.g., https://github.com/pytorch/pytorch/pull/90985 have made this a priority to implement. The essential problem is that our logic for computing the contiguity of tensors performs branches on the passed in input sizes, and this causes us to require guards when constructing tensors from unbacked SymInts. Morally, this should not be a big deal because, we only really care about the regular (non-channels-last) contiguity of the tensor, which should be guaranteed since most people aren't calling `empty_strided` on the tensor, however, because we store a bool (not a SymBool, prior to this PR it doesn't exist) on TensorImpl, we are forced to *immediately* compute these values, even if the value ends up not being used at all. In particular, even when a user allocates a contiguous tensor, we still must compute channels-last contiguity (as some contiguous tensors are also channels-last contiguous, but others are not.)
This PR implements SymBool, and makes TensorImpl use SymBool to store the contiguity information in ExtraMeta. There are a number of knock on effects, which I now discuss below.
* I introduce a new C++ type SymBool, analogous to SymInt and SymFloat. This type supports logical and, logical or and logical negation. I support the bitwise operations on this class (but not the conventional logic operators) to make it clear that logical operations on SymBool are NOT short-circuiting. I also, for now, do NOT support implicit conversion of SymBool to bool (creating a guard in this case). This does matter too much in practice, as in this PR I did not modify the equality operations (e.g., `==` on SymInt) to return SymBool, so all preexisting implicit guards did not need to be changed. I also introduced symbolic comparison functions `sym_eq`, etc. on SymInt to make it possible to create SymBool. The current implementation of comparison functions makes it unfortunately easy to accidentally introduce guards when you do not mean to (as both `s0 == s1` and `s0.sym_eq(s1)` are valid spellings of equality operation); in the short term, I intend to prevent excess guarding in this situation by unit testing; in the long term making the equality operators return SymBool is probably the correct fix.
* ~~I modify TensorImpl to store SymBool for the `is_contiguous` fields and friends on `ExtraMeta`. In practice, this essentially meant reverting most of the changes from https://github.com/pytorch/pytorch/pull/85936 . In particular, the fields on ExtraMeta are no longer strongly typed; at the time I was particularly concerned about the giant lambda I was using as the setter getting a desynchronized argument order, but now that I have individual setters for each field the only "big list" of boolean arguments is in the constructor of ExtraMeta, which seems like an acceptable risk. The semantics of TensorImpl are now that we guard only when you actually attempt to access the contiguity of the tensor via, e.g., `is_contiguous`. By in large, the contiguity calculation in the implementations now needs to be duplicated (as the boolean version can short circuit, but the SymBool version cannot); you should carefully review the duplicate new implementations. I typically use the `identity` template to disambiguate which version of the function I need, and rely on overloading to allow for implementation sharing. The changes to the `compute_` functions are particularly interesting; for most of the functions, I preserved their original non-symbolic implementation, and then introduce a new symbolic implementation that is branch-less (making use of our new SymBool operations). However, `compute_non_overlapping_and_dense` is special, see next bullet.~~ This appears to cause performance problems, so I am leaving this to an update PR.
* (Update: the Python side pieces for this are still in this PR, but they are not wired up until later PRs.) While the contiguity calculations are relatively easy to write in a branch-free way, `compute_non_overlapping_and_dense` is not: it involves a sort on the strides. While in principle we can still make it go through by using a data oblivious sorting network, this seems like too much complication for a field that is likely never used (because typically, it will be obvious that a tensor is non overlapping and dense, because the tensor is contiguous.) So we take a different approach: instead of trying to trace through the logic computation of non-overlapping and dense, we instead introduce a new opaque operator IsNonOverlappingAndDenseIndicator which represents all of the compute that would have been done here. This function returns an integer 0 if `is_non_overlapping_and_dense` would have returned `False`, and an integer 1 otherwise, for technical reasons (Sympy does not easily allow defining custom functions that return booleans). The function itself only knows how to evaluate itself if all of its arguments are integers; otherwise it is left unevaluated. This means we can always guard on it (as `size_hint` will always be able to evaluate through it), but otherwise its insides are left a black box. We typically do NOT expect this custom function to show up in actual boolean expressions, because we will typically shortcut it due to the tensor being contiguous. It's possible we should apply this treatment to all of the other `compute_` operations, more investigation necessary. As a technical note, because this operator takes a pair of a list of SymInts, we need to support converting `ArrayRef<SymNode>` to Python, and I also unpack the pair of lists into a single list because I don't know if Sympy operations can actually validly take lists of Sympy expressions as inputs. See for example `_make_node_sizes_strides`
* On the Python side, we also introduce a SymBool class, and update SymNode to track bool as a valid pytype. There is some subtlety here: bool is a subclass of int, so one has to be careful about `isinstance` checks (in fact, in most cases I replaced `isinstance(x, int)` with `type(x) is int` for expressly this reason.) Additionally, unlike, C++, I do NOT define bitwise inverse on SymBool, because it does not do the correct thing when run on booleans, e.g., `~True` is `-2`. (For that matter, they don't do the right thing in C++ either, but at least in principle the compiler can warn you about it with `-Wbool-operation`, and so the rule is simple in C++; only use logical operations if the types are statically known to be SymBool). Alas, logical negation is not overrideable, so we have to introduce `sym_not` which must be used in place of `not` whenever a SymBool can turn up. To avoid confusion with `__not__` which may imply that `operators.__not__` might be acceptable to use (it isn't), our magic method is called `__sym_not__`. The other bitwise operators `&` and `|` do the right thing with booleans and are acceptable to use.
* There is some annoyance working with booleans in Sympy. Unlike int and float, booleans live in their own algebra and they support less operations than regular numbers. In particular, `sympy.expand` does not work on them. To get around this, I introduce `safe_expand` which only calls expand on operations which are known to be expandable.
TODO: this PR appears to greatly regress performance of symbolic reasoning. In particular, `python test/functorch/test_aotdispatch.py -k max_pool2d` performs really poorly with these changes. Need to investigate.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92149
Approved by: https://github.com/albanD, https://github.com/Skylion007
It turns out our old max/min implementation didn't do anything, because `__max__` and `__min__` are not actually magic methods in Python. So I give 'em the `sym_` treatment, similar to the other non-overrideable builtins.
NB: I would like to use `sym_max` when computing contiguous strides but this appears to make `python test/functorch/test_aotdispatch.py -v -k test_aot_autograd_symbolic_exhaustive_nn_functional_max_pool2d_cpu_float32` run extremely slowly. Needs investigating.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92107
Approved by: https://github.com/albanD, https://github.com/voznesenskym, https://github.com/Skylion007
This PR:
- registers all of the codegened Nodes to the torch._C._functions module, this is where special nodes like AccumulateGrad are already registered.
- creates a autograd.graph.Node abstract base class that all of the newly registered nodes subclass from. We make the subclassing happen by implementing the ``__subclasshook__`` method
- enables static type checking to work and also enables Sphinx to generate documentation for the Node and its methods
- handles both the custom Function and codegened cases
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91475
Approved by: https://github.com/albanD
This PR:
- changes generate_vmap_rule to either be True or False. Previously it
could be True, False, or not set. This simplifies the implementation a
bit.
- changes the vmap staticmethod to always be on the autograd.Function
rather than sometimes defined.
This is how the other staticmethod (forward, backward, jvp) are
implemented and allows us to document it.
There are 4 possible states for the autograd.Function w.r.t. to the
above:
- generate_vmap_rule is True, vmap staticmethod overriden. This raises
an error when used with vmap.
- generate_vmap_rule is False, vmap staticmethod overriden. This is
valid.
- generate_vmap_rule is True, vmap staticmethod not overriden. This is
valid.
- generate_vmap_rule is False, vmap staticmethod not overriden. This
raises an error when used with vmap.
Future:
- setup_context needs the same treatment, but that's a bit tricker to
implement.
Test Plan:
- new unittest
- existing tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91787
Approved by: https://github.com/soulitzer
This PR is a copy of https://github.com/pytorch/pytorch/pull/90849 that merge was reverted.
The PR adds "check sparse tensor invariants" flag to Context that when enabled will trigger sparse tensor data invariants checks in unsafe methods of constructing sparse COO/CSR/CSC/BSR/BSC tensors. The feature includes the following changes to UI:
`torch.sparse.check_sparse_tensor_invariants` class provides different ways to enable/disable the invariant checking.
`torch.sparse_coo/csr/csc/bsr/bsc/compressed_tensor` functions have a new optional argument `check_invariants` to enable/disable the invariant checks explicitly. When the `check_invariants` argument is specified, the global state of the feature is temporarily overridden.
The PR fixes https://github.com/pytorch/pytorch/issues/90833
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92094
Approved by: https://github.com/cpuhrsch
Summary: This commit moves the API specification section of
the BackendConfig tutorial to the docstrings, which is a more
suitable place for this content. This change also reduces some
duplication. There is no new content added in this change.
Reviewers: jerryzh168, vkuzo
Subscribers: jerryzh168, vkuzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91999
Approved by: https://github.com/vkuzo, https://github.com/jerryzh168
This PR adds "check sparse tensor invariants" flag to Context that when enabled will trigger sparse tensor data invariants checks in unsafe methods of constructing sparse COO/CSR/CSC/BSR/BSC tensors. The feature includes the following changes to UI:
- `torch.enable_check_sparse_tensor_invariants` and `torch.is_check_sparse_tensor_invariants_enabled` functions to globally enable/disable the invariant checks and to retrieve the state of the feature, respectively
- `torch.sparse_coo/csr/csc/bsr/bsc/compressed_tensor` functions have a new optional argument `check_invariants` to enable/disable the invariant checks explicitly. When the `check_invariants` argument is specified, the global state of the feature is temporarily overridden.
The PR also fixes https://github.com/pytorch/pytorch/issues/90833
# Main issue
*The following content is outdated after merging the PRs in this ghstack but kept for the record.*
The importance of this feature is that when enabling the invariants checks by default, say, via
<details>
```
$ git diff
diff --git a/torch/__init__.py b/torch/__init__.py
index c8543057c7..19a91d0482 100644
--- a/torch/__init__.py
+++ b/torch/__init__.py
@@ -1239,3 +1239,8 @@ if 'TORCH_CUDA_SANITIZER' in os.environ:
# Populate magic methods on SymInt and SymFloat
import torch.fx.experimental.symbolic_shapes
+
+# temporarily enable sparse tensor arguments validation in unsafe
+# constructors:
+
+torch._C._set_check_sparse_tensor_invariants(True)
```
</details>
a massive number of test failures/errors occur in test_sparse_csr.py tests:
```
$ pytest -sv test/test_sparse_csr.py
<snip>
==== 4293 failed, 1557 passed, 237 skipped, 2744 errors in 69.71s (0:01:09) ====
```
that means that we are silently constructing sparse compressed tensors that do not satisfy the sparse tensor invariants. In particular, the following errors are raised:
```
AssertionError: "resize_as_sparse_compressed_tensor_: self and src must have the same layout" does not match "expected values to be a strided and contiguous tensor"
RuntimeError: CUDA error: device-side assert triggered
RuntimeError: `col_indices[..., crow_indices[..., i - 1]:crow_indices[..., i]] for all i = 1, ..., nrows are sorted and distinct along the last dimension values` is not satisfied.
RuntimeError: expected col_indices to be a strided and contiguous tensor
RuntimeError: expected row_indices to be a strided and contiguous tensor
RuntimeError: expected values to be a strided and contiguous tensor
RuntimeError: for_each: failed to synchronize: cudaErrorAssert: device-side assert triggered
RuntimeError: tensor dimensionality must be sum of batch, base, and dense dimensionalities (=0 + 2 + 0) but got 3
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90849
Approved by: https://github.com/amjames, https://github.com/cpuhrsch
This PR:
- Updates autograd.Function.forward docs to reflect how you either
define a forward with ctx or a separate forward and setup_context
- Updates the "Extending Autograd" docs to suggest the usage of
autograd.Function with separate forward and setup_context. This should
be the default because there is a low barrier to go from this to
an autograd.Function that is fully supported by functorch transforms.
- Adds a new "Extending torch.func with autograd.Function" doc that
explains how to use autograd.Function with torch.func. It also
explains how to use generate_vmap_rule and how to manually write a
vmap staticmethod.
While writing this, I noticed that the implementation of
setup_context staticmethod/generate_vmap_rule/vmap staticmethod are a
bit inconsistent with the other method/attributes on autograd.Function:
- https://github.com/pytorch/pytorch/issues/91451
- I'm happy to fix those if we think it is a problem, either in this PR
or a followup (this PR is getting long, I want some initial docs
out that I can point early adopters at, and fixing the problems in the
future isn't really BC-breaking).
Test Plan:
- view docs preview
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91452
Approved by: https://github.com/soulitzer
Docs copy-pasted from functorch docs with minor adjustments. We are
keeping the functorch docs for BC, though that's up for debate -- we
could also just say "see .. in torch.func" for some, but not all doc
pages (we still want to keep around any examples that use
make_functional so that users can tell what the difference between that
and the new functional_call is).
Test Plan:
- docs preview
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91319
Approved by: https://github.com/samdow
This PR moves the definitions for:
* `sym_int`
* `sym_ceil` (used only for `sym_int`)
* `sym_floor` (used only for `sym_int`)
* `sym_float`
from `torch/fx/experimental/symbolic_shapes.py` to `torch/__init__.py`, where `SymInt` and `SymFloat` are already defined.
This removes the need for several in-line imports, and enables proper JIT script gating for #91318. I'm very open to doing this in a better way!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91317
Approved by: https://github.com/ezyang, https://github.com/anijain2305
Fixes#91107
Added `softmax` docs in
- `pytorch/torch/_tensor_docs.py`
- `pytorch/torch/_torch_docs.py `
- `pytorch/docs/XXX.rst` files. Here XXX represents all those files where I made the change
Although I have added `softmax` in `docs` directory, I was not sure which files/folders required the edits so there could be issues
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91292
Approved by: https://github.com/lezcano
Fixes#91107
Added `softmax` docs in
- `pytorch/torch/_tensor_docs.py`
- `pytorch/torch/_torch_docs.py `
- `pytorch/docs/XXX.rst` files. Here XXX represents all those files where I made the change
Although I have added `softmax` in `docs` directory, I was not sure which files/folders required the edits so there could be issues
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91292
Approved by: https://github.com/lezcano
Essentially the same change as #67946, except that the default is to disallow reduced precision reductions in `BFloat16` GEMMs (for now). If performance is severely regressed, we can change the default, but this option appears to be necessary to pass some `addmm` `BFloat16` tests on H100.
CC @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89172
Approved by: https://github.com/ngimel
This PR sets up torch.func and populates it with the following APIs:
- grad
- grad_and_value
- vjp
- jvp
- jacrev
- jacfwd
- hessian
- functionalize
- vmap
It also renames all instances of `functorch` in the APIs for those docs
to `torch.func`.
We rewrite the `__module__` fields on some of the above APIs so that the
APIs fit PyTorch's public api definition.
- For an API to be public, it must have a `__module__` that points to a
public PyTorch submodule. However, `torch._functorch.eager_transforms`
is not public due to the leading underscore.
- The solution is to rewrite `__module__` to point to where the API is
exposed (torch.func). This is what both Numpy and JAX do for their
APIs.
- h/t pmeier in
https://github.com/pytorch/pytorch/issues/90284#issuecomment-1348595246
for idea and code
- The helper function, `exposed_in`, is confined to
torch._functorch/utils for now because we're not completely sure if
this should be the long-term solution.
Implication for functorch.* APIs:
- functorch.grad is the same object as torch.func.grad
- this means that the functorch.grad docstring is actually the
torch.func.grad docstring and will refer to torch.func instead of
functorch.
- This isn't really a problem since the plan on record is to deprecate
functorch in favor of torch.func. We can fix these if we really want,
but I'm not sure if a solution is worth maintaining.
Test Plan:
- view docs preview
Future:
- vmap should actually just be torch.vmap. This requires an extra step
where I need to test internal callsites, so, I'm separating it into a
different PR.
- make_fx should be in torch.func to be consistent with `import
functorch`. This one is a bit more of a headache to deal with w.r.t.
public api, so going to deal with it separately.
- beef up func.rst with everything else currently on the functorch
documention website. func.rst is currently just an empty shell.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91016
Approved by: https://github.com/samdow
`torch.compile` can be used either as decorator or to optimize model directly, for example:
```
@torch.compile
def foo(x):
return torch.sin(x) + x.max()
```
or
```
mod = torch.nn.ReLU()
optimized_mod = torch.compile(mod, mode="max-autotune")
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89607
Approved by: https://github.com/soumith
Preparation for the next PR in this stack: #89559.
I replaced
- `self.assertTrue(torch.equal(...))` with `self.assertEqual(..., rtol=0, atol=0, exact_device=True)`,
- the same for `self.assertFalse(...)` with `self.assertNotEqual(...)`, and
- `assert torch.equal(...)` with `torch.testing.assert_close(..., rtol=0, atol=0)` (note that we don't need to set `check_device=True` here since that is the default).
There were a few instances where the result of `torch.equal` is used directly. In that cases I've replaced with `(... == ...).all().item()` while sometimes also dropping the `.item()` depending on the context.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89527
Approved by: https://github.com/mruberry
After our failed attempt to remove `assert_allclose` in #87974, we decided to add it to the documentation after all. Although we drop the expected removal date, the function continues to be deprecated in favor of `assert_close`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89526
Approved by: https://github.com/mruberry
Summary: The recommended way to use QConfigMapping is through
`get_default_qconfig_mapping`. However, the docs still references
usages that use `QConfigMapping().set_global(...)`. This doesn't
actually work well in practice when the model has fixed qparams
ops for example. This commit updates these usages.
Reviewers: vkuzo
Subscribers: vkuzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87299
Approved by: https://github.com/jerryzh168
Fixes#43144
This uses the Backend system added by [82682](https://github.com/pytorch/pytorch/pull/82682) to change allocators dynamically during the code execution. This will allow us to use RMM, use CUDA managed memory for some portions of the code that do not fit in GPU memory. Write static memory allocators to reduce fragmentation while training models and improve interoperability with external DL compilers/libraries.
For example, we could have the following allocator in c++
```c++
#include <sys/types.h>
#include <cuda_runtime_api.h>
#include <iostream>
extern "C" {
void* my_malloc(ssize_t size, int device, cudaStream_t stream) {
void *ptr;
std::cout<<"alloc "<< size<<std::endl;
cudaMalloc(&ptr, size);
return ptr;
}
void my_free(void* ptr) {
std::cout<<"free "<<std::endl;
cudaFree(ptr);
}
}
```
Compile it as a shared library
```
nvcc allocator.cc -o alloc.so -shared --compiler-options '-fPIC'
```
And use it from PyTorch as follows
```python
import torch
# Init caching
# b = torch.zeros(10, device='cuda')
new_alloc = torch.cuda.memory.CUDAPluggableAllocator('alloc.so', 'my_malloc', 'my_free')
old = torch.cuda.memory.get_current_allocator()
torch.cuda.memory.change_current_allocator(new_alloc)
b = torch.zeros(10, device='cuda')
# This will error since the current allocator was already instantiated
torch.cuda.memory.change_current_allocator(old)
```
Things to discuss
- How to test this, needs compiling external code ...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86786
Approved by: https://github.com/albanD
# Summary
Creates a callable native function that can determine which implementation of scaled dot product will get called. This allows to bump re-order the runtime dispatch of SDP to enable autograd.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89029
Approved by: https://github.com/cpuhrsch
Currently all of the distributed errors are thrown from the `TORCH_CHECK` macro which throws a generic `RuntimeError`. This change introduced a new error type `DistBackendError` which derives from `RuntimeError` to signify there was an error with the backend communication library. This allows for better error handling and analysis at higher levels in the stack. Motivation: https://docs.google.com/document/d/1j6VPOkC6znscliFuiDWMuMV1_fH4Abgdq7TCHMcXai4/edit#heading=h.a9rc38misyx8
Changes:
- introduce new error type
- Update `C10D_NCCL_CHECK`
Sample script to demonstrate new error type
```python
# python -m torch.distributed.run --nproc_per_node=2 <script>.py
import torch
import torch.distributed as dist
if __name__ == "__main__":
dist.init_process_group("nccl")
dist.broadcast(torch.tensor([1, 2, 3]).cuda(), 0)
```
Differential Revision: [D40998803](https://our.internmc.facebook.com/intern/diff/D40998803)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88134
Approved by: https://github.com/rohan-varma
Summary:
Improved roundup_power2_divisions knob so it allows better control of rouding in the PyTorch CUDA Caching Allocator.
This new version allows setting the number of divisions per power of two interval starting from 1MB and ending at 64GB and above. An example use case is when rouding is desirable for small allocations but there are also very large allocations which are persistent, thus would not benefit from rounding and take up extra space.
Test Plan: Tested locally
Differential Revision: D40103909
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87290
Approved by: https://github.com/zdevito
- This PR defines a new `api.py` meant to hold the public API for FSDP (minus `FullyShardedDataParallel` itself). This is needed because several of the `_<...>_utils.py` files rely on the public API, and we cannot import from `torch.distributed.fsdp.fully_sharded_data_parallel` without a circular import. Calling the file `api.py` follows the convention used by `ShardedTensor`.
- This PR cleans up the wording in the `BackwardPrefetch`, `ShardingStrategy`, `MixedPrecision`, and `CPUOffload` docstrings.
- This PR adds the aforementioned classes to `fsdp.rst` to have them rendered in public docs.
- To abide by the public bindings contract (`test_public_bindings.py`), the aforementioned classes are removed from `fully_sharded_data_parallel.py`'s `__all__`. This is technically BC breaking if someone uses `from torch.distributed.fsdp.fully_sharded_data_parallel import *`; however, that does not happen in any of our own external or internal code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87917
Approved by: https://github.com/mrshenli
# Summary
Add in a torch.backends.cuda flag and update context manager to pic between the three implementations of the scaled_dot_product_attention.
cc @cpuhrsch @jbschlosser @bhosmer @mikaylagawarecki
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87946
Approved by: https://github.com/cpuhrsch
This refactor was prompted by challenges handling mixed int/float
operations in C++. A previous version of this patch
added overloads for each permutation of int/float and was unwieldy
https://github.com/pytorch/pytorch/pull/87722/ This PR takes a different
approach.
The general outline of the patch is to combine the C++ types SymIntNode
and SymFloatNode into a single type, SymNode. This is type erased; we
no longer know statically at C++ if we have an int/float and have to test
it with the is_int()/is_float() virtual methods. This has a number of
knock on effects.
- We no longer have C++ classes to bind to Python. Instead, we take an
entirely new approach to our Python API, where we have a SymInt/SymFloat
class defined entirely in Python, which hold a SymNode (which corresponds
to the C++ SymNode). However, SymNode is not pybind11-bound; instead,
it lives as-is in Python, and is wrapped into C++ SymNode using PythonSymNode
when it goes into C++. This implies a userland rename.
In principle, it is also possible for the canonical implementation of SymNode
to be written in C++, and then bound to Python with pybind11 (we have
this code, although it is commented out.) However, I did not implement
this as we currently have no C++ implementations of SymNode.
Because we do return SymInt/SymFloat from C++ bindings, the C++ binding
code needs to know how to find these classes. Currently, this is done
just by manually importing torch and getting the attributes.
- Because SymInt/SymFloat are easy Python wrappers, __sym_dispatch__ now
takes SymInt/SymFloat, rather than SymNode, bringing it in line with how
__torch_dispatch__ works.
Some miscellaneous improvements:
- SymInt now has a constructor that takes SymNode. Note that this
constructor is ambiguous if you pass in a subclass of SymNode,
so an explicit downcast is necessary. This means toSymFloat/toSymInt
are no more. This is a mild optimization as it means rvalue reference
works automatically.
- We uniformly use the caster for c10::SymInt/SymFloat, rather than
going the long way via the SymIntNode/SymFloatNode.
- Removed some unnecessary toSymInt/toSymFloat calls in normalize_*
functions, pretty sure this doesn't do anything.
- guard_int is now a free function, since to guard on an int you cannot
assume the method exists. A function can handle both int and SymInt
inputs.
- We clean up the magic method definition code for SymInt/SymFloat/SymNode.
ONLY the user classes (SymInt/SymFloat) get magic methods; SymNode gets
plain methods; this is to help avoid confusion between the two types.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
cc @jansel @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87817
Approved by: https://github.com/albanD, https://github.com/anjali411
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}