Summary: Fixed a bunch of fbcode imports that happened to work but confused autodeps. After this autodeps still suggests "improvements" to TARGETS (which breaks our builds) but at least it can find all the imports.
Test Plan:
```
fbpython fbcode/tools/build/buck/linters/lint_autoformat.py --linter=autodeps --default-exec-timeout=1800 -- fbcode/caffe2/TARGETS fbcode/caffe2/test/TARGETS
```
Before:
```
ERROR while processing caffe2/test/TARGETS: Cannot find an owner for "test_export" (from caffe2/test/export/testing.py:229) when processing rule "test_export". Please make sure it's listed in the srcs parameter of another rule. See https://fbur$
ERROR while processing caffe2/test/TARGETS: Cannot find an owner for "testing" (from caffe2/test/export/test_export.py:87) when processing rule "test_export". Please make sure it's listed in the srcs parameter of another rule. See https://fburl$
ERROR while processing caffe2/test/TARGETS: Cannot find an owner for "test_export" (from caffe2/test/export/test_serdes.py:9) when processing rule "test_export". Please make sure it's listed in the srcs parameter of another rule. See https://fb$
ERROR while processing caffe2/test/TARGETS: Cannot find an owner for "testing" (from caffe2/test/export/test_serdes.py:10) when processing rule "test_export". Please make sure it's listed in the srcs parameter of another rule. See https://fburl$
ERROR while processing caffe2/test/TARGETS: Cannot find an owner for "testing" (from caffe2/test/export/test_retraceability.py:7) when processing rule "test_export". Please make sure it's listed in the srcs parameter of another rule. See https:$
ERROR while processing caffe2/test/TARGETS: Cannot find an owner for "test_export" (from caffe2/test/export/test_retraceability.py:6) when processing rule "test_export". Please make sure it's listed in the srcs parameter of another rule. See ht$
ERROR while processing caffe2/test/TARGETS: Cannot find an owner for "testing" (from caffe2/test/export/test_export_nonstrict.py:7) when processing rule "test_export". Please make sure it's listed in the srcs parameter of another rule. See http$
ERROR while processing caffe2/test/TARGETS: Cannot find an owner for "test_export" (from caffe2/test/export/test_export_nonstrict.py:6) when processing rule "test_export". Please make sure it's listed in the srcs parameter of another rule. See $
ERROR while processing caffe2/test/TARGETS: Cannot find an owner for "test_export" (from caffe2/test/export/test_export_training_ir_to_run_decomp.py:8) when processing rule "test_export". Please make sure it's listed in the srcs parameter of an$
ERROR while processing caffe2/test/TARGETS: Cannot find an owner for "testing" (from caffe2/test/export/test_export_training_ir_to_run_decomp.py:10) when processing rule "test_export". Please make sure it's listed in the srcs parameter of anoth$
ERROR while processing caffe2/test/TARGETS: Found "//python/typeshed_internal:typeshed_internal_library" owner for "cv2" but it is protected by visibility rules: [] (from caffe2/test/test_bundled_images.py:7) when processing rule "test_bundled_$
ERROR while processing caffe2/test/TARGETS: Cannot find an owner for "caffe2.test.profiler_test_cpp_thread_lib" (from caffe2/test/profiler/test_cpp_thread.py:29) when processing rule "profiler_test_cpp_thread". Please make sure it's listed in t$
ERROR while processing caffe2/test/TARGETS: Cannot find an owner for "torch._utils_internal.get_file_path_2" (from caffe2/test/test_custom_ops.py:23) when processing rule "custom_ops". Please make sure it's listed in the srcs parameter of anoth$
ERROR while processing caffe2/test/TARGETS: Cannot find an owner for "torch._utils_internal.get_file_path_2" (from caffe2/test/test_public_bindings.py:13) when processing rule "public_bindings". Please make sure it's listed in the srcs paramete$
ERROR while processing caffe2/test/TARGETS: Cannot find an owner for "torch._C._profiler.symbolize_tracebacks" (from caffe2/test/test_cuda.py:3348) when processing rule "test_cuda". Please make sure it's listed in the srcs parameter of another $
ERROR while processing caffe2/test/TARGETS: Cannot find an owner for "torch._C._profiler.gather_traceback" (from caffe2/test/test_cuda.py:3348) when processing rule "test_cuda". Please make sure it's listed in the srcs parameter of another rule$
ERROR while processing caffe2/test/TARGETS: Cannot find an owner for include <torch/csrc/autograd/profiler_kineto.h> (from caffe2/test/profiler/test_cpp_thread.cpp:2) when processing profiler_test_cpp_thread_lib. Some things to try:
```
Differential Revision: D62049222
Pull Request resolved: https://github.com/pytorch/pytorch/pull/135614
Approved by: https://github.com/oulgen, https://github.com/laithsakka
Previously setting garbage_collection_threshold or max_split_size_mb along with expandable_segments:True could cause the allocator to hit assert failures when running nearly out of memory. This PR ensures garbage_collection and max_split freeing do not accidentally try to release expandable segments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/134338
Approved by: https://github.com/ezyang
This PR adds support to use expandable segments with private memory pools which should unblock using it with cuda graphs and cuda graph trees. Currently, the allocator silently avoids using expandable segments when allocating in a private pool due to checkpoint saving/restoring not meshing well with how we keep track of unmapped blocks.
The PR itself is pretty short, most of the logic for checkpointing and reapplying state for non-expandable segments transfers over without much work.
Expandable segments reserve a virtual address space of size equal to the amount of physical memory on the GPU. Every time we want to `malloc()` or `free()` memory in a memory pool with expandable segments turned on, we map/unmap pages of physical GPU memory under the hood to create a new block that we return to the caller. This is beneficial due to the fact that each memory pool functions as a single segment of memory with a contiguous block of memory addresses that can grow and shrink as needed, avoiding fragmentation from allocating multiple non-contiguous segments that may not be merged together.
The caching allocator handles this by creating an unmapped block for the entire reserved virtual address space at init, which is treated similarly to an unallocated block in a free pool. When callers call `malloc()`, it's split and mapped to create allocated blocks, and calling `free()` similarly caches and merges free blocks in a free pool to be used later. Expandable blocks are unmapped and returned back to Cuda when they are cleaned up, or when we hit an OOM and the allocator attempts to remap cached free blocks. The code paths to map, free, and unmap blocks in expandable segments is similar to that for normal blocks and does all the same work of updating stats on memory usage, moving blocks between active and free pools, and returning memory to Cuda.
With Cuda Graph Trees and private memory pools, we need the ability to take checkpoints of the current state of the memory allocator after each graph capture as well as reapplying the state before capturing a new graph after replaying a captured graph so that the new cuda graph capture has access to the state of the allocator at the point after replaying a previously captured graph so it can reuse empty blocks and allocate new ones.
As mentioned in a below comment, memory in a private pool is cached until the private pool is destroyed and allocations can only grow from extra graph captures, any freeing of memory would result in invalid memory addresses and would break cuda graphs.
One implementation detail to note for unmapped blocks with expandable segments is that unmapped blocks are kept track in a member variable `unmapped` of a `BlockPool`. `unmapped` is *not* part of the checkpointed state of the caching allocator and isn't restored when reapplying checkpoints since we never free/unmap memory back to cuda and is persisted across graph captures / replays.
Checkpointing the current state of the memory allocator works as expected with expandable segments. Checkpointing grabs the first block of every segment in the active and free pools of the private pool and traverses the linked list of blocks in the segment to capture the state of every segment, which is then saved and kept for when it is needed to be reapplied. For expandable blocks, the last block in every segment will be an unallocated unmapped block containing the remaining amount of unmapped memory at graph capture time, and this too is saved in the checkpoint.
Reapplying the checkpoints works by freeing all allocated blocks and merging them into a single block per segment, then for each segment, we manually split and allocate all blocks from the checkpoint and then free the blocks marked as unallocated in the checkpoint state. For expandable segments, we need to make some modifications to not split unmapped blocks and avoid manually mapping then freeing unmapped blocks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/128068
Approved by: https://github.com/eqy, https://github.com/eellison
Fixes#125224
For large ranges, calls to CUDA `randint` use a different `unroll_factor` to generate random ints. This `unroll_factor` was not considered correctly in the calculation of the Philox offsets. Thus, some of the random states were reused, resulting in lower entropy (see #125224).
This also affects multiple other random functions, such as `torch.rand` and `torch.randn`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/126066
Approved by: https://github.com/eqy, https://github.com/lezcano
This PR adds support to use expandable segments with private memory pools which should unblock using it with cuda graphs and cuda graph trees. Currently, the allocator silently avoids using expandable segments when allocating in a private pool due to checkpoint saving/restoring not meshing well with how we keep track of unmapped blocks.
The PR itself is pretty short, most of the logic for checkpointing and reapplying state for non-expandable segments transfers over without much work.
Expandable segments reserve a virtual address space of size equal to the amount of physical memory on the GPU. Every time we want to `malloc()` or `free()` memory in a memory pool with expandable segments turned on, we map/unmap pages of physical GPU memory under the hood to create a new block that we return to the caller. This is beneficial due to the fact that each memory pool functions as a single segment of memory with a contiguous block of memory addresses that can grow and shrink as needed, avoiding fragmentation from allocating multiple non-contiguous segments that may not be merged together.
The caching allocator handles this by creating an unmapped block for the entire reserved virtual address space at init, which is treated similarly to an unallocated block in a free pool. When callers call `malloc()`, it's split and mapped to create allocated blocks, and calling `free()` similarly caches and merges free blocks in a free pool to be used later. Expandable blocks are unmapped and returned back to Cuda when they are cleaned up, or when we hit an OOM and the allocator attempts to remap cached free blocks. The code paths to map, free, and unmap blocks in expandable segments is similar to that for normal blocks and does all the same work of updating stats on memory usage, moving blocks between active and free pools, and returning memory to Cuda.
With Cuda Graph Trees and private memory pools, we need the ability to take checkpoints of the current state of the memory allocator after each graph capture as well as reapplying the state before capturing a new graph after replaying a captured graph so that the new cuda graph capture has access to the state of the allocator at the point after replaying a previously captured graph so it can reuse empty blocks and allocate new ones.
As mentioned in a below comment, memory in a private pool is cached until the private pool is destroyed and allocations can only grow from extra graph captures, any freeing of memory would result in invalid memory addresses and would break cuda graphs.
One implementation detail to note for unmapped blocks with expandable segments is that unmapped blocks are kept track in a member variable `unmapped` of a `BlockPool`. `unmapped` is *not* part of the checkpointed state of the caching allocator and isn't restored when reapplying checkpoints since we never free/unmap memory back to cuda and is persisted across graph captures / replays.
Checkpointing the current state of the memory allocator works as expected with expandable segments. Checkpointing grabs the first block of every segment in the active and free pools of the private pool and traverses the linked list of blocks in the segment to capture the state of every segment, which is then saved and kept for when it is needed to be reapplied. For expandable blocks, the last block in every segment will be an unallocated unmapped block containing the remaining amount of unmapped memory at graph capture time, and this too is saved in the checkpoint.
Reapplying the checkpoints works by freeing all allocated blocks and merging them into a single block per segment, then for each segment, we manually split and allocate all blocks from the checkpoint and then free the blocks marked as unallocated in the checkpoint state. For expandable segments, we need to make some modifications to not split unmapped blocks and avoid manually mapping then freeing unmapped blocks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/128068
Approved by: https://github.com/zdevito, https://github.com/eqy
Fixes: #128478
In backward() implementation checkpointing code was quering device type from the rng_state tensors saved on forward(). These tensors are CPU only tensors and don't carry device information with them. As a result CUDA device was assumed as a default. Which is not correct if user runs on some other device. For example, on XPU.
This patch saves full device information on forward() and uses it on backward() to get device type. Previously forward save only device index.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/128671
Approved by: https://github.com/guangyey, https://github.com/soulitzer
On Jetson IGX, `python test/test_cuda.py -k test_graph_capture_oom` fails with the following error:
```
RuntimeError: NVML_SUCCESS == r INTERNAL ASSERT FAILED at "/opt/pytorch/pytorch/c10/cuda/CUDACachingAllocator.cpp":841, please report a bug to PyTorch.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/lib/python3.10/unittest/case.py", line 59, in testPartExecutor
yield
File "/usr/lib/python3.10/unittest/case.py", line 591, in run
self._callTestMethod(testMethod)
File "/usr/lib/python3.10/unittest/case.py", line 549, in _callTestMethod
method()
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_utils.py", line 2759, in wrapper
method(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_utils.py", line 2759, in wrapper
method(*args, **kwargs)
File "/opt/pytorch/pytorch/test/test_cuda.py", line 2255, in test_graph_capture_oom
with self.assertRaisesRegex(RuntimeError, oom_regex):
File "/usr/lib/python3.10/unittest/case.py", line 239, in __exit__
self._raiseFailure('"{}" does not match "{}"'.format(
File "/usr/lib/python3.10/unittest/case.py", line 163, in _raiseFailure
raise self.test_case.failureException(msg)
AssertionError: "out of memory" does not match "NVML_SUCCESS == r INTERNAL ASSERT FAILED at "/opt/pytorch/pytorch/c10/cuda/CUDACachingAllocator.cpp":841, please report a bug to PyTorch. "
```
This is a known issue as nvml support on Jetson is limited, and the OOM reporting in CUDACachingAllocator.cpp requires nvml to be properly loaded, which fails on Jetson.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/128661
Approved by: https://github.com/eqy, https://github.com/atalman
Use `typing_extensions.deprecated` for deprecation annotation if possible. Otherwise, add `category=FutureWarning` to `warnings.warn("message")` if the category is missing.
Note that only warnings that their messages contain `[Dd]eprecat(ed|ion)` are updated in this PR.
Resolves#126888
- #126888
This PR is split from PR #126898.
- #126898
------
Pull Request resolved: https://github.com/pytorch/pytorch/pull/127689
Approved by: https://github.com/Skylion007
Use `typing_extensions.deprecated` for deprecation annotation if possible. Otherwise, add `category=FutureWarning` to `warnings.warn("message")` if the category is missing.
Note that only warnings that their messages contain `[Dd]eprecat(ed|ion)` are updated in this PR.
UPDATE: Use `FutureWarning` instead of `DeprecationWarning`.
Resolves#126888
- #126888
Pull Request resolved: https://github.com/pytorch/pytorch/pull/126898
Approved by: https://github.com/albanD
# Motivation
## for `torch.amp.GradScaler`,
- `torch.cpu.amp.GradScaler(args...)` is completely equivalent to `torch. amp.GradScaler("cpu", args...)`.
- `torch.cuda.amp.GradScaler(args...)` is completely equivalent to `torch.amp.GradScaler("cuda", args...)`.
So, we intend to depreate them and **strongly recommend** developer to use `torch.amp.GradScaler`.
## for `custom_fwd` and `custom_bwd`,
this is a good solution to make the custom function run with or without effect even in an autocast-enabled region and can be shared by other backends, like CPU and XPU.
So we generalize it to be device-agnostic and put them int `torch/amp/autocast_mode.py` and re-expose to `torch.amp.custom_fwd` and `torch.amp.custom_bwd`. Meanwhile, we deprecate `torch.cuda.amp.custom_fwd` and `torch.cuda.amp.custom_bwd`.
# Additional Context
Add UT to cover the deprecated warning.
No need for more UTs to cover the functionality of `torch.amp.custom_f/bwd`, the existing UTs that previously covered the functionality of `torch.cuda.amp.custom_f/bwd` can cover them.
To facilitate the review, we separate these code changes to two PRs. The first PR cover `torch.amp.GradScaler`. The follow-up covers `custom_fwd` and `custom_bwd`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/126527
Approved by: https://github.com/jgong5, https://github.com/gujinghui, https://github.com/janeyx99, https://github.com/EikanWang
This PR is meant to address issue #123451, more specifically, the ```test_graph_optims``` and ```test_graph_scaling_fused_optimizers``` functions in ```test_cuda.py``` have been updated so that they now use the new OptimizerInfo infrastructure.
Lintrunner passed:
```
$ lintrunner test/test_cuda.py
ok No lint issues.
```
Tests passed:
```
>python test_cuda.py -k test_graph_optims
Ran 19 tests in 7.463s
OK (skipped=9)
>python test_cuda.py -k test_graph_scaling_fused_optimizers
Ran 6 tests in 2.800s
OK (skipped=3)
```
Both the functions have been moved to the newly created TestCase class ```TestCudaOptims```. The test is mostly the same except the ```@optims``` decorator is used at the top of the function to implicitly call the function using each of the optimizers mentioned in the decorator instead of explicitly using a for loop to iterate through each of the optimizers.
I was unable to use the ```_get_optim_inputs_including_global_cliquey_kwargs``` to get all kwargs for each of the optimizers since some of the kwargs that are used in the original ```test_graph_optims``` function are not being returned by the new OptimizerInfo infrastructure, more specifically, for the ```torch.optim.rmsprop.RMSprop``` optimizer, the following kwargs are not returned whenever ```_get_optim_inputs_including_global_cliquey_kwargs``` is called:
```
{'foreach': False, 'maximize': True, 'weight_decay': 0}
{ 'foreach': True, 'maximize': True, 'weight_decay': 0}
```
I ran into the same issue for ```test_graph_scaling_fused_optimizers```, for the ```torch.optim.adamw.AdamW``` optimizer, whenever ```optim_info.optim_inputs_func(device=device)``` was called, the following kwarg was not returned:
```
{'amsgrad': True}
```
Due to this issue, I resorted to using a dictionary to store the kwargs for each of the optimizers, I am aware that this is less than ideal. I was wondering whether I should use the OptimizerInfo infrastructure to get all the kwargs regardless of the fact that it lacks some kwargs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/125127
Approved by: https://github.com/janeyx99
# Motivation
We generalize a device-agnostic API `torch.amp.autocast` in [#125103](https://github.com/pytorch/pytorch/pull/125103). After that,
- `torch.cpu.amp.autocast(args...)` is completely equivalent to `torch.amp.autocast('cpu', args...)`, and
- `torch.cuda.amp.autocast(args...)` is completely equivalent to `torch.amp.autocast('cuda', args...)`
no matter in eager mode or JIT mode.
Base on this point, we would like to deprecate `torch.cpu.amp.autocast` and `torch.cuda.amp.autocast` to **strongly recommend** developer to use `torch.amp.autocast` that is a device-agnostic API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/126062
Approved by: https://github.com/eqy, https://github.com/albanD
- Original `test_grad_scaling_autocast_fused_optimizers` does not work since there is no "fused" in `optim_inputs`
- We should use different `grad_scaler`, they should not share 1 `scale`, there is no issue exposed here because the default `_growth_interval` is 2000 so it will not growth and there is also no inf is found so it will not reduced. The one in `test_cuda.py` should also have this issue,
- I set a manual seed to reproduce purpose if there is any numerical failure
- I use Tensor tracker here because we failed this UT in dynamo case, the cpp generated code are not exactly same with fused/non fused kernel.
- I make it check both `cuda` and `cpu`.
- I find some SGD numerical issue with `clang`, and fixed it by using `fmadd` instead of `add/mul` in fused sgd veckernel.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/124904
Approved by: https://github.com/jgong5, https://github.com/janeyx99
This PR targets the issue mentioned in #123451 , and solves the specific task to update`test_graph_grad_scaling` in `test/test_cuda.py` to use the new OptimizerInfo infrastructure.
`test_graph_grad_scaling` is moved to a new `TestCase` class called `TestCudaOptims` in order to use `instantiate_device_type_tests`. The test content remained the same. `@onlyCUDA` is applied to the new test; the original use of the wrapper function is also changed to a `@parametrize` decorator for better style.
If we think that this migration is successful, we can delete the original test item under `TestCuda`. Currently it is left untouched to avoid any unexpected issues.
Local linter passed.
```
$ lintrunner test/test_cuda.py
ok No lint issues.
```
Local tests passed.
```
> python .\test\test_cuda.py -k test_graph_grad_scaling
Ran 7 tests in 0.458s
OK (skipped = 3)
```
Co-authored-by: Jane (Yuan) Xu <31798555+janeyx99@users.noreply.github.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/123581
Approved by: https://github.com/janeyx99
We've had issues using addr2line. On certain versions of
CentOS it is on a version that has a performance regression making it very slow,
and even normallly it is not that fast, taking several seconds even when parallelized
for a typical memory trace dump.
Folly Symbolize or LLVMSymbolize are fast but it requires PyTorch take a dependency on those libraries to do this, and given the number of environments we run stuff in, we end up hitting cases where we fallback to slow addr2line behavior.
This adds a standalone symbolizer to PyTorch similar to the unwinder which has
no external dependencies and is ~20x faster than addr2line for unwinding PyTorch frames.
I've tested this on some memory profiling runs using all combinations of {gcc, clang} x {dwarf4, dwarf5} and it seems to do a good job at getting line numbers and function names right. It is also careful to route all reads of library data through the `CheckedLexer` object, which ensure it is not reading out of bounds of the section. Errors are routed through UnwindError so that those exceptions get caught and we produce a ?? frame rather than crash. I also added a fuzz test which gives all our symbolizer options random addresses in the process to make sure they do not crash.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/123966
Approved by: https://github.com/ezyang
Update ruff to 0.4.1 .
This version fixes a lot false negatives/false positives, is 20-40% faster, and has various other bug fixes.
Below is a before and after table showing the execution time of ruff lint and ruff format in milliseconds courtesy of https://astral.sh/blog/ruff-v0.4.0
| Repository | Linter (v0.3) | Linter (v0.4) | Formatter (v0.3) | Formatter (v0.4) |
|----------------------------------------------------|---------------|---------------|------------------|------------------|
| [pytorch/pytorch](https://github.com/pytorch/pytorch) | 328.7 | 251.8 | 351.1 | 274.9 |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/124549
Approved by: https://github.com/ezyang
See #113541
The PR allows for registering and controlling multiple RNG states using indices, ensuring cudagraph-safe operations, and includes both C++ and Python API changes to support this functionality.
cc @eellison @anijain2305 @jansel @ezyang @ptrblck @csarofeen @mcarilli
Pull Request resolved: https://github.com/pytorch/pytorch/pull/114068
Approved by: https://github.com/ezyang
@tfsingh I got to it first--wanted to land this stack and close the gap ASAP.
This PR also fixes a discrepancy between `_init_group` and `__set_state__` because we have the constants live on params' device always.
There are some next steps though:
- ASGD can be made faster by making etas, mus, steps be on CPU when NOT capturable. (I had mistakenly thought foreachifying was faster and so we landed https://github.com/pytorch/pytorch/pull/107857, but it is slower). No one has complained yet though. ¯\_(ツ)_/¯
Pull Request resolved: https://github.com/pytorch/pytorch/pull/121264
Approved by: https://github.com/albanD
ghstack dependencies: #121260
Finishes the work started in https://github.com/pytorch/pytorch/pull/118697. Thanks @MarouaneMaatouk for the attempt, but due to inactivity I have opened this PR for Adamax. Note that the new capturable implementation is much simpler and I've modified the foreach capturable impl--it now calls fewer kernels and is more easily comparable to forloop.
Next steps:
* This PR discovered two bugs: #121178 and #121238.
* Move the now hefty graph optim tests in test_cuda to use OptimInfo.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/121183
Approved by: https://github.com/albanD
Summary: Show the stack when SEGMENT_FREE and SEGMENT_UNMAP occurs. This may be useful for debugging such as when empty_cache() may cause a segment to be freed. If the free context is unavailable, resort to the segment allocation stack.
Test Plan: CI
Differential Revision: D52984953
Pull Request resolved: https://github.com/pytorch/pytorch/pull/118055
Approved by: https://github.com/zdevito
add skips to tests that involve record_context_cpp on ARM as it is only supported on linux x86_64 arch. Error is reported as below:
```
Traceback (most recent call last):
File "/usr/lib/python3.10/unittest/case.py", line 59, in testPartExecutor
yield
File "/usr/lib/python3.10/unittest/case.py", line 591, in run
self._callTestMethod(testMethod)
File "/usr/lib/python3.10/unittest/case.py", line 549, in _callTestMethod
method()
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_utils.py", line 2674, in wrapper
method(*args, **kwargs)
File "/opt/pytorch/pytorch/test/test_cuda.py", line 3481, in test_direct_traceback
c = gather_traceback(True, True, True)
RuntimeError: record_context_cpp is not support on non-linux non-x86_64 platforms
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/117344
Approved by: https://github.com/malfet, https://github.com/drisspg
…reference) (#109065)
Summary:
Modify the way we update gc_count in CUDACachingAlloctor to make it faster.
Originally D48481557, but reverted due to nullptr dereference in some cases (D49003756). This diff changed to use correct constructor for search key (so avoid nullptr dereference). Also, added nullptr check (and returns 0 if it is) in gc_count functions.
Differential Revision: D49068760
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/117064
Approved by: https://github.com/zdevito
Updates flake8 to v6.1.0 and fixes a few lints using sed and some ruff tooling.
- Replace `assert(0)` with `raise AssertionError()`
- Remove extraneous parenthesis i.e.
- `assert(a == b)` -> `assert a == b`
- `if(x > y or y < z):`->`if x > y or y < z:`
- And `return('...')` -> `return '...'`
Co-authored-by: Nikita Shulga <2453524+malfet@users.noreply.github.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/116591
Approved by: https://github.com/albanD, https://github.com/malfet
The following two cases fail due to a small oversight `CUDAGraph::reset()` that causes failures in graph destructor
```Python
import torch
x = torch.zeros(4, device="cuda")
g = torch.cuda.CUDAGraph()
with torch.cuda.graph(g):
x = x + 1
g.reset()
del g
```
that fails with:
```
terminate called after throwing an instance of 'c10::Error'
what(): uc >= 0 INTERNAL ASSERT FAILED at ".../pytorch/c10/cuda/CUDACachingAllocator.cpp":2157, please report a bug to PyTorch.
```
and reset and subsequent re-capture
```Python
import torch
x = torch.zeros(4, device="cuda")
g = torch.cuda.CUDAGraph()
with torch.cuda.graph(g):
x = x + 1
g.reset()
with torch.cuda.graph(g):
x = x + 1
g.replay()
```
which fails with:
```
Traceback (most recent call last):
File "test_graph.py", line 11, in <module>
with torch.cuda.graph(g):
File ".../pytorch/torch/cuda/graphs.py", line 192, in __enter__
self.cuda_graph.capture_begin(
File ".../pytorch/torch/cuda/graphs.py", line 77, in capture_begin
super().capture_begin(pool=pool, capture_error_mode=capture_error_mode)
RuntimeError: This CUDAGraph instance already owns a captured graph. To capture a new graph, create a new instance.
```
This PR fixes `CUDAGraph::reset()` function for above to use cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108896
Approved by: https://github.com/ezyang
> capture_error_mode (str, optional): specifies the cudaStreamCaptureMode for the graph capture stream.
Can be "global", "thread_local" or "relaxed". During cuda graph capture, some actions, such as cudaMalloc,
may be unsafe. "global" will error on actions in other threads, "thread_local" will only error for
actions in the current thread, and "relaxed" will not error on these actions.
Inductor codegen is single-threaded, so it should be safe to enable "thread_local" for inductor's cuda graph capturing. We have seen errors when inductor cudagraphs has been used concurrently with data preprocessing in other threads.
Differential Revision: [D48656014](https://our.internmc.facebook.com/intern/diff/D48656014)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107407
Approved by: https://github.com/albanD, https://github.com/eqy
This updates ruff to 0.285 which is faster, better, and have fixes a bunch of false negatives with regards to fstrings.
I also enabled RUF017 which looks for accidental quadratic list summation. Luckily, seems like there are no instances of it in our codebase, so enabling it so that it stays like that. :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107519
Approved by: https://github.com/ezyang
This updates ruff to 0.285 which is faster, better, and have fixes a bunch of false negatives with regards to fstrings.
I also enabled RUF017 which looks for accidental quadratic list summation. Luckily, seems like there are no instances of it in our codebase, so enabling it so that it stays like that. :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107519
Approved by: https://github.com/ezyang
Previously when we recorded a free action in a memory trace, we would provide
the stack for when the block was allocated. This is faster because we do not
have to record stacks for free, which would otherwise double the number of stacks
collected. However, sometimes knowing the location of a free is useful for
figuring out why a tensor was live. So this PR adds this behavior. If
performance ends up being a concern the old behavior is possible by passing
"alloc" to the context argument rather than "all".
Also refactors some of glue logic to be consistent across C++ and Python and
routes the Python API through the C++ version.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106758
Approved by: https://github.com/albanD
This PR:
- adds a capturable API for NAdam similar to Adam(W)
- adds tests accordingly
- discovered and fixed bugs in the differentiable implementation (now tested through the capturable codepath).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106615
Approved by: https://github.com/albanD
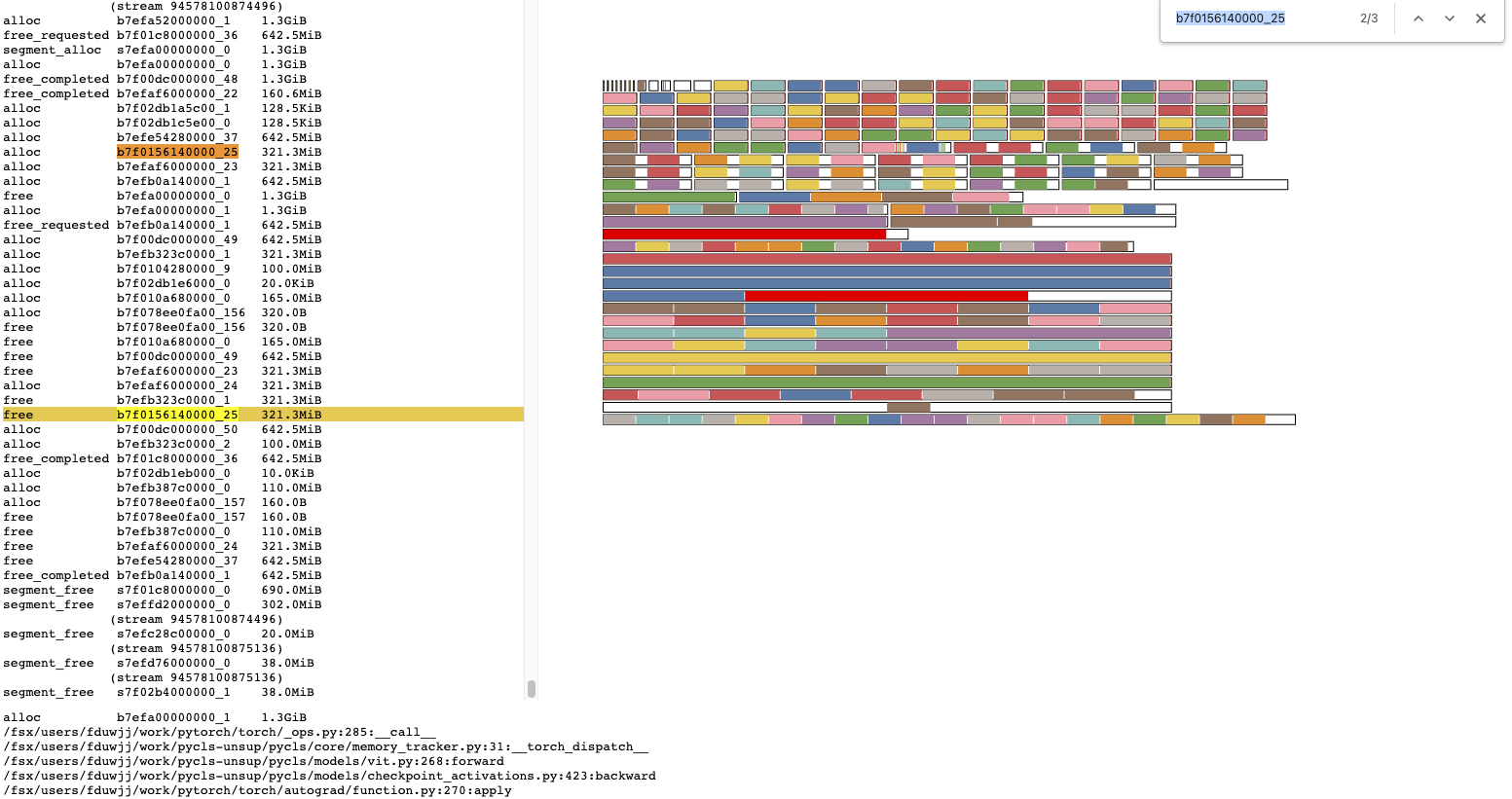
We want to display the stack for the original cudaMalloc that created a segment.
Previously we could only report the last time the segment memory was used,
or the record of the segment_alloc could appear in the list of allocator actions.
This PR ensure regardless of whether we still have the segment_alloc action,
the context for a segment is still available. The visualizer is updated to
be able to incorporate this information.
This PR adds a new field to Block. However the previous stacked cleanup PR
removed a field of the same size, making the change to Block size-neutral.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106113
Approved by: https://github.com/aaronenyeshi
For free blocks of memory in the allocator, we previously kept a linked list
of the stack frames of previous allocations that lived there. This was only
ever used in one flamegraph visualization and never proved useful at
understanding what was going on. When memory history tracing was added, it
became redundant, since we can see the history of the free space from recording
the previous actions anyway.
This patch removes this functionality and simplifies the snapshot format:
allocated blocks directly have a 'frames' attribute rather than burying stack frames in the history.
Previously the memory history tracked the real size of allocations before rounding.
Since history was added, 'requested_size' has been added directly to the block which records the same information,
so this patch also removes that redundancy.
None of this functionality has been part of a PyTorch release with BC guarentees, so it should be safe to alter
this part of the format.
This patch also updates our visualization tools to work with the simplified format. Visualization tools keep
support for the old format in `_legacy` functions so that during the transition old snapshot files can still be read.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106079
Approved by: https://github.com/eellison
Mostly refactor, that moves all the tests from `test_cuda` that benefit from multiGPU environment into its own file.
- Add `TestCudaMallocAsync` class for Async tests ( to separate them from `TestCudaComm`)
- Move individual tests from `TestCuda` to `TestCudaMultiGPU`
- Move `_create_scaling_models_optimizers` and `_create_scaling_case` to `torch.testing._internal.common_cuda`
- Add newly created `test_cuda_multigpu` to the multigpu periodic test
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at f4d46fa</samp>
This pull request fixes a flaky test and improves the testing of gradient scaling on multiple GPUs. It adds verbose output for two CUDA tests, and refactors some common code into helper functions in `torch/testing/_internal/common_cuda.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104059
Approved by: https://github.com/huydhn
Reference cycles are freed by the cycle collector rather than being cleaned up
when the objects in the cycle first become unreachable. If a cycle points to a tensor,
the CUDA memory for that tensor will not be freed until garbage collection runs.
Accumulation of CUDA allocations can lead to out of memory errors (OOMs), as well as
non-deterministic allocation behavior which is harder to debug.
This visualizer installs a garbage collection hook to look for cycles containing
CUDA tensors and saves a visualization of the garbage:
```
from torch.cuda._cycleviz import warn_tensor_cycles
warn_tensor_cycles()
# do some work that results in a cycle getting garbage collected
# ...
> WARNING:root:Reference cycle includes a CUDA Tensor see visualization of cycle /tmp/tmpeideu9gl.html
```
Reland to make windows skip the test.
This reverts commit 7b3b6dd426.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104051
Approved by: https://github.com/aaronenyeshi, https://github.com/malfet
Reference cycles are freed by the cycle collector rather than being cleaned up
when the objects in the cycle first become unreachable. If a cycle points to a tensor,
the CUDA memory for that tensor will not be freed until garbage collection runs.
Accumulatin of CUDA allocations can lead to out of memory errors (OOMs), as well as
non-deterministic allocation behavior which is harder to debug.
This visualizer installs a garbage collection hook to look for cycles containing
CUDA tensors and saves a visualization of the garbage:
```
from torch.cuda._cycleviz import warn_tensor_cycles
warn_tensor_cycles()
# do some work that results in a cycle getting garbage collected
# ...
> WARNING:root:Reference cycle includes a CUDA Tensor see visualization of cycle /tmp/tmpeideu9gl.html
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102656
Approved by: https://github.com/aaronenyeshi
This replaces the invidual visualization routines in _memory_viz.py with
a single javascript application.
The javascript application can load pickled snapshot dumps directly using
drag/drop, requesting them via fetch, or by embedding them in a webpage.
The _memory_viz.py commands use the embedding approach.
We can also host MemoryViz.js on a webpage to use the drag/drop approach, e.g.
https://zdevito.github.io/assets/viz/
(eventually this should be hosted with the pytorch docs).
All views/multiple cuda devices are supported on one page.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103565
Approved by: https://github.com/eellison, https://github.com/albanD
Skip all cuda graph-related unit tests by setting env var `PYTORCH_TEST_SKIP_CUDAGRAPH=1`
This PR refactors the `TEST_CUDA` python variable in test_cuda.py into common_utils.py. This PR also creates a new python variable `TEST_CUDA_GRAPH` in common_utils.py, which has an env var switch to turn off all cuda graph-related tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103032
Approved by: https://github.com/malfet
Do not try to parse raised exception for no good reason
Add short description
Reduce script to a single line
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at ea4164e</samp>
> _`test_no_triton_on_import`_
> _Cleans up the code, adds docs_
> _No hidden errors_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102674
Approved by: https://github.com/cpuhrsch, https://github.com/albanD
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 08f7a6a</samp>
This pull request adds support for triton kernels in `torch` and `torch/cuda`, and refactors and tests the existing triton kernel for BSR matrix multiplication. It also adds a test case to ensure that importing `torch` does not implicitly import `triton`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98403
Approved by: https://github.com/malfet, https://github.com/cpuhrsch
On Arm, I got
```
Traceback (most recent call last):
File "/opt/pytorch/pytorch/test/test_cuda.py", line 5260, in test_cpp_memory_snapshot_pickle
mem = run()
File "/opt/pytorch/pytorch/test/test_cuda.py", line 5257, in run
t = the_script_fn()
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_utils.py", line 496, in prof_func_call
return prof_callable(func_call, *args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_utils.py", line 493, in prof_callable
return callable(*args, **kwargs)
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
File "/opt/pytorch/pytorch/test/test_cuda.py", line 5254, in the_script_fn
@torch.jit.script
def the_script_fn():
return torch.rand(311, 411, device='cuda')
~~~~~~~~~~ <--- HERE
RuntimeError: record_context_cpp is not support on non-linux non-x86_64 platforms
```
dfe484a3b3/torch/csrc/profiler/unwind/unwind.cpp (L4-L24) seems related
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101366
Approved by: https://github.com/zdevito
When we run cudagraph trees we are not allowed to have permanent workspace allocations like in cublas because we might need to reclaim that memory for a previous cudagraph recording, and it is memory that is not accounted for in output weakrefs so it does not work with checkpointing. Previously, I would check that we didn't have any additional allocations through snapshotting. This was extremely slow so I had to turn it off.
This PR first does the quick checking to see if we are in an error state, then if we are does the slow logic of creating snapshot. Also turns on history recording so we get a stacktrace of where the bad allocation came from.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99985
Approved by: https://github.com/zdevito
Why?
* To reduce the latency of hot path in https://github.com/pytorch/pytorch/pull/97377
Concern - I had to add `set_offset` in all instances of `GeneratorImpl`. I don't know if there is a better way.
~~~~
import torch
torch.cuda.manual_seed(123)
print(torch.cuda.get_rng_state())
torch.cuda.set_rng_state_offset(40)
print(torch.cuda.get_rng_state())
tensor([123, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0], dtype=torch.uint8)
tensor([123, 0, 0, 0, 0, 0, 0, 0, 40, 0, 0, 0, 0, 0,
0, 0], dtype=torch.uint8)
~~~~
Reland of https://github.com/pytorch/pytorch/pull/98965
(cherry picked from commit 8214fe07e8)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99565
Approved by: https://github.com/anijain2305
Common advice we give for handling memory fragmentation issues is to
allocate a big block upfront to reserve memory which will get split up later.
For programs with changing tensor sizes this can be especially helpful to
avoid OOMs that happen the first time we see a new largest input and would
otherwise have to allocate new segments.
However the issue with allocating a block upfront is that is nearly impossible
to correctly estimate the size of that block. If too small, space in the block
will run out and the allocator will allocate separate blocks anyway. Too large,
and other non-PyTorch libraries might stop working because they cannot allocate
any memory.
This patch provides the same benefits as using a pre-allocating block but
without having to choose its size upfront. Using the cuMemMap-style APIs,
it adds the ability to expand the last block in a segment when more memory is
needed.
Compared to universally using cudaMallocAsync to avoid fragmentation,
this patch can fix this common fragmentation issue while preserving most
of the existing allocator behavior. This behavior can be enabled and disabled dynamically.
This should allow users to, for instance, allocate long-lived parameters and state in individual buffers,
and put temporary state into the large expandable blocks, further reducing
fragmentation.
See inline comments for information about the implementation and its limitations.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96995
Approved by: https://github.com/eellison
CUDA Graph Trees
Design doc: https://docs.google.com/document/d/1ZrxLGWz7T45MSX6gPsL6Ln4t0eZCSfWewtJ_qLd_D0E/edit
Not currently implemented :
- Right now, we are using weak tensor refs from outputs to check if a tensor has dies. This doesn't work because a) aliasing, and b) aot_autograd detaches tensors (see note [Detaching saved tensors in AOTAutograd]). Would need either https://github.com/pytorch/pytorch/issues/91395 to land to use storage weak refs or manually add a deleter fn that does what I want. This is doable but theres some interactions with the caching allocator checkpointing so saving for a stacked pr.
- Reclaiming memory from the inputs during model recording. This isn't terribly difficult but deferring to another PR. You would need to write over the input memory during warmup, and therefore copy the inputs to cpu. Saving for a stacked pr.
- Warning on overwriting previous generation outputs. and handling nested torch.compile() calls in generation tracking
Differential Revision: [D43999887](https://our.internmc.facebook.com/intern/diff/D43999887)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89146
Approved by: https://github.com/ezyang
This refactors the stack trace facility specific to memory profiling
in python+cuda to make a generic facility to generate combined stack
traces.
The generic facility (combined_traceback.h) does not require
python to be around to work, but will return python stacks if it is
present.
This facility is then used to add support for stack trace gathering in memory profiling that
happens directly from C++.
It is also used to expose a python API for gathering and symbolizing
combineds stacks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95541
Approved by: https://github.com/ezyang
When we checkpoint the state of the private pool allocator, we will need to make sure that its current live allocated blocks will get properly cleaned up when the tensors they correspond to die. Return DataPtrs for these new allocated blocks that the callee can swap onto live Tensors.
The exact api for setting the checkpoint can be manipulated after this as the cudagraph implementation is built out, but this at least shows its sufficiently general.
This should be the last PR touching cuda caching allocator necessary for new cudagraphs integration.
Differential Revision: [D43999888](https://our.internmc.facebook.com/intern/diff/D43999888)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95020
Approved by: https://github.com/zdevito
Copying note from cuda caching allocator:
```
* Note [Checkpointing PrivatePoolState]
*
* Refer above to Note [Interaction with CUDA graph capture]. Allocations made
* during graph capture are made from a separate private pool. During graph
* capture allocations behave as usual. During graph replay the allocator
* state does not change even as new tensors are created. The private pool
* will not free its blocks to the main caching allocator until cuda graph use
* is finished to prevent an allocation from eager clobbering the memory from
* a live but unaccounted for tensor that was created during replay.
*
* `make_graphed_callables`, a series of separate callables chained in
* successive cuda graphs, can share a memory pool because after a cuda graph
* recording the allocations in the shared private pool exactly reflect the
* tensors that are allocated.
*
* We would like to extend callable chaining to support a graphed callable
* tree. In this scenario, we have a tree of callable chains which will be
* captured with cuda graphs. In the diagram below, we have a tree with four
* callables, A, B, C, and D. Suppose we have captured, and subsequently
* replayed, A, B, and C. Then on a new invocation, we replay A and B, but
* would now like to record D. At this point the private pool will not reflect
* any of the live tensors created during graph replay. Allocations made
* during a new recording with the pool could overwrite those live tensors.
*
* In order to record a new graph capture after replaying prior callables in
* the tree, we need the allocator to reflect the state of the live tensors.
* We checkpoint the state of the private after each recording, and then
* reapply it when we are starting a new recording chain. Additionally, we
* must free the allocations for any tensors that died between the end of our
* previous graph replaying and our new recording (TODO). All of the allocated
* segments that existed in the checkpointed state must still exist in the
* pool. There may also exist new segments, which we will free (TODO : link
* note [live tensors between iterations] when it exists).
*
*
* ---------------> A ---------------> B ---------------> C
* |
* |
* |
* |
* ---------------> D
```
A few TODOs:
- need to add logic for freeing tensors that have died between a last replay and current new recording
- Add logic for free that might be called on a pointer multiple times (because we are manually freeing live tensors)
The two scenarios above have not been exercised in the tests yet.
Differential Revision: [D43999889](https://our.internmc.facebook.com/intern/diff/D43999889)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94653
Approved by: https://github.com/zdevito
Adds the ability to quickly generate stack traces for C++,
and combine Python, TorchScript, and C++ frames into a single trace.
This makes it possible for the memory tracer to record allocations inside
C++ code (e.g. convolution temporaries, backward operators).
The unwinder code is ~10x faster than execinfo.h's backward because it
cache fast unwinder routines for instruction pointers that have already been seen.
It is also only 1.2--2x slower than copying the entire stack (the approach perf takes),
while using 2 orders of magnitude less space per stack.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95357
Approved by: https://github.com/bertmaher
Fixes https://github.com/pytorch/serve/issues/1937
A fairly common query I see folks running while using pytorch is
`nvidia-smi --format=csv,noheader,nounits --query-gpu=utilization.gpu,utilization.memory,memory.total,memory.used,temperature.gpu,power.draw,clocks.current.sm,clocks.current.memory -l 10`
Existing metrics we have
* For kernel utilization`torch.cuda.utilization()`
* For memory utilization we have them under `torch.cuda.memory` the memory allocated with `torch.cuda.memory.memory_allocated()`
* For total available memory we have `torch.cuda.get_device_properties(0).total_memory`
Which means the only metrics we're missing are
* Temperature: now in `torch.cuda.temperature()`
* Power draw: now in `torch.cuda.power()`
* Clock speed: now in `torch.cuda.clock_speed()`
With some important details on each
* Clock speed settings: I picked the SM clock domain which is documented here https://docs.nvidia.com/deploy/nvml-api/group__nvmlDeviceEnumvs.html#group__nvmlDeviceEnumvs_1g805c0647be9996589fc5e3f6ff680c64
* Temperature: I use `pynvml.nvmlDeviceGetTemperature(handle, 0)` where 0 refers to the GPU die temperature
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91717
Approved by: https://github.com/ngimel
With the release of ROCm 5.3 hip now supports a hipGraph implementation.
All necessary backend work and hipification is done to support the same functionality as cudaGraph.
Unit tests are modified to support a new TEST_GRAPH feature which allows us to create a single check for graph support instead of attempted to gather the CUDA level in annotations for every graph test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88202
Approved by: https://github.com/jithunnair-amd, https://github.com/pruthvistony, https://github.com/malfet
Summary:
The caching allocator can be configured to round memory allocations in order to reduce fragmentation. Sometimes however, the overhead from rounding can be higher than the fragmentation it helps reduce.
We have added a new stat to CUDA caching allocator stats to help track if rounding is adding too much overhead and help tune the roundup_power2_divisions flag:
- "requested_bytes.{current,peak,allocated,freed}": memory requested by client code, compare this with allocated_bytes to check if allocation rounding adds too much overhead
Test Plan: Added test case in caffe2/test/test_cuda.py
Differential Revision: D40810674
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88575
Approved by: https://github.com/zdevito
Follow-up of #86167 ; The number of pools was mistakenly ignored and the default workspace size appears to be too small to match selected cuBLAS kernels before the explicit allocation change.
CC @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89027
Approved by: https://github.com/ngimel
Essentially the same change as #67946, except that the default is to disallow reduced precision reductions in `BFloat16` GEMMs (for now). If performance is severely regressed, we can change the default, but this option appears to be necessary to pass some `addmm` `BFloat16` tests on H100.
CC @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89172
Approved by: https://github.com/ngimel
Summary:
1. use pytree to allow any input format for make_graphed_callables
2. add allow_unused_input argument for make_graphed_callables
Test Plan: buck2 test mode/dev-nosan //caffe2/test:cuda -- --print-passing-details
Differential Revision: D42077976
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90941
Approved by: https://github.com/ngimel
Preparation for the next PR in this stack: #89559.
I replaced
- `self.assertTrue(torch.equal(...))` with `self.assertEqual(..., rtol=0, atol=0, exact_device=True)`,
- the same for `self.assertFalse(...)` with `self.assertNotEqual(...)`, and
- `assert torch.equal(...)` with `torch.testing.assert_close(..., rtol=0, atol=0)` (note that we don't need to set `check_device=True` here since that is the default).
There were a few instances where the result of `torch.equal` is used directly. In that cases I've replaced with `(... == ...).all().item()` while sometimes also dropping the `.item()` depending on the context.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89527
Approved by: https://github.com/mruberry
Fixes#87894
This PR adds a warning if captured graph is empty (consists of zero nodes).
The example snippet where would it be useful:
```python
import torch
x = torch.randn(10)
z = torch.zeros(10)
g = torch.cuda.CUDAGraph()
with torch.cuda.graph(g):
z = x * x
# Warn user
```
and in #87894
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88754
Approved by: https://github.com/ezyang
Summary:
Improved roundup_power2_divisions knob so it allows better control of rouding in the PyTorch CUDA Caching Allocator.
This new version allows setting the number of divisions per power of two interval starting from 1MB and ending at 64GB and above. An example use case is when rouding is desirable for small allocations but there are also very large allocations which are persistent, thus would not benefit from rounding and take up extra space.
Test Plan: Tested locally
Differential Revision: D40103909
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87290
Approved by: https://github.com/zdevito
As per #87979, `custom_bwd` seems to forcefully use `torch.float16` for `torch.autograd.Function.backward` regardless of the `dtype` used in the forward.
Changes:
- store the `dtype` in `args[0]`
- update tests to confirm the dtype of intermediate result tensors that are outputs of autocast compatible `torch` functions
cc @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88029
Approved by: https://github.com/ngimel
We currently can take snapshots of the state of the allocated cuda memory, but we do not have a way to correlate these snapshots with the actions the allocator that were taken between snapshots. This PR adds a simple fixed-sized buffer that records the major actions that the allocator takes (ALLOC, FREE, SEGMENT_ALLOC, SEGMENT_FREE, OOM, SNAPSHOT) and includes these with the snapshot information. Capturing period snapshots with a big enough trace buffer makes it possible to see how the allocator state changes over time.
We plan to use this functionality to guide how settings in the allocator can be adjusted and eventually have a more robust overall algorithm.
As a component of this functionality, we also add the ability to get a callback when the allocator will throw an OOM, primarily so that snapshots can be taken immediately to see why the program ran out of memory (most programs have some C++ state that would free tensors before the OutOfMemory exception can be caught).
This PR also updates the _memory_viz.py script to pretty-print the trace information and provide a better textual summary of snapshots distinguishing between internal and external fragmentation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86241
Approved by: https://github.com/ngimel
Sometimes the driving process want to save memory snapshots but isn't Python.
Add a simple API to turn it on without python stack traces. It still
saves to the same format for the vizualization and summary scripts, using
the C++ Pickler.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86190
Approved by: https://github.com/ezyang
{kind=link}