Summary:
When an error is raised and `__exit__` in a context manager returns `True`, the error is suppressed; otherwise the error is raised. No return value should be given to maintain the default behavior of context manager.
Fixes https://github.com/pytorch/pytorch/issues/32639. The `get_lr` function was overridden with a function taking an epoch parameter, which is not allowed. However, the relevant error was not being raised.
```python
In [1]: import torch
...:
...: class MultiStepLR(torch.optim.lr_scheduler._LRScheduler):
...: def __init__(self, optimizer, gamma, milestones, last_epoch = -1):
...: self.init_lr = [group['lr'] for group in optimizer.param_groups]
...: self.gamma = gamma
...: self.milestones = milestones
...: super().__init__(optimizer, last_epoch)
...:
...: def get_lr(self, step):
...: global_step = self.last_epoch #iteration number in pytorch
...: gamma_power = ([0] + [i + 1 for i, m in enumerate(self.milestones) if global_step >= m])[-1]
...: return [init_lr * (self.gamma ** gamma_power) for init_lr in self.init_lr]
...:
...: optimizer = torch.optim.SGD([torch.rand(1)], lr = 1)
...: scheduler = MultiStepLR(optimizer, gamma = 1, milestones = [10, 20])
```
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-1-7fad6ba050b0> in <module>
14
15 optimizer = torch.optim.SGD([torch.rand(1)], lr = 1)
---> 16 scheduler = MultiStepLR(optimizer, gamma = 1, milestones = [10, 20])
<ipython-input-1-7fad6ba050b0> in __init__(self, optimizer, gamma, milestones, last_epoch)
6 self.gamma = gamma
7 self.milestones = milestones
----> 8 super().__init__(optimizer, last_epoch)
9
10 def get_lr(self, step):
~/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/optim/lr_scheduler.py in __init__(self, optimizer, last_epoch)
75 self._step_count = 0
76
---> 77 self.step()
78
79 def state_dict(self):
~/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/optim/lr_scheduler.py in step(self, epoch)
141 print("1a")
142 # try:
--> 143 values = self.get_lr()
144 # except TypeError:
145 # raise RuntimeError
TypeError: get_lr() missing 1 required positional argument: 'step'
```
May be related to https://github.com/pytorch/pytorch/issues/32898.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32997
Differential Revision: D19737731
Pulled By: vincentqb
fbshipit-source-id: 5cf84beada69b91f91e36b20c3278e9920343655
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27254
`MultiplicativeLR` consumes a function providing the multiplicative factor at each epoch. It mimics `LambdaLR` in its syntax.
Test Plan: Imported from OSS
Differential Revision: D17728088
Pulled By: vincentqb
fbshipit-source-id: 1c4a8e19a4f24c87b5efccda01630c8a970dc5c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27850
Many of these are real problems in the documentation (i.e., link or
bullet point doesn't display correctly).
Test Plan: - built and viewed the documentation for each change locally.
Differential Revision: D17908123
Pulled By: zou3519
fbshipit-source-id: 65c92a352c89b90fb6b508c388b0874233a3817a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26423
Enable chainable schedulers as requested in #13022 by implementing the changes mentioned below from [comment](https://github.com/pytorch/pytorch/pull/21800#issuecomment-513370208).
* Changing the behavior of schedulers to the chainable formula when available
* Using the closed form whenever epoch is different from None until the next release with a deprecation warning
* Making `get_computed_values` the supported way of obtaining the last computed learning rate by the scheduler (see [comment](https://github.com/pytorch/pytorch/pull/21800#issuecomment-513940729) for new syntax)
* Returning a deprecation warning when invoking the undocumented get_lr function (see [comment](https://github.com/pytorch/pytorch/pull/21800#discussion_r294305485)) referring to `get_computed_values`, and deprecating it in the next release.
* `CosineAnnealingWarmRestart` still takes an epoch parameter as it is the only one with a mechanic relying on fractional epoch
* `MultiplicativeLR` is consumes a function providing the multiplicative factor at each epoch. It mimics `LambdaLR` in its syntax.
# #20527
### Before
The user calls scheduler with a constant epoch either across loops or in the same loop.
```
import torch.optim as optim
from torch import nn
conv = nn.Conv2d(3,3,3)
optimizer = optim.Adam(conv.parameters())
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, 2)
# Scheduler with sometimes-constant epoch number
for epoch in [0, 0, 1, 1, 2, 2, 3, 3]:
lr_scheduler.step(epoch)
print(optimizer.param_groups[0]['lr'])
```
### After
If the user wants to step
```
import torch.optim as optim
from torch import nn
conv = nn.Conv2d(3,3,3)
optimizer = optim.Adam(conv.parameters())
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, 2)
last_epoch = -1
for epoch in [0, 0, 1, 1, 2, 2, 3, 3]:
# Check if epoch number has changed manually
if epoch-last_epoch > 0:
lr_scheduler.step()
last_epoch = epoch
print(epoch, scheduler.get_computed_values())
```
# #22107
### Before
```
import torch
from torchvision.models import resnet18
net = resnet18()
optimizer = torch.optim.SGD(net.parameters(), 0.1)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[3, 6, 9], gamma=0.1)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 3, gamma=0.1)
for i in range(10):
# Scheduler computes and returns new learning rate, leading to unexpected behavior
print(i, scheduler.get_lr())
scheduler.step()
```
### After
```
import torch
from torchvision.models import resnet18
net = resnet18()
optimizer = torch.optim.SGD(net.parameters(), 0.1)
lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[3, 6, 9], gamma=0.1)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 3, gamma=0.1)
for i in range(10):
# Returns last computed learning rate by scheduler
print(i, lr_scheduler.get_computed_values())
lr_scheduler.step()
```
# ghstack
This contains the changes from #24352. Opening again since they were reverted.
This reverts commit 1c477b7e1f.
Test Plan: Imported from OSS
Differential Revision: D17460427
Pulled By: vincentqb
fbshipit-source-id: 8c10f4e7246d6756ac91df734e8bed65bdef63c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24352
Enable chainable schedulers as requested in #13022 by implementing the changes mentioned below from [comment](https://github.com/pytorch/pytorch/pull/21800#issuecomment-513370208).
* Changing the behavior of schedulers to the chainable formula when available
* Using the closed form whenever epoch is different from None until the next release with a deprecation warning
* Making `get_computed_values` the supported way of obtaining the last computed learning rate by the scheduler (see [comment](https://github.com/pytorch/pytorch/pull/21800#issuecomment-513940729) for new syntax)
* Returning a deprecation warning when invoking the undocumented get_lr function (see [comment](https://github.com/pytorch/pytorch/pull/21800#discussion_r294305485)) referring to `get_computed_values`, and deprecating it in the next release.
* `CosineAnnealingWarmRestart` still takes an epoch parameter as it is the only one with a mechanic relying on fractional epoch
* `MultiplicativeLR` is consumes a function providing the multiplicative factor at each epoch. It mimics `LambdaLR` in its syntax.
# #20527
### Before
The user calls scheduler with a constant epoch either across loops or in the same loop.
```
import torch.optim as optim
from torch import nn
conv = nn.Conv2d(3,3,3)
optimizer = optim.Adam(conv.parameters())
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, 2)
# Scheduler with sometimes-constant epoch number
for epoch in [0, 0, 1, 1, 2, 2, 3, 3]:
lr_scheduler.step(epoch)
print(optimizer.param_groups[0]['lr'])
```
### After
If the user wants to step
```
import torch.optim as optim
from torch import nn
conv = nn.Conv2d(3,3,3)
optimizer = optim.Adam(conv.parameters())
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, 2)
last_epoch = -1
for epoch in [0, 0, 1, 1, 2, 2, 3, 3]:
# Check if epoch number has changed manually
if epoch-last_epoch > 0:
lr_scheduler.step()
last_epoch = epoch
print(epoch, scheduler.get_computed_values())
```
# #22107
### Before
```
import torch
from torchvision.models import resnet18
net = resnet18()
optimizer = torch.optim.SGD(net.parameters(), 0.1)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[3, 6, 9], gamma=0.1)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 3, gamma=0.1)
for i in range(10):
# Scheduler computes and returns new learning rate, leading to unexpected behavior
print(i, scheduler.get_lr())
scheduler.step()
```
### After
```
import torch
from torchvision.models import resnet18
net = resnet18()
optimizer = torch.optim.SGD(net.parameters(), 0.1)
lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[3, 6, 9], gamma=0.1)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 3, gamma=0.1)
for i in range(10):
# Returns last computed learning rate by scheduler
print(i, lr_scheduler.get_computed_values())
lr_scheduler.step()
```
Test Plan: Imported from OSS
Differential Revision: D17349760
Pulled By: vincentqb
fbshipit-source-id: 0a6ac01e2a6b45000bc6f9df732033dd81f0d89f
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/23480.
I only verified that the schedule reaches the restart at the expected step as specified in the issue, it would be good to have someone else verify correctness here.
Script:
```
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(torch.optim.SGD([torch.randn(1, requires_grad=True)], lr=0.5), T_0=1, T_mult=2)
for i in range(9):
print(i)
print(scheduler.get_lr())
scheduler.step()
```
Output:
```
0
[0.5]
1
[0.5]
2
[0.25]
3
[0.5]
4
[0.42677669529663687]
5
[0.25]
6
[0.07322330470336313]
7
[0.5]
8
[0.4809698831278217]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23833
Differential Revision: D16657251
Pulled By: gchanan
fbshipit-source-id: 713973cb7cbfc85dc333641cbe9feaf917718eb9
Summary:
Resolves issue https://github.com/pytorch/pytorch/issues/19003
The author of this issue also asked that `cycle_momentum` default to `False` if the optimizer does not have a momentum parameter, but I'm not sure what the best way to do this would be. Silently changing the value based on the optimizer may confuse the user in some cases (say the user explicitly set `cycle_momentum=True` but doesn't know that the Adam optimizer doesn't use momentum).
Maybe printing a warning when switching this argument's value would suffice?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20401
Differential Revision: D15765463
Pulled By: ezyang
fbshipit-source-id: 88ddabd9e960c46f3471f37ea46013e6b4137eaf
Summary:
This PR addresses the problem described in the comment: https://github.com/pytorch/pytorch/pull/20203#issuecomment-499231276
and previously coded bad behaviour:
- a warning was raised all the times when lr schedulling is initialized
Now the code checks that:
- on the second call of `lr_scheduler.step`, ensure that `optimizer.step` has been already called, otherwise raise a warning (as it was done in #20203 )
- if optimizer's step is overridden -> raise once another warning to aware user about the new pattern:
`opt.step()` -> `lrs.step()` as we can not check this .
Now tests check that
- at initialization (`lrs = StepLR(...)`)there is no warnings
- if we replace `optimizer.step` by something else (similarly to the [code of nvidia/apex](https://github.com/NVIDIA/apex/blob/master/apex/amp/_process_optimizer.py#L287)) there is another warning raised.
cc ezyang
PS. honestly I would say that there is a lot of overhead introduced for simple warnings. I hope all these checks will be removed in future `1.2.0` or other versions...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21460
Differential Revision: D15701776
Pulled By: ezyang
fbshipit-source-id: eac5712b9146d9d3392a30f6339cd33d90c497c7
Summary:
Fixes a typo in the CyclicLR docs by adding the lr_scheduler directory and puts in other required arguments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21021
Differential Revision: D15530109
Pulled By: soumith
fbshipit-source-id: 98781bdab8d82465257229e50fa3bd0015da1286
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20880
This clarifies how the momentum parameters should be used.
Reviewed By: soumith
Differential Revision: D15482450
fbshipit-source-id: e3649a38876c5912cb101d8e404abca7c3431766
Summary:
Class attributes preferably be explicitly initiated within
the __init__() call. Otherwise, overriding step() is
prone to bugs.
This patch partially reverts #7889
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20059
Differential Revision: D15195747
Pulled By: soumith
fbshipit-source-id: 3d1a51d8c725d6f14e3e91ee94c7bc7a7d6c1713
Summary:
Because of merge error with master in #15042, open a new PR for ezyang.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17226
Differential Revision: D14418145
Pulled By: mrshenli
fbshipit-source-id: 099ba225b28e6aba71760b81b2153ad1c40fbaae
Summary:
Added the formula for the corner case. Updated unit tests.
Fixes#17913
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19180
Differential Revision: D14942023
Pulled By: ezyang
fbshipit-source-id: 167c109b97a7830d5b24541dc91e4788d531feec
Summary:
Hello everyone :) !!
I've found that lr_scheduler was initialized with last_epoch as -1.
This causes that even after the first step (not the one in init but explicit step of scheduler),
learning rate of scheduler's optimizer remains as the previous.
```python
>>> import torch
>>> cc = torch.nn.Conv2d(10,10,3)
>>> myinitial_lr = 0.1
>>> myoptimizer = torch.optim.Adam(cc.parameters(), lr=myinitial_lr)
>>> mylrdecay = 0.5
>>> myscheduler = torch.optim.lr_scheduler.ExponentialLR(myoptimizer,mylrdecay)
>>> myscheduler.get_lr()
[0.2] # this is because of get_lr calculates lr by 0.1 * 0.5^-1
>>> myscheduler.optimizer.param_groups[0]["lr"]
0.1 # this is not consistent with get_lr value
>>> myscheduler.last_epoch
-1
>>> myscheduler.step()
>>> myscheduler.get_lr()
[0.1] # this should be the value right after the init, not after first step
>>> myscheduler.optimizer.param_groups[0]["lr"]
0.1 # since this is after first step, it should have been decayed as 0.05
>>> myscheduler.last_epoch
0
>>> myscheduler.step()
>>> myscheduler.last_epoch
1
>>> myscheduler.get_lr()
[0.05]
>>> myscheduler.optimizer.param_groups[0]["lr"]
0.05
>>> myscheduler.last_epoch
1
```
First problem is, even after the init of lr_scheduler, you get the inconsistent parameter values.
The second problem is, you are stuck with same learning rate in the first 2 epochs if the step function of lr_scheduler is not called in the beginning of the epoch loop.
Of course, you can avoid this by calling lr_scheduler's step in the beginning,
but I don't think this is proper use since, incase of optimizer, step is called in the end of the iteration loop.
I've simply avoided all above issues by setting last_epoch as 0 after the initialization.
This also makes sense when you init with some value of last_epoch which is not -1.
For example, if you want to init with last epoch 10,
lr should not be set with decayed 1 step further. Which is
last_epoch gets +1 in the previous code.
base_lr * self.gamma ** self.last_epoch
Instead, it should be set with step 10 exact value.
I hope this fix find it's way with all your help :)
I'm really looking forward & excited to become a contributor for pytorch!
Pytorch Rocks!!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/7889
Differential Revision: D15012769
Pulled By: ezyang
fbshipit-source-id: 258fc3009ea7b7390a3cf2e8a3682eafb506b08b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18598
ghimport-source-id: c74597e5e7437e94a43c163cee0639b20d0d0c6a
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18598 Turn on F401: Unused import warning.**
This was requested by someone at Facebook; this lint is turned
on for Facebook by default. "Sure, why not."
I had to noqa a number of imports in __init__. Hypothetically
we're supposed to use __all__ in this case, but I was too lazy
to fix it. Left for future work.
Be careful! flake8-2 and flake8-3 behave differently with
respect to import resolution for # type: comments. flake8-3 will
report an import unused; flake8-2 will not. For now, I just
noqa'd all these sites.
All the changes were done by hand.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14687478
fbshipit-source-id: 30d532381e914091aadfa0d2a5a89404819663e3
Summary:
This implements a cyclical learning rate (CLR) schedule with an optional inverse cyclical momentum. More info about CLR: https://github.com/bckenstler/CLR
This is finishing what #2016 started. Resolves#1909.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18001
Differential Revision: D14451845
Pulled By: sampepose
fbshipit-source-id: 8f682e0c3dee3a73bd2b14cc93fcf5f0e836b8c9
Summary:
Modified step_lr for StepLR, MultiStepLR, ExponentialLR and CosineAnnealingLR. In this way, multiple schedulers can be used simultaneously to modify the learning rates.
Related issue: https://github.com/pytorch/pytorch/issues/13022
Added unit tests combining multiple schedulers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14010
Reviewed By: ezyang
Differential Revision: D13494941
Pulled By: chandlerzuo
fbshipit-source-id: 7561270245639ba1f2c00748f8e4a5f7dec7160c
Summary:
I opened an issue explaining some of my frustrations with the current state of schedulers.
While most points that I raised in [that issue](https://github.com/pytorch/pytorch/issues/8741#issuecomment-404449697) need to be discussed more thoroughly before being implemented, there are some that are not so difficult to fix.
This PR changes the way the LambdaLR scheduler gets serialized:
> The lr_lambda functions are only saved if the are callable objects (which can be stateful).
> There is no point in saving functions/lambdas as you need their definition before unpickling and they are stateless.
This has the big advantage that the scheduler is serializable, even if you use lambda functions or locally defined functions (aka a function in a function).
Does this functionality need any unit tests?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9927
Differential Revision: D9055505
Pulled By: soumith
fbshipit-source-id: 6c1cec588beedd098ec7d2bce6a9add27f29e48f
* Clarify patience in ReduceLROnPlateau docs
It's unclear which definition of patience we have. The two ways to
interpret it are:
- How many bad epochs can you see before you start considering changing the learning rate.
- How many bad epochs can you see before you change the learning rate.
This PR clarifies the docs with an example. If `patience = 2`, then
after 2 bad epochs, we begin considering changing the learning rate.
After seeing one more epoch (the 3rd epoch), if that epoch is also bad,
then we change the learning rate after it.
* address comments
* Fix LaTex rendering in CosineAnnealingLR
Backslashes were interpreted by Python as escapes in the string, so \frac
turned into frac, which is not a valid LaTex command.
This could be fixed with double backslashes, but the easiest solution is to
just use a raw (r) docstring.
* Fix sphinx warnings for LRN doc headings
* Move LRN docstring from __init__ to class level
The docstring was not rendered by sphinx at
http://pytorch.org/docs/master/nn.html#torch.nn.LocalResponseNorm
because it was in the constructor.
* Remove superfluous backticks from LRN formula
{kind=link}
{kind=link}
{kind=link}
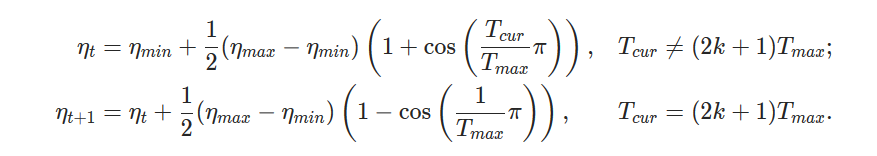{kind=link}
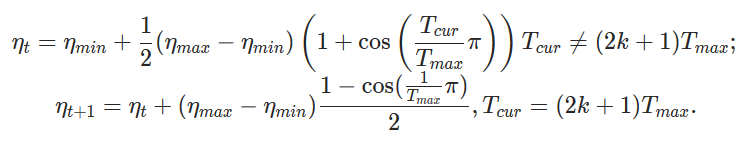{kind=link}
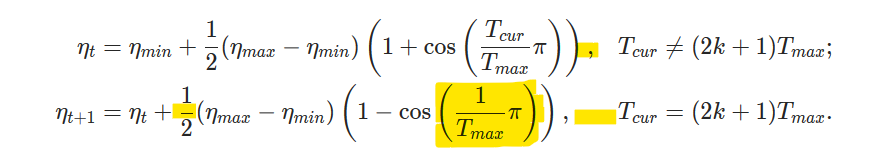{kind=link}
{kind=link}
{kind=link}