Summary:
When creating a new DDP instance for the same model when an old DDP instance existed, the autograd hooks from the old DDP instance might not be cleared. Also, relying on python gc to clear out old autograd hooks is fragile and may not work 100% of the time.
As a result, in this PR I'm adding a way to explicitly remove these hooks from DDP
Test Plan:
Unit test added
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96490
Approved by: https://github.com/zhaojuanmao, https://github.com/rohan-varma
Summary: Enable the functionality of delaying all reduce in DDP to specify the parameters whose all reduce will be hooked to a specific param. This prevents AllReduce blocking All2All in some recommendation models.
Test Plan: GitHub CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96673
Approved by: https://github.com/zhaojuanmao
Implements native mixed precision support for DDP in a similar fashion to how it is enabled for FSDP. The implementation works as follows:
1. In DDP init, we save `_mp_param` and `_fp_param` variables to manage mixed precision parameter usage. In particular, _mp_param will represent the parameter in the reduced precision, while _fp_param will represent the param in regular precision. During forward/backward, we swap back and forth as needed.
2. The root module gets a root pre-forward hook that kicks off copies to the reduced precision for all submodules. An event is recorded for each submodule to allow for waiting, as we run these asynchronously.
3. Each module gets a pre-forward hook that waits on its corresponding event. note that modules might be reused during training, in this case the wait is only done for the first module. After this wait, the module's parameters are in reduced precision.
4. In the pre-forward hook, we register a backward hook on the lower precision parameters in order to run reduced precision allreduce + parameter upcast. We can't rely on the Reducer's constructor setting up these hooks because the gradient is accumulated on the low precision param, so we need to register them ourselves.
5. In the backward pass, when the hook runs, we first run allreduce + divide in the reduced precision. Next, we upcast parameters and gradients back to fp32 asynchronously. We also queue a callback at the end of backward to wait on these upcasts so that the upcast is complete before optim.step() runs.
6. Parameters that don't require grad are also cast since they may be used in computation, they are upcast back in the final autograd callback.
7. DDP Ignored parameters are not touched.
Follow-ups:
1. Unify comm hooks and make it work with apply optimizer in backward
2. implement keep_low_precision_grads,
3. allow BN, LN, or custom units to run in reduced precision,
4. support for cast_forward_inputs
5. Unify certain APIs / helpers with FSDP where possible, such as for _cast_forward_inputs
6. Integrate this with replicate() API.
7. The order in which we kick off copies and wait for them is set by the iteration order of module.modules(), but this might not be how the modules are used in the actual training. In the worst case, the last module in module.modules() could be used first which would result in waiting for all copies unnecessarily. For static graphs, we should record the module execution order and copy / wait in this order.
8. Entirely unused modules probably don't need to be cast.
Differential Revision: [D42515803](https://our.internmc.facebook.com/intern/diff/D42515803/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92882
Approved by: https://github.com/zhaojuanmao
Applies the remaining flake8-comprehension fixes and checks. This changes replace all remaining unnecessary generator expressions with list/dict/set comprehensions which are more succinct, performant, and better supported by our torch.jit compiler. It also removes useless generators such as 'set(a for a in b)`, resolving it into just the set call.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94676
Approved by: https://github.com/ezyang
Applies some more harmless pyupgrades. This one gets rid of deprecated aliases in unit_tests and more upgrades yield for loops into yield from generators which are more performance and propagates more information / exceptions from original generator. This is the modern recommended way of forwarding generators.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94309
Approved by: https://github.com/albanD
removes this unused var, the overall buffer comm hook feature is also not being used, we should deprecate / remove it as it is still a private API.
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93128
Approved by: https://github.com/awgu
Allow _apply_optim_in_backward to work with DDP.
Example:
```
dist.init_process_group("nccl", rank=rank, world_size=2)
torch.cuda.set_device(rank)
e = enc().cuda(rank)
_apply_optimizer_in_backward(
optimizer_class=torch.optim.SGD,
params=e.parameters(),
optimizer_kwargs={"lr": 0.03},
)
e = DDP(e, device_ids=[rank])
inp = torch.randn(1, 10, device=rank)
e(inp).sum().backward()
```
Constraints:
1. Custom communication hook not yet supported
2. _apply_optim_in_backward needs to be called _before_ wrapping model in DDP.
3. DDP will remove the gradient hooks _apply_optim_in_backward registers, so these gradient hooks will not be fired and cannot be used.
4. All DDP managed parameters have grads set to None by default once optimizer is applied. There is no support for setting only some parameter grads to None, this must be done manually by user (and DDP_OVERLAPPED_OPTIM_SET_GRADS_TO_NONE=0 needs to be set.)
Differential Revision: [D41329694](https://our.internmc.facebook.com/intern/diff/D41329694/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D41329694/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89194
Approved by: https://github.com/zhaojuanmao
This is a new version of #15648 based on the latest master branch.
Unlike the previous PR where I fixed a lot of the doctests in addition to integrating xdoctest, I'm going to reduce the scope here. I'm simply going to integrate xdoctest, and then I'm going to mark all of the failing tests as "SKIP". This will let xdoctest run on the dashboards, provide some value, and still let the dashboards pass. I'll leave fixing the doctests themselves to another PR.
In my initial commit, I do the bare minimum to get something running with failing dashboards. The few tests that I marked as skip are causing segfaults. Running xdoctest results in 293 failed, 201 passed tests. The next commits will be to disable those tests. (unfortunately I don't have a tool that will insert the `#xdoctest: +SKIP` directive over every failing test, so I'm going to do this mostly manually.)
Fixes https://github.com/pytorch/pytorch/issues/71105
@ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82797
Approved by: https://github.com/ezyang
### Description
Across PyTorch's docstrings, both `callable` and `Callable` for variable types. The Callable should be capitalized as we are referring to the `Callable` type, and not the Python `callable()` function.
### Testing
There shouldn't be any testing required.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82487
Approved by: https://github.com/albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75753
As per the design in https://github.com/pytorch/pytorch/issues/72138,
convert DDP parameters to ReplicatedTensor during its forward pass. Concretely,
this is done as follows:
1) Create a separate `_replicated_tensor_module` which is a copy of self.module
without creating copies of the Tensors themselves.
2) Use `_replicated_tensor_module` instead of `self.module` during the forward
pass.
3) Have a context manager `_ddp_replicated_tensor` to enable this, since
certain edge cases can fail where self.module is changed out of band resulting
in discrepancy between self.module and `_replicated_tensor_module`.
Differential Revision: [D35533736](https://our.internmc.facebook.com/intern/diff/D35533736/)
Approved by: https://github.com/wanchaol, https://github.com/rohan-varma
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74063
Address the issue https://github.com/pytorch/pytorch/issues/66229 as part of BE effort.
Basically:
1. We remove the stale comment which confuses users.
2. Add more unit tests to test the forward/backward hook working for DDP.
ghstack-source-id: 151463380
Test Plan: CI
Reviewed By: rohan-varma
Differential Revision: D34800830
fbshipit-source-id: 21133209323b2b5eda0dd6472f6309d4fb779b97
(cherry picked from commit b9b165c8305572128395daffafc13fcac8b85e29)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72843
# [Debug Story] Training Hanging and DDP Bucketing
**What are the characteristics of the hanging training instance?**
The model uses TorchRec `PooledEmbeddingArch` and corresponding sharding solution.
The model config difference to trigger this hanging issue is turning on position weighted embedding tables.
A feature processor module, `GroupedPositionWeightedModule`, is constructed on all ranks, but `GroupedPositionWeightedModule.foward(...)` is only [called on subset ranks of the whole world](https://fburl.com/code/yqrmtvli).
**What was the initial manifested error?**
The training was stuck in the first iteration.
**What are useful debugging tools this time?**
After turning off [static_graph in DDP](https://fburl.com/code/4io81p5i), we saw there were sparse feature lengths becoming negative values after all-to-all collectives. Hanging becomes fatal failure.
After turning on [torch.distributed DETAIL debugging mode](https://fburl.com/code/cp8e28mm), we saw 2 trainers sent out mismatched collectives, one doing all-to-all, the other doing all-reduce. So we know the negative values comes from all-to-all being matched with all-reduce. the error had happened ahead, which is the wrong timing of either doing all-reduce or all-to-all.
With more added loggings inside of DDP, it turned out the DDP decided to do all-reduce at different timings across different ranks.
**What is DDP bucketing?**
Once a gradient is ready on a rank, DDP uses all-reduce to synchronize the average of this gradient across all ranks.
Say we have 4 tensor ops. A, B, C, D.
In the most naive version, we could do one synchronization when all gradients in the full backward graph are ready.
The time sequence would be,
* D.grad
* C.grad
* B.grad
* A.grad
* All reduce on [D.grad, C.grad, B.grad, A.grad].
But that would be a huge waste of communication channel bandwidth.
With DDP bucketing, we could put ahead some gradient synchronization batch by batch. The above time sequence now becomes,
* D.grad
* C.grad
* All reduce on [D.grad, C.grad].
* B.grad
* A.grad
* All reduce on [B.grad, A.grad].
With gradient computation overlaps with communication, bucketing technique brings better DDP execution performance.
**What exactly went wrong in this case?**
1. The bucketing doesn’t honor backward graph execution order.
2. There are other collectives comm ops in backward graph.
3. There are unused parameters (i.e unused sub-module) in subset ranks of the whole world.
Using the above example again, we have 4 tensor ops. A, B, C, D.
Say we have 2 trainers,
B is the feature processor module.
B only runs on trainer 0 (both forward and backward), but not on trainer1.
C is the All-to-all (Pooled embeddings distribution).
C sends out all-to-all collective in both its forward and backward pass.
Keep assuming all other ops run on both trainers.
trainer_0 op sequence is,
A, B (feature preproc), C (all-to-all), D | D.grad, C.grad (reverse all-to-all), B.grad (feature proc grads), A.grad
trainer_1 op sequence is,
A, C (all-to-all), D | D.grad, C.grad (reverse all-to-all), A.grad
Even though the correct bucketing should be (same bucketing for both ranks),
* bucket_0, [D.grad, C.grad]
* bucket_1, [B.grad, A.grad]
but because of 1), they end up like,
* bucket_0, [B.grad, D.grad]
* bucket_1, [C.grad, A.grad]
Plus 2) and 3), the time sequence could like,
(check mark represents the gradient is ready)
(bucket is ready to do synchronization if all its enclosing gradients are ready)
* trainer_0
* t0,
* D.grad
* bucket_0, [B.grad, D.grad ✓]
* t1,
* **C.grad all-to-all**
* C.grad ✓
* bucket_1, [C.grad ✓, A.grad]
* t2
* B.grad
* bucket_0, [B.grad ✓, D.grad ✓] ✓
* t3
* All-reduce for bucket_0
* t4
* A.grad
* bucket_1, [C.grad ✓, A.grad ✓] ✓
* trainer_1
* t0,
* D.grad
* bucket_0, [B.grad ✓, D.grad ✓] ✓. (Because B is not used on trainer_1, DDP marks its gradient as ready immediately.)
* t1,
* **All-reduce for bucket_0**
* t2
* C.grad all-to-all
* bucket_1, [C.grad ✓, A.grad]
* t3
* A.grad
* bucket_1, [C.grad ✓, A.grad ✓] ✓
This is why trainer_0 all-to-all is matched up with trainer_1 all-reduce.
**What is the solution for fixing DDP?**
Disable DDP bucketing for the first iteration. D34051938
This is because after the first iteration, buckets will be built again based on real backward graph execution order.
So the slow gradient synchronization only affects the first iteration.
Test Plan:
buck build mode/dev-nosan caffe2/test/distributed:distributed_gloo_spawn
BACKEND=gloo WORLD_SIZE=3 buck-out/gen/caffe2/test/distributed/distributed_gloo_spawn\#binary.par -r test_ddp_logging_data_cpu
P484179296
buck build mode/dev-nosan caffe2/test/distributed:distributed_nccl_spawn
BACKEND=nccl WORLD_SIZE=2 buck-out/gen/caffe2/test/distributed/distributed_nccl_spawn\#binary.par -r test_ddp_logging_data_cpu -r test_ddp_get_bucket_sizes
P484177200
Reviewed By: zhaojuanmao
Differential Revision: D34051938
fbshipit-source-id: 0c7f35875687095c3199f19990e73a8349b6e5b9
(cherry picked from commit bb8f11306ea51c2bd3ffd3ab001d62ce369a08ee)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73166
This PR refactors, cleans up, and optimizes the implementation of `TORCH_DISTRIBUTED_DEBUG`. It also introduces three new user APIs: `get_debug_level()`, `set_debug_level()`, and `set_debug_level_from_env()` to retrieve and modify the debug level after a process has started.
ghstack-source-id: 149778566
Test Plan: Run the existing unit tests.
Reviewed By: rohan-varma
Differential Revision: D34371226
fbshipit-source-id: e18443b411adcbaf39b2ec999178c198052fcd5b
(cherry picked from commit 26d6bb1584b83a0490d8b766482656a5887fa21d)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72886
**Test Plan**
Searching for `_schedule_shadow_all_reduce_for_fwd_pass` shows that it is defined but never used.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D34255651
Pulled By: awgu
fbshipit-source-id: 205a0325c2cdc05e127a183cb86fa2fc2e0db99d
(cherry picked from commit 4492f03a3f)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72456
It is easier to log if static graph is set at construction time now that it is natively supported in DDP constructor, as opposed to waiting for the first iteration to finish. In some failure cases we're seeing the first iteration does not finish and thus we don't have this data which is vaulable to debug.
ghstack-source-id: 148840679
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D34045204
fbshipit-source-id: 72a187c1ce031db217de4b3ad20a64f2a74995bc
(cherry picked from commit 1d622c88f3)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71608
Per title
ghstack-source-id: 147577178
Test Plan: CI
Reviewed By: cbalioglu
Differential Revision: D33696382
fbshipit-source-id: 5b638d3edf5f03ba476356d61e96ca604de18c8f
(cherry picked from commit 436b547fb0)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71606
Per title
ghstack-source-id: 147577172
Test Plan: CI
Reviewed By: cbalioglu
Differential Revision: D33694037
fbshipit-source-id: a148d5ce6031f0cc20f33785cfe2c27d1fc2d682
(cherry picked from commit ace3261e0c)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71483
claify that peak memory saving should be checked after first iteration when using gradient_as_bucket_view
ghstack-source-id: 147271113
Test Plan: unit test
Reviewed By: rohan-varma
Differential Revision: D33662424
fbshipit-source-id: f760da38e166ae85234e526ddf1526269ea25d42
(cherry picked from commit a40dda20da)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71459
1. add static_graph feature to DDP constructor;
2. still keep _set_static_graph() API, so that existing use cases are not affected, also it can be called internally by DDP constructor
3. four cases are covered:
static_graph = False, _set_static_graph() is called;
static_graph = False, _set_static_graph() is not called;
static_graph = True, _set_static_graph() is not called;
static_graph = True, _set_static_graph() is called;
ghstack-source-id: 147263797
Test Plan: unit tests
Reviewed By: rohan-varma
Differential Revision: D33646738
fbshipit-source-id: 8c1730591152aab91afce7133d2adf1efd723855
(cherry picked from commit dc246a1129)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68827
Add a note about current checkpoint support with DDP. Note that this
does not include the features enabled with _set_static_graph yet, as it is an
undocumented private API. Once we support static graph as beta feature in OSS
we can add to the note here.
ghstack-source-id: 144285041
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D32624957
fbshipit-source-id: e21d156a1c4744b6e2a807b5b5289ed26701886f
Summary:
`default_collate`, `default_convert`, and `pin_memory` convert sequences into lists. I believe they should keep the original type when possible (e.g., I have a class that inherits from `list`, which comes from a 3rd party library that I can't change, and provides extra functionality).
Note it's easy to do when the type supports an iterable in its creation but it's not always the case (e.g., `range`).
Even though this can be accomplished if using a custom `default_collate`/`default_convert`, 1) this is behavior they should support out-of-the-box IMHO, and 2) `pin_memory` still does it.
cc VitalyFedyunin ejguan NivekT
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68779
Reviewed By: wenleix
Differential Revision: D32651129
Pulled By: ejguan
fbshipit-source-id: 17c390934bacc0e4ead060469cf15dde815550b4
Summary:
Patch bfloat16 support in NCCL, PR https://github.com/pytorch/pytorch/issues/63260 adds bfloat16 support but is
still not complete to enable bfloat16 for allreduce in end-to-end training.
This patch does the followings:
* fix minimum NCCL version from 2.9.7 to 2.10, NCCL adds bf16 support in
v2.10.3-1 (commit 7e51592)
* update bfloat16 datatype flag in `csrc/cuda/nccl.cpp` so that NCCL
operations like all reduce can use it
* enable unit tests for bfloat16 datatype if possible
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67843
Reviewed By: H-Huang
Differential Revision: D32248132
Pulled By: mrshenli
fbshipit-source-id: 081e96e725af3b933dd65ec157c5ad11c6873525
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66680
Closes https://github.com/pytorch/pytorch/issues/66215. Tracks models
with sync BN so we can find workflows that use them and target for perf
optimization.
ghstack-source-id: 140875182
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D31679477
fbshipit-source-id: 0e68cd1a7aabbc5b26227895c53d33b8e98bfb8e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66015
Fixes https://github.com/pytorch/pytorch/issues/61982 by clone of
tensors in DDPSink. Only applies once for static_graph and generally for unused
params which already has overhead, so perf hit should not be an issue. Will
verify with benchmark.
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D31346633
fbshipit-source-id: 5b9245ade628565cffe01731f6a0dcbb6126029b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64515
For performance reasons, we would like to ensure that we can await
user collectives as part of custom buffer reduction in parallel to other work.
As a result, add support to return futures from custom buffer hooks and await
those futures at end of backwards pass.
Also added some docs to clarify how to use these APIs.
ghstack-source-id: 138793803
Test Plan: I
Reviewed By: zhaojuanmao
Differential Revision: D30757761
fbshipit-source-id: e1a2ead9ca850cb345fbee079cf0614e91bece44
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65181
This PR changes `state_dict()` during sync to `named_parameters` and `named_buffers` explicitly. the underlying motivation is that, `state_dict()` doesn't necessarily equals to "params + buffers" for all cases, state_dict is used for checkpoint purpose mainly, and params/buffers are used for training, we might have cases that params/buffers be in different forms with state_dict (i.e. state_dict we might want to save in small pieces of tensors while in training we want to concat the tensors together for performance reasons).
ghstack-source-id: 138701159
Test Plan: wait for ci
Reviewed By: divchenko, rohan-varma
Differential Revision: D31007085
fbshipit-source-id: 4e1c4fbc07110163fb9b09b043ef7b4b75150f18
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64514
sync_params is a misnomer since we don't actually synchroniz
parameters. While removing this I realized
`self._check_and_sync_module_buffers` does almost everything we need it to, so
just refactored that and made DDP forward call into it.
ghstack-source-id: 138684982
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D30751231
fbshipit-source-id: add7c684f5c6c71dad9e9597c7759849fa74f47a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64113
Since there is only one model replica per process, `replicas`
can be simplified from `std::vector<std::vector<at::Tensor>>` to
`std::vector<at::Tensor>` in the Reducer class.
Test Plan:
All tests are passing
`pytest test/distributed/test_c10d_gloo.py -vs`
Imported from OSS
Reviewed By: mrshenli
Differential Revision: D30615965
fbshipit-source-id: d2ec809d99b788c200b01411333e7dbad1269b51
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64474
No need for a nested list here.
ghstack-source-id: 137526312
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D30745960
fbshipit-source-id: 66a8f9847e9fe1e02c51b79647e93bf7665cf4d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64472
Sometimes, user module can reassign tensor buffer, as in:
```
self.buffer = torch.randn(1, 2) # in init
self.buffer += 1 # in forward
```
in this case, `self.modules_buffers` will become outdated and we should
repopulate self.modules_buffers if we need to sync module buffers.
See https://github.com/pytorch/pytorch/issues/63916 for full description of the
issue.
ghstack-source-id: 137526309
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D30745921
fbshipit-source-id: 25eb1edbf445703a481802e07f3058d38ea6fc64
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63260
Add BF16 all-reduce communication hook. Skip if CUDA version < 11 or NCCL version < 2.9.7.
Reviewed By: SciPioneer
Differential Revision: D30238317
fbshipit-source-id: bad35bf7d43f10f1c40997a282b831b61ef592bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62996
No need to set this because autograd engine already propagates TLS
states.
ghstack-source-id: 135438220
Test Plan: CI
Reviewed By: albanD
Differential Revision: D30202078
fbshipit-source-id: e5e917269a03afd7a6b8e61f28b45cdb71ac3e64
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61753
Reland of https://github.com/pytorch/pytorch/pull/57081.
Main difference is that the former diff moved `prepare_for_backward` check into `DDPSink` backward, but that resulted in issues due to potential autograd engine races. The original diff moved `prepare_for_backward` into `DDPSink` as part of a long-term plan to always call it within `DDPSink`.
In particular this doesn't work because `prepare_for_backward` sets `expect_autograd_hooks=true` which enables autograd hooks to fire, but there were several use cases internally where autograd hooks were called before DDPSink called `prepare_for_backward`, resulting in errors/regression.
We instead keep the call to `prepare_for_backward` in the forward pass, but still run outputs through `DDPSink` when find_unused_parameters=True. As a result, outputs that are not used when computing loss have `None` gradients and we don't touch them if they are globally `None`. Note that the hooks still fire with a undefined gradient which is how we avoid the Reducer erroring out with the message that some hooks did not fire.
Added the unittests that were part of the reverted diff.
ghstack-source-id: 135388925
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D29726179
fbshipit-source-id: 54c8819e0aa72c61554104723a5b9c936501e719
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62748
Previously after buckets were rebuilt the first bucket size was always
defaulted to 1MB, this diff allows first bucket to be tuned like the rest of
the bucket sizes can.
Setting `dist._DEFAULT_FIRST_BUCKET_BYTES = 1` results in the following logs as
expected:
I0804 12:31:47.592272 246736 reducer.cpp:1694] 3 buckets rebuilt with size
limits: 1, 1048, 1048 bytes.
ghstack-source-id: 135074696
Test Plan: CI
Reviewed By: SciPioneer, wanchaol
Differential Revision: D30110041
fbshipit-source-id: 96f76bec012de129d1645e7f50e266d4b255ec66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62662
Replaced the methods set_tensor(.) and get_tensor() in the python exposed API from the C++ logic with buffer() and set_buffer(.) to be a cleaner interface.
Reviewed By: SciPioneer
Differential Revision: D30012869
fbshipit-source-id: bd8efab583dd89c96f9aeb3dd48a12073f0b1482
Summary:
**Overview:**
This removes the preceding `_` from `_Join`, `_Joinable`, and `_JoinHook` in preparation for adding the generic join context manager tutorial (see [here](https://github.com/pytorch/tutorials/pull/1610)). This also adds a docs page, which can be linked from the tutorial. [Here](https://github.com/pytorch/pytorch/files/6919475/render.pdf) is a render of the docs page.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62605
Test Plan:
`DistributedDataParallel.join()`:
```
touch /tmp/barrier && TEMP_DIR="/tmp" BACKEND="nccl" WORLD_SIZE="2" gpurun python test/distributed/test_distributed_fork.py -- TestDistBackendWithFork.test_ddp_uneven_inputs TestDistBackendWithFork.test_ddp_uneven_inputs_stop_iteration_sync_bn TestDistBackendWithFork.test_ddp_grad_div_uneven_inputs TestDistBackendWithFork.test_ddp_uneven_input_join_disable TestDistBackendWithFork.test_ddp_uneven_input_exception
```
`ZeroRedundancyOptimizer`:
```
gpurun4 python test/distributed/optim/test_zero_redundancy_optimizer.py
```
NOTE: DDP overlap tests are failing due to a landing race. See https://github.com/pytorch/pytorch/pull/62592. Once the fix is landed, I will rebase, and tests should be passing.
`Join`:
```
gpurun4 python test/distributed/algorithms/test_join.py
```
Reviewed By: mrshenli
Differential Revision: D30055544
Pulled By: andwgu
fbshipit-source-id: a5ce1f1d9f1904de3bdd4edd0b31b0a612d87026
Summary:
**Overview:**
This adds two approaches to overlapping `DistributedDataParallel.backward()` with `ZeroRedundancyOptimizer.step()` by providing two hook constructors: `hook_with_zero_step()` and `hook_with_zero_step_interleaved()`. The former waits for all backward computation to finish before starting optimizer computation, while the latter launches a partial optimizer computation using the contents of a gradient bucket once that bucket's all-reduce completes. The two approaches each suffer from their own weaknesses, and which one to use depends on the specific hardware configuration.
Both approaches can share changes to `ZeroRedundancyOptimizer`. A user should pass `overlap_with_ddp=True` to `ZeroRedundancyOptimizer`, construct a DDP communication hook using either `hook_with_zero_step()` or `hook_with_zero_step_interleaved()`, and register that communication hook. `ZeroRedundancyOptimizer.step()` should still be called in the training loop, though the optimizer computation and communication will be offloaded to originate from the communication hook. Currently, the first two iterations are vacuous, meaning they do not result in parameter updates and the inputs are ignored. This is required to finalize the DDP bucket strategy and to then initialize the `ZeroRedundancyOptimizer`'s local optimizer based on that bucketing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62157
Test Plan:
The existing `ZeroRedundancyOptimizer` tests pass, and new unit tests for both hooks pass:
- ~~`test_ddp_with_zero_step_parity_cpu`~~ (removed for now due to flakiness in CI -- under investigation, could possibly be similar Gloo issue as with `hook_with_zero_step_interleaved()`)
- `test_ddp_with_zero_step_parity_gpu`
- `test_ddp_with_zero_step_interleaved_parity_gpu`
These were tested on the AI AWS cluster.
An analogous `test_ddp_with_zero_step_interleaved_parity_cpu` is missing due to existing bugs with Gloo. See https://github.com/pytorch/pytorch/pull/62302.
Both approaches have been verified using an internal accuracy benchmark.
Reviewed By: mrshenli
Differential Revision: D29971046
Pulled By: andwgu
fbshipit-source-id: a7234c23c7ea253f144a698fd7e3c0fe039de5e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62457
Specify `Future[torch.Tensor]` as DDP communication hook return type, which should be explicitly a single tensor. The previous API takes a list that has a single tensor.
Note that now the typing info no longer accepts the internal type of `torch._C.Future`, which does not support torchscript and hence cannot support `Future[torch.Tensor]`.
ghstack-source-id: 134771419
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_default_ddp_comm_hooks_nccl
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_ddp_invalid_comm_hook_return_type
Reviewed By: rohan-varma
Differential Revision: D30007390
fbshipit-source-id: 246667c9b575b4c6e617b0a5b373151f1bd81e7f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62232
Logs the bucket sizes in DDP logging so that we know which workflow ran with what bucket size config. Will be used to verify how changing bucket sizes in DDP affects perf.
Based on the test, we can see inconsistency where the "first" bucket size actually is (last before rebuild buckets, first after).
ghstack-source-id: 134663867
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D29922299
fbshipit-source-id: 538b331c96e77048164ad130b377433be100a761
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62231
`compute_bucket_assignment_by_size` is responsible for setting per-bucket size limits, return this information from the function so that we are aware of size limits for each bucket.
This is currently not being consumed, but will be in the next diff when we log bucket size limits to DDP logging. This will help us run experiments under different bucket size configs and analyze the impact.
ghstack-source-id: 134480575
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D29919056
fbshipit-source-id: dd5a096fa23d22e5d9dc1602899270a110db4a19
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61992
This test previously was not enabled for static graph but to ensure
this feature is supported with DDPSink, enable it for static graph which
currently passes outputs to DDPSink.
ghstack-source-id: 134471406
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D29830887
fbshipit-source-id: 2d3f750d9eb4289558ed21acccd172d83d9b82cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61497
Reverts [DDP] Support not all outputs used in loss calculation
ghstack-source-id: 133589153
Test Plan: CI, ping authors to run their workflow on this diff
Reviewed By: zhaojuanmao
Differential Revision: D29642892
fbshipit-source-id: 81a15b9ab3329602f34d3758bb0799005a053d4f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61401
Reverts https://github.com/pytorch/pytorch/pull/59359, which is causing a few internal issues in DDP training. We will evaluate the internal use cases and reland it after reconsidering the design.
Also moves `prepare_for_backward` back into forward pass instead of DDP Sink for `find_unused_parameters`. This ensures that hooks will always fire in the backwards pass, which is behavior that internal training workloads rely on. Calling `prepare_for_backward` in DDPSink autograd function is not the best solution since other autograd threads may have been executing which can cause races.
ghstack-source-id: 133589152
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D29608948
fbshipit-source-id: f060f41cd103573ddff8da50cdbb6c56768dab46
Summary:
**Overview:**
This refactors the computation on non-joined processes relating to the join context manager. The concept was inspired by a comment from pritamdamania.
**Changes:**
This introduces a `_Joinable` abstract base class, which requires a `_join_hook()` method and `_join_device()` and `_join_process_group()` property methods. Any class that we want to be compatible with the generic join context manager should inherit from `_Joinable` and implement `_join_hook()`, `_join_device()`, and `_join_process_group()`. (The `device` and `process_group` information has been moved from `_JoinHook` to `_Joinable`.)
The generic join context manager now takes in a `List[_Joinable]` instead of `List[_JoinHook]`. The motivation for this is that previously, by passing the `_JoinHook`s into the context manager, the class providing a `_JoinHook` can modify the context manager's behavior, but the context manager cannot modify the class's behavior. This is solved by giving the context manager a reference to the class's instance.
This implementation reserves the field `_join_config` in every `_Joinable` to store a `_JoinConfig` instance, which holds all dynamic fields needed from the `_Joinable` for the join context manager: `enable`, `throw_on_early_termination`, and `is_first_joinable`. ("dynamic" here means that for a given `_Joinable` instance, the values for those fields may change across different join context usages.) In particular, these fields are needed to implement a method `notify_join_context()`, which encapsulates the computation performed on non-joined processes relating to the join context manager --- (1) the all-reduce to indicate that the process has not yet joined and (2) the all-reduce to check whether to throw an exception if `throw_on_uneven_inputs=True`. The idea is that every `_Joinable` class only needs to make a call to `notify_join_context()` before its per-iteration collective communications; it is a simple one-line addition.
Only the first `_Joinable` instance passed into the context manager actually performs the collective communications in `notify_join_context()`. In that case, the method returns an async work handle for the initial all-reduce indicating that the process not yet joined. Otherwise, the method returns `None`. This conditional logic is handled internally without additional input from the user.
**New API:**
Now, the example usage would look like:
```
ddp_model = DistributedDataParallel(...)
zero_optim = ZeroRedundancyOptimizer(ddp_model.parameters(), ...)
with _Join([ddp_model, zero_optim]):
...
```
Any arguments meant for a join hook (e.g. `divide_by_initial_world_size`) must be specified as keyword arguments. For example:
```
with _Join([ddp_model, zero_optim], divide_by_initial_world_size=False):
...
```
They will be forwarded to every `_join_hook()` function via `**kwargs`. This creates a clear separation between the variables needed by the context manager (`enable` and `throw_on_early_termination`) and those needed by the `_Joinable` class (e.g. `divide_by_initial_world_size`).
**Recap:**
After this change, the relevant information to use the generic join context manager looks like the following (omitting prefix `_` from names):
- Suppose we have a class `C` (e.g. `DistributedDataParallel`) that we want to be able to use the `Join` context.
- We make `C` inherit from `Joinable` and implement `join_hook() -> JoinHook`, `join_device()`, and `join_process_group()`.
- To implement `join_hook()`, we define a `CJoinHook` class inheriting from `JoinHook` and implement `main_hook()` and `post_hook()` as needed.
- We locate a place before `C`'s per-iteration collective communications and add a call to `Join.notify_join_context()`.
- We call `Joinable.__init__(self)` in `C`'s constructor.
- The `C.join_config` field will be used internally by the context manager. This does not affect `C`'s serializability.
- Run time arguments for `C`'s join hook can be passed in as keyword arguments to the context manager: `with Join([C()], arg1=..., arg2=...):`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61555
Test Plan:
I ran the existing DDP join tests:
```
touch /tmp/barrier && TEMP_DIR="/tmp" BACKEND="nccl" WORLD_SIZE="2" gpurun python test/distributed/test_distributed_fork.py -- TestDistBackendWithFork.test_ddp_uneven_inputs TestDistBackendWithFork.test_ddp_uneven_inputs_stop_iteration_sync_bn TestDistBackendWithFork.test_ddp_grad_div_uneven_inputs TestDistBackendWithFork.test_ddp_uneven_input_join_disable TestDistBackendWithFork.test_ddp_uneven_input_exception
```
I ran the ZeRO join tests:
```
gpurun4 python test/distributed/optim/test_zero_redundancy_optimizer.py TestZeroRedundancyOptimizerDistributed.test_zero_join_gpu TestZeroRedundancyOptimizerDistributed.test_zero_join_cpu
```
Reviewed By: zou3519
Differential Revision: D29690359
Pulled By: andwgu
fbshipit-source-id: 2950f78de755eb5fb13b95b803dd7c705879a9c7
Summary:
Targets https://github.com/pytorch/pytorch/issues/54318.
**Overview:**
DDP offers a `join()` context manager to accommodate training on uneven inputs. This creates a new generic `_Join()` API permitting custom hooks, refactors DDP `join()` to call this generic `_Join()`, and implements a hook for ZeRO. (For now, the generic `_Join()` is implemented as private, but this may change after design discussions are cleared.)
There are two classes introduced: `_JoinHook`, the class defining the customizable join hook, and `_Join`, the generic join context manager.
The `_JoinHook` provides two entry points: `main_hook()`, which is called repeatedly while there exists a non-joined process, and `post_hook()`, which is called once all process have joined with the additional `bool` argument `is_last_joiner`. The class also requires `process_group` and `device` information by defining corresponding abstract property methods. Thus, to implement a join hook, (1) inherit from `_JoinHook`, (2) override `main_hook()` and `post_hook()` as appropriate, and (3) override `process_group()` and `device()` to provide process group and device information to be used by the join context manager implementation for collective communications.
The `_Join` constructor requires `join_hooks: List[_JoinHook]` and optionally `enable: bool = True` and `throw_on_early_termination: bool = False`. A training loop only needs to be wrapped with `with _Join(join_hooks):` (using the appropriate `join_hooks`) to be able to train on uneven inputs without hanging/erroring. The context manager requires a `dist.all_reduce(torch.ones(1))` to be called on every non-joined process each time before it performs its collective communications in order to indicate that the process has not yet joined. It also requires that all `process_group` attributes in the `_JoinHook` objects are the same.
**Notes:**
- The argument `is_last_joiner` to `post_hook()` may be useful for finding an authoritative rank when synchronizing.
- `enable` is a flag that can be set to `False` if the user knows the current training loop will not have uneven inputs. This may be used to disable join-related computation in the classes providing join hooks.
- `throw_on_early_termination` is a flag that can be set to `True` to notify processes to terminate upon detecting uneven inputs (i.e. upon the first process joining when there exists a non-joined process). Notably, the notification requires an all-reduce, so to prevent hanging/erroring, non-joined process must participate in the all-reduce. The first-joining process raises a `RuntimeError`, and the other processes are expected (but not required) to do the same. This may be used to implement training on uneven inputs in cases that do not conform to the generic join context manager (e.g. `SyncBatchNorm`).
- Classes providing a join hook should do so via a `_join_hook()` method that returns a `_JoinHook` instance with the methods appropriately overridden.
- If there are multiple join hooks, the device specified by the first is used by the join context manager implementation to perform its collective communications.
- If there are multiple join hooks, both the main and post-hooks are iterated in the order in which the `_JoinHook` objects are passed into the context manager constructor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60757
Test Plan:
The current implementation preserves backward compatibility by not changing the existing DDP `join()` API at all. To check this, I ran through the uneven input tests (`test_ddp_grad_div_uneven_inputs`, `test_ddp_uneven_inputs_stop_iteration_sync_bn`, `test_ddp_uneven_inputs`, `test_ddp_uneven_input_join_disable`, `test_ddp_uneven_input_exception`) on the AI AWS cluster:
```
touch /tmp/barrier && TEMP_DIR="/tmp" BACKEND="nccl" WORLD_SIZE="2" gpurun python test/distributed/test_distributed_fork.py --
```
Because the existing DDP join logic does not provide correct gradients to the joined processes if `gradient_as_bucket_view=False` and a joined process requires those gradients to correctly update its shard of the parameters in `ZeroRedundancyOptimizer.step()`, DDP and ZeRO are not fully compatible at the moment. To work around this and to test ZeRO's join hook separately, I added a test `_test_zero_join()` (with `test_zero_join_gpu()` and `test_zero_join_cpu()` flavors), which compares DDP with a local optimizer on uneven inputs against ZeRO on uneven inputs with the gradients set manually.
Reviewed By: iramazanli, mrshenli
Differential Revision: D29624636
Pulled By: andwgu
fbshipit-source-id: ec70a290e02518b0d8b683f9fed2126705b896c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61376
After SPMD is retired, the API of `get_tensors` becomes `get_tensor`. Fix some comments that refer to the obsolete API.
The `allreduce` hook example does not do division inside, which actually is incorrect.
ghstack-source-id: 133174272
Test Plan: N/A
Reviewed By: rohan-varma
Differential Revision: D29596857
fbshipit-source-id: 2046b185225cd6d1d104907b5f9b4009b6e87c99
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61020
Makes uneven input support with `join` context manager work with
custom communication hooks. This will ensure that the two features can work
well together. Added relevant unittests to test allreduce and powerSGD hooks.
Instead of calling `allreduce`, the join manager now calls into `_run_reduction_hook` which will automatically run whatever hook is installed.
ghstack-source-id: 132950108
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D29480028
fbshipit-source-id: c91dc467a62c5f1e0ec702a2944ae3deb10f93f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61019
Changes uneven input logic of running allreduce to using `GradBucket` structure. This is to enable support for comm. hook with join in the next diff.
ghstack-source-id: 132950107
Test Plan: ci
Reviewed By: SciPioneer
Differential Revision: D29480027
fbshipit-source-id: 7c42c53653052f71b86a75e14a5fc7ae656433f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61017
Removes SPMD nested vector logic from this codepath. This is mostly in preparation for the next diffs in this stack which enable support for join with comm. hook.
ghstack-source-id: 132924223
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D29477360
fbshipit-source-id: f8132a94b1abfe28586aa78ac47e13a7ce6bb137
Summary:
We recently landed a change to ensure that when running under ``find_unused_parameters=True``, not all module outputs have to be used in loss computation and DDP will work as expected. Mention this update in the documentation and add some additional clarification.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60275
Reviewed By: SciPioneer
Differential Revision: D29502609
Pulled By: rohan-varma
fbshipit-source-id: ddb3129cff9492018e61813413b30711af212309
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60882
Fixes https://github.com/pytorch/pytorch/issues/60733, which
identified an issue with a previous PR that resulted in DDP no longer
supporting cases where newly created tensors are returned that don't have a
grad_fn. The result of this is the grad_fn is set to that of the `DDPSink`
custom backward which results in errors during the backwards pass.
This PR fixes the issue by ensuring we don't touch the `grad_fn` of the tensors
if it is `None`. Added relevant tests as well.
ghstack-source-id: 132632515
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D29423822
fbshipit-source-id: a9e01046c7be50aa43ffb955f6e0f48fef4bc881
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59359
Move `prepare_for_backward` into `_DDPSink` backward instead of calling it in DDP forward pass so that we can run multiple backwards in DDP with `retain_graph=True`.
ghstack-source-id: 131774159
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D28855226
fbshipit-source-id: 6b7b25d75b7696f5b5629078233433f97663d61c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60118
Pipe + DDP has a few issues:
1) with static graph, does not synchronize gradients on first backward pass (i.e. delay allreduce is not run). does not work since https://github.com/pytorch/pytorch/pull/55248
2) when find_unused_parameters=True, also does not results in gradient synchronization. does not work since https://github.com/pytorch/pytorch/pull/57081
The reason for both cases is that calling `DDPSink.apply(output_tensor)` does not call the custom `backward` of `DDPSink` when the `output_tensor` is actually an `OwnerRRef`, which is the case when running DDP in `Pipe`. This is because we do `backward` on the `rref.local_value()` which does not have this autograd recording.
To fix, we unwrap the RRef and reconstruct it as needed, similar to the fix in https://github.com/pytorch/pytorch/pull/49908.
to test:
All tests in pipe_with_ddp_test pass.
The reason these tests did not catch the errors earlier is because all ranks received the same model inputs. So if gradient synchronization did not occur, then grads would still be the same because the model is the same on all ranks (guaranteed by ddp). Fixed the tests to use different inputs across ranks.
ghstack-source-id: 131688187
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D29167283
fbshipit-source-id: fe62310db2dc6de8519eb361b1df8ae4dfce3ab8
Summary: We updated the training scripts and re-trained the Resnext model with msuru_suru_union and ig_msuru_suru_union datasets
Test Plan:
Main command line to run:
*./deeplearning/projects/classy_vision/fb/projects/msuru_suru/scripts/train_cluster.sh*
Config we used is *msuru_suru_config.json*, which is "Normal ResNeXt101 with finetunable head".
Experiments:
- msuru_suru_union f279939874
- Train/test split
- msuru_suru_union_dataset_train_w_shard: 143,632,674 rows
- msuru_suru_union_dataset_test_w_shard: 1,831,236 rows
- Results
{F625232741}
{F625232819}
- ig_msuru_suru_union f279964200
- Train/test split
- ig_msuru_suru_union_dataset_train_w_shard: 241,884,760 rows
- ig_msuru_suru_union_dataset_test_w_shard: 3,477,181 rows
- Results
{F625234126}
{F625234457}
Differential Revision: D29154971
fbshipit-source-id: d534d830020f4f8e596bb6b941966eb84a1e8adb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59284
Logs a few python-side errors to DDP logging.
TODO: Most python errors actually have to do with user input correctness, so they throw before reducer is constructed and thus there is no logger. For this case, should we allow `logger` to be created optionally without a reducer, just for the purpose of logging errors, so that we can gain insight into these errors in scuba?
ghstack-source-id: 130412973
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D28820290
fbshipit-source-id: 610e5dba885b173c52351f7ab25c923edce639e0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59281
Adds ability to log when reducer/ddp encounters an error. We add fields "has_error" and "error" to indicate that an error has
occured in this iteration, and the other fields (performance stats) are not
guaranteed to be updated.
Errors encountered in python-side DDP will be added in the next diff.
ghstack-source-id: 130412974
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28652717
fbshipit-source-id: 9772abc2647a92dac6a325da6976ef5eb877c589
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59065
Cleaner to use work.result() instead of sending back the tensor from
this function.
ghstack-source-id: 130338813
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D28551203
fbshipit-source-id: d871fed78be91f0647687ea9d6fc86e576dc53a6
Summary:
Fixes https://github.com/pytorch/pytorch/issues/57878.
This adds `NCCL_ASYNC_ERROR_HANDLING` as a DDP relevant environment variable and includes a check for that variable in the test `test_dump_DDP_relevant_env_vars()`. Notably, the modified test now checks for the new variable but does not check for any of the other previously-existing relevant environment variables that were not already tested for (e.g. `NCCL_BLOCKING_WAIT`).
The change was tested via the following on an AI AWS cluster:
`WORLD_SIZE=2 BACKEND=nccl gpurun pytest test/distributed/test_distributed_spawn.py -k test_dump_DDP_relevant_env_vars -vs`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59109
Reviewed By: H-Huang, SciPioneer
Differential Revision: D28761148
Pulled By: andwgu
fbshipit-source-id: 7be4820e61a670b001408d0dd273f65029b1d2fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58595
No longer needed since this list is always of size 1.
ghstack-source-id: 129498229
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D28548426
fbshipit-source-id: 7d6dba92fff685ec7f52ba7a3d350e36405e2578
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57081
Changes in this diff:
Enable passthrough autograd function when find_unused_parameters=True.
With above, move prepare_for_backward which does unused parameter checking logic to beginning of backwards pass, only when find_unused_parameters=True.
Enhance process of unused parameter checking to account for outputs not being used in loss.
The way (3) is implemented is by triggering the autograd hook corresponding to parameters that did not participate in loss computation. Since they did not participate, the autograd hook is triggered with a gradient of None, and the reducer handles this appropriately to ensure that the gradient is not touched.
Tested by ensuring that when a model output is not used in loss, the corresponding grad is not modified. Also verified that the grads are the same in local vs DDP training case. Also verified that gradients are not touched in this case, i.e. if grad is originally None, it stays as None, not zero, after.
Note that in this diff we are not enabling the pass through autograd function for regular case find_unused_parameters=False because that has a much bigger blast radius and needs additional careful analysis especially with regard to the performance.
ghstack-source-id: 129425139
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D28048628
fbshipit-source-id: 71d7b6af8626804710017a4edd753787aa9bba61
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58089
make ddp logging api to be private
ghstack-source-id: 128796419
Test Plan: unit test
Reviewed By: rohan-varma
Differential Revision: D28365412
fbshipit-source-id: 374c01d443ffb47a3706f59e296d6e47eb5f4c85
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58105
When find_unused_parameters=True but static_graph is also set, static graph handles unused parameter accounting, so this code path is not needed
ghstack-source-id: 128736289
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D28371954
fbshipit-source-id: 0b42a9c0fd2bba26a0de288436e9c7139e292578
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57073
Enhances use of DDPSink to work for all output types DDP supports as per https://github.com/pytorch/pytorch/issues/55876.
TODO: Add additional testing for tuple, list, dict return types
ghstack-source-id: 128726768
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D27756985
fbshipit-source-id: 2e0408649fb2d6a46d6c33155a24c4c1723dd799
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57999
make ddp logging api to be private
ghstack-source-id: 128607185
Test Plan: unit test
Reviewed By: rohan-varma
Differential Revision: D28338485
fbshipit-source-id: bd2ae7c78904e93eed88be91876f5a832b5b7886
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55248
This PR provides enable static graph training when users call _set_static_graph(). This can help support more use cases in DDP without performance regression, also can potentially improve performance when there are unused parameters in the graph.
1. first iteration records graph states like how many times a grad is calculated, whether the grad is used or not. then first iteration queues a delay_all_reduce call back to all reduce grads.
2. Since autograd call back is associated with current target graph task, the delay_all_all call back should be associated with out-most backward graph task. A DDP sink layer is added in DDP forward loop so that we can queue the delay_all_reduce call back in the sink layer.
3. after first iterations, DDP will use the saved graph states to determine whether a grad is used or not. whether a grad is ready for communication.
4. rebuilt bucket is called in second iteration, after graph states are recorded in first iteration.
5. if the graph states change, DDP will throw errors
ghstack-source-id: 128599464
Test Plan: unit tests. adding more tests
Reviewed By: rohan-varma
Differential Revision: D27539964
fbshipit-source-id: 74de1ad2719465be67bab8688d6e293cd6e3a246
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57771
This mapping didn't work properly when certain parameters didn't
require grad. Fixed that and added a test.
ghstack-source-id: 128527537
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D28265636
fbshipit-source-id: 7b342ce012b2b7e33058b4c619ffb98992ed05b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56755
Rehash of https://github.com/pytorch/pytorch/pull/47488
Adds a flag to ddp join() context manager that enables throwing a
StopIteration across all ranks when this flag is specified.
To do this, we implement the design in #47250. When running with this flag, we schedule an additional allreduce in the case that a joined rank needs to throw a StopIteration. In non-joined ranks forward pass, we match this allreduce and if at least one rank tells us to throw, we raise a StopIteration.
Tested by modifying existing tests, as well as adding additional tests validating that this works with SyncBatchNorm models and a model with custom collectives in the forward pass.
Currently running perf benchmarks, will post when those are available, but we expect a small (~2%) perf reduction when enabling this feature due to the blocking allreduce. Hence we will only recommend it for models with collective comm.
ghstack-source-id: 127883115
Test Plan: Ci
Reviewed By: SciPioneer
Differential Revision: D27958369
fbshipit-source-id: c26f7d315d95f17bbdc28b4a0561916fcbafb7ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54995
provide an DDP private API to explicitly set the training is static, also set this flag in logger
ghstack-source-id: 127755713
Test Plan: unit tests
Reviewed By: rohan-varma
Differential Revision: D27444965
fbshipit-source-id: 06ef1c372296815944b2adb33fbdf4e1217c1359
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56730
add a test to verify DDP with torch map will result in the same results when using grad_as_bucket_view=true and false.
torch.amp scale factor does not have dependencies on old gradients, thus it is not affected by grad_as_bucket_view=true or false, see
how torch.amp is implemeted here https://github.com/pytorch/pytorch/pull/33366/files.
This diff verified ddp can work as expected with amp.GradScaler and amp.autocast when when using grad_as_bucket_view=true and false.
ghstack-source-id: 127526358
Test Plan: unit tests
Reviewed By: rohan-varma
Differential Revision: D27950132
fbshipit-source-id: 8ed26935fdcb4514fccf01bb510e31bf6aedac69
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56641
currently ddpLoggingData is flat struct, which requires internal DDP developers and external users to know about the struct field names. This is not flexible to delete or add new fields in the future. also it is hard to access ddpLoggingData.
With maps/dict, developers and users can easily access the fields without knowing the field names, also easier to add/remove a new/old field.
Since C++ does not support map values to be different types, right now ddpLoggingData containes two types of maps.
ghstack-source-id: 127482694
Test Plan: unit tests
Reviewed By: SciPioneer
Differential Revision: D27923723
fbshipit-source-id: c90199c14925fc50ef219000e2f809dc7601cce1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55946
As `ddp_gpu_size` field of `SyncBatchNorm` will always be 1 for GPU modules, remove this field and the relevant code.
ghstack-source-id: 126883498
Test Plan: waitforbuildbot
Reviewed By: zhaojuanmao
Differential Revision: D27746021
fbshipit-source-id: b4518c07e6f0c6943fbd7a7548500a7d4337126c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55075
Constructs and passes in a mapping with parameter names to Reducer to log information about unused parameters in error messages about unused parameters/not all parameters getting gradient.
Use case:
1) User runs DDP forward + bwd, and it has some unused parameters that will result in ddp error in next iteration
2) Next forward pass calls `Reducer::ensure_prior_reduction_finished()` where we check all params got gradient from the previous bwd pass. DDP would throw here in this case.
3) Reducer maintains mapping and tracks used parameters, and computes which parameters did not get gradient and logs this as part of the error.
Implementation details:
0) The following is only enabled for debug modes of INFO or DETAIL.
1) To save memory, we don't map param -> param name so that we don't have to copy the entire tensor, instead we map param_index -> param_name and use the existing concept of variable_index in Reducer to look up parameter names.
2) DDP constructs param index -> param name mapping. The name is the fully qualified name: f"{module_name}:{param_name}" and passes it into Reducer
3) Reducer maintains per-iteration std::set<int> of variable indices that have had `mark_variable_ready` called.
4) When some params go unused, we take a set difference to detect the unused params.
5) Unittests to test the logged unused params, as well as for nested modules, are added
ghstack-source-id: 126581051
Test Plan: CI, UT
Reviewed By: zhaojuanmao
Differential Revision: D27356394
fbshipit-source-id: 89f436af4e74145b0a8eda92b3c4e2af8e747332
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55353
Remove all the code branches that will only be executed when `device_ids > 1`.
Some helper functions are also removed:
1. `_verify_replicas_within_process` and `verify_replicas_within_process`
2. `_replicate_modules_within_process`
3. `parallel_apply`
The next step is deprecating `_module_copies` field.
ghstack-source-id: 126201121
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D27552201
fbshipit-source-id: 128d0216a202f5b1ba4279517d68c3badba92a6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54454
According to the pitch in https://github.com/pytorch/pytorch/issues/47012
1. Let DDP error out if `device_ids` contains multiple devices.
2. If device_ids is not specified, DDP will use the provided model (module argument in DDP constructor) as-is, regardless if the model is on one GPU or multiple GPUs or on CPU.
3. Remove the assertion that prevents SPMD in DDP `join()` method, because now SPMD is already forbidden by the constructor. Also remove the relevant unit test `test_ddp_uneven_inputs_replicated_error`.
#Closes: https://github.com/pytorch/pytorch/issues/47012
ghstack-source-id: 125644392
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:distributed_gloo_spawn -- test_cuda
buck test mode/dev-nosan caffe2/test/distributed:distributed_gloo_spawn -- test_rnn
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_nccl_backend_multi_device_ids_not_allowed
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_nccl_backend_single_device_module_device_ids_None
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_nccl_backend_multi_device_module_device_ids_None
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_ddp_multi_device_module_config
waitforbuildbot
Reviewed By: pritamdamania87
Differential Revision: D27226092
fbshipit-source-id: 3ee1e4bc46e5e362fc82cf7a24b2fafb34fcf1b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54919
Log the use of uneven inputs API for better tracking and use case
detection.
ghstack-source-id: 125446499
Test Plan: CI, added ut
Reviewed By: zhaojuanmao, SciPioneer
Differential Revision: D27410764
fbshipit-source-id: abc8055a2e15a3ee087d9959f8881b05a0ea933e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54219
There is no need for this ``pass``.
ghstack-source-id: 125124311
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D27105234
fbshipit-source-id: 95496fa785fdc66a6c3c8ceaa14af565588325df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54159
See https://github.com/pytorch/pytorch/issues/54059 for discussion.
In short, users might want to run evaluation on a single rank
in `torch.no_grad()` mode. When this happens, we need to make
sure that we skip all rebuild bucket logics, as the forward only
runs on one rank and not all peers can sure the bucket configuration
sync communication.
Test Plan: Imported from OSS
Reviewed By: zhaojuanmao
Differential Revision: D27119666
Pulled By: mrshenli
fbshipit-source-id: 4b2f8cce937cdd893e89d8d10c9267d255ba52ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53795
There are 4 calls in ddp implementation to dist.get_rank(), move these
to a helper property to ensure that users don't actually call `dist.get_rank()`
instead of `dist.get_rank(self.process_group)`.
Keeping API private for now because not sure if there is a user need to call `model.distributed_rank`, but can make it public if we think it's a useful api.
ghstack-source-id: 123640713
Test Plan: Ci
Reviewed By: mrshenli
Differential Revision: D26972368
fbshipit-source-id: a5f1cac243bca5c6f90a44f74d39cfffcc2b9a5a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53793
This call should pass in the process group so it works appropriately
for subgroups instead of whole world being passed into DDP.
Aside: This wasn't caught by tests since we don't have good testing around
passing subgroups into DDP, I believe nearly all tests use the entire world.
Should we add better testing for subgroups which may potentially bring up more
subtle bugs?
ghstack-source-id: 123640712
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D26972367
fbshipit-source-id: 8330bd51e2ad66841e4c12e96b67d3e78581ec74
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53145
add a new API to allow users to set sample rate for runtime stats, also add per iteration latency breakdowns to DDPLoggingData struct. e.g.
if users set sample rate to be 1, they can analyze per iteration latency change over time (not avged)
ghstack-source-id: 123443369
Test Plan: unit test
Reviewed By: SciPioneer
Differential Revision: D26763957
fbshipit-source-id: baff6a09c2a590e6eb91362ca6f47ae8fa6ddb0e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52966
Logs registerd comm hook if there is one, else logs
"builtin_allreduce"
ghstack-source-id: 123174803
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D26709388
fbshipit-source-id: 484fdbbd6643ec261b3797bd8d9824b2b6a1a490
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52887
This diff changes the way to do model consistency check (i.e. `_verify_replicas_across_processes`) in DDP.
There were a few things that could be improved with the way we verify model across processes in DDP initialization:
1. We should do this check before syncing module states in DDP init, otherwise with Gloo backend this will throw but we would like to throw the error corresponding to different models on different ranks. To do this, we move the methods to be standalone C++ functions (not part of reducer) and move this check to before synchronizing parameters.
2. Refactor DDP init in the following ways:
- Run model consistency check before creating reducer, 2
- add helper functions to build params to pass into reducer
- add helper function to call `_verify_model_across_ranks`
- move `def parameters` to a helper function `_get_parameters` to be used more broadly within DDP
In follow up changes we will add the ability to detect which rank had inconsistent model (https://github.com/pytorch/pytorch/issues/52876 would be useful for this to determine which ranks(s) had errors).
ghstack-source-id: 123171877
Test Plan:
CI/unittest
buck test mode/dev-nosan //caffe2/test/distributed:c10d
BACKEND="nccl" WORLD_SIZE="2" ~/fbcode/buck-out/dev/gen/caffe2/test/distributed/distributed_nccl_fork#binary.par -r test_ddp_model_diff_across_ranks
Reviewed By: zhaojuanmao
Differential Revision: D26565290
fbshipit-source-id: f0e1709585b53730e86915e768448f5b8817a608
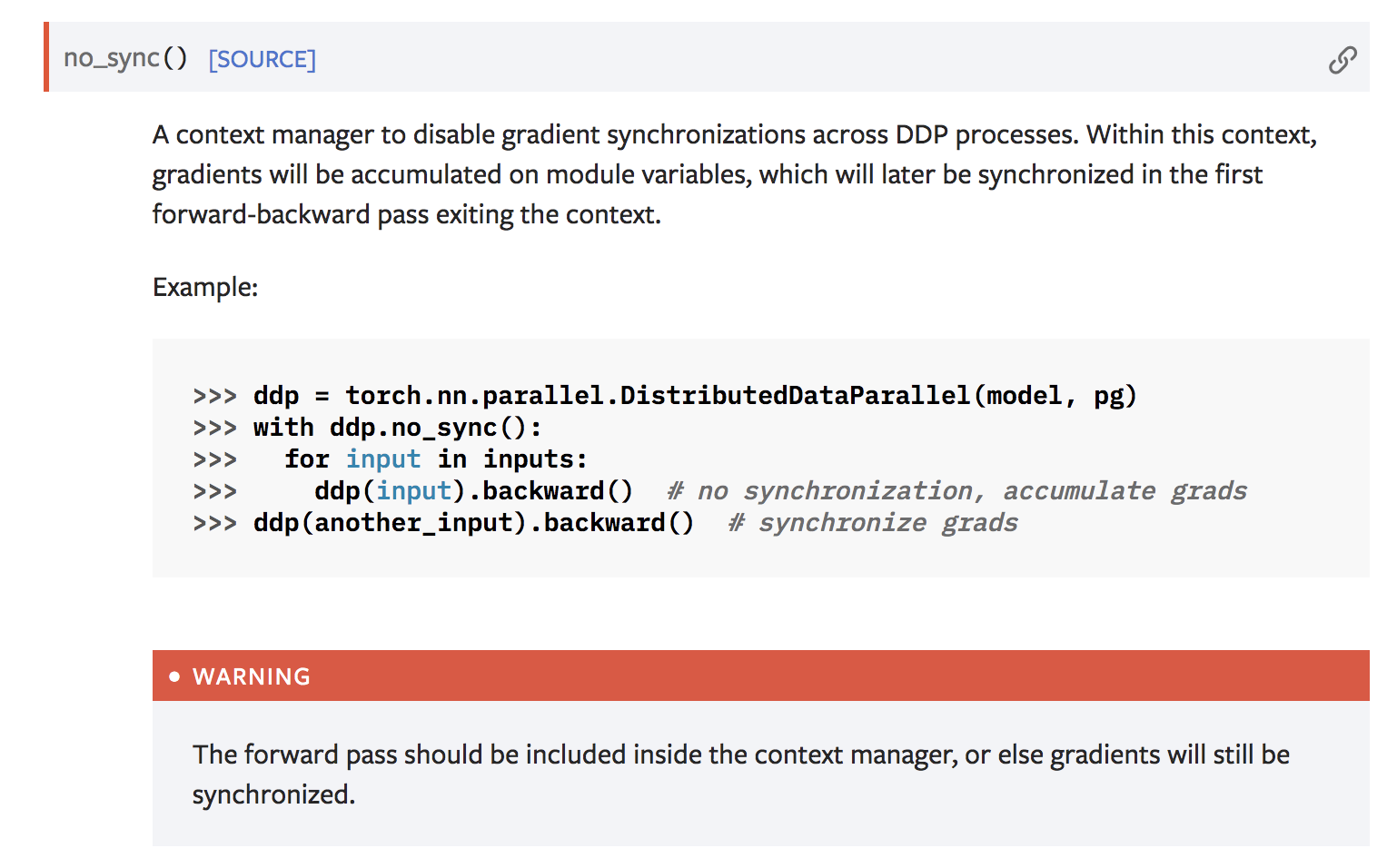{kind=link}