Summary:
Fixes https://github.com/pytorch/pytorch/issues/52257
## Background
Reverts MHA behavior for `bias` flag to that of v1.5: flag enables or disables both in and out projection biases.
Updates type annotations for both in and out projections biases from `Tensor` to `Optional[Tensor]` for `torch.jit.script` usage.
Note: With this change, `_LinearWithBias` defined in `torch/nn/modules/linear.py` is no longer utilized. Completely removing it would require updates to quantization logic in the following files:
```
test/quantization/test_quantized_module.py
torch/nn/quantizable/modules/activation.py
torch/nn/quantized/dynamic/modules/linear.py
torch/nn/quantized/modules/linear.py
torch/quantization/quantization_mappings.py
```
This PR takes a conservative initial approach and leaves these files unchanged.
**Is it safe to fully remove `_LinearWithBias`?**
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52537
Test Plan:
```
python test/test_nn.py TestNN.test_multihead_attn_no_bias
```
## BC-Breaking Note
In v1.6, the behavior of `MultiheadAttention`'s `bias` flag was incorrectly changed to affect only the in projection layer. That is, setting `bias=False` would fail to disable the bias for the out projection layer. This regression has been fixed, and the `bias` flag now correctly applies to both the in and out projection layers.
Reviewed By: bdhirsh
Differential Revision: D26583639
Pulled By: jbschlosser
fbshipit-source-id: b805f3a052628efb28b89377a41e06f71747ac5b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51909
Several scenarios don't work when trying to script `F.normalize`, notably when you try to symbolically trace through it with using the default argument:
```
import torch.nn.functional as F
import torch
from torch.fx import symbolic_trace
def f(x):
return F.normalize(x)
gm = symbolic_trace(f)
torch.jit.script(gm)
```
which leads to the error
```
RuntimeError:
normalize(Tensor input, float p=2., int dim=1, float eps=9.9999999999999998e-13, Tensor? out=None) -> (Tensor):
Expected a value of type 'float' for argument 'p' but instead found type 'int'.
:
def forward(self, x):
normalize_1 = torch.nn.functional.normalize(x, p = 2, dim = 1, eps = 1e-12, out = None); x = None
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
return normalize_1
Reviewed By: jamesr66a
Differential Revision: D26324308
fbshipit-source-id: 30dd944a6011795d17164f2c746068daac570cea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48965
This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API.
Test Plan: Existing unit tests. Benchmarks are in #48966
Reviewed By: ezyang
Differential Revision: D25590732
Pulled By: robieta
fbshipit-source-id: 6bd74788f06cdd673f3a2db898143d18c577eb42
Summary:
Fixes https://github.com/pytorch/pytorch/issues/47979
For MHA module, it is preferred to use the combined weight branch as much as possible when query/key/value are same (in case of same values by `torch.equal` or exactly same object by `is` ops). This PR will enable the faster branch when a single object with `nan` is passed to MHA.
For the background knowledge
```
import torch
a = torch.tensor([float('NaN'), 1, float('NaN'), 2, 3])
print(a is a) # True
print(torch.equal(a, a)) # False
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48126
Reviewed By: gchanan
Differential Revision: D25042082
Pulled By: zhangguanheng66
fbshipit-source-id: 6bb17a520e176ddbb326ddf30ee091a84fcbbf27
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46758
It's in general helpful to support int32 indices and offsets, especially when such tensors are large and need to be transferred to accelerator backends. Since it may not be very useful to support the combination of int32 indices and int64 offsets, here we enforce that these two must have the same type.
Test Plan: unit tests
Reviewed By: ngimel
Differential Revision: D24470808
fbshipit-source-id: 94b8a1d0b7fc9fe3d128247aa042c04d7c227f0b
Summary:
Fix https://github.com/pytorch/pytorch/issues/44601
I added bicubic grid sampler in both cpu and cuda side, but haven't in AVX2
There is a [colab notebook](https://colab.research.google.com/drive/1mIh6TLLj5WWM_NcmKDRvY5Gltbb781oU?usp=sharing) show some test results. The notebook use bilinear for test, since I could only use distributed version of pytorch in it. You could just download it and modify the `mode_torch=bicubic` to show the results.
There are some duplicate code about getting and setting values, since the helper function used in bilinear at first clip the coordinate beyond boundary, and then get or set the value. However, in bicubic, there are more points should be consider. I could refactor that part after making sure the overall calculation are correct.
Thanks
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44780
Reviewed By: mrshenli
Differential Revision: D24681114
Pulled By: mruberry
fbshipit-source-id: d39c8715e2093a5a5906cb0ef040d62bde578567
Summary:
Many of our functions contain same warnings about results reproducibility. Make them use common template.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45748
Reviewed By: colesbury
Differential Revision: D24089114
Pulled By: ngimel
fbshipit-source-id: e6aa4ce6082f6e0f4ce2713c2bf1864ee1c3712a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44433
Not entirely sure why, but changing the type of beta from `float` to `double in autocast_mode.cpp and FunctionsManual.h fixes my compiler errors, failing instead at link time
fixing some type errors, updated fn signature in a few more files
removing my usage of Scalar, making beta a double everywhere instead
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D23636720
Pulled By: bdhirsh
fbshipit-source-id: caea2a1f8dd72b3b5fd1d72dd886b2fcd690af6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43680
As discussed [here](https://github.com/pytorch/pytorch/issues/43342),
adding in a Python-only implementation of the triplet-margin loss that takes a
custom distance function. Still discussing whether this is necessary to add to
PyTorch Core.
Test Plan:
python test/run_tests.py
Imported from OSS
Reviewed By: albanD
Differential Revision: D23363898
fbshipit-source-id: 1cafc05abecdbe7812b41deaa1e50ea11239d0cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44486
SmoothL1Loss had a completely different (and incorrect, see #43228) path when target.requires_grad was True.
This PR does the following:
1) adds derivative support for target via the normal derivatives.yaml route
2) kill the different (and incorrect) path for when target.requires_grad was True
3) modify the SmoothL1Loss CriterionTests to verify that the target derivative is checked.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23630699
Pulled By: gchanan
fbshipit-source-id: 0f94d1a928002122d6b6875182867618e713a917
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43025
- Use new overloads that better reflect the arguments to interpolate.
- More uniform interface for upsample ops allows simplifying the Python code.
- Also reorder overloads in native_functions.yaml to give them priority.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37177
ghstack-source-id: 106938111
Test Plan:
test_nn has pretty good coverage.
Relying on CI for ONNX, etc.
Didn't test FC because this change is *not* forward compatible.
To ensure backwards compatibility, I ran this code before this change
```python
def test_func(arg):
interp = torch.nn.functional.interpolate
with_size = interp(arg, size=(16,16))
with_scale = interp(arg, scale_factor=[2.1, 2.2], recompute_scale_factor=False)
with_compute = interp(arg, scale_factor=[2.1, 2.2])
return (with_size, with_scale, with_compute)
traced_func = torch.jit.trace(test_func, torch.randn(1,1,1,1))
sample = torch.randn(1, 3, 7, 7)
output = traced_func(sample)
assert not torch.allclose(output[1], output[2])
torch.jit.save(traced_func, "model.pt")
torch.save((sample, output), "data.pt")
```
then this code after this change
```python
model = torch.jit.load("model.pt")
sample, golden = torch.load("data.pt")
result = model(sample)
for r, g in zip(result, golden):
assert torch.allclose(r, g)
```
Reviewed By: AshkanAliabadi
Differential Revision: D21209991
fbshipit-source-id: 5b2ebb7c3ed76947361fe532d1dbdd6faa3544c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44471
L1Loss had a completely different (and incorrect, see #43228) path when target.requires_grad was True.
This PR does the following:
1) adds derivative support for target via the normal derivatives.yaml route
2) kill the different (and incorrect) path for when target.requires_grad was True
3) modify the L1Loss CriterionTests to verify that the target derivative is checked.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23626008
Pulled By: gchanan
fbshipit-source-id: 2828be16b56b8dabe114962223d71b0e9a85f0f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44437
MSELoss had a completely different (and incorrect, see https://github.com/pytorch/pytorch/issues/43228) path when target.requires_grad was True.
This PR does the following:
1) adds derivative support for target via the normal derivatives.yaml route
2) kill the different (and incorrect) path for when target.requires_grad was True
3) modify the MSELoss CriterionTests to verify that the target derivative is checked.
TODO:
1) do we still need check_criterion_jacobian when we run grad/gradgrad checks?
2) ensure the Module tests check when target.requires_grad
3) do we actually test when reduction='none' and reduction='mean'?
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23612166
Pulled By: gchanan
fbshipit-source-id: 4f74d38d8a81063c74e002e07fbb7837b2172a10
Summary:
According to pytorch/rfcs#3
From the goals in the RFC:
1. Support subclassing `torch.Tensor` in Python (done here)
2. Preserve `torch.Tensor` subclasses when calling `torch` functions on them (done here)
3. Use the PyTorch API with `torch.Tensor`-like objects that are _not_ `torch.Tensor`
subclasses (done in https://github.com/pytorch/pytorch/issues/30730)
4. Preserve `torch.Tensor` subclasses when calling `torch.Tensor` methods. (done here)
5. Propagating subclass instances correctly also with operators, using
views/slices/indexing/etc. (done here)
6. Preserve subclass attributes when using methods or views/slices/indexing. (done here)
7. A way to insert code that operates on both functions and methods uniformly
(so we can write a single function that overrides all operators). (done here)
8. The ability to give external libraries a way to also define
functions/methods that follow the `__torch_function__` protocol. (will be addressed in a separate PR)
This PR makes the following changes:
1. Adds the `self` argument to the arg parser.
2. Dispatches on `self` as well if `self` is not `nullptr`.
3. Adds a `torch._C.DisableTorchFunction` context manager to disable `__torch_function__`.
4. Adds a `torch::torch_function_enabled()` and `torch._C._torch_function_enabled()` to check the state of `__torch_function__`.
5. Dispatches all `torch._C.TensorBase` and `torch.Tensor` methods via `__torch_function__`.
TODO:
- [x] Sequence Methods
- [x] Docs
- [x] Tests
Closes https://github.com/pytorch/pytorch/issues/28361
Benchmarks in https://github.com/pytorch/pytorch/pull/37091#issuecomment-633657778
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37091
Reviewed By: ngimel
Differential Revision: D22765678
Pulled By: ezyang
fbshipit-source-id: 53f8aa17ddb8b1108c0997f6a7aa13cb5be73de0
Summary:
Raise and assert used to have a hard-coded error message "Exception". User provided error message was ignored. This PR adds support to represent user's error message in TorchScript.
This breaks backward compatibility because now we actually need to script the user's error message, which can potentially contain unscriptable expressions. Such programs can break when scripting, but saved models can still continue to work.
Increased an op count in test_mobile_optimizer.py because now we need aten::format to form the actual exception message.
This is built upon an WIP PR: https://github.com/pytorch/pytorch/pull/34112 by driazati
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41907
Reviewed By: ngimel
Differential Revision: D22778301
Pulled By: gmagogsfm
fbshipit-source-id: 2b94f0db4ae9fe70c4cd03f4048e519ea96323ad
Summary:
Current losses in PyTorch only include a (partial) implementation of Huber loss through `smooth l1` based on Fast RCNN - which essentially uses a delta value of 1. Changing/Renaming the [`_smooth_l1_loss()`](3e1859959a/torch/nn/functional.py (L2487)) and refactoring to include delta, enables to use the actual function.
Supplementary to this, I have also made a functional and criterion versions for anyone that wants to set the delta explicitly - based on the functional `smooth_l1_loss()` and the criterion `Smooth_L1_Loss()`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37599
Differential Revision: D21559311
Pulled By: vincentqb
fbshipit-source-id: 34b2a5a237462e119920d6f55ba5ab9b8e086a8c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41575
Fixes https://github.com/pytorch/pytorch/issues/34294
This updates the C++ argument parser to correctly handle `TensorList` operands. I've also included a number of updates to the testing infrastructure, this is because we're now doing a much more careful job of testing the signatures of aten kernels, using the type information about the arguments as read in from `Declarations.yaml`. The changes to the tests are required because we're now only checking for `__torch_function__` attributes on `Tensor`, `Optional[Tensor]` and elements of `TensorList` operands, whereas before we were checking for `__torch_function__` on all operands, so the relatively simplistic approach the tests were using before -- assuming all positional arguments might be tensors -- doesn't work anymore. I now think that checking for `__torch_function__` on all operands was a mistake in the original design.
The updates to the signatures of the `lambda` functions are to handle this new, more stringent checking of signatures.
I also added override support for `torch.nn.functional.threshold` `torch.nn.functional.layer_norm`, which did not yet have python-level support.
Benchmarks are still WIP.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34725
Reviewed By: mruberry
Differential Revision: D22357738
Pulled By: ezyang
fbshipit-source-id: 0e7f4a58517867b2e3f193a0a8390e2ed294e1f3
Summary:
BCELoss currently uses different broadcasting semantics than numpy. Since previous versions of PyTorch have thrown a warning in these cases telling the user that input sizes should match, and since the CUDA and CPU results differ when sizes do not match, it makes sense to upgrade the size mismatch warning to an error.
We can consider supporting numpy broadcasting semantics in BCELoss in the future if needed.
Closes https://github.com/pytorch/pytorch/issues/40023
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41426
Reviewed By: zou3519
Differential Revision: D22540841
Pulled By: ezyang
fbshipit-source-id: 6c6d94c78fa0ae30ebe385d05a9e3501a42b3652
Summary:
This is a duplicate of https://github.com/pytorch/pytorch/pull/38362
"This PR completes Interpolate's deprecation process for recomputing the scales values, by updating the default value of the parameter recompute_scale_factor as planned for pytorch 1.6.0.
The warning message is also updated accordingly."
I'm recreating this PR as previous one is not being updated.
cc gchanan
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39453
Reviewed By: hl475
Differential Revision: D21955284
Pulled By: houseroad
fbshipit-source-id: 911585d39273a9f8de30d47e88f57562216968d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37173
This function is only called in one place, so inline it. This eliminates
boilerplate related to overloads and allows for further simplification
of shared logic in later diffs.
All shared local variables have the same names (from closed_over_args),
and no local variables accidentally collide.
ghstack-source-id: 106938108
Test Plan: Existing tests for interpolate.
Differential Revision: D21209995
fbshipit-source-id: acfadf31936296b2aac0833f704764669194b06f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37172
This improves readability by keeping cases with similar behavior close
together. It should also have a very tiny positive impact on perf.
ghstack-source-id: 106938109
Test Plan: Existing tests for interpolate.
Differential Revision: D21209996
fbshipit-source-id: c813e56aa6ba7370b89a2784fcb62cc146005258
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37171
Every one of these branches returns or raises, so there's no need for elif.
This makes it a little easier to reorder and move conditions.
ghstack-source-id: 106938110
Test Plan: Existing test for interpolate.
Differential Revision: D21209992
fbshipit-source-id: 5c517e61ced91464b713f7ccf53349b05e27461c
Summary:
## Description
* Updated assert statement to remove check on 3rd dimension (features) for keys and values in MultiheadAttention / Transform
* The feature dimension for keys and values can now be of different sizes
* Refer to https://github.com/pytorch/pytorch/issues/27623
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39402
Reviewed By: zhangguanheng66
Differential Revision: D21841678
Pulled By: Nayef211
fbshipit-source-id: f0c9e5e0f33259ae2abb6bf9e7fb14e3aa9008eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38478
Before this PR, the QAT ConvBN module inlined the batch normalization code
in order to reproduce Conv+BN folding.
This PR updates the module to use BN directly. This is mathematically
equivalent to previous behavior as long as we properly scale
and fake quant the conv weights, but allows us to reuse the BN code
instead of reimplementing it.
In particular, this should help with speed since we can use dedicated
BN kernels, and also with DDP since we can hook up SyncBatchNorm.
Test Plan:
```
python test/test_quantization.py TestQATModule
```
Imported from OSS
Differential Revision: D21603230
fbshipit-source-id: ecf8afdd833b67c2fbd21a8fd14366079fa55e64
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/38120
Test Plan: build docs locally and attach a screenshot to this PR.
Differential Revision: D21477815
Pulled By: zou3519
fbshipit-source-id: 420bbcfcbd191d1a8e33cdf4a90c95bf00a5d226
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37169
This allows some cleanup of the code below by making lines shorter.
ghstack-source-id: 102773593
Test Plan: Existing tests for interpolate.
Reviewed By: kimishpatel
Differential Revision: D21209988
fbshipit-source-id: cffcdf9a580b15c4f1fa83e3f27b5a69f66bf6f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37168
It looks like this was made a separate function because of the `dim` argument,
but that argument is always equal to `input.dim() - 2`. Remove the argument
and consolidate all call sites into one. This also means that this will be
called on paths that previously didn't call it, but all those cases throw
exceptions anyway.
ghstack-source-id: 102773596
Test Plan: Existing tests for interpolate.
Reviewed By: kimishpatel
Differential Revision: D21209993
fbshipit-source-id: 2c274a3a6900ebfdb8d60b311a4c3bd956fa7c37
Summary:
xref gh-32838, gh-34032
This is a major refactor of parts of the documentation to split it up using sphinx's `autosummary` feature which will build out `autofuction` and `autoclass` stub files and link to them. The end result is that the top module pages like torch.nn.rst and torch.rst are now more like table-of-contents to the actual single-class or single-function documentations pages.
Along the way, I modified many of the docstrings to eliminate sphinx warnings when building. I think the only thing I changed from a non-documentation perspective is to add names to `__all__` when adding them to `globals()` in `torch.__init__.py`
I do not know the CI system: are the documentation build artifacts available after the build, so reviewers can preview before merging?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37419
Differential Revision: D21337640
Pulled By: ezyang
fbshipit-source-id: d4ad198780c3ae7a96a9f22651e00ff2d31a0c0f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36815
Pytorch does not have native channel shuffle op.
This diff adds that for both fp and quantized tensors.
For FP implementation is inefficient one. For quantized there is a native
QNNPACK op for this.
ghstack-source-id: 103267234
Test Plan:
buck run caffe2/test:quantization --
quantization.test_quantized.TestQuantizedOps.test_channel_shuffle
X86 implementation for QNNPACK is sse2 so this may not be the most efficient
for x86.
Reviewed By: dreiss
Differential Revision: D21093841
fbshipit-source-id: 5282945f352df43fdffaa8544fe34dba99a5b97e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37539
Bug fix
Test Plan:
This passed fbtranslate local integration test when I toggle fp16 to true on GPU.
Also it passed in with D21312488
Reviewed By: zhangguanheng66
Differential Revision: D21311505
fbshipit-source-id: 7ebd7375ef2c1b2ba4ac6fe7be5e7be1a490a319
Summary:
This PR fixes a couple of syntax errors in `torch/` that prevent MyPy from running, fixes simple type annotation errors (e.g. missing `from typing import List, Tuple, Optional`), and adds granular ignores for errors in particular modules as well as for missing typing in third party packages.
As a result, running `mypy` in the root dir of the repo now runs on:
- `torch/`
- `aten/src/ATen/function_wrapper.py` (the only file already covered in CI)
In CI this runs on GitHub Actions, job Lint, sub-job "quick-checks", task "MyPy typecheck". It should give (right now): `Success: no issues found in 329 source files`.
Here are the details of the original 855 errors when running `mypy torch` on current master (after fixing the couple of syntax errors that prevent `mypy` from running through):
<details>
```
torch/utils/tensorboard/_proto_graph.py:1: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.node_def_pb2'
torch/utils/tensorboard/_proto_graph.py:2: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.attr_value_pb2'
torch/utils/tensorboard/_proto_graph.py:3: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.tensor_shape_pb2'
torch/utils/backcompat/__init__.py:1: error: Cannot find implementation or library stub for module named 'torch._C'
torch/for_onnx/__init__.py:1: error: Cannot find implementation or library stub for module named 'torch.for_onnx.onnx'
torch/cuda/nvtx.py:2: error: Cannot find implementation or library stub for module named 'torch._C'
torch/utils/show_pickle.py:59: error: Name 'pickle._Unpickler' is not defined
torch/utils/show_pickle.py:113: error: "Type[PrettyPrinter]" has no attribute "_dispatch"
torch/utils/tensorboard/_onnx_graph.py:1: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.graph_pb2'
torch/utils/tensorboard/_onnx_graph.py:2: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.node_def_pb2'
torch/utils/tensorboard/_onnx_graph.py:3: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.versions_pb2'
torch/utils/tensorboard/_onnx_graph.py:4: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.attr_value_pb2'
torch/utils/tensorboard/_onnx_graph.py:5: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.tensor_shape_pb2'
torch/utils/tensorboard/_onnx_graph.py:9: error: Cannot find implementation or library stub for module named 'onnx'
torch/contrib/_tensorboard_vis.py:10: error: Cannot find implementation or library stub for module named 'tensorflow.core.util'
torch/contrib/_tensorboard_vis.py:11: error: Cannot find implementation or library stub for module named 'tensorflow.core.framework'
torch/contrib/_tensorboard_vis.py:12: error: Cannot find implementation or library stub for module named 'tensorflow.python.summary.writer.writer'
torch/utils/hipify/hipify_python.py:43: error: Need type annotation for 'CAFFE2_TEMPLATE_MAP' (hint: "CAFFE2_TEMPLATE_MAP: Dict[<type>, <type>] = ...")
torch/utils/hipify/hipify_python.py:636: error: "object" has no attribute "items"
torch/nn/_reduction.py:27: error: Name 'Optional' is not defined
torch/nn/_reduction.py:27: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/nn/_reduction.py:47: error: Name 'Optional' is not defined
torch/nn/_reduction.py:47: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/utils/tensorboard/_utils.py:17: error: Skipping analyzing 'matplotlib.pyplot': found module but no type hints or library stubs
torch/utils/tensorboard/_utils.py:17: error: Skipping analyzing 'matplotlib': found module but no type hints or library stubs
torch/utils/tensorboard/_utils.py:18: error: Skipping analyzing 'matplotlib.backends.backend_agg': found module but no type hints or library stubs
torch/utils/tensorboard/_utils.py:18: error: Skipping analyzing 'matplotlib.backends': found module but no type hints or library stubs
torch/nn/modules/utils.py:27: error: Name 'List' is not defined
torch/nn/modules/utils.py:27: note: Did you forget to import it from "typing"? (Suggestion: "from typing import List")
caffe2/proto/caffe2_pb2.py:17: error: Unexpected keyword argument "serialized_options" for "FileDescriptor"; did you mean "serialized_pb"?
caffe2/proto/caffe2_pb2.py:25: error: Unexpected keyword argument "serialized_options" for "EnumDescriptor"
caffe2/proto/caffe2_pb2.py:31: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:35: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:39: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:43: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:47: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:51: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:55: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:59: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:63: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:67: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:71: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:75: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:102: error: Unexpected keyword argument "serialized_options" for "EnumDescriptor"
caffe2/proto/caffe2_pb2.py:108: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:112: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:124: error: Unexpected keyword argument "serialized_options" for "EnumDescriptor"
caffe2/proto/caffe2_pb2.py:130: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:134: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:138: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:142: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:146: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:150: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:154: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:158: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:162: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:166: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:170: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:174: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:178: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:182: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:194: error: Unexpected keyword argument "serialized_options" for "EnumDescriptor"
caffe2/proto/caffe2_pb2.py:200: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:204: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:208: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:212: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:224: error: Unexpected keyword argument "serialized_options" for "EnumDescriptor"
caffe2/proto/caffe2_pb2.py:230: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:234: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:238: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:242: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:246: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:250: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:254: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:267: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:274: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:281: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:288: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:295: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:302: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:327: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:334: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:341: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:364: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:371: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:378: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:385: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:392: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:399: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:406: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:413: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:420: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:427: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:434: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:441: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:448: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:455: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:462: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:488: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:495: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:502: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:509: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:516: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:523: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:530: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:537: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:544: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:551: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:558: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:565: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:572: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:596: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:603: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:627: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:634: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:641: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:648: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:655: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:662: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:686: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:693: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:717: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:724: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:731: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:738: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:763: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:770: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:777: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:784: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:808: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:815: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:822: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:829: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:836: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:843: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:850: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:857: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:864: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:871: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:878: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:885: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:892: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:916: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:923: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:930: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:937: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:944: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:951: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:958: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:982: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:989: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:996: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1003: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1010: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1017: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1024: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1031: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1038: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1045: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1052: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1059: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1066: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1090: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1097: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1104: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1128: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1135: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1142: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1166: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1173: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1180: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1187: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1194: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1218: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1225: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1232: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1239: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1246: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1253: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1260: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1267: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1274: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1281: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1305: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1312: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1319: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1326: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1333: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1340: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1347: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1354: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1361: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1368: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1375: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1382: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1389: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1396: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1420: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1427: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1434: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1441: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1465: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1472: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1479: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1486: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1493: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1500: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1507: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1514: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1538: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1545: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1552: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1559: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1566: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1667: error: "GeneratedProtocolMessageType" has no attribute "Segment"
torch/multiprocessing/queue.py:4: error: No library stub file for standard library module 'multiprocessing.reduction'
caffe2/proto/torch_pb2.py:18: error: Unexpected keyword argument "serialized_options" for "FileDescriptor"; did you mean "serialized_pb"?
caffe2/proto/torch_pb2.py:27: error: Unexpected keyword argument "serialized_options" for "EnumDescriptor"
caffe2/proto/torch_pb2.py:33: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/torch_pb2.py:50: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:57: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:81: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:88: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:95: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:102: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:109: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:116: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:123: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:130: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:137: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:144: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:151: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:175: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:182: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:189: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:196: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:220: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:227: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:234: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:241: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:265: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:272: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:279: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:286: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:293: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:300: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:307: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:314: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:321: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:328: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:335: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:342: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:366: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:373: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:397: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:404: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:411: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:418: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:425: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:432: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:17: error: Unexpected keyword argument "serialized_options" for "FileDescriptor"; did you mean "serialized_pb"?
caffe2/proto/metanet_pb2.py:29: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/metanet_pb2.py:36: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:43: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:50: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:57: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:64: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:88: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/metanet_pb2.py:95: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:102: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:126: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/metanet_pb2.py:133: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:140: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:164: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/metanet_pb2.py:171: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:178: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:202: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/metanet_pb2.py:209: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:216: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:240: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/metanet_pb2.py:247: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:254: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:261: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:268: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:275: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:282: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:289: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:296: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/__init__.py:13: error: Skipping analyzing 'caffe2.caffe2.fb.session.proto': found module but no type hints or library stubs
torch/multiprocessing/pool.py:3: error: No library stub file for standard library module 'multiprocessing.util'
torch/multiprocessing/pool.py:3: note: (Stub files are from https://github.com/python/typeshed)
caffe2/python/scope.py:10: error: Skipping analyzing 'past.builtins': found module but no type hints or library stubs
caffe2/python/__init__.py:7: error: Module has no attribute "CPU"
caffe2/python/__init__.py:8: error: Module has no attribute "CUDA"
caffe2/python/__init__.py:9: error: Module has no attribute "MKLDNN"
caffe2/python/__init__.py:10: error: Module has no attribute "OPENGL"
caffe2/python/__init__.py:11: error: Module has no attribute "OPENCL"
caffe2/python/__init__.py:12: error: Module has no attribute "IDEEP"
caffe2/python/__init__.py:13: error: Module has no attribute "HIP"
caffe2/python/__init__.py:14: error: Module has no attribute "COMPILE_TIME_MAX_DEVICE_TYPES"; maybe "PROTO_COMPILE_TIME_MAX_DEVICE_TYPES"?
caffe2/python/__init__.py:15: error: Module has no attribute "ONLY_FOR_TEST"; maybe "PROTO_ONLY_FOR_TEST"?
caffe2/python/__init__.py:34: error: Item "_Loader" of "Optional[_Loader]" has no attribute "exec_module"
caffe2/python/__init__.py:34: error: Item "None" of "Optional[_Loader]" has no attribute "exec_module"
caffe2/python/__init__.py:35: error: Module has no attribute "cuda"
caffe2/python/__init__.py:37: error: Module has no attribute "cuda"
caffe2/python/__init__.py:49: error: Module has no attribute "add_dll_directory"
torch/random.py:4: error: Cannot find implementation or library stub for module named 'torch._C'
torch/_classes.py:2: error: Cannot find implementation or library stub for module named 'torch._C'
torch/onnx/__init__.py:1: error: Cannot find implementation or library stub for module named 'torch._C'
torch/hub.py:21: error: Skipping analyzing 'tqdm.auto': found module but no type hints or library stubs
torch/hub.py:24: error: Skipping analyzing 'tqdm': found module but no type hints or library stubs
torch/hub.py:27: error: Name 'tqdm' already defined (possibly by an import)
torch/_tensor_str.py:164: error: Not all arguments converted during string formatting
torch/_ops.py:1: error: Cannot find implementation or library stub for module named 'torch._C'
torch/_linalg_utils.py:26: error: Name 'Optional' is not defined
torch/_linalg_utils.py:26: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_linalg_utils.py:26: error: Name 'Tensor' is not defined
torch/_linalg_utils.py:63: error: Name 'Tensor' is not defined
torch/_linalg_utils.py:63: error: Name 'Optional' is not defined
torch/_linalg_utils.py:63: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_linalg_utils.py:70: error: Name 'Optional' is not defined
torch/_linalg_utils.py:70: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_linalg_utils.py:70: error: Name 'Tensor' is not defined
torch/_linalg_utils.py:88: error: Name 'Tensor' is not defined
torch/_linalg_utils.py:88: error: Name 'Optional' is not defined
torch/_linalg_utils.py:88: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_linalg_utils.py:88: error: Name 'Tuple' is not defined
torch/_linalg_utils.py:88: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/_jit_internal.py:17: error: Need type annotation for 'boolean_dispatched'
torch/_jit_internal.py:474: error: Need type annotation for '_overloaded_fns' (hint: "_overloaded_fns: Dict[<type>, <type>] = ...")
torch/_jit_internal.py:512: error: Need type annotation for '_overloaded_methods' (hint: "_overloaded_methods: Dict[<type>, <type>] = ...")
torch/_jit_internal.py:648: error: Incompatible types in assignment (expression has type "FinalCls", variable has type "_SpecialForm")
torch/sparse/__init__.py:11: error: Name 'Tensor' is not defined
torch/sparse/__init__.py:71: error: Name 'Tensor' is not defined
torch/sparse/__init__.py:71: error: Name 'Optional' is not defined
torch/sparse/__init__.py:71: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/sparse/__init__.py:71: error: Name 'Tuple' is not defined
torch/sparse/__init__.py:71: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/nn/init.py:109: error: Name 'Tensor' is not defined
torch/nn/init.py:126: error: Name 'Tensor' is not defined
torch/nn/init.py:142: error: Name 'Tensor' is not defined
torch/nn/init.py:165: error: Name 'Tensor' is not defined
torch/nn/init.py:180: error: Name 'Tensor' is not defined
torch/nn/init.py:194: error: Name 'Tensor' is not defined
torch/nn/init.py:287: error: Name 'Tensor' is not defined
torch/nn/init.py:315: error: Name 'Tensor' is not defined
torch/multiprocessing/reductions.py:8: error: No library stub file for standard library module 'multiprocessing.util'
torch/multiprocessing/reductions.py:9: error: No library stub file for standard library module 'multiprocessing.reduction'
torch/multiprocessing/reductions.py:17: error: No library stub file for standard library module 'multiprocessing.resource_sharer'
torch/jit/_builtins.py:72: error: Module has no attribute "_no_grad_embedding_renorm_"
torch/jit/_builtins.py:80: error: Module has no attribute "stft"
torch/jit/_builtins.py:81: error: Module has no attribute "cdist"
torch/jit/_builtins.py:82: error: Module has no attribute "norm"
torch/jit/_builtins.py:83: error: Module has no attribute "nuclear_norm"
torch/jit/_builtins.py:84: error: Module has no attribute "frobenius_norm"
torch/backends/cudnn/__init__.py:8: error: Cannot find implementation or library stub for module named 'torch._C'
torch/backends/cudnn/__init__.py:86: error: Need type annotation for '_handles' (hint: "_handles: Dict[<type>, <type>] = ...")
torch/autograd/profiler.py:13: error: Name 'ContextDecorator' already defined (possibly by an import)
torch/autograd/function.py:2: error: Cannot find implementation or library stub for module named 'torch._C'
torch/autograd/function.py:2: note: See https://mypy.readthedocs.io/en/latest/running_mypy.html#missing-imports
torch/autograd/function.py:109: error: Unsupported dynamic base class "with_metaclass"
torch/serialization.py:609: error: "Callable[[Any], Any]" has no attribute "cache"
torch/_lowrank.py:11: error: Name 'Tensor' is not defined
torch/_lowrank.py:13: error: Name 'Optional' is not defined
torch/_lowrank.py:13: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_lowrank.py:14: error: Name 'Optional' is not defined
torch/_lowrank.py:14: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_lowrank.py:14: error: Name 'Tensor' is not defined
torch/_lowrank.py:82: error: Name 'Tensor' is not defined
torch/_lowrank.py:82: error: Name 'Optional' is not defined
torch/_lowrank.py:82: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_lowrank.py:82: error: Name 'Tuple' is not defined
torch/_lowrank.py:82: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/_lowrank.py:130: error: Name 'Tensor' is not defined
torch/_lowrank.py:130: error: Name 'Optional' is not defined
torch/_lowrank.py:130: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_lowrank.py:130: error: Name 'Tuple' is not defined
torch/_lowrank.py:130: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/_lowrank.py:167: error: Name 'Tensor' is not defined
torch/_lowrank.py:167: error: Name 'Optional' is not defined
torch/_lowrank.py:167: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_lowrank.py:167: error: Name 'Tuple' is not defined
torch/_lowrank.py:167: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/quantization/observer.py:45: error: Variable "torch.quantization.observer.ABC" is not valid as a type
torch/quantization/observer.py:45: note: See https://mypy.readthedocs.io/en/latest/common_issues.html#variables-vs-type-aliases
torch/quantization/observer.py:45: error: Invalid base class "ABC"
torch/quantization/observer.py:127: error: Name 'Tensor' is not defined
torch/quantization/observer.py:127: error: Name 'Tuple' is not defined
torch/quantization/observer.py:127: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/quantization/observer.py:172: error: Module has no attribute "per_tensor_symmetric"
torch/quantization/observer.py:172: error: Module has no attribute "per_channel_symmetric"
torch/quantization/observer.py:192: error: Name 'Tensor' is not defined
torch/quantization/observer.py:192: error: Name 'Tuple' is not defined
torch/quantization/observer.py:192: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/quantization/observer.py:233: error: Module has no attribute "per_tensor_symmetric"
torch/quantization/observer.py:233: error: Module has no attribute "per_channel_symmetric"
torch/quantization/observer.py:534: error: Name 'Tensor' is not defined
torch/quantization/observer.py:885: error: Name 'Tensor' is not defined
torch/quantization/observer.py:885: error: Name 'Tuple' is not defined
torch/quantization/observer.py:885: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/quantization/observer.py:894: error: Cannot determine type of 'max_val'
torch/quantization/observer.py:894: error: Cannot determine type of 'min_val'
torch/quantization/observer.py:899: error: Cannot determine type of 'min_val'
torch/quantization/observer.py:902: error: Name 'Tensor' is not defined
torch/quantization/observer.py:925: error: Name 'Tensor' is not defined
torch/quantization/observer.py:928: error: Cannot determine type of 'min_val'
torch/quantization/observer.py:929: error: Cannot determine type of 'max_val'
torch/quantization/observer.py:946: error: Argument "min" to "histc" has incompatible type "Tuple[Tensor, Tensor]"; expected "Union[int, float, bool]"
torch/quantization/observer.py:946: error: Argument "max" to "histc" has incompatible type "Tuple[Tensor, Tensor]"; expected "Union[int, float, bool]"
torch/quantization/observer.py:1056: error: Module has no attribute "per_tensor_symmetric"
torch/quantization/observer.py:1058: error: Module has no attribute "per_channel_symmetric"
torch/nn/quantized/functional.py:76: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:76: error: Name 'BroadcastingList2' is not defined
torch/nn/quantized/functional.py:259: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:259: error: Name 'Optional' is not defined
torch/nn/quantized/functional.py:259: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/nn/quantized/functional.py:289: error: Module has no attribute "ops"
torch/nn/quantized/functional.py:290: error: Module has no attribute "ops"
torch/nn/quantized/functional.py:308: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:326: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:356: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:371: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:400: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:400: error: Name 'Optional' is not defined
torch/nn/quantized/functional.py:400: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/nn/quantized/functional.py:430: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:448: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/linear.py:26: error: Module has no attribute "ops"
torch/nn/quantized/modules/linear.py:28: error: Module has no attribute "ops"
torch/nn/quantized/modules/functional_modules.py:40: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:47: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:54: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:61: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:68: error: Name 'List' is not defined
torch/nn/quantized/modules/functional_modules.py:68: note: Did you forget to import it from "typing"? (Suggestion: "from typing import List")
torch/nn/quantized/modules/functional_modules.py:68: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:75: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:140: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:146: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:151: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:157: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:162: error: Name 'List' is not defined
torch/nn/quantized/modules/functional_modules.py:162: note: Did you forget to import it from "typing"? (Suggestion: "from typing import List")
torch/nn/quantized/modules/functional_modules.py:162: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:168: error: Name 'Tensor' is not defined
torch/multiprocessing/spawn.py:9: error: Module 'torch.multiprocessing' has no attribute '_prctl_pr_set_pdeathsig'
torch/multiprocessing/__init__.py:28: error: Module has no attribute "__all__"
torch/jit/frontend.py:9: error: Cannot find implementation or library stub for module named 'torch._C._jit_tree_views'
torch/jit/annotations.py:6: error: Module 'torch._jit_internal' has no attribute 'BroadcastingList2'; maybe "BroadcastingList1" or "BroadcastingListCls"?
torch/jit/annotations.py:6: error: Module 'torch._jit_internal' has no attribute 'BroadcastingList3'; maybe "BroadcastingList1" or "BroadcastingListCls"?
torch/jit/annotations.py:9: error: Cannot find implementation or library stub for module named 'torch._C'
torch/distributions/distribution.py:16: error: Need type annotation for 'arg_constraints' (hint: "arg_constraints: Dict[<type>, <type>] = ...")
torch/distributions/distribution.py:74: error: Name 'arg_constraints' already defined on line 16
torch/distributions/distribution.py:84: error: Name 'support' already defined on line 15
torch/functional.py:114: error: Name 'Tuple' is not defined
torch/functional.py:114: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/functional.py:114: error: Name 'Optional' is not defined
torch/functional.py:114: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:189: error: Incompatible types in assignment (expression has type "None", variable has type "Tensor")
torch/functional.py:200: error: Argument 1 to "_indices_product" has incompatible type "Tuple[int, ...]"; expected "List[int]"
torch/functional.py:204: error: No overload variant of "__setitem__" of "list" matches argument types "Tensor", "int"
torch/functional.py:204: note: Possible overload variants:
torch/functional.py:204: note: def __setitem__(self, int, int) -> None
torch/functional.py:204: note: def __setitem__(self, slice, Iterable[int]) -> None
torch/functional.py:204: error: No overload variant of "__getitem__" of "list" matches argument type "Tensor"
torch/functional.py:204: note: def __getitem__(self, int) -> int
torch/functional.py:204: note: def __getitem__(self, slice) -> List[int]
torch/functional.py:207: error: "Tensor" has no attribute "copy_"
torch/functional.py:212: error: No overload variant of "__setitem__" of "list" matches argument types "Tensor", "int"
torch/functional.py:212: note: Possible overload variants:
torch/functional.py:212: note: def __setitem__(self, int, int) -> None
torch/functional.py:212: note: def __setitem__(self, slice, Iterable[int]) -> None
torch/functional.py:212: error: No overload variant of "__getitem__" of "list" matches argument type "Tensor"
torch/functional.py:212: note: def __getitem__(self, int) -> int
torch/functional.py:212: note: def __getitem__(self, slice) -> List[int]
torch/functional.py:215: error: Incompatible types in assignment (expression has type "None", variable has type "Tensor")
torch/functional.py:334: error: Name 'Optional' is not defined
torch/functional.py:334: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:429: error: Argument 2 to "pad" has incompatible type "Tuple[int, int]"; expected "List[int]"
torch/functional.py:431: error: Module has no attribute "stft"
torch/functional.py:766: error: Module has no attribute "cdist"
torch/functional.py:768: error: Module has no attribute "cdist"
torch/functional.py:770: error: Module has no attribute "cdist"
torch/functional.py:775: error: Name 'Optional' is not defined
torch/functional.py:775: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:780: error: Name 'Optional' is not defined
torch/functional.py:780: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:780: error: Name 'number' is not defined
torch/functional.py:780: error: Name 'norm' already defined on line 775
torch/functional.py:785: error: Name 'Optional' is not defined
torch/functional.py:785: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:785: error: Name 'number' is not defined
torch/functional.py:785: error: Name 'norm' already defined on line 775
torch/functional.py:790: error: Name 'Optional' is not defined
torch/functional.py:790: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:790: error: Name 'norm' already defined on line 775
torch/functional.py:795: error: Name 'norm' already defined on line 775
torch/functional.py:960: error: Name 'Any' is not defined
torch/functional.py:960: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Any")
torch/functional.py:960: error: Name 'Tuple' is not defined
torch/functional.py:960: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/functional.py:1036: error: Argument 1 to "len" has incompatible type "int"; expected "Sized"
torch/functional.py:1041: error: Name 'Optional' is not defined
torch/functional.py:1041: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:1041: error: Name 'Tuple' is not defined
torch/functional.py:1041: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/functional.py:1056: error: Name 'Optional' is not defined
torch/functional.py:1056: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:1056: error: Name 'Tuple' is not defined
torch/functional.py:1056: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/distributions/von_mises.py:87: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/negative_binomial.py:25: error: Incompatible types in assignment (expression has type "_IntegerGreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/multivariate_normal.py:116: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/laplace.py:23: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/independent.py:34: error: Need type annotation for 'arg_constraints' (hint: "arg_constraints: Dict[<type>, <type>] = ...")
torch/distributions/cauchy.py:28: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/poisson.py:28: error: Incompatible types in assignment (expression has type "_IntegerGreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/one_hot_categorical.py:32: error: Incompatible types in assignment (expression has type "_Simplex", base class "Distribution" defined the type as "None")
torch/distributions/normal.py:27: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/lowrank_multivariate_normal.py:79: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/gamma.py:30: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/exponential.py:23: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/fishersnedecor.py:25: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/dirichlet.py:44: error: Incompatible types in assignment (expression has type "_Simplex", base class "Distribution" defined the type as "None")
torch/nn/quantized/dynamic/modules/rnn.py:230: error: Incompatible types in assignment (expression has type "int", variable has type "Tensor")
torch/nn/quantized/dynamic/modules/rnn.py:232: error: Incompatible types in assignment (expression has type "int", variable has type "Tensor")
torch/nn/quantized/dynamic/modules/rnn.py:236: error: Incompatible return value type (got "Tuple[Any, Tensor, Any]", expected "Tuple[int, int, int]")
torch/nn/quantized/dynamic/modules/rnn.py:351: error: Incompatible types in assignment (expression has type "Type[LSTM]", base class "RNNBase" defined the type as "Type[RNNBase]")
torch/nn/quantized/dynamic/modules/rnn.py:381: error: Module has no attribute "quantized_lstm"
torch/nn/quantized/dynamic/modules/rnn.py:385: error: Module has no attribute "quantized_lstm"
torch/nn/quantized/dynamic/modules/rnn.py:414: error: Argument 1 to "forward_impl" of "LSTM" has incompatible type "PackedSequence"; expected "Tensor"
torch/nn/quantized/dynamic/modules/rnn.py:416: error: Incompatible types in assignment (expression has type "PackedSequence", variable has type "Tensor")
torch/nn/quantized/dynamic/modules/rnn.py:418: error: Incompatible return value type (got "Tuple[Tensor, Tuple[Tensor, Tensor]]", expected "Tuple[PackedSequence, Tuple[Tensor, Tensor]]")
torch/nn/quantized/dynamic/modules/rnn.py:420: error: Argument 1 of "permute_hidden" is incompatible with supertype "RNNBase"; supertype defines the argument type as "Tensor"
torch/nn/quantized/dynamic/modules/rnn.py:420: error: Return type "Tuple[Tensor, Tensor]" of "permute_hidden" incompatible with return type "Tensor" in supertype "RNNBase"
torch/nn/quantized/dynamic/modules/rnn.py:426: error: Argument 2 of "check_forward_args" is incompatible with supertype "RNNBase"; supertype defines the argument type as "Tensor"
torch/nn/intrinsic/qat/modules/conv_fused.py:232: error: Incompatible types in assignment (expression has type "Type[ConvBnReLU2d]", base class "ConvBn2d" defined the type as "Type[ConvBn2d]")
torch/distributions/beta.py:27: error: Incompatible types in assignment (expression has type "_Interval", base class "Distribution" defined the type as "None")
torch/distributions/geometric.py:31: error: Incompatible types in assignment (expression has type "_IntegerGreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/continuous_bernoulli.py:38: error: Incompatible types in assignment (expression has type "_Interval", base class "Distribution" defined the type as "None")
torch/distributions/bernoulli.py:30: error: Incompatible types in assignment (expression has type "_Boolean", base class "Distribution" defined the type as "None")
torch/quantization/fake_quantize.py:126: error: Module has no attribute "per_tensor_symmetric"
torch/quantization/fake_quantize.py:132: error: Module has no attribute "per_channel_symmetric"
torch/distributions/transformed_distribution.py:41: error: Need type annotation for 'arg_constraints' (hint: "arg_constraints: Dict[<type>, <type>] = ...")
torch/jit/__init__.py:1: error: Cannot find implementation or library stub for module named 'torch._C'
torch/jit/__init__.py:15: error: Module 'torch.utils' has no attribute 'set_module'
torch/jit/__init__.py:70: error: Name 'Attribute' already defined on line 68
torch/jit/__init__.py:213: error: On Python 3 '{}'.format(b'abc') produces "b'abc'"; use !r if this is a desired behavior
torch/jit/__init__.py:215: error: On Python 3 '{}'.format(b'abc') produces "b'abc'"; use !r if this is a desired behavior
torch/jit/__init__.py:1524: error: Unsupported dynamic base class "with_metaclass"
torch/jit/__init__.py:1869: error: Name 'ScriptModule' already defined on line 1524
torch/jit/__init__.py:1998: error: Need type annotation for '_jit_caching_layer'
torch/jit/__init__.py:1999: error: Need type annotation for '_jit_function_overload_caching'
torch/distributions/relaxed_categorical.py:34: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/relaxed_categorical.py:108: error: Incompatible types in assignment (expression has type "_Simplex", base class "Distribution" defined the type as "None")
torch/distributions/relaxed_bernoulli.py:31: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/relaxed_bernoulli.py:114: error: Incompatible types in assignment (expression has type "_Interval", base class "Distribution" defined the type as "None")
torch/distributions/logistic_normal.py:31: error: Incompatible types in assignment (expression has type "_Simplex", base class "Distribution" defined the type as "None")
torch/distributions/log_normal.py:26: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/half_normal.py:27: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/half_cauchy.py:28: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/gumbel.py:28: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/nn/quantized/modules/conv.py:18: error: Module 'torch.nn.utils' has no attribute 'fuse_conv_bn_weights'
torch/nn/quantized/modules/conv.py:209: error: Name 'Optional' is not defined
torch/nn/quantized/modules/conv.py:209: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/nn/quantized/modules/conv.py:214: error: Module has no attribute "ops"
torch/nn/quantized/modules/conv.py:321: error: Name 'Optional' is not defined
torch/nn/quantized/modules/conv.py:321: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/nn/quantized/modules/conv.py:323: error: Module has no attribute "ops"
torch/nn/quantized/modules/conv.py:447: error: Name 'Optional' is not defined
torch/nn/quantized/modules/conv.py:447: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/nn/quantized/modules/conv.py:449: error: Module has no attribute "ops"
torch/nn/quantized/modules/conv.py:513: error: Name 'nn.modules.conv._ConvTransposeNd' is not defined
torch/nn/quantized/modules/conv.py:525: error: Name 'List' is not defined
torch/nn/quantized/modules/conv.py:525: note: Did you forget to import it from "typing"? (Suggestion: "from typing import List")
torch/nn/quantized/modules/conv.py:527: error: Name 'List' is not defined
torch/nn/quantized/modules/conv.py:527: note: Did you forget to import it from "typing"? (Suggestion: "from typing import List")
torch/nn/intrinsic/quantized/modules/conv_relu.py:8: error: Module 'torch.nn.utils' has no attribute 'fuse_conv_bn_weights'
torch/nn/intrinsic/quantized/modules/conv_relu.py:21: error: Incompatible types in assignment (expression has type "Type[ConvReLU2d]", base class "Conv2d" defined the type as "Type[Conv2d]")
torch/nn/intrinsic/quantized/modules/conv_relu.py:62: error: Incompatible types in assignment (expression has type "Type[ConvReLU3d]", base class "Conv3d" defined the type as "Type[Conv3d]")
torch/distributions/weibull.py:25: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/kl.py:35: error: Need type annotation for '_KL_MEMOIZE' (hint: "_KL_MEMOIZE: Dict[<type>, <type>] = ...")
torch/distributions/studentT.py:27: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/mixture_same_family.py:48: error: Need type annotation for 'arg_constraints' (hint: "arg_constraints: Dict[<type>, <type>] = ...")
torch/distributions/__init__.py:158: error: Name 'transforms' is not defined
torch/onnx/utils.py:21: error: Cannot find implementation or library stub for module named 'torch._C'
torch/distributed/rendezvous.py:4: error: Cannot find implementation or library stub for module named 'urlparse'
torch/distributed/rendezvous.py:4: error: Name 'urlparse' already defined (possibly by an import)
torch/distributed/rendezvous.py:4: error: Name 'urlunparse' already defined (possibly by an import)
torch/distributed/rendezvous.py:9: error: Module 'torch.distributed' has no attribute 'FileStore'
torch/distributed/rendezvous.py:9: error: Module 'torch.distributed' has no attribute 'TCPStore'
torch/distributed/rendezvous.py:65: error: On Python 3 '{}'.format(b'abc') produces "b'abc'"; use !r if this is a desired behavior
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'AllreduceOptions'; maybe "ReduceOptions" or "AllreduceCoalescedOptions"?
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'AllreduceCoalescedOptions'; maybe "AllreduceOptions"?
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'AllToAllOptions'
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'BroadcastOptions'
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'GatherOptions'; maybe "ScatterOptions"?
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'ReduceOptions'; maybe "AllreduceOptions", "ReduceScatterOptions", or "ReduceOp"?
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'ReduceScatterOptions'; maybe "ScatterOptions" or "ReduceOptions"?
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'ScatterOptions'; maybe "ReduceScatterOptions" or
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36584
Reviewed By: seemethere, ailzhang
Differential Revision: D21155985
Pulled By: ezyang
fbshipit-source-id: f628d4293992576207167e7c417998fad15898d1
Summary:
Add the support to accept both float, byte, and bool tensors for `attn_mask`. No breakage is expected.
- If a bool tensor is provided, positions with `True` are not allowed to attend while `False` values will be unchanged.
- if a byte tensor is provided, it will be converted to bool tensor. Positions with non-zero are not allowed to attend while zero values will be unchanged.
- If a float tensor is provided, it will be added to the attention weight.
Note: the behavior of the float mask tensor is slightly different from the first two options because it is added to the attention weight, rather than calling `masked_fill_` function. Also, converting a byte tensor to bool tensor within `multi_head_attention_forward` causes extra overhead. Therefore, a bool mask is recommended here.
For `key_padding_mask`:
- if a bool tensor is provided, it will be converted to bool tensor. The positions with the value of `True` will be ignored while the position with the value of `False` will be unchanged.
- If a byte tensor is provided, the positions with the value of non-zero will be ignored while the position with the value of zero will be unchanged.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33763
Differential Revision: D20925358
Pulled By: zhangguanheng66
fbshipit-source-id: de174056be183cdad0f3de8024ee0a3c5eb364c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35187
When I touch these files, lint will always introduce some unintended change, to prevent it from happening, we need to format the code first.
change is generated by:
arc f
Test Plan: integration test.
Differential Revision: D20587596
fbshipit-source-id: 512cf6b86bd6632a61c80ed53e3a9e229feecc2a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35885
For the ops I added recently, ensure all the typehints are
present, so that JIT can script them.
We might want to look into a test for this in the future.
Test Plan:
scripting works for all of them now:
https://gist.github.com/vkuzo/1d92fdea548ad596310fffcbe95e4438
Imported from OSS
Differential Revision: D20818431
fbshipit-source-id: 0de61eaf70c08d625128c6fffd05788e6e5bb920
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35431
Resolving z-a-f's comments on earlier PRs on making
the docblocks easier to read.
Test Plan:
render the new docblocks in http://rst.aaroniles.net/
CI
Imported from OSS
Differential Revision: D20658668
fbshipit-source-id: 5ea4a21d6b8dc9d744e2f4ede2f9d5d799fb902f
Summary:
This one doesn't actually do anything so we don't need an op for it.
It is used inside `torch.nn.functional.unfold` which is already tested
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34509
Pulled By: driazati
Differential Revision: D20676445
fbshipit-source-id: b72d1308bdec593367ec4e14bf9a901d0b62e1cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34747
Adds the hardswish FP operator from MobileNetV3 to PyTorch. This is for
common operator coverage, since this is widely used. A future PR will
add the quantized version. CUDA is saved for a future PR as well.
Test Plan:
tests pass:
```
python test/test_torch.py TestTorchDeviceTypeCPU.test_hardswish_cpu_float32
```
microbenchmark:
https://gist.github.com/vkuzo/b10d3b238f24e58c585314e8b5385aca
(batch_size == 1: 11.5GiB/s, batch_size == 4: 11.9GiB/s)
Imported from OSS
Differential Revision: D20451404
fbshipit-source-id: c7e13c9ab1a83e27a1ba18182947c82c896efae2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34545
This is for common operator coverage, since this is widely used. A future PR
will add the quantized version.
Some initial questions for reviewers, since it's my first FP operator
diff:
* do we need a backwards.out method for this?
* do we need CUDA? If yes, should it be this PR or is it ok to split
Test Plan:
```
// test
python test/test_torch.py TestTorchDeviceTypeCPU.test_hardsigmoid_cpu_float32
// benchmark
python -m pt.hardsigmoid_test
...
Forward Execution Time (us) : 40.315
Forward Execution Time (us) : 42.603
```
Imported from OSS
Differential Revision: D20371692
fbshipit-source-id: 95668400da9577fd1002ce3f76b9777c6f96c327
Summary:
Now that lists are no longer specialized, we can register only one operator for list ops that are generic to their element type.
This PR reorgs lists into three sets of ops:
- CREATE_GENERIC_LIST_OPS
- CREATE_SPECIALIZED_LIST_OPS
- CREATE_COMPARATOR_LIST_OPS_SPECIALIZED (we didn't bind certain specialized ops to Tensor)
This is important to land quickly because mobile is finalizing its bytecode soon, after which we could not remove these ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34520
Reviewed By: iseeyuan
Differential Revision: D20429775
Pulled By: eellison
fbshipit-source-id: ae6519f9b0f731eaa2bf4ac20736317d0a66b8a0
Summary:
`torch.nn.functional.interpolate` was written as a builtin op when we scripted the standard library, because it has four possible overloads. As a result, whenever we make a change to `interpolate`, we need to make changes in two places, and it also makes it impossible to optimize the interpolate op. The builtin is tech debt.
I talked with ailzhang, and the symbolic script changes are good to remove (i guess that makes a third place we needed to re-implement interpolate).
I'm trying to get rid of unneccessary builtin operators because we're standardizing mobile bytecode soon, so we should try to get this landed as soon as possible.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34514
Differential Revision: D20391089
Pulled By: eellison
fbshipit-source-id: abc84cdecfac67332bcba6b308fca4db44303121
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33504
Fix resolution fo functions that are bound onto torch in torch/functional.py. This does not fix compilation of all of those functions, those will be done in follow ups. Does torch.stft as a start.
Fixes#21478
Test Plan: Imported from OSS
Differential Revision: D20014591
Pulled By: eellison
fbshipit-source-id: bb362f1b5479adbb890e72a54111ef716679d127
Summary:
This PR improves performance of EmbeddingBag on cuda by removing 5 kernel launches (2 of those are synchronizing memcopies).
- 2 memcopies are checking values of offsets[0] and offsets[-1] to be in expected range (0 for the former, less than number of indices for the latter). It seems strange to check only those 2 values, if users are providing invalid offsets, invalid values can be anywhere in the array, not only the first and last element. After this PR, the checks are skipped on cuda, the first value is forced to 0, if the last value is larger than expected, cuda kernel will assert. It is less nice than ValueError, but then again, the kernel could have asserted if other offset values were invalid. On the cpu, the checks are moved inside the cpu implementation from functional.py, and will throw RuntimeError instead of ValueError.
- 3 or 4 initializations (depending on the mode) of the output tensors with .zeros() are unnecessary, because every element of those tensors is written to, so their data can be uninitialized on the start.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33589
Reviewed By: jianyuh
Differential Revision: D20078011
Pulled By: ngimel
fbshipit-source-id: 2fb2e2080313af64adc5cf1b9fc6ffbdc6efaf16
Summary:
This adds `__torch_function__` support for all functions in `torch.functional` and `torch.nn.functional`.
The changes to C++ code and codegen scripts are to facilitate adding `__torch_function__` support for the native functions in `torch._C._nn`. Note that I moved the `handle_torch_function` C++ function to a header that both `python_torch_functions.cpp` and `python_nn_functions.cpp` include. The changes to `python_nn_functions.cpp` mirror the changes I made to `python_torch_functions.cpp` when `__torch_function__` support was first added in https://github.com/pytorch/pytorch/issues/27064. Due to the somewhat different way the `torch._C` and `torch._C._nn` namespaces are initialized I needed to create a new static reference to the `torch._C._nn` namespace (`THPNNVariableFunctions`). I'm not sure if that is the best way to do this. In principle I could import these namespaces in each kernel and avoid the global variable but that would have a runtime cost.
I added `__torch_function__` support to the Python functions in `torch.nn.functional` following the approach in https://github.com/pytorch/pytorch/issues/32194.
I re-enabled the test that checks if all functions in the `torch` namespace are explicitly tested for `__torch_function__` support. I also generalized the check to work for `torch.functional` and `torch.nn.functional` as well. This test was explicitly disabled in https://github.com/pytorch/pytorch/issues/30730 and I'm happy to disable it again if you think that's appropriate. I figured now was as good a time as any to try to re-enable it.
Finally I adjusted the existing torch API tests to suppress deprecation warnings and add keyword arguments used by some of the code in `torch.nn.functional` that were missed when I originally added the tests in https://github.com/pytorch/pytorch/issues/27064.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32799
Differential Revision: D19956809
Pulled By: ezyang
fbshipit-source-id: 40d34e0109cc4b9f3ef62f409d2d35a1d84e3d22
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33008
Corrects D19373507 to allow valid use cases that fail now. Multiplies batch size by the number of elements in a group to get the correct number of elements over which statistics are computed.
**Details**:
The current implementation disallows GroupNorm to be applied to tensors of shape e.g. `(1, C, 1, 1)` to prevent cases where statistics are computed over 1 element and thus result in a tensor filled with zeros.
However, in GroupNorm the statistics are calculated across channels. So in case where one has an input tensor of shape `(1, 256, 1, 1)` for `GroupNorm(32, 256)`, the statistics will be computed over 8 elements and thus be meaningful.
One use case is [Atrous Spatial Pyramid Pooling (ASPPPooling)](791c172a33/torchvision/models/segmentation/deeplabv3.py (L50)), where GroupNorm could be used in place of BatchNorm [here](791c172a33/torchvision/models/segmentation/deeplabv3.py (L55)). However, now this is prohibited and results in failures.
Proposed solution consists in correcting the computation of the number of elements over which statistics are computed. The number of elements per group is taken into account in the batch size.
Test Plan: check that existing tests pass
Reviewed By: fmassa
Differential Revision: D19723407
fbshipit-source-id: c85c244c832e6592e9aedb279d0acc867eef8f0c
Summary:
The PR https://github.com/pytorch/pytorch/pull/31791 adds support for float[] constant, which affects some cases of ONNX interpolate support.
This PR adds float[] constants support in ONNX, updates interpolate in ONNX, and re-enable the disabled tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32554
Reviewed By: hl475
Differential Revision: D19566596
Pulled By: houseroad
fbshipit-source-id: 843f62c86126fdf4f9c0117b65965682a776e7e9
Summary:
The default value is removed because it is explained right below.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32945
Reviewed By: soumith
Differential Revision: D19706567
Pulled By: ailzhang
fbshipit-source-id: 1b7cc87991532f69b81aaae2451d944f70dda427
Summary:
Pull Request resolved: https://github.com/pytorch/glow/pull/4049
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27477
We would like to add the intra-op parallelization support for the EmbeddingBag operator.
This should bring speedup for the DLRM benchmark:
https://github.com/pytorch/pytorch/pull/24385
Benchmark code:
```
from __future__ import absolute_import, division, print_function, unicode_literals
import torch
import time
eb = torch.nn.EmbeddingBag(1000000, 64, mode='sum')
input = torch.LongTensor(1500).random_(0, 1000000)
offsets = torch.zeros(64, dtype=torch.int64)
niter = 10000
s = time.time()
for _ in range(niter):
out = eb(input, offsets)
time_per_iter = (time.time() - s) / niter
print('time_per_iter', time_per_iter)
print('GB/s', (input.numel() * 64 * 4 + out.numel() * 4) / time_per_iter / 1e9)
```
The following results are single core on Skylake T6:
- Before our change (with the original caffe2::EmbeddingLookup)
time_per_iter 6.313693523406982e-05
GB/s 6.341517821789133
- After our change using the EmbeddingLookupIdx API which takes the offsets instead of lengths.
time_per_iter 5.7627105712890626e-05
GB/s 6.947841559053659
- With Intel's PR: https://github.com/pytorch/pytorch/pull/24385
time_per_iter 7.393271923065185e-05
GB/s 5.415518381664018
For multi-core performance, because Clang doesn't work with OMP, I can only see the single-core performance on SKL T6.
ghstack-source-id: 97124557
Test Plan:
With D16990830:
```
buck run mode/dev //caffe2/caffe2/perfkernels:embedding_bench
```
With D17750961:
```
buck run mode/opt //experimental/jianyuhuang/embeddingbag:eb
buck run mode/opt-lto //experimental/jianyuhuang/embeddingbag:eb
```
OSS test
```
python run_test.py -i nn -- TestNNDeviceTypeCPU.test_EmbeddingBag_per_sample_weights_and_new_offsets_cpu
```
Buck test
```
buck test mode/dev-nosan //caffe2/test:nn -- "test_EmbeddingBag_per_sample_weights_and_new_offsets_cpu"
OMP_NUM_THREADS=3 buck test mode/opt -c pytorch.parallel_backend=tbb //caffe2/test:nn -- "test_EmbeddingBag_per_sample_weights_and_new_offsets" --print-passing-details
```
Generate the AVX2 code for embedding_lookup_idx_avx2.cc:
```
python hp_emblookup_codegen.py --use-offsets
```
Differential Revision: D17768404
fbshipit-source-id: 8dcd15a62d75b737fa97e0eff17f347052675700
Summary:
Perf improvements to multi_head_attention_forward
- qkv_same and kv_same were not used outside of that branch. Further, kv_same was calculated even though it is not used if qkv_same
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30142
Differential Revision: D18610938
Pulled By: cpuhrsch
fbshipit-source-id: 19b7456f20aef90032b0f42d7da8c8a2d5563ee3
Summary:
Added check for indicies in Reduction::None case.
### Benchmark results
Note: Due to the size of the input tensors this time the random number generation is responsible for a significant portion of the total time. It is better to look at the individual net time-outputs (which do not include the input preparation).
Script used for benchmark.: [nnl_loss2d_benchmark.py](https://gist.github.com/andreaskoepf/5864aa91e243317cb282c1e7fe576e1b)
#### WITH PR applied
```
using reduction: none
CPU forward 1000 took 7.916500908322632e-05
CPU forward 10000 took 0.0002642290201038122
CPU forward 100000 took 0.003828087996225804
CPU forward 1000000 took 0.037140720000024885
CPU forward 10000000 took 0.33387596398824826
CPU forward TOTAL time 7.218988707987592
using reduction: mean
CPU forward 1000 took 9.165197843685746e-05
CPU forward 10000 took 0.0005258890159893781
CPU forward 100000 took 0.0050761590246111155
CPU forward 1000000 took 0.047345594997750595
CPU forward 10000000 took 0.4790863030066248
CPU forward TOTAL time 7.9106070210109465
CPU for- & backward 1000 took 0.0005489500181283802
CPU for- & backward 10000 took 0.0015284279943443835
CPU for- & backward 100000 took 0.015138130984269083
CPU for- & backward 1000000 took 0.15741890601930209
CPU for- & backward 10000000 took 1.6703072849777527
CPU for- & backward TOTAL time 9.555764263990568
using reduction: sum
CPU forward 1000 took 8.789298590272665e-05
CPU forward 10000 took 0.000514078012201935
CPU forward 100000 took 0.005135576997417957
CPU forward 1000000 took 0.04715992201818153
CPU forward 10000000 took 0.4821214270195924
CPU forward TOTAL time 7.9119505700073205
CPU for- & backward 1000 took 0.00047759301378391683
CPU for- & backward 10000 took 0.0015945070190355182
CPU for- & backward 100000 took 0.018208994006272405
CPU for- & backward 1000000 took 0.15904426100314595
CPU for- & backward 10000000 took 1.5679037219961174
CPU for- & backward TOTAL time 9.495157692988869
```
#### WITHOUT original TH impl
```
using reduction: none
CPU forward 1000 took 0.0003981560003012419
CPU forward 10000 took 0.0035912430030293763
CPU forward 100000 took 0.035353766987100244
CPU forward 1000000 took 0.3428319719969295
CPU forward 10000000 took 3.364342701010173
CPU forward TOTAL time 11.166179805004504
using reduction: mean
CPU forward 1000 took 8.63690220285207e-05
CPU forward 10000 took 0.0004704220045823604
CPU forward 100000 took 0.0045734510058537126
CPU forward 1000000 took 0.046232511987909675
CPU forward 10000000 took 0.4191019559802953
CPU forward TOTAL time 7.846049971994944
CPU for- & backward 1000 took 0.0005974550149403512
CPU for- & backward 10000 took 0.0014057719963602722
CPU for- & backward 100000 took 0.013776941981632262
CPU for- & backward 1000000 took 0.13876214998890646
CPU for- & backward 10000000 took 1.3666698939923663
CPU for- & backward TOTAL time 9.10526105100871
using reduction: sum
CPU forward 1000 took 7.598899537697434e-05
CPU forward 10000 took 0.00046885499614290893
CPU forward 100000 took 0.0044489419960882515
CPU forward 1000000 took 0.04495517900795676
CPU forward 10000000 took 0.418376043002354
CPU forward TOTAL time 7.789334400993539
CPU for- & backward 1000 took 0.0004464260127861053
CPU for- & backward 10000 took 0.0017732900159899145
CPU for- & backward 100000 took 0.01626713399309665
CPU for- & backward 1000000 took 0.11790941300569102
CPU for- & backward 10000000 took 1.4346664609911386
CPU for- & backward TOTAL time 9.294745502003934
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28304
Differential Revision: D18350157
Pulled By: ezyang
fbshipit-source-id: e9437debe51386a483f4265193c475cdc90b28e4
Summary:
Replaces fused TH kernels with a 2-liner of regular Tensor functions.
Benchmarking revealed that performance improves compared to PyTorch 1.2.
Refs: https://github.com/pytorch/pytorch/issues/24631, https://github.com/pytorch/pytorch/issues/24632, https://github.com/pytorch/pytorch/issues/24764, https://github.com/pytorch/pytorch/issues/24765
VitalyFedyunin
### Benchmarking results on my laptop:
## 1.4.0a0+f63c9e8 output
```
PyTorch version: 1.4.0a0+f63c9e8
CPU Operator sanity check:
tensor(0.5926, grad_fn=<MeanBackward0>)
tensor([-0.0159, -0.0170, -0.0011, -0.0083, -0.0140, -0.0217, -0.0290, -0.0262,
-0.0078, -0.0129])
double backward
tensor(-0.1540, grad_fn=<SumBackward0>)
ok
GPU Operator sanity check:
tensor(0.5601, device='cuda:0', grad_fn=<MeanBackward0>)
tensor([-0.0393, -0.0316, -0.0233, -0.0140, -0.0141, -0.0161, -0.0322, -0.0238,
-0.0054, -0.0151], device='cuda:0')
double backward
tensor(-0.2148, device='cuda:0', grad_fn=<SumBackward0>)
ok
CPU warmup 1000 took 9.025700273923576e-05
CPU warmup 10000 took 0.0009383050055475906
CPU warmup 100000 took 0.0015631120040779933
CPU warmup TOTAL time 0.0026368020044174045
CPU forward 1000 took 6.919399311300367e-05
CPU forward 10000 took 0.00014462800754699856
CPU forward 100000 took 0.0011234670091653243
CPU forward 1000000 took 0.014555767003912479
CPU forward 10000000 took 0.13409724000666756
CPU forward 100000000 took 1.246048310000333
CPU forward TOTAL time 1.3961777170043206
CPU for- & backward 1000 took 0.0003219560021534562
CPU for- & backward 10000 took 0.00037290599721018225
CPU for- & backward 100000 took 0.001975035003852099
CPU for- & backward 1000000 took 0.02621342398924753
CPU for- & backward 10000000 took 0.2944270490115741
CPU for- & backward 100000000 took 1.6856628700043075
CPU for- & backward TOTAL time 2.0091958299890393
GPU warmup 1000 took 0.0002462909906171262
GPU warmup 10000 took 9.991199476644397e-05
GPU warmup 100000 took 0.00034347400651313365
GPU warmup TOTAL time 0.0007382350013358518
GPU forward 1000 took 9.67290106927976e-05
GPU forward 10000 took 9.349700121674687e-05
GPU forward 100000 took 9.384499571751803e-05
GPU forward 1000000 took 0.0004975290066795424
GPU forward 10000000 took 0.0017606960027478635
GPU forward 100000000 took 0.003572814996005036
GPU forward TOTAL time 0.006185991995153017
GPU for- & backward 1000 took 0.00035818999458570033
GPU for- & backward 10000 took 0.0003240450023440644
GPU for- & backward 100000 took 0.0003223370003979653
GPU for- & backward 1000000 took 0.00036740700306836516
GPU for- & backward 10000000 took 0.0003690610028570518
GPU for- & backward 100000000 took 0.0003672500024549663
GPU for- & backward TOTAL time 0.002197896988946013
```
## 1.2 output
```
PyTorch version: 1.2.0
CPU Operator sanity check:
tensor(0.5926, grad_fn=<SoftMarginLossBackward>)
tensor([-0.0159, -0.0170, -0.0011, -0.0083, -0.0140, -0.0217, -0.0290, -0.0262,
-0.0078, -0.0129])
double backward
tensor(-0.1540, grad_fn=<SumBackward0>)
ok
GPU Operator sanity check:
tensor(0.5601, device='cuda:0', grad_fn=<SoftMarginLossBackward>)
tensor([-0.0393, -0.0316, -0.0233, -0.0140, -0.0141, -0.0161, -0.0322, -0.0238,
-0.0054, -0.0151], device='cuda:0')
double backward
tensor(-0.2148, device='cuda:0', grad_fn=<SumBackward0>)
ok
CPU warmup 1000 took 8.422900282312185e-05
CPU warmup 10000 took 0.00036992700188420713
CPU warmup 100000 took 0.003682684007799253
CPU warmup TOTAL time 0.004169487991021015
CPU forward 1000 took 5.521099956240505e-05
CPU forward 10000 took 0.00036948200431652367
CPU forward 100000 took 0.003762389998883009
CPU forward 1000000 took 0.03725024699815549
CPU forward 10000000 took 0.3614480490068672
CPU forward 100000000 took 3.6139175269927364
CPU forward TOTAL time 4.016912263003178
CPU for- & backward 1000 took 0.0002734809968387708
CPU for- & backward 10000 took 0.0006605249946005642
CPU for- & backward 100000 took 0.005437346000690013
CPU for- & backward 1000000 took 0.051245586000732146
CPU for- & backward 10000000 took 0.5291594529990107
CPU for- & backward 100000000 took 5.23841712900321
CPU for- & backward TOTAL time 5.8253340990049765
GPU warmup 1000 took 0.0005757809994975105
GPU warmup 10000 took 0.0004058420017827302
GPU warmup 100000 took 0.0003764610009966418
GPU warmup TOTAL time 0.0013992580061312765
GPU forward 1000 took 0.0003543390048434958
GPU forward 10000 took 0.0003633670130511746
GPU forward 100000 took 0.0004807310033356771
GPU forward 1000000 took 0.0005875999922864139
GPU forward 10000000 took 0.0016903509967960417
GPU forward 100000000 took 0.014400018990272656
GPU forward TOTAL time 0.0179396449966589
GPU for- & backward 1000 took 0.0006167769897729158
GPU for- & backward 10000 took 0.0006845899915788323
GPU for- & backward 100000 took 0.000631830989732407
GPU for- & backward 1000000 took 0.0010741150035755709
GPU for- & backward 10000000 took 0.0017265130009036511
GPU for- & backward 100000000 took 0.014847910992102697
GPU for- & backward TOTAL time 0.01965981800458394
```
### Code used for performance test
```
import torch
import torch.nn.functional as F
import torch.nn as nn
from timeit import default_timer
torch.manual_seed(0)
cpu = torch.device('cpu')
gpu = torch.device('cuda')
loss_fn = F.soft_margin_loss
def run_benchmark(name, depth, require_grad, device, fn):
total_start = default_timer()
for i in range(3, 3 + depth):
start = default_timer()
n = 10 ** i
a = torch.rand(n, requires_grad=require_grad, device=device)
b = torch.rand(n, device=device)
fn(a, b)
end = default_timer()
print('{} {} took {}'.format(name, n, end-start))
total_end = default_timer()
print('{} TOTAL time {}'.format(name, total_end-total_start))
def fwd_only(a, b):
out = loss_fn(a, b)
def fwd_bck(a, b):
out = loss_fn(a, b)
out.backward()
def sanity_check(name, device):
print('{} Operator sanity check:'.format(name))
a = torch.rand(10, requires_grad=True, device=device)
b = torch.rand(10, device=device)
out = loss_fn(a,b)
print(out)
out.backward()
print(a.grad)
print('double backward')
loss = loss_fn(a, b)
loss2 = torch.autograd.grad(loss, a, create_graph=True)
z = loss2[0].sum()
print(z)
z.backward()
print('ok')
print()
print('PyTorch version:', torch.__version__)
sanity_check('CPU', cpu)
sanity_check('GPU', gpu)
print()
run_benchmark('CPU warmup', 3, False, cpu, fwd_only)
run_benchmark('CPU forward', 6, False, cpu, fwd_only)
run_benchmark('CPU for- & backward', 6, True, cpu, fwd_bck)
print()
run_benchmark('GPU warmup', 3, False, gpu, fwd_only)
run_benchmark('GPU forward', 6, False, gpu, fwd_only)
run_benchmark('GPU for- & backward', 6, True, gpu, fwd_bck)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27673
Differential Revision: D17889288
Pulled By: ezyang
fbshipit-source-id: 9ddffe4dbbfab6180847a8fec32443910f18f0a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27850
Many of these are real problems in the documentation (i.e., link or
bullet point doesn't display correctly).
Test Plan: - built and viewed the documentation for each change locally.
Differential Revision: D17908123
Pulled By: zou3519
fbshipit-source-id: 65c92a352c89b90fb6b508c388b0874233a3817a
Summary:
Fix issue https://github.com/pytorch/pytorch/issues/26698.
With different query/keys/value dimensions, `nn.MultiheadAttention` has DDP incompatibility issue because in that case `in_proj_weight` attribute is created but not used. Fix it and add a distributed unit test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26826
Differential Revision: D17583807
Pulled By: zhangguanheng66
fbshipit-source-id: c393584c331ed4f57ebaf2d4015ef04589c973f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26778
- Add support for linear and cubic interpolate in opset 11.
- Add support for 1d and 3d interpolate in nearest mode for opset 7 and 8.
- Add tests for all cases of interpolate in ORT tests (nearest/linear/cubic, 1d/2d/3d, upsample/downsample).
Original PR resolved: https://github.com/pytorch/pytorch/pull/24805
Reviewed By: hl475
Differential Revision: D17564911
Pulled By: houseroad
fbshipit-source-id: 591e1f5b361854ace322eca1590f8f84d29c1a5d
Summary:
- Add support for linear and cubic interpolate in opset 11.
- Add support for 1d and 3d interpolate in nearest mode for opset 7 and 8.
- Add tests for all cases of interpolate in ORT tests (nearest/linear/cubic, 1d/2d/3d, upsample/downsample).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24805
Reviewed By: hl475
Differential Revision: D17330801
Pulled By: houseroad
fbshipit-source-id: 1bdefff9e72f5e70c51f4721e1d7347478b7505b
Summary:
Adds documentation for `nn.functional.bilinear`, as requested in https://github.com/pytorch/pytorch/issues/9886.
The format follows that of `nn.functional.linear`, and borrows from `nn.bilinear` in its description of `Tensor` shapes.
I am happy to add more extensive documentation (e.g. "Args," "Example(s)"). From what I gather, the format of comments is inconsistent across functions in `nn.functional.py` and between modules (e.g. `nn.functional` and `nn`). It's my first PR, so guidance for contributing documentation and other code would be greatly appreciated!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24951
Differential Revision: D17091261
Pulled By: soumith
fbshipit-source-id: efe2ad764700dfd6f30eedc03de4e1cd0d10ac72
Summary:
Resolves: https://github.com/pytorch/pytorch/issues/20785
Addresses https://github.com/pytorch/pytorch/issues/24470 for `affine_grid`
Subsumes and closes: https://github.com/pytorch/pytorch/pull/24878 and likewise closes: https://github.com/pytorch/pytorch/issues/24821
Adds the `align_corners` option to `grid_sample` and `affine_grid`, paralleling the option that was added to `interpolate` in version 0.4.0.
In short, setting `align_corners` to `False` allows these functions to be resolution agnostic.
This ensures, for example, that a grid generated from a neural net trained to warp 1024x1024 images will also work to warp the same image upsampled/downsampled to other resolutions like 512x512 or 2048x2048 without producing scaling/stretching artifacts.
Refer to the documentation and https://github.com/pytorch/pytorch/issues/20785 for more details.
#### BC-Breaking Changes
- **Important**: BC-Breaking change because of new default for `align_corners`
The old functionality can still be achieved by setting `align_corners=True`, but the default is now set to `align_corners=False`, since this is the more correct setting, and since this matches the default setting of `interpolate`.
- **Should not cause BC issues**: BC-Breaking change for pathological use case
2D affine transforms on 1D coordinates and 3D affine transforms on 2D coordinates (that is, when one of the spatial dimensions has an empty span) are ill-defined, and not an intended use case of `affine_grid`. Whereas before, all grid point components along such dimension were set arbitrarily to `-1` (that is, before multiplying be the affine matrix), they are now all set instead to `0`, which is a much more consistent and defensible arbitrary choice. A warning is triggered for such cases.
#### Documentation
- Update `affine_grid` documentation to express that it does indeed support 3D affine transforms. This support was already there but not documented.
- Add documentation warnings for BC-breaking changes in `grid_sample` and `affine_grid` (see above).
#### Refactors
- `affine_grid` no longer dispatches to cuDNN under any circumstances.
The decision point for when the cuDNN `affine_grid_generator` is compatible with the native PyTorch version and when it fails is a headache to maintain (see [these conditions](5377478e94/torch/nn/_functions/vision.py (L7-L8))). The native PyTorch kernel is now used in all cases.
- The kernels for `grid_sample` are slightly refactored to make maintenance easier.
#### Tests
Two new tests are added in `test_nn.py`:
- `test_affine_grid_error_checking` for errors and warnings in `affine_grid`
- `test_affine_grid_3D` for testing `affine_grid`'s 3D functionality. The functionality existed prior to this, but wasn't tested.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24929
Differential Revision: D16949064
Pulled By: ailzhang
fbshipit-source-id: b133ce0d47a2a5b3e2140b9d05fb05fca9140926
Summary:
Resolves: https://github.com/pytorch/pytorch/issues/20785
Adds the `align_corners` option to `grid_sample` and `affine_grid`, paralleling the option that was added to `interpolate` in version 0.4.0.
In short, setting `align_corners` to `False` allows these functions to be resolution agnostic.
This ensures, for example, that a grid generated from a neural net trained to warp 1024x1024 images will also work to warp the same image upsampled/downsampled to other resolutions like 512x512 or 2048x2048 without producing scaling/stretching artifacts.
Refer to the documentation and https://github.com/pytorch/pytorch/issues/20785 for more details.
**Important**: BC-Breaking Change because of new default
The old functionality can still be achieved by setting `align_corners=True`, but the default is now set to `align_corners=False`, since this is the more correct setting, and since this matches the default setting of `interpolate`.
The vectorized 2D cpu version of `grid_sampler` is refactored a bit. I don’t suspect that this refactor would affect the runtime much, since it is mostly done in inlined functions, but I may be wrong, and this has to be verified by profiling.
~The tests are not yet updated to reflect the new default. New tests should probably also be added to test both settings of `align_corners`.~ _Tests are now updated._
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23923
Differential Revision: D16887357
Pulled By: ailzhang
fbshipit-source-id: ea09aad7853ef16536e719a898db8ba31595daa5
Summary:
fix https://github.com/pytorch/pytorch/issues/21044
Bicubic interpolation can cause overshoot.
Opencv keeps results dtype aligned with input dtype:
- If input is uint8, the result is clamped [0, 255]
- If input is float, the result is unclamped.
In Pytorch case, we only accept float input, so we'll keep the result unclamped, and add some notes so that users can explicitly call `torch.clamp()` when necessary.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23321
Differential Revision: D16464796
Pulled By: ailzhang
fbshipit-source-id: 177915e525d1f54c2209e277cf73e40699ed1acd
Summary:
* Deletes all weak script decorators / associated data structures / methods
* In order to keep supporting the standard library in script, this enables recursive script on any function defined in `torch.nn`
* Most changes in `torch/nn` are the result of `ag -Q "weak" torch/nn/ -l | xargs sed -i '/weak/d'`, only `rnn.py` needed manual editing to use the `ignore` and `export` to continue supporting the overloaded `forward` methods
* `Sequential`/`ModuleList` no longer need to be added to constants since they are compiled on demand
This should also fix https://github.com/pytorch/pytorch/issues/22212
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22212
Differential Revision: D15988346
Pulled By: driazati
fbshipit-source-id: af223e3ad0580be895377312949997a70e988e4f
Summary:
The changes include:
1. Allow key/value to have different number of features with query. It supports the case when key and value have different feature dimensions.
2. Support three separate proj_weight, in addition to a single in_proj_weight. The proj_weight of key and value may have different dimension with that of query so three separate proj_weights are necessary. In case that key and value have same dimension as query, it is preferred to use a single large proj_weight for performance reason. However, it should be noted that using a single large weight or three separate weights is a size-dependent decision.
3. Give an option to use static k and v in the multihead_attn operator (see saved_k and saved_v). Those static key/value tensors can now be re-used when training the model.
4. Add more test cases to cover the arguments.
Note: current users should not be affected by the changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21288
Differential Revision: D15738808
Pulled By: zhangguanheng66
fbshipit-source-id: 288b995787ad55fba374184b3d15b5c6fe9abb5c
Summary:
Currently multihead attention for half type is broken
```
File "/home/ngimel/pytorch/torch/nn/functional.py", line 3279, in multi_head_attention_forward
attn_output = torch.bmm(attn_output_weights, v)
RuntimeError: Expected object of scalar type Float but got scalar type Half for argument https://github.com/pytorch/pytorch/issues/2 'mat2'
```
because softmax converts half inputs into fp32 inputs. This is unnecessary - all the computations in softmax will be done in fp32 anyway, and the results need to be converted into fp16 for the subsequent batch matrix multiply, so nothing is gained by writing them out in fp32. This PR gets rid of type casting in softmax, so that half works.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21658
Differential Revision: D15807487
Pulled By: zhangguanheng66
fbshipit-source-id: 4709ec71a36383d0d35a8f01021e12e22b94992d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20665
Add gelu activation forward on CPU in pytorch
Compare to current python implemented version of gelu in BERT model like
def gelu(self, x):
x * 0.5 * (1.0 + torch.erf(x / self.sqrt_two))
The torch.nn.functional.gelu function can reduce the forward time from 333ms to 109ms (with MKL) / 112ms (without MKL) for input size = [64, 128, 56, 56] on a devvm.
Reviewed By: zheng-xq
Differential Revision: D15400974
fbshipit-source-id: f606b43d1dd64e3c42a12c4991411d47551a8121
Summary:
Remove the internal functions in multi_head_attention_forward. Those internal functions cause 10-15% performance regression and there is possibly a JIT issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20653
Differential Revision: D15398888
Pulled By: cpuhrsch
fbshipit-source-id: 0a3f053a4ade5009e73d3974fa6733c2bff9d929
Summary:
I believe the `True` and `False` in the doc are reversed :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20961
Differential Revision: D15510806
Pulled By: soumith
fbshipit-source-id: 62566bb595e187506b23dedc24892e48f35b1147
Summary:
Attention mask should be of shape `(L, S)` since it is added to `attn_output_weights`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20850
Differential Revision: D15495587
Pulled By: ezyang
fbshipit-source-id: 61d6801da5291df960daab273e874df28aedbf6e
Summary:
Remove weak_script. After recently splitting the forward() function in MultiheadAttention module, we notice a memory leak on GPU. Fix the problem by removing those "weak_script" decorator.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20563
Differential Revision: D15368262
Pulled By: zhangguanheng66
fbshipit-source-id: 475db93c9ee0dbaea8fb914c004e7d1e0d419bc2
Summary:
Moving functions from torch/nn/modules/activation.py to torch/nn/functional.py. For functions not implemented (_get_input_buffer and _set_input_buffer), a TODO is added.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20415
Differential Revision: D15318078
Pulled By: jamarshon
fbshipit-source-id: 5ca698e2913821442cf8609cc61ac8190496a3c6
Summary:
This PR add Poisson NLL loss to aten and substitute the python implementation with a call to the c++.
Fixes#19186.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19316
Differential Revision: D15012957
Pulled By: ezyang
fbshipit-source-id: 0a3f56e8307969c2f9cc321b5357a496c3d1784e
Summary:
fixes#20215
The confusing behavior was caused by typos in type annotation :(
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20306
Differential Revision: D15276216
Pulled By: ailzhang
fbshipit-source-id: 1b0c9635a72a05c9b537f80d85b117b5077fbec7
Summary:
in functional interfaces we do boolean dispatch, but all to max_pool\*d_with_indices. This change it to emit max_pool\*d op instead when it's not necessary to expose with_indices ops to different backends (for jit).
It also bind max_pool\*d to the torch namespace, which is the same behavior with avg_pool\*d
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19449
Differential Revision: D15016839
Pulled By: wanchaol
fbshipit-source-id: f77cd5f0bcd6d8534c1296d89b061023a8288a2c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/10654
The issue is that in tracing `.size` returns an int tensor, and when an int tensor is multiplied by a scalar the int dominates and the scalar gets casted 0.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18875
Differential Revision: D14814441
Pulled By: eellison
fbshipit-source-id: a4e96a2698f2fcbf3ec4b2bb4c43a30250f30ad9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18598
ghimport-source-id: c74597e5e7437e94a43c163cee0639b20d0d0c6a
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18598 Turn on F401: Unused import warning.**
This was requested by someone at Facebook; this lint is turned
on for Facebook by default. "Sure, why not."
I had to noqa a number of imports in __init__. Hypothetically
we're supposed to use __all__ in this case, but I was too lazy
to fix it. Left for future work.
Be careful! flake8-2 and flake8-3 behave differently with
respect to import resolution for # type: comments. flake8-3 will
report an import unused; flake8-2 will not. For now, I just
noqa'd all these sites.
All the changes were done by hand.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14687478
fbshipit-source-id: 30d532381e914091aadfa0d2a5a89404819663e3
Summary:
Addind the same warning message already present in the mse_loss function to the L1 losses when input and target sizes are different.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18565
Differential Revision: D14671415
Pulled By: soumith
fbshipit-source-id: 01f5e1fb1ea119dbb2aecf1d94d0cb462f284982
Summary:
To address the issue of broadcasting giving the wrong result in `nn.MSELoss()` as mentioned here https://github.com/pytorch/pytorch/issues/16045 . In particular, the issue often arises when computing the loss between tensors with shapes (n, 1) and (n,)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18349
Differential Revision: D14594176
Pulled By: soumith
fbshipit-source-id: f23ae68a4bf42f3554ad7678a314ba2c7532a6db
Summary:
In the loss doc description, replace the deprecated 'reduct' and 'size_average' parameters with the 'reduction' parameter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17300
Differential Revision: D14195789
Pulled By: soumith
fbshipit-source-id: 625e650ec20f13b2d22153a4a535656cf9c8f0eb
Summary:
Eventually we should remove these when we're certain that all our ops
handle memory overlaps correctly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17576
Differential Revision: D14349990
Pulled By: zou3519
fbshipit-source-id: c3a09f6113b9b1bf93e7f13c0b426c45b2cdf21f
Summary:
one_hot docs is missing [here](https://pytorch.org/docs/master/nn.html#one-hot).
I dug around and could not find a way to get this working properly.
Differential Revision: D14104414
Pulled By: zou3519
fbshipit-source-id: 3f45c8a0878409d218da167f13b253772f5cc963
Summary:
- Moved a few functions from `autograd` namespace to `aten` namespace to be visible from JIT nativeResolver.
- Added a hack to loop up keyword only argument. Will add proper support for kw only later
- Simulate function overload in aten using `_<number>` as function name suffix.
- Even `forward` returns multiple outputs like in `kthvalue`, there's at most one requires grad that we currently support.
- Removed the `TensorList` related ops here since partial `TensorList` support is prone to bugs. Our symbolic diff for `cat` was never tested with autodiff, and it seems broken. Need to find another proper way to support these ops(either by properly supporting `TensorList` or sth like `prim::ConstantChunk` and leave them for next PR.
Ops supported in this PR:
```
erf
expand_as
index
kthvalue
mean
permute
pow
rsub
select
sqrt
squeeze
t
to
topk
transpose
view
var
embedding
logsumexp
// grad is None
_dim_arange
contiguous
nonzero
ones_like
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16689
Differential Revision: D14020806
Pulled By: ailzhang
fbshipit-source-id: a5e2c144a7be5a0d39d7ac5f93cb402ec12503a5
Summary:
The use case for making this PR is the following bug :
(with F = torch.nn.functional)
`F.max_pool2d.__module__` is `torch._jit_internal`
`F.max_pool2d.__name__` is `fn`
With this PR you get:
`F.max_pool2d.__module__` is `torch.nn.functional`
`F.max_pool2d.__name__` is `max_pool2d`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16922
Differential Revision: D14020053
Pulled By: driazati
fbshipit-source-id: c109c1f04640f3b2b69bc4790b16fef7714025dd
Summary:
Here is a stab at implementing an option to zero out infinite losses (and NaN gradients).
It might be nicer to move the zeroing to the respective kernels.
The default is currently `False` to mimic the old behaviour, but I'd be half inclined to set the default to `True`, because the behaviour wasn't consistent between CuDNN and Native anyways and the NaN gradients aren't terribly useful.
This topic seems to come up regularly, e.g. in #14335
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16199
Differential Revision: D14020462
Pulled By: ezyang
fbshipit-source-id: 5ba8936c66ec6e61530aaf01175dc49f389ae428
Summary:
This PR is a follow up of #15460, it did the following things:
* remove the undefined tensor semantic in jit script/tracing mode
* change ATen/JIT schema for at::index and other index related ops with `Tensor?[]` to align with what at::index is really doing and to adopt `optional[tensor]` in JIT
* change python_print to correctly print the exported script
* register both TensorList and ListOfOptionalTensor in JIT ATen ops to support both
* Backward compatibility for `torch.jit.annotate(Tensor, None)`
List of follow ups:
* remove the undefined tensor semantic in jit autograd, autodiff and grad_of
* remove prim::Undefined fully
For easy reviews, please turn on `hide white space changes` in diff settings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16379
Differential Revision: D13855677
Pulled By: wanchaol
fbshipit-source-id: 0e21c14d7de250c62731227c81bfbfb7b7da20ab
Summary:
Changelog:
- Modify concantenation of [1] to a tuple by using cases for list and non-list types.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16489
Differential Revision: D13875838
Pulled By: soumith
fbshipit-source-id: fade65cc47385986b773b9bde9b4601ab93fe1cf
Summary:
Remove calls to torch.jit._unwrap_optional that are no longer needed.
The remaining instances would require control flow logic for exceptions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16245
Differential Revision: D13804292
Pulled By: eellison
fbshipit-source-id: 08c5cbe4b956519be2333de5cf4e202488aff626
Summary:
Fixes#12643, amends to #3341.
- Allow multidimensional input ~~(but apply softmax over `dim=-1`)~~ with `dim` argument
- Cleaner: Less lines of code
- Faster (1.32x speedup vs original, 2x speedup vs using `torch.Distributions`)
- Small fixes in docstring
- Remove some references in docstring. Was the linked (excellent) ipynb the first to do the straight-through trick? Instead, I propose changing to reference to the two papers most known for it.
- Add deprecationwarning for `eps`. It's not needed anymore.
- Initial commit keeps some code alternatives commented to exploit CI
- As of discussion when `gumbel_softmax` was added (#3341), this was merged into `torch.nn.functional` before all the work with `Distributions` and `Pyro`, and there will probably be multiple other best practices for this in the future.
I've tested building using the `Distributions`-api, but it was too slow, see below.
I therefore propose not using `Distributions` to keep it fast and simple, but adding a comment in docstring that `gumbel_softmax` may be deprecated in the future.
```
dist = torch.distributions.RelaxedOneHotCategorical(temperature=tau, logits=logits, validate_args=False)
y_soft = dist.rsample()
```
Pros:
* Built using tricks like `logsumexp` etc
* Explicitly uses `torch.distributions.utils._finfo` to avoid overflow (old implementation had an `eps` flag)
* Maintained for this exact purpose.
Cons:
* Very slow. Construction of distribution adds overhead see timings below. May be solved in future with speedups of `TransformedDistribution` and `Distribution`.
* Assumes which `dim` to apply softmax over.
```
y_soft = logits.new(logits.shape)
y_soft = (logits - y_soft.exponential_().log()) / tau # Gumbel noise
y_soft = y_soft.softmax(dim) # Gumbel softmax noise
```
Pros:
* Faster
```
import time
start = time.time()
num_draws = 1000000
logits = torch.randn(1,3)
for draw in range(num_draws):
y_draw = gumbel_softmax(logits, hard=True)
counts = counts + y_draw
print(end - start)
>> 12.995795965194702
>> 7.658372640609741
>> 20.3382670879364
````
Decide on which path to chose. I'll commit in changes to the unit tests in a while to show that it passes both old tests and new tests. I'll also remove the commented code about `RelaxedOneHotCategorical`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13339
Differential Revision: D13092434
Pulled By: ezyang
fbshipit-source-id: 4c21788df336f4e9c2ac289022e395b261227b4b
Summary:
1) Reverts https://github.com/pytorch/pytorch/pull/12302 which added support for batched pdist. Except I kept the (non-batched) test improvements that came with that PR, because they are nice to have. Motivation: https://github.com/pytorch/pytorch/issues/15511
2) For the non-batched pdist, improved the existing kernel by forcing fp64 math and properly checking cuda launch errors
3) Added a 'large tensor' test that at least on my machine, fails on the batch pdist implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15901
Reviewed By: ezyang
Differential Revision: D13616730
Pulled By: gchanan
fbshipit-source-id: 620d3f9b9acd492dc131bad9d2ff618d69fc2954
Summary:
1. Port the FractionalMaxPool3d implementation from THNN/THCUNN to ATen.
2. Expose this function to Python module nn.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15575
Differential Revision: D13612848
Pulled By: chandlerzuo
fbshipit-source-id: 5f474b39005efa7788e984e8a805456dcdc43f6c
Summary:
Previously we were only constant propping prim::Constants, but we should be constant propping prim::None as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15979
Differential Revision: D13664692
Pulled By: eellison
fbshipit-source-id: 01839403576c21fc030c427e49275b8e1210fa8f
Summary:
- Fixed a few typos and grammar errors.
- Changed the sentences a bit.
- Changed the format of the tuples to be consistent with padding notations in the other places. For example, `ReflectionPad2d`'s dostring contains :math:`H_{out} = H_{in} + \text{padding\_top} + \text{padding\_bottom}`.
I also made sure that the generated html doesn't break.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15984
Differential Revision: D13649939
Pulled By: soumith
fbshipit-source-id: 0abfa22a7bf1cbc6546ac4859652ce8741d41232
Summary:
This updates pdist to work for batched inputs, and updates the
documentation to reflect issues raised.
closes#9406
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12302
Reviewed By: ezyang
Differential Revision: D13528485
Pulled By: erikbrinkman
fbshipit-source-id: 63d93a6e1cc95b483fb58e9ff021758b341cd4de
Summary:
Addresses #918, interpolation results should be similar to tf
* Adds bicubic interpolation operator to `nn.functional.interpolate`
* Corresponding test in `test_nn.py`
The operator is added in legacy `TH` to be aligned with the other upsampling operators; they can be refactored/moved to ATen all at once when #10482 is resolved
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9849
Differential Revision: D9007525
Pulled By: driazati
fbshipit-source-id: 93ef49a34ce4e5ffd4bda94cd9a6ddc939f0a4cc
Summary:
This PR adds `None` buffers as parameters (similarly to #14715). It also cleans up a bunch of the `test_jit.py` tests that should be covered by `common_nn.py` and brings in `criterion_tests` to test loss functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14778
Differential Revision: D13330849
Pulled By: driazati
fbshipit-source-id: 924cc4cf94e0dcd11e811a55222fd2ebc42a9e76
Summary:
Fixes#6622 .
We used to average over all elements for kl divergence, which is not aligned with its math definition.
This PR corrects the default reduction behavior of KL divergence that it now naverages over batch dimension.
- In KL, default behavior `reduction=mean` averages over batch dimension. While for most other loss functions, `reduction=mean` averages over all elements.
- We used to support scalar tensor as well. For BC purpose, we still support it, no reduction is performed on scalar tensor.
- Added a new reduction mode called `batchmean` which has the correct behavior for KL. Add a warning to make `batchmean` as default for KL instead of `mean` in next major release.
- [deprecated]I chose to not add a new reduction option, since "mean over batch dimension" is kinda special, and it only makes sense in few cases like KL. We don't want to explain why there's a option "batchmean" but it's not applicable for all other functions. I'm open to discussion on this one, as I cannot think of a perfect solution for this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14457
Differential Revision: D13236016
Pulled By: ailzhang
fbshipit-source-id: 905cc7b3bfc35a11d7cf098b1ebc382170a087a7
Summary:
Remove no_grad_embedding_renorm_ from aten. Setting the derivatives of the inputs to false has different semantics from calling with no_grad(), because it will not error if an input is modified and then has it's grad accessed.
Instead, make a custom op, and use NoGradGuard.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14639
Differential Revision: D13285604
Pulled By: eellison
fbshipit-source-id: c7d343fe8f22e369669e92799f167674f124ffe7
Summary:
This PR adds a polyfill for `typing.List` for Python versions that don't
support `typing` as a builtin. It also moves the type defintions from
`annotations.py` so that they can be used in `torch.nn`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14482
Differential Revision: D13237570
Pulled By: driazati
fbshipit-source-id: 6575b7025c2d98198aee3b170f9c4323ad5314bd
Summary:
To convert `max_unpool` functions to weak script, this PR adds support
for `T` as default arguments for `BroadcastingListN[T]`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14361
Differential Revision: D13192231
Pulled By: driazati
fbshipit-source-id: a25b75a0e88ba3dfa22d6a83775e9778d735e249
Summary:
This PR adds weak modules for all activation modules and uses `test_nn` module tests to test weak modules that have been annotated with `weak_module` and therefore are in `torch._jit_internal._weak_types`
Also depends on #14379
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14238
Differential Revision: D13252887
Pulled By: driazati
fbshipit-source-id: e9638cf74089884a32b8f0f38396cf432c02c988
Summary:
Resubmitting PR #14415
The tests added for Embedding + EmbeddingBag had random numbers as input, which affected the random number generator & caused the flakey test to break.
Everything but the last two commits have already been accepted
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14509
Differential Revision: D13247917
Pulled By: eellison
fbshipit-source-id: ea6963c47f666c07687787e2fa82020cddc6aa15
Summary:
Add support for Embedding and EmbeddingBag in script. Both functions require with torch.no_grad(), which we don't have any plans to support in the near future. To work around this, I added a embedding_renorm function without derivatives.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14415
Reviewed By: wanchaol
Differential Revision: D13219647
Pulled By: eellison
fbshipit-source-id: c90706aa6fbd48686eb10f3efdb65844be7b8717
Summary:
This PR adds weak modules for all activation modules and uses `test_nn` module tests to test weak modules that have been annotated with `weak_module` and therefore are in `torch._jit_internal._weak_types`
Also depends on #14379
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14238
Differential Revision: D13192230
Pulled By: driazati
fbshipit-source-id: 36488960b6c91448b38c0fa65422539a93af8c5e
Summary:
This PR allows to overload functions based on the value of a parameter (so long as it is a constant). See max_pool1d for an example usage.
This is the first step in enabling the use of max_pool functions for the standard library that can return `Tensor` or `Tuple[Tensor, Tensor]` based on the `return_indices` flag. This will give the JIT identical results to the Python versions of the functions.
Fixes#14081
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14425
Differential Revision: D13222104
Pulled By: driazati
fbshipit-source-id: 8cb676b8b13ebcec3262234698edf4a7d7dcbbe1
Summary:
Port AffineGrid to C++, because script does not support compiling Function classes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14392
Differential Revision: D13219698
Pulled By: eellison
fbshipit-source-id: 3ddad8a84c72010b5a6c6f7f9712be614202faa6
Summary:
This PR allows to overload functions based on the value of a parameter (so long as it is a constant). See `max_pool1d` for an example usage.
This is the first step in enabling the use of `max_pool` functions for the standard library that can return `Tensor` or `Tuple[Tensor, Tensor]` based on the `return_indices` flag. This will give the JIT identical results to the Python versions of the functions.
Depends on #14232 for `Optional[BroadcastingList[T]]`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14081
Differential Revision: D13192228
Pulled By: driazati
fbshipit-source-id: fce33c400c1fd06e59747d98507c5fdcd8d4c113
Summary:
1. Support `Optional[BroadcastingList1[int]]` like type annotation to accept a int or a list[int]
2. Convert gumbel_softmax, lp pooling weak functions and modules
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14232
Differential Revision: D13164506
Pulled By: wanchaol
fbshipit-source-id: 6c2a2b9a0613bfe907dbb5934122656ce2b05700
Summary:
This PR inserts `prim::None` constants for undefined tensors. This comes in the standard library if an `Optional[Tensor]` is statically determined to be `None`:
```python
torch.jit.script
def fn(x=None):
# type: (Optional[Tensor]) -> Tensor
return torch.jit._unwrap_optional(x)
torch.jit.script
def fn2():
# type: () -> Tensor
return fn()
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14120
Differential Revision: D13124625
Pulled By: driazati
fbshipit-source-id: 9eaa82e478c49c503f68ed89d8c770e8273ea569
Summary:
This PR did three things:
1. It export the BatchNorm functional and module, and rewrite some of the components to stay align with the current supported JIT features
2. In the process of export, add necessary compiler support for in_place op aug assign
4. change the test_jit behavior in add_module_test to utilize a single rng state during module initialization
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14016
Differential Revision: D13112064
Pulled By: wanchaol
fbshipit-source-id: 31e3aee5fbb509673c781e7dbb6d8884cfa55d91
Summary:
This PR did two thing:
1. it fix the optional import/export to include any type including tensor types (previously we only support base types), this is essential to unblock optional tensor type annotation in our test logic
2. it tries to export mult_margin_loss functional to serve as a example of optional undefined tensor use case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13877
Differential Revision: D13076090
Pulled By: wanchaol
fbshipit-source-id: c9597295efc8cf4b6462f99a93709aae8dcc0df8
Summary:
I'm now traveling and don't have access to a good computer to compile test by myself. Will see the outcome of CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12199
Differential Revision: D13062326
Pulled By: nairbv
fbshipit-source-id: 85873525caa94906ccaf2c739eb4cd55a72a4ffd
Summary:
Convert some more functions to match up with features added. Some
conversions were unsuccessful but the type line was left in for later.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13707
Differential Revision: D13030210
Pulled By: driazati
fbshipit-source-id: 02d5712779b83b7f18d0d55539e336321335e0cc
Summary:
* Adds `OptionalType` support for import/export
* Optionals get exported along with their contained type, i.e. 'Optional[int]'
* Allows concrete types and `None` to be passed to an op that takes an optional
* Converts `softmax`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13647
Differential Revision: D12954672
Pulled By: driazati
fbshipit-source-id: 159e9bfb7f3e398bec3912d414c393098cc7455a
Summary:
This PR is a part of task to unblock standard library export.
* we treat None differently from Tensor and other types, when passing None as Tensor, it's an undefined tensor rather than the None IValue.
* Refine the type system so that we have correct tensor types hierarchy (Dynamic/Tensor/CompleteTensor), Dynamic should be at the top of the inheritance hierarchy.
* It also tries to export bilinear as an example of undefined tensor(None) input.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13650
Differential Revision: D12967026
Pulled By: wanchaol
fbshipit-source-id: 6aedccc7ce2a12fadd13d9e620c03e1260103a5a
Summary:
To support `_Reduction` in the jit this PR moves it out to a new file so that it goes through the paths for python modules in the script compiler and converts `F.ctc_loss` to weak script
Depends on #13484 for saving rng state
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13401
Differential Revision: D12868501
Pulled By: driazati
fbshipit-source-id: 23cec0fb135744578c73e31ac825e238db495d27
Summary:
This PR adds functions defined in `torch._C._nn` as builtin functions (including inplace variants). This allows for the conversion of more functions to weak script
NB: many `torch.nn.functional` functions will have to be slightly rewritten to avoid early returns (as with `threshold` in this PR)
Converts these functions to weak script:
* `threshold`
* `relu`
* `hardtanh`
* `relu6`
* `elu`
* `selu`
* `celu`
* `leaky_relu`
* `rrelu`
* `tanh`
* `sigmoid`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13322
Differential Revision: D12852203
Pulled By: driazati
fbshipit-source-id: 220670df32cb1ff39d120bdc04aa1bd41209c809
Summary:
To convert `nn.functional.dropout`
* `_VF` had to be exposed as a Python module so this PR adds a module class to forward to `torch._C._VariableFunctions`
* rng state between calls in the tests needed to be made consistent
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13484
Differential Revision: D12929622
Pulled By: driazati
fbshipit-source-id: 78b455db9c8856b94d2dda573fb7dc74d5784f56
Summary:
```
The previous threshold implementation was not vectorized or parallelized.
This speeds up ResNet-50 CPU inference [1] from ~88 ms to ~67 ms
CPU timings:
https://gist.github.com/colesbury/d0d1be6974841d62696dbde329a8fde8
1 thread (before vs. after)
10240: 17.4 us vs. 6.9 µs per loop
102400: 141 us vs. 39.8 µs per loop
16 threads (before vs. after)
10240: 17.4 us vs. 6.7 µs per loop
102400: 141 us vs. 14.3 µs per loop
CUDA timings are not measurably different.
[1]: compiled with MKL-DNN, 8 threads, batch norm merged into convolutions
https://gist.github.com/colesbury/8a64897dae97558b3b82da665048c782
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13182
Reviewed By: soumith
Differential Revision: D12825105
Pulled By: colesbury
fbshipit-source-id: 557da608ebb87db8a04adbb0d2882af4f2eb3c15
Summary:
Made the previous description for max_norm more precise, avoiding 'this' and describing what actually happens in the code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13310
Differential Revision: D12840813
Pulled By: SsnL
fbshipit-source-id: 98090c884267a62ce93cd85da84252d46926dfa5
Summary:
1. Refactor DDPG predictor. Merge the critic predictor with ParametricDQNPredictor since they are the same
2. Fix bug where loss was multiplied by the batch size
3. Create DDPGFeedPredictor which uses the feed predictor output format
4. Add support for gridworld simulation memoization to DDPG. Also memoize normalization tables.
Reviewed By: kittipatv
Differential Revision: D10161240
fbshipit-source-id: 2813890043de1241c1fb9b9c2b6a897403f9fc12
Summary:
Addresses #9499. Completed work on the forward function, tests should be passing for that. Working on backward function now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10885
Differential Revision: D9643786
Pulled By: SsnL
fbshipit-source-id: 2930d6f3d2975c45b2ba7042c55773cbdc8fa3ac
Summary:
* Moves `weak_script` annotation to `torch/_jit_internal.py` folder to resolve dependency issue between `torch.jit` and `torch.nn`
* Add `torch._jit.weak_script` to `tanhshrink` and `softsign`, their tests now pass instead of giving an `unknown builtin op` error
* Blacklist converted `torch.nn.functional` functions from appearing in the builtin op list if they don't actually have corresponding `aten` ops
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12723
Differential Revision: D10452986
Pulled By: driazati
fbshipit-source-id: c7842bc2d3ba0aaf7ca6e1e228523dbed3d63c36
Summary:
include atomicAdd commentary as this is less well known
There is some discussion in #12207
Unfortunately, I cannot seem to get the ..include working in `_tensor_docs.py` and `_torch_docs.py`. I could use a hint for that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12217
Differential Revision: D10419739
Pulled By: SsnL
fbshipit-source-id: eecd04fb7486bd9c6ee64cd34859d61a0a97ec4e
Summary:
There were two problems with SN + DP:
1. In SN, the updated _u vector is saved back to module via a `setattr`. However, in DP, everything is run on a replica, so those updates are lost.
2. In DP, the buffers are broadcast via a `broadcast_coalesced`, so on replicas they are all views. Therefore, the `detach_` call won't work.
Fixes are:
1. Update _u vector in-place so, by the shared storage between 1st replica and the parallelized module, the update is retained
2. Do not call `detach_`.
3. Added comments in SN about the subtlety.
4. Added a note to the DP doc on this particular behavior of DP.
cc crcrpar taesung89 The controller you requested could not be found. yaoshengfu
Fixes https://github.com/pytorch/pytorch/issues/11476
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12671
Differential Revision: D10410232
Pulled By: SsnL
fbshipit-source-id: c447951844a30366d8c196bf9436340e88f3b6d9
Summary:
Add dtype argument to softmax/log_softmax functions.
Computing softmax in fp32 precision is necessary for mixed precision training, and converting output of the previous layer into fp32 and then reading it as fp32 in softmax is expensive, memory and perf-wise, this PR allows one to avoid it.
For most input data/dtype combinations, input data is converted to dtype and then softmax is computed. If input data is half type and dtype is fp32, kernels with the corresponding template arguments are called.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11719
Reviewed By: ezyang
Differential Revision: D10175514
Pulled By: zou3519
fbshipit-source-id: 06d285af91a0b659932236d41ad63b787eeed243
Summary:
- fixes https://github.com/pytorch/pytorch/issues/10723
- migrate PReLU to ATen and deprecate legacy PReLU
- performance:
CPU with weight.numel() = 1
```
>>> m = nn.PReLU()
>>> x = torch.randn(100, 100, 100, requires_grad=True)
>>> %timeit -r 100 y = m(x)
100 loops, best of 100: 9.43 ms per loop
>>> y = m(x).sum()
>>> %timeit -r 100 y.backward(retain_graph=True)
10 loops, best of 100: 24.4 ms per loop
>>> m = nn.PReLU()
>>> x = torch.randn(100, 100, 100, requires_grad=True)
>>> %timeit -r 100 y = m(x)
1000 loops, best of 100: 695 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 y.backward(retain_graph=True)
100 loops, best of 100: 2.47 ms per loop
```
CPU with weight.numel() = channels
```
>>> m = nn.PReLU(100)
>>> x = torch.randn(100, 100, 100, requires_grad=True)
>>> %timeit -r 100 y = m(x)
1000 loops, best of 100: 603 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 y.backward(retain_graph=True)
100 loops, best of 100: 13.3 ms per loop
>>> m = nn.PReLU(100)
>>> x = torch.randn(100, 100, 100, requires_grad=True)
>>> %timeit -r 100 y = m(x)
1000 loops, best of 100: 655 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 y.backward(retain_graph=True)
100 loops, best of 100: 2.45 ms per loop
```
CUDA with weight.numel() = 1
```
>>> m = nn.PReLU().cuda()
>>> x = torch.randn(100, 100, 100, requires_grad=True).cuda()
>>> %timeit -r 100 torch.cuda.synchronize(); y = m(x); torch.cuda.synchronize();
10000 loops, best of 100: 187 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 torch.cuda.synchronize(); y.backward(retain_graph=True); torch.cuda.synchronize();
100 loops, best of 100: 2.01 ms per loop
>>> m = nn.PReLU().cuda()
>>> x = torch.randn(100, 100, 100, requires_grad=True).cuda()
>>> %timeit -r 100 torch.cuda.synchronize(); y = m(x); torch.cuda.synchronize();
1000 loops, best of 100: 195 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 torch.cuda.synchronize(); y.backward(retain_graph=True); torch.cuda.synchronize();
100 loops, best of 100: 2.28 ms per loop
```
CUDA with weight.numel() = channel
```
>>> m = nn.PReLU(100).cuda()
>>> x = torch.randn(100, 100, 100, requires_grad=True).cuda()
>>> %timeit -r 100 torch.cuda.synchronize(); y = m(x); torch.cuda.synchronize();
1000 loops, best of 100: 174 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 torch.cuda.synchronize(); y.backward(retain_graph=True); torch.cuda.synchronize();
100 loops, best of 100: 2.27 ms per loop
>>> m = nn.PReLU(100).cuda()
>>> x = torch.randn(100, 100, 100, requires_grad=True).cuda()
>>> %timeit -r 100 torch.cuda.synchronize(); y = m(x); torch.cuda.synchronize();
10000 loops, best of 100: 181 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 torch.cuda.synchronize(); y.backward(retain_graph=True); torch.cuda.synchronize();
100 loops, best of 100: 2.26 ms per loop
```
The huge performance regression in CPU when weight.numel() = 1 is addressed by replacing at::CPU_tensor_apply* with parallelized kernels.
ezyang SsnL zou3519 soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11758
Differential Revision: D9995799
Pulled By: weiyangfb
fbshipit-source-id: d289937c78075f46a54dafbde92fab0cc4b5b86e
Summary:
Related to #11624 adding maxes to the function def of embedding_bag.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11784
Differential Revision: D9892598
Pulled By: ezyang
fbshipit-source-id: e6372ccf631826ddf1e1885b2f8f75f354a36c0b
Summary:
I'm reading the doc of `torch.nn.functional.pad` and it looks a bit confusing to me. Hopefully this PR makes it clearer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11623
Differential Revision: D9818255
Pulled By: soumith
fbshipit-source-id: 4f6b17b0211c6927007f44bfdf42df5f84d47536
Summary:
This also removes the usage of torch.onnx.symbolic_override in instance_norm. Fixes#8439.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10792
Differential Revision: D9800643
Pulled By: li-roy
fbshipit-source-id: fa13a57de5a31fbfa2d4d02639d214c867b9e1f1
Summary:
Ping ezyang
This addresses your comment in #114. Strangely, when running the doc build (`make html`) none of my changes are actually showing, could you point out what I'm doing wrong?
Once #11329 is merged it might make sense to link to the reproducibility note everywhere.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11434
Differential Revision: D9751208
Pulled By: ezyang
fbshipit-source-id: cc672472449564ff099323c39603e8ff2b2d35c9
Summary:
This PR does two things:
1. Replaces the implementation of the `Dropout` module with a call to the ATen function,
2. Replaces `Dropout2d` with a new `FeatureDropout` module that shall take the place of `Dropout2d` and `Dropout3d`. I contemplated calling it `Dropout2d` and making `Dropout3d` an alias for it, but similar to our decision for `BatchNorm{1,2,3}d` (c.f. https://github.com/pytorch/pytorch/pull/9188), we can deviate from Python PyTorch in favor of the ideal-world solution, which is to have a single module, since both actually just call `feature_dropout`.
I also replaced the implementation of `dropout3d` with a call to `dropout2d` in Python. The code is the same and it's easier for developers to parse than having to manually match the tokens to make sure it's really 100% the same code (which it is, if I matched the tokens correctly).
ebetica ezyang SsnL
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11458
Differential Revision: D9756603
Pulled By: goldsborough
fbshipit-source-id: fe847cd2cda2b6da8b06779255d76e32a974807c
Summary:
Also add single grad whitelist to the jit test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10782
Reviewed By: ezyang
Differential Revision: D9583378
Pulled By: erikbrinkman
fbshipit-source-id: 069e5ae68ea7f3524dec39cf1d5fe9cd53941944
Summary:
Test only for existence for now. I had to skip a lot of them so there a FIXME in the test.
Also I'm not testing torch.* because of namespace issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10311
Differential Revision: D9196341
Pulled By: SsnL
fbshipit-source-id: 9c2ca1ffe660bc1cc664474993f8a21198525ccc
Summary:
closes#9702 .
cc jph00
Commit structure:
1. Change the index calculation logic. I will explain using 1-D for simplicity.
Previously we have (in pseudo code):
```
// 1. get the float locations from grid
scalar_t x = from_grid()
// 2. find the integral surrounding indices
int x_left = floor(x)
int x_right = x_left + 1
// 3. calculate the linear interpolate weights
scalar_t w_left = x_right - x
scalar_t w_right = x - x_left
// 4. manipulate the integral surrounding indices if needed
// (e.g., clip for border padding_mode)
x_left = manipulate(x_left, padding_mode)
x_right = manipulate(x_right, padding_mode)
// 5. interpolate
output_val = interpolate(w_left, w_right, x_left, x_right)
```
This is actually incorrect (and also unintuitive) because it calculates the
weights before manipulate out-of-boundary indices. Fortunately, this
isn't manifested in both of the current supported modes, `'zeros'` and
`'border'` padding:
+ `'zeros'`: doesn't clip
+ `'border'`: clips, but for out-of-bound `x` both `x_left` and `x_right` are
clipped to the same value, so weights don't matter
But this is a problem with reflection padding, since after each time we reflect,
the values of `w_left` and `w_right` should be swapped.
So in this commit I change the algorithm to (numbers corresponding to the
ordering in the above pseudo-code)
```
1. get float location
4. clip the float location
2. find the integral surrounding indices
3. calculate the linear interpolate weights
```
In the backward, because of this change, I need to add new variables to track
`d manipulate_output / d manipulate_input`, which is basically a multiplier
on the gradient calculated for `grid`. From benchmarking this addition doesn't
cause obvious slow downs.
2. Implement reflection padding. The indices will keep being reflected until
they become within boundary.
Added variant of `clip_coordinates` and `reflect_coordinates` to be used in
backward. E.g.,
```cpp
// clip_coordinates_set_grad works similarly to clip_coordinates except that
// it also returns the `d output / d input` via pointer argument `grad_in`.
// This is useful in the backward pass of grid_sampler.
scalar_t clip_coordinates_set_grad(scalar_t in, int64_t clip_limit, scalar_t *grad_in)
```
For example, if `in` is clipped in `'border'` mode, `grad_in` is set to `0`.
If `in` is reflected **odd** times in `'reflection'` mode, `grad_in`
is set to `-1`.
3. Implement nearest interpolation.
4. Add test cases
5. Add better input checking
Discussed with goldsborough for moving `operator<<` of `at::Device`,
`at::DeviceType` and `at::Layout` into `at` namespace. (Otherwise
`AT_CHECK` can't find them.)
6. Support empty tensors. cc gchanan
+ Make empty tensors not acceptable by cudnn.
+ Add `AT_ASSERT(kernel block size > 0)` if using `GET_BLOCKS`
+ Cache `numel` in `TensorGeometry`
I was going to use `numel` to test if cudnn descriptor should accept a
tensor, but it isn't used eventually. I can revert this if needed.
7. Add more test cases, including on input checking and empty tensors
8. Remove an obsolete comment
9. Update docs. Manually tested by generating docs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10051
Differential Revision: D9123950
Pulled By: SsnL
fbshipit-source-id: ac3b4a0a36b39b5d02e83666cc6730111ce216f6
Summary:
- fixes#9141, #9301
- use logsigmoid at multilabel_soft_margin_loss to make it more stable (NOT fixing legacy MultiLabelSoftMarginCriterion)
- return (N) instead of (N, C) to match the same behavior as MultiMarginLoss
- Note that with this PR, the following behavior is expected:
```
loss = F.multilabel_soft_margin_loss(outputs, labels, reduction='none')
loss_mean = F.multilabel_soft_margin_loss(outputs, labels, reduction='elementwise_mean')
loss_sum = F.multilabel_soft_margin_loss(outputs, labels, reduction='sum')
loss.sum() == loss_sum # True
loss.mean() == loss_mean # True
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9965
Differential Revision: D9038402
Pulled By: weiyangfb
fbshipit-source-id: 0fa94c7b3cd370ea62bd6333f1a0e9bd0b8ccbb9
Summary:
There is a regression in softmin in 0.4.1 that was not present in 0.4.0. The behavior of softmin(x) should match softmax(-x) however instead it is implemented (in v0.4.1) as -softmax(x). These are not the same. The fix is trivial because the bug is due to operator precedence.
This is a major regression that broke my training. I'm not sure how a unit test did not catch this.
```
x = torch.tensor([1, 2, 3.5, 4])
print(F.softmin(x, dim=0)) # this has the wrong output in 0.4.1 but correct in 0.4.0
print(F.softmax(-x, dim=0)) # this is what softmax should be
print(F.softmax(x, dim=0))
print(-F.softmax(x, dim=0)) # this is how softmax is implemented incorrectly
```
In 0.4.1 this produces
tensor([-0.0278, -0.0755, -0.3385, -0.5581])
tensor([0.6668, 0.2453, 0.0547, 0.0332])
tensor([0.0278, 0.0755, 0.3385, 0.5581])
tensor([-0.0278, -0.0755, -0.3385, -0.5581])
In 0.4.0 this produces the correct values
tensor([ 0.6668, 0.2453, 0.0547, 0.0332])
tensor([ 0.6668, 0.2453, 0.0547, 0.0332])
tensor([ 0.0278, 0.0755, 0.3385, 0.5581])
tensor([-0.0278, -0.0755, -0.3385, -0.5581])
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10066
Differential Revision: D9106995
Pulled By: soumith
fbshipit-source-id: 7332503c6077e8461ad6cd72422c749cf6ca595b
Summary:
_pointwise loss has some python special casing, we converted reduction to aten enums too early.
fixes#10009
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10018
Differential Revision: D9075489
Pulled By: li-roy
fbshipit-source-id: 4bf2f5e2911e757602c699ee1ec58223c61d0162
Summary:
The CPU and CUDA variants are a direct transposition of Graves et al.'s description of the algorithm with the
modification that is is in log space.
The there also is a binding for the (much faster) CuDNN implementation.
This could eventually fix#3420
I still need to add tests (TestNN seems much more elaborate than the other testing) and fix the bugs than invariably turn up during the testing. Also, I want to add some more code comments.
I could use feedback on all sorts of things, including:
- Type handling (cuda vs. cpu for the int tensors, dtype for the int tensors)
- Input convention. I use log probs because that is what the gradients are for.
- Launch parameters for the kernels
- Errors and obmissions and anything else I'm not even aware of.
Thank you for looking!
In terms of performance it looks like it is superficially comparable to WarpCTC (and thus, but I have not systematically investigated this).
I have read CuDNN is much faster than implementations because it does *not* use log-space, but also the gathering step is much much faster (but I avoided trying tricky things, it seems to contribute to warpctc's fragility). I might think some more which existing torch function (scatter or index..) I could learn from for that step.
Average timings for the kernels from nvprof for some size:
```
CuDNN:
60.464us compute_alphas_and_betas
16.755us compute_grads_deterministic
Cuda:
121.06us ctc_loss_backward_collect_gpu_kernel (= grads)
109.88us ctc_loss_gpu_kernel (= alphas)
98.517us ctc_loss_backward_betas_gpu_kernel (= betas)
WarpCTC:
299.74us compute_betas_and_grad_kernel
66.977us compute_alpha_kernel
```
Of course, I still have the (silly) outer blocks loop rather than computing consecutive `s` in each thread which I might change, and there are a few other things where one could look for better implementations.
Finally, it might not be unreasonable to start with these implementations, as the performance of the loss has to be seen in the context of the entire training computation, so this would likely dilute the relative speedup considerably.
My performance measuring testing script:
```
import timeit
import sys
import torch
num_labels = 10
target_length = 30
input_length = 50
eps = 1e-5
BLANK = 0#num_labels
batch_size = 16
torch.manual_seed(5)
activations = torch.randn(input_length, batch_size, num_labels + 1)
log_probs = torch.log_softmax(activations, 2)
probs = torch.exp(log_probs)
targets = torch.randint(1, num_labels+1, (batch_size * target_length,), dtype=torch.long)
targets_2d = targets.view(batch_size, target_length)
target_lengths = torch.tensor(batch_size*[target_length])
input_lengths = torch.tensor(batch_size*[input_length])
activations = log_probs.detach()
def time_cuda_ctc_loss(grout, *args):
torch.cuda.synchronize()
culo, culog_alpha = torch._ctc_loss(*args)
g, = torch.autograd.grad(culo, args[0], grout)
torch.cuda.synchronize()
def time_cudnn_ctc_loss(groupt, *args):
torch.cuda.synchronize()
culo, cugra= torch._cudnn_ctc_loss(*args)
g, = torch.autograd.grad(culo, args[0], grout)
torch.cuda.synchronize()
def time_warp_ctc_loss(grout, *args):
torch.cuda.synchronize()
culo = warpctc.ctc_loss(*args, blank_label=BLANK, size_average=False, length_average=False, reduce=False)
g, = torch.autograd.grad(culo, args[0], grout)
torch.cuda.synchronize()
if sys.argv[1] == 'cuda':
lpcu = log_probs.float().cuda().detach().requires_grad_()
args = [lpcu, targets_2d.cuda(), input_lengths.cuda(), target_lengths.cuda(), BLANK]
grout = lpcu.new_ones((batch_size,))
torch.cuda.synchronize()
print(timeit.repeat("time_cuda_ctc_loss(grout, *args)", number=1000, globals=globals()))
elif sys.argv[1] == 'cudnn':
lpcu = log_probs.float().cuda().detach().requires_grad_()
args = [lpcu, targets.int(), input_lengths.int(), target_lengths.int(), BLANK, True]
grout = lpcu.new_ones((batch_size,))
torch.cuda.synchronize()
print(timeit.repeat("time_cudnn_ctc_loss(grout, *args)", number=1000, globals=globals()))
elif sys.argv[1] == 'warpctc':
import warpctc
activations = activations.cuda().detach().requires_grad_()
args = [activations, input_lengths.int(), targets.int(), target_lengths.int()]
grout = activations.new_ones((batch_size,), device='cpu')
torch.cuda.synchronize()
print(timeit.repeat("time_warp_ctc_loss(grout, *args)", number=1000, globals=globals()))
```
I'll also link to a notebook that I used for writing up the algorithm in simple form and then test the against implementations against it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9628
Differential Revision: D8952453
Pulled By: ezyang
fbshipit-source-id: 18e073f40c2d01a7c96c1cdd41f6c70a06e35860
Summary:
As in the title. Lets us simplify a lot of code.
Depends on #9363, so please review only the last commit.
zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9414
Reviewed By: zdevito
Differential Revision: D8836496
Pulled By: apaszke
fbshipit-source-id: 9b3c3d1f001a9dc522f8478abc005b6b86cfa3e3
Summary:
It implements per-channel alpha_dropout. It also creates corresponding function classes and unifies the process of dropout and alpha_dropout.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9073
Differential Revision: D8727008
Pulled By: ezyang
fbshipit-source-id: 9d509f9c5db4e98f7b698cdfc4443505a4d2b331
Summary:
Commits:
1. In extension doc, get rid of all references of `Variable` s (Closes#6947 )
+ also add minor improvements
+ also added a section with links to cpp extension :) goldsborough
+ removed mentions of `autograd.Function.requires_grad` as it's not used anywhere and hardcoded to `return_Py_True`.
2. Fix several sphinx warnings
3. Change `*` in equations in `module/conv.py` to `\times`
4. Fix docs for `Fold` and `Unfold`.
+ Added better shape check for `Fold` (it previously may give bogus result when there are not enough blocks). Added test for the checks.
5. Fix doc saying `trtrs` not available for CUDA (#9247 )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9239
Reviewed By: soumith
Differential Revision: D8762492
Pulled By: SsnL
fbshipit-source-id: 13cd91128981a94493d5efdf250c40465f84346a
Summary:
This PR addresses #5823.
* fix docstring: upsample doesn't support LongTensor
* Enable float scale up & down sampling for linear/bilinear/trilinear modes. (following SsnL 's commit)
* Enable float scale up & down sampling for nearest mode. Note that our implementation is slightly different from TF that there's actually no "align_corners" concept in this mode.
* Add a new interpolate function API to replace upsample. Add deprecate warning for upsample.
* Add an area mode which is essentially Adaptive_average_pooling into resize_image.
* Add test cases for interpolate in test_nn.py
* Add a few comments to help understand *linear interpolation code.
* There is only "*cubic" mode missing in resize_images API which is pretty useful in practice. And it's labeled as hackamonth here #1552. I discussed with SsnL that we probably want to implement all new ops in ATen instead of THNN/THCUNN. Depending on the priority, I could either put it in my queue or leave it for a HAMer.
* After the change, the files named as *Upsampling*.c works for both up/down sampling. I could rename the files if needed.
Differential Revision: D8729635
Pulled By: ailzhang
fbshipit-source-id: a98dc5e1f587fce17606b5764db695366a6bb56b
Summary:
1. Let `ModuleTest` raise when they fail on non-contiguous inputs. Fix legacy modules.
2. Fix BN (both THNN and cuDNN) not working on non-contiguous inputs.
3. Fix CUDA EmbeddingBag not working on non-contiguous inputs. To prevent calling `.contiguous()` on in both `forward` and `backward`,
a. prefix all current `embedding_bag*` functions with `_`, indicating that they require input to be contiguous (there is a check in each function).
b. create `embedding_bag`, which makes input arguments `.contiguous()`, and calls `_embedding_bag`
3. Make many ATen `embedding*` functions to work on non-contiguous inputs so we don't need to call `input = input.contiguous()` in Python `nn.functional.embedding`.
4. Fix dense-sparse addition when the sparse input is not coalesced and indices or values tensor is not contiguous. This came up in the test cases of Embedding modules with `sparse=True`. Added tests.
5. Update `TensorUtils.cpp` to use `AT_*` macros.
Request:
review from cpuhrsch on the `Embedding*` changes.
review from ezyang on ATen sparse & BN changes.
Closes https://github.com/pytorch/pytorch/pull/9114
Differential Revision: D8717299
Pulled By: SsnL
fbshipit-source-id: 0acc6f1c9522b5b605361e75112c16bbe1e98527
Summary:
The tests were using the old args, which caused them to emit a lot of deprecation warnings.
closes#9103.
Reviewed By: ezyang
Differential Revision: D8720581
Pulled By: li-roy
fbshipit-source-id: 3b79527f6fe862fb48b99a6394e8d7b89fc7a8c8
* Add pos_weight argument to nn.BCEWithLogitsLoss and F.binary_cross_entropy_with_logits (#5660)
- Add an option to control precision/recall in imbalanced datasets
- Add tests (but new_criterion_tests)
* Move pos_weight to the end of args list in the documentation.
`pos_weight` was moved to the end because it is the last argument in both
`nn.BCEWithLogitsLoss` and `binary_cross_entropy_with_logits`
* 1. added hardshrink() to ATen (CPU + GPU); 2. removed nn.Hardshrink(); 3. reusing previous tests for nn.Hardshrink() and included CUDA tests at test_nn; 4. default parameter lambda=0.5 is not working yet
* optimized memory read/write
* 1. pass in lambd as scalar for CPU/CUDA_apply*; 2. removed tests for hardshrink at test_legacy_nn
* fixes test_utils
* 1. replace zeros_like with empty_like; 2. use scalar_cast in cuda
* 1. printing lambd value; 2. default lambd=0.5 is still failing
* getting around Scalar bug buy removing default value of lambd from native_functions.yaml, and declare it at nn/functional.py
* cleaned up debug printf
* move softmax/logsoftmax to ATen
* specify cpu and gpu accum types
* use accreal for CPU
* expose softmax backward to python, fix legacy interface
* fix Distributions.cu to use common AccumulateType
* fix cuda 8 build
* delete commented out lines
* rebase on master, fix breakages
* Add max mode support to EmbeddingBag
* Lint fix
* Fix compilation issue on other platforms
* Rebase + don't waste memory when not in max mode
* Oops, missed a spot
* Fix whitespace from merge
* less precision
* Lower precision to avoid spurious failures
* Minor typo
* Switch to size()
* Added ReLU unit to LP pooling, so the gradient does not become NAN if all inputs are zero.
* Added workaround for odd p. Added a bit of doc.
* Make the linter happy.
* Codemod to update our codebase to 0.4 standard
* Update some of the test scri[ts
* remove Variable in test_clip_grad_value
* fix _symbolic_override_wrapper_maker
Fixes#5554
Adds an error message for when NLLLoss is passed an input and target
whose batch sizes don't match. Ideally this check should live in ATen
but since there is NLLLoss logic in python the check is there right now.
According to the code in _torch/nn/functional.py:1399_
(```if target.size()[1:] != input.size()[2:]:```),
if the size of input is (N, C, d_1, d_2, ..., d_K), the size of target should be (N, d_1, d_2, ..., d_K).
* Changes in bilinear upsampling
* Add align_corners option to upsampling module & functional when using linearly interpolating modes
When align_corners=True, it uses the old original upsampling scheme, which gives visually better results,
but doesn't properly align input and output pixels, and thus cause the output vary basing on input.
This PR adds this align_corners option, and changes the default behavior to align_corners=False, with
proper warning if this option is not specified upon using nn.Upsample or nn.functional.upsample to let
be aware of this new change.
Adds tests in test_nn.py for spatial invariance when align_corners=False, and usual module tests for
align_corners=False.
* remove redundant checks and unnecessary variables; fix the cast
* fix negative indices
This PR addresses issue #5024
* Expose Conv2dBackward in python
* Separate interface for exposing gardients of operators
* Revert old changes
* Add tests
* Add conv1d gradients. Refactor tests for grad convolutions
* Refactor names and change examples
* Remove Varibale from tests for conv backward
* add reduce=True arg to MarginRankingLoss
* make default margin arg match for legacy
* remove accidentally added test
* fix test
* fix native_functions.yaml alphabetical order
* support n-d inputs in bilinear and move to aten
* support n-d inputs in bilinear and move to aten
* add asserts to bilinear inputs
* address comments
* cast int64_t in asserts
* implement TripletMarginLoss as a native function
* implement TripletMarginLoss as native function
* fix compile error
* address comments
* address comments
* Add keepdim arg to pairwise distance
* Fix some minor errors in existing docs.
* Fix Convolution and Pooling docs in torch.nn.functional
* Cleaned up torch.nn.functional docs
* Address @SsnL 's comments
* Add multiplication sign missing in docs
* Fix more typos, and clear some warnings
* Change infinity symbol in LPPool2d
* Revert some changes in torch.nn.functional
* Few more minor changes
* implement CosineEmbeddingLoss as a native function and add reduce=True arg to it
* fix flake8
* address comments
* add reference function to tests
* fix flake8
The nn.* counterpart of #5443 . Mostly removed Variable wrapper. Also added doc for nn.RReLU.
Notice that torch.randn(*, requires_grad=True) isn't documented until #5462 is done.
This replaces the torch.Tensor constructors with factories that produce
Variables. Similarly, functions on the torch module (e.g. torch.randn)
now return Variables.
To keep the PR to a reasonable size, I've left most of the unused tensor
code. Subsequent PRs will remove the dead code, clean-up calls to
torch.autograd.Variable, and rename Variable to Tensor everywhere.
There are some breaking changes because Variable and Tensors had
slightly different semantics. There's a list of those changes here:
https://github.com/pytorch/pytorch/wiki/Breaking-Changes-from-Variable-and-Tensor-merge
* at::maybe_data_ptr and Check.h => TensorUtils.h
* THNN support for optional BN running_*
* ATen support for optional BN running_*
* Python nn.* support for optional BN running_*; Improve IN and BN doc
* Add tests for IN and BN new option
* Layer Norm
* Fix LRN doc
* functional interface for LN and IN
* Layer norm tests
* fix BN double backward returning undefined tensors
* fix jit test using wrong dim inputs for BN
* add/improve BN, IN and LN GPU tests with half type
* Udpate docs to be consistent with Conv notation
Fix onnx
Clarified onnx symbokic wrapper
* fix typo
* Address comments
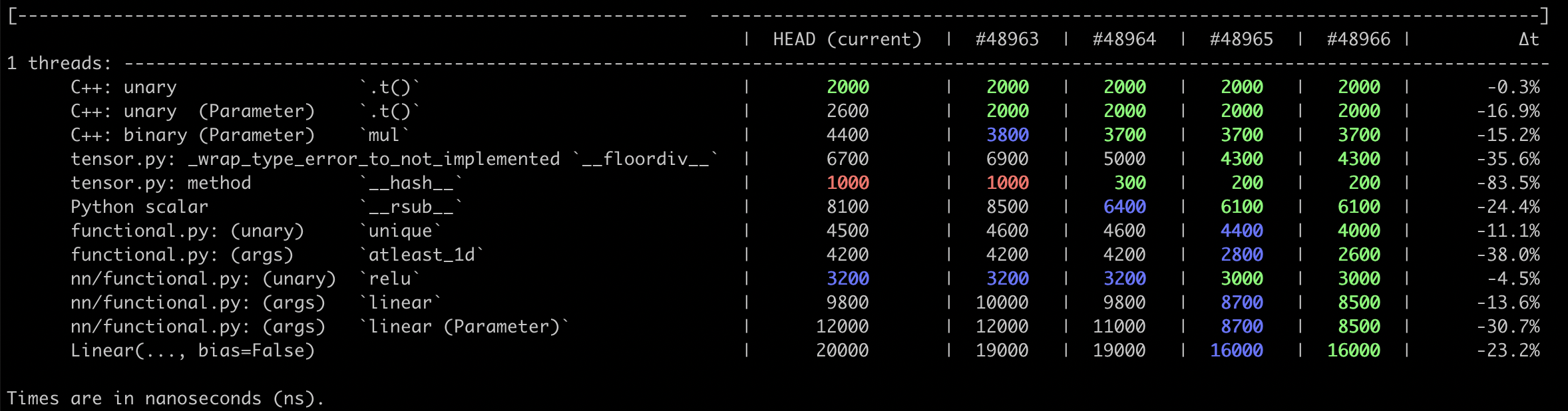{kind=link}
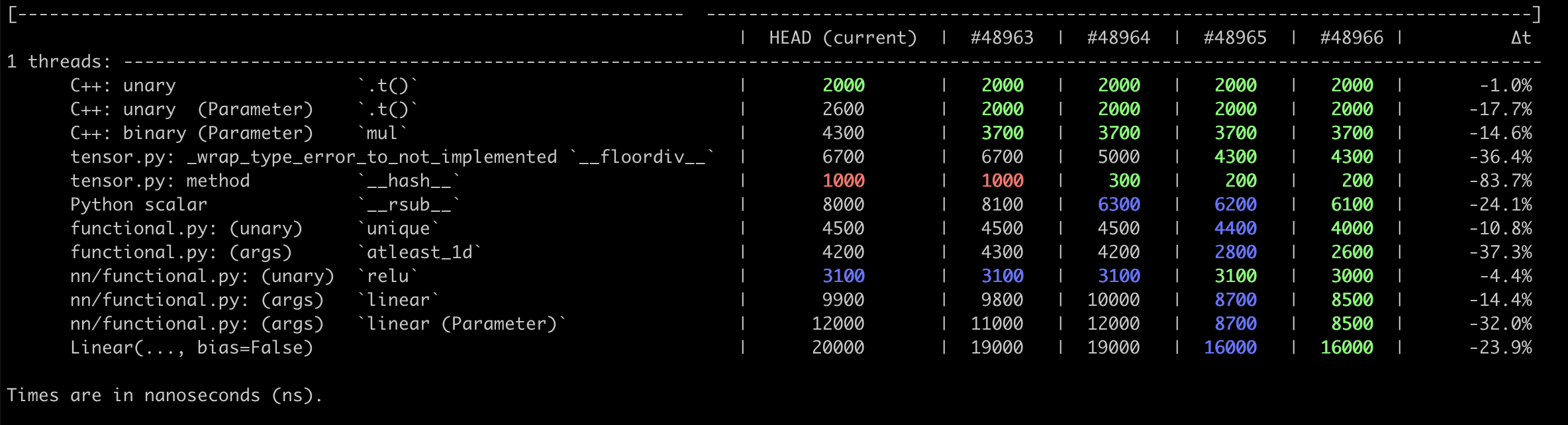{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}