Summary:
as title
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17476
Differential Revision: D14218312
Pulled By: suo
fbshipit-source-id: 64df096a3431a6f25cd2373f0959d415591fed15
Summary:
Based on https://github.com/pytorch/pytorch/pull/12413, with the following additional changes:
- Inside `native_functions.yml` move those outplace operators right next to everyone's corresponding inplace operators for convenience of checking if they match when reviewing
- `matches_jit_signature: True` for them
- Add missing `scatter` with Scalar source
- Add missing `masked_fill` and `index_fill` with Tensor source.
- Add missing test for `scatter` with Scalar source
- Add missing test for `masked_fill` and `index_fill` with Tensor source by checking the gradient w.r.t source
- Add missing docs to `tensor.rst`
Differential Revision: D14069925
Pulled By: ezyang
fbshipit-source-id: bb3f0cb51cf6b756788dc4955667fead6e8796e5
Summary:
one_hot docs is missing [here](https://pytorch.org/docs/master/nn.html#one-hot).
I dug around and could not find a way to get this working properly.
Differential Revision: D14104414
Pulled By: zou3519
fbshipit-source-id: 3f45c8a0878409d218da167f13b253772f5cc963
Summary:
This prevent people (reviewer, PR author) from forgetting adding things to `torch.rst`.
When something new is added to `_torch_doc.py` or `functional.py` but intentionally not in `torch.rst`, people should manually whitelist it in `test_docs_coverage.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16039
Differential Revision: D14070903
Pulled By: ezyang
fbshipit-source-id: 60f2a42eb5efe81be073ed64e54525d143eb643e
Summary:
This PR is a simple fix for the mistake in the first note for `torch.device` in the "tensor attributes" doc.

```
>>> # You can substitute the torch.device with a string
>>> torch.randn((2,3), 'cuda:1')
```
Above code will cause error like below:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-53-abdfafb67ab1> in <module>()
----> 1 torch.randn((2,3), 'cuda:1')
TypeError: randn() received an invalid combination of arguments - got (tuple, str), but expected one of:
* (tuple of ints size, torch.Generator generator, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
* (tuple of ints size, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
```
Simply adding the argument name `device` solves the problem: `torch.randn((2,3), device='cuda:1')`.
However, another concern is that this note seems redundant as **there is already another note covering this usage**:
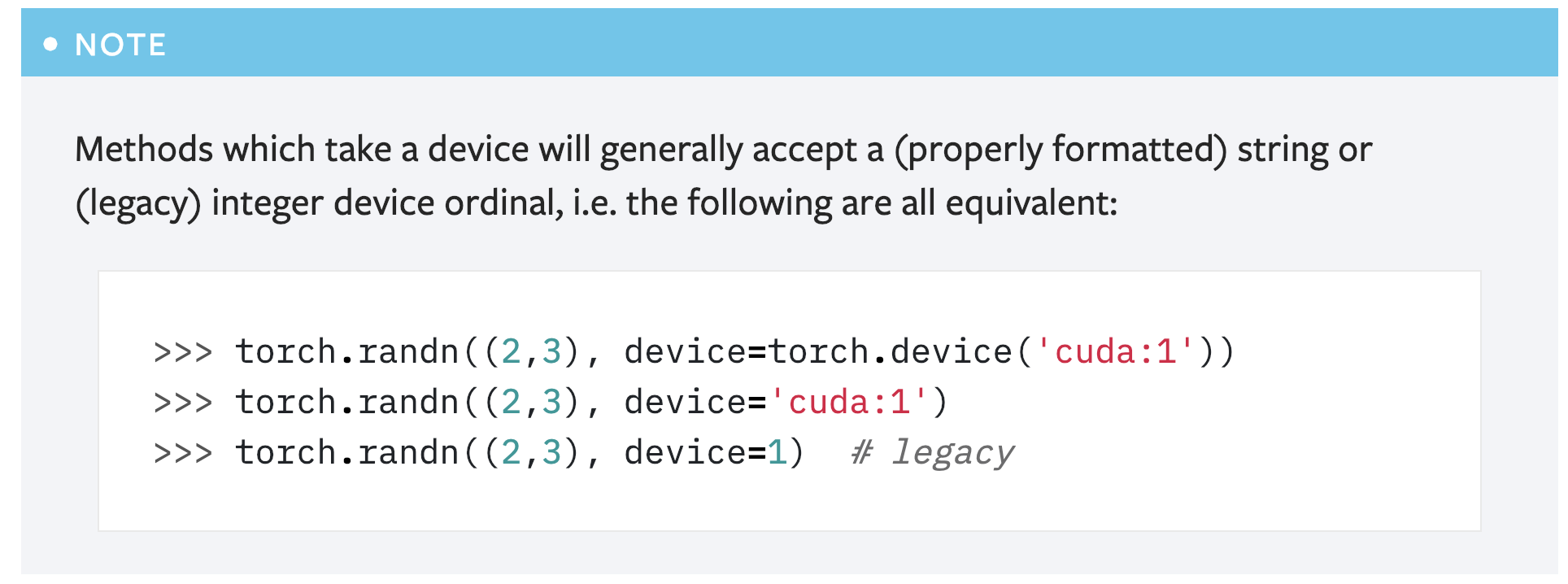
So maybe it's better to just remove this note?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16839
Reviewed By: ezyang
Differential Revision: D13989209
Pulled By: gchanan
fbshipit-source-id: ac255d52528da053ebfed18125ee6b857865ccaf
Summary:
Some batched updates:
1. bool is a type now
2. Early returns are allowed now
3. The beginning of an FAQ section with some guidance on the best way to do GPU training + CPU inference
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16866
Differential Revision: D13996729
Pulled By: suo
fbshipit-source-id: 3b884fd3a4c9632c9697d8f1a5a0e768fc918916
Summary:
Now that `cuda.get/set_rng_state` accept `device` objects, the default value should be an device object, and doc should mention so.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14324
Reviewed By: ezyang
Differential Revision: D13528707
Pulled By: soumith
fbshipit-source-id: 32fdac467dfea6d5b96b7e2a42dc8cfd42ba11ee
Summary:
Changelog:
- Renames `potrs` to `cholesky_solve` to remain consistent with Tensorflow and Scipy (not really, they call their function chol_solve)
- Default argument for upper in cholesky_solve is False. This will allow a seamless interface between `cholesky` and `cholesky_solve`, since the `upper` argument in both function are the same.
- Rename all tests
- Create a tentative alias for `cholesky_solve` under the name `potrs`, and add deprecated warning to not promote usage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15334
Differential Revision: D13507724
Pulled By: soumith
fbshipit-source-id: b826996541e49d2e2bcd061b72a38c39450c76d0
Summary:
Some of the codeblocks were showing up as normal text and the "unsupported modules" table was formatted incorrectly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15227
Differential Revision: D13468847
Pulled By: driazati
fbshipit-source-id: eb7375710d4f6eca1d0f44dfc43c7c506300cb1e
Summary:
Documents what is supported in the script standard library.
* Adds `my_script_module._get_method('forward').schema()` method to get function schema from a `ScriptModule`
* Removes `torch.nn.functional` from the list of builtins. The only functions not supported are `nn.functional.fold` and `nn.functional.unfold`, but those currently just dispatch to their corresponding aten ops, so from a user's perspective it looks like they work.
* Allow printing of `IValue::Device` by getting its string representation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14912
Differential Revision: D13385928
Pulled By: driazati
fbshipit-source-id: e391691b2f87dba6e13be05d4aa3ed2f004e31da
Summary:
Tracing records variable names and we have new types and stuff in the IR, so this updates the graph printouts in the docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14914
Differential Revision: D13385101
Pulled By: jamesr66a
fbshipit-source-id: 6477e4861f1ac916329853763c83ea157be77f23
Summary:
Added a few examples and explains to how publish/load models.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14862
Differential Revision: D13384790
Pulled By: ailzhang
fbshipit-source-id: 008166e84e59dcb62c0be38a87982579524fb20e
Summary:
pytorch_theme.css is no longer necessary for the cpp or html docs site build. The new theme styles are located at https://github.com/pytorch/pytorch_sphinx_theme. The Lato font is also no longer used in the new theme.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14779
Differential Revision: D13356125
Pulled By: ezyang
fbshipit-source-id: c7635eb7512c7dcaddb9cad596ab3dbc96480144
Summary:
When I wrote the frontend API, it is designed on not letting users use the default_group directly on any functions. It should really be private.
All collectives are supposed to either use group.WORLD, or anything that comes out of new_group. That was the initial design.
We need to make a TODO on removing group.WORLD one day. It exists for backward compatibility reasons and adds lots of complexity.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14767
Reviewed By: pietern
Differential Revision: D13330655
Pulled By: teng-li
fbshipit-source-id: ace107e1c3a9b3910a300b22815a9e8096fafb1c
Summary:
* s/environmental/environment/g
* Casing (CUDA, InfiniBand, Ethernet)
* Don't embed torch.multiprocessing.spawn but link to it (not part of the package)
* spawn _function_ instead of _utility_ (it's mentioned after the launch utility which is a proper utility)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14605
Differential Revision: D13273480
Pulled By: pietern
fbshipit-source-id: da6b4b788134645f2dcfdd666d1bbfc9aabd97b1
Summary:
Removed an incorrect section. We don't support this. I wrote this from my memory :(
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14530
Differential Revision: D13253471
Pulled By: teng-li
fbshipit-source-id: c3f1ffc6c98ef8789157e885776e0b775ec47b15
Summary:
Add to the Tensor doc info about `.device`, `.is_cuda`, `.requires_grad`, `.is_leaf` and `.grad`.
Update the `register_backward_hook` doc with a warning stating that it does not work in all cases.
Add support in the `_add_docstr` function to add docstring to attributes.
There is an explicit cast here but I am not sure how to handle it properly. The thing is that the doc field for getsetdescr is written as being a const char * (as all other doc fields in descriptors objects) in cpython online documentation. But in the code, it is the only one that is not const.
I assumed here that it is a bug in the code because it does not follow the doc and the convention of the others descriptors and so I cast out the const.
EDIT: the online doc I was looking at is for 3.7 and in that version both the code and the doc are const. For older versions, both are non const.
Please let me know if this should not be done. And if it should be done if there is a cleaner way to do it !
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14339
Differential Revision: D13243266
Pulled By: ezyang
fbshipit-source-id: 75b7838f7cd6c8dc72b0c61950e7a971baefaeeb
Summary:
- to fix#12241
- add `_sparse_sum()` to ATen, and expose as `torch.sparse.sum()`, not support `SparseTensor.sum()` currently
- this PR depends on #11253, and will need to be updated upon it lands
- [x] implement forward
- [x] implement backward
- performance [benchmark script](https://gist.github.com/weiyangfb/f4c55c88b6092ef8f7e348f6b9ad8946#file-sparse_sum_benchmark-py):
- sum all dims is fastest for sparse tensor
- when input is sparse enough nnz = 0.1%, sum of sparse tensor is faster than dense in CPU, but not necessary in CUDA
- CUDA backward is comparable (<2x) between `sum several dims` vs `sum all dims` in sparse
- CPU backward uses binary search is still slow in sparse, takes `5x` time in `sum [0, 2, 3] dims` vs `sum all dims`
- optimize CUDA backward for now
- using thrust for sort and binary search, but runtime not improved
- both of CPU and CUDA forward are slow in sparse (`sum several dims` vs `sum all dims`), at most `20x` slower in CPU, and `10x` in CUDA
- improve CPU and CUDA forward kernels
(nnz, sizes, sum_dims, keepdim, sum all or dims, bk=backward) | CPU (sparse vs dense) | CUDA(sparse vs dense)
-- | -- | --
(1000, [1000, 1000, 2, 2], [0, 1], False, sumAll) | 8.77 µs vs 72.9 µs | 42.5 µs vs 108 µs
(1000, [1000, 1000, 2, 2], [0, 1], False, sumD) | 112 µs vs 4.47 ms | 484 µs vs 407 µs
(1000, [1000, 1000, 2, 2], [0, 1], False, sumAll, bk) | 141 µs vs 148 µs | 647 µs vs 231 µs
(1000, [1000, 1000, 2, 2], [0, 1], False, sumD, bk) | 235 µs vs 1.23 ms | 781 µs vs 213 µs
(1000, [1000, 1000, 2, 2], [2, 3], False, sumD) | 48.5 µs vs 360 µs | 160 µs vs 2.03 ms
(1000, [1000, 1000, 2, 2], [2, 3], False, sumD, bk) | 258 µs vs 1.22 ms | 798 µs vs 224 µs
(1000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD) | 204 µs vs 882 µs | 443 µs vs 133 µs
(1000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD, bk) | 709 µs vs 1.15 ms | 893 µs vs 202 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumAll) | 39.8 µs vs 81 µs | 42.4 µs vs 113 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumD) | 747 µs vs 4.7 ms | 2.4 ms vs 414 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumAll, bk) | 1.04 ms vs 126 µs | 5.03 ms vs 231 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumD, bk) | 1.12 ms vs 1.24 ms | 5.99 ms vs 213 µs
(10000, [1000, 1000, 2, 2], [2, 3], False, sumD) | 133 µs vs 366 µs | 463 µs vs 2.03 ms
(10000, [1000, 1000, 2, 2], [2, 3], False, sumD, bk) | 1.56 ms vs 1.22 ms | 6.11 ms vs 229 µs
(10000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD) | 1.53 ms vs 799 µs | 824 µs vs 134 µs
(10000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD, bk) | 5.15 ms vs 1.09 ms | 7.02 ms vs 205 µs
- after improving CPU and CUDA forward kernels
- in `(1000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD)` forward, CPU takes ~~`171 µs`~~, in which `130 µs` is spent on `coalesce()`, for CUDA, total time is ~~`331 µs`~~, in which `141 µs` is spent on `coalesce()`, we need to reduce time at other places outside `coalesce()`.
- after a few simple tweaks, now in the forward, it is at most `10x` slower in CPU, and `7x` in CUDA. And time takes in `sum dense dims only [2, 3]` is `~2x` of `sum all dims`. Speed of `sum all sparse dims [0, 1]` is on bar with `sum all dims`
(nnz, sizes, sum_dims, keepdim, sum all or dims, bk=backward) | CPU (sparse vs dense) | CUDA(sparse vs dense)
-- | -- | --
(1000, [1000, 1000, 2, 2], [0, 1], False, sumAll) | 7 µs vs 69.5 µs | 31.5 µs vs 61.6 µs
(1000, [1000, 1000, 2, 2], [0, 1], False, sumD) | 11.3 µs vs 4.72 ms | 35.2 µs vs 285 µs
(1000, [1000, 1000, 2, 2], [0, 1], False, sumAll, bk) | 197 µs vs 124 µs | 857 µs vs 134 µs
(1000, [1000, 1000, 2, 2], [0, 1], False, sumD, bk) | 124 µs vs 833 µs | 796 µs vs 106 µs
(1000, [1000, 1000, 2, 2], [2, 3], False, sumD) | 20.5 µs vs 213 µs | 39.4 µs vs 1.24 ms
(1000, [1000, 1000, 2, 2], [2, 3], False, sumD, bk) | 131 µs vs 830 µs | 881 µs vs 132 µs
(1000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD) | 95.8 µs vs 409 µs | 246 µs vs 87.2 µs
(1000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD, bk) | 624 µs vs 820 µs | 953 µs vs 124 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumAll) | 45.3 µs vs 72.9 µs | 33.9 µs vs 57.2 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumD) | 81.4 µs vs 4.49 ms | 39.7 µs vs 280 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumAll, bk) | 984 µs vs 111 µs | 6.41 ms vs 121 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumD, bk) | 1.45 ms vs 828 µs | 6.77 ms vs 113 µs
(10000, [1000, 1000, 2, 2], [2, 3], False, sumD) | 74.9 µs vs 209 µs | 37.7 µs vs 1.23 ms
(10000, [1000, 1000, 2, 2], [2, 3], False, sumD, bk) | 1.48 ms vs 845 µs | 6.96 ms vs 132 µs
(10000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD) | 1.14 ms vs 411 µs | 252 µs vs 87.8 µs
(10000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD, bk) | 4.53 ms vs 851 µs | 7.12 ms vs 128 µs
- time takes in CUDA backward of sparse is super long with large variance (in case of nnz=10000, it normally takes 6-7ms). To improve backward of sparse ops, we will need to debug at places other than CUDA kernels. here is a benchmark of `torch.copy_()`:
```
>>> d = [1000, 1000, 2, 2]
>>> nnz = 10000
>>> I = torch.cat([torch.randint(0, d[0], size=(nnz,)),
torch.randint(0, d[1], size=(nnz,))], 0).reshape(2, nnz)
>>> V = torch.randn(nnz, d[2], d[3])
>>> size = torch.Size(d)
>>> S = torch.sparse_coo_tensor(I, V, size).coalesce().cuda()
>>> S2 = torch.sparse_coo_tensor(I, V, size).coalesce().cuda().requires_grad_()
>>> data = S2.clone()
>>> S.copy_(S2)
>>> y = S * 2
>>> torch.cuda.synchronize()
>>> %timeit y.backward(data, retain_graph=True); torch.cuda.synchronize()
7.07 ms ± 3.06 ms per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12430
Differential Revision: D12878313
Pulled By: weiyangfb
fbshipit-source-id: e16dc7681ba41fdabf4838cf05e491ca9108c6fe
Summary:
The doc covers pretty much all we have had on distributed for PT1 stable release, tracked in https://github.com/pytorch/pytorch/issues/14080
Tested by previewing the sphinx generated webpages. All look good.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14444
Differential Revision: D13227675
Pulled By: teng-li
fbshipit-source-id: 752f00df096af38dd36e4a337ea2120ffea79f86
Summary:
This issue was noticed, and fix proposed, by raulpuric.
Checkpointing is implemented by rerunning a forward-pass segment for each checkpointed segment during backward. This can result in the RNG state advancing more than it would without checkpointing, which can cause checkpoints that include dropout invocations to lose end-to-end bitwise accuracy as compared to non-checkpointed passes.
The present PR contains optional logic to juggle the RNG states such that checkpointed passes containing dropout achieve bitwise accuracy with non-checkpointed equivalents.** The user requests this behavior by supplying `preserve_rng_state=True` to `torch.utils.checkpoint` or `torch.utils.checkpoint_sequential`.
Currently, `preserve_rng_state=True` may incur a moderate performance hit because restoring MTGP states can be expensive. However, restoring Philox states is dirt cheap, so syed-ahmed's [RNG refactor](https://github.com/pytorch/pytorch/pull/13070#discussion_r235179882), once merged, will make this option more or less free.
I'm a little wary of the [def checkpoint(function, *args, preserve_rng_state=False):](https://github.com/pytorch/pytorch/pull/14253/files#diff-58da227fc9b1d56752b7dfad90428fe0R75) argument-passing method (specifically, putting a kwarg after a variable argument list). Python 3 seems happy with it.
Edit: It appears Python 2.7 is NOT happy with a [kwarg after *args](https://travis-ci.org/pytorch/pytorch/builds/457706518?utm_source=github_status&utm_medium=notification). `preserve_rng_state` also needs to be communicated in a way that doesn't break any existing usage. I'm open to suggestions (a global flag perhaps)?
**Batchnorm may still be an issue, but that's a battle for another day.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14253
Differential Revision: D13166665
Pulled By: soumith
fbshipit-source-id: 240cddab57ceaccba038b0276151342344eeecd7
Summary:
Update range documentation to show that we don't support start or increment parameters
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13730
Differential Revision: D12982016
Pulled By: eellison
fbshipit-source-id: cc1462fc1af547ae80c6d3b87999b7528bade8af
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}